Мерки за дисперсия. Изчисляване на групова, междугрупова и обща дисперсия (според правилото за добавяне на дисперсии)
Където σ 2 j е вътрешногруповата дисперсия на j -тата група.
За негрупирани данни остатъчна дисперсияе мярка за точността на приближението, т.е. приближаване на регресионната линия към оригиналните данни: 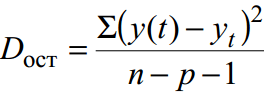
където y(t) е прогнозата според уравнението на тенденцията; y t – начална серия от динамика; n е броят на точките; p е броят на коефициентите на регресионното уравнение (броят на обяснителните променливи).
В този пример се нарича безпристрастна оценка на дисперсията.
Пример #1. Разпределението на работниците от три предприятия от една асоциация по тарифни категории се характеризира със следните данни:
| Категория на заплатата на работника | Броят на работниците в предприятието | ||
| предприятие 1 | предприятие 2 | предприятие 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Определете:
1. дисперсия за всяко предприятие (вътрешногрупова дисперсия);
2. средна стойност на вътрешногруповите дисперсии;
3. междугрупова дисперсия;
4. обща дисперсия.
Решение.
Преди да се пристъпи към решаване на проблема, е необходимо да се установи коя характеристика е ефективна и коя факторна. В разглеждания пример действащият признак е "Тарифна категория", а факторният признак е "Номер (име) на предприятието".
След това имаме три групи (предприятия), за които е необходимо да се изчисли средната групова и вътрешногруповата дисперсия:

| Търговско дружество | средна група, | дисперсия в рамките на групата, |
| 1 | 4 | 1,8 |
Средната стойност на вътрешногруповите дисперсии ( остатъчна дисперсия), изчислено по формулата:

където можете да изчислите:
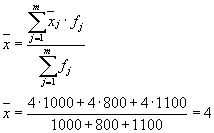
или:

тогава:
Общата дисперсия ще бъде равна на: s 2 \u003d 1,6 + 0 \u003d 1,6.
Общата дисперсия може също да се изчисли с помощта на една от следните две формули:

Когато решавате практически проблеми, често трябва да се справяте със знак, който приема само две алтернативни стойности. В този случай те не говорят за тежестта на определена стойност на характеристика, а за нейния дял в съвкупността. Ако съотношението единици на популацията, които притежават изследваната характеристика, се означи с " Р", а не притежаване - чрез" р”, тогава дисперсията може да се изчисли по формулата:
s 2 = p×q
Пример #2. Според данните за развитието на шестима работници от бригадата, определете междугруповата вариация и оценете влиянието на работната смяна върху тяхната производителност на труда, ако общата вариация е 12,2.
| No на работната бригада | Работна мощност, бр. | |
| в първа смяна | на 2-ра смяна | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Решение. Изходни данни
| х | f1 | f2 | е 3 | f4 | f5 | f6 | Обща сума |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Обща сума | 31 | 33 | 37 | 37 | 40 | 38 |
След това имаме 6 групи, за които е необходимо да се изчисли груповата средна и вътрешногруповата дисперсия.
1. Намерете средните стойности на всяка група.
2. Намерете средния квадрат на всяка група.
Обобщаваме резултатите от изчислението в таблица:
| Номер на групата | Групово средно | Вътрешногрупова дисперсия |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. Вътрешногрупова дисперсияхарактеризира промяната (вариацията) на изследваната (резултатна) черта в рамките на групата под влияние на всички фактори, с изключение на фактора, който е в основата на групирането:
Изчисляваме средната стойност на вътрешногруповите дисперсии по формулата:
4. Междугрупова дисперсияхарактеризира промяната (вариацията) на изследваната (резултатна) черта под влиянието на фактор (факторна черта), лежащ в основата на групирането.
Междугруповата дисперсия се определя като:
където
Тогава
Обща дисперсияхарактеризира промяната (вариацията) на изследваната (резултатна) черта под въздействието на всички фактори (факторни черти) без изключение. По условието на задачата то е равно на 12,2.
Емпирична корелационна връзкаизмерва каква част от общата флуктуация на резултантния атрибут е причинена от изследвания фактор. Това е съотношението на факторната дисперсия към общата дисперсия:
Определяме емпиричната корелационна връзка:
Връзките между характеристиките могат да бъдат слаби или силни (близки). Техните критерии се оценяват по скалата на Chaddock:
0,1 0,3 0,5 0,7 0,9 В нашия пример връзката между функция Y фактор X е слаба
Коефициент на определяне.
Нека да определим коефициента на детерминация:
По този начин 0,67% от вариацията се дължи на разлики между признаците, а 99,37% се дължи на други фактори.
Заключение: в този случай продукцията на работниците не зависи от работата в определена смяна, т.е. влиянието на работната смяна върху тяхната производителност на труда не е значително и се дължи на други фактори.
Пример #3. Въз основа на данните за средната работна заплата и квадрата на отклоненията от нейната стойност за две групи работници, намерете общата дисперсия, като приложите правилото за добавяне на дисперсията:
Решение:Средна стойност на дисперсиите в рамките на групата
Междугруповата дисперсия се определя като:
Общата дисперсия ще бъде: 480 + 13824 = 14304
Тази страница описва стандартен пример за намиране на дисперсията, можете също да разгледате други задачи за намирането й
Пример 1. Определяне на групова, средна за група, междугрупова и обща дисперсия
Пример 2. Намиране на дисперсията и коефициента на вариация в групираща таблица
Пример 3. Намиране на дисперсията в дискретна серия
Пример 4. Имаме следните данни за група от 20 задочни студенти. Необходимо е да се изгради интервална серия на разпределението на признака, да се изчисли средната стойност на признака и да се изследва неговата дисперсия
Нека изградим интервално групиране. Нека определим диапазона на интервала по формулата:
![]()
където X max е максималната стойност на групиращия признак;
X min е минималната стойност на групиращия признак;
n е броят на интервалите:
Приемаме n=5. Стъпката е: h \u003d (192 - 159) / 5 \u003d 6,6
Нека направим интервално групиране

За по-нататъшни изчисления ще изградим спомагателна таблица:

X "i - средата на интервала. (например средата на интервала 159 - 165,6 \u003d 162,3)
Средният растеж на учениците се определя по формулата на среднопретеглената аритметична стойност:

Определяме дисперсията по формулата:
Формулата може да се преобразува по следния начин:

От тази формула следва, че дисперсията е разликата между средната стойност на квадратите на опциите и квадрата и средната стойност.
Дисперсия във вариационни сериис равни интервали по метода на моментите може да се изчисли по следния начин, като се използва второто свойство на дисперсия (разделяне на всички опции на стойността на интервала). Дефиниция на дисперсия, изчислено по метода на моментите, по следната формула отнема по-малко време:

където i е стойността на интервала;
A - условна нула, която е удобна за използване в средата на интервала с най-висока честота;
m1 е квадратът на момента от първи ред;
m2 - момент от втори ред
Дисперсия на характеристиките (ако в статистическата популация атрибутът се променя по такъв начин, че има само две взаимно изключващи се опции, тогава такава променливост се нарича алтернативна) може да се изчисли по формулата:

Замествайки в тази дисперсионна формула q = 1- p, получаваме:

Видове дисперсия
Обща дисперсияизмерва вариацията на даден признак в цялата популация като цяло под влиянието на всички фактори, които причиняват тази вариация. Тя е равна на средния квадрат на отклоненията на отделните стойности на атрибута x от общата средна стойност x и може да се определи като проста дисперсия или претеглена дисперсия.
Вътрешногрупова дисперсия характеризира случайна вариация, т.е. част от вариацията, която се дължи на влиянието на неотчетени фактори и не зависи от знака-фактор, лежащ в основата на групирането. Тази дисперсия е равна на средния квадрат на отклоненията на отделните стойности на атрибута в групата X от средната аритметична на групата и може да се изчисли като проста дисперсия или като претеглена дисперсия.
По този начин, мерки за дисперсия в рамките на групатавариация на признак в група и се определя по формулата:

където xi - средна група;
ni е броят на единиците в групата.
Например, вътрешногруповите отклонения, които трябва да бъдат определени в задачата за изследване на ефекта от квалификацията на работниците върху нивото на производителността на труда в цеха, показват вариации в производството във всяка група, причинени от всички възможни фактори (техническо състояние на оборудването, наличие на инструменти и материали, възраст на работниците, интензивност на труда и др.), с изключение на разликите в квалификационната категория (в рамките на групата всички работници имат една и съща квалификация).
Математическото очакване и дисперсията са най-често използваните числени характеристики на случайна променлива. Те характеризират най-важните характеристики на разпределението: неговото положение и степен на дисперсия. В много проблеми на практиката пълно, изчерпателно описание на случайна променлива - законът за разпределение - или не може да бъде получено изобщо, или изобщо не е необходимо. В тези случаи те са ограничени до приблизително описание на случайна променлива с помощта на числени характеристики.
Математическото очакване често се нарича просто средна стойност на случайна променлива. Дисперсията на случайна променлива е характеристика на дисперсията, дисперсията на случайна променлива около нейното математическо очакване.
Математическо очакване на дискретна случайна променлива
Нека подходим към понятието математическо очакване, като първо изхождаме от механичната интерпретация на разпределението на дискретна случайна променлива. Нека единичната маса е разпределена между точките на оста x х1 , х 2 , ..., хн, и всяка материална точка има съответстваща й маса от стр1 , стр 2 , ..., стрн. Необходимо е да се избере една точка на оста x, която характеризира позицията на цялата система от материални точки, като се вземат предвид техните маси. Естествено е да приемем за такава точка центъра на масата на системата от материални точки. Това е среднопретеглената стойност на случайната променлива х, в която абсцисата на всяка точка хазвлиза с "тежест", равна на съответната вероятност. Средната стойност на така получената случайна променлива хсе нарича неговото математическо очакване.
Математическото очакване на дискретна случайна променлива е сумата от продуктите на всичките й възможни стойности и вероятностите на тези стойности:
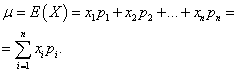
Пример 1Организира печеливша лотария. Има 1000 печалби, 400 от които са по 10 рубли всяка. 300 - 20 рубли всяка 200-100 рубли всеки. и 100 - 200 рубли всяка. Каква е средната печалба за човек, закупил един билет?
Решение. Ще намерим средната печалба, ако общата сума на печалбите, която е равна на 10*400 + 20*300 + 100*200 + 200*100 = 50 000 рубли, се раздели на 1000 (общата сума на печалбите). Тогава получаваме 50000/1000 = 50 рубли. Но изразът за изчисляване на средната печалба може да бъде представен и в следната форма:
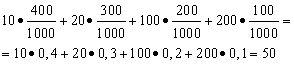
От друга страна, при тези условия размерът на печалбата е случайна променлива, която може да приеме стойности от 10, 20, 100 и 200 рубли. с вероятности, равни съответно на 0,4; 0,3; 0,2; 0,1. Следователно очакваната средна печалба е равна на сумата от произведенията на размера на печалбите и вероятността да бъдат получени.
Пример 2Издателят реши да издаде нова книга. Той ще продаде книгата за 280 рубли, от които 200 ще бъдат дадени на него, 50 на книжарницата и 30 на автора. Таблицата дава информация за разходите за издаване на книга и вероятността за продажба на определен брой копия от книгата.
Намерете очакваната печалба на издателя.
Решение. Случайната величина "печалба" е равна на разликата между приходите от продажбата и себестойността на разходите. Например, ако се продадат 500 копия от книга, тогава приходите от продажбата са 200 * 500 = 100 000, а разходите за публикуване са 225 000 рубли. Така издателят е изправен пред загуба от 125 000 рубли. Следната таблица обобщава очакваните стойности на случайната променлива - печалба:
| Номер | печалба хаз | Вероятност страз | хаз страз |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Обща сума: | 1,00 | 25000 |
Така получаваме математическото очакване на печалбата на издателя:
![]() .
.
Пример 3Шанс за попадение с един изстрел стр= 0,2. Определете консумацията на черупки, които осигуряват математическото очакване на броя на ударите, равен на 5.
Решение. От същата формула за очакване, която използвахме досега, изразяваме х- консумация на черупки:
![]() .
.
Пример 4Определете математическото очакване на случайна променлива хброй попадения с три изстрела, ако вероятността за попадение с всеки изстрел стр = 0,4 .
Съвет: намерете вероятността от стойностите на случайна променлива по Формула на Бернули .
Свойства на очакванията
Разгледайте свойствата на математическото очакване.
Имот 1.Математическото очакване на постоянна стойност е равно на тази константа:
Имот 2.Постоянният фактор може да бъде изваден от знака за очакване:
![]()
Имот 3.Математическото очакване на сумата (разликата) на случайните променливи е равно на сумата (разликата) на техните математически очаквания:
Имот 4.Математическото очакване на произведението на случайните променливи е равно на произведението на техните математически очаквания:
Имот 5.Ако всички стойности на случайната променлива хнамаляване (увеличаване) със същото число ОТ, тогава неговото математическо очакване ще намалее (увеличи) със същото число:
![]()
Когато не можете да се ограничите само до математическо очакване
В повечето случаи само математическото очакване не може да характеризира адекватно една случайна променлива.
Нека случайни променливи хи Yсе дават от следните закони на разпределение:
| Значение х | Вероятност |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Значение Y | Вероятност |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
Математическите очаквания на тези величини са еднакви – равни на нула:
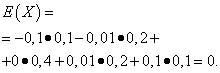
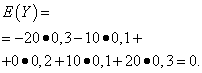
Разпределението им обаче е различно. Случайна стойност хможе да приема само стойности, които са малко по-различни от математическото очакване и случайната променлива Yможе да приема стойности, които се отклоняват значително от математическото очакване. Подобен пример: средната работна заплата не позволява да се прецени съотношението на високо- и нископлатените работници. С други думи, по математическото очакване не може да се прецени какви отклонения от него, поне средно, са възможни. За да направите това, трябва да намерите дисперсията на случайна променлива.
Дисперсия на дискретна случайна променлива
дисперсиядискретна случайна променлива хсе нарича математическо очакване на квадрата на неговото отклонение от математическото очакване:
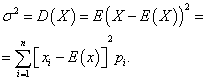
Стандартното отклонение на случайна променлива хе аритметичната стойност на корен квадратен от неговата дисперсия:
![]() .
.
Пример 5Изчисляване на дисперсии и стандартни отклонения на случайни променливи хи Y, чиито закони на разпределение са дадени в таблиците по-горе.
Решение. Математически очаквания на случайни променливи хи Y, както е намерено по-горе, са равни на нула. Според дисперсионната формула за д(х)=д(г)=0 получаваме:

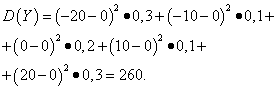
След това стандартните отклонения на случайни променливи хи Yпредставляват
![]() .
.
По този начин, със същите математически очаквания, дисперсията на случайната променлива хмного малък и случаен Y- значителен. Това е следствие от разликата в разпределението им.
Пример 6Инвеститорът има 4 алтернативни инвестиционни проекта. Таблицата обобщава данните за очакваната печалба в тези проекти със съответната вероятност.
| Проект 1 | Проект 2 | Проект 3 | Проект 4 |
| 500, П=1 | 1000, П=0,5 | 500, П=0,5 | 500, П=0,5 |
| 0, П=0,5 | 1000, П=0,25 | 10500, П=0,25 | |
| 0, П=0,25 | 9500, П=0,25 |
Намерете за всяка алтернатива математическото очакване, дисперсията и стандартното отклонение.
Решение. Нека покажем как се изчисляват тези количества за 3-тата алтернатива:
Таблицата обобщава намерените стойности за всички алтернативи.
Всички алтернативи имат едно и също математическо очакване. Това означава, че в дългосрочен план всички имат еднакъв доход. Стандартното отклонение може да се тълкува като мярка за риск – колкото по-голямо е то, толкова по-голям е рискът на инвестицията. Инвеститор, който не иска много риск, ще избере проект 1, защото има най-малкото стандартно отклонение (0). Ако инвеститорът предпочита риск и висока доходност за кратък период, тогава той ще избере проекта с най-голямо стандартно отклонение - проект 4.
Свойства на дисперсия
Нека представим свойствата на дисперсията.
Имот 1.Дисперсията на постоянна стойност е нула:
Имот 2.Константният коефициент може да бъде изваден от дисперсионния знак чрез повдигане на квадрат:
![]() .
.
Имот 3.Дисперсията на случайна променлива е равна на математическото очакване на квадрата на тази стойност, от което се изважда квадратът на математическото очакване на самата стойност:
![]() ,
,
където ![]() .
.
Имот 4.Дисперсията на сумата (разликата) на случайните променливи е равна на сумата (разликата) на техните дисперсии:
Пример 7Известно е, че дискретна случайна променлива хприема само две стойности: −3 и 7. Освен това е известно математическото очакване: д(х) = 4 . Намерете дисперсията на дискретна случайна променлива.
Решение. Означаваме с стрвероятността, с която една случайна променлива приема стойност х1 = −3 . Тогава вероятността на стойността х2 = 7 ще бъде 1 − стр. Нека изведем уравнението за математическото очакване:
д(х) = х 1 стр + х 2 (1 − стр) = −3стр + 7(1 − стр) = 4 ,
където получаваме вероятностите: стр= 0,3 и 1 − стр = 0,7 .
Законът за разпределение на случайна променлива:
| х | −3 | 7 |
| стр | 0,3 | 0,7 |
Изчисляваме дисперсията на тази случайна променлива, използвайки формулата от свойство 3 на дисперсията:
д(х) = 2,7 + 34,3 − 16 = 21 .
Намерете сами математическото очакване на случайна променлива и след това вижте решението
Пример 8Дискретна случайна променлива хприема само две стойности. Приема по-голямата стойност от 3 с вероятност 0,4. Освен това е известна дисперсията на случайната променлива д(х) = 6 . Намерете математическото очакване на случайна променлива.
Пример 9Една урна съдържа 6 бели и 4 черни топки. От урната се вземат 3 топки. Броят на белите топки сред изтеглените топки е дискретна случайна променлива х. Намерете математическото очакване и дисперсията на тази случайна променлива.
Решение. Случайна стойност хможе да приеме стойностите 0, 1, 2, 3. Съответните вероятности могат да бъдат изчислени от правило за умножение на вероятностите. Законът за разпределение на случайна променлива:
| х | 0 | 1 | 2 | 3 |
| стр | 1/30 | 3/10 | 1/2 | 1/6 |
Оттук и математическото очакване на тази случайна променлива:
М(х) = 3/10 + 1 + 1/2 = 1,8 .
Дисперсията на дадена случайна променлива е:
д(х) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Математическо очакване и дисперсия на непрекъсната случайна променлива
За непрекъсната случайна променлива механичната интерпретация на математическото очакване ще запази същото значение: центърът на масата за единица маса, разпределена непрекъснато по оста x с плътност f(х). За разлика от дискретна случайна променлива, за която аргументът на функцията хазпроменя рязко, за непрекъсната случайна променлива, аргументът се променя непрекъснато. Но математическото очакване на непрекъсната случайна променлива също е свързано с нейната средна стойност.
За да намерите математическото очакване и дисперсията на непрекъсната случайна променлива, трябва да намерите определени интеграли . Ако е дадена функция на плътност на непрекъсната случайна променлива, тогава тя влиза директно в интегранта. Ако е дадена функция на разпределение на вероятностите, тогава като я диференцирате, трябва да намерите функцията на плътност.
Средната аритметична стойност на всички възможни стойности на непрекъсната случайна променлива се нарича негова математическо очакване, означено с или .
Дисперсията на случайна променлива е мярка за разпространението на стойностите на тази променлива. Малката вариация означава, че стойностите са групирани близо една до друга. Голямото отклонение показва силно разсейване на стойностите. Концепцията за дисперсията на случайна променлива се използва в статистиката. Например, ако сравните дисперсията на стойностите на две величини (като резултатите от наблюденията на пациенти мъже и жени), можете да тествате значимостта на някаква променлива. Дисперсията се използва и при изграждането на статистически модели, тъй като малката дисперсия може да е знак, че пренастройвате стойностите.стъпки
Примерно изчисляване на дисперсията
-
Запишете пробните стойности.В повечето случаи само извадки от определени популации са достъпни за статистиците. Например, като правило, статистиците не анализират разходите за поддържане на популацията на всички автомобили в Русия - те анализират произволна извадка от няколко хиляди коли. Такава извадка ще помогне да се определи средната цена на автомобил, но най-вероятно получената стойност ще бъде далеч от реалната.
- Например, нека анализираме броя на кифлите, продадени в кафене за 6 дни, взети в произволен ред. Извадката има следния вид: 17, 15, 23, 7, 9, 13. Това е извадка, а не съвкупност, тъй като нямаме данни за продадени кифли за всеки ден, в който работи кафенето.
- Ако ви е дадена популация, а не извадка от стойности, преминете към следващия раздел.
-
Запишете формулата за изчисляване на дисперсията на извадката.Дисперсията е мярка за разпространението на стойностите на някакво количество. Колкото по-близо е стойността на дисперсията до нула, толкова по-близо са групирани стойностите. Когато работите с извадка от стойности, използвайте следната формула, за да изчислите дисперсията:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-х) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))е дисперсията. Дисперсията се измерва в квадратни единици.
- x i (\displaystyle x_(i))- всяка стойност в извадката.
- x i (\displaystyle x_(i))трябва да извадите x̅, да го повдигнете на квадрат и след това да добавите резултатите.
- x̅ – извадкова средна (извадкова средна).
- n е броят на стойностите в извадката.
-
Изчислете средната стойност на извадката.Означава се като x̅. Средната стойност на извадката се изчислява като нормална средна аритметична стойност: добавете всички стойности в извадката и след това разделете резултата на броя на стойностите в извадката.
- В нашия пример добавете стойностите в извадката: 15 + 17 + 23 + 7 + 9 + 13 = 84
Сега разделете резултата на броя на стойностите в извадката (в нашия пример има 6): 84 ÷ 6 = 14.
Примерна средна x̅ = 14. - Средната стойност на извадката е централната стойност, около която се разпределят стойностите в извадката. Ако стойностите в клъстера на извадката около извадката са средни, тогава дисперсията е малка; в противен случай дисперсията е голяма.
- В нашия пример добавете стойностите в извадката: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Извадете средната стойност на извадката от всяка стойност в извадката.Сега изчислете разликата x i (\displaystyle x_(i))- x̅, където x i (\displaystyle x_(i))- всяка стойност в извадката. Всеки получен резултат показва степента, до която определена стойност се отклонява от средната стойност на извадката, тоест колко далеч е тази стойност от средната стойност на извадката.
- В нашия пример:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Правилността на получените резултати е лесна за проверка, тъй като тяхната сума трябва да е равна на нула. Това е свързано с определянето на средната стойност, тъй като отрицателните стойности (разстояния от средната стойност до по-малки стойности) са напълно компенсирани от положителни стойности (разстояния от средната стойност до по-големи стойности).
- В нашия пример:
-
Както беше отбелязано по-горе, сумата от разликите x i (\displaystyle x_(i))- x̅ трябва да е равно на нула. Това означава, че средната дисперсия винаги е нула, което не дава представа за разпространението на стойностите на някакво количество. За да разрешите тази задача, повдигнете на квадрат всяка разлика x i (\displaystyle x_(i))- х. Това ще доведе до получаване само на положителни числа, които, когато се съберат, никога няма да дадат 0.
- В нашия пример:
(x 1 (\displaystyle x_(1))-х) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))-х) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Намерихте квадрата на разликата - x̅) 2 (\displaystyle ^(2))за всяка стойност в извадката.
- В нашия пример:
-
Изчислете сумата на квадратите на разликите.Тоест намерете частта от формулата, която е написана така: ∑[( x i (\displaystyle x_(i))-х) 2 (\displaystyle ^(2))]. Тук знакът Σ означава сумата от квадратните разлики за всяка стойност x i (\displaystyle x_(i))в пробата. Вече намерихте разликите на квадрат (x i (\displaystyle (x_(i))-х) 2 (\displaystyle ^(2))за всяка стойност x i (\displaystyle x_(i))в пробата; сега просто добавете тези квадратчета.
- В нашия пример: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Разделете резултата на n - 1, където n е броят на стойностите в извадката.Преди време, за да изчислят дисперсията на извадката, статистиците просто разделиха резултата на n; в този случай ще получите средната стойност на квадратната дисперсия, която е идеална за описание на дисперсията на дадена проба. Но не забравяйте, че всяка извадка е само малка част от общата съвкупност от стойности. Ако вземете различна проба и направите същите изчисления, ще получите различен резултат. Както се оказва, разделянето на n - 1 (вместо само на n) дава по-добра оценка на дисперсията на съвкупността, което е това, което търсите. Деленето на n - 1 е станало обичайно, така че е включено във формулата за изчисляване на дисперсията на извадката.
- В нашия пример извадката включва 6 стойности, тоест n = 6.
Дисперсия на извадката = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- В нашия пример извадката включва 6 стойности, тоест n = 6.
-
Разликата между дисперсията и стандартното отклонение.Имайте предвид, че формулата съдържа експонента, така че дисперсията се измерва в квадратни единици на анализираната стойност. Понякога такава стойност е доста трудна за работа; в такива случаи се използва стандартното отклонение, което е равно на корен квадратен от дисперсията. Ето защо дисперсията на извадката се означава като s 2 (\displaystyle s^(2)), и стандартното отклонение на извадката като s (\displaystyle s).
- В нашия пример примерното стандартно отклонение е: s = √33,2 = 5,76.
Изчисляване на дисперсията на популацията
-
Анализирайте някакъв набор от стойности.Комплектът включва всички стойности на разглежданото количество. Например, ако изучавате възрастта на жителите на Ленинградска област, тогава населението включва възрастта на всички жители на този регион. В случай на работа с агрегат се препоръчва да създадете таблица и да въведете стойностите на агрегата в нея. Разгледайте следния пример:
- В дадена стая има 6 аквариума. Всеки аквариум съдържа следния брой риби:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- В дадена стая има 6 аквариума. Всеки аквариум съдържа следния брой риби:
-
Запишете формулата за изчисляване на дисперсията на съвкупността.Тъй като популацията включва всички стойности на определено количество, следната формула ви позволява да получите точната стойност на дисперсията на популацията. За да разграничат вариацията на популацията от вариацията на извадката (която е само приблизителна), статистиците използват различни променливи:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / н
- σ 2 (\displaystyle ^(2))- дисперсия на популацията (разчетена като "сигма на квадрат"). Дисперсията се измерва в квадратни единици.
- x i (\displaystyle x_(i))- всяка стойност в съвкупността.
- Σ е знакът на сумата. Тоест за всяка стойност x i (\displaystyle x_(i))извадете μ, повдигнете го на квадрат и след това добавете резултатите.
- μ е средната популация.
- n е броят на стойностите в общата съвкупност.
-
Изчислете средната стойност на населението.Когато се работи с генералната съвкупност, нейната средна стойност се означава като μ (mu). Средната популация се изчислява като обичайната средна аритметична стойност: добавете всички стойности в популацията и след това разделете резултата на броя на стойностите в популацията.
- Имайте предвид, че средните стойности не винаги се изчисляват като средно аритметично.
- В нашия пример населението означава: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Извадете средната популация от всяка стойност в популацията.Колкото по-близо е стойността на разликата до нула, толкова по-близо е конкретната стойност до средната за съвкупността. Намерете разликата между всяка стойност в популацията и нейната средна стойност и ще получите първи поглед върху разпределението на стойностите.
- В нашия пример:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- В нашия пример:
-
Квадратирайте всеки получен резултат.Стойностите на разликата ще бъдат както положителни, така и отрицателни; ако поставите тези стойности на числова ос, тогава те ще лежат отдясно и отляво на средната стойност на съвкупността. Това не е добре за изчисляване на дисперсията, тъй като положителните и отрицателните числа взаимно се компенсират. Затова повдигнете на квадрат всяка разлика, за да получите изключително положителни числа.
- В нашия пример:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))за всяка стойност на популацията (от i = 1 до i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), където x n (\displaystyle x_(n))е последната стойност в популацията. - За да изчислите средната стойност на получените резултати, трябва да намерите тяхната сума и да я разделите на n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / н
- Сега нека напишем горното обяснение с помощта на променливи: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n и получете формула за изчисляване на дисперсията на съвкупността.
- В нашия пример:
Дисперсия в статистикатасе намира като отделни стойности на характеристиката в квадрата на . В зависимост от първоначалните данни, тя се определя по формулите за проста и претеглена дисперсия:
1. (за негрупирани данни) се изчислява по формулата:
2. Претеглена дисперсия (за серия от варианти):
 където n е честотата (коефициент на повторяемост X)
където n е честотата (коефициент на повторяемост X)
Пример за намиране на дисперсията
Тази страница описва стандартен пример за намиране на дисперсията, можете също да разгледате други задачи за намирането й
Пример 1. Имаме следните данни за група от 20 задочни студенти. Необходимо е да се изгради интервална серия на разпределението на признака, да се изчисли средната стойност на признака и да се изследва неговата дисперсия
 Нека изградим интервално групиране. Нека определим диапазона на интервала по формулата:
Нека изградим интервално групиране. Нека определим диапазона на интервала по формулата:
![]() където X max е максималната стойност на групиращия признак;
където X max е максималната стойност на групиращия признак;
X min е минималната стойност на групиращия признак;
n е броят на интервалите:
Приемаме n=5. Стъпката е: h \u003d (192 - 159) / 5 \u003d 6,6
Нека направим интервално групиране
 За по-нататъшни изчисления ще изградим спомагателна таблица:
За по-нататъшни изчисления ще изградим спомагателна таблица:
 X'i е средата на интервала. (например средата на интервала 159 - 165.6 = 162.3)
X'i е средата на интервала. (например средата на интервала 159 - 165.6 = 162.3)
Средният растеж на учениците се определя по формулата на среднопретеглената аритметична стойност:
 Определяме дисперсията по формулата:
Определяме дисперсията по формулата:
Формулата на дисперсията може да се преобразува, както следва:

От тази формула следва, че дисперсията е разликата между средната стойност на квадратите на опциите и квадрата и средната стойност.
Дисперсия във вариационни сериис равни интервали по метода на моментите може да се изчисли по следния начин, като се използва второто свойство на дисперсия (разделяне на всички опции на стойността на интервала). Дефиниция на дисперсия, изчислено по метода на моментите, по следната формула отнема по-малко време:

където i е стойността на интервала;
A - условна нула, която е удобна за използване в средата на интервала с най-висока честота;
m1 е квадратът на момента от първи ред;
m2 - момент от втори ред
(ако в статистическата популация атрибутът се променя по такъв начин, че има само две взаимно изключващи се опции, тогава такава променливост се нарича алтернативна) може да се изчисли по формулата:

Замествайки в тази дисперсионна формула q = 1- p, получаваме:

Видове дисперсия
Обща дисперсияизмерва вариацията на даден признак в цялата популация като цяло под влиянието на всички фактори, които причиняват тази вариация. Тя е равна на средния квадрат на отклоненията на отделните стойности на атрибута x от общата средна стойност x и може да се определи като проста дисперсия или претеглена дисперсия.
характеризира случайна вариация, т.е. част от вариацията, която се дължи на влиянието на неотчетени фактори и не зависи от знака-фактор, лежащ в основата на групирането. Тази дисперсия е равна на средния квадрат на отклоненията на отделните стойности на атрибута в групата X от средната аритметична на групата и може да се изчисли като проста дисперсия или като претеглена дисперсия.
По този начин, мерки за дисперсия в рамките на групатавариация на признак в група и се определя по формулата:

където xi - средна група;
ni е броят на единиците в групата.
Например, вътрешногруповите отклонения, които трябва да бъдат определени в задачата за изследване на ефекта от квалификацията на работниците върху нивото на производителността на труда в цеха, показват вариации в производството във всяка група, причинени от всички възможни фактори (техническо състояние на оборудването, наличие на инструменти и материали, възраст на работниците, интензивност на труда и др.), с изключение на разликите в квалификационната категория (в рамките на групата всички работници имат една и съща квалификация).
Средната стойност на дисперсиите в рамките на групата отразява случайната, т.е. онази част от вариацията, която е възникнала под влиянието на всички други фактори, с изключение на фактора за групиране. Изчислява се по формулата:

Той характеризира систематичната вариация на резултантния признак, която се дължи на влиянието на признака-фактор, лежащ в основата на групирането. Тя е равна на средния квадрат на отклоненията на груповите средни стойности от общата средна стойност. Междугруповата дисперсия се изчислява по формулата:

Правило за добавяне на дисперсии в статистиката
Според правило за добавяне на дисперсииобщата дисперсия е равна на сумата от средната стойност на вътрешногруповите и междугруповите дисперсии:
![]()
Значението на това правилое, че общата дисперсия, която възниква под влиянието на всички фактори, е равна на сумата от дисперсиите, които възникват под влиянието на всички други фактори, и дисперсията, която възниква поради групиращия фактор.
Използвайки формулата за добавяне на дисперсии, е възможно да се определи третото неизвестно от две известни дисперсии, както и да се прецени силата на влиянието на атрибута за групиране.
Свойства на дисперсия
1. Ако всички стойности на атрибута се намалят (увеличат) със същата постоянна стойност, тогава дисперсията няма да се промени от това.
2. Ако всички стойности на атрибута се намалят (увеличат) с еднакъв брой пъти n, тогава дисперсията съответно ще намалее (увеличи) с n^2 пъти.
 Ораторското изкуство като първообраз на журналистиката
Ораторското изкуство като първообраз на журналистиката Цитати за Наполеон - dslinkov — LiveJournal
Цитати за Наполеон - dslinkov — LiveJournal Аз отмъщение Човекът на булдозера унищожи града
Аз отмъщение Човекът на булдозера унищожи града