За какво е дисперсията? Остатъчна дисперсия
стъпки
Примерно изчисляване на дисперсията
-
Запишете пробните стойности.В повечето случаи само извадки от определени популации са достъпни за статистиците. Например, като правило, статистиците не анализират разходите за поддръжка на съвкупността от всички автомобили в Русия - те анализират произволна извадкаот няколко хиляди коли. Такава извадка ще помогне да се определи средната цена на автомобил, но най-вероятно получената стойност ще бъде далеч от реалната.
- Например, нека анализираме броя на кифлите, продадени в кафене за 6 дни, взети в произволен ред. Пробата има следващ изглед: 17, 15, 23, 7, 9, 13. Това е извадка, а не съвкупност, защото нямаме данни за продадени кифли за всеки ден, в който кафенето е отворено.
- Ако ви е дадена популация, а не извадка от стойности, преминете към следващия раздел.
-
Запишете формулата за изчисляване на дисперсията на извадката.Дисперсията е мярка за разпространението на стойностите на някакво количество. Колкото по-близо е стойността на дисперсията до нула, толкова по-близо са групирани стойностите. Когато работите с извадка от стойности, използвайте следната формула, за да изчислите дисперсията:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-х) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))е дисперсията. Дисперсията се измерва в квадратни единициизмервания.
- x i (\displaystyle x_(i))- всяка стойност в извадката.
- x i (\displaystyle x_(i))трябва да извадите x̅, да го повдигнете на квадрат и след това да добавите резултатите.
- x̅ – извадкова средна (извадкова средна).
- n е броят на стойностите в извадката.
-
Изчислете средната стойност на извадката.Означава се като x̅. Средната стойност на извадката се изчислява като нормална средна аритметична стойност: добавете всички стойности в извадката и след това разделете резултата на броя на стойностите в извадката.
- В нашия пример добавете стойностите в извадката: 15 + 17 + 23 + 7 + 9 + 13 = 84
Сега разделете резултата на броя на стойностите в извадката (в нашия пример има 6): 84 ÷ 6 = 14.
Примерна средна x̅ = 14. - Средната стойност на извадката е централната стойност, около която се разпределят стойностите в извадката. Ако стойностите в клъстера на извадката около извадката са средни, тогава дисперсията е малка; в противен случай дисперсията е голяма.
- В нашия пример добавете стойностите в извадката: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Извадете средната стойност на извадката от всяка стойност в извадката.Сега изчислете разликата x i (\displaystyle x_(i))- x̅, където x i (\displaystyle x_(i))- всяка стойност в извадката. Всеки получен резултат показва степента, до която определена стойност се отклонява от средната стойност на извадката, тоест колко далеч е тази стойност от средната стойност на извадката.
- В нашия пример:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Правилността на получените резултати е лесна за проверка, тъй като тяхната сума трябва да е равна на нула. Това е свързано с определянето на средната стойност, тъй като отрицателни стойности(разстояния от средната стойност до по-малки стойности) са напълно компенсирани положителни стойности(разстояния от средни до големи стойности).
- В нашия пример:
-
Както беше отбелязано по-горе, сумата от разликите x i (\displaystyle x_(i))- x̅ трябва да е равно на нула. Означава, че средна дисперсиявинаги е равно на нула, което не дава никаква представа за разпространението на стойностите на определена величина. За да разрешите тази задача, повдигнете на квадрат всяка разлика x i (\displaystyle x_(i))- х. Това ще доведе до получаване само на положителни числа, което при добавяне никога няма да даде 0.
- В нашия пример:
(x 1 (\displaystyle x_(1))-х) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))-х) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Намерихте квадрата на разликата - x̅) 2 (\displaystyle ^(2))за всяка стойност в извадката.
- В нашия пример:
-
Изчислете сумата на квадратите на разликите.Тоест намерете частта от формулата, която е написана така: ∑[( x i (\displaystyle x_(i))-х) 2 (\displaystyle ^(2))]. Тук знакът Σ означава сумата от квадратните разлики за всяка стойност x i (\displaystyle x_(i))в пробата. Вече намерихте разликите на квадрат (x i (\displaystyle (x_(i))-х) 2 (\displaystyle ^(2))за всяка стойност x i (\displaystyle x_(i))в пробата; сега просто добавете тези квадратчета.
- В нашия пример: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Разделете резултата на n - 1, където n е броят на стойностите в извадката.Преди време, за да изчислят дисперсията на извадката, статистиците просто разделиха резултата на n; в този случай ще получите средната стойност на квадратната дисперсия, която е идеална за описание на дисперсията на дадена проба. Но не забравяйте, че всяка проба е само малка част. населениестойности. Ако вземете различна проба и направите същите изчисления, ще получите различен резултат. Както се оказа, деленето на n - 1 (а не само n) дава повече точна оценкавариация на населението, което е това, което ви интересува. Деленето на n - 1 е станало обичайно, така че е включено във формулата за изчисляване на дисперсията на извадката.
- В нашия пример извадката включва 6 стойности, тоест n = 6.
Дисперсия на извадката = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- В нашия пример извадката включва 6 стойности, тоест n = 6.
-
Разликата между дисперсията и стандартното отклонение.Имайте предвид, че формулата съдържа експонента, така че дисперсията се измерва в квадратни единици на анализираната стойност. Понякога такава стойност е доста трудна за работа; в такива случаи се използва стандартното отклонение, което е равно на корен квадратен от дисперсията. Ето защо дисперсията на извадката се означава като s 2 (\displaystyle s^(2)), а стандартно отклонениепроби - как s (\displaystyle s).
- В нашия пример примерното стандартно отклонение е: s = √33,2 = 5,76.
Изчисляване на дисперсията на популацията
-
Анализирайте някакъв набор от стойности.Комплектът включва всички стойности на разглежданото количество. Например, ако изследвате възрастта на жителите Ленинградска област, тогава населението включва възрастта на всички жители на тази област. В случай на работа с агрегат се препоръчва да създадете таблица и да въведете стойностите на агрегата в нея. Разгледайте следния пример:
- В дадена стая има 6 аквариума. Всеки аквариум съдържа следния брой риби:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- В дадена стая има 6 аквариума. Всеки аквариум съдържа следния брой риби:
-
Запишете формулата за изчисляване на дисперсията на съвкупността.Тъй като популацията включва всички стойности на определено количество, следната формула ви позволява да получите точната стойност на дисперсията на популацията. За да разграничат вариацията на популацията от вариацията на извадката (която е само приблизителна), статистиците използват различни променливи:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / н
- σ 2 (\displaystyle ^(2))- дисперсия на популацията (разчетена като "сигма на квадрат"). Дисперсията се измерва в квадратни единици.
- x i (\displaystyle x_(i))- всяка стойност в съвкупността.
- Σ е знакът на сумата. Тоест за всяка стойност x i (\displaystyle x_(i))извадете μ, повдигнете го на квадрат и след това добавете резултатите.
- μ е средната популация.
- n е броят на стойностите в общата съвкупност.
-
Изчислете средната стойност на населението.Когато се работи с генералната съвкупност, нейната средна стойност се означава като μ (mu). Средната популация се изчислява като обичайната средна аритметична стойност: добавете всички стойности в популацията и след това разделете резултата на броя на стойностите в популацията.
- Имайте предвид, че средните стойности не винаги се изчисляват като средно аритметично.
- В нашия пример населението означава: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Извадете средната популация от всяка стойност в популацията.Колкото по-близо е стойността на разликата до нула, толкова по-близо е конкретната стойност до средната за съвкупността. Намерете разликата между всяка стойност в популацията и нейната средна стойност и ще получите първи поглед върху разпределението на стойностите.
- В нашия пример:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- В нашия пример:
-
Квадратирайте всеки получен резултат.Стойностите на разликата ще бъдат както положителни, така и отрицателни; ако поставите тези стойности на числова ос, тогава те ще лежат отдясно и отляво на средната стойност на съвкупността. Това не е подходящо за изчисляване на дисперсията, тъй като положителни и отрицателни числавзаимно се компенсират. Затова повдигнете на квадрат всяка разлика, за да получите изключително положителни числа.
- В нашия пример:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))за всяка стойност на популацията (от i = 1 до i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), където x n (\displaystyle x_(n)) – последна стойноств общата популация. - За да изчислите средната стойност на получените резултати, трябва да намерите тяхната сума и да я разделите на n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / н
- Сега нека напишем горното обяснение с помощта на променливи: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n и получете формула за изчисляване на дисперсията на съвкупността.
- В нашия пример:
Нека изчислим вГОСПОЖИЦАEXCELдисперсия и стандартно отклонение на извадката. Ние също изчисляваме дисперсията на случайна променлива, ако е известно нейното разпределение.
Първо помислете дисперсия, тогава стандартно отклонение.
Дисперсия на извадката
Дисперсия на извадката (дисперсия на извадката,пробадисперсия) характеризира разпространението на стойностите в масива спрямо .
И трите формули са математически еквивалентни.
От първата формула се вижда, че дисперсия на извадкатае сумата от квадратите на отклоненията на всяка стойност в масива от средноразделено на размера на извадката минус 1.
дисперсия пробиизползва се функцията DISP(), бълг. името на VAR, т.е. ВАРИАНЦИЯ. От MS EXCEL 2010 се препоръчва използването на неговия аналог DISP.V() , англ. името ВАРС, т.е. Дисперсия на пробата. Освен това, започвайки от версията на MS EXCEL 2010, има функция DISP.G (), англ. VARP име, т.е. Популация VARIance, която изчислява дисперсияза население. Цялата разлика се свежда до знаменателя: вместо n-1 като DISP.V(), DISP.G() има само n в знаменателя. Преди MS EXCEL 2010 функцията VARP() се използваше за изчисляване на дисперсията на популацията.
Дисперсия на извадката
=КВАДРАТ(Проба)/(БРОЙ(Проба)-1)
=(SUMSQ(Извадка)-БРОЙ(Извадка)*СРЕДНО(Извадка)^2)/ (БРОЙ(Извадка)-1)- обичайната формула
=SUM((Пример -СРЕДНО(Пример))^2)/ (БРОЙ(Пример)-1) –
Дисперсия на извадкатае равно на 0 само ако всички стойности са равни една на друга и съответно са равни средна стойност. Обикновено колкото по-голяма е стойността дисперсия, толкова по-голямо е разпространението на стойностите в масива.
Дисперсия на извадкатае точкова оценка дисперсияразпределение на случайната променлива, от която проба. Относно сградата доверителни интервали при оценяване дисперсияможе да се прочете в статията.
Дисперсия на случайна променлива
Да изчисля дисперсияслучайна променлива, трябва да я знаете.
За дисперсияслучайната променлива X често използва нотацията Var(X). дисперсияе равно на квадрата на отклонението от средната E(X): Var(X)=E[(X-E(X)) 2 ]
дисперсияизчислено по формулата:

където x i е стойността, която може да приеме произволна стойност, а μ е средната стойност (), p(x) е вероятността случайната променлива да приеме стойността x.
Ако случайната променлива има , тогава дисперсияизчислено по формулата:

Измерение дисперсиясъответства на квадрата на мерната единица на първоначалните стойности. Например, ако стойностите в извадката са измервания на теглото на детайла (в kg), тогава размерът на дисперсията ще бъде kg 2 . Това може да бъде трудно за тълкуване, следователно, за характеризиране на разпространението на стойности, стойност, равна на корен квадратен от дисперсия – стандартно отклонение.
Някои имоти дисперсия:
Var(X+a)=Var(X), където X е случайна променлива, а a е константа.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Това свойство на дисперсия се използва в статия за линейна регресия.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), където X и Y са случайни променливи, Cov(X;Y) е ковариацията на тези случайни променливи.
Ако случайните променливи са независими, тогава техните ковариацияе 0 и следователно Var(X+Y)=Var(X)+Var(Y). Това свойство на дисперсията се използва в изхода.
Нека покажем това за независими променливи Var(X-Y)=Var(X+Y). Наистина Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Това свойство на дисперсията се използва за начертаване.
Примерно стандартно отклонение
Примерно стандартно отклонениее мярка за това колко широко са разпръснати стойностите в извадката спрямо техните .
По дефиниция, стандартно отклонениее равно на корен квадратен от дисперсия:

Стандартно отклонениене взема предвид големината на стойностите в вземане на проби, а само степента на разпръскване на ценностите около тях средата. Нека вземем пример, за да илюстрираме това.
Нека изчислим стандартното отклонение за 2 проби: (1; 5; 9) и (1001; 1005; 1009). И в двата случая s=4. Очевидно е, че съотношението на стандартното отклонение към стойностите на масива е значително различно за пробите. За такива случаи използвайте Коефициентът на вариация(Coefficient of Variation, CV) - отношение стандартно отклонениедо средното аритметика, изразено като процент.
В MS EXCEL 2007 и по-нова версия ранни версиида изчисля Примерно стандартно отклонениеизползва се функцията =STDEV(), бълг. името STDEV, т.е. стандартно отклонение. От MS EXCEL 2010 се препоръчва използването на неговия аналог = STDEV.B () , англ. име STDEV.S, т.е. Примерно стандартно отклонение.
Освен това, започвайки от версията на MS EXCEL 2010, има функция STDEV.G () , англ. име STDEV.P, т.е. Популация Стандартно отклонение, което изчислява стандартно отклонениеза население. Цялата разлика се свежда до знаменателя: вместо n-1 като STDEV.V(), STDEV.G() има само n в знаменателя.
Стандартно отклонениеможе също да се изчисли директно от формулите по-долу (вижте примерния файл)
=SQRT(SQUADROTIV(Проба)/(БРОЙ(Проба)-1))
=SQRT((SUMSQ(Проба)-БРОЙ(Проба)*СРЕДНО(Проба)^2)/(БРОЙ(Проба)-1))
Други мерки за дисперсия
Функцията SQUADRIVE() изчислява с umm на квадратни отклонения на стойностите от техните средата. Тази функция ще върне същия резултат като формулата =VAR.G( проба)*ПРОВЕРКА( проба) , където проба- препратка към диапазон, съдържащ масив от примерни стойности (). Изчисленията във функцията QUADROTIV() се правят по формулата:

Функцията SROOT() също е мярка за разсейването на набор от данни. Функцията AVERAGE() изчислява средната стойност абсолютни стойностиотклонения от средата. Тази функция ще върне същия резултат като формулата =SUMPRODUCT(ABS(Пример-СРЕДЕН(Пример)))/БРОЙ(Пример), където проба- препратка към диапазон, съдържащ масив от примерни стойности.
Изчисленията във функцията SROOTKL () се правят по формулата:

Само тази характеристика обаче все още не е достатъчна за изследване на случайна променлива. Представете си двама стрелци, които стрелят по мишена. Единият стреля точно и улучва близо до центъра, а другият ... просто се забавлява и дори не се прицелва. Но смешното е, че средно аритметичнорезултатът ще бъде абсолютно същият като при първия стрелец! Тази ситуация условно се илюстрира със следните случайни променливи:
„Снайперисткото“ математическо очакване е равно на , обаче, " интересна личност»: - също е нула!
Следователно е необходимо да се определи количествено докъде разпръснатикуршуми (произволни стойности) спрямо центъра на целта ( математическо очакване). добре и разсейванепреведено от латински само като дисперсия .
Нека да видим как се дефинира това. числена характеристикана един от примерите от 1-ва част на урока: 
Там открихме разочароващо математическо очакване на тази игра и сега трябва да изчислим нейната дисперсия, която означенопрез .
Нека да разберем колко далеч са "разпръснати" печалбите/загубите спрямо средната стойност. Очевидно за това трябва да изчислим различиямежду стойности на случайна променливаи тя математическо очакване:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Сега изглежда е необходимо да се обобщят резултатите, но този начин не е добър - поради причината, че трептенията вляво ще се компенсират взаимно с трептенията вдясно. Така например "аматьорският" стрелец (пример по-горе)разликите ще са ![]() , и когато се добавят, те ще дадат нула, така че няма да получим никаква оценка за разсейването на неговата стрелба.
, и когато се добавят, те ще дадат нула, така че няма да получим никаква оценка за разсейването на неговата стрелба.
За да избегнете това раздразнение, помислете модулиразлики, но по технически причини подходът се е утвърдил, когато те са повдигнати на квадрат. По-удобно е решението да се подреди в таблица: 
И тук е необходимо да се изчисли среднопретеглена стойностстойността на квадратните отклонения. Какво е? Тяхно е очаквана стойност, което е мярката за разсейване:
![]() – определениедисперсия. Веднага става ясно от определението, че дисперсията не може да бъде отрицателна- вземете бележка за практика!
– определениедисперсия. Веднага става ясно от определението, че дисперсията не може да бъде отрицателна- вземете бележка за практика!
Нека си припомним как да намерим очакването. Умножете разликите на квадрат по съответните вероятности (Продължение на таблицата):
- образно казано, това е "теглителна сила",
и обобщете резултатите:
Не мислите ли, че на фона на печалбите резултатът се оказа твърде голям? Точно така – повдигахме на квадрат и за да се върнем към размерността на нашата игра, трябва да извадим корен квадратен. Тази стойностНаречен стандартно отклонение
и се обозначава с гръцката буква "сигма":
Понякога това значение се нарича стандартно отклонение .
Какво е значението му? Ако се отклоним от математическото очакване наляво и надясно със средната стойност стандартно отклонение:![]()
– тогава най-вероятните стойности на случайната променлива ще бъдат „концентрирани“ в този интервал. Какво всъщност виждаме:
Но така се случи, че при анализа на разсейването почти винаги се работи с концепцията за дисперсия. Нека да видим какво означава това във връзка с игрите. Ако при стрелците говорим за "точността" на попаденията спрямо центъра на мишената, то тук дисперсията характеризира две неща:
Първо, очевидно е, че с увеличаването на ставките дисперсията също се увеличава. Така например, ако увеличим 10 пъти, тогава математическото очакване ще се увеличи 10 пъти, а дисперсията ще се увеличи 100 пъти (щом е квадратична стойност). Но имайте предвид, че правилата на играта не са се променили! Само ставките се промениха, грубо казано, преди залагахме 10 рубли, сега 100.
Второ, повече интересен моменте, че дисперсията характеризира стила на играта. Мислено фиксирайте ставките на играта на някакво определено нивои вижте какво има тук:
Игра с ниска вариация е предпазлива игра. Играчът е склонен да избира най-надеждните схеми, при които не губи/печели твърде много наведнъж. Например системата червено/черно в рулетката (вижте Пример 4 от статията случайни променливи) .
Игра с висока вариация. Тя често се нарича дисперсияигра. Това е приключенски или агресивен стил на игра, при който играчът избира "адреналинови" схеми. Да си спомним поне "Мартингейл", в която заложените суми са с порядъци по-големи от „тихата“ игра от предходния параграф.
Ситуацията в покера е показателна: има т.нар стегнатииграчи, които са склонни да бъдат предпазливи и да "разклащат" средствата си за игра (банкрол). Не е изненадващо, че банкролът им не се колебае много (ниска вариация). Обратно, ако даден играч има висока вариация, тогава той е агресорът. Той често поема рискове, прави големи залози и може както да разбие огромна банка, така и да се разпадне.
Същото се случва във Форекс и т.н. - има много примери.
Освен това във всички случаи няма значение дали играта е за стотинка или за хиляди долари. Всяко ниво има играчи с ниска и висока вариация. Е, за средната победа, както си спомняме, "отговорен" очаквана стойност.
Вероятно сте забелязали, че намирането на дисперсията е дълъг и труден процес. Но математиката е щедра:
Формула за намиране на дисперсията
Тази формулаполучен директно от определението за дисперсия и ние веднага го пускаме в обращение. Ще копирам табелата с нашата игра отгоре: 
и намереното очакване .
Изчисляваме дисперсията по втория начин. Първо, нека намерим математическото очакване - квадратът на случайната променлива. от дефиниция на математическото очакване:
AT този случай:
Така, според формулата:
Както се казва, усетете разликата. И на практика, разбира се, е по-добре да се прилага формулата (освен ако условието не изисква друго).
Ние владеем техниката на решаване и проектиране:
Пример 6

Намерете неговото математическо очакване, дисперсия и стандартно отклонение.
Тази задача се среща навсякъде и като правило остава без смислен смисъл.
Можете да си представите няколко крушки с цифри, които светят в лудница с определени вероятности :)
Решение: Удобно е основните изчисления да се обобщят в таблица. Първо записваме първоначалните данни в горните два реда. След това изчисляваме продуктите, след това и накрая сумите в дясната колона: 
Всъщност почти всичко е готово. В третия ред беше начертано готово математическо очакване: ![]() .
.
Дисперсията се изчислява по формулата:
И накрая, стандартното отклонение:
- лично аз обикновено закръглявам до 2 знака след десетичната запетая.
Всички изчисления могат да се извършват на калкулатор, а още по-добре - в Excel:
Тук е трудно да сбъркаш :)
Отговор:
Тези, които желаят, могат да опростят живота си още повече и да се възползват от моите калкулатор (демонстрация), което не само незабавно ще реши тази задача, но и изграждат тематична графика (Ела скоро). Програмата може изтеглете в библиотеката– ако сте изтеглили поне един учебен материалили да получите друг начин. Благодаря за подкрепата на проекта!
Няколко задачи за независимо решение:
Пример 7
Изчислете дисперсията на случайната променлива от предишния пример по дефиниция.
И подобен пример:
Пример 8
Дискретна случайна променлива се дава от собствен закон за разпределение:

Да, стойностите на случайната променлива могат да бъдат доста големи (пример от истинска работа) , а тук по възможност използвайте Excel. Както, между другото, в пример 7 - той е по-бърз, по-надежден и по-приятен.
Решения и отговори в долната част на страницата.
В края на 2-ра част на урока ще анализираме още един типична задача, дори може да се каже, малък ребус:
Пример 9
Дискретна случайна променлива може да приема само две стойности: и , и . Известни са вероятността, математическото очакване и дисперсията.
Решение: Да започнем с неизвестна вероятност. Тъй като една случайна променлива може да приеме само две стойности, тогава сумата от вероятностите на съответните събития:
и тъй като , тогава .
Остава да намерим ..., лесно да се каже :) Но добре, започна се. По дефиниция на математическото очакване: ![]() - заменете известните стойности:
- заменете известните стойности:
![]() - и нищо повече не може да се изтръгне от това уравнение, освен че можете да го пренапишете в обичайната посока:
- и нищо повече не може да се изтръгне от това уравнение, освен че можете да го пренапишете в обичайната посока: ![]()

или: ![]()
О следващи стъпкиМисля, че можете да познаете. Нека създадем и решим системата: 
Десетични знаци- това, разбира се, е пълно безобразие; умножете двете уравнения по 10: 
и разделете на 2: 
Така е много по-добре. От първото уравнение изразяваме: ![]() (това е по-лесният начин)- заместител във второто уравнение:
(това е по-лесният начин)- заместител във второто уравнение:
![]()
Ние строим на квадрати направете опростявания: 
Умножаваме по: 
Като резултат, квадратно уравнение, намерете неговия дискриминант:
- перфектно!
и получаваме две решения:
1) ако ![]() , тогава
, тогава ![]() ;
;
2) ако ![]() , тогава .
, тогава .
Първата двойка стойности удовлетворява условието. С голяма вероятност всичко е правилно, но въпреки това записваме закона за разпределение: 
и извършете проверка, а именно намерете очакването:
Дисперсията е мярка за дисперсия, която описва относителното отклонение между стойностите на данните и средната стойност. Това е най-често използваната мярка за дисперсия в статистиката, изчислена чрез сумиране на квадрат на отклонението на всяка стойност на данните от средната стойност. Формулата за изчисляване на дисперсията е показана по-долу:
![]()
s 2 - дисперсия на извадката;
x cf е средната стойност на извадката;
н — размер на извадката (брой стойности на данните),
(x i – x cf) е отклонението от средната стойност за всяка стойност от набора от данни.
За по-добро разбиранеформули, нека вземем пример. Не обичам много да готвя, така че рядко го правя. Все пак, за да не умра от глад, от време на време трябва да отида до печката, за да изпълня плана за насищане на тялото си с протеини, мазнини и въглехидрати. Наборът от данни по-долу показва колко пъти Ренат готви храна всеки месец:
Първата стъпка при изчисляването на дисперсията е да се определи средната стойност на извадката, която в нашия пример е 7,8 пъти на месец. Останалите изчисления могат да бъдат улеснени с помощта на следната таблица.

Последната фаза на изчисляване на дисперсията изглежда така:
![]()
За тези, които обичат да правят всички изчисления наведнъж, уравнението ще изглежда така:
Използване на метода за броене на суровини (пример за готвене)
Има още ефективен методизчисляване на дисперсията, известен като метод на "сурово броене". Въпреки че на пръв поглед уравнението може да изглежда доста тромаво, всъщност не е толкова страшно. Можете да проверите това и след това да решите кой метод ви харесва най-добре.

е сумата от всяка стойност на данните след повдигане на квадрат,
е квадратът на сумата от всички стойности на данните.
Не си губете ума точно сега. Нека поставим всичко под формата на таблица и тогава ще видите, че тук има по-малко изчисления, отколкото в предишния пример.


Както можете да видите, резултатът е същият като при използване на предишния метод. Предимства този методстават очевидни, когато размерът на извадката (n) нараства.
Изчисляване на дисперсия в Excel
Както вероятно вече се досещате, Excel има формула, която ви позволява да изчислите дисперсията. Освен това, като се започне от Excel 2010, можете да намерите 4 разновидности на дисперсионната формула:
1) VAR.V – Връща дисперсията на извадката. Булевите стойности и текстът се игнорират.
2) VAR.G – Връща дисперсията на популацията. Булевите стойности и текстът се игнорират.
3) VASP – Връща примерната вариация, като взема предвид булевите и текстовите стойности.
4) VARP – Връща дисперсията на съвкупността, като взема предвид логическите и текстовите стойности.
Първо, нека да разгледаме разликата между извадка и популация. Предназначение Описателна статистикае да се обобщят или покажат данните по такъв начин, че бързо да се получи общата картина, така да се каже, преглед. Статистическото заключение ви позволява да правите изводи за популация въз основа на извадка от данни от тази популация. Популацията представлява всички възможни резултати или измервания, които са от интерес за нас. Извадката е подмножество от популация.
Например, ние се интересуваме от съвкупността от група ученици на един от руски университетии трябва да определим средния резултат на групата. Можем да броим средна производителностстуденти и тогава получената цифра ще бъде параметър, тъй като цялата популация ще бъде включена в нашите изчисления. Ако обаче искаме да изчислим GPA на всички ученици у нас, тогава тази група ще бъде нашата извадка.
Разликата във формулата за изчисляване на дисперсията между извадката и съвкупността е в знаменателя. Където за извадката ще бъде равно на (n-1), а за генералната съвкупност само n.
Сега нека се заемем с функциите за изчисляване на дисперсията с окончания НО,в описанието на което се казва, че изчислението взема предвид текстови и логически стойности. В този случай, когато се изчислява дисперсията на определен масив от данни, където ги няма числови стойности, Excel ще интерпретира текста и фалшивите булеви стойности като 0, а истинските булеви стойности като 1.
Така че, ако имате масив от данни, няма да е трудно да изчислите дисперсията му с помощта на една от изброените по-горе функции на Excel.

Диапазон на вариация (или диапазон на вариация) -е разликата между максимума и минимални стойностизнак:
В нашия пример диапазонът на изменение на сменната продукция на работниците е: в първа бригада R=105-95=10 деца, във втора бригада R=125-75=50 деца. (5 пъти повече). Това предполага, че продукцията на 1-ва бригада е по-„стабилна“, но втората бригада има повече резерви за растеж на продукцията, т.к. ако всички работници достигнат максималната производителност за тази бригада, тя може да произведе 3 * 125 = 375 части, а в 1-ва бригада само 105 * 3 = 315 части.
Ако екстремни стойностичертите не са типични за популацията, тогава се използват квартилни или децилни диапазони. Квартилният диапазон RQ= Q3-Q1 обхваща 50% от населението, първият децилен диапазон RD1 = D9-D1 покрива 80% от данните, вторият децилен диапазон RD2= D8-D2 покрива 60%.
Недостатъкът на индикатора диапазон на вариацияе, но стойността му не отразява всички колебания на атрибута.
Най-простият обобщаващ показател, който отразява всички колебания на даден признак, е средно линейно отклонение, което е средноаритметичното на абсолютните отклонения на отделните опции от средната им стойност:
,
за групирани данни ![]() ,
,
където хi е стойността на характеристиката в дискретна серияили средата на интервал в интервално разпределение.
В горните формули разликите в числителя се вземат по модул, в противен случай, според свойството на средната аритметична стойност, числителят винаги ще бъде равен на нула. Следователно средното линейно отклонение в статистическата практика се използва рядко, само в случаите, когато сумирането на показатели без отчитане на знака има икономически смисъл. С негова помощ се анализират например съставът на служителите, рентабилността на производството, външнотърговският оборот.
Дисперсия на характеристиките- това е среден квадратотклонения на варианта от средната им стойност:
проста вариация ![]() ,
,
претеглена дисперсия  .
.
Формулата за изчисляване на дисперсията може да бъде опростена:
По този начин дисперсията е равна на разликата между средната стойност на квадратите на варианта и квадрата на средната стойност на варианта на съвкупността:  .
.
Въпреки това, поради сумирането на квадратните отклонения, дисперсията дава изкривена представа за отклоненията, така че средната стойност се изчислява от нея. стандартно отклонение, което показва колко средно се отклоняват конкретните варианти на признака от средната им стойност. Изчислено чрез извличане корен квадратенот дисперсия:
за негрупирани данни 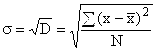 ,
,
за вариационна серия
как по-малка стойностдисперсия и стандартно отклонение, колкото по-хомогенна е популацията, толкова по-надеждна (типична) ще бъде средна стойност.
Линейна средна и средна стандартно отклонение- именувани числа, т.е. те са изразени в мерни единици на атрибута, са идентични по съдържание и близки по значение.
броя абсолютни показателипрепоръчват се вариации с помощта на таблици.
Таблица 3 - Изчисляване на характеристиките на вариацията (на примера на периода на данните за смяната на продукцията на работните екипи)
Брой работници |
Средата на интервала |
Прогнозни стойности |
|||||
Обща сума: |
|||||||
Средна производителност на смени на работниците: ![]()
Средно линейно отклонение: ![]()
Изходна дисперсия: 
Стандартното отклонение на продукцията на отделните работници от средната продукция:
.
1 Изчисляване на дисперсията по метода на моментите
Изчисляването на отклоненията е свързано с тромави изчисления (особено ако се изрази средната стойност Голям бройс няколко знака след десетичната запетая). Изчисленията могат да бъдат опростени чрез използване на опростена формула и дисперсионни свойства.
Дисперсията има следните свойства:
- ако всички стойности на атрибута са намалени или увеличени с една и съща стойност A, тогава дисперсията няма да намалее от това:
 ,
,
 , тогава или
, тогава или 
Използвайки свойствата на дисперсията и първо намалявайки всички варианти на популацията със стойността A и след това разделяйки на стойността на интервала h, получаваме формула за изчисляване на дисперсията във вариационни серии с на равни интервали начин на моменти: ,
,
където е дисперсията, изчислена по метода на моментите;
h е стойността на интервала на вариационната серия;
– нови (трансформирани) вариантни стойности;
НО- постоянен, който се използва като среда на интервала с най-висока честота; или опция, която има най-висока честота;  е квадратът на момента от първи ред;
е квадратът на момента от първи ред;
е момент от втори ред.
Нека изчислим дисперсията по метода на моментите въз основа на данните за сменната продукция на работния екип.
Таблица 4 - Изчисляване на дисперсията по метода на моментите
Групи производствени работници, бр. |
Брой работници |
Средата на интервала |
Прогнозни стойности |
||
Процедура за изчисление:


- изчислете дисперсията:
2 Изчисляване на дисперсията на алтернативен признак
Сред знаците, изследвани от статистиката, има такива, които имат само две взаимно изключващи се значения. Това са алтернативни знаци. Дават им се две количествени стойности: опции 1 и 0. Честотата на опции 1, която се обозначава с p, е делът на единиците, които имат даден атрибут. Разликата 1-p=q е честотата на опциите 0. Така,
xi |
|
Средно аритметично на алтернативен признак ![]() , тъй като p+q=1.
, тъй като p+q=1.
Дисперсия на характеристиките
, защото 1-p=q
По този начин дисперсията на алтернативен атрибут е равна на произведението от дела на единиците, които имат този атрибут, и дела на единиците, които нямат този атрибут.
Ако стойностите 1 и 0 са еднакво често срещани, т.е. p=q, дисперсията достига своя максимум pq=0,25.
Дисперсията на алтернативната функция се използва в извадкови проучваниякато качеството на продукта.
3 Междугрупова дисперсия. Правило за добавяне на дисперсии
Дисперсията, за разлика от други характеристики на вариацията, е количество на добавката. Тоест в съвкупността, която е разделена на групи според факторния критерий х , резултатна дисперсия гможе да се разложи на дисперсия във всяка група (вътре в групата) и дисперсия между групите (между групата). Тогава, наред с изследването на вариацията на признака в цялата популация като цяло, става възможно да се изследва вариацията във всяка група, както и между тези групи.
Обща дисперсияизмерва вариацията на черта привърху цялата съвкупност под влиянието на всички фактори, предизвикали тази вариация (отклонения). То е равно на средното квадратно отклонение индивидуални ценностизнак приот общата средна стойност и може да се изчисли като проста или претеглена дисперсия.
Междугрупова дисперсияхарактеризира вариацията на ефективния признак при, породени от влиянието на знак-фактора хв основата на групирането. Той характеризира вариацията на груповите средни стойности и е равен на средния квадрат на отклоненията на груповите средни от общата средна стойност:  ,
,
където е средноаритметичната стойност на i-та група;
– брой единици в i-та група (честота на i-та група);
- общ средно население.
Вътрешногрупова дисперсияотразява случайната вариация, т.е. тази част от вариацията, която е причинена от влиянието на неотчетени фактори и не зависи от фактора-атрибут, лежащ в основата на групирането. Той характеризира вариацията индивидуални ценностиспрямо груповите средства, равни на средния квадрат на отклоненията на отделните стойности на атрибута прив рамките на група от средната аритметична стойност на тази група (средна група) и се изчислява като проста или претеглена дисперсия за всяка група: ![]() или
или ![]() ,
,
където е броят на единиците в групата.
Въз основа вътрешногрупови отклоненияза всяка група може да се определи общата средна стойност на дисперсиите в рамките на групата:
.
Връзката между трите дисперсии се нарича правила за добавяне на дисперсии, според която общата дисперсия е равна на сумата от междугруповата дисперсия и средната от вътрешногруповите дисперсии:
Пример. При изследване на влиянието на тарифната категория (квалификация) на работниците върху нивото на производителност на труда им бяха получени следните данни.
Таблица 5 - Разпределение на работниците по средночасова продукция.
№ п/н |
Работници 4-та категория |
Работници от 5-та категория |
|||||
Тренирам |
Тренирам |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
AT този примерработниците се разделят на две групи по факторен критерий х- квалификации, които се характеризират с техния ранг. Ефективният признак - производство - варира както под негово влияние (междугрупова вариация), така и поради други случайни фактори (вътрешногрупова вариация). Предизвикателството е да се измерят тези вариации, като се използват три вариации: обща, междугрупова и вътрегрупова. Емпиричният коефициент на детерминация показва съотношението на вариацията на получената характеристика припод влияние на факторен знак х. Остатъка обща вариация припричинени от промени в други фактори.
В примера емпиричният коефициент на детерминация е: ![]() или 66,7%,
или 66,7%,
Това означава, че 66,7% от изменението на производителността на труда на работниците се дължи на различията в квалификацията, а 33,3% се дължи на влиянието на други фактори.
Емпирична корелационна връзкапоказва плътността на връзката между групирането и ефективните характеристики. Изчислява се като корен квадратен от емпиричния коефициент на детерминация:
Емпиричното съотношение на корелация, както и , могат да приемат стойности от 0 до 1.
Ако няма връзка, тогава =0. В този случай =0, т.е. груповите средни са равни едно на друго и няма междугрупова вариация. Това означава, че групиращият признак - факторът не влияе върху формирането на общата вариация.
Ако връзката е функционална, тогава =1. В този случай дисперсията на груповите средни стойности е обща дисперсия(), тоест няма вътрешногрупова вариация. Това означава, че функцията за групиране напълно определя вариацията на получената характеристика, която се изследва.
Колкото стойността на корелационната връзка е по-близка до единица, толкова по-близо, по-близко до функционалната зависимост е връзката между признаците.
За качествена оценка на близостта на връзката между знаците се използват отношенията на Чадок.
В примера ![]() , което сочи тясна връзкамежду производителността на работниците и тяхната квалификация.
, което сочи тясна връзкамежду производителността на работниците и тяхната квалификация.
 Ораторското изкуство като първообраз на журналистиката
Ораторското изкуство като първообраз на журналистиката Цитати за Наполеон - dslinkov — LiveJournal
Цитати за Наполеон - dslinkov — LiveJournal Аз отмъщение Човекът на булдозера унищожи града
Аз отмъщение Човекът на булдозера унищожи града