Šta je uzorkovanje u statistici. Više nije uvijek bolje
Da bismo odredili vjerovatnoće događaja koji nas zanimaju, koristimo metodu uzorkovanja: provodimo n nezavisni eksperimenti, u svakom od kojih se događaj A može dogoditi (ili se ne dogoditi) (vjerovatnost R pojava događaja A u svakom eksperimentu je konstantna). Zatim relativna učestalost p* pojavljivanja događaja ALI u nizu n testovi se uzimaju kao tačka procene za verovatnoću str pojava događaja ALI u posebnom testu. U ovom slučaju se poziva vrijednost p* uzorak udjela pojave događaja ALI, i r - generalni udio .
Na osnovu posledica centralne granične teoreme (Moivre-Laplaceov teorem), relativna frekvencija događaja sa velikom veličinom uzorka može se smatrati normalno distribuiranom sa parametrima M(p*)=p i
Stoga, za n>30, interval povjerenja za opći razlomak može se izgraditi korištenjem formula:
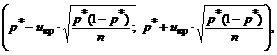
gdje se u cr nalazi prema tabelama Laplaceove funkcije, uzimajući u obzir datu vjerovatnoću pouzdanosti γ: 2F(u cr)=γ.
Sa malom veličinom uzorka n≤30, marginalna greška ε se određuje iz Studentove distributivne tabele: ![]() gdje je t cr =t(k; α) i broj stupnjeva slobode k=n-1 vjerovatnoća α=1-γ (dvostrano područje).
gdje je t cr =t(k; α) i broj stupnjeva slobode k=n-1 vjerovatnoća α=1-γ (dvostrano područje).
Formule su važeće ako je selekcija izvršena nasumično na ponovljen način (opšta populacija je beskonačna), u suprotnom je potrebno izvršiti korekciju za neponovljiv izbor (tabela).
Prosječna greška uzorkovanja za opću proporciju
| Populacija | Beskrajno | krajnji volumen N |
| Vrsta odabira | Ponovljeno | neponavljanje |
| Prosječna greška uzorkovanja |
Formule za izračunavanje veličine uzorka uz odgovarajuću metodu slučajnog odabira
| Metoda odabira | Formule veličine uzorka | ||
| za sredinu | za dionicu | ||
| Ponovljeno | |||
| neponavljanje | |||
Problemi oko opšteg udela
Na pitanje "Da li data vrijednost p 0 pokriva interval povjerenja?" - može se odgovoriti testiranjem statističke hipoteze H 0:p=p 0 . Pretpostavlja se da se eksperimenti izvode prema Bernoullijevoj šemi testa (nezavisno, vjerovatnoća str pojava događaja ALI konstanta). Prema zapremini uzorka n odrediti relativnu frekvenciju p* pojave događaja A: gdje m- broj pojavljivanja događaja ALI u nizu n testovi. Za testiranje hipoteze H 0 koriste se statistike koje, uz dovoljno veliku veličinu uzorka, imaju standardnu normalnu distribuciju (Tablica 1).Tabela 1 - Hipoteze o opštem udjelu
Hipoteza | H0:p=p0 | H 0: p 1 = p 2 |
| Pretpostavke | Bernoullijeva testna shema | Bernoullijeva testna shema |
| Uzorak procjena | 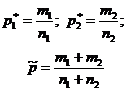 |
|
| Statistika K | 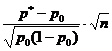 |  |
| Distribucija statistike K | Standardno normalno N(0,1) |
Primjer #1. Koristeći nasumično ponovno uzorkovanje, menadžment kompanije sproveo je nasumično istraživanje među 900 zaposlenih. Među ispitanicima je bilo 270 žena. Nacrtajte interval povjerenja koji, s vjerovatnoćom od 0,95, pokriva pravi udio žena u cijelom timu firme.
Rješenje. Po stanju, udio žena u uzorku je (relativna učestalost žena među svim ispitanicima). Budući da se selekcija ponavlja i veličina uzorka je velika (n=900), marginalna greška uzorkovanja se određuje formulom ![]()
Vrijednost u cr nalazi se iz tabele Laplaceove funkcije iz relacije 2F(u cr)=γ, tj. ![]() Laplaceova funkcija (Dodatak 1) uzima vrijednost 0,475 pri ucr =1,96. Dakle, marginalna greška
Laplaceova funkcija (Dodatak 1) uzima vrijednost 0,475 pri ucr =1,96. Dakle, marginalna greška ![]() i željeni interval pouzdanosti
i željeni interval pouzdanosti
(p – ε, p + ε) = (0,3 – 0,18; 0,3 + 0,18) = (0,12; 0,48)
Dakle, sa vjerovatnoćom od 0,95, može se garantovati da je udio žena u cijelom timu firme u rasponu od 0,12 do 0,48.
Primjer #2. Vlasnik parkinga dan smatra "srećnim" ako je parking popunjen više od 80%. Tokom godine obavljeno je 40 kontrola parkirališta, od kojih su 24 „uspješne“. Sa vjerovatnoćom od 0,98, pronađite interval povjerenja za procjenu pravog procenta "sretnih" dana u godini.
Rješenje. Uzorak frakcije „dobrih“ dana je
Prema tabeli Laplaceove funkcije nalazimo vrijednost u cr za datu
nivo samopouzdanja
F(2.23) = 0.49, u cr = 2.33.
S obzirom da se odabir ne ponavlja (tj. dvije provjere nisu obavljene istog dana), nalazimo marginalnu grešku: ![]()
gdje je n=40 , N = 365 (dana). Odavde ![]()
i interval povjerenja za opći razlomak: (p – ε, p + ε) = (0,6 – 0,17; 0,6 + 0,17) = (0,43; 0,77)
Sa vjerovatnoćom od 0,98, može se očekivati da je udio "dobrih" dana u toku godine u rasponu od 0,43 do 0,77.
Primjer #3. Nakon provjere 2500 artikala iz serije, ustanovili su da je 400 predmeta najviše ocjene, ali n–m nije. Koliko proizvoda trebate provjeriti da biste utvrdili udio premium razreda sa tačnošću od 0,01 sa sigurnošću od 95%?
Tražimo rješenje prema formuli za određivanje veličine uzorka za ponovnu selekciju.
F(t) = γ/2 = 0,95/2 = 0,475 i prema Laplaceovoj tabeli ova vrijednost odgovara t=1,96
Frakcija uzorka w = 0,16; greška uzorkovanja ε = 0,01
Primjer #4. Serija proizvoda je prihvaćena ako je vjerovatnoća da će proizvod zadovoljiti standard najmanje 0,97. Među nasumično odabranih 200 proizvoda iz testirane serije, 193 proizvoda zadovoljavaju standard. Da li je moguće prihvatiti seriju na nivou značajnosti α=0,02?
Rješenje. Formuliramo glavne i alternativne hipoteze.
H 0: p = p 0 \u003d 0,97 - nepoznati opći dio str jednako navedenoj vrijednosti p 0 =0,97. U odnosu na uslov - vjerovatnoća da će dio iz testirane partije biti u skladu sa standardom je 0,97; one. serija proizvoda može biti prihvaćena.
H1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Uočena statistička vrijednost K(tabela) izračunati za date vrijednosti p 0 =0,97, n=200, m=193
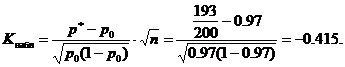
Kritična vrijednost se nalazi iz tablice Laplaceove funkcije iz jednakosti
![]()
Prema uslovu α=0,02, dakle F(Kcr)=0,48 i Kcr=2,05. Kritično područje je lijevo, tj. je interval (-∞;-K kp)= (-∞;-2,05). Uočena vrijednost Kobs = -0,415 ne pripada kritičnom području, stoga, na ovom nivou značajnosti, nema razloga da se odbaci glavna hipoteza. Može se prihvatiti serija proizvoda.
Primjer broj 5. Dvije fabrike proizvode istu vrstu dijelova. Za procjenu njihovog kvaliteta uzeti su uzorci proizvoda ovih tvornica i dobijeni su sljedeći rezultati. Od 200 odabranih proizvoda prve fabrike, 20 je bilo neispravnih, a od 300 proizvoda druge fabrike 15 je bilo neispravno.
Na nivou značajnosti od 0,025 saznajte postoji li značajna razlika u kvaliteti dijelova koje proizvode ove tvornice.
Prema uslovu α=0,025, dakle F(Kcr)=0,4875 i Kcr=2,24. Kod dvostrane alternative, površina dozvoljenih vrijednosti ima oblik (-2,24; 2,24). Posmatrana vrijednost Kobs =2,15 spada u ovaj interval, tj. na ovom nivou značaja, nema razloga da se odbaci glavna hipoteza. Fabrike proizvode proizvode istog kvaliteta.
Uzorak
Uzorak ili okvir za uzorkovanje- skup slučajeva (subjekata, objekata, događaja, uzoraka), pomoću određene procedure, odabranih iz opšte populacije za učešće u studiji.
Karakteristike uzorka:
- Kvalitativne karakteristike uzorka - koga tačno biramo i koje metode konstrukcije uzorka koristimo za to.
- Kvantitativna karakteristika uzorka je koliko slučajeva biramo, drugim riječima, veličina uzorka.
Potreba za uzorkovanjem
- Predmet proučavanja je veoma širok. Na primjer, potrošači proizvoda globalne kompanije su ogroman broj geografski raspršenih tržišta.
- Postoji potreba za prikupljanjem primarnih informacija.
Veličina uzorka
Veličina uzorka- broj slučajeva uključenih u uzorak. Iz statističkih razloga, preporučuje se da broj slučajeva bude najmanje 30-35.
Zavisni i nezavisni uzorci
Kada se porede dva (ili više) uzoraka, njihova zavisnost je važan parametar. Ako je moguće uspostaviti homomorfni par (tj. kada jedan slučaj iz uzorka X odgovara jednom i samo jednom slučaju iz uzorka Y i obrnuto) za svaki slučaj u dva uzorka (a ova osnova odnosa je važna za osobinu mjereno u uzorcima), takvi uzorci se nazivaju zavisan. Primjeri zavisnih selekcija:
- par blizanaca
- dva mjerenja bilo koje karakteristike prije i nakon eksperimentalnog izlaganja,
- muževi i žene
- itd.
Ako ne postoji takav odnos između uzoraka, onda se ovi uzorci smatraju nezavisni, na primjer:
Shodno tome, zavisni uzorci uvijek imaju istu veličinu, dok se veličina nezavisnih uzoraka može razlikovati.
Uzorci se upoređuju korištenjem različitih statističkih kriterija:
- i sl.
Reprezentativnost
Uzorak se može smatrati reprezentativnim ili nereprezentativnim.
Primjer nereprezentativnog uzorka
- Studije sa eksperimentalnim i kontrolnim grupama, koje su smeštene u različitim uslovima.
- Proučavajte sa eksperimentalnim i kontrolnim grupama koristeći strategiju uparene selekcije
- Studija koristeći samo jednu grupu - eksperimentalnu.
- Studija po mješovitom (faktorskom) planu – sve grupe su smještene u različite uslove.
Tipovi uzoraka
Uzorci su podijeljeni u dvije vrste:
- vjerovatnoća
- nevjerovatnost
Uzorci vjerovatnoće
- Jednostavno uzorkovanje vjerovatnoće:
- Jednostavno ponovno uzorkovanje. Upotreba takvog uzorka zasniva se na pretpostavci da će svaki ispitanik jednako vjerovatno biti uključen u uzorak. Na osnovu popisa opšte populacije sastavljaju se kartice sa brojem ispitanika. Stavljaju se u špil, promiješaju i iz njih se nasumično vadi karta, zapisuje se broj, a zatim se vraća nazad. Nadalje, postupak se ponavlja onoliko puta koliko nam je potrebna veličina uzorka. Minus: ponavljanje izbornih jedinica.
Procedura za konstruisanje jednostavnog slučajnog uzorka uključuje sljedeće korake:
1. potrebno je da dobijete kompletan spisak pripadnika opšte populacije i numerišete ovu listu. Takva lista, podsjetimo, naziva se okvir uzorkovanja;
2. odrediti očekivanu veličinu uzorka, odnosno očekivani broj ispitanika;
3. izdvojiti onoliko brojeva iz tabele slučajnih brojeva koliko nam je potrebno jedinica uzorka. Ako uzorak treba da obuhvati 100 ljudi, iz tabele se uzima 100 nasumičnih brojeva. Ove nasumične brojeve može generisati kompjuterski program.
4. izaberite sa osnovne liste ona zapažanja čiji brojevi odgovaraju napisanim slučajnim brojevima
- Jednostavan slučajni uzorak ima očigledne prednosti. Ova metoda je izuzetno laka za razumevanje. Rezultati studije mogu se proširiti na ispitanu populaciju. Većina pristupa statističkom zaključivanju uključuje prikupljanje informacija korištenjem jednostavnog slučajnog uzorka. Međutim, jednostavna metoda slučajnog uzorkovanja ima najmanje četiri značajna ograničenja:
1. Često je teško stvoriti okvir uzorkovanja koji bi omogućio jednostavan slučajni uzorak.
2. Jednostavan slučajni uzorak može rezultirati velikom populacijom, ili populacijom raspoređenom na velikom geografskom području, što značajno povećava vrijeme i troškove prikupljanja podataka.
3. Rezultate primjene jednostavnog slučajnog uzorka često karakterizira niska preciznost i veća standardna greška od rezultata primjene drugih probabilističkih metoda.
4. Kao rezultat primene SRS može se formirati nereprezentativni uzorak. Iako uzorci dobijeni jednostavnim slučajnim odabirom, u prosjeku, adekvatno predstavljaju opću populaciju, neki od njih krajnje netačno predstavljaju populaciju koja se proučava. Vjerovatnoća za to je posebno velika sa malom veličinom uzorka.
- Jednostavno uzorkovanje bez ponavljanja. Procedura za konstruisanje uzorka je ista, samo se karte sa brojevima ispitanika ne vraćaju nazad u špil.
- Sistematsko uzorkovanje vjerovatnoće. To je pojednostavljena verzija jednostavnog uzorka vjerovatnoće. Na osnovu liste opšte populacije, ispitanici se biraju u određenom intervalu (K). Vrijednost K se određuje nasumično. Najpouzdaniji rezultat postiže se homogenom općom populacijom, inače se veličina koraka i neki unutrašnji ciklični obrasci uzorka mogu poklopiti (miješanje uzorka). Protiv: isto kao u jednostavnom uzorku vjerovatnoće.
- Serijsko (ugniježđeno) uzorkovanje. Jedinice uzorka su statističke serije (porodica, škola, tim, itd.). Odabrani elementi su podvrgnuti kontinuiranom ispitivanju. Izbor statističkih jedinica može se organizovati prema vrsti slučajnog ili sistematskog uzorkovanja. Protiv: Mogućnost veće homogenosti nego u opštoj populaciji.
- Zonirani uzorak. U slučaju heterogene populacije, prije korištenja vjerovatnoće uzorkovanja bilo kojom tehnikom selekcije, preporučuje se podjela populacije na homogene dijelove, takav uzorak se naziva zonirani uzorak. Grupe za zoniranje mogu biti i prirodne formacije (na primjer, gradske četvrti) i bilo koje obilježje na kojem se temelji studija. Znak na osnovu kojeg se vrši podjela naziva se znakom stratifikacije i zoniranja.
- "Pogodan" izbor. Procedura uzorkovanja „pogodnosti“ sastoji se u uspostavljanju kontakata sa „pogodnim“ jedinicama za uzorkovanje – sa grupom učenika, sportskim timom, sa prijateljima i komšijama. Ako je potrebno dobiti informacije o reakcijama ljudi na novi koncept, takav uzorak je sasvim razuman. Uzorkovanje "pogodnosti" često se koristi za preliminarno testiranje upitnika.
Incredible Samples
Odabir u takvom uzorku se ne vrši po principu slučajnosti, već prema subjektivnim kriterijima - dostupnosti, tipičnosti, ravnopravnoj zastupljenosti itd.
- Kvotno uzorkovanje – uzorkovanje je izgrađeno kao model koji reproducira strukturu opšte populacije u obliku kvota (proporcija) proučavanih karakteristika. Broj elemenata uzorka sa različitom kombinacijom ispitivanih karakteristika određuje se na način da odgovara njihovom udjelu (udjelu) u općoj populaciji. Tako, na primjer, ako imamo opštu populaciju od 5.000 ljudi, od čega 2.000 žena i 3.000 muškaraca, onda ćemo u kvotnom uzorku imati 20 žena i 30 muškaraca, odnosno 200 žena i 300 muškaraca. Uzorci kvota se najčešće zasnivaju na demografskim kriterijumima: spol, starost, region, prihod, obrazovanje i dr. Protiv: obično takvi uzorci nisu reprezentativni, jer nemoguće je uzeti u obzir nekoliko društvenih parametara odjednom. Prednosti: lako dostupan materijal.
- Metoda grudve snijega. Uzorak je konstruiran na sljedeći način. Od svakog ispitanika, počevši od prvog, traži se da kontaktira svoje prijatelje, kolege, poznanike koji bi odgovarali uslovima selekcije i koji bi mogli učestvovati u istraživanju. Dakle, sa izuzetkom prvog koraka, uzorak se formira uz učešće samih objekata proučavanja. Metoda se često koristi kada je potrebno pronaći i intervjuisati teško dostupne grupe ispitanika (npr. ispitanici sa visokim primanjima, ispitanici koji pripadaju istoj profesionalnoj grupi, ispitanici koji imaju slične hobije/strasti, itd. )
- Spontano uzorkovanje - uzorkovanje tzv. "prvog pristiglog". Često se koristi u televizijskim i radijskim anketama. Veličina i sastav spontanih uzoraka nije unaprijed poznat, a određen je samo jednim parametrom – aktivnošću ispitanika. Nedostaci: nemoguće je utvrditi kakvu opštu populaciju ispitanici predstavljaju, a kao rezultat toga, nemoguće je utvrditi reprezentativnost.
- Anketa o ruti - često se koristi ako je jedinica učenja porodica. Na karti naselja u kojem će se vršiti anketa sve ulice su numerisane. Pomoću tabele (generatora) slučajnih brojeva biraju se veliki brojevi. Smatra se da se svaki veliki broj sastoji od 3 komponente: broj ulice (2-3 prva broja), kućni broj, broj stana. Na primjer, broj 14832: 14 je broj ulice na karti, 8 je kućni broj, 32 je broj stana.
- Zonsko uzorkovanje sa izborom tipičnih objekata. Ako se nakon zoniranja iz svake grupe odabere tipičan objekt, tj. objekat koji se po većini karakteristika proučavanih u studiji približava prosjeku, takav uzorak se naziva zoniranim sa izborom tipičnih objekata.
6.Modalni odabir. 7. stručni uzorak. 8. Heterogeni uzorak.
Strategije izgradnje grupe
Odabir grupa za njihovo učešće u psihološkom eksperimentu vrši se korištenjem različitih strategija, koje su neophodne kako bi se osigurala najveća moguća usklađenost s internom i eksternom valjanošću.
Randomizacija
Randomizacija, ili slučajni odabir, koristi se za kreiranje jednostavnih nasumičnih uzoraka. Upotreba takvog uzorka zasniva se na pretpostavci da će svaki član populacije podjednako vjerovatno biti uključen u uzorak. Na primjer, da napravite nasumični uzorak od 100 studenata, možete staviti papire sa imenima svih studenata u šešir, a zatim iz njega izvaditi 100 papirića - to će biti slučajni odabir (Goodwin J., str. 147).
Odabir u paru
Odabir u paru- strategija za konstruisanje grupa uzoraka, u kojoj se grupe ispitanika sastoje od subjekata koji su ekvivalentni u pogledu sporednih parametara koji su značajni za eksperiment. Ova strategija je efikasna za eksperimente sa eksperimentalnim i kontrolnim grupama sa najboljom opcijom - privlačenjem parova blizanaca (mono- i dizigotnih), jer vam omogućava da kreirate ...
Stratometrijska selekcija
Stratometrijska selekcija- randomizacija sa alokacijom stratuma (ili klastera). Ovom metodom uzorkovanja opšta populacija se deli na grupe (stratume) sa određenim karakteristikama (pol, starost, političke sklonosti, obrazovanje, nivo prihoda itd.), a biraju se subjekti sa odgovarajućim karakteristikama.
Približno modeliranje
Približno modeliranje- izrada ograničenih uzoraka i generalizacija zaključaka o ovom uzorku na širu populaciju. Na primjer, prilikom učešća u studiji studenata 2. godine univerziteta, podaci ove studije se proširuju na "ljude od 17 do 21 godine". Prihvatljivost takvih generalizacija je krajnje ograničena.
Aproksimativno modeliranje je formiranje modela koji za jasno definisanu klasu sistema (procesa) opisuje njegovo ponašanje (ili željene pojave) sa prihvatljivom tačnošću.
Bilješke
Književnost
Nasledov A. D. Matematičke metode psihološkog istraživanja. - Sankt Peterburg: Govor, 2004.
- Iljasov F. N. Reprezentativnost rezultata istraživanja u marketinškim istraživanjima. Sotsiologicheskie issledovaniya. 2011. br. 3. str. 112-116.
vidi takođe
- U nekim vrstama studija uzorak je podijeljen u grupe:
- eksperimentalni
- kontrolu
- Kohorta
Linkovi
- Koncept uzorkovanja. Glavne karakteristike uzorka. Tipovi uzoraka
Wikimedia fondacija. 2010 .
Sinonimi:Pogledajte šta je "Izbor" u drugim rječnicima:
uzorak- grupa subjekata koji predstavljaju određenu populaciju i odabrani su za eksperiment ili studiju. Suprotan koncept je totalitet opšteg. Uzorak je dio opće populacije. Rječnik praktičnog psihologa. JARBOL, ... ... Velika psihološka enciklopedija
uzorak- uzorkovanje Dio opće populacije elemenata koji je obuhvaćen posmatranjem (često se naziva populacija uzorka, a uzorak je sama metoda uzorkovanja posmatranja). U matematičkoj statistici je prihvaćeno ... ... Priručnik tehničkog prevodioca
- (uzorak) 1. Mala količina robe odabrana da predstavlja njenu cjelokupnu količinu. Vidi: prodaja po uzorku. 2. Mala količina proizvoda data potencijalnim kupcima kako bi im se dala prilika da je potroše ... ... Pojmovnik poslovnih pojmova
Uzorak- dio opće populacije elemenata koji je obuhvaćen posmatranjem (često se naziva uzorkovana populacija, a uzorkovanje je metoda samog uzorkovanja posmatranja). U matematičkoj statistici je usvojen princip slučajnog odabira; ovo je… … Ekonomsko-matematički rječnik
- (uzorak) Slučajni odabir podgrupe elemenata iz glavne populacije, čije karakteristike se koriste za procjenu cjelokupne populacije u cjelini. Uzorkovanje se koristi kada je predugo ili preskupo ispitivanje cijele populacije... Ekonomski rječnik
Cm … Rečnik sinonima
Statističke studije su dugotrajne i skupe, pa se pojavila ideja da se kontinuirano posmatranje zamijeni selektivnim.
Osnovna svrha nekontinuiranog posmatranja je dobijanje karakteristika statističke populacije koja se proučava za njen ispitani dio.
Selektivno posmatranje- radi se o metodi statističkog istraživanja, u kojoj se generalizujući pokazatelji stanovništva utvrđuju samo za jedan dio, na osnovu odredbi slučajnog odabira.
U metodi uzorkovanja proučava se samo određeni dio populacije koja se proučava, dok se statistička populacija koja se proučava naziva se opšta populacija.
Uzorkom ili jednostavno uzorkom se može nazvati dio jedinica odabranih iz opće populacije, koji će biti podvrgnut statističkom istraživanju.
Vrijednost metode uzorkovanja: uz minimalan broj jedinica koje se proučavaju, statističko istraživanje će se vršiti u kraćim vremenskim periodima i uz najmanju cijenu sredstava i rada.
U općoj populaciji, udio jedinica koje imaju osobinu koja se proučava naziva se općim udjelom (označeno R), a prosječna vrijednost proučavane varijabilne osobine je opći prosjek (označeno X).
U populaciji uzorka, udio proučavane osobine naziva se udio uzorka, ili dio (označen sa w), prosječna vrijednost u uzorku je srednja vrijednost uzorka.
Ako se tokom perioda istraživanja poštuju sva pravila njegove naučne organizacije, tada će metoda uzorkovanja dati prilično točne rezultate, te je stoga preporučljivo koristiti ovu metodu za provjeru podataka kontinuiranog promatranja.
Ova metoda je postala široko rasprostranjena u državnoj i vanresornoj statistici, jer pri ispitivanju minimalnog broja jedinica koje se proučavaju omogućava temeljno i precizno proučavanje.
Proučavana statistička populacija se sastoji od jedinica sa različitim karakteristikama. Sastav uzorka može se razlikovati od sastava opšte populacije, ova neslaganja između karakteristika uzorka i opšte populacije predstavlja grešku uzorkovanja.
Greške svojstvene selektivnom posmatranju karakterišu veličinu neslaganja između podataka selektivnog posmatranja i celokupne populacije. Greške koje se javljaju prilikom uzorkovanja nazivaju se greške reprezentativnosti i dijele se na slučajne i sistematske.
Ako populacija uzorka ne reproducira precizno cijelu populaciju zbog nekontinuirane prirode promatranja, onda se to naziva slučajnim greškama, a njihove se veličine određuju s dovoljnom preciznošću na osnovu zakona velikih brojeva i teorije vjerovatnoće.
Sistematske greške nastaju kao rezultat kršenja principa slučajnog odabira jedinica populacije za posmatranje.
2. Vrste i šeme selekcije
Veličina greške uzorkovanja i metode za njeno određivanje zavise od vrste i šeme selekcije.
Postoje četiri vrste odabira skupa jedinica posmatranja:
1) slučajni;
2) mehanički;
3) tipičan;
4) serijski (ugniježđeni).
slučajni odabir- najčešći metod odabira u slučajnom uzorku, naziva se i metodom lutrije, u kojoj se za svaku jedinicu statističke populacije priprema listić sa serijskim brojem.
Zatim se nasumično bira potreban broj jedinica statističke populacije. Pod ovim uslovima, svaki od njih ima istu verovatnoću da uđe u uzorak, na primer, izvlačenje dobitaka, kada se iz ukupnog broja izdatih listića nasumično odabere određeni deo brojeva koji čine dobitak. U ovom slučaju, svim brojevima se pruža jednaka prilika da uđu u uzorak.
Mehanička selekcija- ovo je metoda kada se cijela populacija podijeli u grupe homogene veličine prema slučajnom kriteriju, zatim se iz svake grupe uzima samo jedna jedinica.Sve jedinice proučavane statističke populacije su unaprijed raspoređene određenim redoslijedom, ali zavisno na veličini uzorka, potreban broj jedinica se mehanički bira u određenom intervalu.
Tipičan izbor - ovo je metoda u kojoj se statistička populacija koja se proučava prema bitnoj, tipičnoj osobini dijeli na kvalitativno homogene, slične grupe, zatim se iz svake od ove grupe nasumično bira određeni broj jedinica, proporcionalno udjelu grupe u cjelokupno stanovništvo.
Tipična selekcija daje preciznije rezultate, jer uključuje predstavnike svih tipičnih grupa u uzorku.
Serijski (gniježđeni) odabir. Cijele grupe (serije, gnijezda), odabrane nasumično ili mehanički, podliježu selekciji. Za svaku takvu grupu, seriju, vrši se kontinuirano posmatranje, a rezultati se prenose na cijelu populaciju.
Točnost uzorkovanja također ovisi o šemi odabira. Uzorkovanje se može izvršiti prema šemi ponovljene i neponovljene selekcije.
Ponovna selekcija. Svaka odabrana jedinica ili serija se vraća cijeloj populaciji i može se ponovo uzorkovati.Ovo je takozvana šema vraćene lopte.
Repetitivna selekcija. Svaka ispitana jedinica se povlači i ne vraća stanovništvu, pa se ne preispituje. Ova šema se zove nevraćena lopta.
Selekcija koja se ne ponavlja daje preciznije rezultate, jer sa istom veličinom uzorka, opservacija pokriva više jedinica proučavane populacije.
Kombinovani izbor može proći kroz jednu ili više faza. Uzorak se naziva jednostepenim ako su jedinice populacije odabrane jednom podvrgnute proučavanju.
Uzorak se naziva višestepenim ako selekcija populacije prolazi kroz faze, uzastopne faze, a svaka faza, faza selekcije ima svoju jedinicu selekcije.
Višefazno uzorkovanje – u svim fazama uzorkovanja zadržava se ista jedinica uzorkovanja, ali se provodi nekoliko faza, faza uzorkovanja, koje se međusobno razlikuju po širini programa istraživanja i veličini uzorka.
Karakteristike parametara opće populacije i populacije uzorka označene su sljedećim simbolima:
N- obim opšte populacije;
n- veličina uzorka;
X– opšti prosjek;
X je srednja vrijednost uzorka;
R– generalni udeo;
w - udio uzorka;
2 - opšta varijansa (disperzija osobine u opštoj populaciji);
2 - varijansa uzorka iste karakteristike;
? - standardna devijacija u opštoj populaciji;
? je standardna devijacija u uzorku.
3. Greške uzorkovanja
Svaka jedinica u opservaciji uzorka treba da ima jednaku priliku da bude odabrana sa ostalima - to je osnova slučajnog uzorka.
Samonasumično uzorkovanje - ovo je odabir jedinica iz cjelokupne opće populacije lutrijom ili na drugi sličan način.
Princip slučajnosti je da na uključivanje ili isključivanje objekta iz uzorka ne može uticati bilo koji drugi faktor osim slučajnosti.
Udio uzorka je omjer broja jedinica u uzorku i broja jedinica u općoj populaciji:
Samoslučajna selekcija u svom čistom obliku je inicijalna među svim drugim vrstama selekcije, sadrži i implementira osnovne principe selektivnog statističkog posmatranja.
Dvije glavne vrste generalizirajućih indikatora koje se koriste u metodi uzorkovanja su prosječna vrijednost kvantitativnog atributa i relativna vrijednost alternativnog atributa.
Udio uzorka (w), ili posebnost, određen je omjerom broja jedinica koje imaju osobinu koja se proučava m, na ukupan broj jedinica uzorkovanja (n):
Da bi se okarakterisala pouzdanost indikatora uzorka, razlikuju se prosječne i marginalne greške uzorka.
Greška uzorkovanja, koja se također naziva greška reprezentativnosti, je razlika između odgovarajućeg uzorka i općih karakteristika:
?x = |x - x |;
?w =|h – p|.
Samo uzorkovana opažanja imaju grešku uzorkovanja
Srednja vrijednost uzorka i proporcija uzorka- to su slučajne varijable koje poprimaju različite vrijednosti u zavisnosti od jedinica proučavane statističke populacije koje su uključene u uzorak. Shodno tome, greške uzorkovanja su također slučajne varijable i također mogu poprimiti različite vrijednosti. Stoga se utvrđuje prosjek mogućih grešaka – prosječna greška uzorkovanja.
Prosječna greška uzorkovanja određena je veličinom uzorka: što je veća populacija, ako su sve ostale jednake, to je manja prosječna greška uzorkovanja. Pokrivajući uzorkovanu anketu sa sve većim brojem jedinica opšte populacije, sve preciznije karakterišemo celokupnu populaciju.
Prosječna greška uzorkovanja zavisi od stepena varijacije proučavane osobine, a stepen varijacije karakteriše varijansa? 2 ili w(l - w)- za alternativni znak. Što je manja varijacija i varijansa karakteristika, manja je srednja greška uzorkovanja, i obrnuto.
Za nasumično ponovno uzorkovanje, srednje greške se teoretski izračunavaju pomoću sljedećih formula:
1) za prosječnu kvantitativnu osobinu:
gdje? 2 - prosječna vrijednost disperzije kvantitativne osobine.
2) za dionicu (alternativni znak):
Dakle, kakva je varijansa osobine u populaciji? 2 nije točno poznato, u praksi koriste vrijednost varijanse S 2 izračunatu za populaciju uzorka na osnovu zakona velikih brojeva, prema kojem populacija uzorka s dovoljno velikom veličinom uzorka precizno reproducira karakteristike opće populacije .
Formule za srednju grešku uzorkovanja za nasumično ponovno uzorkovanje su sljedeće. Za prosječnu vrijednost kvantitativnog atributa: opća varijansa se izražava kroz izborni predmet sljedećim omjerom:
gdje je S 2 vrijednost disperzije.
Mehaničko uzorkovanje- ovo je izbor jedinica u skupu uzoraka iz općeg, koji je podijeljen u jednake grupe prema neutralnom kriteriju; se radi na način da se iz svake takve grupe u uzorku odabere samo jedna jedinica.
Mehaničkim odabirom jedinice statističke populacije koja se proučava preliminarno se raspoređuju po određenom redoslijedu, nakon čega se u određenom intervalu mehanički odabire određeni broj jedinica. U ovom slučaju, veličina intervala u općoj populaciji jednaka je recipročnom udjelu uzorka.
Sa dovoljno velikom populacijom, mehanički odabir u smislu tačnosti rezultata blizak je slučajnom, pa se za određivanje prosječne greške mehaničkog uzorkovanja koriste formule slučajnog nerepetitivnog uzorkovanja.
Za odabir jedinica iz heterogene populacije koristi se tzv. tipični uzorak, koristi se kada se sve jedinice opće populacije mogu podijeliti u nekoliko kvalitativno homogenih, sličnih grupa prema karakteristikama od kojih zavise proučavani pokazatelji.
Zatim se iz svake tipične grupe vrši pojedinačni odabir jedinica u uzorak slučajnim ili mehaničkim uzorkom.
Tipično uzorkovanje se obično koristi u proučavanju složenih statističkih populacija.
Tipično uzorkovanje daje preciznije rezultate. Tipizacija opšte populacije obezbeđuje reprezentativnost takvog uzorka, zastupljenost svake tipološke grupe u njemu, što omogućava da se isključi uticaj međugrupne varijanse na prosečnu grešku uzorka. Stoga, pri određivanju prosječne greške tipičnog uzorka, prosjek varijansi unutar grupe djeluje kao indikator varijacije.
Serijsko uzorkovanje uključuje slučajni odabir iz opće populacije grupa jednake veličine kako bi se sve jedinice bez izuzetka podvrgle posmatranju u takvim grupama.
Budući da se sve jedinice bez izuzetka ispituju unutar grupa (serija), prosječna greška uzorkovanja (pri odabiru jednakih serija) zavisi samo od međugrupne (međuserijalne) varijanse.
4. Načini proširenja rezultata uzorka na populaciju
Karakterizacija opšte populacije na osnovu rezultata uzorka je krajnji cilj posmatranja uzorka.
Metoda uzorkovanja se koristi za dobijanje karakteristika opšte populacije za određene indikatore uzorka. Ovisno o ciljevima studije, to se provodi direktnim preračunavanjem indikatora uzorka za opštu populaciju ili metodom izračunavanja faktora korekcije.
Metoda direktnog preračunavanja je da se uz njega uračunavaju indikatori udjela uzorka w ili srednje X proširuju se na opću populaciju, uzimajući u obzir grešku uzorkovanja.
Metoda korekcijskih faktora se koristi kada je svrha metode uzorkovanja da se preciziraju rezultati kompletnog računovodstva. Ova metoda se koristi za preciziranje podataka godišnjih popisa stoke stanovništva.
Plan:
1. Problemi matematičke statistike.
2. Tipovi uzoraka.
3. Metode odabira.
4. Statistička distribucija uzorka.
5. Empirijska funkcija distribucije.
6. Poligon i histogram.
7. Numeričke karakteristike varijacione serije.
8. Statističke procjene parametara distribucije.
9. Intervalne procjene parametara distribucije.
1. Zadaci i metode matematičke statistike
Math statistics je grana matematike koja se bavi metodama prikupljanja, analize i obrade rezultata statističkih opservacijskih podataka u naučne i praktične svrhe.
Neka se zahtijeva proučavanje skupa homogenih objekata s obzirom na neku kvalitativnu ili kvantitativnu osobinu koja karakterizira te objekte. Na primjer, ako postoji serija dijelova, tada standard dijela može poslužiti kao kvalitativni znak, a kontrolirana veličina dijela može poslužiti kao kvantitativni znak.
Ponekad se provodi kontinuirana studija, tj. ispitati svaki objekt s obzirom na željenu osobinu. U praksi, sveobuhvatna anketa se rijetko koristi. Na primjer, ako populacija sadrži vrlo veliki broj objekata, tada je fizički nemoguće provoditi kontinuirano istraživanje. Ako je istraživanje objekta povezano s njegovim uništenjem ili zahtijeva velike materijalne troškove, onda nema smisla provoditi potpunu anketu. U takvim slučajevima, ograničen broj objekata (skup uzoraka) se nasumično bira iz cijele populacije i podvrgava njihovom proučavanju.
Osnovni zadatak matematičke statistike je proučavanje cjelokupne populacije na osnovu podataka uzorka, u zavisnosti od cilja, tj. proučavanje vjerojatnosnih svojstava populacije: zakon raspodjele, numeričke karakteristike itd. za donošenje menadžerskih odluka u uslovima neizvesnosti.
2. Tipovi uzoraka
Populacija je skup objekata od kojih je napravljen uzorak.
Uzorak populacije (uzorak) je kolekcija nasumično odabranih objekata.
Veličina populacije je broj objekata u ovoj kolekciji. Obim opšte populacije je označen N, selektivno - n.
primjer:
Ako se od 1000 dijelova odabere 100 dijelova za ispitivanje, onda je obim opšte populacije N = 1000 i veličinu uzorka n = 100.
Uzorkovanje se može obaviti na dva načina: nakon što se objekat odabere i posmatra nad njim, može se vratiti ili ne vratiti opštoj populaciji. To. Uzorci se dijele na ponovljene i neponovljene.
Ponovljenopozvao uzorkovanje, na kojem se odabrani objekt (prije odabira sljedećeg) vraća općoj populaciji.
Neponavljanjepozvao uzorkovanje, pri čemu se odabrani objekt ne vraća općoj populaciji.
U praksi se obično koristi slučajni odabir koji se ne ponavlja.
Da bi podaci uzorka mogli sa dovoljno pouzdanosti suditi o osobini od interesa u opštoj populaciji, neophodno je da je objekti uzorka ispravno predstavljaju. Uzorak mora ispravno predstavljati proporcije populacije. Uzorak mora biti predstavnik (zastupnik).
Na osnovu zakona velikih brojeva, može se tvrditi da će uzorak biti reprezentativan ako se izvodi nasumično.
Ako je veličina opće populacije dovoljno velika, a uzorak je samo beznačajan dio ove populacije, onda se briše razlika između ponovljenih i neponovljenih uzoraka; u graničnom slučaju, kada se uzme u obzir beskonačna opšta populacija, a uzorak ima konačnu veličinu, ova razlika nestaje.
primjer:
U američkom časopisu Literary Review, koristeći statističke metode, napravljena je studija o prognozama u vezi sa ishodom predstojećih američkih predsjedničkih izbora 1936. godine. Kandidati za ovo radno mjesto bili su F.D. Roosevelt i A. M. Landon. Priručnici telefonskih pretplatnika uzeti su kao izvor za opću populaciju proučavanih Amerikanaca. Od toga je nasumično odabrano 4 miliona adresa, na koje su urednici magazina poslali razglednice sa molbom da izraze svoj stav prema kandidatima za predsjednika. Nakon obrade rezultata ankete, magazin je objavio sociološku prognozu da će Landon sa velikom razlikom pobijediti na predstojećim izborima. I... pogrešio sam: Ruzvelt je pobedio.
Ovaj primjer se može posmatrati kao primjer nereprezentativnog uzorka. Činjenica je da je u Sjedinjenim Državama u prvoj polovini dvadesetog vijeka samo imućni dio stanovništva, koji je podržavao Landonove stavove, imao telefone.
3. Metode odabira
U praksi se koriste različite metode selekcije koje se mogu podijeliti u 2 tipa:
1. Selekcija ne zahtijeva podjelu populacije na dijelove (a) jednostavno nasumično bez ponavljanja; b) jednostavno nasumično ponavljanje).
2. Selekcija, u kojoj se opća populacija dijeli na dijelove. (a) tipičan izbor; b) mehanički odabir; u) serial izbor).
Simple random nazovi ovo izbor, u kojem se objekti izdvajaju jedan po jedan iz cjelokupne opće populacije (nasumično).
Tipičnopozvao izbor, u kojoj se objekti ne biraju iz cjelokupne opće populacije, već iz svakog od njenih „tipičnih“ dijelova. Na primjer, ako je dio napravljen na više strojeva, tada se odabir ne vrši iz cijelog skupa dijelova proizvedenih na svim strojevima, već iz proizvoda svake mašine posebno. Takva selekcija se koristi kada osobina koja se ispituje primjetno fluktuira u različitim "tipičnim" dijelovima opće populacije.
Mehaničkipozvao izbor, u kojem je opća populacija "mehanički" podijeljena u onoliko grupa koliko ima objekata koje treba uključiti u uzorak, a iz svake grupe se bira po jedan objekt. Na primjer, ako trebate odabrati 20% dijelova koje je napravila mašina, tada se bira svaki 5. dio; ako je potrebno odabrati 5% dijelova - svaki 20. itd. Ponekad takav odabir možda neće osigurati reprezentativan uzorak (ako se izabere svaki 20. valjak za okretanje, a rezač se zamijeni odmah nakon odabira, tada će biti odabrani svi valjci okrenuti tupim rezačima).
Serialpozvao izbor, u kojem se objekti biraju iz opće populacije ne jedan po jedan, već u „serijama“, koji su podvrgnuti kontinuiranom istraživanju. Na primjer, ako proizvode proizvodi velika grupa automatskih mašina, onda se proizvodi samo nekoliko mašina podvrgavaju kontinuiranom ispitivanju.
U praksi se često koristi kombinirana selekcija u kojoj se kombiniraju gore navedene metode.
4. Statistička distribucija uzorka
Neka se uzorak uzme iz opće populacije, a vrijednost x 1-posmatrano jednom, x 2 -n 2 puta, ... x k - n k puta. n= n 1 +n 2 +...+n k je veličina uzorka. Uočene vrijednostipozvao opcije, a niz je varijanta napisana uzlaznim redoslijedom - varijacione serije. Broj zapažanjapozvao frekvencije (apsolutne frekvencije) i njihov odnos prema veličini uzorka- relativne frekvencije ili statističke vjerovatnoće.
Ako je broj opcija velik ili je uzorak napravljen iz kontinuirane opće populacije, tada se serija varijacija ne sastavlja po pojedinačnim vrijednostima bodova, već po intervalima vrijednosti opće populacije. Takva serija se zove interval. Dužina intervala mora biti jednaka.
Statistička distribucija uzorka naziva se lista opcija i njihovih odgovarajućih frekvencija ili relativnih frekvencija.
Statistička distribucija se također može specificirati kao niz intervala i njihovih odgovarajućih frekvencija (zbir frekvencija koje spadaju u ovaj interval vrijednosti)
Serija varijacija frekvencija može se predstaviti tabelom:
| x i |
x 1 |
x2 |
… |
x k |
| n i |
n 1 |
n 2 |
… |
nk |
Slično, može se predstaviti tačkasti varijacioni niz relativnih frekvencija.
i:
primjer:
Ispostavilo se da je broj slova u nekom tekstu X jednak 1000. Prvo slovo je bilo "i", drugo - slovo "i", treće - slovo "a", četvrto - "u". Zatim su došla slova "o", "e", "y", "e", "s".
Zapišimo mjesta koja oni zauzimaju u abecedi, odnosno imamo: 33, 10, 1, 32, 16, 6, 21, 31, 29.
Nakon što ove brojeve poredimo rastućim redom, dobijamo niz varijacija: 1, 6, 10, 16, 21, 29, 31, 32, 33.
Učestalosti pojavljivanja slova u tekstu: "a" - 75, "e" -87, "i" - 75, "o" - 110, "y" - 25, "s" - 8, "e" - 3, "yu" - 7, "I" - 22.
Sastavljamo tačkasti varijacioni niz frekvencija:
primjer:
Specificirana je distribucija frekvencije uzorkovanja volumena n = 20.
Napravite tačku varijacije serije relativnih frekvencija.
| x i |
2 |
6 |
12 |
| n i |
3 |
10 |
7 |
Rješenje:
Pronađite relativne frekvencije:
| x i |
2 |
6 |
12 |
| w i |
0,15 |
0,5 |
0,35 |
Prilikom konstruiranja intervalne distribucije postoje pravila za izbor broja intervala ili veličine svakog intervala. Ovdje je kriterij optimalni omjer: povećanjem broja intervala reprezentativnost se poboljšava, ali se povećava količina podataka i vrijeme za njihovu obradu. Razlika x max - x min između najveće i najmanje vrijednosti poziva se varijanta u velikim razmjerima uzorci.
Za brojanje intervala k obično primjenjuju empirijsku formulu Sturgess (što podrazumijeva zaokruživanje na najbliži prikladan cijeli broj): k = 1 + 3,322 log n .
Prema tome, vrijednost svakog intervala h može se izračunati pomoću formule:
5. Empirijska funkcija distribucije
Razmotrite neki uzorak iz opće populacije. Neka je poznata statistička distribucija frekvencija kvantitativnog atributa X. Uvedemo zapis: n xje broj opservacija u kojima je uočena vrijednost karakteristike manja od x; n je ukupan broj opservacija (veličina uzorka). Relativna frekvencija događaja X<х равна n x /n . Ako se x promijeni, tada se mijenja i relativna frekvencija, tj. relativna frekvencijan x /nje funkcija od x. Jer nalazi se empirijski, naziva se empirijski.
Empirijska funkcija distribucije (funkcija distribucije uzorka) pozovite funkciju, koji za svaki x određuje relativnu frekvenciju događaja X<х.
gdje je broj opcija manji od x,
n - veličina uzorka.
Za razliku od empirijske funkcije distribucije uzorka, naziva se funkcija distribucije F(x) populacije teorijska funkcija raspodjele.
Razlika između empirijske i teorijske funkcije distribucije je u tome što teorijska funkcija F (x) određuje vjerovatnoću događaja X
To. preporučljivo je koristiti empirijsku funkciju distribucije uzorka za približan prikaz teorijske (integralne) funkcije raspodjele opće populacije.
f*(x) ima sva svojstva F(x).
1. Vrijednosti f*(x) pripadaju intervalu.
2. F*(x) je neopadajuća funkcija.
3. Ako je najmanja varijanta, onda je F*(x) = 0, na x < x1; ako je x k najveća varijanta, onda je F*(x) = 1, za x > x k .
One. f*(x) služi za procjenu F(x).
Ako je uzorak dat varijacionim nizom, tada empirijska funkcija ima oblik:
Graf empirijske funkcije naziva se kumulativnim.
primjer:
Nacrtajte empirijsku funkciju preko date distribucije uzorka.
Rješenje:
Veličina uzorka n = 12 + 18 +30 = 60. Najmanja opcija je 2, tj. na x <
2. Događaj X<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F*(x)=12/60=0,2 u 2 <
x <
6. Događaj X<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
x <
10. Jer x=10 je onda najveća opcija F*(x) = 1 na x>10. Željena empirijska funkcija ima oblik:
kumulirati:
Kumulat omogućava da se razumeju informacije predstavljene grafički, na primer, da se odgovori na pitanja: „Odredite broj zapažanja u kojima je vrednost atributa bila manja od 6 ili ne manja od 6. F*(6) = 0,2 » Tada je broj opservacija u kojima je vrijednost uočene karakteristike manja od 6 0,2* n \u003d 0,2 * 60 \u003d 12. Broj zapažanja u kojima vrijednost uočene karakteristike nije manja od 6 je (1-0,2) * n = 0,8 * 60 = 48.
Ako je data serija varijacije intervala, tada se za kompilaciju empirijske funkcije distribucije pronađu sredine intervala i iz njih se dobije empirijska funkcija distribucije slično kao serija varijacija tačke.
6. Poligon i histogram
Radi jasnoće, izgrađeni su različiti grafovi statističke distribucije: polinom i histogram
Frekvencijski poligon- ovo je izlomljena linija, čiji segmenti povezuju tačke ( x 1 ;n 1 ), ( x 2 ;n 2 ),..., ( x k ; n k ), gdje su opcije, a frekvencije koje im odgovaraju.
Poligon relativnih frekvencija - ovo je izlomljena linija, čiji segmenti spajaju tačke ( x 1 ;w 1 ), (x 2 ;w 2 ),..., ( x k ;w k ), gdje su x i opcije, w i relativne frekvencije koje im odgovaraju.
primjer:
Nacrtajte polinom relativne frekvencije preko date distribucije uzorka:
Rješenje:
U slučaju kontinuiranog obilježja, preporučljivo je izgraditi histogram, za koji se interval, koji sadrži sve promatrane vrijednosti obilježja, podijeli na nekoliko parcijalnih intervala dužine h i za svaki parcijalni interval se nađe n i - zbir varijantnih frekvencija koje spadaju u i-ti interval. (Na primjer, kada mjerimo visinu ili težinu osobe, imamo posla sa kontinuiranim znakom).
Histogram frekvencije- ovo je stepenasta figura, koja se sastoji od pravougaonika, čije su osnove parcijalni intervali dužine h, a visine su jednake omjeru (gustina frekvencije).
Square i-ti parcijalni pravougaonik jednak je zbiru frekvencija varijante i-tog intervala, tj. područje histograma frekvencije je jednako zbiru svih frekvencija, tj. veličina uzorka.
primjer:
Dati su rezultati promjene napona (u voltima) u električnoj mreži. Sastavite niz varijacija, napravite poligon i histogram frekvencije ako su vrijednosti napona sljedeće: 227, 215, 230, 232, 223, 220, 228, 222, 221, 226, 226, 215, 218, 2 216, 220, 225, 212, 217, 220.
Rješenje:
Hajde da napravimo niz varijacija. Imamo n = 20, x min =212, x max =232.
Koristimo Sturgessovu formulu da izračunamo broj intervala.
Intervalni varijacioni niz frekvencija ima oblik:
|
|
Gustoća frekvencije |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
Napravimo histogram frekvencija:
Konstruirajmo poligon frekvencija tako što ćemo prvo pronaći sredine intervala:
Histogram relativnih frekvencija nazovimo stepenastu figuru koja se sastoji od pravougaonika čije su osnove parcijalni intervali dužine h, a visine jednake omjeru w i/h (relativna gustina frekvencije).
Square I-ti parcijalni pravougaonik jednak je relativnoj frekvenciji varijante koja je upala u i-ti interval. One. površina histograma relativnih frekvencija jednaka je zbiru svih relativnih frekvencija, tj. jedinica.
7. Numeričke karakteristike varijacione serije
Razmotrite glavne karakteristike opće populacije i populacije uzorka.
Opća sekundarna naziva se aritmetička sredina vrijednosti karakteristike opće populacije.
Za različite vrijednosti x 1 , x 2 , x 3 , …, x n . znak opšte populacije volumena N imamo:
Ako vrijednosti atributa imaju odgovarajuće frekvencije N 1 +N 2 +…+N k =N , tada
srednja vrijednost uzorka naziva se aritmetička sredina vrijednosti karakteristike populacije uzorka.
Ako vrijednosti atributa imaju odgovarajuće frekvencije n 1 +n 2 +…+n k = n, tada
primjer:
Izračunajte srednju vrijednost uzorka za uzorak: x 1 = 51,12; x 2 = 51,07 x 3 = 52,95; x 4 = 52,93; x 5 = 51,1; x 6 = 52,98; x 7 = 52,29; x 8 \u003d 51,23; x 9 = 51,07; x10 = 51,04.
Rješenje:
Opšta varijansa naziva se aritmetička sredina kvadrata odstupanja vrijednosti X karakteristike opće populacije od općeg prosjeka.
Za različite vrijednosti x 1 , x 2 , x 3 , …, x N predznaka populacije volumena N imamo:
Ako vrijednosti atributa imaju odgovarajuće frekvencije N 1 +N 2 +…+N k =N , tada
Opća standardna devijacija (standard) zove se kvadratni korijen opće varijanse
Varijanca uzorka naziva se aritmetička sredina kvadrata odstupanja posmatranih vrijednosti obilježja od srednje vrijednosti.
Za različite vrijednosti x 1 , x 2 , x 3 , ..., x n predznaka populacije uzorka volumena n imamo:
Ako vrijednosti atributa imaju odgovarajuće frekvencije n 1 +n 2 +…+n k = n, tada
Standardna devijacija uzorka (standardna) naziva se kvadratni korijen varijanse uzorka.
primjer:
Skup uzorkovanja je dat tablicom distribucije. Pronađite varijansu uzorka.
Rješenje:
Teorema: Varijanca je jednaka razlici između srednje vrednosti kvadrata vrednosti obeležja i kvadrata ukupne srednje vrednosti.
primjer:
Pronađite varijansu za ovu distribuciju.
Rješenje:
8. Statističke procjene parametara distribucije
Neka se opća populacija proučava nekim uzorkom. U ovom slučaju moguće je dobiti samo približnu vrijednost nepoznatog parametra Q, koji služi kao njegova procjena. Očigledno je da procjene mogu varirati od uzorka do uzorka.
Statistička procjenaQ* nepoznati parametar teorijske raspodjele naziva se funkcija f, koja ovisi o promatranim vrijednostima uzorka. Zadatak statističke procjene nepoznatih parametara iz uzorka je da iz dostupnih podataka statističkih opservacija konstruiše takvu funkciju koja bi dala najtačnije približne vrijednosti stvarnih, istraživaču nepoznatih, vrijednosti ovih parametara.
Statističke procjene se dijele na tačke i intervale, ovisno o načinu na koji su date (broj ili interval).
Tačkasta procjena se naziva statistička procjena. parametar Q teorijske raspodjele određen jednom vrijednošću parametra Q *=f (x 1 , x 2 , ..., x n), gdje jex 1 , x 2 , ...,xn- rezultati empirijskih opažanja kvantitativnog atributa X određenog uzorka.
Takve procjene parametara dobivene iz različitih uzoraka najčešće se razlikuju jedna od druge. Apsolutna razlika /Q *-Q / se zove greška uzorkovanja (procjena).
Da bi statističke procjene dale pouzdane rezultate o procijenjenim parametrima, neophodno je da one budu nepristrasne, efikasne i konzistentne.
Point Estimation, čije je matematičko očekivanje jednako (nije jednako) procijenjenom parametru, naziva se nepromijenjen (pomaknut). M(Q *)=Q .
razlika M( Q *)-Q se poziva pristrasnost ili sistematska greška. Za nepristrasne procjene, sistematska greška je 0.
efikasan procjena Q *, koji, za datu veličinu uzorka n, ima najmanju moguću varijansu: D min(n = const). Efektivni procjenitelj ima najmanji raspon u poređenju sa drugim nepristrasnim i konzistentnim procjeniteljima.
Bogatise zove takva statistika procjena Q *, što za nteži po vjerovatnoći procijenjenom parametru Q , tj. sa povećanjem veličine uzorka n procjena teži po vjerovatnoći pravoj vrijednosti parametra Q.
Zahtjev konzistentnosti je u skladu sa zakonom velikih brojeva: što je više početnih informacija o objektu koji se proučava, to je tačniji rezultat. Ako je veličina uzorka mala, onda tačkasta procjena parametra može dovesti do ozbiljnih grešaka.
Bilo koji uzorak (volumenn) može se smatrati uređenim skupomx 1 , x 2 , ...,xn nezavisne identično distribuirane slučajne varijable.
Uzorak znači za različite zapremine uzoraka n iz iste populacije će biti različiti. Odnosno, srednja vrednost uzorka se može posmatrati kao slučajna varijabla, što znači da se može govoriti o distribuciji uzorke srednje vrednosti i njenim numeričkim karakteristikama.
Srednja vrijednost uzorka zadovoljava sve zahtjeve koji se postavljaju za statističke procjene, tj. daje nepristrasnu, efikasnu i dosljednu procjenu srednje vrijednosti stanovništva.
To se može dokazati. Dakle, varijansa uzorka je pristrasna procjena opšte varijanse, dajući joj potcijenjenu vrijednost. Odnosno, uz malu veličinu uzorka, to će dati sistematsku grešku. Za nepristrasnu, dosljednu procjenu, dovoljno je uzeti količinu, što se naziva ispravljena varijansa. tj.
U praksi, za procjenu opće varijanse, korigirana varijansa se koristi kada n < 30. U drugim slučajevima ( n >30) odstupanje od jedva primetno. Dakle, za velike vrijednosti n greška pristrasnosti se može zanemariti.
Takođe se može dokazati da je relativna frekvencijan i / n je nepristrasna i konzistentna procjena vjerovatnoće P(X=x i ). Empirijska funkcija distribucije F*(x ) je nepristrasna i konzistentna procjena teorijske funkcije raspodjele F(x)=P(X< x ).
primjer:
Pronađite nepristrasne procjene srednje vrijednosti i varijanse iz tabele uzorka.
| x i |
|||
| n i |
Rješenje:
Veličina uzorka n=20.
Nepristrasna procjena matematičkog očekivanja je srednja vrijednost uzorka.
Da bismo izračunali nepristrasnu procjenu varijanse, prvo pronalazimo varijansu uzorka:
Sada pronađimo nepristrasnu procjenu:
9. Intervalne procjene parametara distribucije
Interval je statistička procjena određena dvjema numeričkim vrijednostima - krajevima intervala koji se proučava.
Broj> 0, gdje je | Q - Q*|< , karakterizira tačnost procjene intervala.
Trustedpozvao interval , što sa datom vjerovatnoćompokriva nepoznatu vrijednost parametra Q . Dopunjavanje intervala pouzdanosti skupom svih mogućih vrijednosti parametara Q pozvao kritično područje. Ako se kritično područje nalazi samo na jednoj strani intervala povjerenja, tada se naziva interval povjerenja jednostrano: lijevo, ako kritična regija postoji samo na lijevoj strani, i desnoruke osim na desnoj strani. U suprotnom, poziva se interval pouzdanosti bilateralni.
Pouzdanost ili nivo samopouzdanja, Q procjene (koristeći Q *) navedite vjerovatnoću kojom je ispunjena sljedeća nejednakost: | Q - Q*|< .
Najčešće se vjerovatnoća povjerenja unaprijed postavlja (0,95; 0,99; 0,999) i nameće joj se zahtjev da bude blizu jedan.
Vjerovatnoćapozvao vjerovatnoću greške ili nivo značajnosti.
Neka | Q - Q*|< , onda. To znači da sa vjerovatnoćommože se tvrditi da je prava vrijednost parametra Q pripada intervalu. Što je odstupanje manje, to je tačnija procjena.
Granice (krajevi) intervala pouzdanosti se nazivaju granice poverenja ili kritične granice.
Vrijednosti granica intervala povjerenja zavise od zakona raspodjele parametra Q*.
Vrijednost odstupanjanaziva se polovina širine intervala pouzdanosti tačnost procjene.
Metode za konstruisanje intervala pouzdanosti prvi je razvio američki statističar Y. Neumann. Preciznost procjene, vjerovatnoća povjerenja i veličina uzorka n međusobno povezani. Stoga, znajući specifične vrijednosti dvije veličine, uvijek možete izračunati treću.
Pronalaženje intervala povjerenja za procjenu matematičkog očekivanja normalne distribucije ako je poznata standardna devijacija.
Neka se napravi uzorak iz opšte populacije, u skladu sa zakonom normalne distribucije. Neka je poznata opšta standardna devijacija, ali je matematičko očekivanje teorijske distribucije nepoznato a().
Vrijedi sljedeća formula:
One. prema navedenoj vrijednosti odstupanjamoguće je pronaći s kojom vjerovatnoćom nepoznata opšta sredina pripada intervalu. I obrnuto. Iz formule se može vidjeti da s povećanjem veličine uzorka i fiksne vrijednosti vjerovatnoće pouzdanosti, vrijednost- smanjuje se, tj. povećava se tačnost procjene. Sa povećanjem pouzdanosti (vjerovatnoće povjerenja), vrijednost-povećava, tj. smanjuje se tačnost procjene.
primjer:
Kao rezultat testova, dobijene su sljedeće vrijednosti -25, 34, -20, 10, 21. Poznato je da se pridržavaju zakona normalne distribucije sa standardnom devijacijom od 2. Pronađite procjenu a* za matematičko očekivanje a. Nacrtajte interval pouzdanosti od 90% za to.
Rješenje:
Nađimo nepristrasnu procjenu
Onda
Interval pouzdanosti za a ima oblik: 4 - 1,47< a< 4+ 1,47 или 2,53 < a < 5, 47
Pronalaženje intervala povjerenja za procjenu matematičkog očekivanja normalne distribucije ako je standardna devijacija nepoznata.
Neka bude poznato da opća populacija podliježe zakonu normalne distribucije, gdje su a i. Preciznost pokrivanja intervala pouzdanosti sa pouzdanošćuprava vrijednost parametra a, u ovom slučaju, izračunava se po formuli:
, gdje je n veličina uzorka, , - Studentov koeficijent (treba ga naći iz datih vrijednosti n i iz tabele "Kritične tačke Studentove distribucije").
primjer:
Kao rezultat testova dobijene su sljedeće vrijednosti -35, -32, -26, -35, -30, -17. Poznato je da se pridržavaju zakona normalne distribucije. Naći interval pouzdanosti za populacijsku sredinu a sa nivoom pouzdanosti od 0,9.
Rješenje:
Nađimo nepristrasnu procjenu.
Hajde da nađemo.
Onda
Interval pouzdanosti će poprimiti oblik(-29,2 - 5,62; -29,2 + 5,62) ili (-34,82; -23,58).
Pronalaženje intervala povjerenja za varijansu i standardnu devijaciju normalne distribucije
Neka se slučajni uzorak volumena uzme iz nekog općeg skupa vrijednosti raspoređenih prema normalnom zakonun < 30 za koje se izračunavaju varijanse uzorka: pristrasnoi ispravljeno s 2. Zatim pronaći procjene intervala sa datom pouzdanošćuza opštu disperzijuDopšta standardna devijacijakoriste se sljedeće formule.
ili,
Vrijednosti- pronađite pomoću tablice vrijednosti kritičnih tačakaPearsonove distribucije.
Interval povjerenja za varijansu se nalazi iz ovih nejednakosti kvadriranjem svih dijelova nejednakosti.
primjer:
Provjeren je kvalitet 15 vijaka. Pod pretpostavkom da je greška u njihovoj proizvodnji podložna zakonu normalne distribucije i standardnoj devijaciji uzorkajednak 5 mm, pouzdano odreditiinterval pouzdanosti za nepoznati parametar
Granice intervala predstavljamo kao dvostruku nejednakost:
Krajevi dvostranog intervala povjerenja za varijansu mogu se odrediti bez izvođenja aritmetike za dati nivo povjerenja i veličinu uzorka koristeći odgovarajuću tablicu (Granice intervala povjerenja za varijansu u zavisnosti od broja stupnjeva slobode i pouzdanosti) . Da bi se to uradilo, krajevi intervala dobijeni iz tabele pomnože se ispravljenom varijansom s 2.
primjer:
Rešimo prethodni problem na drugačiji način.
Rješenje:
Pronađimo ispravljenu varijansu:
Prema tabeli „Granice intervala poverenja za varijansu u zavisnosti od broja stepeni slobode i pouzdanosti“ nalazimo granice intervala poverenja za varijansu nak=14 i: donja granica 0,513 i gornja granica 2,354.
Dobijene granice pomnožite sas 2 i izdvojimo korijen (jer nam je potreban interval povjerenja ne za varijansu, već za standardnu devijaciju).
Kao što se može vidjeti iz primjera, vrijednost intervala povjerenja ovisi o načinu njegove konstrukcije i daje bliske, ali različite rezultate.
Za uzorke dovoljno velike veličine (n>30) granice intervala pouzdanosti za opštu standardnu devijaciju mogu se odrediti formulom: - neki broj, koji je tabelarno dat u odgovarajućoj referentnoj tabeli.
Ako 1- q<1, то формула имеет вид:
primjer:
Rešimo prethodni problem na treći način.
Rješenje:
Prethodno pronađenos= 5,17. q(0,95; 15) = 0,46 - nalazimo prema tabeli.
onda:
Često se dešava da je potrebno analizirati određenu društvenu pojavu i dobiti informacije o njoj. Takvi zadaci se često javljaju u statistici i statističkim istraživanjima. Verifikacija potpuno definisanog društvenog fenomena je često nemoguća. Na primjer, kako saznati mišljenje stanovništva ili svih stanovnika određenog grada o bilo kojem pitanju? Pitati apsolutno sve je gotovo nemoguće i vrlo naporno. U takvim slučajevima potreban nam je uzorak. Upravo je to koncept na kojem se zasnivaju gotovo sva istraživanja i analize.
Šta je uzorak
Prilikom analize određenog društvenog fenomena potrebno je dobiti informacije o njemu. Ako uzmemo bilo koju studiju, možemo vidjeti da nije svaka jedinica totaliteta predmeta proučavanja predmet istraživanja i analize. U obzir se uzima samo određeni dio ove ukupnosti. Ovaj proces je uzorkovanje: kada se ispituju samo određene jedinice iz skupa.
Naravno, mnogo zavisi od vrste uzorka. Ali postoje i osnovna pravila. Glavni kaže da odabir iz populacije mora biti apsolutno slučajan. Jedinice stanovništva koje će se koristiti ne bi trebale biti odabrane zbog bilo kojeg kriterija. Grubo govoreći, ako je potrebno prikupiti populaciju od stanovništva određenog grada i odabrati samo muškarce, onda će doći do greške u istraživanju, jer odabir nije izvršen nasumično, već je odabran prema spolu. Gotovo sve metode uzorkovanja temelje se na ovom pravilu.
Pravila uzorkovanja
Da bi odabrani skup odražavao glavne kvalitete čitavog fenomena, on mora biti izgrađen prema određenim zakonima, pri čemu glavnu pažnju treba obratiti na sljedeće kategorije:
- uzorak (populacija uzorka);
- opća populacija;
- reprezentativnost;
- greška reprezentativnosti;
- jedinica stanovništva;
- metode uzorkovanja.
Karakteristike selektivnog posmatranja i uzorkovanja su sljedeće:
- Svi dobijeni rezultati temelje se na matematičkim zakonima i pravilima, odnosno, uz pravilno izvođenje studije i ispravne proračune, rezultati neće biti iskrivljeni na subjektivnoj osnovi
- Omogućuje postizanje rezultata mnogo brže i sa manje vremena i sredstava, proučavajući ne cijeli niz događaja, već samo dio njih.
- Može se koristiti za proučavanje različitih objekata: od specifičnih pitanja, na primjer, starosti, spola grupe koja nas zanima, do proučavanja javnog mnijenja ili nivoa materijalne podrške stanovništva.
Selektivno posmatranje
Selektivno - to je takvo statističko promatranje u kojem se istraživanju ne podvrgava cijela populacija proučavane, već samo neki njen dio, odabran na određeni način, a rezultati proučavanja ovog dijela odnose se na cijelu populaciju. Ovaj dio se naziva okvir uzorkovanja. Ovo je jedini način da se proučava veliki broj predmeta proučavanja.
Ali selektivno promatranje može se koristiti samo u slučajevima kada je potrebno proučavati samo malu grupu jedinica. Na primjer, kada se proučava omjer muškaraca i žena u svijetu, koristit će se selektivno posmatranje. Iz očiglednih razloga, nemoguće je uzeti u obzir svakog stanovnika naše planete.
Ali sa istim proučavanjem, ali ne svih stanovnika zemlje, već određenog 2 "A" razreda u određenoj školi, određenom gradu, određenoj zemlji, selektivno posmatranje se može izostaviti. Uostalom, sasvim je moguće analizirati čitav niz predmeta proučavanja. Treba pobrojati dječake i djevojčice ovog razreda - to će biti omjer.

Uzorak i populacija
Zapravo i nije tako teško kao što zvuči. U svakom predmetu proučavanja postoje dva sistema: opšta i uzorkovana populacija. Šta je? Sve jedinice pripadaju generalu. A uzorku - one jedinice ukupne populacije koje su uzete za uzorak. Ako je sve urađeno kako treba, tada će odabrani dio biti smanjeni raspored cijele (opće) populacije.
Ako govorimo o općoj populaciji, onda možemo razlikovati samo dvije njene varijante: određenu i neodređenu opću populaciju. Zavisi od toga da li je ukupan broj jedinica datog sistema poznat ili ne. Ako se radi o određenoj populaciji, onda će uzorkovanje biti lakše jer se zna koliki procenat od ukupnog broja jedinica će biti uzorkovani.
Ovaj trenutak je veoma neophodan u istraživanju. Na primjer, ako je potrebno istražiti postotak nekvalitetnih konditorskih proizvoda u određenom pogonu. Pretpostavimo da je populacija već definirana. Pouzdano se zna da ovo preduzeće proizvodi 1000 konditorskih proizvoda godišnje. Ako od ove hiljade napravimo uzorak od 100 nasumičnih konditorskih proizvoda i pošaljemo ih na ispitivanje, onda će greška biti minimalna. Grubo govoreći, 10% svih proizvoda je bilo predmet istraživanja, a na osnovu rezultata, uzimajući u obzir grešku reprezentativnosti, možemo govoriti o lošem kvalitetu svih proizvoda.
A ako uzmete uzorak od 100 konditorskih proizvoda iz neodređene opće populacije, gdje je zapravo bilo, recimo, milion jedinica, onda će rezultat uzorka i samo istraživanje biti kritično nevjerojatan i netačan. Osjetite razliku? Stoga je sigurnost opće populacije u većini slučajeva izuzetno važna i uvelike utiče na rezultat studije.

Reprezentativnost stanovništva
Dakle, sada jedno od najvažnijih pitanja – kakav bi trebao biti uzorak? Ovo je najvažnija tačka studije. U ovoj fazi potrebno je izračunati uzorak i u njega odabrati jedinice iz ukupnog broja. Populacija je odabrana ispravno ako su određene karakteristike i karakteristike opšte populacije ostale u uzorku. To se zove reprezentativnost.
Drugim riječima, ako dio nakon selekcije zadrži iste tendencije i karakteristike kao i cijela količina ispitivanog, onda se takva populacija naziva reprezentativnom. Ali ne može se svaki određeni uzorak odabrati iz reprezentativne populacije. Postoje i takvi objekti istraživanja čiji uzorak jednostavno ne može biti reprezentativan. Odatle dolazi koncept greške reprezentativnosti. Ali hajde da pričamo o ovome još malo.
Kako napraviti selekciju
Dakle, kako bi se maksimizirala reprezentativnost, postoje tri osnovna pravila uzorkovanja:

Greška (greška) reprezentativnosti
Osnovna karakteristika kvaliteta odabranog uzorka je koncept "greške reprezentativnosti". Šta je? To su određena odstupanja između indikatora selektivnog i kontinuiranog posmatranja. Prema indikatorima greške, reprezentativnost se dijeli na pouzdanu, običnu i približnu. Drugim riječima, prihvatljiva su odstupanja do 3%, od 3 do 10%, odnosno od 10 do 20%. Iako je u statistici poželjno da greška ne prelazi 5-6%. Inače, ima razloga govoriti o nedovoljnoj reprezentativnosti uzorka. Da bi se izračunala greška reprezentativnosti i kako ona utiče na uzorak ili populaciju, uzimaju se u obzir mnogi faktori:
- Vjerovatnoća s kojom će se dobiti tačan rezultat.
- Broj jedinica uzorkovanja. Kao što je ranije spomenuto, što je manji broj jedinica u uzorku, to će biti veća greška reprezentativnosti, i obrnuto.
- Homogenost ispitivane populacije. Što je populacija heterogena, to će biti veća greška reprezentativnosti. Sposobnost populacije da bude reprezentativna zavisi od homogenosti svih njenih sastavnih jedinica.
- Metoda odabira jedinica u populaciji uzorka.
U specifičnim studijama, procentualnu grešku srednje vrednosti obično postavlja sam istraživač, na osnovu programa posmatranja i prema podacima iz prethodnih studija. U pravilu se prihvatljivom smatra maksimalna greška uzorkovanja (greška reprezentativnosti) unutar 3-5%.

Više nije uvijek bolje
Također je vrijedno zapamtiti da je glavna stvar u organizaciji selektivnog promatranja svesti njegov volumen na prihvatljiv minimum. Istovremeno, ne treba težiti pretjeranom smanjenju granica greške uzorkovanja, jer to može dovesti do neopravdanog povećanja količine podataka uzorka i, posljedično, do povećanja cijene uzorkovanja.
U isto vrijeme, veličina greške reprezentativnosti ne bi trebala biti pretjerano povećana. Uostalom, u ovom slučaju, iako će doći do smanjenja veličine uzorka, to će dovesti do pogoršanja pouzdanosti dobivenih rezultata.
Koja pitanja obično postavlja istraživač?
Svako istraživanje, ako se provodi, ima neku svrhu i da dobije neke rezultate. Prilikom provođenja uzorka istraživanja, po pravilu, početna pitanja su:

Metode odabira istraživačkih jedinica u uzorku
Nije svaki uzorak reprezentativan. Ponekad je jedan te isti znak različito izražen u cjelini i u svom dijelu. Da bi se postigli zahtjevi reprezentativnosti, preporučljivo je koristiti različite metode uzorkovanja. Štoviše, korištenje jedne ili druge metode ovisi o specifičnim okolnostima. Neke od ovih metoda uzorkovanja uključuju:
- slučajni odabir;
- mehanički odabir;
- tipičan izbor;
- serijski (ugniježđeni) odabir.
Slučajni odabir je sistem aktivnosti usmjerenih na slučajni odabir jedinica populacije, kada je vjerovatnoća uključenja u uzorak jednaka za sve jedinice opšte populacije. Ovu tehniku je preporučljivo primijeniti samo u slučaju homogenosti i malog broja njezinih svojstava. U suprotnom postoji rizik da se neke karakteristične karakteristike ne odraze u uzorku. Karakteristike slučajnog odabira su u osnovi svih drugih metoda uzorkovanja.
Sa mehaničkim odabirom jedinica se vrši u određenom intervalu. Ukoliko je potrebno formirati uzorak konkretnih krivičnih djela, moguće je ukloniti svaki 5., 10. ili 15. karton iz svih statističkih evidencija evidentiranih krivičnih djela, u zavisnosti od njihovog ukupnog broja i raspoloživih veličina uzorka. Nedostatak ove metode je što je prije selekcije potrebno imati kompletan obračun jedinica populacije, zatim je potrebno izvršiti rangiranje, a tek nakon toga moguće je uzorkovanje u određenom intervalu. Ova metoda oduzima dosta vremena, pa se ne koristi često.

Tipična (regionalizirana) selekcija je tip uzorka u kojem se opća populacija dijeli na homogene grupe prema određenom atributu. Ponekad istraživači koriste druge termine umjesto "grupa": "okruzi" i "zone". Zatim se iz svake grupe nasumično bira određeni broj jedinica proporcionalno udjelu grupe u ukupnoj populaciji. Tipičan odabir se često provodi u nekoliko faza.
Serijsko uzorkovanje je metoda u kojoj se odabir jedinica vrši po grupama (serijama) i sve jedinice odabrane grupe (serije) podliježu ispitivanju. Prednost ove metode je što je ponekad teže odabrati pojedinačne jedinice nego serije, na primjer, kada se proučava osoba koja služi kaznu. U okviru odabranih područja, zona primjenjuje se proučavanje svih jedinica bez izuzetka, na primjer, proučavanje svih lica na izdržavanju kazne u određenoj ustanovi.
 Govorništvo kao prototip novinarstva
Govorništvo kao prototip novinarstva Citati o Napoleonu - dslinkov — LiveJournal
Citati o Napoleonu - dslinkov — LiveJournal Moja osveta Čovjek na buldožeru je uništio grad
Moja osveta Čovjek na buldožeru je uništio grad