Mengapa penyebaran diperlukan? Varians sisa
Langkah
Mengira varians sampel
-
Catatkan nilai sampel. Dalam kebanyakan kes, ahli statistik hanya mempunyai akses kepada sampel populasi tertentu. Sebagai contoh, sebagai peraturan, ahli statistik tidak menganalisis kos penyelenggaraan agregat semua kereta di Rusia - mereka menganalisis sampel rawak daripada beberapa ribu kereta. Sampel sedemikian akan membantu menentukan kos purata kereta, tetapi kemungkinan besar nilai yang terhasil akan jauh dari yang sebenar.
- Sebagai contoh, mari kita analisa bilangan roti yang dijual di kafe selama 6 hari, diambil secara rawak. Sampel mempunyai pandangan seterusnya: 17, 15, 23, 7, 9, 13. Ini adalah sampel, bukan populasi, kerana kami tidak mempunyai data tentang roti yang dijual untuk setiap hari kafe dibuka.
- Jika anda diberi populasi dan bukannya sampel nilai, teruskan ke bahagian seterusnya.
-
Tulis formula untuk mengira varians sampel. Serakan ialah ukuran sebaran nilai kuantiti tertentu. Semakin hampir nilai varians kepada sifar, semakin hampir nilai-nilai itu dikumpulkan bersama. Apabila bekerja dengan sampel nilai, gunakan formula berikut untuk mengira varians:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))– ini adalah penyebaran. Serakan diukur dalam unit persegi ukuran.
- x i (\displaystyle x_(i))– setiap nilai dalam sampel.
- x i (\displaystyle x_(i)) anda perlu menolak xᅳ, kuasa dua, dan kemudian tambah hasilnya.
- xᅳ – min sampel (min sampel).
- n – bilangan nilai dalam sampel.
-
Kirakan min sampel. Ia dilambangkan sebagai xᅳ. Min sampel dikira sebagai min aritmetik mudah: tambah semua nilai dalam sampel, dan kemudian bahagikan hasilnya dengan bilangan nilai dalam sampel.
- Dalam contoh kami, tambahkan nilai dalam sampel: 15 + 17 + 23 + 7 + 9 + 13 = 84
Sekarang bahagikan hasilnya dengan bilangan nilai dalam sampel (dalam contoh kami terdapat 6): 84 ÷ 6 = 14.
Sampel min xᅳ = 14. - Purata sampel ialah nilai pusat di mana nilai dalam sampel diedarkan. Jika nilai dalam kelompok sampel di sekeliling sampel bermakna, maka varians adalah kecil; jika tidak varians adalah besar.
- Dalam contoh kami, tambahkan nilai dalam sampel: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Kurangkan min sampel daripada setiap nilai dalam sampel. Sekarang hitung perbezaannya x i (\displaystyle x_(i))- xᅳ, di mana x i (\displaystyle x_(i))– setiap nilai dalam sampel. Setiap keputusan yang diperoleh menunjukkan tahap sisihan nilai tertentu daripada min sampel, iaitu sejauh mana nilai ini daripada min sampel.
- Dalam contoh kami:
x 1 (\displaystyle x_(1))- xᅳ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- xᅳ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x = 23 - 14 = 9
x 4 (\displaystyle x_(4))- xᅳ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- xᅳ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- xᅳ = 13 - 14 = -1 - Ketepatan keputusan yang diperoleh adalah mudah untuk diperiksa, kerana jumlahnya harus sama dengan sifar. Ini berkaitan dengan penentuan nilai purata, sejak nilai negatif(jarak dari nilai purata ke nilai yang lebih kecil) diberi pampasan sepenuhnya nilai positif(jarak dari purata ke nilai besar).
- Dalam contoh kami:
-
Seperti yang dinyatakan di atas, jumlah perbezaan x i (\displaystyle x_(i))- xᅳ mestilah sama dengan sifar. Ini bermakna bahawa varians purata sentiasa sama dengan sifar, yang tidak memberikan sebarang idea tentang penyebaran nilai kuantiti tertentu. Untuk menyelesaikan masalah ini, kuasa duakan setiap perbezaan x i (\displaystyle x_(i))- x̅. Ini akan menyebabkan anda hanya mendapat nombor positif, yang apabila ditambah tidak akan memberikan 0.
- Dalam contoh kami:
(x 1 (\displaystyle x_(1))- x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2)))- x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Anda menjumpai kuasa dua beza - x̅) 2 (\displaystyle ^(2)) bagi setiap nilai dalam sampel.
- Dalam contoh kami:
-
Hitung hasil tambah kuasa dua perbezaan itu. Iaitu, cari bahagian formula yang ditulis seperti ini: ∑[( x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))]. Di sini tanda Σ bermaksud jumlah perbezaan kuasa dua untuk setiap nilai x i (\displaystyle x_(i)) dalam sampel. Anda telah menemui perbezaan kuasa dua (x i (\displaystyle (x_(i)))- x̅) 2 (\displaystyle ^(2)) bagi setiap nilai x i (\displaystyle x_(i)) dalam sampel; sekarang hanya tambah petak ini.
- Dalam contoh kami: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Bahagikan hasilnya dengan n - 1, dengan n ialah bilangan nilai dalam sampel. Beberapa ketika dahulu, untuk mengira varians sampel, ahli statistik hanya membahagikan hasilnya dengan n; dalam kes ini, anda akan mendapat min varians kuasa dua, yang sesuai untuk menerangkan varians sampel yang diberikan. Tetapi ingat bahawa mana-mana sampel hanyalah sebahagian kecil penduduk nilai. Jika anda mengambil sampel lain dan melakukan pengiraan yang sama, anda akan mendapat hasil yang berbeza. Ternyata, membahagikan dengan n - 1 (bukan hanya n) memberikan lebih banyak penilaian yang tepat varians populasi, yang anda minati. Pembahagian dengan n – 1 telah menjadi biasa, jadi ia termasuk dalam formula untuk mengira varians sampel.
- Dalam contoh kami, sampel termasuk 6 nilai, iaitu, n = 6.
Varians sampel = s 2 = 166 6 − 1 = (\gaya paparan s^(2)=(\frac (166)(6-1))=) 33,2
- Dalam contoh kami, sampel termasuk 6 nilai, iaitu, n = 6.
-
Perbezaan antara varians dan sisihan piawai. Ambil perhatian bahawa formula mengandungi eksponen, jadi serakan diukur dalam unit kuasa dua nilai yang dianalisis. Kadangkala magnitud sedemikian agak sukar untuk dikendalikan; dalam kes sedemikian, gunakan sisihan piawai, yang sama dengan punca kuasa dua varians. Itulah sebabnya varians sampel ditandakan sebagai s 2 (\displaystyle s^(2)), A sisihan piawai sampel - bagaimana s (\displaystyle s).
- Dalam contoh kami, sisihan piawai sampel ialah: s = √33.2 = 5.76.
Mengira Varians Populasi
-
Menganalisis beberapa set nilai. Set termasuk semua nilai kuantiti yang sedang dipertimbangkan. Sebagai contoh, jika anda mengkaji umur penduduk Wilayah Leningrad, maka penduduk termasuk umur semua penduduk kawasan ini. Apabila bekerja dengan populasi, adalah disyorkan untuk membuat jadual dan memasukkan nilai populasi ke dalamnya. Pertimbangkan contoh berikut:
- Dalam bilik tertentu terdapat 6 akuarium. Setiap akuarium mengandungi bilangan ikan berikut:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- Dalam bilik tertentu terdapat 6 akuarium. Setiap akuarium mengandungi bilangan ikan berikut:
-
Tulis formula untuk mengira varians populasi. Memandangkan populasi merangkumi semua nilai kuantiti tertentu, formula di bawah membolehkan anda mendapatkan nilai sebenar varians populasi. Untuk membezakan varians populasi daripada varians sampel (yang hanya anggaran), ahli statistik menggunakan pelbagai pembolehubah:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n
- σ 2 (\displaystyle ^(2))– serakan penduduk (dibaca sebagai “sigma kuasa dua”). Serakan diukur dalam unit persegi.
- x i (\displaystyle x_(i))– setiap nilai secara keseluruhannya.
- Σ – tanda jumlah. Iaitu, daripada setiap nilai x i (\displaystyle x_(i)) anda perlu tolak μ, kuasa dua, dan kemudian tambah hasilnya.
- μ – min populasi.
- n – bilangan nilai dalam populasi.
-
Kirakan min populasi. Apabila bekerja dengan populasi, puratanya dilambangkan sebagai μ (mu). Purata populasi dikira sebagai min aritmetik mudah: tambah semua nilai dalam populasi, dan kemudian bahagikan hasilnya dengan bilangan nilai dalam populasi.
- Perlu diingat bahawa purata tidak selalu dikira sebagai min aritmetik.
- Dalam contoh kami, populasi bermakna: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\gaya paparan (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Kurangkan min populasi daripada setiap nilai dalam populasi. Semakin hampir nilai bezanya dengan sifar, semakin dekat nilai khusus dengan min populasi. Cari perbezaan antara setiap nilai dalam populasi dan minnya, dan anda akan mendapat idea pertama tentang pengagihan nilai.
- Dalam contoh kami:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- Dalam contoh kami:
-
Kuadratkan setiap keputusan yang diperolehi. Nilai perbezaan akan menjadi positif dan negatif; Jika nilai ini diplot pada garis nombor, ia akan terletak di sebelah kanan dan kiri min populasi. Ini tidak sesuai untuk mengira varians, kerana positif dan nombor negatif saling memberi pampasan. Jadi kuasai setiap perbezaan untuk mendapatkan nombor positif secara eksklusif.
- Dalam contoh kami:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) untuk setiap nilai populasi (dari i = 1 hingga i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), Di mana x n (\displaystyle x_(n)) – nilai terakhir dalam populasi umum. - Untuk mengira nilai purata keputusan yang diperoleh, anda perlu mencari jumlahnya dan membahagikannya dengan n :(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/n
- Sekarang mari kita tuliskan penjelasan di atas menggunakan pembolehubah: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n dan dapatkan formula untuk mengira varians populasi.
- Dalam contoh kami:
Jom kira masukMSEXCELvarians sampel dan sisihan piawai. Kami juga akan mengira varians pembolehubah rawak jika taburannya diketahui.
Mari kita pertimbangkan dahulu penyebaran, kemudian sisihan piawai.
Varians sampel
Varians sampel (varians sampel,sampelvarians) mencirikan sebaran nilai dalam tatasusunan berbanding .
Kesemua 3 formula adalah setara secara matematik.
Dari formula pertama jelas bahawa varians sampel ialah jumlah sisihan kuasa dua bagi setiap nilai dalam tatasusunan daripada purata, dibahagikan dengan saiz sampel tolak 1.
kelainan sampel fungsi DISP() digunakan, Bahasa Inggeris. nama VAR, i.e. VARiance. Daripada versi MS EXCEL 2010, adalah disyorkan untuk menggunakan analog DISP.V(), Inggeris. nama VARS, i.e. Contoh VARiance. Di samping itu, bermula dari versi MS EXCEL 2010, terdapat fungsi DISP.Г(), Bahasa Inggeris. nama VARP, i.e. Populasi VARiance, yang mengira penyebaran Untuk penduduk. Keseluruhan perbezaan datang kepada penyebut: bukannya n-1 seperti DISP.V(), DISP.G() hanya mempunyai n dalam penyebut. Sebelum MS EXCEL 2010, fungsi VAR() digunakan untuk mengira varians populasi.
Varians sampel
=QUADROTCL(Sampel)/(COUNT(Sampel)-1)
=(JUMLAH(Sampel)-COUNT(Sampel)*PURATA(Sampel)^2)/ (COUNT(Sampel)-1)– formula biasa
=SUM((Sampel -PURATA(Sampel))^2)/ (COUNT(Sampel)-1) –
Varians sampel adalah sama dengan 0, hanya jika semua nilai adalah sama antara satu sama lain dan, dengan itu, sama nilai purata. Biasanya, semakin besar nilainya kelainan, semakin besar sebaran nilai dalam tatasusunan.
Varians sampel ialah anggaran mata kelainan taburan pembolehubah rawak dari mana ia dibuat sampel. Mengenai pembinaan selang keyakinan semasa menilai kelainan boleh baca dalam artikel.
Varians pembolehubah rawak
Untuk mengira penyebaran pembolehubah rawak, anda perlu mengetahuinya.
Untuk kelainan pembolehubah rawak X selalunya dilambangkan Var(X). Penyerakan sama dengan kuasa dua sisihan daripada min E(X): Var(X)=E[(X-E(X)) 2 ]
penyebaran dikira dengan formula:

di mana x i ialah nilai yang boleh diambil pembolehubah rawak, dan μ ialah nilai purata (), р(x) ialah kebarangkalian bahawa pembolehubah rawak akan mengambil nilai x.
Jika pembolehubah rawak mempunyai , maka penyebaran dikira dengan formula:

Dimensi kelainan sepadan dengan kuasa dua unit ukuran nilai asal. Contohnya, jika nilai dalam sampel mewakili ukuran berat bahagian (dalam kg), maka dimensi varians ialah kg 2 . Ini mungkin sukar untuk ditafsirkan, jadi untuk mencirikan sebaran nilai, nilai yang sama dengan punca kuasa dua kelainan – sisihan piawai.
Beberapa hartanah kelainan:
Var(X+a)=Var(X), dengan X ialah pembolehubah rawak dan a ialah pemalar.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Sifat penyebaran ini digunakan dalam artikel tentang regresi linear.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), dengan X dan Y ialah pembolehubah rawak, Cov(X;Y) ialah kovarians bagi pembolehubah rawak ini.
Jika pembolehubah rawak adalah bebas, maka mereka kovarians adalah sama dengan 0, dan oleh itu Var(X+Y)=Var(X)+Var(Y). Sifat serakan ini digunakan dalam terbitan.
Mari kita tunjukkan untuk kuantiti bebas Var(X-Y)=Var(X+Y). Sesungguhnya, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Sifat serakan ini digunakan untuk membina .
Sisihan piawai sampel
Sisihan piawai sampel ialah ukuran sejauh mana taburan nilai dalam sampel berbanding dengan nilai .
Mengikut definisi, sisihan piawai sama dengan punca kuasa dua bagi kelainan:

Sisihan Piawai tidak mengambil kira magnitud nilai dalam sampel, tetapi hanya tahap penyebaran nilai di sekelilingnya purata. Untuk menggambarkan ini, mari kita berikan satu contoh.
Mari kita hitung sisihan piawai untuk 2 sampel: (1; 5; 9) dan (1001; 1005; 1009). Dalam kedua-dua kes, s=4. Adalah jelas bahawa nisbah sisihan piawai kepada nilai tatasusunan sampel adalah berbeza dengan ketara. Untuk kes sedemikian ia digunakan Pekali variasi(Pekali Variasi, CV) - nisbah Sisihan Piawai kepada purata aritmetik, dinyatakan sebagai peratusan.
Dalam MS EXCEL 2007 dan kemudian versi terdahulu untuk mengira Sisihan piawai sampel fungsi =STDEVAL() digunakan, Bahasa Inggeris. nama STDEV, i.e. SISIhan Piawai. Daripada versi MS EXCEL 2010, adalah disyorkan untuk menggunakan analognya =STANDDEV.B() , Bahasa Inggeris. nama STDEV.S, i.e. Sampel STandard DEViation.
Selain itu, bermula dari versi MS EXCEL 2010, terdapat fungsi STANDARDEV.G(), Bahasa Inggeris. nama STDEV.P, i.e. Sisihan Piawai Populasi, yang mengira sisihan piawai Untuk penduduk. Keseluruhan perbezaan datang kepada penyebut: bukannya n-1 seperti dalam STANDARDEV.V(), STANDARDEVAL.G() hanya mempunyai n dalam penyebut.
Sisihan Piawai juga boleh dikira terus menggunakan formula di bawah (lihat fail contoh)
=ROOT(QUADROTCL(Sampel)/(COUNT(Contoh)-1))
=ROOT((SUM(Sampel)-COUNT(Sampel)*PURATA(Sampel)^2)/(COUNT(Sampel)-1))
Langkah-langkah taburan lain
Fungsi SQUADROTCL() mengira dengan jumlah sisihan kuasa dua nilai daripada mereka purata. Fungsi ini akan mengembalikan hasil yang sama seperti formula =DISP.G( Sampel)*SEMAK( Sampel), Di mana Sampel- rujukan kepada julat yang mengandungi tatasusunan nilai sampel (). Pengiraan dalam fungsi QUADROCL() dibuat mengikut formula:

Fungsi SROTCL() juga merupakan ukuran penyebaran set data. Fungsi SROTCL() mengira purata nilai mutlak penyelewengan nilai daripada purata. Fungsi ini akan mengembalikan hasil yang sama seperti formula =SUMPRODUCT(ABS(Sampel-PURATA(Sampel)))/COUNT(Sampel), Di mana Sampel- rujukan kepada julat yang mengandungi tatasusunan nilai sampel.
Pengiraan dalam fungsi SROTCL () dibuat mengikut formula:

Walau bagaimanapun, ciri ini sahaja tidak mencukupi untuk mengkaji pembolehubah rawak. Mari kita bayangkan dua penembak menembak sasaran. Seorang menembak dengan tepat dan terkena dekat tengah, manakala yang lain... hanya berseronok dan tidak mensasarkan pun. Tapi yang kelakarnya dia purata hasilnya akan sama seperti penembak pertama! Keadaan ini secara konvensional digambarkan oleh pembolehubah rawak berikut:
Jangkaan matematik "penembak tepat" adalah sama dengan, bagaimanapun, " personaliti yang menarik": – ia juga sifar!
Oleh itu, terdapat keperluan untuk mengukur sejauh mana bertaburan peluru (nilai pembolehubah rawak) berbanding dengan pusat sasaran ( jangkaan matematik). Baiklah berselerak diterjemahkan daripada bahasa Latin tidak lain adalah penyebaran .
Mari lihat bagaimana ini ditentukan ciri berangka menggunakan salah satu contoh daripada bahagian 1 pelajaran: 
Di sana kami mendapati jangkaan matematik yang mengecewakan bagi permainan ini, dan kini kami perlu mengira variansnya, yang dilambangkan dengan melalui .
Mari kita ketahui sejauh mana kemenangan/kerugian "tersebar" berbanding dengan nilai purata. Jelas sekali, untuk ini kita perlu mengira perbezaan antara nilai pembolehubah rawak dan dia jangkaan matematik:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Sekarang nampaknya anda perlu merumuskan hasilnya, tetapi cara ini tidak sesuai - atas sebab turun naik ke kiri akan membatalkan satu sama lain dengan turun naik ke kanan. Jadi, sebagai contoh, penembak "amatur". (contoh di atas) perbezaan akan menjadi ![]() , dan apabila ditambah mereka akan memberikan sifar, jadi kami tidak akan mendapat sebarang anggaran serakan penembakannya.
, dan apabila ditambah mereka akan memberikan sifar, jadi kami tidak akan mendapat sebarang anggaran serakan penembakannya.
Untuk mengatasi masalah ini anda boleh pertimbangkan modul perbezaan, tetapi atas sebab teknikal pendekatan telah berakar umbi apabila ia kuasa dua. Lebih mudah untuk merumuskan penyelesaian dalam jadual: 
Dan di sini ia memohon untuk mengira purata wajaran nilai sisihan kuasa dua. Dan APA ini? Ia milik mereka jangkaan matematik, iaitu ukuran serakan:
![]() – takrifan kelainan. Daripada takrifan itu jelas sekali varians tidak boleh negatif- ambil perhatian untuk latihan!
– takrifan kelainan. Daripada takrifan itu jelas sekali varians tidak boleh negatif- ambil perhatian untuk latihan!
Mari kita ingat bagaimana untuk mencari nilai yang diharapkan. Darabkan perbezaan kuasa dua dengan kebarangkalian yang sepadan (jadual diteruskan):
- secara kiasan, ini adalah "daya tarikan",
dan meringkaskan keputusan:
Tidakkah anda fikir jika dibandingkan dengan kemenangan, hasilnya ternyata terlalu besar? Betul - kami menduakannya, dan untuk kembali ke dimensi permainan kami, kami perlu mengekstrak punca kuasa dua. Nilai ini dipanggil sisihan piawai
dan dilambangkan dengan huruf Yunani "sigma":
Nilai ini kadangkala dipanggil sisihan piawai .
Apakah maksudnya? Jika kita menyimpang dari jangkaan matematik ke kiri dan kanan dengan purata sisihan piawai:![]()
– maka nilai yang paling berkemungkinan bagi pembolehubah rawak akan "tertumpu" pada selang ini. Apa yang sebenarnya kita perhatikan:
Walau bagaimanapun, ia berlaku bahawa apabila menganalisis penyebaran seseorang hampir selalu beroperasi dengan konsep penyebaran. Mari kita fikirkan maksudnya berkaitan dengan permainan. Jika dalam kes anak panah kita bercakap tentang "ketepatan" pukulan berbanding dengan pusat sasaran, maka di sini penyebaran mencirikan dua perkara:
Pertama, adalah jelas bahawa apabila pertaruhan meningkat, penyebaran juga meningkat. Jadi, sebagai contoh, jika kita meningkat sebanyak 10 kali, maka jangkaan matematik akan meningkat sebanyak 10 kali, dan varians akan meningkat sebanyak 100 kali. (kerana ini adalah kuantiti kuadratik). Tetapi ambil perhatian bahawa peraturan permainan itu sendiri tidak berubah! Hanya kadar yang telah berubah, secara kasarnya, sebelum kita bertaruh 10 rubel, kini 100.
Kedua, lebih point yang menarik ialah varians mencirikan gaya permainan. Betulkan secara mental pertaruhan permainan pada tahap tertentu, dan mari kita lihat apa itu:
Permainan varians rendah ialah permainan berhati-hati. Pemain cenderung untuk memilih skim yang paling boleh dipercayai, di mana dia tidak kalah/menang terlalu banyak pada satu masa. Contohnya, sistem merah/hitam dalam rolet (lihat contoh 4 artikel Pembolehubah rawak) .
Permainan varians tinggi. Dia sering dipanggil tersebar permainan. Ini adalah gaya permainan yang mencabar atau agresif di mana pemain memilih skim "adrenalin". Sekurang-kurangnya kita ingat "Martingale", di mana jumlah yang dipertaruhkan adalah susunan magnitud yang lebih besar daripada permainan "tenang" mata sebelumnya.
Keadaan dalam poker adalah petunjuk: ada yang dipanggil ketat pemain yang cenderung berhati-hati dan "goyah" terhadap dana permainan mereka (bankroll). Tidak menghairankan, bankroll mereka tidak turun naik dengan ketara (variance rendah). Sebaliknya, jika pemain mempunyai varians yang tinggi, maka dia adalah seorang penceroboh. Dia sering mengambil risiko, membuat pertaruhan besar dan sama ada boleh memecahkan bank besar atau kalah berkeping-keping.
Perkara yang sama berlaku dalam Forex, dan seterusnya - terdapat banyak contoh.
Lebih-lebih lagi, dalam semua kes, tidak kira sama ada permainan itu dimainkan untuk sen atau beribu-ribu dolar. Setiap peringkat mempunyai pemain penyebaran rendah dan tinggi. Seperti yang kita ingat, purata kemenangan adalah "bertanggungjawab" jangkaan matematik.
Anda mungkin perasan bahawa mencari varians adalah proses yang panjang dan teliti. Tetapi matematik adalah murah hati:
Formula untuk mencari varians
Formula ini diperolehi terus daripada takrif varians, dan kami segera menggunakannya. Saya akan menyalin tanda dengan permainan kami di atas: 
dan jangkaan matematik yang ditemui.
Mari kita mengira varians dengan cara kedua. Pertama, mari kita cari jangkaan matematik - kuasa dua pembolehubah rawak. Oleh penentuan jangkaan matematik:
DALAM dalam kes ini:
Oleh itu, mengikut formula:
Seperti yang mereka katakan, rasai perbezaannya. Dan dalam praktiknya, tentu saja, lebih baik menggunakan formula (kecuali syaratnya memerlukan sebaliknya).
Kami menguasai teknik menyelesaikan dan mereka bentuk:
Contoh 6

Cari jangkaan matematiknya, varians dan sisihan piawai.
Tugas ini ditemui di mana-mana, dan, sebagai peraturan, pergi tanpa makna yang bermakna.
Anda boleh bayangkan beberapa mentol lampu dengan nombor yang menyala di rumah gila dengan kebarangkalian tertentu :)
Penyelesaian: Adalah mudah untuk meringkaskan pengiraan asas dalam jadual. Pertama, kami menulis data awal dalam dua baris teratas. Kemudian kami mengira produk, kemudian dan akhirnya jumlah dalam lajur kanan: 
Sebenarnya hampir semuanya sudah siap. Baris ketiga menunjukkan jangkaan matematik siap sedia: ![]() .
.
Kami mengira varians menggunakan formula:
Dan akhirnya, sisihan piawai:
– Secara peribadi, saya biasanya membundarkan kepada 2 tempat perpuluhan.
Semua pengiraan boleh dilakukan pada kalkulator, atau lebih baik lagi – dalam Excel:
Sukar untuk tersilap di sini :)
Jawab:
Mereka yang berhajat boleh memudahkan lagi kehidupan mereka dan mengambil kesempatan daripada saya kalkulator (demo), yang bukan sahaja akan menyelesaikan serta-merta tugasan ini, tetapi juga akan membina grafik tematik (kami akan sampai ke sana tidak lama lagi). Program itu boleh muat turun dari perpustakaan– jika anda telah memuat turun sekurang-kurangnya satu bahan pendidikan, atau dapatkan cara lain. Terima kasih kerana menyokong projek ini!
Beberapa tugasan untuk keputusan bebas:
Contoh 7
Kira varians pembolehubah rawak dalam contoh sebelumnya mengikut takrifan.
Dan contoh serupa:
Contoh 8
Pembolehubah rawak diskret ditentukan oleh undang-undang taburannya:

Ya, nilai pembolehubah rawak boleh menjadi agak besar (contoh daripada kerja sebenar) , dan di sini, jika boleh, gunakan Excel. Sebagai contoh, dalam Contoh 7 - ia lebih pantas, lebih dipercayai dan lebih menyeronokkan.
Penyelesaian dan jawapan di bahagian bawah halaman.
Pada akhir bahagian ke-2 pelajaran, kita akan melihat satu lagi tugas biasa, seseorang mungkin berkata, rebus kecil:
Contoh 9
Pembolehubah rawak diskret hanya boleh mengambil dua nilai: dan , dan . Kebarangkalian, jangkaan matematik dan varians diketahui.
Penyelesaian: Mari kita mulakan dengan kebarangkalian yang tidak diketahui. Oleh kerana pembolehubah rawak boleh mengambil hanya dua nilai, jumlah kebarangkalian kejadian yang sepadan ialah:
dan sejak , kemudian .
Yang tinggal hanyalah mencari..., senang cakap :) Tapi oh well, here we go. Mengikut takrif jangkaan matematik: ![]() – menggantikan kuantiti yang diketahui:
– menggantikan kuantiti yang diketahui:
![]() – dan tiada lagi yang boleh dikeluarkan daripada persamaan ini, kecuali anda boleh menulis semula dalam arah biasa:
– dan tiada lagi yang boleh dikeluarkan daripada persamaan ini, kecuali anda boleh menulis semula dalam arah biasa: ![]()

atau: ![]()
TENTANG tindakan selanjutnya, saya rasa anda boleh meneka. Mari kita karang dan selesaikan sistem: 
perpuluhan- ini, sudah tentu, adalah kehinaan yang lengkap; darab kedua-dua persamaan dengan 10: 
dan bahagikan dengan 2: 
Itu lebih baik. Daripada persamaan 1 kita nyatakan: ![]() (ini adalah cara yang lebih mudah)– gantikan ke dalam persamaan ke-2:
(ini adalah cara yang lebih mudah)– gantikan ke dalam persamaan ke-2:
![]()
Kami sedang membina kuasa dua dan buat penyederhanaan: 
Darab dengan: 
Hasilnya ialah persamaan kuadratik, kami mendapatinya mendiskriminasi:
- Hebat!
dan kami mendapat dua penyelesaian:
1) jika ![]() , Itu
, Itu ![]() ;
;
2) jika ![]() , Itu .
, Itu .
Keadaan ini dipenuhi oleh pasangan nilai pertama. Dengan kebarangkalian yang tinggi semuanya betul, tetapi, bagaimanapun, mari kita tuliskan undang-undang pengedaran: 
dan lakukan semakan, iaitu, cari jangkaan:
Serakan ialah ukuran serakan yang menggambarkan sisihan perbandingan antara nilai data dan min. Ia ialah ukuran serakan yang paling banyak digunakan dalam statistik, dikira dengan menjumlahkan dan menduakan sisihan setiap nilai data daripada min. Formula untuk mengira varians diberikan di bawah:
![]()
s 2 – varians sampel;
x av—min sampel;
n — saiz sampel (bilangan nilai data),
(x i – x avg) ialah sisihan daripada nilai purata bagi setiap nilai set data.
Untuk pemahaman yang lebih baik formula, mari kita lihat contoh. Saya tidak begitu suka memasak, jadi saya jarang melakukannya. Walau bagaimanapun, untuk tidak kelaparan, dari semasa ke semasa saya perlu pergi ke dapur untuk melaksanakan rancangan mengenyangkan badan saya dengan protein, lemak dan karbohidrat. Set data di bawah menunjukkan bilangan kali Renat memasak setiap bulan:
Langkah pertama dalam mengira varians adalah untuk menentukan min sampel, yang dalam contoh kita ialah 7.8 kali sebulan. Selebihnya pengiraan boleh dibuat lebih mudah menggunakan jadual berikut.

Fasa terakhir pengiraan varians kelihatan seperti ini:
![]()
Bagi mereka yang suka melakukan semua pengiraan sekali gus, persamaan akan kelihatan seperti ini:
Menggunakan kaedah pengiraan mentah (contoh masakan)
Ada lagi cara yang berkesan pengiraan varians, yang dikenali sebagai kaedah "pengiraan mentah". Walaupun persamaan itu mungkin kelihatan agak rumit pada pandangan pertama, ia sebenarnya tidak begitu menakutkan. Anda boleh memastikan perkara ini, dan kemudian memutuskan kaedah yang paling anda sukai.

ialah jumlah setiap nilai data selepas kuasa dua,
ialah kuasa dua bagi jumlah semua nilai data.
Jangan hilang akal sekarang. Mari letakkan ini semua ke dalam jadual dan anda akan melihat bahawa terdapat lebih sedikit pengiraan yang terlibat daripada contoh sebelumnya.


Seperti yang anda lihat, hasilnya adalah sama seperti semasa menggunakan kaedah sebelumnya. Kelebihan kaedah ini menjadi jelas apabila saiz sampel (n) bertambah.
Pengiraan varians dalam Excel
Seperti yang anda mungkin sudah meneka, Excel mempunyai formula yang membolehkan anda mengira varians. Selain itu, bermula dengan Excel 2010, anda boleh menemui 4 jenis formula varians:
1) VARIANCE.V – Mengembalikan varians sampel. Nilai dan teks Boolean diabaikan.
2) DISP.G - Mengembalikan varians populasi. Nilai dan teks Boolean diabaikan.
3) VARIANCE - Mengembalikan varians sampel, dengan mengambil kira nilai Boolean dan teks.
4) VARIANCE - Mengembalikan varians populasi, dengan mengambil kira nilai logik dan teks.
Mula-mula, mari kita fahami perbezaan antara sampel dan populasi. Tujuan statistik deskriptif adalah untuk meringkaskan atau memaparkan data supaya cepat mendapatkan gambaran keseluruhan, gambaran keseluruhan, boleh dikatakan. Inferens statistik membolehkan anda membuat inferens tentang populasi berdasarkan sampel data daripada populasi tersebut. Populasi mewakili semua kemungkinan hasil atau ukuran yang menarik minat kita. Sampel ialah subset populasi.
Sebagai contoh, kami berminat dengan keseluruhan kumpulan pelajar dari salah satu universiti Rusia dan kita perlu menentukan skor purata kumpulan. Kita boleh mengira prestasi purata pelajar, dan kemudian angka yang terhasil akan menjadi parameter, kerana pengiraan kami akan melibatkan keseluruhan populasi. Namun, jika kita ingin mengira GPA semua pelajar di negara kita, maka kumpulan ini akan menjadi sampel kita.
Perbezaan dalam formula untuk mengira varians antara sampel dan populasi ialah penyebut. Di mana untuk sampel ia akan sama dengan (n-1), dan untuk populasi umum sahaja n.
Sekarang mari kita lihat fungsi untuk mengira varians dengan pengakhiran A, keterangan yang menyatakan bahawa teks dan nilai logik diambil kira dalam pengiraan. Dalam kes ini, apabila mengira varians tatasusunan data tertentu, jika tidak ada nilai angka Excel akan mentafsir teks dan nilai Boolean palsu sebagai sama dengan 0, dan nilai Boolean benar sama dengan 1.
Jadi, jika anda mempunyai tatasusunan data, mengira variansnya tidak sukar menggunakan salah satu fungsi Excel yang disenaraikan di atas.

Julat variasi (atau julat variasi) - ialah perbezaan antara maksimum dan nilai minimum tanda:
Dalam contoh kami, julat variasi dalam keluaran syif pekerja ialah: dalam briged pertama R = 105-95 = 10 kanak-kanak, dalam briged kedua R = 125-75 = 50 kanak-kanak. (5 kali ganda lagi). Ini menunjukkan bahawa output briged 1 lebih "stabil", tetapi briged kedua mempunyai lebih banyak rizab untuk meningkatkan output, kerana Jika semua pekerja mencapai output maksimum untuk briged ini, ia boleh menghasilkan 3 * 125 = 375 bahagian, dan dalam briged pertama hanya 105 * 3 = 315 bahagian.
Jika nilai yang melampau ciri-ciri tidak tipikal untuk populasi, maka julat kuartil atau desil digunakan. Julat kuartil RQ= Q3-Q1 meliputi 50% daripada jumlah populasi, julat desil pertama RD1 = D9-D1 meliputi 80% data, julat desil kedua RD2= D8-D2 - 60%.
Kelemahan penunjuk skop variasi adalah, tetapi nilainya tidak mencerminkan semua turun naik atribut.
Penunjuk umum termudah yang mencerminkan semua turun naik ciri ialah sisihan linear purata, iaitu min aritmetik bagi sisihan mutlak pilihan individu daripada nilai puratanya:
,
untuk data berkumpulan ![]() ,
,
dengan xi ialah nilai ciri dalam siri diskret atau pertengahan selang dalam taburan selang.
Dalam formula di atas, perbezaan dalam pengangka diambil modulo, jika tidak, mengikut sifat min aritmetik, pengangka akan sentiasa sama dengan sifar. Oleh itu, sisihan linear purata jarang digunakan dalam amalan statistik, hanya dalam kes di mana penjumlahan penunjuk tanpa mengambil kira tanda telah pengertian ekonomi. Dengan bantuannya, sebagai contoh, komposisi tenaga kerja, keuntungan pengeluaran, dan pusing ganti perdagangan asing dianalisis.
Varians sesuatu sifat- Ini persegi tengah sisihan daripada nilai purata mereka:
varians mudah ![]() ,
,
berwajaran varians  .
.
Formula untuk mengira varians boleh dipermudahkan:
Oleh itu, varians adalah sama dengan perbezaan antara min kuasa dua pilihan dan kuasa dua min pilihan populasi:  .
.
Walau bagaimanapun, disebabkan penjumlahan sisihan kuasa dua, varians memberikan idea yang herot tentang sisihan, jadi purata dikira berdasarkannya sisihan piawai, yang menunjukkan berapa banyak secara purata varian khusus sesuatu sifat menyimpang daripada nilai puratanya. Dikira dengan mendapatkan semula punca kuasa dua daripada penyebaran:
untuk data tidak terkumpul 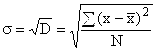 ,
,
Untuk siri variasi
Bagaimana kurang nilai varians dan sisihan piawai, lebih homogen populasi, lebih dipercayai (tipikal) ia akan menjadi nilai purata.
Purata linear dan purata sisihan piawai- nombor bernama, iaitu, dinyatakan dalam unit ukuran ciri, adalah sama dalam kandungan dan hampir dalam makna.
Kira penunjuk mutlak variasi disyorkan menggunakan jadual.
Jadual 3 - Pengiraan ciri variasi (menggunakan contoh tempoh data pada output syif pekerja krew)
Bilangan pekerja |
Tengah selang |
Nilai yang dikira |
|||||
Jumlah: |
|||||||
Purata keluaran syif pekerja: ![]()
Sisihan linear purata: ![]()
Varian pengeluaran: 
Sisihan piawai keluaran pekerja individu daripada keluaran purata:
.
1 Pengiraan serakan menggunakan kaedah momen
Mengira varians melibatkan pengiraan yang rumit (terutamanya jika nilai purata dinyatakan sebilangan besar dengan berbilang tempat perpuluhan). Pengiraan boleh dipermudahkan dengan menggunakan formula yang dipermudahkan dan sifat serakan.
Penyerakan mempunyai sifat berikut:
- Jika semua nilai ciri dikurangkan atau ditingkatkan dengan nilai A yang sama, maka penyebaran tidak akan berkurang:
 ,
,
 , kemudian atau
, kemudian atau 
Menggunakan sifat serakan dan mula-mula mengurangkan semua varian populasi dengan nilai A, dan kemudian membahagikan dengan nilai selang h, kami memperoleh formula untuk mengira serakan dalam siri variasi dengan pada selang waktu yang sama dengan cara: ,
,
di manakah serakan dikira menggunakan kaedah momen;
h – nilai selang siri variasi;
– pilihan nilai baharu (berubah);
A- tetap, yang digunakan sebagai pertengahan selang dengan frekuensi tertinggi; atau pilihan yang mempunyai kekerapan tertinggi;  – segi empat sama momen tertib pertama;
– segi empat sama momen tertib pertama;
– detik urutan kedua.
Mari kita mengira serakan menggunakan kaedah momen berdasarkan data pada output syif pekerja pasukan.
Jadual 4 - Pengiraan varians menggunakan kaedah momen
Kumpulan pekerja pengeluaran, pcs. |
Bilangan pekerja |
Tengah selang |
Nilai yang dikira |
||
Prosedur pengiraan:


- Kami mengira varians:
2 Pengiraan varians ciri alternatif
Di antara ciri-ciri yang dikaji oleh statistik, terdapat juga yang hanya mempunyai dua makna yang saling eksklusif. Ini adalah tanda alternatif. Mereka diberi masing-masing dua nilai kuantitatif: pilihan 1 dan 0. Kekerapan pilihan 1, yang dilambangkan dengan p, ialah perkadaran unit yang mempunyai ciri ini. Perbezaan 1-р=q ialah kekerapan pilihan 0. Oleh itu,
xi |
|
Purata aritmetik bagi tanda alternatif ![]() , kerana p+q=1.
, kerana p+q=1.
Varians sifat alternatif
, kerana 1-р=q
Oleh itu, varians ciri alternatif adalah sama dengan hasil perkadaran unit yang memiliki ciri ini dan bahagian unit yang tidak memiliki ciri ini.
Jika nilai 1 dan 0 berlaku sama kerap, iaitu p=q, varians mencapai maksimum pq=0.25.
Varians ciri alternatif digunakan dalam sampel tinjauan, sebagai contoh, kualiti produk.
3 Varians antara kumpulan. Peraturan penambahan varians
Penyerakan, tidak seperti ciri variasi lain, adalah kuantiti bahan tambahan. Iaitu, dalam agregat, yang dibahagikan kepada kumpulan mengikut ciri-ciri faktor X , varians ciri terhasil y boleh diuraikan kepada varians dalam setiap kumpulan (dalam kumpulan) dan varians antara kumpulan (antara kumpulan). Kemudian, bersama-sama dengan mengkaji variasi sifat di seluruh populasi secara keseluruhan, menjadi mungkin untuk mengkaji variasi dalam setiap kumpulan, serta antara kumpulan ini.
Jumlah varians mengukur variasi dalam sesuatu sifat di secara keseluruhannya di bawah pengaruh semua faktor yang menyebabkan variasi ini (penyimpangan). Ia sama dengan kuasa dua sisihan min nilai individu tanda di daripada purata besar dan boleh dikira sebagai varians mudah atau wajaran.
Varians antara kumpulan mencirikan variasi sifat yang terhasil di disebabkan oleh pengaruh tanda-faktor X, yang menjadi asas pengelompokan. Ia mencirikan variasi purata kumpulan dan bersamaan dengan min kuasa dua sisihan purata kumpulan daripada purata keseluruhan:  ,
,
di manakah min aritmetik bagi kumpulan ke-i;
– bilangan unit dalam kumpulan ke-i (kekerapan kumpulan ke-i);
– am purata penduduk.
Varians dalam kumpulan mencerminkan variasi rawak, iaitu bahagian variasi yang disebabkan oleh pengaruh faktor yang tidak diambil kira dan tidak bergantung pada atribut faktor yang menjadi asas pengelompokan. Ia mencirikan variasi nilai individu relatif kepada min kumpulan, sama dengan sisihan kuasa dua purata nilai individu atribut di dalam kumpulan daripada min aritmetik kumpulan ini (min kumpulan) dan dikira sebagai varians mudah atau wajaran untuk setiap kumpulan: ![]() atau
atau ![]() ,
,
di manakah bilangan unit dalam kumpulan itu.
berdasarkan varians dalam kumpulan bagi setiap kumpulan adalah mungkin untuk menentukan min keseluruhan bagi varians dalam kumpulan:
.
Hubungan antara tiga penyebaran dipanggil peraturan untuk menambah varians, mengikut mana jumlah varians adalah sama dengan jumlah varians antara kumpulan dan purata varians dalam kumpulan:
Contoh. Apabila mengkaji pengaruh kategori tarif (kelayakan) pekerja pada tahap produktiviti buruh mereka, data berikut diperolehi.
Jadual 5 – Taburan pekerja mengikut purata keluaran setiap jam.
№ p/p |
Pekerja kategori ke-4 |
Pekerja kategori ke-5 |
|||||
Output |
Output |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
DALAM dalam contoh ini pekerja dibahagikan kepada dua kumpulan mengikut ciri faktor X– kelayakan, yang dicirikan oleh pangkat mereka. Sifat yang terhasil—pengeluaran—berbeza di bawah pengaruhnya (variasi antara kumpulan) dan disebabkan oleh faktor rawak lain (variasi dalam kumpulan). Matlamatnya adalah untuk mengukur variasi ini menggunakan tiga varians: jumlah, antara kumpulan dan dalam kumpulan. di Pekali penentuan empirikal menunjukkan perkadaran variasi dalam ciri yang terhasil X di bawah pengaruh tanda faktor . Selebihnya di jumlah variasi
disebabkan oleh perubahan faktor lain. ![]() Dalam contoh, pekali penentuan empirikal ialah:
Dalam contoh, pekali penentuan empirikal ialah:
atau 66.7%,
Ini bermakna 66.7% daripada variasi dalam produktiviti pekerja adalah disebabkan oleh perbezaan dalam kelayakan, dan 33.3% adalah disebabkan oleh pengaruh faktor lain. Hubungan korelasi empirikal
menunjukkan perkaitan rapat antara kumpulan dan ciri prestasi. Dikira sebagai punca kuasa dua bagi pekali penentuan empirikal:
Nisbah korelasi empirikal, seperti , boleh mengambil nilai dari 0 hingga 1.
Jika tiada sambungan, maka =0. Dalam kes ini =0, iaitu bermakna kumpulan adalah sama antara satu sama lain dan tiada variasi antara kumpulan. Ini bermakna ciri kumpulan - faktor tidak mempengaruhi pembentukan variasi umum. Jika sambungan berfungsi, maka =1. Dalam kes ini, varians min kumpulan adalah sama dengan jumlah varians
(), iaitu, tiada variasi dalam kumpulan. Ini bermakna ciri pengelompokan menentukan sepenuhnya variasi ciri yang terhasil yang dikaji.
Semakin hampir nilai nisbah korelasi dengan perpaduan, semakin dekat, lebih dekat dengan pergantungan fungsi, adalah hubungan antara ciri-ciri.
Dalam contoh ![]() , yang menunjukkan sambungan rapat antara produktiviti pekerja dan kelayakan mereka.
, yang menunjukkan sambungan rapat antara produktiviti pekerja dan kelayakan mereka.
 Perang Revolusi Amerika, perang antara Great Britain dan Loyalists (setia kepada kerajaan British Crown yang sah) - pembentangan
Perang Revolusi Amerika, perang antara Great Britain dan Loyalists (setia kepada kerajaan British Crown yang sah) - pembentangan "Adalah mengejutkan jika salah seorang dari Rusia tidak mengenali Krylov"
"Adalah mengejutkan jika salah seorang dari Rusia tidak mengenali Krylov" John Milton dan puisinya "Syurga Hilang" "Syurga Didapat Semula" dan "Samson the Fighter"
John Milton dan puisinya "Syurga Hilang" "Syurga Didapat Semula" dan "Samson the Fighter"