Kaedah statistik matematik dalam VK. Untuk pelajar dan pelajar sekolah - buku, statistik matematik
“Sesetengah orang fikir mereka sentiasa betul. Orang seperti itu tidak boleh menjadi saintis yang baik dan tidak berminat dalam statistik... Kes itu diturunkan dari syurga ke bumi, di mana ia menjadi sebahagian daripada dunia sains.” (Diamand S.)
“Peluang hanyalah ukuran kejahilan kita. Fenomena rawak, jika kita mentakrifkannya, akan menjadi fenomena yang kita tidak tahu undang-undangnya." (A. Poincaré “Sains dan Hipotesis”)
“Syukurlah. Bukankah begitu
Sentiasa setanding dengan yang tidak berubah...
Peluang sering memerintah acara,
Menjana kedua-dua kegembiraan dan kesakitan.
Dan kehidupan menetapkan tugas di hadapan kita:
Bagaimana untuk memahami peranan peluang"
(dari buku "Mathematics studies randomness" oleh B.A. Kordemsky)
Dunia itu sendiri adalah semula jadi - inilah cara kita sering mempertimbangkan dan mengkaji undang-undang fizik, kimia, dll., namun tiada apa yang berlaku tanpa campur tangan kebetulan, yang timbul di bawah pengaruh hubungan sebab-akibat sampingan yang tidak stabil yang mengubah perjalanan fenomena atau pengalaman apabila ia berulang. "Kesan rawak" dicipta dengan keteraturan yang wujud "prapenentuan tersembunyi", i.e. peluang mempunyai keperluan untuk hasil semula jadi.
Ahli matematik menganggap peristiwa rawak hanya dalam dilema "menjadi atau tidak menjadi" - sama ada ia akan berlaku atau tidak.
Definisi. Cabang matematik gunaan di mana ciri kuantitatif peristiwa rawak jisim atau fenomena dikaji dipanggil statistik matematik.
Definisi. Gabungan unsur-unsur teori kebarangkalian dan statistik matematik dipanggil stokastik.
Definisi. Stokastik- ini adalah cabang matematik yang timbul dan berkembang dalam hubungan rapat dengan aktiviti praktikal manusia. Hari ini, unsur-unsur stokastik dimasukkan dalam matematik untuk semua orang dan menjadi aspek baharu yang penting dalam pendidikan matematik dan am.
Definisi. perangkaan matematik– sains kaedah matematik sistematisasi, pemprosesan dan penggunaan data statistik untuk kesimpulan saintifik dan praktikal.
Mari kita bercakap tentang ini dengan lebih terperinci.
Pandangan yang diterima umum sekarang ialah statistik matematik ialah sains kaedah umum untuk memproses keputusan eksperimen. Dalam menyelesaikan masalah ini, apakah yang mesti ada pada eksperimen agar pertimbangan yang dibuat berdasarkannya adalah betul? Statistik matematik menjadi, sebahagiannya, sains reka bentuk eksperimen.
Makna perkataan "statistik" telah mengalami perubahan ketara sejak dua abad yang lalu, tulis saintis moden terkenal Hodges dan Lehman, "perkataan "statistik" mempunyai akar yang sama dengan perkataan "negeri" (negeri) dan asalnya bermaksud seni. dan sains pengurusan: guru perangkaan pertama di universiti abad ke-18 Jerman hari ini akan dipanggil saintis sosial. Kerana keputusan kerajaan sedikit sebanyak berdasarkan data tentang populasi, industri, dll. ahli statistik, secara semula jadi, mula berminat dengan data sedemikian, dan secara beransur-ansur perkataan "statistik" mula bermakna pengumpulan data tentang populasi, tentang negeri, dan kemudian pengumpulan dan pemprosesan data secara umum. Tidak ada gunanya mengekstrak data melainkan sesuatu yang berguna datang daripadanya, dan ahli statistik secara semula jadi terlibat dalam mentafsir data.
Ahli statistik moden mengkaji kaedah yang boleh membuat inferens tentang populasi daripada data yang biasanya diperoleh daripada sampel "populasi."
Definisi. ahli perangkaan– seseorang yang berurusan dengan sains kaedah matematik untuk sistematisasi, pemprosesan dan penggunaan data statistik untuk kesimpulan saintifik dan praktikal.
Statistik matematik timbul pada abad ke-17 dan berkembang selari dengan teori kebarangkalian. Perkembangan selanjutnya statistik matematik (separuh kedua abad ke-19 dan awal abad ke-20) adalah disebabkan, pertama sekali, oleh P.L. Chebyshev, A.A. Markov, A.M. Lyapunov, K. Gauss, A. Quetelet, F. Galton, K. Pearson, dan lain-lain Pada ke-20, sumbangan yang paling penting kepada statistik matematik dibuat oleh A.N. Kolmogorov, V.I. Romanovsky, E.E. Slutsky, N.V. Smirnov, B.V. Gnedenko, serta Pelajar Inggeris, R. Fisher, E. Purson dan saintis Amerika (Y. Neumann, A. Wald).
Masalah statistik matematik dan maksud kesilapan dalam dunia sains
Penubuhan corak yang menjadi subjek fenomena rawak jisim adalah berdasarkan kajian data statistik daripada keputusan pemerhatian menggunakan kaedah teori kebarangkalian.
Tugas pertama statistik matematik adalah untuk menunjukkan cara mengumpul dan mengumpulkan maklumat statistik yang diperoleh hasil daripada pemerhatian atau hasil daripada eksperimen yang direka khas.
Tugas kedua statistik matematik adalah untuk membangunkan kaedah untuk menganalisis data statistik bergantung kepada objektif kajian.
Statistik matematik moden sedang membangunkan kaedah untuk menentukan bilangan ujian yang diperlukan sebelum permulaan kajian (perancangan eksperimen) dan semasa kajian (analisis berurutan). Ia boleh ditakrifkan sebagai sains membuat keputusan di bawah ketidakpastian.
Secara ringkas, kita boleh mengatakan bahawa tugas statistik matematik adalah untuk mencipta kaedah untuk mengumpul dan memproses data statistik.
Apabila mengkaji fenomena rawak jisim, diandaikan bahawa semua ujian dijalankan di bawah keadaan yang sama, i.e. sekumpulan faktor utama yang boleh diambil kira (boleh diukur) dan mempunyai kesan yang ketara terhadap keputusan ujian mengekalkan nilai yang sama mungkin.
Faktor rawak memesongkan keputusan yang akan diperolehi jika hanya faktor utama yang ada, menjadikannya rawak. Sisihan keputusan setiap ujian daripada yang benar dipanggil ralat pemerhatian, iaitu pembolehubah rawak. Adalah perlu untuk membezakan antara ralat sistematik dan rawak.
Eksperimen saintifik tidak dapat difikirkan tanpa kesilapan seperti lautan tanpa garam. Sebarang aliran fakta yang menambah pengetahuan kita membawa beberapa jenis kesilapan. Menurut pepatah yang terkenal, dalam kehidupan kebanyakan orang tidak dapat memastikan apa-apa kecuali kematian dan cukai, dan saintis itu menambah: "Dan kesilapan pengalaman."
Seorang ahli perangkaan ialah "bloodhoound" yang memburu kesilapan. Alat statistik untuk pengesanan ralat.
Perkataan "ralat" tidak bermaksud "salah pengiraan" yang mudah. Akibat daripada salah pengiraan adalah sumber ralat eksperimen yang kecil dan agak tidak menarik.
Sesungguhnya, instrumen kami pecah; mata dan telinga kita boleh menipu kita; ukuran kami tidak pernah tepat sepenuhnya, kadangkala pengiraan aritmetik kami juga tersilap. Ralat percubaan adalah sesuatu yang lebih penting daripada ukuran pita yang tidak tepat atau ilusi optik. Dan memandangkan tugas statistik yang paling penting ialah membantu saintis menganalisis ralat sesuatu eksperimen, kita mesti cuba memahami apakah ralat itu sebenarnya.
Apa sahaja masalah yang diusahakan oleh saintis, ia pasti akan menjadi lebih kompleks daripada yang dia mahukan. Katakan dia mengukur kejatuhan radioaktif pada latitud yang berbeza. Keputusan akan bergantung pada ketinggian tempat sampel dikumpulkan, jumlah hujan tempatan dan ketinggian siklon di kawasan yang lebih luas.
Ralat eksperimen adalah bahagian penting dalam mana-mana eksperimen yang benar-benar saintifik.
Hasil yang sama boleh menjadi ralat dan maklumat bergantung pada masalah dan sudut pandangan. Jika ahli biologi ingin menyiasat bagaimana perubahan dalam pemakanan mempengaruhi pertumbuhan, maka kehadiran perlembagaan yang berkaitan adalah punca kesilapan; jika dia mengkaji hubungan antara keturunan dan pertumbuhan, punca kesilapan adalah perbezaan dalam pemakanan. Jika seorang ahli fizik ingin mengkaji hubungan antara kekonduksian elektrik dan suhu, perbezaan dalam ketumpatan bahan pengalir adalah punca ralat; jika dia mengkaji hubungan antara ketumpatan ini dan kekonduksian elektrik, perubahan suhu akan menjadi punca ralat.
Penggunaan ralat perkataan ini mungkin kelihatan meragukan, dan mungkin lebih baik untuk mengatakan bahawa kesan yang diperoleh dikelirukan oleh pengaruh "tidak disengajakan" atau "tidak diingini". Kami mereka bentuk percubaan untuk mengkaji pengaruh yang diketahui, tetapi faktor rawak yang tidak dapat kami ramalkan atau analisa memesongkan keputusan dengan menambahkan kesannya sendiri.
Perbezaan antara kesan yang dirancang dan kesan akibat sebab rawak adalah seperti perbezaan antara pergerakan kapal di laut, belayar di sepanjang laluan tertentu, dan kapal hanyut tanpa hala tuju di bawah kehendak angin dan arus yang berubah-ubah. Pergerakan kapal kedua boleh dipanggil pergerakan rawak. Ada kemungkinan kapal ini tiba di beberapa pelabuhan, tetapi kemungkinan besar ia tidak akan tiba di mana-mana tempat tertentu.
Ahli perangkaan menggunakan perkataan "rawak" untuk menandakan fenomena yang hasilnya pada masa berikutnya adalah mustahil untuk diramalkan.
Ralat yang disebabkan oleh kesan yang diramalkan dalam eksperimen kadangkala lebih sistematik daripada rawak.
Ralat sistematik lebih mengelirukan daripada ralat rawak. Gangguan yang datang dari stesen radio lain boleh mencipta iringan muzik yang sistematik yang kadangkala anda boleh meramalkan jika anda mengetahui lagunya. Tetapi "iringan" ini mungkin menjadi sebab mengapa kita boleh membuat pertimbangan yang salah tentang kata-kata atau muzik program yang kita cuba dengar.
Walau bagaimanapun, penemuan ralat sistematik sering membawa kita ke jejak penemuan baru. Mengetahui bagaimana ralat rawak berlaku membantu kami mengesan ralat sistematik dan oleh itu menghapuskannya.
Sifat penaakulan yang sama adalah biasa dalam urusan seharian kita. Berapa kerap kita perasan: "Ini bukan kemalangan!" Setiap kali kita boleh mengatakan ini, kita berada di jalan untuk penemuan.
Contohnya, A.L. Chizhevsky, menganalisis proses sejarah: peningkatan kematian, wabak, wabak perang, pergerakan besar orang, perubahan iklim secara tiba-tiba, dll. menemui hubungan antara proses yang tidak berkaitan ini dan tempoh aktiviti suria, yang mempunyai kitaran: 11 tahun, 33 tahun.
Definisi. Di bawah ralat sistematik difahami sebagai ralat yang berulang dan sama untuk semua ujian. Ia biasanya dikaitkan dengan kelakuan eksperimen yang tidak betul.
Definisi. Di bawah kesilapan rawak merujuk kepada ralat yang timbul di bawah pengaruh faktor rawak dan berbeza secara rawak dari eksperimen ke eksperimen.
Biasanya, pengagihan ralat rawak adalah simetri kira-kira sifar, dari mana kesimpulan penting berikut: jika tiada ralat sistematik, hasil ujian sebenar adalah jangkaan matematik pembolehubah rawak, nilai khusus yang ditetapkan dalam setiap ujian.
Objek kajian dalam statistik matematik boleh menjadi ciri kualitatif atau kuantitatif fenomena atau proses yang dikaji.
Dalam kes ciri kualitatif, bilangan kejadian ciri ini dalam siri percubaan yang dipertimbangkan dikira; nombor ini mewakili pembolehubah rawak (diskrit) yang sedang dikaji. Contoh atribut kualiti termasuk kecacatan pada bahagian siap, data demografi, dsb. Jika ciri adalah kuantitatif, maka dalam eksperimen pengukuran langsung atau tidak langsung dibuat dengan perbandingan dengan beberapa piawai - satu unit ukuran - menggunakan pelbagai alat pengukur. Sebagai contoh, jika terdapat sekumpulan bahagian, maka piawai bahagian boleh berfungsi sebagai tanda kualitatif, dan saiz bahagian terkawal boleh berfungsi sebagai tanda kuantitatif.
Definisi asas
Sebahagian besar statistik matematik dikaitkan dengan keperluan untuk menerangkan koleksi objek yang besar.
Definisi. Keseluruhan set objek yang hendak dikaji dipanggil penduduk umum.
Populasi umum boleh terdiri daripada keseluruhan penduduk negara, pengeluaran bulanan tumbuhan, populasi ikan yang hidup dalam takungan tertentu, dsb.
Tetapi populasi bukan hanya satu set. Jika set objek yang kami minati terlalu banyak, atau objek sukar diakses, atau ada sebab lain yang tidak membenarkan kami mengkaji semua objek, kami mengambil jalan keluar untuk mengkaji beberapa bahagian objek.
Definisi. Bahagian objek yang tertakluk kepada pemeriksaan, penyelidikan, dsb. dipanggil populasi sampel atau hanya persampelan.
Definisi. Bilangan unsur dalam populasi dan sampel dipanggil mereka jilid.
Bagaimana untuk memastikan bahawa sampel terbaik mewakili keseluruhan, i.e. adakah ia akan menjadi wakil?
Jika keseluruhannya, i.e. jika populasinya sedikit atau tidak diketahui sepenuhnya oleh kami, kami tidak boleh menawarkan sesuatu yang lebih baik daripada pemilihan rawak semata-mata. Kesedaran yang lebih tinggi membolehkan anda bertindak lebih baik, tetapi masih, pada beberapa peringkat, kejahilan berlaku dan, akibatnya, pilihan rawak.
Tetapi bagaimana untuk membuat pilihan rawak semata-mata? Sebagai peraturan, pemilihan berlaku mengikut ciri-ciri yang mudah diperhatikan, demi penyelidikan yang dijalankan.
Pelanggaran prinsip pemilihan rawak membawa kepada kesilapan yang serius. Tinjauan yang dijalankan oleh majalah American Literary Review mengenai keputusan pilihan raya presiden pada tahun 1936 menjadi terkenal kerana kegagalannya. Calon-calon dalam pilihan raya ini ialah F.D. Roosevelt dan A.M. Landon.
Siapa yang menang?
Para editor menggunakan buku telefon sebagai populasi umum. Selepas memilih 4 juta alamat secara rawak, dia menghantar poskad bertanya tentang sikap terhadap calon presiden di seluruh negara. Selepas membelanjakan sejumlah besar untuk mel dan pemprosesan poskad, majalah itu mengumumkan bahawa Landon akan memenangi pilihan raya presiden yang akan datang secara besar-besaran. Keputusan pilihan raya adalah bertentangan dengan ramalan ini.
Dua kesilapan dibuat di sini sekaligus. Pertama, buku telefon tidak menyediakan sampel yang mewakili populasi AS—kebanyakannya ketua isi rumah yang kaya. Kedua, bukan semua orang menghantar jawapan, tetapi sebahagian besarnya daripada wakil dunia perniagaan, yang menyokong Landon.
Pada masa yang sama, ahli sosiologi J. Gallan dan E. Warner dengan betul meramalkan kemenangan F.D. Roosevelt, berdasarkan hanya empat ribu soal selidik. Sebab kejayaan ini bukan sahaja persampelan yang betul. Mereka mengambil kira bahawa masyarakat dibahagikan kepada kumpulan sosial yang lebih homogen berhubung dengan calon presiden. Oleh itu, sampel dari lapisan boleh menjadi agak kecil dengan hasil ketepatan yang sama. Akhirnya, Roosevelt, yang merupakan penyokong reformasi untuk bahagian penduduk yang kurang kaya, menang.
Mempunyai hasil tinjauan mengikut strata, adalah mungkin untuk mencirikan masyarakat secara keseluruhan.
Apakah sampel?
Ini adalah siri nombor.
Marilah kita memikirkan dengan lebih terperinci tentang konsep asas yang mencirikan siri sampel.
Satu sampel saiz n telah diekstrak daripada populasi umum > n 1, dengan n 1 ialah bilangan kali penampilan x 1, n 2 - x 2, dsb. diperhatikan.
Nilai yang diperhatikan bagi x i dipanggil varian, dan urutan varian yang ditulis dalam tertib menaik dipanggil siri variasi. Nombor cerapan n i dipanggil frekuensi dan n i /n - frekuensi relatif (atau frekuensi).
Definisi. Nilai berbeza pembolehubah rawak dipanggil pilihan.
Definisi. Siri variasi ialah satu siri yang disusun dalam susunan pilihan menaik (atau menurun) dengan frekuensi (frekuensi) yang sepadan.
Apabila mengkaji siri variasi, bersama-sama dengan konsep kekerapan, konsep kekerapan terkumpul digunakan. Frekuensi terkumpul (frekuensi) untuk setiap selang didapati dengan menjumlahkan secara berurutan frekuensi semua selang sebelumnya.
Definisi. Pengumpulan frekuensi atau frekuensi dipanggil terkumpul. Anda boleh mengumpul frekuensi dan selang waktu.
Ciri-ciri siri boleh berbentuk kuantitatif dan kualitatif.
Ciri kuantitatif (variasi).- Ini adalah ciri-ciri yang boleh dinyatakan dalam nombor. Mereka dibahagikan kepada diskret dan berterusan.
Ciri-ciri kualitatif (atributif).– ini adalah ciri yang tidak dinyatakan dalam nombor.
Pembolehubah Berterusan adalah pembolehubah yang dinyatakan sebagai nombor nyata.
Pembolehubah Diskret adalah pembolehubah yang hanya boleh dinyatakan sebagai integer.
Sampel dicirikan kecenderungan pusat: min, mod dan median. Nilai purata sampel ialah min aritmetik semua nilainya. Mod pensampelan ialah nilai yang paling kerap berlaku. Median sampel ialah nombor yang "membahagikan" separuh populasi tertib semua nilai dalam sampel.
Siri variasi boleh diskret atau berterusan.
Tugasan
Sampel diberi: 1.3; 1.8; 1.2; 3.0; 2.1; 5; 2.4; 1.2; 3.2;1.2; 4; 2.4.
Ini adalah pelbagai pilihan. Mengatur pilihan ini dalam tertib menaik, kami mendapat siri variasi: 1.2; 1.2; 1.2; 1.3; 1.8; 2.1; 2.4; 2.4; 3.0; 3.2; 4; 5.
Nilai purata siri ini ialah 2.4.
Median bagi siri itu ialah 2.25.
Mod siri itu ialah –1,2.
Mari kita tentukan konsep-konsep ini.
Definisi. Median siri variasi Nilai pembolehubah rawak yang jatuh di tengah-tengah siri variasi (Me) dipanggil.
Median bagi siri nombor tertib dengan bilangan sebutan ganjil ialah nombor yang ditulis di tengah, dan median siri nombor tertib dengan nombor genap ialah min aritmetik bagi dua nombor yang ditulis di tengah. Median bagi siri nombor arbitrari ialah median bagi siri tertib yang sepadan.
Definisi. Fesyen siri variasi Mereka memanggil pilihan (nilai pembolehubah rawak) yang sepadan dengan frekuensi tertinggi (Mo), i.e. yang berlaku lebih kerap daripada yang lain.
Definisi. Nilai min aritmetik bagi siri variasi ialah hasil daripada membahagikan jumlah nilai pembolehubah statistik dengan bilangan nilai ini, iaitu dengan bilangan sebutan.
Peraturan untuk mencari min aritmetik sampel:
- darab setiap pilihan dengan kekerapannya (kepelbagaian);
- tambah semua produk yang terhasil;
- bahagikan jumlah yang ditemui dengan jumlah semua frekuensi.
Definisi. Julat baris dipanggil perbezaan antara R=x max -x min, i.e. nilai terbesar dan terkecil daripada pilihan ini.
Mari kita semak sama ada kita menemui nilai min siri, median dan mod ini dengan betul, berdasarkan takrifan.
Kami mengira bilangan sebutan, terdapat 12 daripadanya - bilangan sebutan genap, yang bermaksud kita perlu mencari min aritmetik bagi dua nombor yang ditulis di tengah, iaitu pilihan ke-6 dan ke-7. (2.1+2.4)\2=2.25 – median.
Fesyen. Fesyen adalah 1.2, kerana hanya nombor ini berlaku 3 kali, dan selebihnya berlaku kurang daripada 3 kali.
Kami mendapati min aritmetik seperti ini:
(1,2*3+1,3+1,8+2,1+2,4*2+3,0+3,2 +4+5)\12=2,4
Jom buat meja
Jadual sedemikian dipanggil jadual kekerapan. Di dalamnya, nombor dalam baris kedua adalah frekuensi; mereka menunjukkan kekerapan nilai tertentu berlaku dalam sampel.
Definisi. Kekerapan relatif nilai sampel ialah nisbah kekerapannya kepada bilangan semua nilai sampel.
Frekuensi relatif disebut frekuensi. Frekuensi dan frekuensi dipanggil skala. Mari cari julat siri: R=5-1.2=3.8; Julat siri ini ialah 3.8.
Makanan untuk difikirkan
Min aritmetik ialah nilai konvensional. Pada hakikatnya ia tidak wujud. Pada hakikatnya terdapat jumlah keseluruhan. Oleh itu, min aritmetik bukanlah ciri satu pemerhatian; ia mencirikan siri ini secara keseluruhan.
Nilai purata boleh ditafsirkan sebagai pusat penyebaran nilai-nilai ciri yang diperhatikan, i.e. nilai di sekelilingnya yang semua nilai yang diperhatikan turun naik, dan jumlah algebra sisihan daripada purata sentiasa sifar, i.e. jumlah sisihan daripada purata ke atas atau ke bawah adalah sama.
Min aritmetik ialah kuantiti abstrak (mengeratkan). Walaupun apabila menyatakan satu siri nombor asli sahaja, nilai purata boleh dinyatakan sebagai pecahan. Contoh: purata markah ujian ialah 3.81.
Nilai purata didapati bukan sahaja untuk kuantiti homogen. Purata hasil bijirin di seluruh negara (jagung - 50-60 sen sehektar dan soba - 5-6 sen sehektar, rai, gandum, dll.), purata penggunaan makanan, purata pendapatan negara per kapita , purata bekalan perumahan, perumahan purata wajaran kos, purata intensiti buruh pembinaan bangunan, dsb. - ini adalah ciri-ciri negara sebagai sistem ekonomi negara tunggal, ini adalah apa yang dipanggil purata sistem.
Dalam statistik, ciri-ciri seperti mod dan median. Mereka dipanggil purata struktur, kerana nilai ciri ini ditentukan oleh struktur umum siri data.
Kadangkala siri mungkin mempunyai dua mod, kadangkala siri mungkin tiada mod.
Fesyen adalah penunjuk yang paling boleh diterima apabila mengenal pasti pembungkusan produk tertentu, yang diutamakan oleh pembeli; harga untuk barangan daripada jenis tertentu, biasa di pasaran; sebagai saiz kasut, pakaian, yang paling banyak permintaan; sukan yang majoriti penduduk sesebuah negara, bandar, kampung, sekolah, dan lain-lain lebih suka untuk menyertainya.
Dalam pembinaan, terdapat 8 pilihan untuk papak dalam lebar, dan 3 jenis lebih kerap digunakan: 1 m, 1.2 m dan 1.5 m Panjangnya, terdapat 33 pilihan untuk papak, tetapi papak dengan panjang 4.8 m paling kerap digunakan; 5.7 m dan 6.0 m, fesyen papak paling kerap ditemui di antara 3 saiz ini. Perkara yang sama boleh dikatakan mengenai jenama tingkap.
Mod siri data ditemui apabila seseorang ingin mengenal pasti beberapa penunjuk biasa.
Mod boleh dinyatakan dalam nombor dan perkataan dari sudut statistik, mod ialah kekerapan yang melampau.
Median membolehkan anda mengambil kira maklumat tentang siri data yang diberikan oleh min aritmetik dan sebaliknya.
Kaedah statistik matematik
1. Pengenalan
Statistik matematik adalah sains yang berkaitan dengan pembangunan kaedah untuk mendapatkan, menghuraikan dan memproses data eksperimen untuk mengkaji corak fenomena jisim rawak.
Dalam statistik matematik, dua bidang boleh dibezakan: statistik deskriptif dan statistik induktif (inferens statistik). Statistik deskriptif berkaitan dengan pengumpulan, sistematisasi dan pembentangan data eksperimen dalam bentuk yang mudah. Statistik induktif berdasarkan data ini membolehkan seseorang membuat kesimpulan tertentu mengenai objek yang data dikumpulkan atau anggaran parameternya.
Bidang statistik matematik yang biasa ialah:
1) teori persampelan;
2) teori penilaian;
3) menguji hipotesis statistik;
4) analisis regresi;
5) analisis varians.
Statistik matematik adalah berdasarkan beberapa konsep awal yang tanpanya mustahil untuk mengkaji kaedah moden memproses data eksperimen. Antara yang pertama ialah konsep populasi umum dan sampel.
Dalam pengeluaran perindustrian besar-besaran, selalunya perlu untuk menentukan sama ada kualiti produk memenuhi piawaian tanpa memeriksa setiap produk yang dihasilkan. Memandangkan kuantiti produk yang dihasilkan adalah sangat besar atau ujian produk dikaitkan dengan menjadikannya tidak boleh digunakan, sebilangan kecil produk diperiksa. Berdasarkan pemeriksaan ini, adalah perlu untuk memberikan kesimpulan tentang keseluruhan siri produk. Sudah tentu, anda tidak boleh mengatakan bahawa semua transistor daripada kumpulan 1 juta keping adalah baik atau buruk dengan menyemak salah satu daripadanya. Sebaliknya, memandangkan proses memilih sampel untuk ujian dan ujian itu sendiri boleh memakan masa dan membawa kepada kos yang tinggi, skop ujian produk haruslah sedemikian rupa sehingga dapat memberikan perwakilan yang boleh dipercayai bagi keseluruhan kumpulan produk, semasa bersaiz minimum. Untuk tujuan ini, kami memperkenalkan beberapa konsep.
Keseluruhan set objek yang dikaji atau data eksperimen dipanggil populasi umum. Kami akan menandakan dengan N bilangan objek atau jumlah data yang membentuk populasi umum. Nilai N dipanggil isipadu populasi. Jika N>>1, iaitu, N sangat besar, maka N = ¥ biasanya dianggap.
Sampel rawak, atau ringkasnya sampel, ialah sebahagian daripada populasi yang dipilih secara rawak daripadanya. Perkataan "rawak" bermaksud kebarangkalian untuk memilih mana-mana objek daripada populasi adalah sama. Ini adalah andaian penting, tetapi selalunya sukar untuk diuji dalam amalan.
Saiz sampel ialah bilangan objek atau jumlah data yang membentuk sampel dan dilambangkan dengan n. Pada masa hadapan, kami akan menganggap bahawa elemen sampel boleh diberikan, masing-masing, nilai berangka x 1, x 2, ... x n. Sebagai contoh, dalam proses kawalan kualiti transistor bipolar yang dihasilkan, ini boleh menjadi ukuran keuntungan DC mereka.
2. Ciri berangka sampel
2.1 Min sampel
Untuk sampel tertentu bersaiz n, purata sampelnya
ditentukan oleh hubungandi mana x i ialah nilai unsur sampel. Biasanya anda ingin menerangkan sifat statistik sampel rawak rawak dan bukannya satu daripadanya. Ini bermakna model matematik sedang dipertimbangkan, yang menganggap bilangan sampel yang cukup besar bersaiz n. Dalam kes ini, elemen sampel dianggap sebagai pembolehubah rawak Xi, mengambil nilai xi dengan ketumpatan kebarangkalian f(x), iaitu ketumpatan kebarangkalian populasi umum. Kemudian min sampel juga merupakan pembolehubah rawak
sama denganSeperti sebelum ini, kami akan menandakan pembolehubah rawak dengan huruf besar, dan nilai pembolehubah rawak dengan huruf kecil.
Nilai purata populasi dari mana sampel diambil akan dipanggil purata am dan dilambangkan dengan m x. Boleh dijangka jika saiz sampel adalah signifikan, min sampel tidak akan berbeza dengan ketara daripada min populasi. Oleh kerana min sampel ialah pembolehubah rawak, jangkaan matematik boleh didapati untuknya:

Oleh itu, jangkaan matematik bagi min sampel adalah sama dengan min am. Dalam kes ini, min sampel dikatakan sebagai anggaran tidak berat sebelah bagi min populasi. Kami akan kembali ke penggal ini nanti. Oleh kerana min sampel ialah pembolehubah rawak yang turun naik di sekitar min am, adalah wajar untuk menganggar turun naik ini menggunakan varians min sampel. Pertimbangkan sampel yang saiz n adalah lebih kecil daripada saiz populasi N (n<< N). Предположим, что при формировании выборки характеристики генеральной совокупности не меняются, что эквивалентно предположению N = ¥. Тогда
Pembolehubah rawak X i dan X j (i¹j) boleh dianggap bebas, oleh itu,

Mari kita gantikan hasil yang diperoleh ke dalam formula untuk varians:
di mana s 2 ialah varians populasi.
Daripada formula ini ia mengikuti bahawa dengan peningkatan saiz sampel, turun naik purata sampel sekitar purata am berkurangan sebagai s 2 /n. Mari kita gambarkan ini dengan contoh. Biarkan terdapat isyarat rawak dengan jangkaan matematik dan varians masing-masing sama dengan m x = 10, s 2 = 9.
Sampel isyarat diambil pada masa yang sama jarak t 1, t 2, ...,
 X(t)
X(t) X 1
t 1 t 2 . . . t n t
Oleh kerana sampel adalah pembolehubah rawak, kami akan menyatakannya X(t 1), X(t 2), . . . , X(tn).
Mari kita tentukan bilangan sampel supaya sisihan piawai anggaran jangkaan matematik isyarat tidak melebihi 1% daripada jangkaan matematiknya. Oleh kerana m x = 10, adalah perlu bahawa
Sebaliknya, oleh itu atau Dari sini kita memperoleh n ³ 900 sampel.2.2 Varians sampel
Untuk data sampel, adalah penting untuk mengetahui bukan sahaja min sampel, tetapi juga penyebaran nilai sampel di sekitar min sampel. Jika min sampel ialah anggaran min populasi, maka varians sampel mestilah anggaran varians populasi. Varians sampel
bagi sampel yang terdiri daripada pembolehubah rawak ditentukan seperti berikut
Menggunakan perwakilan varians sampel ini, kita dapati jangkaan matematiknya
Dalam program pendidikan universiti, anda tidak mungkin menemui disiplin berasingan yang dipanggil "statistik matematik" walau bagaimanapun, unsur-unsur statistik matematik sering dikaji bersama-sama dengan teori kebarangkalian, tetapi hanya selepas mempelajari kursus utama teori kebarangkalian.
Statistik matematik: maklumat am
Statistik matematik ialah satu cabang matematik yang membangunkan kaedah untuk merekod, menghuraikan dan menganalisis data daripada sebarang pemerhatian dan eksperimen, yang tujuannya adalah untuk membina model kebarangkalian bagi fenomena rawak jisim.
Statistik matematik sebagai sains timbul pada abad ke-17. dan dibangunkan selari dengan teori kebarangkalian. Mereka memberi sumbangan besar kepada perkembangan sains pada abad ke-19-20. Chebyshev P.L., Gauss K., Kolmogorov A.N. dll.
Tugas umum statistik matematik adalah untuk mencipta kaedah untuk mengumpul dan memproses data statistik untuk mendapatkan kesimpulan saintifik dan praktikal.
Bahagian utama statistik matematik ialah:
- kaedah persampelan (membiasakan dengan konsep persampelan, kaedah mengumpul dan memproses data, dsb.);
- penilaian statistik parameter sampel (anggaran, selang keyakinan, dsb.);
- pengiraan ciri ringkasan sampel (pengiraan pilihan, momen, dll.);
- teori korelasi (persamaan regresi, dll.);
- ujian statistik hipotesis;
- analisis varians sehala.
KEPADA paling biasa Masalah statistik matematik yang dipelajari di universiti dan sering ditemui dalam amalan termasuk:
- masalah menentukan anggaran parameter pensampelan;
- tugas untuk menguji hipotesis statistik;
- masalah menentukan jenis hukum pengagihan berdasarkan data statistik.
Masalah menentukan anggaran parameter sampel
Kajian statistik matematik bermula dengan definisi konsep seperti "sampel", "frekuensi", "frekuensi relatif", "fungsi empirikal", "poligon", "kumulasi", "histogram", dll. Seterusnya kajian tentang konsep anggaran (berat sebelah dan tidak berat sebelah): min sampel, varians, varians diperbetulkan, dsb.
Tugasan
Pengukuran pertumbuhan kanak-kanak dalam kumpulan tadika yang lebih muda diwakili oleh sampel:
92, 96, 95, 96, 94, 97, 98, 94, 95, 96.
Mari cari beberapa ciri sampel ini.
Penyelesaian
Saiz sampel (bilangan ukuran; N): 10.
Nilai sampel terendah: 92. Nilai sampel tertinggi: 98.
Julat sampel: 98 – 92 = 6.
Mari tuliskan siri kedudukan (pilihan dalam susunan menaik):
92, 94, 94, 95, 95, 96, 96, 96, 97, 98.
Mari kumpulkan siri dan tulis dalam jadual (kami akan menetapkan setiap pilihan bilangan kejadiannya):
| x i | 92 | 94 | 95 | 96 | 97 | 98 | N |
| n i | 1 | 2 | 2 | 3 | 1 | 1 | 10 |
Mari kita hitung frekuensi relatif dan frekuensi terkumpul, tulis hasilnya dalam jadual:
| x i | 92 | 94 | 95 | 96 | 97 | 98 | Jumlah |
| n i | 1 | 2 | 2 | 3 | 1 | 1 | 10 |
| 0,1 | 0,2 | 0,2 | 0,3 | 0,1 | 0,1 | 1 | |
| Frekuensi terkumpul | 1 | 3 | 5 | 8 | 1 | 10 |
Mari bina poligon frekuensi pensampelan (tanda pada graf pilihan di sepanjang paksi OX, frekuensi di sepanjang paksi OY, sambungkan titik dengan garis).
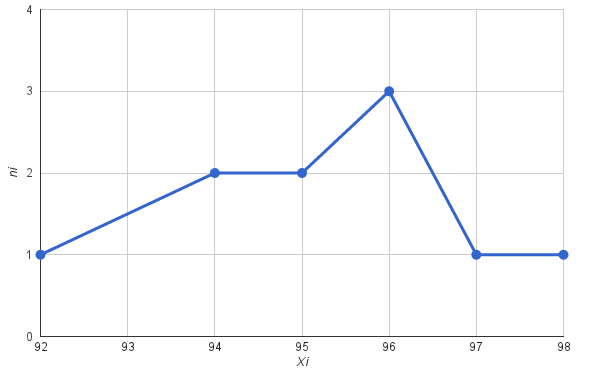
Kami mengira min dan varians sampel menggunakan formula (masing-masing):

Anda juga boleh mencari ciri-ciri lain bagi sampel, tetapi untuk idea umum ciri-ciri yang ditemui adalah mencukupi.
Masalah menguji hipotesis statistik
Masalah kepunyaan jenis ini adalah lebih kompleks daripada masalah jenis sebelumnya dan penyelesaiannya selalunya lebih besar dan intensif buruh. Sebelum mula menyelesaikan masalah, konsep hipotesis statistik, hipotesis nol dan bersaing, dsb. dikaji terlebih dahulu.
Mari kita pertimbangkan masalah paling mudah jenis ini.
Tugasan
Dua sampel bebas isipadu 11 dan 14 diberikan, diekstrak daripada populasi normal X, Y. Varians yang dibetulkan juga diketahui, bersamaan dengan 0.75 dan 0.4, masing-masing. Adalah perlu untuk menguji hipotesis nol tentang kesamaan varians am pada tahap keertian γ
=0.05. Pilih hipotesis bersaing seperti yang dikehendaki.
Penyelesaian
Hipotesis nol untuk masalah kami ditulis seperti berikut:
Sebagai hipotesis yang bersaing, pertimbangkan perkara berikut:
Mari kita hitung nisbah varians diperbetulkan yang lebih besar kepada yang lebih kecil dan dapatkan nilai yang diperhatikan bagi kriteria tersebut:
![]()
Oleh kerana hipotesis bersaing yang kami pilih adalah dalam bentuk , kawasan kritikal adalah tangan kanan.
Menggunakan jadual untuk tahap keertian 0.05 dan bilangan darjah kebebasan bersamaan dengan 10 (11 – 1 = 10) dan 13 (14 – 1 = 13), kita dapati titik kritikal, masing-masing:
Oleh kerana nilai pemerhatian bagi kriteria adalah kurang daripada nilai kritikal (1.875<2,67), то нет оснований отвергнуть гипотезу о равенстве генеральных дисперсий. Таким образом, исправленные дисперсии различаются между собой незначимо.
Masalah yang dipertimbangkan tidak mudah pada pandangan pertama, tetapi ia agak standard dan boleh diselesaikan mengikut templat. Masalah sedemikian berbeza antara satu sama lain, sebagai peraturan, dalam nilai kriteria dan kawasan kritikal.
Lebih intensif buruh (kerana ia mengandungi banyak pengiraan, sebahagian daripadanya diringkaskan dalam jadual) adalah tugas untuk menguji hipotesis tentang jenis taburan populasi. Apabila menyelesaikan masalah sedemikian, pelbagai kriteria digunakan, contohnya, kriteria Pearson.
Masalah menentukan jenis undang-undang pengedaran daripada data statistik
Masalah jenis ini tergolong dalam bahagian yang mengkaji unsur-unsur teori korelasi. Jika kita menganggap pergantungan Y pada X, maka kita boleh mengingati kaedah kuasa dua terkecil untuk menentukan jenis pergantungan. Walau bagaimanapun, dalam statistik matematik semuanya jauh lebih rumit dan dalam teori korelasi kuantiti dua dimensi dipertimbangkan, nilai yang biasanya diberikan dalam bentuk jadual.
| x 1 | x 1 | … | x n | n y | |
| y 1 | n 11 | n 21 | … | n n1 | |
| y 1 | n 12 | n 22 | … | n n2 | |
| … | … | … | … | … | … |
| y m | n 1m | n 2m | … | n nm | |
| n x | … | N |
Mari kita berikan rumusan salah satu tugas bahagian ini.
Tugasan
Tentukan persamaan sampel bagi garis lurus regresi Y pada X. Data diberikan dalam jadual korelasi.
| Y | X | n y | |||
| 10 | 20 | 30 | 40 | ||
| 5 | 1 | 3 | 4 | ||
| 6 | 2 | 1 | 3 | ||
| 7 | 3 | 2 | 5 | ||
| 8 | 1 | 1 | |||
| n x | 1 | 5 | 4 | 3 | N=13 |
Kesimpulan
Sebagai kesimpulan, kami perhatikan bahawa tahap kerumitan masalah dalam statistik matematik berbeza-beza apabila bergerak dari satu jenis ke jenis yang lain. Masalah jenis pertama agak mudah dan tidak memerlukan pemahaman khusus tentang teori anda hanya boleh menulis formula dan menyelesaikan hampir semua masalah. Masalah jenis kedua dan ketiga adalah sedikit lebih rumit dan untuk berjaya menyelesaikannya, sejumlah "pengetahuan" dalam disiplin ini diperlukan.
Kami akan memberikan senarai hanya dua buku, tetapi buku-buku ini telah lama menjadi buku rujukan untuk penulis artikel ini.
- Gmurman V.E. Teori kebarangkalian dan statistik matematik: buku teks. – ed. ke-12, disemak. – M.: Publishing House Yurayt, 2010. – 479 p.
- Gmurman V.E. Panduan untuk menyelesaikan masalah dalam teori kebarangkalian dan statistik matematik. – M.: Sekolah Tinggi, 2005. – 404 p.
Penyelesaian statistik matematik tersuai
Kami mengucapkan selamat maju jaya dalam menguasai statistik matematik. Jika ada masalah, sila hubungi kami. Kami dengan senang hati akan membantu!
pengenalan
2. Konsep asas statistik matematik
2.1 Konsep asas kaedah persampelan
2.2 Taburan persampelan
2.3 Fungsi taburan empirikal, histogram
Kesimpulan
Rujukan
pengenalan
Statistik matematik ialah sains kaedah matematik untuk mensistematisasi dan menggunakan data statistik untuk kesimpulan saintifik dan praktikal. Dalam kebanyakan bahagiannya, statistik matematik adalah berdasarkan teori kebarangkalian, yang membolehkan seseorang menilai kebolehpercayaan dan ketepatan kesimpulan yang dibuat berdasarkan bahan statistik terhad (contohnya, untuk menganggar saiz sampel yang diperlukan untuk mendapatkan keputusan ketepatan yang diperlukan. dalam tinjauan sampel).
Teori kebarangkalian menganggap pembolehubah rawak dengan taburan tertentu atau eksperimen rawak yang sifatnya diketahui sepenuhnya. Subjek teori kebarangkalian ialah sifat dan hubungan kuantiti ini (taburan).
Tetapi selalunya eksperimen adalah kotak hitam yang hanya menghasilkan keputusan tertentu yang mana perlu membuat kesimpulan tentang sifat eksperimen itu sendiri. Pemerhati mempunyai satu set keputusan berangka (atau ia boleh dibuat berangka) yang diperoleh dengan mengulangi eksperimen rawak yang sama di bawah keadaan yang sama.
Dalam kes ini, sebagai contoh, soalan berikut timbul: Jika kita memerhati satu pembolehubah rawak, bagaimana kita boleh membuat kesimpulan yang paling tepat tentang pengedarannya berdasarkan satu set nilainya dalam beberapa eksperimen?
Contoh siri eksperimen sedemikian boleh menjadi tinjauan sosiologi, satu set penunjuk ekonomi, atau, akhirnya, urutan kepala dan ekor apabila syiling dilambung seribu kali.
Semua faktor di atas menentukan perkaitan dan kepentingan topik kerja pada peringkat sekarang, bertujuan untuk kajian mendalam dan menyeluruh tentang konsep asas statistik matematik.
Sehubungan itu, tujuan kerja ini adalah untuk mensistematikkan, mengumpul dan menyatukan pengetahuan tentang konsep-konsep statistik matematik.
1. Subjek dan kaedah statistik matematik
Statistik matematik ialah sains kaedah matematik untuk menganalisis data yang diperoleh semasa pemerhatian jisim (ukuran, eksperimen). Bergantung kepada sifat matematik hasil pemerhatian khusus, statistik matematik dibahagikan kepada statistik nombor, analisis statistik multivariate, analisis fungsi (proses) dan siri masa, statistik objek bukan berangka. Sebahagian besar statistik matematik adalah berdasarkan model kebarangkalian. Terdapat tugas umum untuk menerangkan data, menilai dan menguji hipotesis. Mereka juga mempertimbangkan tugas yang lebih khusus berkaitan dengan menjalankan tinjauan sampel, memulihkan kebergantungan, membina dan menggunakan klasifikasi (tipologi), dsb.
Untuk menerangkan data, jadual, rajah dan perwakilan visual lain, contohnya, medan korelasi, dibina. Model probabilistik biasanya tidak digunakan. Beberapa kaedah penerangan data bergantung pada teori lanjutan dan keupayaan komputer moden. Ini termasuk, khususnya, analisis kluster, bertujuan untuk mengenal pasti kumpulan objek yang serupa antara satu sama lain, dan penskalaan multidimensi, yang membolehkan anda mewakili objek secara visual pada satah, memesongkan jarak antara mereka pada tahap yang paling sedikit.
Kaedah untuk menilai dan menguji hipotesis adalah berdasarkan model kebarangkalian penjanaan data. Model ini dibahagikan kepada parametrik dan bukan parametrik. Dalam model parametrik, diandaikan bahawa objek yang dikaji diterangkan oleh fungsi taburan bergantung pada sebilangan kecil (1-4) parameter berangka. Dalam model bukan parametrik, fungsi pengedaran diandaikan berterusan secara arbitrari. Dalam statistik matematik, parameter dan ciri taburan (jangkaan matematik, median, varians, kuantil, dll.), fungsi ketumpatan dan taburan, kebergantungan antara pembolehubah (berdasarkan pekali korelasi linear dan bukan parametrik, serta anggaran parametrik atau bukan parametrik bagi fungsi yang menyatakan dependencies) dinilai dan lain-lain. Mereka menggunakan anggaran titik dan selang (memberi sempadan untuk nilai sebenar).
Dalam statistik matematik terdapat teori umum pengujian hipotesis dan sejumlah besar kaedah yang dikhaskan untuk menguji hipotesis tertentu. Hipotesis dipertimbangkan tentang nilai parameter dan ciri, tentang menguji kehomogenan (iaitu, mengenai kebetulan ciri atau fungsi pengedaran dalam dua sampel), tentang persetujuan fungsi pengedaran empirikal dengan fungsi pengedaran tertentu atau dengan parametrik keluarga fungsi sedemikian, tentang simetri taburan, dsb.
Amat penting ialah bahagian statistik matematik yang berkaitan dengan menjalankan tinjauan sampel, dengan sifat-sifat pelbagai skim persampelan dan pembinaan kaedah yang mencukupi untuk menilai dan menguji hipotesis.
Masalah pemulihan kebergantungan telah dikaji secara aktif selama lebih daripada 200 tahun, sejak pembangunan kaedah kuasa dua terkecil oleh K. Gauss pada tahun 1794. Pada masa ini, kaedah yang paling relevan untuk mencari subset bermaklumat bagi pembolehubah dan kaedah bukan parametrik.
Pembangunan kaedah untuk penghampiran data dan pengurangan dimensi penerangan bermula lebih daripada 100 tahun yang lalu, apabila K. Pearson mencipta kaedah komponen utama. Analisis faktor dan banyak generalisasi tak linear kemudiannya dibangunkan.
Pelbagai kaedah membina (analisis kelompok), menganalisis dan menggunakan (analisis diskriminasi) klasifikasi (tipologi) juga dipanggil kaedah pengecaman corak (dengan dan tanpa guru), pengelasan automatik, dll.
Kaedah matematik dalam statistik adalah berdasarkan sama ada pada penggunaan jumlah (berdasarkan Teorem Had Pusat teori kebarangkalian) atau indeks perbezaan (jarak, metrik), seperti dalam statistik objek yang bersifat bukan angka. Biasanya hanya keputusan asimptotik yang dibuktikan dengan ketat. Pada masa kini komputer memainkan peranan yang besar dalam statistik matematik. Ia digunakan untuk kedua-dua pengiraan dan simulasi (khususnya, dalam kaedah pendaraban sampel dan dalam mengkaji kesesuaian keputusan asimptotik).
Konsep asas statistik matematik
2.1 Konsep asas kaedah persampelan
Biarkan pembolehubah rawak yang diperhatikan dalam eksperimen rawak. Diandaikan bahawa ruang kebarangkalian diberikan (dan tidak akan menarik minat kita).
Kami akan menganggap bahawa, setelah menjalankan eksperimen ini di bawah keadaan yang sama, kami telah memperoleh nombor , , , - nilai pembolehubah rawak ini dalam yang pertama, kedua, dsb. eksperimen. Pembolehubah rawak mempunyai taburan yang sebahagian atau sepenuhnya tidak diketahui oleh kita.
Mari kita lihat lebih dekat satu set yang dipanggil sampel.
Dalam satu siri eksperimen yang telah dijalankan, sampel ialah satu set nombor. Tetapi jika siri eksperimen ini diulang lagi, maka bukannya set ini kita akan mendapat set nombor baharu. Daripada nombor, nombor lain akan muncul - salah satu nilai pembolehubah rawak. Iaitu, (dan, dan, dsb.) ialah nilai pembolehubah yang boleh mengambil nilai yang sama sebagai pembolehubah rawak, dan sama kerap (dengan kebarangkalian yang sama). Oleh itu, sebelum percubaan - pembolehubah rawak, diedarkan secara identik dengan , dan selepas percubaan - nombor yang kita perhatikan dalam percubaan pertama ini, i.e. salah satu nilai yang mungkin bagi pembolehubah rawak.
Saiz sampel ialah satu set pembolehubah rawak bebas dan teragih sama ("salinan"), yang, seperti , mempunyai taburan.
Apakah yang dimaksudkan dengan "membuat inferens tentang pengedaran daripada sampel"? Taburan dicirikan oleh fungsi taburan, ketumpatan atau jadual, satu set ciri berangka - , , dsb. Menggunakan sampel, anda perlu dapat membina anggaran untuk semua ciri ini.
.2 Taburan persampelan
Mari kita pertimbangkan pelaksanaan pensampelan pada satu hasil asas - satu set nombor ![]() , ,
, , ![]() . Pada ruang kebarangkalian yang sesuai, kami memperkenalkan pembolehubah rawak mengambil nilai, , dengan kebarangkalian dengan (jika mana-mana nilai bertepatan, kami menambah kebarangkalian bilangan kali yang sepadan). Jadual taburan kebarangkalian dan fungsi taburan pembolehubah rawak kelihatan seperti ini:
. Pada ruang kebarangkalian yang sesuai, kami memperkenalkan pembolehubah rawak mengambil nilai, , dengan kebarangkalian dengan (jika mana-mana nilai bertepatan, kami menambah kebarangkalian bilangan kali yang sepadan). Jadual taburan kebarangkalian dan fungsi taburan pembolehubah rawak kelihatan seperti ini:
Taburan kuantiti dipanggil taburan empirikal atau persampelan. Mari kita mengira jangkaan matematik dan varians kuantiti dan memperkenalkan notasi untuk kuantiti ini:
Marilah kita mengira detik pesanan dengan cara yang sama

Dalam kes umum, kita menandakan dengan kuantiti

Jika, apabila membina semua ciri yang telah kami perkenalkan, kami menganggap sampel , , satu set pembolehubah rawak, maka ciri ini sendiri - , , , , - akan menjadi pembolehubah rawak. Ciri-ciri taburan persampelan ini digunakan untuk menganggar (anggaran) ciri-ciri yang tidak diketahui yang sepadan bagi taburan sebenar.
Sebab untuk menggunakan ciri pengedaran untuk menganggarkan ciri pengedaran sebenar (atau ) ialah kedekatan pengedaran ini secara amnya.
Pertimbangkan, sebagai contoh, melambung dadu biasa. biarlah ![]() - bilangan mata yang digugurkan semasa balingan ke-, . Mari kita anggap bahawa satu muncul dalam sampel sekali, dua - sekali, dsb. Kemudian pembolehubah rawak akan mengambil nilai 1
, , 6
dengan kebarangkalian , , masing-masing. Tetapi perkadaran ini mendekati pertumbuhan mengikut undang-undang bilangan besar. Iaitu, pengagihan nilai dalam erti kata tertentu menghampiri pengagihan sebenar bilangan mata yang muncul apabila melambung dadu yang betul.
- bilangan mata yang digugurkan semasa balingan ke-, . Mari kita anggap bahawa satu muncul dalam sampel sekali, dua - sekali, dsb. Kemudian pembolehubah rawak akan mengambil nilai 1
, , 6
dengan kebarangkalian , , masing-masing. Tetapi perkadaran ini mendekati pertumbuhan mengikut undang-undang bilangan besar. Iaitu, pengagihan nilai dalam erti kata tertentu menghampiri pengagihan sebenar bilangan mata yang muncul apabila melambung dadu yang betul.
Kami tidak akan menjelaskan apa yang dimaksudkan dengan kedekatan sampel dan pengedaran sebenar. Dalam perenggan berikut, kami akan melihat dengan lebih dekat setiap ciri yang diperkenalkan di atas dan memeriksa sifatnya, termasuk kelakuannya apabila saiz sampel bertambah.
.3 Fungsi taburan empirikal, histogram
Oleh kerana pengedaran yang tidak diketahui boleh diterangkan, sebagai contoh, dengan fungsi pengedarannya, kami akan membina "anggaran" untuk fungsi ini berdasarkan sampel.
Definisi 1.
Fungsi taburan empirikal yang dibina daripada sampel isipadu dipanggil fungsi rawak, untuk setiap sama dengan
Peringatan: Fungsi rawak

dipanggil penunjuk peristiwa. Bagi setiap satu, ia adalah pembolehubah rawak yang mempunyai taburan Bernoulli dengan parameter . kenapa?
Dalam erti kata lain, untuk sebarang nilai , sama dengan kebarangkalian sebenar pembolehubah rawak adalah kurang daripada , dianggarkan oleh perkadaran unsur sampel kurang daripada .
Jika elemen sampel , , disusun dalam tertib menaik (pada setiap hasil asas), satu set pembolehubah rawak baharu akan diperoleh, dipanggil siri variasi:
Unsur , , dipanggil ahli ke siri variasi atau statistik tertib ke.
Contoh 1.
Sampel:
Siri variasi:
| nasi. 1. Contoh 1 |
 |
Fungsi taburan empirikal mempunyai lompatan pada titik sampel, magnitud lompatan pada satu titik adalah sama dengan , di mana bilangan elemen sampel yang bertepatan dengan .
Anda boleh membina fungsi taburan empirikal menggunakan siri variasi:

Satu lagi ciri pengedaran ialah jadual (untuk taburan diskret) atau ketumpatan (untuk yang benar-benar berterusan). Analog empirikal atau selektif jadual atau ketumpatan ialah histogram yang dipanggil.
Histogram dibina menggunakan data terkumpul. Anggaran julat nilai pembolehubah rawak (atau julat data sampel) dibahagikan, tanpa mengira sampel, kepada bilangan selang tertentu (tidak semestinya sama). Biarkan , , menjadi selang pada baris, dipanggil selang kumpulan. Mari kita nyatakan dengan bilangan elemen sampel yang jatuh dalam selang:
| (1) |
Pada setiap selang, segi empat tepat dibina, yang luasnya berkadar dengan . Jumlah luas semua segi empat tepat mestilah sama dengan satu. Biarkan panjang selang. Tinggi segiempat tepat di atas ialah
Angka yang terhasil dipanggil histogram.
Contoh 2.
Terdapat siri variasi (lihat contoh 1):
Berikut ialah logaritma perpuluhan, oleh itu, i.e. apabila sampel digandakan, bilangan selang kumpulan meningkat sebanyak 1. Ambil perhatian bahawa lebih banyak selang kumpulan, lebih baik. Tetapi, jika kita mengambil bilangan selang, katakan, dari susunan , maka dengan pertumbuhan histogram tidak akan mendekati ketumpatan.
Pernyataan berikut adalah benar:
Jika ketumpatan taburan unsur-unsur sampel ialah fungsi berterusan, maka untuk itu, terdapat penumpuan mengikut arah dalam kebarangkalian histogram kepada ketumpatan.
Jadi pilihan logaritma adalah munasabah, tetapi bukan satu-satunya yang mungkin.
Kesimpulan
Statistik matematik (atau teori) adalah berdasarkan kaedah dan konsep teori kebarangkalian, tetapi dalam erti kata tertentu menyelesaikan masalah songsang.
Jika kita memerhatikan manifestasi dua (atau lebih) tanda secara serentak, i.e. kita mempunyai satu set nilai beberapa pembolehubah rawak - apa yang boleh kita katakan tentang pergantungan mereka? Adakah dia ada atau tidak? Dan jika ada, maka apakah pergantungan ini?
Selalunya mungkin untuk membuat beberapa andaian tentang pengedaran yang tersembunyi dalam kotak hitam atau tentang sifatnya. Dalam kes ini, berdasarkan data eksperimen, adalah perlu untuk mengesahkan atau menafikan andaian ini (“hipotesis”). Perlu diingat bahawa jawapan "ya" atau "tidak" hanya boleh diberikan dengan tahap kepastian tertentu, dan semakin lama kita boleh meneruskan eksperimen, semakin tepat kesimpulan yang boleh dibuat. Situasi yang paling sesuai untuk penyelidikan adalah apabila seseorang dengan yakin boleh menegaskan sifat tertentu eksperimen yang diperhatikan - contohnya, kehadiran hubungan fungsi antara kuantiti yang diperhatikan, kenormalan taburan, simetrinya, kehadiran ketumpatan dalam taburan atau taburannya. sifat diskret, dsb.
Jadi, masuk akal untuk mengingati tentang statistik (matematik) jika
· terdapat percubaan rawak, yang sifatnya tidak diketahui sebahagian atau sepenuhnya,
· kami dapat menghasilkan semula percubaan ini dalam keadaan yang sama beberapa kali (atau lebih baik lagi, mana-mana).
Rujukan
1. Baumol U. Teori ekonomi dan penyelidikan operasi. – M.; Sains, 1999.
2. Bolshev L.N., Smirnov N.V. Jadual statistik matematik. M.: Nauka, 1995.
3. Borovkov A.A. perangkaan matematik. M.: Nauka, 1994.
4. Korn G., Korn T. Buku Panduan matematik untuk saintis dan jurutera. - St. Petersburg: Lan Publishing House, 2003.
5. Korshunov D.A., Chernova N.I. Pengumpulan masalah dan latihan statistik matematik. Novosibirsk: Rumah Penerbitan Institut Matematik dinamakan sempena. S.L. Sobolev SB RAS, 2001.
6. Peheletsky I.D. Matematik: buku teks untuk pelajar. - M.: Akademi, 2003.
7. Sukhodolsky V.G. Kuliah tentang matematik tinggi untuk humanis. - Rumah Penerbitan St. Petersburg Universiti Negeri St. Petersburg. 2003
8. Feller V. Pengenalan kepada teori kebarangkalian dan aplikasinya. - M.: Mir, T.2, 1984.
9. Harman G., Analisis faktor moden. - M.: Perangkaan, 1972.
Harman G., Analisis faktor moden. - M.: Perangkaan, 1972.
 Kesan tekanan ke atas kadar tindak balas kimia
Kesan tekanan ke atas kadar tindak balas kimia Tindak balas cermin perak: larutkan perak oksida dalam air ammonia
Tindak balas cermin perak: larutkan perak oksida dalam air ammonia Terjemahan dan maksud OFF dalam Bahasa Inggeris dan Rusia Apa maksud on dan off dalam Bahasa Inggeris
Terjemahan dan maksud OFF dalam Bahasa Inggeris dan Rusia Apa maksud on dan off dalam Bahasa Inggeris