Binomial distribusjonsfunksjon. Varians av binomialfordelingen
Når du beregner den kumulative fordelingsfunksjonen, bør du selvfølgelig bruke den nevnte forbindelsen mellom binomial- og betafordelingen. Denne metoden er åpenbart bedre enn direkte summering når n > 10.
I klassiske lærebøker om statistikk, for å få verdiene til binomialfordelingen, anbefales det ofte å bruke formler basert på grensesetninger (som Moivre-Laplace-formelen). Det bør bemerkes at fra et rent beregningsmessig synspunkt verdien av disse teoremene er nær null, spesielt nå, når nesten alle skrivebord har en kraftig datamaskin. Den største ulempen med de ovennevnte tilnærmingene er deres fullstendig utilstrekkelige nøyaktighet for verdier på n som er karakteristiske for de fleste applikasjoner. Ikke mindre en ulempe er mangelen på klare anbefalinger om anvendeligheten av denne eller den tilnærmingen (standardtekster gir bare asymptotiske formuleringer; de er ikke ledsaget av nøyaktighetsestimater og er derfor til liten nytte). Jeg vil si at begge formlene bare passer for n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Jeg vurderer ikke her problemet med å finne kvantiler: For diskrete fordelinger er det trivielt, og i de problemene der slike fordelinger oppstår, er det som regel ikke relevant. Hvis det fortsatt er behov for kvantiler, anbefaler jeg å omformulere problemet på en slik måte at man arbeider med p-verdier (observerte signifikanser). Her er et eksempel: når du implementerer noen brute-force-algoritmer, må du sjekke ved hvert trinn statistisk hypotese om en binomial tilfeldig variabel. Ifølge klassisk tilnærming På hvert trinn må du beregne kriteriestatistikken og sammenligne verdien med grensen til det kritiske settet. Siden algoritmen imidlertid er uttømmende, er det nødvendig å bestemme grensen for det kritiske settet på nytt hver gang (tross alt endres prøvestørrelsen fra trinn til trinn), noe som uproduktivt øker tidskostnadene. Moderne tilnærming anbefaler å beregne den observerte signifikansen og sammenligne den med tillitssannsynlighet, sparer på å søke etter kvantiler.
Derfor, i kodene nedenfor er det ingen beregning av den inverse funksjonen, i stedet er funksjonen rev_binomialDF gitt, som beregner sannsynligheten p for suksess i en individuell prøve gitt det gitte antallet n forsøk, antall m suksesser i dem og; verdien y av sannsynligheten for å oppnå disse m suksessene. Dette bruker den nevnte forbindelsen mellom binomial- og betafordelingen.
Faktisk lar denne funksjonen deg få grensene for konfidensintervaller. Anta faktisk at i n binomiale forsøk har vi m suksesser. Som kjent, venstre kant av en tosidig konfidensintervall for parameter p med konfidensnivå er lik 0 hvis m = 0, og for er en løsning på ligningen  . På samme måte er den høyre grensen 1 hvis m = n, og for er en løsning på ligningen
. På samme måte er den høyre grensen 1 hvis m = n, og for er en løsning på ligningen  . Det følger at for å finne den venstre grensen må vi løse den relative ligningen
. Det følger at for å finne den venstre grensen må vi løse den relative ligningen  , og for å finne den rette – ligningen
, og for å finne den rette – ligningen  . De løses i funksjonene binom_leftCI og binom_rightCI, som returnerer henholdsvis øvre og nedre grenser for det tosidige konfidensintervallet.
. De løses i funksjonene binom_leftCI og binom_rightCI, som returnerer henholdsvis øvre og nedre grenser for det tosidige konfidensintervallet.
Jeg vil gjerne merke at hvis du ikke trenger helt utrolig nøyaktighet, så for tilstrekkelig stor n kan du bruke følgende tilnærming [B.L. van der Waerden, Matematisk statistikk. M: IL, 1960, kap. 2, avsnitt 7]:  , hvor g – kvantil normalfordeling. Verdien av denne tilnærmingen er at det er veldig enkle tilnærminger som lar deg beregne kvantiler av en normalfordeling (se teksten om beregning av normalfordelingen og den tilsvarende delen av denne oppslagsboken). I min praksis (hovedsakelig med n > 100) ga denne tilnærmingen omtrent 3-4 sifre, som som regel er nok.
, hvor g – kvantil normalfordeling. Verdien av denne tilnærmingen er at det er veldig enkle tilnærminger som lar deg beregne kvantiler av en normalfordeling (se teksten om beregning av normalfordelingen og den tilsvarende delen av denne oppslagsboken). I min praksis (hovedsakelig med n > 100) ga denne tilnærmingen omtrent 3-4 sifre, som som regel er nok.
For å beregne ved hjelp av følgende koder trenger du filene betaDF.h, betaDF.cpp (se avsnittet om betadistribusjon), samt logGamma.h, logGamma.cpp (se vedlegg A). Du kan også se et eksempel på bruk av funksjonene.
Fil binomialDF.h
| #ifndef __BINOMIAL_H__ #inkluder "betaDF.h" dobbel binomialDF(doble forsøk, doble suksesser, dobbel p); /* * La det være "prøver" av uavhengige observasjoner * med sannsynlighet "p" for suksess i hver. |
* Regn ut sannsynligheten B(suksesser|forsøk,p) for at antall * suksesser ligger mellom 0 og "suksesser" (inklusive).
| */ double rev_binomialDF(doble forsøk, doble suksesser, dobbel y); /* * La sannsynligheten y for minst m suksesser forekomme * i forsøk som tester Bernoulli-skjemaet. Funksjonen finner sannsynligheten p* for suksess i en individuell prøve. |
= 0) && (y 0) && (m >= 0) && (m= 0,5) && (y La oss vurdere binomialfordelingen, beregne dens matematiske forventning, varians og modus. Ved å bruke MS EXCEL-funksjonen BINOM.DIST(), vil vi konstruere grafer over fordelingsfunksjonen og sannsynlighetstettheten. La oss estimere fordelingsparameteren p, matematisk forventning
distribusjon og standardavvik . La oss også vurdere Bernoulli-fordelingen. Definisjon . La dem finne sted n tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet s eller en "feil"-hendelse med en sannsynlighetq=1-p (såkalt).
Bernoulli-opplegg, Bernoulli prøvelser . La oss også vurdere Bernoulli-fordelingen. Sannsynligheten for å motta nøyaktig
x Bernoulli suksess i disse tester er lik: Antall suksesser i utvalget er en tilfeldig variabel som harBinomial fordeling) . La dem finne sted(engelsk) . La oss også vurdere Bernoulli-fordelingen.– Binomial
distribusjon Og er parametrene for denne fordelingen. Husk å bruke det Bernoulli planer
- og deretter
- Binomial distribusjon,
- følgende vilkår må være oppfylt: . La dem finne sted Hver test må ha nøyaktig to utfall, konvensjonelt kalt "suksess" og "fiasko."
Resultatet av hver test bør ikke avhenge av resultatene fra tidligere tester (testuavhengighet).
sannsynlighet for suksess må være konstant for alle tester. Binomialfordeling i MS EXCEL I MS EXCEL, fra og med versjon 2010, for Binomial fordeling det er en funksjon BINOM.DIST(), engelsk navn - BINOM.DIST(), som lar deg beregne sannsynligheten for at prøven vil inneholde nøyaktig X "suksess" (dvs. sannsynlighetstetthetsfunksjon Bernoulli p(x), se formel ovenfor), og
kumulativ distribusjonsfunksjon (sannsynligheten for at utvalget vil ha(engelsk) eller færre "suksesser", inkludert 0). Før MS EXCEL 2010 hadde EXCEL en funksjon BINOMDIST(), som også lar deg beregne
distribusjonsfunksjon sannsynlighetstetthet(engelsk) .

p(x). BINOMIST() er igjen i MS EXCEL 2010 for kompatibilitet. Eksempelfilen inneholder grafer sannsynlighetstetthetsfordeling(. La oss også vurdere Bernoulli-fordelingen.; . La dem finne sted) .
Binomial fordeling har betegnelsen B perfekt typediagram Rute, For distribusjonstetthet – Histogram med gruppering. For mer informasjon om å lage diagrammer, les artikkelen Grunnleggende diagramtyper.
Binomial fordeling: For å gjøre det enklere å skrive formler, er det opprettet navn for parametere i eksempelfilen må være konstant for alle tester.: n og s.

Eksempelfilen viser ulike sannsynlighetsberegninger ved bruk av MS EXCEL-funksjoner:

Som du kan se på bildet ovenfor, antas det at:
- Den uendelige populasjonen som utvalget er tatt fra inneholder 10 % (eller 0,1) gyldige elementer (parameter . La dem finne sted, tredje funksjonsargument = BINOM.DIST() )
- For å beregne sannsynligheten for at i et utvalg av 10 elementer (parameter . La oss også vurdere Bernoulli-fordelingen., det andre argumentet til funksjonen) vil det være nøyaktig 5 gyldige elementer (det første argumentet), du må skrive formelen: =BINOM.FORDELING(5; 10; 0.1; FALSE)
- Det siste, fjerde elementet er satt = FALSE, dvs. funksjonsverdien returneres distribusjonstetthet.
Hvis verdien til det fjerde argumentet = TRUE, returnerer funksjonen BINOM.DIST() verdien B eller bare Distribusjonsfunksjon. I dette tilfellet kan du beregne sannsynligheten for at antall passende elementer i utvalget vil være fra viss rekkevidde, for eksempel 2 eller mindre (inkludert 0).
For å gjøre dette må du skrive formelen:
= BINOM.FORDELING(2; 10; 0,1; SANN)
Binomial fordeling: For en ikke-heltallsverdi av x, . For eksempel vil følgende formler returnere samme verdi:
=BINOM.FORDELING( 2
; 10; 0,1; EKTE)
=BINOM.FORDELING( 2,9
; 10; 0,1; EKTE)
Binomial fordeling: I eksempelfilen eller færre "suksesser", inkludert 0).(engelsk) distribusjonsfunksjon også beregnet ved hjelp av definisjonen og funksjonen NUMBERCOMB() .
Distribusjonsindikatorer
I eksempelfil på regneark Eksempel Det er formler for å beregne noen distribusjonsindikatorer:
- =n*p;
- (standardavvik i annen) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
La oss utlede formelen matematisk forventning må være konstant for alle tester. bruker Bernoulli krets.
Per definisjon tilfeldig variabel X inn Bernoulli-opplegg(Bernoulli tilfeldig variabel) har (sannsynligheten for at utvalget vil ha:
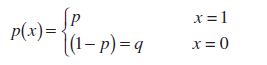
Denne fordelingen kalles Bernoulli distribusjon.
Binomial fordeling: Bernoulli distribusjon – spesielt tilfelle må være konstant for alle tester. med parameter n=1.
La oss generere 3 arrays med 100 tall hver med forskjellige sannsynligheter suksess: 0,1; 0,5 og 0,9. For å gjøre dette i vinduet Generering av tilfeldig tall installere følgende parametere for hver sannsynlighet p:

Binomial fordeling: Hvis du angir alternativet Tilfeldig spredning (Tilfeldig frø), så kan du velge en bestemt tilfeldig sett genererte tall. For eksempel, ved å sette dette alternativet =25, kan du generere de samme settene med tilfeldige tall på forskjellige datamaskiner (hvis, selvfølgelig, andre distribusjonsparametere er de samme). Opsjonsverdien kan ha heltallsverdier fra 1 til 32.767 Tilfeldig spredning kan være forvirrende. Det ville være bedre å oversette det som Slå nummer med tilfeldige tall.
Som et resultat vil vi ha 3 kolonner med 100 tall, på grunnlag av hvilke vi for eksempel kan estimere sannsynligheten for suksess . La dem finne sted i henhold til formelen: Antall suksesser/100(cm. eksempel filark Generation Bernoulli).

Binomial fordeling: For Bernoulli distribusjoner med p=0,5 kan du bruke formelen =RANDBETWEEN(0;1) som tilsvarer .
Generering av tilfeldig tall. Binomial fordeling
La oss anta at det er 7 defekte produkter i prøven. Dette betyr at det er «svært sannsynlig» at andelen defekte produkter har endret seg . La dem finne sted, som er et kjennetegn ved vår produksjonsprosess. Selv om en slik situasjon er "svært sannsynlig", er det en mulighet (alfarisiko, type 1 feil, "falsk alarm") . La dem finne sted forble uendret, og det økte antallet defekte produkter skyldtes stikkprøver.
Som du kan se i figuren nedenfor, er 7 antallet defekte produkter som er akseptabelt for en prosess med p=0,21 ved samme verdi Alfa. Dette illustrerer at når terskelverdien for defekte varer i en prøve overskrides, . La dem finne sted"mest sannsynlig" har økt. Uttrykket "mest sannsynlig" betyr at det bare er 10 % sannsynlighet (100 %-90 %) for at avviket i prosentandelen av defekte produkter over terskelen kun skyldes tilfeldige årsaker.
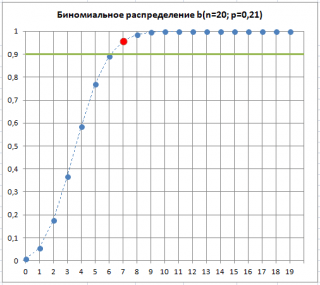
Dermed kan overskridelse av terskelantallet for defekte produkter i prøven tjene som et signal om at prosessen har blitt opprørt og har begynt å produsere brukte produkter. O høyere prosentandel av defekte produkter.
Binomial fordeling: Før MS EXCEL 2010 hadde EXCEL en funksjon CRITBINOM(), som tilsvarer BINOM.INV(). CRITBINOM() er igjen i MS EXCEL 2010 og høyere for kompatibilitet.
Forholdet mellom binomialfordelingen og andre distribusjoner
Hvis parameteren . La oss også vurdere Bernoulli-fordelingen. må være konstant for alle tester. har en tendens til det uendelige, og . La dem finne sted har en tendens til 0, så i dette tilfellet tester er lik: kan tilnærmes.
Vi kan formulere betingelser når tilnærmingen Giftfordeling fungerer bra:
- . La dem finne sted<0,1 (jo mindre . La dem finne sted og mer . La oss også vurdere Bernoulli-fordelingen., jo mer nøyaktig tilnærmingen er);
- . La dem finne sted>0,9 (med tanke på det tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet=1- . La dem finne sted, beregninger i dette tilfellet må gjennomføres tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet(EN det er en funksjon BINOM.DIST(), må erstattes med . La oss også vurdere Bernoulli-fordelingen.- Bernoulli). Derfor, jo mindre tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet og mer . La oss også vurdere Bernoulli-fordelingen., jo mer nøyaktig tilnærmingen er).
På 0,1<=p<=0,9 и n*p>10 tester er lik: kan tilnærmes.
I sin tur, tester er lik: kan tjene som en god tilnærming når populasjonsstørrelsen er N Hypergeometrisk fordeling mye større enn prøvestørrelse n (dvs. N>>n eller n/N<<1).
Flere detaljer om forholdet mellom distribusjonene ovenfor finner du i artikkelen. Det er også eksempler på tilnærming, og vilkårene for når det er mulig og med hvilken nøyaktighet er forklart.
RÅD: Du kan lese om andre MS EXCEL-distribusjoner i artikkelen.
Hilsen alle lesere!
Statistisk analyse omhandler som kjent innsamling og bearbeiding av reelle data. Virksomheten er nyttig, og ofte lønnsom, fordi... Riktige konklusjoner lar deg unngå feil og tap i fremtiden, og noen ganger gjette riktig denne fremtiden. De innsamlede dataene gjenspeiler tilstanden til noen observerte fenomener. Data er ofte (men ikke alltid) numeriske og kan manipuleres matematisk for å trekke ut tilleggsinformasjon.
Imidlertid er ikke alle fenomener målt på en kvantitativ skala som 1, 2, 3 ... 100500 ... Et fenomen kan ikke alltid anta et uendelig eller stort antall forskjellige tilstander. For eksempel kan en persons kjønn være enten M eller F. Skytteren treffer enten målet eller bommer. Du kan stemme enten "For" eller "Imot" osv. osv. Med andre ord reflekterer slike data tilstanden til et alternativt attributt - enten "ja" (hendelsen skjedde) eller "nei" (hendelsen skjedde ikke). Den inntreffende hendelsen (positivt utfall) kalles også "suksess". Slike fenomener kan også være utbredte og tilfeldige. Derfor kan de måles og statistisk valide konklusjoner kan trekkes.
Eksperimenter med slike data kalles Bernoulli-opplegg, til ære for den berømte sveitsiske matematikeren som fant ut at med et stort antall forsøk, har forholdet mellom positive utfall og det totale antallet forsøk en tendens til sannsynligheten for at denne hendelsen inntreffer.
Alternativ karakteristisk variabel
For å bruke matematiske apparater i analysen, bør resultatene av slike observasjoner registreres i numerisk form. For å gjøre dette tildeles et positivt utfall tallet 1, et negativt utfall - 0. Vi har med andre ord å gjøre med en variabel som bare kan ha to verdier: 0 eller 1.
Hvilken fordel kan man få ut av dette? Egentlig ikke mindre enn fra vanlige data. Dermed er det enkelt å beregne antall positive utfall - bare summer opp alle verdiene, dvs. alle 1 (suksess). Du kan gå lenger, men dette vil kreve at du introduserer et par notasjoner.
Det første å merke seg er at positive utfall (som er lik 1) har en viss sannsynlighet for å inntreffe. For eksempel, å få hoder når du kaster en mynt er ½ eller 0,5. Denne sannsynligheten er tradisjonelt betegnet med den latinske bokstaven . La dem finne sted. Derfor er sannsynligheten for at en alternativ hendelse inntreffer lik 1 - s, som også er betegnet med tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet, altså q = 1 – p. Disse notasjonene kan tydelig systematiseres i form av en variabel distribusjonstabell X.
Nå har vi en liste over mulige verdier og deres sannsynligheter. Vi kan begynne å beregne slike bemerkelsesverdige egenskaper ved en tilfeldig variabel som matematisk forventning(engelsk) spredning. La meg minne deg på at den matematiske forventningen beregnes som summen av produktene av alle mulige verdier og deres tilsvarende sannsynligheter:
![]()
La oss beregne forventningen ved å bruke notasjonen i tabellene ovenfor.
Det viser seg at den matematiske forventningen til et alternativt tegn er lik sannsynligheten for denne hendelsen - . La dem finne sted.
La oss nå definere hva variansen til et alternativt attributt er. La meg også minne deg på at spredning er det gjennomsnittlige kvadratet av avvik fra den matematiske forventningen. Den generelle formelen (for diskrete data) er:
Derav variansen til det alternative attributtet:

Det er lett å se at denne spredningen har maksimalt 0,25 (med p=0,5).
Standardavviket er roten til variansen:
Maksimumsverdien overstiger ikke 0,5.
Som du kan se, har både den matematiske forventningen og variansen til det alternative attributtet en veldig kompakt form.
Binomial fordeling av en tilfeldig variabel
La oss nå se på situasjonen fra en annen vinkel. Faktisk, hvem bryr seg om at det gjennomsnittlige tapet av hoder per kast er 0,5? Det er umulig å forestille seg. Det er mer interessant å stille spørsmålet om antall hoder som vises for et gitt antall kast.
Med andre ord er forskeren ofte interessert i sannsynligheten for at et visst antall vellykkede hendelser inntreffer. Dette kan være antall defekte produkter i den testede batchen (1 - defekt, 0 - bra) eller antall gjenopprettinger (1 - frisk, 0 - syk) osv. Antallet slike "suksesser" vil være lik summen av alle verdiene til variabelen X, dvs. antall enkeltutfall.
Tilfeldig variabel sannsynlighetstetthetsfordeling kalles binomial og tar verdier fra 0 til . La oss også vurdere Bernoulli-fordelingen.(på sannsynlighetstetthetsfordeling= 0 - alle deler er egnet, med sannsynlighetstetthetsfordeling = . La oss også vurdere Bernoulli-fordelingen.– alle deler er defekte). Det forutsettes at alle verdier Bernoulli uavhengig av hverandre. La oss vurdere hovedkarakteristikkene til en binomial variabel, det vil si at vi vil etablere dens matematiske forventning, spredning og distribusjon.
Forventningen til en binomial variabel er veldig lett å oppnå. La oss huske at det er en sum av matematiske forventninger til hver merverdi, og det er likt for alle, derfor:
For eksempel er den matematiske forventningen til antall hoder som faller i 100 kast 100 × 0,5 = 50.
Nå utleder vi formelen for spredningen av en binomial variabel. er summen av varianser. Herfra
Standardavvik, henholdsvis
For 100 myntkast er standardavviket
Vurder til slutt fordelingen av binomialverdien, dvs. sannsynligheten for at den tilfeldige variabelen sannsynlighetstetthetsfordeling vil få ulike verdier k, Hvor 0≤k≤n. For en mynt kan dette problemet se slik ut: Hva er sannsynligheten for å få 40 hoder på 100 kast?
For å forstå beregningsmetoden, se for deg at mynten bare kastes 4 ganger. Hver side kan falle ut hver gang. Vi spør oss selv: hva er sannsynligheten for å få 2 hoder av 4 kast. Hvert kast er uavhengig av hverandre. Dette betyr at sannsynligheten for å få en hvilken som helst kombinasjon vil være lik produktet av sannsynlighetene for et gitt utfall for hvert enkelt kast. La O være hoder, P være haler. Da kan for eksempel en av kombinasjonene som passer oss se ut som OOPP, det vil si:

Sannsynligheten for en slik kombinasjon er lik produktet av to sannsynligheter for å få hoder og ytterligere to sannsynligheter for å ikke få hoder (den omvendte hendelsen, beregnet som 1 - s), dvs. 0,5×0,5×(1-0,5)×(1-0,5)=0,0625. Dette er sannsynligheten for en av kombinasjonene som passer oss. Men spørsmålet handlet om det totale antallet ørner, og ikke om noen bestemt rekkefølge. Deretter må du legge sammen sannsynlighetene for alle kombinasjoner der det er nøyaktig 2 hoder. Det er klart at de alle er like (produktet endres ikke når faktorene endres). Derfor må du beregne antallet og deretter multiplisere med sannsynligheten for en slik kombinasjon. La oss telle alle kombinasjoner av 4 kast med 2 hoder: RROO, RORO, ROOR, ORRO, OROR, OORR. Det er 6 alternativer totalt.

Derfor er den ønskede sannsynligheten for å få 2 hoder etter 4 kast 6×0,0625=0,375.
Det er imidlertid kjedelig å telle på denne måten. Allerede for 10 mynter vil det være svært vanskelig å få det totale antallet alternativer med brute force. Derfor har smarte mennesker for lenge siden funnet opp en formel som de beregner antall forskjellige kombinasjoner av . La oss også vurdere Bernoulli-fordelingen. elementer av k, Hvor . La oss også vurdere Bernoulli-fordelingen.– totalt antall elementer, k– antall elementer, hvis arrangementsalternativer beregnes. Formel kombinasjon av . La oss også vurdere Bernoulli-fordelingen. elementer av k er dette:
![]()
Lignende ting skjer i kombinatorikkdelen. Jeg sender alle som ønsker å forbedre sine kunnskaper dit. Derav, forresten, navnet på binomialfordelingen (formelen ovenfor er en koeffisient i utvidelsen av Newtons binomiale).
Formelen for å bestemme sannsynlighet kan lett generaliseres til en hvilken som helst mengde . La oss også vurdere Bernoulli-fordelingen.(engelsk) k. Som et resultat har formelen for binomialfordelingen følgende form.
Med ord: antall kombinasjoner som oppfyller betingelsen multipliseres med sannsynligheten for en av dem.
For praktisk bruk er det nok bare å kjenne formelen til binomialfordelingen. Eller du vet kanskje ikke engang - nedenfor viser vi hvordan du bestemmer sannsynligheten ved å bruke Excel. Men det er bedre å vite.
Ved å bruke denne formelen beregner vi sannsynligheten for å få 40 hoder på 100 kast:
Eller bare 1,08%. Til sammenligning er sannsynligheten for at den matematiske forventningen til dette eksperimentet, det vil si 50 hoder, lik 7,96%. Maksimal sannsynlighet for en binomial verdi tilhører verdien som tilsvarer den matematiske forventningen.
Beregne sannsynligheten for en binomialfordeling i Excel
Hvis du bare bruker papir og en kalkulator, er beregninger ved hjelp av binomialfordelingsformelen, til tross for fravær av integraler, ganske vanskelige. For eksempel er verdien 100! – har mer enn 150 tegn. Det er umulig å beregne dette manuelt. Tidligere, og selv nå, ble omtrentlige formler brukt for å beregne slike mengder. For øyeblikket er det tilrådelig å bruke spesiell programvare, for eksempel MS Excel. Dermed kan enhver bruker (selv en humanist av utdannelse) enkelt beregne sannsynligheten for verdien av en binomisk distribuert tilfeldig variabel.
For å konsolidere materialet vil vi foreløpig bruke Excel som en vanlig kalkulator, dvs. La oss utføre en trinnvis beregning ved å bruke formelen for binomialfordeling. La oss beregne for eksempel sannsynligheten for å få 50 hoder. Nedenfor er et bilde med beregningstrinnene og det endelige resultatet.

Som du kan se, er mellomresultatene av en slik skala at de ikke passer inn i en celle, selv om enkle funksjoner som FACTOR (beregning av en faktorial), POWER (heve et tall til en potens), samt multiplikasjons- og divisjonsoperatorer brukes overalt. Dessuten er denne beregningen ganske tungvint i alle fall, den er ikke kompakt, fordi mange celler er involvert. Ja, og det er litt vanskelig å finne ut med en gang.
Generelt gir Excel en ferdig funksjon for å beregne sannsynlighetene for en binomialfordeling. Funksjonen kalles BINOM.FORDELING.

Antall suksesser– antall vellykkede tester. Vi har 50 av dem.
Antall tester– antall kast: 100 ganger.
Sannsynlighet for suksess– Sannsynligheten for å få hoder i ett kast er 0,5.
Integral– enten 1 eller 0 er angitt Hvis 0, beregnes sannsynligheten P(B=k); hvis 1, vil binomialfordelingsfunksjonen beregnes, dvs. summen av alle sannsynligheter fra B=0 til B=k inklusive.
Klikk OK og få samme resultat som ovenfor, kun alt ble beregnet av en funksjon.

Veldig praktisk. For eksperimentets skyld, i stedet for den siste parameteren 0, setter vi 1. Vi får 0,5398. Dette betyr at med 100 myntkast er sannsynligheten for å få hoder mellom 0 og 50 nesten 54%. Men først så det ut til at det burde være 50 %. Generelt gjøres beregninger raskt og enkelt.
En ekte analytiker må forstå hvordan funksjonen oppfører seg (hva er dens fordeling), så vi vil beregne sannsynlighetene for alle verdier fra 0 til 100. Det vil si at vi vil stille spørsmålet: hva er sannsynligheten for at ikke en eneste ørn vil dukke opp, at 1 ørn vil dukke opp, 2, 3, 50, 90 eller 100. Beregningen vises i følgende selvbevegende bilde. Den blå linjen er selve binomialfordelingen, den røde prikken er sannsynligheten for et spesifikt antall suksesser k.

Man kan spørre seg om binomialfordelingen er lik... Ja, veldig lik. Even Moivre (i 1733) sa at binomialfordelingen med store utvalg nærmer seg (jeg vet ikke hva den het da), men ingen hørte på ham. Bare Gauss, og deretter Laplace 60-70 år senere, gjenoppdaget og studerte normalfordelingsloven nøye. Grafen over viser tydelig at den maksimale sannsynligheten faller på den matematiske forventningen, og ettersom den avviker fra den, avtar den kraftig. Akkurat som vanlig lov.
Binomialfordelingen er av stor praktisk betydning og forekommer ganske ofte. Ved hjelp av Excel gjøres beregninger raskt og enkelt. Så du kan trygt bruke den.
Med dette foreslår jeg å si farvel til neste møte. Alt godt, hold deg frisk!
Kapittel 7.
Spesifikke lover for distribusjon av tilfeldige variabler
Typer av lover for distribusjon av diskrete tilfeldige variabler
La en diskret tilfeldig variabel ta verdiene det er en funksjon BINOM.DIST(), 1 , det er en funksjon BINOM.DIST(), 2 , …, x n,…. Sannsynlighetene for disse verdiene kan beregnes ved hjelp av forskjellige formler, for eksempel ved å bruke de grunnleggende teoremene til sannsynlighetsteori, Bernoullis formel eller noen andre formler. For noen av disse formlene har fordelingsloven et eget navn.
De vanligste lovene for distribusjon av en diskret tilfeldig variabel er binomial, geometrisk, hypergeometrisk og Poisson-fordelingslov.
Binomialfordelingslov
La det produseres . La oss også vurdere Bernoulli-fordelingen. uavhengige forsøk, i hver av dem kan hendelsen dukke opp eller ikke EN. Sannsynligheten for at denne hendelsen skal skje i hver enkelt prøve er konstant, avhenger ikke av prøvenummeret og er lik r=R(EN). Derav sannsynligheten for at hendelsen ikke inntreffer EN i hver test er også konstant og lik tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet=1–r. Tenk på den tilfeldige variabelen X lik antall forekomster av hendelsen EN V . La oss også vurdere Bernoulli-fordelingen. tester. Selvfølgelig er verdiene til denne mengden like
det er en funksjon BINOM.DIST(), 1 =0 – hendelse EN V . La oss også vurdere Bernoulli-fordelingen. tester dukket ikke opp;
det er en funksjon BINOM.DIST(), 2 =1 – hendelse EN V . La oss også vurdere Bernoulli-fordelingen. dukket opp en gang i prøvelser;
det er en funksjon BINOM.DIST(), 3 =2 – hendelse EN V . La oss også vurdere Bernoulli-fordelingen. tester dukket opp to ganger;
…………………………………………………………..
x n +1 = . La oss også vurdere Bernoulli-fordelingen.- arrangement EN V . La oss også vurdere Bernoulli-fordelingen. alt dukket opp under testene . La oss også vurdere Bernoulli-fordelingen. en gang.
Sannsynlighetene for disse verdiene kan beregnes ved å bruke Bernoulli-formelen (4.1):
Hvor Til=0, 1, 2, …,n .
Binomialfordelingslov X, lik antall suksesser i . La oss også vurdere Bernoulli-fordelingen. Bernoulli tester, med sannsynlighet for suksess r.
Så, en diskret tilfeldig variabel har en binomialfordeling (eller er fordelt i henhold til binomialloven) hvis dens mulige verdier er 0, 1, 2, ..., . La oss også vurdere Bernoulli-fordelingen., og de tilsvarende sannsynlighetene beregnes ved hjelp av formel (7.1).
Binomialfordelingen avhenger av to parametere r(engelsk) . La oss også vurdere Bernoulli-fordelingen..
Fordelingsserien til en tilfeldig variabel fordelt i henhold til binomialloven har formen:
| X | … | k | … | . La oss også vurdere Bernoulli-fordelingen. | ||
| R | | … | … | |
Eksempel 7.1 . Tre uavhengige skudd skytes mot målet. Sannsynligheten for å treffe hvert skudd er 0,4. Tilfeldig variabel X– antall treff på målet. Konstruer distribusjonsserien.
Løsning. Mulige verdier for en tilfeldig variabel X er det er en funksjon BINOM.DIST(), 1 =0; det er en funksjon BINOM.DIST(), 2 =1; det er en funksjon BINOM.DIST(), 3 =2; det er en funksjon BINOM.DIST(), 4 = 3. La oss finne de tilsvarende sannsynlighetene ved å bruke Bernoullis formel. Det er ikke vanskelig å vise at bruken av denne formelen her er fullstendig berettiget. Merk at sannsynligheten for ikke å treffe målet med ett skudd vil være lik 1-0,4=0,6. Vi får

Distribusjonsserien har følgende form:
| X | ||||
| R | 0,216 | 0,432 | 0,288 | 0,064 |
Det er lett å verifisere at summen av alle sannsynligheter er lik 1. Selve stokastisk variabel X fordelt etter binomialloven. ■
La oss finne den matematiske forventningen og variansen til en tilfeldig variabel fordelt i henhold til binomialloven.
Ved løsning av eksempel 6.5 ble det vist at den matematiske forventningen til antall forekomster av hendelsen EN V . La oss også vurdere Bernoulli-fordelingen. uavhengige forsøk, hvis sannsynligheten for forekomst EN i hver test er konstant og lik r, lik . La oss også vurdere Bernoulli-fordelingen.· r
Dette eksemplet brukte en tilfeldig variabel fordelt i henhold til binomialloven. Derfor er løsningen til eksempel 6.5 i hovedsak et bevis på følgende teorem.
Teorem 7.1. Den matematiske forventningen til en diskret tilfeldig variabel fordelt i henhold til binomialloven er lik produktet av antall forsøk og sannsynligheten for "suksess", dvs. M(X)=n· r.
Teorem 7.2. Variansen til en diskret tilfeldig variabel fordelt i henhold til binomialloven er lik produktet av antall forsøk med sannsynligheten for "suksess" og sannsynligheten for "fiasko", dvs. D(X)=nрq.
Asymmetrien og kurtosisen til en tilfeldig variabel fordelt i henhold til binomialloven bestemmes av formlene
Disse formlene kan oppnås ved å bruke konseptet med innledende og sentrale øyeblikk.
Den binomiale distribusjonsloven ligger til grunn for mange virkelige situasjoner. For store verdier . La oss også vurdere Bernoulli-fordelingen. Binomialfordelingen kan tilnærmes ved å bruke andre distribusjoner, spesielt Poisson-fordelingen.
Giftfordeling
La det være n Bernoulli-tester, med antall tester . La oss også vurdere Bernoulli-fordelingen. stor nok. Det ble vist tidligere at i dette tilfellet (hvis dessuten sannsynligheten r hendelser EN svært liten) for å finne sannsynligheten for at hendelsen EN vises T En gang i tester kan du bruke Poisson-formelen (4.9). Hvis den tilfeldige variabelen X betyr antall forekomster av hendelsen EN V . La oss også vurdere Bernoulli-fordelingen. Bernoulli tester, da sannsynligheten for at X vil ta verdien k kan beregnes ved hjelp av formelen
 , (7.2)
, (7.2)
Hvor λ = nр.
Giftfordelingsloven kalles fordelingen av en diskret tilfeldig variabel X, for hvilke mulige verdier er ikke-negative heltall, og sannsynlighetene r t disse verdiene er funnet ved hjelp av formel (7.2).
Størrelse λ = nр ringte parameter Poisson-fordelinger.
En tilfeldig variabel fordelt i henhold til Poissons lov kan få et uendelig antall verdier. Siden for denne fordelingen sannsynligheten r Forekomsten av en hendelse i hver rettssak er liten, så denne fordelingen kalles noen ganger loven om sjeldne hendelser.
Fordelingsserien til en tilfeldig variabel fordelt i henhold til Poissons lov har formen
| X | … | T | … | ||||
| R | … | … |
Det er lett å verifisere at summen av sannsynlighetene til den andre raden er lik 1. For å gjøre dette må du huske at funksjonen kan utvides til en Maclaurin-serie, som konvergerer for evt. det er en funksjon BINOM.DIST(),. I dette tilfellet har vi
 . (7.3)
. (7.3)
Som nevnt erstatter Poissons lov den binomiale loven i visse begrensende tilfeller. Et eksempel er den tilfeldige variabelen X, hvis verdier er lik antall feil over en viss tidsperiode under gjentatt bruk av en teknisk enhet. Det antas at dette er en svært pålitelig enhet, dvs. Sannsynligheten for feil i en applikasjon er svært liten.
I tillegg til slike begrensende tilfeller er det i praksis tilfeldige variabler fordelt etter Poissons lov som ikke er assosiert med binomialfordelingen. For eksempel brukes Poisson-fordelingen ofte når det gjelder antall hendelser som skjer i løpet av en tidsperiode (antall anrop mottatt på en telefonsentral i løpet av en time, antall biler som ankommer en bilvask i løpet av en dag, antall maskinstopp per uke osv.). Alle disse hendelsene skal danne den såkalte strømmen av hendelser, som er et av de grunnleggende begrepene i køteori. Parameter λ karakteriserer den gjennomsnittlige intensiteten av strømmen av hendelser.
Binomialfordelingen er en av de viktigste sannsynlighetsfordelingene til en diskret varierende tilfeldig variabel. Binomialfordelingen er sannsynlighetsfordelingen til tallet m forekomst av en hendelse EN V . La oss også vurdere Bernoulli-fordelingen. gjensidig uavhengige observasjoner. Ofte en begivenhet EN kalles "suksess" for en observasjon, og den motsatte hendelsen kalles "feil", men denne betegnelsen er veldig betinget.
Binomiale distribusjonsforhold:
- totalt gjennomført . La oss også vurdere Bernoulli-fordelingen. forsøk der arrangementet EN kan forekomme eller ikke;
- hendelse EN i hvert forsøk kan forekomme med samme sannsynlighet . La dem finne sted;
- tester er gjensidig uavhengige.
Sannsynligheten for at i . La oss også vurdere Bernoulli-fordelingen. testhendelse EN det kommer akkurat m ganger, kan beregnes ved å bruke Bernoullis formel:
![]()
![]() ,
,
Hvor . La dem finne sted- sannsynlighet for at en hendelse inntreffer EN;
tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet = 1 - . La dem finne sted- sannsynligheten for at den motsatte hendelsen inntreffer.
La oss finne ut av det hvorfor er binomialfordelingen relatert til Bernoullis formel på måten beskrevet ovenfor? . Arrangement - antall suksesser kl . La oss også vurdere Bernoulli-fordelingen. tester er delt inn i en rekke alternativer, i hver av dem oppnås suksess i m tester og feil - i . La oss også vurdere Bernoulli-fordelingen. - m tester. La oss vurdere ett av disse alternativene - sannsynlighetstetthetsfordeling1 . Ved å bruke regelen for å legge til sannsynligheter, multipliserer vi sannsynlighetene for motsatte hendelser:
![]() ,
,
og hvis vi betegner tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med sannsynlighet = 1 - . La dem finne sted, Det
![]() .
.
Ethvert annet alternativ der m suksess og . La oss også vurdere Bernoulli-fordelingen. - m feil. Antall slike alternativer er lik antall måter man kan . La oss også vurdere Bernoulli-fordelingen. test få m suksess.
Summen av alle sannsynligheter m hendelsesforekomstnummer EN(tall fra 0 til . La oss også vurdere Bernoulli-fordelingen.) er lik én:
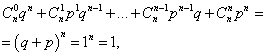
hvor hvert ledd representerer et ledd i Newtons binomiale. Derfor kalles fordelingen under vurdering binomialfordelingen.
I praksis er det ofte nødvendig å beregne sannsynligheter «ikke mer enn m suksess i . La oss også vurdere Bernoulli-fordelingen. tester" eller "minst m suksess i . La oss også vurdere Bernoulli-fordelingen. tester". Følgende formler brukes til dette.
Integralfunksjonen, altså sannsynlighet F(m) hva er i . La oss også vurdere Bernoulli-fordelingen. observasjonshendelse EN det kommer ikke flere m en gang, kan beregnes ved hjelp av formelen:
I sin tur sannsynlighet F(≥m) hva er i . La oss også vurdere Bernoulli-fordelingen. observasjonshendelse EN kommer ikke mindre m en gang, beregnes med formelen:
Noen ganger er det mer praktisk å beregne sannsynligheten for at . La oss også vurdere Bernoulli-fordelingen. observasjonshendelse EN det kommer ikke flere m ganger, gjennom sannsynligheten for den motsatte hendelsen:
![]() .
.
Hvilken formel du skal bruke avhenger av hvilken av dem som har summen som inneholder færre ledd.
Egenskapene til binomialfordelingen beregnes ved å bruke følgende formler .
Matematisk forventning:.
Spredning: .
Standardavvik: .
Binomialfordeling og beregninger i MS Excel
Binomisk sannsynlighet P n ( m) og verdiene til integralfunksjonen F(m) kan beregnes ved hjelp av MS Excel-funksjonen BINOM.DIST. Vinduet for den tilsvarende beregningen er vist nedenfor (venstreklikk for å forstørre).

MS Excel krever at du oppgir følgende data:
- antall suksesser;
- antall tester;
- sannsynlighet for suksess;
- integral - logisk verdi: 0 - hvis du trenger å regne ut sannsynligheten P n ( m) og 1 - hvis sannsynligheten F(m).
Eksempel 1. Bedriftslederen oppsummerte informasjon om antall solgte kameraer de siste 100 dagene. Tabellen oppsummerer informasjonen og beregner sannsynlighetene for at et visst antall kameraer vil bli solgt per dag.
Dagen avsluttes med overskudd dersom det selges 13 eller flere kameraer. Sannsynlighet for at dagen vil bli lønnsomt:
![]()
Sannsynlighet for at en dag vil bli jobbet uten fortjeneste:
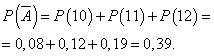
La sannsynligheten for at en dag jobbes med overskudd være konstant og lik 0,61, og antall solgte kameraer per dag er ikke avhengig av dagen. Da kan vi bruke binomialfordelingen, hvor hendelsen EN- dagen skal jobbes med overskudd, - uten overskudd.
Sannsynligheten for at alle 6 dager vil bli regnet ut med overskudd:
![]() .
.
Vi får det samme resultatet ved å bruke MS Excel-funksjonen BINOM.DIST (verdien av integralverdien er 0):
P 6 (6 ) = BINOM.FORDELING(6; 6; 0,61; 0) = 0,052.
Sannsynligheten for at 4 eller flere dager av 6 dager vil bli arbeidet med fortjeneste:
Hvor ![]() ,
,
![]() ,
,
Ved å bruke MS Excel-funksjonen BINOM.DIST beregner vi sannsynligheten for at av 6 dager ikke mer enn 3 dager vil bli fullført med overskudd (verdien av integralverdien er 1):
P 6 (≤3 ) = BINOM.FORDELING(3; 6; 0,61; 1) = 0,435.
Sannsynlighet for at alle 6 dager vil bli regnet ut med tap:
![]() ,
,
Vi kan beregne den samme indikatoren ved å bruke MS Excel-funksjonen BINOM.DIST:
P 6 (0 ) = BINOM.FORDELING(0; 6; 0,61; 0) = 0,0035.
Løs problemet selv og se deretter løsningen
Eksempel 2. Det er 2 hvite kuler og 3 svarte kuler i urnen. En ball tas ut av urnen, fargen settes og settes tilbake. Forsøket gjentas 5 ganger. Antall forekomster av hvite kuler er en diskret tilfeldig variabel X, fordelt i henhold til binomialloven. Tegn en fordelingslov for en tilfeldig variabel. Definer modus, matematisk forventning og spredning.
La oss fortsette å løse problemer sammen
Eksempel 3. Fra budtjenesten dro vi til nettstedene . La oss også vurdere Bernoulli-fordelingen.= 5 bud. Hver kurer er sannsynlig . La dem finne sted= 0,3, uavhengig av andre, er sent for objektet. Diskret tilfeldig variabel X- antall sene kurerer. Konstruer en distribusjonsserie for denne tilfeldige variabelen. Finn dens matematiske forventning, varians, standardavvik. Finn sannsynligheten for at minst to kurerer kommer for sent til gjenstandene.
 Forholdet mellom menneske og natur Forholdet mellom menneske og natur
Forholdet mellom menneske og natur Forholdet mellom menneske og natur Sammensatte ord med en forbindelsesvokal
Sammensatte ord med en forbindelsesvokal Urinsyre i blodet: normer og avvik, hvorfor det øker, kosthold for å redusere det Sluttproduktet av nitrogenmetabolismen er
Urinsyre i blodet: normer og avvik, hvorfor det øker, kosthold for å redusere det Sluttproduktet av nitrogenmetabolismen er