Finn egenvektorene til matrisen. System av homogene lineære ligninger
En egenvektor til en kvadratisk matrise er en som, multiplisert med en gitt matrise, resulterer i en kollineær vektor. Med enkle ord, når man multipliserer en matrise med en egenvektor, forblir sistnevnte den samme, men multiplisert med et visst tall.
DefinisjonEn egenvektor er en ikke-null vektor V, som, når multiplisert med en kvadratisk matrise M, blir selv økt med et eller annet tall λ. I algebraisk notasjon ser det slik ut:
M × V = λ × V,
hvor λ er egenverdien til matrisen M.
La oss vurdere numerisk eksempel. For enkel opptak vil tall i matrisen være atskilt med semikolon. La oss ha en matrise:
- M = 0; 4;
- 6; 10.
La oss multiplisere det med en kolonnevektor:
- V = -2;
Når vi multipliserer en matrise med en kolonnevektor, får vi også en kolonnevektor. Streng matematisk språk Formelen for å multiplisere en 2 × 2 matrise med en kolonnevektor vil se slik ut:
- M × V = M11 × V11 + M12 × V21;
- M21 × V11 + M22 × V21.
M11 betyr elementet i matrisen M plassert i den første raden og den første kolonnen, og M22 betyr elementet i den andre raden og den andre kolonnen. For matrisen vår er disse elementene lik M11 = 0, M12 = 4, M21 = 6, M22 10. For en kolonnevektor er disse verdiene lik V11 = –2, V21 = 1. I følge denne formelen, vi får følgende resultat av produktet av en kvadratisk matrise med en vektor:
- M × V = 0 × (-2) + (4) × (1) = 4;
- 6 × (-2) + 10 × (1) = -2.
For enkelhets skyld, la oss skrive kolonnevektoren i en rad. Så vi multipliserte kvadratmatrisen med vektoren (-2; 1), noe som resulterte i vektoren (4; -2). Det er klart at dette er den samme vektoren multiplisert med λ = -2. Lambda inn i dette tilfellet angir egenverdien til matrisen.
En egenvektor til en matrise er en kollineær vektor, det vil si et objekt som ikke endrer sin posisjon i rommet når det multipliseres med en matrise. Begrepet kollinearitet i vektor algebra ligner på begrepet parallellisme i geometri. I geometrisk tolkning kollineære vektorer– Dette er parallellrettede segmenter av ulik lengde. Siden Euklids tid vet vi at en linje har et uendelig antall parallelle linjer, så det er logisk å anta at hver matrise har et uendelig antall egenvektorer.
Fra forrige eksempel er det klart at egenvektorer kan være (-8; 4), og (16; -8), og (32, -16). Disse er alle kollineære vektorer som tilsvarer egenverdien λ = -2. Når vi multipliserer den opprinnelige matrisen med disse vektorene, vil vi likevel ende opp med en vektor som er 2 ganger forskjellig fra originalen. Det er derfor, når du løser problemer med å finne en egenvektor, er det nødvendig å finne bare lineært uavhengige vektorobjekter. Oftest, for en n × n matrise, er det et n antall egenvektorer. Kalkulatoren vår er designet for analyse av andreordens kvadratmatriser, så nesten alltid vil resultatet finne to egenvektorer, bortsett fra tilfeller der de faller sammen.
I eksemplet ovenfor kjente vi egenvektoren til den opprinnelige matrisen på forhånd og bestemte tydelig lambdatallet. Men i praksis skjer alt omvendt: egenverdiene finnes først og først deretter egenvektorene.
LøsningsalgoritmeLa oss se på den opprinnelige matrisen M igjen og prøve å finne begge dens egenvektorer. Så matrisen ser slik ut:
- M = 0; 4;
- 6; 10.
Først må vi bestemme egenverdien λ, som krever beregning av determinanten til følgende matrise:
- (0 - λ); 4;
- 6; (10 − λ).
Denne matrisen oppnås ved å trekke den ukjente λ fra elementene på hoveddiagonalen. Determinanten bestemmes ved å bruke standardformelen:
- detA = M11 × M21 − M12 × M22
- detA = (0 − λ) × (10 − λ) − 24
Siden vektoren vår må være ikke-null, aksepterer vi den resulterende ligningen som lineært avhengig og likestiller vår determinant detA til null.
(0 − λ) × (10 − λ) − 24 = 0
La oss åpne parentesene og få karakteristisk ligning matriser:
λ 2 − 10λ − 24 = 0
Dette er standard kvadratisk ligning, som må løses gjennom diskriminanten.
D = b 2 − 4ac = (-10) × 2 − 4 × (-1) × 24 = 100 + 96 = 196
Roten til diskriminanten er sqrt(D) = 14, derfor λ1 = -2, λ2 = 12. Nå for hver lambda-verdi må vi finne egenvektoren. La oss uttrykke systemkoeffisientene for λ = -2.
- M - λ × E = 2; 4;
- 6; 12.
I denne formelen er E identitetsmatrise. Basert på den resulterende matrisen lager vi et system lineære ligninger:
2x + 4y = 6x + 12y,
hvor x og y er egenvektorelementene.
La oss samle alle X-ene til venstre og alle Y-ene til høyre. Åpenbart - 4x = 8y. Del uttrykket med - 4 og få x = –2y. Nå kan vi bestemme den første egenvektoren til matrisen ved å ta alle verdier av de ukjente (husk uendeligheten av lineært avhengige egenvektorer). La oss ta y = 1, så x = –2. Derfor ser den første egenvektoren ut som V1 = (–2; 1). Gå tilbake til begynnelsen av artikkelen. Det var dette vektorobjektet vi multipliserte matrisen med for å demonstrere konseptet med en egenvektor.
La oss nå finne egenvektoren for λ = 12.
- M - X x E = -12; 4
- 6; -2.
La oss lage det samme systemet med lineære ligninger;
- -12x + 4y = 6x - 2y
- -18x = -6y
- 3x = y.
Nå tar vi x = 1, derfor y = 3. Dermed ser den andre egenvektoren ut som V2 = (1; 3). Når du multipliserer den opprinnelige matrisen med gitt vektor, vil resultatet alltid være den samme vektoren multiplisert med 12. Dette avslutter løsningsalgoritmen. Nå vet du hvordan du manuelt bestemmer egenvektoren til en matrise.
- avgjørende faktor;
- spor, det vil si summen av elementene på hoveddiagonalen;
- rang, altså maksimalt beløp lineært uavhengige rader/kolonner.
Programmet fungerer i henhold til algoritmen ovenfor, og forkorter løsningsprosessen så mye som mulig. Det er viktig å påpeke at i programmet er lambda betegnet med bokstaven "c". La oss se på et numerisk eksempel.
Eksempel på hvordan programmet fungererLa oss prøve å bestemme egenvektorene for følgende matrise:
- M = 5; 1. 3;
- 4; 14.
La oss legge inn disse verdiene i cellene på kalkulatoren og få svaret i følgende skjema:
- Matriserangering: 2;
- Matrisedeterminant: 18;
- Matrisespor: 19;
- Beregning av egenvektoren: c 2 − 19.00c + 18.00 (karakteristisk ligning);
- Egenvektorberegning: 18 (første lambdaverdi);
- Egenvektorberegning: 1 (andre lambdaverdi);
- Ligningssystem for vektor 1: -13x1 + 13y1 = 4x1 − 4y1;
- Ligningssystem for vektor 2: 4x1 + 13y1 = 4x1 + 13y1;
- Egenvektor 1: (1; 1);
- Egenvektor 2: (-3,25; 1).
Dermed fikk vi to lineært uavhengige egenvektorer.
KonklusjonLineær algebra og analytisk geometri er standardfag for enhver nybegynner teknisk spesialitet. Et stort nummer av vektorer og matriser er skremmende, og i slike tungvinte beregninger er det lett å gjøre feil. Programmet vårt lar studentene sjekke beregningene sine eller automatisk løse problemet med å finne en egenvektor. Det er andre lineære algebrakalkulatorer i vår katalog; bruk dem i studiene eller arbeidet.
Slik setter du inn matematiske formler til nettsiden?
Hvis du noen gang trenger å legge til en eller to matematiske formler på en nettside, er den enkleste måten å gjøre dette på som beskrevet i artikkelen: matematiske formler settes enkelt inn på nettstedet i form av bilder som genereres automatisk av Wolfram Alpha . Foruten enkelhet, dette universell metode vil bidra til å forbedre nettstedets synlighet søkemotorer. Det har fungert lenge (og tror jeg vil fungere for alltid), men er allerede moralsk utdatert.
Hvis du stadig bruker matematiske formler på nettstedet ditt, anbefaler jeg at du bruker MathJax - et spesielt JavaScript-bibliotek som viser matematisk notasjon i nettlesere som bruker MathML, LaTeX eller ASCIIMathML-markering.
Det er to måter å begynne å bruke MathJax på: (1) ved å bruke en enkel kode kan du raskt koble et MathJax-skript til nettstedet ditt, som vil rett øyeblikk automatisk last fra en ekstern server (liste over servere); (2) last ned MathJax-skriptet fra en ekstern server til serveren din og koble det til alle sidene på nettstedet ditt. Den andre metoden – mer kompleks og tidkrevende – vil øke hastigheten på innlastingen av sidene til nettstedet ditt, og hvis den overordnede MathJax-serveren blir midlertidig utilgjengelig av en eller annen grunn, vil dette ikke påvirke ditt eget nettsted på noen måte. Til tross for disse fordelene, valgte jeg den første metoden da den er enklere, raskere og ikke krever tekniske ferdigheter. Følg mitt eksempel, og på bare 5 minutter vil du kunne bruke alle funksjonene til MathJax på nettstedet ditt.
Du kan koble til MathJax-biblioteksskriptet fra en ekstern server ved å bruke to kodealternativer hentet fra MathJax hovednettsted eller på dokumentasjonssiden:
Et av disse kodealternativene må kopieres og limes inn i koden til nettsiden din, helst mellom tagger og eller rett etter taggen. I henhold til det første alternativet laster MathJax raskere og bremser siden mindre. Men det andre alternativet overvåker og laster automatisk de nyeste versjonene av MathJax. Hvis du setter inn den første koden, må den oppdateres med jevne mellomrom. Hvis du setter inn den andre koden, vil sidene lastes saktere, men du trenger ikke å overvåke MathJax-oppdateringer konstant.
Den enkleste måten å koble MathJax på er i Blogger eller WordPress: i nettstedets kontrollpanel legger du til en widget som er utformet for å sette inn tredjeparts JavaScript-kode, kopierer den første eller andre versjonen av nedlastingskoden presentert ovenfor, og plasser widgeten nærmere. til begynnelsen av malen (forresten, dette er ikke i det hele tatt nødvendig, siden MathJax-skriptet lastes asynkront). Det er alt. Lær nå markup-syntaksen til MathML, LaTeX og ASCIIMathML, og du er klar til å sette inn matematiske formler på nettstedets nettsider.
Enhver fraktal er konstruert i henhold til en bestemt regel, som konsekvent brukes et ubegrenset antall ganger. Hver slik tid kalles en iterasjon.
Den iterative algoritmen for å konstruere en Menger-svamp er ganske enkel: den originale kuben med side 1 er delt av plan parallelt med flatene i 27 like terninger. En sentral kube og 6 terninger ved siden av den langs ansiktene fjernes fra den. Resultatet er et sett bestående av de resterende 20 mindre terningene. Gjør vi det samme med hver av disse kubene, får vi et sett bestående av 400 mindre terninger. Hvis vi fortsetter denne prosessen i det uendelige, får vi en Menger-svamp.
www.site lar deg finne. Nettstedet utfører beregningen. Om noen sekunder vil serveren utstedes riktig løsning. Den karakteristiske ligningen for matrisen vil være algebraisk uttrykk, funnet av regelen for å beregne determinanten for matrisens matris, mens det langs hoveddiagonalen vil være forskjeller i verdiene til diagonalelementene og variabelen. Når du beregner den karakteristiske ligningen for en matrise online, vil hvert element i matrisen multipliseres med de tilsvarende andre elementene i matrisen. Du kan bare finne den på nettet for en firkantet matrise. Operasjonen med å finne den karakteristiske ligningen for en nettmatrise er redusert til beregning algebraisk sum produktet av matriseelementene som et resultat av å finne determinanten til matrisen, kun med det formål å bestemme den karakteristiske ligningen for matrisen online. Denne operasjonen tar Spesielt sted i matriseteori, lar en finne egenverdier og vektorer ved å bruke røtter. Oppgaven med å finne den karakteristiske ligningen for en matrise på nettet består i å multiplisere elementene i matrisen og deretter summere disse produktene etter en bestemt regel. www.site finner den karakteristiske ligningen for en matrise med en gitt dimensjon på nettet. Å beregne den karakteristiske ligningen for en matrise online for en gitt dimensjon er å finne et polynom med numeriske eller symbolske koeffisienter, funnet i henhold til regelen for beregning av determinanten til en matrise - som summen av produktene av de tilsvarende elementene i matrisen, bare for formålet med å bestemme den karakteristiske ligningen for matrisen online. Å finne et polynom med hensyn til en variabel for en kvadratisk matrise, som en definisjon av den karakteristiske ligningen for matrisen, er vanlig i matriseteori. Verdien av røttene til polynomet til den karakteristiske ligningen for nettmatrisen brukes til å bestemme egenvektorene og egenverdier for matrise. Videre, hvis determinanten til matrisen er lik null, vil den karakteristiske ligningen til matrisen fortsatt eksistere, i motsetning til den inverse matrisen. For å beregne den karakteristiske ligningen for en matrise eller finne karakteristiske ligninger for flere matriser samtidig, må du bruke mye tid og krefter, mens serveren vår vil finne den karakteristiske ligningen for en matrise online i løpet av sekunder. I dette tilfellet vil svaret på å finne den karakteristiske ligningen for en nettmatrise være riktig og med tilstrekkelig nøyaktighet, selv om tallene ved å finne den karakteristiske ligningen for en nettmatrise vil være irrasjonelle. På nettstedet www.site er symbolske oppføringer i matriseelementer tillatt, det vil si at den karakteristiske ligningen for en nettmatrise kan representeres i generell symbolsk form når man beregner den karakteristiske ligningen til en nettmatrise. Det er nyttig å sjekke svaret som er oppnådd når du løser problemet med å finne den karakteristiske ligningen for en matrise online ved å bruke nettstedet www.site. Når du utfører operasjonen med å beregne et polynom - den karakteristiske ligningen til en matrise, må du være forsiktig og ekstremt fokusert når du løser dette problemet. På sin side vil nettstedet vårt hjelpe deg å sjekke løsningen din på temaet karakteristisk ligning av en matrise på nettet. Hvis du ikke har tid til lange kontroller av løste problemer, vil www.nettstedet sikkert være et praktisk verktøy for å sjekke når du finner og beregner den karakteristiske ligningen for en matrise på nettet.
". Den første delen angir de bestemmelsene som er minimalt nødvendige for å forstå kjemometri, og den andre delen inneholder fakta som du trenger å vite for en dypere forståelse av metodene multivariat analyse. Presentasjonen er illustrert med eksempler laget i en Excel-arbeidsbok Matrix.xls, som følger med dette dokumentet.
Lenker til eksempler er plassert i teksten som Excel-objekter. Disse eksemplene er abstrakte, de er på ingen måte knyttet til oppgaver analytisk kjemi. Ekte eksempler Bruken av matrisealgebra i kjemometri er diskutert i andre tekster som dekker en rekke kjemometriske anvendelser.
De fleste målinger gjort i analytisk kjemi er ikke direkte, men indirekte. Dette betyr at i forsøket, i stedet for verdien til ønsket analytt C (konsentrasjon), oppnås en annen verdi x(signal), relatert, men ikke lik C, dvs. x(C) ≠ C. Som regel, typen avhengighet x(C) er ukjent, men heldigvis i analytisk kjemi er de fleste målinger proporsjonale. Dette betyr at med økende konsentrasjon av C in en ganger vil signal X øke like mye, dvs. x(en C) = en x(C). I tillegg er signalene også additive, så signalet fra en prøve der to stoffer med konsentrasjonene C 1 og C 2 er tilstede vil være lik summen signaler fra hver komponent, dvs. x(C1 + C2) = x(C1)+ x(C2). Proporsjonalitet og additivitet gir til sammen linearitet. Mange eksempler kan gis for å illustrere linearitetsprinsippet, men det er nok å nevne de to mest lysende eksempler- kromatografi og spektroskopi. Den andre funksjonen som ligger i et eksperiment i analytisk kjemi er multikanal. Moderne analyseutstyr måler signaler for mange kanaler samtidig. For eksempel måles intensiteten av lystransmisjon for flere bølgelengder på en gang, dvs. område. Derfor forholder vi oss i eksperimentet til mange signaler x 1 , x 2 ,...., x n, som karakteriserer settet med konsentrasjoner C 1 , C 2 , ..., C m av stoffer som er tilstede i systemet som studeres.
Ris. 1 spektra
Så et analytisk eksperiment er preget av linearitet og flerdimensjonalitet. Derfor er det praktisk å betrakte eksperimentelle data som vektorer og matriser og manipulere dem ved å bruke apparatet til matrisealgebra. Fruktbarheten av denne tilnærmingen er illustrert av eksemplet vist i, som presenterer tre spektre tatt ved 200 bølgelengder fra 4000 til 4796 cm -1. Det første (x 1) og andre (x 2) spektra ble oppnådd for standardprøver der konsentrasjonene av to stoffer A og B er kjent: i den første prøven [A] = 0,5, [B] = 0,1, og i andre prøve [A] = 0,2, [B] = 0,6. Hva kan sies om en ny, ukjent prøve, hvis spektrum er betegnet x 3?
La oss vurdere tre eksperimentelle spektra x 1, x 2 og x 3 som tre vektorer med dimensjon 200. Ved å bruke lineær algebra kan vi enkelt vise at x 3 = 0,1 x 1 +0,3 x 2, derfor, i den tredje prøven, er det bare stoffene A og B er åpenbart tilstede i konsentrasjoner [A] = 0,5×0,1 + 0,2×0,3 = 0,11 og [B] = 0,1×0,1 + 0,6×0,3 = 0,19.
1. Grunnleggende informasjon 1.1 MatriserMatrise kalt en rektangulær talltabell, for eksempel

Ris. 2 Matrise
Matriser er merket med store, fete bokstaver (A) og deres elementer med tilsvarende små bokstaver med indekser, dvs. en ij. Den første indeksen nummererer radene, og den andre - kolonnene. I kjemometri er det vanlig å betegne maksimal verdi indeks med samme bokstav som selve indeksen, men med stor bokstav. Derfor kan matrise A også skrives som ( en ij , Jeg = 1,..., Jeg; j = 1,..., J). For eksempelmatrisen Jeg = 4, J= 3 og en 23 = −7.5.
Par med tall Jeg Og J kalles matrisens dimensjon og betegnes som Jeg× J. Et eksempel på en matrise i kjemometri er et sett med spektre oppnådd for Jeg prøver for J bølgelengder.
1.2. De enkleste operasjonene med matriserMatriser kan være multiplisere med tall. I dette tilfellet multipliseres hvert element med dette tallet. For eksempel -

Ris. 3 Multiplisere en matrise med et tall
To matriser med samme dimensjon kan være element for element brette Og trekke fra. For eksempel,

Ris. 4 Matrisetillegg
Som et resultat av multiplikasjon med et tall og addisjon, oppnås en matrise med samme dimensjon.
En nullmatrise er en matrise som består av nuller. Det er betegnet O. Åpenbart er A +O = A, A −A = O og 0A = O.
Matrisen kan være transponere. Under denne operasjonen blir matrisen snudd, dvs. rader og kolonner byttes. Transponering er indikert med et primtall, A" eller senket A t. Derfor, hvis A = ( en ij , Jeg = 1,..., Jeg; j = 1,...,J), deretter A t = ( en ji , j = 1,...,J; i = 1,..., Jeg). For eksempel

Ris. 5 Matrisetransponering
Det er åpenbart at (A t) t = A, (A + B) t = A t + B t.
1.3. MatrisemultiplikasjonMatriser kan være multiplisere, men bare hvis de har de riktige dimensjonene. Hvorfor det er slik vil fremgå av definisjonen. Produkt av matrise A, dimensjon Jeg× K, og matrise B, dimensjon K× J, kalt matrise C, dimensjon Jeg× J, hvis elementer er tall
For produktet AB er det derfor nødvendig at antall kolonner i venstre matrise A er lik antall rader i høyre matrise B. Et eksempel på et matriseprodukt -

Fig.6 Produkt av matriser
Regelen for matrisemultiplikasjon kan formuleres som følger. For å finne et element av matrisen C i skjæringspunktet Jeg-te linje og j kolonne ( c ij) må multipliseres element for element Jeg-th rad av den første matrisen A på j kolonne i den andre matrisen B og legg til alle resultatene. Så i eksemplet som vises, oppnås et element fra den tredje raden og den andre kolonnen som summen av de elementmessige produktene av den tredje raden A og den andre kolonnen B

Fig.7 Element av produktet av matriser
Produktet av matriser avhenger av rekkefølgen, dvs. AB ≠ BA, i det minste av dimensjonale årsaker. De sier at det er ikke-kommutativt. Produktet av matriser er imidlertid assosiativt. Dette betyr at ABC = (AB)C = A(BC). I tillegg er den også distributiv, d.v.s. A (B +C) = AB +AC. Tydeligvis AO = O.
1.4. Firkantede matriserHvis antallet matrisekolonner er lik antall rader ( Jeg = J=N), så kalles en slik matrise kvadrat. I denne delen vil vi kun vurdere slike matriser. Blant disse matrisene kan det skilles ut matriser med spesielle egenskaper.
Enkelt matrise (betegnet I, og noen ganger E) er en matrise der alle elementer er lik null, med unntak av diagonale, som er lik 1, dvs.
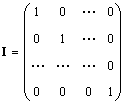
Åpenbart AI = IA = A.
Matrisen kalles diagonal, hvis alle dens elementer unntatt diagonale ( en ii) er lik null. For eksempel

Ris. 8 Diagonal matrise
Matrise A kalles øvre trekantet, hvis alle dens elementer som ligger under diagonalen er lik null, dvs. en ij= 0, kl Jeg>j. For eksempel

Ris. 9 Øvre trekantet matrise
Den nedre trekantede matrisen er definert på samme måte.
Matrise A kalles symmetrisk, hvis A t = A . Med andre ord en ij = en ji. For eksempel

Ris. 10 Symmetrisk matrise
Matrise A kalles ortogonal, Hvis
A t A = AA t = I .
Matrisen kalles normal Hvis
1.5. Spor og determinantNeste kvadratisk matrise A (betegnet med Tr(A) eller Sp(A)) er summen av dens diagonale elementer,
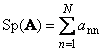
For eksempel,

Ris. 11 Matrisesporing
Det er åpenbart det
Sp(α A ) = α Sp(A ) og
Sp(A +B) = Sp(A)+ Sp(B).
Det kan vises
Sp(A) = Sp(At), Sp(I) = N,
og også det
Sp(AB) = Sp(BA).
En annen viktig egenskap kvadratisk matrise er dens avgjørende faktor(betegnet det(A )). Definisjon av determinant i generell sak ganske komplisert, så vi starter med det enkleste alternativet - en matrise A med dimensjon (2x2). Deretter
For en (3×3) matrise vil determinanten være lik
Når det gjelder matrisen ( N× N) determinanten beregnes som summen 1·2·3· ... · N= N! vilkår, som hver er like
![]()
Indekser k 1 , k 2 ,..., k N er definert som alle mulige ordnede permutasjoner r tall i settet (1, 2, ..., N). Å beregne determinanten til en matrise er en kompleks prosedyre, som i praksis utføres ved hjelp av spesielle programmer. For eksempel,

Ris. 12 Matrisedeterminant
La oss bare merke oss de åpenbare egenskapene:
det(I) = 1, det(A) = det(A t),
det(AB) = det(A)det(B).
1.6. VektorerHvis matrisen består av bare én kolonne ( J= 1), så kalles et slikt objekt vektor. Mer presist, en kolonnevektor. For eksempel
Man kan også vurdere matriser som består av én rad, for eksempel
![]()
Dette objektet er også en vektor, men rad vektor. Når man analyserer data er det viktig å forstå hvilke vektorer vi har å gjøre med – kolonner eller rader. Så spekteret tatt for en prøve kan betraktes som en radvektor. Deretter bør settet med spektralintensiteter ved en viss bølgelengde for alle prøver behandles som en kolonnevektor.
Dimensjonen til en vektor er antall elementer.
Det er klart at enhver kolonnevektor kan gjøres om til en radvektor ved transposisjon, dvs.

I tilfeller der formen på vektoren ikke er spesifikt spesifisert, men bare sies å være en vektor, så betyr de en kolonnevektor. Vi vil også følge denne regelen. En vektor er merket med en liten, oppreist, fet bokstav. En nullvektor er en vektor der alle elementene er null. Den er betegnet 0.
1.7. De enkleste operasjonene med vektorerVektorer kan legges til og multipliseres med tall på samme måte som matriser. For eksempel,

Ris. 13 Operasjoner med vektorer
To vektorer x og y kalles kolineær, hvis det er et tall α slik at
1.8. Produkter av vektorerTo vektorer av samme dimensjon N kan multipliseres. La det være to vektorer x = ( x 1 , x 2 ,...,x N) t og y = ( y 1 , y 2 ,...,y N) t. Guidet av rad-for-kolonne multiplikasjonsregelen kan vi komponere to produkter fra dem: x t y og xy t. Første arbeid
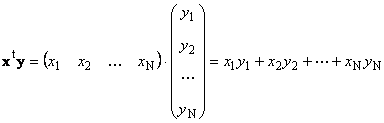
kalt skalar eller innvendig. Resultatet er et tall. Notasjonen (x ,y )= x t y brukes også for det. For eksempel,
Ris. 14 Indre (skalær) produkt
Andre stykke

kalt utvendig. Resultatet er en dimensjonsmatrise ( N× N). For eksempel,

Ris. 15 Utvendig arbeid
Vektorer, skalært produkt som er lik null kalles ortogonal.
1.9. VektornormSkalarproduktet av en vektor med seg selv kalles en skalar firkant. Denne verdien

definerer en firkant lengde vektor x. For å angi lengde (også kalt normen vektor) brukes notasjonen
For eksempel,
Ris. 16 Vektornorm
En vektor med lengdeenhet (||x || = 1) kalles normalisert. En vektor som ikke er null (x ≠ 0) kan normaliseres ved å dele den på lengden, dvs. x = ||x || (x/ ||x ||) = ||x || e. Her er e = x/ ||x || - normalisert vektor.
Vektorer kalles ortonormale hvis de alle er normaliserte og parvis ortogonale.
1.10. Vinkel mellom vektorerDet skalære produktet bestemmer og hjørneφ mellom to vektorer x og y
![]()
Hvis vektorene er ortogonale, så er cosφ = 0 og φ = π/2, og hvis de er kolineære, så er cosφ = 1 og φ = 0.
1.11. Vektorrepresentasjon av en matriseHver matrise A av størrelse Jeg× J kan representeres som et sett med vektorer
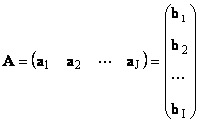
Her hver vektor a j er j kolonne, og radvektoren b Jeg er Jeg rad av matrise A
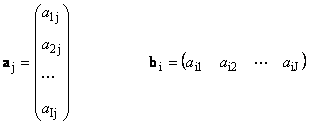
Vektorer av samme dimensjon ( N) kan legges til og multipliseres med et tall, akkurat som matriser. Resultatet vil være en vektor med samme dimensjon. La det være flere vektorer med samme dimensjon x 1, x 2,...,x K og samme antall tall α α 1, α 2,...,α K. Vektor
y = α 1 x 1 + α 2 x 2 +...+ α K x K
kalt lineær kombinasjon vektorer x k .
Hvis det er slike tall som ikke er null α k ≠ 0, k = 1,..., K at y = 0, så et slikt sett med vektorer x k kalt lineært avhengig. Ellers sies vektorene å være lineært uavhengige. For eksempel er vektorene x 1 = (2, 2) t og x 2 = (−1, −1) t lineært avhengige, fordi x 1 +2x 2 = 0
1.13. Matrix rangeringVurder et sett med K vektorer x 1, x 2,...,x K dimensjoner N. Rangeringen til dette systemet av vektorer er det maksimale antallet lineært uavhengige vektorer. For eksempel i settet
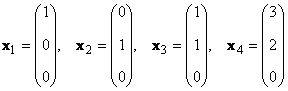
det er bare to lineært uavhengige vektorer, for eksempel x 1 og x 2, så rangeringen er 2.
Selvfølgelig, hvis det er flere vektorer i et sett enn deres dimensjon ( K>N), så er de nødvendigvis lineært avhengige.
Matrix rangering(angitt med rang(A)) er rangeringen til systemet av vektorer som det består av. Selv om enhver matrise kan representeres på to måter (kolonne- eller radvektorer), påvirker ikke dette rangeringsverdien, fordi
1.14. invers matriseEn kvadratisk matrise A kalles ikke-singular hvis den har en unik omvendt matrise A -1 bestemt av betingelsene
AA −1 = A −1 A = I .
Den inverse matrisen eksisterer ikke for alle matriser. En nødvendig og tilstrekkelig betingelse for ikke-degenerasjon er
det(A) ≠ 0 eller rang(A) = N.
Matriseinversjon er en kompleks prosedyre som det finnes spesielle programmer for. For eksempel,

Ris. 17 Matriseinversjon
La oss presentere formlene for det enkleste tilfellet - en 2×2 matrise

Hvis matrisene A og B er ikke-singular, da
(AB) −1 = B −1 A −1.
1.15. Pseudoinvers matriseHvis matrisen A er entall og den inverse matrisen ikke eksisterer, kan du i noen tilfeller bruke pseudoomvendt matrise, som er definert som en matrise A+ slik at
AA + A = A.
Den pseudoinverse matrisen er ikke den eneste, og dens form avhenger av konstruksjonsmetoden. For eksempel for rektangulær matrise Moore-Penrose-metoden kan brukes.
Hvis antall kolonner mindre antall linjer da
A + =(A t A ) −1 A t
For eksempel,

Ris. 17a Pseudo-inversjon av en matrise
Hvis antall kolonner flere tall linjer da
A + =A t (AA t) −1
1.16. Multiplisere en vektor med en matriseVektoren x kan multipliseres med en matrise A med passende dimensjon. I dette tilfellet multipliseres kolonnevektoren på høyre Ax, og radvektoren multipliseres på venstre x t A. Hvis vektordimensjonen J, og matrisedimensjonen Jeg× J da vil resultatet være en vektor av dimensjon Jeg. For eksempel,

Ris. 18 Multiplisere en vektor med en matrise
Hvis matrisen A er kvadratisk ( Jeg× Jeg), så har vektoren y = Ax samme dimensjon som x. Det er åpenbart det
A (α 1 x 1 + α 2 x 2) = α 1 Ax 1 + α 2 Ax 2.
Derfor kan matriser betraktes som lineære transformasjoner av vektorer. Spesielt Ix = x, Ox = 0.
2. Ytterligere informasjon 2.1. Systemer av lineære ligningerLa A være en matrise av størrelse Jeg× J, og b er dimensjonsvektoren J. Tenk på ligningen
Ax = b
i forhold til vektoren x, dimensjon Jeg. I hovedsak er det et system av Jeg lineære ligninger med J ukjent x 1 ,...,x J. En løsning finnes hvis og bare hvis
rang(A) = rang(B) = R,
hvor B er den utvidede dimensjonsmatrisen Jeg×( J+1), bestående av en matrise A supplert med en kolonne b, B = (A b). Ellers er ligningene inkonsekvente.
Hvis R = Jeg = J, da er løsningen unik
x = A −1 b .
Hvis R < Jeg, så er det mange ulike løsninger, som kan uttrykkes gjennom en lineær kombinasjon J−R vektorer. System homogene ligninger Ax = 0 med kvadratisk matrise A ( N× N) har ingen triviell løsning(x ≠ 0) hvis og bare hvis det(A) = 0. If R= rang(A) 0.
Tilsvarende definert negativ(x t Ax< 0), ikke-negativ(x t Axe ≥ 0) og negativ(x t Ax ≤ 0) visse matriser.
2.4. Kolesky nedbrytningHvis en symmetrisk matrise A er positiv bestemt, er det en unik trekantet matrise U med positive elementer som
A = U t U .
For eksempel,

Ris. 19 Kolesky nedbrytning
2.5. Polar nedbrytningLa A være en ikke-degenerert kvadratisk matrise dimensjoner N× N. Så er det en unik polar opptreden
A = SR,
hvor S er en ikke-negativ symmetrisk matrise og R er en ortogonal matrise. Matrisene S og R kan defineres eksplisitt:
S 2 = AA t eller S = (AA t) ½ og R = S −1 A = (AA t) −½ A .
For eksempel,
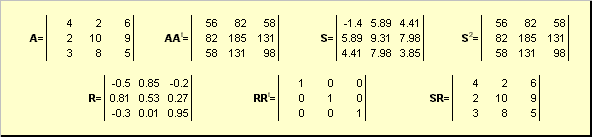
Ris. 20 Polar nedbrytning
Hvis matrisen A er entall, så er ikke dekomponeringen unik - nemlig: S er fortsatt én, men det kan være mange R. Den polare dekomponeringen representerer matrisen A som en kombinasjon av kompresjon/forlengelse S og rotasjon R .
2.6. Egenvektorer og egenverdierLa A være en kvadratisk matrise. Vektoren v kalles egenvektor matrise A if
Av = λv,
hvor tallet λ kalles egenverdi matriser A. Dermed reduseres transformasjonen som matrisen A utfører på vektoren v til en enkel strekking eller kompresjon med en koeffisient λ. Egenvektoren bestemmes opp til multiplikasjon med en konstant α ≠ 0, dvs. hvis v er en egenvektor, så er αv også en egenvektor.
2.7. EgenverdierMatrisen A har dimensjon ( N× N) kan ikke være mer enn N egenverdier. De tilfredsstiller karakteristisk ligning
det(A − λI ) = 0,
å være algebraisk ligning N-te orden. Spesielt for en 2×2 matrise har den karakteristiske ligningen formen
For eksempel,

Ris. 21 Egenverdier
Sett med egenverdier λ 1 ,..., λ N matrise A kalles spektrum EN.
Spekteret har ulike egenskaper. Spesielt
det(A) = λ 1 ×...×λ N, Sp(A) = λ1 +...+λ N.
Egenverdiene til en vilkårlig matrise kan være komplekse tall, men hvis matrisen er symmetrisk (A t = A), så er egenverdiene reelle.
2.8. EgenvektorerMatrisen A har dimensjon ( N× N) kan ikke være mer enn N egenvektorer, som hver tilsvarer sin egenverdi. For å bestemme egenvektoren v n trenger å løse et system med homogene ligninger
(A − λ n I) v n = 0 .
Den har en ikke-triviell løsning, siden det(A − λ n I) = 0.
For eksempel,

Ris. 22 egenvektorer
Egenvektorene til en symmetrisk matrise er ortogonale.
Egenverdier (tall) og egenvektorer.Eksempler på løsninger
Vær deg selv
Fra begge ligningene følger det at .
La oss si det da: ![]() .
.
Som et resultat: ![]() – andre egenvektor.
– andre egenvektor.
La oss gjenta viktige poeng løsninger:
– det resulterende systemet har absolutt felles vedtak(ligningene er lineært avhengige);
– vi velger "y" på en slik måte at den er heltall og den første "x"-koordinaten er heltall, positiv og så liten som mulig.
– vi sjekker at den aktuelle løsningen tilfredsstiller hver likning i systemet.
Svar ![]() .
.
Det var nok mellomliggende "sjekkpunkter", så det er i prinsippet unødvendig å sjekke likestilling.
I ulike informasjonskilder er koordinatene til egenvektorer ofte ikke skrevet i kolonner, men i rader, for eksempel: ![]() (og for å være ærlig er jeg selv vant til å skrive dem ned i linjer). Dette alternativet er akseptabelt, men i lys av temaet lineære transformasjoner er det teknisk mer praktisk å bruke kolonnevektorer.
(og for å være ærlig er jeg selv vant til å skrive dem ned i linjer). Dette alternativet er akseptabelt, men i lys av temaet lineære transformasjoner er det teknisk mer praktisk å bruke kolonnevektorer.
Kanskje virket løsningen veldig lang for deg, men dette er bare fordi jeg kommenterte det første eksemplet i detalj.
Eksempel 2
Matriser
La oss trene på egenhånd! Et omtrentlig eksempel på en siste oppgave på slutten av leksjonen.
Noen ganger må du gjøre tilleggsoppgave, nemlig:
skriv den kanoniske matrisenedbrytningenHva det er?
Hvis egenvektorene til matrisen dannes basis, så kan det representeres som:
Hvor er en matrise satt sammen av koordinater til egenvektorer, - diagonal matrise med tilsvarende egenverdier.
Denne matrisedekomponeringen kalles kanonisk eller diagonal.
La oss se på matrisen til det første eksemplet. Dens egenvektorer ![]() lineært uavhengig(ikke-kollineær) og danner et grunnlag. La oss lage en matrise av koordinatene deres:
lineært uavhengig(ikke-kollineær) og danner et grunnlag. La oss lage en matrise av koordinatene deres:
![]()
På hoveddiagonal matriser i riktig rekkefølge egenverdiene er lokalisert, og de resterende elementene er lik null:
– Jeg understreker nok en gang viktigheten av rekkefølge: «to» tilsvarer 1. vektor og er derfor plassert i 1. kolonne, «tre» – til 2. vektor.
Ved å bruke den vanlige algoritmen for å finne den inverse matrisen eller Gauss-Jordan-metoden finner vi ![]() . Nei, det er ikke en skrivefeil! - før du er sjelden, som solformørkelse en hendelse når inversen faller sammen med den opprinnelige matrisen.
. Nei, det er ikke en skrivefeil! - før du er sjelden, som solformørkelse en hendelse når inversen faller sammen med den opprinnelige matrisen.
Det gjenstår å skrive ned den kanoniske dekomponeringen av matrisen: ![]()

Systemet kan løses vha elementære transformasjoner og i de følgende eksemplene vil vi ty til denne metoden. Men her fungerer «skole»-metoden mye raskere. Fra den tredje likningen uttrykker vi: – erstatter i den andre likningen: 
Siden den første koordinaten er null, får vi et system, fra hver ligning som det følger at .
Igjen, vær oppmerksom på den obligatoriske tilstedeværelsen av et lineært forhold. Hvis bare en triviell løsning oppnås ![]() , så ble enten egenverdien funnet feil, eller systemet ble kompilert/løst med en feil.
, så ble enten egenverdien funnet feil, eller systemet ble kompilert/løst med en feil.
Kompakte koordinater gir verdien
Egenvektor: 
Og nok en gang sjekker vi at løsningen fant ![]() tilfredsstiller hver likning i systemet. I påfølgende avsnitt og i påfølgende oppgaver anbefaler jeg å ta dette ønsket som en obligatorisk regel.
tilfredsstiller hver likning i systemet. I påfølgende avsnitt og i påfølgende oppgaver anbefaler jeg å ta dette ønsket som en obligatorisk regel.
2) For egenverdien, ved å bruke samme prinsipp, får vi følgende system: 
Fra den andre ligningen i systemet uttrykker vi: – erstatte inn i den tredje ligningen: 
Siden "zeta"-koordinaten er lik null, får vi et system fra hver ligning som den følger lineær avhengighet.
La ![]()
Sjekker at løsningen ![]() tilfredsstiller hver likning i systemet.
tilfredsstiller hver likning i systemet.
Dermed er egenvektoren: .
3) Og til slutt tilsvarer systemet egenverdien: 
Den andre ligningen ser den enkleste ut, så la oss uttrykke den og erstatte den med 1. og 3. likning:
![]()
Alt er bra - det har oppstått et lineært forhold, som vi erstatter med uttrykket:
Som et resultat ble "x" og "y" uttrykt gjennom "z": . I praksis er det ikke nødvendig å oppnå nettopp slike relasjoner; i noen tilfeller er det mer praktisk å uttrykke både gjennom eller og gjennom . Eller til og med "tog" - for eksempel "X" til "I", og "I" til "Z"
La oss si det da:
Vi sjekker at løsningen er funnet ![]() tilfredsstiller hver likning i systemet og skriver den tredje egenvektoren
tilfredsstiller hver likning i systemet og skriver den tredje egenvektoren
Svar: egenvektorer: 
Geometrisk definerer disse vektorene tre forskjellige romlige retninger ("Der og tilbake igjen"), langs hvilken en lineær transformasjon transformerer ikke-null vektorer (egenvektorer) til kollineære vektorer.
Hvis tilstanden krevde å finne den kanoniske dekomponeringen, er dette mulig her, fordi forskjellige egenverdier tilsvarer forskjellige lineært uavhengige egenvektorer. Å lage en matrise  fra deres koordinater, en diagonal matrise
fra deres koordinater, en diagonal matrise  fra aktuell egenverdier og finn den inverse matrisen.
fra aktuell egenverdier og finn den inverse matrisen.
Hvis du etter betingelse trenger å skrive matrise lineær transformasjon på grunnlag av egenvektorer, så gir vi svaret i skjemaet . Det er en forskjell, og forskjellen er betydelig! Fordi denne matrisen er "de" matrisen.
Problem med mer enkle beregninger Til uavhengig avgjørelse:
Eksempel 5
Finn egenvektorer til en lineær transformasjon gitt av en matrise 
Når du skal finne dine egne tall, prøv å ikke gå helt til et 3. grads polynom. I tillegg kan dine systemløsninger avvike fra mine løsninger - det er ingen sikkerhet her; og vektorene du finner kan avvike fra eksempelvektorene opp til proporsjonaliteten til deres respektive koordinater. For eksempel, og. Det er mer estetisk tiltalende å presentere svaret i skjemaet, men det er greit om du stopper ved det andre alternativet. Imidlertid er det alt rimelige grenser, versjonen ser ikke særlig bra ut lenger.
Et omtrentlig endelig utvalg av oppgaven på slutten av leksjonen.
Hvordan løse problemet ved flere egenverdier?Generell algoritme forblir den samme, men den har sine egne egenskaper, og det er tilrådelig å holde noen deler av løsningen i en mer streng akademisk stil:
Eksempel 6
Finn egenverdier og egenvektorer 
Løsning 
La oss selvfølgelig bruke stor bokstav i den fabelaktige første kolonnen: 
Og etter nedbrytning kvadratisk trinomium med multiplikatorer:
Som et resultat oppnås egenverdier, hvorav to er multipler.
La oss finne vår egen vektorer:
1) La oss håndtere en ensom soldat i henhold til et "forenklet" opplegg:

Fra de to siste ligningene er likheten tydelig synlig, som åpenbart bør erstattes med den første ligningen i systemet:
Du finner ikke en bedre kombinasjon:
Egenvektor:
2-3) Nå fjerner vi et par vaktposter. I dette tilfellet kan du få enten to eller en egenvektor. Uavhengig av hvor mange røttene er, erstatter vi verdien med determinanten  , som gir oss følgende homogene system av lineære ligninger:
, som gir oss følgende homogene system av lineære ligninger: 
grunnleggende system av løsninger
Faktisk, gjennom hele leksjonen gjorde vi ingenting annet enn å finne vektorene til det grunnleggende systemet. Bare foreløpig dette semesteret trengte det egentlig ikke. Forresten, de flinke studentene som hoppet over temaet homogene ligninger i kamuflasjedrakter vil bli tvunget til å prøve det nå.

Den eneste handlingen var å fjerne de ekstra linjene. Resultatet er en en-til-tre-matrise med et formelt "trinn" i midten.
– grunnleggende variabel, – frie variabler. Det er to frie variabler, derfor er det også to vektorer av det grunnleggende systemet.
La oss uttrykke den grunnleggende variabelen i form av frie variabler: . Nullmultiplikatoren foran "X" lar den ta på absolutt alle verdier (som er tydelig synlig fra ligningssystemet).
I sammenheng med dette problemet er det mer praktisk å skrive den generelle løsningen ikke i en rad, men i en kolonne:
Paret tilsvarer en egenvektor:
Paret tilsvarer en egenvektor:
Merk
: sofistikerte lesere kan velge disse vektorene muntlig - ganske enkelt ved å analysere systemet  , men litt kunnskap er nødvendig her: det er tre variabler, rangeringen av systemmatrisen er én, noe som betyr at det grunnleggende løsningssystemet består av 3 – 1 = 2 vektorer. Imidlertid er de funnet vektorene godt synlige selv uten denne kunnskapen, rent på et intuitivt nivå. I dette tilfellet vil den tredje vektoren bli skrevet enda mer "vakker": . Jeg advarer imidlertid om det i et annet eksempel enkelt utvalg Det viser seg kanskje ikke å være tilfelle, derfor er klausulen ment for erfarne personer. I tillegg, hvorfor ikke ta, si, som den tredje vektoren? Tross alt tilfredsstiller dens koordinater også hver likning i systemet, og vektorene
, men litt kunnskap er nødvendig her: det er tre variabler, rangeringen av systemmatrisen er én, noe som betyr at det grunnleggende løsningssystemet består av 3 – 1 = 2 vektorer. Imidlertid er de funnet vektorene godt synlige selv uten denne kunnskapen, rent på et intuitivt nivå. I dette tilfellet vil den tredje vektoren bli skrevet enda mer "vakker": . Jeg advarer imidlertid om det i et annet eksempel enkelt utvalg Det viser seg kanskje ikke å være tilfelle, derfor er klausulen ment for erfarne personer. I tillegg, hvorfor ikke ta, si, som den tredje vektoren? Tross alt tilfredsstiller dens koordinater også hver likning i systemet, og vektorene  lineært uavhengig. Dette alternativet er i prinsippet egnet, men "skjevt", siden den "andre" vektoren er en lineær kombinasjon av vektorer i det grunnleggende systemet.
lineært uavhengig. Dette alternativet er i prinsippet egnet, men "skjevt", siden den "andre" vektoren er en lineær kombinasjon av vektorer i det grunnleggende systemet.
Svar: egenverdier: , egenvektorer: 
Et lignende eksempel for en uavhengig løsning:
Eksempel 7
Finn egenverdier og egenvektorer 
Et omtrentlig utvalg av det endelige designet på slutten av leksjonen.
Det skal bemerkes at i både det 6. og 7. eksemplet får vi en trippel av lineært uavhengige egenvektorer, og derfor er den opprinnelige matrisen representativ i kanonisk utvidelse. Men slike bringebær skjer ikke i alle tilfeller:
Eksempel 8

Løsning: la oss komponere og løse den karakteristiske ligningen: 
La oss utvide determinanten i den første kolonnen: 
Vi utfører ytterligere forenklinger i henhold til den betraktede metoden, og unngår tredjegradspolynomet: 
![]() – egenverdier.
– egenverdier.
La oss finne egenvektorene:
1) Det er ingen problemer med roten: 
Ikke bli overrasket, i tillegg til settet er det også variabler i bruk - det er ingen forskjell her.
Fra den tredje likningen uttrykker vi den og erstatter den med 1. og 2. likning: 
Fra begge ligningene følger det:
La da: 

2-3) For flere verdier får vi systemet  .
.
La oss skrive ned matrisen til systemet og, ved hjelp av elementære transformasjoner, bringe den til en trinnvis form:
 Analyse av fabelen "Svane, gjedde og kreft": historieskriving, bilder
Analyse av fabelen "Svane, gjedde og kreft": historieskriving, bilder Guide: hva du skal spise på restaurantdagen på det regionale biblioteket "Anastasia Denisova's Cheese Factory"
Guide: hva du skal spise på restaurantdagen på det regionale biblioteket "Anastasia Denisova's Cheese Factory" Joseph Brodsky "Working ABC"
Joseph Brodsky "Working ABC"