Tegn en tilstandsgraf for en Markov-kjede. Homogene Markov-kjeder
1. matrise R2 kjedeovergang fra stat Jeg inn i en stat j to
steg;
2. sannsynlighetsfordeling over tilstander i øyeblikket t=2;
3. sannsynligheten for at i øyeblikket t=1 vil kretstilstanden være A2;
4. stasjonær distribusjon.
Løsning. For en diskret Markov-kjede i tilfelle dens homogenitet, forholdet
hvor P1 er matrisen av overgangssannsynligheter i ett trinn;
Pn - matrise av overgangssannsynligheter for n trinn;
1. Finn overgangsmatrisen P2 i to trinn
La sannsynlighetsfordelingen over tilstander på S-ste trinn bestemmes av vektoren
.
Å kjenne matrisen PN overgang i n trinn, er det mulig å bestemme sannsynlighetsfordelingen over tilstander på (S+n)-trinn ![]() . (5)
. (5)
2. Finn sannsynlighetsfordelingen over tilstandene til systemet for øyeblikket t=2. Vi legger inn (5) S=0 og n=2. Deretter ![]() .
.
Vi får .
3. Finn sannsynlighetsfordelingen over tilstandene til systemet for øyeblikket t=1.
Vi legger inn (5) s=0 og n=1, så .
Hvordan kan du se at sannsynligheten for at i øyeblikket t=1 vil kretstilstanden være A2, er lik p2(1)=0,69.
Sannsynlighetsfordelingen over tilstander kalles stasjonær hvis den ikke endres fra trinn til trinn, altså
Så fra relasjon (5) kl n=1 får vi
4. Finn den stasjonære fordelingen. Siden =2 har vi =(p1; p2). La oss skrive ned systemet lineære ligninger(6) i koordinert form

Den siste tilstanden kalles normalisering. I system (6) er en ligning alltid en lineær kombinasjon av andre. Derfor kan den slettes. La oss i fellesskap løse den første ligningen av systemet og normaliseringen. Vi har 0,6 p1=0,3s2, det er s2=2p1. Deretter p1+2p1=1 eller , det vil si . Følgelig.
Svar:
1) to-trinns overgangsmatrisen for en gitt Markov-kjede har formen ![]() ;
;
2) sannsynlighetsfordelingen over statene for øyeblikket t=2 er lik ![]() ;
;
3) sannsynligheten for at i øyeblikket t=1 vil kretstilstanden være A2, er lik p2(t)=0,69;
4) den stasjonære fordelingen har formen
Gitt en matrise  intensiteter av overganger av en kontinuerlig Markov-kjede. Komponer en merket tilstandsgraf som tilsvarer matrisen Λ; lage et system differensiallikninger Kolmogorov for statlige sannsynligheter; finn den begrensende sannsynlighetsfordelingen. Løsning. Homogen Markov-kjede med endelig antall stater A1, A2,…MEN preget av overgangsintensitetsmatrisen
intensiteter av overganger av en kontinuerlig Markov-kjede. Komponer en merket tilstandsgraf som tilsvarer matrisen Λ; lage et system differensiallikninger Kolmogorov for statlige sannsynligheter; finn den begrensende sannsynlighetsfordelingen. Løsning. Homogen Markov-kjede med endelig antall stater A1, A2,…MEN preget av overgangsintensitetsmatrisen  ,
,
hvor ![]() - intensiteten av overgangen til Markov-kjeden fra staten AI inn i en stat Aj; рij(Δt)- overgangssannsynlighet Ai→Aj per tidsintervall Δ
t.
- intensiteten av overgangen til Markov-kjeden fra staten AI inn i en stat Aj; рij(Δt)- overgangssannsynlighet Ai→Aj per tidsintervall Δ
t.
Det er praktisk å spesifisere systemoverganger fra tilstand til tilstand ved å bruke en merket tilstandsgraf, hvor buer som tilsvarer intensiteter er merket λ
ij>0. Lag en merket tilstandsgraf for gitt matrise overgangsintensiteter 
La være sannsynlighetsvektoren Rj(t),
j=1, 2,...,, systemet er i tilstanden MENj i øyeblikket t.
Det er åpenbart at 0≤ Rj(t)≤1 og . Deretter etter differensieringsregelen vektor funksjon skalært argument vi får ![]() . Sannsynligheter Rj(t) tilfredsstille Kolmogorov-systemet av differensialligninger (SDUK), som i matriseform har formen . (7)
. Sannsynligheter Rj(t) tilfredsstille Kolmogorov-systemet av differensialligninger (SDUK), som i matriseform har formen . (7)
Hvis systemet i det første øyeblikket var i staten Aj, bør SDUK løses under de opprinnelige betingelsene
RJeg(0)=1, рj(0)=0, j≠i,j=1, 2,…,.
(8)
Settet med SDUK (7) og startbetingelser (8) beskriver unikt en homogen Markov-kjede med kontinuerlig tid og et begrenset antall tilstander.
La oss komponere en SDUK for en gitt Markov-kjede. Siden =3, altså j=1, 2, 3.
Fra relasjon (7) får vi  .
.
Derfor vil vi ha 
Den siste tilstanden kalles normalisering.
Sannsynlighetsfordelingen over tilstander kalles stasjonær, hvis det ikke endres over tid, det vil si hvor Rj=konst, j=1,2,…,. Herfra ![]() .
.
Så får vi fra SDUK (7) et system for å finne den stasjonære fordelingen ![]() (9)
(9)
For dette problemet fra SDUK vil vi ha 
Fra normaliseringstilstanden vi får 3p2+p2+p2=1 eller ![]() . Derfor har grensefordelingen formen .
. Derfor har grensefordelingen formen .
Merk at dette resultatet kan fås direkte fra den merkede tilstandsgrafen ved å bruke regelen: for en stasjonær fordeling, summen av produkter λ
jipi, j≠Jeg, for piler som kommer fra Jeg tilstanden er lik summen av produktene λ
jipi, j≠Jeg, for pilene inkludert i Jeg delstaten. Egentlig, 
Det er åpenbart at det resulterende systemet tilsvarer det som er kompilert i henhold til SDUK. Derfor har den samme løsning.
Svar: den stasjonære fordelingen har formen .
En Markov-kjede er en serie med hendelser der hver påfølgende hendelse avhenger av den forrige. I artikkelen vil vi analysere dette konseptet mer detaljert.
Markov-kjede er en vanlig og ganske enkel måte å modellere på tilfeldige hendelser. Den brukes på en rekke områder, fra tekstgenerering til finansiell modellering. av de fleste kjent eksempel er SubredditSimulator . PÅ denne saken Markov-kjeden brukes til å automatisere opprettingen av innhold gjennom hele subredditen.
Markov-kjeden er oversiktlig og enkel å bruke fordi den kan implementeres uten å bruke noen statistiske eller matematiske konsepter. Markov-kjeden er ideell for å studere sannsynlighetsmodellering og datavitenskap.
Scenario
Tenk deg at det bare er to værforhold: kan være enten sol eller overskyet. Du kan alltid nøyaktig bestemme været i dette øyeblikket. Garantert klart eller overskyet.
Nå vil du lære hvordan du kan forutsi været for morgendagen. Intuitivt forstår du at været ikke kan endre seg dramatisk på en dag. Mange faktorer påvirker dette. Morgendagens vær avhenger direkte av dagens vær osv. Så for å forutsi været samler du inn data over flere år og kommer til den konklusjonen at etter en overskyet dag er sannsynligheten for en solskinnsdag 0,25. Det er logisk å anta at sannsynligheten for to overskyede dager på rad er 0,75, siden vi kun har to mulige værforhold.

Nå kan du forutsi været i flere dager fremover basert på gjeldende vær.
Dette eksemplet viser nøkkelkonsepter Markov-kjeder. En Markov-kjede består av et sett med overganger som er definert av en sannsynlighetsfordeling, som igjen tilfredsstiller Markov-egenskapen.
Merk at i eksemplet avhenger sannsynlighetsfordelingen kun av overgangene fra gjeldende dag til neste. den unik eiendom Markov-prosessen - den gjør dette uten å bruke minne. Som regel er en slik tilnærming ikke i stand til å lage en sekvens der noen trend vil bli observert. For eksempel, mens en Markov-kjede er i stand til å simulere en skrivestil basert på frekvensen til et ord, er den ikke i stand til å lage tekster med dyp betydning, siden det bare kan fungere med store tekster. Dette er grunnen til at en Markov-kjede ikke kan produsere kontekstavhengig innhold.
Modell
Formelt sett er en Markov-kjede en probabilistisk automat. Over vanligvis representert som en matrise. Hvis Markov-kjeden har N mulige tilstander, vil matrisen se ut som N x N, der oppføringen (I, J) vil være sannsynligheten for overgang fra tilstand I til tilstand J. I tillegg må en slik matrise være stokastisk , det vil si at rader eller kolonner skal utgjøre én. I en slik matrise vil hver rad ha sin egen sannsynlighetsfordeling.

Generelt bilde av en Markov-kjede med tilstander i form av sirkler og kanter i form av overganger.

Omtrentlig overgangsmatrise med tre mulige tilstander.
En Markov-kjede har en starttilstandsvektor, representert som en matrise N x 1. Den beskriver sannsynlighetsfordelingene for å starte i hver av de N mulige tilstandene. Oppføringen I beskriver sannsynligheten for å starte kjeden i tilstand I.
Disse to strukturene er nok til å representere en Markov-kjede.
Vi har allerede diskutert hvordan man kan få sannsynligheten for en overgang fra en tilstand til en annen, men hva med å oppnå denne sannsynligheten i flere trinn? For å gjøre dette, må vi bestemme sannsynligheten for overgang fra tilstand I til tilstand J i M-trinn. Det er faktisk veldig enkelt. Overgangsmatrisen P kan bestemmes ved å beregne (I, J) ved å heve P til potensen av M. For små verdier av M kan dette gjøres manuelt ved gjentatt multiplikasjon. Men for store verdier M hvis du er kjent med lineær algebra, mer effektiv måteå heve en matrise til en potens vil først diagonalisere den matrisen.
Markov-kjeden: konklusjon
Når du nå vet hva en Markov-kjede er, kan du enkelt implementere den i et av programmeringsspråkene. Enkle Markov-kjeder er grunnlaget for å lære mer komplekse metoder modellering.
Alle mulige tilstander i systemet i en homogen Markov-kjede, og er den stokastiske matrisen som definerer denne kjeden, sammensatt av overgangssannsynligheter ![]() (Se side 381).
(Se side 381).
Angi med sannsynligheten for at systemet er i en tilstand om gangen hvis det er kjent at systemet på det tidspunktet var i en tilstand (,). Åpenbart, ![]() . Ved å bruke teoremene om addisjon og multiplikasjon av sannsynligheter kan vi enkelt finne:
. Ved å bruke teoremene om addisjon og multiplikasjon av sannsynligheter kan vi enkelt finne:
![]()
![]()
eller i matrisenotasjon
![]()
Derfor, ved å gi suksessivt verdiene til , får vi den viktige formelen
Hvis det er grenser
![]()
eller i matrisenotasjon
![]()
deretter mengdene ![]() kalles begrensende eller endelige overgangssannsynligheter.
kalles begrensende eller endelige overgangssannsynligheter.
For å finne ut i hvilke tilfeller det er begrensende overgangssannsynligheter, og for å utlede de tilsvarende formlene, introduserer vi følgende terminologi.
Vi vil kalle en stokastisk matrise og den tilsvarende homogene Markov-kjeden regulær hvis matrisen ikke har noen karakteristiske tall som er forskjellige fra enhet og lik i modul til enhet, og regelmessig hvis i tillegg enhet er enkel rot karakteristisk ligning matriser.
En regulær matrise kjennetegnes ved at i sin normale form (69) (s. 373) er matrisene primitive. For en vanlig matrise, i tillegg .
I tillegg kalles en homogen Markov-kjede uoppløselig, dekomponerbar, asyklisk, syklisk, hvis den stokastiske matrisen for denne kjeden er henholdsvis uoppløselig, nedbrytbar, primitiv, imprimitiv.
Siden en primitiv stokastisk matrise er en spesiell type vanlig matrise, er en asyklisk Markov-kjede en spesiell type vanlig kjede.
Vi vil vise at begrensende overgangssannsynligheter bare eksisterer for vanlige homogene Markov-kjeder.
Faktisk, la være det minimale polynomet til en vanlig matrise. Deretter
I følge teorem 10 kan vi anta det
Basert på formel (24) Kap. V (side 113)
 (96)
(96)
hvor ![]() er den reduserte tilstøtende matrisen og
er den reduserte tilstøtende matrisen og

Hvis er en vanlig matrise, da
og derfor på høyre side av formel (96) har alle leddene, bortsett fra den første, en tendens til null som . Derfor, for en vanlig matrise, er det en matrise sammensatt av begrensende overgangssannsynligheter, og
Det motsatte er åpenbart. Hvis det er et gap
da kan ikke matrisen ha karakteristisk tall, for hvilke , og , siden da ville grensen ikke eksistert [Den samme grensen må eksistere på grunn av eksistensen av grensen (97").]
Vi har bevist at for en korrekt (og eneste korrekt) homogen Markov-kjede eksisterer det en matrise . Denne matrisen bestemmes av formel (97).
La oss vise hvordan matrisen kan uttrykkes i form av det karakteristiske polynomet
og den tilhørende matrisen ![]() .
.
Fra identitet
i kraft av (95), (95") og (98) følger det:

Derfor kan formel (97) erstattes av formelen
 (97)
(97)
For en vanlig Markov-kjede, siden det er en spesiell type av en vanlig kjede, eksisterer matrisen og bestemmes av hvilken som helst av formlene (97), (97"). I dette tilfellet har formelen (97") også formen
2. Tenk på en vanlig kjede av generell type (uregelmessig). Vi skriver den tilsvarende matrisen i normal form
 (100)
(100)
hvor er primitive stokastiske matriser, og uoppløselige matriser har maksimale karakteristiske tall . Forutsatt
 ,
, 
skriv i skjemaet

 (101)
(101)

Men ![]() , siden alle de karakteristiske tallene i matrisen er mindre enn enhet i absolutt verdi. Derfor
, siden alle de karakteristiske tallene i matrisen er mindre enn enhet i absolutt verdi. Derfor
 (102)
(102)
Siden er primitive stokastiske matriser, så er matrisene i henhold til formlene (99) og (35) (s. 362) positive
![]()
og i hver kolonne i en av disse matrisene er alle elementene like med hverandre:
![]() .
.
Merk at normalformen (100) av den stokastiske matrisen tilsvarer inndelingen av systemtilstandene i grupper:
Hver gruppe i (104) tilsvarer sin egen gruppe av serier i (101). I følge terminologien til L. N. Kolmogorov kalles tilstandene i systemet som er inkludert i essensielle, og statene som er inkludert i de resterende gruppene kalles uvesentlige.
Fra formen (101) av matrisen følger det at for ethvert begrenset antall trinn (fra øyeblikk til øyeblikk), er bare overgangen til systemet mulig a) fra en essensiell tilstand til en essensiell tilstand i samme gruppe, b ) fra en ubetydelig tilstand til en essensiell tilstand, og c) fra en ubetydelig tilstand til den ikke-essensielle tilstanden til samme eller en tidligere gruppe.
Fra formen (102) av matrisen følger det at i prosessen når overgangen bare er mulig fra en hvilken som helst tilstand til en essensiell tilstand, dvs. sannsynligheten for overgang til en hvilken som helst ubetydelig tilstand har en tendens til null med antall trinn. Derfor kalles essensielle tilstander noen ganger også grensetilstander.
3. Fra formel (97) følger det:
![]() .
.
Dette viser at hver kolonne i matrisen er en egenvektor til den stokastiske matrisen for det karakteristiske tallet.
For en vanlig matrise er tallet 1 en enkel rot av den karakteristiske ligningen, og dette tallet tilsvarer bare én (opptil en skalarfaktor) matriseegenvektor . Derfor, i en hvilken som helst kolonne i matrisen, er alle elementer lik det samme ikke-negative tallet:
Således, i en vanlig kjede, avhenger de begrensende overgangssannsynlighetene av starttilstanden.
Omvendt, hvis i en vanlig homogen Markov-kjede de individuelle overgangssannsynlighetene ikke avhenger av starttilstanden, dvs. formler (104) holder, så er det i skjema (102) for matrisen obligatorisk . Men så er kjeden også vanlig.
For en asyklisk kjede, som er et spesialtilfelle av en vanlig kjede, er en primitiv matrise. Derfor, for noen (se setning 8 på s. 377). Men så og ![]() .
.
Motsatt følger det at for noen, og dette, ifølge setning 8, betyr at matrisen er primitiv, og derfor er den gitte homogene Markov-kjeden asyklisk.
Vi formulerer resultatene som er oppnådd i form av følgende teorem:
Teorem 11. 1. For at alle begrensende overgangssannsynligheter skal eksistere i en homogen Markov-kjede, er det nødvendig og tilstrekkelig at kjeden er regulær. I dette tilfellet bestemmes matrisen , sammensatt av de begrensende overgangssannsynlighetene, av formel (95) eller (98).
2. For at de begrensende overgangssannsynlighetene skal være uavhengig av starttilstanden i en regulær homogen Markov-kjede, er det nødvendig og tilstrekkelig at kjeden er regulær. I dette tilfellet bestemmes matrisen av formel (99).
3. For at alle begrensende overgangssannsynligheter skal være forskjellig fra null i en regulær homogen Markov-kjede, er det nødvendig og tilstrekkelig at kjeden er asyklisk.
4. La oss introdusere kolonner med absolutte sannsynligheter
![]() (105)
(105)
hvor er sannsynligheten for at systemet er i tilstanden (,) for øyeblikket. Ved å bruke teoremene om addisjon og multiplikasjon av sannsynligheter finner vi:
![]() (,),
(,),
eller i matrisenotasjon
hvor er den transponerte matrisen for matrisen.
Alle absolutte sannsynligheter (105) bestemmes fra formel (106) hvis startsannsynlighetene og matrisen for overgangssannsynligheter er kjent
La oss introdusere de begrensende absolutte sannsynlighetene i betraktning
![]()
Ved å passere begge deler av likhet (106) til grensen ved , får vi:
Merk at eksistensen av en matrise med begrensende overgangssannsynligheter innebærer eksistensen av begrensende absolutte sannsynligheter ![]() for eventuelle innledende sannsynligheter
for eventuelle innledende sannsynligheter ![]() og vice versa.
og vice versa.
Fra formel (107) og fra formen (102) av matrisen følger det at de begrensende absolutte sannsynlighetene som tilsvarer ubetydelige tilstander er lik null.
Multiplisere begge sider av matriselikheten
til høyre får vi i kraft av (107):
dvs. kolonnen med marginale absolutte sannsynligheter er egenvektoren til matrisen for det karakteristiske tallet.
Hvis en gitt kjede Markov regular, da er en enkel rot av den karakteristiske ligningen til matrisen. I dette tilfellet er kolonnen med begrensende absolutte sannsynligheter unikt bestemt fra (108) (siden og ).
La en vanlig Markov-kjede gis. Så fra (104) og fra (107) følger det:
![]() (109)
(109)
I dette tilfellet avhenger ikke de begrensende absolutte sannsynlighetene av de opprinnelige sannsynlighetene.
Motsatt kan det ikke være avhengig av i nærvær av formel (107) hvis og bare hvis alle rader i matrisen er like, dvs.
![]() ,
,
og derfor (av setning 11) er en regulær matrise.
Hvis er en primitiv matrise, da , og derfor på grunn av (109)
Omvendt, hvis alle og ikke er avhengige av de innledende sannsynlighetene, så er alle elementene i hver kolonne i matrisen like og i henhold til (109), og dette, ifølge setning 11, betyr at det er en primitiv matrise, dvs. denne kjeden er asyklisk.
Det følger av ovenstående at teorem 11 kan formuleres som følger:
Teorem 11. 1. For at alle begrensende absolutte sannsynligheter skal eksistere i en homogen Markov-kjede for eventuelle initialsannsynligheter, er det nødvendig og tilstrekkelig at kjeden er regulær.
2. For at en homogen Markov-kjede skal ha begrensende absolutte sannsynligheter for eventuelle initialsannsynligheter og ikke være avhengig av disse initialsannsynlighetene, er det nødvendig og tilstrekkelig at kjeden er regelmessig.
3. For at en homogen Markov-kjede skal ha positive begrensende absolutte sannsynligheter for eventuelle initialsannsynligheter og disse begrensende sannsynlighetene ikke skal avhenge av de initiale, er det nødvendig og tilstrekkelig at kjeden er asyklisk.
5. Tenk nå på den homogene Markov-kjeden generell type med matrisen av overgangssannsynligheter .
La oss ta normalformen (69) av matrisen og betegne med imprimitivitetsindeksene til matrisene i (69). La være det minste felles multiplum av heltall . Da har ikke matrisen karakteristiske tall som i absolutt verdi er lik én, men forskjellig fra én, dvs. er en regulær matrise; på samme tid - den minste indikatoren, der - den riktige matrisen. Vi kaller et tall perioden for en gitt homogen Markov-kjede og. Omvendt, hvis og ![]() definert av formlene (110) og (110").
definert av formlene (110) og (110").
De gjennomsnittlige begrensende absolutte sannsynlighetene som tilsvarer ikke-essensielle tilstander er alltid lik null.
Hvis det er et tall i normal form av matrisen (og bare i dette tilfellet), avhenger ikke de gjennomsnittlige begrensende absolutte sannsynlighetene av startsannsynlighetene og bestemmes unikt fra ligning (111).
Denne artikkelen gir generell idé om hvordan man genererer tekster ved å modellere Markov-prosesser. Spesielt vil vi bli kjent med Markov-kjeder, og som praksis vil vi implementere en liten tekstgenerator i Python.
Til å begynne med skriver vi ut definisjonene vi trenger, men som ennå ikke er veldig klare for oss fra Wikipedia-siden, for i det minste omtrentlig å forestille oss hva vi har å gjøre med:
Markov-prosessen t t
Markov kjede
Hva betyr alt dette? La oss finne ut av det.
Grunnleggende
Det første eksemplet er ekstremt enkelt. Ved å bruke en setning fra en barnebok vil vi mestre det grunnleggende konseptet til en Markov-kjede, samt definere hva som er i vår kontekst korpus, lenker, sannsynlighetsfordeling og histogrammer. Selv om forslaget er engelske språk, essensen av teorien vil være lett å forstå.
Dette tilbudet er ramme, det vil si grunnlaget som teksten vil bli generert på i fremtiden. Den består av åtte ord, men samtidig unike ord bare fem er lenker(vi snakker om Markov kjeder). For klarhet, la oss fargelegge hver lenke i sin egen farge:

Og skriv ned antall forekomster av hver av lenkene i teksten:

Bildet over viser at ordet fisk vises i teksten 4 ganger oftere enn hvert av de andre ordene ( En, to, rød, blå). Det vil si sannsynligheten for å møte i vårt korpus ordet fisk 4 ganger høyere enn sannsynligheten for å møte annethvert ord i bildet. Når vi snakker på matematikkspråket, kan vi bestemme fordelingsloven for en tilfeldig variabel og beregne med hvilken sannsynlighet et av ordene vil vises i teksten etter det gjeldende. Sannsynligheten beregnes som følger: du må dele antall forekomster av ordet vi trenger i korpuset med totalt antall alle ordene i den. For ordet fisk denne sannsynligheten er 50 % siden den vises 4 ganger i en 8-ords setning. For hver av de gjenværende koblingene er denne sannsynligheten 12,5% (1/8).
Viser fordelingen grafisk tilfeldige variabler mulig med hjelp histogrammer. I dette tilfellet er hyppigheten av forekomsten av hver av koblingene i setningen tydelig synlig:

Så teksten vår består av ord og unike lenker, og vi viste sannsynlighetsfordelingen for utseendet til hver av koblingene i setningen på et histogram. Hvis det ser ut til at du ikke bør rote med statistikk, les. Og muligens redde livet ditt.
Essensen av definisjonen
La oss nå legge til tekstelementer som alltid er underforstått, men som ikke uttrykkes i dagligtale - begynnelsen og slutten av setningen:

Enhver setning inneholder disse usynlige "begynnelsen" og "slutten", la oss legge dem til som lenker til distribusjonen vår:

La oss gå tilbake til definisjonen gitt i begynnelsen av artikkelen:
Markov-prosessen er en tilfeldig prosess hvis utvikling etter evt angi verdi tidsparameter t er ikke avhengig av utviklingen som gikk forut t, forutsatt at verdien av prosessen i dette øyeblikket er fast.
Markov kjede - spesielt tilfelle Markov-prosessen, når rommet til dens tilstander er diskret (dvs. ikke mer enn tellelig).
Så hva betyr dette? Grovt sett modellerer vi en prosess der systemets tilstand i neste øyeblikk bare avhenger av tilstanden i det nåværende øyeblikket, og ikke på noen måte er avhengig av alle tidligere tilstander.
Forestill deg hva som er foran deg vindu, som bare viser den nåværende tilstanden til systemet (i vårt tilfelle er det ett ord), og du må bestemme hva det neste ordet vil være basert bare på dataene som presenteres i dette vinduet. I vårt korpus følger ordene etter hverandre etter følgende mønster:

Dermed dannes ordpar (selv slutten av setningen har sitt eget par - en tom verdi):

La oss gruppere disse parene etter det første ordet. Vi vil se at hvert ord har sitt eget sett med lenker, som i sammenheng med setningen vår kan Følg etter ham:

La oss presentere denne informasjonen på en annen måte - hver lenke vil bli tildelt en rekke av alle ord som kan vises i teksten etter denne lenken:

La oss ta en nærmere titt. Vi ser at hver lenke har ord som kan komme etter det i en setning. Hvis vi viste diagrammet ovenfor til noen andre, kunne den personen, med en viss sannsynlighet, rekonstruere vår første tilbud, altså korpuset.
Eksempel. La oss begynne med ordet Start. Deretter velger du et ord En, siden i henhold til vår ordning er det Enkelt ord, som kan følge begynnelsen av en setning. Bak ordet En også bare ett ord kan følge - fisk. Nå ser det nye forslaget i mellomversjon ut En fisk. Videre blir situasjonen mer komplisert fisk ord kan gå med like stor sannsynlighet i 25 % "to", "rød", "blå" og slutten av setningen Slutt. Hvis vi antar at det neste ordet er - "to" gjenoppbyggingen vil fortsette. Men vi kan velge en lenke Slutt. I dette tilfellet, basert på skjemaet vårt, vil en setning genereres tilfeldig som er veldig forskjellig fra korpuset - En fisk.
Vi har nettopp modellert en Markov-prosess - vi har bestemt hvert neste ord kun på grunnlag av kunnskap om det gjeldende. For fullstendig assimilering av materialet, la oss bygge diagrammer som viser avhengighetene mellom elementene i vårt korpus. Ovaler representerer lenker. Pilene fører til potensielle lenker som kan følge ordet i ovalen. I nærheten av hver pil - sannsynligheten for at neste lenke vil vises etter den gjeldende:

Utmerket! Vi lærte nødvendig informasjonå gå videre og analysere mer komplekse modeller.
Utvide vokabularbasen
I denne delen av artikkelen skal vi bygge en modell etter samme prinsipp som før, men vi vil utelate noen trinn i beskrivelsen. Hvis du har noen problemer, gå tilbake til teorien i den første blokken.
La oss ta fire sitater til fra samme forfatter (også på engelsk, det vil ikke skade oss):
"I dag er du deg. Det er sannere enn sant. Det er ingen i live som er deg enn deg."
«Du har hjerner i hodet. Du har føtter i skoene. Du kan styre deg selv i hvilken som helst retning du velger. Du er helt alene."
"Jo mer som du lese, jo mer ting du vil vite. Jo mer du lærer, jo flere steder vil du gå."
Tenk venstre og tenk høyre og tenk lavt og tenk høyt. Åh, tankene du kan tenke deg bare du prøver."
Korpusets kompleksitet har økt, men i vårt tilfelle er dette bare et pluss - nå vil tekstgeneratoren kunne produsere mer meningsfulle setninger. Faktum er at på alle språk er det ord som forekommer i tale oftere enn andre (for eksempel bruker vi preposisjonen "in" mye oftere enn ordet "kryogen"). Hvordan flere ord i vårt korpus (og derav avhengighetene mellom dem), jo mer informasjon har generatoren om hvilket ord som mest sannsynlig vil vises i teksten etter det gjeldende.
Den enkleste måten å forklare dette på er fra programmets synspunkt. Vi vet at for hver lenke er det et sett med ord som kan følge den. Og også, hvert ord er preget av antall forekomster i teksten. Vi må på en eller annen måte fange all denne informasjonen på ett sted; en ordbok som lagrer "(nøkkel, verdi)"-par er best egnet for dette formålet. Ordboknøkkelen vil registrere den nåværende tilstanden til systemet, det vil si en av koblingene i korpuset (f.eks. "de" på bildet nedenfor); og en annen ordbok vil bli lagret i ordbokverdien. I en nestet ordbok vil nøklene være ord som kan vises i teksten etter gjeldende korpusenhet ( "tenker" og mer kan gå i teksten etter "de"), og verdiene - antall forekomster av disse ordene i teksten etter lenken vår (ordet "tenker" vises i teksten etter ordet "de" 1 gang, ord mer etter ordet "de"- 4 ganger):

Les avsnittet ovenfor flere ganger for å få det riktig. Vær oppmerksom på at den nestede ordboken i dette tilfellet er det samme histogrammet, det hjelper oss å spore koblingene og hyppigheten av deres forekomst i teksten i forhold til andre ord. Det skal bemerkes at selv en slik vokabularbase er veldig liten for riktig generering av tekster i naturlig språk- den bør inneholde mer enn 20 000 ord, og helst mer enn 100 000. Og enda bedre - mer enn 500 000. Men la oss se på ordbokgrunnlaget vi har.
Markov-kjeden i dette tilfellet er konstruert på samme måte som det første eksemplet - hvert neste ord velges bare på grunnlag av kunnskap om gjeldende ord, alle andre ord tas ikke i betraktning. Men på grunn av lagring i ordboken av data om hvilke ord som vises oftere enn andre, kan vi velge å akseptere vektet avgjørelse. La oss se på et spesifikt eksempel:
Mer:
Det vil si hvis det gjeldende ordet er ordet mer, etter det kan det være ord med lik sannsynlighet i 25 % "tingene" og "steder", og med en sannsynlighet på 50% - ordet "at". Men sannsynlighetene kan være og alle er like med hverandre:
synes at:
Arbeid med vinduer
Så langt har vi kun vurdert ettordsvinduer. Du kan øke størrelsen på vinduet slik at tekstgeneratoren produserer flere "verifiserte" setninger. Dette betyr at jo større vinduet er, jo mindre avvik fra skroget vil være under generering. Å øke vindusstørrelsen tilsvarer overgangen til Markov-kjeden til mer høy orden. Tidligere bygde vi en kjede av første orden, for et vindu på to ord får vi en kjede av andre orden, av tre - av tredje, og så videre.
Vindu er dataene i nåværende tilstand systemer som brukes til å ta beslutninger. Hvis vi kombinerer et stort vindu og et lite datasett, vil vi sannsynligvis få samme setning hver gang. La oss ta ordbokbasen fra vårt første eksempel og utvide vinduet til størrelse 2:

Utvidelsen har resultert i at hvert vindu nå kun har ett alternativ for neste systemtilstand – uansett hva vi gjør vil vi alltid få samme setning, identisk med vårt korpus. Derfor, for å eksperimentere med vinduer, og for at tekstgeneratoren skal returnere unikt innhold, lager du en vokabularbase på 500 000 ord eller mer.
Implementering i Python
Diktogram datastruktur
Dictogram (dict er en innebygd ordbokdatatype i Python) vil vise forholdet mellom lenker og hvor ofte de forekommer i teksten, dvs. deres distribusjon. Men samtidig vil den ha ordbokegenskapen vi trenger - programkjøringstiden vil ikke avhenge av mengden inndata, noe som betyr at vi lager en effektiv algoritme.
Importer tilfeldig klasse Dictogram(dict): def __init__(self, iterable=None): # Initialiser distribusjonen vår som et nytt klasseobjekt, # legg til eksisterende elementer super(Dictogram, self).__init__() self.types = 0 # antall av unike nøkler i distribusjon self.tokens = 0 # Total av alle ord i distribusjonen hvis iterable: self.update(iterable) def update(self, iterable): # Oppdater distribusjonen med elementer fra det # eksisterende iterable datasettet for element i iterable: if item in self: self += 1 self .tokens += 1 else: self = 1 self.types += 1 self.tokens += 1 def count(self, item): # Returner elementets tellerverdi, eller 0 hvis element i self: return self return 0 def return_random_word (selv): random_key = random.sample(self, 1) # En annen måte: # random.choice(histogram.keys()) returner random_key def return_weighted_random_word(self): # Generer et pseudo-tilfeldig tall mellom 0 og (n- 1), # hvor n er det totale antallet ord random_int = random.randint(0, self.tokens-1) index = 0 list_of_keys = self.keys() # skriv ut "random index:", random_int for i i området( 0, self.types): index += self] # print index if(index > random_int): # print list_of_keys[i] return list_of_keys[i]
Ethvert objekt som kan itereres over kan sendes til konstruktøren av diktogramstrukturen. Elementene i dette objektet vil være ordene for å initialisere diktogrammet, for eksempel alle ordene fra en bok. I dette tilfellet teller vi elementene slik at for å få tilgang til noen av dem, vil det ikke være nødvendig å kjøre gjennom hele datasettet hver gang.
Vi laget også to returfunksjoner tilfeldig ord. Den ene funksjonen velger en tilfeldig nøkkel i ordboken, og den andre, med tanke på antall forekomster av hvert ord i teksten, returnerer ordet vi trenger.
Markov kjedestruktur
fra histogrammer import Dictogram def make_markov_model(data): markov_model = dict() for i in range(0, len(data)-1): if data[i] in markov_model: # Bare legg til en allerede eksisterende markov_model distribusjon].update ( ]) annet: markov_model] = Diktogram(]) returnerer markov_modellI implementeringen ovenfor har vi en ordbok som lagrer vinduer som nøkkelen i "(nøkkel, verdi)"-paret og distribusjoner som verdiene i det paret.
Struktur av en Markov-kjede av N. orden
fra histogrammer import Dictogram def make_higher_order_markov_model(order, data): markov_model = dict() for i in range(0, len(data)-order): # Create window window = tuple(data) # Legg til i ordbok hvis vindu i markov_model: # Fest til en eksisterende distribusjon markov_model.update(]) else: markov_model = Dictogram(]) return markov_modelVeldig lik en første-orders Markov-kjede, men i dette tilfellet lagrer vi tuppel som en nøkkel i et "(nøkkel, verdi)"-par i en ordbok. Vi bruker den i stedet for en liste, siden tuppelen er beskyttet mot eventuelle endringer, og dette er viktig for oss - tross alt skal nøklene i ordboken ikke endres.
Modellanalyse
Flott, vi har implementert en ordbok. Men hvordan nå generere innhold basert på gjeldende tilstand og gå til neste tilstand? La oss gå gjennom modellen vår:
Fra histogrammer import Diktogram import tilfeldig fra samlinger import deque import re def gener_random_start(modell): # For å generere et startord, fjern kommentarfeltet: # return random.choice(model.keys()) # For å generere det "riktige" startordet , bruk koden nedenfor: # Riktig innledende ord er de som var begynnelsen på setninger i if "END" i modellkorpus: seed_word = "END" mens seed_word == "END": seed_word = model["END"].return_weighted_random_word() return seed_word return random.choice( model .keys()) def generate_random_sentence(length, markov_model): current_word = generate_random_start(markov_model) sentence = for i in range(0, length): current_dictogram = markov_model random_weighted_word = current_dictogram.return_weighted_random_word() current_word = random_weighted_word sentence.append(current_word ) setning = setning.capitalize() returnerer " ".join(setning) + "." tilbake setning
Hva blir det neste?
Prøv å tenke på hvor du selv kan bruke en tekstgenerator basert på Markov-kjeder. Bare ikke glem at det viktigste er hvordan du analyserer modellen og hvilke spesielle begrensninger du setter på generasjon. Forfatteren av denne artikkelen brukte for eksempel et stort vindu når han opprettet tweet-generatoren, begrenset det genererte innholdet til 140 tegn, og brukte bare "riktige" ord for å starte setninger, det vil si de som var begynnelsen på setninger i korpus.
måter matematiske beskrivelser Markovs stokastiske prosesser i et system med diskrete tilstander (DS) avhenger av på hvilke tidspunkter (på forhånd kjent eller tilfeldig) overgangene til systemet fra tilstand til tilstand kan skje.
Hvis overgangen av systemet fra stat til stat er mulig på forhåndsbestemte tider, har vi å gjøre med tilfeldig Markov-prosessen med diskret tid. Hvis overgangen er mulig på et hvilket som helst tilfeldig tidspunkt, så har vi å gjøre med tilfeldig Markov-prosess med kontinuerlig tid.
La det være fysisk system S, som kan være i n stater S 1 , S 2 , …, S n. Overganger fra stat til stat er bare mulig til tider t 1 , t 2 , …, t k La oss kalle disse øyeblikkene av tid for trinn. Vi vil vurdere SP i systemet S som en funksjon av heltallsargumentet 1, 2, ..., k, hvor argumentet er trinnnummeret.
Eksempel: S 1 → S 2 → S 3 → S 2 .
La oss betegne Si (k) er en hendelse som består i at etter k trinn systemet er i tilstand S Jeg.
For enhver k hendelser S 1 ( k), S 2 ( k),..., S n (k) form hele gruppen av arrangementer og er uforenlig.
Prosessen i systemet kan representeres som en hendelseskjede.
Eksempel: S 1 (0) , S 2 (1), S 3 (2), S 5 (3), ….
En slik sekvens kalles Markov kjede
, hvis for hvert trinn sannsynligheten for overgang fra en hvilken som helst stat Si i enhver stat S j er ikke avhengig av når og hvordan systemet kom til staten Si.
La når som helst etter evt k-go step system S kan være i en av statene S 1 , S 2 , …, S n, dvs. én hendelse fra en komplett gruppe hendelser kan forekomme: S 1 (k), S 2 ( k) , …, S n (k). La oss betegne sannsynlighetene for disse hendelsene:
P 1 (1) = P(S 1 (1)); P 2 (1) = P(S 2 (1)); …; P n(1) = P(S n (k));
P 1 (2) = P(S 1 (2)); P 2 (2) = P(S2(2)); …; P n(2) = P(S n (2));
P 1 (k) = P(S 1 (k)); P 2 (k) = P(S 2 (k)); …; P n(k) = P(S n (k)).
Det er lett å se at for hvert trinn nummerer betingelsen
P 1 (k) + P 2 (k) +…+ P n(k) = 1.
La oss kalle disse sannsynlighetene oppgi sannsynligheter.følgelig vil oppgaven høres ut som følger: finn sannsynlighetene for systemtilstandene for evt. k.
Eksempel. La det være et system som kan være i hvilken som helst av de seks statene. da kan prosessene som forekommer i det avbildes enten i form av en graf over endringer i systemets tilstand (fig. 7.9, en), eller i form av en graf over systemtilstander (fig. 7.9, b).
en) 
Ris. 7.9
Dessuten kan prosessene i systemet avbildes som en sekvens av tilstander: S 1 , S 3 , S 2 , S 2 , S 3 , S 5 , S 6 , S 2 .
Oppgi sannsynlighet på ( k+ 1)-th trinn avhenger bare av staten ved k- m trinn.
For ethvert trinn k det er noen sannsynligheter for at systemet går fra en hvilken som helst tilstand til en hvilken som helst annen tilstand, la oss kalle disse sannsynlighetene overgangssannsynligheter for en Markov-kjede.
Noen av disse sannsynlighetene vil være 0 hvis overgangen fra en tilstand til en annen ikke er mulig i ett trinn.
Markov-kjeden heter homogen hvis overgangstilstandene ikke avhenger av trinnnummeret, ellers kalles det heterogen.
La det være en homogen Markov-kjede og la systemet S Det har n mulige tilstander: S 1 , …, S n. La sannsynligheten for overgang til en annen tilstand i ett trinn være kjent for hver tilstand, dvs. P ij(fra Si i S j i ett trinn), så kan vi skrive overgangssannsynlighetene som en matrise.
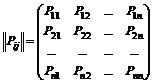 . (7.1)
. (7.1)
På diagonalen til denne matrisen er sannsynlighetene for at systemet går fra tilstanden Si i samme tilstand Si.
Bruker de tidligere introduserte hendelsene ![]() , kan overgangssannsynlighetene skrives som betingede sannsynligheter:
, kan overgangssannsynlighetene skrives som betingede sannsynligheter: ![]() .
.
Tydeligvis summen av vilkårene ![]() i hver rad i matrisen (1) er lik én, siden hendelsene
i hver rad i matrisen (1) er lik én, siden hendelsene ![]() danne en komplett gruppe av uforenlige hendelser.
danne en komplett gruppe av uforenlige hendelser.
Når man vurderer Markov-kjeder, samt når man analyserer en Markov tilfeldig prosess, brukes ulike tilstandsgrafer (fig. 7.10). 
Ris. 7.10
Dette systemet kan være i hvilken som helst av seks stater, mens P ij er sannsynligheten for systemovergang fra staten Si inn i en stat S j. For dette systemet skriver vi ligningene om at systemet var i en eller annen tilstand og fra det i løpet av tiden t kom ikke ut: 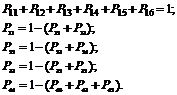
PÅ generell sak Markov-kjeden er inhomogen, dvs. sannsynligheten P ij endringer fra trinn til trinn. Anta at en matrise av overgangssannsynligheter ved hvert trinn er gitt, deretter sannsynligheten for at systemet S på k-Trinn vil være i staten Si, kan bli funnet ved hjelp av formelen ![]()
Å kjenne matrisen for overgangssannsynligheter og opprinnelige tilstand system, kan du finne sannsynlighetene for tilstander ![]() etter evt k-trinn. La systemet være i tilstanden i det første øyeblikket Sm. Så for t = 0
etter evt k-trinn. La systemet være i tilstanden i det første øyeblikket Sm. Så for t = 0
.
Finn sannsynlighetene etter det første trinnet. Ut av staten Sm systemet vil gå inn i stater S 1 , S 2 osv. med sannsynligheter Pm 1 , Pm 2 , …, Pmm, …, Pmn. Så etter det første trinnet vil sannsynlighetene være like
. (7.2)
La oss finne sannsynlighetene for staten etter det andre trinnet: . Vi vil beregne disse sannsynlighetene ved hjelp av formelen full sannsynlighet med hypoteser: ![]() .
.
Hypotesene vil være følgende utsagn:
- etter det første trinnet var systemet i tilstanden S1-H1;
- etter det andre trinnet var systemet i tilstanden S2-H2;
- etter n-Trinn var systemet i tilstanden S n -H n .
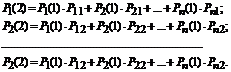
Sannsynlighet for enhver tilstand etter det andre trinnet:
![]() (7.3)
(7.3)
Formel (7.3) oppsummerer alle overgangssannsynligheter P ij, men bare de andre enn null er tatt i betraktning. Sannsynligheten for enhver stat etter k-ste trinn:
![]() (7.4)
(7.4)
Dermed er sannsynligheten for staten etter k-ste trinn bestemmes av tilbakevendende formel(7.4) når det gjelder sannsynligheter ( k- 1) trinn.
Oppgave 6. Matrisen av overgangssannsynligheter for en Markov-kjede i ett trinn er gitt. Finn overgangsmatrisen til en gitt krets i tre trinn  .
.
Løsning. Overgangsmatrisen til et system er en matrise som inneholder alle overgangssannsynlighetene til dette systemet: 
Hver rad i matrisen inneholder sannsynlighetene for hendelser (overgang fra tilstanden Jeg inn i en stat j), som danner en komplett gruppe, så summen av sannsynlighetene for disse hendelsene er lik én: ![]()
Angi med p ij (n) sannsynligheten for at systemet som et resultat av n trinn (tester) vil bevege seg fra tilstand i til tilstand j . For eksempel p 25 (10) - sannsynligheten for overgang fra den andre tilstanden til den femte i ti trinn. Merk at for n=1 får vi overgangssannsynligheter p ij (1)=p ij .
Vi står overfor oppgaven: å kjenne overgangssannsynlighetene p ij , finn sannsynlighetene p ij (n) for systemovergangen fra tilstanden Jeg inn i en stat j per n trinn. For å gjøre dette introduserer vi en mellomliggende (mellom Jeg og j) tilstand r. Med andre ord vil vi anta det fra starttilstanden Jeg per m trinn, vil systemet gå til en mellomtilstand r med sannsynlighet p ij (n-m) , hvoretter, for de resterende n-m trinn fra mellomtilstanden r vil den gå over til slutttilstanden j med sannsynlighet p ij (n-m) . I henhold til total sannsynlighetsformel får vi: ![]() .
.
Denne formelen kalles Markovs likhet. Ved å bruke denne formelen kan du finne alle sannsynlighetene p ij (n) og følgelig selve matrisen P n. Siden matriseregningen fører til målet raskere, la oss skrive ned matriserelasjonen som følger av den oppnådde formelen i en generell form.
Beregn overgangsmatrisen til Markov-kjeden i tre trinn ved å bruke den resulterende formelen: 
Svar: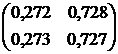 .
.
Oppgave 1. Overgangssannsynlighetsmatrisen for Markov-kjeden er: 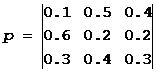 .
.
Fordelingen over tilstander på tidspunktet t=0 bestemmes av vektoren:
π 0 \u003d (0,5; 0,2; 0,3)
Finne: a) fordeling over tilstander i øyeblikkene t=1,2,3,4 .
c) stasjonær distribusjon.
 Hvordan komme i gang som veileder?
Hvordan komme i gang som veileder? Fjernundervisning i engelsk
Fjernundervisning i engelsk Vanlige og uregelmessige engelske verb
Vanlige og uregelmessige engelske verb