Formel for standardavvik. Hvordan beregne standardavvik? Spredning
Den mest perfekte egenskapen til variasjon er standardavviket, som kalles standarden (eller standardavviket). Standardavvik() er lik kvadratroten av middelkvadraten av avvikene til individuelle funksjonsverdier fra det aritmetiske gjennomsnittet:
Standardavviket er enkelt:


Det vektede standardavviket brukes for grupperte data:

Mellom middelkvadrat og gjennomsnittlig lineære avvik under normalfordelingsforhold finner følgende forhold sted: ~ 1,25.
Standardavviket, som er det viktigste absolutte variasjonsmålet, brukes til å bestemme verdiene til ordinatene til normalfordelingskurven, i beregninger relatert til organisering av prøveobservasjon og fastsettelse av nøyaktigheten til prøvekarakteristikker, så vel som i å vurdere grensene for variasjonen av en egenskap i en homogen populasjon.
Dispersjon, dens typer, standardavvik.
Varians av en tilfeldig variabel- et mål på spredningen av en gitt tilfeldig variabel, dvs. dens avvik fra den matematiske forventningen. I statistikk brukes ofte betegnelsen eller. Kvadratroten av variansen kalles standardavviket, standardavviket eller standardspredningen.
Total varians (σ2) måler variasjonen av en egenskap i hele befolkningen under påvirkning av alle faktorene som forårsaket denne variasjonen. Samtidig er det, takket være grupperingsmetoden, mulig å isolere og måle variasjonen på grunn av grupperingstrekket, og variasjonen som oppstår under påvirkning av uoversiktlige faktorer.
Intergruppevarians (σ 2 m.gr) karakteriserer systematisk variasjon, dvs. forskjeller i størrelsen på den studerte egenskapen som oppstår under påvirkning av egenskapen - faktoren som ligger til grunn for grupperingen.
standardavvik(synonymer: standardavvik, standardavvik, standardavvik; lignende termer: standardavvik, standardspredning) - i sannsynlighetsteori og statistikk, den vanligste indikatoren på spredningen av verdiene til en tilfeldig variabel i forhold til dens matematiske forventning. Med begrensede arrays av utvalg av verdier, i stedet for den matematiske forventningen, brukes det aritmetiske gjennomsnittet av settet med samples.
Standardavviket måles i enheter av selve den tilfeldige variabelen og brukes til å beregne standardfeilen til det aritmetiske gjennomsnittet, ved å konstruere konfidensintervaller, ved statistisk testing av hypoteser og ved måling av den lineære sammenhengen mellom tilfeldige variabler. Det er definert som kvadratroten av variansen til en tilfeldig variabel.
Standardavvik:

Standardavvik(estimering av standardavviket til en tilfeldig variabel x i forhold til dens matematiske forventning basert på et objektivt estimat av variansen):

hvor er spredningen; — Jeg-th prøveelement; — prøvestørrelse; - aritmetisk gjennomsnitt av prøven:
![]()
Det skal bemerkes at begge estimatene er partiske. I det generelle tilfellet er det umulig å konstruere et objektivt estimat. Imidlertid er et estimat basert på et objektivt variansestimat konsistent.
Essens, omfang og prosedyre for å bestemme modus og median.
I tillegg til kraftlovgjennomsnitt i statistikk, for en relativ karakteristikk av størrelsen på en varierende egenskap og den interne strukturen til distribusjonsserier, brukes strukturelle gjennomsnitt, som hovedsakelig er representert ved modus og median.
Mote– Dette er den vanligste varianten av serien. Mote brukes for eksempel til å bestemme størrelsen på klær, sko, som er mest etterspurt blant kjøpere. Modusen for en diskret serie er varianten med høyest frekvens. Når du beregner modusen for intervallvariasjonsserien, må du først bestemme det modale intervallet (ved maksimal frekvens), og deretter verdien av den modale verdien til attributtet i henhold til formelen:

- - moteverdi
- - nedre grense for det modale intervallet
- - intervallverdi
- - modal intervallfrekvens
- - frekvensen til intervallet før modalen
- - frekvensen av intervallet etter modalen
Median - dette er verdien av funksjonen som ligger til grunn for den rangerte serien og deler denne serien i to like store deler.
For å bestemme medianen i en diskret serie i nærvær av frekvenser, beregner du først halvsummen av frekvenser , og bestemmer deretter hvilken verdi av varianten som faller på den. (Hvis den sorterte raden inneholder et oddetall funksjoner, beregnes mediantallet ved hjelp av formelen:
M e \u003d (n (antall funksjoner i aggregatet) + 1) / 2,
i tilfelle av et partall av funksjoner, vil medianen være lik gjennomsnittet av de to funksjonene i midten av raden).
Ved beregning medianer for en intervallvariasjonsserie, bestemme først medianintervallet som medianen befinner seg innenfor, og deretter verdien av medianen i henhold til formelen:

- er ønsket median
- er den nedre grensen for intervallet som inneholder medianen
- - intervallverdi
- - summen av frekvensene eller antall medlemmer av serien
Summen av de akkumulerte frekvensene til intervallene foran medianen
- er frekvensen til medianintervallet
Eksempel. Finn modus og median.
Løsning:
I dette eksemplet er det modale intervallet innenfor aldersgruppen 25-30 år, siden dette intervallet står for den høyeste frekvensen (1054).
La oss beregne modusverdien:
Det betyr at elevens modale alder er 27 år.
Regn ut medianen. Medianintervallet er i aldersgruppen 25-30 år, siden det innenfor dette intervallet finnes en variant som deler befolkningen i to like deler (Σf i /2 = 3462/2 = 1731). Deretter erstatter vi de nødvendige numeriske dataene i formelen og får verdien av medianen:

Det betyr at den ene halvparten av elevene er under 27,4 år, og den andre halvparten er over 27,4 år.
I tillegg til modus og median, kan indikatorer som kvartiler brukes, som deler den rangerte serien i 4 like deler, desiler- 10 deler og persentiler - per 100 deler.
Konseptet med selektiv observasjon og dets omfang.
Selektiv observasjon gjelder ved bruk av kontinuerlig observasjon fysisk umulig på grunn av store mengder data eller økonomisk upraktisk. Fysisk umulighet oppstår for eksempel når man studerer passasjerstrømmer, markedspriser, familiebudsjetter. Økonomisk uhensiktsmessighet oppstår når man vurderer kvaliteten på varer knyttet til deres ødeleggelse, for eksempel smaking, testing av murstein for styrke, etc.
Statistiske enheter valgt for observasjon utgjør et utvalg eller utvalg, og hele matrisen deres - den generelle populasjonen (GS). I dette tilfellet angir antall enheter i prøven n, og i hele HS - N. Holdning n/N kalt den relative størrelsen eller andelen av prøven.
Kvaliteten på prøveresultatene avhenger av utvalgets representativitet, det vil si hvor representativt det er i HS. For å sikre representativiteten til utvalget, er det nødvendig å observere prinsippet om tilfeldig utvalg av enheter, som forutsetter at inkluderingen av en HS-enhet i utvalget ikke kan påvirkes av noen annen faktor enn tilfeldigheter.
Finnes 4 måter for tilfeldig valgå prøve:
- Egentlig tilfeldig utvalg eller "lotto-metode", når serienumre tildeles statistiske verdier, legges inn på bestemte objekter (for eksempel fat), som deretter blandes i en beholder (for eksempel i en pose) og velges tilfeldig. I praksis utføres denne metoden ved hjelp av en tilfeldig tallgenerator eller matematiske tabeller med tilfeldige tall.
- Mekanisk utvalg, i henhold til hvilket hver ( N/n)-te verdi av den generelle befolkningen. For eksempel, hvis den inneholder 100 000 verdier, og du vil velge 1000, vil hver 100 000 / 1000 = 100. verdi falle inn i prøven. Dessuten, hvis de ikke er rangert, blir den første valgt tilfeldig fra de første hundre, og tallene til de andre vil være hundre flere. For eksempel, hvis enhet nummer 19 var den første, så skal nummer 119 være neste, så nummer 219, så nummer 319, og så videre. Hvis populasjonsenhetene er rangert, velges #50 først, deretter #150, deretter #250, og så videre.
- Valget av verdier fra en heterogen datamatrise utføres stratifisert(stratifisert) metode, når den generelle befolkningen tidligere er delt inn i homogene grupper, som tilfeldig eller mekanisk seleksjon brukes på.
- En spesiell prøvetakingsmetode er serie seleksjon, der ikke individuelle mengder er tilfeldig eller mekanisk valgt, men deres serier (sekvenser fra et eller annet nummer til noen på rad), innenfor hvilke kontinuerlig observasjon utføres.
Kvaliteten på prøveobservasjoner avhenger også av prøvetakingstype: gjentatt eller ikke-repeterende.
På omvalg de statistiske verdiene eller seriene deres som falt inn i utvalget blir returnert til den generelle befolkningen etter bruk, og har en sjanse til å komme inn i et nytt utvalg. Samtidig har alle verdier i den generelle befolkningen samme sannsynlighet for å bli inkludert i utvalget.
Ikke-gjentakende valg betyr at de statistiske verdiene eller deres serier inkludert i utvalget ikke returneres til den generelle befolkningen etter bruk, og derfor øker sannsynligheten for å komme inn i neste prøve for de gjenværende verdiene til sistnevnte.
Ikke-repeterende prøvetaking gir mer nøyaktige resultater, så det brukes oftere. Men det er situasjoner hvor det ikke kan brukes (studie av passasjerstrømmer, forbrukernes etterspørsel osv.) og så foretas et omvalg.
Den marginale feilen til observasjonsutvalget, gjennomsnittsfeilen til utvalget, rekkefølgen de er beregnet i.
La oss vurdere i detalj metodene ovenfor for å danne en utvalgspopulasjon og feilene som oppstår i dette tilfellet. representativitet .
Faktisk-tilfeldig utvalget er basert på tilfeldig utvalg av enheter fra den generelle populasjonen uten noen innslag av konsistens. Teknisk sett utføres riktig tilfeldig utvalg ved å trekke lodd (for eksempel lotterier) eller ved en tabell med tilfeldige tall.
Egentlig tilfeldig seleksjon "i sin rene form" i praksisen med selektiv observasjon brukes sjelden, men det er den første blant andre typer seleksjon, den implementerer de grunnleggende prinsippene for selektiv observasjon. La oss vurdere noen spørsmål om teorien om prøvetakingsmetoden og feilformelen for et enkelt tilfeldig utvalg.
Prøvetakingsfeil- dette er forskjellen mellom verdien av parameteren i den generelle befolkningen, og dens verdi beregnet fra resultatene av prøveobservasjon. For en gjennomsnittlig kvantitativ karakteristikk bestemmes prøvetakingsfeilen av
Indikatoren kalles marginal prøvetakingsfeil.
Utvalgsgjennomsnittet er en tilfeldig variabel som kan få ulike verdier avhengig av hvilke enheter som er i utvalget. Derfor er prøvetakingsfeil også tilfeldige variabler og kan få ulike verdier. Bestem derfor gjennomsnittet av mulige feil - gjennomsnittlig prøvetakingsfeil, som avhenger av:
Prøvestørrelse: jo større tall, jo mindre er gjennomsnittsfeilen;
Graden av endring av den studerte egenskapen: jo mindre variasjonen av egenskapen er, og følgelig variansen, jo mindre er den gjennomsnittlige prøvetakingsfeilen.
På tilfeldig omvalg gjennomsnittsfeilen beregnes:
.
I praksis er den generelle variansen ikke nøyaktig kjent, men i sannsynlighetsteori bevist det ![]() .
.
Siden verdien for tilstrekkelig stor n er nær 1, kan vi anta at . Deretter kan den gjennomsnittlige prøvetakingsfeilen beregnes:
.
Men i tilfeller med et lite utvalg (for n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
På tilfeldig prøvetaking de gitte formlene korrigeres med verdien . Da er den gjennomsnittlige feilen for ikke-sampling:  og
og  .
.
Fordi alltid er mindre enn , da er faktoren () alltid mindre enn 1. Dette betyr at gjennomsnittsfeilen ved ikke-repeterende seleksjon alltid er mindre enn ved gjentatt seleksjon.
Mekanisk prøvetaking brukes når befolkningen generelt er ordnet på en eller annen måte (for eksempel velgerlister i alfabetisk rekkefølge, telefonnumre, husnummer, leiligheter). Utvelgelsen av enheter utføres med et visst intervall, som er lik den gjensidige prosentandelen av prøven. Så, med et utvalg på 2 %, velges hver 50 enhet = 1 / 0,02, med 5 %, hver 1 / 0,05 = 20 enhet av den generelle befolkningen.
Opprinnelsen velges på forskjellige måter: tilfeldig, fra midten av intervallet, med en endring i opprinnelsen. Det viktigste er å unngå systematiske feil. For eksempel, med en prøve på 5 %, hvis den 13. er valgt som den første enheten, så de neste 33, 53, 73 osv.
Når det gjelder nøyaktighet, er det mekaniske utvalget nært opp til riktig tilfeldig prøvetaking. Derfor, for å bestemme gjennomsnittsfeilen ved mekanisk prøvetaking, brukes formler for riktig tilfeldig utvalg.
På typisk utvalg den undersøkte befolkningen er foreløpig delt inn i homogene enkelttypegrupper. For eksempel, når man kartlegger foretak, kan disse være næringer, undersektorer, mens man studerer befolkningen - områder, sosiale eller aldersgrupper. Deretter gjøres det et uavhengig utvalg fra hver gruppe på en mekanisk eller riktig tilfeldig måte.
Typisk prøvetaking gir mer nøyaktige resultater enn andre metoder. Typifiseringen av den generelle populasjonen sikrer representasjonen av hver typologisk gruppe i utvalget, noe som gjør det mulig å utelukke påvirkning av intergruppevarians på gjennomsnittlig utvalgsfeil. Derfor, når du finner feilen til et typisk utvalg i henhold til regelen for tillegg av varians (), er det nødvendig å bare ta hensyn til gjennomsnittet av gruppevariansene. Da er den gjennomsnittlige prøvetakingsfeilen:
ved omvalg
,
med engangsvalg  ,
,
hvor  er gjennomsnittet av variasjonene mellom gruppene i utvalget.
er gjennomsnittet av variasjonene mellom gruppene i utvalget.
Seriell (eller nestet) utvalg
brukes når populasjonen deles inn i serier eller grupper før oppstart av utvalgsundersøkelsen. Disse seriene kan være pakker med ferdige produkter, studentgrupper, team. Serier for undersøkelse velges mekanisk eller tilfeldig, og innenfor serien gjennomføres en fullstendig undersøkelse av enheter. Derfor avhenger den gjennomsnittlige prøvetakingsfeilen bare av variansen mellom grupper (interserier), som beregnes med formelen: 
hvor r er antall valgte serier;
- gjennomsnittet av den i-te serien.
Den gjennomsnittlige serielle prøvetakingsfeilen beregnes:
når det velges på nytt:
,
med engangsvalg:  ,
,
der R er det totale antallet serier.
Kombinert utvalg er en kombinasjon av de vurderte seleksjonsmetodene.
Den gjennomsnittlige prøvetakingsfeilen for enhver utvalgsmetode avhenger hovedsakelig av utvalgets absolutte størrelse og i mindre grad av utvalgets prosentandel. Anta at det gjøres 225 observasjoner i det første tilfellet av en befolkning på 4 500 enheter og i det andre tilfellet av 225 000 enheter. Variansene i begge tilfeller er lik 25. Så, i det første tilfellet, med et utvalg på 5 %, vil samplingsfeilen være: 
I det andre tilfellet, med et utvalg på 0,1 %, vil det være lik:

På denne måten, med en nedgang i prøveprosenten med 50 ganger, økte prøvefeilen litt, siden prøvestørrelsen ikke endret seg.
Anta at utvalgsstørrelsen økes til 625 observasjoner. I dette tilfellet er prøvetakingsfeilen: 
En økning i utvalget med 2,8 ganger med samme størrelse på den generelle befolkningen reduserer størrelsen på utvalgsfeilen med mer enn 1,6 ganger.
Metoder og midler for å danne en utvalgspopulasjon.
I statistikk brukes ulike metoder for å danne prøvesett, som bestemmes av målene for studien og avhenger av spesifikasjonene til studieobjektet.
Hovedbetingelsen for å gjennomføre en utvalgsundersøkelse er å forhindre forekomst av systematiske feil som oppstår ved brudd på prinsippet om like muligheter for hver enhet av den generelle befolkningen til å delta i utvalget. Forebygging av systematiske feil oppnås som et resultat av bruk av vitenskapelig baserte metoder for dannelse av en utvalgspopulasjon.
Det er følgende måter å velge enheter fra den generelle befolkningen på:
1) individuelt utvalg - individuelle enheter velges i utvalget;
2) gruppeutvelgelse - kvalitativt homogene grupper eller serier av enheter som studeres faller inn i utvalget;
3) kombinert utvalg er en kombinasjon av individuell og gruppeutvalg.
Metoder for seleksjon bestemmes av reglene for dannelsen av prøvetakingspopulasjonen.
Eksemplet kan være:
- skikkelig tilfeldig består i at utvalget er dannet som et resultat av tilfeldig (utilsiktet) utvalg av enkeltenheter fra den generelle befolkningen. I dette tilfellet bestemmes vanligvis antall enheter valgt i prøvesettet basert på den aksepterte andelen av prøven. Utvalgsandelen er forholdet mellom antall enheter i utvalgspopulasjonen n og antall enheter i den generelle befolkningen N, dvs.
- mekanisk består i at utvalget av enheter i utvalget gjøres fra den generelle populasjonen, delt inn i like intervaller (grupper). I dette tilfellet er størrelsen på intervallet i den generelle populasjonen lik den gjensidige andelen av utvalget. Så, med et utvalg på 2 %, velges hver 50. enhet (1:0,02), med en prøve på 5 %, hver 20. enhet (1:0,05), osv. I samsvar med den aksepterte andelen seleksjon er den generelle befolkningen så å si mekanisk delt inn i like grupper. Kun én enhet velges fra hver gruppe i utvalget.
- typisk - hvor den generelle befolkningen først deles inn i homogene typiske grupper. Deretter, fra hver typisk gruppe, gjøres et individuelt utvalg av enheter i utvalget ved hjelp av en tilfeldig eller mekanisk prøve. Et viktig trekk ved en typisk prøve er at den gir mer nøyaktige resultater sammenlignet med andre metoder for å velge enheter i en prøve;
- serie- der den generelle befolkningen er delt inn i grupper av samme størrelse - serier. Serier velges i prøvesettet. Innenfor serien gjennomføres en kontinuerlig observasjon av enhetene som falt inn i serien;
- kombinert- prøvetaking kan være to-trinns. I dette tilfellet blir den generelle befolkningen først delt inn i grupper. Deretter velges gruppene, og innenfor sistnevnte velges individuelle enheter.
I statistikk skilles følgende metoder for å velge enheter i et utvalg::
- enkelt trinn prøve - hver utvalgt enhet blir umiddelbart utsatt for studier på et gitt grunnlag (faktisk tilfeldige og serielle prøver);
- flertrinn utvalg - utvalg gjøres fra den generelle populasjonen av enkeltgrupper, og individuelle enheter velges fra gruppene (et typisk utvalg med en mekanisk metode for å velge enheter i utvalgspopulasjonen).
I tillegg er det:
- gjenvalg- i henhold til skjemaet for den returnerte ballen. I dette tilfellet returneres hver enhet eller serie som har falt i utvalget til den generelle populasjonen og har derfor en sjanse til å bli inkludert i utvalget igjen;
- ikke-repeterende utvalg- i henhold til ordningen med den ikke returnerte ballen. Den har mer nøyaktige resultater for samme prøvestørrelse.
Bestemmelse av nødvendig utvalgsstørrelse (ved hjelp av Students tabell).
Et av de vitenskapelige prinsippene i prøvetakingsteori er å sikre at et tilstrekkelig antall enheter velges. Teoretisk er behovet for å overholde dette prinsippet presentert i bevisene for grensesetningene for sannsynlighetsteori, som lar deg fastslå hvor mange enheter som skal velges fra den generelle befolkningen slik at det er tilstrekkelig og sikrer representativiteten til utvalget.
En reduksjon i standardfeilen til prøven, og følgelig en økning i nøyaktigheten av estimatet er alltid forbundet med en økning i prøvestørrelsen, derfor er det allerede på stadiet for å organisere en prøveobservasjon nødvendig å bestemme hva prøvestørrelsen bør være for å sikre den nødvendige nøyaktigheten av observasjonsresultatene. Beregningen av den nødvendige prøvestørrelsen bygges ved hjelp av formler utledet fra formlene for marginale prøvetakingsfeil (A), tilsvarende en eller annen type og metode for utvelgelse. Så, for en tilfeldig gjentatt prøvestørrelse (n), har vi:

Essensen av denne formelen er at med et tilfeldig omvalg av det nødvendige antallet, er prøvestørrelsen direkte proporsjonal med kvadratet på konfidensen (t2) og varians av variasjonstrekket (?2) og er omvendt proporsjonal med kvadratet av den marginale prøvetakingsfeilen (?2). Spesielt, ved å doble den marginale feilen, kan den nødvendige utvalgsstørrelsen reduseres med en faktor på fire. Av de tre parameterne er to (t og?) satt av forskeren.
Samtidig har forskeren I forbindelse med utvalgsundersøkelsen bør spørsmålet avgjøres: i hvilken kvantitativ kombinasjon er det bedre å inkludere disse parameterne for å gi den optimale varianten? I ett tilfelle kan han være mer fornøyd med påliteligheten til de oppnådde resultatene (t) enn med målingen av nøyaktighet (?), i det andre - omvendt. Det er vanskeligere å løse problemet angående verdien av den marginale prøvetakingsfeilen, siden forskeren ikke har denne indikatoren ved utformingen av en prøveobservasjon, derfor er det i praksis vanlig å sette den marginale prøvetakingsfeilen, som en regel innenfor 10 % av det forventede gjennomsnittlige nivået for egenskapen. Å etablere et antatt gjennomsnittsnivå kan tilnærmes på ulike måter: ved å bruke data fra lignende tidligere undersøkelser, eller ved å bruke data fra utvalgsrammen og ta et lite pilotutvalg.
Det vanskeligste å fastslå når man designer en prøveobservasjon er den tredje parameteren i formel (5.2) - variansen til utvalgspopulasjonen. I dette tilfellet er det nødvendig å bruke all informasjon som er tilgjengelig for etterforskeren, hentet fra tidligere lignende og pilotundersøkelser.
Definisjonsspørsmål Den nødvendige utvalgsstørrelsen blir mer komplisert hvis utvalgsundersøkelsen involverer studier av flere funksjoner ved utvalgsenheter. I dette tilfellet er gjennomsnittsnivåene for hver av egenskapene og deres variasjon, som regel, forskjellige, og derfor er det mulig å bestemme hvilken spredning av hvilke av egenskapene som skal foretrekkes, bare under hensyntagen til formålet og målene med undersøkelsen.
Ved utforming av en prøveobservasjon antas en forhåndsbestemt verdi av den tillatte prøvetakingsfeilen i samsvar med målene for en bestemt studie og sannsynligheten for konklusjoner basert på resultatene av observasjonen.
Generelt lar formelen for den marginale feilen til prøvemiddelverdien deg bestemme:
Størrelsen på mulige avvik for indikatorene for den generelle befolkningen fra indikatorene for utvalgspopulasjonen;
Den nødvendige prøvestørrelsen, som gir den nødvendige nøyaktigheten, der grensene for en mulig feil ikke vil overstige en viss spesifisert verdi;
Sannsynligheten for at feilen i utvalget vil ha en gitt grense.
Elevens fordeling i sannsynlighetsteori er det en én-parameter familie av absolutt kontinuerlige distribusjoner.
Serier av dynamikk (intervall, moment), lukking av serier av dynamikk.
Serie av dynamikk- dette er verdiene til statistiske indikatorer som presenteres i en viss kronologisk sekvens.
Hver tidsserie inneholder to komponenter:
1) indikatorer for tidsperioder (år, kvartaler, måneder, dager eller datoer);
2) indikatorer som karakteriserer objektet som studeres for tidsperioder eller på tilsvarende datoer, som kalles seriens nivåer.
Nivåene i serien er uttrykt både absolutte og gjennomsnittlige eller relative verdier. Avhengig av arten av indikatorene bygges dynamiske serier av absolutte, relative og gjennomsnittlige verdier. Dynamiske serier av relative og gjennomsnittlige verdier bygges på grunnlag av avledede serier av absolutte verdier. Det er intervall- og momentserier av dynamikk.
Dynamisk intervallserie inneholder verdiene til indikatorer for visse tidsperioder. I intervallseriene kan nivåene summeres ved å få volumet av fenomenet for en lengre periode, eller såkalte akkumulerte totaler.
Dynamisk øyeblikksserie reflekterer verdiene til indikatorer på et bestemt tidspunkt (tidspunkt). I øyeblikksserier kan forskeren bare være interessert i forskjellen mellom fenomener, noe som gjenspeiler endringen i nivået til serien mellom bestemte datoer, siden summen av nivåene her ikke har noe reelt innhold. Akkumulerte totaler er ikke beregnet her.
Den viktigste betingelsen for riktig konstruksjon av dynamiske serier er sammenlignbarheten av nivåene av serier knyttet til ulike perioder. Nivåer bør presenteres i homogene mengder, det bør være samme fullstendighet av dekning av ulike deler av fenomenet.
Til For å unngå å forvrenge den virkelige dynamikken, utføres foreløpige beregninger i den statistiske studien (lukkingen av tidsserien), som går foran den statistiske analysen av tidsserien. Lukking av tidsserier forstås som kombinasjonen av to eller flere serier til én serie, hvis nivåer er beregnet i henhold til annen metodikk eller ikke samsvarer med territorielle grenser osv. Lukkingen av dynamikkserien kan også innebære reduksjon av de absolutte nivåene til dynamikkseriene til et felles grunnlag, noe som eliminerer inkompatibiliteten til nivåene til dynamikkseriene.
Konseptet med sammenlignbarhet av tidsserier, koeffisienter, vekst og vekstrater.
Serie av dynamikk- dette er serier av statistiske indikatorer som karakteriserer utviklingen av naturlige og sosiale fenomener i tid. Statistiske samlinger utgitt av Statens statistikkkomité i Russland inneholder et stort antall tidsserier i tabellform. Serier av dynamikk tillater avslørende mønstre for utvikling av de studerte fenomenene.
Tidsserier inneholder to typer indikatorer. Tidsindikatorer(år, kvartaler, måneder osv.) eller tidspunkter (i begynnelsen av året, i begynnelsen av hver måned osv.). Radnivåindikatorer. Indikatorer for nivåene av tidsserier kan uttrykkes i absolutte verdier (produksjon av et produkt i tonn eller rubler), relative verdier (andel av bybefolkningen i%) og gjennomsnittsverdier (gjennomsnittlig lønn for industriarbeidere) etter år osv.). I tabellform inneholder tidsserien to kolonner eller to rader.
Riktig konstruksjon av tidsserier innebærer oppfyllelse av en rekke krav:
- alle indikatorer på en rekke dynamikker må være vitenskapelig underbygget, pålitelige;
- indikatorer for en rekke dynamikker bør være sammenlignbare i tid, dvs. må beregnes for samme tidsperioder eller på samme datoer;
- indikatorer for en rekke dynamikker bør være sammenlignbare på tvers av territoriet;
- indikatorer for en serie dynamikker bør være sammenlignbare i innhold, dvs. beregnet i henhold til en enkelt metodikk, på samme måte;
- indikatorer for en rekke dynamikker bør være sammenlignbare på tvers av utvalget av gårder som vurderes. Alle indikatorer for en serie av dynamikk skal gis i samme måleenheter.
Statistiske indikatorer kan karakterisere enten resultatene av prosessen som studeres over en periode, eller tilstanden til fenomenet som studeres på et bestemt tidspunkt, dvs. indikatorer kan være intervall (periodisk) og øyeblikkelig. Følgelig kan serien av dynamikk i utgangspunktet være enten intervall eller moment. Momentserien med dynamikk kan på sin side være med like og ulikt tidsintervaller.
Den innledende serien med dynamikk kan konverteres til en serie gjennomsnittsverdier og en serie relative verdier (kjede og base). Slike tidsserier kalles avledede tidsserier.
Metoden for å beregne gjennomsnittsnivået i serien av dynamikk er forskjellig, på grunn av typen av serier av dynamikk. Bruk eksempler, vurder typene av tidsserier og formler for å beregne gjennomsnittsnivået.
Absolutte gevinster (Δy) viser hvor mange enheter det påfølgende nivået i serien har endret seg i forhold til det forrige (kolonne 3. - kjede absolutte inkrementer) eller sammenlignet med initialnivået (kolonne 4. - grunnleggende absolutte inkrementer). Beregningsformlene kan skrives som følger:

Med en nedgang i seriens absolutte verdier vil det være henholdsvis en "reduksjon", "reduksjon".
Indikatorene for absolutt vekst indikerer at for eksempel i 1998 økte produksjonen av produkt "A" med 4 000 tonn sammenlignet med 1997, og med 34 000 tonn sammenlignet med 1994; for andre år, se tabell. 11,5 gr. 3 og 4.
Vekstfaktor viser hvor mange ganger nivået i serien har endret seg sammenlignet med den forrige (kolonne 5 - kjedevekst- eller nedgangsfaktorer) eller sammenlignet med initialnivået (kolonne 6 - grunnleggende vekst- eller nedgangsfaktorer). Beregningsformlene kan skrives som følger:

Veksthastigheter vis hvor mange prosent neste nivå i serien er sammenlignet med det forrige (kolonne 7 - kjedeveksthastigheter) eller sammenlignet med startnivået (kolonne 8 - grunnleggende vekstrater). Beregningsformlene kan skrives som følger:

Så, for eksempel, i 1997 var produksjonsvolumet av produkt "A" sammenlignet med 1996 105,5% (
Vekstrater vis hvor mange prosent nivået i rapporteringsperioden økte sammenlignet med den forrige (kolonne 9 - kjedeveksthastigheter) eller sammenlignet med initialnivået (kolonne 10 - grunnleggende vekstrater). Beregningsformlene kan skrives som følger:
T pr \u003d T p - 100% eller T pr \u003d absolutt økning / nivå av forrige periode * 100%
Så, for eksempel, i 1996, sammenlignet med 1995, ble produktet "A" produsert mer med 3,8 % (103,8 % - 100 %) eller (8:210) x 100 %, og sammenlignet med 1994. - med 9 % ( 109 % - 100 %).
Hvis de absolutte nivåene i serien synker, vil hastigheten være mindre enn 100%, og følgelig vil det være en nedgang (veksthastighet med et minustegn).
Absolutt verdi på 1 % økning(kolonne 11) viser hvor mange enheter som må produseres i en gitt periode for at nivået i forrige periode skal øke med 1 %. I vårt eksempel var det i 1995 nødvendig å produsere 2,0 tusen tonn, og i 1998 - 2,3 tusen tonn, dvs. mye større.
Det er to måter å bestemme størrelsen på den absolutte verdien av 1% vekst:
Del nivået for forrige periode med 100;
Del de absolutte kjedevekstratene med tilsvarende kjedeveksthastigheter.
Absolutt verdi på 1 % økning = 
I dynamikk, spesielt over en lang periode, er det viktig å i fellesskap analysere veksthastigheten med innholdet i hver prosentvis økning eller reduksjon.
Merk at den betraktede metodikken for å analysere tidsserier er anvendelig både for tidsserier, hvis nivåer er uttrykt i absolutte verdier (t, tusen rubler, antall ansatte, etc.), og for tidsserier, nivåene av som er uttrykt i relative indikatorer (% av skrap, % askeinnhold av kull, etc.) eller gjennomsnittsverdier (gjennomsnittlig avling i c/ha, gjennomsnittlig lønn osv.).
Sammen med de betraktede analytiske indikatorene beregnet for hvert år i sammenligning med forrige eller innledende nivå, når man analyserer tidsserien, er det nødvendig å beregne gjennomsnittlige analytiske indikatorer for perioden: gjennomsnittsnivået for serien, den gjennomsnittlige årlige absolutte økningen (nedgang) og gjennomsnittlig årlig vekstrate og vekstrate.
Metoder for å beregne gjennomsnittsnivået til en serie av dynamikk ble diskutert ovenfor. I intervallserien med dynamikk vi vurderer, beregnes gjennomsnittsnivået til serien ved formelen for det aritmetiske gjennomsnittet enkelt:
Gjennomsnittlig årlig produksjon av produktet for 1994-1998. utgjorde 218,4 tusen tonn.
Den gjennomsnittlige årlige absolutte økningen beregnes også ved formelen for det enkle aritmetiske gjennomsnittet:
Årlige absolutte økninger varierte over årene fra 4 til 12 tusen tonn (se gr. 3), og gjennomsnittlig årlig produksjonsøkning for perioden 1995 - 1998. utgjorde 8,5 tusen tonn.
Metoder for å beregne gjennomsnittlig vekstrate og gjennomsnittlig vekstrate krever mer detaljerte vurderinger. La oss vurdere dem på eksemplet med de årlige indikatorene for serienivået gitt i tabellen.
Det midterste nivået av dynamikkspekteret.
Serier med dynamikk (eller tidsserier)- dette er de numeriske verdiene til en viss statistisk indikator i påfølgende øyeblikk eller tidsperioder (dvs. arrangert i kronologisk rekkefølge).
De numeriske verdiene til en bestemt statistisk indikator som utgjør en serie med dynamikk kalles nivåer av et tall og er vanligvis betegnet med bokstaven y. Første medlem av serien y 1 kalt initial eller grunnlinje, og den siste y n - endelig. Momentene eller tidsperiodene som nivåene refererer til, er angitt med t.
Dynamiske serier presenteres som regel i form av en tabell eller graf, og en tidsskala bygges langs x-aksen t, og langs ordinaten - skalaen til nivåene i serien y.
Gjennomsnittlige indikatorer for en serie av dynamikk
Hver serie med dynamikk kan betraktes som et bestemt sett n tidsvarierende indikatorer som kan oppsummeres som gjennomsnitt. Slike generaliserte (gjennomsnittlige) indikatorer er spesielt nødvendige når man sammenligner endringer i en eller annen indikator i ulike perioder, i ulike land osv.
Et generalisert kjennetegn ved en serie dynamikker kan for det første være: gjennomsnittlig radnivå. Metoden for å beregne gjennomsnittsnivået avhenger av om det er en momentserie eller en intervallserie (periode).
Når intervall serie, bestemmes gjennomsnittsnivået av formelen til et enkelt aritmetisk gjennomsnitt av nivåene i serien, dvs.
=
Hvis tilgjengelig øyeblikk rad som inneholder n nivåer ( y1, y2, …, yn) med like intervaller mellom datoer (tidspunkter), så kan en slik serie enkelt konverteres til en rekke gjennomsnittsverdier. Samtidig er indikatoren (nivået) ved begynnelsen av hver periode samtidig indikatoren ved slutten av forrige periode. Deretter kan gjennomsnittsverdien av indikatoren for hver periode (intervall mellom datoer) beregnes som en halv sum av verdiene på i begynnelsen og slutten av perioden, dvs. hvordan . Antallet slike gjennomsnitt vil være . Som nevnt tidligere, for serier av gjennomsnitt, beregnes gjennomsnittsnivået fra det aritmetiske gjennomsnittet.
Derfor kan vi skrive: .
.
Etter å ha konvertert telleren får vi: ,
,
hvor Y1 og Yn- det første og siste nivået i serien; Yi- mellomnivå.
Dette gjennomsnittet er kjent i statistikk som gjennomsnittlig kronologisk for øyeblikksserier. Hun fikk dette navnet fra ordet "cronos" (tid, lat.), da det beregnes ut fra indikatorer som endrer seg over tid.
Ved ulikhet intervaller mellom datoer, kan det kronologiske gjennomsnittet for øyeblikksserien beregnes som det aritmetiske gjennomsnittet av gjennomsnittsverdiene av nivåene for hvert par av øyeblikk, vektet av avstandene (tidsintervallene) mellom datoene, dvs.  .
.
I dette tilfellet det antas at i intervallene mellom datoene fikk nivåene forskjellige verdier, og vi er fra to kjente ( yi og yi+1) bestemmer vi gjennomsnittene, hvorfra vi så beregner det totale gjennomsnittet for hele den analyserte perioden.
Hvis det antas at hver verdi yi forblir uendret til neste (i+ 1)-
øyeblikket, dvs. den nøyaktige datoen for endringen i nivåene er kjent, så kan beregningen utføres ved å bruke den vektede aritmetiske gjennomsnittsformelen:
,
hvor er tiden da nivået forble uendret.
I tillegg til gjennomsnittsnivået i serien med dynamikk, beregnes også andre gjennomsnittsindikatorer - gjennomsnittlig endring i nivåene til serien (grunnleggende og kjedemetoder), gjennomsnittlig endringshastighet.
Grunnlinje betyr absolutt endring er kvotienten av den siste grunnleggende absolutte endringen delt på antall endringer. Det er
Kjede betyr absolutt endring nivåer av en serie er kvotienten for å dele summen av alle kjede absolutte endringer med antall endringer, dvs.
Ved fortegnet for de gjennomsnittlige absolutte endringene bedømmes også karakteren av endringen i fenomenet i gjennomsnitt: vekst, nedgang eller stabilitet.
Av regelen for kontroll av grunnleggende og kjedeabsolutte endringer følger det at grunn- og kjedegjennomsnittsendringene må være like.
Sammen med den gjennomsnittlige absolutte endringen beregnes også den gjennomsnittlige relative ved hjelp av basis- og kjedemetodene.
Grunnlinje gjennomsnittlig relativ endring bestemmes av formelen:
Kjede betyr relativ endring bestemmes av formelen:
Naturligvis bør de grunnleggende og kjedegjennomsnittlige relative endringene være de samme, og ved å sammenligne dem med kriterieverdien 1, konkluderes det om karakteren av endringen i fenomenet i gjennomsnitt: vekst, nedgang eller stabilitet.
Ved å trekke 1 fra basis- eller kjedens gjennomsnittlig relative endring, vil den tilsvarende gjennomsnittlig endringshastighet, etter tegnet som man også kan bedømme arten av endringen i fenomenet som studeres, reflektert av denne serien av dynamikk.
Sesongsvingninger og sesongindekser.
Sesongsvingninger er stabile intraårlige svingninger.
Grunnprinsippet for å klare å oppnå maksimal effekt er maksimering av inntekt og minimering av kostnader. Ved å studere sesongsvingninger løses problemet med maksimumsligningen på hvert nivå av året.
Når man studerer sesongsvingninger, løses to sammenhengende oppgaver:
1. Identifikasjon av spesifikasjonene for utviklingen av fenomenet i intra-årlig dynamikk;
2. Måling av sesongsvingninger med konstruksjon av en sesongbølgemodell;
Sesongkalkuner telles vanligvis for å måle sesongvariasjoner. Generelt sett bestemmes de av forholdet mellom de opprinnelige ligningene til en serie dynamikk og de teoretiske ligningene som tjener som sammenligningsgrunnlag.
Siden tilfeldige avvik legges over sesongsvingninger, beregnes gjennomsnittsindeksene for sesongvariasjoner for å eliminere dem.
I dette tilfellet, for hver periode av årssyklusen, bestemmes generaliserte indikatorer i form av gjennomsnittlige sesongindekser:
Gjennomsnittlige indekser for sesongsvingninger er fri for påvirkning av tilfeldige avvik fra hovedutviklingstrenden.
Avhengig av arten av trenden, kan formelen for den gjennomsnittlige sesongindeksen ha følgende former:
1.For serier med intra-årlig dynamikk med en uttalt hovedutviklingstrend:
2. For serien av intra-årlig dynamikk der det ikke er noen oppadgående eller nedadgående trend, eller er ubetydelig:
Hvor er det generelle gjennomsnittet;
Metoder for å analysere hovedtrenden.
Utviklingen av fenomener over tid påvirkes av faktorer som er forskjellige i natur og påvirkningsstyrke. Noen av dem er tilfeldige i naturen, andre har en nesten konstant effekt og danner en viss utviklingstrend i rekken av dynamikk.
En viktig oppgave med statistikk er å identifisere en trend i serien av dynamikk, frigjort fra virkningen av ulike tilfeldige faktorer. For dette formålet behandles tidsseriene ved hjelp av metodene for intervallforstørrelse, glidende gjennomsnitt og analytisk justering, etc.
Intervallgrovningsmetode er basert på utvidelse av tidsperioder, som inkluderer nivåene til en serie av dynamikk, dvs. er erstatning av data knyttet til små tidsperioder med data fra større perioder. Det er spesielt effektivt når de første nivåene i serien er i korte perioder. For eksempel erstattes serier med indikatorer knyttet til daglige hendelser med serier knyttet til ukentlig, månedlig osv. Dette vil tydeligere vise seg "Fenomenets utviklingsakse". Gjennomsnittet, beregnet på grunnlag av forstørrede intervaller, gjør det mulig å identifisere retningen og karakteren (vekstakselerasjon eller retardasjon) til hovedutviklingstrenden.
glidende gjennomsnittsmetode lik den forrige, men i dette tilfellet erstattes de faktiske nivåene med gjennomsnittsnivåer beregnet for suksessivt bevegelige (glidende) forstørrede intervaller som dekker m radnivåer.
For eksempel hvis akseptert m=3, deretter beregnes først gjennomsnittet av de tre første nivåene i serien, deretter - fra samme antall nivåer, men fra det andre på rad, deretter - fra det tredje osv. Dermed "sklir" gjennomsnittet, som det var, langs serien av dynamikk, og beveger seg i en periode. Beregnet fra m medlemmer av de bevegelige gjennomsnittene refererer til midten (sentrum) av hvert intervall.
Denne metoden eliminerer bare tilfeldige svingninger. Hvis serien har en sesongbasert bølge, vil den forbli etter utjevning med glidende gjennomsnittsmetode.
Analytisk justering. For å eliminere tilfeldige svingninger og identifisere en trend, er nivåene i serien justert i henhold til analytiske formler (eller analytisk justering). Essensen er å erstatte empiriske (faktiske) nivåer med teoretiske nivåer, som beregnes i henhold til en viss ligning, tatt som en matematisk modell av trenden, der teoretiske nivåer betraktes som en funksjon av tid: . I dette tilfellet betraktes hvert faktisk nivå som summen av to komponenter: , hvor er en systematisk komponent og uttrykt ved en viss ligning, og er en tilfeldig variabel som forårsaker svingninger rundt trenden.
Oppgaven med analytisk justering er som følger:
1. Bestemme på grunnlag av faktiske data hvilken type hypotetisk funksjon som best kan reflektere utviklingstrenden til indikatoren som studeres.
2. Finne parametrene til den spesifiserte funksjonen (ligningen) fra empiriske data
3. Beregning i henhold til den funnet ligningen av teoretiske (jevnede) nivåer.
Valget av en bestemt funksjon utføres som regel på grunnlag av en grafisk representasjon av empiriske data.
Modellene er regresjonsligninger, hvis parametere er beregnet etter minste kvadraters metode
Nedenfor er de mest brukte regresjonsligningene for utjevning av tidsserier, som indikerer hvilke utviklingstrender de er mest egnet til å reflektere.
For å finne parametrene til ligningene ovenfor, er det spesielle algoritmer og dataprogrammer. Spesielt for å finne parametrene til ligningen til en rett linje, kan følgende algoritme brukes:

Hvis periodene eller øyeblikkene er nummerert slik at St = 0 oppnås, vil algoritmene ovenfor bli betydelig forenklet og bli til

De justerte nivåene på kartet vil være plassert på én rett linje som passerer i nærmeste avstand fra de faktiske nivåene i denne dynamiske serien. Summen av kvadrerte avvik er en refleksjon av påvirkningen av tilfeldige faktorer.
Med dens hjelp beregner vi den gjennomsnittlige (standard) feilen til ligningen:

Her er n antall observasjoner, og m er antall parametere i ligningen (vi har to av dem - b 1 og b 0).
Hovedtrenden (trenden) viser hvordan systematiske faktorer påvirker nivåene til en serie av dynamikk, og svingningen av nivåer rundt trenden () fungerer som et mål på effekten av gjenværende faktorer.
For å vurdere kvaliteten på tidsseriemodellen som brukes, brukes den også Fishers F-test. Det er forholdet mellom to varianser, nemlig forholdet mellom variansen forårsaket av regresjonen, dvs. studert faktor, til spredningen forårsaket av tilfeldige årsaker, dvs. gjenværende varians:
![]()
I utvidet form kan formelen for dette kriteriet representeres som følger:
![]()
hvor n er antall observasjoner, dvs. antall radnivåer,
m er antall parametere i ligningen, y er det faktiske nivået av serien,
Justert nivå for raden, - gjennomsnittsnivået for raden.
Mer vellykket enn andre, modellen er kanskje ikke alltid tilstrekkelig tilfredsstillende. Den kan bare gjenkjennes som sådan hvis kriteriet F for den krysser en viss kritisk grense. Denne grensen settes ved hjelp av F-fordelingstabeller.
Essens og klassifisering av indekser.
En indeks i statistikk er forstått som en relativ indikator som karakteriserer endringen i størrelsen på et fenomen i tid, rom eller i sammenligning med en hvilken som helst standard.
Hovedelementet i indeksrelasjonen er den indekserte verdien. En indeksert verdi forstås som verdien av et tegn for en statistisk populasjon, hvis endring er gjenstand for studiet.
Indekser tjener tre hovedformål:
1) vurdering av endringer i et komplekst fenomen;
2) bestemmelse av påvirkningen av individuelle faktorer på endringen av et komplekst fenomen;
3) sammenligning av størrelsen på et eller annet fenomen med størrelsen på den siste perioden, størrelsen på et annet territorium, så vel som med standarder, planer, prognoser.
Indeksene er klassifisert etter 3 kriterier:
2) etter graden av dekning av elementene i befolkningen;
3) ved metoder for å beregne generelle indekser.
Etter innhold av indekserte verdier er indeksene delt inn i indekser for kvantitative (volumetriske) indikatorer og indekser for kvalitative indikatorer. Indekser av kvantitative indikatorer - indekser for fysisk volum av industriell produksjon, fysisk volum av salg, antall, etc. Indekser av kvalitative indikatorer - indekser for priser, kostnader, arbeidsproduktivitet, gjennomsnittlig lønn, etc.
I henhold til graden av dekning av enheter i befolkningen er indeksene delt inn i to klasser: individuelle og generelle. For å karakterisere dem introduserer vi følgende konvensjoner brukt i praksisen med å bruke indeksmetoden:
q- mengde (volum) av ethvert produkt i natura ; R- enhetspris for produksjon; z- enhetskostnad for produksjon; t- tid brukt på produksjon av en produksjonsenhet (arbeidsintensitet) ; w- produksjonsproduksjon i verdi per tidsenhet; v- produksjon i fysiske termer per tidsenhet; T- total tidsbruk eller antall ansatte.
For å skille hvilken periode eller objekt de indekserte verdiene tilhører, er det vanlig å sette abonnenter etter det tilsvarende symbolet nederst til høyre. Så, for eksempel, i dynamikkindeksene, som regel, for de sammenlignede (gjeldende, rapporterende) periodene, brukes abonnenten 1 og for periodene som sammenligningen gjøres med,
Individuelle indekser tjene til å karakterisere endringen i individuelle elementer av et komplekst fenomen (for eksempel en endring i produksjonsvolumet for en type produkt). De representerer de relative verdiene av dynamikk, oppfyllelse av forpliktelser, sammenligning av indekserte verdier.
Den individuelle indeksen for det fysiske produksjonsvolumet bestemmes
Fra et analytisk synspunkt er de gitte individuelle dynamikkindeksene lik vekstkoeffisientene (ratene) og karakteriserer endringen i den indekserte verdien i inneværende periode sammenlignet med basisen, dvs. viser hvor mange ganger den har økt (redusert) ) eller hvor mange prosent det er vekst (nedgang). Indeksverdier er uttrykt i koeffisienter eller prosenter.
Generell (sammensatt) indeks reflekterer endringen i alle elementer i et komplekst fenomen.
Samlet indeks er den grunnleggende formen for indeksen. Det kalles aggregat fordi telleren og nevneren er et sett med "aggregat"
Gjennomsnittlige indekser, deres definisjon.
I tillegg til aggregerte indekser, brukes en annen form for dem i statistikken - vektede gjennomsnittsindekser. Beregningen deres brukes når den tilgjengelige informasjonen ikke tillater beregning av den generelle aggregerte indeksen. Så hvis det ikke er data om priser, men det er informasjon om kostnadene for produkter i inneværende periode og individuelle prisindekser for hvert produkt er kjent, kan den generelle prisindeksen ikke bestemmes som en samlet, men det er mulig å beregne det som et gjennomsnitt av individuelle. På samme måte, hvis mengdene av enkeltprodukter produsert ikke er kjent, men de individuelle indeksene og produksjonskostnadene for basisperioden er kjent, kan den samlede indeksen for det fysiske produksjonsvolumet bestemmes som et vektet gjennomsnitt.
Gjennomsnittlig indeks - dette er en indeks beregnet som et gjennomsnitt av individuelle indekser. Den aggregerte indeksen er den grunnleggende formen for den generelle indeksen, så gjennomsnittsindeksen må være identisk med den aggregerte indeksen. Ved beregning av gjennomsnittsindekser brukes to former for gjennomsnitt: aritmetiske og harmoniske.
Den aritmetiske gjennomsnittsindeksen er identisk med den aggregerte indeksen dersom vektene til de enkelte indeksene er vilkårene for nevneren til den aggregerte indeksen. Bare i dette tilfellet vil verdien av indeksen beregnet av den aritmetiske gjennomsnittsformelen være lik den samlede indeksen.
Det er definert som en generaliserende karakteristikk av størrelsen på variasjonen til en egenskap i aggregatet. Det er lik kvadratroten av gjennomsnittlig kvadrat av avvikene til de individuelle verdiene til funksjonen fra det aritmetiske gjennomsnittet, dvs. roten til og kan bli funnet slik:
1. For den primære raden:
2. For en variantserie:

Transformasjonen av standardavviksformelen fører den til en form som er mer praktisk for praktiske beregninger:
Standardavvik bestemmer hvor mye, i gjennomsnitt, spesifikke alternativer avviker fra deres gjennomsnittsverdi, og dessuten er det et absolutt mål på egenskapsfluktuasjonen og uttrykkes i de samme enhetene som alternativene, og er derfor godt tolket.
Eksempler på å finne standardavviket: ,
For alternative funksjoner ser formelen for standardavviket slik ut:
![]()
hvor p er andelen enheter i populasjonen som har en bestemt egenskap;
q - andelen enheter som ikke har denne funksjonen.
Begrepet gjennomsnittlig lineært avvik
Gjennomsnittlig lineært avvik er definert som det aritmetiske gjennomsnittet av de absolutte verdiene av avvikene til individuelle opsjoner fra .
1. For den primære raden:

2. For en variantserie:
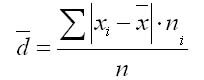
hvor summen av n er summen av frekvensene til variasjonsseriene.
Et eksempel på å finne gjennomsnittlig lineært avvik:
Fordelen med gjennomsnittlig absolutt avvik som mål på spredning over variasjonsområdet er åpenbar, siden dette målet er basert på å ta hensyn til alle mulige avvik. Men denne indikatoren har betydelige ulemper. Vilkårlig avvisning av algebraiske tegn på avvik kan føre til at de matematiske egenskapene til denne indikatoren er langt fra elementære. Dette kompliserer i stor grad bruken av gjennomsnittlig absolutt avvik for å løse problemer knyttet til sannsynlighetsberegninger.
Derfor brukes det gjennomsnittlige lineære avviket som et mål på variasjonen til et trekk sjelden i statistisk praksis, nemlig når summering av indikatorer uten å ta hensyn til tegn gir økonomisk mening. Med dens hjelp analyseres for eksempel omsetningen i utenrikshandelen, sammensetningen av ansatte, produksjonsrytmen osv.
rot betyr kvadrat
RMS brukt, for eksempel for å beregne den gjennomsnittlige størrelsen på sidene av n kvadratiske seksjoner, gjennomsnittsdiametrene til stammer, rør, etc. Det er delt inn i to typer.
Rotens middelkvadrat er enkel. Hvis det, når du erstatter individuelle verdier av en egenskap med en gjennomsnittsverdi, er nødvendig å holde summen av kvadrater av de opprinnelige verdiene uendret, vil gjennomsnittet være et kvadratisk gjennomsnitt.
Det er kvadratroten av kvotienten av summen av kvadrater av individuelle funksjonsverdier delt på antallet:
Gjennomsnittlig kvadrat vektet beregnes med formelen:

hvor f er et tegn på vekt.
Gjennomsnittlig kubikk
Gjennomsnittlig kubikk brukt, for eksempel ved bestemmelse av gjennomsnittlig sidelengde og terninger. Den er delt inn i to typer.
Gjennomsnittlig kubikk enkel:


Ved beregning av gjennomsnittsverdier og spredning i intervallfordelingsserien, erstattes de sanne verdiene for attributtet med de sentrale verdiene for intervallene, som er forskjellige fra det aritmetiske gjennomsnittet av verdiene inkludert i intervall. Dette fører til en systematisk feil i beregningen av variansen. V.F. Sheppard bestemte det feil i variansberegningen, forårsaket av å bruke de grupperte dataene, er 1/12 av kvadratet av intervallverdien, både oppover og nedover i størrelsen på variansen.
Sheppard-tillegg bør brukes hvis fordelingen er nær normalen, refererer til en funksjon med en kontinuerlig variasjon, bygget på en betydelig mengde initialdata (n> 500). Men basert på det faktum at begge feilene, som virker i forskjellige retninger, kompenserer hverandre i en rekke tilfeller, er det noen ganger mulig å nekte å innføre endringer.
Jo mindre varians og standardavvik er, jo mer homogen blir populasjonen og jo mer typisk vil gjennomsnittet være.
I praksis med statistikk blir det ofte nødvendig å sammenligne variasjoner av ulike funksjoner. For eksempel er det av stor interesse å sammenligne variasjoner i arbeidstakernes alder og deres kvalifikasjoner, tjenestetid og lønn, kostnad og fortjeneste, tjenestetid og arbeidsproduktivitet mv. For slike sammenligninger er indikatorer på den absolutte variasjonen av egenskaper uegnet: det er umulig å sammenligne variasjonen i arbeidserfaring, uttrykt i år, med variasjonen av lønn, uttrykt i rubler.
For å utføre slike sammenligninger, samt sammenligninger av fluktuasjonen til samme attributt i flere populasjoner med forskjellig aritmetisk gjennomsnitt, brukes en relativ variasjonsindikator - variasjonskoeffisienten.
Strukturelle gjennomsnitt
For å karakterisere den sentrale trenden i statistiske fordelinger er det ofte rasjonelt å bruke, sammen med det aritmetiske gjennomsnittet, en viss verdi av attributtet X, som på grunn av visse trekk ved dens plassering i distribusjonsserien kan karakterisere nivået.
Dette er spesielt viktig når ekstremverdiene til funksjonen i distribusjonsserien har uklare grenser. I denne forbindelse er den nøyaktige bestemmelsen av det aritmetiske gjennomsnittet som regel umulig eller veldig vanskelig. I slike tilfeller kan gjennomsnittsnivået bestemmes ved å ta for eksempel funksjonsverdien som er plassert i midten av frekvensserien eller som forekommer oftest i den aktuelle serien.
Slike verdier avhenger bare av frekvensenes natur, dvs. strukturen til fordelingen. De er typiske når det gjelder plassering i frekvensserien, derfor betraktes slike verdier som egenskaper for distribusjonssenteret og har derfor blitt definert som strukturelle gjennomsnitt. De brukes til å studere den interne strukturen og strukturen til serien med distribusjon av attributtverdier. Disse indikatorene inkluderer.
Standardavvik er en klassisk indikator på variabilitet fra beskrivende statistikk.
Standardavvik, standardavvik, RMS, prøvestandardavvik (engelsk standardavvik, STD, STDev) er et veldig vanlig mål for spredning i beskrivende statistikk. Men fordi teknisk analyse er beslektet med statistikk, denne indikatoren kan (og bør) brukes i teknisk analyse for å oppdage graden av spredning av prisen på det analyserte instrumentet over tid. Angitt med det greske symbolet Sigma "σ".
Takk til Karl Gauss og Pearson for at vi har mulighet til å bruke standardavviket.
Ved hjelp av standardavvik i teknisk analyse, snur vi dette "spredningsindeks"i "volatilitetsindikator«Beholde meningen, men endre begrepene.
Hva er standardavvik
Men i tillegg til mellomliggende hjelpeberegninger, standardavvik er ganske akseptabelt for selvberegning og applikasjoner innen teknisk analyse. Som bemerket av en aktiv leser av vårt magasinburdock, " Jeg forstår fortsatt ikke hvorfor RMS ikke er inkludert i settet med standardindikatorer for innenlandske handelssentre«.
Egentlig, standardavvik kan på en klassisk og "ren" måte måle variabiliteten til et instrument. Men dessverre er ikke denne indikatoren så vanlig i verdipapiranalyse.
Bruk av standardavviket
Manuell beregning av standardavviket er lite interessant. men nyttig for erfaring. Standardavviket kan uttrykkes formel STD=√[(∑(x-x ) 2)/n] , som høres ut som rotsummen av kvadrerte forskjeller mellom prøveelementene og gjennomsnittet, delt på antall elementer i prøven.
Hvis antallet elementer i prøven overstiger 30, får nevneren til brøken under roten verdien n-1. Ellers brukes n.
steg for steg standardavviksberegning:
- beregne det aritmetiske gjennomsnittet av datautvalget
- trekk dette gjennomsnittet fra hvert element i prøven
- alle resulterende forskjeller kvadreres
- summer alle de resulterende kvadratene
- del den resulterende summen med antall elementer i prøven (eller med n-1 hvis n>30)
- beregne kvadratroten av den resulterende kvotienten (kalt spredning)
For å beregne det geometriske gjennomsnittet enkelt, brukes formelen:
geometrisk vektet
For å bestemme det geometriske vektede gjennomsnittet, brukes formelen:
Gjennomsnittlig diameter på hjul, rør, gjennomsnittssidene av kvadratene bestemmes ved hjelp av rotmiddelkvadrat.
RMS-verdier brukes til å beregne noen indikatorer, for eksempel variasjonskoeffisienten, som karakteriserer utgangsrytmen. Her bestemmes standardavviket fra den planlagte produksjonen for en viss periode av følgende formel:
Disse verdiene karakteriserer nøyaktig endringen i økonomiske indikatorer sammenlignet med deres grunnverdi, tatt i gjennomsnittsverdien.
Kvadratisk enkel
Den enkle midlere kvadratet beregnes med formelen:

Kvadratisk vektet
Den vektede rotmiddelkvadraten er:

22. Absolutte variasjonsmål inkluderer:
variasjonsspekter
gjennomsnittlig lineært avvik
spredning
standardavvik
Variasjonsområde (r)
Spennvariasjon er forskjellen mellom maksimums- og minimumsverdiene for attributtet
Den viser grensene der verdien av attributtet endres i den studerte populasjonen.
Arbeidserfaringen til fem søkere i forrige jobb er: 2,3,4,7 og 9 år. Løsning: variasjonsområde = 9 - 2 = 7 år.
For en generalisert karakteristikk av forskjellene i verdiene til attributtet, beregnes de gjennomsnittlige variasjonsindikatorene basert på tillatelsen for avvik fra det aritmetiske gjennomsnittet. Forskjellen tas som avvik fra gjennomsnittet.
Samtidig, for å unngå å bli til null summen av avvik av egenskapsalternativene fra gjennomsnittet (nullegenskapen til gjennomsnittet), må man enten ignorere tegnene på avviket, det vil si ta denne summen modulo , eller kvadrere avviksverdiene
Gjennomsnittlig lineært og kvadratisk avvik
Gjennomsnittlig lineært avvik er det aritmetiske gjennomsnittet av de absolutte avvikene til de individuelle verdiene til attributtet fra gjennomsnittet.
Det gjennomsnittlige lineære avviket er enkelt:
Arbeidserfaringen til fem søkere i forrige jobb er: 2,3,4,7 og 9 år.
I vårt eksempel: år;
Svar: 2,4 år.
Gjennomsnittlig lineært avvik vektet gjelder grupperte data:
Det gjennomsnittlige lineære avviket, på grunn av dets konvensjonalitet, brukes relativt sjelden i praksis (spesielt for å karakterisere oppfyllelsen av kontraktsmessige forpliktelser når det gjelder enhetlig levering; i analysen av produktkvalitet, tatt i betraktning de teknologiske egenskapene til produksjonen ).
Standardavvik
Den mest perfekte egenskapen til variasjon er standardavviket, som kalles standarden (eller standardavviket). Standardavvik() er lik kvadratroten av middelkvadraten av avvikene til de individuelle verdiene til attributtet fra det aritmetiske gjennomsnittet:
Standardavviket er enkelt:


Det vektede standardavviket brukes for grupperte data:

Mellom middelkvadrat og gjennomsnittlig lineære avvik under normalfordelingsforhold finner følgende forhold sted: ~ 1,25.
Standardavviket, som er det viktigste absolutte variasjonsmålet, brukes til å bestemme verdiene til ordinatene til normalfordelingskurven, i beregninger relatert til organisering av prøveobservasjon og fastsettelse av nøyaktigheten til prøvekarakteristikker, så vel som i å vurdere grensene for variasjonen av en egenskap i en homogen populasjon.
Ved statistisk testing av hypoteser, ved måling av en lineær sammenheng mellom tilfeldige variabler.
Standardavvik:
Standardavvik(et estimat av standardavviket til den tilfeldige variabelen Gulv, vegger rundt oss og taket, x i forhold til dens matematiske forventning basert på et objektivt estimat av variansen):
hvor - varians; - Gulvet, veggene rundt oss og taket, Jeg-th prøveelement; - prøvestørrelse; - aritmetisk gjennomsnitt av prøven:
Det skal bemerkes at begge estimatene er partiske. I det generelle tilfellet er det umulig å konstruere et objektivt estimat. Imidlertid er et estimat basert på et objektivt variansestimat konsistent.
tre sigma regel
tre sigma regel() - nesten alle verdier av en normalfordelt tilfeldig variabel ligger i intervallet. Mer strengt – med ikke mindre enn 99,7 % sikkerhet, ligger verdien av en normalfordelt tilfeldig variabel i det angitte intervallet (forutsatt at verdien er sann, og ikke oppnådd som et resultat av prøvebehandling).
Hvis den sanne verdien er ukjent, bør du ikke bruke, men gulvet, veggene rundt oss og taket, s. Dermed blir regelen om tre sigma oversatt til regelen om tre etasjer, vegger rundt oss og taket, s .
Tolkning av verdien av standardavviket
En stor verdi av standardavviket viser en stor spredning av verdier i det presenterte settet med gjennomsnittsverdien til settet; en liten verdi, henholdsvis, indikerer at verdiene i settet er gruppert rundt gjennomsnittsverdien.
For eksempel har vi tre tallsett: (0, 0, 14, 14), (0, 6, 8, 14) og (6, 6, 8, 8). Alle tre settene har gjennomsnittsverdier på 7 og standardavvik på henholdsvis 7, 5 og 1. Det siste settet har et lite standardavvik fordi verdiene i settet er gruppert rundt gjennomsnittet; det første settet har den største verdien av standardavviket - verdiene i settet avviker sterkt fra gjennomsnittsverdien.
I generell forstand kan standardavviket betraktes som et mål på usikkerhet. For eksempel, i fysikk, brukes standardavviket til å bestemme feilen til en serie påfølgende målinger av en viss mengde. Denne verdien er veldig viktig for å bestemme plausibiliteten til fenomenet som studeres sammenlignet med verdien forutsagt av teorien: hvis middelverdien av målingene er veldig forskjellig fra verdiene forutsagt av teorien (stort standardavvik), så de oppnådde verdiene eller metoden for å oppnå dem bør kontrolleres på nytt.
Praktisk bruk
I praksis lar standardavviket deg bestemme hvor mye verdiene i settet kan avvike fra gjennomsnittsverdien.
Klima
Anta at det er to byer med samme gjennomsnittlige daglige maksimumstemperatur, men den ene ligger ved kysten og den andre er i innlandet. Kystbyer er kjent for å ha mange forskjellige daglige maksimumstemperaturer mindre enn byer i innlandet. Derfor vil standardavviket til de maksimale døgntemperaturene i kystbyen være mindre enn i den andre byen, til tross for at de har samme gjennomsnittsverdi på denne verdien, som i praksis betyr at sannsynligheten for at den maksimale lufttemperaturen på hver dag i året vil være sterkere forskjellig fra gjennomsnittsverdien, høyere for en by som ligger inne på kontinentet.
Sport
La oss anta at det er flere fotballag som er rangert i henhold til et sett med parametere, for eksempel antall mål scoret og sluppet inn, scoringssjanser osv. Det er mest sannsynlig at det beste laget i denne gruppen vil ha de beste verdiene i flere parametere. Jo mindre lagets standardavvik for hver av de presenterte parameterne, desto mer forutsigbart er lagets resultat, slike lag er balansert. På den annen side har et lag med stort standardavvik vanskelig for å spå resultatet, noe som igjen forklares med ubalanse, for eksempel et sterkt forsvar men et svakt angrep.
Bruken av standardavviket til parametrene til laget lar en til en viss grad forutsi resultatet av kampen mellom to lag, vurdere styrker og svakheter til lagene, og derav de valgte kampmetodene.
Teknisk analyse
se også
Litteratur
| Denne artikkelen foreslås slettet.
En forklaring av årsakene og en tilhørende diskusjon finner du på siden Wikipedia:Skal slettes/17. desember 2012. |
* Borovikov, V. STATISTIKK. Kunsten å analysere datadata: For fagfolk / V. Borovikov. - St. Petersburg. : Peter, 2003. - 688 s. - ISBN 5-272-00078-1.
| Statistiske indikatorer | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| beskrivende statistikk |
|
||||||||||
| Statistisk uttak og undersøkelse hypoteser |
| ||||||||||
 Onkel Vanya handlingen i stykket. "Onkel Ivan. Holdning til andres professor
Onkel Vanya handlingen i stykket. "Onkel Ivan. Holdning til andres professor Lille Tsakhes, med kallenavnet Zinnober
Lille Tsakhes, med kallenavnet Zinnober Maikov, Apollon Nikolaevich - kort biografi
Maikov, Apollon Nikolaevich - kort biografi