การกระจายตัวมีไว้เพื่ออะไร? การกระจายสารตกค้าง
ขั้นตอน
ตัวอย่างการคำนวณความแปรปรวน
-
บันทึกค่าตัวอย่างในกรณีส่วนใหญ่ นักสถิติจะใช้ได้เฉพาะตัวอย่างของประชากรบางกลุ่มเท่านั้น ตัวอย่างเช่น ตามกฎแล้ว นักสถิติจะไม่วิเคราะห์ค่าใช้จ่ายในการบำรุงรักษาโดยรวมของรถยนต์ทุกคันในรัสเซีย - พวกเขาวิเคราะห์ สุ่มตัวอย่างจากรถหลายพันคัน ตัวอย่างดังกล่าวจะช่วยกำหนดต้นทุนเฉลี่ยต่อคัน แต่ส่วนใหญ่แล้วมูลค่าที่ได้จะห่างไกลจากค่าจริง
- ตัวอย่างเช่น ลองวิเคราะห์จำนวนซาลาเปาที่ขายในร้านกาแฟใน 6 วัน โดยเรียงลำดับแบบสุ่ม ตัวอย่างมี มุมมองถัดไป: 17, 15, 23, 7, 9, 13 นี่คือตัวอย่าง ไม่ใช่ประชากร เพราะเราไม่มีข้อมูลซาลาเปาที่ขายในแต่ละวันที่คาเฟ่เปิด
- หากคุณได้รับข้อมูลประชากรและไม่ใช่ตัวอย่างค่า ให้ข้ามไปยังส่วนถัดไป
-
จดสูตรคำนวณความแปรปรวนของกลุ่มตัวอย่างการกระจายเป็นการวัดการแพร่กระจายของค่าของปริมาณบางอย่าง ยิ่งค่าการกระจายตัวเข้าใกล้ศูนย์มากเท่าใด ค่าก็จะยิ่งอยู่ใกล้กันมากขึ้นเท่านั้น เมื่อทำงานกับตัวอย่างค่า ให้ใช้สูตรต่อไปนี้เพื่อคำนวณความแปรปรวน:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))] / (น - 1)
- s 2 (\displaystyle s^(2))คือการกระจายตัว วัดการกระจายตัวเป็น ตารางหน่วยการวัด
- x i (\displaystyle x_(i))- แต่ละค่าในตัวอย่าง
- x i (\displaystyle x_(i))คุณต้องลบ x̅ ยกกำลังสอง แล้วจึงเพิ่มผลลัพธ์
- x̅ – ค่าเฉลี่ยตัวอย่าง (ค่าเฉลี่ยตัวอย่าง)
- n คือจำนวนของค่าในตัวอย่าง
-
คำนวณค่าเฉลี่ยตัวอย่างมันเขียนแทนด้วย x̅ ค่าเฉลี่ยตัวอย่างคำนวณเหมือนค่าเฉลี่ยเลขคณิตทั่วไป: เพิ่มค่าทั้งหมดในตัวอย่างแล้วหารผลลัพธ์ด้วยจำนวนค่าในตัวอย่าง
- ในตัวอย่างของเรา เพิ่มค่าในตัวอย่าง: 15 + 17 + 23 + 7 + 9 + 13 = 84
ตอนนี้หารผลลัพธ์ด้วยจำนวนค่าในตัวอย่าง (ในตัวอย่างของเรามี 6): 84 ÷ 6 = 14
ค่าเฉลี่ยตัวอย่าง x̅ = 14. - ค่าเฉลี่ยตัวอย่างคือค่ากลางที่มีการแจกแจงค่าในตัวอย่าง หากค่าในกลุ่มตัวอย่างรอบค่าเฉลี่ยตัวอย่างแสดงว่าความแปรปรวนมีขนาดเล็ก มิฉะนั้นการกระจายตัวจะมีขนาดใหญ่
- ในตัวอย่างของเรา เพิ่มค่าในตัวอย่าง: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
ลบค่าเฉลี่ยตัวอย่างออกจากแต่ละค่าในตัวอย่างตอนนี้คำนวณความแตกต่าง x i (\displaystyle x_(i))- x̅ ที่ไหน x i (\displaystyle x_(i))- แต่ละค่าในตัวอย่าง ผลลัพธ์ที่ได้แต่ละรายการจะบ่งชี้ขอบเขตที่ค่าใดค่าหนึ่งเบี่ยงเบนไปจากค่าเฉลี่ยตัวอย่าง นั่นคือ ค่านี้อยู่ห่างจากค่าเฉลี่ยตัวอย่างมากน้อยเพียงใด
- ในตัวอย่างของเรา:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - ความถูกต้องของผลลัพธ์ที่ได้รับนั้นง่ายต่อการตรวจสอบเนื่องจากผลรวมจะต้องเท่ากับศูนย์ สิ่งนี้เกี่ยวข้องกับคำจำกัดความของค่าเฉลี่ยเนื่องจาก ค่าลบ(ระยะทางจากค่าเฉลี่ยไปยังค่าที่น้อยกว่า) จะได้รับการชดเชยทั้งหมด ค่าบวก(ระยะทางจากค่าเฉลี่ยถึงค่ามาก)
- ในตัวอย่างของเรา:
-
ตามที่ระบุไว้ข้างต้น ผลรวมของความแตกต่าง x i (\displaystyle x_(i))- x̅ ต้องเท่ากับศูนย์ มันหมายความว่า ความแปรปรวนเฉลี่ยมีค่าเท่ากับศูนย์เสมอซึ่งไม่ได้ให้ความคิดใด ๆ เกี่ยวกับการแพร่กระจายของค่าของปริมาณที่แน่นอน ในการแก้ปัญหานี้ ให้ยกกำลังสองผลต่าง x i (\displaystyle x_(i))- x̅ ซึ่งจะส่งผลให้คุณได้รับ ตัวเลขที่เป็นบวกซึ่งเมื่อเพิ่มจะไม่ให้ 0
- ในตัวอย่างของเรา:
(x 1 (\displaystyle x_(1))-x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))-x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - คุณพบกำลังสองของผลต่าง - x̅) 2 (\displaystyle ^(2))สำหรับแต่ละค่าในตัวอย่าง
- ในตัวอย่างของเรา:
-
คำนวณผลรวมของผลต่างกำลังสองนั่นคือ หาส่วนของสูตรที่เขียนดังนี้: ∑[( x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))]. ในที่นี้ เครื่องหมาย Σ หมายถึงผลรวมของผลต่างกำลังสองสำหรับแต่ละค่า x i (\displaystyle x_(i))ในตัวอย่าง คุณพบผลต่างกำลังสองแล้ว (xi (\displaystyle (x_(i))-x̅) 2 (\displaystyle ^(2))สำหรับแต่ละค่า x i (\displaystyle x_(i))ในตัวอย่าง ตอนนี้เพียงแค่เพิ่มสี่เหลี่ยมเหล่านี้
- ในตัวอย่างของเรา: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
หารผลลัพธ์ด้วย n - 1 โดยที่ n คือจำนวนของค่าในตัวอย่างเมื่อนานมาแล้ว ในการคำนวณความแปรปรวนของตัวอย่าง นักสถิติเพียงแค่นำผลลัพธ์ที่ได้ไปหารด้วย n; ในกรณีนี้ คุณจะได้ค่าเฉลี่ยของความแปรปรวนกำลังสอง ซึ่งเหมาะสำหรับการอธิบายความแปรปรวนของกลุ่มตัวอย่างที่กำหนด แต่จำไว้ว่าตัวอย่างใด ๆ เป็นเพียงส่วนเล็ก ๆ ประชากรค่า หากคุณใช้ตัวอย่างอื่นและทำการคำนวณแบบเดียวกัน คุณจะได้ผลลัพธ์ที่แตกต่างกัน เมื่อปรากฎว่าการหารด้วย n - 1 (ไม่ใช่แค่ n) ให้มากขึ้น ประมาณการที่แม่นยำความแปรปรวนของประชากร ซึ่งเป็นสิ่งที่คุณสนใจ การหารด้วย n - 1 กลายเป็นเรื่องธรรมดา ดังนั้นจึงรวมอยู่ในสูตรสำหรับคำนวณความแปรปรวนตัวอย่าง
- ในตัวอย่างของเรา ตัวอย่างมีค่า 6 ค่า นั่นคือ n = 6
ความแปรปรวนตัวอย่าง = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- ในตัวอย่างของเรา ตัวอย่างมีค่า 6 ค่า นั่นคือ n = 6
-
ความแตกต่างระหว่างความแปรปรวนและส่วนเบี่ยงเบนมาตรฐานโปรดทราบว่าสูตรมีเลขยกกำลัง ดังนั้นความแปรปรวนจะถูกวัดเป็นหน่วยตารางของค่าที่วิเคราะห์ บางครั้งค่าดังกล่าวค่อนข้างใช้งานยาก ในกรณีเช่นนี้ จะใช้ค่าเบี่ยงเบนมาตรฐานซึ่งเท่ากับรากที่สองของความแปรปรวน นั่นคือเหตุผลที่ความแปรปรวนตัวอย่างแสดงเป็น s 2 (\displaystyle s^(2)), ก ส่วนเบี่ยงเบนมาตรฐานตัวอย่าง - อย่างไร s (\displaystyle s).
- ในตัวอย่างของเรา ค่าเบี่ยงเบนมาตรฐานตัวอย่างคือ: s = √33.2 = 5.76
การคำนวณความแปรปรวนของประชากร
-
วิเคราะห์ชุดของค่าบางอย่างชุดประกอบด้วยค่าทั้งหมดของปริมาณที่อยู่ระหว่างการพิจารณา ตัวอย่างเช่น หากคุณศึกษาอายุของผู้อยู่อาศัย ภูมิภาคเลนินกราดจากนั้นประชากรจะรวมอายุของผู้ที่อาศัยอยู่ในพื้นที่นี้ทั้งหมด ในกรณีที่ทำงานกับการรวมขอแนะนำให้สร้างตารางและป้อนค่าของการรวมลงไป พิจารณาตัวอย่างต่อไปนี้:
- มีตู้ปลา 6 ตู้ในห้องหนึ่ง พิพิธภัณฑ์สัตว์น้ำแต่ละแห่งมีจำนวนปลาดังต่อไปนี้:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- มีตู้ปลา 6 ตู้ในห้องหนึ่ง พิพิธภัณฑ์สัตว์น้ำแต่ละแห่งมีจำนวนปลาดังต่อไปนี้:
-
จดสูตรคำนวณความแปรปรวนของประชากรเนื่องจากประชากรมีค่าทั้งหมดของปริมาณที่แน่นอน สูตรต่อไปนี้ช่วยให้คุณได้รับค่าที่แน่นอนของความแปรปรวนของประชากร ในการแยกแยะความแปรปรวนของประชากรออกจากความแปรปรวนของกลุ่มตัวอย่าง (ซึ่งเป็นเพียงค่าประมาณ) นักสถิติใช้ตัวแปรต่างๆ:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / น
- σ 2 (\displaystyle ^(2))- ความแปรปรวนของประชากร (อ่านว่า "ซิกมากำลังสอง") การกระจายวัดเป็นตารางหน่วย
- x i (\displaystyle x_(i))- แต่ละค่าในการรวม
- Σ เป็นเครื่องหมายของผลรวม นั่นคือสำหรับแต่ละค่า x i (\displaystyle x_(i))ลบ μ ยกกำลังสอง แล้วเพิ่มผลลัพธ์
- μ คือค่าเฉลี่ยประชากร
- n คือจำนวนของค่าในประชากรทั่วไป
-
คำนวณค่าเฉลี่ยของประชากรเมื่อทำงานกับประชากรทั่วไป ค่าเฉลี่ยจะแสดงเป็น μ (mu) ค่าเฉลี่ยของประชากรคำนวณเป็นค่าเฉลี่ยเลขคณิตตามปกติ: เพิ่มค่าทั้งหมดในประชากรแล้วหารผลลัพธ์ด้วยจำนวนของค่าในประชากร
- โปรดทราบว่าค่าเฉลี่ยไม่ได้คำนวณเป็นค่าเฉลี่ยเลขคณิตเสมอไป
- ในตัวอย่างของเรา ค่าเฉลี่ยของประชากร: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
ลบค่าเฉลี่ยประชากรออกจากแต่ละค่าในประชากรยิ่งค่าความแตกต่างเข้าใกล้ศูนย์มากเท่าใด ค่าเฉพาะก็ยิ่งเข้าใกล้ค่าเฉลี่ยประชากรมากขึ้นเท่านั้น ค้นหาความแตกต่างระหว่างค่าแต่ละค่าในประชากรและค่าเฉลี่ย แล้วคุณจะได้ดูการกระจายของค่าก่อน
- ในตัวอย่างของเรา:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- ในตัวอย่างของเรา:
-
ยกกำลังสองแต่ละผลลัพธ์ที่คุณได้รับค่าความแตกต่างจะเป็นทั้งบวกและลบ หากคุณใส่ค่าเหล่านี้บนเส้นจำนวน ค่าเหล่านั้นจะอยู่ทางขวาและซ้ายของค่าเฉลี่ยประชากร สิ่งนี้ไม่เหมาะสำหรับการคำนวณความแปรปรวนเนื่องจากค่าบวกและ ตัวเลขติดลบชดเชยซึ่งกันและกัน ดังนั้น ยกกำลังสองความแตกต่างเพื่อให้ได้จำนวนบวกโดยเฉพาะ
- ในตัวอย่างของเรา:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))สำหรับค่าประชากรแต่ละค่า (จาก i = 1 ถึง i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), ที่ไหน x n (\displaystyle x_(n)) – ค่าสุดท้ายในประชาชนทั่วไป - ในการคำนวณค่าเฉลี่ยของผลลัพธ์ที่ได้ คุณต้องหาผลรวมและหารด้วย n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / น
- ตอนนี้ให้เขียนคำอธิบายข้างต้นโดยใช้ตัวแปร: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n และรับสูตรสำหรับคำนวณความแปรปรวนของประชากร
- ในตัวอย่างของเรา:
ลองคำนวณดูครับนางสาวเก่งความแปรปรวนและส่วนเบี่ยงเบนมาตรฐานของกลุ่มตัวอย่าง เรายังคำนวณความแปรปรวนของตัวแปรสุ่มหากทราบการแจกแจง
พิจารณาก่อน การกระจายตัว, แล้ว ส่วนเบี่ยงเบนมาตรฐาน.
ความแปรปรวนของตัวอย่าง
ความแปรปรวนของตัวอย่าง (ความแปรปรวนตัวอย่างตัวอย่างความแปรปรวน) แสดงลักษณะการแพร่กระจายของค่าในอาร์เรย์ที่สัมพันธ์กับ
ทั้ง 3 สูตรมีค่าเทียบเท่ากันทางคณิตศาสตร์
จะเห็นได้จากสูตรแรกว่า ความแปรปรวนของตัวอย่างคือผลรวมของการเบี่ยงเบนกำลังสองของแต่ละค่าในอาร์เรย์ จากค่าเฉลี่ยหารด้วยขนาดตัวอย่างลบ 1
การกระจายตัว ตัวอย่างใช้ฟังก์ชัน DISP() ภาษาอังกฤษ ชื่อของ VAR เช่น ความแปรปรวน ตั้งแต่ MS EXCEL 2010 ขอแนะนำให้ใช้อะนาล็อก DISP.V() , eng ชื่อ VARS เช่น ความแปรปรวนตัวอย่าง นอกจากนี้ตั้งแต่เวอร์ชัน MS EXCEL 2010 มีฟังก์ชัน DISP.G () eng ชื่อ VARP เช่น ความแปรปรวนของประชากรซึ่งคำนวณ การกระจายตัวสำหรับ ประชากร. ความแตกต่างทั้งหมดลงมาที่ตัวส่วน: แทนที่จะเป็น n-1 เช่น DISP.V() , DISP.G() มีเพียง n ในตัวส่วน ก่อนหน้า MS EXCEL 2010 มีการใช้ฟังก์ชัน VARP() เพื่อคำนวณความแปรปรวนของประชากร
ความแปรปรวนของตัวอย่าง
=SQUARE(ตัวอย่าง)/(COUNT(ตัวอย่าง)-1)
=(SUMSQ(ตัวอย่าง)-COUNT(ตัวอย่าง)*AVERAGE(Sample)^2)/ (COUNT(Sample)-1)- สูตรปกติ
=SUM((ตัวอย่าง -AVERAGE(ตัวอย่าง))^2)/ (COUNT(ตัวอย่าง)-1) –
ความแปรปรวนของตัวอย่างมีค่าเท่ากับ 0 ก็ต่อเมื่อค่าทั้งหมดเท่ากันและมีค่าเท่ากัน ค่าเฉลี่ย. โดยปกติค่ายิ่งมาก การกระจายตัวยิ่งการแพร่กระจายของค่าในอาร์เรย์มากขึ้น
ความแปรปรวนของตัวอย่างเป็น ประมาณการจุด การกระจายตัวการกระจายของตัวแปรสุ่มซึ่ง ตัวอย่าง. เกี่ยวกับการสร้าง ช่วงความมั่นใจ เมื่อทำการประเมิน การกระจายตัวสามารถอ่านได้ในบทความ
ความแปรปรวนของตัวแปรสุ่ม
ในการคำนวณ การกระจายตัวตัวแปรสุ่ม คุณต้องรู้
สำหรับ การกระจายตัวตัวแปรสุ่ม X มักใช้สัญลักษณ์ Var(X) การกระจายตัวเท่ากับกำลังสองของส่วนเบี่ยงเบนจากค่าเฉลี่ย E(X): Var(X)=E[(X-E(X)) 2 ]
การกระจายตัวคำนวณโดยสูตร:

โดยที่ x i คือค่าที่รับได้ ค่าสุ่มและ μ คือค่าเฉลี่ย (), p(x) คือความน่าจะเป็นที่ตัวแปรสุ่มจะใช้ค่า x
ถ้าตัวแปรสุ่มมี แล้ว การกระจายตัวคำนวณโดยสูตร:

มิติ การกระจายตัวตรงกับกำลังสองของหน่วยการวัดของค่าเดิม ตัวอย่างเช่น หากค่าในตัวอย่างเป็นการวัดน้ำหนักของชิ้นส่วน (เป็นกิโลกรัม) มิติของความแปรปรวนจะเป็นกิโลกรัม 2 . สิ่งนี้อาจตีความได้ยาก ดังนั้น ในการระบุลักษณะการกระจายของค่า ค่าเท่ากับรากที่สองของ การกระจายตัว – ส่วนเบี่ยงเบนมาตรฐาน.
คุณสมบัติบางอย่าง การกระจายตัว:
Var(X+a)=Var(X) โดยที่ X เป็นตัวแปรสุ่ม และ a เป็นค่าคงที่
Var(aХ)=ก 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
คุณสมบัติการกระจายนี้ใช้ใน บทความเกี่ยวกับการถดถอยเชิงเส้น.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y) โดยที่ X และ Y เป็นตัวแปรสุ่ม Cov(X;Y) คือความแปรปรวนร่วมของตัวแปรสุ่มเหล่านี้
หากตัวแปรสุ่มเป็นอิสระต่อกัน ความแปรปรวนร่วมเป็น 0 ดังนั้น Var(X+Y)=Var(X)+Var(Y) คุณสมบัติของความแปรปรวนนี้ใช้ในเอาต์พุต
ให้เราแสดงว่าสำหรับ ตัวแปรอิสระวาร์(X-Y)=วาร์(X+Y). แท้จริงแล้ว Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 วาร์(Y)= วาร์(X)+วาร์(Y)= วาร์(X+Y). คุณสมบัติของความแปรปรวนนี้ใช้ในการลงจุด
ค่าเบี่ยงเบนมาตรฐานตัวอย่าง
ค่าเบี่ยงเบนมาตรฐานตัวอย่างเป็นการวัดว่าค่าในตัวอย่างกระจัดกระจายมากน้อยเพียงใดเมื่อเทียบกับค่า .
ตามคำนิยาม ส่วนเบี่ยงเบนมาตรฐานเท่ากับสแควร์รูทของ การกระจายตัว:

ส่วนเบี่ยงเบนมาตรฐานไม่คำนึงถึงขนาดของค่าใน การสุ่มตัวอย่างแต่เป็นเพียงระดับของการกระเจิงของค่ารอบตัวเท่านั้น กลาง. ลองมาเป็นตัวอย่างเพื่ออธิบายสิ่งนี้
ลองคำนวณค่าเบี่ยงเบนมาตรฐานสำหรับ 2 ตัวอย่าง: (1; 5; 9) และ (1001; 1005; 1009) ในทั้งสองกรณี s=4 เห็นได้ชัดว่าอัตราส่วนของส่วนเบี่ยงเบนมาตรฐานต่อค่าของอาร์เรย์นั้นแตกต่างกันอย่างมากสำหรับตัวอย่าง สำหรับกรณีดังกล่าว ให้ใช้ ค่าสัมประสิทธิ์ของการแปรผัน(ค่าสัมประสิทธิ์ของการเปลี่ยนแปลง CV) - อัตราส่วน ส่วนเบี่ยงเบนมาตรฐานเป็นค่าเฉลี่ย เลขคณิตแสดงเป็นเปอร์เซ็นต์
ใน MS EXCEL 2007 ขึ้นไป รุ่นแรกในการคำนวณ ค่าเบี่ยงเบนมาตรฐานตัวอย่างใช้ฟังก์ชัน =STDEV() ภาษาอังกฤษ ชื่อ STDEV เช่น ส่วนเบี่ยงเบนมาตรฐาน. ตั้งแต่ MS EXCEL 2010 ขอแนะนำให้ใช้อะนาล็อก = STDEV.B () , eng ชื่อ STDEV.S เช่น ตัวอย่างค่าเบี่ยงเบนมาตรฐาน
นอกจากนี้ตั้งแต่เวอร์ชัน MS EXCEL 2010 มีฟังก์ชัน STDEV.G () , eng ชื่อ STDEV.P เช่น ประชากร STandard DEViation ซึ่งคำนวณ ส่วนเบี่ยงเบนมาตรฐานสำหรับ ประชากร. ความแตกต่างทั้งหมดลงมาที่ตัวส่วน: แทนที่จะเป็น n-1 เช่น STDEV.V() , STDEV.G() มีเพียง n ในตัวส่วน
ส่วนเบี่ยงเบนมาตรฐานสามารถคำนวณได้โดยตรงจากสูตรด้านล่าง (ดูไฟล์ตัวอย่าง)
=SQRT(SQUADROTIV(ตัวอย่าง)/(COUNT(ตัวอย่าง)-1))
=SQRT((SUMSQ(ตัวอย่าง)-COUNT(ตัวอย่าง)*AVERAGE(Sample)^2)/(COUNT(Sample)-1))
มาตรการกระจายอื่น ๆ
ฟังก์ชัน SQUADRIVE() คำนวณด้วย umm ของการเบี่ยงเบนกำลังสองของค่าจากพวกเขา กลาง. ฟังก์ชันนี้จะส่งคืนผลลัพธ์เดียวกับสูตร =VAR.G( ตัวอย่าง)*ตรวจสอบ( ตัวอย่าง) , ที่ไหน ตัวอย่าง- การอ้างอิงถึงช่วงที่มีอาร์เรย์ของค่าตัวอย่าง () การคำนวณในฟังก์ชัน QUADROTIV() ทำตามสูตร:

ฟังก์ชัน SROOT() เป็นการวัดการกระจายของชุดข้อมูลด้วย ฟังก์ชัน AVERAGE() จะคำนวณค่าเฉลี่ย ค่าสัมบูรณ์เบี่ยงเบนจาก กลาง. ฟังก์ชันนี้จะส่งคืนผลลัพธ์เช่นเดียวกับสูตร =SUMPRODUCT(ABS(ตัวอย่าง-ค่าเฉลี่ย(ตัวอย่าง)))/COUNT(ตัวอย่าง), ที่ไหน ตัวอย่าง- การอ้างอิงถึงช่วงที่มีอาร์เรย์ของค่าตัวอย่าง
การคำนวณในฟังก์ชัน SROOTKL () ทำตามสูตร:

อย่างไรก็ตาม คุณลักษณะนี้เพียงอย่างเดียวยังไม่เพียงพอสำหรับการศึกษาตัวแปรสุ่ม ลองนึกภาพนักกีฬาสองคนที่กำลังยิงไปที่เป้าหมาย อันหนึ่งยิงอย่างแม่นยำและเข้าใกล้จุดศูนย์กลาง ส่วนอีกอัน ... แค่สนุกและไม่ได้เล็งด้วยซ้ำ แต่ที่ตลกก็คือ เฉลี่ยผลลัพธ์จะเหมือนกับผู้ยิงคนแรกทุกประการ! สถานการณ์นี้แสดงตามเงื่อนไขโดยตัวแปรสุ่มต่อไปนี้:
ความคาดหวังทางคณิตศาสตร์ของ "sniper" เท่ากับ " บุคลิกภาพที่น่าสนใจ»: - ยังเป็นศูนย์!
ดังนั้นจึงจำเป็นต้องคำนวณว่าไกลแค่ไหน กระจัดกระจายสัญลักษณ์แสดงหัวข้อย่อย (ค่าสุ่ม) ที่สัมพันธ์กับศูนย์กลางของเป้าหมาย ( ความคาดหวังทางคณิตศาสตร์). ดีและ กระจัดกระจายแปลจากภาษาละตินเท่านั้นเป็น การกระจายตัว .
มาดูกันว่าสิ่งนี้ถูกกำหนดอย่างไร ลักษณะที่เป็นตัวเลขในตัวอย่างหนึ่งของส่วนที่ 1 ของบทเรียน: 
เราพบความคาดหวังทางคณิตศาสตร์ที่น่าผิดหวังของเกมนี้ และตอนนี้เราต้องคำนวณความแปรปรวนของมัน ซึ่ง แสดงผ่าน .
มาดูกันว่าการชนะ/แพ้นั้น "กระจัดกระจาย" แค่ไหนเมื่อเทียบกับค่าเฉลี่ย แน่นอนเราต้องคำนวณสำหรับสิ่งนี้ ความแตกต่างระหว่าง ค่าของตัวแปรสุ่มและเธอ ความคาดหวังทางคณิตศาสตร์:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
ตอนนี้ดูเหมือนว่าจำเป็นต้องสรุปผลลัพธ์ แต่วิธีนี้ไม่ดี - ด้วยเหตุผลที่การแกว่งไปทางซ้ายจะหักล้างกันด้วยการสั่นไปทางขวา ตัวอย่างเช่น นักกีฬา "มือสมัครเล่น" (ตัวอย่างด้านบน)ความแตกต่างจะเป็น ![]() และเมื่อเพิ่มเข้าไป พวกเขาจะให้เป็นศูนย์ ดังนั้นเราจะไม่ได้รับค่าประมาณของการกระเจิงของการยิงของเขา
และเมื่อเพิ่มเข้าไป พวกเขาจะให้เป็นศูนย์ ดังนั้นเราจะไม่ได้รับค่าประมาณของการกระเจิงของการยิงของเขา
เพื่อหลีกเลี่ยงความรำคาญนี้ให้พิจารณา โมดูลความแตกต่าง แต่ด้วยเหตุผลทางเทคนิค แนวทางดังกล่าวมีรากเหง้าเมื่อมีการยกกำลังสอง สะดวกกว่าในการจัดเรียงโซลูชันในตาราง: 
และนี่คือการคำนวณ ถัวเฉลี่ยถ่วงน้ำหนักค่าของการเบี่ยงเบนกำลังสอง มันคืออะไร? มันเป็นของพวกเขา มูลค่าที่คาดหวังซึ่งเป็นการวัดการกระจาย:
![]() – คำนิยามการกระจายตัว เป็นที่ชัดเจนทันทีจากคำจำกัดความว่า ความแปรปรวนไม่สามารถเป็นค่าลบได้- จดไว้ปฏิบัติ!
– คำนิยามการกระจายตัว เป็นที่ชัดเจนทันทีจากคำจำกัดความว่า ความแปรปรวนไม่สามารถเป็นค่าลบได้- จดไว้ปฏิบัติ!
มาจำวิธีค้นหาความคาดหวังกันเถอะ คูณผลต่างกำลังสองด้วยความน่าจะเป็นที่สอดคล้องกัน (ความต่อเนื่องของตาราง):
- พูดเปรียบเปรยนี่คือ "แรงฉุด"
และสรุปผล:
คุณไม่คิดว่าเบื้องหลังของการชนะผลลัพธ์ที่ได้จะใหญ่เกินไปเหรอ? ถูกต้อง เรากำลังยกกำลังสอง และเพื่อที่จะกลับไปสู่มิติของเกมของเรา เราต้องหารากที่สอง ค่านี้เรียกว่า ส่วนเบี่ยงเบนมาตรฐาน
และเขียนแทนด้วยตัวอักษรกรีก "sigma":
บางครั้งก็เรียกความหมายนี้ว่า ส่วนเบี่ยงเบนมาตรฐาน .
ความหมายของมันคืออะไร? หากเราเบี่ยงเบนความคาดหวังทางคณิตศาสตร์ไปทางซ้ายและทางขวาโดยค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน:![]()
– จากนั้นค่าที่เป็นไปได้มากที่สุดของตัวแปรสุ่มจะ "เข้มข้น" ในช่วงเวลานี้ สิ่งที่เราเห็นจริง:
อย่างไรก็ตาม มันเกิดขึ้นในการวิเคราะห์การกระเจิงเกือบทุกครั้งด้วยแนวคิดของการกระจาย มาดูกันว่ามันหมายถึงอะไรเกี่ยวกับเกม หากในกรณีของมือปืนเรากำลังพูดถึง "ความแม่นยำ" ของการยิงที่สัมพันธ์กับศูนย์กลางของเป้าหมาย การกระจายจะแสดงลักษณะสองสิ่งต่อไปนี้:
อย่างแรก เห็นได้ชัดว่าเมื่ออัตราเพิ่มขึ้น ความแปรปรวนก็เพิ่มขึ้นด้วย ตัวอย่างเช่น ถ้าเราเพิ่มขึ้น 10 เท่า ความคาดหวังทางคณิตศาสตร์จะเพิ่มขึ้น 10 เท่า และความแปรปรวนจะเพิ่มขึ้น 100 เท่า (ทันทีที่มันเป็นค่ากำลังสอง). แต่โปรดทราบว่ากฎของเกมไม่มีการเปลี่ยนแปลง! เฉพาะอัตราเท่านั้นที่เปลี่ยนแปลง พูดคร่าวๆ เราเคยเดิมพัน 10 รูเบิล ตอนนี้ 100
ประการที่สองเพิ่มเติม จุดที่น่าสนใจคือความแปรปรวนกำหนดลักษณะของเกม แก้ไขอัตราเกมทางจิตใจ ได้ในระดับหนึ่งและดูว่ามีอะไรอยู่ที่นี่:
เกมที่มีความแปรปรวนต่ำเป็นเกมที่ระมัดระวัง ผู้เล่นมักจะเลือกแผนการที่น่าเชื่อถือที่สุด โดยที่เขาไม่แพ้/ชนะมากเกินไปในคราวเดียว ตัวอย่างเช่น ระบบสีแดง/ดำในรูเล็ต (ดูตัวอย่างที่ 4 ของบทความ ตัวแปรสุ่ม) .
เกมที่มีความแปรปรวนสูง เธอมักจะถูกเรียกว่า การกระจายตัวเกม. นี่คือรูปแบบการเล่นแบบผจญภัยหรือก้าวร้าวที่ผู้เล่นเลือกแผน "อะดรีนาลีน" อย่างน้อยก็จำไว้ "มาร์ติงเกล"ซึ่งจำนวนเงินเดิมพันเป็นลำดับความสำคัญที่มากกว่าเกม "เงียบ" ในย่อหน้าก่อนหน้า
สถานการณ์ในโป๊กเกอร์เป็นสิ่งบ่งชี้: มีสิ่งที่เรียกว่า แน่นผู้เล่นที่มักจะระมัดระวังและ "เขย่า" กับเงินในเกมของพวกเขา (แบ๊งค์). ไม่น่าแปลกใจที่แบ๊งค์ของพวกเขาไม่ผันผวนมากนัก (ความแปรปรวนต่ำ) ในทางกลับกัน หากผู้เล่นมีความแปรปรวนสูง ก็จะเป็นฝ่ายรุกราน เขามักจะเสี่ยง ทำการเดิมพันจำนวนมาก และทั้งคู่สามารถทำลายธนาคารขนาดใหญ่และแตกเป็นชิ้นๆ
สิ่งเดียวกันนี้เกิดขึ้นใน Forex และอื่นๆ - มีตัวอย่างมากมาย
ยิ่งไปกว่านั้น ในทุกกรณี ไม่สำคัญว่าเกมนี้จะมีราคาเพียงเพนนีหรือหลายพันดอลลาร์ ทุกระดับมีผู้เล่นที่มีความแปรปรวนต่ำและสูง สำหรับการชนะโดยเฉลี่ยอย่างที่เราจำได้ "รับผิดชอบ" มูลค่าที่คาดหวัง.
คุณอาจสังเกตเห็นว่าการค้นหาความแปรปรวนเป็นกระบวนการที่ยาวนานและต้องใช้ความอุตสาหะ แต่คณิตศาสตร์นั้นใจกว้าง:
สูตรการหาค่าความแปรปรวน
สูตรนี้มาจากนิยามของความแปรปรวนโดยตรง และเรานำมันไปใช้ในทันที ฉันจะคัดลอกจานด้วยเกมของเราจากด้านบน: 
และความคาดหวังที่พบ
เราคำนวณความแปรปรวนด้วยวิธีที่สอง ก่อนอื่น มาหาความคาดหวังทางคณิตศาสตร์ - กำลังสองของตัวแปรสุ่ม โดย ความหมายของความคาดหวังทางคณิตศาสตร์:
ที่ กรณีนี้:
ดังนั้น ตามสูตร:
อย่างที่พวกเขาพูด รู้สึกถึงความแตกต่าง และแน่นอนว่าในทางปฏิบัติควรใช้สูตร (เว้นแต่เงื่อนไขจะกำหนดไว้เป็นอย่างอื่น)
เราเชี่ยวชาญในเทคนิคการแก้ปัญหาและการออกแบบ:
ตัวอย่างที่ 6

ค้นหาความคาดหวังทางคณิตศาสตร์ ความแปรปรวน และส่วนเบี่ยงเบนมาตรฐาน
งานนี้พบได้ทุกที่และตามกฎแล้วไปโดยไม่มีความหมาย
คุณสามารถจินตนาการถึงหลอดไฟหลายดวงพร้อมตัวเลขที่สว่างขึ้นในโรงบาลที่มีความน่าจะเป็น :)
วิธีการแก้: สะดวกในการสรุปการคำนวณหลักในตาราง อันดับแรก เราเขียนข้อมูลเริ่มต้นในสองบรรทัดบนสุด จากนั้นเราจะคำนวณผลิตภัณฑ์ จากนั้นและสุดท้ายคือผลรวมในคอลัมน์ด้านขวา: 
ที่จริงมีพร้อมเกือบทุกอย่าง ในบรรทัดที่สาม มีการวาดความคาดหวังทางคณิตศาสตร์สำเร็จรูป: ![]() .
.
การกระจายคำนวณโดยสูตร:
และสุดท้าย ค่าเบี่ยงเบนมาตรฐาน:
- โดยส่วนตัวแล้วผมมักจะปัดเศษเป็นทศนิยม 2 ตำแหน่ง
การคำนวณทั้งหมดสามารถทำได้บนเครื่องคิดเลข และดีกว่า - ใน Excel:
มันยากที่จะผิดพลาดที่นี่ :)
ตอบ:
ผู้ที่ต้องการทำให้ชีวิตของพวกเขาง่ายขึ้นและใช้ประโยชน์จากฉัน เครื่องคิดเลข (การสาธิต)ซึ่งจะไม่เพียงแก้ปัญหาได้ทันที งานนี้แต่ยังสร้าง กราฟิกเฉพาะเรื่อง (มาเร็ว ๆ นี้). โปรแกรมสามารถ ดาวน์โหลดในห้องสมุด– หากคุณดาวน์โหลดอย่างน้อยหนึ่งรายการ สื่อการศึกษาหรือได้รับ อีกวิธีหนึ่ง. ขอบคุณที่สนับสนุนโครงการ!
งานสองสามอย่างสำหรับ การตัดสินใจที่เป็นอิสระ:
ตัวอย่างที่ 7
คำนวณความแปรปรวนของตัวแปรสุ่มของตัวอย่างก่อนหน้าตามนิยาม
และตัวอย่างที่คล้ายกัน:
ตัวอย่างที่ 8
ตัวแปรสุ่มแบบไม่ต่อเนื่องถูกกำหนดโดยกฎการกระจายของมันเอง:

ใช่ ค่าของตัวแปรสุ่มอาจมีขนาดค่อนข้างใหญ่ (ตัวอย่างจาก งานจริง) และที่นี่ ถ้าเป็นไปได้ ให้ใช้ Excel อย่างไรก็ตามในตัวอย่างที่ 7 นั้นเร็วกว่าเชื่อถือได้และน่าพอใจกว่า
วิธีแก้ไขและคำตอบที่ด้านล่างของหน้า
ในตอนท้ายของบทเรียนส่วนที่ 2 เราจะวิเคราะห์อีกครั้ง งานทั่วไปบางคนอาจพูดว่า rebus ขนาดเล็ก:
ตัวอย่างที่ 9
ตัวแปรสุ่มแบบไม่ต่อเนื่องสามารถรับค่าได้เพียงสองค่าเท่านั้น: และ และ ทราบความน่าจะเป็น ความคาดหวังทางคณิตศาสตร์ และความแปรปรวน
วิธีการแก้: เริ่มจากความน่าจะเป็นที่ไม่รู้จัก เนื่องจากตัวแปรสุ่มสามารถรับได้เพียงสองค่า ดังนั้นผลรวมของความน่าจะเป็นของเหตุการณ์ที่เกี่ยวข้อง:
และตั้งแต่นั้นเป็นต้นมา
มันยังคงค้นหา ... พูดง่าย ๆ :) แต่เอาล่ะมันเริ่มแล้ว ตามคำจำกัดความของความคาดหวังทางคณิตศาสตร์: ![]() - แทนที่ค่าที่ทราบ:
- แทนที่ค่าที่ทราบ:
![]() - และไม่มีอะไรสามารถบีบออกจากสมการนี้ได้อีก ยกเว้นว่าคุณสามารถเขียนใหม่ในทิศทางปกติ:
- และไม่มีอะไรสามารถบีบออกจากสมการนี้ได้อีก ยกเว้นว่าคุณสามารถเขียนใหม่ในทิศทางปกติ: ![]()

หรือ: ![]()
อ ขั้นตอนถัดไปฉันคิดว่าคุณสามารถเดาได้ มาสร้างและแก้ไขระบบกัน: 
ทศนิยม- แน่นอนว่านี่เป็นความอัปยศอย่างสมบูรณ์ คูณสมการทั้งสองด้วย 10: 
และหารด้วย 2: 
นั่นดีกว่ามาก จากสมการที่ 1 เราแสดง: ![]() (นี่เป็นวิธีที่ง่ายกว่า)- แทนที่ในสมการที่ 2:
(นี่เป็นวิธีที่ง่ายกว่า)- แทนที่ในสมการที่ 2:
![]()
เรากำลังสร้าง กำลังสองและทำให้ง่ายขึ้น: 
เราคูณด้วย: 
ผลที่ตามมา, สมการกำลังสองค้นหาการเลือกปฏิบัติ:
- สมบูรณ์แบบ!
และเราได้คำตอบสองทาง:
1) ถ้า ![]() , แล้ว
, แล้ว ![]() ;
;
2) ถ้า ![]() , แล้ว .
, แล้ว .
ค่าคู่แรกเป็นไปตามเงื่อนไข ด้วยความเป็นไปได้สูงทุกอย่างถูกต้อง แต่อย่างไรก็ตามเราเขียนกฎการกระจาย: 
และทำการตรวจสอบ กล่าวคือ ค้นหาความคาดหวัง:
การกระจายเป็นการวัดการกระจายที่อธิบายความเบี่ยงเบนสัมพัทธ์ระหว่างค่าข้อมูลและค่าเฉลี่ย เป็นการวัดการกระจายที่ใช้บ่อยที่สุดในสถิติ คำนวณโดยการหาผลรวม ยกกำลังสอง ส่วนเบี่ยงเบนของค่าข้อมูลแต่ละค่าจากค่าเฉลี่ย สูตรการคำนวณความแปรปรวนแสดงไว้ด้านล่าง:
![]()
s 2 - ความแปรปรวนตัวอย่าง;
x cf คือค่าเฉลี่ยของตัวอย่าง
น — ขนาดตัวอย่าง (จำนวนค่าข้อมูล)
(x i – x cf) คือค่าเบี่ยงเบนจากค่าเฉลี่ยสำหรับแต่ละค่าของชุดข้อมูล
สำหรับ ความเข้าใจที่ดีขึ้นสูตร ลองมาเป็นตัวอย่าง ฉันไม่ค่อยชอบทำอาหารเลยไม่ค่อยได้ทำ อย่างไรก็ตามเพื่อไม่ให้หิวโหยฉันต้องไปที่เตาเป็นครั้งคราวเพื่อดำเนินการตามแผนที่จะทำให้ร่างกายของฉันอิ่มด้วยโปรตีนไขมันและคาร์โบไฮเดรต ชุดข้อมูลด้านล่างแสดงจำนวนครั้งที่ Renat ทำอาหารในแต่ละเดือน:
ขั้นตอนแรกในการคำนวณความแปรปรวนคือการกำหนดค่าเฉลี่ยตัวอย่าง ซึ่งในตัวอย่างของเราคือ 7.8 ครั้งต่อเดือน การคำนวณที่เหลือสามารถทำได้โดยใช้ตารางต่อไปนี้

ขั้นตอนสุดท้ายของการคำนวณความแปรปรวนมีลักษณะดังนี้:
![]()
สำหรับผู้ที่ชอบคำนวณทั้งหมดในครั้งเดียว สมการจะมีลักษณะดังนี้:
ใช้วิธีการนับวัตถุดิบ (ตัวอย่างการทำอาหาร)
มีมากขึ้น วิธีการที่มีประสิทธิภาพการคำนวณความแปรปรวนที่เรียกว่าวิธีการ "นับดิบ" แม้ว่าในแวบแรกสมการอาจดูค่อนข้างยุ่งยาก แต่อันที่จริงแล้วมันไม่ได้น่ากลัวเลย คุณสามารถยืนยันสิ่งนี้ จากนั้นตัดสินใจว่าวิธีใดที่คุณชอบที่สุด

คือผลรวมของแต่ละค่าข้อมูลหลังจากการยกกำลังสอง
คือกำลังสองของผลรวมของค่าข้อมูลทั้งหมด
อย่าเพิ่งเสียสติในตอนนี้ ลองใส่ทั้งหมดในรูปแบบของตารางแล้วคุณจะเห็นว่ามีการคำนวณน้อยกว่าในตัวอย่างก่อนหน้านี้


อย่างที่คุณเห็นผลลัพธ์จะเหมือนกับเมื่อใช้วิธีก่อนหน้า ข้อดี วิธีนี้เห็นได้ชัดเมื่อขนาดตัวอย่าง (n) โตขึ้น
การคำนวณผลต่างใน Excel
ตามที่คุณอาจเดาได้ Excel มีสูตรที่ให้คุณคำนวณความแปรปรวนได้ นอกจากนี้ เริ่มจาก Excel 2010 คุณสามารถค้นหาสูตรการกระจายได้ 4 แบบ:
1) VAR.V - ส่งกลับค่าความแปรปรวนของตัวอย่าง ค่าบูลีนและข้อความจะถูกละเว้น
2) VAR.G - ส่งกลับค่าความแปรปรวนของประชากร ค่าบูลีนและข้อความจะถูกละเว้น
3) VASP - ส่งกลับความแปรปรวนตัวอย่างโดยคำนึงถึงค่าบูลีนและข้อความ
4) VARP - ส่งกลับค่าความแปรปรวนของประชากร โดยคำนึงถึงค่าตรรกะและข้อความ
ก่อนอื่น มาดูความแตกต่างระหว่างกลุ่มตัวอย่างกับประชากรกันก่อน วัตถุประสงค์ สถิติเชิงพรรณนาคือการสรุปหรือแสดงข้อมูลในลักษณะที่เห็นภาพรวมได้อย่างรวดเร็ว การอนุมานทางสถิติทำให้คุณสามารถอนุมานเกี่ยวกับประชากรตามตัวอย่างข้อมูลจากประชากรนี้ ประชากรแสดงถึงผลลัพธ์หรือการวัดที่เป็นไปได้ทั้งหมดที่เราสนใจ กลุ่มตัวอย่างเป็นส่วนย่อยของประชากร
ตัวอย่างเช่น เราสนใจจำนวนรวมของนักเรียนกลุ่มใดกลุ่มหนึ่ง มหาวิทยาลัยในรัสเซียและเราต้องกำหนดคะแนนเฉลี่ยของกลุ่ม เราสามารถนับได้ ประสิทธิภาพเฉลี่ยนักเรียนแล้วตัวเลขที่ได้จะเป็นพารามิเตอร์เนื่องจากประชากรทั้งหมดจะมีส่วนร่วมในการคำนวณของเรา แต่ถ้าเราต้องการคำนวณ GPA ของนักเรียนทั้งหมดในประเทศของเรา กลุ่มนี้จะเป็นกลุ่มตัวอย่างของเรา
ความแตกต่างในสูตรการคำนวณความแปรปรวนระหว่างกลุ่มตัวอย่างและประชากรอยู่ในตัวส่วน โดยที่ตัวอย่างจะเท่ากับ (n-1) และสำหรับประชากรทั่วไปเท่านั้น n
ทีนี้มาจัดการกับฟังก์ชั่นการคำนวณความแปรปรวนด้วยการสิ้นสุด แต่,ในคำอธิบายที่กล่าวว่าการคำนวณคำนึงถึงข้อความและค่าตรรกะ ในกรณีนี้ เมื่อคำนวณความแปรปรวนของอาร์เรย์ข้อมูลบางตัวที่ไม่มี ค่าตัวเลข, Excel จะตีความข้อความและบูลีนเท็จเป็น 0 และบูลีนจริงเป็น 1
ดังนั้น หากคุณมีอาร์เรย์ของข้อมูล การคำนวณความแปรปรวนนั้นไม่ใช่เรื่องยากโดยใช้หนึ่งในฟังก์ชัน Excel ที่ระบุไว้ด้านบน

ช่วงการเปลี่ยนแปลง (หรือช่วงของการเปลี่ยนแปลง) -คือความแตกต่างระหว่างค่าสูงสุดและ ค่าต่ำสุดเข้าสู่ระบบ:
ในตัวอย่างของเรา ช่วงของการเปลี่ยนแปลงในผลผลิตกะของพนักงานคือ: ในกลุ่มที่หนึ่ง R=105-95=10 ลูก ในกลุ่มที่สอง R=125-75=50 ลูก (มากกว่า 5 เท่า). สิ่งนี้ชี้ให้เห็นว่าผลผลิตของกองพลที่ 1 นั้น "เสถียร" มากกว่า แต่กองพลที่สองมีปริมาณสำรองมากขึ้นสำหรับการเติบโตของผลผลิตเพราะ หากคนงานทั้งหมดมีผลผลิตสูงสุดสำหรับกองพลนี้ จะสามารถผลิตได้ 3 * 125 = 375 ส่วน และในกองพลที่ 1 มีเพียง 105 * 3 = 315 ส่วน
ถ้า ก ค่ามากลักษณะไม่ปกติสำหรับประชากร จากนั้นจึงใช้ช่วงควอร์ไทล์หรือเดซิไล ช่วงควอไทล์ RQ= Q3-Q1 ครอบคลุม 50% ของประชากร ช่วงเดซิไลต์แรก RD1 = D9-D1 ครอบคลุม 80% ของข้อมูล ช่วงเดซิไลที่สอง RD2= D8-D2 ครอบคลุม 60%
ข้อเสียของตัวบ่งชี้ ช่วงการเปลี่ยนแปลงคือ แต่ค่าของมันไม่ได้สะท้อนถึงความผันผวนทั้งหมดของแอตทริบิวต์
ตัวบ่งชี้ทั่วไปที่ง่ายที่สุดที่สะท้อนความผันผวนทั้งหมดของลักษณะคือ ค่าเฉลี่ยความเบี่ยงเบนเชิงเส้นซึ่งเป็นค่าเฉลี่ยเลขคณิตของความเบี่ยงเบนสัมบูรณ์ของแต่ละตัวเลือกจากค่าเฉลี่ย:
,
สำหรับข้อมูลที่จัดกลุ่ม ![]() ,
,
โดยที่ xi คือค่าของคุณสมบัติใน ซีรีส์ที่ไม่ต่อเนื่องหรือช่วงกลางของช่วงเวลาในการแจกแจงช่วงเวลา
ในสูตรข้างต้น ความแตกต่างในตัวเศษจะถูกนำมาโมดูโล มิฉะนั้น ตามคุณสมบัติของค่าเฉลี่ยเลขคณิต ตัวเศษจะเท่ากับศูนย์เสมอ ดังนั้นจึงไม่ค่อยใช้ค่าเบี่ยงเบนเชิงเส้นเฉลี่ยในทางปฏิบัติทางสถิติเฉพาะในกรณีที่ผลรวมของตัวบ่งชี้โดยไม่คำนึงถึงสัญญาณ ความรู้สึกทางเศรษฐกิจ. ด้วยความช่วยเหลือ ตัวอย่างเช่น องค์ประกอบของพนักงาน ความสามารถในการทำกำไรของการผลิต และมูลค่าการค้าต่างประเทศจะถูกวิเคราะห์
ความแปรปรวนของคุณลักษณะ- นี่คือ จัตุรัสกลางส่วนเบี่ยงเบนของตัวแปรจากค่าเฉลี่ย:
ความแปรปรวนอย่างง่าย ![]() ,
,
ความแปรปรวนถ่วงน้ำหนัก  .
.
สูตรการคำนวณความแปรปรวนสามารถทำให้ง่ายขึ้น:
ดังนั้น ความแปรปรวนจะเท่ากับความแตกต่างระหว่างค่าเฉลี่ยของกำลังสองของตัวแปรและกำลังสองของค่าเฉลี่ยของตัวแปรของประชากร:  .
.
อย่างไรก็ตาม เนื่องจากผลรวมของส่วนเบี่ยงเบนกำลังสอง ความแปรปรวนทำให้เกิดแนวคิดที่บิดเบี้ยวของการเบี่ยงเบน ดังนั้นจึงคำนวณค่าเฉลี่ยจากค่าดังกล่าว ส่วนเบี่ยงเบนมาตรฐานซึ่งแสดงว่ารูปแบบเฉพาะของแอตทริบิวต์เบี่ยงเบนจากค่าเฉลี่ยโดยเฉลี่ยมากน้อยเพียงใด คำนวณโดยการแยก รากที่สองจากการกระจาย:
สำหรับข้อมูลที่ไม่ได้จัดกลุ่ม 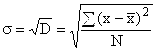 ,
,
สำหรับ ชุดการเปลี่ยนแปลง
ยังไง มูลค่าน้อยลงการกระจายตัวและส่วนเบี่ยงเบนมาตรฐาน ยิ่งประชากรมีความเป็นเนื้อเดียวกันมากเท่าใด ความน่าเชื่อถือ (โดยทั่วไป) ก็จะยิ่งมากขึ้นเท่านั้น ค่าเฉลี่ย.
ค่าเฉลี่ยเชิงเส้นและค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน- ตัวเลขที่มีชื่อนั่นคือแสดงเป็นหน่วยการวัดแอตทริบิวต์เหมือนกันในเนื้อหาและความหมายใกล้เคียงกัน
นับ ตัวชี้วัดที่แน่นอนแนะนำให้ใช้รูปแบบต่างๆ โดยใช้ตาราง
ตารางที่ 3 - การคำนวณลักษณะของการแปรผัน (ในตัวอย่างช่วงเวลาของข้อมูลในเอาต์พุตกะของทีมงาน)
จำนวนคนงาน |
ช่วงกลางของช่วงเวลา |
ค่าโดยประมาณ |
|||||
ทั้งหมด: |
|||||||
ผลผลิตกะเฉลี่ยของคนงาน: ![]()
ค่าเบี่ยงเบนเชิงเส้นเฉลี่ย: ![]()
การกระจายเอาต์พุต: 
ส่วนเบี่ยงเบนมาตรฐานของผลลัพธ์ของพนักงานแต่ละคนจากผลลัพธ์เฉลี่ย:
.
1 การคำนวณการกระจายโดยวิธีช่วงเวลา
การคำนวณผลต่างเกี่ยวข้องกับการคำนวณที่ยุ่งยาก (โดยเฉพาะอย่างยิ่งหากแสดงค่าเฉลี่ย จำนวนมากที่มีทศนิยมหลายตำแหน่ง) การคำนวณสามารถทำให้ง่ายขึ้นได้โดยใช้สูตรที่ง่ายขึ้นและคุณสมบัติการกระจายตัว
การกระจายมีคุณสมบัติดังต่อไปนี้:
- หากค่าทั้งหมดของแอตทริบิวต์ลดลงหรือเพิ่มขึ้นตามค่า A เดียวกัน ความแปรปรวนจะไม่ลดลงจากนี้:
 ,
,
 แล้วหรือ
แล้วหรือ 
การใช้คุณสมบัติของความแปรปรวนและขั้นแรกให้ลดความแปรปรวนของประชากรด้วยค่า A จากนั้นหารด้วยค่าของช่วงเวลา ชั่วโมง เราได้สูตรสำหรับคำนวณความแปรปรวนในชุดความผันแปรด้วย ในช่วงเวลาเท่ากัน ช่วงเวลา: ,
,
การกระจายที่คำนวณโดยวิธีการของช่วงเวลาอยู่ที่ไหน
h คือค่าของช่วงเวลาของอนุกรมการเปลี่ยนแปลง
– ค่าตัวแปรใหม่ (แปลง)
แต่- คงที่ซึ่งใช้เป็นช่วงกลางของช่วงที่มีความถี่สูงสุด หรือตัวเลือกที่มี ความถี่สูงสุด;  คือกำลังสองของโมเมนต์ลำดับที่หนึ่ง
คือกำลังสองของโมเมนต์ลำดับที่หนึ่ง
เป็นช่วงเวลาแห่งลำดับที่สอง
ลองคำนวณความแปรปรวนด้วยวิธีของช่วงเวลาตามข้อมูลในเอาต์พุตกะของทีมทำงาน
ตารางที่ 4 - การคำนวณการกระจายโดยวิธีช่วงเวลา
กลุ่มคนงานฝ่ายผลิต ชิ้น. |
จำนวนคนงาน |
ช่วงกลางของช่วงเวลา |
ค่าโดยประมาณ |
||
ขั้นตอนการคำนวณ:


- คำนวณความแปรปรวน:
2 การคำนวณความแปรปรวนของคุณสมบัติทางเลือก
ในบรรดาสัญญาณที่ศึกษาโดยสถิติ มีสัญญาณที่มีความหมายร่วมกันเพียงสองความหมายเท่านั้น นี่เป็นสัญญาณทางเลือก พวกเขาจะได้รับสอง ค่าเชิงปริมาณ: ตัวเลือก 1 และ 0 ความถี่ของตัวเลือก 1 ซึ่งแทนด้วย p คือสัดส่วนของหน่วยที่มีแอตทริบิวต์ที่กำหนด ผลต่าง 1-p=q คือความถี่ของตัวเลือก 0 ดังนั้น
สิบเอ็ด |
|
ค่าเฉลี่ยเลขคณิตของคุณลักษณะทางเลือก ![]() เนื่องจาก p+q=1
เนื่องจาก p+q=1
ความแปรปรวนของคุณลักษณะ
, เพราะ 1-p = คิว
ดังนั้น ความแปรปรวนของแอตทริบิวต์ทางเลือกจะเท่ากับผลคูณของสัดส่วนของหน่วยที่มีแอตทริบิวต์นี้และสัดส่วนของหน่วยที่ไม่มีแอตทริบิวต์นี้
หากค่า 1 และ 0 มีค่าเท่ากัน เช่น p=q ความแปรปรวนจะถึงค่าสูงสุด pq=0.25
ความแปรปรวนของคุณลักษณะทางเลือกถูกใช้ใน การสำรวจตัวอย่างเช่น คุณภาพของสินค้า.
3 การกระจายระหว่างกลุ่ม กฎการบวกผลต่าง
การกระจาย ซึ่งแตกต่างจากลักษณะอื่นของการแปรผันคือ ปริมาณสารเติมแต่ง. นั่นคือโดยรวมซึ่งแบ่งออกเป็นกลุ่มตามเกณฑ์ปัจจัย เอ็กซ์ , ความแปรปรวนที่เป็นผลลัพธ์ ยสามารถแบ่งออกเป็นความแปรปรวนภายในแต่ละกลุ่ม (ภายในกลุ่ม) และความแปรปรวนระหว่างกลุ่ม (ระหว่างกลุ่ม) จากนั้น ควบคู่ไปกับการศึกษาความแปรผันของคุณลักษณะทั่วทั้งประชากรโดยรวม จึงเป็นไปได้ที่จะศึกษาความแปรผันในแต่ละกลุ่ม ตลอดจนระหว่างกลุ่มเหล่านี้
ความแปรปรวนทั้งหมดวัดการเปลี่ยนแปลงของลักษณะ ที่เหนือประชากรทั้งหมดภายใต้อิทธิพลของปัจจัยทั้งหมดที่ทำให้เกิดการเปลี่ยนแปลงนี้ (การเบี่ยงเบน) มันเท่ากับค่าเบี่ยงเบนกำลังสองเฉลี่ย ค่าส่วนบุคคลเข้าสู่ระบบ ที่ของค่าเฉลี่ยโดยรวมและสามารถคำนวณเป็นความแปรปรวนอย่างง่ายหรือแบบถ่วงน้ำหนักได้
ความแปรปรวนระหว่างกลุ่มลักษณะการเปลี่ยนแปลงของคุณสมบัติที่มีประสิทธิภาพ ที่เกิดจากอิทธิพลของปัจจัยเครื่องหมาย เอ็กซ์ภายใต้การจัดกลุ่ม มันแสดงลักษณะของการเปลี่ยนแปลงของค่าเฉลี่ยกลุ่มและเท่ากับค่าเฉลี่ยกำลังสองของการเบี่ยงเบนของค่าเฉลี่ยกลุ่มจากค่าเฉลี่ยทั้งหมด:  ,
,
ค่าเฉลี่ยเลขคณิตของกลุ่ม i-th อยู่ที่ไหน
– จำนวนหน่วยในกลุ่ม i-th (ความถี่ของกลุ่ม i-th)
- ทั่วไป ค่าเฉลี่ยของประชากร.
ความแปรปรวนภายในกลุ่มสะท้อนความแปรผันแบบสุ่ม กล่าวคือ ส่วนหนึ่งของความแปรผันนั้นเกิดจากอิทธิพลของปัจจัยที่ไม่ได้นับรวมและไม่ขึ้นอยู่กับปัจจัยเชิงคุณลักษณะที่อยู่ภายใต้การจัดกลุ่ม มันแสดงลักษณะการเปลี่ยนแปลง ค่าส่วนบุคคลเทียบกับค่าเฉลี่ยของกลุ่มเท่ากับกำลังสองเฉลี่ยของการเบี่ยงเบนของแต่ละค่าของแอตทริบิวต์ ที่ภายในกลุ่มจากค่าเฉลี่ยเลขคณิตของกลุ่มนี้ (ค่าเฉลี่ยกลุ่ม) และคำนวณเป็นค่าความแปรปรวนอย่างง่ายหรือแบบถ่วงน้ำหนักสำหรับแต่ละกลุ่ม: ![]() หรือ
หรือ ![]() ,
,
จำนวนหน่วยในกลุ่มอยู่ที่ไหน
ซึ่งเป็นรากฐาน ความแปรปรวนภายในกลุ่มในแต่ละกลุ่มสามารถกำหนดได้ ค่าเฉลี่ยโดยรวมของความแปรปรวนภายในกลุ่ม:
.
ความสัมพันธ์ระหว่างความแปรปรวนทั้งสามเรียกว่า กฎการบวกผลต่างโดยที่ความแปรปรวนทั้งหมดเท่ากับผลรวมของความแปรปรวนระหว่างกลุ่มและค่าเฉลี่ยของความแปรปรวนภายในกลุ่ม:
ตัวอย่าง. เมื่อศึกษาอิทธิพลของหมวดหมู่อัตราค่าไฟฟ้า (คุณสมบัติ) ของคนงานต่อระดับผลิตภาพของแรงงาน ข้อมูลต่อไปนี้ได้รับ
ตารางที่ 5 - การกระจายคนงานตามผลผลิตเฉลี่ยต่อชั่วโมง
№ หน้า/หน้า |
คนงานประเภทที่ 4 |
คนงานประเภทที่ 5 |
|||||
ออกกำลังกาย |
ออกกำลังกาย |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
ที่ ตัวอย่างนี้คนงานแบ่งออกเป็นสองกลุ่มตามเกณฑ์ปัจจัย เอ็กซ์- คุณสมบัติซึ่งโดดเด่นด้วยอันดับของพวกเขา ลักษณะที่มีประสิทธิภาพ - การผลิต - แตกต่างกันไปทั้งภายใต้อิทธิพล (การเปลี่ยนแปลงระหว่างกลุ่ม) และเนื่องจากปัจจัยสุ่มอื่น ๆ (การเปลี่ยนแปลงภายในกลุ่ม) ความท้าทายคือการวัดความผันแปรเหล่านี้โดยใช้ความแปรปรวนสามแบบ ได้แก่ ผลรวม ระหว่างกลุ่ม และภายในกลุ่ม ค่าสัมประสิทธิ์เชิงประจักษ์ของการกำหนดแสดงสัดส่วนของการแปรผันของคุณลักษณะที่เป็นผลลัพธ์ ที่ภายใต้อิทธิพลของเครื่องหมายปัจจัย เอ็กซ์. ส่วนที่เหลือ รูปแบบทั่วไป ที่เกิดจากการเปลี่ยนแปลงของปัจจัยอื่นๆ
ในตัวอย่าง ค่าสัมประสิทธิ์เชิงประจักษ์ของการกำหนดคือ: ![]() หรือ 66.7%
หรือ 66.7%
ซึ่งหมายความว่า 66.7% ของการเปลี่ยนแปลงในผลิตภาพแรงงานของคนงานมีสาเหตุมาจากความแตกต่างในด้านคุณสมบัติ และ 33.3% เกิดจากอิทธิพลของปัจจัยอื่นๆ
ความสัมพันธ์เชิงประจักษ์แสดงให้เห็นถึงความแน่นแฟ้นของความสัมพันธ์ระหว่างการจัดกลุ่มและคุณสมบัติที่มีประสิทธิภาพ มันถูกคำนวณเป็นรากที่สองของค่าสัมประสิทธิ์เชิงประจักษ์ของการกำหนด:
อัตราส่วนสหสัมพันธ์เชิงประจักษ์ เช่นเดียวกับ สามารถรับค่าได้ตั้งแต่ 0 ถึง 1
หากไม่มีการเชื่อมต่อ ดังนั้น =0 ในกรณีนี้ =0 นั่นคือค่าเฉลี่ยของกลุ่มเท่ากันและไม่มีการเปลี่ยนแปลงระหว่างกลุ่ม ซึ่งหมายความว่าเครื่องหมายการจัดกลุ่ม - ปัจจัยไม่ส่งผลต่อการก่อตัวของรูปแบบทั่วไป
หากความสัมพันธ์ใช้งานได้ ดังนั้น =1 ในกรณีนี้ ความแปรปรวนของค่าเฉลี่ยกลุ่มคือ ความแปรปรวนทั้งหมด() นั่นคือไม่มีการเปลี่ยนแปลงภายในกลุ่ม ซึ่งหมายความว่าคุณลักษณะการจัดกลุ่มจะกำหนดการเปลี่ยนแปลงของคุณลักษณะผลลัพธ์ที่กำลังศึกษาอย่างสมบูรณ์
ยิ่งค่าของความสัมพันธ์ของความสัมพันธ์มีค่าใกล้เคียงกับค่าใดค่าหนึ่งมากเท่าใด ความสัมพันธ์ระหว่างคุณลักษณะก็จะยิ่งใกล้มากขึ้นเท่านั้น
สำหรับการประเมินเชิงคุณภาพของความใกล้ชิดของการเชื่อมต่อระหว่างสัญญาณจะใช้ความสัมพันธ์ของ Chaddock
ในตัวอย่าง ![]() ซึ่งบ่งชี้ว่า ปิดการเชื่อมต่อระหว่างผลิตภาพของคนงานและคุณสมบัติของพวกเขา
ซึ่งบ่งชี้ว่า ปิดการเชื่อมต่อระหว่างผลิตภาพของคนงานและคุณสมบัติของพวกเขา
 จะเริ่มต้นเป็นติวเตอร์ได้อย่างไร?
จะเริ่มต้นเป็นติวเตอร์ได้อย่างไร? การเรียนภาษาอังกฤษทางไกล
การเรียนภาษาอังกฤษทางไกล คำกริยาภาษาอังกฤษปกติและผิดปกติ
คำกริยาภาษาอังกฤษปกติและผิดปกติ