ช่วงความเชื่อมั่น มันคืออะไรและใช้ได้อย่างไร? ความน่าจะเป็นของความเชื่อมั่นและระดับนัยสำคัญ
ตรวจสอบแล้ว การประมาณจุดพารามิเตอร์การกระจายจะถูกประมาณในรูปแบบของตัวเลขที่ใกล้เคียงกับค่าของพารามิเตอร์ที่ไม่รู้จักมากที่สุด การประมาณการดังกล่าวใช้สำหรับการวัดจำนวนมากเท่านั้น ยิ่งขนาดตัวอย่างเล็กลง การเลือกพารามิเตอร์ก็จะยิ่งผิดพลาดได้ง่ายขึ้น สำหรับการปฏิบัติ สิ่งสำคัญไม่เพียงแต่จะต้องได้รับการประมาณจุดเท่านั้น แต่ยังต้องกำหนดช่วงเวลาที่เรียกว่าด้วย ไว้วางใจระหว่างขอบเขตที่กำหนดให้ ความน่าจะเป็นที่น่าเชื่อถือ
ที่ไหน - ระดับนัยสำคัญ x n, x b - ขอบเขตล่างและบนของช่วงเวลาที่ตั้งอยู่ ความหมายที่แท้จริงพารามิเตอร์ที่กำลังประเมิน
ใน กรณีทั่วไป ช่วงความมั่นใจสามารถสร้างบนพื้นฐานได้ ความไม่เท่าเทียมกันของ Chebyshevสำหรับกฎการกระจายใดๆ ของตัวแปรสุ่มที่มีโมเมนต์ของลำดับสองตัวแรก ขีดจำกัดบนของความน่าจะเป็นของการเบี่ยงเบนของตัวแปรสุ่ม x จากจุดศูนย์กลางของการแจกแจง X c ตกลงไปในช่วงเวลาทีเอสเอ็กซ์ อธิบายโดยความไม่เท่าเทียมกันของ Chebyshev

โดยที่ S x - การประมาณค่าเบี่ยงเบนมาตรฐานของการแจกแจงที - จำนวนบวก.
ในการหาช่วงความเชื่อมั่น คุณไม่จำเป็นต้องรู้กฎการกระจายตัวของผลการสังเกต แต่คุณจำเป็นต้องรู้ค่าประมาณของค่าเบี่ยงเบนมาตรฐาน ช่วงเวลาที่ได้รับจากความไม่เท่าเทียมกันของ Chebyshev นั้นกว้างเกินไปสำหรับการฝึกฝน ดังนั้น ความน่าจะเป็นของความเชื่อมั่นที่ 0.9 สำหรับกฎการกระจายหลายฉบับจึงสอดคล้องกับช่วงความเชื่อมั่นที่ 1.6เอส เอ็กซ์ - ความไม่เท่าเทียมกันของ Chebyshev ยอมแพ้ ในกรณีนี้ 3,16 เอส เอ็กซ์ - ด้วยเหตุนี้จึงไม่แพร่หลายมากนัก
ในการปฏิบัติทางมาตรวิทยาส่วนใหญ่จะใช้ การประมาณเชิงปริมาณช่วงความมั่นใจ ภายใต้ 100 ป-เปอร์เซ็นต์ควอนไทล์ x p เข้าใจว่าเป็น abscissa ของเส้นแนวตั้ง ทางด้านซ้ายของพื้นที่ใต้เส้นโค้งความหนาแน่นของการแจกแจงเท่ากับ P% กล่าวอีกนัยหนึ่ง ปริมาณ- นี่คือค่าของตัวแปรสุ่ม (ข้อผิดพลาด) ที่มีความน่าจะเป็นของความเชื่อมั่นที่กำหนด เช่น ค่ามัธยฐานของการแจกแจงคือควอนไทล์ 50% x 0.5
ในทางปฏิบัติ โดยทั่วไปจะเรียกว่าควอไทล์ 25 และ 75% พับหรือ ปริมาณการกระจายตัวระหว่างนั้น 50% ของค่าที่เป็นไปได้ทั้งหมดของตัวแปรสุ่มอยู่ และอีก 50% ที่เหลืออยู่นอกค่าเหล่านั้น ช่วงของค่าของตัวแปรสุ่ม x ระหว่าง x 0 05 ถึง x 0 95 ครอบคลุม 90% ของค่าที่เป็นไปได้ทั้งหมดและเรียกว่า ช่วงเวลาระหว่างควอนไทล์ที่มีความน่าจะเป็น 90%ความยาวของมันคือวัน 0.9 = x 0.95 - x 0.05
จากแนวทางนี้ จึงมีการนำแนวคิดนี้ไปใช้ ค่าความผิดพลาดเชิงปริมาณเหล่านั้น. ค่าความผิดพลาดที่มีความน่าจะเป็นของความเชื่อมั่นที่กำหนด P - ขีด จำกัด ของช่วงความไม่แน่นอน±ดีดี = ± (x พี - x 1-p)/2 = ±ดีพี /2. ตามความยาวจะมีค่า P% ของตัวแปรสุ่ม (ข้อผิดพลาด)คิว = (1- P)% ของจำนวนทั้งหมดยังคงอยู่นอกช่วงเวลานี้
เพื่อให้ได้ค่าประมาณช่วงเวลาของตัวแปรสุ่มแบบกระจายตามปกติ จำเป็นต้องมี:
หาค่าประมาณจุดของ MO x̅ และส่วนเบี่ยงเบนมาตรฐาน S x ตัวแปรสุ่มตามสูตร (6.8) และ (6.11) ตามลำดับ
เลือกความน่าจะเป็นของความเชื่อมั่น P จากช่วงค่าที่แนะนำ 0.90 0.95; 0.99;
ค้นหาขอบเขต xn บนและล่างของ xn ตามสมการ
ได้รับโดยคำนึงถึง (6.1) ค่าของ xn และ xb ถูกกำหนดจากตารางค่าของฟังก์ชันการแจกแจงอินทิกรัลฉ(ต ) หรือฟังก์ชันลาปลาซ Ф(1)
ช่วงความเชื่อมั่นที่ได้จะเป็นไปตามเงื่อนไข
(6.13)
ที่ไหน - จำนวนค่าที่วัดได้ซีพี - อาร์กิวเมนต์ของฟังก์ชัน Laplace Ф(1) ซึ่งสอดคล้องกับความน่าจะเป็น Р/2 ในกรณีนี้ซีพี เรียกว่าปัจจัยเชิงปริมาณ ครึ่งหนึ่งของความยาวช่วงความเชื่อมั่น ![]() เรียกว่าขีดจำกัดความเชื่อมั่นของความผิดพลาดของผลการวัด
เรียกว่าขีดจำกัดความเชื่อมั่นของความผิดพลาดของผลการวัด
ตัวอย่างที่ 6.1 ทำการวัดความต้านทานคงที่ 50 ครั้ง กำหนดช่วงความเชื่อมั่นสำหรับค่า MO ของความต้านทานคงที่ หากกฎการกระจายเป็นปกติพร้อมกับพารามิเตอร์ม. x = R = 590 โอห์ม, ส x = 90 โอห์ม ด้วยความน่าจะเป็นของความเชื่อมั่น P = 0.9
เนื่องจากสมมติฐานเกี่ยวกับความปกติของกฎการกระจายไม่ได้ขัดแย้งกับข้อมูลการทดลอง ช่วงความเชื่อมั่นจึงถูกกำหนดโดยสูตร
ดังนั้น Ф(z р ) = 0.45 จากตารางที่ให้ไว้ในภาคผนวก 1 เราพบว่าซีพี = 1.65. ดังนั้นช่วงความเชื่อมั่นจึงเขียนเป็น
หรือ 590 - 21< R < 590 + 21. Окончательно 509 Ом < ร< 611 Ом.
หากกฎการกระจายของตัวแปรสุ่มแตกต่างจากกฎปกติ จำเป็นต้องสร้างกฎขึ้นมา แบบจำลองทางคณิตศาสตร์และกำหนดช่วงความมั่นใจในการใช้งาน
วิธีที่พิจารณาในการหาช่วงความเชื่อมั่นนั้นใช้ได้เพียงพอ จำนวนมากการสังเกตเมื่อไหร่ ส= ส x - ควรจำไว้ว่าค่าประมาณที่คำนวณได้ของส่วนเบี่ยงเบนมาตรฐานส เป็นเพียงการประมาณค่าจริงบางส่วนเท่านั้นส- การกำหนดช่วงความเชื่อมั่นสำหรับความน่าจะเป็นที่กำหนดจะมีความน่าเชื่อถือน้อยกว่า จำนวนน้อยลงการสังเกต คุณไม่สามารถใช้สูตรได้ การกระจายตัวแบบปกติด้วยการสังเกตจำนวนน้อย หากไม่สามารถหาค่าเบี่ยงเบนมาตรฐานตามทฤษฎีได้จากการทดลองเบื้องต้นที่มีการสังเกตจำนวนมากเพียงพอ
การคำนวณช่วงความเชื่อมั่นในกรณีที่การกระจายผลการสังเกตเป็นเรื่องปกติ แต่ไม่ทราบความแปรปรวน เช่น ด้วยการสังเกตจำนวนน้อย n ก็เป็นไปได้ที่จะดำเนินการโดยใช้การแจกแจงแบบนักเรียนส(ที,เค - มันอธิบายความหนาแน่นของการแจกแจงของอัตราส่วน (เศษส่วนของนักเรียน):

ที่ไหน Q - มูลค่าที่แท้จริงของปริมาณที่วัดได้ ค่า x̅ , ส x . และสเอ็กซ์ คำนวณโดยใช้ข้อมูลการทดลองและเป็นตัวแทนค่าประมาณจุดของ MO ค่าเบี่ยงเบนมาตรฐานของผลการวัด และค่าเบี่ยงเบนมาตรฐานของค่าเฉลี่ย ค่าเลขคณิต.
ความน่าจะเป็นที่เศษส่วนของนักเรียนซึ่งเป็นผลมาจากการสังเกตที่เกิดขึ้น จะใช้ค่าที่แน่นอนในช่วงเวลา (-ทีพี ; +ทีพี)
(6.14)
ที่ไหนเค - จำนวนองศาอิสระเท่ากับ (n - 1) ปริมาณทีพี (ในกรณีนี้เรียกว่า ค่าสัมประสิทธิ์ของนักเรียน)คำนวณโดยใช้สองสูตรสุดท้ายสำหรับ ความหมายที่แตกต่างกันความน่าจะเป็นของความเชื่อมั่นและจำนวนการวัดจัดทำเป็นตาราง (ดูตารางในภาคผนวก 1) ดังนั้น เมื่อใช้การแจกแจงแบบนักเรียน คุณจะพบความน่าจะเป็นที่ค่าเบี่ยงเบนของค่าเฉลี่ยเลขคณิตจากค่าที่แท้จริงของค่าที่วัดได้ไม่เกิน
ในกรณีที่การแจกแจงของข้อผิดพลาดแบบสุ่มไม่ปกติ การแจกแจงของนักเรียนมักใช้กับการประมาณ โดยยังไม่ทราบระดับของการกระจาย การแจกแจงนักเรียนใช้สำหรับจำนวนการวัด n < 30, поскольку уже при
n = 20,...,30 มันจะกลายเป็นปกติ และแทนที่จะเป็นสมการ (6.14) เราสามารถใช้สมการ (6.13) ได้ ผลการวัดเขียนในรูปแบบ: ![]() ;
ป = Р d โดยที่ Р d คือค่าเฉพาะของความน่าจะเป็นของความเชื่อมั่น ปัจจัยที ด้วยการวัดจำนวนมาก n เท่ากับปัจจัยเชิงปริมาณซีพี สำหรับตัวเล็ก เขา เท่ากับสัมประสิทธิ์การทดสอบของนักเรียน
;
ป = Р d โดยที่ Р d คือค่าเฉพาะของความน่าจะเป็นของความเชื่อมั่น ปัจจัยที ด้วยการวัดจำนวนมาก n เท่ากับปัจจัยเชิงปริมาณซีพี สำหรับตัวเล็ก เขา เท่ากับสัมประสิทธิ์การทดสอบของนักเรียน
ผลการวัดที่ได้รับไม่เหมือนกัน หมายเลขเฉพาะ, a คือช่วงเวลาซึ่งด้วยความน่าจะเป็นที่แน่นอน P d จะมีการระบุค่าที่แท้จริงของปริมาณที่วัดได้ การเน้นที่จุดกึ่งกลางของช่วง x ไม่ได้หมายความว่าค่าจริงอยู่ใกล้ค่านั้นมากกว่าจุดอื่นๆ ในช่วงเวลาดังกล่าว สามารถอยู่ที่ไหนก็ได้ในช่วงเวลาดังกล่าว และมีความน่าจะเป็น 1 - Р d แม้อยู่ภายนอกก็ตาม
ตัวอย่างที่ 6.2 การหาค่าการสูญเสียแม่เหล็กจำเพาะสำหรับตัวอย่างต่างๆ ของเหล็กไฟฟ้าเกรด 2212 หนึ่งชุด ให้ผลลัพธ์ดังนี้ 1.21; 1.17; 1.18; 1.13; 1.19; 1.14; 1.20 และ 1.18 วัตต์/กก. สมมติว่าไม่มีข้อผิดพลาดอย่างเป็นระบบและมีการกระจายข้อผิดพลาดแบบสุ่มตามปกติ จำเป็นต้องกำหนดช่วงความเชื่อมั่นที่ค่าความน่าจะเป็นของความเชื่อมั่นที่ 0.9 และ 0.95 ในการแก้ปัญหา ให้ใช้สูตรลาปลาซและการแจกแจงของนักเรียน
การใช้สูตร (6.8) ใน (6.11) เราจะหาค่าประมาณของค่าเฉลี่ยเลขคณิตและส่วนเบี่ยงเบนมาตรฐานของผลการวัด มีค่าเท่ากับ 1.18 และ 0.0278 W/kg ตามลำดับ สมมติว่าการประมาณการ MSD เท่ากับค่าเบี่ยงเบน เราจะพบว่า:

จากที่นี่โดยใช้ค่าของฟังก์ชัน Laplace ที่ระบุในตารางในภาคผนวก 1 เราจะพิจารณาสิ่งนั้นซีพี = 1.65. สำหรับ P = 0.95 สัมประสิทธิ์ซีพี =1.96. ช่วงความเชื่อมั่นที่สอดคล้องกับ P = 0.9 และ 0.95 คือ 1.18 ± 0.016 และ 1.18 ± 0.019 วัตต์/กก.
ในกรณีที่ไม่มีเหตุผลให้เชื่อได้ว่าค่าเบี่ยงเบนมาตรฐานและการประมาณค่าเท่ากัน ช่วงความเชื่อมั่นจะพิจารณาจากการแจกแจงของนักเรียน:

จากตารางในภาคผนวก 1 เราพบว่าเสื้อ 0.9 = 1.9 และ เสื้อ 0.95 = 2.37. ดังนั้นช่วงความเชื่อมั่นคือ 1.18±0.019 และ 1.18±0.023 วัตต์/กก. ตามลำดับ
คำถามทดสอบ
1. ข้อผิดพลาดในการวัดสามารถถือเป็นตัวแปรสุ่มภายใต้เงื่อนไขใดได้บ้าง
2. ทำรายการคุณสมบัติของฟังก์ชันการแจกแจงอินทิกรัลและดิฟเฟอเรนเชียลของตัวแปรสุ่ม
3. ตั้งชื่อพารามิเตอร์ตัวเลขของกฎการกระจาย
4. สามารถตั้งศูนย์กระจายสินค้าได้อย่างไร?
5. ช่วงเวลาการจัดจำหน่ายคืออะไร? ข้อใดที่พบการประยุกต์ใช้ในมาตรวิทยา?
6. ตั้งชื่อคลาสหลักของการแจกแจงที่ใช้ในมาตรวิทยา
7. ระบุลักษณะการแจกแจงที่รวมอยู่ในระดับของการแจกแจงรูปสี่เหลี่ยมคางหมู
8. การแจกแจงแบบเอ็กซ์โปเนนเชียลคืออะไร? คุณสมบัติและลักษณะของพวกเขาคืออะไร?
9. การแจกแจงแบบปกติคืออะไร? มันเล่นทำไม. บทบาทพิเศษในมาตรวิทยา?
10. ฟังก์ชันลาปลาสคืออะไร และใช้เพื่ออะไร?
11. ครอบครัวของการแจกแจงของนักเรียนมีการอธิบายอย่างไร และนำไปใช้ที่ไหน?
12. คุณรู้ประมาณจุดใดของกฎหมายการกระจายสินค้า? ข้อกำหนดสำหรับพวกเขาคืออะไร?
13. ช่วงความเชื่อมั่นคืออะไร? คุณรู้วิธีการทำอะไรบ้าง?
ซึ่งด้วยความน่าจะเป็นอย่างใดอย่างหนึ่งจะมีพารามิเตอร์ทั่วไปอยู่ ความน่าจะเป็นที่รับรู้ว่าเพียงพอสำหรับการตัดสินอย่างมั่นใจเกี่ยวกับพารามิเตอร์ทั่วไปตามตัวบ่งชี้ตัวอย่างจะถูกเรียก น่าเชื่อถือ.
แนวคิดเรื่องความน่าจะเป็นของความเชื่อมั่นเป็นไปตามหลักการที่ว่าเหตุการณ์ไม่น่าเป็นไปได้ถือว่าเป็นไปไม่ได้ในทางปฏิบัติ และเหตุการณ์ที่มีความน่าจะเป็นใกล้เคียงกับเหตุการณ์หนึ่งถือว่าเกือบจะแน่นอน โดยทั่วไปแล้ว ความน่าจะเป็น P 1 = 0.95, P 2 = 0.99, P 3 = 0.999 จะถูกใช้เป็นความน่าจะเป็นของความเชื่อมั่น ค่าบางอย่างความน่าจะเป็นสอดคล้องกัน ระดับนัยสำคัญโดยที่เราหมายถึงความแตกต่าง α = 1-Р ความน่าจะเป็น 0.95 สอดคล้องกับระดับนัยสำคัญ α 1 = 0.05 (5%) ความน่าจะเป็น 0.99 - α 2 = 0.01 (1%) ความน่าจะเป็น 0.999 - α 3 = 0.001 (0.1%)
ซึ่งหมายความว่าเมื่อประเมินพารามิเตอร์ทั่วไปโดยใช้ตัวบ่งชี้ตัวอย่าง มีความเสี่ยงที่จะเกิดข้อผิดพลาดในกรณีแรกทุกๆ การทดสอบ 20 ครั้ง กล่าวคือ ใน 5% ของกรณี; ในครั้งที่สอง - 1 ครั้งต่อการทดสอบ 100 ครั้งเช่น ใน 1% ของกรณี; ในครั้งที่สาม - 1 ครั้งต่อการทดสอบ 1,000 ครั้งเช่น ใน 0.1% ของกรณี ดังนั้นระดับนัยสำคัญจึงแสดงถึงความน่าจะเป็นที่จะได้รับ การเบี่ยงเบนแบบสุ่มจากผลลัพธ์ที่สร้างขึ้นด้วยความน่าจะเป็นที่แน่นอน ความน่าจะเป็นที่ยอมรับเป็นความเชื่อมั่นจะกำหนดช่วงความเชื่อมั่นระหว่างพวกเขา สามารถใช้เพื่อประเมินปริมาณเฉพาะและขีดจำกัดที่อาจอยู่ในความน่าจะเป็นที่แตกต่างกัน
สำหรับ ความน่าจะเป็นที่แตกต่างกันช่วงความเชื่อมั่นจะเป็นดังนี้:
P 1 = 0.95 ช่วง - 1.96σ ถึง + 1.96σ (รูปที่ 5)
P 2 = 0.99 ช่วง - 2.58σ ถึง + 2.58σ
P 3 = 0.999 ช่วง - 3.03σ ถึง + 3.03σ
ค่าเบี่ยงเบนมาตรฐานต่อไปนี้สอดคล้องกับความน่าจะเป็นของความเชื่อมั่น:
ความน่าจะเป็น P 1 = 0.95 สอดคล้องกับ t 1 = 1.96σ
ความน่าจะเป็น P 2 = 0.99 สอดคล้องกับ t 2 = 2.58σ
ความน่าจะเป็น P 3 = 0.999 สอดคล้องกับ t 3 = 3.03σ
การเลือกเกณฑ์ความเชื่อมั่นอย่างใดอย่างหนึ่งจะขึ้นอยู่กับความสำคัญของเหตุการณ์ ระดับนัยสำคัญในกรณีนี้คือความน่าจะเป็นที่ถูกตัดสินว่าละเลยในการศึกษาหรือปรากฏการณ์ที่กำหนด
ข้อผิดพลาดโดยเฉลี่ย (m) หรือข้อผิดพลาดในการเป็นตัวแทน
ตามกฎแล้วลักษณะตัวอย่างไม่ตรงกับค่าสัมบูรณ์กับพารามิเตอร์ทั่วไปที่เกี่ยวข้อง ปริมาณความเบี่ยงเบนของตัวบ่งชี้ตัวอย่างจากพารามิเตอร์ทั่วไปเรียกว่าข้อผิดพลาดทางสถิติหรือข้อผิดพลาดในการเป็นตัวแทน ข้อผิดพลาดทางสถิติมีอยู่ในคุณลักษณะตัวอย่างเท่านั้น ซึ่งเกิดขึ้นในกระบวนการเลือกตัวเลือก ประชากร.
ข้อผิดพลาดโดยเฉลี่ยคำนวณโดยใช้สูตร:
โดยที่ σ คือค่าเบี่ยงเบนมาตรฐาน
n - จำนวนการวัด (ขนาดตัวอย่าง)
แสดงเป็นหน่วยเดียวกับ .
ข้อผิดพลาดโดยเฉลี่ยจะแปรผกผันกับตัวเลข ประชากรตัวอย่าง- ยิ่งขนาดตัวอย่างใหญ่ก็ยิ่งเล็กลง ข้อผิดพลาดโดยเฉลี่ยดังนั้นจึงมีความคลาดเคลื่อนน้อยกว่าระหว่างค่าลักษณะเฉพาะในกลุ่มตัวอย่างและประชากรทั่วไป
ค่าคลาดเคลื่อนในการสุ่มตัวอย่างเฉลี่ยสามารถใช้เพื่อประมาณค่าเฉลี่ยทั่วไปตามกฎการแจกแจงแบบปกติ ดังนั้น 68.3% ของค่าเฉลี่ยเลขคณิตตัวอย่างทั้งหมดอยู่ภายใน ±1, 95.5% ของค่าเฉลี่ยตัวอย่างทั้งหมดอยู่ภายใน ±2 และ 99.7% ของค่าเฉลี่ยตัวอย่างทั้งหมดอยู่ภายใน ±3
ความแม่นยำในการประมาณค่า ความน่าจะเป็นของความมั่นใจ(ความน่าเชื่อถือ)
ช่วงความเชื่อมั่น
เมื่อสุ่มตัวอย่างในปริมาณน้อย ควรใช้การประมาณช่วงเนื่องจาก สิ่งนี้จะหลีกเลี่ยง ความผิดพลาดร้ายแรงตรงกันข้ามกับการประมาณค่าแบบจุด
ช่วงเป็นการประมาณที่กำหนดโดยตัวเลขสองตัว - จุดสิ้นสุดของช่วงที่ครอบคลุมพารามิเตอร์ที่กำลังประมาณ การประมาณช่วงช่วยให้เราสามารถสร้างความถูกต้องและความน่าเชื่อถือของการประมาณการได้
ให้อันที่ค้นพบจากข้อมูลตัวอย่าง ลักษณะทางสถิติ* ทำหน้าที่เป็นค่าประมาณของพารามิเตอร์ที่ไม่รู้จัก เราจะนับ จำนวนคงที่(อาจจะ ตัวแปรสุ่ม- เป็นที่ชัดเจนว่า * ยิ่งกำหนดพารามิเตอร์ b ได้แม่นยำยิ่งขึ้นเท่าใดก็จะยิ่งน้อยลงเท่านั้น ค่าสัมบูรณ์ความแตกต่าง | - กล่าวอีกนัยหนึ่ง ถ้า >0 และ | -< , то чем меньше, тем оценка точнее. Таким образом, положительное число характеризует точность оценки.
อย่างไรก็ตาม วิธีการทางสถิติไม่อนุญาตให้เราระบุอย่างเด็ดขาดว่าการประมาณการ * เป็นไปตามความไม่เท่าเทียมกัน | -<, можно лишь говорить о вероятности, с которой это неравенство осуществляется.
ความน่าเชื่อถือ (ความน่าจะเป็นของความเชื่อมั่น) ของการประมาณค่าโดย * คือความน่าจะเป็นที่ทำให้เกิดความไม่เท่าเทียมกัน | -<. Обычно надежность оценки задается наперед, причем в качестве берут число, близкое к единице. Наиболее часто задают надежность, равную 0,95; 0,99 и 0,999.
ให้ความน่าจะเป็นที่ | -<, равна т.е.
แทนที่ความไม่เท่าเทียมกัน | -< равносильным ему двойным неравенством -<| - *|<, или *- <<*+, имеем
ป(*-< <*+)=.
ช่วงความเชื่อมั่น (*-, *+) เรียกว่าช่วงความเชื่อมั่นที่ครอบคลุมพารามิเตอร์ที่ไม่รู้จักพร้อมความน่าเชื่อถือที่กำหนด
ช่วงความเชื่อมั่นสำหรับการประมาณค่าความคาดหวังทางคณิตศาสตร์ของการแจกแจงแบบปกติจากการแจกแจงที่ทราบ
การประมาณช่วงที่มีความน่าเชื่อถือของความคาดหวังทางคณิตศาสตร์ a ของคุณลักษณะเชิงปริมาณแบบกระจายตามปกติ X โดยอิงตามค่าเฉลี่ยตัวอย่าง x โดยมีค่าเบี่ยงเบนมาตรฐานที่ทราบของประชากรคือช่วงความเชื่อมั่น
x - เสื้อ(/n^?)< a < х + t(/n^?),
โดยที่ t(/n^?)= คือความแม่นยำของการประมาณค่า n คือขนาดตัวอย่าง t คือค่าของอาร์กิวเมนต์ของฟังก์ชัน Laplace Ф(t) โดยที่ Ф(t)=/2
จากความเท่าเทียมกัน t(/n^?)= สามารถสรุปได้ดังต่อไปนี้:
1. เมื่อขนาดตัวอย่างเพิ่มขึ้น n จำนวนจะลดลง ดังนั้นความแม่นยำของการประมาณจึงเพิ่มขึ้น
2. การเพิ่มขึ้นของความน่าเชื่อถือของการประมาณการ = 2Ф(t) นำไปสู่การเพิ่มขึ้นใน t (Ф(t) เป็นฟังก์ชันที่เพิ่มขึ้น) และดังนั้นจึงเพิ่มขึ้น กล่าวอีกนัยหนึ่ง การเพิ่มความน่าเชื่อถือของการประมาณการแบบคลาสสิกส่งผลให้ความแม่นยำลดลง
ตัวอย่าง. ตัวแปรสุ่ม X มีการแจกแจงแบบปกติโดยมีค่าเบี่ยงเบนมาตรฐานที่ทราบ =3 ค้นหาช่วงความเชื่อมั่นในการประมาณค่าความคาดหวังทางคณิตศาสตร์ที่ไม่ทราบ a โดยยึดตามค่าเฉลี่ยของกลุ่มตัวอย่าง x หากขนาดของกลุ่มตัวอย่างคือ n = 36 และให้ความน่าเชื่อถือของการประมาณค่า = 0.95
สารละลาย. มาหาที. จากความสัมพันธ์ 2Ф(t) = 0.95 เราได้ Ф(t) = 0.475 จากตารางเราจะพบว่า t=1.96
มาหาความถูกต้องของการประมาณกัน:
การวัดช่วงความเชื่อมั่นที่แม่นยำ
T(/n^?)= (1.96.3)/ /36 = 0.98
ช่วงความเชื่อมั่นคือ: (x - 0.98; x + 0.98) ตัวอย่างเช่น ถ้า x = 4.1 ช่วงความเชื่อมั่นจะมีขีดจำกัดความเชื่อมั่นดังต่อไปนี้:
x - 0.98 = 4.1 - 0.98 = 3.12; x + 0.98 = 4.1 + 0.98 = 5.08
ดังนั้นค่าของพารามิเตอร์ที่ไม่รู้จัก a ซึ่งสอดคล้องกับข้อมูลตัวอย่างจึงเป็นไปตามความไม่เท่าเทียมกัน 3.12< а < 5,08. Подчеркнем, что было бы ошибочным написать Р (3,12 < а < 5,08) = 0,95. Действительно, так как а - постоянная величина, то либо она заключена в найденном интервале (тогда событие 3,12 < а < 5,08 достоверно и его вероятность равна единице), либо в нем не заключена (в этом случае событие 3,12 < а < 5,08 невозможно и его вероятность равна нулю). Другими словами, доверительную вероятность не следует связывать с оцениваемым параметром; она связана лишь с границами доверительного интервала, которые, как уже было указано, изменяются от выборки к выборке.
ให้เราอธิบายความหมายของความน่าเชื่อถือที่กำหนด ความเชื่อถือได้ = 0.95 บ่งชี้ว่าหากเก็บตัวอย่างจำนวนมากเพียงพอ 95% ของตัวอย่างจะกำหนดช่วงความเชื่อมั่นซึ่งมีพารามิเตอร์อยู่จริง มีเพียง 5% ของกรณีเท่านั้นที่สามารถเกินช่วงความเชื่อมั่นได้
หากจำเป็นต้องประมาณค่าความคาดหวังทางคณิตศาสตร์ด้วยความแม่นยำและความน่าเชื่อถือที่กำหนดไว้ล่วงหน้า ขนาดตัวอย่างขั้นต่ำที่จะรับประกันความแม่นยำนี้จะพบได้โดยใช้สูตร
ช่วงความเชื่อมั่นสำหรับการประมาณค่าความคาดหวังทางคณิตศาสตร์ของการแจกแจงแบบปกติโดยไม่ทราบค่า
การประมาณช่วงที่มีความน่าเชื่อถือของความคาดหวังทางคณิตศาสตร์ a ของลักษณะเชิงปริมาณแบบกระจายปกติ X โดยอิงตามค่าเฉลี่ยตัวอย่าง x โดยมีค่าเบี่ยงเบนมาตรฐานที่ไม่ทราบของประชากรทั่วไปคือช่วงความเชื่อมั่น
x - t()(s/n^?)< a < х + t()(s/n^?),
โดยที่ s คือค่าเบี่ยงเบนมาตรฐานตัวอย่างที่ “แก้ไขแล้ว” จะพบ t() จากตารางสำหรับค่าที่กำหนดและ n
ตัวอย่าง. ลักษณะเชิงปริมาณ X ของประชากรมีการกระจายตามปกติ จากขนาดตัวอย่างที่ n=16 พบว่าค่าเฉลี่ยตัวอย่าง x = 20.2 และค่าเบี่ยงเบนมาตรฐานที่ "แก้ไขแล้ว" s = 0.8 ประมาณค่าความคาดหวังทางคณิตศาสตร์ที่ไม่ทราบโดยใช้ช่วงความเชื่อมั่นที่มีค่าความน่าเชื่อถือ 0.95
สารละลาย. มาหา t() กัน จากการใช้ตาราง โดย = 0.95 และ n=16 เราจะพบว่า t()=2.13
มาหาขีดจำกัดความมั่นใจกัน:
x - t() (s/n^?) = 20.2 - 2.13 * 0.8/16^? = 19.774
x + t()(s/n^?) = 20.2 + 2.13 * 0.8/16^? = 20.626
ดังนั้น ด้วยความน่าเชื่อถือที่ 0.95 พารามิเตอร์ที่ไม่รู้จัก a จึงอยู่ในช่วงความเชื่อมั่นที่ 19.774< а < 20,626
การประมาณมูลค่าที่แท้จริงของปริมาณที่วัดได้
ปล่อยให้การวัดปริมาณทางกายภาพบางส่วนมีความแม่นยำเท่ากันโดยอิสระ โดยไม่ทราบค่าที่แท้จริง
เราจะพิจารณาผลลัพธ์ของการวัดแต่ละรายการเป็นตัวแปรสุ่ม XXl, X2,…XXn ปริมาณเหล่านี้มีความเป็นอิสระ (การวัดมีความเป็นอิสระ) พวกเขามีความคาดหวังทางคณิตศาสตร์เหมือนกัน a (มูลค่าที่แท้จริงของปริมาณที่วัดได้), ความแปรปรวนเหมือนกัน ^2 (การวัดมีความแม่นยำเท่ากัน) และมีการกระจายตามปกติ (สมมติฐานนี้ได้รับการยืนยันจากประสบการณ์)
ดังนั้นสมมติฐานทั้งหมดที่เกิดขึ้นในการหาช่วงความเชื่อมั่นจึงเป็นจริง ดังนั้นเราจึงมีอิสระในการใช้สูตร กล่าวอีกนัยหนึ่ง ค่าที่แท้จริงของค่าที่วัดได้สามารถประมาณได้จากค่าเฉลี่ยเลขคณิตของผลลัพธ์ของการวัดแต่ละรายการโดยใช้ช่วงความเชื่อมั่น
ตัวอย่าง. จากข้อมูลของการวัดปริมาณทางกายภาพที่มีความแม่นยำเท่ากันโดยอิสระทั้ง 9 รายการ พบว่าค่าเฉลี่ยเลขคณิตของผลลัพธ์ของการวัดแต่ละรายการคือ x = 42.319 และค่าเบี่ยงเบนมาตรฐานที่ "แก้ไขแล้ว" s = 5.0 จำเป็นต้องประมาณมูลค่าที่แท้จริงของค่าที่วัดได้โดยมีความน่าเชื่อถือ = 0.95
สารละลาย. มูลค่าที่แท้จริงของปริมาณที่วัดได้เท่ากับค่าคาดหวังทางคณิตศาสตร์ ดังนั้น ปัญหาจึงอยู่ที่การประมาณค่าความคาดหวังทางคณิตศาสตร์ (ไม่ทราบค่า) โดยใช้ช่วงความเชื่อมั่นที่ครอบคลุม a โดยมีความน่าเชื่อถือที่กำหนด = 0.95
x - t()(s/n^?)< a < х + t()(s/n^?)
ใช้ตารางโดยใช้ y = 0.95 และ l = 9 เราพบ
มาหาความถูกต้องของการประมาณกัน:
t())(s/n^?) = 2.31 * 5/9^?=3.85
มาหาขีดจำกัดความมั่นใจกัน:
x - t() (s/n^?) = 42.319 - 3.85 = 38.469;
x + t() (s/n^?) = 42.319 +3.85 = 46.169
ดังนั้น ด้วยความน่าเชื่อถือที่ 0.95 ค่าที่แท้จริงของค่าที่วัดได้จึงอยู่ในช่วงความเชื่อมั่นที่ 38.469< а < 46,169.
ช่วงความเชื่อมั่นสำหรับการประมาณค่าส่วนเบี่ยงเบนมาตรฐานของการแจกแจงแบบปกติ
ให้ลักษณะเชิงปริมาณ X ของประชากรทั่วไปกระจายตามปกติ จำเป็นต้องประมาณค่าเบี่ยงเบนมาตรฐานทั่วไปที่ไม่ทราบจากค่าเบี่ยงเบนมาตรฐานตัวอย่างที่ "แก้ไขแล้ว" ในการดำเนินการนี้ เราจะใช้การประมาณค่าช่วงเวลา
การประมาณช่วง (ที่มีความน่าเชื่อถือ) ของค่าเบี่ยงเบนมาตรฐาน o ของคุณลักษณะเชิงปริมาณแบบกระจายปกติ X โดยยึดตามค่าเบี่ยงเบนมาตรฐานตัวอย่างที่ "แก้ไขแล้ว" s คือช่วงความเชื่อมั่น
ส (1 -- คิว)< < s (1 + q) (при q < 1),
0 < < s (1 + q) (при q > 1),
โดยที่ q พบได้จากตารางที่ให้ n n
ตัวอย่างที่ 1 คุณลักษณะเชิงปริมาณ X ของประชากรทั่วไปมีการกระจายตามปกติ จากขนาดตัวอย่างที่ n = 25 พบค่าเบี่ยงเบนมาตรฐานที่ "แก้ไขแล้ว" ที่ s = 0.8 ค้นหาช่วงความเชื่อมั่นที่ครอบคลุมส่วนเบี่ยงเบนมาตรฐานทั่วไปด้วยความน่าเชื่อถือ 0.95
สารละลาย. การใช้ตารางที่มีข้อมูล = 0.95 และ n = 25 เราจะพบ q = 0.32
ช่วงความเชื่อมั่นที่ต้องการ s (1 -- q)< < s (1 + q) таков:
0,8(1-- 0,32) < < 0,8(1+0,32), или 0,544 < < 1,056.
ตัวอย่างที่ 2 คุณลักษณะเชิงปริมาณ X ของประชากรทั่วไปมีการกระจายตามปกติ จากขนาดตัวอย่างที่ n=10 พบค่าเบี่ยงเบนมาตรฐานที่ "แก้ไขแล้ว" ที่ s = 0.16 ค้นหาช่วงความเชื่อมั่นที่ครอบคลุมส่วนเบี่ยงเบนมาตรฐานทั่วไปด้วยความน่าเชื่อถือ 0.999
สารละลาย. เมื่อใช้ตารางภาคผนวกตามข้อมูล = 0.999 และ n=10 เราจะพบว่า 17= 1.80 (q > 1) ช่วงความเชื่อมั่นที่ต้องการคือ:
0 < < 0,16(1 + 1,80), или 0 < < 0,448.
ระดับความแม่นยำในการวัด
ในทฤษฎีข้อผิดพลาด เป็นเรื่องปกติที่จะต้องระบุลักษณะความแม่นยำในการวัด (ความแม่นยำของเครื่องมือ) โดยใช้ค่าเบี่ยงเบนมาตรฐานของข้อผิดพลาดในการวัดแบบสุ่ม สำหรับการประเมิน จะใช้ค่าเบี่ยงเบนมาตรฐานที่ "แก้ไขแล้ว" เนื่องจากโดยปกติแล้วผลการวัดจะเป็นอิสระซึ่งกันและกัน มีความคาดหวังทางคณิตศาสตร์เหมือนกัน (ค่าที่แท้จริงของค่าที่วัดได้) และมีการกระจายตัวเท่ากัน (ในกรณีของการวัดที่มีความแม่นยำเท่ากัน) ทฤษฎีที่สรุปไว้ในย่อหน้าก่อนหน้านี้จึงนำไปใช้ในการประเมิน ความแม่นยำของการวัด
ตัวอย่าง. จากการวัดที่มีความแม่นยำเท่ากัน 15 ครั้ง พบค่าเบี่ยงเบนมาตรฐานที่ "แก้ไขแล้ว" ที่ s = 0.12 ค้นหาความแม่นยำในการวัดด้วยความน่าเชื่อถือ 0.99
สารละลาย. ความแม่นยำในการวัดมีลักษณะเฉพาะคือค่าเบี่ยงเบนมาตรฐานของข้อผิดพลาดแบบสุ่ม ดังนั้นปัญหาจึงอยู่ที่การค้นหาช่วงความเชื่อมั่น s (1 -- q)< < s (1 + q) , покрывающего с заданной надежностью 0,99
การใช้ตารางภาคผนวกสำหรับ = 0.99 และ n = 15 เราพบ q = 0.73
ช่วงความเชื่อมั่นที่ต้องการ
0,12(1-- 0,73) < < 0,12(1+0,73), или 0.03 < < 0,21.
การประมาณความน่าจะเป็น (การแจกแจงแบบทวินาม) จากความถี่สัมพัทธ์
การประมาณช่วง (ที่มีความน่าเชื่อถือ) ของความน่าจะเป็นที่ไม่ทราบค่า p ของการแจกแจงแบบทวินามด้วยความถี่สัมพัทธ์ w คือช่วงความเชื่อมั่น (โดยมีจุดสิ้นสุดโดยประมาณ p1 และ p2)
หน้า 1< p < p2,
โดยที่ n คือจำนวนการทดสอบทั้งหมด m คือจำนวนครั้งของเหตุการณ์ w - ความถี่สัมพัทธ์เท่ากับอัตราส่วน m/n; t คือค่าของอาร์กิวเมนต์ของฟังก์ชัน Laplace โดยที่ Ф(t) = /2
ความคิดเห็น สำหรับค่าขนาดใหญ่ของ n (ของลำดับของร้อย) สามารถใช้เป็นขีดจำกัดโดยประมาณของช่วงความเชื่อมั่นได้
บ่อยครั้งที่ผู้ประเมินราคาต้องวิเคราะห์ตลาดอสังหาริมทรัพย์ในส่วนที่ทรัพย์สินนั้นถูกประเมินตั้งอยู่ หากตลาดได้รับการพัฒนา การวิเคราะห์ทั้งชุดของวัตถุที่นำเสนออาจเป็นเรื่องยาก ดังนั้นจึงใช้ตัวอย่างของวัตถุในการวิเคราะห์ ตัวอย่างนี้ไม่ได้เป็นเนื้อเดียวกันเสมอไป บางครั้งจำเป็นต้องเคลียร์จุดที่รุนแรง - ข้อเสนอของตลาดสูงเกินไปหรือต่ำเกินไป เพื่อจุดประสงค์นี้จึงถูกนำมาใช้ ช่วงความมั่นใจ- การศึกษานี้มีวัตถุประสงค์เพื่อทำการวิเคราะห์เปรียบเทียบสองวิธีในการคำนวณช่วงความเชื่อมั่น และเลือกตัวเลือกการคำนวณที่เหมาะสมที่สุดเมื่อทำงานกับตัวอย่างที่แตกต่างกันในระบบ estimatica.pro
ช่วงความเชื่อมั่นคือช่วงของค่าคุณลักษณะที่คำนวณตามกลุ่มตัวอย่าง ซึ่งมีความน่าจะเป็นที่ทราบอยู่แล้วว่ามีพารามิเตอร์โดยประมาณของประชากรทั่วไป
จุดของการคำนวณช่วงความเชื่อมั่นคือการสร้างช่วงดังกล่าวโดยอาศัยข้อมูลตัวอย่าง เพื่อให้สามารถระบุด้วยความน่าจะเป็นที่กำหนดว่าค่าของพารามิเตอร์โดยประมาณจะอยู่ในช่วงเวลานี้ กล่าวอีกนัยหนึ่ง ช่วงความเชื่อมั่นประกอบด้วยค่าที่ไม่ทราบของค่าประมาณที่มีความน่าจะเป็นที่แน่นอน ยิ่งช่วงห่างมากขึ้น ความคลาดเคลื่อนก็จะยิ่งสูงขึ้น
มีวิธีการต่างๆ ในการกำหนดช่วงความเชื่อมั่น ในบทความนี้เราจะดู 2 วิธี:
- ผ่านค่ามัธยฐานและส่วนเบี่ยงเบนมาตรฐาน
- ผ่านค่าวิกฤตของสถิติ t (สัมประสิทธิ์นักเรียน)
ขั้นตอนของการวิเคราะห์เปรียบเทียบวิธีการต่าง ๆ ในการคำนวณ CI:
1. สร้างตัวอย่างข้อมูล
2. เราประมวลผลโดยใช้วิธีการทางสถิติ: เราคำนวณค่าเฉลี่ย ค่ามัธยฐาน ความแปรปรวน ฯลฯ
3. คำนวณช่วงความเชื่อมั่นได้สองวิธี
4. วิเคราะห์ตัวอย่างที่ทำความสะอาดแล้วและช่วงความเชื่อมั่นที่ได้
ขั้นตอนที่ 1 การสุ่มตัวอย่างข้อมูล
ตัวอย่างถูกสร้างขึ้นโดยใช้ระบบ estimatica.pro ตัวอย่างรวมข้อเสนอ 91 รายการสำหรับการขายอพาร์ทเมนต์ 1 ห้องในโซนราคาที่ 3 พร้อมเลย์เอาต์ประเภท "ครุสชอฟ"
ตารางที่ 1. ตัวอย่างเริ่มต้น
|
ราคา 1 ตร.ม. หน่วย |
|
รูปที่ 1. ตัวอย่างเบื้องต้น

ขั้นตอนที่ 2 การประมวลผลตัวอย่างเริ่มต้น
การประมวลผลตัวอย่างโดยใช้วิธีทางสถิติจำเป็นต้องคำนวณค่าต่อไปนี้:
1. ค่าเฉลี่ยเลขคณิต

2. ค่ามัธยฐาน - ตัวเลขที่แสดงลักษณะของตัวอย่าง: ครึ่งหนึ่งขององค์ประกอบตัวอย่างมีค่ามากกว่าค่ามัธยฐาน ส่วนอีกครึ่งหนึ่งมีค่าน้อยกว่าค่ามัธยฐาน
 (สำหรับตัวอย่างที่มีค่าเลขคี่)
(สำหรับตัวอย่างที่มีค่าเลขคี่)
3. พิสัย - ความแตกต่างระหว่างค่าสูงสุดและค่าต่ำสุดในกลุ่มตัวอย่าง

4. ความแปรปรวน - ใช้เพื่อประมาณค่าความแปรผันของข้อมูลได้แม่นยำยิ่งขึ้น

5. ค่าเบี่ยงเบนมาตรฐานตัวอย่าง (ต่อไปนี้ - SD) เป็นตัวบ่งชี้ที่พบบ่อยที่สุดของการกระจายตัวของค่าการปรับรอบค่าเฉลี่ยเลขคณิต

6. ค่าสัมประสิทธิ์การเปลี่ยนแปลง - สะท้อนถึงระดับการกระจายของค่าการปรับ

7. ค่าสัมประสิทธิ์การแกว่ง - สะท้อนถึงความผันผวนสัมพัทธ์ของค่าราคาสุดขีดในตัวอย่างรอบค่าเฉลี่ย

ตารางที่ 2. ตัวบ่งชี้ทางสถิติของกลุ่มตัวอย่างดั้งเดิม
ค่าสัมประสิทธิ์การแปรผันซึ่งระบุลักษณะความเป็นเนื้อเดียวกันของข้อมูลคือ 12.29% แต่ค่าสัมประสิทธิ์การแกว่งสูงเกินไป ดังนั้น เราสามารถพูดได้ว่าตัวอย่างดั้งเดิมไม่เป็นเนื้อเดียวกัน ดังนั้น เรามาคำนวณช่วงความเชื่อมั่นกันดีกว่า
ขั้นตอนที่ 3 การคำนวณช่วงความเชื่อมั่น
วิธีที่ 1. การคำนวณโดยใช้ค่ามัธยฐานและส่วนเบี่ยงเบนมาตรฐาน
ช่วงความเชื่อมั่นถูกกำหนดดังนี้ ค่าต่ำสุด - ค่าเบี่ยงเบนมาตรฐานจะถูกลบออกจากค่ามัธยฐาน ค่าสูงสุด - ส่วนเบี่ยงเบนมาตรฐานจะถูกบวกเข้ากับค่ามัธยฐาน

ดังนั้น ช่วงความเชื่อมั่น (47179 CU; 60689 CU)
ข้าว. 2. ค่าที่ตกอยู่ในช่วงความเชื่อมั่น 1.

วิธีที่ 2 การสร้างช่วงความเชื่อมั่นโดยใช้ค่าวิกฤตของสถิติ t (สัมประสิทธิ์นักเรียน)
เอส.วี. Gribovsky ในหนังสือของเขา "วิธีการทางคณิตศาสตร์สำหรับการประมาณมูลค่าทรัพย์สิน" อธิบายวิธีการคำนวณช่วงความเชื่อมั่นผ่านค่าสัมประสิทธิ์นักเรียน เมื่อคำนวณโดยใช้วิธีนี้ ตัวประมาณค่าจะต้องตั้งค่าระดับนัยสำคัญ ∝ ด้วยตัวเอง ซึ่งจะกำหนดความน่าจะเป็นที่จะสร้างช่วงความเชื่อมั่น โดยปกติแล้ว จะใช้ระดับนัยสำคัญที่ 0.1 0.05 และ 0.01 สอดคล้องกับความน่าจะเป็นของความเชื่อมั่นที่ 0.9; 0.95 และ 0.99 ด้วยวิธีนี้ ค่าที่แท้จริงของความคาดหวังและความแปรปรวนทางคณิตศาสตร์จะถือว่าไม่เป็นที่รู้จักในทางปฏิบัติ (ซึ่งเกือบจะเป็นจริงเสมอเมื่อแก้ไขปัญหาการประมาณค่าเชิงปฏิบัติ)
สูตรช่วงความเชื่อมั่น:

n - ขนาดตัวอย่าง;
ค่าวิกฤตของสถิติ t (การกระจายตัวของนักเรียน) ที่มีระดับนัยสำคัญ ∝ จำนวนองศาอิสระ n-1 ซึ่งกำหนดจากตารางสถิติพิเศษหรือใช้ MS Excel (→"สถิติ"→ STUDIST)
∝ - ระดับนัยสำคัญ รับ ∝=0.01

ข้าว. 2. ค่าที่ตกอยู่ในช่วงความเชื่อมั่น 2.

ขั้นตอนที่ 4 การวิเคราะห์วิธีการต่าง ๆ ในการคำนวณช่วงความเชื่อมั่น
สองวิธีในการคำนวณช่วงความเชื่อมั่น - ผ่านค่ามัธยฐานและค่าสัมประสิทธิ์ของนักเรียน - นำไปสู่ค่าช่วงเวลาที่แตกต่างกัน ดังนั้นเราจึงได้ตัวอย่างที่ทำความสะอาดแล้วสองตัวอย่างที่แตกต่างกัน
ตารางที่ 3. สถิติสำหรับสามตัวอย่าง
|
ตัวบ่งชี้ |
ตัวอย่างเบื้องต้น |
1 ตัวเลือก |
ตัวเลือกที่ 2 |
|
ค่าเฉลี่ย |
|||
|
การกระจายตัว |
|||
|
โคฟ. รูปแบบต่างๆ |
|||
|
โคฟ. การสั่น |
|||
|
จำนวนวัตถุที่เลิกใช้ ชิ้น |
|||
จากการคำนวณที่ดำเนินการ เราสามารถพูดได้ว่าค่าช่วงความเชื่อมั่นที่ได้รับโดยวิธีการต่างๆ ตัดกัน ดังนั้นคุณสามารถใช้วิธีการคำนวณใดๆ ก็ได้ตามดุลยพินิจของผู้ประเมิน
อย่างไรก็ตาม เราเชื่อว่าเมื่อทำงานในระบบ estimatica.pro ขอแนะนำให้เลือกวิธีการคำนวณช่วงความเชื่อมั่น ขึ้นอยู่กับระดับของการพัฒนาตลาด:
- หากตลาดยังไม่ได้รับการพัฒนา ให้ใช้วิธีการคำนวณโดยใช้ค่ามัธยฐานและส่วนเบี่ยงเบนมาตรฐาน เนื่องจากจำนวนวัตถุที่เลิกใช้ในกรณีนี้มีน้อย
- หากตลาดได้รับการพัฒนา ให้ใช้การคำนวณผ่านค่าวิกฤตของสถิติ t (สัมประสิทธิ์ของนักเรียน) เนื่องจากเป็นไปได้ที่จะสร้างตัวอย่างเริ่มต้นขนาดใหญ่
ในการเตรียมบทความมีการใช้สิ่งต่อไปนี้:
1. Gribovsky S.V., Sivets S.A., Levykina I.A. วิธีทางคณิตศาสตร์ในการประเมินมูลค่าทรัพย์สิน มอสโก, 2014
2. ระบบข้อมูล estimatica.pro
การวิเคราะห์ข้อผิดพลาดแบบสุ่มขึ้นอยู่กับทฤษฎีข้อผิดพลาดแบบสุ่ม ซึ่งทำให้รับประกันได้ว่าจะสามารถคำนวณค่าที่แท้จริงของค่าที่วัดได้และประเมินข้อผิดพลาดที่เป็นไปได้
ทฤษฎีข้อผิดพลาดแบบสุ่มขึ้นอยู่กับสมมติฐานต่อไปนี้:
ด้วยการวัดจำนวนมากข้อผิดพลาดแบบสุ่มที่มีขนาดเท่ากัน แต่มีสัญญาณต่างกันเกิดขึ้นบ่อยเท่า ๆ กัน
ข้อผิดพลาดขนาดใหญ่นั้นพบได้น้อยกว่าข้อผิดพลาดเล็กๆ (ความน่าจะเป็นของข้อผิดพลาดจะลดลงเมื่อขนาดเพิ่มขึ้น)
ด้วยการวัดจำนวนมากอย่างไม่สิ้นสุด ค่าที่แท้จริงของปริมาณที่วัดได้จะเท่ากับค่าเฉลี่ยเลขคณิตของผลการวัดทั้งหมด
การปรากฏตัวของผลการวัดอย่างใดอย่างหนึ่งเป็นเหตุการณ์สุ่มอธิบายโดยกฎการกระจายแบบปกติ
ในทางปฏิบัติ จะมีความแตกต่างระหว่างชุดการวัดทั่วไปและชุดตัวอย่าง
ภายใต้จำนวนประชากร
หมายถึงชุดของค่าการวัดที่เป็นไปได้ทั้งหมดหรือค่าความผิดพลาดที่เป็นไปได้  .
.
สำหรับประชากรกลุ่มตัวอย่าง
จำนวนการวัด  จำกัดและกำหนดอย่างเคร่งครัดในแต่ละกรณี พวกเขาคิดว่าถ้า
จำกัดและกำหนดอย่างเคร่งครัดในแต่ละกรณี พวกเขาคิดว่าถ้า  แล้วค่าเฉลี่ยของชุดการวัดนี้
แล้วค่าเฉลี่ยของชุดการวัดนี้  ใกล้เคียงกับมูลค่าที่แท้จริงมากพอ
ใกล้เคียงกับมูลค่าที่แท้จริงมากพอ
1. การประมาณช่วงโดยใช้ความน่าจะเป็นของความเชื่อมั่น
สำหรับตัวอย่างขนาดใหญ่และการแจกแจงแบบปกติ คุณลักษณะการประเมินโดยทั่วไปของการวัดคือการกระจายตัว  และสัมประสิทธิ์การแปรผัน
และสัมประสิทธิ์การแปรผัน  :
:
 ;
;
 .
(1.1)
.
(1.1)
การกระจายตัวบ่งบอกถึงความเป็นเนื้อเดียวกันของการวัด ยิ่งสูง.  ยิ่งการกระจายของการวัดมีมากขึ้น
ยิ่งการกระจายของการวัดมีมากขึ้น
ค่าสัมประสิทธิ์ของการแปรผันบ่งบอกถึงความแปรปรวน ยิ่งสูง.  ยิ่งความแปรปรวนของการวัดสัมพันธ์กับค่าเฉลี่ยยิ่งมากขึ้น
ยิ่งความแปรปรวนของการวัดสัมพันธ์กับค่าเฉลี่ยยิ่งมากขึ้น
เพื่อประเมินความน่าเชื่อถือของผลการวัด จึงได้นำแนวคิดเรื่องช่วงความเชื่อมั่นและความน่าจะเป็นของความเชื่อมั่นมาใช้
เชื่อถือได้
เรียกว่าช่วง
ค่านิยม  ,
ซึ่งมูลค่าที่แท้จริงตกลงไปในนั้น
,
ซึ่งมูลค่าที่แท้จริงตกลงไปในนั้น  ปริมาณที่วัดได้ด้วยความน่าจะเป็นที่กำหนด
ปริมาณที่วัดได้ด้วยความน่าจะเป็นที่กำหนด
ความน่าจะเป็นของความมั่นใจ
(ความน่าเชื่อถือ) ของการวัดคือความน่าจะเป็นที่ค่าที่แท้จริงของค่าที่วัดได้จะอยู่ภายในช่วงความเชื่อมั่นที่กำหนด เช่น ไปที่โซน  - ค่านี้จะถูกกำหนดเป็นเศษส่วนของหน่วยหรือเป็นเปอร์เซ็นต์
- ค่านี้จะถูกกำหนดเป็นเศษส่วนของหน่วยหรือเป็นเปอร์เซ็นต์
 ,
,
ที่ไหน  - ฟังก์ชันอินทิกรัลลาปลาซ ( ตารางที่ 1.1
)
- ฟังก์ชันอินทิกรัลลาปลาซ ( ตารางที่ 1.1
)
ฟังก์ชันอินทิกรัลลาปลาสถูกกำหนดโดยนิพจน์ต่อไปนี้:
 .
.
อาร์กิวเมนต์ของฟังก์ชันนี้คือ ปัจจัยการรับประกัน :
ตารางที่ 1.1
ฟังก์ชันอินทิกรัลลาปลาซ

บนพื้นฐานของข้อมูลบางอย่าง หากมีความน่าจะเป็นของความเชื่อมั่นเกิดขึ้น  (มักจะถือว่าเท่ากับ
(มักจะถือว่าเท่ากับ  ) จากนั้นจะถูกตั้งค่า ความแม่นยำในการวัด
(ช่วงความมั่นใจ
) จากนั้นจะถูกตั้งค่า ความแม่นยำในการวัด
(ช่วงความมั่นใจ
 ) ขึ้นอยู่กับอัตราส่วน
) ขึ้นอยู่กับอัตราส่วน
 .
.
ครึ่งหนึ่งของช่วงความเชื่อมั่นคือ
 ,
(1.3)
,
(1.3)
ที่ไหน  - อาร์กิวเมนต์ของฟังก์ชัน Laplace ถ้า
- อาร์กิวเมนต์ของฟังก์ชัน Laplace ถ้า  (ตารางที่ 1.1
);
(ตารางที่ 1.1
);
 - ฟังก์ชั่นนักศึกษา ถ้า
- ฟังก์ชั่นนักศึกษา ถ้า  (ตารางที่ 1.2
).
(ตารางที่ 1.2
).
ดังนั้น ช่วงความเชื่อมั่นจึงแสดงลักษณะเฉพาะของความแม่นยำในการวัดตัวอย่างที่กำหนด และความน่าจะเป็นของความเชื่อมั่นจะกำหนดลักษณะเฉพาะของความน่าเชื่อถือของการวัด
ตัวอย่าง
เสร็จแล้ว  การวัดความแข็งแกร่งของพื้นผิวถนนส่วนทางหลวงด้วยโมดูลัสยืดหยุ่นโดยเฉลี่ย
การวัดความแข็งแกร่งของพื้นผิวถนนส่วนทางหลวงด้วยโมดูลัสยืดหยุ่นโดยเฉลี่ย  และค่าที่คำนวณได้ของส่วนเบี่ยงเบนมาตรฐาน
และค่าที่คำนวณได้ของส่วนเบี่ยงเบนมาตรฐาน  .
.
จำเป็น กำหนดความแม่นยำที่ต้องการการวัดระดับความมั่นใจที่แตกต่างกัน  โดยรับค่าต่างๆ
โดยรับค่าต่างๆ  โดย ตารางที่ 1.1
.
โดย ตารางที่ 1.1
.
ในกรณีนี้ ดังนั้น |
ดังนั้น สำหรับวิธีการและวิธีการวัดที่กำหนด ช่วงความเชื่อมั่นจึงเพิ่มขึ้นประมาณ  ครั้งถ้าคุณเพิ่มขึ้น
ครั้งถ้าคุณเพิ่มขึ้น  เปิดเท่านั้น
เปิดเท่านั้น  .
.
 ความสัมพันธ์ระหว่างมนุษย์กับธรรมชาติ ความสัมพันธ์ระหว่างมนุษย์กับธรรมชาติ
ความสัมพันธ์ระหว่างมนุษย์กับธรรมชาติ ความสัมพันธ์ระหว่างมนุษย์กับธรรมชาติ คำประสมที่มีสระเชื่อมกัน
คำประสมที่มีสระเชื่อมกัน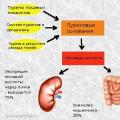 กรดยูริกในเลือด: บรรทัดฐานและการเบี่ยงเบน, เหตุใดจึงเพิ่มขึ้น, อาหารเพื่อลดกรด ผลิตภัณฑ์สุดท้ายของการเผาผลาญไนโตรเจนคือ
กรดยูริกในเลือด: บรรทัดฐานและการเบี่ยงเบน, เหตุใดจึงเพิ่มขึ้น, อาหารเพื่อลดกรด ผลิตภัณฑ์สุดท้ายของการเผาผลาญไนโตรเจนคือ