ฟังก์ชันการกระจายทวินาม ความแปรปรวนการกระจายทวินาม
แน่นอน เมื่อคำนวณฟังก์ชันการแจกแจงสะสม เราควรใช้ความสัมพันธ์ที่กล่าวถึงระหว่างการแจกแจงทวินามและเบตา วิธีนี้ดีกว่าผลบวกโดยตรงเมื่อ n > 10
ในตำราคลาสสิกเกี่ยวกับสถิติ เพื่อให้ได้ค่าของการแจกแจงทวินาม มักแนะนำให้ใช้สูตรตามทฤษฎีบทจำกัด (เช่น สูตร Moivre-Laplace) ควรสังเกตว่า จากมุมมองของการคำนวณล้วนๆค่าของทฤษฎีบทเหล่านี้เกือบเป็นศูนย์ โดยเฉพาะตอนนี้ เมื่อมีคอมพิวเตอร์ทรงพลังในแทบทุกโต๊ะ ข้อเสียเปรียบหลักของการประมาณข้างต้นคือความแม่นยำไม่เพียงพออย่างสมบูรณ์สำหรับค่า n ทั่วไปสำหรับการใช้งานส่วนใหญ่ ข้อเสียไม่น้อยคือการไม่มีคำแนะนำที่ชัดเจนเกี่ยวกับการบังคับใช้ของการประมาณอย่างใดอย่างหนึ่ง (เฉพาะสูตรเชิงซีมโทติกเท่านั้นที่ให้ไว้ในข้อความมาตรฐาน ไม่มีการประมาณค่าความแม่นยำ ดังนั้นจึงมีประโยชน์เพียงเล็กน้อย) ฉันจะบอกว่าทั้งสองสูตรใช้ได้เฉพาะกับ n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
ฉันไม่ได้พิจารณาถึงปัญหาในการค้นหาควอนไทล์: สำหรับการแจกแจงแบบไม่ต่อเนื่องนั้นเป็นเรื่องเล็กน้อย และในปัญหาเหล่านั้นที่การแจกแจงดังกล่าวเกิดขึ้น ตามกฎแล้วจะไม่เกี่ยวข้อง หากยังต้องการควอนไทล์ ผมขอแนะนำให้จัดรูปแบบปัญหาใหม่ในลักษณะที่จะทำงานกับค่า p (สังเกตนัยสำคัญ) นี่คือตัวอย่าง: เมื่อใช้งานอัลกอริธึมการแจงนับ จะต้องตรวจสอบในแต่ละขั้นตอน สมมติฐานทางสถิติเกี่ยวกับตัวแปรสุ่มทวินาม ตาม วิธีการแบบคลาสสิกในแต่ละขั้นตอน จำเป็นต้องคำนวณสถิติเกณฑ์และเปรียบเทียบค่ากับขอบเขตของชุดวิกฤติ อย่างไรก็ตาม เนื่องจากอัลกอริธึมมีการแจกแจงนับ จึงจำเป็นต้องกำหนดขอบเขตของชุดวิกฤติในแต่ละครั้งอีกครั้ง (หลังจากทั้งหมด ขนาดกลุ่มตัวอย่างจะเปลี่ยนจากขั้นตอนหนึ่งไปอีกขั้น) ซึ่งทำให้ต้นทุนเวลาเพิ่มขึ้นอย่างไม่เกิดผล แนวทางสมัยใหม่แนะนำให้คำนวณนัยสำคัญที่สังเกตได้และเปรียบเทียบกับ ระดับความเชื่อมั่นประหยัดในการค้นหาปริมาณ
ดังนั้น รหัสต่อไปนี้จะไม่คำนวณฟังก์ชันผกผัน แต่ให้ฟังก์ชัน rev_binomialDF ซึ่งคำนวณความน่าจะเป็น p ของความสำเร็จในการทดลองครั้งเดียวโดยพิจารณาจากจำนวน n ของการทดลอง จำนวน m ของความสำเร็จในนั้น และค่า y ของความน่าจะเป็นที่จะสำเร็จ m เหล่านี้ สิ่งนี้ใช้ความสัมพันธ์ดังกล่าวระหว่างการแจกแจงทวินามและเบต้า
อันที่จริง ฟังก์ชันนี้ช่วยให้คุณได้รับขอบเขตของช่วงความเชื่อมั่น อันที่จริง สมมติว่าเราประสบความสำเร็จ m ในการทดลองแบบทวินาม n ครั้ง อย่างที่คุณทราบ เส้นขอบด้านซ้ายของสองด้าน ช่วงความมั่นใจสำหรับพารามิเตอร์ p ที่มีระดับความเชื่อมั่นเท่ากับ 0 ถ้า m = 0 และ for คือคำตอบของสมการ  . ในทำนองเดียวกัน ขอบขวาคือ 1 ถ้า m = n และ for คือคำตอบของสมการ
. ในทำนองเดียวกัน ขอบขวาคือ 1 ถ้า m = n และ for คือคำตอบของสมการ  . นี่หมายความว่าในการหาขอบด้านซ้าย เราต้องแก้สมการ
. นี่หมายความว่าในการหาขอบด้านซ้าย เราต้องแก้สมการ  และเพื่อค้นหาสิ่งที่ถูกต้อง - สมการ
และเพื่อค้นหาสิ่งที่ถูกต้อง - สมการ  . พวกเขาได้รับการแก้ไขในฟังก์ชัน binom_leftCI และ binom_rightCI ซึ่งส่งคืนขอบเขตบนและล่างของช่วงความมั่นใจสองด้านตามลำดับ
. พวกเขาได้รับการแก้ไขในฟังก์ชัน binom_leftCI และ binom_rightCI ซึ่งส่งคืนขอบเขตบนและล่างของช่วงความมั่นใจสองด้านตามลำดับ
ฉันต้องการทราบว่าหากไม่ต้องการความแม่นยำที่น่าเหลือเชื่ออย่างยิ่ง ดังนั้นสำหรับ n ที่มีขนาดใหญ่เพียงพอ คุณสามารถใช้ค่าประมาณต่อไปนี้ [B.L. van der Waerden สถิติทางคณิตศาสตร์ ม: อิลลินอยส์, 1960, Ch. 2 วินาที 7]:  โดยที่ g คือควอนไทล์ การกระจายแบบปกติ. ค่าของการประมาณนี้คือมีการประมาณที่ง่ายมากที่ช่วยให้คุณสามารถคำนวณควอนไทล์ของการแจกแจงแบบปกติ (ดูข้อความเกี่ยวกับการคำนวณการแจกแจงแบบปกติและส่วนที่เกี่ยวข้องของข้อมูลอ้างอิงนี้) ในทางปฏิบัติของฉัน (ส่วนใหญ่สำหรับ n > 100) การประมาณนี้ให้ตัวเลขประมาณ 3-4 หลักซึ่งตามกฎก็เพียงพอแล้ว
โดยที่ g คือควอนไทล์ การกระจายแบบปกติ. ค่าของการประมาณนี้คือมีการประมาณที่ง่ายมากที่ช่วยให้คุณสามารถคำนวณควอนไทล์ของการแจกแจงแบบปกติ (ดูข้อความเกี่ยวกับการคำนวณการแจกแจงแบบปกติและส่วนที่เกี่ยวข้องของข้อมูลอ้างอิงนี้) ในทางปฏิบัติของฉัน (ส่วนใหญ่สำหรับ n > 100) การประมาณนี้ให้ตัวเลขประมาณ 3-4 หลักซึ่งตามกฎก็เพียงพอแล้ว
การคำนวณด้วยรหัสต่อไปนี้ต้องใช้ไฟล์ betaDF.h , betaDF.cpp (ดูหัวข้อเกี่ยวกับการแจกจ่ายเบต้า) รวมถึง logGamma.h , logGamma.cpp (ดูภาคผนวก A) คุณยังสามารถดูตัวอย่างการใช้ฟังก์ชันได้อีกด้วย
ไฟล์ทวินามDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF (การทดลองสองครั้ง ความสำเร็จสองครั้ง double p); /* * ให้มี "การทดลอง" ของการสังเกตอิสระ * ด้วยความน่าจะเป็น "p" ของความสำเร็จในแต่ละครั้ง * คำนวณความน่าจะเป็น B(successes|trials,p) ที่จำนวน * ของความสำเร็จอยู่ระหว่าง 0 และ "successes" (รวม) */ double rev_binomialDF (การทดลองสองครั้ง, ความสำเร็จสองครั้ง, สองเท่า y); /* * ให้ความน่าจะเป็น y ของความสำเร็จอย่างน้อย m * เป็นที่ทราบในการทดลองของโครงการ Bernoulli ฟังก์ชันค้นหาความน่าจะเป็น p * ของความสำเร็จในการทดลองครั้งเดียว * * ความสัมพันธ์ต่อไปนี้ใช้ในการคำนวณ * * 1 - p = rev_Beta(trials-successes| successes+1, y) */ double binom_leftCI (การทดลองสองครั้ง, ความสำเร็จสองครั้ง, ระดับสองเท่า); /* ให้มี "การทดลอง" ของการสังเกตอิสระ * ด้วยความน่าจะเป็น "p" ของความสำเร็จในแต่ละ * และจำนวนความสำเร็จคือ "ความสำเร็จ" * ขอบซ้ายของช่วงความเชื่อมั่นสองด้าน * คำนวณด้วยระดับนัยสำคัญ */ double binom_rightCI (ดับเบิ้ล n, ดับเบิ้ล, ดับเบิ้ลเลเวล); /* ให้มี "การทดลอง" ของการสังเกตอิสระ * ด้วยความน่าจะเป็น "p" ของความสำเร็จในแต่ละ * และจำนวนความสำเร็จคือ "ความสำเร็จ" * ขอบเขตด้านขวาของช่วงความเชื่อมั่นสองด้าน * คำนวณด้วยระดับนัยสำคัญ */ #endif /* สิ้นสุด #ifndef __BINOMIAL_H__ */ |
ไฟล์ทวินามDF.cpp
| /****************************************************** **** **********/ /* การกระจายทวินาม */ /****************************** **** *********************************/ #include |
พิจารณาการแจกแจงทวินาม คำนวณความคาดหวังทางคณิตศาสตร์ ความแปรปรวน โหมด การใช้ฟังก์ชัน MS EXCEL BINOM.DIST() เราจะพล็อตฟังก์ชันการแจกแจงและกราฟความหนาแน่นของความน่าจะเป็น ให้เราประมาณค่าพารามิเตอร์การกระจาย p ความคาดหวังทางคณิตศาสตร์การกระจายและ ส่วนเบี่ยงเบนมาตรฐาน. พิจารณาการกระจายเบอร์นูลลีด้วย
คำนิยาม. ปล่อยให้พวกเขาถูกจัดขึ้น นการทดสอบโดยแต่ละเหตุการณ์สามารถเกิดขึ้นได้เพียง 2 เหตุการณ์เท่านั้น: เหตุการณ์ "สำเร็จ" ด้วยความน่าจะเป็น พี หรือเหตุการณ์ "ล้มเหลว" ที่มีความน่าจะเป็น q =1-p (สิ่งที่เรียกว่า โครงการเบอร์นูลลีเบอร์นูลลีการทดลอง).
ความน่าจะเป็นที่จะได้รับอย่างแน่นอน x ความสำเร็จเหล่านี้ น การทดสอบมีค่าเท่ากับ:
จำนวนความสำเร็จในกลุ่มตัวอย่าง x เป็นตัวแปรสุ่มที่มี การกระจายทวินาม(ภาษาอังกฤษ) ทวินามการกระจาย) พีและ น– เป็นพารามิเตอร์ของการแจกแจงนี้
จำได้ว่าตอนสมัคร แผนการของเบอร์นูลลีและเช่นเดียวกัน การกระจายทวินามต้องเป็นไปตามเงื่อนไขต่อไปนี้:
- การทดลองแต่ละครั้งต้องมีผลลัพธ์สองอย่างเท่านั้น ซึ่งเรียกว่า "ความสำเร็จ" และ "ความล้มเหลว" ตามเงื่อนไข
- ผลการทดสอบแต่ละครั้งไม่ควรขึ้นอยู่กับผลการทดสอบครั้งก่อนๆ (การทดสอบอิสระ)
- โอกาสสำเร็จ พี ควรคงที่สำหรับการทดสอบทั้งหมด
การกระจายทวินามใน MS EXCEL
ใน MS EXCEL เริ่มตั้งแต่เวอร์ชัน 2010 สำหรับ การกระจายทวินามมีฟังก์ชัน BINOM.DIST() ชื่อภาษาอังกฤษ- BINOM.DIST() ซึ่งช่วยให้คุณคำนวณความน่าจะเป็นที่กลุ่มตัวอย่างจะตรงกันทุกประการ X"ความสำเร็จ" (เช่น ฟังก์ชั่นความหนาแน่นของความน่าจะเป็น p(x) ดูสูตรด้านบน) และ ฟังก์ชันการกระจายอินทิกรัล(ความน่าจะเป็นที่กลุ่มตัวอย่างจะมี xหรือน้อยกว่า "ความสำเร็จ" รวมถึง 0)
ก่อนหน้า MS EXCEL 2010 นั้น EXCEL มีฟังก์ชัน BINOMDIST() ซึ่งช่วยให้คุณคำนวณได้ ฟังก์ชันการกระจายและ ความหนาแน่นของความน่าจะเป็นพี(x). BINOMDIST() ถูกทิ้งไว้ใน MS EXCEL 2010 เพื่อความเข้ากันได้
ไฟล์ตัวอย่างมีกราฟ ความหนาแน่นของการกระจายความน่าจะเป็นและ .

การกระจายทวินามมีนามว่า บี(น; พี) .
บันทึก: สำหรับอาคาร ฟังก์ชันการกระจายอินทิกรัลประเภทแผนภูมิที่พอดี กำหนดการ, สำหรับ ความหนาแน่นของการกระจาย – ฮิสโตแกรมพร้อมการจัดกลุ่ม. สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการสร้างแผนภูมิ อ่านบทความประเภทหลักของแผนภูมิ
บันทึก: เพื่อความสะดวกในการเขียนสูตรในไฟล์ตัวอย่าง มีการสร้างชื่อสำหรับพารามิเตอร์แล้ว การกระจายทวินาม: น และ น.

ไฟล์ตัวอย่างแสดงการคำนวณความน่าจะเป็นต่างๆ โดยใช้ฟังก์ชัน MS EXCEL:

ดังที่เห็นในภาพด้านบน สันนิษฐานว่า:
- ประชากรอนันต์ที่สร้างตัวอย่างประกอบด้วยองค์ประกอบที่ดี 10% (หรือ 0.1) (พารามิเตอร์ พี, อาร์กิวเมนต์ฟังก์ชันที่สาม =BINOM.DIST() )
- เพื่อคำนวณความน่าจะเป็นที่ในกลุ่มตัวอย่าง 10 องค์ประกอบ (พารามิเตอร์ นอาร์กิวเมนต์ที่สองของฟังก์ชัน) จะมีองค์ประกอบที่ถูกต้อง 5 องค์ประกอบ (อาร์กิวเมนต์แรก) คุณต้องเขียนสูตร: =BINOM.DIST(5, 10, 0.1, เท็จ)
- องค์ประกอบสุดท้ายที่สี่ถูกตั้งค่า = FALSE นั่นคือ ค่าฟังก์ชันจะถูกส่งกลับ ความหนาแน่นของการกระจาย.
หากค่าของอาร์กิวเมนต์ที่สี่ = TRUE ฟังก์ชัน BINOM.DIST() จะส่งกลับค่า ฟังก์ชันการกระจายอินทิกรัลหรือง่ายๆ ฟังก์ชันการกระจาย. ในกรณีนี้เราสามารถคำนวณความน่าจะเป็นที่จำนวนองค์ประกอบที่ดีในกลุ่มตัวอย่างจะมาจาก บางช่วงเช่น 2 หรือน้อยกว่า (รวม 0)
ในการทำเช่นนี้คุณต้องเขียนสูตร:
= BINOM.DIST(2, 10, 0.1, ทรู)
บันทึก: สำหรับค่าที่ไม่ใช่จำนวนเต็มของ x, . ตัวอย่างเช่น สูตรต่อไปนี้จะคืนค่าเดิม:
=BINOM.DIST( 2
; สิบ; 0.1; จริง)
=BINOM.DIST( 2,9
; สิบ; 0.1; จริง)
บันทึก: ในไฟล์ตัวอย่าง ความหนาแน่นของความน่าจะเป็นและ ฟังก์ชันการกระจายยังคำนวณโดยใช้คำจำกัดความและฟังก์ชัน COMBIN()
ตัวชี้วัดการกระจาย
ที่ ไฟล์ตัวอย่างในชีต Exampleมีสูตรสำหรับคำนวณตัวบ่งชี้การกระจายบางตัว:
- =n*p;
- (ค่าเบี่ยงเบนมาตรฐานกำลังสอง) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
เราได้รับสูตร ความคาดหวังทางคณิตศาสตร์ การกระจายทวินามโดยใช้ โครงการเบอร์นูลลี.
ตามคำจำกัดความ ค่าสุ่ม Xin โครงการเบอร์นูลลี(ตัวแปรสุ่มเบอร์นูลลี) has ฟังก์ชันการกระจาย:
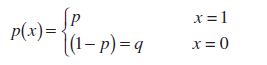
การกระจายนี้เรียกว่า การกระจายเบอร์นูลลี.
บันทึก: การกระจายเบอร์นูลลี – กรณีพิเศษ การกระจายทวินามด้วยพารามิเตอร์ n=1
มาสร้าง 3 อาร์เรย์ 100 หมายเลขด้วย ความน่าจะเป็นที่แตกต่างกันความสำเร็จ: 0.1; 0.5 และ 0.9 การทำเช่นนี้ในหน้าต่าง การสร้างตัวเลขสุ่มชุด ตัวเลือกต่อไปนี้สำหรับแต่ละความน่าจะเป็น p:

บันทึก: หากคุณตั้งค่าตัวเลือก สุ่มกระเจิง (สุ่มเมล็ด) จากนั้นคุณสามารถเลือกเฉพาะ ชุดสุ่มตัวเลขที่สร้างขึ้น ตัวอย่างเช่น โดยการตั้งค่าตัวเลือกนี้ =25 คุณสามารถสร้างชุดตัวเลขสุ่มชุดเดียวกันบนคอมพิวเตอร์เครื่องอื่นได้ (หากแน่นอน พารามิเตอร์การแจกแจงอื่นๆ เหมือนกัน) ค่าตัวเลือกสามารถใช้ค่าจำนวนเต็มได้ตั้งแต่ 1 ถึง 32,767 ชื่อตัวเลือก สุ่มกระเจิงสามารถสับสน จะดีกว่าถ้าแปลเป็น ตั้งตัวเลขด้วยตัวเลขสุ่ม.
ผลที่ได้คือเราจะมี 3 คอลัมน์ 100 ตัวเลข โดยอิงจากข้อมูลนั้น เช่น เราสามารถประมาณความน่าจะเป็นของความสำเร็จได้ พีตามสูตร: จำนวนความสำเร็จ/100(ซม. ไฟล์ตัวอย่าง การสร้าง Bernoulli).

บันทึก: สำหรับ การกระจายเบอร์นูลลีด้วย p=0.5 คุณสามารถใช้สูตร =RANDBETWEEN(0;1) ซึ่งสอดคล้องกับ
การสร้างตัวเลขสุ่ม การกระจายทวินาม
สมมติว่ามีสินค้าที่มีข้อบกพร่อง 7 รายการในตัวอย่างนี้ ซึ่งหมายความว่า "มีโอกาสมาก" ที่สัดส่วนของผลิตภัณฑ์ที่บกพร่องจะเปลี่ยนไป พีซึ่งเป็นลักษณะเฉพาะของกระบวนการผลิตของเรา แม้ว่าสถานการณ์นี้จะ "เป็นไปได้มาก" แต่ก็มีความเป็นไปได้ (ความเสี่ยงอัลฟา ข้อผิดพลาดประเภทที่ 1 "สัญญาณเตือนที่ผิดพลาด") ที่ พียังคงไม่เปลี่ยนแปลง และจำนวนสินค้าที่มีข้อบกพร่องเพิ่มขึ้นเกิดจากการสุ่มตัวอย่าง
ดังที่เห็นในรูปด้านล่าง 7 คือจำนวนสินค้าที่มีข้อบกพร่องที่ยอมรับได้สำหรับกระบวนการที่มีค่า p=0.21 ที่ค่าเท่ากัน อัลฟ่า. สิ่งนี้แสดงให้เห็นว่าเมื่อเกินเกณฑ์ของสินค้าที่มีข้อบกพร่องในตัวตัวอย่าง พี“น่าจะ” เพิ่มขึ้น วลี "มีแนวโน้มมากที่สุด" หมายความว่ามีโอกาสเพียง 10% (100%-90%) ที่ความเบี่ยงเบนของเปอร์เซ็นต์ของผลิตภัณฑ์ที่มีข้อบกพร่องที่อยู่เหนือเกณฑ์นั้นเกิดจากสาเหตุแบบสุ่มเท่านั้น
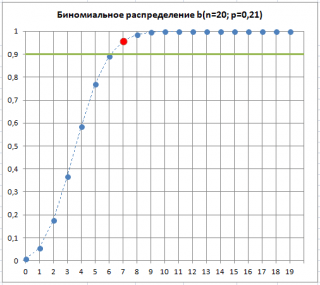
ดังนั้นการเกินจำนวนเกณฑ์ของผลิตภัณฑ์ที่มีข้อบกพร่องในตัวอย่างอาจเป็นสัญญาณว่ากระบวนการนี้มีปัญหาและเริ่มผลิตข เกี่ยวกับเปอร์เซ็นต์ของผลิตภัณฑ์ที่มีข้อบกพร่องสูงขึ้น
บันทึก: ก่อน MS EXCEL 2010, EXCEL มีฟังก์ชัน CRITBINOM() ซึ่งเทียบเท่ากับ BINOM.INV() CRITBINOM() เหลืออยู่ใน MS EXCEL 2010 และสูงกว่าสำหรับความเข้ากันได้
ความสัมพันธ์ของการแจกแจงทวินามกับการแจกแจงแบบอื่น
ถ้าพารามิเตอร์ น การกระจายทวินามมีแนวโน้มที่จะไม่มีที่สิ้นสุดและ พีมีแนวโน้มเป็น 0 ดังนั้นในกรณีนี้ การกระจายทวินามสามารถประมาณได้
เป็นไปได้ที่จะกำหนดเงื่อนไขเมื่อค่าประมาณ การกระจายปัวซองทำงานได้ดี:
- พี<0,1 (น้อย พีและอื่น ๆ น, การประมาณที่แม่นยำยิ่งขึ้น);
- พี>0,9 (พิจารณาว่า q=1- พี, การคำนวณในกรณีนี้จะต้องดำเนินการโดยใช้ q(อา Xจะต้องถูกแทนที่ด้วย น- x). ดังนั้น ยิ่งน้อย qและอื่น ๆ นการประมาณค่าที่แม่นยำยิ่งขึ้น)
ที่ 0.1<=p<=0,9 и n*p>10 การกระจายทวินามสามารถประมาณได้
ในทางกลับกัน การกระจายทวินามสามารถใช้เป็นค่าประมาณที่ดีเมื่อขนาดประชากรเป็น N การกระจายแบบไฮเปอร์เรขาคณิตใหญ่กว่าขนาดกลุ่มตัวอย่างมาก n (เช่น N>>n หรือ n/N<<1).
คุณสามารถอ่านเพิ่มเติมเกี่ยวกับความสัมพันธ์ของการแจกแจงด้านบนได้ในบทความ มีการยกตัวอย่างของการประมาณค่าที่นั่นด้วย และจะมีการอธิบายเงื่อนไขเมื่อเป็นไปได้และแม่นยำเพียงใด
คำแนะนำ: คุณสามารถอ่านเกี่ยวกับการแจกแจงอื่นๆ ของ MS EXCEL ได้ในบทความ
สวัสดีผู้อ่านทุกคน!
การวิเคราะห์ทางสถิติ อย่างที่คุณทราบ เกี่ยวข้องกับการรวบรวมและการประมวลผลข้อมูลจริง มันมีประโยชน์และมักจะทำกำไรได้เพราะ ข้อสรุปที่ถูกต้องช่วยให้คุณหลีกเลี่ยงข้อผิดพลาดและความสูญเสียในอนาคต และบางครั้งก็คาดเดาอนาคตนี้ได้อย่างถูกต้อง ข้อมูลที่รวบรวมได้สะท้อนถึงสถานะของปรากฏการณ์ที่สังเกตได้บางอย่าง ข้อมูลมักจะเป็นตัวเลข (แต่ไม่เสมอไป) และสามารถจัดการด้วยการจัดการทางคณิตศาสตร์ต่างๆ เพื่อดึงข้อมูลเพิ่มเติม
อย่างไรก็ตาม ไม่ใช่ว่าปรากฏการณ์ทั้งหมดจะถูกวัดในระดับเชิงปริมาณ เช่น 1, 2, 3 ... 100500 ... ไม่ใช่ว่าปรากฏการณ์ทั้งหมดสามารถเกิดขึ้นได้ในสถานะต่างๆ ที่ไม่มีที่สิ้นสุดหรือเป็นจำนวนมาก ตัวอย่างเช่น เพศของบุคคลอาจเป็น M หรือ F ก็ได้ นักแม่นปืนตีเป้าหมายหรือพลาดเป้า คุณสามารถลงคะแนนได้ทั้ง "สำหรับ" หรือ "ต่อต้าน" เป็นต้น เป็นต้น กล่าวอีกนัยหนึ่ง ข้อมูลดังกล่าวสะท้อนถึงสถานะของแอตทริบิวต์ทางเลือก - "ใช่" (เหตุการณ์ได้เกิดขึ้น) หรือ "ไม่" (เหตุการณ์ยังไม่เกิดขึ้น) เหตุการณ์ที่จะเกิดขึ้น (ผลบวก) เรียกอีกอย่างว่า "ความสำเร็จ" ปรากฏการณ์ดังกล่าวอาจมีขนาดใหญ่และสุ่มได้ ดังนั้นจึงสามารถวัดผลได้และสามารถสรุปผลทางสถิติได้
การทดลองกับข้อมูลดังกล่าวเรียกว่า โครงการเบอร์นูลลีเพื่อเป็นเกียรติแก่นักคณิตศาสตร์ชาวสวิสที่มีชื่อเสียงซึ่งพบว่าด้วยการทดลองจำนวนมาก อัตราส่วนของผลลัพธ์ที่เป็นบวกต่อจำนวนการทดลองทั้งหมดมีแนวโน้มว่าจะมีเหตุการณ์นี้เกิดขึ้น
ตัวแปรคุณสมบัติสำรอง
เพื่อที่จะใช้เครื่องมือทางคณิตศาสตร์ในการวิเคราะห์ ผลลัพธ์ของการสังเกตดังกล่าวควรเขียนในรูปแบบตัวเลข ในการทำเช่นนี้ ผลลัพธ์ที่เป็นบวกถูกกำหนดเป็นตัวเลข 1 ค่าลบหนึ่ง - 0 กล่าวอีกนัยหนึ่ง เรากำลังจัดการกับตัวแปรที่รับได้เพียงสองค่าเท่านั้น: 0 หรือ 1
ได้ประโยชน์อะไรจากสิ่งนี้? ในความเป็นจริงไม่น้อยกว่าจากข้อมูลทั่วไป ดังนั้นจึงง่ายที่จะนับจำนวนผลลัพธ์ที่เป็นบวก - เพียงพอที่จะสรุปค่าทั้งหมดนั่นคือ ทั้งหมด 1 (ความสำเร็จ) คุณสามารถไปต่อได้ แต่สำหรับสิ่งนี้ คุณต้องแนะนำสัญกรณ์สองสามอย่าง
สิ่งแรกที่ควรทราบคือผลลัพธ์ที่เป็นบวก (ซึ่งเท่ากับ 1) มีความเป็นไปได้ที่จะเกิดขึ้น ตัวอย่างเช่น การได้หัวในการโยนเหรียญคือ ½ หรือ 0.5 ความน่าจะเป็นนี้มักจะเขียนแทนด้วยตัวอักษรละติน พี. ดังนั้น ความน่าจะเป็นของเหตุการณ์ทางเลือกที่เกิดขึ้นคือ 1-pซึ่งแสดงด้วย q, นั่นคือ q = 1 – p. การกำหนดเหล่านี้สามารถจัดระบบด้วยสายตาในรูปแบบของแผ่นกระจายตัวแปร X.
ตอนนี้เรามีรายการค่าที่เป็นไปได้และความน่าจะเป็น คุณสามารถเริ่มคำนวณคุณสมบัติที่ยอดเยี่ยมของตัวแปรสุ่มเช่น มูลค่าที่คาดหวังและ การกระจายตัว. ฉันขอเตือนคุณว่าความคาดหวังทางคณิตศาสตร์คำนวณเป็นผลรวมของผลิตภัณฑ์ของค่าที่เป็นไปได้ทั้งหมดและความน่าจะเป็นที่สอดคล้องกัน:
![]()
มาคำนวณค่าที่คาดหวังโดยใช้สัญกรณ์ในตารางด้านบนกัน
ปรากฎว่าการคาดหมายทางคณิตศาสตร์ของเครื่องหมายทางเลือก เท่ากับความน่าจะเป็นของเหตุการณ์นี้ - พี.
ตอนนี้ มากำหนดว่าความแปรปรวนของคุณลักษณะทางเลือกคืออะไร ผมขอเตือนคุณด้วยว่าความแปรปรวนเป็นค่าเฉลี่ยกำลังสองของการเบี่ยงเบนจากการคาดหมายทางคณิตศาสตร์ สูตรทั่วไป (สำหรับข้อมูลที่ไม่ต่อเนื่อง) คือ:
ดังนั้นความแปรปรวนของคุณสมบัติทางเลือก:

สังเกตได้ง่ายว่าการกระจายนี้มีค่าสูงสุด 0.25 (at พี=0.5).
ส่วนเบี่ยงเบนมาตรฐาน - รูทของความแปรปรวน:
ค่าสูงสุดไม่เกิน 0.5
อย่างที่คุณเห็น ทั้งการคาดหมายทางคณิตศาสตร์และความแปรปรวนของเครื่องหมายทางเลือกมีรูปแบบกะทัดรัดมาก
การกระจายทวินามของตัวแปรสุ่ม
พิจารณาสถานการณ์จากมุมที่ต่างออกไป อันที่จริง ใครจะสนว่าการสูญเสียหัวโดยเฉลี่ยในการโยนครั้งเดียวคือ 0.5? มันเป็นไปไม่ได้แม้แต่จะจินตนาการ เป็นเรื่องที่น่าสนใจกว่าที่จะตั้งคำถามเกี่ยวกับจำนวนหัวที่ออกมาสำหรับการโยนตามจำนวนที่กำหนด
กล่าวอีกนัยหนึ่ง ผู้วิจัยมักสนใจความน่าจะเป็นของเหตุการณ์ที่ประสบความสำเร็จจำนวนหนึ่งเกิดขึ้น อาจเป็นจำนวนสินค้าที่มีข้อบกพร่องในล็อตที่ทดสอบ (1 - ชำรุด 0 - ดี) หรือจำนวนการฟื้นตัว (1 - แข็งแรง 0 - ป่วย) เป็นต้น จำนวนของ "ความสำเร็จ" ดังกล่าวจะเท่ากับผลรวมของค่าทั้งหมดของตัวแปร X, เช่น. จำนวนผลลัพธ์เดียว
ค่าสุ่ม บีเรียกว่าทวินามและรับค่าตั้งแต่ 0 ถึง น(ที่ บี= 0 - ทุกส่วนดีด้วย บี = น- ชำรุดทุกส่วน) ถือว่าค่าทั้งหมด xเป็นอิสระจากกัน พิจารณาคุณสมบัติหลักของตัวแปรทวินาม นั่นคือ เราจะสร้างความคาดหวังทางคณิตศาสตร์ ความแปรปรวน และการแจกแจง
ความคาดหวังของตัวแปรทวินามนั้นหาได้ง่ายมาก โปรดจำไว้ว่ามีผลรวมของความคาดหวังทางคณิตศาสตร์ของมูลค่าเพิ่มแต่ละรายการ และทุกคนก็เหมือนกัน ดังนั้น:
ตัวอย่างเช่น ความคาดหวังของจำนวนหัวในการโยน 100 ครั้งคือ 100 × 0.5 = 50
ตอนนี้เราได้สูตรสำหรับความแปรปรวนของตัวแปรทวินาม คือผลรวมของผลต่าง จากที่นี่
ส่วนเบี่ยงเบนมาตรฐานตามลำดับ
สำหรับการโยนเหรียญ 100 ครั้ง ค่าเบี่ยงเบนมาตรฐานคือ
และสุดท้าย ให้พิจารณาการกระจายตัวของปริมาณทวินาม นั่นคือ ความน่าจะเป็นที่ตัวแปรสุ่ม บีจะใช้ค่านิยมต่างกัน k, ที่ไหน 0≤k≤n. สำหรับเหรียญ ปัญหานี้อาจฟังดูเหมือน: ความน่าจะเป็นที่จะได้หัว 40 ครั้งในการโยน 100 ครั้งเป็นเท่าใด
เพื่อให้เข้าใจวิธีการคำนวณ ลองนึกภาพว่าโยนเหรียญเพียง 4 ครั้งเท่านั้น ข้างใดข้างหนึ่งสามารถหลุดออกได้ทุกครั้ง เราถามตัวเอง: ความน่าจะเป็นที่จะได้หัว 2 จาก 4 ครั้งเป็นเท่าใด การโยนแต่ละครั้งเป็นอิสระจากกัน ซึ่งหมายความว่าความน่าจะเป็นที่จะได้ชุดค่าผสมใดๆ จะเท่ากับผลคูณของความน่าจะเป็นของผลลัพธ์ที่กำหนดสำหรับการโยนแต่ละครั้ง ให้ O เป็นหัว P เป็นก้อย ตัวอย่างเช่น หนึ่งในชุดค่าผสมที่เหมาะกับเราอาจดูเหมือน OOPP นั่นคือ:

ความน่าจะเป็นของการรวมดังกล่าวจะเท่ากับผลคูณของความน่าจะเป็นสองอย่างของการขึ้นหัว และความน่าจะเป็นอีกสองความน่าจะเป็นของการไม่ขึ้นหัว (เหตุการณ์ย้อนกลับคำนวณเป็น 1-p), เช่น. 0.5×0.5×(1-0.5)×(1-0.5)=0.0625. นี่คือความน่าจะเป็นของชุดค่าผสมที่เหมาะกับเรา แต่คำถามเกี่ยวกับจำนวนนกอินทรีทั้งหมด ไม่ได้เกี่ยวกับลำดับใดๆ จากนั้นคุณต้องเพิ่มความน่าจะเป็นของชุดค่าผสมทั้งหมดที่มีนกอินทรี 2 ตัวพอดี เป็นที่ชัดเจนว่าเหมือนกันหมด (ผลิตภัณฑ์ไม่เปลี่ยนจากการเปลี่ยนตำแหน่งของปัจจัย) ดังนั้น คุณต้องคำนวณจำนวนของพวกเขา แล้วคูณด้วยความน่าจะเป็นของชุดค่าผสมดังกล่าว มานับการผสมกันของ 4 นกอินทรี 2 ตัว: RROO, RORO, ROOR, ORRO, OROR, OORR เพียง 6 ตัวเลือก

ดังนั้น ความน่าจะเป็นที่ต้องการในการได้หัว 2 ครั้งหลังจากโยน 4 ครั้งคือ 6×0.0625=0.375
อย่างไรก็ตาม การนับด้วยวิธีนี้เป็นเรื่องที่น่าเบื่อ สำหรับ 10 เหรียญแล้ว เป็นเรื่องยากมากที่จะได้จำนวนตัวเลือกทั้งหมดโดยใช้กำลังเดรัจฉาน ดังนั้นคนฉลาดจึงคิดค้นสูตรขึ้นเมื่อนานมาแล้วด้วยความช่วยเหลือในการคำนวณจำนวนชุดค่าผสมต่างๆ นองค์ประกอบโดย k, ที่ไหน นคือจำนวนองค์ประกอบทั้งหมด kคือจำนวนขององค์ประกอบที่มีการคำนวณตัวเลือกการจัดเรียง สูตรผสมของ นองค์ประกอบโดย kเป็น:
![]()
สิ่งที่คล้ายกันเกิดขึ้นในส่วน combinatorics ฉันส่งทุกคนที่ต้องการพัฒนาความรู้ของพวกเขาที่นั่น ดังนั้น อย่างไรก็ตาม ชื่อของการกระจายทวินาม (สูตรข้างต้นคือสัมประสิทธิ์ในการขยายตัวของทวินามของนิวตัน)
สูตรสำหรับกำหนดความน่าจะเป็นสามารถสรุปได้ง่าย ๆ กับจำนวนใด ๆ นและ k. ดังนั้น สูตรการแจกแจงทวินามจึงมีรูปแบบดังนี้
กล่าวอีกนัยหนึ่ง: คูณจำนวนของชุดค่าผสมที่ตรงกันด้วยความน่าจะเป็นของหนึ่งในนั้น
สำหรับการใช้งานจริง แค่รู้สูตรการแจกแจงทวินามก็เพียงพอแล้ว และคุณอาจไม่รู้ด้วยซ้ำ ด้านล่างนี้คือวิธีกำหนดความน่าจะเป็นโดยใช้ Excel แต่จะดีกว่าที่จะรู้
ลองใช้สูตรนี้เพื่อคำนวณความน่าจะเป็นที่จะได้หัว 40 ครั้งในการโยน 100 ครั้ง:
หรือเพียง 1.08% สำหรับการเปรียบเทียบ ความน่าจะเป็นของการคาดหมายทางคณิตศาสตร์ของการทดลองนี้คือ 50 หัว คือ 7.96% ความน่าจะเป็นสูงสุดของค่าทวินามเป็นของค่าที่สอดคล้องกับการคาดหมายทางคณิตศาสตร์
การคำนวณความน่าจะเป็นของการแจกแจงทวินามใน Excel
หากคุณใช้เพียงกระดาษและเครื่องคิดเลข การคำนวณโดยใช้สูตรการแจกแจงทวินามแม้จะไม่มีอินทิกรัลก็ตาม ก็ค่อนข้างยาก ตัวอย่างเช่น ค่า 100! - มีมากกว่า 150 ตัวอักษร เป็นไปไม่ได้ที่จะคำนวณด้วยตนเอง ก่อนหน้านี้และแม้กระทั่งตอนนี้ มีการใช้สูตรโดยประมาณในการคำนวณปริมาณดังกล่าว ปัจจุบันแนะนำให้ใช้ซอฟต์แวร์พิเศษ เช่น MS Excel ดังนั้น ผู้ใช้ใดๆ (แม้แต่นักมนุษยนิยมด้วยการศึกษา) สามารถคำนวณความน่าจะเป็นของค่าของตัวแปรสุ่มแบบกระจายทวินามได้อย่างง่ายดาย
ในการรวมเนื้อหา เราจะใช้ Excel ในขณะนี้เป็นเครื่องคิดเลขทั่วไป เช่น มาทำการคำนวณทีละขั้นตอนโดยใช้สูตรการแจกแจงทวินามกัน มาคำนวณกัน เช่น ความน่าจะเป็นที่จะได้หัว 50 ครั้ง ด้านล่างเป็นภาพที่มีขั้นตอนการคำนวณและผลสุดท้าย

อย่างที่คุณเห็น ผลลัพธ์ขั้นกลางเป็นมาตราส่วนที่ไม่พอดีในเซลล์ แม้ว่าจะมีการใช้ฟังก์ชันง่ายๆ ของประเภทนี้ทุกที่: FACTOR (การคำนวณแฟกทอเรียล), POWER (การเพิ่มตัวเลขเป็นยกกำลัง) เช่นกัน เป็นตัวดำเนินการคูณและหาร นอกจากนี้ การคำนวณนี้ค่อนข้างยุ่งยาก ไม่ว่าในกรณีใด การคำนวณจะไม่กระชับเนื่องจาก หลายเซลล์ที่เกี่ยวข้อง และใช่ มันยากที่จะเข้าใจ
โดยทั่วไป Excel มีฟังก์ชันสำเร็จรูปสำหรับคำนวณความน่าจะเป็นของการแจกแจงทวินาม ฟังก์ชันนี้เรียกว่า BINOM.DIST

จำนวนความสำเร็จคือจำนวนการทดลองที่สำเร็จ เรามี 50 คน
จำนวนการทดลอง- จำนวนการโยน: 100 ครั้ง
ความน่าจะเป็นของความสำเร็จ– ความน่าจะเป็นที่จะได้หัวในการทอยครั้งเดียวคือ 0.5
ปริพันธ์- ระบุ 1 หรือ 0 หากเป็น 0 จะคำนวณความน่าจะเป็น ป(B=k); ถ้า 1 ฟังก์ชันการแจกแจงแบบทวินามจะถูกคำนวณเช่น ผลรวมของความน่าจะเป็นทั้งหมดจาก B=0ก่อน B=kรวม
เรากดตกลงและได้ผลลัพธ์เช่นเดียวกับข้างต้นทุกอย่างเท่านั้นที่คำนวณโดยฟังก์ชันเดียว

สบายมาก. เพื่อการทดลอง แทนที่พารามิเตอร์สุดท้าย 0 เราใส่ 1 เราได้ 0.5398 ซึ่งหมายความว่าในการโยนเหรียญ 100 ครั้ง ความน่าจะเป็นที่จะได้หัวระหว่าง 0 ถึง 50 นั้นเกือบ 54% และในตอนแรกดูเหมือนว่าควรจะเป็น 50% โดยทั่วไป การคำนวณจะทำได้ง่ายและรวดเร็ว
นักวิเคราะห์ตัวจริงต้องเข้าใจว่าฟังก์ชันทำงานอย่างไร (การกระจายคืออะไร) ดังนั้นให้คำนวณความน่าจะเป็นสำหรับค่าทั้งหมดตั้งแต่ 0 ถึง 100 นั่นคือลองถามตัวเองว่าความน่าจะเป็นที่ไม่มีนกอินทรีตัวเดียวตกคืออะไร ว่าอินทรี 1 ตัวจะตกลงมา 2, 3 , 50, 90 หรือ 100 การคำนวณจะแสดงอยู่ในภาพที่เคลื่อนไหวได้เองต่อไปนี้ เส้นสีน้ำเงินคือการแจกแจงแบบทวินาม จุดสีแดงคือความน่าจะเป็นสำหรับจำนวนที่สำเร็จ k

อาจมีคนถามว่า การแจกแจงทวินามไม่เหมือนกับ... ใช่ คล้ายกันมาก แม้แต่ De Moivre (ในปี 1733) ก็กล่าวว่าด้วยตัวอย่างขนาดใหญ่ วิธีการแจกแจงแบบทวินาม (ฉันไม่รู้ว่ามันเรียกว่าอะไร) แต่ไม่มีใครฟังเขาเลย มีเพียงเกาส์และลาปลาซ 60-70 ปีต่อมาเท่านั้นที่ค้นพบและศึกษากฎการกระจายแบบปกติอย่างละเอียดถี่ถ้วน กราฟด้านบนแสดงให้เห็นชัดเจนว่าความน่าจะเป็นสูงสุดอยู่ที่การคาดหมายทางคณิตศาสตร์ และเมื่อเบี่ยงเบนไปจากความคาดหมาย ความน่าจะเป็นจะลดลงอย่างรวดเร็ว เหมือนกับกฎหมายทั่วไป
การแจกแจงทวินามมีความสำคัญในทางปฏิบัติอย่างมาก มันเกิดขึ้นค่อนข้างบ่อย ใช้ Excel คำนวณได้ง่ายและรวดเร็ว ดังนั้นอย่าลังเลที่จะใช้มัน
ในเรื่องนี้ฉันขอลาก่อนการประชุมครั้งต่อไป ดีที่สุดมีสุขภาพที่ดี!
บทที่ 7
กฎเฉพาะของการแจกแจงตัวแปรสุ่ม
ประเภทของกฎการแจกแจงตัวแปรสุ่มแบบไม่ต่อเนื่อง
ให้ตัวแปรสุ่มแบบไม่ต่อเนื่องรับค่า X 1 , X 2 , …, x น, … . ความน่าจะเป็นของค่าเหล่านี้สามารถคำนวณได้โดยใช้สูตรต่างๆ เช่น การใช้ทฤษฎีบทพื้นฐานของทฤษฎีความน่าจะเป็น สูตรของ Bernoulli หรือสูตรอื่นๆ สำหรับบางสูตรเหล่านี้ กฎหมายการจำหน่ายมีชื่อเป็นของตัวเอง
กฎทั่วไปของการแจกแจงตัวแปรสุ่มแบบไม่ต่อเนื่องคือทวินาม เรขาคณิต ไฮเปอร์จีโอเมตริก กฎการแจกแจงของปัวซอง
กฎหมายการกระจายทวินาม
ปล่อยให้มันผลิต นการพิจารณาคดีอิสระ ซึ่งเหตุการณ์อาจเกิดขึ้นหรือไม่เกิดขึ้นก็ได้ แต่. ความน่าจะเป็นของการเกิดเหตุการณ์นี้ในการทดลองแต่ละครั้งจะคงที่ ไม่ขึ้นอยู่กับหมายเลขการทดลองและเท่ากับ R=R(แต่). ดังนั้นความน่าจะเป็นที่เหตุการณ์จะไม่เกิดขึ้น แต่ในการทดสอบแต่ละครั้งจะคงที่และเท่ากับ q=1–R. พิจารณาตัวแปรสุ่ม Xเท่ากับจำนวนครั้งของเหตุการณ์ แต่ใน นการทดสอบ เห็นได้ชัดว่าค่าของปริมาณนี้เท่ากับ
X 1 =0 - เหตุการณ์ แต่ใน นไม่ปรากฏการทดสอบ
X 2 =1 – เหตุการณ์ แต่ใน นการทดลองปรากฏครั้งเดียว;
X 3 =2 - เหตุการณ์ แต่ใน นการทดลองปรากฏสองครั้ง;
…………………………………………………………..
x น +1 = น- เหตุการณ์ แต่ใน นการทดสอบปรากฏทุกอย่าง นครั้งหนึ่ง.
ความน่าจะเป็นของค่าเหล่านี้สามารถคำนวณได้โดยใช้สูตร Bernoulli (4.1):
ที่ไหน ถึง=0, 1, 2, …,น .
กฎหมายการกระจายทวินาม Xเท่ากับจำนวนความสำเร็จใน นทดลองเบอร์นูลลี มีโอกาสสำเร็จ R.
ดังนั้นตัวแปรสุ่มแบบไม่ต่อเนื่องจะมีการแจกแจงแบบทวินาม (หรือกระจายตามกฎทวินาม) หากค่าที่เป็นไปได้คือ 0, 1, 2, …, นและความน่าจะเป็นที่สอดคล้องกันคำนวณโดยสูตร (7.1)
การกระจายทวินามขึ้นอยู่กับสอง พารามิเตอร์ Rและ น.
อนุกรมการแจกแจงของตัวแปรสุ่มที่แจกแจงตามกฎทวินามมีรูปแบบดังนี้
| X | … | k | … | น | ||
| R | | … | … | |
ตัวอย่าง 7.1 . การยิงอิสระสามนัดที่เป้าหมาย ความน่าจะเป็นที่จะตีแต่ละนัดคือ 0.4 ค่าสุ่ม X- จำนวนการตีที่เป้าหมาย สร้างชุดการแจกจ่าย
วิธีการแก้. ค่าที่เป็นไปได้ของตัวแปรสุ่ม Xเป็น X 1 =0; X 2 =1; X 3 =2; X 4=3. ค้นหาความน่าจะเป็นที่สอดคล้องกันโดยใช้สูตรเบอร์นูลลี เป็นการง่ายที่จะแสดงว่าการใช้สูตรนี้ในที่นี้มีความสมเหตุสมผลอย่างสมบูรณ์ โปรดทราบว่าความน่าจะเป็นที่จะไม่โดนเป้าหมายด้วยการยิงครั้งเดียวจะเท่ากับ 1-0.4=0.6 รับ

ชุดการแจกจ่ายมีรูปแบบดังต่อไปนี้:
| X | ||||
| R | 0,216 | 0,432 | 0,288 | 0,064 |
เป็นการง่ายที่จะตรวจสอบว่าผลรวมของความน่าจะเป็นทั้งหมดเท่ากับ 1 ตัวแปรสุ่มเอง Xกระจายตามกฎทวินาม ■
มาหาความคาดหมายทางคณิตศาสตร์และความแปรปรวนของตัวแปรสุ่มที่แจกแจงตามกฎทวินามกัน
เมื่อแก้ตัวอย่าง 6.5 พบว่าการคาดหมายทางคณิตศาสตร์ของจำนวนเหตุการณ์ที่เกิดขึ้น แต่ใน นการทดสอบอิสระถ้าความน่าจะเป็นที่จะเกิดขึ้น แต่ในการทดสอบแต่ละครั้งมีค่าคงที่และเท่ากัน Rเท่ากับ น· R
ในตัวอย่างนี้ ใช้ตัวแปรสุ่มโดยกระจายตามกฎทวินาม ดังนั้น คำตอบของตัวอย่างที่ 6.5 อันที่จริงแล้ว เป็นการพิสูจน์ทฤษฎีบทต่อไปนี้
ทฤษฎีบท 7.1ความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่มแบบไม่ต่อเนื่องที่แจกแจงตามกฎทวินามเท่ากับผลคูณของจำนวนการทดลองและความน่าจะเป็นของ "ความสำเร็จ" กล่าวคือ เอ็ม(X)=น· ร.
ทฤษฎีบท 7.2ความแปรปรวนของตัวแปรสุ่มแบบไม่ต่อเนื่องที่แจกแจงตามกฎทวินามเท่ากับผลคูณของจำนวนการทดลองโดยความน่าจะเป็นของ "ความสำเร็จ" และความน่าจะเป็นของ "ความล้มเหลว" เช่น ดี(X)=เอ็นพีคิว
ความเบ้และความโด่งของตัวแปรสุ่มที่กระจายตามกฎทวินามถูกกำหนดโดยสูตร
สูตรเหล่านี้สามารถรับได้โดยใช้แนวคิดของช่วงเวลาเริ่มต้นและช่วงเวลาศูนย์กลาง
กฎหมายการแจกแจงทวินามรองรับสถานการณ์จริงหลายประการ สำหรับค่าขนาดใหญ่ นการแจกแจงทวินามสามารถประมาณได้ด้วยการแจกแจงแบบอื่น โดยเฉพาะอย่างยิ่งการแจกแจงแบบปัวซอง
การกระจายปัวซอง
ให้มี นการทดลองเบอร์นูลลีพร้อมจำนวนการทดลอง นใหญ่พอ. ก่อนหน้านี้แสดงให้เห็นว่าในกรณีนี้ (หากนอกจากนี้ ความน่าจะเป็น Rพัฒนาการ แต่น้อยมาก) เพื่อหาความน่าจะเป็นที่เหตุการณ์ แต่ปรากฏ tในการทดสอบคุณสามารถใช้สูตรปัวซอง (4.9) ถ้าตัวแปรสุ่ม Xหมายถึง จำนวนครั้งของเหตุการณ์ แต่ใน นการทดลองเบอร์นูลลีแล้วความน่าจะเป็นที่ Xจะรับเอาความหมาย kสามารถคำนวณได้โดยสูตร
 , (7.2)
, (7.2)
ที่ไหน λ = np.
กฎหมายจำหน่ายปัวซองเรียกว่าการกระจายตัวของตัวแปรสุ่มแบบไม่ต่อเนื่อง Xซึ่งค่าที่เป็นไปได้คือจำนวนเต็มไม่เป็นลบ และความน่าจะเป็น p tค่าเหล่านี้หาได้จากสูตร (7.2)
ค่า λ = npเรียกว่า พารามิเตอร์การกระจายปัวซอง
ตัวแปรสุ่มที่กระจายตามกฎของปัวซองสามารถรับค่าได้เป็นอนันต์ เนื่องจากการกระจายนี้ ความน่าจะเป็น Rการเกิดเหตุการณ์ในการทดลองแต่ละครั้งมีน้อย ดังนั้นการแจกแจงนี้บางครั้งเรียกว่ากฎของปรากฏการณ์หายาก
อนุกรมการแจกแจงของตัวแปรสุ่มที่แจกแจงตามกฎปัวซองมีรูปแบบ
| X | … | t | … | ||||
| R | … | … |
เป็นการง่ายที่จะตรวจสอบว่าผลรวมของความน่าจะเป็นของแถวที่สองเท่ากับ 1 ในการทำเช่นนี้ เราต้องจำไว้ว่าฟังก์ชันสามารถขยายเป็นอนุกรม Maclaurin ได้ ซึ่งจะมาบรรจบกันสำหรับค่าใดๆ X. ในกรณีนี้เรามี
 . (7.3)
. (7.3)
ตามที่ระบุไว้ กฎของปัวซองในบางกรณีแทนที่กฎทวินาม ตัวอย่างคือตัวแปรสุ่ม Xซึ่งมีค่าเท่ากับจำนวนความล้มเหลวในช่วงเวลาหนึ่งโดยใช้อุปกรณ์ทางเทคนิคซ้ำๆ สันนิษฐานว่าอุปกรณ์นี้มีความน่าเชื่อถือสูง กล่าวคือ ความน่าจะเป็นของความล้มเหลวในแอปพลิเคชันเดียวมีน้อยมาก
นอกเหนือจากกรณีจำกัดดังกล่าว ในทางปฏิบัติแล้วยังมีการกระจายตัวแปรสุ่มตามกฎหมายปัวซอง ซึ่งไม่เกี่ยวข้องกับการแจกแจงทวินาม ตัวอย่างเช่น การแจกแจงแบบปัวซองมักใช้ในการจัดการกับจำนวนเหตุการณ์ที่เกิดขึ้นในช่วงเวลาหนึ่ง (จำนวนการโทรไปยังการแลกเปลี่ยนโทรศัพท์ระหว่างชั่วโมง จำนวนรถที่มาถึงร้านล้างรถในระหว่างวัน จำนวนเครื่องหยุดต่อสัปดาห์ ฯลฯ .) เหตุการณ์ทั้งหมดเหล่านี้ต้องก่อให้เกิดกระแสของเหตุการณ์ที่เรียกว่า ซึ่งเป็นหนึ่งในแนวคิดพื้นฐานของทฤษฎีการเข้าคิว พารามิเตอร์ λ แสดงลักษณะความเข้มเฉลี่ยของการไหลของเหตุการณ์
การแจกแจงทวินามเป็นหนึ่งในการกระจายความน่าจะเป็นที่สำคัญที่สุดสำหรับตัวแปรสุ่มที่เปลี่ยนแปลงอย่างไม่ต่อเนื่อง การแจกแจงทวินามคือการแจกแจงความน่าจะเป็นของตัวเลข มเหตุการณ์ แต่ใน นการสังเกตที่เป็นอิสระร่วมกัน. มักมีเหตุการณ์ แต่เรียกว่า "ความสำเร็จ" ของการสังเกตและเหตุการณ์ตรงกันข้าม - "ความล้มเหลว" แต่การกำหนดนี้มีเงื่อนไขมาก
เงื่อนไขของการแจกแจงทวินาม:
- ดำเนินการทั้งหมด นการทดลองที่เหตุการณ์ แต่อาจเกิดขึ้นหรือไม่เกิดขึ้นก็ได้
- เหตุการณ์ แต่ในการทดลองแต่ละครั้งสามารถเกิดขึ้นได้ด้วยความน่าจะเป็นเท่ากัน พี;
- การทดสอบเป็นอิสระจากกัน
ความน่าจะเป็นที่ใน นเหตุการณ์ทดสอบ แต่อย่างแน่นอน มครั้ง สามารถคำนวณได้โดยใช้สูตรเบอร์นูลลี:
![]()
![]() ,
,
ที่ไหน พี- ความน่าจะเป็นของเหตุการณ์ที่เกิดขึ้น แต่;
q = 1 - พีคือความน่าจะเป็นของเหตุการณ์ตรงข้ามที่เกิดขึ้น
มาคิดออก เหตุใดการแจกแจงทวินามจึงสัมพันธ์กับสูตรเบอร์นูลลีในลักษณะที่อธิบายไว้ข้างต้น . เหตุการณ์ - จำนวนความสำเร็จที่ นการทดสอบแบ่งออกเป็นหลายตัวเลือก ซึ่งแต่ละการทดสอบจะประสบความสำเร็จใน มการทดลองและความล้มเหลว - in น - มการทดสอบ พิจารณาหนึ่งในตัวเลือกเหล่านี้ - บี1 . ตามกฎของการบวกความน่าจะเป็น เราคูณความน่าจะเป็นของเหตุการณ์ตรงกันข้าม:
![]() ,
,
และถ้าเราแสดงว่า q = 1 - พี, แล้ว
![]() .
.
ความน่าจะเป็นเดียวกันจะมีตัวเลือกอื่นที่ มความสำเร็จและ น - มความล้มเหลว จำนวนตัวเลือกดังกล่าวเท่ากับจำนวนวิธีที่เป็นไปได้จาก นทดสอบรับ มความสำเร็จ.
ผลรวมของความน่าจะเป็นของทั้งหมด มหมายเลขเหตุการณ์ แต่(ตัวเลขตั้งแต่ 0 ถึง น) เท่ากับหนึ่ง:
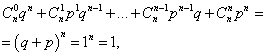
โดยที่แต่ละเทอมเป็นเทอมของทวินามของนิวตัน ดังนั้นการแจกแจงที่พิจารณาจึงเรียกว่าการแจกแจงแบบทวินาม
ในทางปฏิบัติมักจำเป็นต้องคำนวณความน่าจะเป็น "อย่างมากที่สุด มความสำเร็จใน นการทดสอบ" หรือ "อย่างน้อย มความสำเร็จใน นการทดสอบ" สำหรับสิ่งนี้จะใช้สูตรต่อไปนี้
ฟังก์ชันอินทิกรัล นั่นคือ ความน่าจะเป็น F(ม) นั้นใน นเหตุการณ์สังเกต แต่จะไม่มาอีกแล้ว มครั้งหนึ่ง, สามารถคำนวณได้โดยใช้สูตร:
ถึงคราวของมัน ความน่าจะเป็น F(≥ม) นั้นใน นเหตุการณ์สังเกต แต่มาอย่างน้อย มครั้งหนึ่ง, คำนวณโดยสูตร:
บางครั้งจะสะดวกกว่าในการคำนวณความน่าจะเป็นที่ใน นเหตุการณ์สังเกต แต่จะไม่มาอีกแล้ว มครั้ง โดยผ่านความน่าจะเป็นของเหตุการณ์ตรงกันข้าม:
![]() .
.
สูตรใดที่จะใช้ขึ้นอยู่กับว่าสูตรใดมีคำศัพท์น้อยกว่า
ลักษณะของการแจกแจงทวินามคำนวณโดยใช้สูตรต่อไปนี้ .
ค่าที่คาดหวัง: .
การกระจายตัว: .
ส่วนเบี่ยงเบนมาตรฐาน: .
การแจกแจงทวินามและการคำนวณใน MS Excel
ความน่าจะเป็นการกระจายทวินาม พีน ( ม) และค่าของฟังก์ชันปริพันธ์ F(ม) สามารถคำนวณได้โดยใช้ฟังก์ชัน MS Excel BINOM.DIST หน้าต่างสำหรับการคำนวณที่เกี่ยวข้องแสดงอยู่ด้านล่าง (คลิกปุ่มซ้ายของเมาส์เพื่อขยาย)

MS Excel ต้องการให้คุณป้อนข้อมูลต่อไปนี้:
- จำนวนความสำเร็จ
- จำนวนการทดสอบ
- ความน่าจะเป็นของความสำเร็จ
- อินทิกรัล - ค่าตรรกะ: 0 - หากคุณต้องการคำนวณความน่าจะเป็น พีน ( ม) และ 1 - ถ้าความน่าจะเป็น F(ม).
ตัวอย่าง 1ผู้จัดการบริษัทสรุปข้อมูลจำนวนกล้องที่ขายได้ในช่วง 100 วันที่ผ่านมา ตารางสรุปข้อมูลและคำนวณความน่าจะเป็นที่จะขายกล้องจำนวนหนึ่งต่อวัน
วันนั้นจบลงด้วยกำไรหากขายกล้อง 13 ตัวขึ้นไป ความน่าจะเป็นที่วันนั้นจะได้กำไร:
![]()
ความน่าจะเป็นที่วันนั้นจะทำงานโดยไม่มีกำไร:
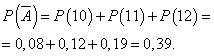
ให้ความน่าจะเป็นที่วันนั้นได้ผลโดยมีกำไรคงที่และเท่ากับ 0.61 และจำนวนกล้องที่ขายต่อวันไม่ได้ขึ้นอยู่กับวันนั้น จากนั้น คุณสามารถใช้การแจกแจงทวินาม โดยที่เหตุการณ์ แต่- วันนั้นจะทำอย่างมีกำไร - ไม่มีกำไร
ความน่าจะเป็นที่ภายใน 6 วันทั้งหมดจะได้รับผลกำไร:
![]() .
.
เราได้รับผลลัพธ์เดียวกันโดยใช้ฟังก์ชัน MS Excel BINOM.DIST (ค่าของค่าปริพันธ์คือ 0):
พี 6 (6 ) = BINOM.DIST(6; 6; 0.61; 0) = 0.052
ความน่าจะเป็นที่ทำกำไรได้ภายใน 6 วัน 4 วันขึ้นไป:
ที่ไหน ![]() ,
,
![]() ,
,
การใช้ฟังก์ชัน MS Excel BINOM.DIST เราคำนวณความน่าจะเป็นที่ภายใน 6 วันไม่เกิน 3 วันจะเสร็จสมบูรณ์พร้อมกำไร (ค่าของมูลค่ารวมคือ 1):
พี 6 (≤3 ) = BINOM.DIST(3, 6, 0.61, 1) = 0.435
ความน่าจะเป็นที่ภายใน 6 วันทั้งหมดจะได้รับการสูญเสีย:
![]() ,
,
เราคำนวณตัวบ่งชี้เดียวกันโดยใช้ฟังก์ชัน MS Excel BINOM.DIST:
พี 6 (0 ) = BINOM.DIST(0; 6; 0.61; 0) = 0.0035
แก้ปัญหาด้วยตัวเองแล้วดูวิธีแก้ปัญหา
ตัวอย่างที่ 2โกศประกอบด้วยลูกบอลสีขาว 2 ลูกและลูกสีดำ 3 ลูก นำลูกบอลออกจากโกศ กำหนดสีแล้วใส่กลับ พยายามทำซ้ำ 5 ครั้ง จำนวนที่ปรากฏของลูกบอลสีขาวเป็นตัวแปรสุ่มแบบไม่ต่อเนื่อง X, แจกจ่ายตามกฎหมายทวินาม. เขียนกฎการกระจายตัวของตัวแปรสุ่ม กำหนดโหมด ความคาดหวังทางคณิตศาสตร์ และความแปรปรวน
เรายังคงแก้ปัญหาด้วยกัน
ตัวอย่างที่ 3จากบริการจัดส่งไปที่วัตถุ น= 5 จัดส่ง. ผู้ส่งสารแต่ละคนมีความน่าจะเป็น พี= 0.3 มาช้าสำหรับวัตถุโดยไม่คำนึงถึงสิ่งอื่น ตัวแปรสุ่มแบบไม่ต่อเนื่อง X- จำนวนผู้ส่งของล่าช้า สร้างชุดการกระจายของตัวแปรสุ่มนี้ หาค่าความคาดหมายทางคณิตศาสตร์ ความแปรปรวน ส่วนเบี่ยงเบนมาตรฐาน ค้นหาความน่าจะเป็นที่ผู้ขนส่งอย่างน้อยสองคนจะมาสายสำหรับวัตถุ
 ลุงวันยา พล็อตเรื่อง “ลุงอีวาน ทัศนคติต่ออาจารย์ของผู้อื่น
ลุงวันยา พล็อตเรื่อง “ลุงอีวาน ทัศนคติต่ออาจารย์ของผู้อื่น Tsakhes น้อยชื่อเล่น Zinnober
Tsakhes น้อยชื่อเล่น Zinnober Maikov, Apollon Nikolaevich - ชีวประวัติสั้น
Maikov, Apollon Nikolaevich - ชีวประวัติสั้น