วิธีการทางสถิติทางคณิตศาสตร์ใน VK สำหรับนักเรียนและเด็กนักเรียน-หนังสือสถิติทางคณิตศาสตร์
“บางคนคิดว่าตนเองถูกเสมอ คนแบบนี้ไม่สามารถเป็นนักวิทยาศาสตร์ที่ดีหรือไม่สนใจสถิติได้... คดีนี้ถูกนำลงมายังโลก และกลายเป็นส่วนหนึ่งของโลกแห่งวิทยาศาสตร์” (ไดมอนด์ เอส)
“โอกาสเป็นเพียงการวัดความไม่รู้ของเราเท่านั้น ปรากฏการณ์สุ่ม ถ้าเรานิยามมัน จะเป็นปรากฏการณ์ที่เราไม่รู้กฎ” (A. Poincaré “วิทยาศาสตร์และสมมติฐาน”)
“ขอบคุณพระเจ้า ไม่เป็นอย่างนั้นเหรอ
เสมอกับความไม่เปลี่ยนรูป...
โอกาสมักจะครอบงำเหตุการณ์
สร้างทั้งความสุขและความเจ็บปวด
และชีวิตก็กำหนดภารกิจต่อหน้าเรา:
จะเข้าใจบทบาทของโอกาสได้อย่างไร”
(จากหนังสือ "คณิตศาสตร์ศึกษาแบบสุ่ม" โดย B.A. Kordemsky)
โลกเองก็เป็นไปตามธรรมชาติ นี่คือวิธีที่เรามักจะพิจารณาและศึกษากฎของฟิสิกส์ เคมี ฯลฯ แต่กลับไม่มีอะไรเกิดขึ้นหากปราศจากการแทรกแซงของโอกาส ซึ่งเกิดขึ้นภายใต้อิทธิพลของความสัมพันธ์เชิงสาเหตุที่ไม่มั่นคงและหลักประกันซึ่งเปลี่ยนแนวทางของ ปรากฏการณ์หรือประสบการณ์เมื่อมันเกิดขึ้นซ้ำแล้วซ้ำเล่า “เอฟเฟกต์แบบสุ่ม” ถูกสร้างขึ้นโดยมีความสม่ำเสมอโดยธรรมชาติของ “การกำหนดไว้ล่วงหน้าที่ซ่อนอยู่” เช่น โอกาสจำเป็นต้องมีผลลัพธ์ตามธรรมชาติ
นักคณิตศาสตร์พิจารณาเหตุการณ์สุ่มเฉพาะในภาวะที่กลืนไม่เข้าคายไม่ออกว่า "จะเป็นหรือไม่เป็น" เท่านั้น ไม่ว่ามันจะเกิดขึ้นหรือไม่ก็ตาม
คำนิยาม.สาขาวิชาคณิตศาสตร์ประยุกต์ซึ่งมีการศึกษาลักษณะเชิงปริมาณของเหตุการณ์หรือปรากฏการณ์สุ่มจำนวนมาก สถิติทางคณิตศาสตร์
คำนิยาม.การรวมกันขององค์ประกอบของทฤษฎีความน่าจะเป็นและสถิติทางคณิตศาสตร์เรียกว่า สุ่ม
คำนิยาม. สุ่ม- นี่คือสาขาวิชาคณิตศาสตร์ที่เกิดขึ้นและพัฒนาโดยเชื่อมโยงอย่างใกล้ชิดกับกิจกรรมเชิงปฏิบัติของมนุษย์ ปัจจุบัน องค์ประกอบของสุ่มรวมอยู่ในคณิตศาสตร์สำหรับทุกคน กลายเป็นแง่มุมใหม่ที่สำคัญของการศึกษาคณิตศาสตร์และการศึกษาทั่วไป
คำนิยาม. สถิติทางคณิตศาสตร์– ศาสตร์แห่งวิธีการทางคณิตศาสตร์ในการจัดระบบ การประมวลผล และการใช้ข้อมูลทางสถิติเพื่อการสรุปทางวิทยาศาสตร์และการปฏิบัติ
เรามาพูดถึงรายละเอียดเพิ่มเติมเกี่ยวกับเรื่องนี้
มุมมองที่ยอมรับกันโดยทั่วไปในขณะนี้คือสถิติทางคณิตศาสตร์เป็นศาสตร์แห่งวิธีทั่วไปในการประมวลผลผลการทดลอง ในการแก้ปัญหาเหล่านี้ การทดลองต้องมีอะไรบ้างจึงจะตัดสินบนพื้นฐานของการทดลองได้ถูกต้อง สถิติทางคณิตศาสตร์กลายเป็นศาสตร์แห่งการออกแบบการทดลองในบางส่วน
ความหมายของคำว่า "สถิติ" มีการเปลี่ยนแปลงที่สำคัญในช่วงสองศตวรรษที่ผ่านมานักวิทยาศาสตร์สมัยใหม่ชื่อดัง Hodges และ Lehman เขียนว่า "คำว่า "สถิติ" มีรากศัพท์เดียวกันกับคำว่า "รัฐ" (รัฐ) และเดิมหมายถึงศิลปะ และวิทยาศาสตร์การจัดการ: ครูสอนสถิติคนแรกในมหาวิทยาลัยในศตวรรษที่ 18 เยอรมนีในปัจจุบันเรียกว่านักสังคมศาสตร์ เนื่องจากการตัดสินใจของรัฐบาลมีขอบเขตขึ้นอยู่กับข้อมูลเกี่ยวกับประชากร อุตสาหกรรม ฯลฯ โดยธรรมชาติแล้วนักสถิติเริ่มสนใจข้อมูลดังกล่าว และคำว่า "สถิติ" ค่อยๆ เริ่มหมายถึงการรวบรวมข้อมูลเกี่ยวกับประชากร เกี่ยวกับรัฐ จากนั้นจึงรวบรวมและประมวลผลข้อมูลโดยทั่วไป ไม่มีประโยชน์ในการดึงข้อมูลออกมาเว้นแต่จะมีสิ่งที่เป็นประโยชน์ออกมา และนักสถิติมักจะมีส่วนร่วมในการตีความข้อมูล
วิธีการศึกษาทางสถิติสมัยใหม่ซึ่งสามารถอนุมานได้เกี่ยวกับประชากรจากข้อมูลที่โดยทั่วไปได้มาจากตัวอย่างของ "ประชากร"
คำนิยาม. นักสถิติ– บุคคลที่เกี่ยวข้องกับศาสตร์แห่งวิธีการทางคณิตศาสตร์ในการจัดระบบ การประมวลผล และการใช้ข้อมูลทางสถิติเพื่อการสรุปทางวิทยาศาสตร์และการปฏิบัติ
สถิติทางคณิตศาสตร์เกิดขึ้นในศตวรรษที่ 17 และพัฒนาควบคู่ไปกับทฤษฎีความน่าจะเป็น การพัฒนาสถิติทางคณิตศาสตร์เพิ่มเติม (ครึ่งหลังของศตวรรษที่ 19 และต้นศตวรรษที่ 20) เนื่องมาจาก P.L. เชบีเชฟ, A.A. มาร์คอฟ, A.M. Lyapunov, K. Gauss, A. Quetelet, F. Galton, K. Pearson และคนอื่นๆ ในวันที่ 20 A.N. โคลโมโกรอฟ, V.I. Romanovsky, E.E. Slutsky, N.V. Smirnov, B.V. Gnedenko เช่นเดียวกับนักศึกษาภาษาอังกฤษ R. Fisher, E. Purson และนักวิทยาศาสตร์ชาวอเมริกัน (Y. Neumann, A. Wald)
ปัญหาสถิติทางคณิตศาสตร์และความหมายของข้อผิดพลาดในโลกวิทยาศาสตร์
การสร้างรูปแบบที่เป็นปรากฏการณ์สุ่มมวลนั้นขึ้นอยู่กับการศึกษาข้อมูลทางสถิติจากผลการสังเกตโดยใช้วิธีทฤษฎีความน่าจะเป็น
งานแรกของสถิติทางคณิตศาสตร์คือการระบุวิธีการรวบรวมและจัดกลุ่มข้อมูลทางสถิติที่ได้รับจากการสังเกตหรือจากการทดลองที่ออกแบบมาเป็นพิเศษ
ภารกิจที่สองของสถิติทางคณิตศาสตร์คือการพัฒนาวิธีการวิเคราะห์ข้อมูลทางสถิติขึ้นอยู่กับวัตถุประสงค์ของการศึกษา
สถิติทางคณิตศาสตร์สมัยใหม่กำลังพัฒนาวิธีการกำหนดจำนวนการทดสอบที่จำเป็นก่อนเริ่มการศึกษา (การวางแผนการทดลอง) และระหว่างการศึกษา (การวิเคราะห์ตามลำดับ) สามารถกำหนดได้ว่าเป็นศาสตร์แห่งการตัดสินใจภายใต้ความไม่แน่นอน
โดยสรุป เราสามารถพูดได้ว่าหน้าที่ของสถิติทางคณิตศาสตร์คือการสร้างวิธีการรวบรวมและประมวลผลข้อมูลทางสถิติ
เมื่อศึกษาปรากฏการณ์สุ่มมวล ให้ถือว่าการทดสอบทั้งหมดดำเนินการภายใต้สภาวะเดียวกัน กล่าวคือ กลุ่มปัจจัยหลักที่สามารถนำมาพิจารณาได้ (วัดได้) และมีผลกระทบอย่างมีนัยสำคัญต่อผลการทดสอบโดยคงค่าเดิมไว้มากที่สุด
ปัจจัยสุ่มบิดเบือนผลลัพธ์ที่จะได้รับหากมีเพียงปัจจัยหลักเท่านั้น ทำให้เป็นแบบสุ่ม ความเบี่ยงเบนของผลลัพธ์ของการทดลองแต่ละครั้งจากค่าจริงเรียกว่าข้อผิดพลาดจากการสังเกตซึ่งเป็นตัวแปรสุ่ม จำเป็นต้องแยกแยะระหว่างข้อผิดพลาดที่เป็นระบบและข้อผิดพลาดแบบสุ่ม
การทดลองทางวิทยาศาสตร์เป็นสิ่งที่คิดไม่ถึงโดยไม่มีข้อผิดพลาดเหมือนกับมหาสมุทรที่ไม่มีเกลือ ข้อเท็จจริงใดๆ ที่เพิ่มเข้ามาในความรู้ของเราทำให้เกิดข้อผิดพลาดบางอย่าง ตามคำพูดที่รู้จักกันดีในชีวิต คนส่วนใหญ่ไม่สามารถมั่นใจในสิ่งใดได้นอกจากความตายและภาษี และนักวิทยาศาสตร์กล่าวเพิ่มเติมว่า: "และข้อผิดพลาดของประสบการณ์"
นักสถิติคือ "หมาล่าเนื้อ" ที่คอยตามล่าหาข้อผิดพลาด เครื่องมือสถิติสำหรับการตรวจจับข้อผิดพลาด
คำว่า "ข้อผิดพลาด" ไม่ได้หมายถึง "การคำนวณผิด" ง่ายๆ ผลที่ตามมาของการคำนวณผิดทำให้เกิดข้อผิดพลาดในการทดลองเพียงเล็กน้อยและไม่น่าสนใจ
แท้จริงแล้วเครื่องมือของเราพัง ตาและหูของเราสามารถหลอกลวงเราได้ การวัดของเราไม่เคยแม่นยำอย่างสมบูรณ์ บางครั้งแม้แต่การคำนวณทางคณิตศาสตร์ของเราก็ยังผิดพลาด ข้อผิดพลาดจากการทดลองเป็นสิ่งที่สำคัญมากกว่าการวัดด้วยเทปวัดที่ไม่ถูกต้องหรือภาพลวงตา และเนื่องจากงานสถิติที่สำคัญที่สุดคือการช่วยให้นักวิทยาศาสตร์วิเคราะห์ข้อผิดพลาดของการทดลอง เราจึงต้องพยายามทำความเข้าใจว่าจริงๆ แล้วข้อผิดพลาดคืออะไร
ไม่ว่านักวิทยาศาสตร์กำลังแก้ไขปัญหาอะไรก็ตาม มันจะกลายเป็นเรื่องที่ซับซ้อนมากกว่าที่เขาต้องการอย่างแน่นอน สมมติว่าเขาวัดการตกของกัมมันตภาพรังสีที่ละติจูดที่ต่างกัน ผลลัพธ์จะขึ้นอยู่กับความสูงของสถานที่เก็บตัวอย่าง ปริมาณฝนในท้องถิ่น และความสูงของพายุไซโคลนในพื้นที่ที่กว้างขึ้น
ข้อผิดพลาดจากการทดลองเป็นส่วนสำคัญของการทดลองทางวิทยาศาสตร์อย่างแท้จริง
ผลลัพธ์เดียวกันอาจเป็นข้อผิดพลาดและข้อมูลได้ ขึ้นอยู่กับปัญหาและมุมมอง หากนักชีววิทยาต้องการตรวจสอบว่าการเปลี่ยนแปลงทางโภชนาการส่งผลต่อการเจริญเติบโตอย่างไร การมีอยู่ขององค์ประกอบที่เกี่ยวข้องถือเป็นสาเหตุของข้อผิดพลาด ถ้าเขาศึกษาความสัมพันธ์ระหว่างพันธุกรรมและการเจริญเติบโต สาเหตุของข้อผิดพลาดจะอยู่ที่ความแตกต่างด้านโภชนาการ หากนักฟิสิกส์ต้องการศึกษาความสัมพันธ์ระหว่างการนำไฟฟ้าและอุณหภูมิ ความหนาแน่นของวัสดุตัวนำที่แตกต่างกันถือเป็นสาเหตุของข้อผิดพลาด หากเขาศึกษาความสัมพันธ์ระหว่างความหนาแน่นนี้กับการนำไฟฟ้า การเปลี่ยนแปลงของอุณหภูมิจะเป็นสาเหตุของข้อผิดพลาด
การใช้คำว่าข้อผิดพลาดนี้อาจดูน่าสงสัย และอาจดีกว่าที่จะกล่าวว่าผลกระทบที่ได้รับนั้นถูกบดบังด้วยอิทธิพลที่ "ไม่ได้ตั้งใจ" หรือ "ไม่พึงประสงค์" เราออกแบบการทดลองเพื่อศึกษาอิทธิพลที่ทราบ แต่ปัจจัยสุ่มที่เราไม่สามารถคาดเดาหรือวิเคราะห์ได้บิดเบือนผลลัพธ์โดยการเพิ่มเอฟเฟกต์ในตัวมันเอง
ความแตกต่างระหว่างผลกระทบที่วางแผนไว้และผลกระทบที่เกิดจากสาเหตุที่สุ่มก็เหมือนกับความแตกต่างระหว่างการเคลื่อนที่ของเรือในทะเล การแล่นไปตามเส้นทางที่แน่นอน และเรือที่ล่องลอยไปอย่างไร้จุดหมายภายใต้เจตจำนงของลมและกระแสน้ำที่เปลี่ยนแปลง การเคลื่อนไหวของเรือลำที่สองสามารถเรียกได้ว่าเป็นการเคลื่อนไหวแบบสุ่ม เป็นไปได้ว่าเรือลำนี้อาจมาถึงท่าเรือบางแห่ง แต่มีความเป็นไปได้มากกว่าว่าจะไม่มาถึงสถานที่ใดโดยเฉพาะ
นักสถิติใช้คำว่า "สุ่ม" เพื่อแสดงถึงปรากฏการณ์ที่ผลลัพธ์ในช่วงเวลาถัดไปไม่สามารถคาดเดาได้โดยสิ้นเชิง
ข้อผิดพลาดที่เกิดจากผลกระทบที่คาดการณ์ไว้ในการทดลองบางครั้งก็เป็นระบบมากกว่าการสุ่ม
ข้อผิดพลาดที่เป็นระบบทำให้เข้าใจผิดมากกว่าข้อผิดพลาดแบบสุ่ม สัญญาณรบกวนที่มาจากสถานีวิทยุอื่นสามารถสร้างดนตรีประกอบที่เป็นระบบ ซึ่งบางครั้งคุณสามารถคาดเดาได้ว่าคุณรู้จักทำนองหรือไม่ แต่ “การร่วมมือ” นี้อาจเป็นสาเหตุที่ทำให้เราตัดสินคำหรือเพลงของรายการที่เรากำลังพยายามฟังไม่ถูกต้อง
อย่างไรก็ตาม การค้นพบข้อผิดพลาดอย่างเป็นระบบมักจะนำเราไปสู่การค้นพบครั้งใหม่ การรู้ว่าข้อผิดพลาดแบบสุ่มเกิดขึ้นได้อย่างไรช่วยให้เราตรวจพบข้อผิดพลาดที่เป็นระบบและกำจัดข้อผิดพลาดเหล่านั้นได้
การใช้เหตุผลแบบเดียวกันเป็นเรื่องปกติในชีวิตประจำวันของเรา บ่อยแค่ไหนที่เราสังเกตเห็น: “นี่ไม่ใช่อุบัติเหตุ!” เมื่อใดก็ตามที่เราสามารถพูดสิ่งนี้ได้ เราก็อยู่บนเส้นทางสู่การค้นพบ
ตัวอย่างเช่น A.L. Chizhevsky วิเคราะห์กระบวนการทางประวัติศาสตร์: อัตราการเสียชีวิตที่เพิ่มขึ้น โรคระบาด การระบาดของสงคราม การเคลื่อนย้ายครั้งใหญ่ของประชาชน การเปลี่ยนแปลงสภาพภูมิอากาศอย่างกะทันหัน ฯลฯ ค้นพบความสัมพันธ์ระหว่างกระบวนการที่ไม่เกี่ยวข้องเหล่านี้กับคาบของกิจกรรมสุริยะซึ่งมีวัฏจักร: 11 ปี 33 ปี
คำนิยาม. ภายใต้ข้อผิดพลาดอย่างเป็นระบบเข้าใจว่าเป็นข้อผิดพลาดที่เกิดซ้ำและเหมือนกันสำหรับการทดสอบทั้งหมด มักเกี่ยวข้องกับการดำเนินการทดสอบที่ไม่เหมาะสม
คำนิยาม. ภายใต้ข้อผิดพลาดแบบสุ่มหมายถึงข้อผิดพลาดที่เกิดขึ้นภายใต้อิทธิพลของปัจจัยสุ่มและแตกต่างกันไปในแต่ละการทดลอง
โดยทั่วไปแล้ว การกระจายของข้อผิดพลาดแบบสุ่มจะสมมาตรประมาณศูนย์ ซึ่งมีข้อสรุปที่สำคัญดังนี้: ในกรณีที่ไม่มีข้อผิดพลาดอย่างเป็นระบบ ผลการทดสอบที่แท้จริงคือความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่ม ซึ่งค่าเฉพาะจะได้รับการแก้ไขในการทดสอบแต่ละครั้ง
วัตถุประสงค์ของการศึกษาทางสถิติทางคณิตศาสตร์อาจเป็นลักษณะเชิงคุณภาพหรือเชิงปริมาณของปรากฏการณ์หรือกระบวนการที่กำลังศึกษา
ในกรณีของคุณลักษณะเชิงคุณภาพ จะนับจำนวนครั้งของคุณลักษณะนี้ในชุดการทดลองที่พิจารณา ตัวเลขนี้แสดงถึงตัวแปรสุ่ม (ไม่ต่อเนื่อง) ที่กำลังศึกษา ตัวอย่างของคุณสมบัติด้านคุณภาพ ได้แก่ ข้อบกพร่องในชิ้นส่วนที่เสร็จแล้ว ข้อมูลทางประชากรศาสตร์ ฯลฯ หากลักษณะเป็นเชิงปริมาณในการทดลองการวัดโดยตรงหรือโดยอ้อมจะทำโดยการเปรียบเทียบกับมาตรฐานบางหน่วย - หน่วยการวัด - โดยใช้เครื่องมือวัดต่างๆ ตัวอย่างเช่น หากมีชิ้นส่วนเป็นชุด มาตรฐานของชิ้นส่วนก็สามารถใช้เป็นสัญญาณเชิงคุณภาพได้ และขนาดที่ควบคุมของชิ้นส่วนก็สามารถใช้เป็นสัญญาณเชิงปริมาณได้
คำจำกัดความพื้นฐาน
ส่วนสำคัญของสถิติทางคณิตศาสตร์มีความเกี่ยวข้องกับความจำเป็นในการอธิบายวัตถุจำนวนมาก
คำนิยาม.วัตถุที่จะศึกษาทั้งชุดเรียกว่า ประชากรทั่วไป
ประชากรทั่วไปอาจเป็นประชากรทั้งหมดของประเทศ ผลผลิตพืชต่อเดือน ประชากรปลาที่อาศัยอยู่ในอ่างเก็บน้ำที่กำหนด เป็นต้น
แต่ประชากรไม่ได้เป็นเพียงชุดเดียว หากชุดของวัตถุที่เราสนใจมีจำนวนมากเกินไป หรือวัตถุนั้นเข้าถึงได้ยาก หรือมีเหตุผลอื่นที่ทำให้เราไม่สามารถศึกษาวัตถุทั้งหมดได้ เราก็หันไปศึกษาวัตถุบางส่วน
คำนิยาม.ส่วนหนึ่งของวัตถุที่ถูกตรวจสอบ วิจัย ฯลฯ เรียกว่า ประชากรตัวอย่างหรือเพียงแค่ การสุ่มตัวอย่าง
คำนิยาม.จำนวนองค์ประกอบในประชากรและกลุ่มตัวอย่างเรียกว่า เล่ม.
จะแน่ใจได้อย่างไรว่าตัวอย่างจะเป็นตัวแทนทั้งหมดได้ดีที่สุด เช่น มันจะเป็นตัวแทนไหม?
หากทั้งหมดนั่นคือ หากเรามีจำนวนประชากรน้อยหรือไม่รู้จักเลย เราไม่สามารถเสนออะไรที่ดีไปกว่าการเลือกแบบสุ่มล้วนๆ ได้ การรับรู้ที่มากขึ้นช่วยให้คุณทำตัวได้ดีขึ้น แต่ถึงกระนั้น ในบางช่วง ความไม่รู้ก็เข้ามาและส่งผลให้มีทางเลือกแบบสุ่ม
แต่จะสุ่มเลือกอย่างหมดจดได้อย่างไร? ตามกฎแล้ว การคัดเลือกจะเกิดขึ้นตามลักษณะที่สังเกตได้ง่ายเพื่อการวิจัย
การละเมิดหลักการสุ่มเลือกทำให้เกิดข้อผิดพลาดร้ายแรง การสำรวจความคิดเห็นที่จัดทำโดยนิตยสาร Literary Review ของอเมริกาเกี่ยวกับผลการเลือกตั้งประธานาธิบดีในปี 1936 มีชื่อเสียงในเรื่องความล้มเหลว ผู้สมัครในการเลือกตั้งครั้งนี้คือ F.D. รูสเวลต์และ A.M. แลนดอน.
ใครชนะ?
บรรณาธิการใช้สมุดโทรศัพท์เป็นประชากรทั่วไป หลังจากสุ่มเลือกที่อยู่ 4 ล้านแห่ง เธอได้ส่งไปรษณียบัตรเพื่อถามเกี่ยวกับทัศนคติต่อผู้สมัครชิงตำแหน่งประธานาธิบดีทั่วประเทศ หลังจากใช้เงินก้อนใหญ่ไปกับการส่งไปรษณีย์และการประมวลผลโปสการ์ด นิตยสารดังกล่าวได้ประกาศว่าแลนดอนจะชนะการเลือกตั้งประธานาธิบดีที่กำลังจะมาถึงอย่างถล่มทลาย ผลการเลือกตั้งกลับตรงกันข้ามกับการคาดการณ์นี้
มีข้อผิดพลาดสองครั้งที่นี่พร้อมกัน ประการแรก สมุดโทรศัพท์ไม่ได้ให้ข้อมูลตัวอย่างที่เป็นตัวแทนของประชากรสหรัฐฯ ซึ่งส่วนใหญ่เป็นหัวหน้าครัวเรือนที่ร่ำรวย ประการที่สอง ไม่ใช่ทุกคนที่ส่งคำตอบ แต่ส่วนใหญ่มาจากตัวแทนของโลกธุรกิจที่สนับสนุนแลนดอน
ในเวลาเดียวกันนักสังคมวิทยา J. Gallan และ E. Warner ทำนายชัยชนะของ F.D. รูสเวลต์โดยใช้แบบสอบถามเพียงสี่พันข้อเท่านั้น สาเหตุของความสำเร็จนี้ไม่ใช่แค่การสุ่มตัวอย่างที่ถูกต้องเท่านั้น พวกเขาคำนึงถึงว่าสังคมถูกแบ่งออกเป็นกลุ่มสังคมที่มีความเป็นเนื้อเดียวกันมากกว่าเมื่อเทียบกับผู้สมัครชิงตำแหน่งประธานาธิบดี ดังนั้นตัวอย่างจากชั้นอาจมีขนาดค่อนข้างเล็กโดยให้ผลลัพธ์ความแม่นยำเท่ากัน ในท้ายที่สุด รูสเวลต์ซึ่งเป็นผู้สนับสนุนการปฏิรูปกลุ่มประชากรที่ร่ำรวยน้อยกว่าได้รับชัยชนะ
เมื่อมีผลการสำรวจแยกตามชั้นต่างๆ ก็สามารถจำแนกลักษณะของสังคมโดยรวมได้
ตัวอย่างคืออะไร?
เหล่านี้เป็นชุดของตัวเลข
ให้เราดูรายละเอียดเพิ่มเติมเกี่ยวกับแนวคิดพื้นฐานที่แสดงลักษณะของชุดตัวอย่าง
ตัวอย่างขนาด n ถูกสกัดจากประชากรทั่วไป > n 1 โดยที่ n 1 คือจำนวนครั้งที่สังเกตลักษณะของ x 1, n 2 - x 2 เป็นต้น
ค่าที่สังเกตได้ของ x i เรียกว่าตัวแปร และลำดับของตัวแปรที่เขียนจากน้อยไปหามากเรียกว่าชุดของรูปแบบ จำนวนการสังเกต n i เรียกว่าความถี่ และ n i /n - ความถี่สัมพัทธ์ (หรือความถี่)
คำนิยาม.เรียกว่าค่าต่างๆ ของตัวแปรสุ่ม ตัวเลือก
คำนิยาม. ซีรี่ส์รูปแบบต่างๆคือชุดที่จัดเรียงตามลำดับตัวเลือกจากน้อยไปหามาก (หรือจากมากไปหาน้อย) โดยมีความถี่ (ความถี่) ที่สอดคล้องกัน
เมื่อศึกษาอนุกรมความแปรผันควบคู่ไปกับแนวคิดเรื่องความถี่ จะใช้แนวคิดเรื่องความถี่สะสม ความถี่สะสม (ความถี่) สำหรับแต่ละช่วงเวลาจะพบโดยการรวมความถี่ของช่วงก่อนหน้าทั้งหมดตามลำดับ
คำนิยาม.การสะสมความถี่หรือความถี่ที่เรียกว่า การสะสม- คุณสามารถสะสมความถี่และช่วงเวลาได้
ลักษณะของซีรี่ส์อาจเป็นได้ทั้งเชิงปริมาณและเชิงคุณภาพ
ลักษณะเชิงปริมาณ (แปรผัน)- สิ่งเหล่านี้เป็นลักษณะที่สามารถแสดงเป็นตัวเลขได้ แบ่งออกเป็นแบบไม่ต่อเนื่องและต่อเนื่อง
ลักษณะเชิงคุณภาพ (ที่มา)– สิ่งเหล่านี้เป็นคุณลักษณะที่ไม่ได้แสดงเป็นตัวเลข
ตัวแปรต่อเนื่องเป็นตัวแปรที่แสดงเป็นจำนวนจริง
ตัวแปรไม่ต่อเนื่องเป็นตัวแปรที่สามารถแสดงเป็นจำนวนเต็มเท่านั้น
ตัวอย่างมีลักษณะเฉพาะ แนวโน้มศูนย์กลาง: ค่าเฉลี่ย โหมด และค่ามัธยฐาน ค่าเฉลี่ยของกลุ่มตัวอย่างคือค่าเฉลี่ยเลขคณิตของค่าทั้งหมด โหมดการสุ่มตัวอย่างคือค่าที่เกิดขึ้นบ่อยที่สุด ค่ามัธยฐานของกลุ่มตัวอย่างคือตัวเลขที่ "แบ่ง" ออกเป็นครึ่งหนึ่งของประชากรตามลำดับของค่าทั้งหมดในกลุ่มตัวอย่าง
ชุดรูปแบบต่างๆ อาจเป็นแบบแยกหรือต่อเนื่องก็ได้
งาน
ตัวอย่างที่ให้: 1.3; 1.8; 1.2; 3.0; 2.1; 5; 2.4; 1.2; 3.2;1.2; 4; 2.4.
นี่คือตัวเลือกต่างๆ เมื่อจัดเรียงตัวเลือกเหล่านี้จากน้อยไปมาก เราจะได้ซีรี่ส์รูปแบบต่างๆ: 1.2; 1.2; 1.2; 1.3; 1.8; 2.1; 2.4; 2.4; 3.0; 3.2; 4; 5.
ค่าเฉลี่ยของซีรี่ส์นี้คือ 2.4
ค่ามัธยฐานของซีรีย์นี้คือ 2.25
โหมดของซีรีย์คือ –1,2
ให้เรากำหนดแนวคิดเหล่านี้
คำนิยาม. ค่ามัธยฐานของอนุกรมรูปแบบต่างๆเรียกว่าค่าของตัวแปรสุ่มที่อยู่ตรงกลางอนุกรมรูปแบบ (Me)
ค่ามัธยฐานของชุดตัวเลขเรียงลำดับที่มีพจน์เป็นเลขคี่คือตัวเลขที่เขียนไว้ตรงกลาง และค่ามัธยฐานของชุดตัวเลขเรียงลำดับที่มีพจน์เป็นจำนวนคู่คือค่าเฉลี่ยเลขคณิตของตัวเลขสองตัวที่เขียนไว้ตรงกลาง ค่ามัธยฐานของชุดตัวเลขตามอำเภอใจคือค่ามัธยฐานของชุดลำดับที่สอดคล้องกัน
คำนิยาม. ซีรีย์แฟชั่นหลากหลายรูปแบบพวกเขาเรียกตัวเลือก (ค่าของตัวแปรสุ่ม) ซึ่งสอดคล้องกับความถี่สูงสุด (Mo) เช่น ซึ่งเกิดขึ้นบ่อยกว่าคนอื่นๆ
คำนิยาม. ค่าเฉลี่ยเลขคณิตของอนุกรมรูปแบบต่างๆคือผลลัพธ์ของการหารผลรวมของค่าของตัวแปรทางสถิติด้วยจำนวนค่าเหล่านี้ กล่าวคือ ด้วยจำนวนเทอม
กฎสำหรับการค้นหาค่าเฉลี่ยเลขคณิตของกลุ่มตัวอย่าง:
- คูณแต่ละตัวเลือกด้วยความถี่ (หลายหลาก)
- รวมผลลัพธ์ที่ได้ทั้งหมด
- หารผลรวมที่พบด้วยผลรวมของความถี่ทั้งหมด
คำนิยาม. ช่วงแถวเรียกว่าความแตกต่างระหว่าง R=x max -x min เช่น ค่าที่ใหญ่ที่สุดและเล็กที่สุดของตัวเลือกเหล่านี้
มาตรวจสอบว่าเราพบค่าเฉลี่ยของอนุกรม ค่ามัธยฐาน และโหมดนี้ถูกต้องหรือไม่ตามคำจำกัดความ
เรานับจำนวนเทอมมี 12 เทอม - เทอมจำนวนคู่ซึ่งหมายความว่าเราต้องค้นหาค่าเฉลี่ยเลขคณิตของตัวเลขสองตัวที่เขียนไว้ตรงกลางนั่นคือตัวเลือกที่ 6 และ 7 (2.1+2.4)\2=2.25 – ค่ามัธยฐาน
แฟชั่น. แฟชั่นเป็น 1.2 เพราะว่า เพียงเลขนี้เกิด 3 ครั้ง ที่เหลือเกิดน้อยกว่า 3 ครั้ง
เราพบค่าเฉลี่ยเลขคณิตดังนี้:
(1,2*3+1,3+1,8+2,1+2,4*2+3,0+3,2 +4+5)\12=2,4
มาจัดโต๊ะกันเถอะ
ตารางดังกล่าวเรียกว่าตารางความถี่ ในนั้นตัวเลขในบรรทัดที่สองคือความถี่ พวกเขาแสดงให้เห็นว่าค่าบางอย่างเกิดขึ้นในตัวอย่างบ่อยเพียงใด
คำนิยาม. ความถี่สัมพัทธ์ค่าตัวอย่างคืออัตราส่วนของความถี่ต่อจำนวนค่าตัวอย่างทั้งหมด
ความถี่สัมพัทธ์จะเรียกว่าความถี่ ความถี่และความถี่เรียกว่าสเกล มาหาช่วงของอนุกรมกัน: R=5-1.2=3.8; ช่วงของซีรีย์คือ 3.8
อาหารสำหรับความคิด
ค่าเฉลี่ยเลขคณิตเป็นค่าทั่วไป ในความเป็นจริงมันไม่มีอยู่จริง ในความเป็นจริงมีจำนวนเงินทั้งหมด ดังนั้นค่าเฉลี่ยเลขคณิตจึงไม่ใช่คุณลักษณะของการสังเกตเพียงอย่างเดียว มันเป็นลักษณะของซีรีส์โดยรวม
ค่าเฉลี่ยสามารถตีความได้ว่าเป็นศูนย์กลางของการกระจายตัวของค่าของลักษณะที่สังเกตได้เช่น ค่าที่ค่าที่สังเกตทั้งหมดมีความผันผวนและผลรวมเชิงพีชคณิตของการเบี่ยงเบนจากค่าเฉลี่ยจะเป็นศูนย์เสมอเช่น ผลรวมของการเบี่ยงเบนจากค่าเฉลี่ยขึ้นหรือลงจะเท่ากัน
ค่าเฉลี่ยเลขคณิตเป็นปริมาณนามธรรม (ทั่วไป) แม้ว่าจะระบุชุดของจำนวนธรรมชาติเท่านั้น ค่าเฉลี่ยก็สามารถแสดงเป็นเศษส่วนได้ ตัวอย่าง: คะแนนสอบเฉลี่ยคือ 3.81
ค่าเฉลี่ยไม่เพียงแต่พบในปริมาณที่เป็นเนื้อเดียวกันเท่านั้น ผลผลิตเมล็ดพืชโดยเฉลี่ยทั่วประเทศ (ข้าวโพด - 50-60 เซ็นต์ต่อเฮกตาร์และบัควีต - 5-6 เซ็นต์ต่อเฮกตาร์ ข้าวไรย์ ข้าวสาลี ฯลฯ) การบริโภคอาหารโดยเฉลี่ย รายได้ประชาชาติเฉลี่ยต่อหัว อุปทานที่อยู่อาศัยเฉลี่ย ที่อยู่อาศัยเฉลี่ยถ่วงน้ำหนัก ต้นทุน, ความเข้มแรงงานเฉลี่ยในการก่อสร้างอาคาร ฯลฯ - สิ่งเหล่านี้คือคุณลักษณะของรัฐในฐานะระบบเศรษฐกิจของประเทศเดียว สิ่งเหล่านี้เรียกว่าค่าเฉลี่ยของระบบ
ในทางสถิติมีลักษณะเช่น โหมดและค่ามัธยฐาน- พวกมันถูกเรียกว่าค่าเฉลี่ยเชิงโครงสร้าง เพราะว่า ค่าของคุณสมบัติเหล่านี้จะถูกกำหนดโดยโครงสร้างทั่วไปของชุดข้อมูล
บางครั้งซีรีส์อาจมีสองโหมด บางครั้งซีรีส์อาจไม่มีโหมด
แฟชั่นเป็นตัวบ่งชี้ที่ยอมรับได้มากที่สุดเมื่อระบุบรรจุภัณฑ์ของผลิตภัณฑ์บางประเภทซึ่งเป็นที่ต้องการของผู้ซื้อ ราคาสินค้าประเภทที่กำหนดซึ่งมีอยู่ทั่วไปในตลาด ทั้งขนาดของรองเท้า เสื้อผ้า ที่เป็นที่ต้องการมากที่สุด กีฬาที่ประชากรส่วนใหญ่ของประเทศ เมือง หมู่บ้าน โรงเรียน ฯลฯ ชอบที่จะเข้าร่วม
ในการก่อสร้างแผ่นคอนกรีตมีความกว้าง 8 แบบและมักใช้ 3 แบบคือ 1 ม. 1.2 ม. และ 1.5 ม. ความยาวมี 33 ตัวเลือกสำหรับแผ่นคอนกรีต แต่แผ่นคอนกรีตที่มีความยาว 4.8 ม. มักเป็น ใช้แล้ว; 5.7 ม. และ 6.0 ม. แบบแผ่นพื้นมักพบใน 3 ขนาดนี้ เช่นเดียวกันอาจกล่าวได้เกี่ยวกับแบรนด์หน้าต่าง
โหมดของชุดข้อมูลจะพบได้เมื่อต้องการระบุตัวบ่งชี้ทั่วไปบางตัว
โหมดสามารถแสดงเป็นตัวเลขและคำ จากมุมมองทางสถิติ โหมดคือความถี่สูงสุด
ค่ามัธยฐานช่วยให้คุณสามารถคำนึงถึงข้อมูลบัญชีเกี่ยวกับชุดข้อมูลที่ได้รับจากค่าเฉลี่ยเลขคณิตและในทางกลับกัน
วิธีการทางสถิติทางคณิตศาสตร์
1. บทนำ
สถิติทางคณิตศาสตร์เป็นศาสตร์ที่เกี่ยวข้องกับการพัฒนาวิธีการรับ อธิบาย และประมวลผลข้อมูลการทดลอง เพื่อศึกษารูปแบบของปรากฏการณ์มวลสุ่ม
ในสถิติทางคณิตศาสตร์ สามารถแยกแยะได้สองด้าน: สถิติเชิงพรรณนา และสถิติอุปนัย (การอนุมานทางสถิติ) สถิติเชิงพรรณนาเกี่ยวข้องกับการสะสม การจัดระบบ และการนำเสนอข้อมูลการทดลองในรูปแบบที่สะดวก สถิติอุปนัยที่อิงตามข้อมูลเหล่านี้ทำให้สามารถสรุปผลบางอย่างเกี่ยวกับวัตถุที่รวบรวมข้อมูลหรือการประมาณค่าพารามิเตอร์ได้
พื้นที่ทั่วไปของสถิติทางคณิตศาสตร์คือ:
1) ทฤษฎีการสุ่มตัวอย่าง
2) ทฤษฎีการประเมิน
3) การทดสอบสมมติฐานทางสถิติ
4) การวิเคราะห์การถดถอย;
5) การวิเคราะห์ความแปรปรวน
สถิติทางคณิตศาสตร์ขึ้นอยู่กับแนวคิดเริ่มต้นจำนวนหนึ่งโดยที่ไม่สามารถศึกษาวิธีการสมัยใหม่ในการประมวลผลข้อมูลการทดลองได้ หนึ่งในนั้นคือแนวคิดเรื่องประชากรทั่วไปและกลุ่มตัวอย่าง
ในการผลิตทางอุตสาหกรรมจำนวนมาก มักจำเป็นต้องพิจารณาว่าคุณภาพของผลิตภัณฑ์เป็นไปตามมาตรฐานหรือไม่ โดยไม่ต้องตรวจสอบผลิตภัณฑ์แต่ละรายการที่ผลิต เนื่องจากปริมาณของผลิตภัณฑ์ที่ผลิตมีจำนวนมากหรือการทดสอบผลิตภัณฑ์เกี่ยวข้องกับการทำให้ใช้ไม่ได้ จึงมีการตรวจสอบผลิตภัณฑ์จำนวนเล็กน้อย จากการตรวจสอบนี้จำเป็นต้องให้ข้อสรุปเกี่ยวกับผลิตภัณฑ์ทั้งชุด แน่นอนว่าคุณไม่สามารถพูดได้ว่าทรานซิสเตอร์ทั้งหมดจากชุด 1 ล้านชิ้นนั้นดีหรือไม่ดีโดยการตรวจสอบหนึ่งในนั้น ในทางกลับกัน เนื่องจากกระบวนการเลือกตัวอย่างสำหรับการทดสอบและการทดสอบเองอาจใช้เวลานานและนำไปสู่ต้นทุนสูง ขอบเขตของการทดสอบผลิตภัณฑ์ควรอยู่ในลักษณะที่สามารถให้การแสดงผลิตภัณฑ์ทั้งชุดที่เชื่อถือได้ ในขณะที่มีขนาดเล็กที่สุด เพื่อจุดประสงค์นี้ เราจึงแนะนำแนวคิดหลายประการ
วัตถุทั้งชุดที่กำลังศึกษาหรือข้อมูลทดลองเรียกว่าประชากรทั่วไป เราจะแสดงด้วย N จำนวนวัตถุหรือจำนวนข้อมูลที่ประกอบเป็นประชากรทั่วไป ค่า N เรียกว่าปริมาตรของประชากร ถ้า N>>1 นั่นคือ N มีขนาดใหญ่มาก โดยปกติแล้วจะพิจารณา N = ¥
ตัวอย่างสุ่มหรือเพียงตัวอย่าง เป็นส่วนหนึ่งของประชากรที่เลือกโดยการสุ่ม คำว่า "สุ่ม" หมายความว่าความน่าจะเป็นในการเลือกวัตถุใดๆ จากประชากรจะเท่ากัน นี่เป็นสมมติฐานที่สำคัญ แต่มักจะทดสอบในทางปฏิบัติได้ยาก
ขนาดตัวอย่างคือจำนวนวัตถุหรือจำนวนข้อมูลที่ประกอบขึ้นเป็นตัวอย่างและเขียนแทนด้วย n- ในอนาคตเราจะสมมติว่าสามารถกำหนดองค์ประกอบตัวอย่างตามลำดับค่าตัวเลข x 1, x 2, ... x n ตัวอย่างเช่น ในกระบวนการควบคุมคุณภาพของทรานซิสเตอร์แบบไบโพลาร์ที่ผลิตขึ้น นี่อาจเป็นการวัด DC Gain ของทรานซิสเตอร์เหล่านั้น
2. ลักษณะเชิงตัวเลขของกลุ่มตัวอย่าง
2.1 ค่าเฉลี่ยตัวอย่าง
สำหรับตัวอย่างเฉพาะขนาด n คือค่าเฉลี่ยตัวอย่าง
ถูกกำหนดโดยความสัมพันธ์โดยที่ x i คือค่าขององค์ประกอบตัวอย่าง โดยทั่วไปแล้ว คุณต้องการอธิบายคุณสมบัติทางสถิติของกลุ่มตัวอย่างแบบสุ่มมากกว่าเพียงตัวอย่างใดตัวอย่างหนึ่ง ซึ่งหมายความว่ากำลังพิจารณาแบบจำลองทางคณิตศาสตร์ ซึ่งถือว่าตัวอย่างขนาด n มีจำนวนเพียงพอ ในกรณีนี้ องค์ประกอบตัวอย่างถือเป็นตัวแปรสุ่ม Xi โดยรับค่า xi โดยมีความหนาแน่นของความน่าจะเป็น f(x) ซึ่งเป็นความหนาแน่นของความน่าจะเป็นของประชากรทั่วไป แล้วค่าเฉลี่ยตัวอย่างก็เป็นตัวแปรสุ่มด้วย
เท่ากับเช่นเดิมเราจะแสดงตัวแปรสุ่มด้วยอักษรตัวใหญ่และค่าของตัวแปรสุ่มด้วยอักษรตัวพิมพ์เล็ก
ค่าเฉลี่ยของประชากรที่ใช้สุ่มตัวอย่างจะเรียกว่าค่าเฉลี่ยทั่วไปและเขียนแทนด้วย m x สามารถคาดหวังได้ว่าหากขนาดของกลุ่มตัวอย่างมีนัยสำคัญ ค่าเฉลี่ยของกลุ่มตัวอย่างจะไม่แตกต่างอย่างมีนัยสำคัญจากค่าเฉลี่ยประชากร เนื่องจากค่าเฉลี่ยตัวอย่างเป็นตัวแปรสุ่ม จึงสามารถหาค่าคาดหวังทางคณิตศาสตร์ได้:

ดังนั้นค่าคาดหวังทางคณิตศาสตร์ของค่าเฉลี่ยตัวอย่างจึงเท่ากับค่าเฉลี่ยทั่วไป ในกรณีนี้ ค่าเฉลี่ยตัวอย่างถือเป็นการประมาณค่าเฉลี่ยประชากรอย่างเป็นกลาง เราจะกลับมาที่เทอมนี้ในภายหลัง เนื่องจากค่าเฉลี่ยตัวอย่างเป็นตัวแปรสุ่มที่ผันผวนรอบๆ ค่าเฉลี่ยทั่วไป จึงเป็นที่พึงปรารถนาที่จะประมาณความผันผวนนี้โดยใช้ความแปรปรวนของค่าเฉลี่ยตัวอย่าง พิจารณาตัวอย่างที่มีขนาด n น้อยกว่าขนาดประชากร N (n<< N). Предположим, что при формировании выборки характеристики генеральной совокупности не меняются, что эквивалентно предположению N = ¥. Тогда
ตัวแปรสุ่ม X i และ X j (i¹j) สามารถพิจารณาได้ว่าเป็นอิสระ ดังนั้น

แทนที่ผลลัพธ์ที่ได้ลงในสูตรความแปรปรวน:
โดยที่ s 2 คือความแปรปรวนของประชากร
จากสูตรนี้จะตามมาว่าเมื่อขนาดตัวอย่างเพิ่มขึ้น ความผันผวนของค่าเฉลี่ยตัวอย่างรอบๆ ค่าเฉลี่ยทั่วไปจะลดลงเป็น s 2 /n ให้เราอธิบายสิ่งนี้ด้วยตัวอย่าง ให้มีสัญญาณสุ่มที่มีค่าคาดหวังทางคณิตศาสตร์และความแปรปรวนตามลำดับเท่ากับ m x = 10, s 2 = 9
ตัวอย่างสัญญาณจะถูกถ่ายโดยมีระยะห่างเท่ากัน t 1, t 2, ...,
 เอ็กซ์(ที)
เอ็กซ์(ที) เอ็กซ์ 1
เสื้อ 1 เสื้อ 2 . - - ไม่ใช่
เนื่องจากตัวอย่างเป็นตัวแปรสุ่ม เราจะแทนพวกมัน X(t 1), X(t 2), . - - , X(เทน)
ให้เรากำหนดจำนวนตัวอย่างเพื่อให้ค่าเบี่ยงเบนมาตรฐานของการประมาณค่าความคาดหวังทางคณิตศาสตร์ของสัญญาณไม่เกิน 1% ของค่าคาดหวังทางคณิตศาสตร์ เนื่องจาก mx = 10 จึงจำเป็น
ในทางกลับกัน หรือ จากที่นี่ เราได้รับตัวอย่าง n ³ 900 ตัวอย่าง2.2 ความแปรปรวนตัวอย่าง
สำหรับข้อมูลตัวอย่าง สิ่งสำคัญคือต้องทราบไม่เพียงแต่ค่าเฉลี่ยตัวอย่างเท่านั้น แต่ยังต้องทราบการแพร่กระจายของค่าตัวอย่างรอบค่าเฉลี่ยตัวอย่างด้วย ถ้าค่าเฉลี่ยตัวอย่างเป็นการประมาณค่าเฉลี่ยประชากร ความแปรปรวนตัวอย่างจะต้องเป็นการประมาณค่าความแปรปรวนประชากร ความแปรปรวนตัวอย่าง
สำหรับตัวอย่างที่ประกอบด้วยตัวแปรสุ่มหาได้ดังนี้
เมื่อใช้การแทนค่าความแปรปรวนตัวอย่างนี้ เราจะพบความคาดหวังทางคณิตศาสตร์ของมัน
ภายในโปรแกรมการศึกษาของมหาวิทยาลัย คุณไม่น่าจะพบสาขาวิชาแยกต่างหากที่เรียกว่า "สถิติทางคณิตศาสตร์" อย่างไรก็ตาม องค์ประกอบของสถิติทางคณิตศาสตร์มักจะได้รับการศึกษาร่วมกับทฤษฎีความน่าจะเป็น แต่หลังจากศึกษาหลักสูตรหลักของทฤษฎีความน่าจะเป็นแล้วเท่านั้น
สถิติทางคณิตศาสตร์ : ข้อมูลทั่วไป
สถิติทางคณิตศาสตร์เป็นสาขาหนึ่งของคณิตศาสตร์ที่พัฒนาวิธีการบันทึก อธิบาย และวิเคราะห์ข้อมูลจากการสังเกตและการทดลองใดๆ โดยมีวัตถุประสงค์เพื่อสร้างแบบจำลองความน่าจะเป็นของปรากฏการณ์สุ่มมวล
สถิติทางคณิตศาสตร์ในฐานะวิทยาศาสตร์เกิดขึ้นในศตวรรษที่ 17 และพัฒนาควบคู่ไปกับทฤษฎีความน่าจะเป็น พวกเขามีส่วนสนับสนุนอย่างมากต่อการพัฒนาวิทยาศาสตร์ในศตวรรษที่ 19-20 Chebyshev P.L., Gauss K., Kolmogorov A.N. ฯลฯ
งานทั่วไปของสถิติทางคณิตศาสตร์คือการสร้างวิธีการรวบรวมและประมวลผลข้อมูลทางสถิติเพื่อให้ได้ข้อสรุปทางวิทยาศาสตร์และการปฏิบัติ
ส่วนหลักของสถิติทางคณิตศาสตร์คือ:
- วิธีการสุ่มตัวอย่าง (การทำความคุ้นเคยกับแนวคิดของการสุ่มตัวอย่างวิธีการรวบรวมและประมวลผลข้อมูล ฯลฯ );
- การประเมินทางสถิติของพารามิเตอร์ตัวอย่าง (การประมาณค่า ช่วงความเชื่อมั่น ฯลฯ)
- การคำนวณลักษณะสรุปของกลุ่มตัวอย่าง (การคำนวณตัวเลือก โมเมนต์ ฯลฯ)
- ทฤษฎีสหสัมพันธ์ (สมการการถดถอย ฯลฯ );
- การทดสอบสมมติฐานทางสถิติ
- การวิเคราะห์ความแปรปรวนทางเดียว
ถึง ที่พบบ่อยที่สุดปัญหาสถิติทางคณิตศาสตร์ที่ศึกษาในมหาวิทยาลัยและมักพบในทางปฏิบัติได้แก่
- ปัญหาในการประมาณค่าพารามิเตอร์การสุ่มตัวอย่าง
- งานทดสอบสมมติฐานทางสถิติ
- ปัญหาการกำหนดประเภทของกฎหมายการกระจายสินค้าโดยอาศัยข้อมูลทางสถิติ
ปัญหาในการประมาณค่าพารามิเตอร์ตัวอย่าง
การศึกษาสถิติทางคณิตศาสตร์เริ่มต้นด้วยคำจำกัดความของแนวคิดเช่น "ตัวอย่าง" "ความถี่" "ความถี่สัมพัทธ์" "ฟังก์ชันเชิงประจักษ์" "รูปหลายเหลี่ยม" "สะสม" "ฮิสโตแกรม" ฯลฯ ถัดมาคือการศึกษาแนวคิดของการประมาณค่า (เอนเอียงและไม่ลำเอียง): ค่าเฉลี่ยตัวอย่าง ความแปรปรวน ความแปรปรวนที่แก้ไข ฯลฯ
งาน
การวัดการเจริญเติบโตของเด็กในกลุ่มอายุน้อยกว่าของโรงเรียนอนุบาลแสดงโดยกลุ่มตัวอย่าง:
92, 96, 95, 96, 94, 97, 98, 94, 95, 96.
เรามาค้นหาคุณลักษณะบางอย่างของตัวอย่างนี้กัน
สารละลาย
ขนาดตัวอย่าง (จำนวนการวัด; เอ็น): 10.
ค่าตัวอย่างต่ำสุด: 92 ค่าตัวอย่างสูงสุด: 98
ช่วงตัวอย่าง: 98 – 92 = 6
มาเขียนซีรีย์จัดอันดับกัน (ตัวเลือกตามลำดับจากน้อยไปหามาก):
92, 94, 94, 95, 95, 96, 96, 96, 97, 98.
มาจัดกลุ่มซีรีส์แล้วเขียนลงในตาราง (เราจะกำหนดจำนวนครั้งของซีรีส์ให้กับแต่ละตัวเลือก):
| x ฉัน | 92 | 94 | 95 | 96 | 97 | 98 | เอ็น |
| ฉัน | 1 | 2 | 2 | 3 | 1 | 1 | 10 |
มาคำนวณความถี่สัมพัทธ์และความถี่สะสมเขียนผลลัพธ์ลงในตาราง:
| x ฉัน | 92 | 94 | 95 | 96 | 97 | 98 | ทั้งหมด |
| ฉัน | 1 | 2 | 2 | 3 | 1 | 1 | 10 |
| 0,1 | 0,2 | 0,2 | 0,3 | 0,1 | 0,1 | 1 | |
| ความถี่สะสม | 1 | 3 | 5 | 8 | 1 | 10 |
มาสร้างรูปหลายเหลี่ยมของความถี่สุ่มตัวอย่างกัน (ทำเครื่องหมายบนกราฟว่ามีตัวเลือกตามแกน OX, ความถี่ตามแกน OY, เชื่อมต่อจุดต่างๆ ด้วยเส้นตรง)
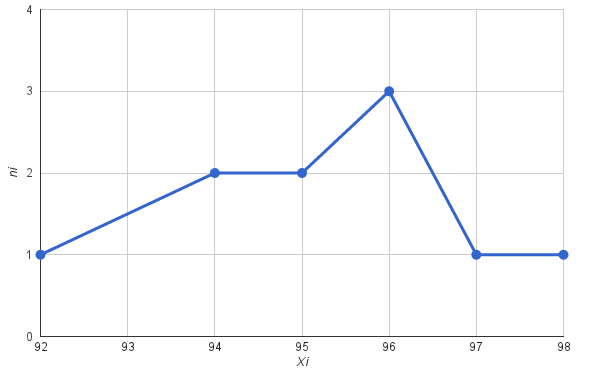
เราคำนวณค่าเฉลี่ยตัวอย่างและความแปรปรวนโดยใช้สูตร (ตามลำดับ):

คุณยังสามารถค้นหาคุณลักษณะอื่นๆ ของกลุ่มตัวอย่างได้ แต่สำหรับแนวคิดทั่วไป คุณลักษณะที่พบก็เพียงพอแล้ว
ปัญหาในการทดสอบสมมติฐานทางสถิติ
ปัญหาประเภทนี้มีความซับซ้อนมากกว่าปัญหาประเภทก่อนหน้า และวิธีแก้ปัญหามักมีขนาดใหญ่และต้องใช้แรงงานมาก ก่อนที่จะเริ่มแก้ปัญหา จะต้องศึกษาแนวคิดของสมมติฐานทางสถิติ สมมติฐานที่เป็นโมฆะและแข่งขันกัน ฯลฯ ก่อน
พิจารณาปัญหาที่ง่ายที่สุดของประเภทนี้
งาน
ให้ตัวอย่างอิสระสองตัวอย่างในปริมาตร 11 และ 14 โดยสกัดจากประชากรปกติ X, Y นอกจากนี้ ยังทราบความแปรปรวนที่แก้ไขแล้ว ซึ่งเท่ากับ 0.75 และ 0.4 ตามลำดับ มีความจำเป็นต้องทดสอบสมมติฐานว่างเกี่ยวกับความเท่าเทียมกันของความแปรปรวนทั่วไปในระดับนัยสำคัญ γ
=0.05. เลือกสมมติฐานที่แข่งขันกันตามต้องการ
สารละลาย
สมมติฐานว่างสำหรับปัญหาของเราเขียนไว้ดังนี้:
ตามสมมติฐานที่แข่งขันกัน ให้พิจารณาสิ่งต่อไปนี้:
ให้เราคำนวณอัตราส่วนของความแปรปรวนที่แก้ไขมากขึ้นกับค่าที่น้อยกว่าและรับค่าที่สังเกตได้ของเกณฑ์:
![]()
เนื่องจากสมมติฐานที่แข่งขันกันที่เราเลือกนั้นมีรูปแบบ บริเวณวิกฤตจึงเป็นมือขวา
การใช้ตารางสำหรับระดับนัยสำคัญ 0.05 และจำนวนองศาอิสระเท่ากับ 10 (11 – 1 = 10) และ 13 (14 – 1 = 13) เราจะพบจุดวิกฤติตามลำดับ:
เนื่องจากค่าที่สังเกตได้ของเกณฑ์มีค่าน้อยกว่าค่าวิกฤติ (1.875<2,67), то нет оснований отвергнуть гипотезу о равенстве генеральных дисперсий. Таким образом, исправленные дисперсии различаются между собой незначимо.
ปัญหาที่พิจารณาไม่ใช่เรื่องง่ายเมื่อมองแวบแรก แต่ค่อนข้างเป็นมาตรฐานและสามารถแก้ไขได้ตามเทมเพลต ตามกฎแล้วปัญหาดังกล่าวแตกต่างกันในค่าของเกณฑ์และขอบเขตวิกฤต
งานที่ต้องใช้แรงงานเข้มข้นมากขึ้น (เนื่องจากมีการคำนวณจำนวนมาก ซึ่งบางรายการสรุปไว้ในตาราง) จึงเป็นงานทดสอบสมมติฐานเกี่ยวกับประเภทการกระจายตัวของประชากร เมื่อแก้ไขปัญหาดังกล่าว จะใช้เกณฑ์ต่างๆ เช่น เกณฑ์ของ Pearson
ปัญหาการกำหนดประเภทของกฎหมายการกระจายจากข้อมูลทางสถิติ
ปัญหาประเภทนี้อยู่ในส่วนที่ศึกษาองค์ประกอบของทฤษฎีสหสัมพันธ์ หากเราพิจารณาการขึ้นต่อกันของ Y บน X เราก็สามารถจำวิธีกำลังสองน้อยที่สุดเพื่อกำหนดประเภทของการพึ่งพาได้ อย่างไรก็ตามในสถิติทางคณิตศาสตร์ทุกอย่างมีความซับซ้อนมากขึ้นและในทฤษฎีความสัมพันธ์ของปริมาณสองมิติจะได้รับการพิจารณาซึ่งค่าที่มักจะได้รับในรูปแบบของตาราง
| x1 | x1 | … | เอ็กซ์เอ็น | ไม่เป็นไร | |
| คุณ 1 | หมายเลข 11 | เลขที่ 21 | … | n n1 | |
| คุณ 1 | 12 | เลขที่ 22 | … | n n2 | |
| … | … | … | … | … | … |
| ใช่ | 1ม | 2ม | … | นาโนเมตร | |
| ไม่มี | … | เอ็น |
ให้เรากำหนดงานอย่างใดอย่างหนึ่งในส่วนนี้
งาน
หาสมการตัวอย่างเส้นตรงของการถดถอยของ Y บน X ข้อมูลแสดงไว้ในตารางความสัมพันธ์
| ย | เอ็กซ์ | ไม่เป็นไร | |||
| 10 | 20 | 30 | 40 | ||
| 5 | 1 | 3 | 4 | ||
| 6 | 2 | 1 | 3 | ||
| 7 | 3 | 2 | 5 | ||
| 8 | 1 | 1 | |||
| ไม่มี | 1 | 5 | 4 | 3 | เอ็น=13 |
บทสรุป
โดยสรุป เราสังเกตว่าระดับความซับซ้อนของปัญหาในสถิติทางคณิตศาสตร์นั้นแตกต่างกันค่อนข้างมากเมื่อย้ายจากประเภทหนึ่งไปยังอีกประเภทหนึ่ง ปัญหาประเภทแรกนั้นค่อนข้างง่ายและไม่จำเป็นต้องมีความเข้าใจทฤษฎีเป็นพิเศษ คุณสามารถเขียนสูตรและแก้ไขปัญหาได้เกือบทุกปัญหา ปัญหาประเภทที่สองและสามนั้นซับซ้อนกว่าเล็กน้อยและเพื่อที่จะแก้ไขได้สำเร็จจำเป็นต้องมี "ความรู้" จำนวนหนึ่งในระเบียบวินัยนี้
เราจะให้รายชื่อหนังสือเพียงสองเล่ม แต่หนังสือเหล่านี้กลายเป็นหนังสืออ้างอิงสำหรับผู้เขียนบทความนี้มานานแล้ว
- กรัมเมอร์มาน วี.อี. ทฤษฎีความน่าจะเป็นและสถิติทางคณิตศาสตร์: หนังสือเรียน – ฉบับที่ 12 แก้ไขใหม่ – อ.: สำนักพิมพ์ Yurayt, 2010. – 479 หน้า
- กรัมเมอร์มาน วี.อี. คู่มือการแก้ปัญหาทฤษฎีความน่าจะเป็นและสถิติทางคณิตศาสตร์ – ม.: มัธยมปลาย, 2548. – 404 น.
โซลูชันสถิติทางคณิตศาสตร์ที่กำหนดเอง
เราหวังว่าคุณจะโชคดีในการเรียนรู้สถิติทางคณิตศาสตร์ หากมีปัญหาโปรดติดต่อเรา เรายินดีที่จะช่วยเหลือ!
การแนะนำ
2. แนวคิดพื้นฐานของสถิติทางคณิตศาสตร์
2.1 แนวคิดพื้นฐานของวิธีการสุ่มตัวอย่าง
2.2 การกระจายตัวอย่าง
2.3 ฟังก์ชันการแจกแจงเชิงประจักษ์ ฮิสโตแกรม
บทสรุป
อ้างอิง
การแนะนำ
สถิติทางคณิตศาสตร์เป็นศาสตร์แห่งวิธีการทางคณิตศาสตร์ในการจัดระบบและการใช้ข้อมูลทางสถิติเพื่อการสรุปทางวิทยาศาสตร์และการปฏิบัติ ในหลายส่วน สถิติทางคณิตศาสตร์อิงตามทฤษฎีความน่าจะเป็น ซึ่งช่วยให้สามารถประเมินความน่าเชื่อถือและความแม่นยำของข้อสรุปที่ทำขึ้นบนพื้นฐานของเนื้อหาทางสถิติที่จำกัด (เช่น เพื่อประมาณขนาดตัวอย่างที่ต้องการเพื่อให้ได้ผลลัพธ์ที่มีความแม่นยำที่ต้องการ ในแบบสำรวจตัวอย่าง)
ทฤษฎีความน่าจะเป็นพิจารณาตัวแปรสุ่มด้วยการแจกแจงที่กำหนดหรือการทดลองสุ่มซึ่งทราบคุณสมบัติทั้งหมด หัวข้อของทฤษฎีความน่าจะเป็นคือคุณสมบัติและความสัมพันธ์ของปริมาณเหล่านี้ (การแจกแจง)
แต่บ่อยครั้งที่การทดลองเป็นกล่องดำที่ให้ผลลัพธ์บางอย่างเท่านั้นซึ่งจำเป็นต้องสรุปเกี่ยวกับคุณสมบัติของการทดสอบเอง ผู้สังเกตการณ์มีชุดผลลัพธ์ที่เป็นตัวเลข (หรืออาจเป็นตัวเลขก็ได้) ที่ได้รับจากการทดลองสุ่มแบบเดียวกันซ้ำภายใต้เงื่อนไขเดียวกัน
ตัวอย่างเช่นในกรณีนี้คำถามต่อไปนี้เกิดขึ้น: หากเราสังเกตตัวแปรสุ่มหนึ่งตัวเราจะได้ข้อสรุปที่แม่นยำที่สุดเกี่ยวกับการแจกแจงของมันตามชุดค่าของมันในการทดลองหลายครั้งได้อย่างไร
ตัวอย่างของชุดการทดลองดังกล่าวอาจเป็นการสำรวจทางสังคมวิทยา ชุดตัวชี้วัดทางเศรษฐกิจ หรือสุดท้ายคือลำดับหัวและก้อยเมื่อโยนเหรียญพันครั้ง
ปัจจัยทั้งหมดข้างต้นเป็นตัวกำหนด ความเกี่ยวข้องและความสำคัญของหัวข้องานในปัจจุบันมุ่งเป้าไปที่การศึกษาแนวคิดพื้นฐานของสถิติทางคณิตศาสตร์อย่างลึกซึ้งและครอบคลุม
งานนี้มีวัตถุประสงค์เพื่อจัดระบบ สะสม และรวบรวมความรู้เกี่ยวกับแนวคิดทางสถิติทางคณิตศาสตร์
1. วิชาและวิธีการสถิติทางคณิตศาสตร์
สถิติทางคณิตศาสตร์เป็นศาสตร์แห่งวิธีการทางคณิตศาสตร์ในการวิเคราะห์ข้อมูลที่ได้รับระหว่างการสังเกตมวล (การวัด การทดลอง) ขึ้นอยู่กับลักษณะทางคณิตศาสตร์ของผลการสังเกตเฉพาะ สถิติทางคณิตศาสตร์แบ่งออกเป็นสถิติของตัวเลข การวิเคราะห์ทางสถิติหลายตัวแปร การวิเคราะห์ฟังก์ชัน (กระบวนการ) และอนุกรมเวลา สถิติของวัตถุที่มีลักษณะที่ไม่ใช่ตัวเลข ส่วนสำคัญของสถิติทางคณิตศาสตร์นั้นขึ้นอยู่กับแบบจำลองความน่าจะเป็น มีงานทั่วไปในการอธิบายข้อมูล ประเมิน และทดสอบสมมติฐาน พวกเขายังพิจารณางานที่เฉพาะเจาะจงมากขึ้นที่เกี่ยวข้องกับการดำเนินการสำรวจตัวอย่าง การกู้คืนการพึ่งพา การสร้างและการใช้การจำแนกประเภท (ประเภท) ฯลฯ
เพื่ออธิบายข้อมูล ตาราง แผนภูมิ และการแสดงภาพอื่นๆ เช่น ช่องความสัมพันธ์ที่ถูกสร้างขึ้น มักจะไม่ใช้แบบจำลองความน่าจะเป็น วิธีการอธิบายข้อมูลบางวิธีอาศัยทฤษฎีขั้นสูงและความสามารถของคอมพิวเตอร์สมัยใหม่ โดยเฉพาะอย่างยิ่ง การวิเคราะห์กลุ่มที่มีจุดมุ่งหมายเพื่อระบุกลุ่มของวัตถุที่คล้ายกัน และการปรับขนาดหลายมิติ ซึ่งช่วยให้คุณสามารถแสดงวัตถุบนระนาบด้วยสายตา โดยบิดเบือนระยะห่างระหว่างวัตถุเหล่านั้นให้น้อยที่สุด
วิธีการประเมินและทดสอบสมมติฐานจะขึ้นอยู่กับแบบจำลองความน่าจะเป็นของการสร้างข้อมูล โมเดลเหล่านี้แบ่งออกเป็นแบบอิงพารามิเตอร์และแบบไม่มีพารามิเตอร์ ในแบบจำลองพาราเมตริก สันนิษฐานว่าวัตถุที่อยู่ระหว่างการศึกษานั้นอธิบายโดยฟังก์ชันการแจกแจง ขึ้นอยู่กับพารามิเตอร์ตัวเลขจำนวนเล็กน้อย (1-4) ในแบบจำลองที่ไม่ใช่พารามิเตอร์ ฟังก์ชันการแจกแจงจะถือว่ามีความต่อเนื่องโดยพลการ ในสถิติทางคณิตศาสตร์ พารามิเตอร์และคุณลักษณะของการแจกแจง (ความคาดหวังทางคณิตศาสตร์ ค่ามัธยฐาน ความแปรปรวน ควอนไทล์ ฯลฯ) ความหนาแน่นและฟังก์ชันการกระจาย การขึ้นต่อกันระหว่างตัวแปร (ขึ้นอยู่กับสัมประสิทธิ์สหสัมพันธ์เชิงเส้นและไม่ใช่พารามิเตอร์ รวมถึงการประมาณค่าฟังก์ชันแบบพาราเมตริกหรือแบบไม่มีพารามิเตอร์ การแสดงการพึ่งพา) ได้รับการประเมิน ฯลฯ โดยใช้การประมาณค่าแบบจุดและช่วง (ให้ขอบเขตสำหรับค่าจริง)
ในสถิติทางคณิตศาสตร์ มีทฤษฎีทั่วไปของการทดสอบสมมติฐานและวิธีการจำนวนมากสำหรับการทดสอบสมมติฐานเฉพาะ พวกเขาพิจารณาสมมติฐานเกี่ยวกับค่าของพารามิเตอร์และคุณลักษณะเกี่ยวกับการตรวจสอบความเป็นเนื้อเดียวกัน (นั่นคือเกี่ยวกับความบังเอิญของคุณลักษณะหรือฟังก์ชันการแจกแจงในสองตัวอย่าง) เกี่ยวกับข้อตกลงของฟังก์ชันการแจกแจงเชิงประจักษ์กับฟังก์ชันการแจกแจงที่กำหนดหรือด้วยพารามิเตอร์ ตระกูลของฟังก์ชันดังกล่าว เกี่ยวกับสมมาตรของการแจกแจง ฯลฯ
สิ่งสำคัญอย่างยิ่งคือส่วนของสถิติทางคณิตศาสตร์ที่เกี่ยวข้องกับการสำรวจตัวอย่างพร้อมคุณสมบัติของแผนการสุ่มตัวอย่างที่หลากหลายและการสร้างวิธีการที่เหมาะสมในการประเมินและทดสอบสมมติฐาน
ปัญหาการกู้คืนการพึ่งพาได้รับการศึกษาอย่างแข็งขันมานานกว่า 200 ปีนับตั้งแต่การพัฒนาวิธีกำลังสองน้อยที่สุดโดย K. Gauss ในปี 1794 ปัจจุบันวิธีการที่เกี่ยวข้องมากที่สุดในการค้นหาชุดย่อยของตัวแปรและข้อมูลที่ไม่ใช่พารามิเตอร์
การพัฒนาวิธีการประมาณข้อมูลและการลดขนาดคำอธิบายเริ่มต้นเมื่อกว่า 100 ปีที่แล้ว เมื่อ K. Pearson ได้สร้างวิธีการองค์ประกอบหลักขึ้นมา การวิเคราะห์ปัจจัยและลักษณะทั่วไปแบบไม่เชิงเส้นจำนวนมากได้รับการพัฒนาในภายหลัง
วิธีการต่างๆ ในการสร้าง (การวิเคราะห์กลุ่ม) การวิเคราะห์และการใช้ (การวิเคราะห์จำแนก) การจำแนกประเภท (ประเภท) เรียกอีกอย่างว่าวิธีการจดจำรูปแบบ (มีและไม่มีครู) การจำแนกประเภทอัตโนมัติ ฯลฯ
วิธีการทางคณิตศาสตร์ในสถิติจะขึ้นอยู่กับการใช้ผลรวม (ตามทฤษฎีบทขีดจำกัดจุดศูนย์กลางของทฤษฎีความน่าจะเป็น) หรือดัชนีความแตกต่าง (ระยะทาง หน่วยเมตริก) เช่นเดียวกับในสถิติของวัตถุที่มีลักษณะไม่เป็นตัวเลข โดยปกติแล้วจะมีเพียงผลลัพธ์เชิงเส้นกำกับเท่านั้นที่สามารถพิสูจน์ได้อย่างเข้มงวด ปัจจุบันคอมพิวเตอร์มีบทบาทสำคัญในสถิติทางคณิตศาสตร์ ใช้สำหรับทั้งการคำนวณและการจำลอง (โดยเฉพาะในวิธีการคูณตัวอย่างและในการศึกษาความเหมาะสมของผลลัพธ์เชิงเส้นกำกับ)
แนวคิดพื้นฐานของสถิติทางคณิตศาสตร์
2.1 แนวคิดพื้นฐานของวิธีการสุ่มตัวอย่าง
อนุญาต เป็นตัวแปรสุ่มที่สังเกตได้ในการทดลองสุ่ม สันนิษฐานว่าได้รับพื้นที่ความน่าจะเป็น (และจะไม่สนใจเรา)
เราจะสมมติว่าเมื่อทำการทดลองนี้ครั้งเดียวภายใต้เงื่อนไขเดียวกัน เราได้รับตัวเลข , , , - ค่าของตัวแปรสุ่มนี้ในตัวแรก ที่สอง ฯลฯ การทดลอง ตัวแปรสุ่มมีการแจกแจงที่เราไม่รู้จักบางส่วนหรือทั้งหมด
มาดูชุดที่เรียกว่าตัวอย่างกันดีกว่า
ในชุดการทดลองที่ได้ดำเนินการไปแล้ว ตัวอย่างคือชุดตัวเลข แต่ถ้าทำการทดลองชุดนี้ซ้ำอีกครั้ง เราจะได้ชุดตัวเลขใหม่แทนชุดนี้ แทนที่จะเป็นตัวเลขตัวเลขอื่นจะปรากฏขึ้น - หนึ่งในค่าของตัวแปรสุ่ม นั่นคือ (และ และ ฯลฯ) คือค่าตัวแปรที่สามารถรับค่าเดียวกันกับตัวแปรสุ่มและบ่อยพอๆ กัน (โดยมีความน่าจะเป็นเท่ากัน) ดังนั้น ก่อนการทดลอง - ตัวแปรสุ่ม กระจายเหมือนกันกับ และหลังการทดลอง - จำนวนที่เราสังเกตในการทดลองครั้งแรกนี้ เช่น หนึ่งในค่าที่เป็นไปได้ของตัวแปรสุ่ม
ขนาดตัวอย่างคือชุดของตัวแปรสุ่มที่เป็นอิสระและกระจายเหมือนกัน (“สำเนา”) ซึ่งมีการแจกแจงเช่น
“ทำการอนุมานเกี่ยวกับการกระจายตัวจากตัวอย่าง” หมายความว่าอย่างไร การแจกแจงมีลักษณะเป็นฟังก์ชันการแจกแจง ความหนาแน่น หรือตาราง ชุดของลักษณะตัวเลข - , ฯลฯ เมื่อใช้ตัวอย่าง คุณจะต้องสามารถสร้างการประมาณสำหรับคุณลักษณะเหล่านี้ทั้งหมดได้
.2 การกระจายตัวอย่าง
ลองพิจารณาการดำเนินการสุ่มตัวอย่างกับผลลัพธ์เบื้องต้นหนึ่งรายการ - ชุดตัวเลข ![]() , ,
, , ![]() - บนพื้นที่ความน่าจะเป็นที่เหมาะสม เราแนะนำตัวแปรสุ่มโดยใช้ค่า , , ด้วยความน่าจะเป็นโดย (หากค่าใดค่าหนึ่งตรงกัน เราจะเพิ่มความน่าจะเป็นด้วยจำนวนครั้งที่สอดคล้องกัน) ตารางการแจกแจงความน่าจะเป็นและฟังก์ชันการแจกแจงตัวแปรสุ่มมีลักษณะดังนี้:
- บนพื้นที่ความน่าจะเป็นที่เหมาะสม เราแนะนำตัวแปรสุ่มโดยใช้ค่า , , ด้วยความน่าจะเป็นโดย (หากค่าใดค่าหนึ่งตรงกัน เราจะเพิ่มความน่าจะเป็นด้วยจำนวนครั้งที่สอดคล้องกัน) ตารางการแจกแจงความน่าจะเป็นและฟังก์ชันการแจกแจงตัวแปรสุ่มมีลักษณะดังนี้:
การกระจายตัวของปริมาณเรียกว่าการกระจายตัวเชิงประจักษ์หรือการสุ่มตัวอย่าง ให้เราคำนวณความคาดหวังทางคณิตศาสตร์และความแปรปรวนของปริมาณและแนะนำสัญลักษณ์สำหรับปริมาณเหล่านี้:
ให้เราคำนวณโมเมนต์ของออร์เดอร์ด้วยวิธีเดียวกัน

ในกรณีทั่วไป เราจะแสดงด้วยปริมาณ

หากเมื่อสร้างคุณลักษณะทั้งหมดที่เรานำเสนอ เราพิจารณาตัวอย่าง , , ชุดของตัวแปรสุ่ม ดังนั้นคุณลักษณะเหล่านี้เอง - , , , , - จะกลายเป็นตัวแปรสุ่ม คุณลักษณะเหล่านี้ของการกระจายตัวอย่างใช้ในการประมาณ (ประมาณ) ลักษณะที่ไม่รู้จักที่สอดคล้องกันของการแจกแจงที่แท้จริง
เหตุผลในการใช้คุณลักษณะการกระจายเพื่อประมาณคุณลักษณะของการแจกแจงที่แท้จริง (หรือ ) คือความใกล้เคียงของการแจกแจงเหล่านี้ในภาพรวม
เช่น ลองพิจารณาการทอยลูกเต๋าธรรมดา อนุญาต ![]() - จำนวนแต้มที่ดรอประหว่างการโยนครั้งที่ . สมมติว่ามีรายการหนึ่งปรากฏในตัวอย่างหนึ่งครั้ง สองครั้ง - หนึ่งครั้ง ฯลฯ จากนั้นตัวแปรสุ่มจะรับค่าต่างๆ 1
, , 6
ด้วยความน่าจะเป็น , , ตามลำดับ แต่สัดส่วนเหล่านี้เข้าใกล้การเติบโตตามกฎคนจำนวนมาก นั่นคือการกระจายตัวของค่าในบางแง่จะเข้าใกล้การกระจายที่แท้จริงของจำนวนแต้มที่ปรากฏขึ้นเมื่อทอยลูกเต๋าที่ถูกต้อง
- จำนวนแต้มที่ดรอประหว่างการโยนครั้งที่ . สมมติว่ามีรายการหนึ่งปรากฏในตัวอย่างหนึ่งครั้ง สองครั้ง - หนึ่งครั้ง ฯลฯ จากนั้นตัวแปรสุ่มจะรับค่าต่างๆ 1
, , 6
ด้วยความน่าจะเป็น , , ตามลำดับ แต่สัดส่วนเหล่านี้เข้าใกล้การเติบโตตามกฎคนจำนวนมาก นั่นคือการกระจายตัวของค่าในบางแง่จะเข้าใกล้การกระจายที่แท้จริงของจำนวนแต้มที่ปรากฏขึ้นเมื่อทอยลูกเต๋าที่ถูกต้อง
เราจะไม่ชี้แจงว่าความใกล้เคียงของกลุ่มตัวอย่างและการแจกแจงที่แท้จริงหมายถึงอะไร ในย่อหน้าต่อไปนี้ เราจะพิจารณาคุณลักษณะแต่ละอย่างที่แนะนำข้างต้นโดยละเอียดยิ่งขึ้น และตรวจสอบคุณสมบัติของคุณลักษณะนั้น รวมถึงพฤติกรรมของมันเมื่อขนาดตัวอย่างเพิ่มขึ้น
.3 ฟังก์ชันการแจกแจงเชิงประจักษ์ ฮิสโตแกรม
เนื่องจากสามารถอธิบายการแจกแจงที่ไม่รู้จักได้ เช่น ด้วยฟังก์ชันการกระจาย เราจะสร้าง "การประมาณค่า" สำหรับฟังก์ชันนี้ตามตัวอย่าง
คำจำกัดความ 1.
ฟังก์ชันการแจกแจงเชิงประจักษ์ที่สร้างจากตัวอย่างปริมาตรเรียกว่าฟังก์ชันสุ่ม โดยแต่ละฟังก์ชันมีค่าเท่ากับ
คำเตือน:ฟังก์ชั่นสุ่ม

เรียกว่าเครื่องบ่งชี้เหตุการณ์ สำหรับแต่ละตัวแปร มันเป็นตัวแปรสุ่มที่มีการแจกแจงแบบแบร์นูลลีพร้อมพารามิเตอร์ ทำไม
กล่าวอีกนัยหนึ่ง สำหรับค่าใดๆ เท่ากับความน่าจะเป็นที่แท้จริงของตัวแปรสุ่มที่น้อยกว่า จะถูกประมาณโดยสัดส่วนขององค์ประกอบตัวอย่างที่น้อยกว่า
หากองค์ประกอบตัวอย่าง , , ถูกเรียงลำดับจากน้อยไปมาก (ที่ผลลัพธ์เบื้องต้นแต่ละรายการ) จะได้รับตัวแปรสุ่มชุดใหม่ เรียกว่าชุดรูปแบบ:
องค์ประกอบ , เรียกว่าสมาชิกลำดับที่ 2 ของชุดรูปแบบหรือสถิติลำดับที่ 2
ตัวอย่างที่ 1
ตัวอย่าง:
ซีรี่ส์รูปแบบ:
| ข้าว. 1.ตัวอย่างที่ 1 |
 |
ฟังก์ชันการกระจายเชิงประจักษ์มีการกระโดดที่จุดตัวอย่าง ขนาดของการกระโดดที่จุดหนึ่งเท่ากับ โดยที่จำนวนองค์ประกอบตัวอย่างตรงกับ
คุณสามารถสร้างฟังก์ชันการแจกแจงเชิงประจักษ์ได้โดยใช้อนุกรมรูปแบบ:

ลักษณะการกระจายอีกอย่างหนึ่งคือตาราง (สำหรับการแจกแจงแบบแยกส่วน) หรือความหนาแน่น (สำหรับการแจกแจงแบบต่อเนื่องอย่างแน่นอน) อะนาล็อกเชิงประจักษ์หรือแบบเลือกสรรของตารางหรือความหนาแน่นเรียกว่าฮิสโตแกรม
ฮิสโตแกรมถูกสร้างขึ้นโดยใช้ข้อมูลที่จัดกลุ่ม ช่วงของค่าโดยประมาณของตัวแปรสุ่ม (หรือช่วงของข้อมูลตัวอย่าง) จะถูกแบ่งออกเป็นระยะๆ โดยไม่คำนึงถึงกลุ่มตัวอย่าง (ไม่จำเป็นต้องเหมือนกัน) อนุญาต , , เป็นช่วงบนบรรทัด เรียกว่าช่วงการจัดกลุ่ม ให้เราแสดงด้วยจำนวนองค์ประกอบตัวอย่างที่อยู่ภายในช่วงเวลา:
| (1) |
ในแต่ละช่วงเวลาจะมีการสร้างสี่เหลี่ยมผืนผ้าซึ่งมีพื้นที่เป็นสัดส่วนกับ . พื้นที่รวมของสี่เหลี่ยมทั้งหมดต้องเท่ากับหนึ่ง อนุญาต ความยาวของช่วง. ความสูงของสี่เหลี่ยมด้านบนคือ
ผลลัพธ์ที่ได้เรียกว่าฮิสโตแกรม
ตัวอย่างที่ 2
มีซีรี่ส์รูปแบบต่างๆ (ดูตัวอย่างที่ 1):
นี่คือลอการิทึมฐานสิบ ดังนั้น เช่น เมื่อตัวอย่างเพิ่มขึ้นเป็นสองเท่า จำนวนช่วงการจัดกลุ่มจะเพิ่มขึ้น 1 โปรดทราบว่ายิ่งช่วงการจัดกลุ่มมากเท่าไรก็ยิ่งดีเท่านั้น แต่ถ้าเราใช้จำนวนช่วงเวลา เช่น ตามลำดับของ แล้วเมื่อมีการเติบโต ฮิสโตแกรมจะไม่เข้าใกล้ความหนาแน่น
ข้อความต่อไปนี้เป็นจริง:
ถ้าความหนาแน่นของการแจกแจงขององค์ประกอบตัวอย่างเป็นฟังก์ชันต่อเนื่อง ดังนั้น จึงมีลู่เข้าแบบพอยต์ในความน่าจะเป็นของฮิสโตแกรมกับความหนาแน่น
ดังนั้นการเลือกลอการิทึมจึงสมเหตุสมผล แต่ไม่ใช่ทางเลือกเดียวที่เป็นไปได้
บทสรุป
สถิติทางคณิตศาสตร์ (หรือทางทฤษฎี) ขึ้นอยู่กับวิธีการและแนวคิดของทฤษฎีความน่าจะเป็น แต่ในแง่หนึ่งสามารถแก้ปัญหาผกผันได้
หากเราสังเกตอาการของสัญญาณสองรายการ (หรือมากกว่า) พร้อม ๆ กันนั่นคือ เรามีชุดของค่าของตัวแปรสุ่มหลายตัว - เราจะพูดอะไรเกี่ยวกับการพึ่งพาพวกมันได้บ้าง? เธออยู่หรือเปล่า? และถ้ามีการพึ่งพาอาศัยกันนี้คืออะไร?
มักจะเป็นไปได้ที่จะตั้งสมมติฐานบางประการเกี่ยวกับการแจกแจงที่ซ่อนอยู่ในกล่องดำหรือเกี่ยวกับคุณสมบัติของมัน ในกรณีนี้ ตามข้อมูลการทดลอง จำเป็นต้องยืนยันหรือหักล้างสมมติฐานเหล่านี้ (“สมมติฐาน”) ต้องจำไว้ว่าคำตอบ "ใช่" หรือ "ไม่" จะต้องได้รับด้วยความมั่นใจในระดับหนึ่งเท่านั้น และยิ่งเราทำการทดลองต่อไปได้นานเท่าไร ข้อสรุปก็จะยิ่งแม่นยำมากขึ้นเท่านั้น สถานการณ์ที่ดีที่สุดสำหรับการวิจัยคือเมื่อเราสามารถยืนยันคุณสมบัติบางอย่างของการทดลองที่สังเกตได้อย่างมั่นใจ ตัวอย่างเช่น การมีอยู่ของความสัมพันธ์เชิงฟังก์ชันระหว่างปริมาณที่สังเกตได้ ความปกติของการกระจาย ความสมมาตรของมัน การมีอยู่ของความหนาแน่นในการแจกแจง หรือ ธรรมชาติที่ไม่ต่อเนื่อง ฯลฯ .
ดังนั้นจึงสมเหตุสมผลที่จะจำสถิติ (ทางคณิตศาสตร์) ถ้า
· มีการทดลองแบบสุ่มซึ่งไม่ทราบคุณสมบัติบางส่วนหรือทั้งหมด
· เราสามารถทำซ้ำการทดลองนี้ภายใต้เงื่อนไขเดียวกันเป็นจำนวนครั้ง (หรือดีกว่าก็ได้)
อ้างอิง
1. Baumol U. ทฤษฎีเศรษฐศาสตร์และการวิจัยการดำเนินงาน – ม.; วิทยาศาสตร์, 2542.
2. Bolshev L.N., Smirnov N.V. ตารางสถิติทางคณิตศาสตร์ อ.: เนากา, 2538.
3. โบรอฟคอฟ เอ.เอ. สถิติทางคณิตศาสตร์ อ.: เนากา, 1994.
4. Korn G., Korn T. คู่มือคณิตศาสตร์สำหรับนักวิทยาศาสตร์และวิศวกร. - เซนต์ปีเตอร์สเบิร์ก: สำนักพิมพ์ Lan, 2546.
5. Korshunov D.A. , Chernova N.I. รวบรวมปัญหาและแบบฝึกหัดสถิติทางคณิตศาสตร์ โนโวซีบีสค์: สำนักพิมพ์ของสถาบันคณิตศาสตร์ตั้งชื่อตาม เอส.แอล. โซโบเลฟ เอสบี ราส, 2544.
6. Peheletsky I.D. คณิตศาสตร์: หนังสือเรียนสำหรับนักเรียน - อ.: อคาเดมี่, 2546.
7. สุโขดอลสกี้ วี.จี. การบรรยายเกี่ยวกับคณิตศาสตร์ชั้นสูงสำหรับนักมานุษยวิทยา - สำนักพิมพ์เซนต์ปีเตอร์สเบิร์กแห่งมหาวิทยาลัยแห่งรัฐเซนต์ปีเตอร์สเบิร์ก 2546
8. Feller V. ทฤษฎีความน่าจะเป็นเบื้องต้นและการประยุกต์ - ม.: มีร์ ต.2, 2527.
9. Harman G. การวิเคราะห์ปัจจัยสมัยใหม่ - อ.: สถิติ, 2515.
Harman G. การวิเคราะห์ปัจจัยสมัยใหม่ - อ.: สถิติ, 2515.
 ผลกระทบของแรงกดดันต่ออัตราการเกิดปฏิกิริยาเคมี
ผลกระทบของแรงกดดันต่ออัตราการเกิดปฏิกิริยาเคมี ปฏิกิริยากระจกสีเงิน: ละลายซิลเวอร์ออกไซด์ในน้ำแอมโมเนีย
ปฏิกิริยากระจกสีเงิน: ละลายซิลเวอร์ออกไซด์ในน้ำแอมโมเนีย การแปลและความหมายของคำว่า OFF ในภาษาอังกฤษและภาษารัสเซีย การเปิดและปิดหมายถึงอะไรในภาษาอังกฤษ
การแปลและความหมายของคำว่า OFF ในภาษาอังกฤษและภาษารัสเซีย การเปิดและปิดหมายถึงอะไรในภาษาอังกฤษ