สูตรเบี่ยงเบนมาตรฐาน วิธีการคำนวณค่าเบี่ยงเบนมาตรฐาน? การกระจายตัว
ลักษณะที่สมบูรณ์แบบที่สุดของการแปรผันคือค่าเบี่ยงเบนมาตรฐาน ซึ่งเรียกว่าค่ามาตรฐาน (หรือค่าเบี่ยงเบนมาตรฐาน) ส่วนเบี่ยงเบนมาตรฐาน() เท่ากับรากที่สองของค่าเฉลี่ยกำลังสองของการเบี่ยงเบนของค่าคุณลักษณะแต่ละค่าจากค่าเฉลี่ยเลขคณิต:
ส่วนเบี่ยงเบนมาตรฐานนั้นง่าย:


ค่าเบี่ยงเบนมาตรฐานแบบถ่วงน้ำหนักจะใช้กับข้อมูลที่จัดกลุ่มไว้:

ระหว่างค่าเบี่ยงเบนกำลังสองเฉลี่ยและค่าเบี่ยงเบนเชิงเส้นเฉลี่ยภายใต้เงื่อนไขของการแจกแจงแบบปกติ ความสัมพันธ์ต่อไปนี้เกิดขึ้น: ~ 1.25
ค่าเบี่ยงเบนมาตรฐานซึ่งเป็นตัววัดความแปรปรวนแบบสัมบูรณ์หลักที่ใช้ในการกำหนดค่าของพิกัดของเส้นโค้งการแจกแจงแบบปกติในการคำนวณที่เกี่ยวข้องกับการจัดระเบียบของการสังเกตตัวอย่างและการกำหนดความถูกต้องของลักษณะตัวอย่างรวมทั้งใน การประเมินขอบเขตของการแปรผันของลักษณะเฉพาะในประชากรที่เป็นเนื้อเดียวกัน
การกระจายตัว ประเภทของมัน ส่วนเบี่ยงเบนมาตรฐาน
ความแปรปรวนของตัวแปรสุ่ม- การวัดการแพร่กระจายของตัวแปรสุ่มที่กำหนด เช่น การเบี่ยงเบนจากความคาดหวังทางคณิตศาสตร์ ในสถิติ การกำหนดหรือมักใช้ รากที่สองของความแปรปรวนเรียกว่าค่าเบี่ยงเบนมาตรฐาน ส่วนเบี่ยงเบนมาตรฐาน หรือค่าสเปรดมาตรฐาน
ผลต่างทั้งหมด (σ2) วัดความผันแปรของลักษณะเฉพาะในประชากรทั้งหมดภายใต้อิทธิพลของปัจจัยทั้งหมดที่ก่อให้เกิดการเปลี่ยนแปลงนี้ ในเวลาเดียวกัน ด้วยวิธีการจัดกลุ่ม จึงสามารถแยกและวัดความผันแปรได้เนื่องจากคุณลักษณะการจัดกลุ่ม และการแปรผันที่เกิดขึ้นภายใต้อิทธิพลของปัจจัยที่ยังไม่ได้นับ
ความแปรปรวนระหว่างกลุ่ม (σ 2 ม.ก) แสดงลักษณะการแปรผันอย่างเป็นระบบ กล่าวคือ ความแตกต่างในขนาดของลักษณะที่ศึกษาซึ่งเกิดขึ้นภายใต้อิทธิพลของลักษณะนั้น - ปัจจัยที่เป็นรากฐานของการจัดกลุ่ม
ส่วนเบี่ยงเบนมาตรฐาน(คำพ้องความหมาย: ส่วนเบี่ยงเบนมาตรฐาน, ส่วนเบี่ยงเบนมาตรฐาน, ส่วนเบี่ยงเบนมาตรฐาน; คำที่คล้ายกัน: ส่วนเบี่ยงเบนมาตรฐาน, การแพร่กระจายมาตรฐาน) - ในทฤษฎีความน่าจะเป็นและสถิติซึ่งเป็นตัวบ่งชี้ทั่วไปของการกระจายค่าของตัวแปรสุ่มที่สัมพันธ์กับความคาดหวังทางคณิตศาสตร์ ด้วยอาร์เรย์ที่จำกัดของตัวอย่างค่า แทนที่จะใช้การคาดหมายทางคณิตศาสตร์ ค่าเฉลี่ยเลขคณิตของชุดของตัวอย่างจึงถูกนำมาใช้
ค่าเบี่ยงเบนมาตรฐานถูกวัดในหน่วยของตัวแปรสุ่มและใช้ในการคำนวณความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยเลขคณิต ในการสร้างช่วงความเชื่อมั่น ในการทดสอบทางสถิติของสมมติฐาน และในการวัดความสัมพันธ์เชิงเส้นระหว่างตัวแปรสุ่ม มันถูกกำหนดให้เป็นรากที่สองของความแปรปรวนของตัวแปรสุ่ม
ส่วนเบี่ยงเบนมาตรฐาน:

ส่วนเบี่ยงเบนมาตรฐาน(การประมาณค่าเบี่ยงเบนมาตรฐานของตัวแปรสุ่ม xเทียบกับการคาดหมายทางคณิตศาสตร์โดยอิงจากการประมาณค่าความแปรปรวนอย่างเป็นกลาง):

การกระจายตัวอยู่ที่ไหน — ผมองค์ประกอบตัวอย่าง -th; - ขนาดตัวอย่าง; - ค่าเฉลี่ยเลขคณิตของกลุ่มตัวอย่าง:
![]()
ควรสังเกตว่าการประมาณการทั้งสองมีอคติ ในกรณีทั่วไป เป็นไปไม่ได้ที่จะสร้างค่าประมาณที่เป็นกลาง อย่างไรก็ตาม การประมาณการตามค่าประมาณความแปรปรวนที่ไม่เอนเอียงนั้นมีความสอดคล้องกัน
สาระสำคัญ ขอบเขต และขั้นตอนสำหรับการกำหนดโหมดและค่ามัธยฐาน
นอกเหนือจากค่าเฉลี่ยของกฎแห่งอำนาจในสถิติแล้ว สำหรับลักษณะสัมพัทธ์ของขนาดของลักษณะที่แตกต่างกันและโครงสร้างภายในของอนุกรมการแจกแจงแล้ว ค่าเฉลี่ยเชิงโครงสร้างยังถูกนำมาใช้ ซึ่งส่วนใหญ่แสดงโดย โหมดและค่ามัธยฐาน.
แฟชั่น- นี่คือตัวแปรที่พบบ่อยที่สุดของซีรีส์ แฟชั่นถูกนำมาใช้เช่นในการกำหนดขนาดของเสื้อผ้ารองเท้าซึ่งเป็นที่ต้องการมากที่สุดในหมู่ผู้ซื้อ โหมดสำหรับอนุกรมแบบไม่ต่อเนื่องเป็นตัวแปรที่มีความถี่สูงสุด เมื่อคำนวณโหมดสำหรับชุดรูปแบบช่วงเวลา ก่อนอื่นคุณต้องกำหนดช่วงโมดอล (ตามความถี่สูงสุด) จากนั้นจึงกำหนดค่าของค่าโมดอลของแอตทริบิวต์ตามสูตร:

- - มูลค่าแฟชั่น
- - ขีด จำกัด ล่างของช่วงกิริยา
- - ค่าช่วง
- - ความถี่ช่วงโมดอล
- - ความถี่ของช่วงก่อนโมดอล
- - ความถี่ของช่วงหลังโมดอล
ค่ามัธยฐาน -นี่คือคุณค่าของคุณลักษณะที่รองรับซีรีส์ที่มีการจัดอันดับและแบ่งซีรีส์นี้ออกเป็นสองส่วนเท่าๆ กัน
ในการหาค่ามัธยฐานในชุดที่ไม่ต่อเนื่องเมื่อมีความถี่ ให้คำนวณผลรวมของความถี่ก่อน แล้วจึงกำหนดค่าของตัวแปรที่ตรงกับค่านั้น (หากแถวที่จัดเรียงมีจำนวนจุดสนใจเป็นคี่ ค่ามัธยฐานจะคำนวณโดยสูตร:
M e \u003d (n (จำนวนคุณสมบัติโดยรวม) + 1) / 2,
ในกรณีที่มีจุดสนใจเป็นจำนวนคู่ ค่ามัธยฐานจะเท่ากับค่าเฉลี่ยของจุดสนใจทั้งสองที่อยู่ตรงกลางแถว)
เมื่อคำนวณ ค่ามัธยฐานสำหรับชุดค่าความผันแปรตามช่วงเวลา ขั้นแรกให้กำหนดช่วงค่ามัธยฐานของค่ามัธยฐาน จากนั้นจึงหาค่ามัธยฐานตามสูตร:

- เป็นค่ามัธยฐานที่ต้องการ
- เป็นขอบเขตล่างของช่วงที่มีค่ามัธยฐาน
- - ค่าช่วง
- - ผลรวมของความถี่หรือจำนวนสมาชิกของซีรีส์
ผลรวมของความถี่สะสมของช่วงก่อนค่ามัธยฐาน
- คือความถี่ของช่วงมัธยฐาน
ตัวอย่าง. ค้นหาโหมดและค่ามัธยฐาน
วิธีการแก้:
ในตัวอย่างนี้ ช่วงโมดอลอยู่ภายในกลุ่มอายุ 25-30 ปี เนื่องจากช่วงเวลานี้มีความถี่สูงสุด (1054)
มาคำนวณค่าโหมดกัน:
ซึ่งหมายความว่าอายุกิริยาของนักเรียนคือ 27 ปี
คำนวณค่ามัธยฐาน. ช่วงมัธยฐานอยู่ในกลุ่มอายุ 25-30 ปี เนื่องจากในช่วงเวลานี้มีตัวแปรที่แบ่งประชากรออกเป็นสองส่วนเท่าๆ กัน (Σf i /2 = 3462/2 = 1731) ต่อไป เราแทนที่ข้อมูลตัวเลขที่จำเป็นลงในสูตรและรับค่ามัธยฐาน:

ซึ่งหมายความว่าครึ่งหนึ่งของนักเรียนอายุต่ำกว่า 27.4 ปี และอีกครึ่งหนึ่งมีอายุมากกว่า 27.4 ปี
นอกจากโหมดและค่ามัธยฐานแล้ว ยังสามารถใช้ตัวชี้วัด เช่น ควอไทล์ ได้ โดยแบ่งอนุกรมที่จัดอันดับออกเป็น 4 ส่วนเท่าๆ กัน เดซิลี- 10 ส่วนและเปอร์เซ็นไทล์ - ต่อ 100 ส่วน
แนวคิดของการสังเกตแบบคัดเลือกและขอบเขต
การสังเกตแบบคัดเลือกใช้เมื่อใช้การสังเกตอย่างต่อเนื่อง เป็นไปไม่ได้ทางร่างกายเนื่องจากมีข้อมูลจำนวนมากหรือ เป็นไปไม่ได้ทางเศรษฐกิจ. ความเป็นไปไม่ได้ทางกายภาพเกิดขึ้น เช่น เมื่อศึกษากระแสผู้โดยสาร ราคาตลาด งบประมาณของครอบครัว ความไม่ถูกต้องทางเศรษฐกิจเกิดขึ้นเมื่อประเมินคุณภาพของสินค้าที่เกี่ยวข้องกับการทำลาย เช่น การชิม การทดสอบอิฐเพื่อความแข็งแรง เป็นต้น
หน่วยทางสถิติที่เลือกสำหรับการสังเกตประกอบด้วยตัวอย่างหรือกลุ่มตัวอย่าง และอาร์เรย์ทั้งหมด - ประชากรทั่วไป (GS) ในกรณีนี้ จำนวนหน่วยในตัวอย่างหมายถึง นและใน HS ทั้งหมด - นู๋. ทัศนคติ n/nเรียกว่าขนาดสัมพัทธ์หรือสัดส่วนของกลุ่มตัวอย่าง
คุณภาพของผลการสุ่มตัวอย่างขึ้นอยู่กับความเป็นตัวแทนของกลุ่มตัวอย่าง เช่น ความเป็นตัวแทนใน HS เพื่อให้แน่ใจว่าเป็นตัวแทนของตัวอย่าง จำเป็นต้องสังเกต หลักการสุ่มเลือกหน่วยซึ่งถือว่าการรวมหน่วย HS ไว้ในตัวอย่างจะไม่ได้รับอิทธิพลจากปัจจัยอื่นใดนอกจากความบังเอิญ
มีอยู่ 4 วิธีสุ่มเลือกตัวอย่าง:
- สุ่มจริงๆการเลือกหรือ "วิธีล็อตโต้" เมื่อกำหนดหมายเลขลำดับให้กับค่าทางสถิติ ให้ป้อนวัตถุบางอย่าง (เช่น ถัง) ซึ่งจะถูกผสมในภาชนะบางส่วน (เช่น ในถุง) และเลือกแบบสุ่ม ในทางปฏิบัติ วิธีนี้ใช้เครื่องกำเนิดตัวเลขสุ่มหรือตารางทางคณิตศาสตร์ของตัวเลขสุ่ม
- เครื่องกลคัดเลือกตามที่แต่ละฝ่าย ( ไม่มี) - ค่าของประชากรทั่วไป ตัวอย่างเช่น หากมีค่า 100,000 และคุณต้องการเลือก 1,000 ทุกๆ 100,000 / 1000 = 100 ค่าจะอยู่ในกลุ่มตัวอย่าง ยิ่งกว่านั้น หากพวกเขาไม่มีอันดับ อันดับแรกจะถูกสุ่มเลือกจากร้อยแรก และตัวเลขอื่นๆ จะเพิ่มเป็นร้อย ตัวอย่างเช่น หากหน่วยที่ 19 เป็นหน่วยแรก หมายเลข 119 ควรอยู่ถัดไป จากนั้นตามด้วยหมายเลข 219 ตามด้วยหมายเลข 319 เป็นต้น หากจัดอันดับหน่วยประชากร ระบบจะเลือก #50 ก่อน จากนั้นจึงเลือก #150 ตามด้วย #250 และอื่นๆ
- การเลือกค่าจากอาร์เรย์ข้อมูลที่ต่างกันจะดำเนินการ แบ่งชั้นวิธี (stratified) เมื่อประชากรทั่วไปถูกแบ่งออกเป็นกลุ่มที่เป็นเนื้อเดียวกันซึ่งใช้การคัดเลือกแบบสุ่มหรือทางกล
- วิธีการสุ่มตัวอย่างพิเศษคือ ซีเรียลการเลือก ซึ่งไม่ใช่ปริมาณส่วนบุคคลที่สุ่มเลือกหรือด้วยกลไก แต่เป็นอนุกรมของปริมาณนั้น (ลำดับจากจำนวนหนึ่งถึงบางส่วนในแถว) ซึ่งจะมีการสังเกตอย่างต่อเนื่อง
คุณภาพของการสังเกตตัวอย่างยังขึ้นอยู่กับ ประเภทการสุ่มตัวอย่าง: ซ้ำหรือ ไม่ซ้ำซากจำเจ
ที่ เลือกใหม่ค่าทางสถิติหรืออนุกรมของพวกมันที่ตกลงไปในกลุ่มตัวอย่างจะถูกส่งกลับคืนสู่ประชากรทั่วไปหลังการใช้งาน มีโอกาสที่จะได้ตัวอย่างใหม่ ในเวลาเดียวกัน ค่าทั้งหมดของประชากรทั่วไปมีความเป็นไปได้เหมือนกันที่จะรวมไว้ในกลุ่มตัวอย่าง
การเลือกที่ไม่ซ้ำหมายความว่าค่าทางสถิติหรืออนุกรมของพวกมันที่รวมอยู่ในตัวอย่างจะไม่ถูกส่งคืนไปยังประชากรทั่วไปหลังการใช้งาน ดังนั้นความน่าจะเป็นที่จะเข้าไปในกลุ่มตัวอย่างถัดไปจะเพิ่มขึ้นสำหรับค่าที่เหลือของค่าหลัง
การสุ่มตัวอย่างแบบไม่ซ้ำจะให้ผลลัพธ์ที่แม่นยำยิ่งขึ้น ดังนั้นจึงใช้บ่อยขึ้น แต่มีบางสถานการณ์ที่ไม่สามารถนำมาใช้ได้ (การศึกษาการไหลของผู้โดยสาร ความต้องการของผู้บริโภค ฯลฯ) จากนั้นจึงดำเนินการคัดเลือกใหม่
ข้อผิดพลาดเล็กน้อยของตัวอย่างการสังเกต ข้อผิดพลาดเฉลี่ยของตัวอย่าง ลำดับในการคำนวณ
ให้เราพิจารณารายละเอียดวิธีการข้างต้นในการสร้างกลุ่มตัวอย่างและข้อผิดพลาดที่เกิดขึ้นในกรณีนี้ ตัวแทน .
อันที่จริง-สุ่มตัวอย่างจะขึ้นอยู่กับการเลือกหน่วยจากประชากรทั่วไปโดยการสุ่มโดยไม่มีองค์ประกอบใด ๆ ที่สอดคล้องกัน ในทางเทคนิค การสุ่มเลือกที่เหมาะสมจะดำเนินการโดยการจับสลาก (เช่น ลอตเตอรี่) หรือโดยตารางตัวเลขสุ่ม
การเลือกแบบสุ่มที่จริงแล้ว "ในรูปแบบบริสุทธิ์" ในทางปฏิบัติของการสังเกตแบบคัดเลือกนั้นไม่ค่อยได้ใช้ แต่เป็นการเลือกประเภทแรกในการเลือกประเภทอื่น ๆ ซึ่งใช้หลักการพื้นฐานของการสังเกตแบบคัดเลือก ให้เราพิจารณาคำถามบางข้อเกี่ยวกับทฤษฎีของวิธีการสุ่มตัวอย่างและสูตรข้อผิดพลาดสำหรับตัวอย่างสุ่มอย่างง่าย
ข้อผิดพลาดในการสุ่มตัวอย่าง- นี่คือความแตกต่างระหว่างค่าพารามิเตอร์ในประชากรทั่วไป และค่าที่คำนวณจากผลการสังเกตตัวอย่าง สำหรับคุณลักษณะเชิงปริมาณเฉลี่ย ข้อผิดพลาดในการสุ่มตัวอย่างถูกกำหนดโดย
ตัวบ่งชี้นี้เรียกว่าข้อผิดพลาดในการสุ่มตัวอย่างส่วนเพิ่ม
ค่าเฉลี่ยตัวอย่างเป็นตัวแปรสุ่มที่สามารถรับค่าต่างๆ ได้ ขึ้นอยู่กับหน่วยที่อยู่ในกลุ่มตัวอย่าง ดังนั้นข้อผิดพลาดในการสุ่มตัวอย่างจึงเป็นตัวแปรสุ่มและสามารถรับค่าต่างๆ ได้ ดังนั้น กำหนดค่าเฉลี่ยของข้อผิดพลาดที่เป็นไปได้ - หมายถึงข้อผิดพลาดในการสุ่มตัวอย่างซึ่งขึ้นอยู่กับ:
ขนาดตัวอย่าง: ยิ่งตัวเลขมาก ข้อผิดพลาดเฉลี่ยก็จะยิ่งน้อยลง
ระดับการเปลี่ยนแปลงของลักษณะที่ศึกษา: ยิ่งความแปรผันของลักษณะนั้นน้อยเท่าใด และด้วยเหตุนี้ ความแปรปรวนก็ยิ่งมีข้อผิดพลาดในการสุ่มตัวอย่างเฉลี่ยน้อยลง
ที่ สุ่มเลือกใหม่คำนวณข้อผิดพลาดเฉลี่ย:
.
ในทางปฏิบัติ ไม่ทราบความแปรปรวนทั่วไปอย่างแน่นอน แต่ใน ทฤษฎีความน่าจะเป็นพิสูจน์แล้วว่า ![]() .
.
เนื่องจากค่าของ n ที่มากเพียงพอนั้นใกล้เคียงกับ 1 เราจึงสามารถสรุปได้ว่า จากนั้นสามารถคำนวณข้อผิดพลาดในการสุ่มตัวอย่างเฉลี่ยได้:
.
แต่ในกรณีตัวอย่างเล็กๆ (สำหรับ n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
ที่ การสุ่มตัวอย่างสูตรที่กำหนดได้รับการแก้ไขโดยค่า ข้อผิดพลาดเฉลี่ยของการไม่สุ่มตัวอย่างคือ:  และ
และ  .
.
เพราะ น้อยกว่าเสมอ ดังนั้นปัจจัย () จะน้อยกว่า 1 เสมอ ซึ่งหมายความว่าข้อผิดพลาดเฉลี่ยในการเลือกที่ไม่ซ้ำจะน้อยกว่าการเลือกซ้ำเสมอ
การสุ่มตัวอย่างเครื่องกลใช้เมื่อมีการเรียงลำดับประชากรทั่วไปด้วยวิธีใดวิธีหนึ่ง (เช่น รายชื่อผู้มีสิทธิเลือกตั้งตามลำดับตัวอักษร หมายเลขโทรศัพท์ หมายเลขบ้าน อพาร์ตเมนต์) การเลือกหน่วยจะดำเนินการในช่วงเวลาหนึ่ง ซึ่งเท่ากับส่วนกลับของเปอร์เซ็นต์ของกลุ่มตัวอย่าง ดังนั้น ด้วยตัวอย่าง 2% ทุก ๆ 50 หน่วย = 1 / 0.02 จะถูกเลือก โดย 5% แต่ละหน่วย 1 / 0.05 = 20 หน่วยของประชากรทั่วไป
แหล่งกำเนิดถูกเลือกด้วยวิธีต่างๆ: สุ่มจากตรงกลางของช่วงเวลาโดยมีการเปลี่ยนแปลงจุดเริ่มต้น สิ่งสำคัญคือการหลีกเลี่ยงข้อผิดพลาดอย่างเป็นระบบ ตัวอย่างเช่น กับตัวอย่าง 5% หากเลือกหน่วยที่ 13 เป็นหน่วยแรก ถัดไปจะเป็น 33, 53, 73 เป็นต้น
ในแง่ของความแม่นยำ การเลือกเชิงกลนั้นใกล้เคียงกับการสุ่มตัวอย่างที่เหมาะสม ดังนั้น ในการพิจารณาข้อผิดพลาดเฉลี่ยของการสุ่มตัวอย่างทางกล จึงใช้สูตรการเลือกแบบสุ่มที่เหมาะสม
ที่ การเลือกทั่วไป ประชากรที่สำรวจจะแบ่งออกเป็นกลุ่มเดียวที่เป็นเนื้อเดียวกันในขั้นต้น ตัวอย่างเช่น เมื่อทำการสำรวจวิสาหกิจ สิ่งเหล่านี้อาจเป็นอุตสาหกรรม ภาคย่อย ในขณะที่ศึกษาประชากร - พื้นที่ กลุ่มสังคม หรือกลุ่มอายุ จากนั้นจึงทำการเลือกอย่างอิสระจากแต่ละกลุ่มด้วยวิธีทางกลหรือแบบสุ่มที่เหมาะสม
การสุ่มตัวอย่างทั่วไปให้ผลลัพธ์ที่แม่นยำกว่าวิธีการอื่นๆ การระบุประเภทของประชากรทั่วไปช่วยให้มั่นใจถึงการเป็นตัวแทนของแต่ละกลุ่มการจัดประเภทในกลุ่มตัวอย่าง ซึ่งทำให้สามารถแยกอิทธิพลของความแปรปรวนระหว่างกลุ่มที่มีต่อข้อผิดพลาดของตัวอย่างโดยเฉลี่ยได้ ดังนั้นเมื่อพบข้อผิดพลาดของตัวอย่างทั่วไปตามกฎของการเพิ่มความแปรปรวน () จำเป็นต้องคำนึงถึงค่าเฉลี่ยของความแปรปรวนของกลุ่มเท่านั้น ข้อผิดพลาดในการสุ่มตัวอย่างเฉลี่ยคือ:
ในการคัดเลือกใหม่
,
ด้วยการเลือกที่ไม่เกิดซ้ำ  ,
,
ที่ไหน  คือค่าเฉลี่ยของความแปรปรวนภายในกลุ่มในกลุ่มตัวอย่าง
คือค่าเฉลี่ยของความแปรปรวนภายในกลุ่มในกลุ่มตัวอย่าง
การเลือกซีเรียล (หรือซ้อนกัน)
ใช้เมื่อประชากรถูกแบ่งออกเป็นชุดหรือกลุ่มก่อนเริ่มการสำรวจตัวอย่าง ชุดเหล่านี้สามารถเป็นแพคเกจของผลิตภัณฑ์สำเร็จรูป กลุ่มนักเรียน ทีม ชุดสำหรับการตรวจสอบจะถูกเลือกโดยกลไกหรือแบบสุ่ม และภายในชุดข้อมูลจะทำการสำรวจหน่วยทั้งหมด ดังนั้นข้อผิดพลาดในการสุ่มตัวอย่างโดยเฉลี่ยจึงขึ้นอยู่กับความแปรปรวนระหว่างกลุ่ม (interseries) ซึ่งคำนวณโดยสูตร: 
โดยที่ r คือจำนวนชุดที่เลือก
- ค่าเฉลี่ยของซีรีย์ i-th
คำนวณข้อผิดพลาดในการสุ่มตัวอย่างแบบอนุกรมเฉลี่ย:
เมื่อเลือกใหม่:
,
ด้วยการเลือกที่ไม่เกิดซ้ำ:  ,
,
โดยที่ R คือจำนวนชุดทั้งหมด
รวมการเลือกเป็นการผสมผสานระหว่างวิธีการคัดเลือกที่นำมาพิจารณา
ข้อผิดพลาดในการสุ่มตัวอย่างโดยเฉลี่ยสำหรับวิธีการคัดเลือกใดๆ ขึ้นอยู่กับขนาดสัมบูรณ์ของกลุ่มตัวอย่างเป็นหลักและเปอร์เซ็นต์ของตัวอย่างในระดับที่น้อยกว่า สมมติว่ามีการสังเกต 225 ครั้งในกรณีแรกจากประชากร 4,500 หน่วย และในกรณีที่สอง จาก 225,000 หน่วย ความแปรปรวนในทั้งสองกรณีมีค่าเท่ากับ 25 จากนั้น ในกรณีแรก ด้วยการเลือก 5% ข้อผิดพลาดในการสุ่มตัวอย่างจะเป็น: 
ในกรณีที่สอง ด้วยการเลือก 0.1% จะเท่ากับ:

ทางนี้เมื่อเปอร์เซ็นต์ตัวอย่างลดลง 50 เท่า ข้อผิดพลาดของตัวอย่างก็เพิ่มขึ้นเล็กน้อย เนื่องจากขนาดกลุ่มตัวอย่างไม่เปลี่ยนแปลง
สมมติว่าขนาดกลุ่มตัวอย่างเพิ่มขึ้นเป็น 625 การสังเกต ในกรณีนี้ ข้อผิดพลาดในการสุ่มตัวอย่างคือ: 
การเพิ่มตัวอย่าง 2.8 เท่าโดยมีขนาดเท่ากันของประชากรทั่วไปจะลดขนาดของข้อผิดพลาดในการสุ่มตัวอย่างลงมากกว่า 1.6 เท่า
วิธีการและวิธีการสร้างกลุ่มตัวอย่าง
ในสถิติใช้วิธีการต่างๆ ในการสร้างชุดตัวอย่าง ซึ่งกำหนดโดยวัตถุประสงค์ของการศึกษาและขึ้นอยู่กับลักษณะเฉพาะของวัตถุที่ศึกษา
เงื่อนไขหลักในการดำเนินการสำรวจตัวอย่างคือการป้องกันไม่ให้เกิดข้อผิดพลาดอย่างเป็นระบบที่เกิดจากการละเมิดหลักการของโอกาสที่เท่าเทียมกันสำหรับแต่ละหน่วยของประชากรทั่วไปที่จะเข้าสู่กลุ่มตัวอย่าง การป้องกันข้อผิดพลาดอย่างเป็นระบบเกิดขึ้นได้จากการใช้วิธีทางวิทยาศาสตร์เพื่อสร้างกลุ่มตัวอย่าง
มีวิธีต่อไปนี้ในการเลือกหน่วยจากประชากรทั่วไป:
1) การเลือกรายบุคคล - เลือกแต่ละหน่วยในตัวอย่าง
2) การเลือกกลุ่ม - กลุ่มที่เป็นเนื้อเดียวกันในเชิงคุณภาพหรือชุดของหน่วยที่ศึกษาอยู่ในกลุ่มตัวอย่าง
3) การเลือกแบบรวม คือ การเลือกแบบรายบุคคลและแบบกลุ่ม
วิธีการคัดเลือกถูกกำหนดโดยกฎสำหรับการก่อตัวของประชากรกลุ่มตัวอย่าง
ตัวอย่างสามารถ:
- สุ่มที่เหมาะสมประกอบด้วยข้อเท็จจริงที่ว่ากลุ่มตัวอย่างเกิดขึ้นจากการเลือกสุ่ม (โดยไม่ได้ตั้งใจ) ของแต่ละหน่วยจากประชากรทั่วไป ในกรณีนี้ จำนวนหน่วยที่เลือกในชุดตัวอย่างมักจะถูกกำหนดตามสัดส่วนที่ยอมรับของกลุ่มตัวอย่าง ส่วนแบ่งตัวอย่างคืออัตราส่วนของจำนวนหน่วยในกลุ่มตัวอย่าง n ต่อจำนวนหน่วยในประชากรทั่วไป N นั่นคือ
- เครื่องกลประกอบด้วยการเลือกหน่วยในตัวอย่างจากประชากรทั่วไป แบ่งเป็นช่วงๆ (กลุ่ม) เท่ากัน ในกรณีนี้ ขนาดของช่วงเวลาในประชากรทั่วไปจะเท่ากับส่วนกลับของสัดส่วนของกลุ่มตัวอย่าง ดังนั้น ด้วยตัวอย่าง 2% ทุกๆ 50 หน่วยจะถูกเลือก (1:0.02) โดยมีตัวอย่าง 5% ทุกๆ 20 หน่วย (1:0.05) เป็นต้น ดังนั้น ตามสัดส่วนที่ยอมรับได้ของการคัดเลือก ประชากรทั่วไปจึงถูกแบ่งออกเป็นกลุ่มเท่าๆ กันตามกลไกทางกลไก เลือกเพียงหนึ่งหน่วยจากแต่ละกลุ่มในตัวอย่าง
- ทั่วไป -โดยที่ประชากรทั่วไปถูกแบ่งออกเป็นกลุ่มทั่วไปที่เป็นเนื้อเดียวกันก่อน จากนั้น จากแต่ละกลุ่มทั่วไป การเลือกแต่ละหน่วยเข้าไปในตัวอย่างจะทำโดยสุ่มหรือตัวอย่างทางกล คุณลักษณะที่สำคัญของตัวอย่างทั่วไปคือให้ผลลัพธ์ที่แม่นยำกว่าเมื่อเปรียบเทียบกับวิธีการอื่นในการเลือกหน่วยในตัวอย่าง
- ซีเรียล- ซึ่งประชากรทั่วไปแบ่งออกเป็นกลุ่มที่มีขนาดเท่ากัน - แบบอนุกรม เลือกซีรีส์ในชุดตัวอย่าง ภายในซีรีส์ จะมีการสังเกตยูนิตที่ตกลงไปในซีรีส์อย่างต่อเนื่อง
- รวมกัน- การสุ่มตัวอย่างสามารถเป็นสองขั้นตอน ในกรณีนี้ ประชากรทั่วไปจะถูกแบ่งออกเป็นกลุ่มก่อน จากนั้นกลุ่มจะถูกเลือกและในช่วงหลังจะมีการเลือกแต่ละหน่วย
ในสถิติ วิธีการเลือกหน่วยในตัวอย่างมีความโดดเด่น::
- เวทีเดียวตัวอย่าง - แต่ละหน่วยที่เลือกจะต้องทำการศึกษาตามเกณฑ์ที่กำหนดทันที (อันที่จริงแล้วคือตัวอย่างแบบสุ่มและแบบอนุกรม)
- หลายขั้นตอนการสุ่มตัวอย่าง - การเลือกทำจากประชากรทั่วไปของแต่ละกลุ่ม และแต่ละหน่วยจะถูกเลือกจากกลุ่ม (ตัวอย่างทั่วไปด้วยวิธีการทางกลในการเลือกหน่วยในประชากรตัวอย่าง)
นอกจากนี้ยังมี:
- การเลือกใหม่- ตามแบบแผนของบอลคืน ในกรณีนี้ แต่ละหน่วยหรืออนุกรมที่ตกลงไปในกลุ่มตัวอย่างจะถูกส่งกลับไปยังประชากรทั่วไป ดังนั้นจึงมีโอกาสถูกรวมไว้ในกลุ่มตัวอย่างอีกครั้ง
- การเลือกไม่ซ้ำซ้อน- ตามแบบแผนของบอลไม่คืน ให้ผลลัพธ์ที่แม่นยำกว่าสำหรับขนาดตัวอย่างเดียวกัน
การกำหนดขนาดตัวอย่างที่ต้องการ (โดยใช้ตารางของนักเรียน)
หลักการทางวิทยาศาสตร์ประการหนึ่งในทฤษฎีการสุ่มตัวอย่างคือเพื่อให้แน่ใจว่ามีการเลือกหน่วยจำนวนเพียงพอ ในทางทฤษฎี ความจำเป็นในการปฏิบัติตามหลักการนี้ถูกนำเสนอในการพิสูจน์ทฤษฎีบทขีดจำกัดของทฤษฎีความน่าจะเป็น ซึ่งทำให้คุณสามารถกำหนดจำนวนหน่วยที่ควรเลือกจากประชากรทั่วไป เพื่อให้เพียงพอและรับรองความเป็นตัวแทนของกลุ่มตัวอย่าง
ข้อผิดพลาดมาตรฐานที่ลดลงของตัวอย่าง และดังนั้น การเพิ่มขึ้นของความแม่นยำของการประมาณการจึงสัมพันธ์กับการเพิ่มขนาดตัวอย่างเสมอ ดังนั้น ในขั้นตอนการจัดกลุ่มตัวอย่างจึงจำเป็นต้องตัดสินใจ ขนาดกลุ่มตัวอย่างควรมีขนาดเท่าใดเพื่อให้แน่ใจว่าผลการสังเกตมีความแม่นยำตามที่ต้องการ การคำนวณขนาดตัวอย่างที่ต้องการสร้างขึ้นโดยใช้สูตรที่ได้จากสูตรสำหรับข้อผิดพลาดในการสุ่มตัวอย่างส่วนเพิ่ม (A) ซึ่งสอดคล้องกับประเภทและวิธีการคัดเลือกอย่างใดอย่างหนึ่งหรืออย่างอื่น ดังนั้น สำหรับขนาดตัวอย่างซ้ำแบบสุ่ม (n) เรามี:

สาระสำคัญของสูตรนี้คือด้วยการเลือกจำนวนที่ต้องการใหม่แบบสุ่ม ขนาดกลุ่มตัวอย่างจะเป็นสัดส่วนโดยตรงกับกำลังสองของสัมประสิทธิ์ความเชื่อมั่น (t2)และความแปรปรวนของคุณลักษณะความแปรผัน (?2) และแปรผกผันกับกำลังสองของความคลาดเคลื่อนในการสุ่มตัวอย่างส่วนขอบ (?2) โดยเฉพาะอย่างยิ่ง การเพิ่มข้อผิดพลาดขอบเป็นสองเท่า ขนาดตัวอย่างที่ต้องการสามารถลดลงได้เป็นสี่เท่า จากพารามิเตอร์สามตัว ผู้วิจัยเป็นผู้กำหนดสองตัว (t และ?)
ขณะเดียวกัน ผู้วิจัยสำหรับวัตถุประสงค์ของการสำรวจตัวอย่าง คำถามควรจะตัดสินใจ: การรวมพารามิเตอร์เหล่านี้ในเชิงปริมาณจะดีกว่าอย่างไรเพื่อให้ได้ตัวแปรที่เหมาะสมที่สุด ในกรณีหนึ่ง เขาอาจจะพอใจกับความน่าเชื่อถือของผลลัพธ์ที่ได้ (t) มากกว่าการวัดความถูกต้อง (?) ในอีกทางหนึ่ง - ในทางกลับกัน เป็นการยากที่จะแก้ไขปัญหาเกี่ยวกับมูลค่าของข้อผิดพลาดในการสุ่มตัวอย่างส่วนขอบ เนื่องจากผู้วิจัยไม่มีตัวบ่งชี้นี้ในขั้นตอนการออกแบบการสังเกตตัวอย่าง ดังนั้น ในทางปฏิบัติ จึงเป็นธรรมเนียมที่จะต้องตั้งค่าข้อผิดพลาดในการสุ่มตัวอย่างส่วนขอบ เช่น กฎ ภายใน 10% ของระดับเฉลี่ยที่คาดไว้ของลักษณะ การกำหนดระดับเฉลี่ยที่สมมติขึ้นสามารถทำได้หลายวิธี: ใช้ข้อมูลจากการสำรวจก่อนหน้านี้ที่คล้ายคลึงกัน หรือใช้ข้อมูลจากกรอบการสุ่มตัวอย่างและการเก็บตัวอย่างนำร่องขนาดเล็ก
สิ่งที่ยากที่สุดในการกำหนดเมื่อออกแบบการสังเกตตัวอย่างคือพารามิเตอร์ที่สามในสูตร (5.2) - ความแปรปรวนของประชากรกลุ่มตัวอย่าง ในกรณีนี้ จำเป็นต้องใช้ข้อมูลทั้งหมดที่มีให้ผู้วิจัย ซึ่งได้มาจากการสำรวจที่คล้ายคลึงกันและการสำรวจนำร่องครั้งก่อน
คำถามคำจำกัดความขนาดกลุ่มตัวอย่างที่ต้องการจะซับซ้อนมากขึ้นหากการสำรวจตัวอย่างเกี่ยวข้องกับการศึกษาคุณลักษณะต่างๆ ของหน่วยสุ่มตัวอย่าง ในกรณีนี้ ระดับเฉลี่ยของลักษณะเฉพาะแต่ละอย่างและความผันแปรของมันตามกฎแล้วจะแตกต่างกัน ดังนั้นจึงเป็นไปได้ที่จะตัดสินใจว่าการกระจายตัวใดของลักษณะเฉพาะที่จะให้ความสำคัญกับการพิจารณาเฉพาะวัตถุประสงค์และวัตถุประสงค์ของ การสำรวจ.
เมื่อออกแบบการสังเกตตัวอย่าง ค่าที่กำหนดไว้ล่วงหน้าของข้อผิดพลาดในการสุ่มตัวอย่างที่อนุญาตจะถือว่าสอดคล้องกับวัตถุประสงค์ของการศึกษาเฉพาะและความน่าจะเป็นของข้อสรุปตามผลการสังเกต
โดยทั่วไป สูตรสำหรับข้อผิดพลาดส่วนเพิ่มของค่าเฉลี่ยตัวอย่างช่วยให้คุณกำหนดได้ดังนี้
ขนาดของความเบี่ยงเบนที่เป็นไปได้ของตัวบ่งชี้ของประชากรทั่วไปจากตัวชี้วัดของประชากรตัวอย่าง
ขนาดตัวอย่างที่ต้องการ ให้ความแม่นยำตามที่ต้องการ ซึ่งขีดจำกัดของข้อผิดพลาดที่เป็นไปได้ไม่เกินค่าที่ระบุ
ความน่าจะเป็นที่ข้อผิดพลาดในกลุ่มตัวอย่างจะมีขีดจำกัดที่กำหนด
การกระจายตัวของนักเรียนในทฤษฎีความน่าจะเป็น มันเป็นแฟมิลีหนึ่งพารามิเตอร์ของการแจกแจงแบบต่อเนื่องแน่นอน
ชุดของไดนามิก (ช่วงเวลา โมเมนต์) ปิดชุดไดนามิก
ชุดของไดนามิก- นี่คือค่าของตัวบ่งชี้ทางสถิติที่แสดงตามลำดับเวลาที่แน่นอน
อนุกรมเวลาแต่ละชุดประกอบด้วยสององค์ประกอบ:
1) ตัวชี้วัดของช่วงเวลา (ปี, ไตรมาส, เดือน, วันหรือวันที่);
2) ตัวชี้วัดที่กำหนดลักษณะของวัตถุที่ศึกษาสำหรับช่วงเวลาหรือตามวันที่ที่เกี่ยวข้องซึ่งเรียกว่าระดับของอนุกรม
แสดงระดับของซีรีส์ทั้งค่าสัมบูรณ์และค่าเฉลี่ยหรือค่าสัมพัทธ์ ขึ้นอยู่กับลักษณะของตัวบ่งชี้ ชุดไดนามิกของค่าสัมบูรณ์ ค่าสัมพัทธ์ และค่าเฉลี่ยจะถูกสร้างขึ้น ชุดไดนามิกของค่าสัมพัทธ์และค่าเฉลี่ยถูกสร้างขึ้นบนพื้นฐานของอนุกรมอนุพันธ์ของค่าสัมบูรณ์ มีไดนามิกแบบช่วงเวลาและโมเมนต์
ชุดช่วงไดนามิกมีค่าของตัวบ่งชี้สำหรับช่วงเวลาหนึ่ง ในชุดช่วงเวลา สามารถสรุประดับได้ รับปริมาตรของปรากฏการณ์เป็นระยะเวลานานขึ้น หรือยอดรวมที่เรียกว่าสะสม
ซีรีส์โมเมนต์ไดนามิกสะท้อนถึงค่าของตัวบ่งชี้ ณ จุดใดเวลาหนึ่ง (วันที่ของเวลา) ในชุดปัจจุบัน ผู้วิจัยอาจสนใจเฉพาะความแตกต่างของปรากฏการณ์ ซึ่งสะท้อนถึงการเปลี่ยนแปลงในระดับของชุดข้อมูลระหว่างวันที่กำหนด เนื่องจากผลรวมของระดับที่นี่ไม่มีเนื้อหาจริง ผลรวมสะสมจะไม่ถูกคำนวณที่นี่
เงื่อนไขที่สำคัญที่สุดสำหรับการสร้างซีรีย์ไดนามิกที่ถูกต้องคือการเปรียบเทียบระดับของซีรีย์ที่เกี่ยวข้องกับช่วงเวลาต่างๆ ควรนำเสนอระดับในปริมาณที่เป็นเนื้อเดียวกันควรมีความครบถ้วนสมบูรณ์ของการครอบคลุมส่วนต่าง ๆ ของปรากฏการณ์
ถึงเพื่อหลีกเลี่ยงการบิดเบือนของไดนามิกที่แท้จริง การคำนวณเบื้องต้นจะดำเนินการในการศึกษาทางสถิติ (การปิดของอนุกรมเวลา) ซึ่งนำหน้าการวิเคราะห์ทางสถิติของอนุกรมเวลา การปิดอนุกรมเวลาเป็นที่เข้าใจกันว่าเป็นการรวมกันระหว่างอนุกรมเวลาตั้งแต่สองชุดขึ้นไปเป็นอนุกรมเดียว โดยระดับของอนุกรมเวลาจะคำนวณตามวิธีการที่แตกต่างกันหรือไม่สอดคล้องกับขอบเขตอาณาเขต ฯลฯ การปิดชุดของไดนามิกอาจหมายถึงการลดระดับสัมบูรณ์ของชุดไดนามิกให้เป็นพื้นฐานทั่วไป ซึ่งขจัดความไม่ลงรอยกันของระดับของชุดไดนามิก
แนวคิดในการเปรียบเทียบอนุกรมเวลา สัมประสิทธิ์ อัตราการเติบโตและอัตราการเติบโต
ชุดของไดนามิก- เหล่านี้เป็นชุดของตัวชี้วัดทางสถิติที่แสดงถึงพัฒนาการของปรากฏการณ์ทางธรรมชาติและทางสังคมในเวลา คอลเลกชันทางสถิติที่เผยแพร่โดยคณะกรรมการสถิติแห่งรัฐของรัสเซียมีอนุกรมเวลาจำนวนมากในรูปแบบตาราง ชุดไดนามิกช่วยให้สามารถเปิดเผยรูปแบบการพัฒนาปรากฏการณ์ที่ศึกษาได้
อนุกรมเวลาประกอบด้วยตัวบ่งชี้สองประเภท ตัวบ่งชี้เวลา(ปี ไตรมาส เดือน เป็นต้น) หรือจุดในช่วงเวลา (ต้นปี ต้นเดือน เป็นต้น) ตัวบ่งชี้ระดับแถว. ตัวบ่งชี้ระดับของอนุกรมเวลาสามารถแสดงเป็นค่าสัมบูรณ์ (การผลิตผลิตภัณฑ์เป็นตันหรือรูเบิล) ค่าสัมพัทธ์ (ส่วนแบ่งของประชากรในเมืองเป็น%) และค่าเฉลี่ย (ค่าจ้างเฉลี่ยของคนงานในอุตสาหกรรม ตามปี เป็นต้น) ในรูปแบบตาราง อนุกรมเวลาประกอบด้วยสองคอลัมน์หรือสองแถว
การสร้างอนุกรมเวลาที่ถูกต้องเกี่ยวข้องกับการปฏิบัติตามข้อกำหนดหลายประการ:
- ตัวชี้วัดทั้งหมดของชุดไดนามิกต้องได้รับการพิสูจน์ทางวิทยาศาสตร์และเชื่อถือได้
- ตัวบ่งชี้ของชุดไดนามิกควรเทียบเคียงได้ทันเวลา กล่าวคือ ต้องคำนวณในช่วงเวลาเดียวกันหรือในวันเดียวกัน
- ตัวบ่งชี้ของพลวัตจำนวนหนึ่งควรเปรียบเทียบได้ทั่วทั้งอาณาเขต
- ตัวชี้วัดของชุดไดนามิกควรเทียบเคียงได้ในเนื้อหา กล่าวคือ คำนวณตามวิธีการเดียวในลักษณะเดียวกัน
- ตัวชี้วัดของชุดพลวัตควรเปรียบเทียบได้ในทุกช่วงของฟาร์มที่พิจารณา ตัวบ่งชี้ทั้งหมดของชุดไดนามิกควรกำหนดไว้ในหน่วยวัดเดียวกัน
ตัวชี้วัดทางสถิติสามารถกำหนดลักษณะของผลลัพธ์ของกระบวนการภายใต้การศึกษาในช่วงเวลาหนึ่ง หรือสถานะของปรากฏการณ์ที่กำลังศึกษา ณ จุดใดเวลาหนึ่ง กล่าวคือ ตัวบ่งชี้สามารถเป็นช่วง (เป็นระยะ) และทันที ดังนั้น ในตอนแรก ชุดของไดนามิกอาจเป็นช่วงเวลาหรือช่วงเวลาก็ได้ ในทางกลับกัน อนุกรมโมเมนต์ของไดนามิกสามารถมีช่วงเวลาที่เท่ากันและไม่เท่ากัน
ชุดไดนามิกเริ่มต้นสามารถแปลงเป็นชุดของค่าเฉลี่ยและชุดของค่าสัมพัทธ์ (ห่วงโซ่และฐาน) อนุกรมเวลาดังกล่าวเรียกว่าอนุกรมเวลาที่ได้รับ
วิธีการคำนวณระดับเฉลี่ยในชุดไดนามิกนั้นแตกต่างกัน เนื่องจากประเภทของชุดไดนามิก ใช้ตัวอย่าง พิจารณาประเภทของอนุกรมเวลาและสูตรในการคำนวณระดับเฉลี่ย
กำไรแน่นอน (Δy) แสดงจำนวนหน่วยที่เปลี่ยนแปลงในระดับที่ตามมาของซีรีส์เมื่อเปรียบเทียบกับระดับก่อนหน้า (คอลัมน์ 3 - การเพิ่มขึ้นแบบสัมบูรณ์แบบลูกโซ่) หรือเปรียบเทียบกับระดับเริ่มต้น (คอลัมน์ 4 - การเพิ่มขึ้นแบบสัมบูรณ์พื้นฐาน) สูตรการคำนวณสามารถเขียนได้ดังนี้:

ด้วยการลดลงของค่าสัมบูรณ์ของซีรีส์จะมี "ลดลง", "ลดลง" ตามลำดับ
ตัวบ่งชี้ของการเติบโตอย่างสมบูรณ์ระบุว่า ตัวอย่างเช่น ในปี 1998 การผลิตผลิตภัณฑ์ "A" เพิ่มขึ้น 4,000 ตันเมื่อเทียบกับปี 1997 และ 34,000 ตันเมื่อเทียบกับปี 1994 ปีอื่นๆ ดูตาราง 11.5 กรัม 3 และ 4
ปัจจัยการเจริญเติบโตแสดงจำนวนครั้งที่ระดับของซีรีส์เปลี่ยนแปลงไปเมื่อเทียบกับระดับก่อนหน้า (คอลัมน์ 5 - ปัจจัยการเติบโตหรือการลดลงของลูกโซ่) หรือเปรียบเทียบกับระดับเริ่มต้น (คอลัมน์ 6 - ปัจจัยการเติบโตพื้นฐานหรือลดลง) สูตรการคำนวณสามารถเขียนได้ดังนี้:

อัตราการเติบโตแสดงจำนวนเปอร์เซ็นต์ของระดับถัดไปของซีรีส์เมื่อเปรียบเทียบกับระดับก่อนหน้า (คอลัมน์ 7 - อัตราการเติบโตของลูกโซ่) หรือเปรียบเทียบกับระดับเริ่มต้น (คอลัมน์ 8 - อัตราการเติบโตพื้นฐาน) สูตรการคำนวณสามารถเขียนได้ดังนี้:

ตัวอย่างเช่น ในปี 1997 ปริมาณการผลิตผลิตภัณฑ์ "A" เมื่อเทียบกับปี 1996 คือ 105.5% (
อัตราการเจริญเติบโตแสดงว่าระดับของรอบระยะเวลาการรายงานเพิ่มขึ้นกี่เปอร์เซ็นต์เมื่อเทียบกับช่วงก่อนหน้า (คอลัมน์ 9 - อัตราการเติบโตของลูกโซ่) หรือเปรียบเทียบกับระดับเริ่มต้น (คอลัมน์ 10 - อัตราการเติบโตพื้นฐาน) สูตรการคำนวณสามารถเขียนได้ดังนี้:
T pr \u003d T p - 100% หรือ T pr \u003d การเพิ่มขึ้น / ระดับที่แน่นอนของช่วงเวลาก่อนหน้า * 100%
ตัวอย่างเช่น ในปี 1996 เมื่อเทียบกับปี 1995 ผลิตภัณฑ์ "A" ผลิตได้มากกว่า 3.8% (103.8% - 100%) หรือ (8:210) x 100% และเมื่อเทียบกับปี 1994 - 9% ( 109% - 100%).
หากระดับสัมบูรณ์ในชุดลดลง อัตราจะน้อยกว่า 100% และตามนั้น จะมีอัตราการลดลง (อัตราการเติบโตพร้อมเครื่องหมายลบ)
ค่าสัมบูรณ์เพิ่มขึ้น 1%(คอลัมน์ที่ 11) แสดงจำนวนหน่วยที่ต้องผลิตในช่วงเวลาที่กำหนด เพื่อให้ระดับของช่วงก่อนหน้าเพิ่มขึ้น 1% ในตัวอย่างของเราในปี 1995 จำเป็นต้องผลิต 2.0 พันตันและในปี 1998 - 2.3 พันตันเช่น ใหญ่กว่ามาก
มีสองวิธีในการกำหนดขนาดของค่าสัมบูรณ์ของการเติบโต 1%:
แบ่งระดับของช่วงเวลาก่อนหน้าด้วย 100;
แบ่งอัตราการเติบโตแบบสัมบูรณ์ของลูกโซ่ตามอัตราการเติบโตของลูกโซ่ที่สอดคล้องกัน
ค่าสัมบูรณ์เพิ่มขึ้น 1% = 
ในพลวัตโดยเฉพาะอย่างยิ่งในช่วงเวลาที่ยาวนาน สิ่งสำคัญคือต้องร่วมกันวิเคราะห์อัตราการเติบโตกับเนื้อหาของแต่ละเปอร์เซ็นต์ที่เพิ่มขึ้นหรือลดลง
โปรดทราบว่าวิธีการที่พิจารณาแล้วสำหรับการวิเคราะห์อนุกรมเวลานั้นสามารถใช้ได้ทั้งอนุกรมเวลา ระดับที่แสดงเป็นค่าสัมบูรณ์ (t, พันรูเบิล, จำนวนพนักงาน, ฯลฯ ) และสำหรับอนุกรมเวลา ระดับของ ซึ่งแสดงในตัวบ่งชี้สัมพัทธ์ (% ของเศษ , % ปริมาณเถ้าถ่านหิน ฯลฯ ) หรือค่าเฉลี่ย (ผลผลิตเฉลี่ยใน c/ha ค่าจ้างเฉลี่ย ฯลฯ )
นอกจากตัวชี้วัดเชิงวิเคราะห์ที่พิจารณาแล้วซึ่งคำนวณในแต่ละปีโดยเปรียบเทียบกับระดับก่อนหน้าหรือระดับเริ่มต้น เมื่อวิเคราะห์อนุกรมเวลา จำเป็นต้องคำนวณตัวชี้วัดเชิงวิเคราะห์เฉลี่ยสำหรับช่วงเวลา: ระดับเฉลี่ยของชุดข้อมูล การเพิ่มขึ้นแบบสัมบูรณ์ประจำปีโดยเฉลี่ย (ลดลง) และอัตราการเติบโตเฉลี่ยต่อปีและอัตราการเติบโต
วิธีการคำนวณระดับเฉลี่ยของชุดไดนามิกถูกกล่าวถึงข้างต้น ในชุดช่วงของไดนามิกที่เรากำลังพิจารณา ระดับเฉลี่ยของอนุกรมนั้นคำนวณโดยสูตรของค่าเฉลี่ยเลขคณิตอย่างง่าย:
ผลผลิตเฉลี่ยต่อปีของผลิตภัณฑ์สำหรับปี 2537-2541 จำนวน 218.4 พันตัน
การเพิ่มขึ้นแบบสัมบูรณ์เฉลี่ยต่อปียังคำนวณโดยสูตรของค่าเฉลี่ยเลขคณิตอย่างง่าย:
การเพิ่มขึ้นอย่างสัมบูรณ์ประจำปีแตกต่างกันไปในแต่ละปีตั้งแต่ 4 ถึง 12,000 ตัน (ดูกลุ่มที่ 3) และการผลิตที่เพิ่มขึ้นโดยเฉลี่ยต่อปีสำหรับช่วงปี 2538 - 2541 จำนวน 8.5 พันตัน
วิธีการคำนวณอัตราการเติบโตเฉลี่ยและอัตราการเติบโตเฉลี่ยต้องพิจารณาอย่างละเอียดมากขึ้น ลองพิจารณาจากตัวอย่างของตัวบ่งชี้ประจำปีของระดับอนุกรมที่ระบุในตาราง
ระดับกลางของช่วงไดนามิก
อนุกรมของไดนามิก (หรืออนุกรมเวลา)- ค่าเหล่านี้เป็นค่าตัวเลขของตัวบ่งชี้ทางสถิติในช่วงเวลาหรือช่วงเวลาต่อเนื่องกัน (เช่น จัดเรียงตามลำดับเวลา)
ค่าตัวเลขของตัวบ่งชี้ทางสถิติเฉพาะที่ประกอบขึ้นเป็นชุดของไดนามิกเรียกว่า ระดับของตัวเลขและมักจะเขียนแทนด้วยตัวอักษร y. สมาชิกคนแรกของซีรีส์ ปี1เรียกว่าเริ่มต้นหรือ พื้นฐานและสุดท้าย y n - สุดท้าย. ช่วงเวลาหรือช่วงเวลาที่ระดับอ้างอิงแสดงโดย t.
ตามกฎแล้วซีรีย์ไดนามิกจะถูกนำเสนอในรูปแบบของตารางหรือกราฟและมาตราส่วนเวลาถูกสร้างขึ้นตามแกน x t, และตามพิกัด - มาตราส่วนของระดับของซีรีส์ y.
ตัวชี้วัดเฉลี่ยของชุดไดนามิก
ไดนามิกแต่ละชุดถือได้ว่าเป็นชุดที่แน่นอน นตัวบ่งชี้ที่ผันแปรตามเวลาที่สามารถสรุปได้เป็นค่าเฉลี่ย ตัวชี้วัดทั่วไป (เฉลี่ย) ดังกล่าวมีความจำเป็นอย่างยิ่งเมื่อเปรียบเทียบการเปลี่ยนแปลงของตัวบ่งชี้หนึ่งหรือตัวอื่นในช่วงเวลาที่ต่างกัน ในประเทศต่างๆ เป็นต้น
ลักษณะทั่วไปของชุดไดนามิกสามารถเป็นได้ อย่างแรกเลย ระดับแถวเฉลี่ย. วิธีการคำนวณระดับเฉลี่ยขึ้นอยู่กับว่าเป็นอนุกรมช่วงเวลาหรือช่วงเวลา (จุด)
เมื่อไร ช่วงเวลาอนุกรม ระดับเฉลี่ยของมันถูกกำหนดโดยสูตรของค่าเฉลี่ยเลขคณิตอย่างง่ายของระดับของอนุกรม กล่าวคือ
=
ถ้ามี ช่วงเวลาแถวที่มี นระดับ ( y1, y2, …, น) ด้วยช่วงเวลาเท่ากันระหว่างวันที่ (จุดของเวลา) จากนั้นชุดดังกล่าวสามารถแปลงเป็นชุดของค่าเฉลี่ยได้อย่างง่ายดาย ในเวลาเดียวกัน ตัวบ่งชี้ (ระดับ) ที่จุดเริ่มต้นของแต่ละช่วงเวลาจะเป็นตัวบ่งชี้พร้อมกันเมื่อสิ้นสุดช่วงเวลาก่อนหน้า จากนั้นค่าเฉลี่ยของตัวบ่งชี้สำหรับแต่ละช่วงเวลา (ช่วงเวลาระหว่างวันที่) สามารถคำนวณเป็นผลรวมของค่าได้ครึ่งหนึ่ง ที่ในตอนต้นและปลายงวด กล่าวคือ อย่างไร . จำนวนเฉลี่ยดังกล่าวจะเป็น ดังที่กล่าวไว้ก่อนหน้านี้ สำหรับชุดของค่าเฉลี่ย ระดับเฉลี่ยคำนวณจากค่าเฉลี่ยเลขคณิต
ดังนั้น เราสามารถเขียนได้ว่า .
.
หลังจากแปลงตัวเศษเราได้รับ: ,
,
ที่ไหน Y1และ Yn- ระดับแรกและระดับสุดท้ายของซีรีส์ ยี่- ระดับกลาง
ค่าเฉลี่ยนี้เป็นที่รู้จักในสถิติว่า ลำดับเวลาเฉลี่ยสำหรับชุดช่วงเวลา เธอได้รับชื่อนี้จากคำว่า "cronos" (เวลา, lat.) เนื่องจากคำนวณจากตัวบ่งชี้ที่เปลี่ยนแปลงตลอดเวลา
กรณีไม่เท่ากันช่วงเวลาระหว่างวันที่ ค่าเฉลี่ยตามลำดับเวลาสำหรับชุดช่วงเวลาสามารถคำนวณเป็นค่าเฉลี่ยเลขคณิตของค่าเฉลี่ยของระดับสำหรับช่วงเวลาแต่ละคู่ โดยถ่วงน้ำหนักด้วยระยะทาง (ช่วงเวลา) ระหว่างวันที่ เช่น  .
.
ในกรณีนี้สันนิษฐานว่าในช่วงเวลาระหว่างวันที่ ระดับต่าง ๆ ใช้ค่าต่าง ๆ และเรามาจากสองที่รู้จักกัน ( ยี่และ ยี่+1) เรากำหนดค่าเฉลี่ย จากนั้นเราจะคำนวณค่าเฉลี่ยโดยรวมสำหรับช่วงเวลาที่วิเคราะห์ทั้งหมด
ถ้าสมมุติว่าแต่ละค่า ยี่ยังคงไม่เปลี่ยนแปลงจนกว่าจะถึงครั้งต่อไป (ผม+ 1)-
วินาทีนั้น กล่าวคือ ทราบวันที่ที่แน่นอนของการเปลี่ยนแปลงในระดับ จากนั้นการคำนวณสามารถทำได้โดยใช้สูตรค่าเฉลี่ยเลขคณิตถ่วงน้ำหนัก:
,
ช่วงเวลาที่ระดับยังคงไม่เปลี่ยนแปลงคือที่ไหน
นอกจากระดับเฉลี่ยในชุดไดนามิกแล้ว ตัวชี้วัดเฉลี่ยอื่นๆ ยังคำนวณด้วย - การเปลี่ยนแปลงโดยเฉลี่ยในระดับของซีรีส์ (วิธีพื้นฐานและแบบลูกโซ่) อัตราการเปลี่ยนแปลงเฉลี่ย
เส้นฐาน หมายถึง การเปลี่ยนแปลงอย่างสัมบูรณ์คือผลหารของการเปลี่ยนแปลงสัมบูรณ์พื้นฐานครั้งสุดท้ายหารด้วยจำนวนการเปลี่ยนแปลง นั่นคือ
ห่วงโซ่หมายถึงการเปลี่ยนแปลงแน่นอน ระดับของอนุกรมคือผลหารของการหารผลรวมของการเปลี่ยนแปลงสัมบูรณ์ของสายโซ่ทั้งหมดด้วยจำนวนการเปลี่ยนแปลง กล่าวคือ
จากสัญญาณของการเปลี่ยนแปลงสัมบูรณ์โดยเฉลี่ย ธรรมชาติของการเปลี่ยนแปลงในปรากฏการณ์นี้จะถูกตัดสินโดยเฉลี่ยเช่นกัน: การเติบโต การเสื่อมถอย หรือความมั่นคง
จากกฎสำหรับการควบคุมการเปลี่ยนแปลงแบบพื้นฐานและแบบสัมบูรณ์แบบลูกโซ่ การเปลี่ยนแปลงแบบพื้นฐานและแบบลูกโซ่ต้องเท่ากัน
นอกเหนือจากการเปลี่ยนแปลงสัมบูรณ์โดยเฉลี่ยแล้ว ค่าเฉลี่ยสัมพัทธ์ยังคำนวณโดยใช้วิธีพื้นฐานและแบบลูกโซ่
การเปลี่ยนแปลงสัมพัทธ์เฉลี่ยพื้นฐานถูกกำหนดโดยสูตร:
เชนหมายถึงการเปลี่ยนแปลงสัมพัทธ์ถูกกำหนดโดยสูตร:
โดยธรรมชาติแล้ว การเปลี่ยนแปลงสัมพัทธ์โดยเฉลี่ยแบบพื้นฐานและแบบลูกโซ่ควรเหมือนกัน และเมื่อเปรียบเทียบกับค่าเกณฑ์ที่ 1 แล้ว จะมีการสรุปเกี่ยวกับธรรมชาติของการเปลี่ยนแปลงของปรากฏการณ์โดยเฉลี่ย ได้แก่ การเติบโต การลดลง หรือความเสถียร
โดยการลบ 1 จากการเปลี่ยนแปลงสัมพัทธ์ของค่าเฉลี่ยฐานหรือลูกโซ่ ค่าที่สอดคล้องกัน อัตราการเปลี่ยนแปลงเฉลี่ยโดยสัญญาณที่เราสามารถตัดสินธรรมชาติของการเปลี่ยนแปลงในปรากฏการณ์ที่กำลังศึกษาอยู่ ซึ่งสะท้อนจากไดนามิกชุดนี้
ความผันผวนตามฤดูกาลและดัชนีฤดูกาล
ความผันผวนตามฤดูกาลมีความผันผวนระหว่างปีที่มั่นคง
หลักการพื้นฐานของการจัดการเพื่อให้ได้ผลสูงสุดคือการเพิ่มรายได้สูงสุดและการลดต้นทุนให้เหลือน้อยที่สุด จากการศึกษาความผันผวนตามฤดูกาล จะแก้ปัญหาสมการสูงสุดในแต่ละระดับของปีได้
เมื่อศึกษาความผันผวนตามฤดูกาล จะมีการแก้ไขงานที่เกี่ยวข้องกันสองงาน:
1. การระบุลักษณะเฉพาะของการพัฒนาปรากฏการณ์ในพลวัตภายในปี
2. การวัดความผันผวนตามฤดูกาลด้วยการสร้างแบบจำลองคลื่นตามฤดูกาล
ไก่งวงตามฤดูกาลมักจะนับเพื่อวัดฤดูกาล โดยทั่วไป พวกมันถูกกำหนดโดยอัตราส่วนของสมการดั้งเดิมของชุดไดนามิกต่อสมการเชิงทฤษฎีที่ใช้เป็นพื้นฐานสำหรับการเปรียบเทียบ
เนื่องจากความเบี่ยงเบนแบบสุ่มถูกซ้อนทับบนความผันผวนตามฤดูกาล ดัชนีตามฤดูกาลจึงถูกเฉลี่ยเพื่อกำจัดค่าเหล่านี้
ในกรณีนี้ สำหรับแต่ละรอบระยะเวลาของรอบประจำปี ตัวชี้วัดทั่วไปจะถูกกำหนดในรูปแบบของดัชนีเฉลี่ยตามฤดูกาล:
ดัชนีเฉลี่ยของความผันผวนตามฤดูกาลนั้นปราศจากอิทธิพลของการเบี่ยงเบนแบบสุ่มของแนวโน้มการพัฒนาหลัก
ขึ้นอยู่กับลักษณะของแนวโน้ม สูตรสำหรับดัชนีฤดูกาลเฉลี่ยสามารถอยู่ในรูปแบบต่อไปนี้:
1.สำหรับชุดของไดนามิกระหว่างปีพร้อมแนวโน้มการพัฒนาหลักที่เด่นชัด:
2. สำหรับชุดของไดนามิกระหว่างปีซึ่งไม่มีแนวโน้มขึ้นหรือลง หรือไม่มีนัยสำคัญ:
ค่าเฉลี่ยทั่วไปอยู่ที่ไหน
วิธีการวิเคราะห์แนวโน้มหลัก
การพัฒนาของปรากฏการณ์เมื่อเวลาผ่านไปได้รับอิทธิพลจากปัจจัยที่แตกต่างกันในธรรมชาติและความแข็งแกร่งของอิทธิพล บางส่วนมีลักษณะสุ่ม บางส่วนมีผลเกือบคงที่และสร้างแนวโน้มการพัฒนาบางอย่างในชุดของไดนามิก
งานที่สำคัญของสถิติคือการระบุแนวโน้มในชุดของไดนามิกที่เป็นอิสระจากการกระทำของปัจจัยสุ่มต่างๆ เพื่อจุดประสงค์นี้ อนุกรมเวลาจะได้รับการประมวลผลโดยวิธีการขยายช่วงเวลา ค่าเฉลี่ยเคลื่อนที่ และการจัดตำแหน่งเชิงวิเคราะห์ เป็นต้น
วิธีการหยาบแบบช่วงเวลาขึ้นอยู่กับการขยายช่วงเวลาซึ่งรวมถึงระดับของชุดไดนามิกเช่น เป็นการแทนที่ข้อมูลที่เกี่ยวข้องกับช่วงเวลาเล็ก ๆ ด้วยข้อมูลจากช่วงเวลาที่ใหญ่กว่า จะมีผลอย่างยิ่งเมื่อระดับเริ่มต้นของชุดข้อมูลเป็นช่วงเวลาสั้นๆ ตัวอย่างเช่น ชุดของตัวบ่งชี้ที่เกี่ยวข้องกับเหตุการณ์รายวันจะถูกแทนที่ด้วยชุดที่เกี่ยวข้องกับรายสัปดาห์ รายเดือน ฯลฯ จะแสดงให้เห็นชัดเจนขึ้น "แกนของการพัฒนาปรากฏการณ์". ค่าเฉลี่ยซึ่งคำนวณจากช่วงเวลาที่ขยายใหญ่ขึ้นทำให้สามารถระบุทิศทางและลักษณะ (การเร่งความเร็วหรือการชะลอตัว) ของแนวโน้มการพัฒนาหลักได้
วิธีค่าเฉลี่ยเคลื่อนที่คล้ายกับระดับก่อนหน้า แต่ในกรณีนี้ ระดับจริงจะถูกแทนที่ด้วยระดับเฉลี่ยที่คำนวณสำหรับช่วงขยายที่ขยายใหญ่ขึ้นเรื่อยๆ ที่เคลื่อนที่ต่อเนื่อง (เลื่อน) มระดับแถว
ตัวอย่างเช่นถ้ารับ ม=3,จากนั้นขั้นแรกให้คำนวณค่าเฉลี่ยของสามระดับแรกของซีรีส์จากนั้น - จากจำนวนระดับเดียวกัน แต่เริ่มจากระดับที่สองในแถวจากนั้น - เริ่มจากระดับที่สาม ฯลฯ ดังนั้นค่าเฉลี่ยตามที่เป็น "สไลด์" ตามชุดของไดนามิกเคลื่อนที่เป็นระยะเวลาหนึ่ง คำนวณจาก มสมาชิกของเส้นค่าเฉลี่ยเคลื่อนที่หมายถึงจุดกึ่งกลาง (ศูนย์กลาง) ของแต่ละช่วง
วิธีนี้ช่วยขจัดความผันผวนแบบสุ่มเท่านั้น หากซีรีส์มีเวฟตามฤดูกาล ซีรีส์จะยังคงอยู่หลังจากปรับให้เรียบโดยวิธีค่าเฉลี่ยเคลื่อนที่
การจัดตำแหน่งเชิงวิเคราะห์ เพื่อขจัดความผันผวนแบบสุ่มและระบุแนวโน้ม ระดับของชุดข้อมูลจะถูกจัดแนวตามสูตรการวิเคราะห์ (หรือการจัดตำแหน่งเชิงวิเคราะห์) สาระสำคัญของมันคือการเปลี่ยนระดับเชิงประจักษ์ (ของจริง) ด้วยระดับเชิงทฤษฎี ซึ่งคำนวณตามสมการหนึ่ง ซึ่งถือเป็นแบบจำลองทางคณิตศาสตร์ของแนวโน้ม โดยที่ระดับทฤษฎีถือเป็นฟังก์ชันของเวลา: . ในกรณีนี้ แต่ละระดับที่แท้จริงถือเป็นผลรวมของสององค์ประกอบ: โดยที่องค์ประกอบที่เป็นระบบและแสดงโดยสมการหนึ่งๆ และเป็นตัวแปรสุ่มที่ทำให้เกิดความผันผวนรอบแนวโน้ม
งานของการจัดตำแหน่งเชิงวิเคราะห์มีดังนี้:
1. การพิจารณาบนพื้นฐานของข้อมูลจริง ประเภทของฟังก์ชันสมมุติฐานที่สามารถสะท้อนแนวโน้มการพัฒนาของตัวบ่งชี้ที่อยู่ระหว่างการศึกษาได้อย่างเหมาะสมที่สุด
2. ค้นหาพารามิเตอร์ของฟังก์ชันที่ระบุ (สมการ) จากข้อมูลเชิงประจักษ์
3. การคำนวณตามสมการที่พบของระดับทฤษฎี (ระดับ)
การเลือกฟังก์ชั่นเฉพาะจะดำเนินการตามกฎบนพื้นฐานของการแสดงกราฟิกของข้อมูลเชิงประจักษ์
ตัวแบบคือสมการถดถอยซึ่งพารามิเตอร์คำนวณโดยวิธีกำลังสองน้อยที่สุด
ด้านล่างนี้คือสมการถดถอยที่ใช้บ่อยที่สุดสำหรับอนุกรมเวลาปรับระดับ ซึ่งบ่งชี้ว่าแนวโน้มการพัฒนาใดเหมาะสมที่สุดสำหรับการสะท้อน
ในการหาพารามิเตอร์ของสมการข้างต้น มีอัลกอริธึมพิเศษและโปรแกรมคอมพิวเตอร์ โดยเฉพาะอย่างยิ่ง ในการหาพารามิเตอร์ของสมการของเส้นตรง สามารถใช้อัลกอริทึมต่อไปนี้ได้:

หากกำหนดหมายเลขช่วงเวลาหรือช่วงเวลาเพื่อให้ได้ St = 0 อัลกอริธึมข้างต้นจะถูกทำให้ง่ายขึ้นอย่างมากและกลายเป็น

ระดับที่อยู่ในแนวเดียวกันบนแผนภูมิจะอยู่บนเส้นตรงเส้นเดียวที่ผ่านในระยะที่ใกล้เคียงที่สุดจากระดับจริงของชุดข้อมูลแบบไดนามิกนี้ ผลรวมของการเบี่ยงเบนกำลังสองเป็นผลสะท้อนของอิทธิพลของปัจจัยสุ่ม
ด้วยความช่วยเหลือของมัน เราคำนวณค่าเฉลี่ยข้อผิดพลาด (มาตรฐาน) ของสมการ:

โดยที่ n คือจำนวนการสังเกต และ m คือจำนวนพารามิเตอร์ในสมการ (เรามีสองตัวคือ b 1 และ b 0)
แนวโน้มหลัก (แนวโน้ม) แสดงให้เห็นว่าปัจจัยที่เป็นระบบส่งผลต่อระดับของชุดไดนามิกอย่างไร และความผันผวนของระดับรอบแนวโน้ม () ทำหน้าที่เป็นตัววัดผลกระทบของปัจจัยที่เหลือ
เพื่อประเมินคุณภาพของแบบจำลองอนุกรมเวลาที่ใช้ก็ใช้เช่นกัน การทดสอบ F ของฟิชเชอร์. มันคืออัตราส่วนของสองความแปรปรวน กล่าวคือ อัตราส่วนของความแปรปรวนที่เกิดจากการถดถอย กล่าวคือ ปัจจัยที่ศึกษาถึงการกระจายตัวที่เกิดจากสาเหตุแบบสุ่มคือ ผลต่างที่เหลือ:
![]()
ในรูปแบบขยาย สูตรสำหรับเกณฑ์นี้สามารถแสดงได้ดังนี้:
![]()
โดยที่ n คือจำนวนการสังเกตเช่น จำนวนระดับแถว
m คือจำนวนพารามิเตอร์ในสมการ y คือระดับที่แท้จริงของอนุกรม
ระดับแนวเดียวกันของแถว - ระดับเฉลี่ยของแถว
ประสบความสำเร็จมากกว่ารุ่นอื่นๆ โมเดลอาจไม่เป็นที่พอใจเสมอไป มันสามารถรับรู้ได้ก็ต่อเมื่อเกณฑ์ F สำหรับมันข้ามขีด จำกัด วิกฤตบางอย่าง ขอบเขตนี้ถูกกำหนดโดยใช้ตารางการกระจาย F
สาระสำคัญและการจำแนกดัชนี
ดัชนีทางสถิติเป็นที่เข้าใจกันว่าเป็นตัวบ่งชี้สัมพัทธ์ที่แสดงถึงการเปลี่ยนแปลงในขนาดของปรากฏการณ์ในเวลา พื้นที่ หรือเมื่อเปรียบเทียบกับมาตรฐานใดๆ
องค์ประกอบหลักของความสัมพันธ์ของดัชนีคือค่าที่จัดทำดัชนี ค่าดัชนีเป็นที่เข้าใจกันว่าเป็นค่าของเครื่องหมายของประชากรทางสถิติ ซึ่งการเปลี่ยนแปลงนั้นเป็นเป้าหมายของการศึกษา
ดัชนีมีจุดประสงค์หลักสามประการ:
1) การประเมินการเปลี่ยนแปลงในปรากฏการณ์ที่ซับซ้อน
2) การกำหนดอิทธิพลของแต่ละปัจจัยต่อการเปลี่ยนแปลงของปรากฏการณ์ที่ซับซ้อน
3) การเปรียบเทียบขนาดของปรากฏการณ์บางอย่างกับขนาดของช่วงเวลาที่ผ่านมา ขนาดของอาณาเขตอื่น ตลอดจนมาตรฐาน แผนงาน การพยากรณ์
ดัชนีแบ่งตามเกณฑ์ 3 ประการ:
2) ตามระดับความครอบคลุมขององค์ประกอบของประชากร
3) โดยวิธีการคำนวณดัชนีทั่วไป
ตามเนื้อหาของค่าดัชนี ดัชนีจะแบ่งออกเป็นดัชนีของตัวชี้วัดเชิงปริมาณ (เชิงปริมาตร) และดัชนีของตัวชี้วัดเชิงคุณภาพ ดัชนีของตัวชี้วัดเชิงปริมาณ - ดัชนีของปริมาณทางกายภาพของการผลิตภาคอุตสาหกรรม ปริมาณการขายจริง จำนวน ฯลฯ ดัชนีของตัวชี้วัดเชิงคุณภาพ - ดัชนีราคา ต้นทุน ประสิทธิภาพแรงงาน ค่าจ้างเฉลี่ย ฯลฯ
ตามระดับความครอบคลุมของหน่วยประชากร ดัชนีจะแบ่งออกเป็นสองประเภท: บุคคลและทั่วไป เพื่ออธิบายลักษณะเหล่านี้ เราขอแนะนำอนุสัญญาต่อไปนี้ที่นำมาใช้ในการใช้วิธีดัชนี:
q- ปริมาณ (ปริมาณ) ของผลิตภัณฑ์ใด ๆ ในประเภท ; R- ราคาต่อหน่วยของการผลิต z- ต้นทุนต่อหน่วยการผลิต t- เวลาที่ใช้ในการผลิตหน่วยของผลผลิต (ความเข้มแรงงาน) ; w- ผลผลิตในแง่มูลค่าต่อหน่วยเวลา วี- ผลลัพธ์ในรูปกายภาพต่อหน่วยเวลา ตู่- เวลาที่ใช้ไปทั้งหมดหรือจำนวนพนักงาน
ในการแยกแยะว่าค่าดัชนีเป็นของช่วงเวลาหรือวัตถุใด เป็นเรื่องปกติที่จะใส่ตัวห้อยหลังสัญลักษณ์ที่เกี่ยวข้องที่ด้านล่างขวา ตัวอย่างเช่นในดัชนีของไดนามิกตามกฎสำหรับช่วงเวลาที่เปรียบเทียบ (ปัจจุบันการรายงาน) ตัวห้อย 1 ถูกใช้และสำหรับช่วงเวลาที่ทำการเปรียบเทียบ
ดัชนีรายบุคคลทำหน้าที่กำหนดลักษณะการเปลี่ยนแปลงในแต่ละองค์ประกอบของปรากฏการณ์ที่ซับซ้อน (เช่น การเปลี่ยนแปลงในปริมาณของผลผลิตของผลิตภัณฑ์ประเภทหนึ่ง) พวกเขาเป็นตัวแทนของค่าสัมพัทธ์ของพลวัต, การปฏิบัติตามภาระผูกพัน, การเปรียบเทียบค่าที่จัดทำดัชนี
กำหนดดัชนีแต่ละรายการของปริมาณทางกายภาพของการผลิต
จากมุมมองเชิงวิเคราะห์ ดัชนีไดนามิกแต่ละตัวจะคล้ายกับค่าสัมประสิทธิ์ (อัตรา) ของการเติบโตและกำหนดลักษณะการเปลี่ยนแปลงของค่าดัชนีในช่วงเวลาปัจจุบันเมื่อเทียบกับค่าฐาน กล่าวคือ แสดงจำนวนที่เพิ่มขึ้น (ลดลง) ) หรือเติบโตได้กี่เปอร์เซ็นต์ (ลดลง) ค่าดัชนีจะแสดงเป็นค่าสัมประสิทธิ์หรือเปอร์เซ็นต์
ดัชนีทั่วไป (คอมโพสิต)สะท้อนให้เห็นถึงการเปลี่ยนแปลงในทุกองค์ประกอบของปรากฏการณ์ที่ซับซ้อน
ดัชนีรวมเป็นรูปแบบพื้นฐานของดัชนี เรียกว่าผลรวมเพราะตัวเศษและตัวส่วนเป็นชุดของ "ผลรวม"
ดัชนีเฉลี่ย คำจำกัดความ
นอกจากดัชนีรวมแล้ว สถิติยังใช้รูปแบบอื่นในสถิติ นั่นคือดัชนีถัวเฉลี่ยถ่วงน้ำหนัก การคำนวณของพวกเขาจะใช้เมื่อข้อมูลที่มีอยู่ไม่อนุญาตให้คำนวณดัชนีรวมทั่วไป ดังนั้นหากไม่มีข้อมูลเกี่ยวกับราคา แต่มีข้อมูลเกี่ยวกับต้นทุนของผลิตภัณฑ์ในช่วงเวลาปัจจุบันและทราบดัชนีราคาแต่ละรายการสำหรับแต่ละผลิตภัณฑ์แล้วดัชนีราคาทั่วไปไม่สามารถกำหนดเป็นแบบรวมได้ แต่เป็นไปได้ เพื่อคำนวณเป็นค่าเฉลี่ยของแต่ละคน ในทำนองเดียวกัน หากไม่ทราบปริมาณของผลิตภัณฑ์แต่ละรายการที่ผลิต แต่ทราบดัชนีแต่ละรายการและต้นทุนการผลิตในช่วงเวลาพื้นฐาน ดัชนีโดยรวมของปริมาณการผลิตทางกายภาพสามารถกำหนดเป็นค่าเฉลี่ยถ่วงน้ำหนักได้
ดัชนีเฉลี่ย -นี่คือดัชนีที่คำนวณเป็นค่าเฉลี่ยของแต่ละดัชนี ดัชนีรวมเป็นรูปแบบพื้นฐานของดัชนีทั่วไป ดังนั้นดัชนีเฉลี่ยต้องเหมือนกันกับดัชนีรวม ในการคำนวณดัชนีเฉลี่ย จะใช้ค่าเฉลี่ยสองรูปแบบ: เลขคณิตและฮาร์มอนิก
ดัชนีค่าเฉลี่ยเลขคณิตจะเหมือนกันกับดัชนีรวม ถ้าน้ำหนักของดัชนีแต่ละตัวเป็นเงื่อนไขของตัวส่วนของดัชนีรวม เฉพาะในกรณีนี้ ค่าของดัชนีที่คำนวณโดยสูตรค่าเฉลี่ยเลขคณิตจะเท่ากับดัชนีรวม
มันถูกกำหนดให้เป็นลักษณะทั่วไปของขนาดของการเปลี่ยนแปลงของลักษณะในผลรวม มันเท่ากับรากที่สองของกำลังสองเฉลี่ยของการเบี่ยงเบนของค่าแต่ละค่าของคุณลักษณะจากค่าเฉลี่ยเลขคณิตเช่น รากของและสามารถพบได้ดังนี้:
1. สำหรับแถวหลัก:
2. สำหรับชุดรูปแบบต่างๆ:

การแปลงสูตรส่วนเบี่ยงเบนมาตรฐานนำไปสู่รูปแบบที่สะดวกยิ่งขึ้นสำหรับการคำนวณเชิงปฏิบัติ:
ส่วนเบี่ยงเบนมาตรฐานกำหนดว่าโดยเฉลี่ยแล้ว ตัวเลือกที่เฉพาะเจาะจงเบี่ยงเบนไปจากค่าเฉลี่ยของตัวเลือกนั้นๆ มากน้อยเพียงใด นอกจากนั้น ยังเป็นตัววัดที่แน่นอนของความผันผวนของลักษณะและแสดงเป็นหน่วยเดียวกับตัวเลือก ดังนั้นจึงตีความได้ดี
ตัวอย่างการหาค่าเบี่ยงเบนมาตรฐาน: ,
สำหรับคุณสมบัติทางเลือก สูตรสำหรับส่วนเบี่ยงเบนมาตรฐานจะมีลักษณะดังนี้:
![]()
โดยที่ p คือสัดส่วนของหน่วยในประชากรที่มีคุณสมบัติบางอย่าง
q - สัดส่วนของหน่วยที่ไม่มีคุณสมบัตินี้
แนวคิดของค่าเบี่ยงเบนเชิงเส้นเฉลี่ย
ส่วนเบี่ยงเบนเชิงเส้นเฉลี่ยถูกกำหนดให้เป็นค่าเฉลี่ยเลขคณิตของค่าสัมบูรณ์ของการเบี่ยงเบนของตัวเลือกแต่ละรายการจาก .
1. สำหรับแถวหลัก:

2. สำหรับชุดรูปแบบต่างๆ:
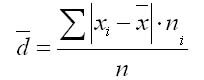
โดยที่ผลรวมของ n คือ ผลรวมของความถี่ของอนุกรมความแปรผัน.
ตัวอย่างการหาค่าเบี่ยงเบนเชิงเส้นเฉลี่ย:
ข้อได้เปรียบของค่าเบี่ยงเบนสัมบูรณ์เฉลี่ยในการวัดการกระจายตัวในช่วงของการเปลี่ยนแปลงนั้นชัดเจน เนื่องจากการวัดนี้พิจารณาจากการพิจารณาความเบี่ยงเบนที่เป็นไปได้ทั้งหมด แต่ตัวบ่งชี้นี้มีข้อเสียที่สำคัญ การปฏิเสธโดยพลการของสัญญาณพีชคณิตของการเบี่ยงเบนสามารถนำไปสู่ความจริงที่ว่าคุณสมบัติทางคณิตศาสตร์ของตัวบ่งชี้นี้อยู่ไกลจากระดับประถมศึกษา สิ่งนี้ซับซ้อนอย่างมากในการใช้ค่าเบี่ยงเบนสัมบูรณ์เฉลี่ยในการแก้ปัญหาที่เกี่ยวข้องกับการคำนวณความน่าจะเป็น
ดังนั้น ค่าเบี่ยงเบนเชิงเส้นเฉลี่ยที่เป็นตัววัดความแปรผันของจุดสนใจจึงไม่ค่อยได้ใช้ในการปฏิบัติทางสถิติ กล่าวคือ เมื่อผลรวมของตัวชี้วัดโดยไม่คำนึงถึงเครื่องหมายย่อมสมเหตุสมผลทางเศรษฐศาสตร์ ด้วยความช่วยเหลือเช่นการวิเคราะห์การหมุนเวียนของการค้าต่างประเทศองค์ประกอบของพนักงานจังหวะการผลิต ฯลฯ
รูตหมายถึงกำลังสอง
ใช้ RMS แล้วตัวอย่างเช่น ในการคำนวณขนาดเฉลี่ยของด้านข้างของส่วน n สี่เหลี่ยม เส้นผ่านศูนย์กลางเฉลี่ยของลำต้น ท่อ ฯลฯ แบ่งออกเป็นสองประเภท
ค่าเฉลี่ยรูตกำลังสองนั้นง่าย หากเมื่อแทนที่ค่าแต่ละค่าของคุณลักษณะด้วยค่าเฉลี่ย จำเป็นต้องรักษาผลรวมของกำลังสองของค่าดั้งเดิมไว้ไม่เปลี่ยนแปลง ค่าเฉลี่ยจะเป็นค่าเฉลี่ยกำลังสอง
เป็นรากที่สองของผลบวกของผลรวมกำลังสองของค่าคุณลักษณะแต่ละรายการหารด้วยจำนวน:
ค่าเฉลี่ยกำลังสองคำนวณโดยสูตร:

โดยที่ f คือเครื่องหมายของน้ำหนัก
ลูกบาศก์เฉลี่ย
ใช้ลูกบาศก์เฉลี่ยตัวอย่างเช่น เมื่อกำหนดความยาวด้านเฉลี่ยและลูกบาศก์ แบ่งออกเป็นสองประเภท
ลูกบาศก์เฉลี่ยง่าย:


เมื่อคำนวณค่าเฉลี่ยและการกระจายในชุดการกระจายช่วงเวลา ค่าที่แท้จริงของแอตทริบิวต์จะถูกแทนที่ด้วยค่ากลางของช่วงเวลาซึ่งแตกต่างจากค่าเฉลี่ยเลขคณิตของค่าที่รวมอยู่ใน ช่วงเวลา สิ่งนี้นำไปสู่ข้อผิดพลาดอย่างเป็นระบบในการคำนวณความแปรปรวน วี.เอฟ. เชพเพิร์ดตัดสินใจว่า ข้อผิดพลาดในการคำนวณผลต่างที่เกิดจากการนำข้อมูลที่จัดกลุ่มไปใช้ คือ 1/12 ของกำลังสองของค่าช่วง ทั้งขึ้นและลงตามขนาดของความแปรปรวน
การแก้ไข Sheppardควรใช้หากการแจกแจงใกล้เคียงกับปกติ หมายถึงคุณลักษณะที่มีลักษณะผันแปรอย่างต่อเนื่อง ซึ่งสร้างขึ้นจากข้อมูลเริ่มต้นจำนวนมาก (n> 500) อย่างไรก็ตาม จากข้อเท็จจริงที่ว่าในหลายกรณี ทั้งข้อผิดพลาด การกระทำในทิศทางที่ต่างกัน ชดเชยซึ่งกันและกัน บางครั้งจึงเป็นไปได้ที่จะปฏิเสธที่จะแนะนำการแก้ไข
ยิ่งความแปรปรวนและค่าเบี่ยงเบนมาตรฐานน้อยเท่าใด ประชากรก็จะยิ่งมีความเหมือนกันมากขึ้นเท่านั้น และค่าเฉลี่ยก็จะยิ่งเป็นแบบทั่วไปมากขึ้น
ในทางปฏิบัติของสถิติ มักจะจำเป็นต้องเปรียบเทียบความผันแปรของคุณลักษณะต่างๆ ตัวอย่างเช่น เป็นเรื่องที่น่าสนใจอย่างยิ่งที่จะเปรียบเทียบความแตกต่างในด้านอายุของคนงานและคุณสมบัติ ระยะเวลาในการให้บริการและค่าจ้าง ต้นทุนและผลกำไร ระยะเวลาในการให้บริการและผลิตภาพแรงงาน เป็นต้น สำหรับการเปรียบเทียบดังกล่าว ตัวบ่งชี้ของความแปรปรวนสัมบูรณ์ของลักษณะเฉพาะไม่เหมาะสม: เป็นไปไม่ได้ที่จะเปรียบเทียบความแปรปรวนของประสบการณ์การทำงานที่แสดงเป็นปีด้วยการเปลี่ยนแปลงของค่าจ้างที่แสดงเป็นรูเบิล
ในการดำเนินการเปรียบเทียบดังกล่าว เช่นเดียวกับการเปรียบเทียบความผันผวนของแอตทริบิวต์เดียวกันในกลุ่มประชากรหลายกลุ่มที่มีค่าเฉลี่ยเลขคณิตต่างกัน จะใช้ตัวบ่งชี้สัมพัทธ์ของการแปรผัน - ค่าสัมประสิทธิ์การแปรผัน
ค่าเฉลี่ยโครงสร้าง
เพื่อกำหนดลักษณะแนวโน้มศูนย์กลางในการแจกแจงทางสถิติ มักจะใช้เหตุผลร่วมกับค่าเฉลี่ยเลขคณิต ค่าบางอย่างของแอตทริบิวต์ X ซึ่งเนื่องจากคุณลักษณะบางอย่างของตำแหน่งในชุดการแจกจ่าย สามารถกำหนดลักษณะระดับได้
นี่เป็นสิ่งสำคัญอย่างยิ่งเมื่อค่าสุดขีดของคุณลักษณะในชุดการแจกจ่ายมีขอบเขตที่คลุมเครือ ในเรื่องนี้การกำหนดค่าเฉลี่ยเลขคณิตที่แน่นอนเป็นไปไม่ได้หรือยากมาก ในกรณีดังกล่าว ระดับเฉลี่ยสามารถกำหนดได้โดยใช้ ตัวอย่างเช่น ค่าคุณลักษณะที่อยู่ตรงกลางของชุดความถี่หรือที่เกิดขึ้นบ่อยที่สุดในชุดข้อมูลปัจจุบัน
ค่าดังกล่าวขึ้นอยู่กับลักษณะของความถี่เท่านั้น เช่น โครงสร้างการกระจาย เป็นเรื่องปกติในแง่ของตำแหน่งในชุดความถี่ ดังนั้นค่าดังกล่าวถือเป็นลักษณะของศูนย์กระจายสินค้าและถูกกำหนดให้เป็นค่าเฉลี่ยเชิงโครงสร้าง ใช้เพื่อศึกษาโครงสร้างภายในและโครงสร้างของชุดการกระจายค่าแอตทริบิวต์ ตัวชี้วัดเหล่านี้ได้แก่
ส่วนเบี่ยงเบนมาตรฐานเป็นตัวบ่งชี้คลาสสิกของความแปรปรวนจากสถิติเชิงพรรณนา
ส่วนเบี่ยงเบนมาตรฐาน, ค่าเบี่ยงเบนมาตรฐาน, RMS, ค่าเบี่ยงเบนมาตรฐานตัวอย่าง (ค่าเบี่ยงเบนมาตรฐานภาษาอังกฤษ, STD, STDev) เป็นการวัดการกระจายตัวในสถิติเชิงพรรณนาทั่วไป แต่เพราะว่า การวิเคราะห์ทางเทคนิคคล้ายกับสถิติ ตัวบ่งชี้นี้สามารถ (และควร) ใช้ในการวิเคราะห์ทางเทคนิคเพื่อตรวจจับระดับการกระจายตัวของราคาของเครื่องมือที่วิเคราะห์เมื่อเวลาผ่านไป แสดงโดยสัญลักษณ์กรีกซิกมา "σ"
ขอบคุณ Karl Gauss และ Pearson สำหรับข้อเท็จจริงที่ว่าเรามีโอกาสที่จะใช้ค่าเบี่ยงเบนมาตรฐาน
โดยใช้ ส่วนเบี่ยงเบนมาตรฐานในการวิเคราะห์ทางเทคนิค, เราเปลี่ยนสิ่งนี้ "ดัชนีกระเจิง" ใน "ตัวบ่งชี้ความผันผวน“รักษาความหมายแต่เปลี่ยนเงื่อนไข
ค่าเบี่ยงเบนมาตรฐานคืออะไร
แต่นอกเหนือจากการคำนวณเสริมระดับกลางแล้ว ส่วนเบี่ยงเบนมาตรฐานเป็นที่ยอมรับสำหรับการคำนวณด้วยตนเองและการประยุกต์ใช้ในการวิเคราะห์ทางเทคนิค ตามที่ระบุไว้โดยผู้อ่านนิตยสารหญ้าเจ้าชู้ของเราอย่างแข็งขัน “ ฉันยังไม่เข้าใจว่าทำไม RMS ไม่รวมอยู่ในชุดตัวบ่งชี้มาตรฐานของศูนย์ซื้อขายในประเทศ«.
จริงๆ, ส่วนเบี่ยงเบนมาตรฐานสามารถวัดความแปรปรวนของเครื่องมือในแบบคลาสสิกและ "บริสุทธิ์" ได้. แต่น่าเสียดายที่ตัวบ่งชี้นี้ไม่ธรรมดาในการวิเคราะห์หลักทรัพย์
การใช้ค่าเบี่ยงเบนมาตรฐาน
การคำนวณค่าเบี่ยงเบนมาตรฐานด้วยตนเองนั้นไม่น่าสนใจนักแต่เป็นประโยชน์สำหรับประสบการณ์ ค่าเบี่ยงเบนมาตรฐานสามารถแสดงได้สูตร STD=√[(∑(x-x ) 2)/n] ซึ่งฟังดูเหมือนผลรวมรากของผลต่างกำลังสองระหว่างรายการตัวอย่างและค่าเฉลี่ย หารด้วยจำนวนรายการในตัวอย่าง
หากจำนวนขององค์ประกอบในกลุ่มตัวอย่างเกิน 30 ตัวส่วนของเศษส่วนภายใต้รูทจะใช้ค่า n-1 มิฉะนั้นจะใช้ n
เป็นขั้นเป็นตอน การคำนวณค่าเบี่ยงเบนมาตรฐาน:
- คำนวณค่าเฉลี่ยเลขคณิตของตัวอย่างข้อมูล
- ลบค่าเฉลี่ยนี้ออกจากแต่ละองค์ประกอบของกลุ่มตัวอย่าง
- ผลต่างที่ได้ทั้งหมดจะถูกยกกำลังสอง
- รวมสี่เหลี่ยมผลลัพธ์ทั้งหมด
- หารผลรวมที่เป็นผลลัพธ์ด้วยจำนวนขององค์ประกอบในกลุ่มตัวอย่าง (หรือโดย n-1 ถ้า n>30)
- คำนวณรากที่สองของผลหารที่ได้ (เรียกว่า การกระจายตัว)
ในการคำนวณค่าเฉลี่ยเรขาคณิตอย่างง่าย ใช้สูตร:
เรขาคณิตถ่วงน้ำหนัก
ในการกำหนดค่าเฉลี่ยถ่วงน้ำหนักทางเรขาคณิต จะใช้สูตร:
เส้นผ่านศูนย์กลางเฉลี่ยของล้อ ท่อ ด้านเฉลี่ยของสี่เหลี่ยมจัตุรัส กำหนดโดยใช้ค่ากลางของรูท
ค่า RMS ใช้ในการคำนวณอินดิเคเตอร์บางตัว เช่น ค่าสัมประสิทธิ์การแปรผัน ซึ่งกำหนดลักษณะจังหวะของเอาต์พุต ที่นี่ค่าเบี่ยงเบนมาตรฐานจากผลลัพธ์ที่วางแผนไว้สำหรับช่วงเวลาหนึ่งถูกกำหนดโดยสูตรต่อไปนี้:
ค่าเหล่านี้แสดงลักษณะการเปลี่ยนแปลงของตัวบ่งชี้ทางเศรษฐกิจได้อย่างแม่นยำเมื่อเปรียบเทียบกับมูลค่าพื้นฐานโดยพิจารณาจากค่าเฉลี่ย
สมการกำลังสองอย่างง่าย
ค่าเฉลี่ยกำลังสองง่ายคำนวณโดยสูตร:

ถ่วงน้ำหนักกำลังสอง
ค่าเฉลี่ยรากถ่วงน้ำหนักกำลังสองคือ:

22. การวัดความแปรผันที่แน่นอนรวมถึง:
ช่วงของการเปลี่ยนแปลง
ค่าเฉลี่ยความเบี่ยงเบนเชิงเส้น
การกระจายตัว
ส่วนเบี่ยงเบนมาตรฐาน
ช่วงของการเปลี่ยนแปลง (r)
รูปแบบช่วงคือความแตกต่างระหว่างค่าสูงสุดและต่ำสุดของแอตทริบิวต์
มันแสดงให้เห็นขีดจำกัดที่ค่าของแอตทริบิวต์เปลี่ยนแปลงในประชากรที่ศึกษา
ประสบการณ์การทำงานของผู้สมัคร 5 คนในงานก่อนหน้านี้คือ 2,3,4,7 และ 9 ปี วิธีแก้ไข: ช่วงของการเปลี่ยนแปลง = 9 - 2 = 7 ปี
สำหรับลักษณะทั่วไปของความแตกต่างในค่าของแอตทริบิวต์ ตัวบ่งชี้ความแปรปรวนเฉลี่ยจะคำนวณตามค่าเผื่อการเบี่ยงเบนจากค่าเฉลี่ยเลขคณิต ความแตกต่างถือเป็นส่วนเบี่ยงเบนจากค่าเฉลี่ย
ในเวลาเดียวกัน เพื่อหลีกเลี่ยงผลรวมของการเบี่ยงเบนของตัวเลือกคุณลักษณะจากค่าเฉลี่ยให้เป็นศูนย์ (คุณสมบัติศูนย์ของค่าเฉลี่ย) เราต้องละเลยสัญญาณของการเบี่ยงเบน นั่นคือ ใช้ผลรวมโมดูโล หรือยกกำลังสองค่าเบี่ยงเบน
ค่าเฉลี่ยส่วนเบี่ยงเบนเชิงเส้นและกำลังสอง
ส่วนเบี่ยงเบนเชิงเส้นเฉลี่ยคือค่าเฉลี่ยเลขคณิตของค่าเบี่ยงเบนสัมบูรณ์ของค่าแต่ละค่าของแอตทริบิวต์จากค่าเฉลี่ย
ส่วนเบี่ยงเบนเชิงเส้นเฉลี่ยนั้นง่าย:
ประสบการณ์การทำงานของผู้สมัคร 5 คนในงานก่อนหน้านี้คือ 2,3,4,7 และ 9 ปี
ในตัวอย่างของเรา: ปี;
ตอบ 2.4 ปี
น้ำหนักเบี่ยงเบนเชิงเส้นเฉลี่ยถ่วงน้ำหนักนำไปใช้กับข้อมูลที่จัดกลุ่ม:
ค่าเบี่ยงเบนเชิงเส้นเฉลี่ยตามธรรมเนียมปฏิบัตินั้นค่อนข้างหายากในทางปฏิบัติ (โดยเฉพาะเพื่อกำหนดลักษณะการปฏิบัติตามข้อผูกพันตามสัญญาในแง่ของความสม่ำเสมอของการส่งมอบในการวิเคราะห์คุณภาพของผลิตภัณฑ์โดยคำนึงถึงคุณสมบัติทางเทคโนโลยีของการผลิต ).
ส่วนเบี่ยงเบนมาตรฐาน
ลักษณะที่สมบูรณ์แบบที่สุดของการแปรผันคือค่าเบี่ยงเบนมาตรฐาน ซึ่งเรียกว่าค่ามาตรฐาน (หรือค่าเบี่ยงเบนมาตรฐาน) ส่วนเบี่ยงเบนมาตรฐาน() เท่ากับรากที่สองของค่าเฉลี่ยกำลังสองของการเบี่ยงเบนของค่าแต่ละค่าของคุณลักษณะจากค่าเฉลี่ยเลขคณิต:
ส่วนเบี่ยงเบนมาตรฐานนั้นง่าย:


ค่าเบี่ยงเบนมาตรฐานแบบถ่วงน้ำหนักจะใช้กับข้อมูลที่จัดกลุ่มไว้:

ระหว่างค่าเบี่ยงเบนกำลังสองเฉลี่ยและค่าเบี่ยงเบนเชิงเส้นเฉลี่ยภายใต้เงื่อนไขของการแจกแจงแบบปกติ ความสัมพันธ์ต่อไปนี้เกิดขึ้น: ~ 1.25
ค่าเบี่ยงเบนมาตรฐานซึ่งเป็นตัววัดความแปรปรวนแบบสัมบูรณ์หลักที่ใช้ในการกำหนดค่าของพิกัดของเส้นโค้งการแจกแจงแบบปกติในการคำนวณที่เกี่ยวข้องกับการจัดระเบียบของการสังเกตตัวอย่างและการกำหนดความถูกต้องของลักษณะตัวอย่างรวมทั้งใน การประเมินขอบเขตของการแปรผันของลักษณะเฉพาะในประชากรที่เป็นเนื้อเดียวกัน
เมื่อทำการทดสอบสมมติฐานทางสถิติ เมื่อวัดความสัมพันธ์เชิงเส้นระหว่างตัวแปรสุ่ม
ส่วนเบี่ยงเบนมาตรฐาน:
ส่วนเบี่ยงเบนมาตรฐาน(ค่าประมาณค่าเบี่ยงเบนมาตรฐานของตัวแปรสุ่ม พื้น ผนังรอบตัวเรา และเพดาน xเทียบกับการคาดหมายทางคณิตศาสตร์โดยอิงจากการประมาณค่าความแปรปรวนอย่างเป็นกลาง):
ที่ไหน - ความแปรปรวน; - พื้น ผนังรอบตัวเรา และเพดาน ผมองค์ประกอบตัวอย่าง -th; - ขนาดตัวอย่าง; - ค่าเฉลี่ยเลขคณิตของกลุ่มตัวอย่าง:
ควรสังเกตว่าการประมาณการทั้งสองมีอคติ ในกรณีทั่วไป เป็นไปไม่ได้ที่จะสร้างค่าประมาณที่เป็นกลาง อย่างไรก็ตาม การประมาณการตามค่าประมาณความแปรปรวนที่ไม่เอนเอียงนั้นมีความสอดคล้องกัน
กฎสามซิกมา
กฎสามซิกมา() - ค่าเกือบทั้งหมดของตัวแปรสุ่มแบบกระจายปกติจะอยู่ในช่วงเวลา . เคร่งครัดยิ่งขึ้น - ด้วยความแน่นอนไม่น้อยกว่า 99.7% ค่าของตัวแปรสุ่มแบบกระจายตามปกติจะอยู่ในช่วงเวลาที่กำหนด (โดยมีเงื่อนไขว่าค่าเป็นจริงและไม่ได้มาจากการประมวลผลตัวอย่าง)
หากไม่ทราบค่าที่แท้จริง คุณไม่ควรใช้แต่พื้น ผนังรอบตัวเรา และเพดาน ส. ดังนั้น กฎสามซิกมาจึงถูกแปลเป็นกฎสามชั้น ผนังรอบตัวเรา และเพดาน ส .
การตีความค่าของส่วนเบี่ยงเบนมาตรฐาน
ค่าเบี่ยงเบนมาตรฐานจำนวนมากแสดงการกระจายค่าจำนวนมากในชุดที่นำเสนอด้วยค่าเฉลี่ยของชุด ค่าเล็กน้อยตามลำดับแสดงว่าค่าในชุดถูกจัดกลุ่มรอบค่าเฉลี่ย
ตัวอย่างเช่น เรามีชุดตัวเลขสามชุด: (0, 0, 14, 14), (0, 6, 8, 14) และ (6, 6, 8, 8) ทั้งสามชุดมีค่าเฉลี่ย 7 และค่าเบี่ยงเบนมาตรฐานเท่ากับ 7, 5 และ 1 ตามลำดับ ชุดสุดท้ายมีค่าเบี่ยงเบนมาตรฐานเล็กน้อยเนื่องจากค่าในชุดมีคลัสเตอร์รอบค่าเฉลี่ย ชุดแรกมีค่าสูงสุดของส่วนเบี่ยงเบนมาตรฐาน - ค่าภายในชุดแตกต่างอย่างมากจากค่าเฉลี่ย
โดยทั่วไป ค่าเบี่ยงเบนมาตรฐานถือได้ว่าเป็นการวัดความไม่แน่นอน ตัวอย่างเช่น ในวิชาฟิสิกส์ ค่าเบี่ยงเบนมาตรฐานถูกใช้เพื่อกำหนดข้อผิดพลาดของชุดการวัดต่อเนื่องของปริมาณบางอย่าง ค่านี้มีความสำคัญมากในการพิจารณาความสมเหตุสมผลของปรากฏการณ์ที่ศึกษาเมื่อเปรียบเทียบกับค่าที่ทฤษฎีทำนายไว้: หากค่าเฉลี่ยของการวัดแตกต่างจากค่าที่ทฤษฎีทำนายไว้มาก (ค่าเบี่ยงเบนมาตรฐานขนาดใหญ่) แล้ว ควรตรวจสอบค่าที่ได้รับหรือวิธีการได้มาอีกครั้ง
การใช้งานจริง
ในทางปฏิบัติ ค่าเบี่ยงเบนมาตรฐานช่วยให้คุณสามารถกำหนดว่าค่าในชุดสามารถแตกต่างจากค่าเฉลี่ยได้มากน้อยเพียงใด
ภูมิอากาศ
สมมติว่ามีสองเมืองที่มีอุณหภูมิสูงสุดเฉลี่ยรายวันเท่ากัน แต่เมืองหนึ่งตั้งอยู่บนชายฝั่งและอีกเมืองหนึ่งอยู่ในแผ่นดิน เมืองชายฝั่งเป็นที่รู้จักกันว่ามีอุณหภูมิสูงสุดในแต่ละวันที่แตกต่างกันมากน้อยกว่าเมืองในแผ่นดิน ดังนั้นค่าเบี่ยงเบนมาตรฐานของอุณหภูมิสูงสุดรายวันในเมืองชายฝั่งจะน้อยกว่าเมืองที่สองแม้ว่าจะมีค่าเฉลี่ยเท่ากันของค่านี้ซึ่งในทางปฏิบัติหมายถึงความน่าจะเป็นที่อุณหภูมิอากาศสูงสุดของ แต่ละวันของปีจะแข็งแกร่งขึ้น แตกต่างจากค่าเฉลี่ย สูงขึ้นสำหรับเมืองที่ตั้งอยู่ในทวีป
กีฬา
สมมุติว่ามีทีมฟุตบอลหลายทีมที่จัดอันดับตามพารามิเตอร์บางชุด เช่น จำนวนประตูที่ทำได้และเสีย โอกาสทำประตู เป็นต้น เป็นไปได้สูงว่าทีมที่ดีที่สุดในกลุ่มนี้จะมีค่าดีที่สุด ในพารามิเตอร์เพิ่มเติม ยิ่งค่าเบี่ยงเบนมาตรฐานของทีมเล็กลงสำหรับแต่ละพารามิเตอร์ที่นำเสนอ ผลลัพธ์ของทีมก็จะยิ่งคาดเดาได้มากขึ้น ทีมดังกล่าวจะมีความสมดุล ในทางกลับกัน ทีมที่มีค่าเบี่ยงเบนมาตรฐานมากมีปัญหาในการทำนายผล ซึ่งจะอธิบายได้จากความไม่สมดุล เช่น การป้องกันที่แข็งแกร่งแต่การโจมตีที่อ่อนแอ
การใช้ค่าเบี่ยงเบนมาตรฐานของพารามิเตอร์ของทีมทำให้สามารถทำนายผลการแข่งขันระหว่างสองทีมได้ในระดับหนึ่ง ประเมินจุดแข็งและจุดอ่อนของทีม และวิธีการต่อสู้ที่เลือก
การวิเคราะห์ทางเทคนิค
ดูสิ่งนี้ด้วย
วรรณกรรม
| บทความนี้เสนอให้ลบ
คำอธิบายเหตุผลและการอภิปรายที่เกี่ยวข้องสามารถพบได้ในเพจ วิกิพีเดีย:จะถูกลบ/17 ธันวาคม 2555 |
* โบโรวิคอฟ, วี.สถิติ. ศิลปะแห่งการวิเคราะห์ข้อมูลคอมพิวเตอร์: สำหรับมืออาชีพ / V. Borovikov - เซนต์ปีเตอร์สเบิร์ก. : ปีเตอร์ 2546. - 688 น. - ISBN 5-272-00078-1.
| ตัวชี้วัดทางสถิติ | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| คำอธิบาย สถิติ |
|
||||||||||
| สถิติ การถอนและ การตรวจสอบ สมมติฐาน |
| ||||||||||
 ลุงวันยา พล็อตเรื่อง “ลุงอีวาน ทัศนคติต่ออาจารย์ของผู้อื่น
ลุงวันยา พล็อตเรื่อง “ลุงอีวาน ทัศนคติต่ออาจารย์ของผู้อื่น Tsakhes น้อยชื่อเล่น Zinnober
Tsakhes น้อยชื่อเล่น Zinnober Maikov, Apollon Nikolaevich - ชีวประวัติสั้น
Maikov, Apollon Nikolaevich - ชีวประวัติสั้น