เงื่อนไขสำหรับการใช้การวิเคราะห์ความแปรปรวนของความแปรปรวน ปัญหาการเปรียบเทียบหลายรายการ
วิธีหนึ่งในการกำจัดอิทธิพลของการฝึกอบรมต่อผลการประเมิน N. r. - การสร้างทักษะที่มั่นคงในการทำงานด้วยวิธีการที่เหมาะสมก่อนดำเนินการทดสอบซ้ำ อย่างไรก็ตาม จำนวนการทดสอบซ้ำเพิ่มขึ้นอย่างหลีกเลี่ยงไม่ได้ ส่งผลให้จำนวนโซลูชันที่จดจำเพิ่มขึ้น เทคนิคนี้สามารถแนะนำได้สำหรับเทคนิคต่างๆ เช่น การทดสอบความเร็วซึ่งประกอบด้วย จำนวนมากองค์ประกอบของวัสดุทดสอบ
สำหรับวิธีการอื่นๆ เห็นได้ชัดว่าวิธีเดียวที่ยอมรับได้ในการลดอิทธิพลของการฝึกคือการเพิ่มช่วงการทดสอบซ้ำ ซึ่งตามที่กล่าวไว้ข้างต้นขัดแย้งกับคำจำกัดความของความน่าเชื่อถือในฐานะคุณลักษณะการทดสอบ
การทดสอบความสามารถทั่วไปส่วนใหญ่มีลักษณะเฉพาะโดยการปรับปรุงตัวบ่งชี้ประสิทธิภาพของ N. ตามอายุของอาสาสมัครเนื่องจากการควบคุมเงื่อนไขการใช้งานได้ดีขึ้น อีกปัจจัยหนึ่งในการเพิ่มตัวบ่งชี้ที่คำนวณได้ของ N. r. คือการชะลอตัวของอัตราตามอายุ การพัฒนาจิตในพื้นที่ของลักษณะเหล่านั้นที่อาจตกเป็นเป้าหมายของการวัดหรือมีอิทธิพลต่อผลการทดสอบ ด้วยเหตุนี้ หลังจากเวลาที่ถือเป็นช่วงการทดสอบซ้ำ ความผันผวนแบบสุ่มในผลการทดสอบจึงเด่นชัดน้อยลง สิ่งนี้ทำให้ตัวบ่งชี้ N.R. พองตัวโดยไม่ตั้งใจ รูปแบบนี้ต้องมีการวัด N.r. แยกกัน ในกลุ่มอายุต่าง ๆ ของวิชาซึ่งมีความสำคัญอย่างยิ่งสำหรับวิธีการตรวจในช่วงอายุที่กว้าง (ดู Stanford-Binet Intelligence Scale, Wechsler Intelligence Measuring Scale)
คุณลักษณะและข้อเสียที่ระบุของวิธีการกำหนดความน่าเชื่อถือโดยการทดสอบซ้ำทำให้เหมาะสำหรับวิธีการจำนวนจำกัดที่อนุญาตให้มีการตรวจสอบซ้ำหลายครั้งเท่านั้น ซึ่งรวมถึงการทดสอบเซนเซอร์มอเตอร์ การทดสอบความเร็ว และเทคนิคอื่นๆ จำนวนมากที่แตกต่างกัน จำนวนมากจุด (ดู สินค้าคงคลังบุคลิกภาพหลายมิติมินนิโซตา)
ความน่าเชื่อถือของปัจจัย-ความแปรปรวน- วิธีการกำหนด ความน่าเชื่อถือ,ขึ้นอยู่กับ การวิเคราะห์ความแปรปรวนผลการทดสอบ ความน่าเชื่อถือของการทดสอบสอดคล้องกับอัตราส่วนของความแปรปรวนที่แท้จริง (เช่น ความแปรปรวนของปัจจัยที่กำลังศึกษา) ต่อความแปรปรวนเชิงประจักษ์ที่ได้รับจริง อย่างหลังประกอบด้วยความแปรปรวนที่แท้จริงและความแปรปรวนของข้อผิดพลาดในการวัด (ดู ข้อผิดพลาดในการวัด)วิธีการวิเคราะห์ปัจจัยเพื่อกำหนดความน่าเชื่อถือยังช่วยลดการกระจายตัวของตัวบ่งชี้ที่แท้จริงอีกด้วย (J. Guilford, 1956)
ในทางกลับกัน ความแปรปรวนของคะแนนจริงอาจประกอบด้วยความแปรปรวนของปัจจัยร่วมสำหรับกลุ่มการทดสอบที่คล้ายกัน (ดู ปัจจัย G)ปัจจัยพิเศษที่ให้การทดสอบจุดโฟกัสเฉพาะ (ดู ปัจจัยกลุ่ม)และการกระจายตัวของปัจจัยที่มีอยู่ในเทคนิคการทดสอบเฉพาะ ดังนั้น ความแปรปรวนของการทดสอบทั้งหมดจะเท่ากับผลรวมของความแปรปรวนสำหรับปัจจัยทั่วไป เฉพาะ และปัจจัยเดี่ยวบวกกับความแปรปรวนของข้อผิดพลาด:
ที่ไหน σ 2 ตัน- ความแปรปรวนของการทดสอบ - ความแปรปรวนของปัจจัยทั่วไป กลุ่ม และรายบุคคล - ความแปรปรวนของข้อผิดพลาด หารสมการด้วย σ 2 ตันเราได้รับ:
![]()
ซึ่งสามารถเขียนได้เป็น:
โดยที่สัดส่วนของความแปรปรวนแสดงโดยปัจจัยร่วม เอ,ฯลฯ
ดังนั้น ค่าสัมประสิทธิ์ความน่าเชื่อถือของการทดสอบคือ:
วิธีปัจจัย-ความแปรปรวนในการกำหนดความน่าเชื่อถือเหมาะสำหรับการประเมินการทดสอบแบบแยกตัวประกอบแล้ว (ดู หลักการวิเคราะห์ปัจจัย)แต่ไม่ใช่สำหรับการทดสอบที่วัดค่าพารามิเตอร์ต่างๆ ที่หลากหลาย เนื่องจากบางค่าอาจไม่รวมอยู่ในนั้น พื้นที่ที่จัดตั้งขึ้น ความถูกต้องเทคนิค
ความน่าเชื่อถือของชิ้นส่วนทดสอบ -ลักษณะเฉพาะ ความน่าเชื่อถือเทคนิคการวินิจฉัยทางจิตที่ได้จากการวิเคราะห์ความเสถียรของผลลัพธ์ของประชากรแต่ละราย ปัญหาการทดสอบหรือรายการเดี่ยว (งาน) ทดสอบ.
วิธีที่ง่ายที่สุดและใช้กันทั่วไปในการกำหนด N.h.t. คือวิธีการแยกส่วน ซึ่งสาระสำคัญคือเพื่อให้ผู้ทดสอบต้องทำงานให้เสร็จสิ้นในสองส่วนที่เท่ากันของการทดสอบ เหตุผลของวิธีนี้คือสรุปได้ว่าโดยมีการกระจายคะแนนแบบปกติหรือใกล้เคียงปกติในการทดสอบแบบเต็ม (ดู การแจกแจงแบบปกติ)การดำเนินการใดๆ โทรสุ่มจากชิ้นส่วนทดสอบจะให้การกระจายที่คล้ายกัน (โดยมีเงื่อนไขว่าชิ้นส่วนนั้นเป็นเนื้อเดียวกันในลักษณะของงานที่เกี่ยวข้องกับการทดสอบโดยรวม)
ในการประเมินความน่าเชื่อถือโดยใช้วิธีการแยก จะมีการเลือกงานสองกลุ่มที่มีลักษณะเทียบเท่าและระดับความยาก (ดู ความสม่ำเสมอภายใน ความยากของรายการทดสอบ)สามารถแบ่งปริมาณงานทดสอบออกเป็นส่วนๆ ที่เทียบเคียงได้:
การกระจายงานเป็นคู่และคี่ (ในกรณีที่งานในการทดสอบได้รับการจัดอันดับอย่างเคร่งครัดตามระดับความยากส่วนตัว)
การกระจายรายการตามหลักการของความใกล้ชิดหรือความเท่าเทียมกันของค่าดัชนีความยากและการเลือกปฏิบัติ (ดู การเลือกปฏิบัติของรายการทดสอบ)หลักการแยกแบบนี้เหมาะสำหรับ การทดสอบความสำเร็จซึ่งผู้สอบต้องตอบสนองทุกข้อ
การกระจายงานตามเวลาที่ต้องใช้ในการแก้ไขแต่ละส่วน (สำหรับ การทดสอบความเร็ว)
สำหรับวิชาในตัวอย่างการกำหนดความน่าเชื่อถือ (แยกกันสำหรับแต่ละส่วนของการทดสอบ) การประมาณความสำเร็จของการตัดสินใจ ค่าเบี่ยงเบนมาตรฐานของการประเมินแถวที่หนึ่งและที่สอง และค่าสัมประสิทธิ์สหสัมพันธ์ของแถวที่เปรียบเทียบจะถูกคำนวณ โดยปกติแล้ว ค่าสัมประสิทธิ์เหล่านี้จะแสดงถึงความน่าเชื่อถือของการทดสอบเพียงครึ่งหนึ่ง
สมการสเปียร์แมน-บราวน์สะท้อนถึงผลกระทบของการเปลี่ยนแปลงจำนวนรายการต่อค่าสัมประสิทธิ์ความน่าเชื่อถือของการทดสอบ:
![]()
ที่ไหน รต- ค่าสัมประสิทธิ์ความน่าเชื่อถือสำหรับงานเต็มจำนวน - ค่าของมันหลังจากเปลี่ยนจำนวนงาน n- อัตราส่วนของจำนวนงานใหม่จากต้นฉบับ (หากจำนวนงานของการทดสอบเต็มคือ 100 และส่วนที่ได้รับจากการแบ่งครึ่งคือ 50 ดังนั้น น= 0.5) จากที่นี่สำหรับการทดสอบฉบับเต็ม:
สูตรที่ให้มาใช้ได้กับกรณีที่ค่าเบี่ยงเบนมาตรฐานเท่ากันของการทดสอบทั้งสองครึ่ง (σx1 =ซิ x2) ถ้า σ x1 แตกต่างจาก ซิx2,เพื่อกำหนดค่าสัมประสิทธิ์ความน่าเชื่อถือจะใช้สูตรฟลานาแกน:
![]()
ตัวบ่งชี้เดียวกันสำหรับตัวอย่างขนาดเล็กคำนวณโดยใช้สูตรของ Christoph:
![]()
เมื่อกำหนด รตการทดสอบทั้งหมด คุณสามารถใช้สูตร Rulon ได้:
โดยที่ คือการกระจายตัวของความแตกต่างระหว่างผลลัพธ์ของแต่ละวิชาในสองครึ่งของการทดสอบ และคือการกระจายตัวของผลลัพธ์ทั้งหมด ใน ในกรณีนี้ค่าสัมประสิทธิ์ความน่าเชื่อถือคำนวณเป็นสัดส่วนของความแปรปรวน "จริง" ของผลการทดสอบ (ดู ความน่าเชื่อถือ ข้อผิดพลาดในการวัด)
เมื่อแยกการทดสอบความเร็ว จะใช้ขั้นตอนพิเศษสำหรับการจัดกลุ่มงาน เวลาขั้นต่ำจะถูกกำหนด (ทีมิน)แก้ข้อสอบทั้งหมดแล้วนับครึ่งเวลาหนึ่งในสี่ของเวลานี้ ทุกวิชาทำงานเป็นเวลาครึ่งหนึ่งของเวลาขั้นต่ำ หลังจากนั้นให้ทำเครื่องหมายงานที่กำลังทำอยู่ในขณะที่ได้รับสัญญาณ และทำงานต่อไปอีกหนึ่งในสี่ของเวลาขั้นต่ำ ค่าสัมประสิทธิ์ความน่าเชื่อถือในกรณีนี้จะสอดคล้องกับระดับความสัมพันธ์ระหว่างจำนวนปัญหาที่แก้ไขก่อนสัญญาณแรก (0.5 ทีนาที) และแก้ไขในช่วงเวลาระหว่างสัญญาณที่หนึ่งและที่สอง (0, 25 ตัน ล้าน).
การแบ่งรายการทดสอบออกเป็นครึ่งหนึ่งเท่าๆ กันเป็นเพียงกรณีพิเศษของ N. ch.t. การแยกออกเป็นสาม สี่ส่วนหรือมากกว่านั้นเป็นไปได้ทีเดียว ในกรณีที่จำกัด จำนวนชิ้นส่วนจะเท่ากับจำนวนคะแนน ในกรณีนี้ จะใช้การวิเคราะห์เพื่อกำหนดความน่าเชื่อถือ ความสม่ำเสมอภายใน
เมื่อแบ่งรายการทดสอบทั้งชุดออกเป็นกลุ่มจำนวนเท่าใดก็ได้เพื่อการหา N.h.t. ที่ถูกต้อง ดังที่ระบุไว้ข้างต้น ต้องเป็นไปตามข้อกำหนดความเท่าเทียมกันของกลุ่มดังกล่าว ดังนั้นเมื่อคำนวณค่าสัมประสิทธิ์ความน่าเชื่อถือโดยใช้วิธีวิเคราะห์ความสอดคล้องภายใน รายการทดสอบที่เลือกจะต้องอยู่ด้วย ระดับสูงเป็นเนื้อเดียวกันในเนื้อหาและความยากลำบาก (เป็นเนื้อเดียวกัน) สำหรับปัญหาที่ต่างกัน ค่าต่างๆ รตด้านล่างของจริง
วิธีที่ใช้กันทั่วไปในการประเมินความน่าเชื่อถือ งานส่วนบุคคลคือการคำนวณสัมประสิทธิ์คูเดอร์-ริชาร์ดสัน:

ความแปรปรวนของคะแนนสอบหลักอยู่ที่ไหน ร- ดัชนีความยากแสดงเป็นเศษส่วน - - (ดู ความยากง่ายของงาน 100 ทดสอบ) q = 1 - ร ร พีบี- ค่าสัมประสิทธิ์การเลือกปฏิบัติ (ดู การเลือกปฏิบัติของรายการทดสอบ)
เพื่อให้การคำนวณง่ายขึ้น สามารถใช้สูตร Guliksen ได้:

ที่ไหน เค- จำนวนงานในการทดสอบ
สมการนี้สามารถทำให้ง่ายขึ้นดังนี้:
![]()
ในกรณีที่ไม่มีสัมประสิทธิ์การเลือกปฏิบัติ เราจะใช้สูตร Kuder-Richardson เวอร์ชันหนึ่ง:
![]()
ตัวอย่างการคำนวณ รตตามวิธีคูเดอร์-ริชาร์ดสัน แสดงไว้ในตาราง 17.
ตารางที่ 17
การหาค่าสัมประสิทธิ์ความน่าเชื่อถือโดยวิธี Kuder-Richardson ( n = 50; = 8,01;เค= 16)

สูตรที่เสนอข้างต้นเพื่อกำหนดค่าสัมประสิทธิ์ความน่าเชื่อถือเหมาะสำหรับกรณีที่งานได้รับการประเมินในระดับไดโคโตมัส (ดู ตาชั่งวัด)ตามหลักการ “ทำ-ไม่ทำ” สำหรับกรณีที่มีการประเมินที่แตกต่างมากขึ้น จะใช้สูตรนี้ ค่าสัมประสิทธิ์อัลฟา:
![]()
โดยที่ผลรวมของความแปรปรวนของผลลัพธ์ของแต่ละงานคือ
ในทางปฏิบัติ การวินิจฉัยทางจิตวิทยาการทดสอบถือว่าเชื่อถือได้หาก รต≥ 0,6.
ค่าสัมประสิทธิ์ความน่าเชื่อถือมีช่วงความเชื่อมั่น ซึ่งการพิจารณาปัจจัยนี้มีความสำคัญอย่างยิ่งเนื่องจากมีปัจจัยจำนวนมากที่สามารถมีอิทธิพลต่อมูลค่าของมันได้ ช่วงความเชื่อมั่นสำหรับ รตกำหนดให้เป็น
![]()
ที่ไหน - ข้อผิดพลาดมาตรฐานปัจจัยความน่าเชื่อถือ ![]() - การเปลี่ยนแปลงของฟิชเชอร์ (พิจารณาจากตารางสถิติ) ในทางปฏิบัติจะใช้เฉพาะขอบเขตล่างเท่านั้น รต(Z คริติคอลที่ γ = 0.05 คือ 1.96 ที่ α = 0.01 -2.58)
- การเปลี่ยนแปลงของฟิชเชอร์ (พิจารณาจากตารางสถิติ) ในทางปฏิบัติจะใช้เฉพาะขอบเขตล่างเท่านั้น รต(Z คริติคอลที่ γ = 0.05 คือ 1.96 ที่ α = 0.01 -2.58)
ลักษณะความน่าเชื่อถือของประเภท N. ch. มีข้อได้เปรียบที่ร้ายแรงเมื่อเปรียบเทียบกับ ความน่าเชื่อถือของการทดสอบซ้ำและ ความน่าเชื่อถือของรูปแบบคู่ขนานสาเหตุหลักมาจากไม่จำเป็นต้องตรวจซ้ำ ดังนั้นอิทธิพลของปัจจัยภายนอกหลายอย่างโดยเฉพาะอย่างยิ่งการฝึกอบรมการจดจำการตัดสินใจ ฯลฯ จะถูกลบออก สถานการณ์นี้กำหนดวิธีการใช้กันอย่างแพร่หลายในการกำหนดลักษณะความน่าเชื่อถือที่มีผลกระทบต่ำเมื่อเปรียบเทียบกับความน่าเชื่อถือประเภทอื่น ข้อเสียของวิธีนี้คือการไม่สามารถตรวจสอบความเสถียรของผลการทดสอบในภายหลังได้ เวลาที่แน่นอน- สิ่งนี้จำเป็นต้องรวมวิธี N. ch. เข้ากับลักษณะความน่าเชื่อถือของเทคนิคทางจิตวิทยาประเภทอื่น
"วาดประวัติศาสตร์"(วาดเรื่องราว อส)- เทคนิคการฉายภาพการวิจัยบุคลิกภาพ เสนอโดย R. Silver ในปี 1987 ออกแบบมาเพื่อตรวจหาภาวะซึมเศร้าตั้งแต่เนิ่นๆ โดยเฉพาะภาวะซึมเศร้าที่แฝงอยู่
“น. และ." เป็นไปตามปกติ เทคนิคการฉายภาพบทบัญญัติ: ก) การรับรู้ของเด็กเกี่ยวกับภาพวาดเดียวกันนั้นแตกต่างกัน b) มีอิทธิพลต่อการรับรู้ ประสบการณ์ส่วนตัว- c) ภาพวาดสามารถสะท้อนองค์ประกอบเชิงปริมาณของบุคลิกภาพได้
วิธีการนี้เป็นการผสมผสานขั้นตอนการวิจัยของเทคนิคการฉายภาพที่แตกต่างกัน ในขั้นแรก ผู้ถูกทดสอบจะต้องเลือกภาพวาดสองภาพจากทั้งหมด 14 ภาพและสร้างเรื่องราวตามภาพเหล่านั้น (ภาพวาดที่เสนอส่วนใหญ่จะประกอบด้วยภาพคนและสัตว์) จากนั้นคุณต้องวาดภาพตามเรื่องราวที่จินตนาการไว้ก่อนหน้านี้ สุดท้ายแนะนำให้เขียนเรื่อง ธีมของภาพและเรื่องราวได้รับการจัดอันดับในระดับ 7 คะแนน (จาก "เชิงลบมาก" ถึง "เชิงบวกมาก") ธีมเชิงลบประกอบด้วยการอ้างอิงถึง "ความโศกเศร้า" "ความโศกเศร้า" "ความตาย" "การไร้หนทาง" "อนาคตที่ปราศจากความหวังในสิ่งที่ดีที่สุด" ฯลฯ และถือเป็นสัญญาณของภาวะซึมเศร้า
“น. และ." มีไว้สำหรับการตรวจกลุ่มเด็กและวัยรุ่นตั้งแต่อายุ 5 ปีขึ้นไป มีการรายงานสูง ความน่าเชื่อถือเทคนิค ดังนั้น, ความน่าเชื่อถือของการทดสอบซ้ำ(ช่วงสอบซ้ำ - หนึ่งสัปดาห์) เมื่อตรวจเด็กที่มีความผิดปกติทางอารมณ์ - 0.87
ข้อมูลเกี่ยวกับ ความถูกต้องอย่างไรก็ตาม มีหลักฐานจำกัดว่าหัวข้อเกี่ยวกับเด็กและวัยรุ่นที่ซึมเศร้าได้รับการประเมินว่าเป็น "การแสดงออกทางลบ" เป็นหลัก ซึ่งไม่พบในกลุ่มอื่น มีข้อมูลเชิงบรรทัดฐานที่ได้รับจากการสำรวจเด็กและวัยรุ่นจำนวน 380 คน แต่ไม่สามารถพิจารณาว่าเป็นตัวแทนได้
ไม่มีข้อมูลเกี่ยวกับการใช้งานใน CIS
แบบทดสอบ "วาดภาพบุคคล"(แบบทดสอบการวาดภาพคน ดีเอพี)- เทคนิคการฉายภาพการวิจัยบุคลิกภาพ พัฒนาโดย K. Machover ในปี 1948 โดยใช้แบบทดสอบ F. Goodenough ซึ่งออกแบบมาเพื่อกำหนดระดับการพัฒนาทางสติปัญญาของเด็กและวัยรุ่นโดยใช้ภาพวาดของมนุษย์ที่พวกเขาสร้างขึ้น (ดู. แบบทดสอบ "วาดผู้ชาย" ก็พอแล้ว)
“น. ชม." คือใช้ตรวจได้ทั้งเด็กและผู้ใหญ่
วิชานี้เสนอดินสอให้ กระดานชนวนที่สะอาดกระดาษสำหรับวาดรูปคน หลังจากวาดภาพเสร็จแล้ว เขาได้รับมอบหมายให้วาดภาพบุคคลที่มีเพศตรงข้าม ขั้นตอนสุดท้ายสำรวจ - สำรวจ K. Machover รวบรวมรายการคำถามพิเศษเกี่ยวกับตัวเลขที่วาด คำถามเหล่านี้เกี่ยวข้องกับอายุ การศึกษา สถานภาพการสมรสนิสัย ฯลฯ
เมื่อตีความข้อมูลที่ได้รับ ผู้เขียนดำเนินการจากแนวคิดที่ว่าภาพวาดเป็นการแสดงออกของ "ฉัน" ของเรื่อง การวิเคราะห์รายละเอียดต่าง ๆ ของภาพวาดนั้นให้ความสนใจเป็นอย่างมากโดยเฉพาะอย่างยิ่งคุณสมบัติของภาพส่วนหลัก ๆ ของร่างกายซึ่งมักจะได้รับการประเมินตามสัญลักษณ์ทางจิตวิเคราะห์ กำลังเรียน ความถูกต้อง“น. ชม." เสื้อ นักจิตวิทยาตะวันตกนำไปสู่ผลลัพธ์ที่ขัดแย้งกันเนื่องจากลักษณะการคาดเดาของการตีความที่เสนอโดยผู้เขียน มีหลักฐานว่าพบเห็นได้ทั่วไป การประเมินเชิงอัตนัยถูกต้องและเชื่อถือได้มากกว่าการประเมินตามรายละเอียดส่วนบุคคลของภาพวาด
ในสหภาพโซเวียต "N. ชม." เดิมทีถูกนำมาใช้ในการวิจัยทางคลินิกและจิตวิทยา วิเคราะห์ลักษณะที่เป็นทางการของภาพวาดเป็นหลัก เช่น ขนาดของรูป ตำแหน่งบนกระดาษ ระดับความสมบูรณ์ของภาพวาด เป็นต้น (Yu. S. Savenko, 1970) ผลลัพธ์ที่ได้รับระหว่างการตรวจร่างกายของผู้ป่วยมีความสัมพันธ์กับ ภาพทางคลินิกโรคที่เสริมสร้างและชี้แจงความคิดของผู้ป่วย ตั้งแต่ทศวรรษที่ 90 ขอบเขตของการใช้แบบทดสอบได้ขยายออกไปอย่างมาก มีการวิจัยมากมายในด้านจิตวิทยาพัฒนาการและการศึกษา
แบบสอบถามความผิดปกติในการปรับตัวทางจิต(NPA) - แบบสอบถามส่วนตัวพัฒนาโดย A.I. Skorik และ L.S. Sverdlov ในปี 1993 ออกแบบมาเพื่อการวินิจฉัยเบื้องต้นเกี่ยวกับความผิดปกติของการปรับตัว
เทคนิคคือการคัดกรองโดยธรรมชาติ (ดู. การคัดกรอง)การวิจัยที่ดำเนินการด้วยความช่วยเหลือของ NPA ช่วยให้เราได้รับ ความคิดทั่วไปเกี่ยวกับการมีหรือไม่มีอาการของการปรับตัวทางจิตซึ่งเป็นคุณสมบัติหลัก ข้อกำหนดสำหรับการวินิจฉัยแบบเร่งด่วนประเภทนี้กำหนดขนาดแบบสอบถามที่เล็กและความง่ายในการประมวลผลข้อมูลหลัก
แบบสอบถาม NPA ประกอบด้วย 37 ข้อความที่เกี่ยวข้องกับ คุณสมบัติส่วนบุคคลและ ลักษณะทางจิตวิทยาหัวเรื่อง สถานะของทรงกลมร่างกาย ความคิดเกี่ยวกับ สุขภาพจิตการรับรู้ถึงความธรรมดาบางอย่าง ปัญหาชีวิต- งานแบบสอบถามต้องการเพียงคำตอบที่ยืนยันหรือปฏิเสธ (“ใช่” - “ไม่”, “จริง” - “เท็จ”, “เห็นด้วย” - “ไม่เห็นด้วย”) ไม่อนุญาตให้ตอบว่า “ฉันไม่รู้” แบบสอบถามนี้สามารถใช้สำหรับการสอบรายบุคคลและกลุ่ม คะแนนหลักจะคำนวณตาม "คีย์" โดยแยกจากแบบสอบถาม 6 ระดับ คุณสมบัติพิเศษของการประมวลผลหลักคือไม่เพียงแค่นับจำนวนการแข่งขันด้วยคีย์ที่มีคะแนน 1 คะแนนสำหรับแต่ละนัด แต่ยังสรุปผลรวม ความถ่วงจำเพาะแต่ละคำตอบที่ตรงกับค่าคีย์ (ดู ความสม่ำเสมอภายใน)ค่าน้ำหนักของแต่ละรายการคำนวณตามการกำหนดโหลดปัจจัย (ดู การวิเคราะห์ปัจจัย)ให้คำตอบในคุณลักษณะที่วัดโดยมาตราส่วน การคำนวณทำในลักษณะที่ให้น้ำหนักของคะแนนแสดงเป็นจำนวนเต็มตั้งแต่ 1 ถึง 9 คะแนนดิบจะถูกแปลงเป็น คะแนน T มาตรฐาน(ซม. การให้คะแนนมาตราส่วน)ผลลัพธ์จะถูกนำเสนอในรูปแบบกราฟิกในรูปแบบพิเศษในแบบฟอร์ม การประเมินโปรไฟล์
แบบวัดแบบสอบถามได้รับการพัฒนาโดยอาศัยผลการวิเคราะห์ปัจจัยในระดับประถมศึกษา วัสดุทางสถิติที่ได้รับในกลุ่มวิชาทางคลินิกที่เกี่ยวข้อง: 1. (B) อธิบายประสบการณ์ของความสะดวกสบายทางร่างกายและจิตใจโดยทั่วไป โดยปกติแล้วในวิชาที่ปรับแล้ว คะแนนในระดับนี้มีแนวโน้มที่จะเพิ่มขึ้น 2. (H) ระดับ "Hypochondria" - สะท้อนถึงระดับของการยึดติดกับความเจ็บป่วยทางร่างกาย ในกรณีที่มีความผิดปกติในการปรับตัว คะแนนในระดับนี้จะเพิ่มขึ้น 3. (M) สเกล "Hypomanic" - บันทึกความรู้สึกสบายใจพร้อมความรู้สึกอิ่มเอมใจ "ความเป็นอยู่ที่ดีที่ถูกบังคับ" และความประมาท หากการปรับตัวบกพร่อง คะแนนจะลดลง 4. (R) สเกลนี้อธิบายถึงสภาวะซึมเศร้า ผลลัพธ์มีความสัมพันธ์เชิงลบกับข้อมูลในระดับ M โดยปกติ คะแนนต่ำ- 5. (N) ระดับ "Neurotization" - อธิบายสถานะของความไม่สมดุลของพืชที่มีประสิทธิภาพซึ่งเกิดขึ้นเมื่อ ความเครียดทางอารมณ์, "ความกังวลใจ". ในกรณีที่มีความผิดปกติในการปรับตัว คะแนนจะเพิ่มขึ้น 6. (S) ขนาดบันทึกการละเมิดในขอบเขตของความสัมพันธ์ทางสังคม สำหรับผู้ที่ปรับไม่ถูกต้อง คะแนนจะเพิ่มขึ้น
เมื่อตีความข้อมูลการดำเนินการทางกฎหมายตามกฎระเบียบ การวิเคราะห์ "โปรไฟล์" มีความสำคัญอันดับแรก นอกจากนี้ ผู้เขียนยังเสนอเกณฑ์ง่ายๆ อย่างเป็นทางการสำหรับการวินิจฉัยการปรับที่ไม่ถูกต้อง สิ่งที่ง่ายที่สุดคือเกณฑ์ตามความสูงของโปรไฟล์ การปรับที่ไม่ถูกต้องเกิดขึ้นหากคะแนนอย่างน้อยสองสเกลเกิน 70 T หรือต่ำกว่า 30 T หรือหนึ่งในสเกลเกิน 80 T หรือต่ำกว่า 20 T ตามที่ผู้เขียนกล่าวไว้ ความน่าจะเป็นที่จะตรวจไม่พบการปรับที่ไม่ถูกต้องที่แท้จริงมีเพียง 5% เท่านั้น . อย่างไรก็ตาม ความน่าจะเป็นที่บุคคลที่มีการปรับตัวเพียงพอจะถูกจัดประเภทว่าไม่เหมาะสมคือ 22.5% ทำให้เกณฑ์นี้ไม่เหมาะสม โดยเฉพาะอย่างยิ่งเมื่อทำการศึกษาทางระบาดวิทยาในวงกว้าง ซับซ้อนและแม่นยำมากขึ้น (ความน่าจะเป็น 10% ที่การปรับตัวจะถูกจัดประเภทเป็นการปรับที่ไม่ถูกต้อง) เป็นเกณฑ์ที่คำนึงถึงผลลัพธ์ที่แตกต่างกันใน "ระดับความเป็นอยู่ที่ดี" (B, M) และ "ระดับความทุกข์" (H, D, N , ส) การวินิจฉัยข้อบกพร่องในกรณีที่ B + M เท่ากับ 79 T หรือเมื่อผลรวมของ H, D, N และ S เกิน 255 T การศึกษาเปรียบเทียบขึ้นอยู่กับวัสดุ กลุ่มที่ตัดกันแสดงให้เห็นความสัมพันธ์สูงของเกณฑ์ที่ซับซ้อนของการปรับตัวที่ไม่เหมาะสมกับการวินิจฉัยที่ได้รับการยืนยัน (ร= 0,85, ร< 0,001).
ความน่าเชื่อถือของการทดสอบซ้ำ NPA (โดยมีช่วงเวลาทดสอบซ้ำ 1 วัน) ในระดับต่างๆ มีความผันผวนในช่วง อาร์ ที = 0.74-0.90. มีข้อมูลเกี่ยวกับ ความถูกต้องของอันปัจจุบันซึ่งศึกษาโดยการเปรียบเทียบข้อมูลจากกลุ่มที่แตกต่างกัน (กลุ่มที่มีสุขภาพจิตดีมีการปรับตัวเพียงพอ มีสุขภาพจิตดีมีความผิดปกติในการปรับตัว และผู้ป่วยที่มีอาการคล้ายโรคประสาท) ข้อมูลเกี่ยวกับความน่าเชื่อถือและความถูกต้องของแบบสอบถาม NPA ให้เหตุผลในการสันนิษฐานถึงประสิทธิผลของเทคนิคในการคัดกรองภาวะการปรับตัวทางจิตแบบรายบุคคลและจำนวนมาก
สัตว์ที่ไม่มีอยู่จริง- เทคนิคการฉายภาพการวิจัยบุคลิกภาพ เสนอโดย M.Z. Drukarevic
ผู้ทดลองถูกขอให้ประดิษฐ์และวาดสัตว์ที่ไม่มีอยู่จริง พร้อมทั้งตั้งชื่อที่ไม่มีอยู่จริงให้กับมันด้วย จากวรรณกรรมที่มีอยู่เป็นที่ชัดเจนว่าขั้นตอนการตรวจสอบไม่ได้มาตรฐาน (ใช้กระดาษวาดรูปที่มีขนาดต่างกันในบางกรณีการวาดด้วยดินสอสีในสีอื่น ๆ - เป็นสีเดียว ฯลฯ ) ไม่มีระบบที่เป็นที่ยอมรับโดยทั่วไปในการประเมินแบบร่าง หลักการทางทฤษฎีที่เป็นรากฐานของการสร้างเทคนิคนี้สอดคล้องกับเทคนิคการฉายภาพอื่นๆ เช่นเดียวกับการทดสอบการวาดภาพอื่น ๆ N. ส่งไปตรวจวินิจฉัย ลักษณะส่วนบุคคลบางครั้งศักยภาพในการสร้างสรรค์ของเธอ
แสดงว่าน่าพอใจ ความถูกต้องมาบรรจบกันวิธีการโดยสร้างการเชื่อมโยงระหว่างผลลัพธ์ที่ได้รับด้วยความช่วยเหลือและข้อมูลของวิธีการส่วนบุคคลอื่น ๆ ตามการตรวจผู้ป่วยในคลินิกจิตเวชและบุคคลที่เข้ารับการคัดเลือกมืออาชีพสำหรับเจ้าหน้าที่ของกระทรวงกิจการภายใน (P.V. Yanshin, 1988, 1990 ). ความถูกต้องยังยืนยันในการสร้างความแตกต่างของผู้ป่วยที่มีโรคประสาทและคนที่มีสุขภาพดี (T. I. Krasko, 1995) นิวเจอร์ซีย์ - หนึ่งในเทคนิคการวาดภาพที่ได้รับความนิยมมากที่สุดและนักจิตวิทยาใน CIS ใช้กันอย่างแพร่หลายในการตรวจเด็กและผู้ใหญ่ ป่วยและมีสุขภาพดี ส่วนใหญ่มักจะเป็นเทคนิคการกำหนดทิศทาง นั่นคือข้อมูลที่ช่วยให้เราตั้งสมมติฐานบางประการเกี่ยวกับลักษณะบุคลิกภาพได้ .
การกระจายแบบปกติ- ประเภทของการกระจายตัวของตัวแปร เอ็นอาร์ สังเกตได้เมื่อลักษณะ (ตัวแปร) เปลี่ยนแปลงไปภายใต้อิทธิพลของปัจจัยที่ค่อนข้างอิสระหลายประการ กราฟของสมการ N.r. เป็นเส้นโค้งรูประฆังสมมาตรเดียวซึ่งมีแกนสมมาตรเป็นแนวดิ่ง (พิกัด) ที่ลากผ่านจุด 0 (รูปที่ 46)

ข้าว. 46. เปอร์เซ็นต์การกระจายตัวของเคสภายใต้เส้นโค้งปกติ
เส้นโค้ง N.r. ถูกสร้างขึ้นเพื่อให้วิธีแก้ปัญหาการประมาณอย่างง่ายสำหรับปัญหาความน่าจะเป็นของความถี่ของเหตุการณ์ เส้นโค้งปกติอธิบายได้ด้วยสูตรของเดอ มัวฟวร์
![]()
คุณ- ความสูงของเส้นโค้งเหนือค่าที่กำหนดแต่ละค่า x ฉัน , -ค่าเฉลี่ยเลขคณิต x ฉัน, - ส่วนเบี่ยงเบนมาตรฐานจาก .
ตามทฤษฎีก็มี ชุดอนันต์เส้นโค้งปกติที่มีค่า con-let เป็น M และ σ ที่ การทำให้เป็นมาตรฐานคะแนนการทดสอบและในบางกรณีจะใช้ N. r. โดยมีลักษณะดังต่อไปนี้: M = 0; σ= 1; พื้นที่ใต้เส้นโค้งปกติเท่ากับหนึ่ง การแจกแจงนี้เรียกว่ามาตรฐาน (เดี่ยว) N. r. สำหรับ N.r. ภายในค่า x 1 M + σ อยู่ที่ประมาณ 68% ภายใน M ± 2σ - 95%, M ± 3σ - 99.7% ของพื้นที่ใต้เส้นโค้ง ความถี่ของเคสที่อยู่ภายในช่วงเวลาที่จำกัดด้วยค่าตั้งแต่ M ± σ ถึง M ± σ คือ 68.26%; 95.44%; 99.72%; 99.98% ตามลำดับ (รูปที่ 46) ความสูงของส่วนโค้ง (คุณ)เหนือค่า M มีค่าประมาณ 0.3989 ความไม่สมมาตรของเส้นโค้งมาตรฐาน เช่นเดียวกับเส้นโค้งปกติอื่นๆ คือศูนย์ ความโด่ง (Q) คือสาม (ดู การประเมินประเภทการกระจายสินค้า)การกระจายตัวของตัวบ่งชี้ที่ได้รับในการศึกษาเชิงประจักษ์ทางจิตวิทยาและจิตวินิจฉัยที่มีการสังเกตจำนวนมากตามกฎจะเข้าใกล้ N. r.
ในทางปฏิบัติ บทบาทที่สำคัญมีการคำนวณพื้นที่ทางด้านซ้ายของจุดใดๆ บนแกน x ซึ่งจำกัดด้วยส่วนของเส้นโค้งปกติและพิกัดของจุดนี้ เนื่องจากพื้นที่มาตรฐาน N.r. เท่ากับความสามัคคีแล้วส่วนแบ่งของพื้นที่นี้สะท้อนถึงความถี่ของคดีด้วย x ฉันน้อยกว่าค่าที่กำหนดบนแกน เอ็กซ์การแก้สมการเดอมัววร์สำหรับค่าใดๆ เอ็กซ์ไม่สะดวกในการกำหนดพื้นที่ทางด้านซ้ายของค่าที่กำหนดใน N. r. ต่างๆ (ตามแนวแกน z) มีตารางพิเศษ (ดูตารางที่ 1 ของภาคผนวก III)
คุณภาพที่สำคัญที่สุดเอ็นอาร์ คือ ตระกูลของเส้นโค้งปกติมีลักษณะเป็นสัดส่วนที่เท่ากันของพื้นที่ที่วางอยู่ใต้พื้นที่ที่ขอบเขต ค่าที่เท่ากันซิ นอกจากนี้ เส้นโค้งปกติใดๆ สามารถลดลงเป็นเส้นโค้งหน่วยได้ และตอบคำถามเกี่ยวกับพื้นที่ระหว่างจุดที่เลือกบนเส้นโค้ง หรือความสูงของเส้นโค้งเหนือจุดใดๆ บนแกน เอ็กซ์รูปร่างของเส้นโค้งปกติจะไม่เปลี่ยนแปลงเมื่อค่าเฉลี่ยถูกลบและหารด้วย σ ดังนั้น หากคุณต้องการค้นหาว่าส่วนใดของพื้นที่อยู่ทางด้านซ้ายของค่า x = เอ็กซ์แอล
จัตุรัสทางด้านซ้ายของ zสำหรับค่านี้จะเป็น 0.1020 (10.2%) ดังนั้น จำนวนผู้ที่มีคะแนนต่ำกว่า 8.3 คือ 89.8% และจำนวนผู้ที่มีคะแนนในช่วง 8.3-10.4 คือ 97.5-89.8 = 7.7%
จำนวนกรณีภายในค่าเบี่ยงเบนมาตรฐานสามารถกำหนดได้อย่างง่ายดายโดยไม่ต้องคำนวณ ดังนั้น 13.6% ของผู้ตอบแบบสอบถามอยู่ในช่วงประมาณการที่สอดคล้องกับ -2 และ - (ดูรูปที่ 46)
การวิเคราะห์ความแปรปรวนเป็นวิธีการทางสถิติที่ออกแบบมาเพื่อประเมินอิทธิพลของปัจจัยต่างๆ ที่มีต่อผลลัพธ์ของการทดลอง รวมถึงการวางแผนการทดลองที่คล้ายกันในภายหลัง
ในขั้นต้น (พ.ศ. 2461) การวิเคราะห์ความแปรปรวนได้รับการพัฒนาโดยนักคณิตศาสตร์และนักสถิติชาวอังกฤษ R.A. ฟิสเชอร์จะประมวลผลผลการทดลองทางการเกษตรเพื่อระบุเงื่อนไขในการได้รับผลผลิตสูงสุดของพืชผลทางการเกษตรหลากหลายพันธุ์
เมื่อตั้งค่าการทดสอบ ต้องเป็นไปตามเงื่อนไขต่อไปนี้:
การทดลองแต่ละรูปแบบจะต้องดำเนินการในหน่วยสังเกตการณ์หลายหน่วย (กลุ่มสัตว์ พื้นที่ภาคสนาม ฯลฯ)
การกระจายหน่วยการสังเกตระหว่างตัวแปรการทดลองควรเป็นแบบสุ่มและไม่ได้ตั้งใจ
การวิเคราะห์ความแปรปรวนใช้ เอฟ-เกณฑ์(เกณฑ์ R.A. Fisher) ซึ่งแสดงถึงอัตราส่วนของความแปรปรวนสองประการ:
โดยที่ d ข้อเท็จจริง d คงเหลือคือแฟกทอเรียล (กลุ่มระหว่างกัน) และความแปรปรวนที่เหลือ (ภายในกลุ่ม) ต่อระดับความเป็นอิสระ ตามลำดับ
ปัจจัยและความแปรปรวนคงเหลือคือการประมาณค่าความแปรปรวนของประชากร โดยคำนวณจากข้อมูลตัวอย่างโดยคำนึงถึงจำนวนระดับความอิสระของการแปรผัน
การกระจายแบบแฟกทอเรียล (ระหว่างกลุ่ม) อธิบายความแปรผันของคุณลักษณะที่มีประสิทธิผลภายใต้อิทธิพลของปัจจัยที่กำลังศึกษา
ความแปรปรวนคงเหลือ (ภายในกลุ่ม) อธิบายความแปรผันในลักษณะที่มีประสิทธิผลเนื่องจากอิทธิพลของปัจจัยอื่นๆ (ยกเว้นอิทธิพลของปัจจัยที่กำลังศึกษา)
โดยสรุป ปัจจัยและความแปรปรวนคงเหลือให้ความแปรปรวนรวม ซึ่งแสดงถึงอิทธิพลของลักษณะเฉพาะของปัจจัยทั้งหมดที่มีต่อผลลัพธ์
ขั้นตอนการดำเนินการวิเคราะห์ความแปรปรวน:
1. ข้อมูลการทดลองจะถูกป้อนลงในตารางการคำนวณและกำหนดจำนวนและค่าเฉลี่ยในแต่ละกลุ่มของประชากรที่กำลังศึกษาตลอดจนจำนวนรวมและค่าเฉลี่ยสำหรับประชากรทั้งหมด (ตารางที่ 1)
ตารางที่ 1
|
ค่าของคุณลักษณะผลลัพธ์สำหรับหน่วย i-th ในกลุ่ม j-th x ij |
จำนวนการสังเกต f j |
ค่าเฉลี่ย (กลุ่มและผลรวม), x j |
|
|
x 11, x 12, …, x 1 น x 21, x 22, …, x 2 น x ม. 1, x ม. 2, …, x ล้าน |
|
||
|
|
|





จำนวนการสังเกตทั้งหมด nคำนวณเป็นผลรวมของจำนวนการสังเกต ฉ เจในแต่ละกลุ่ม:

หากทุกกลุ่มมีจำนวนองค์ประกอบเท่ากัน แสดงว่าค่าเฉลี่ยโดยรวม  หาได้จากค่าเฉลี่ยกลุ่มเป็นค่าเฉลี่ยเลขคณิตอย่างง่าย:
หาได้จากค่าเฉลี่ยกลุ่มเป็นค่าเฉลี่ยเลขคณิตอย่างง่าย:

หากจำนวนองค์ประกอบในกลุ่มต่างกัน แสดงว่าค่าเฉลี่ยโดยรวม  คำนวณโดยใช้สูตรค่าเฉลี่ยเลขคณิตถ่วงน้ำหนัก:
คำนวณโดยใช้สูตรค่าเฉลี่ยเลขคณิตถ่วงน้ำหนัก:

2. กำหนดค่าความแปรปรวนทั้งหมด ดี โดยทั่วไปเป็นผลรวมของการเบี่ยงเบนกำลังสองของค่าแต่ละค่าของคุณลักษณะผลลัพธ์  จากค่าเฉลี่ยทั้งหมด
จากค่าเฉลี่ยทั้งหมด  :
:

3. คำนวณความแปรปรวนแฟกทอเรียล (ระหว่างกลุ่ม) ดี ข้อเท็จจริงเป็นผลรวมของค่าเบี่ยงเบนกำลังสองของค่าเฉลี่ยกลุ่ม  จากค่าเฉลี่ยทั้งหมด
จากค่าเฉลี่ยทั้งหมด  คูณด้วยจำนวนข้อสังเกต:
คูณด้วยจำนวนข้อสังเกต:

4. กำหนดมูลค่าของผลต่างที่เหลือ (ภายในกลุ่ม) ดี เพลงประกอบละครเป็นความแตกต่างระหว่างผลรวม ดี โดยทั่วไปและแฟกทอเรียล ดี ข้อเท็จจริงความแตกต่าง:

5. คำนวณจำนวนองศาอิสระของตัวประกอบ 
 ความแปรปรวนเป็นผลต่างระหว่างจำนวนกลุ่ม มและหน่วย:
ความแปรปรวนเป็นผลต่างระหว่างจำนวนกลุ่ม มและหน่วย:

6. กำหนดจำนวนองศาอิสระสำหรับการกระจายตัวของสารตกค้าง  เป็นความแตกต่างระหว่างจำนวนค่าแต่ละค่าของคุณลักษณะ nและจำนวนกลุ่ม ม:
เป็นความแตกต่างระหว่างจำนวนค่าแต่ละค่าของคุณลักษณะ nและจำนวนกลุ่ม ม:

7. คำนวณค่าการกระจายตัวของปัจจัยต่อความอิสระหนึ่งระดับ ง ข้อเท็จจริงเป็นอัตราส่วนผลต่างปัจจัย ดี ข้อเท็จจริงถึงจำนวนองศาอิสระของการกระจายตัวของปัจจัย  :
:

8. กำหนดค่าของการกระจายตัวที่เหลือต่อความอิสระหนึ่งระดับ ง เพลงประกอบละครเป็นอัตราส่วนผลต่างคงเหลือ ดี เพลงประกอบละครถึงจำนวนองศาอิสระของการกระจายตัวของสารตกค้าง  :
:

9. กำหนดค่าที่คำนวณได้ของเกณฑ์ F ถูกกำหนด เอฟ-การคำนวณเป็นอัตราส่วนของความแปรปรวนของปัจจัยต่อระดับความเป็นอิสระ ง ข้อเท็จจริงความแปรปรวนคงเหลือต่อระดับความเป็นอิสระ ง เพลงประกอบละคร :

10. การใช้ตารางทดสอบฟิชเชอร์ F โดยคำนึงถึงระดับนัยสำคัญที่ใช้ในการศึกษา ตลอดจนคำนึงถึงระดับความเป็นอิสระของปัจจัยและความแปรปรวนตกค้าง จะได้ค่าทางทฤษฎี เอฟ โต๊ะ .
ระดับนัยสำคัญ 5% สอดคล้องกับระดับความน่าจะเป็น 95% และระดับนัยสำคัญ 1% สอดคล้องกับระดับความน่าจะเป็น 99% ในกรณีส่วนใหญ่ จะใช้ระดับนัยสำคัญ 5%
ค่าทางทฤษฎี เอฟ โต๊ะในระดับนัยสำคัญที่กำหนดจะถูกกำหนดจากตารางที่จุดตัดของแถวและคอลัมน์ ซึ่งสอดคล้องกับระดับความเป็นอิสระของความแปรปรวนสองระดับ:
ตามบรรทัด – ที่เหลือ;
ตามคอลัมน์ – แฟกทอเรียล
11. ผลการคำนวณแสดงไว้ในตาราง (ตารางที่ 2)
เทคนิคการตรวจสอบที่กล่าวถึงข้างต้น สมมติฐานทางสถิติเกี่ยวกับความสำคัญของความแตกต่างระหว่างสองวิธีมีการใช้งานที่จำกัดในทางปฏิบัติ นี่เป็นเพราะความจริงที่ว่าเพื่อที่จะระบุผลกระทบของเงื่อนไขและปัจจัยที่เป็นไปได้ทั้งหมดต่อลักษณะที่มีประสิทธิภาพสนามและ การทดลองในห้องปฏิบัติการตามกฎแล้วจะดำเนินการโดยใช้ไม่ใช่สองตัวอย่าง แต่ใช้ตัวอย่างจำนวนมากขึ้น (1220 หรือมากกว่า)
บ่อยครั้งที่นักวิจัยเปรียบเทียบค่าเฉลี่ยของหลายตัวอย่างรวมกัน คอมเพล็กซ์เดียว- เช่น ศึกษาเรื่องอิทธิพล ประเภทต่างๆและปริมาณปุ๋ยต่อผลผลิตพืชผล มีการทดลองซ้ำอีกครั้ง ตัวเลือกที่แตกต่างกัน- ในกรณีเหล่านี้ การเปรียบเทียบแบบคู่จะกลายเป็นเรื่องยุ่งยาก และ การวิเคราะห์ทางสถิติคอมเพล็กซ์ทั้งหมดต้องใช้วิธีพิเศษ วิธีการนี้พัฒนาขึ้นในปี พ.ศ สถิติทางคณิตศาสตร์, ได้ชื่อแล้ว การวิเคราะห์ความแปรปรวน- มันถูกใช้ครั้งแรกโดยนักสถิติชาวอังกฤษ อาร์. ฟิชเชอร์ ในการประมวลผลผลการทดลองทางการเกษตร (1938)
การวิเคราะห์ความแปรปรวน- นี่คือวิธีการ การประเมินทางสถิติความน่าเชื่อถือของการสำแดงการพึ่งพาลักษณะผลลัพธ์ของปัจจัยหนึ่งหรือหลายปัจจัย โดยใช้วิธีการวิเคราะห์ความแปรปรวน สมมติฐานทางสถิติจะได้รับการทดสอบเกี่ยวกับค่าเฉลี่ยในประชากรทั่วไปหลายๆ กลุ่มที่มีการแจกแจงแบบปกติ
การวิเคราะห์ความแปรปรวนเป็นหนึ่งในวิธีการหลักในการประเมินผลการทดลองทางสถิติ นอกจากนี้ยังถูกนำมาใช้มากขึ้นในการวิเคราะห์ข้อมูลทางเศรษฐกิจ การวิเคราะห์ความแปรปรวนทำให้สามารถกำหนดขอบเขตของตัวบ่งชี้ตัวอย่างของความสัมพันธ์ระหว่างคุณลักษณะผลลัพธ์และปัจจัยได้เพียงพอที่จะขยายข้อมูลที่ได้รับจากตัวอย่างไปยังประชากรทั่วไป ข้อดีของวิธีนี้คือให้ข้อสรุปที่เชื่อถือได้จากกลุ่มตัวอย่างขนาดเล็ก
โดยการศึกษาความแปรผันของคุณลักษณะที่มีประสิทธิผลภายใต้อิทธิพลของปัจจัยหนึ่งหรือหลายปัจจัยโดยใช้การวิเคราะห์ความแปรปรวน นอกเหนือจากการประมาณทั่วไปเกี่ยวกับความสำคัญของการพึ่งพาแล้ว ยังสามารถประเมินความแตกต่างในขนาดของค่าเฉลี่ยที่เกิดขึ้นที่ ระดับของปัจจัยต่างๆ และความสำคัญของปฏิสัมพันธ์ของปัจจัยต่างๆ การวิเคราะห์ความแปรปรวนใช้เพื่อศึกษาการพึ่งพาทั้งเชิงปริมาณและ สัญญาณเชิงคุณภาพรวมถึงการรวมกันของพวกเขา
สาระสำคัญของวิธีนี้คือ การศึกษาทางสถิติความน่าจะเป็นของอิทธิพลของปัจจัยหนึ่งปัจจัยขึ้นไปตลอดจนปฏิสัมพันธ์กับลักษณะผลลัพธ์ ตามนี้ ปัญหาหลักสามประการได้รับการแก้ไขโดยใช้การวิเคราะห์ความแปรปรวน: 1) คะแนนโดยรวมความสำคัญของความแตกต่างระหว่างวิธีการกลุ่ม 2) การประเมินความน่าจะเป็นของการมีปฏิสัมพันธ์ระหว่างปัจจัย 3) การประเมินความสำคัญของความแตกต่างระหว่างคู่ของค่าเฉลี่ย บ่อยครั้งที่นักวิจัยต้องแก้ไขปัญหาดังกล่าวเมื่อทำการทดลองภาคสนามและสัตว์เทคนิคเมื่อมีการศึกษาอิทธิพลของปัจจัยหลายประการต่อลักษณะที่มีประสิทธิผล
รูปแบบหลักของการวิเคราะห์ความแปรปรวนประกอบด้วยการระบุแหล่งที่มาหลักของความแปรผันในลักษณะที่มีประสิทธิผล และการกำหนดปริมาตรของการแปรผัน (ผลรวมของการเบี่ยงเบนกำลังสอง) ตามแหล่งที่มาของการก่อตัว การกำหนดจำนวนองศาอิสระที่สอดคล้องกับองค์ประกอบต่างๆ การเปลี่ยนแปลงทั้งหมด- การคำนวณการกระจายตัวเป็นอัตราส่วนของปริมาตรของการแปรผันที่สอดคล้องกับจำนวนระดับความเป็นอิสระ การวิเคราะห์ความสัมพันธ์ระหว่างความแปรปรวน ประเมินความน่าเชื่อถือของความแตกต่างระหว่างวิธีการและข้อสรุป
รูปแบบนี้จะถูกเก็บรักษาไว้ทั้งในรูปแบบการวิเคราะห์ความแปรปรวนอย่างง่าย เมื่อข้อมูลถูกจัดกลุ่มตามคุณลักษณะเดียว และในแบบจำลองที่ซับซ้อน เมื่อข้อมูลถูกจัดกลุ่มด้วยสองและ จำนวนมากสัญญาณ อย่างไรก็ตาม ด้วยจำนวนคุณลักษณะของกลุ่มที่เพิ่มขึ้น กระบวนการสลายความแปรปรวนทั้งหมดตามแหล่งที่มาของการก่อตัวจึงมีความซับซ้อนมากขึ้น
ตาม แผนผังการวิเคราะห์ความแปรปรวนสามารถแสดงในรูปแบบของห้าขั้นตอนตามลำดับ:
1) ความหมายและการขยายความแปรผัน
2) การกำหนดจำนวนระดับความอิสระของการแปรผัน
3) การคำนวณความแปรปรวนและอัตราส่วน
4) การวิเคราะห์ความแปรปรวนและความสัมพันธ์
5) การประเมินความสำคัญของความแตกต่างระหว่างค่าเฉลี่ยและการกำหนดข้อสรุปเพื่อทดสอบสมมติฐานที่เป็นโมฆะ
ส่วนที่ต้องใช้แรงงานมากที่สุดในการวิเคราะห์ความแปรปรวนคือขั้นตอนแรก ซึ่งก็คือการกำหนดและสลายความแปรผันตามแหล่งที่มาของการก่อตัว ลำดับการสลายตัวของปริมาตรรวมของการแปรผันถูกกล่าวถึงโดยละเอียดในบทที่ 5
พื้นฐานในการแก้ปัญหาการวิเคราะห์ความแปรปรวนคือกฎการขยายตัว (บวก) การแปรผัน ซึ่งความแปรผันรวม (ความผันผวน) ของคุณลักษณะผลลัพธ์จะแบ่งออกเป็น 2 แบบ คือ การแปรผันที่เกิดจากการกระทำของปัจจัยที่กำลังศึกษา และความแปรผันที่เกิดจากการกระทำของเหตุสุ่มนั่นก็คือ
สมมติว่าประชากรที่อยู่ระหว่างการศึกษาถูกแบ่งตามลักษณะของปัจจัยออกเป็นหลายกลุ่ม ซึ่งแต่ละกลุ่มมีลักษณะเฉพาะของตัวเอง เฉลี่ยสัญญาณที่มีประสิทธิภาพ ในเวลาเดียวกัน ความแปรผันของค่าเหล่านี้สามารถอธิบายได้ด้วยเหตุผลสองประเภท: เหตุผลที่กระทำต่อสัญญาณที่มีประสิทธิผลอย่างเป็นระบบและสามารถปรับเปลี่ยนได้ในระหว่างการทดลอง และเหตุผลที่ไม่สามารถปรับเปลี่ยนได้ เห็นได้ชัดว่าความแปรผันระหว่างกลุ่ม (แฟคทอเรียลหรือเป็นระบบ) ขึ้นอยู่กับการกระทำของปัจจัยที่กำลังศึกษาเป็นหลัก และการแปรผันภายในกลุ่ม (ที่เหลือหรือสุ่ม) ขึ้นอยู่กับการกระทำของปัจจัยสุ่มเป็นหลัก
เพื่อประเมินความน่าเชื่อถือของความแตกต่างระหว่างค่าเฉลี่ยแบบกลุ่ม จำเป็นต้องพิจารณาความแปรผันระหว่างกลุ่มและภายในกลุ่ม หากความแปรผันระหว่างกลุ่ม (แฟคทอเรียล) เกินกว่าความแปรผันภายในกลุ่ม (สารตกค้าง) อย่างมีนัยสำคัญ ปัจจัยนั้นมีอิทธิพลต่อลักษณะผลลัพธ์ โดยเปลี่ยนค่าของค่าเฉลี่ยกลุ่มอย่างมีนัยสำคัญ แต่คำถามเกิดขึ้น: อะไรคือความสัมพันธ์ระหว่างรูปแบบระหว่างกลุ่มและภายในกลุ่มที่ถือว่าเพียงพอที่จะสรุปความน่าเชื่อถือ (ความสำคัญ) ของความแตกต่างระหว่างค่าเฉลี่ยของกลุ่ม
เพื่อประเมินความสำคัญของความแตกต่างระหว่างค่าเฉลี่ยและกำหนดข้อสรุปสำหรับการทดสอบสมมติฐานว่าง (H0:x1 = x2 =... = xn) การวิเคราะห์ความแปรปรวนจะใช้มาตรฐานประเภทหนึ่ง - เกณฑ์ G ซึ่งเป็นกฎการกระจายของ ก่อตั้งโดยอาร์. ฟิชเชอร์ เกณฑ์นี้คืออัตราส่วนของความแปรปรวนสองค่า: แฟกทอเรียล ซึ่งเกิดจากการกระทำของปัจจัยที่กำลังศึกษา และค่าคงเหลือ เนื่องจากการกระทำของสาเหตุสุ่ม:
![]()
ความสัมพันธ์การกระจายตัว Γ = £>u : นักสถิติชาวอเมริกัน Snedecor เสนอให้ระบุ £*2 ด้วยตัวอักษร G เพื่อเป็นเกียรติแก่ R. Fisher ผู้ประดิษฐ์การวิเคราะห์ความแปรปรวน
ความแปรปรวน °2 io2 เป็นค่าประมาณของความแปรปรวน ประชากร- หากสุ่มตัวอย่างที่มีความแปรปรวน °2 °2 จากประชากรกลุ่มเดียวกันซึ่งมีการแปรผันของค่าอยู่ ตัวละครสุ่มจากนั้นความคลาดเคลื่อนในค่า °2 °2 ก็เป็นแบบสุ่มเช่นกัน
หากการทดลองทดสอบอิทธิพลของปัจจัยหลายประการ (A, B, C ฯลฯ) ต่อลักษณะที่มีประสิทธิผลพร้อมกัน ความแปรปรวนเนื่องจากการกระทำของแต่ละรายการควรจะเทียบเคียงกับ °เช่นgPนั่นคือ
ถ้าค่าของการกระจายตัวของแฟคเตอร์มากกว่าค่าคงเหลืออย่างมีนัยสำคัญ แฟคเตอร์จะส่งผลต่อคุณลักษณะผลลัพธ์อย่างมีนัยสำคัญและในทางกลับกัน
ในการทดลองหลายปัจจัย นอกเหนือจากการแปรผันเนื่องจากการกระทำของแต่ละปัจจัยแล้ว ยังมีความแปรผันเกือบทุกครั้งอันเนื่องมาจากปฏิสัมพันธ์ของปัจจัย ($ав: ^лс ^вс $ліс) สาระสำคัญของการโต้ตอบคือผลกระทบของปัจจัยหนึ่งเปลี่ยนแปลงไปอย่างมีนัยสำคัญ ระดับที่แตกต่างกันประการที่สอง (เช่น ประสิทธิผลของคุณภาพดินในปริมาณปุ๋ยที่แตกต่างกัน)
ปฏิสัมพันธ์ของปัจจัยต่างๆ ควรได้รับการประเมินโดยการเปรียบเทียบความแปรปรวนที่สอดคล้องกัน 3 ^v.gr:

เมื่อคำนวณค่าที่แท้จริงของเกณฑ์ B ค่าความแปรปรวนก็จะยิ่งมากขึ้นในตัวเศษ ดังนั้น B > 1 แน่นอนว่ายิ่งเกณฑ์มีขนาดใหญ่เท่าใด ความแตกต่างที่มากขึ้นระหว่างการกระจายตัว ถ้า B = 1 คำถามในการประเมินความสำคัญของความแตกต่างในความแปรปรวนจะถูกลบออก
เพื่อกำหนดขีดจำกัดของความผันผวนแบบสุ่มในอัตราส่วนของการกระจาย G. Fischer ได้พัฒนาตารางการกระจาย B พิเศษ (ภาคผนวก 4 และ 5) เกณฑ์จะสัมพันธ์กับความน่าจะเป็นและขึ้นอยู่กับจำนวนระดับความอิสระของการแปรผัน k1และ k2 ของทั้งสองเปรียบเทียบความแปรปรวน โดยทั่วไปแล้วจะใช้สองตารางเพื่อให้สรุปได้เกี่ยวกับค่าสูงสุด มูลค่าสูงเกณฑ์ระดับนัยสำคัญ 0.05 และ 0.01 ระดับนัยสำคัญ 0.05 (หรือ 5%) หมายความว่าเฉพาะใน 5 กรณีจาก 100 เกณฑ์ B เท่านั้นที่สามารถรับค่าเท่ากับหรือสูงกว่าที่ระบุไว้ในตาราง การลดระดับนัยสำคัญจาก 0.05 เป็น 0.01 จะทำให้มูลค่าของเกณฑ์เพิ่มขึ้นระหว่างความแปรปรวนสองค่าเนื่องจากผลของเหตุผลแบบสุ่มเท่านั้น
ค่าของเกณฑ์ยังขึ้นอยู่กับจำนวนองศาความเป็นอิสระของทั้งสองค่าที่เปรียบเทียบกันโดยตรงอีกด้วย หากจำนวนระดับความเป็นอิสระมีแนวโน้มที่จะเป็นอนันต์ (k-me) อัตราส่วน B สำหรับการกระจายตัวสองครั้งมีแนวโน้มที่จะเป็นเอกภาพ
ค่าตารางของเกณฑ์ B แสดงค่าที่เป็นไปได้ ตัวแปรสุ่มอัตราส่วนของความแปรปรวนสองค่าในระดับนัยสำคัญที่กำหนด และจำนวนระดับความเป็นอิสระที่สอดคล้องกันสำหรับแต่ละค่าความแปรปรวนที่ถูกเปรียบเทียบ ตารางที่ระบุแสดงค่า B สำหรับตัวอย่างที่สร้างจากประชากรทั่วไปกลุ่มเดียวกัน โดยที่สาเหตุของการเปลี่ยนแปลงค่าเป็นเพียงการสุ่มเท่านั้น
ค่า Γ หาได้จากตาราง (ภาคผนวก 4 และ 5) ที่จุดตัดของคอลัมน์ที่เกี่ยวข้อง (จำนวนองศาอิสระสำหรับการกระจายตัวที่มากขึ้น - k1) และแถว (จำนวนองศาอิสระสำหรับการกระจายตัวน้อยลง - k2 ). ดังนั้น หากความแปรปรวนที่มากกว่า (ตัวเศษ Г) คือ k1 = 4 และความแปรปรวนที่น้อยกว่า (ตัวส่วน Г) คือ k2 = 9 ดังนั้น Га ที่ระดับนัยสำคัญ а = 0.05 จะเป็น 3.63 (ภาคผนวก 4) ดังนั้น จากสาเหตุที่สุ่ม เนื่องจากมีตัวอย่างขนาดเล็ก ความแปรปรวนของตัวอย่างหนึ่งจึงสามารถเกินความแปรปรวนของตัวอย่างที่สองได้ 3.63 เท่า ที่ระดับนัยสำคัญ 5% เมื่อระดับนัยสำคัญลดลงจาก 0.05 เป็น 0.01 ค่าตารางของเกณฑ์ G ดังที่ระบุไว้ข้างต้นจะเพิ่มขึ้น ดังนั้น ด้วยดีกรีอิสระที่เท่ากัน k1 = 4 และ k2 = 9 และ a = 0.01 ค่าตารางของเกณฑ์ G จะเป็น 6.99 (ภาคผนวก 5)
พิจารณาขั้นตอนการกำหนดจำนวนองศาอิสระในการวิเคราะห์ความแปรปรวน จำนวนระดับความเป็นอิสระ ซึ่งสอดคล้องกับผลรวมของค่าเบี่ยงเบนกำลังสอง จะถูกแยกย่อยเป็นองค์ประกอบที่สอดคล้องกันในลักษณะเดียวกันกับการสลายตัวของผลรวมของค่าเบี่ยงเบนกำลังสอง (^total = No^gr + ]¥vhr) นั่นคือ จำนวนทั้งหมดองศาอิสระ (k") แบ่งออกเป็นจำนวนองศาอิสระสำหรับรูปแบบระหว่างกลุ่มระหว่างกัน (k1) และกลุ่มภายใน (k2)
ถ้าอย่างนั้น ประชากรตัวอย่างประกอบด้วย เอ็นการสังเกตหารด้วย ต กลุ่ม (จำนวนตัวเลือกการทดลอง) และ n กลุ่มย่อย (จำนวนการซ้ำ) ดังนั้นจำนวนดีกรีอิสระ k จะเป็นดังนี้:
ก) สำหรับ จำนวนเงินทั้งหมดส่วนเบี่ยงเบนกำลังสอง (i7zag)
b) สำหรับผลรวมระหว่างกลุ่มของการเบี่ยงเบนกำลังสอง ^m.gP)
c) สำหรับผลรวมภายในกลุ่มของการเบี่ยงเบนกำลังสอง วี v.gR)
ตามกฎสำหรับการเพิ่มรูปแบบต่างๆ:
ตัวอย่างเช่น ถ้าในการทดลอง มีรูปแบบการทดลองสี่แบบเกิดขึ้น (t = 4) ในการทำซ้ำห้าครั้งในแต่ละครั้ง (n = 5) และ ปริมาณรวมการสังเกต N = = ต o p = 4 * 5 = 20 ดังนั้นจำนวนองศาอิสระจะเท่ากับ:

เมื่อทราบผลรวมของการเบี่ยงเบนกำลังสองและจำนวนองศาอิสระ เราสามารถประมาณค่าประมาณที่เป็นกลาง (แก้ไขแล้ว) สำหรับความแปรปรวนสามค่าได้:

สมมติฐานว่าง H0 ได้รับการทดสอบโดยใช้เกณฑ์ B ในลักษณะเดียวกับการทดสอบของนักเรียน ในการตัดสินใจตรวจสอบ H0 จำเป็นต้องคำนวณมูลค่าที่แท้จริงของเกณฑ์แล้วเปรียบเทียบด้วย ค่าตาราง Ba สำหรับระดับนัยสำคัญที่ยอมรับ และจำนวนระดับความเป็นอิสระ k1และ k2 สำหรับการกระจายตัวสองครั้ง
ถ้า Bfakg > Ba ดังนั้นตามระดับนัยสำคัญที่ยอมรับ เราสามารถสรุปได้ว่าความแตกต่าง ผลต่างตัวอย่างถูกกำหนดไม่เพียงแต่โดยปัจจัยสุ่มเท่านั้น พวกเขามีความสำคัญ ในกรณีนี้ สมมติฐานว่างถูกปฏิเสธ และมีเหตุผลที่จะยืนยันว่าปัจจัยมีอิทธิพลต่อลักษณะผลลัพธ์อย่างมีนัยสำคัญ ถ้า< Ба, то нулевую гипотезу принимают и есть основание утверждать, что различия между сравниваемыми дисперсиями находятся в границах возможных случайных колебаний: действие фактора на результативный признак не является существенным.
การใช้แบบจำลองการวิเคราะห์ความแปรปรวนเฉพาะนั้นขึ้นอยู่กับทั้งจำนวนปัจจัยที่กำลังศึกษาและวิธีการสุ่มตัวอย่าง
c ขึ้นอยู่กับจำนวนปัจจัยที่กำหนดความแปรผันของคุณลักษณะผลลัพธ์ ตัวอย่างสามารถสร้างขึ้นตามปัจจัยหนึ่ง สองหรือมากกว่านั้น ตามนี้ การวิเคราะห์ความแปรปรวนแบ่งออกเป็นปัจจัยเดียวและหลายปัจจัย มิฉะนั้นจะเรียกว่าคอมเพล็กซ์การกระจายตัวแบบปัจจัยเดียวและหลายปัจจัย
รูปแบบการสลายตัวของความแปรผันทั้งหมดขึ้นอยู่กับการก่อตัวของกลุ่ม อาจเป็นแบบสุ่ม (การสังเกตของกลุ่มหนึ่งไม่เกี่ยวข้องกับการสังเกตของกลุ่มที่สอง) และแบบไม่สุ่ม (การสังเกตสองตัวอย่างมีความสัมพันธ์กันตามเงื่อนไขการทดลองทั่วไป) จะได้ตัวอย่างอิสระและขึ้นอยู่กับตัวอย่างตามลำดับ ตัวอย่างอิสระสามารถสร้างได้ทั้งจำนวนที่เท่ากันและไม่สม่ำเสมอ การก่อตัวของตัวอย่างที่ต้องพึ่งพาจะมีขนาดเท่ากัน
หากกลุ่มถูกสร้างขึ้นตามลำดับแบบสุ่ม ปริมาตรรวมของการแปรผันของลักษณะผลลัพธ์จะรวมถึงแฟกทอเรียล (กลุ่มระหว่าง) และความแปรผันที่เหลือ การแปรผันของการทำซ้ำ นั่นคือ
ในทางปฏิบัติ ในกรณีส่วนใหญ่ จำเป็นต้องพิจารณาตัวอย่างที่ต้องพึ่งพาเมื่อเงื่อนไขสำหรับกลุ่มและกลุ่มย่อยมีความเท่าเทียมกัน ดังนั้นใน ประสบการณ์ภาคสนามพื้นที่ทั้งหมดถูกแบ่งออกเป็นบล็อก โดยมีเงื่อนไขที่เข้มงวดที่สุด ในกรณีนี้ แต่ละตัวเลือกของการทดสอบจะได้รับโอกาสที่เท่ากันในการนำเสนอในทุกบล็อก ซึ่งจะทำให้เงื่อนไขสำหรับตัวเลือกและประสบการณ์ที่ทดสอบทั้งหมดเท่ากัน วิธีสร้างการทดลองนี้เรียกว่าวิธีบล็อกแบบสุ่ม การทดลองกับสัตว์ก็ทำเช่นเดียวกัน
เมื่อประมวลผลข้อมูลเศรษฐกิจและสังคมโดยใช้วิธีการวิเคราะห์ความแปรปรวน จำเป็นต้องจำไว้ว่าเนื่องจากปัจจัยจำนวนมากและความสัมพันธ์กันของปัจจัยเหล่านั้น จึงเป็นเรื่องยากแม้จะกำหนดระดับเงื่อนไขอย่างระมัดระวังที่สุดก็ตาม ในการกำหนดระดับของวัตถุประสงค์ อิทธิพลของแต่ละปัจจัยต่อลักษณะผลลัพธ์ ดังนั้น ระดับความแปรผันที่เหลือจึงถูกกำหนดไม่เพียงแต่จากสาเหตุแบบสุ่มเท่านั้น แต่ยังพิจารณาจากปัจจัยสำคัญที่ไม่ได้นำมาพิจารณาเมื่อสร้างแบบจำลองการวิเคราะห์ความแปรปรวนด้วย ด้วยเหตุนี้ ความแปรปรวนคงเหลือที่เป็นพื้นฐานสำหรับการเปรียบเทียบจึงไม่เพียงพอต่อวัตถุประสงค์ จึงมีการประเมินค่าสูงเกินไปอย่างชัดเจน และไม่สามารถทำหน้าที่เป็นเกณฑ์สำหรับความสำคัญของอิทธิพลของปัจจัยต่างๆ ได้ ในเรื่องนี้เมื่อสร้างแบบจำลองการวิเคราะห์ความแปรปรวนจะกลายเป็น ปัญหาที่เกิดขึ้นจริงการเลือก ปัจจัยที่สำคัญที่สุดและปรับระดับเงื่อนไขสำหรับการสำแดงการกระทำของแต่ละคน นอกจาก. การใช้การวิเคราะห์ความแปรปรวนถือว่าปกติหรือใกล้เคียง การกระจายตัวแบบปกติประชากรทางสถิติที่อยู่ระหว่างการศึกษา หากไม่ตรงตามเงื่อนไขนี้ ค่าประมาณที่ได้จากการวิเคราะห์ความแปรปรวนจะเกินความจริง
การวิเคราะห์ความแปรปรวนคือการวิเคราะห์ความแปรปรวนของคุณลักษณะที่มีประสิทธิผลภายใต้อิทธิพลของปัจจัยตัวแปรที่ได้รับการควบคุม (ในวรรณคดีต่างประเทศเรียกว่า ANOVA – “การวิเคราะห์ความแปรปรวน”)
ลักษณะผลลัพธ์เรียกอีกอย่างว่าลักษณะเฉพาะและปัจจัยที่มีอิทธิพลเรียกว่าลักษณะอิสระ
ข้อจำกัดของวิธีการ: คุณลักษณะอิสระสามารถวัดได้ในระดับที่กำหนด ลำดับ หรือเมตริก ขึ้นอยู่กับคุณลักษณะเฉพาะ - ในระดับเมตริกเท่านั้น เพื่อทำการวิเคราะห์ความแปรปรวน จะมีการระบุการไล่ระดับของคุณลักษณะแฟคเตอร์หลายระดับ และองค์ประกอบตัวอย่างทั้งหมดจะถูกจัดกลุ่มตามการไล่ระดับเหล่านี้
การตั้งสมมติฐานในการวิเคราะห์ความแปรปรวน
สมมติฐานว่าง: “ค่าเฉลี่ยของลักษณะผลลัพธ์ในทุกเงื่อนไขของปัจจัย (หรือการไล่ระดับของปัจจัย) จะเท่ากัน”
สมมติฐานทางเลือก: “ค่าเฉลี่ยของลักษณะที่มีประสิทธิภาพใน เงื่อนไขที่แตกต่างกันการกระทำของปัจจัยนั้นแตกต่างกัน”
การวิเคราะห์ความแปรปรวนสามารถแบ่งออกเป็นหลายประเภท ขึ้นอยู่กับ:
ตามจำนวนปัจจัยอิสระที่พิจารณา
จำนวนตัวแปรผลลัพธ์ที่สัมผัสกับปัจจัย
เกี่ยวกับธรรมชาติ ธรรมชาติของการได้มา และการมีอยู่ของความสัมพันธ์ระหว่างตัวอย่างค่าที่เปรียบเทียบ
หากมีปัจจัยหนึ่งที่กำลังศึกษาอิทธิพลอยู่ การวิเคราะห์ความแปรปรวนเรียกว่าการวิเคราะห์ปัจจัยเดียว และแบ่งออกเป็นสองประเภท:
- การวิเคราะห์ตัวอย่างที่ไม่เกี่ยวข้อง (เช่น ต่างกัน) - ตัวอย่างเช่น ผู้ตอบแบบสอบถามกลุ่มหนึ่งแก้ไขปัญหาในสภาพที่เงียบสงบ กลุ่มที่สอง - ในห้องที่มีเสียงดัง (ในกรณีนี้ก็คือ สมมติฐานว่างจะประมาณนี้ “เวลาเฉลี่ยในการแก้ปัญหาประเภทนี้จะเท่ากันทั้งในห้องที่เงียบและเสียงดัง” กล่าวคือ ไม่ได้ขึ้นอยู่กับปัจจัยด้านเสียง)
- การวิเคราะห์ตัวอย่างที่เชื่อมโยง นั่นคือการวัดสองครั้งดำเนินการกับกลุ่มผู้ตอบแบบสอบถามกลุ่มเดียวกันภายใต้เงื่อนไขที่ต่างกัน ตัวอย่างเดียวกัน: ครั้งแรกที่ปัญหาได้รับการแก้ไขอย่างเงียบ ๆ ครั้งที่สอง - ปัญหาที่คล้ายกัน - ในสภาวะที่มีการรบกวนทางเสียง (ในทางปฏิบัติ การทดลองดังกล่าวควรได้รับการดำเนินการด้วยความระมัดระวัง เนื่องจากอาจมีปัจจัยที่ไม่สามารถนับรวมได้คือ "ความสามารถในการเรียนรู้" ซึ่งผู้วิจัยเสี่ยงต่อการเปลี่ยนแปลงเงื่อนไข กล่าวคือ เสียงรบกวน)
หากมีการศึกษาอิทธิพลของปัจจัยสองปัจจัยขึ้นไปพร้อมกัน เรากำลังเผชิญกับ การวิเคราะห์ความแปรปรวนหลายตัวแปร ซึ่งสามารถแบ่งย่อยตามประเภทตัวอย่างได้
หากตัวแปรหลายตัวได้รับผลกระทบจากปัจจัย - เรากำลังพูดถึงโอ การวิเคราะห์หลายตัวแปร - การทำการวิเคราะห์ความแปรปรวนหลายตัวแปรจะดีกว่าการวิเคราะห์ตัวแปรเดียวเฉพาะเมื่อตัวแปรตามไม่เป็นอิสระจากกันและมีความสัมพันธ์ซึ่งกันและกัน
โดยทั่วไป งานของการวิเคราะห์ความแปรปรวนคือการระบุความแปรผันเฉพาะสามประการจากความแปรปรวนทั่วไปของลักษณะ:
ความแปรปรวนที่เกิดจากการกระทำของตัวแปรอิสระ (ปัจจัย) แต่ละตัวที่กำลังศึกษาอยู่
ความแปรปรวนอันเนื่องมาจากปฏิสัมพันธ์ของตัวแปรอิสระที่กำลังศึกษาอยู่
ความแปรปรวนแบบสุ่มเนื่องจากสถานการณ์ที่ไม่สามารถระบุได้ทั้งหมด
เพื่อประเมินความแปรปรวนที่เกิดจากการกระทำของตัวแปรที่ศึกษาและการโต้ตอบของตัวแปรเหล่านั้น จะมีการคำนวณอัตราส่วนของตัวบ่งชี้ที่สอดคล้องกันของความแปรปรวนและความแปรปรวนแบบสุ่ม ตัวบ่งชี้ความสัมพันธ์นี้คือการทดสอบ Fisher F
กว่าใน ในระดับที่มากขึ้นความแปรปรวนของลักษณะนั้นเกิดจากการกระทำของปัจจัยที่มีอิทธิพลหรือปฏิสัมพันธ์ของมัน ยิ่งค่าเชิงประจักษ์ของเกณฑ์ยิ่งสูง  .
.
ในสูตรการคำนวณเกณฑ์  รวมถึงการประมาณค่าความแปรปรวนด้วย ดังนั้นวิธีนี้จึงอยู่ในหมวดหมู่ของค่าพารามิเตอร์
รวมถึงการประมาณค่าความแปรปรวนด้วย ดังนั้นวิธีนี้จึงอยู่ในหมวดหมู่ของค่าพารามิเตอร์
การวิเคราะห์ความแปรปรวนแบบทางเดียวแบบไม่มีพารามิเตอร์สำหรับตัวอย่างอิสระคือการทดสอบ Kruskal-Wallace คล้ายกับการทดสอบ Mann-Whitney สำหรับตัวอย่างอิสระ 2 ตัวอย่าง ยกเว้นว่าจะรวมอันดับสำหรับแต่ละตัวอย่าง  กลุ่ม
กลุ่ม
นอกจากนี้ สามารถใช้เกณฑ์มัธยฐานในการวิเคราะห์ความแปรปรวนได้ เมื่อใช้งาน แต่ละกลุ่มจะมีการกำหนดจำนวนการสังเกตที่เกินค่ามัธยฐานที่คำนวณได้สำหรับทุกกลุ่ม และจำนวนการสังเกตที่น้อยกว่าค่ามัธยฐาน หลังจากนั้นจึงสร้างตารางฉุกเฉินแบบสองมิติ
การทดสอบฟรีดแมนเป็นการสรุปทั่วไปแบบไม่มีพารามิเตอร์ของการทดสอบทีแบบคู่สำหรับกรณีตัวอย่างที่มีการวัดซ้ำ เมื่อจำนวนตัวแปรที่ถูกเปรียบเทียบมากกว่าสองตัว
ไม่เหมือน การวิเคราะห์ความสัมพันธ์ในการวิเคราะห์ความแปรปรวน ผู้วิจัยดำเนินการจากการสันนิษฐานว่าตัวแปรบางตัวทำหน้าที่เป็นตัวที่มีอิทธิพล (เรียกว่าปัจจัยหรือตัวแปรอิสระ) ในขณะที่ตัวแปรอื่นๆ (ลักษณะผลลัพธ์หรือตัวแปรตาม) ได้รับอิทธิพลจากปัจจัยเหล่านี้ แม้ว่าสมมติฐานนี้จะเป็นไปตามขั้นตอนการคำนวณทางคณิตศาสตร์ แต่ก็ยังต้องใช้ความระมัดระวังในการสรุปเกี่ยวกับเหตุและผล
ตัวอย่างเช่นหากเราตั้งสมมติฐานเกี่ยวกับการพึ่งพาความสำเร็จของงานของเจ้าหน้าที่ในปัจจัย H (ความกล้าหาญทางสังคมตาม Cattell) ก็จะไม่รวมสิ่งที่ตรงกันข้าม: ความกล้าหาญทางสังคมของผู้ถูกกล่าวหาสามารถเกิดขึ้น (เพิ่มขึ้น) ในฐานะ ผลลัพธ์ของความสำเร็จในการทำงานของเขา - นี่คือด้านหนึ่ง ในทางกลับกัน เราควรตระหนักว่า “ความสำเร็จ” วัดกันอย่างไร? หากไม่ได้ขึ้นอยู่กับลักษณะวัตถุประสงค์ (เช่น "ปริมาณการขาย" ที่ทันสมัยในปัจจุบัน ฯลฯ ) แต่ การประเมินโดยผู้เชี่ยวชาญเพื่อนร่วมงานก็มีความเป็นไปได้ที่ "ความสำเร็จ" จะถูกแทนที่ด้วยลักษณะพฤติกรรมหรือส่วนบุคคล (โดยเจตนา การสื่อสาร การแสดงอาการภายนอกของความก้าวร้าว ฯลฯ )
การวิเคราะห์ความแปรปรวน– วิธีการวิจัยทางสถิติที่ศึกษาอิทธิพลของปัจจัยส่วนบุคคลที่มีต่อตัวบ่งชี้ประสิทธิภาพ ช่วยให้คุณสามารถเลือกหนึ่งในหลายปัจจัยและประเมินอิทธิพลของมันต่อการเปลี่ยนแปลงของคุณลักษณะที่มีประสิทธิผลและอิทธิพลของปัจจัยอื่น ๆ ทั้งหมดในผลรวมต่อการเปลี่ยนแปลงของคุณลักษณะที่มีประสิทธิผล
วัตถุประสงค์ของการวิเคราะห์ความแปรปรวนคือเพื่อทดสอบความสำคัญของความแตกต่างระหว่างค่าเฉลี่ยโดยการเปรียบเทียบความแปรปรวน ความแปรปรวนของคุณลักษณะที่วัดได้จะถูกแยกย่อยออกเป็นเงื่อนไขอิสระ ซึ่งแต่ละเงื่อนไขจะระบุลักษณะอิทธิพลของปัจจัยเฉพาะหรือปฏิสัมพันธ์ของปัจจัยนั้นๆ การเปรียบเทียบข้อกำหนดดังกล่าวในภายหลังช่วยให้เราสามารถประเมินความสำคัญของแต่ละปัจจัยที่กำลังศึกษาอยู่ตลอดจนการผสมผสานกัน
ขั้นตอนของการวิเคราะห์ความแปรปรวน:
1. มีการระบุปัจจัยหลายประการที่อาจส่งผลต่อ Y
2. จากปัจจัยทั้งหมด มีปัจจัยหลักประการหนึ่งที่โดดเด่น
3. ข้อมูลทั้งหมดจะถูกจัดกลุ่มตามคุณลักษณะที่เลือก (หมายเลข, ช่วงเวลา)
4. ความแปรปรวนรวม Y ถูกคำนวณ (จากประชากรทั้งหมด):
5. คำนวณความแปรปรวนระหว่างกลุ่ม - โดยแสดงลักษณะการแปรผันของ Y ภายใต้อิทธิพลของปัจจัยที่เป็นรากฐานของการจัดกลุ่ม:  ,
,
ที่ไหน: n เจ– ปริมาณกลุ่ม  – ค่าเฉลี่ยของคุณลักษณะภายในกลุ่ม
– ค่าเฉลี่ยของคุณลักษณะภายในกลุ่ม
6. ความแปรผันของ Y ภายใต้อิทธิพลของปัจจัยอื่น ๆ ได้รับการประเมินโดยใช้ค่าเฉลี่ยของความแปรปรวนภายในกลุ่ม:  .
.
7. ตรวจสอบ: ผลรวมของความแปรปรวนระหว่างกลุ่มและค่าเฉลี่ยของความแปรปรวนภายในกลุ่มควรเท่ากับ ความแปรปรวนทั้งหมด(ทฤษฎีบทการบวกความแปรปรวน):  .
.
8. ความถูกต้องของการเลือกปัจจัยประเมินโดยใช้ตัวบ่งชี้สัมพัทธ์ของการเปลี่ยนแปลง:
– ค่าสัมประสิทธิ์การตัดสินใจ:  – กำหนดลักษณะสัดส่วนของการแปรผัน Y เนื่องจากอิทธิพลของปัจจัย (เช่น 70% - เช่น 70% ของการแปรผัน Y อธิบายโดยอิทธิพลของปัจจัย)
– กำหนดลักษณะสัดส่วนของการแปรผัน Y เนื่องจากอิทธิพลของปัจจัย (เช่น 70% - เช่น 70% ของการแปรผัน Y อธิบายโดยอิทธิพลของปัจจัย)
– ความสัมพันธ์เชิงประจักษ์:  – แสดงลักษณะความใกล้ชิดของการเชื่อมต่อ (ตามมาตราส่วน Chaddock)
– แสดงลักษณะความใกล้ชิดของการเชื่อมต่อ (ตามมาตราส่วน Chaddock)
ตามกฎแล้ว การวิเคราะห์ความแปรปรวนจะดำเนินการในลักษณะวนซ้ำ เมื่อวิเคราะห์อิทธิพลของปัจจัยที่มีต่อ Y ตามลำดับจนกว่าจะระบุปัจจัยที่สำคัญที่สุดได้
30. การใช้วิธีดัชนีในการวิเคราะห์ข้อมูลทางเศรษฐกิจ
ดัชนี– ตัวบ่งชี้สัมพัทธ์ที่แสดงถึงการเปลี่ยนแปลงขนาดของปรากฏการณ์ในเวลา ในอวกาศ หรือเมื่อเปรียบเทียบกับระยะใดๆ
วิธีการจัดทำดัชนี– วิธีการวิจัยทางสถิติด้วยความช่วยเหลือในการพัฒนาปรากฏการณ์ในเวลาอวกาศเมื่อเปรียบเทียบกับมาตรฐานและศึกษาบทบาทของปัจจัยในการเปลี่ยนแปลงปรากฏการณ์ที่ซับซ้อน
ดัชนีทางสถิติ– นี่คือค่าสัมพัทธ์ของการเปรียบเทียบผลรวมที่ซับซ้อนกับแต่ละหน่วยโดยการเปรียบเทียบค่าสัมบูรณ์
พื้นฐานของวิธีดัชนีในการพิจารณาการเปลี่ยนแปลงในการผลิตและการหมุนเวียนของสินค้าคือการเปลี่ยนจากรูปแบบวัสดุธรรมชาติในการแสดงออกของมวลสินค้าโภคภัณฑ์ไปเป็นมาตรการต้นทุน (การเงิน) โดยการแสดงออกทางการเงินของมูลค่าของสินค้าแต่ละชิ้นที่ไม่มีใครเทียบเคียงได้เนื่องจากคุณค่าของผู้บริโภคถูกกำจัดและบรรลุความสามัคคี
เมื่อคำนวณดัชนี สิ่งต่อไปนี้จะมีความโดดเด่น:
– ระดับการเปรียบเทียบ (ระดับของงวดปัจจุบัน, องค์กรนี้)
– พื้นฐานของการเปรียบเทียบ (ระดับของช่วงเวลาฐาน ระดับที่วางแผนไว้ ระดับของวัตถุบางอย่าง)
ประเภทของดัชนี:
1. ตามระดับความครอบคลุม: ส่วนบุคคล, ทั่วไป
2. จากการเปรียบเทียบ: ไดนามิก (เปลี่ยนแปลงตามเวลา) อาณาเขต
3. ไดนามิก: พื้นฐาน ( ฉัน 1 = ถาม 1 / ถาม 0 ;ฉัน 2 = ถาม 2 / ถาม 0 ) และลูกโซ่ ( ฉัน 1 = ถาม 1 / ถาม 0 ;ฉัน 2 = ถาม 2 / ถาม 1 ).
4. ตามลักษณะของขอบเขตการวิจัย: เชิงปริมาณ, เชิงคุณภาพ
5. ตามขอบเขตของปรากฏการณ์: ค่าคงที่ องค์ประกอบที่แปรผัน
6. ตามระยะเวลาการคำนวณ : รายปี, รายไตรมาส..
รายบุคคล– ระบุลักษณะการเปลี่ยนแปลงในแต่ละหน่วยของประชากรทางสถิติหรือคุณสมบัติของหน่วยของประชากร ตัวเศษคือสิ่งที่กำลังศึกษาอยู่ ตัวส่วนคือฐานที่ใช้เปรียบเทียบ
 ,
,
 ,
, ,
,
ทั่วไป– กำหนดลักษณะผลลัพธ์สรุปของการเปลี่ยนแปลงในทุกหน่วยโดยรวม:
เพื่อระบุลักษณะการเปลี่ยนแปลง: ฉัน ถาม = ถาม 1 / ถาม 0 .
รวม– ตัวเศษและตัวส่วนประกอบด้วยชุดองค์ประกอบที่เชื่อมโยงกันของประชากรที่กำลังศึกษา การเปรียบเทียบหน่วยที่แตกต่างกันทำได้โดยการแนะนำปัจจัยพิเศษในดัชนี - ผู้วัดร่วม ในกรณีนี้ ค่าของมิเตอร์ร่วมทั้งในเศษและส่วนได้รับการแก้ไขที่ระดับเดียวกัน (ฐานหรือกระแส):
 (ปาสเช่),
(ปาสเช่),  (ลาสเปย์เรส), ฉัน หน้า
=
ฉัน ร
ฉัน ถาม- แล้ว:
(ลาสเปย์เรส), ฉัน หน้า
=
ฉัน ร
ฉัน ถาม- แล้ว:  ,
, .
.
 (ฟิชเชอร์).
(ฟิชเชอร์).
เฉลี่ย(ใช้หมวดหมู่ทางเศรษฐกิจที่แท้จริงเป็นตัวเปรียบเทียบ):
–
 (รูปแบบถ่วงน้ำหนักค่าเฉลี่ยฮาร์มอนิก);
(รูปแบบถ่วงน้ำหนักค่าเฉลี่ยฮาร์มอนิก);
–
 (ค่าเฉลี่ยถ่วงน้ำหนักเลขคณิต)
(ค่าเฉลี่ยถ่วงน้ำหนักเลขคณิต)
ดัชนีตัวแปร,องค์ประกอบและการเปลี่ยนแปลงโครงสร้างอย่างต่อเนื่อง –ความสามารถในการทำกำไรโดยเฉลี่ย:
 ,
,
 ,
,
การเปลี่ยนแปลงโดยสมบูรณ์ในตัวบ่งชี้ภายใต้อิทธิพลของปัจจัย:
Δ หน้า = ∑ พี 1 ถาม 1 – ∑ พี 0 ถาม 0 .
Δ พี = ∑ พี 1 ถาม 1 – ∑ พี 0 ถาม 1 .
Δ ถาม = ∑ พี 0 ถาม 1 – ∑ พี 0 ถาม 0 .
 คุณสมบัติทางเคมีของไซเลนซิลิคอนไฮไดรด์ 4
คุณสมบัติทางเคมีของไซเลนซิลิคอนไฮไดรด์ 4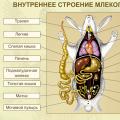 งานห้องปฏิบัติการ “โครงสร้างโครงกระดูกของสัตว์เลี้ยงลูกด้วยนม โครงสร้างภายนอกและภายในของงานห้องปฏิบัติการของสัตว์เลี้ยงลูกด้วยนม
งานห้องปฏิบัติการ “โครงสร้างโครงกระดูกของสัตว์เลี้ยงลูกด้วยนม โครงสร้างภายนอกและภายในของงานห้องปฏิบัติการของสัตว์เลี้ยงลูกด้วยนม Stolypin, Pyotr Arkadyevich - ชีวประวัติสั้น ๆ
Stolypin, Pyotr Arkadyevich - ชีวประวัติสั้น ๆ