Phân tích phương sai đề cập đến một số. Giả thuyết được kiểm tra là không có sự khác biệt giữa các nhóm.
Các phương pháp xác minh đã thảo luận ở trên giả thuyết thống kê về tầm quan trọng của sự khác biệt giữa hai mức trung bình trong thực tế được sử dụng hạn chế. Điều này là do thực tế là để xác định ảnh hưởng của tất cả các điều kiện và yếu tố có thể có đối với đặc điểm kết quả, các thí nghiệm tại hiện trường và trong phòng thí nghiệm, theo quy định, được thực hiện không phải bằng hai mà là số lượng mẫu lớn hơn (1220 mẫu trở lên). ).
Thông thường, các nhà nghiên cứu so sánh phương tiện của một số mẫu được kết hợp thành một phức hợp duy nhất. Ví dụ, khi nghiên cứu ảnh hưởng của các loại và liều lượng phân bón đến năng suất cây trồng, người ta lặp lại thí nghiệm trong tùy chọn khác nhau. Trong những trường hợp này, việc so sánh theo cặp trở nên cồng kềnh và việc phân tích thống kê toàn bộ tổ hợp yêu cầu sử dụng một phương pháp đặc biệt. Phương pháp này, được phát triển trong thống kê toán học, được gọi là phân tích phương sai. Nó lần đầu tiên được sử dụng bởi nhà thống kê người Anh R. Fisher khi xử lý kết quả của các thí nghiệm nông học (1938).
Phân tích phương sai là một phương pháp đánh giá thống kêđộ tin cậy của biểu hiện về sự phụ thuộc của tính năng hiệu quả vào một hoặc nhiều yếu tố. Sử dụng phương pháp phân tích phương sai, các giả thuyết thống kê được kiểm tra về mức trung bình trong một số quần thể nói chung có phân phối bình thường.
Phân tích phương sai là một trong những phương pháp chính để đánh giá thống kê kết quả của một thí nghiệm. Nó cũng ngày càng được sử dụng nhiều hơn trong phân tích thông tin kinh tế. Việc phân tích phương sai cho phép thiết lập các chỉ số chọn lọc về mối quan hệ giữa các dấu hiệu hiệu quả và yếu tố là đủ để phổ biến dữ liệu thu được từ mẫu cho dân số nói chung. Ưu điểm của phương pháp này là đưa ra kết luận khá đáng tin cậy từ các mẫu nhỏ.
Bằng cách kiểm tra sự thay đổi của thuộc tính kết quả dưới tác động của một hoặc nhiều yếu tố, sử dụng phân tích phương sai, ngoài ước tính chung về tầm quan trọng của các yếu tố phụ thuộc, người ta có thể thu được đánh giá về sự khác biệt trong các giá trị trung bình mà được hình thành ở các mức độ khác nhau của các yếu tố và ý nghĩa tác động qua lại của các yếu tố. Phân tích phương sai được sử dụng để nghiên cứu sự phụ thuộc của cả định lượng và tính năng định tính, cũng như sự kết hợp của chúng.
Bản chất của phương pháp này là nghiên cứu thống kê xác suất ảnh hưởng của một hoặc nhiều yếu tố, cũng như sự tương tác của chúng đối với tính năng hiệu quả. Theo đó, với sự trợ giúp của phân tích phân tán, ba nhiệm vụ chính được giải quyết: 1) Tổng điểm tầm quan trọng của sự khác biệt giữa các phương tiện nhóm; 2) đánh giá khả năng tương tác của các yếu tố; 3) đánh giá tầm quan trọng của sự khác biệt giữa các cặp phương tiện. Thông thường, các nhà nghiên cứu phải giải quyết những vấn đề như vậy khi tiến hành các thí nghiệm thực địa và kỹ thuật chăn nuôi, khi nghiên cứu ảnh hưởng của một số yếu tố đến đặc điểm kết quả.
Sơ đồ nguyên tắc của phân tích phân tán bao gồm việc thiết lập các nguồn biến thể chính của tính năng hiệu quả và xác định khối lượng biến thể (tổng các độ lệch bình phương) bởi các nguồn hình thành của nó; xác định số bậc tự do tương ứng với các thành phần biến thể chung; tính toán phương sai theo tỷ lệ của các khối lượng biến thể tương ứng với số bậc tự do của chúng; phân tích mối quan hệ giữa các độ phân tán; đánh giá độ tin cậy của sự khác biệt giữa các giá trị trung bình và đưa ra kết luận.
Sơ đồ này được bảo toàn cả trong các mô hình ANOVA đơn giản, khi dữ liệu được nhóm theo một thuộc tính và trong các mô hình phức tạp, khi dữ liệu được nhóm theo hai hoặc nhiều thuộc tính. Tuy nhiên, với sự gia tăng số lượng các đặc điểm nhóm, quá trình phân tách biến thể chung theo các nguồn hình thành của nó trở nên phức tạp hơn.
Theo sơ đồ mạch phân tích phương sai có thể được trình bày dưới dạng năm giai đoạn liên tiếp:
1) định nghĩa và phân tách biến thể;
2) xác định số bậc tự do dao động;
3) tính toán độ phân tán và tỷ lệ của chúng;
4) phân tích sự phân tán và tỷ lệ của chúng;
5) đánh giá độ tin cậy của sự khác biệt giữa các phương tiện và việc đưa ra kết luận về việc kiểm tra giả thuyết không.
Phần tốn nhiều thời gian nhất của việc phân tích phương sai là giai đoạn đầu tiên - định nghĩa và phân tách biến thể theo nguồn hình thành của nó. Trình tự mở rộng tổng khối lượng biến đổi đã được thảo luận chi tiết trong Chương 5.
Cơ sở để giải các bài toán phân tích độ phân tán là quy luật mở rộng (cộng) biến thiên, theo đó tổng biến thiên (biến động) của thuộc tính kết quả được chia thành hai: biến thiên do tác động của nhân tố nghiên cứu (nhân tố ), và độ biến thiên do tác động của các nguyên nhân ngẫu nhiên gây ra, đó là
Chúng ta hãy giả sử rằng dân số đang nghiên cứu được chia theo một thuộc tính yếu tố thành nhiều nhóm, mỗi nhóm được đặc trưng bởi đặc điểm riêng của nó. trung bình dấu hiệu hiệu quả. Đồng thời, sự thay đổi của các giá trị này có thể được giải thích bằng hai loại lý do: những nguyên nhân tác động một cách có hệ thống đến tính năng hiệu quả và có thể điều chỉnh được trong quá trình thử nghiệm và những nguyên nhân không thể điều chỉnh được. Rõ ràng là sự thay đổi giữa các nhóm (giai thừa hoặc hệ thống) chủ yếu phụ thuộc vào tác động của yếu tố được nghiên cứu và trong nhóm (dư hoặc ngẫu nhiên) - vào tác động của các yếu tố ngẫu nhiên.
Để đánh giá tầm quan trọng của sự khác biệt giữa các phương tiện nhóm, cần xác định các biến thể giữa các nhóm và trong nhóm. Nếu biến thể giữa các nhóm (giai thừa) vượt quá đáng kể biến thể trong nhóm (dư), thì yếu tố đó đã ảnh hưởng đến đặc điểm kết quả, làm thay đổi đáng kể các giá trị của trung bình nhóm. Nhưng câu hỏi đặt ra là tỷ lệ giữa các biến thể giữa các nhóm và giữa các nhóm có thể được coi là đủ để kết luận về độ tin cậy (ý nghĩa) của sự khác biệt giữa các phương tiện nhóm.
Để đánh giá tầm quan trọng của sự khác biệt giữa các phương tiện và đưa ra kết luận về việc kiểm tra giả thuyết không (H0: x1 = x2 = ... = xn), phân tích phương sai sử dụng một loại tiêu chuẩn - tiêu chí G, luật phân phối của được thành lập bởi R. Fisher. Tiêu chí này là tỷ lệ của hai phương sai: giai thừa, được tạo ra bởi tác động của yếu tố đang nghiên cứu và phần dư, do tác động của các nguyên nhân ngẫu nhiên:
![]()
Tỷ lệ phân tán r = t>u : £ * 2 do nhà thống kê người Mỹ Snedecor đề nghị được ký hiệu bằng chữ G để vinh danh người phát minh ra phép phân tích phương sai R. Fisher.
Phương sai của °2 và io2 là ước tính của phương sai dân số. Nếu các mẫu có phương sai °2 °2 được lấy từ cùng một quần thể chung, trong đó sự thay đổi về giá trị có nhân vật ngẫu nhiên, thì sự khác biệt về giá trị của °2 °2 cũng là ngẫu nhiên.
Nếu thử nghiệm kiểm tra ảnh hưởng của một số yếu tố (A, B, C, v.v.) đến tính năng hiệu quả cùng một lúc, thì độ phân tán do tác động của từng yếu tố phải tương đương với °e.gP, đó là
Nếu giá trị của phương sai nhân tố lớn hơn đáng kể so với phần dư, thì nhân tố đó ảnh hưởng đáng kể đến thuộc tính kết quả và ngược lại.
Trong các thử nghiệm đa yếu tố, bên cạnh sự khác biệt do tác động của từng yếu tố, hầu như luôn có sự khác biệt do sự tương tác của các yếu tố ($av: ^ls ^ss $liіs). Bản chất của sự tương tác là ảnh hưởng của một yếu tố thay đổi đáng kể thành các cấp độ khác nhau thứ hai (ví dụ, hiệu quả của chất lượng đất ở các liều lượng phân bón khác nhau).
Sự tương tác của các yếu tố cũng nên được đánh giá bằng cách so sánh các phương sai tương ứng 3 ^w.gr:

Khi tính giá trị thực của tiêu chí B, giá trị lớn nhất của phương sai được lấy ở tử số, do đó B > 1. Rõ ràng, tiêu chí B càng lớn thì sự khác biệt giữa các phương sai càng lớn. Nếu B = 1 thì vấn đề đánh giá mức độ ý nghĩa của các phương sai khác nhau bị loại bỏ.
Để xác định giới hạn của dao động ngẫu nhiên, tỷ lệ phương sai G. Fisher đã phát triển các bảng đặc biệt của phân phối B (Phụ lục 4 và 5). Tiêu chí B có liên quan hàm với xác suất và phụ thuộc vào số bậc tự do biến thiên k1 và k2 của hai phương sai được so sánh. Hai bảng thường được sử dụng để rút ra kết luận về giới hạn giá trị cao tiêu chí về mức ý nghĩa 0,05 và 0,01. Mức ý nghĩa 0,05 (hoặc 5%) có nghĩa là chỉ trong 5 trường hợp trong số 100 tiêu chí B có thể nhận giá trị bằng hoặc cao hơn giá trị được chỉ ra trong bảng. Mức ý nghĩa giảm từ 0,05 xuống 0,01 dẫn đến giá trị của tiêu chí B giữa hai phương sai tăng lên do tác động của các nguyên nhân ngẫu nhiên.
Giá trị của tiêu chí cũng phụ thuộc trực tiếp vào số bậc tự do của hai độ phân tán được so sánh. Nếu số bậc tự do có xu hướng vô cùng (k-me), thì tỷ lệ sẽ cho hai phân tán có xu hướng thống nhất.
Giá trị dạng bảng của tiêu chí B cho thấy khả năng biến ngẫu nhiên tỷ số của hai phương sai ở một mức ý nghĩa cho trước và số bậc tự do tương ứng của mỗi phương sai được so sánh. Trong các bảng này, giá trị của B được đưa ra cho các mẫu được tạo từ cùng một tổng thể chung, trong đó lý do thay đổi giá trị chỉ là ngẫu nhiên.
Giá trị của G được tìm thấy từ các bảng (Phụ lục 4 và 5) tại giao điểm của cột tương ứng (số bậc tự do cho độ phân tán lớn hơn - k1) và hàng (số bậc tự do cho độ phân tán nhỏ hơn - k2). Vì vậy, nếu phương sai lớn hơn (tử số G) k1 = 4 và phương sai nhỏ hơn (mẫu số G) k2 = 9, thì Ga ở mức ý nghĩa a = 0,05 sẽ là 3,63 (ứng dụng 4). Vì vậy, do tác động của các nguyên nhân ngẫu nhiên, vì các mẫu nhỏ, phương sai của một mẫu có thể, ở mức ý nghĩa 5%, vượt quá phương sai của mẫu thứ hai 3,63 lần. Khi giảm mức ý nghĩa từ 0,05 xuống 0,01, giá trị bảng của tiêu chí D, như đã lưu ý ở trên, sẽ tăng lên. Vì vậy, với cùng bậc tự do k1 = 4 và k2 = 9 và a = 0,01, giá trị dạng bảng của tiêu chí G sẽ là 6,99 (ứng dụng 5).
Xem xét quy trình xác định số bậc tự do trong phân tích phương sai. Số bậc tự do, tương ứng với tổng bình phương độ lệch, được phân tách thành các thành phần tương ứng tương tự như phân tách tổng bình phương độ lệch Tổng số bậc tự do (k") được phân tách thành số bậc tự do đối với các biến thể giữa các nhóm (k1) và nội nhóm (k2).
Như vậy, nếu một dân số mẫu bao gồm N quan sát chia cho t nhóm (số lượng tùy chọn thử nghiệm) và P nhóm con (số lần lặp lại) thì số bậc tự do k tương ứng sẽ là:
a) cho tổng các độ lệch bình phương (dszar)
b) cho tổng các độ lệch bình phương giữa các nhóm ^m.gP)
c) cho tổng các độ lệch bình phương trong nhóm V wgr)
Theo quy tắc cộng biến thiên:
Ví dụ: nếu bốn biến thể của thử nghiệm được hình thành trong thử nghiệm (m = 4) trong năm lần lặp lại, mỗi biến thể (n = 5) và tổng cộng quan sát N = = t o p \u003d 4 * 5 \u003d 20, thì số bậc tự do tương ứng bằng:

Biết tổng bình phương độ lệch của số bậc tự do, có thể xác định các ước lượng không chệch (đã điều chỉnh) cho ba phương sai:

Giả thuyết không H0 theo tiêu chí B được kiểm tra theo cách tương tự như bằng kiểm định u của Sinh viên. Để ra quyết định kiểm tra H0 cần tính toán giá trị thực của tiêu chí và so sánh với bảng giá trị Ba cho mức ý nghĩa được chấp nhận a và số bậc tự do k1 và k2 cho hai phân tán.
Nếu Bfakg > Ba, thì theo mức ý nghĩa được chấp nhận, chúng ta có thể kết luận rằng sự khác biệt về phương sai mẫu được xác định không chỉ bởi các yếu tố ngẫu nhiên; chúng có ý nghĩa. Trong trường hợp này, giả thuyết không bị bác bỏ và có lý do để tin rằng yếu tố ảnh hưởng đáng kể đến thuộc tính kết quả. Nếu như< Ба, то нулевую гипотезу принимают и есть основание утверждать, что различия между сравниваемыми дисперсиями находятся в границах возможных случайных колебаний: действие фактора на результативный признак не является существенным.
Việc sử dụng một hoặc một mô hình ANOVA khác phụ thuộc vào số lượng các yếu tố được nghiên cứu và phương pháp lấy mẫu.
Tùy thuộc vào số lượng các yếu tố xác định sự thay đổi của tính năng hiệu quả, các mẫu có thể được hình thành bởi một, hai hoặc nhiều yếu tố. Theo phân tích này, phương sai được chia thành đơn yếu tố và đa yếu tố. Mặt khác, nó còn được gọi là phức hợp phân tán đơn yếu tố và đa yếu tố.
Sơ đồ phân hủy của biến thể chung phụ thuộc vào sự hình thành của các nhóm. Nó có thể là ngẫu nhiên (các quan sát của một nhóm không liên quan đến các quan sát của nhóm thứ hai) và không ngẫu nhiên (các quan sát của hai mẫu được kết nối với nhau bởi các điều kiện chung của thí nghiệm). Theo đó, các mẫu độc lập và phụ thuộc được lấy. Các mẫu độc lập có thể được hình thành với cả số lượng bằng nhau và không đồng đều. Sự hình thành của các mẫu phụ thuộc giả định số lượng bằng nhau của chúng.
Nếu các nhóm được hình thành theo thứ tự không bạo lực, thì tổng lượng biến thể của đặc điểm kết quả bao gồm, cùng với biến thể giai thừa (liên nhóm) và biến thể còn lại, biến thể của các lần lặp lại, nghĩa là
Trong thực tế, trong hầu hết các trường hợp, cần xem xét các mẫu phụ thuộc khi các điều kiện đối với các nhóm và nhóm con được cân bằng. Vâng, trong kinh nghiệm thực tế toàn bộ trang web được chia thành các khối, với các điều kiện virivnyanniya nhất. Đồng thời, mỗi biến thể của thử nghiệm đều có cơ hội như nhau để được thể hiện trong tất cả các khối, giúp đạt được sự cân bằng về điều kiện cho tất cả các tùy chọn, trải nghiệm đã thử nghiệm. Phương pháp xây dựng kinh nghiệm này được gọi là phương pháp khối ngẫu nhiên. Các thí nghiệm với động vật được thực hiện tương tự.
Khi xử lý dữ liệu kinh tế - xã hội bằng phương pháp phân tích phân tán, cần lưu ý rằng do có nhiều yếu tố và mối quan hệ qua lại của chúng nên rất khó, ngay cả khi đã sắp xếp các điều kiện cẩn thận nhất, để thiết lập mức độ ảnh hưởng khách quan của từng nhân tố riêng lẻ đến thuộc tính hiệu quả. Do đó, mức độ biến động còn lại không chỉ được xác định bởi các nguyên nhân ngẫu nhiên mà còn bởi các yếu tố quan trọng không được tính đến khi xây dựng mô hình ANOVA. Do đó, độ phân tán còn lại làm cơ sở để so sánh đôi khi trở nên không phù hợp với mục đích của nó, nó rõ ràng được đánh giá quá cao về độ lớn và không thể đóng vai trò là tiêu chí cho tầm quan trọng của ảnh hưởng của các yếu tố. Về vấn đề này, khi xây dựng các mô hình phân tích phương sai, vấn đề lựa chọn trở nên phù hợp. yếu tố quan trọng và san bằng các điều kiện để biểu hiện hành động của từng người trong số họ. Bên cạnh đó. việc sử dụng phân tích phương sai giả định phân phối bình thường hoặc gần với phân phối bình thường của các quần thể thống kê đang được nghiên cứu. Nếu điều kiện này không được đáp ứng, thì các ước tính thu được trong phân tích phương sai sẽ bị phóng đại.
Phân tích phương sai(từ tiếng Latinh Dispersio - phân tán / trong tiếng Anh là Analysis Of Variance - ANOVA) được sử dụng để nghiên cứu ảnh hưởng của một hoặc nhiều biến định tính (nhân tố) đến một biến định lượng phụ thuộc (phản ứng).
| |
Việc phân tích phương sai dựa trên giả định rằng một số biến có thể được coi là nguyên nhân (nhân tố, biến độc lập): và những biến khác là hậu quả (biến phụ thuộc). Các biến độc lập đôi khi được gọi chính xác là các yếu tố có thể điều chỉnh bởi vì trong thí nghiệm, nhà nghiên cứu có cơ hội thay đổi chúng và phân tích kết quả thu được.
mục tiêu chính phân tích phương sai(ANOVA) là nghiên cứu về tầm quan trọng của sự khác biệt giữa các phương tiện bằng cách so sánh (phân tích) các phương sai. Tách biệt tổng phương sai với nhiều nguồn, cho phép bạn so sánh phương sai gây ra bởi sự khác biệt giữa các nhóm với phương sai gây ra bởi sự thay đổi trong nhóm. Nếu giả thuyết không là đúng (về sự bằng nhau của các phương tiện trong một số nhóm quan sát được chọn từ dân số chung), ước tính phương sai liên quan đến sự biến thiên trong nhóm phải gần với ước tính phương sai giữa các nhóm. Nếu bạn chỉ so sánh giá trị trung bình của hai mẫu, phân tích phương sai sẽ cho kết quả giống như kiểm tra t mẫu độc lập thông thường (nếu bạn đang so sánh hai nhóm đối tượng hoặc quan sát độc lập) hoặc kiểm tra t mẫu phụ thuộc ( nếu bạn đang so sánh hai biến trên cùng một tập hợp đối tượng hoặc quan sát).
Bản chất của phân tích phương sai nằm ở chỗ chia tổng phương sai của đặc điểm nghiên cứu thành các thành phần riêng biệt do ảnh hưởng của các yếu tố cụ thể và kiểm định các giả thuyết về tầm quan trọng của ảnh hưởng của các yếu tố này đối với đặc điểm nghiên cứu. So sánh các thành phần của sự phân tán với nhau bằng cách sử dụng phép thử F của Fisher, có thể xác định tỷ lệ nào trong tổng mức độ biến thiên của tính trạng kết quả là do tác động của các yếu tố điều chỉnh.
Tài liệu nguồn để phân tích phương sai là dữ liệu nghiên cứu của ba hoặc nhiều mẫu: , có thể bằng nhau hoặc không bằng nhau về số lượng, cả được kết nối và ngắt kết nối. Theo số lượng các yếu tố điều chỉnh được xác định, phân tích phương sai có thể được một yếu tố(đồng thời nghiên cứu ảnh hưởng của một yếu tố đến kết quả thí nghiệm), hai yếu tố(khi nghiên cứu ảnh hưởng của hai yếu tố) và đa yếu tố(cho phép bạn đánh giá không chỉ ảnh hưởng của từng yếu tố một cách riêng biệt mà còn cả sự tương tác của chúng).
Phân tích phương sai thuộc nhóm các phương pháp tham số và do đó nó chỉ nên được sử dụng khi chứng minh rằng phân phối là bình thường.
Phân tích phương sai được sử dụng nếu biến phụ thuộc được đo lường theo thang tỷ lệ, khoảng hoặc thứ tự và các biến ảnh hưởng không phải là số (thang tên).
ví dụ về nhiệm vụ
Trong các vấn đề được giải quyết bằng cách phân tích phương sai, có một phản ứng có tính chất số, bị ảnh hưởng bởi một số biến có tính chất danh nghĩa. Ví dụ, một số loại khẩu phần vỗ béo vật nuôi hoặc hai cách giữ chúng, v.v.
Ví dụ 1: Trong tuần, một số quầy thuốc hoạt động ở ba địa điểm khác nhau. Trong tương lai, chúng ta chỉ có thể để lại một. Cần xác định xem có sự khác biệt có ý nghĩa thống kê giữa lượng bán thuốc tại các ki ốt hay không. Nếu có, chúng tôi sẽ chọn ki-ốt có doanh số bán hàng trung bình hàng ngày cao nhất. Nếu sự khác biệt về khối lượng bán hàng hóa ra là không đáng kể về mặt thống kê, thì các chỉ số khác sẽ là cơ sở để chọn một ki-ốt.
Ví dụ 2: So sánh sự tương phản của các phương tiện nhóm. Bảy đảng phái chính trị được sắp xếp theo thứ tự từ cực kỳ tự do đến cực kỳ bảo thủ và độ tương phản tuyến tính được sử dụng để kiểm tra xem liệu có xu hướng tăng khác 0 trong phương tiện nhóm hay không—tức là, liệu có sự gia tăng tuyến tính đáng kể về tuổi trung bình hay không khi xem xét các nhóm được sắp xếp theo thứ tự hướng từ tự do sang bảo thủ.
Ví dụ 3: Phân tích phương sai hai chiều. Số lượng bán sản phẩm, ngoài quy mô của cửa hàng, thường bị ảnh hưởng bởi vị trí của kệ với sản phẩm. ví dụ này chứa số liệu bán hàng hàng tuần được đặc trưng bởi bốn cách bố trí kệ và ba quy mô cửa hàng. Kết quả phân tích cho thấy rằng cả hai yếu tố - vị trí của kệ hàng hóa và quy mô của cửa hàng - đều ảnh hưởng đến số lượng bán hàng, nhưng sự tương tác của chúng không đáng kể.
Ví dụ 4: ANOVA đơn biến: Thiết kế khối đầy đủ hai lần xử lý ngẫu nhiên. Ảnh hưởng đến việc nướng bánh mì của tất cả kết hợp có thể ba chất béo và ba máy cắt bột. Bốn mẫu bột lấy từ bốn các nguồn khác nhau, đóng vai trò là các yếu tố ngăn chặn. Tầm quan trọng của sự tương tác giữa chất béo và chất béo cần được xác định. Sau đó, để xác định các tùy chọn khác nhau để chọn độ tương phản, cho phép bạn tìm ra sự kết hợp của các mức độ yếu tố khác nhau.
Ví dụ 5: Mô hình của một kế hoạch phân cấp (lồng nhau) với các hiệu ứng hỗn hợp. Ảnh hưởng của bốn đầu được chọn ngẫu nhiên được gắn trong một máy công cụ đối với sự biến dạng của các giá đỡ catốt bằng thủy tinh được sản xuất đã được nghiên cứu. (Các đầu được tích hợp sẵn trong máy nên không thể sử dụng cùng một đầu cho các máy khác nhau.) Hiệu ứng đầu được coi là một yếu tố ngẫu nhiên. Thống kê ANOVA cho thấy không có sự khác biệt đáng kể giữa các máy, nhưng có dấu hiệu cho thấy đầu máy có thể khác nhau. Sự khác biệt giữa tất cả các máy là không đáng kể, nhưng đối với hai trong số chúng, sự khác biệt giữa các loại đầu là rất đáng kể.
Ví dụ 6: Phân tích các phép đo lặp lại đơn biến bằng cách sử dụng sơ đồ phân chia. Thí nghiệm này được thực hiện để xác định ảnh hưởng của mức độ lo lắng của một cá nhân đối với thành tích thi trong bốn lần thử liên tiếp. Dữ liệu được tổ chức sao cho chúng có thể được coi là các nhóm tập con của toàn bộ tập dữ liệu ("toàn bộ ô"). Ảnh hưởng của lo lắng không đáng kể, trong khi ảnh hưởng của cố gắng là đáng kể.
Danh sách các phương pháp
- Các mô hình thí nghiệm nhân tố. Ví dụ: các yếu tố ảnh hưởng đến sự thành công của việc giải các bài toán; các yếu tố ảnh hưởng đến doanh số bán hàng.
Dữ liệu bao gồm một số chuỗi quan sát (xử lý), được coi là hiện thực hóa các mẫu độc lập. Giả thuyết ban đầu là không có sự khác biệt trong phương pháp điều trị, tức là người ta cho rằng tất cả các quan sát có thể được coi là một mẫu từ tổng dân số:
- Mô hình tham số một nhân tố: Phương pháp của Scheffe.
- Mô hình phi tham số một yếu tố [Lagutin M.B., 237]: Tiêu chí Kruskal-Wallis [Hollender M., Wolf D.A., 131], Tiêu chí của Jonkheer [Lagutin M.B., 245].
- Trường hợp tổng quát của mô hình với các nhân tố không đổi, định lý Cochran [Afifi A., Eisen S., 234].
Dữ liệu là các quan sát lặp lại hai lần:
- Mô hình phi tham số hai yếu tố: Tiêu chí của Friedman [Lapach, 203], Tiêu chí của Page [Lagutin M.B., 263]. Ví dụ: so sánh hiệu quả của các phương pháp sản xuất, tập quán nông nghiệp.
- Mô hình phi tham số hai yếu tố cho dữ liệu không đầy đủ
Câu chuyện
Tên đến từ đâu phân tích phương sai? Có vẻ lạ khi quy trình so sánh các phương tiện được gọi là phân tích phương sai. Trên thực tế, điều này là do khi kiểm tra ý nghĩa thống kê của sự khác biệt giữa giá trị trung bình của hai (hoặc một số) nhóm, chúng ta thực sự đang so sánh (phân tích) phương sai mẫu. Khái niệm cơ bản về phân tích phương sai được đề xuất người câu cá vào năm 1920. Có lẽ một thuật ngữ tự nhiên hơn sẽ là phân tích tổng bình phương hoặc phân tích biến thể, nhưng do truyền thống, thuật ngữ phân tích phương sai được sử dụng. Ban đầu, phân tích phương sai được phát triển để xử lý dữ liệu thu được trong quá trình thực hiện các thí nghiệm được thiết kế đặc biệt và được coi là phương pháp duy nhất khám phá chính xác các mối quan hệ nhân quả. Phương pháp này được sử dụng để đánh giá các thí nghiệm trong sản xuất cây trồng. Sau đó, ý nghĩa khoa học chung của phân tích tán sắc đối với các thí nghiệm trong tâm lý học, sư phạm, y học, v.v., đã trở nên rõ ràng.
Văn học
- Sheff G. Phân tích độ phân tán. - M., 1980.
- Ahrens H. Lôi Vũ. Phân tích đa biến phương sai.
- Kobzar A.I. Thống kê toán học ứng dụng. - M.: Fizmatlit, 2006.
- Lapach S. N., Chubenko A. V., Babich P. N. Thống kê trong khoa học và kinh doanh. - Kiev: Morion, 2002.
- Lagutin M. B. Thống kê toán học trực quan. Trong hai tập. - M.: P-center, 2003.
- Afifi A., Eisen S. Phân tích thống kê: Phương pháp có sự hỗ trợ của máy tính.
- Hollender M., Wolf D.A. Các phương pháp thống kê phi tham số.
liên kết
- Phân tích phân tán - sách giáo khoa điện tử statsoft.
Cái tâm không chỉ ở kiến thức, mà còn ở khả năng vận dụng kiến thức vào thực tế. (Aristote)
Phân tích phương sai
tổng quan giới thiệu
Trong phần này, chúng ta sẽ xem xét các phương pháp, giả định và thuật ngữ cơ bản của ANOVA.
Lưu ý rằng trong tài liệu tiếng Anh, phân tích phương sai thường được gọi là phân tích biến thể. Vì vậy, để cho ngắn gọn, dưới đây đôi khi chúng tôi sẽ sử dụng thuật ngữ ANOVA (MỘT phân tích o f va sự nổi loạn) cho ANOVA thông thường và thuật ngữ MANOVAđể phân tích đa biến phương sai. Trong phần này, chúng ta sẽ lần lượt xem xét các ý tưởng chính của phân tích phương sai ( ANOVA), phân tích hiệp phương sai ( ANCOVA), phân tích đa biến phương sai ( MANOVA) và phân tích hiệp phương sai đa biến ( MANCOVA). Sau một cuộc thảo luận ngắn gọn về giá trị của phân tích độ tương phản và tiêu chí hậu hoc Chúng ta hãy xem xét các giả định làm cơ sở cho các phương pháp phân tích phương sai. Ở phần cuối của phần này, các ưu điểm của phương pháp tiếp cận đa biến đối với phân tích các biện pháp lặp lại được giải thích so với phương pháp một chiều truyền thống.
Ý tưởng chính
Mục đích của việc phân tích phương sai. Mục đích chính của phân tích phương sai là nghiên cứu tầm quan trọng của sự khác biệt giữa các phương tiện. chương (Chương 8) giới thiệu ngắn gọn về kiểm định ý nghĩa thống kê. Nếu bạn chỉ so sánh giá trị trung bình của hai mẫu, phân tích phương sai sẽ cho kết quả giống như phân tích bình thường. t- tiêu chí cho các mẫu độc lập (nếu so sánh hai nhóm đối tượng hoặc quan sát độc lập), hoặc t- tiêu chí cho mẫu phụ thuộc (nếu so sánh hai biến trên cùng một tập đối tượng hoặc cùng một quan sát). Nếu bạn không quen thuộc với các tiêu chí này, chúng tôi khuyên bạn nên tham khảo phần giới thiệu tổng quan của chương (Chương 9).
Tên đến từ đâu Phân tích phương sai? Có vẻ lạ khi quy trình so sánh các phương tiện được gọi là phân tích phương sai. Trên thực tế, điều này là do khi chúng tôi kiểm tra ý nghĩa thống kê của sự khác biệt giữa các phương tiện, chúng tôi thực sự đang phân tích các phương sai.
Chia tổng bình phương
Đối với cỡ mẫu n phương sai mẫuđược tính bằng tổng các bình phương độ lệch từ giá trị trung bình của mẫu chia cho n-1 (cỡ mẫu trừ đi một). Do đó, đối với cỡ mẫu cố định n, phương sai là một hàm của tổng bình phương (độ lệch), được biểu thị, để cho ngắn gọn, SS(từ tiếng Anh Tổng bình phương - Sum of Squares). Việc phân tích phương sai dựa trên việc chia (hoặc tách) phương sai thành các phần. Hãy xem xét tập dữ liệu sau:
Phương tiện của hai nhóm khác nhau đáng kể (2 và 6, tương ứng). Tổng bình phương độ lệch bên trong của mỗi nhóm là 2. Cộng chúng lại với nhau, chúng ta có 4. Nếu bây giờ chúng ta lặp lại các phép tính này loại trừ thành viên nhóm, nghĩa là, nếu chúng ta tính toán SS dựa trên giá trị trung bình cộng của hai mẫu, chúng tôi nhận được 28. Nói cách khác, phương sai (tổng bình phương) dựa trên độ biến thiên trong nhóm dẫn đến các giá trị nhỏ hơn nhiều so với khi tính toán dựa trên độ biến thiên tổng (so với tổng thể). nghĩa là). Lý do cho điều này rõ ràng là sự khác biệt đáng kể giữa các mức trung bình và sự khác biệt này giữa các mức trung bình giải thích sự khác biệt hiện có giữa các tổng bình phương. Thật vậy, nếu chúng ta sử dụng mô-đun Phân tích phương sai, sẽ thu được kết quả như sau:
Như có thể thấy từ bảng, tổng số bình phương SS= 28 chia thành tổng bình phương do nội nhóm sự thay đổi ( 2+2=4 ; xem hàng thứ hai của bảng) và tổng bình phương do sự khác biệt về giá trị trung bình. (28-(2+2)=24; xem dòng đầu tiên của bảng).
SS sai lầm vàSS tác dụng. Biến thiên nội nhóm ( SS) thường được gọi là phương sai lỗi.Điều này có nghĩa là nó thường không thể dự đoán hoặc giải thích khi một thí nghiệm được thực hiện. Mặt khác, SS tác dụng(hoặc tính biến thiên giữa các nhóm) có thể được giải thích bằng sự khác biệt giữa các phương tiện trong các nhóm được nghiên cứu. Nói cách khác, thuộc về một nhóm nhất định giải thích biến đổi giữa các nhóm, bởi vì chúng tôi biết rằng các nhóm này có các phương tiện khác nhau.
Kiểm tra ý nghĩa.Ý tưởng chính của kiểm định ý nghĩa thống kê được thảo luận trong chương Các khái niệm cơ bản về thống kê(Chương 8). Cũng chương này giải thích lý do tại sao nhiều bài kiểm tra sử dụng tỷ lệ phương sai được giải thích và không giải thích được. Một ví dụ về việc sử dụng này là bản thân việc phân tích phương sai. Kiểm định ý nghĩa trong ANOVA dựa trên việc so sánh phương sai do sự khác biệt giữa các nhóm (được gọi là hiệu ứng bình phương trung bình hoặc bệnh đa xơ cứngTác dụng) và phân tán do lây lan trong nhóm (được gọi là lỗi bình phương trung bình hoặc bệnh đa xơ cứnglỗi). Nếu giả thuyết không là đúng (bình đẳng về phương tiện trong hai quần thể), thì chúng ta có thể mong đợi một sự khác biệt tương đối nhỏ trong phương tiện mẫu do tính biến thiên ngẫu nhiên. Do đó, theo giả thuyết không, phương sai trong nhóm thực tế sẽ trùng với tổng phương sai được tính toán mà không tính đến thành viên nhóm. Kết quả phương sai trong nhóm có thể được so sánh bằng cách sử dụng F- phép thử kiểm tra xem tỷ lệ phương sai có lớn hơn đáng kể so với 1 hay không. Trong ví dụ trên, F- Kiểm định cho thấy sự khác biệt giữa các giá trị trung bình là có ý nghĩa thống kê.
Logic cơ bản của ANOVA. Tóm lại, chúng ta có thể nói rằng mục đích của phân tích phương sai là để kiểm tra ý nghĩa thống kê của sự khác biệt giữa các phương tiện (đối với các nhóm hoặc biến). Kiểm tra này được thực hiện bằng cách sử dụng phân tích phương sai, tức là bằng cách chia tổng phương sai (độ biến thiên) thành các phần, một trong số đó là do lỗi ngẫu nhiên (tức là độ biến thiên trong nhóm) và phần thứ hai liên quan đến sự khác biệt về giá trị trung bình. Thành phần cuối cùng của phương sai sau đó được sử dụng để phân tích ý nghĩa thống kê của sự khác biệt giữa các phương tiện. Nếu sự khác biệt này là đáng kể, thì giả thuyết không bị bác bỏ và giả thuyết thay thế rằng có sự khác biệt giữa các phương tiện được chấp nhận.
Các biến phụ thuộc và độc lập. Các biến có giá trị được xác định bằng các phép đo trong quá trình thử nghiệm (ví dụ: điểm được ghi trong bài kiểm tra) được gọi là sự phụ thuộc biến. Các biến có thể được thao tác trong một thử nghiệm (ví dụ: phương pháp đào tạo hoặc các tiêu chí khác cho phép bạn chia các quan sát thành các nhóm) được gọi là các nhân tố hoặc độc lập biến. Những khái niệm này được mô tả chi tiết hơn trong chương Các khái niệm cơ bản về thống kê(Chương 8).
Phân tích đa biến phương sai
Trong ví dụ đơn giản ở trên, bạn có thể ngay lập tức tính t-test mẫu độc lập bằng cách sử dụng tùy chọn mô-đun thích hợp Thống kê cơ bản và bảng. Tất nhiên, kết quả thu được trùng khớp với kết quả phân tích phương sai. Tuy nhiên, phân tích phương sai chứa linh hoạt và mạnh mẽ phương tiện kỹ thuật, có thể được sử dụng cho các nghiên cứu phức tạp hơn nhiều.
Rất nhiều yếu tố. Thế giới vốn dĩ phức tạp và đa chiều. Các tình huống trong đó một số hiện tượng được mô tả hoàn toàn bằng một biến là cực kỳ hiếm. Ví dụ, nếu chúng ta đang cố gắng học cách trồng cà chua lớn, chúng ta nên xem xét các yếu tố liên quan đến cấu trúc gen của cây, loại đất, ánh sáng, nhiệt độ, v.v. Do đó, khi tiến hành một thí nghiệm điển hình, bạn phải đối phó với một số lượng lớn các yếu tố. Lý do chính tại sao sử dụng ANOVA lại thích hợp hơn là so sánh lại hai mẫu ở các mức nhân tố khác nhau bằng cách sử dụng t- tiêu chí là phân tích phương sai nhiều hơn hiệu quả và, đối với các mẫu nhỏ, nhiều thông tin hơn.
quản lý nhân tố. Giả sử rằng trong ví dụ về phân tích hai mẫu được thảo luận ở trên, chúng tôi thêm một yếu tố nữa, ví dụ: Sàn nhà- Giới tính. Cho mỗi nhóm gồm 3 nam và 3 nữ. Thiết kế của thí nghiệm này có thể được trình bày dưới dạng bảng 2 nhân 2:
| Cuộc thí nghiệm. Nhóm 1 | Cuộc thí nghiệm. nhóm 2 | |
|---|---|---|
| đàn ông | 2 | 6 |
| 3 | 7 | |
| 1 | 5 | |
| Trung bình | 2 | 6 |
| Phụ nữ | 4 | 8 |
| 5 | 9 | |
| 3 | 7 | |
| Trung bình | 4 | 8 |
Trước khi thực hiện các phép tính, bạn có thể thấy rằng trong ví dụ này, tổng phương sai có ít nhất ba nguồn:
(1) lỗi ngẫu nhiên (trong phương sai nhóm),
(2) sự thay đổi liên quan đến tư cách thành viên trong nhóm thử nghiệm và
(3) sự thay đổi do giới tính của đối tượng quan sát.
(Lưu ý rằng có một nguồn khác có thể thay đổi - tương tác của các yếu tố, mà chúng ta sẽ thảo luận sau). Điều gì xảy ra nếu chúng ta không bao gồm sàn nhà –giới tính như một yếu tố trong phân tích và tính toán thông thường t-tiêu chuẩn? Nếu chúng ta tính tổng bình phương, bỏ qua sàn nhà -giới tính(nghĩa là kết hợp các đối tượng có giới tính khác nhau vào một nhóm khi tính phương sai trong nhóm, trong khi thu được tổng bình phương cho mỗi nhóm bằng SS= 10, và tổng bình phương SS= 10+10 = 20) thì ta được giá trị lớn hơn phương sai trong nhóm so với phân tích chính xác hơn với phân nhóm bổ sung theo một nửa- giới tính(trong trường hợp này, trung bình trong nhóm sẽ bằng 2 và tổng bình phương trong nhóm sẽ bằng SS = 2+2+2+2 = 8). Sự khác biệt này là do giá trị trung bình của đàn ông - con đựcít hơn mức trung bình cho phụ nữ -nữ giới và sự khác biệt về phương tiện này làm tăng tổng số biến thiên trong nhóm nếu giới tính không được tính đến. Kiểm soát phương sai lỗi làm tăng độ nhạy (sức mạnh) của thử nghiệm.
Ví dụ này cho thấy một ưu điểm khác của phân tích phương sai so với phân tích thông thường. t-tiêu chuẩn cho hai mẫu. Phân tích phương sai cho phép bạn nghiên cứu từng yếu tố bằng cách kiểm soát các giá trị của các yếu tố khác. Trên thực tế, đây là lý do chính khiến nó có sức mạnh thống kê lớn hơn (cần cỡ mẫu nhỏ hơn để thu được kết quả có ý nghĩa). Vì lý do này, phân tích phương sai, ngay cả trên các mẫu nhỏ, cho kết quả có ý nghĩa thống kê hơn so với phân tích đơn giản. t- tiêu chuẩn.
hiệu ứng tương tác
Có một lợi thế khác của việc sử dụng ANOVA so với phân tích thông thường. t- tiêu chí: phân tích phương sai cho phép bạn phát hiện sự tương tác giữa các yếu tố và do đó cho phép nghiên cứu các mô hình phức tạp hơn. Để minh họa, hãy xem xét một ví dụ khác.
Hiệu ứng chính, tương tác theo cặp (hai yếu tố). Chúng ta hãy giả sử rằng có hai nhóm sinh viên và về mặt tâm lý, các sinh viên của nhóm thứ nhất sẵn sàng hoàn thành các nhiệm vụ được giao và có mục đích hơn các sinh viên của nhóm thứ hai, bao gồm những sinh viên lười biếng hơn. Hãy chia ngẫu nhiên mỗi nhóm thành hai nửa và giao cho một nửa của mỗi nhóm một nhiệm vụ khó và nửa còn lại làm một nhiệm vụ dễ. Sau đó, chúng tôi đo lường mức độ chăm chỉ của học sinh đối với các nhiệm vụ này. Mức trung bình cho nghiên cứu (hư cấu) này được trình bày trong bảng:
Kết luận gì có thể được rút ra từ những kết quả này? Có thể kết luận rằng: (1) học sinh làm việc chăm chỉ hơn với một nhiệm vụ khó khăn; (2) những sinh viên năng động có làm việc chăm chỉ hơn những sinh viên lười biếng không? Không có tuyên bố nào trong số này phản ánh bản chất của bản chất hệ thống của các mức trung bình được đưa ra trong bảng. Phân tích kết quả, sẽ đúng hơn nếu nói rằng chỉ những sinh viên có động lực mới làm việc chăm chỉ hơn với những nhiệm vụ phức tạp, trong khi chỉ những sinh viên lười biếng mới làm việc chăm chỉ hơn với những nhiệm vụ dễ dàng. Nói cách khác, bản chất của học sinh và mức độ phức tạp của nhiệm vụ tương tác nhau ảnh hưởng đến số lượng nỗ lực cần thiết. Đó là một ví dụ tương tác cặp giữa bản chất của học sinh và mức độ phức tạp của nhiệm vụ. Lưu ý rằng câu 1 và 2 mô tả hiệu ứng chính.
Tương tác của các đơn đặt hàng cao hơn. Trong khi các tương tác theo cặp tương đối dễ giải thích, thì các tương tác bậc cao khó giải thích hơn nhiều. Chúng ta hãy tưởng tượng rằng trong ví dụ được xem xét ở trên, một yếu tố nữa được đưa vào sàn nhà -Giới tính và chúng tôi đã nhận được bảng trung bình sau:
Kết luận gì bây giờ có thể được rút ra từ kết quả thu được? Các đồ thị trung bình giúp dễ dàng giải thích các hiệu ứng phức tạp. Mô-đun phân tích phương sai cho phép bạn xây dựng các biểu đồ này chỉ bằng một cú nhấp chuột.
Hình ảnh trong biểu đồ bên dưới thể hiện tương tác ba chiều đang được nghiên cứu.

Nhìn vào biểu đồ, chúng ta có thể thấy rằng có sự tương tác giữa bản chất và độ khó của bài kiểm tra đối với phụ nữ: phụ nữ có động lực làm việc chăm chỉ hơn với bài khó hơn là bài dễ. Ở nam giới, sự tương tác tương tự được đảo ngược. Có thể thấy rằng mô tả về sự tương tác giữa các yếu tố trở nên khó hiểu hơn.
Cách chung để mô tả các tương tác. TRONG trường hợp chung sự tương tác giữa các yếu tố được mô tả là sự thay đổi trong một hiệu ứng dưới ảnh hưởng của một hiệu ứng khác. Trong ví dụ đã thảo luận ở trên, tương tác hai yếu tố có thể được mô tả là sự thay đổi trong tác động chính của yếu tố đặc trưng cho mức độ phức tạp của nhiệm vụ, dưới tác động của yếu tố mô tả tính cách của học sinh. Đối với sự tương tác của ba yếu tố từ đoạn trước, chúng ta có thể nói rằng sự tương tác của hai yếu tố (độ phức tạp của nhiệm vụ và tính cách của học sinh) thay đổi dưới ảnh hưởng của giới tính – Giới tính. Nếu nghiên cứu sự tương tác của bốn yếu tố, chúng ta có thể nói rằng sự tương tác của ba yếu tố thay đổi dưới tác động của yếu tố thứ tư, tức là. có nhiều loại tương tác khác nhau ở các mức độ khác nhau của nhân tố thứ tư. Hóa ra trong nhiều lĩnh vực, sự tương tác của năm hoặc thậm chí hơn yếu tố không phải là bất thường.
Kế hoạch phức tạp
Kế hoạch liên nhóm và nội nhóm (kế hoạch đo lường lại)
Khi so sánh hai các nhóm khác nhau thường được sử dụng t- tiêu chí cho các mẫu độc lập (từ mô-đun Thống kê và bảng cơ bản). Khi hai biến được so sánh trên cùng một tập đối tượng (quan sát), nó được sử dụng t-tiêu chí cho các mẫu phụ thuộc. Để phân tích phương sai, điều quan trọng là các mẫu có phụ thuộc hay không. Nếu có phép đo lặp lại của cùng một biến (trong các điều kiện khác nhau hoặc trong thời điểm khác nhau) cho cùng một đối tượng, sau đó họ nói về sự hiện diện yếu tố biện pháp lặp đi lặp lại(còn được gọi là yếu tố nội nhóm vì tổng bình phương trong nhóm được tính toán để đánh giá tầm quan trọng của nó). Nếu so sánh các nhóm đối tượng khác nhau (ví dụ: nam và nữ, ba chủng vi khuẩn, v.v.), thì sự khác biệt giữa các nhóm được mô tả yếu tố liên nhóm. Các phương pháp tính toán tiêu chí ý nghĩa cho hai loại yếu tố được mô tả là khác nhau, nhưng logic và cách hiểu chung của chúng là giống nhau.
Các kế hoạch liên nhóm và nội bộ. Trong nhiều trường hợp, thử nghiệm yêu cầu bao gồm cả yếu tố giữa các nhóm và yếu tố đo lường lặp lại trong thiết kế. Ví dụ, các kỹ năng toán học của học sinh nam và nữ được đánh giá (trong đó sàn nhà -Giới tính-intergroup factor) vào đầu và cuối học kỳ. Hai khía cạnh kỹ năng của mỗi học sinh tạo thành yếu tố bên trong nhóm (yếu tố đo lường lặp lại). Việc giải thích các tác động chính và tương tác giữa các nhóm và các yếu tố đo lường lặp lại là giống nhau và cả hai loại yếu tố này rõ ràng có thể tương tác với nhau (ví dụ: phụ nữ đạt được các kỹ năng trong học kỳ và nam giới mất các kỹ năng đó).
Kế hoạch chưa hoàn thành (lồng nhau)
Trong nhiều trường hợp, hiệu ứng tương tác có thể bị bỏ qua. Điều này xảy ra khi người ta biết rằng không có hiệu ứng tương tác trong dân số hoặc khi thực hiện đầy đủ yếu tố kế hoạch là không thể. Ví dụ, ảnh hưởng của bốn chất phụ gia nhiên liệu đến mức tiêu thụ nhiên liệu đang được nghiên cứu. Bốn ô tô và bốn tài xế được chọn. Đầy yếu tố thí nghiệm yêu cầu mỗi kết hợp: bổ sung, người lái xe, ô tô, xuất hiện ít nhất một lần. Điều này cần ít nhất 4 x 4 x 4 = 64 nhóm thử nghiệm, quá tốn thời gian. Ngoài ra, hầu như không có bất kỳ sự tương tác nào giữa người lái và phụ gia nhiên liệu. Với suy nghĩ này, bạn có thể sử dụng kế hoạch hình vuông la tinh, chỉ chứa 16 nhóm thử nghiệm (bốn chất phụ gia được chỉ định bằng các chữ cái A, B, C và D):
Hình vuông Latinh được mô tả trong hầu hết các sách thiết kế thí nghiệm (ví dụ: Hays, 1988; Lindman, 1974; Milliken và Johnson, 1984; Winer, 1962) và sẽ không được thảo luận chi tiết ở đây. Lưu ý rằng hình vuông Latin là KhôngNđầy các kế hoạch không bao gồm tất cả các kết hợp của các cấp độ yếu tố. Ví dụ: tài xế 1 lái xe 1 chỉ có phụ gia A, tài xế 3 lái xe 1 chỉ có phụ gia C. chất phụ gia ( A, B, C và D) được lồng trong các ô của bảng ô tô x tài xế - như trứng trong ổ. Quy tắc ghi nhớ này rất hữu ích để hiểu bản chất lồng nhau hoặc lồng nhau các kế hoạch. mô-đun Phân tích phương sai cung cấp những cách đơn giản để phân tích các kế hoạch thuộc loại này.
phân tích hiệp phương sai
ý chính
Trong chuong Ý tưởng chínhđã có một cuộc thảo luận ngắn về ý tưởng kiểm soát các yếu tố và cách đưa vào các yếu tố cộng có thể giảm tổng sai số bình phương và tăng sức mạnh thống kê của thiết kế. Tất cả điều này có thể được mở rộng cho các biến với một tập giá trị liên tục. Khi các biến liên tục như vậy được đưa vào làm nhân tố trong thiết kế, chúng được gọi là đồng biến.
đồng biến cố định
Giả sử rằng chúng ta đang so sánh các kỹ năng toán học của hai nhóm học sinh được dạy từ hai cuốn sách giáo khoa khác nhau. Cũng giả sử rằng chúng ta có dữ liệu chỉ số thông minh (IQ) cho mỗi học sinh. Chúng ta có thể cho rằng chỉ số IQ có liên quan đến kỹ năng toán học và sử dụng thông tin này. Đối với mỗi nhóm trong số hai nhóm học sinh, có thể tính được hệ số tương quan giữa chỉ số IQ và kỹ năng toán học. Sử dụng hệ số tương quan này, có thể phân biệt giữa tỷ lệ phương sai trong các nhóm được giải thích bởi ảnh hưởng của IQ và tỷ lệ phương sai không giải thích được (xem thêm Các khái niệm cơ bản về thống kê(chương 8) và Thống kê và bảng cơ bản(Chương 9)). Phần còn lại của phương sai được sử dụng trong phân tích dưới dạng phương sai lỗi. Nếu có mối tương quan giữa chỉ số IQ và các kỹ năng toán học, thì sai số có thể giảm đáng kể. SS/(N-1) .
Ảnh hưởng của hiệp phương sai đếnF- tiêu chuẩn. F- tiêu chí đánh giá ý nghĩa thống kê của sự khác biệt giữa các giá trị trung bình trong các nhóm, trong khi tỷ lệ phương sai giữa các nhóm được tính toán ( bệnh đa xơ cứngtác dụng) đến phương sai lỗi ( bệnh đa xơ cứnglỗi) . Nếu như bệnh đa xơ cứnglỗi giảm, ví dụ, khi tính đến yếu tố IQ, giá trị F tăng.
Rất nhiều đồng biến. Lý do được sử dụng ở trên cho một đồng biến (IQ) đơn lẻ dễ dàng mở rộng cho nhiều đồng biến. Ví dụ: ngoài IQ, bạn có thể bao gồm phép đo động lực, tư duy không gian, v.v. Thay vì hệ số tương quan thông thường, nó sử dụng nhiều yếu tố tương quan.
Khi giá trịF -tiêu chí giảm.Đôi khi việc giới thiệu các đồng biến trong thiết kế thử nghiệm làm giảm giá trị F- tiêu chuẩn . Điều này thường chỉ ra rằng các đồng biến không chỉ tương quan với biến phụ thuộc (chẳng hạn như kỹ năng toán học) mà còn với các yếu tố (chẳng hạn như sách giáo khoa khác nhau). Giả sử IQ được đo vào cuối học kỳ, sau gần đào tạo hàng năm hai nhóm học sinh trên hai cuốn sách giáo khoa khác nhau. Mặc dù các học sinh được chia thành các nhóm một cách ngẫu nhiên, nhưng có thể sự khác biệt trong sách giáo khoa lớn đến mức cả chỉ số IQ và kỹ năng toán học ở các nhóm khác nhau sẽ khác nhau rất nhiều. Trong trường hợp này, các hiệp phương sai không chỉ làm giảm phương sai lỗi mà còn giảm phương sai giữa các nhóm. Nói cách khác, sau khi kiểm soát sự khác biệt về chỉ số IQ giữa các nhóm, sự khác biệt về kỹ năng toán học sẽ không còn đáng kể nữa. Có thể nói khác đi. Sau khi “loại bỏ” ảnh hưởng của IQ, ảnh hưởng của sách giáo khoa đối với sự phát triển các kỹ năng toán học vô tình bị loại bỏ.
Trung bình điều chỉnh. Khi hiệp phương sai ảnh hưởng đến yếu tố giữa các nhóm, người ta nên tính toán điều chỉnh trung bình, I E. phương tiện như vậy, thu được sau khi loại bỏ tất cả các ước tính của hiệp phương sai.
Tương tác giữa các đồng biến và các nhân tố. Giống như các tương tác giữa các yếu tố được khám phá, các tương tác giữa các đồng biến và giữa các nhóm yếu tố cũng có thể được khám phá. Giả sử một trong những cuốn sách giáo khoa đặc biệt phù hợp với những học sinh thông minh. Cuốn sách thứ hai gây nhàm chán cho những học sinh thông minh, và cùng một cuốn sách khó cho những học sinh kém thông minh hơn. Kết quả là có mối tương quan thuận giữa chỉ số IQ và kết quả học tập ở nhóm thứ nhất (học sinh thông minh hơn, kết quả tốt hơn) và tương quan âm bằng 0 hoặc nhẹ trong nhóm thứ hai (học sinh càng thông minh thì càng ít có khả năng tiếp thu các kỹ năng toán học từ sách giáo khoa thứ hai). Trong một số nghiên cứu, tình huống này được thảo luận như một ví dụ về sự vi phạm các giả định của phân tích hiệp phương sai. Tuy nhiên, do mô-đun Phân tích phương sai sử dụng các phương pháp phân tích hiệp phương sai phổ biến nhất, nên đặc biệt, có thể đánh giá ý nghĩa thống kê của sự tương tác giữa các yếu tố và hiệp phương sai.
biến hiệp phương sai
Trong khi các đồng biến cố định được thảo luận khá thường xuyên trong sách giáo khoa, thì các đồng biến thay đổi ít được đề cập hơn nhiều. Thông thường, khi tiến hành thí nghiệm với các phép đo lặp lại, chúng ta quan tâm đến sự khác nhau về số đo của cùng một đại lượng tại các thời điểm khác nhau. Cụ thể, chúng tôi quan tâm đến tầm quan trọng của những khác biệt này. Nếu phép đo hiệp biến được thực hiện đồng thời với phép đo biến phụ thuộc, thì có thể tính được mối tương quan giữa biến đồng biến và biến phụ thuộc.
Ví dụ, bạn có thể nghiên cứu sở thích toán học và các kỹ năng toán học vào đầu và cuối học kỳ. Sẽ rất thú vị nếu kiểm tra xem những thay đổi về sở thích toán học có tương quan với những thay đổi về kỹ năng toán học hay không.
mô-đun Phân tích phương sai V SỐ LIỆU THỐNG KÊ tự động đánh giá ý nghĩa thống kê của những thay đổi về đồng biến trong các kế hoạch đó, nếu có thể.
Thiết kế đa biến: Phân tích ANOVA và hiệp phương sai đa biến
kế hoạch liên nhóm
Tất cả các ví dụ được xem xét trước đó chỉ bao gồm một biến phụ thuộc. Khi có nhiều biến phụ thuộc đồng thời thì chỉ tăng độ phức tạp của phép tính, còn nội dung và nguyên tắc cơ bản không thay đổi.
Ví dụ, một nghiên cứu đang được thực hiện trên hai cuốn sách giáo khoa khác nhau. Đồng thời, sự thành công của học sinh trong nghiên cứu vật lý và toán học được nghiên cứu. Trong trường hợp này, có hai biến phụ thuộc và bạn cần tìm hiểu xem hai sách giáo khoa khác nhau ảnh hưởng đến chúng đồng thời như thế nào. Để làm điều này, bạn có thể sử dụng phân tích phương sai đa biến (MANOVA). Thay vì một chiều F tiêu chí, đa chiều F kiểm định (Wilks l-test) dựa trên so sánh ma trận hiệp phương sai sai số và ma trận hiệp phương sai giữa các nhóm.
Nếu các biến phụ thuộc có tương quan với nhau thì mối tương quan này cần được tính đến khi tính toán kiểm định ý nghĩa. Rõ ràng, nếu cùng một phép đo được lặp lại hai lần, thì không thể thu được gì mới trong trường hợp này. Nếu một thứ nguyên tương quan với nó được thêm vào một thứ nguyên hiện có, thì một số thông tin mới, nhưng biến mới chứa thông tin dư thừa, được phản ánh trong hiệp phương sai giữa các biến.
Giải thích kết quả. Nếu tiêu chí đa biến tổng thể là có ý nghĩa, thì chúng ta có thể kết luận rằng tác động tương ứng (ví dụ như loại sách giáo khoa) là có ý nghĩa. Tuy nhiên, họ thức dậy câu hỏi tiếp theo. Loại sách giáo khoa có ảnh hưởng đến việc cải thiện chỉ các kỹ năng toán học, chỉ các kỹ năng vật lý hay cả hai. Trên thực tế, sau khi có được một tiêu chí đa biến có ý nghĩa, cho một tác động hoặc tương tác chính duy nhất, một chiều F tiêu chuẩn. Nói cách khác, các biến phụ thuộc đóng góp vào tầm quan trọng của thử nghiệm đa biến được kiểm tra riêng.
Kế hoạch với các phép đo lặp đi lặp lại
Nếu các kỹ năng toán học và thể chất của học sinh được đo vào đầu và cuối học kỳ, thì đây là các phép đo lặp lại. Nghiên cứu về tiêu chí quan trọng trong các kế hoạch như vậy là phát triển logic trường hợp một chiều. Lưu ý rằng các phương pháp ANOVA đa biến cũng thường được sử dụng để điều tra tầm quan trọng của các yếu tố đo lặp lại đơn biến có nhiều hơn hai cấp độ. Các ứng dụng tương ứng sẽ được thảo luận sau trong phần này.
Tổng các giá trị của biến và phân tích đa biến của phương sai
Ngay cả những người dùng có kinh nghiệm về ANOVA đơn biến và đa biến cũng thường bị nhầm lẫn khi nhận được các kết quả khác nhau khi áp dụng ANOVA đa biến cho ba biến và khi áp dụng ANOVA đơn biến cho tổng của ba biến dưới dạng một biến.
Ý tưởng tổng kết các biến là mỗi biến chứa một số biến thực, được điều tra, cũng như một lỗi đo lường ngẫu nhiên. Do đó, khi lấy trung bình các giá trị của các biến, sai số phép đo sẽ gần bằng 0 cho tất cả các phép đo và các giá trị lấy trung bình sẽ đáng tin cậy hơn. Trên thực tế, trong trường hợp này, áp dụng ANOVA cho tổng các biến là hợp lý và là một kỹ thuật hiệu quả. Tuy nhiên, nếu các biến phụ thuộc có tính chất đa biến thì việc tính tổng các giá trị của các biến là không phù hợp.
Ví dụ: để các biến phụ thuộc bao gồm bốn biện pháp thành công trong xã hội. Mỗi chỉ báo đặc trưng cho một khía cạnh hoàn toàn độc lập hoạt động của con người(ví dụ: thành công trong nghề nghiệp, thành công trong kinh doanh, hạnh phúc gia đình, v.v.). Thêm các biến này lại với nhau giống như thêm một quả táo và một quả cam. Tổng của các biến này sẽ không phải là một thước đo đơn biến phù hợp. Vì vậy, những dữ liệu đó phải được coi như những chỉ số đa chiều trong phân tích đa biến phương sai.
Phân tích tương phản và bài kiểm tra bài hoc
Tại sao các bộ phương tiện riêng lẻ được so sánh?
Thông thường, các giả thuyết về dữ liệu thử nghiệm được hình thành không chỉ đơn giản là về các tác động hoặc tương tác chính. Một ví dụ là giả thuyết sau: một cuốn sách giáo khoa nhất định chỉ cải thiện kỹ năng toán học ở học sinh nam, trong khi một cuốn sách giáo khoa khác có hiệu quả gần như ngang nhau đối với cả hai giới, nhưng vẫn kém hiệu quả hơn đối với nam giới. Có thể dự đoán rằng hiệu suất của sách giáo khoa tương tác với giới tính của học sinh. Tuy nhiên, dự đoán này cũng được áp dụng thiên nhiên tương tác. Một sự khác biệt đáng kể giữa hai giới tính được mong đợi đối với học sinh trong một cuốn sách và kết quả thực tế không phụ thuộc vào giới tính đối với học sinh trong cuốn sách kia. Loại giả thuyết này thường được khám phá bằng cách sử dụng phân tích tương phản.
Phân tích độ tương phản
Nói tóm lại, phân tích độ tương phản cho phép chúng ta đánh giá ý nghĩa thống kê của một số kết hợp tuyến tính của các hiệu ứng phức tạp. Phân tích độ tương phản là yếu tố chính và không thể thiếu của bất kỳ kế hoạch ANOVA phức tạp nào. mô-đun Phân tích phương sai có đủ khả năng khác nhau phân tích độ tương phản, cho phép bạn làm nổi bật và phân tích bất kỳ loại so sánh phương tiện nào.
hậu thế so sánh
Đôi khi, do xử lý một thử nghiệm, một hiệu ứng bất ngờ được phát hiện. Mặc dù trong hầu hết các trường hợp nhà nghiên cứu sáng tạo có thể giải thích bất kỳ kết quả nào, điều này không tạo cơ hội để phân tích sâu hơn và thu được các ước tính cho dự báo. Vấn đề này là một trong những vấn đề mà tiêu chí hậu hoc, nghĩa là các tiêu chí không sử dụng tiên nghiệm các giả thuyết. Để minh họa, hãy xem xét thí nghiệm sau. Giả sử 100 thẻ chứa các số từ 1 đến 10. Sau khi bỏ tất cả các thẻ này vào tiêu đề, chúng tôi chọn ngẫu nhiên 20 lần 5 thẻ và tính giá trị trung bình cho mỗi mẫu (giá trị trung bình của các số được viết trên thẻ). Liệu chúng ta có thể mong đợi rằng có hai mẫu có giá trị trung bình khác nhau đáng kể không? Điều này rất hợp lý! Bằng cách chọn hai mẫu có giá trị trung bình tối đa và tối thiểu, người ta có thể thu được sự khác biệt về giá trị trung bình rất khác với sự khác biệt về giá trị trung bình, ví dụ, của hai mẫu đầu tiên. Sự khác biệt này có thể được điều tra, ví dụ, bằng cách sử dụng phân tích độ tương phản. Không đi vào chi tiết, có một số cái gọi là hậu thế tiêu chí dựa chính xác vào kịch bản đầu tiên (lấy trung bình cực đại từ 20 mẫu), tức là các tiêu chí này dựa trên việc chọn các phương tiện khác nhau nhất để so sánh tất cả các phương tiện trong thiết kế. Các tiêu chí này được áp dụng để không tạo ra hiệu ứng nhân tạo hoàn toàn do ngẫu nhiên, chẳng hạn như để tìm ra sự khác biệt đáng kể giữa các phương tiện khi không có. mô-đun Phân tích phương sai cung cấp một loạt các tiêu chí như vậy. Khi gặp phải kết quả không mong muốn trong một thử nghiệm liên quan đến nhiều nhóm, hậu thế thủ tục kiểm tra ý nghĩa thống kê của các kết quả thu được.
Tổng bình phương loại I, II, III và IV
Hồi quy đa biến và phân tích phương sai
tồn tại mối quan hệ thân thiết giữa phương pháp hồi quy đa biến và phân tích phương sai (phân tích các biến). Trong cả hai phương pháp, nó được điều tra mô hình tuyến tính. Nói tóm lại, hầu hết tất cả các thiết kế thử nghiệm đều có thể được khám phá bằng cách sử dụng hồi quy đa biến. Hãy xem xét kế hoạch 2 x 2 nhóm chéo đơn giản sau đây.
| DV | MỘT | b | AxB |
|---|---|---|---|
| 3 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 |
| 4 | 1 | -1 | -1 |
| 5 | 1 | -1 | -1 |
| 6 | -1 | 1 | -1 |
| 6 | -1 | 1 | -1 |
| 3 | -1 | -1 | 1 |
| 2 | -1 | -1 | 1 |
Cột A và B chứa các mã đặc trưng cho mức độ của các yếu tố A và B, cột AxB chứa tích của hai cột A và B. Chúng ta có thể phân tích các dữ liệu này bằng phương pháp hồi quy đa biến. Biến đổi DVđược định nghĩa là một biến phụ thuộc, các biến từ MỘT trước AxB như các biến độc lập. Việc nghiên cứu ý nghĩa của các hệ số hồi quy sẽ trùng khớp với các tính toán trong phân tích phương sai của ý nghĩa các tác động chính của các nhân tố MỘT Và b và hiệu ứng tương tác AxB.
Kế hoạch không cân bằng và cân bằng
Khi tính toán ma trận tương quan cho tất cả các biến, chẳng hạn đối với dữ liệu mô tả ở trên, có thể thấy tác động chính của các nhân tố MỘT Và b và hiệu ứng tương tác AxB không tương quan. Tính chất này của các hiệu ứng còn được gọi là tính trực giao. Họ nói rằng những ảnh hưởng MỘT Và b - trực giao hoặc độc lập từ nhau. Nếu tất cả các tác động trong kế hoạch là trực giao với nhau, như trong ví dụ trên, thì kế hoạch được gọi là cân đối.
Các kế hoạch cân bằng có “tài sản tốt”. Các tính toán trong phân tích các kế hoạch như vậy là rất đơn giản. Tất cả các tính toán được giảm xuống để tính toán mối tương quan giữa các hiệu ứng và các biến phụ thuộc. Vì các hiệu ứng là trực giao, các mối tương quan từng phần (như toàn bộ đa chiều hồi quy) không được tính toán. Tuy nhiên, trong đời thực kế hoạch không phải lúc nào cũng cân bằng.
Xem xét dữ liệu thực với số lượng quan sát không bằng nhau trong các ô.
| Yếu tố A | yếu tố B | |
|---|---|---|
| B1 | B2 | |
| A1 | 3 | 4, 5 |
| A2 | 6, 6, 7 | 2 |
Nếu chúng ta mã hóa dữ liệu này như trên và tính toán ma trận tương quan cho tất cả các biến, thì hóa ra các yếu tố thiết kế có tương quan với nhau. Các yếu tố trong kế hoạch bây giờ không trực giao và các kế hoạch như vậy được gọi là không cân đối. Lưu ý rằng trong ví dụ này, mối tương quan giữa các yếu tố hoàn toàn liên quan đến sự khác biệt về tần số của 1 và -1 trong các cột của ma trận dữ liệu. Nói cách khác, các thiết kế thử nghiệm với thể tích ô không bằng nhau (chính xác hơn là thể tích không cân xứng) sẽ không cân bằng, nghĩa là các hiệu ứng và tương tác chính sẽ trộn lẫn với nhau. Trong trường hợp này, để tính toán ý nghĩa thống kê của các hiệu ứng, bạn cần tính toán đầy đủ hồi quy đa biến. Có một số chiến lược ở đây.
Tổng bình phương loại I, II, III và IV
Tổng bình phương loạiTÔIVàIII. Để nghiên cứu tầm quan trọng của từng nhân tố trong mô hình đa biến, người ta có thể tính toán tương quan từng phần của từng nhân tố, với điều kiện là tất cả các nhân tố khác đã được tính đến trong mô hình. Bạn cũng có thể nhập các yếu tố vào mô hình theo cách từng bước, cố định tất cả các yếu tố đã được nhập vào mô hình và bỏ qua tất cả các yếu tố khác. Nói chung, đây là sự khác biệt giữa kiểu III Và kiểuTÔI tổng bình phương (thuật ngữ này đã được giới thiệu trong SAS, xem ví dụ SAS, 1982; một cuộc thảo luận chi tiết cũng có thể được tìm thấy trong Searle, 1987, trang 461; Woodward, Bonett, và Brecht, 1990, trang 216; hoặc Milliken và Johnson, 1984, trang 138).
Tổng bình phương loạiII. Chiến lược hình thành mô hình “trung gian” tiếp theo là: kiểm soát tất cả các tác động chính trong nghiên cứu về tầm quan trọng của một tác động chính duy nhất; trong việc kiểm soát tất cả các hiệu ứng chính và tất cả các tương tác theo cặp, khi tầm quan trọng của một tương tác theo cặp duy nhất được kiểm tra; trong việc kiểm soát tất cả các tác động chính của tất cả các tương tác theo cặp và tất cả các tương tác của ba yếu tố; trong nghiên cứu về sự tương tác riêng biệt của ba yếu tố, v.v. Tổng bình phương cho các hiệu ứng được tính theo cách này được gọi là kiểuII tổng bình phương. Vì thế, kiểuII tổng bình phương kiểm soát tất cả các hiệu ứng có cùng thứ tự trở xuống, bỏ qua tất cả các hiệu ứng có thứ tự cao hơn.
Tổng bình phương loạiIV. Cuối cùng, đối với một số kế hoạch đặc biệt có các ô bị thiếu (kế hoạch không đầy đủ), có thể tính toán cái gọi là kiểu IV tổng bình phương. Phương pháp này sẽ được thảo luận sau liên quan đến các kế hoạch không đầy đủ (các kế hoạch bị thiếu ô).
Giải thích phỏng đoán tổng bình phương loại I, II, III
Tổng bình phương kiểuIII dễ hiểu nhất. Nhắc lại rằng tổng các bình phương kiểuIII kiểm tra các hiệu ứng sau khi kiểm soát tất cả các hiệu ứng khác. Ví dụ, sau khi tìm thấy một ý nghĩa thống kê kiểuIIIảnh hưởng của yếu tố MỘT trong mô-đun Phân tích phương sai, chúng ta có thể nói rằng có một tác động đáng kể duy nhất của yếu tố MỘT, sau khi giới thiệu tất cả các hiệu ứng (yếu tố) khác và giải thích hiệu ứng này cho phù hợp. Có lẽ trong 99% tất cả các ứng dụng phân tích phương sai, loại tiêu chí này được nhà nghiên cứu quan tâm. Loại tổng bình phương này thường được tính trong mô-đun Phân tích phương sai theo mặc định, bất kể tùy chọn có được chọn hay không Phương pháp hồi quy hay không (các phương pháp tiêu chuẩn được áp dụng trong mô-đun Phân tích phương sai thảo luận dưới đây).
Hiệu ứng đáng kể thu được bằng cách sử dụng tổng bình phương kiểu hoặc kiểuII tổng các bình phương không dễ diễn giải như vậy. Chúng được giải thích tốt nhất trong bối cảnh hồi quy đa biến từng bước. Nếu sử dụng tổng bình phương kiểuTÔI tác động chính của yếu tố B được cho là có ý nghĩa (sau khi đưa yếu tố A vào mô hình, nhưng trước khi thêm tương tác giữa A và B), có thể kết luận rằng có tác động chính đáng kể của yếu tố B, với điều kiện là có không có sự tương tác giữa các yếu tố A và B. (Nếu sử dụng tiêu chí kiểuIII, yếu tố B cũng có ý nghĩa, thì chúng ta có thể kết luận rằng có tác động chính đáng kể của yếu tố B, sau khi đưa tất cả các yếu tố khác và tương tác của chúng vào mô hình).
Xét về phương tiện cận biên của giả thuyết kiểuTÔI Và kiểuII thường không có một giải thích đơn giản. Trong những trường hợp này, người ta nói rằng người ta không thể giải thích tầm quan trọng của các tác động bằng cách chỉ xem xét các phương tiện cận biên. khá trình bày P giá trị trung bình có liên quan đến một giả thuyết phức hợp kết hợp phương tiện và cỡ mẫu. Ví dụ, kiểuII các giả thuyết cho yếu tố A trong ví dụ thiết kế 2 x 2 đơn giản được thảo luận trước đó sẽ là (xem Woodward, Bonett và Brecht, 1990, trang 219):
nij- số quan sát trong một ô
uij- giá trị trung bình trong một ô
N. j- trung bình cận biên
Không đi sâu vào chi tiết (để biết thêm chi tiết, xem Milliken và Johnson, 1984, chương 10), rõ ràng đây không phải là những giả thuyết đơn giản và trong hầu hết các trường hợp, không có giả thuyết nào được nhà nghiên cứu đặc biệt quan tâm. Tuy nhiên, có những trường hợp giả thuyết kiểuTÔI có thể được quan tâm.
Cách tiếp cận tính toán mặc định trong mô-đun Phân tích phương sai
Mặc định nếu tùy chọn không được chọn Phương pháp hồi quy, mô-đun Phân tích phương sai sử dụng mô hình trung bình tế bào. Đặc điểm của mô hình này là tổng bình phương cho các hiệu ứng khác nhau được tính cho các tổ hợp tuyến tính của phương tiện ô. Trong một thí nghiệm giai thừa đầy đủ, điều này dẫn đến tổng bình phương giống như tổng bình phương đã thảo luận trước đó như kiểu III. Tuy nhiên, trong tùy chọn So sánh theo lịch trình(trong cửa sổ Phân tích kết quả phương sai), người dùng có thể đưa ra giả thuyết về bất kỳ sự kết hợp tuyến tính nào của phương tiện ô có trọng số hoặc không có trọng số. Do đó, người dùng có thể kiểm tra không chỉ các giả thuyết kiểuIII, nhưng các giả thuyết thuộc bất kỳ loại nào (bao gồm cả kiểuIV). Cái này Cách tiếp cận chungđặc biệt hữu ích khi kiểm tra các thiết kế bị thiếu ô (được gọi là thiết kế không hoàn chỉnh).
Đối với các thiết kế giai thừa đầy đủ, cách tiếp cận này cũng hữu ích khi muốn phân tích các phương tiện cận biên có trọng số. Ví dụ: giả sử rằng trong thiết kế 2 x 2 đơn giản được xem xét trước đó, chúng tôi muốn so sánh trọng số (về mức độ yếu tố) b) trung bình cận biên cho yếu tố A. Điều này hữu ích khi phân phối các quan sát trên các ô không được người thử nghiệm chuẩn bị mà được xây dựng ngẫu nhiên và tính ngẫu nhiên này được phản ánh trong phân phối số lượng quan sát theo cấp độ của yếu tố B trong tổng hợp .
Ví dụ, có một yếu tố - tuổi của góa phụ. Một mẫu người trả lời có thể được chia thành hai nhóm: dưới 40 tuổi và trên 40 tuổi (yếu tố B). Yếu tố thứ hai (yếu tố A) trong kế hoạch là liệu các góa phụ có nhận được hỗ trợ xã hội từ một số cơ quan hay không (trong khi một số góa phụ được chọn ngẫu nhiên, những người khác đóng vai trò kiểm soát). Trong trường hợp này, phân bố theo tuổi của góa phụ trong mẫu phản ánh phân bố theo tuổi thực tế của góa phụ trong dân số. Đánh giá hiệu quả của nhóm hỗ trợ xã hội cho góa phụ mọi lứa tuổi sẽ tương ứng với giá trị trung bình có trọng số của hai nhóm tuổi (với trọng số tương ứng với số lượng quan sát trong nhóm).
So sánh theo lịch trình
Lưu ý rằng tổng tỷ lệ tương phản đã nhập không nhất thiết phải bằng 0 (không). Thay vào đó, chương trình sẽ tự động điều chỉnh để các giả thuyết tương ứng không trộn lẫn với mức trung bình chung.
Để minh họa điều này, chúng ta hãy quay trở lại kế hoạch 2 x 2 đơn giản đã thảo luận trước đó. Hãy nhớ lại rằng số lượng ô của thiết kế không cân bằng này là -1, 2, 3 và 1. Giả sử chúng ta muốn so sánh trung bình cận biên có trọng số của yếu tố A (được tính trọng số theo tần suất của các mức yếu tố B). Bạn có thể nhập tỷ lệ tương phản:
Lưu ý rằng các hệ số này không cộng lại bằng 0. Chương trình sẽ thiết lập các hệ số sao cho chúng cộng lại bằng 0, trong khi vẫn giữ nguyên giá trị của chúng. giá trị tương đối, I E.:
1/3 2/3 -3/4 -1/4
Những sự tương phản này sẽ so sánh các mức trung bình có trọng số cho yếu tố A.
Các giả thuyết về ý nghĩa chính. Giả thuyết rằng giá trị trung bình gốc không trọng số là 0 có thể được khám phá bằng cách sử dụng các hệ số:
Giả thuyết rằng giá trị trung bình chính có trọng số là 0 được kiểm tra với:
Trong mọi trường hợp, chương trình không sửa các tỷ lệ tương phản.
Phân tích các kế hoạch với các ô bị thiếu (kế hoạch không đầy đủ)
Các thiết kế thừa có chứa các ô trống (xử lý kết hợp các ô không có quan sát) được gọi là không đầy đủ. Trong những thiết kế như vậy, một số yếu tố thường không trực giao và một số tương tác không thể tính toán được. hoàn toàn không tồn tại phương pháp tốt nhất phân tích các kế hoạch đó.
Phương pháp hồi quy
Trong một số chương trình cũ dựa trên phân tích thiết kế ANOVA bằng hồi quy đa biến, các yếu tố mặc định trong thiết kế không hoàn chỉnh được đưa ra bởi theo cách thông thường(coi như kế hoạch đã hoàn thành). Một phân tích hồi quy đa biến sau đó được thực hiện cho các yếu tố được mã hóa giả này. Thật không may, phương pháp này dẫn đến những kết quả rất khó, nếu không muốn nói là không thể diễn giải vì không rõ mỗi tác động đóng góp như thế nào vào sự kết hợp tuyến tính của các phương tiện. Hãy xem xét ví dụ đơn giản sau đây.
| Yếu tố A | yếu tố B | |
|---|---|---|
| B1 | B2 | |
| A1 | 3 | 4, 5 |
| A2 | 6, 6, 7 | Bỏ lỡ |
Nếu hồi quy đa biến có dạng Biến phụ thuộc = Hằng số + Nhân tố A + Nhân tố B, thì giả thuyết về tầm quan trọng của các yếu tố A và B đối với sự kết hợp tuyến tính của các phương tiện sẽ như sau:
Yếu tố A: Ô A1,B1 = Ô A2,B1
Yếu tố B: Ô A1,B1 = Ô A1,B2
Trường hợp này là đơn giản. Trong hơn kế hoạch phức tạp không thể thực sự xác định chính xác những gì sẽ được điều tra.
Các ô trung bình, phân tích phương pháp phương sai , giả thuyết loại IV
Một cách tiếp cận được đề xuất trong tài liệu và dường như được ưa chuộng hơn là nghiên cứu ý nghĩa (về nhiệm vụ nghiên cứu) tiên nghiệm các giả thuyết về các phương tiện quan sát được trong các ô của kế hoạch. Thảo luận chi tiết về cách tiếp cận này có thể tìm thấy trong Dodge (1985), Heiberger (1989), Milliken và Johnson (1984), Searle (1987), hoặc Woodward, Bonett và Brecht (1990). Tổng bình phương liên quan đến các giả thuyết về sự kết hợp tuyến tính của các phương tiện trong các thiết kế không hoàn chỉnh, điều tra các ước tính về một phần của các hiệu ứng, còn được gọi là tổng bình phương. IV.
Tự động tạo các loại giả thuyếtIV. Khi các thiết kế đa biến có một mẫu ô bị thiếu phức tạp, nên xác định các giả thuyết trực giao (độc lập) mà việc điều tra của chúng tương đương với việc điều tra các tác động hoặc tương tác chính. Các chiến lược thuật toán (tính toán) (dựa trên ma trận thiết kế giả nghịch đảo) đã được phát triển để tạo ra các trọng số phù hợp cho các phép so sánh đó. Thật không may, các giả thuyết cuối cùng không được xác định duy nhất. Tất nhiên, chúng phụ thuộc vào thứ tự xác định các hiệu ứng và hiếm khi dễ diễn giải. Do đó, nên nghiên cứu kỹ bản chất của các tế bào bị thiếu, sau đó đưa ra các giả thuyết kiểuIV, phù hợp nhất với mục tiêu nghiên cứu. Sau đó khám phá những giả thuyết này bằng cách sử dụng tùy chọn So sánh theo lịch trình trong cửa sổ kết quả. Cách dễ nhất để chỉ định so sánh trong trường hợp này là yêu cầu đưa ra một vectơ tương phản cho tất cả các yếu tố cùng nhau trong cửa sổ So sánh theo lịch trình Sau khi gọi hộp thoại So sánh theo lịch trình tất cả các nhóm của kế hoạch hiện tại sẽ được hiển thị và những nhóm bị bỏ qua sẽ được đánh dấu.
Các ô bị bỏ qua và Kiểm tra hiệu ứng cụ thể
Có một số loại kế hoạch trong đó vị trí của các ô bị thiếu không phải là ngẫu nhiên mà được lên kế hoạch cẩn thận, cho phép phân tích đơn giản các tác động chính mà không ảnh hưởng đến các tác động khác. Ví dụ: khi không có sẵn số lượng ô cần thiết trong một kế hoạch, các kế hoạch thường được sử dụng. hình vuông la tinhđể ước tính tác động chính của một số yếu tố với một số lượng lớn các cấp độ. Ví dụ: thiết kế giai thừa 4 x 4 x 4 x 4 cần 256 ô. Đồng thời, bạn có thể sử dụng quảng trường Hy Lạp-La tinhđể ước tính các tác động chính, chỉ có 16 ô trong kế hoạch (chương. lập kế hoạch thí nghiệm, tập IV, chứa miêu tả cụ thể kế hoạch như vậy). Các thiết kế chưa hoàn chỉnh trong đó các hiệu ứng chính (và một số tương tác) có thể được ước tính bằng cách sử dụng các kết hợp phương tiện tuyến tính đơn giản được gọi là cân bằng kế hoạch không đầy đủ.
Trong các thiết kế cân bằng, phương pháp tạo độ tương phản (trọng số) tiêu chuẩn (mặc định) cho các hiệu ứng chính và tương tác sau đó sẽ tạo ra một phân tích bảng phương sai trong đó tổng bình phương cho các hiệu ứng tương ứng không trộn lẫn với nhau. Lựa chọn hiệu ứng cụ thể cửa sổ kết quả sẽ tạo ra các độ tương phản bị thiếu bằng cách ghi số 0 vào các ô sơ đồ bị thiếu. Ngay sau khi tùy chọn được yêu cầu hiệu ứng cụ thểđối với người dùng đang nghiên cứu một số giả thuyết, một bảng kết quả sẽ xuất hiện với các trọng số thực tế. Lưu ý rằng trong một thiết kế cân bằng, tổng bình phương của các hiệu ứng tương ứng chỉ được tính nếu các hiệu ứng đó trực giao (độc lập) với tất cả các hiệu ứng và tương tác chính khác. Nếu không, hãy sử dụng tùy chọn So sánh theo lịch trìnhđể khám phá những so sánh có ý nghĩa giữa các phương tiện.
Các ô bị thiếu và các hiệu ứng/thành viên lỗi kết hợp
nếu tùy chọn phương pháp hồi quy trong bảng khởi chạy của mô-đun Phân tích phương sai không được chọn, mô hình trung bình ô sẽ được sử dụng khi tính tổng bình phương cho các hiệu ứng (cài đặt mặc định). Nếu thiết kế không cân bằng, thì khi kết hợp các hiệu ứng không trực giao (xem phần thảo luận ở trên về tùy chọn Thiếu ô và hiệu ứng cụ thể) người ta có thể thu được một tổng bình phương gồm các thành phần không trực giao (hoặc trùng nhau). Các kết quả thu được theo cách này thường không thể giải thích được. Do đó, người ta phải rất cẩn thận khi lựa chọn và thực hiện các thiết kế thí nghiệm phức tạp chưa hoàn thiện.
Có rất nhiều cuốn sách thảo luận về các kế hoạch một cách chi tiết. loại khác. (Dodge, 1985; Heiberger, 1989; Lindman, 1974; Milliken và Johnson, 1984; Searle, 1987; Woodward và Bonett, 1990), nhưng loại thông tin này nằm ngoài phạm vi của sách giáo khoa này. Tuy nhiên, ở phần sau của phần này, chúng tôi sẽ trình bày phân tích nhiều loại khác nhau các kế hoạch.
Các giả định và hiệu ứng vi phạm giả định
Độ lệch so với giả định về phân phối bình thường
Giả sử rằng biến phụ thuộc được đo lường trên thang số. Cũng giả sử rằng biến phụ thuộc có phân phối chuẩn trong mỗi nhóm. Phân tích phương sai chứa một loạt các biểu đồ và số liệu thống kê để chứng minh giả định này.
Hiệu ứng vi phạm.Ở tất cả F tiêu chí này rất khó bị sai lệch so với tính chuẩn mực (xem Lindman, 1974 để biết kết quả chi tiết). Nếu độ nhọn lớn hơn 0, thì giá trị của thống kê F có thể trở nên rất nhỏ. Giả thuyết không được chấp nhận, mặc dù nó có thể không đúng. Tình hình đảo ngược khi độ nhọn nhỏ hơn 0. Độ lệch của phân phối thường ít ảnh hưởng đến F số liệu thống kê. Nếu số lượng quan sát trong một ô đủ lớn thì độ lệch khỏi tính chuẩn không có ý nghĩa đặc biệt bởi Đức hạnh của trung tâm định lý giới hạn , theo đó, phân phối của giá trị trung bình gần với bình thường, bất kể phân phối ban đầu. Thảo luận chi tiết về tính bền vững F số liệu thống kê có thể được tìm thấy trong Box và Anderson (1955), hoặc Lindman (1974).
Tính đồng nhất của sự phân tán
giả định. Giả định rằng phương sai của các nhóm khác nhau trong kế hoạch là như nhau. Giả định này được gọi là giả định độ phân tán đồng nhất. Nhớ lại rằng ở phần đầu của phần này, khi mô tả cách tính tổng các sai số bình phương, chúng ta đã thực hiện tính tổng trong mỗi nhóm. Nếu các phương sai trong hai nhóm khác nhau, thì việc cộng chúng lại không tự nhiên lắm và không đưa ra ước tính về tổng phương sai trong nhóm (vì trong trường hợp này không có phương sai chung nào cả). mô-đun Phân tích phân tán -ANOVA/MANOVA chứa một tập hợp lớn chỉ tiêu thống kê phát hiện sai lệch so với các giả định về tính đồng nhất của phương sai.
Hiệu ứng vi phạm. Lindman (1974, trang 33) cho thấy rằng F tiêu chí khá ổn định đối với việc vi phạm các giả định về tính đồng nhất của phương sai ( sự không đồng nhất phân tán, xem thêm Box, 1954a, 1954b; Từ, 1938).
Trường hợp đặc biệt: tương quan của phương tiện và phương sai. Có những lúc F số liệu thống kê có thể đánh lạc hướng.Điều này xảy ra khi các giá trị trung bình trong các ô thiết kế tương quan với phương sai. mô-đun Phân tích phương sai cho phép bạn vẽ biểu đồ phương sai hoặc biểu đồ phân tán độ lệch chuẩn dựa trên các phương tiện để phát hiện mối tương quan như vậy. Lý do tại sao một mối tương quan như vậy là nguy hiểm như sau. Hãy tưởng tượng rằng có 8 ô trong kế hoạch, 7 trong số đó có mức trung bình gần như giống nhau và trong một ô, mức trung bình lớn hơn nhiều so với phần còn lại. Sau đó F thử nghiệm có thể phát hiện một tác động có ý nghĩa thống kê. Nhưng giả sử rằng trong một ô có giá trị trung bình lớn và phương sai lớn hơn nhiều so với các ô khác, tức là giá trị trung bình và phương sai trong các ô phụ thuộc (giá trị trung bình càng lớn thì phương sai càng lớn). Trong trường hợp này, giá trị trung bình lớn là không đáng tin cậy, vì nó có thể do sự khác biệt lớn trong dữ liệu gây ra. Tuy nhiên F thống kê dựa trên thống nhất phương sai trong các ô sẽ thu được giá trị trung bình lớn, mặc dù tiêu chí dựa trên phương sai trong mỗi ô sẽ không coi tất cả các khác biệt về giá trị trung bình là đáng kể.
Bản chất này của dữ liệu (giá trị trung bình lớn và phương sai lớn) thường gặp phải khi có các quan sát ngoại lệ. Một hoặc hai quan sát ngoại lệ làm dịch chuyển mạnh giá trị trung bình và làm tăng đáng kể phương sai.
Tính đồng nhất của phương sai và hiệp phương sai
giả định. Trong các thiết kế đa biến, với các biện pháp phụ thuộc đa biến, tính đồng nhất của các giả định về phương sai được mô tả trước đó cũng được áp dụng. Tuy nhiên, vì có các biến phụ thuộc đa biến, nên các mối tương quan chéo (hiệp phương sai) của chúng phải đồng nhất trên tất cả các ô của sơ đồ. mô-đun Phân tích phương sai cung cấp những cách khác kiểm tra các giả định này.
hiệu ứng vi phạm. Tương tự đa chiều F- tiêu chí - λ-test của Wilks. Không có nhiều thông tin về tính ổn định (độ bền) của phép thử λ Wilks đối với việc vi phạm các giả định trên. Tuy nhiên, kể từ khi giải thích các kết quả mô-đun Phân tích phương sai thường dựa trên tầm quan trọng của các hiệu ứng một chiều (sau khi thiết lập tầm quan trọng tiêu chí chung), cuộc thảo luận về độ bền chủ yếu liên quan đến phân tích phương sai một chiều. Do đó, tầm quan trọng của các hiệu ứng một chiều cần được kiểm tra cẩn thận.
Trường hợp đặc biệt: phân tích hiệp phương sai. Vi phạm đặc biệt nghiêm trọng về tính đồng nhất của phương sai/hiệp phương sai có thể xảy ra khi các đồng biến được đưa vào thiết kế. Đặc biệt, nếu mối tương quan giữa hiệp phương sai và các biện pháp phụ thuộc khác nhau trong các ô khác nhau của thiết kế, thì có thể xảy ra việc diễn giải sai kết quả. Cần nhớ rằng trong phân tích hiệp phương sai, về bản chất, phân tích hồi quy được thực hiện trong mỗi ô để tách riêng phần phương sai tương ứng với hiệp phương sai. Giả định về tính đồng nhất của phương sai/hiệp phương sai giả định rằng phân tích hồi quy này được thực hiện theo ràng buộc sau: tất cả phương trình hồi quy(độ dốc) giống nhau cho tất cả các ô. Nếu điều này không có ý định, thì lỗi lớn có thể xảy ra. mô-đun Phân tích phương sai có một số tiêu chí đặc biệt để kiểm tra giả định này. Có thể nên sử dụng các tiêu chí này để đảm bảo rằng các phương trình hồi quy cho các ô khác nhau gần như giống nhau.
Tính đối xứng hình cầu và phức tạp: lý do sử dụng phương pháp đo lặp lại đa biến trong phân tích phương sai
Trong các thiết kế có chứa các yếu tố đo lường lặp đi lặp lại với nhiều hơn hai cấp độ, việc áp dụng phân tích phương sai đơn biến đòi hỏi các giả định bổ sung: giả định đối xứng phức tạp và giả định về tính hình cầu. Những giả định này hiếm khi được đáp ứng (xem bên dưới). Do đó, trong những năm gần đây, phân tích phương sai đa biến đã trở nên phổ biến trong các kế hoạch như vậy (cả hai phương pháp được kết hợp trong mô-đun Phân tích phương sai).
Giả định đối xứng phức tạp Giả định đối xứng phức tạp là các phương sai (tổng số trong nhóm) và hiệp phương sai (theo nhóm) đối với các phép đo lặp lại khác nhau là đồng nhất (giống nhau). Đây là điều kiện đủ để kiểm định F đơn biến đối với các biện pháp lặp lại có giá trị (nghĩa là các giá trị F được báo cáo trung bình phù hợp với phân phối F). Tuy nhiên, trong trường hợp nàyđiều kiện này là không cần thiết.
Giả thiết về tính cầu. Giả định về tính hình cầu là cần thiết và đủ điều kiệnđể kiểm định F là hợp lý. Nó bao gồm thực tế là trong các nhóm, tất cả các quan sát đều độc lập và được phân phối đồng đều. Bản chất của những giả định này, cũng như tác động của việc vi phạm chúng, thường không được mô tả rõ ràng trong sách về phân tích phương sai - điều này sẽ được mô tả trong các đoạn sau. Nó cũng sẽ chỉ ra rằng kết quả của phương pháp đơn biến có thể khác với kết quả của phương pháp đa biến và giải thích điều này có nghĩa là gì.
Sự cần thiết phải độc lập của các giả thuyết. Cách chung để phân tích dữ liệu trong phân tích phương sai là phù hợp với mô hình. Nếu, đối với mô hình tương ứng với dữ liệu, có một số tiên nghiệm các giả thuyết, sau đó phương sai được tách ra để kiểm định các giả thuyết này (tiêu chí về tác động chính, tương tác). Từ quan điểm tính toán, cách tiếp cận này tạo ra một số tập hợp tương phản (tập hợp so sánh các phương tiện trong thiết kế). Tuy nhiên, nếu các tương phản không độc lập với nhau, thì việc phân chia các phương sai trở nên vô nghĩa. Ví dụ, nếu hai tương phản MỘT Và b giống hệt nhau và phần tương ứng được chọn từ phương sai, sau đó phần tương ứng được chọn hai lần. Ví dụ: thật ngớ ngẩn và vô nghĩa khi chỉ ra hai giả thuyết: “giá trị trung bình ở ô 1 cao hơn giá trị trung bình ở ô 2” và “giá trị trung bình ở ô 1 cao hơn giá trị trung bình ở ô 2”. Vì vậy, các giả thuyết phải độc lập hoặc trực giao.
Các giả thuyết độc lập trong các phép đo lặp lại. thuật toán chung, được thực hiện trong mô-đun Phân tích phương sai, sẽ cố gắng tạo độ tương phản độc lập (trực giao) cho mỗi hiệu ứng. Đối với yếu tố đo lường lặp đi lặp lại, những sự tương phản này làm nảy sinh nhiều giả thuyết về khác biệt giữa các mức độ của yếu tố được xem xét. Tuy nhiên, nếu những khác biệt này có tương quan với nhau trong các nhóm, thì kết quả là sự tương phản không còn độc lập nữa. Ví dụ, trong quá trình đào tạo mà người học được đánh giá ba lần trong một học kỳ, có thể xảy ra trường hợp những thay đổi giữa chiều thứ nhất và chiều thứ hai có tương quan nghịch với sự thay đổi giữa chiều thứ hai và thứ ba của các môn học. Những người đã nắm vững phần lớn nội dung giữa chiều thứ nhất và chiều thứ 2 nắm vững một phần nhỏ hơn trong khoảng thời gian đã trôi qua giữa chiều thứ 2 và chiều thứ 3. Trên thực tế, đối với hầu hết các trường hợp khi phân tích phương sai được sử dụng trong các phép đo lặp lại, có thể giả định rằng những thay đổi về mức độ có mối tương quan giữa các đối tượng. Tuy nhiên, khi điều này xảy ra, các giả định về tính đối xứng và hình cầu phức tạp không được đáp ứng và không thể tính được độ tương phản độc lập.
Tác hại của các vi phạm và cách khắc phục. Khi các giả định về tính đối xứng hoặc hình cầu phức tạp không được đáp ứng, phân tích phương sai có thể tạo ra kết quả sai. Trước khi các thủ tục đa biến được phát triển đầy đủ, một số giả định đã được đưa ra để bù đắp cho việc vi phạm các giả định này. (Ví dụ, xem Greenhouse & Geisser, 1959 và Huynh & Feldt, 1970). Các phương pháp này ngày nay vẫn được sử dụng rộng rãi (đó là lý do tại sao chúng được trình bày trong học phần Phân tích phương sai).
Phân tích đa biến của phương pháp tiếp cận phương sai đối với các biện pháp lặp đi lặp lại. Nói chung, các vấn đề về tính đối xứng phức tạp và tính hình cầu đề cập đến thực tế là các tập hợp độ tương phản được đưa vào nghiên cứu về tác động của các yếu tố đo lường lặp lại (với nhiều hơn 2 cấp độ) không độc lập với nhau. Tuy nhiên, chúng không nhất thiết phải độc lập nếu chúng được sử dụng. đa chiều một tiêu chí để kiểm tra đồng thời ý nghĩa thống kê của hai hoặc nhiều yếu tố đo lường lặp lại tương phản. Đây là lý do tại sao phương pháp phân tích phương sai đa biến ngày càng được sử dụng nhiều hơn để kiểm định mức ý nghĩa của các nhân tố đo lường lặp lại đơn biến với nhiều hơn 2 mức. Cách tiếp cận này được sử dụng rộng rãi vì nó thường không yêu cầu giả định về tính đối xứng phức tạp và giả định về tính hình cầu.
Các trường hợp không thể sử dụng phương pháp phân tích phương sai đa biến. Có những ví dụ (kế hoạch) khi không thể áp dụng phương pháp phân tích phương sai đa biến. Đây thường là những trường hợp có một số lượng nhỏ đối tượng trong thiết kế và nhiều cấp độ trong yếu tố đo lường lặp lại. Sau đó, có thể có quá ít quan sát để thực hiện phân tích đa biến. Ví dụ: nếu có 12 thực thể, P = 4 hệ số đo lường lặp đi lặp lại, và mỗi yếu tố có k = 3 cấp độ. Khi đó sự tương tác của 4 yếu tố sẽ “tiêu hao” (k-1)P = 2 4 = 16 bậc tự do. Tuy nhiên, chỉ có 12 đối tượng nên không thể thực hiện kiểm định đa biến trong ví dụ này. mô-đun Phân tích phương sai sẽ phát hiện độc lập những quan sát này và chỉ tính toán các tiêu chí một chiều.
Sự khác biệt trong kết quả đơn biến và đa biến. Nếu nghiên cứu bao gồm một số lượng lớn các biện pháp lặp lại, thì có thể có trường hợp phương pháp đo lường lặp lại đơn biến của ANOVA mang lại kết quả rất khác so với kết quả thu được bằng phương pháp đa biến. Điều này có nghĩa là sự khác biệt giữa các mức của phép đo lặp lại tương ứng có tương quan giữa các đối tượng. Đôi khi thực tế này là một số lợi ích độc lập.
Phân tích đa biến phương sai và mô hình hóa cấu trúc của phương trình
Trong những năm gần đây, mô hình phương trình cấu trúc đã trở nên phổ biến như một giải pháp thay thế cho phân tích phân tán đa biến (ví dụ, xem Bagozzi và Yi, 1989; Bagozzi, Yi và Singh, 1991; Cole, Maxwell, Arvey và Salas, 1993). Cách tiếp cận này cho phép bạn kiểm tra các giả thuyết không chỉ về phương tiện trong các nhóm khác nhau mà còn về ma trận tương quan của các biến phụ thuộc. Ví dụ: bạn có thể nới lỏng các giả định về tính đồng nhất của phương sai và hiệp phương sai và đưa các lỗi vào mô hình một cách rõ ràng đối với từng nhóm phương sai và hiệp phương sai. mô-đun SỐ LIỆU THỐNG KÊMô hình phương trình cấu trúc (SEPATH) (xem Tập III) cho phép phân tích như vậy.
Phân tích phương sai
1. Khái niệm phân tích phương sai
Phân tích phương sai- đây là một phân tích về tính biến đổi của một đặc điểm dưới tác động của bất kỳ yếu tố biến được kiểm soát nào. Trong tài liệu nước ngoài, phân tích phương sai thường được gọi là ANOVA, tạm dịch là phân tích phương sai (Analysis of Variance).
Nhiệm vụ phân tích phương sai bao gồm việc cô lập tính biến đổi của một loại khác với tính biến đổi chung của tính trạng:
a) sự thay đổi do tác động của từng biến độc lập được nghiên cứu;
b) sự thay đổi do tương tác của các biến độc lập được nghiên cứu;
c) biến thể ngẫu nhiên do tất cả các biến chưa biết khác.
Độ biến thiên do tác động của các biến được nghiên cứu và tương tác của chúng tương quan với độ biến thiên ngẫu nhiên. Một chỉ số của tỷ lệ này là bài kiểm tra F của Fisher.
Công thức tính tiêu chí F bao gồm các ước tính về phương sai, nghĩa là các tham số phân phối của một tính năng, do đó, tiêu chí F là một tiêu chí tham số.
hơn trong hơn mức độ biến thiên của một tính trạng là do các biến (nhân tố) nghiên cứu hoặc do tác động qua lại của chúng thì càng cao giá trị thực nghiệm của tiêu chí.
Số không giả thuyết trong phân tích phương sai sẽ nói rằng các giá trị trung bình của tính năng hiệu quả được nghiên cứu trong tất cả các cấp độ đều giống nhau.
Thay thế giả thuyết sẽ nêu rằng các giá trị trung bình của thuộc tính hiệu quả trong các cấp độ khác nhau của yếu tố được nghiên cứu là khác nhau.
Phân tích phương sai cho phép chúng ta chỉ ra sự thay đổi trong một đặc điểm, nhưng không chỉ ra phương hướng những thay đổi này.
Hãy bắt đầu phân tích phương sai với trường hợp đơn giản nhất, khi chúng ta nghiên cứu tác động của chỉ một biến (nhân tố đơn).
2. Phân tích phương sai một chiều cho các mẫu không liên quan
2.1. Mục đích của phương pháp
Phương pháp phân tích phương sai đơn biến được sử dụng trong trường hợp những thay đổi trong thuộc tính hiệu quả được nghiên cứu dưới tác động của việc thay đổi điều kiện hoặc mức độ của bất kỳ yếu tố nào. Trong phiên bản này của phương pháp, ảnh hưởng của từng cấp độ của yếu tố là khác biệt mẫu đề kiểm tra. Phải có ít nhất ba cấp độ của yếu tố. (Có thể có hai cấp độ, nhưng trong trường hợp này, chúng tôi sẽ không thể thiết lập các phụ thuộc phi tuyến tính và có vẻ hợp lý hơn khi sử dụng các cấp độ đơn giản hơn).
Một biến thể phi tham số của loại phân tích này là thử nghiệm Kruskal-Wallis H.
giả thuyết
H 0: Sự khác biệt giữa các hạng nhân tố (các điều kiện khác nhau) không rõ rệt hơn sự khác biệt ngẫu nhiên trong mỗi nhóm.
H 1: Sự khác biệt giữa các phân cấp nhân tố (các điều kiện khác nhau) rõ rệt hơn so với sự khác biệt ngẫu nhiên trong mỗi nhóm.
2.2. Hạn chế của phân tích phương sai đơn biến đối với các mẫu không liên quan
1. Phân tích phương sai đơn biến yêu cầu ít nhất ba cấp bậc của nhân tố và ít nhất hai đối tượng trong mỗi cấp độ.
2. Tính trạng quy định phải phân bố chuẩn trong mẫu nghiên cứu.
Đúng vậy, người ta thường không chỉ ra liệu chúng ta đang nói về sự phân bố của một đặc điểm trong toàn bộ mẫu được khảo sát hay trong phần đó tạo nên phức hợp phân tán.
3. Ví dụ giải bài toán bằng phương pháp phân tích phương sai đơn nhân tố đối với mẫu không liên quan sử dụng ví dụ:
Ba nhóm khác nhau của sáu đối tượng đã nhận được danh sách mười từ. Các từ được trình bày cho nhóm đầu tiên với tốc độ thấp 1 từ mỗi 5 giây, nhóm thứ hai với tốc độ trung bình 1 từ mỗi 2 giây và nhóm thứ ba với tốc độ cao 1 từ mỗi giây. Hiệu suất sao chép được dự đoán là phụ thuộc vào tốc độ trình bày từ. Các kết quả được trình bày trong Bảng. 1.
Số lượng từ được sao chép Bảng 1
|
số chủ đề |
tốc độ thấp |
tốc độ cao |
|
|
tổng cộng | |||
H 0: Khác biệt về lượng từ giữa các nhóm không rõ rệt hơn sự khác biệt ngẫu nhiên bên trong mỗi nhóm.
H1: Sự khác biệt về khối lượng từ giữa các nhóm rõ rệt hơn sự khác biệt ngẫu nhiên bên trong mỗi nhóm. Sử dụng các giá trị thực nghiệm được trình bày trong Bảng. 1, chúng tôi sẽ thiết lập một số giá trị cần thiết để tính tiêu chí F.
Việc tính toán các đại lượng chính để phân tích phương sai một chiều được trình bày trong bảng:
ban 2
bàn số 3
Chuỗi hoạt động trong ANOVA một chiều cho các mẫu bị ngắt kết nối

Thường được sử dụng trong bảng này và các bảng tiếp theo, ký hiệu SS là từ viết tắt của "tổng bình phương". Chữ viết tắt này thường được sử dụng trong các nguồn dịch.
SS sự thật nghĩa là sự biến đổi của tính trạng do tác động của nhân tố nghiên cứu;
SS chung- sự biến đổi chung của tính trạng;
S CA- sự thay đổi do các yếu tố không được tính đến, sự thay đổi "ngẫu nhiên" hoặc "dư".
bệnh đa xơ cứng - "hình vuông ở giữa", hoặc giá trị trung bình của tổng bình phương, giá trị trung bình của SS tương ứng.
df - số bậc tự do, khi xem xét các tiêu chí phi tham số, chúng tôi ký hiệu bằng chữ cái Hy Lạp v.
Kết luận: H 0 bị bác bỏ. H 1 được chấp nhận. Sự khác biệt về khối lượng tái tạo từ giữa các nhóm rõ rệt hơn so với sự khác biệt ngẫu nhiên trong mỗi nhóm (α=0,05). Vì vậy, tốc độ trình bày các từ ảnh hưởng đến khối lượng tái tạo của chúng.
Một ví dụ về giải quyết vấn đề trong Excel được trình bày dưới đây:
Dữ liệu ban đầu:

Dùng lệnh: Công cụ->Phân tích dữ liệu->Phân tích phương sai một chiều, ta được kết quả như sau:

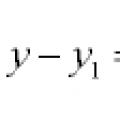 Phương trình đường thẳng và đường cong trong mặt phẳng
Phương trình đường thẳng và đường cong trong mặt phẳng Phương trình thuần nhất tổng quát Phương trình thuần nhất tổng quát cấp 2
Phương trình thuần nhất tổng quát Phương trình thuần nhất tổng quát cấp 2 Nhờ dấu phẩy Do thực tế là trong họ
Nhờ dấu phẩy Do thực tế là trong họ