Формула для расчета дисперсии дискретной случайной величины. Математическое ожидание и дисперсия случайной величины
Дисперсия в статистике определяется как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. Распространенный способ расчета квадратов отклонений вариантов от средней с их последующим усреднением.
![]()
В экономически-статистическом анализе вариацию признака принято оценивать чаще всего с помощью среднего квадратического отклонения, оно представляет собой корень квадратный из дисперсии.
 (3)
(3)
Характеризует абсолютную колеблемость значений варьирующего признака выражается в тех же единицах измерения, что и варианты. В статистике часто возникает необходимость сравнения вариации различных признаков. Для таких сравнений используется относительный показатель вариации, коэффициент вариации.
Свойства дисперсии:
1)если из всех вариант вычесть какое-либо число, то дисперсия от этого не изменится;
2) если все значения вариант разделить на какое-либо число b, то дисперсия уменьшится в b^2 раз, т.е.
3) если исчислить средний квадрат отклонений от какого-либо числа с неравного средней арифметической, то он будет больше дисперсии . При этом на вполне определенную величину на квадрат разности между средней величиной поc.
![]()
Дисперсию можно определить как разницу между средним квадратом и средней в квадрате.
17. Групповая и межгрупповая вариации. Правило сложения дисперсии
Если статистическая совокупность разбита на группы или части по изучаемому признаку, то для такой совокупности могут быть исчислены следующие виды дисперсии: групповые (частные), средне групповые (частных), и межгрупповая.
Общая
дисперсия
–
отражает вариацию признака за счет всех
условий и причин, действующих в данной
статистической совокупности.
![]()
Групповая дисперсия - равна среднему квадрату отклонений отдельных значений признака внутри группы от средней арифметической этой группы, называемой групповой средней. При этом групповая средняя не совпадает с общей средней для всей совокупности.
![]()
Групповая дисперсия отражает вариацию признака только за счет условий и причин, действующих внутри группы.
Средняя групповых дисперсий - определяется как среднее взвешенное арифметическое из дисперсий групповых, причем весами являются объемы групп.
Межгрупповая дисперсия - равна среднему квадрату отклонений групповых средних от общей средней.
Межгрупповая дисперсия характеризует вариацию результативного признака за счет группировочного признака.
Между рассмотренными видами дисперсий существует определенное соотношение: общая дисперсия равна сумме средней групповой и межгрупповой дисперсии.
Это соотношение называется правилом сложения дисперсии.
18. Динамический ряд и его составные элементы. Виды динамических рядов.
Ряд в статистике - это цифровые данные, показывающие, изменение явления во времени или в пространстве и дающие возможность производить статистическое сравнение явлений как в процессе их развития во времени, так и по различным формам и видам процессов. Благодаря этому можно обнаружить взаимную зависимость явлений.
Процесс развития движения социальных явлений во времени в статистике принято называть динамикой. Для отображения динамики строят ряды динамики (хронологические, временные), которые представляют собой ряды изменяющихся во времени значений статистического показателя (например, число осуждённых за 10 лет), расположенных в хронологическом порядке. Их составными элементами являются цифровые значения данного показателя и периоды или моменты времени, к которым они относятся.
Важнейшая характеристика рядов динамики - их размер (объём, величина) того или иного явления, достигнутых в определённых период или к определённому моменту. Соответственно, величина членов ряда динамики - его уровень. Различают начальный, средний и конечный уровни динамического ряда. Начальный уровень показывает величину первого, конечный - величину последнего члена ряда. Средний уровень представляет собой среднюю хронологическую вариационного рада и исчисляется в зависимости от того, является ли динамический ряд интервальным или моментным.
Ещё одна важная характеристика динамического ряда - время, прошедшее от начального до конечного наблюдения, или число таких наблюдений.
Существуют различные виды рядов динамики, их можно классифицировать по следующим признакам.
1) В зависимости от способа выражения уровней ряды динамики подразделяются на ряды абсолютных и производных показателей (относительных и средних величин).
2) В зависимости от того, как выражают уровни ряда состояние явления на определённые моменты времени (на начало месяца, квартала, года и т.п.) или его величину за определённые интервалы времени (например, за сутки, месяц, год и т.п.), различают соответственно моментные и интервальные ряды динамики. Моментные ряды в аналитической работе правоохранительных органов используются сравнительно редко.
В теории статистики выделяют рады динамики и по ряду других классификационных признаков: в зависимости от расстояния между уровнями - с равностоящими уровнями и неравностоящими уровнями во времени; в зависимости от наличия основной тенденции изучаемого процесса - стационарные и не стационарные. При анализе динамических рядов исходят из следующего уровни ряда представляют в виде составляющих:
Y t = TP + Е (t)
где ТР – детерминированная составляющая определяющая общую тенденцию изменения во времени или тренд.
Е (t) – случайная компонента, вызывающая колеблимость уровней.
Математическое ожидание и дисперсия - чаще всего применяемые числовые характеристики случайной величины. Они характеризуют самые важные черты распределения: его положение и степень разбросанности. Во многих задачах практики полная, исчерпывающая характеристика случайной величины - закон распределения - или вообще не может быть получена, или вообще не нужна. В этих случаях ограничиваются приблизительным описанием случайной величины с помощью числовых характеристик.
Математическое ожидание часто называют просто средним значением случайной величины. Дисперсия случайной величины - характеристика рассеивания, разбросанности случайной величины около её математического ожидания.
Математическое ожидание дискретной случайной величины
Подойдём к понятию математического ожидания, сначала исходя из механической интерпретации распределения дискретной случайной величины. Пусть единичная масса распределена между точками оси абсцисс x 1 , x 2 , ..., x n , причём каждая материальная точка имеет соответствующую ей массу из p 1 , p 2 , ..., p n . Требуется выбрать одну точку на оси абсцисс, характеризующую положение всей системы материальных точек, с учётом их масс. Естественно в качестве такой точки взять центр массы системы материальных точек. Это есть среднее взвешенное значение случайной величины X , в которое абсцисса каждой точки x i входит с "весом", равным соответствующей вероятности. Полученное таким образом среднее значение случайной величины X называется её математическим ожиданием.
Математическим ожиданием дискретной случайной величины называется сумма произведений всех возможных её значений на вероятности этих значений:
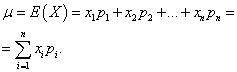
Пример 1. Организована беспроигрышная лотерея. Имеется 1000 выигрышей, из них 400 по 10 руб. 300 - по 20 руб. 200 - по 100 руб. и 100 - по 200 руб. Каков средний размер выигрыша для купившего один билет?
Решение. Средний выигрыш мы найдём, если общую сумму выигрышей, которая равна 10*400 + 20*300 + 100*200 + 200*100 = 50000 руб, разделим на 1000 (общая сумма выигрышей). Тогда получим 50000/1000 = 50 руб. Но выражение для подсчёта среднего выигрыша можно представить и в следующем виде:
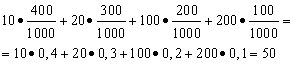
С другой стороны, в данных условиях размер выигрыша является случайной величиной, которая может принимать значения 10, 20, 100 и 200 руб. с вероятностями, равными соответственно 0,4; 0,3; 0,2; 0,1. Следовательно, ожидаемый средний выигрыш равен сумме произведений размеров выигрышей на вероятности их получения.
Пример 2. Издатель решил издать новую книгу. Продавать книгу он собирается за 280 руб., из которых 200 получит он сам, 50 - книжный магазин и 30 - автор. В таблице дана информация о затратах на издание книги и вероятности продажи определённого числа экземпляров книги.
Найти ожидаемую прибыль издателя.
Решение. Случайная величина "прибыль" равна разности доходов от продажи и стоимости затрат. Например, если будет продано 500 экземпляров книги, то доходы от продажи равны 200*500=100000, а затраты на издание 225000 руб. Таким образом, издателю грозит убыток размером в 125000 руб. В следующей таблице обобщены ожидаемые значения случайной величины - прибыли:
| Число | Прибыль x i | Вероятность p i | x i p i |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Всего: | 1,00 | 25000 |
Таким образом, получаем математическое ожидание прибыли издателя:
![]() .
.
Пример 3. Вероятность попадания при одном выстреле p = 0,2 . Определить расход снарядов, обеспечивающих математическое ожидание числа попаданий, равное 5.
Решение. Из всё той же формулы математического ожидания, которую мы использовали до сих пор, выражаем x - расход снарядов:
![]() .
.
Пример 4. Определить математическое ожидание случайной величины x числа попаданий при трёх выстрелах, если вероятность попадания при каждом выстреле p = 0,4 .
Подсказка: вероятность значений случайной величины найти по формуле Бернулли .
Свойства математического ожидания
Рассмотрим свойства математического ожидания.
Свойство 1. Математическое ожидание постоянной величины равно этой постоянной:
Свойство 2. Постоянный множитель можно выносить за знак математического ожидания:
![]()
Свойство 3. Математическое ожидание суммы (разности) случайных величин равно сумме (разности) их математических ожиданий:
Свойство 4. Математическое ожидание произведения случайных величин равно произведению их математических ожиданий:
Свойство 5. Если все значения случайной величины X уменьшить (увеличить) на одно и то же число С , то её математическое ожидание уменьшится (увеличится) на то же число:
![]()
Когда нельзя ограничиваться только математическим ожиданием
В большинстве случаев только математическое ожидание не может в достаточной степени характеризовать случайную величину.
Пусть случайные величины X и Y заданы следующими законами распределения:
| Значение X | Вероятность |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Значение Y | Вероятность |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
Математические ожидания этих величин одинаковы - равны нулю:
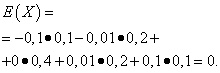
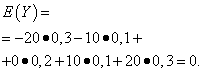
Однако характер распределения их различный. Случайная величина X может принимать только значения, мало отличающиеся от математического ожидания, а случайная величина Y может принимать значения, значительно отклоняющиеся от математического ожидания. Аналогичный пример: средняя заработная плата не даёт возможности судить об удельном весе высоко- и низкооплачиваемых рабочих. Иными словами, по математическому ожиданию нельзя судить о том, какие отклонения от него, хотя бы в среднем, возможны. Для этого нужно найти дисперсию случайной величины.
Дисперсия дискретной случайной величины
Дисперсией дискретной случайной величины X называется математическое ожидание квадрата отклонения её от математического ожидания:
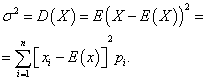
Средним квадратическим отклонением случайной величины X называется арифметическое значение квадратного корня её дисперсии:
![]() .
.
Пример 5. Вычислить дисперсии и средние квадратические отклонения случайных величин X и Y , законы распределения которых приведены в таблицах выше.
Решение. Математические ожидания случайных величин X и Y , как было найдено выше, равны нулю. Согласно формуле дисперсии при Е (х )=Е (y )=0 получаем:

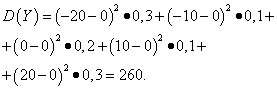
Тогда средние квадратические отклонения случайных величин X и Y составляют
![]() .
.
Таким образом, при одинаковых математических ожиданиях дисперсия случайной величины X очень мала, а случайной величины Y - значительная. Это следствие различия в их распределении.
Пример 6. У инвестора есть 4 альтернативных проекта инвестиций. В таблице обобщены данные об ожидаемой прибыли в этих проектах с соответствующей вероятностью.
| Проект 1 | Проект 2 | Проект 3 | Проект 4 |
| 500, P =1 | 1000, P =0,5 | 500, P =0,5 | 500, P =0,5 |
| 0, P =0,5 | 1000, P =0,25 | 10500, P =0,25 | |
| 0, P =0,25 | 9500, P =0,25 |
Найти для каждой альтернативы математическое ожидание, дисперсию и среднее квадратическое отклонение.
Решение. Покажем, как вычисляются эти величины для 3-й альтернативы:
В таблице обобщены найденные величины для всех альтернатив.
У всех альтернатив одинаковы математические ожидания. Это означает, что в долгосрочном периоде у всех - одинаковые доходы. Стандартное отклонение можно интерпретировать как единицу измерения риска - чем оно больше, тем больше риск инвестиций. Инвестор, который не желает большого риска, выберет проект 1, так как у него наименьшее стандартное отклонение (0). Если же инвестор отдаёт предпочтение риску и большим доходам в короткий период, то он выберет проект наибольшим стандартным отклонением - проект 4.
Свойства дисперсии
Приведём свойства дисперсии.
Свойство 1. Дисперсия постоянной величины равна нулю:
Свойство 2. Постоянный множитель можно выносить за знак дисперсии, возводя его при этом в квадрат:
![]() .
.
Свойство 3. Дисперсия случайной величины равна математическому ожиданию квадрата этой величины, из которого вычтен квадрат математического ожидания самой величины:
![]() ,
,
где ![]() .
.
Свойство 4. Дисперсия суммы (разности) случайных величин равна сумме (разности) их дисперсий:
Пример 7. Известно, что дискретная случайная величина X принимает лишь два значения: −3 и 7. Кроме того, известно математическое ожидание: E (X ) = 4 . Найти дисперсию дискретной случайной величины.
Решение. Обозначим через p вероятность, с которой случайная величина принимает значение x 1 = −3 . Тогда вероятностью значения x 2 = 7 будет 1 − p . Выведем уравнение для математического ожидания:
E (X ) = x 1 p + x 2 (1 − p ) = −3p + 7(1 − p ) = 4 ,
откуда получаем вероятности: p = 0,3 и 1 − p = 0,7 .
Закон распределения случайной величины:
| X | −3 | 7 |
| p | 0,3 | 0,7 |
Дисперсию данной случайной величины вычислим по формуле из свойства 3 дисперсии:
D (X ) = 2,7 + 34,3 − 16 = 21 .
Найти математическое ожидание случайной величины самостоятельно, а затем посмотреть решение
Пример 8. Дискретная случайная величина X принимает лишь два значения. Большее из значений 3 она принимает с вероятностью 0,4. Кроме того, известна дисперсия случайной величины D (X ) = 6 . Найти математическое ожидание случайной величины.
Пример 9. В урне 6 белых и 4 чёрных шара. Из урны вынимают 3 шара. Число белых шаров среди вынутых шаров является дискретной случайной величиной X . Найти математическое ожидание и дисперсию этой случайной величины.
Решение. Случайная величина X может принимать значения 0, 1, 2, 3. Соответствующие им вероятности можно вычислить по правилу умножения вероятностей . Закон распределения случайной величины:
| X | 0 | 1 | 2 | 3 |
| p | 1/30 | 3/10 | 1/2 | 1/6 |
Отсюда математическое ожидание данной случайной величины:
M (X ) = 3/10 + 1 + 1/2 = 1,8 .
Дисперсия данной случайной величины:
D (X ) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Математическое ожидание и дисперсия непрерывной случайной величины
Для непрерывной случайной величины механическая интерпретация математического ожидания сохранит тот же смысл: центр массы для единичной массы, распределённой непрерывно на оси абсцисс с плотностью f (x ). В отличие от дискретной случайной величиной, у которой аргумент функции x i изменяется скачкообразно, у непрерывной случайной величины аргумент меняется непрерывно. Но математическое ожидание непрерывной случайной величины также связано с её средним значением.
Чтобы находить математическое ожидание и дисперсию непрерывной случайной величины, нужно находить определённые интегралы . Если дана функция плотности непрерывной случайной величины, то она непосредственно входит в подынтегральное выражение. Если дана функция распределения вероятностей, то, дифференцируя её, нужно найти функцию плотности.
Арифметическое среднее всех возможных значений непрерывной случайной величины называется её математическим ожиданием , обозначаемым или .
В случае, если совокупность разбита на группы по изучаемому признаку, то для данной совокупности могут быть исчислены следующие виды дисперсии: общая, групповые (внутригрупповые), средняя из групповых (средняя из внутригрупповых), межгрупповая.
Первоначально рассчитывает коэффициент детерминации, который показывает какую часть общей вариации изучаемого признака составляет вариация межгрупповая, т.е. обусловленная группировочным признаком:
Эмпирическое корреляционное отношение характеризует тесноту связи между признаками группировочным (факторным) и результативным.
Эмпирическое корреляционное отношение может принимать значения от 0 до 1.
Для оценки тесноты связи на основе показателя эмпирического корреляционного отношения можно воспользоваться соотношениями Чеддока:
Пример 4. Имеются следующие данные о выполнении работ проектно-изыскательскими организациями разной формы собственности:
Определить:
1) общую дисперсию;
2) групповые дисперсии;
3) среднюю из групповых дисперсий;
4) межгрупповую дисперсию;
5) общую дисперсию на основе правила сложения дисперсий;
6) коэффициент детерминации и эмпирическое корреляционное отношение.
Сделайте выводы.
Решение:
1. Определим средний объём выполнения работ предприятий двух форм собственности:
Рассчитаем общую дисперсию:
![]()
2. Определим групповые средние:
![]() млн руб.;
млн руб.;
![]() млн руб.
млн руб.
Групповые дисперсии:
![]() ;
;
3. Рассчитаем среднюю из групповых дисперсий:
4. Определим межгрупповую дисперсию:
5. Рассчитаем общую дисперсию на основе правила сложения дисперсий:
6. Определим коэффициент детерминации:
![]() .
.
Таким образом, объём работ, выполненных проектно-изыскательскими организациями на 22% зависит от формы собственности предприятий.
Эмпирическое корреляционное отношение рассчитываем по формуле
![]() .
.
Величина рассчитанного показателя свидетельствует о том, что зависимость объема работ от формы собственности предприятия невелика.
Пример 5. В результате обследования технологической дисциплины производственных участков получены следующие данные:
Определите коэффициент детерминации
Дисперсия случайной величины - мера разброса данной случайной величины , то есть её отклонения от математического ожидания. В статистике для обозначения дисперсии часто употребляется обозначение (сигма в квадрате). Квадратный корень из дисперсии , равный , называется стандартным отклонением или стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения.
Хотя для оценки всей выборки очень удобно использовать лишь одно значение (такое как среднее значение или моду и медиану), этот подход легко может привести к неправильным выводам. Причина такого положения лежит не в самой величине, а в том, что одна величина никак не отражает разброс значений данных.
Например, в выборке:
среднее значение равно 5.
Однако, в самой выборке нет ни одного элемента со значением 5. Возможно, Вам потребуется знать степень близости каждого элемента выборки к ее среднему значению. Или, другими словами, вам потребуется знать дисперсию значений. Зная степень изменения данных, Вы можете лучше интерпретировать среднее значение , медиану и моду . Степень изменения значений выборки определяется путем вычисления их дисперсии и стандартного отклонения.
Дисперсия и квадратный корень из дисперсии, называемый стандартным отклонением, характеризуют среднее отклонение от среднего значения выборки. Среди этих двух величин наибольшее значение имеет стандартное отклонение . Это значение можно представить как среднее расстояние, на котором находятся элементы от среднего элемента выборки.
Дисперсию трудно интерпретировать содержательно. Однако, квадратный корень из этого значения является стандартным отклонением и хорошо поддается интерпретации.
Стандартное отклонение вычисляется путем определения сначала дисперсии и затем вычисления квадратного корня из дисперсии.
Например, для массива данных, приведенных на рисунке, будут получены следующие значения:

Рисунок 1
Здесь среднее значение квадратов разностей равно 717,43. Для получения стандартного отклонения осталось лишь взять квадратный корень из этого числа.
Результат составит приблизительно 26,78.
Следует помнить, что стандартное отклонение интерпретируется как среднее расстояние, на котором находятся элементы от среднего значения выборки.
Стандартное отклонение показывает, насколько хорошо среднее значение описывает всю выборку.
Допустим, Вы являетесь руководителем производственного отдела по сборке ПК. В квартальном отчете говорится, что выпуск за последний квартал составил 2500 ПК. Плохо это или хорошо? Вы попросили (или уже в отчете есть эта графа) в отчете отобразить стандартное отклонение по этим данным. Цифра стандартного отклонения, например, равна 2000. Становится понятным для Вас, как руководителя отдела, что производственная линия требует лучшего управления (слишком большие отклонения по количеству собираемых ПК).
Вспомним: при большой величине стандартного отклонения данные широко разбросаны относительно среднего значения, а при маленькой – они группируются близко к среднему значению.
Четыре статистические функции ДИСП(), ДИСПР(), СТАНДОТКЛОН() и СТАНДОТКЛОНП() – предназначены для вычисления дисперсии и стандартного отклонения чисел в интервале ячеек. Перед тем как вычислять дисперсию и стандартное отклонение набора данных, нужно определить, представляют ли эти данные генеральную совокупность или выборку из генеральной совокупности. В случае выборки из генеральной совокупности следует использовать функции ДИСП() и СТАНДОТКЛОН(), а в случае генеральной совокупности – функции ДИСПР() и СТАНДОТЛОНП():
| Генеральная совокупность | Функция |
 | ДИСПР() |
 | СТАНДОТЛОНП() |
| Выборка | |
 | ДИСП() |
 | СТАНДОТКЛОН() |
Дисперсия (а так же стандартное отклонение), как мы отмечали, свидетельствуют о том, в какой степени входящие в набор данных величины разбросаны вокруг среднего арифметического.
Малое значение дисперсии или стандартного отклонения говорит о том, что все данные сосредоточены вокруг среднего арифметического, а большое значение этих величин – о том, что данные разбросаны в широком диапазоне значений.
Дисперсию достаточно трудно интерпретировать содержательно (что значит малое значение, большое значение?). Выполнение Задания 3 позволит визуально, на графике, показать смысл дисперсии для набора данных.
Задания
· Задание 1.
· 2.1. Дать понятия: дисперсия и стандартное отклонение; их символьное обозначение при статистической обработке данных.
· 2.2. Оформить рабочий лист в соответствии с рисунком 1 и произвести необходимые расчеты.
· 2.3. Привести основные формулы, используемые при расчетах
· 2.4. Пояснить все обозначения ( , , )
· 2.5. Пояснить практическое значение понятия дисперсия и стандартное отклонение.
Задание 2.
1.1. Дать понятия: генеральная совокупность и выборка; математическое ожидание и среднее арифметическое их символьное обозначение при статистической обработке данных.
1.2. В соответствии с рисунком 2 оформить рабочий лист и произвести расчеты.
1.3. Привести основные формулы, используемые при расчетах (для генеральной совокупности и выборке).

Рисунок 2
1.4. Объяснить, почему возможны получения таких значений средних арифметических в выборках как 46,43 и 48,78 (см. файл Приложение). Сделать выводы.
Задание 3.
Имеется две выборки с различным набором данных, но среднее для них будет одинаковым:

Рисунок 3
3.1. Оформить рабочий лист в соответствии с рисунком 3 и произвести необходимые расчеты.
3.2. Приведите основные формулы расчета.
3.3. Постройте графики в соответствии с рисунками 4, 5.
3.4. Поясните полученные зависимости.
3.5. Аналогичные вычисления проведите для данных двух выборок.
Исходная выборка 11119999
Значения второй выборки подбираете так, что бы среднее арифметическое для второй выборки было таким же, например,:

Подберите значения для второй выборки самостоятельно. Оформите вычисления и построения графиков подобно рисункам 3, 4, 5. Покажите основные формулы, которые использовали при вычислениях.
Сделайте соответствующие выводы.
Все задания оформить в виде отчета со всеми необходимыми рисунками, графиками, формулами и краткими пояснениями.
Примечание: построение графиков обязательно пояснить с рисунками и краткими пояснениями.
Вариационный размах (или размах вариации) - это разница между максимальным и минимальным значениями признака:
В нашем примере размах вариации сменной выработки рабочих составляет: в первой бригаде R=105-95=10 дет., во второй бригаде R=125-75=50 дет. (в 5 раз больше). Это говорит о том, что выработка 1-й бригады более «устойчива», но резервов роста выработки больше у второй бригады, т.к. в случае достижения всеми рабочими максимальной для этой бригады выработки, ею может быть изготовлено 3*125=375 деталей, а в 1-й бригаде только 105*3=315 деталей.
Если крайние значения признака не типичны для совокупности, то используют квартильный или децильный размахи. Квартильный размах RQ= Q3-Q1 охватывает 50% объема совокупности, децильный размах первый RD1 = D9-D1охватывает 80% данных, второй децильный размах RD2= D8-D2 – 60 %.
Недостатком показателя вариационного размаха является, но что его величина не отражает все колебания признака.
Простейшим обобщающим показателем, отражающим все колебания признака, является среднее линейное отклонение
, представляющее собой среднюю арифметическую абсолютных отклонений отдельных вариант от их средней величины:
,
для сгруппированных данных ![]() ,
,
где хi – значение признака в дискретном ряду или середина интервала в интервальном распределении.
В вышеприведенных формулах разности в числителе взяты по модулю, иначе, согласно свойству средней арифметической, числитель всегда будет равен нулю. Поэтому среднее линейное отклонение в статистической практике применяют редко, только в тех случаях, когда суммирование показателей без учета знака имеет экономический смысл. С его помощью, например, анализируется состав работающих, рентабельность производства, оборот внешней торговли.
Дисперсия признака
– это средний квадрат отклонений вариант от их средней величины:
простая дисперсия![]() ,
,
взвешенная дисперсия .
.
Формулу для расчета дисперсии можно упростить:
Таким образом, дисперсия равна разности средней из квадратов вариант и квадрата средней из вариант совокупности: .
.
Однако, вследствие суммирования квадратов отклонений дисперсия дает искаженное представление об отклонениях, поэтому ее на основе рассчитывают среднее квадратическое отклонение
, которое показывает, на сколько в среднем отклоняются конкретные варианты признака от их среднего значения. Вычисляется путем извлечения квадратного корня из дисперсии:
для несгруппированных данных ,
,
для вариационного ряда
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность, тем более надежной (типичной) будет средняя величина.
Среднее линейное и среднее квадратичное отклонение - именованные числа, т. е. выражаются в единицах измерения признака, идентичны по содержанию и близки по значению.
Рассчитывать абсолютные показатели вариации рекомендуется с помощью таблиц.
Таблица 3 – Расчет характеристик вариации (на примере срока данных о сменной выработке рабочих бригады)
Число рабочих, |
Расчетные значения |
||||||
Итого: |
|||||||
Среднесменная выработка рабочих:![]()
Среднее линейное отклонение:![]()
Дисперсия выработки: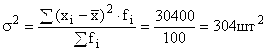
Среднее квадратическое отклонение выработки отдельных рабочих от средней выработки:
.
1 Расчет дисперсии способом моментов
Вычисление дисперсий связано с громоздкими расчетами (особенно если средняя величина выражена большим числом с несколькими десятичными знаками). Расчеты можно упростить, если использовать упрощенную формулу и свойства дисперсии.
Дисперсия обладает следующими свойствами:
- если все значения признака уменьшить или увеличить на одну и ту же величину А, то дисперсия от этого не уменьшится:
 ,
,
 , то или
, то или 
Используя свойства дисперсии и сначала уменьшив все варианты совокупности на величину А, а затем разделив на величину интервала h, получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:
 ,
,
где – дисперсия, исчисленная по способу моментов;
h – величина интервала вариационного ряда;
– новые (преобразованные) значения вариант;
А– постоянная величина, в качестве которой используют середину интервала, обладающего наибольшей частотой; либо вариант, имеющий наибольшую частоту; 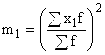 – квадрат момента первого порядка;
– квадрат момента первого порядка;
– момент второго порядка.
Выполним расчет дисперсии способом моментов на основе данных о сменной выработке рабочих бригады.
Таблица 4 – Расчет дисперсии по способу моментов
Группы рабочих по выработке, шт. |
Число рабочих, |
Середина интервала, |
Расчетные значения |
||
Порядок расчета:


- рассчитываем дисперсию:
2 Расчет дисперсии альтернативного признака
Среди признаков, изучаемых статистикой, есть и такие, которым свойственны лишь два взаимно исключающих значения. Это альтернативные признаки. Им придается соответственно два количественных значения: варианты 1 и 0. Частостью варианты 1, которая обозначается p, является доля единиц, обладающих данным признаком. Разность 1-р=q является частостью варианты 0. Таким образом,
хi |
|
Средняя арифметическая альтернативного признака![]() , т. к. p+q=1.
, т. к. p+q=1.
Дисперсия альтернативного признака
, т.к. 1-р=q
Таким образом, дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком.
Если значения 1 и 0 встречаются одинаково часто, т. е. p=q, дисперсия достигает своего максимума pq=0,25.
Дисперсия альтернативного признака используется в выборочных обследованиях, например, качества продукции.
3 Межгрупповая дисперсия. Правило сложения дисперсий
Дисперсия, в отличие от других характеристик вариации, является аддитивной величиной. То есть в совокупности, которая разделена на группы по факторному признаку х, дисперсия результативного признака y может быть разложена на дисперсию в каждой группе (внутригрупповую) и дисперсию между группами (межгрупповую). Тогда, наряду с изучением вариации признака по всей совокупности в целом, становится возможным изучение вариации в каждой группе, а также между этими группами.
Общая дисперсия
измеряет вариацию признака у
по всей совокупности под влиянием всех факторов, вызвавших эту вариацию (отклонения). Она равна среднему квадрату отклонений отдельных значений признака у
от общей средней и может быть вычислена как простая или взвешенная дисперсия.
Межгрупповая дисперсия
характеризует вариацию результативного признака у
, вызванную влиянием признака-фактора х
, положенного в основу группировки. Она характеризует вариацию групповых средних и равна среднему квадрату отклонений групповых средних от общей средней : ,
,
где – средняя арифметическая i-той группы;
– численность единиц в i-той группе (частота i-той группы);
– общая средняя совокупности.
Внутригрупповая дисперсия
отражает случайную вариацию, т. е. ту часть вариации, которая вызвана влиянием неучтенных факторов и не зависит от признака-фактора, положенного в основу группировки. Она характеризует вариацию индивидуальных значений относительно групповых средних, равна среднему квадрату отклонений отдельных значений признака у
внутри группы от средней арифметической этой группы (групповой средней) и вычисляется как простая или взвешенная дисперсия для каждой группы: ![]() или
или ![]() ,
,
где – число единиц в группе.
На основании внутригрупповых дисперсий по каждой группе можно определить общую среднюю из внутригрупповых дисперсий
:
.
Взаимосвязь между тремя дисперсиями получила название правила сложения дисперсий
, согласно которому общая дисперсия равна сумме межгрупповой дисперсии и средней из внутригрупповых дисперсий:
Пример
. При изучении влияния тарифного разряда (квалификации) рабочих на уровень производительности их труда получены следующие данные.
Таблица 5 – Распределение рабочих по среднечасовой выработке.
№ п/п |
Рабочие 4-го разряда |
Рабочие 5-го разряда |
|||||
Выработка |
Выработка |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
В данном примере рабочие разделены на две группы по факторному признаку х
– квалификации, которая характеризуется их разрядом. Результативный признак – выработка – варьируется как под его влиянием (межгрупповая вариация), так и за счет других случайных факторов (внутригрупповая вариация). Задача заключается в измерении этих вариаций с помощью трех дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации показывает долю вариации результативного признака у
под влиянием факторного признака х
. Остальная часть общей вариации у
вызвана изменением прочих факторов.
В примере эмпирический коэффициент детерминации равен:![]() или 66,7 %,
или 66,7 %,
Это означает, что на 66,7% вариация производительности труда рабочих обусловлена различиями в квалификации, а на 33,3% – влиянием прочих факторов.
Эмпирическое корреляционное отношение
показывает тесноту связи между группировочным и результативными признаками. Рассчитывается как корень квадратный из эмпирического коэффициента детерминации:
Эмпирическое корреляционное отношение , как и , может принимать значения от 0 до 1.
Если связь отсутствует, то =0. В этом случае =0, то есть групповые средние равны между собой и межгрупповой вариации нет. Значит группировочный признак – фактор не влияет на образование общей вариации.
Если связь функциональная, то =1. В этом случае дисперсия групповых средних равна общей дисперсии (), то есть внутригрупповой вариации нет. Это означает, что группировочный признак полностью определяет вариацию изучаемого результативного признака.
Чем ближе значение корреляционного отношения к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи между признаками пользуются соотношениями Чэддока.
В примере ![]() , что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
, что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
 От «полевика» до «пляжника»
От «полевика» до «пляжника» Плутарх из Херонеи (Plutarch)
Плутарх из Херонеи (Plutarch) Самые сильные землетрясения в мире
Самые сильные землетрясения в мире