Какой термин обозначает достоверность статистической информации. Смотреть что такое "достоверность статистическая" в других словарях
Основные черты всякой зависимости между переменными.
Можно отметить два самых простых свойства зависимости между переменными: (a) величина зависимости и (b) надежность зависимости.
- Величина . Величину зависимости легче понять и измерить, чем надежность. Например, если любой мужчина в выборке имел значение числа лейкоцитов (WCC) выше чем любая женщина, то вы можете сказать, что зависимость между двумя переменными (Пол и WCC) очень высокая. Другими словами, вы могли бы предсказать значения одной переменной по значениям другой.
- Надежность ("истинность"). Надежность взаимозависимости - менее наглядное понятие, чем величина зависимости, однако чрезвычайно важное. Надежность зависимости непосредственно связана с репрезентативностью определенной выборки, на основе которой строятся выводы. Другими словами, надежность говорит о том, насколько вероятно, что зависимость будет вновь обнаружена (иными словами, подтвердится) на данных другой выборки, извлеченной из той же самой популяции.
Следует помнить, что конечной целью почти никогда не является изучение данной конкретной выборки значений; выборка представляет интерес лишь постольку, поскольку она дает информацию обо всей популяции. Если исследование удовлетворяет некоторым специальным критериям, то надежность найденных зависимостей между переменными выборки можно количественно оценить и представить с помощью стандартной статистической меры.
Величина зависимости и надежность представляют две различные характеристики зависимостей между переменными. Тем не менее, нельзя сказать, что они совершенно независимы. Чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем более она надежна (см. следующий раздел).
Статистическая значимость результата (p-уровень) представляет собой оцененную меру уверенности в его "истинности" (в смысле "репрезентативности выборки"). Выражаясь более технически, p-уровень – это показатель, находящийся в убывающей зависимости от надежности результата. Более высокий p-уровень соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию.
Например, p-уровень = 0.05 (т.е. 1/20) показывает, что имеется 5% вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. Во многих исследованиях p-уровень 0.05 рассматривается как "приемлемая граница" уровня ошибки.
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать "значимым". Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным.
На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований.
Обычно во многих областях результат p .05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%).
Результаты, значимые на уровне p .01 обычно рассматриваются как статистически значимые, а результаты с уровнем p .005 или p . 001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования .
Понятно, что чем большее число анализов будет проведено с совокупностью собранных данных, тем большее число значимых (на выбранном уровне) результатов будет обнаружено чисто случайно.
Некоторые статистические методы, включающие много сравнений, и, таким образом, имеющие значительный шанс повторить такого рода ошибки, производят специальную корректировку или поправку на общее число сравнений. Тем не менее, многие статистические методы (особенно простые методы разведочного анализа данных) не предлагают какого-либо способа решения данной проблемы.
Если связь между переменными "объективно" слабая, то не существует иного способа проверить такую зависимость кроме как исследовать выборку большого объема. Даже если выборка совершенно репрезентативна, эффект не будет статистически значимым, если выборка мала. Аналогично, если зависимость "объективно" очень сильная, тогда она может быть обнаружена с высокой степенью значимости даже на очень маленькой выборке.
Чем слабее зависимость между переменными, тем большего объема требуется выборка, чтобы значимо ее обнаружить.
Разработано много различных мер взаимосвязи между переменными. Выбор определенной меры в конкретном исследовании зависит от числа переменных, используемых шкал измерения, природы зависимостей и т.д.
Большинство этих мер, тем не менее, подчиняются общему принципу: они пытаются оценить наблюдаемую зависимость, сравнивая ее с "максимальной мыслимой зависимостью" между рассматриваемыми переменными. Говоря технически, обычный способ выполнить такие оценки заключается в том, чтобы посмотреть, как варьируются значения переменных и затем подсчитать, какую часть всей имеющейся вариации можно объяснить наличием "общей" ("совместной") вариации двух (или более) переменных.
Значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными.
Таким образом, для того чтобы определить уровень статистической значимости, нужна функция, которая представляла бы зависимость между "величиной" и "значимостью" зависимости между переменными для каждого объема выборки.
Такая функция указала бы точно "насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет". Другими словами, эта функция давала бы уровень значимости
(p -уровень), и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции.
Эта "альтернативная" гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой .
Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейной и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда точно одна и та же. Тем не менее, в большинстве случаев ее форма известна, и ее можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с классом распределений, называемым нормальным .
При обосновании статистического вывода следует решить вопрос, где же проходит линия между принятием и отвержением нулевой гипотезы? В силу наличия в эксперименте случайных влияний эта граница не может быть проведена абсолютно точно. Она базируется на понятии уровня значимости. Уровнем значимости называется вероятность ошибочного отклонения нулевой гипотезы. Или, иными словами, уровень значимости - это вероятность ошибки первого рода при принятии решения. Для обозначения этой вероятности, как правило, употребляют либо греческую букву α, либо латинскую букву р. В дальнейшем мы будем употреблять букву р.
Исторически сложилось так, что в прикладных науках, использующих статистику, и в частности в психологии, считается, что низшим уровнем статистической значимости является уровень р = 0,05; достаточным - уровень р = 0,01 и высшим уровень р = 0,001. Поэтому в статистических таблицах, которые приводятся в приложении к учебникам по статистике, обычно даются табличные значения для уровней р = 0,05, р = 0,01 и р = 0,001. Иногда даются табличные значения для уровней р - 0,025 и р = 0,005.
Величины 0,05, 0,01 и 0,001 - это так называемые стандартные уровни статистической значимости. При статистическом анализе экспериментальных данных психолог в зависимости от задач и гипотез исследования должен выбрать необходимый уровень значимости. Как видим, здесь наибольшая величина, или нижняя граница уровня статистической значимости, равняется 0,05 - это означает, что допускается пять ошибок в выборке из ста элементов (случаев, испытуемых) или одна ошибка из двадцати элементов (случаев, испытуемых). Считается, что ни шесть, ни семь, ни большее количество раз из ста мы ошибиться не можем. Цена таких ошибок будет слишком велика.
Заметим, что в современных статистических пакетах на ЭВМ используются не стандартные уровни значимости, а уровни, подсчитываемые непосредственно в процессе работы с соответствующим статистическим методом. Эти уровни, обозначаемые буквой р, могут иметь различное числовое выражение в интервале от 0 до 1, например, р = 0,7, р = 0,23 или р = 0,012. Понятно, что в первых двух случаях полученные уровни значимости слишком велики и говорить о том, что результат значим нельзя. В то же время в последнем случае результаты значимы на уровне 12 тысячных. Это достоверный уровень.
Правило принятия статистического вывода таково: на основании полученных экспериментальных данных психолог подсчитывает по выбранному им статистическому методу так называемую эмпирическую статистику, или эмпирическое значение. Эту величину удобно обозначить как Ч эмп . Затем эмпирическая статистика Ч эмп сравнивается с двумя критическими величинами, которые соответствуют уровням значимости в 5% и в 1% для выбранного статистического метода и которые обозначаются как Ч кр . Величины Ч кр находятся для данного статистического метода по соответствующим таблицам, приведенным в приложении к любому учебнику по статистике. Эти величины, как правило, всегда различны и их в дальнейшем для удобства можно назвать как Ч кр1 и Ч кр2 . Найденные по таблицам величины критических значений Ч кр1 и Ч кр2 удобно представлять в следующей стандартной форме записи:
Подчеркнем, однако, что мы использовали обозначения Ч эмп и Ч кр как сокращение слова «число». Во всех статистических методах приняты свои символические обозначения всех этих величин: как подсчитанной по соответствующему статистическому методу эмпирической величины, так и найденных по соответствующим таблицам критических величин. Например, при подсчете рангового коэффициента корреляции Спирмена по таблице критических значений этого коэффициента были найдены следующие величины критических значений, которые для этого метода обозначаются греческой буквой ρ («ро»). Так для р = 0,05 по таблице найдена величина ρ кр 1 = 0,61 и для р = 0,01 величина ρ кр 2 = 0,76.
В принятой в дальнейшем изложении стандартной форме записи это выглядит следующим образом:

Теперь нам необходимо сравнить наше эмпирическое значение с двумя найденными по таблицам критическими значениями. Лучше всего это сделать, расположив все три числа на так называемой «оси значимости». «Ось значимости» представляет собой прямую, на левом конце которой располагается 0, хотя он, как правило, не отмечается на самой этой прямой, и слева направо идет увеличение числового ряда. По сути дела это привычная школьная ось абсцисс ОХ декартовой системы координат. Однако особенность этой оси в том, что на ней выделено три участка, «зоны». Одна крайняя зона называется зоной незначимости, вторая крайняя зона - зоной значимости, а промежуточная - зоной неопределенности. Границами всех трех зон являются Ч кр1 для р = 0,05 и Ч кр2 для р = 0,01, как это показано на рисунке.
В зависимости от правила принятия решения (правила вывода), предписанного в данном статистическом методе возможно два варианта.
Первый вариант: альтернативная гипотеза принимается, если Ч эмп ≥Ч кр .

Или второй вариант: альтернативная гипотеза принимается, если Ч эмп ≤Ч кр .

Подсчитанное Ч эмп по какому либо статистическому методу должно обязательно попасть в одну из трех зон.
Если эмпирическое значение попадает в зону незначимости, то принимается гипотеза Н 0 об отсутствии различий.
Если Ч эмп попало в зону значимости, принимается альтернативная гипотеза Н 1 о наличии различий, а гипотеза Н 0 отклоняется.
Если Ч эмп попадает в зону неопределенности, перед исследователем стоит дилемма. Так, в зависимости от важности решаемой задачи он может считать полученную статистическую оценку достоверной на уровне 5%, и принять, тем самым гипотезу Н 1 , отклонив гипотезу Н 0 , либо - недостоверной на уровне 1%, приняв тем самым, гипотезу Н 0 . Подчеркнем, однако, что это именно тот случай, когда психолог может допустить ошибки первого или второго рода. Как уже говорилось выше, в этих обстоятельствах лучше всего увеличить объем выборки.
Подчеркнем также, что величина Ч эмп может точно совпасть либо с Ч кр1 либо Ч кр2 . В первом случае можно считать, что оценка достоверна точно на уровне в 5% и принять гипотезу Н 1 , или, напротив, принять гипотезу Н 0 . Во втором случае, как правило, принимается альтернативная гипотеза Н 1 о наличии различий, а гипотеза Н 0 отклоняется.
Понятие о статистической достоверности
Статистическая достоверность имеет существенное значение в расчетной практике ФКС. Ранее было отмечено, что из одной и той же генеральной совокупности может быть избрано множество выборок:
Если они подобраны корректно, то их средние показатели и показатели генеральной совокупности незначительно отличаются друг от друга величиной ошибки репрезентативности с учетом принятой надежности;
Если они избираются из разных генеральных совокупностей, различие между ними оказывается существенным. В статистике повсеместно рассматривается сравнение выборок;
Если они отличаются несущественно, непринципиально, незначительно, т. е. фактически принадлежат одной и той же генеральной совокупности, различие между ними называется статистически недостоверным.
Статистически достоверным различием выборок называется выборка, которая различается значимо и принципиально, т. е. принадлежит разным генеральным совокупностям.
В ФКС оценка статистической достоверности различий выборок означает решение множества практических задач. Например, введение новых методик обучения, программ, комплексов упражнений, тестов, контрольных упражнений связано с их экспериментальной проверкой, которая должна показать, что испытуемая группа принципиально отлична от контрольной. Поэтому применяют специальные статистические методы, называемые критериями статистической достоверности, позволяющие обнаружить наличие или отсутствие статистически достоверного различия между выборками.
Все критерии делятся на две группы: параметрические и непараметрические. Параметрические критерии предусматривают обязательное наличие нормального закона распределения, т.е. имеется в виду обязательное определение основных показателей нормального закона - средней арифметической величины х и среднего квадратического отклонения о. Параметрические критерии являются наиболее точными и корректными. Непараметрические критерии основаны на ранговых (порядковых) отличиях между элементами выборок.
Приведем основные критерии статистической достоверности, используемые в практике ФКС: критерий Стьюдента, критерий Фишера, критерий Вилкоксона, критерий Уайта, критерий Ван-дер-Вардена (критерий знаков).
Критерий Стьюдента назван в честь английского ученого К. Госсета (Стьюдент - псевдоним), открывшего данный метод. Критерий Стьюдента является параметрическим, используется для сравнения абсолютных показателей выборок. Выборки могут быть различными по объему.
Критерий Стьюдента определяется так.
1. Находим критерий Стьюдента t по следующей формуле:
где Xi, x 2 - средние арифметические сравниваемых выборок; /я ь w 2 - ошибки репрезентативности, выявленные на основании показателей сравниваемых выборок.
2. Практика в ФКС показала, что для спортивной работы достаточно принять надежность счета Р = 0,95.
63 Для надежности счета: Р= 0,95 (а = 0,05), при числе степеней; свободы k = «! + п 2 - 2 по таблице приложения 4 находим величи- \ ну граничного значения критерия (^гр).
3. На основании свойств нормального закона распределения в критерии Стьюдента осуществляется сравнение t и t^.
4. Делаем выводы:
Если t > ftp, то различие между сравниваемыми выборками статистически достоверно;
Если t < 7 Ф, то различие статистически недостоверно.
Для исследователей в области ФКС оценка статистической достоверности является первым шагом в решении конкретной задачи: принципиально или непринципиально различаются между; собой сравниваемые выборки. Последующий шаг заключается в; оценке этого различия с педагогической точки зрения, что определяется условием задачи.
Статистическая значимость
Результаты, полученные с помощью определенной процедуры исследования, называют статистически значимыми , если вероятность их случайного появления очень мала. Эту концепцию можно проиллюстрировать на примере кидания монеты. Предположим, что монету подбросили 30 раз; 17 раз выпал «орел» и 13 раз выпала «решка». Является ли значимым отклонение этого результата от ожидаемого (15 выпадений «орла» и 15 - «решки»), или это отклонение случайно? Чтобы ответить на этот вопрос, можно, например, много раз кидать ту же монету по 30 раз подряд, и при этом отмечать, сколько раз повторится соотношение «орлов» и «решек», равное 17:13. Статистический анализ избавляет нас от этого утомительного процесса. С его помощью после первых 30 киданий монеты можно произвести оценку возможного числа случайных выпадений 17 «орлов» и 13 «решек». Такая оценка называется вероятностным утверждением.
В научной литературе по индустриально-организационной психологии вероятностное утверждение в математической форме обозначается выражением р (вероятность) < (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (р < 0,01). Этот факт важен для понимания литературы, но не следует считать, что он говорит о бессмысленности проведения наблюдений, не соответствующих этим стандартам. Так называемые незначимые результаты исследований (наблюдения, которые можно получить случайно более одного или пяти раз из 100) могут быть весьма полезными для выявления тенденций и как руководство к будущим исследованиям.
Необходимо также заметить, что не все психологи соглашаются с традиционными стандартами и процедурами (например, Cohen, 1994; Sauley & Bedeian, 1989). Вопросы, связанные с измерениями, сами по себе являются главной темой работы многих исследователей, изучающих точность методов измерений и предпосылки, которые лежат в основе существующих методов и стандартов, а также разрабатывают новые медики и инструменты. Может быть, когда-нибудь в будущем исследования в этой власти приведут к изменению традиционных стандартов оценки статистической значимости, и эти изменения завоюют всеобщее признание. (Пятое отделение Американской психологической ассоциации объединяет психологов, которые специализируются на изучении оценок, измерений и статистики.)
В отчетах об исследованиях вероятностное утверждение, такое как р < 0,05, связано некоторой статистикой, то есть числом, которое получено в результате проведения определенного набора математических вычислительных процедур. Вероятностное подтверждение получают путем сравнения этой статистики с данными из специальных таблиц, которые публикуются для этой цели. В индустриально-организационных психологических исследованиях часто встречаются такие статистики, как r, F, t, г> (читается «хи квадрат») и R (читается «множественный R»). В каждом случае статистику (одно число), полученную в результате анализа серии наблюдений, можно сравнить числами из опубликованной таблицы. После этого можно сформулировать вероятностное утверждение о вероятности случайного получения этого числа, то есть сделать вывод о значимости наблюдений.
Для понимания исследований, описанных в этой книге, достаточно иметь ясное представление о концепции статистической значимости и необязательно знать, как рассчитываются упомянутые выше статистики. Однако было бы полезно обсудить одно предположение, которое лежит в основе всех этих процедур. Это предположение о том, что все наблюдаемые переменные распределяются приблизительно по нормальному закону. Кроме того, при чтении отчетов об индустриально-организационных психологических исследованиях часто встречаются еще три концепции, которые играют важную роль - во-первых, корреляция и корреляционная связь, во-вторых, детерминант/ предсказывающая переменная и «ANOVA» (дисперсионный анализ), в-третьих, группа статистических методов под общим названием «метаанализ».
Рассмотрим типичный пример применения статистических методов в медицине. Создатели препарата предполагают, что он увеличивает диурез пропорционально принятой дозе. Для проверки этого предположения они назначают пяти добровольцам разные дозы препарата.
По результатам наблюдений строят график зависимости диуреза от дозы (рис. 1.2А). Зависимость видна невооруженным глазом. Исследователи поздравляют друг друга с открытием, а мир - с новым диуретиком.
На самом деле данные позволяют достоверно утверждать лишь то, что зависимость диуреза от дозы наблюдалась у этих пяти добровольцев. То, что эта зависимость проявится у всех людей, которые будут принимать препарат, - не более чем предполо-
зЯ

 с
с
жение. Нельзя сказать, что оно беспочвенно - иначе, зачем ставить эксперименты?
Но вот препарат поступил в продажу. Все больше людей принимают его в надежде увеличить свой диурез. И что же мы видим? Мы видим рис 1.2Б, который свидетельствует об отсутствии какой либо связи между дозой препарата и диурезом. Черными кружками отмечены данные первоначального исследования. Статистика располагает методами, позволяющими оценить вероятность получения столь «непредставительной», более того, сбивающей с толку выборки. Оказывается в отсутствие связи между диурезом и дозой препарата полученная «зависимость» наблюдалась бы примерно в 5 из 1000 экспериментов. Итак, в данном случае исследователям просто не повезло. Если бы они применили даже самые совершенные статистические методы, это все равно не спасло бы их от ошибки.
Этот вымышленный, но совсем не далекий от реальности пример, мы привели не для того, чтобы указать на бесполез
ность статистики. Он говорит о другом, о вероятностном характере ее выводов. В результате применения статистического метода мы получаем не истину в последней инстанции, а всего лишь оценку вероятности того или иного предположения. Кроме того, каждый статистический метод основан на собственной математической модели и результаты его правильны настолько насколько эта модель соответствует действительности.
Еще по теме ДОСТОВЕРНОСТЬ И СТАТИСТИЧЕСКАЯ ЗНАЧИМОСТЬ:
- Статистически значимые отличия показателей качества жизни
- Статистическая совокупность. Учетные признаки. Понятие о сплошных и выборочных исследованиях. Требования к статистической совокупности и использованию учетно-отчетных документов
- РЕФЕРАТ. ИССЛЕДОВАНИЕ ДОСТОВЕРНОСТИ ПОКАЗАНИЙ ТОНОМЕТРА ДЛЯ ИЗМЕРЕНИЯ ВНУТРИГЛАЗНОГО ДАВЛЕНИЯ ЧЕРЕЗ ВЕКО2018, 2018
 Корпускулярные и волновые свойства частиц
Корпускулярные и волновые свойства частиц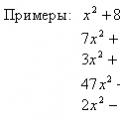 Уравнения онлайн X 5 0 решение
Уравнения онлайн X 5 0 решение Предельные монокарбоновые кислоты
Предельные монокарбоновые кислоты