Закон больших чисел и предельные теоремы. Закон больших чисел
Если явление устойчивости средних
имеет место в действительности, то в математической модели, с помощью которой мы изучаем случайные явления, должна существовать отражающая этот факт теорема.
В условиях этой теоремы введем ограничения на случайные величины X
1 , X
2 , …, X n
:
а) каждая случайная величина Х i имеет математическое ожидание
M (Х i ) = a ;
б) дисперсия каждой случайной величины конечна или, можно сказать, что дисперсии ограничены сверху одним и тем же числом, например С , т. е.
D (Х i ) < C, i = 1, 2, …, n ;
в) случайные величины попарно независимы, т. е. любые две X i и X j при i ¹ j независимы.
Тогда, очевидно
D (X 1 + X 2 + … + X n )= D (X 1) + D (X 2) + ... + D (X n ).
Сформулируем закон больших чисел в форме Чебышева.
Теорема Чебышева: при неограниченном увеличении числа n независимых испытаний «средняя арифметическая наблюдаемых значений случайной величины сходится по вероятности к ее математическому ожиданию », т. е. для любого положительного ε
Р (| – а| < ε ) = 1. (4.1.1)
Смысл выражения «средняя арифметическая = сходится по вероятности к a» состоит в том, что вероятность того, что будет сколь угодно мало отличаться от a , неограниченно приближается к 1 с ростом числа n .
Доказательство. Для конечного числа n независимых испытаний применим неравенство Чебышева для случайной величины = :
Р (|– M ()| < ε ) ≥ 1 – . (4.1.2)
Учитывая ограничения а – в, вычислим M ( ) и D ( ):
M ( ) = = = = = = а ;
D
(
) = =  = = = = .
= = = = .
Подставляя M ( ) и D ( ) в неравенство (4.1.2), получим
Р (| – а| < ε )≥1 – .
Если в неравенстве (4.1.2) взять сколь угодно малое ε >0и n ® ¥, то получим
 = 1,
= 1,
что и доказывает теорему Чебышева.
Из рассмотренной теоремы вытекает важный практический вывод: неизвестное нам значение математического ожидания случайной величины мы вправе заменить средним арифметическим значением, полученным по достаточно большому числу опытов. При этом, чем больше опытов для вычисления, тем с большей вероятностью (надежностью) можно ожидать, что связанная с этой заменой ошибка ( – а )не превзойдет заданную величину ε .
Кроме того, можно решать другие практические задачи. Например, по значениям вероятности (надежности) Р = Р (| – а| < ε )и максимальной допустимой ошибке ε определить необходимое число опытов n ; по Р и п определить ε; по ε и п определить границу вероятности события | – а | < ε.
Частный случай . Пусть при n испытаниях наблюдаются n значений случайной величины X, имеющей математическое ожидание M (X ) и дисперсию D (X ). Полученные значения можно рассматривать как случайные величины Х 1 , Х 2 , Х 3 , ... , Х n ,. Это следует понимать так: серия из п испытаний проводится неоднократно, поэтому в результате i -го испытания, i = l, 2, 3, ..., п , в каждой серии испытаний появится то или иное значение случайной величины X , не известное заранее. Следовательно, i -e значение x i случайной величины, полученное в i -м испытании, изменяется случайным образом, если переходить от одной серии испытаний к другой. Таким образом, каждое значение x i можно считать случайной величиной X i .
Предположим, что испытания удовлетворяют следующим требованиям:
1. Испытания независимы. Это означает, что результаты Х
1 , Х
2 ,
Х
3 , ..., Х n
испытаний – независимые случайные величины.
2. Испытания проводятся в одинаковых условиях – это означает, с точки зрения теории вероятностей, что каждая из случайных величин Х 1 , Х 2 , Х 3 , ... , Х n имеет такой же закон распределения, что и исходная величина X , поэтому M (X i ) = M (X )и D (X i ) = D (X ), i = 1, 2, .... п.
Учитывая вышеуказанные условия, получим
Р (| – а| < ε )≥1 – . (4.1.3)
Пример 4.1.1. X равна 4. Сколько требуется произвести независимых опытов, чтобы с вероятностью не менее 0,9 можно было ожидать, что среднее арифметическое значение этой случайной величины будет отличаться от математического ожидания менее чем на 0,5?
Решение .По условию задачи ε = 0,5; Р (| – а|< 0,5) ≥ 0,9. Применив формулу (4.1.3) для случайной величины Х , получим
P (|– M (X )| < ε ) ≥ 1 – .
Из соотношения
1 – = 0,9
определим
п = = = 160.
Ответ : требуется произвести 160 независимых опытов.
Если предположить, что средняя арифметическая распределена нормально, то получаем:
Р (| – а| < ε )= 2Φ () ≥ 0,9.
Откуда, воспользовавшись таблицей функции Лапласа, получим ≥
≥
1,645, или ≥ 6,58, т. е. n
≥49.
Пример4.1.2. Дисперсия случайной величины Х равна D(Х ) = 5. Произведено 100 независимых опытов, по которым вычислено . Вместо неизвестного значения математического ожидания а принята . Определить максимальную величину ошибки, допускаемую при этом с вероятностью не менее 0,8.
Решение. По условию задачи n = 100, Р (| – а| < ε ) ≥0,8. Применим формулу (4.1.3)
Р (| – а| < ε ) ≥1 – .
Из соотношения
1 – = 0,8
определим ε :
ε 2 = = = 0,25.
Следовательно, ε = 0,5.
Ответ : максимальная величина ошибки ε = 0,5.
4.2. Закон больших чисел в форме Бернулли
Хотя в основе любого статистического вывода лежит понятие вероятности, мы лишь в немногих случаях можем определить вероятность события непосредственно. Иногда эту вероятность можно установить из соображений симметрии, равной возможности и т.п., но универсального метода, который позволял бы для произвольного события указать его вероятность, не существует. Теорема Бернулли дает возможность приближенной оценки вероятности, если для интересующего нас события А можно проводить повторные независимые испытания. Пусть произведено п независимых испытаний, в каждом из которых вероятность появления некоторого события А постоянна и равна р.
Теорема Бернулли. При неограниченном возрастании числа независимых испытаний п относительная частота появления события А сходится по вероятности к вероятности p появления события А ,т. е.
P (½ - p ½≤ ε) = 1, (4.2.1)
где ε – сколь угодно малое положительное число.
Для конечного n
при условии, что  , неравенство Чебышева для случайной величины будет иметь вид:
, неравенство Чебышева для случайной величины будет иметь вид:
P (| – p| < ε ) ≥ 1 – .(4.2.2)
Доказательство. Применим теорему Чебышева. Пусть X i – число появлений события А в i -ом испытании, i = 1, 2, . . . , n . Каждая из величин X i может принять лишь два значения:
X i = 1 (событие А наступило) с вероятностью p ,
X i = 0 (событие А не наступило) с вероятностью q = 1– p .
Пусть Y n = . Сумма X 1 + X 2 + … + X n равна числу m появлений события А в n испытаниях (0 m n ), а, значит, Y n = – относительная частота появления события А в n испытаниях. Математическое ожидание и дисперсия X i равны соответственно:
M ( ) = 1∙p + 0∙q = p ,
Теория вероятностей изучает закономерности, свойственные массовым случайным явлениям. Как и любая другая наука, теория вероятностей предназначена для того, чтобы возможно точнее предсказать результат того или иного явления или эксперимента. Если явление носит единичный характер, то теория вероятностей способна предсказать лишь вероятность исхода в весьма широких пределах. Закономерности проявляются только при большом числе случайных явлений, происходящих в однородных условиях.
Группа теорем, устанавливающих соответствие между теоретическими и экспериментальными характеристиками случайных величин и случайных событий при большом числе испытаний над ними, а также касающихся предельных законов распределения, объединяются под общим названием предельных теорем теории вероятностей .
Есть два типа предельных теорем: закон больших чисел и центральная предельная теорема.
Закон больших чисел , занимающий важнейшее место в теории вероятностей, является связующим звеном между теорией вероятностей как математической наукой и закономерностями случайных явлений при массовых наблюдениях над ними.
Закон играет очень важную роль в практических применениях теории вероятностей к явлениям природы и техническим процессам, связанным с массовым производством.
Предельные законы распределения составляют предмет группы теорем – количественной формы закона больших чисел. Т.е. закон больших чисел – ряд теорем, в каждой из которых устанавливается факт приближения средних характеристик большого числа испытаний к некоторым определенным постоянным, т.е. устанавливают факт сходимости по вероятности некоторых случайных величин к постоянным. Это теоремы Бернулли, Пуассона, Ляпунова, Маркова, Чебышева.
1. а ) Теорема Бернулли – закон больших чисел (была сформулирована и доказана ранее в п. 3 § 6 при рассмотрении предельной интегральной теоремы Муавра-Лапласа.)
При неограниченном увеличении числа однородных независимых опытов частота события будет сколь угодно мало отличаться от вероятности события в отдельном опыте. Иначе, вероятность того, что отклонение относительной частоты наступления события А
от постоянной вероятности р
события А
очень мало при стремится к 1 при любом : ![]() .
.
b) Теорема Чебышева.
При неограниченном увеличении числа независимых испытаний среднее арифметическое наблюдаемых значений случайной величины, имеющей конечную дисперсию, сходится по вероятности к ее математическому ожиданию иначе, если независимые одинаково распределенные случайные величины с математическим ожиданием и ограниченной дисперсией , то при любом справедливо:  .
.
Теорема Чебышева (обобщенная).
Если случайные величины в последовательности попарно независимы, а их дисперсии удовлетворяют условию ![]() , то для любого положительного ε > 0 справедливо утверждение:
, то для любого положительного ε > 0 справедливо утверждение:
 или, что то же
или, что то же  .
.
c) Теорема Маркова. (закон больших чисел в общей формулировке)
Если дисперсии произвольных случайных величин в последовательности удовлетворяют условию: ![]() , то для любого положительного ε > 0 имеет место утверждение теоремы Чебышева: .
, то для любого положительного ε > 0 имеет место утверждение теоремы Чебышева: .
d) Теорема Пуассона.
При неограниченном увеличении числа независимых опытов в переменных условиях частота события А сходится по вероятности к среднему арифметическому его вероятностей при данных испытаниях.
Замечание. Ни в одной из форм закона больших чисел мы не имеем дела с законами распределения случайных величин. Вопрос, связанный с отысканием предельного закона распределения суммы , когда число слагаемых неограниченно возрастает, рассматривает центральная предельная теорема. одинаково распределены, то придем к интегральной теореме Муавра-Лапласа (п. 3 § 6), представляющей собой простейший частный случай центральной предельной теоремы.
В начале курса мы уже говорили о том, что математические законы теории вероятностей получены абстрагированием реальных статистических закономерностей, свойственных массовым случайным явлениям. Наличие этих закономерностей связано именно с массовостью явлений, то есть с большим числом выполняемых однородных опытов или с большим числом складывающихся случайных воздействий, порождающих в своей совокупности случайную величину, подчиненную вполне определенному закону. Свойство устойчивости массовых случайных явлений известно человечеству еще с глубокой древности. В какой бы области оно ни проявлялось, суть его сводится к следующему: конкретные особенности каждого отдельного случайного явления почти не сказываются на среднем результате масс и таких явлений; случайные отклонения от среднего, неизбежные в каждом отдельном явлении, в массе взаимно погашаются, нивелируются, выравниваются. Именно эта устойчивость средних и представляет собой физическое содержание «закона больших чисел», понимаемого в широком смысле слова: при очень большом числе случайных явлений средний их результат практически перестает быть случайным и может быть предсказан с большой степенью определенности.
В узком смысле слова под «законом больших чисел» в теории вероятностей понимается ряд математических теорем, в каждой из которых для тех или иных условий устанавливается факт приближения средних характеристик большого числа опытов к некоторым определенным постоянным.
В 2.3 мы уже формулировали простейшую из этих теорем - теорему Я. Бернулли. Она утверждает, что при большом числе опытов частота события приближается (точнее - сходится по вероятности) к вероятности этого события. С другими, более общими формами закона больших чисел мы познакомимся в данной главе. Все они устанавливают факт и условия сходимости по вероятности тех или иных случайных величин к постоянным, не случайным величинам.
Закон больших чисел играет важную роль в практических применениях теории вероятностей. Свойство случайных величин при определенных условиях вести себя практически как не случайные позволяет уверенно оперировать с этими величинами, предсказывать результаты массовых случайных явлений почти с полной определенностью.
Возможности таких предсказаний в области массовых случайных явлений еще больше расширяются наличием другой группы предельных теорем, касающихся уже не предельных значений случайных величин, а предельных законов распределения. Речь идет о группе теорем, известных под названием «центральной предельной теоремы». Мы уже говорили о том, что при суммировании достаточно большого числа случайных величин закон распределения суммы неограниченно приближается к нормальному при соблюдении некоторых условий. Эти условия, которые математически можно формулировать различным образом - в более или менее общем виде, - по существу сводятся к требованию, чтобы влияние на сумму отдельных слагаемых было равномерно малым, т. е. чтобы в состав суммы не входили члены, явно преобладающие над совокупностью остальных по своему влиянию на рассеивание суммы. Различные формы центральной предельной теоремы различаются между собой теми условиями, для которых устанавливается это предельное свойство суммы случайных величин.
Различные формы закона больших чисел вместе с различными формами центральной предельной теоремы образуют совокупность так называемых предельных теорем теории вероятностей. Предельные теоремы дают возможность не только осуществлять научные прогнозы в области случайных явлений, но и оценивать точность этих прогнозов.
В данной главе мы рассмотрим только некоторые, наиболее простые формы предельных теорем. Сначала будут рассмотрены теоремы, относящиеся к группе «закона больших чисел», затем - теоремы, относящиеся к группе «центральной предельной теоремы».
Вполне естественна потребность количественно уточнить утверждение о том, что в «больших» сериях испытаний частоты появления события «близки» к его вероятности. Следует ясно представить себе известную деликатность этой задачи. В наиболее типичных для теории вероятностей случаях дело обстоит так, что в сколь угодно длинных сериях испытаний остаются теоретически возможными оба крайних значения частоты
\frac{\mu}{n}=\frac{n}{n}=1 и \frac{\mu}{n}=\frac{0}{n}=0
Поэтому, каково бы ни было число испытаний n , нельзя утверждать с полной достоверностью, что будет выполнено, скажем, неравенство
<\frac{1}{10}
Например, если событие A заключается в выпадении при бросании игральной кости шестерки, то при n бросаниях с вероятностью {\left(\frac{1}{6}\right)\!}^n>0 мы все время будем получать одни шестерки, т. е. с вероятностью {\left(\frac{1}{6}\right)\!}^n получим частоту появления шестерок, равную единице, а с вероятностью {\left(1-\frac{1}{6}\right)\!}^n>0 шестерка не выпадает ни одного раза, т. е. частота появления шестерок окажется равной нулю.
Во всех подобных задачах любая нетривиальная оценка близости между частотой и вероятностью действует не с полной достоверностью, а лишь с некоторой меньшей единицы вероятностью. Можно, например, доказать, что в случае независимых испытаний с постоянной вероятностью p появления события неравенство
\vline\,\frac{\mu}{n}-p\,\vline\,<0,\!02
для частоты \frac{\mu}{n} будет выполняться при n=10\,000 (и любом p ) с вероятностью
P>0,\!9999.
Здесь мы прежде всего хотим подчеркнуть, что в приведенной формулировке количественная оценка близости частоты \frac{\mu}{n} к вероятности p связана с введением новой вероятности P .
Реальный смысл оценки (8) таков: если произвести N серий по n испытаний и сосчитать число M серий, в которых выполняется неравенство (7), то при достаточно большом N приближенно будет
\frac{M}{N}\approx P>0,\!9999.
Но если мы захотим уточнить соотношение (9) как в отношении степени близости \frac{M}{N} к вероятности P , так и в отношении надежности, с которой можно утверждать, что такая близость будет иметь место, то придется обратиться к рассмотрениям, аналогичным тем, которые мы уже провели в применении к близости \frac{\mu}{n} и p . При желании такое рассуждение можно повторять неограниченное число раз, но вполне понятно, что это не позволит нам совсем освободиться от необходимости на последнем этапе обратиться к вероятностям в примитивном грубом понимании этого термина.
Не следует думать, что подобного рода затруднения являются какой-то особенностью теории вероятностей. При математическом изучении реальных явлений мы всегда их схематизируем. Отклонения хода действительных явлений от теоретической схемы можно, в свою очередь, подвергнуть математическому изучению. Но для этого сами эти отклонения надо уложить в некоторую схему и этой последней пользоваться уже без формального математического анализа отклонений от нее.
Заметим, впрочем, что при реальном применении оценки
P\!\left\{\,\vline\,\frac{\mu}{n}-p\,\vline\,<0,\!02\right\}>0,\!9999.
к единичной серии из n испытаний мы опираемся и на некоторые соображения симметрии: неравенство (10) указывает, что при очень большом числе N серий соотношение (7) будет выполняться не менее чем в 99,99% случаев; естественно с большой уверенностью ожидать, что, в частности, неравенство (7) осуществится в интересующей нас определенной серии из n испытаний, если мы имеем основания считать, что эта серия в ряду других серий занимает рядовое, ничем особенным не отмеченное положение.
Вероятности, которыми принято пренебрегать в различных практических положениях, различны. Выше уже отмечалось, что при ориентировочных расчетах расхода снарядов, гарантирующего выполнение поставленной задачи, удовлетворяются нормой расхода снарядов, при которой поставленная задача решается с вероятностью 0,95, т. е. пренебрегают вероятностями, не превышающими 0,05. Это объясняется тем, что переход на расчеты, исходящие из пренебрежения, скажем, лишь вероятностями, меньшими 0,01, приводил бы к большому увеличению норм расхода снарядов, т. е. практически во многих случаях к выводу о невозможности выполнить поставленную задачу за тот короткий промежуток времени, который для этого имеется, или с фактически могущим быть использованным запасом снарядов.
Иногда и в научных исследованиях ограничиваются статистическими приемами, рассчитанными исходя из пренебрежения вероятностями в 0,05. Но это следует делать лишь в случаях, когда собирание более обширного материала очень затруднительно. Рассмотрим в виде примера таких приемов следующую задачу. Допустим, что в определенных условиях употребительный препарат для лечения какого-либо заболевания дает положительный результат в 50%, т. е. с вероятностью 0,5. Предлагается новый препарат и для проверки его преимуществ над старым планируется применить его в десяти случаях, выбранных беспристрастно из числа больных, находящихся в том же положении, что и те, для которых установлена эффективность старого препарата в 50%. При этом устанавливается, что преимущество нового препарата будет считаться доказанным, если он даст положительный результат не менее чем в восьми случаях из десяти. Легко подсчитать, что такое решение связано с пренебрежением вероятностью получить ошибочный вывод (т. е. вывод о доказанности преимущества нового препарата, в то время как он равноценен или даже хуже старого) как раз порядка 0,05. В самом деле, если в каждом из десяти испытаний вероятность положительного исхода равна p , то вероятности получить при десяти испытаниях 10,9 или 8 положительных исходов, равны соответственно
P_{10}=p^{10},\qquad P_9=10p^9(1-p),\qquad P_8=45p^8(1-p)^2.
В сумме для случая p=\frac{1}{2} получаем P=P_{10}+P_9+P_8=\frac{56}{1024}\approx0,\!05 .
Таким образом, в предположении, что на самом деле новый препарат точно равноценен старому, мы рискуем сделать ошибочный вывод о том, что новый препарат превосходит старый, с вероятностью порядка 0,05. Чтобы свести эту вероятность приблизительно к 0,01, не увеличивая числа испытаний n=10 , пришлось бы установить, что преимущество нового препарата будет считаться доказанным лишь тогда, когда его применение даст положительный результат не менее чем в девяти случаях из десяти. Если это требование покажется сторонникам нового препарата слишком суровым, то придется назначить число испытаний n значительно большим, чем 10. Если, например, при n=100 установить, что преимущества нового препарата будут считаться доказанными при \mu>65 , то вероятность ошибки будет лишь P\approx0,\!0015 .
Если норма в 0,05 для серьезных научных исследований явно недостаточна, то вероятностью ошибки в 0,001 или в 0,003 по большей части принято пренебрегать даже в столь академических и обстоятельных исследованиях, как обработка астрономических наблюдений. Впрочем, иногда научные выводы, основанные на применении вероятностных закономерностей, обладают и значительно большей достоверностью (т. е. построены на пренебрежении значительно меньшими вероятностями). Об этом еще будет сказано далее.
В рассмотренных примерах мы уже неоднократно применяли частные случаи биномиальной формулы (6)
P_m=C_n^mp^m(1-p)^{n-m}
для вероятности P_m получить ровно т положительных исходов при n независимых испытаниях, в каждом из которых положительный исход имеет вероятность р. Рассмотрим при помощи этой формулы вопрос, поставленный в начале этого параграфа, о вероятности
<\varepsilon\right\},
где \mu - фактическое число положительных исходов. Очевидно, эта вероятность может быть записана в виде суммы тех P_m , для которых m удовлетворяет неравенству
\vline\,\frac{m}{n}-p\,\vline\,<\varepsilon,
то есть в виде
P=\sum_{m=m_1}^{m_2}P_m,
где m_1 - наименьшее из значений m , удовлетворяющих неравенству (12), а m_2 - наибольшее из таких m .
Формула (13) при сколько-нибудь больших n мало пригодна для непосредственных вычислений. Поэтому имело очень большое значение открытие Муавром для случая p=\frac{1}{2} и Лапласом при любом p асимптотической формулы, которая позволяет очень просто находить и изучать поведение вероятностей P_m при больших n . Формула эта имеет вид
P\sim\frac{1}{\sqrt{2\pi np(1-p)}}\exp\!\left[-\frac{(m-np)^2}{2np(1-p)}\right].
Если p не слишком близко к нулю или единице, то она достаточно точна уже при n порядка 100. Если положить
T=\frac{m-np}{\sqrt{np(1-p)}},
То формула (14) приобретет вид
P\sim\frac{1}{\sqrt{2\pi np(1-p)}}\,e^{-t^2/2}.
Из (13) и (16) можно вывести приближенное представление вероятности (11)
P\sim\frac{1}{\sqrt{2\pi}}\int\limits_{-T}^{T}e^{-t^2/2}\,dt=F(T),
где
T=\varepsilon\sqrt{\frac{n}{p(1-p)}}
Разность между левой и правой частями в (17) при постоянном и отличном от нуля и единицы p стремится при n\to\infty равномерно относительно \varepsilon к нулю. Для функции F(T) составлены подробные таблицы. Вот краткая выдержка из них
\begin{array}{c|c|c|c|c}T&1&2&3&4\\\hline F&0,\!68269&0,\!95450&0,\!99730&0,\!99993\end{array}
При T\to\infty значение функции F(T) стремится к единице.
Произведем при помощи формулы (17) оценку вероятности
P=\mathbf{P}\!\left\{\,\vline\,\frac{\mu}{n}-p\,\vline\,<0,\!02\right\}\approx F\!\left(\frac{2}{\sqrt{p(1-p)}}\right) при n=10\,000,~\varepsilon=0,\!02 , так как T=\frac{2}{\sqrt{p(1-p)}} .
Так как функция F(T) монотонно возрастает с возрастанием T , то для не зависящей от p оценки P снизу надо взять наименьшее возможное (при различных p ) значение T . Такое наименьшее значение получится при p=\frac{1}{2} , и оно будет равно 4. Поэтому приближенно
P\geqslant F(4)=0,\!99993.
В неравенстве (19) не учтена ошибка, происходящая из-за приближенного характера формулы (17). Производя оценку связанной с этим обстоятельством погрешности, можно во всяком случае установить, что P>0,\!9999 .
В связи с рассмотренным примером применения формулы (17) следует отметить, что оценки остаточного члена формулы (17), дававшиеся в теоретических сочинениях по теории вероятностей, долго оставались мало удовлетворительными. Поэтому применения формулы (17) и ей подобных к расчетам при не очень больших n или при вероятностях p , очень близких к 0 или к 1 (а такие вероятности во многих случаях и имеют особенно большое значение) часто основывались лишь на опыте проверок такого рода результатов для ограниченного числа примеров, а не на достоверно установленных оценках возможной ошибки. Более подробное исследование, кроме того, показало, что во многих практически важных случаях приведенные выше асимптотические формулы нуждаются не только в оценке остаточного члена, но и в уточнении (так как без такого уточнения остаточный член слишком велик). В обоих направлениях наиболее полные результаты принадлежат С. Н. Бернштейну.
Соотношения (11), (17) и (18) можно переписать в виде
\mathbf{P}\!\left\{\,\vline\,\frac{\mu}{n}-p\,\vline\, Для достаточно больших t
правая часть формулы (20), не содержащая n
, сколь угодно близка к единице, т. е. к значению вероятности, которое соответствует полной достоверности. Мы видим, таким образом, что, как правило, отклонения частоты \frac{\mu}{n}
от вероятности p
имеют порядок
\frac{1}{\sqrt{n}}
. Такая пропорциональность точности действия вероятностных закономерностей квадратному корню из числа наблюдений типична и для многих других вопросов. Иногда говорят даже в порядке несколько упрощенной популяризации о "законе квадратного корня из n
" как основном законе теории вероятностей. Полную отчетливость эта мысль получила благодаря введению великим русским математиком П. Л. Чебышевым в систематическое употребление метода сведения различных вероятностных задач к подсчетам «математических ожиданий» и "дисперсий" для сумм и средних арифметических "случайных величин". Случайной величиной
называется величина, которая в данных условиях S
может принимать различные значения с определенными вероятностями. Для нас достаточно рассмотреть случайные величины, могущие принимать лишь конечное число различных значений. Чтобы указать, как говорят, распределение вероятностей
такого рода случайной величины \xi
, достаточно указать возможные ее значения x_1,x_2,\ldots,x_r
и вероятности P_r=\mathbf{P}\{\xi=x_r\}.
\sum_{r=1}^{s}P_r=1.
Примером случайной величины может служить изучавшееся выше число \mu
положительных исходов при п испытаниях. Математическим ожиданием
величины \xi
называется выражение M(\xi)=\sum_{r=1}^{s}P_rx_r,
D(\xi)=\sum_{r=1}^{s}P_r(x_r-M(\xi))^2.
\sigma_{\xi}=\sqrt{D(\xi)}=\sqrt{\sum_{r=1}^{s}P_r(x_r-M(\xi))^2}
В основе простейших применений дисперсий и средних квадратических отклонений лежит знаменитое неравенство Чебышева
\mathbf{P}\{|\xi-M(\xi)|\leqslant t_{\sigma_{\xi}}\}\geqslant1-\frac{1}{t^2},
Оно показывает, что отклонения случайной величины \xi
от её математического ожидания M(\xi)
, значительно превышающие среднее квадратическое отклонение \sigma_{\xi}
, встречаются редко. При образовании сумм случайных величин \xi=\xi^{(1)}+ \xi^{(2)}+\cdots+\xi^{(n)}
для их математических ожиданий всегда имеет место равенство M(\xi)=M(\xi^{(1)})+M(\xi^{(2)})+\cdots+M(\xi^{(n)}).
D(\xi)=D(\xi^{(1)})+D(\xi^{(2)})+\cdots+D(\xi^{(n)}).
верно только при некоторых ограничениях. Для справедливости равенства (23) достаточно, например, чтобы величины \xi^{(i)}
и \xi^{(j)}
с различными номерами не были, как говорят, «коррелированны» между собой, т. е. чтобы при i\ne j
выполнялось равенство M\Bigl\{(\xi^{(i)}-M(\xi^{(i)}))(\xi^{(j)}-M(\xi^{(j)}))\Bigl\}=0
Коэффициентом корреляции между случайными величинами \xi^{(i)}
и \xi^{(j)}
называется выражение R=\frac{M\Bigl\{\Bigl(\xi^{(i)}-M(\xi^{(i)})\Bigl)\Bigl(\xi^{(j)}-M(\xi^{(j)})\Bigl)\Bigl\}}{\sigma_{\xi^{(i)}}\,\sigma_{\xi^{(j)}}}.
Если \sigma_{\xi^{(i)}}>0
в \sigma_{\xi^{(j)}}>0
, то условие (24) равносильно тому, что R=0
. Коэффициент корреляции R
характеризует степень зависимости между случайными величинами. Всегда |R|\leqslant1
, причем R=\pm1
только при наличии линейной связи \eta=a\xi+b\quad(a\ne0).
Для независимых величин R=0
. В частности, равенство (24) соблюдается, если величины \xi^{(i)}
и \xi^{(j)}
независимы между собой. Таким образом, для взаимно независимых слагаемых всегда действует равенство (23). Для средних арифметических \zeta=\frac{1}{n}\Bigl(\xi^{(1)}+\xi^{(2)}+\cdots+\xi^{(n)}\Bigl)
из (23) вытекает D(\zeta_=\frac{1}{n^2}\Bigl(D(\xi^{(1)})+ D(\xi^{(2)})+\cdots+ D(\xi^{(n)})\Bigl).
Предположим теперь, что для всех слагаемых дисперсии не превосходят некоторой постоянной D(\xi^{(i)})\leqslant C^2.
Тогда по (25) D(\zeta)\leqslant\frac{C^2}{n},
\mathbf{P}\!\left\{|\zeta-M(\zeta)|\leqslant\frac{tC}{\sqrt{n}}\right\}\geqslant1-\frac{1}{t^2}
Неравенство (26) содержит в себе так называемый закон больших чисел в форме, установленной Чебышевым: если величины \xi^{(i)}
взаимно независимы и имеют ограниченные дисперсии, то при возрастании n
их средние арифметические \zeta
, всё реже заметно отклоняются от своих математических ожиданий M(\zeta)
. Более точно говорят, что последовательность случайных величин
\xi^{(1)},\,\xi^{(2)},\,\ldots\,\xi^{(n)},\,\ldots
\mathbf{P}\{|\zeta-M(\zeta)|\leqslant \varepsilon\}\to1\quad (n\to\infty).
Чтобы получить из неравенства (26) предельное соотношение (27), достаточно положить T=\varepsilon\cdot\frac{\sqrt{n}}{C}.
Большой ряд исследований А.А. Маркова, С.Н. Бернштейна, А.Я. Хинчина и других посвящен вопросу возможно большего расширения условий применимости предельного соотношения (27), т. е. условий применимости закона больших чисел. Эти исследования имеют принципиальное значение. Однако еще более важным является точное исследование распределения вероятностей отклонений \zeta-M(\zeta)
. Великой заслугой русской классической школы в теории вероятностей является установление того факта, что при очень широких условиях асимптотически (т. е. со все большей точностью при неограниченно растущих n
) справедливо равенство \mathbf{P}\!\left\{t_1\sigma_{\zeta}<\zeta-M(\zeta) Чебышев дал почти полное доказательство этой формулы для случая независимых и ограниченных слагаемых. Марков восполнил недостающее звено в рассуждениях Чебышева и расширил условия применимости формулы (28). Еще более общие условия были даны Ляпуновым. Вопрос о распространении формулы (28) на суммы зависимых слагаемых с особенной полнотой был изучен С. Н. Бернштейном. Формула (28) охватила столь большое число частных задач, что долгое время ее называли центральной предельной теоремой теории вероятностей. Хотя при новейшем развитии теории вероятностей она оказалась включенной в ряд более общих закономерностей, ее значение трудно переоценить и в настоящее Время.
Если слагаемые независимы и их дисперсии одинаковы и равны: D(\xi^{(i)})=\sigma^2,
то формуле (28) удобно, учитывая соотношение (25), придать вид \mathbf{P}\!\left\{\frac{t_1\sigma}{\sqrt{n}}<\zeta-M(\zeta)<\frac{t_2\sigma}{\sqrt{n}}\right\}\sim\frac{1}{\sqrt{2\pi}}\int\limits_{t_1}^{t_2}e^{-t^2/2}\,dt\,.
Покажем, что соотношение (29) содержит в себе решение задачи об отклонениях частоты \frac{\mu}{n}
от вероятности p
, которой мы занимались ранее. Для этого введем случайные величины \xi^{(i)}
определяя их следующим условием: \xi^{(i)}=0
, если i
-е испытание имело отрицательный исход, \xi^{(i)}=1
, если i
-е испытание имело положительный исход. Легко проверить, что тогда \mathbf{P}\!\left\{t_1\sqrt{\frac{p(1-p)}{n}}<\frac{\mu}{n}-p Лемма Чебышева
. Если случайная величина х
, для которой существует математическое ожидание М
[x
], может принимать только неотрицательные значения, то для любого положительного числа a имеет место неравенство Неравенство Чебышева.
Если х
– случайная величина с математическим ожиданием М
[x
] и дисперсией D
[x
], то для любого положительного e имеет место неравенство Теорема Чебышева.
(закон больших чисел). Пусть х
1 , х
2 , …, x n
,… - последовательность независимых случайных величин с одним и тем же математическим ожиданием m
и дисперсиями, ограниченными одной и той же константой с
Доказательство теоремы основано на неравенстве вытекающей из неравенства Чебышева. Из теоремы Чебышева как следствие может быть получена Теорема Бернулли.
Пусть производится n
независимых опытов, в каждом из которых с вероятностью р
может наступить некоторое событие А
, и пусть v n
– случайная величина, равная числу наступлений события А
в этих n
опытах. Тогда для любого e > 0 имеет место предельное равенство Отметим, что неравенство (4) применительно к условиям теоремы Бернулли дает: Теорему Чебышева можно сформулировать в несколько более общем виде: Обобщенная теорема Чебышева.
Пусть х 1
, х 2
, …, x n
,… - последовательность независимых случайных величин с математическими ожиданиями M
[x
1 ] = m 1 , M
[x 2
] = m 2 ,…
и дисперсиями, ограниченными одной и той же постоянной с
. Тогда для любого положительного числа e имеет место предельное равенство Пусть х -число появлений 6 очков при 3600 бросаниях кости. Тогда М [x
] = 3600 = 600. Воспользуемся теперь неравенством (1) при a = 900: Используем неравенство (6) при n = 10000, р = , q = . Тогда Пример.
Вероятность наступления события А в каждом из 1000 независимых опытов равна 0,8. Найдите вероятность того, что число наступлений события А в этих 1000 опытах отклонится от своего математического ожидания по абсолютной величине меньше чем на 50. Пусть х - число наступлений события А в указанных 1000 опытах. Тогда М [x
] = 1000 × 0,8 = 800 и D [x
] = 1000 × 0,8 × 0,2 = 160. Теперь неравенство (2) дает: Пример.
Дисперсия каждой из 1000 независимых случайных величин x k (k = 1, 2,..., 1000) равна 4. Оцените вероятность того, что отклонение средней арифметической этих величин от средней арифметической их математических ожиданий по абсолютной величине не превзойдет 0,1. Согласно неравенству (4) при с = 4 и e = 0,1 имеем.
В сумме эти вероятности по всем различным возможным значениям величины \xi
всегда равны единице:
а дисперсией
величины \xi
называют математическое ожидание квадрата отклонения \xi-M(\xi)
, т. е. выражение
Корень квадратный из дисперсии
называется средним квадратическим отклонением
(величины от ее математического ожидания M(\xi)
).
Аналогичное равенство для дисперсий
и в силу неравенства Чебышева при любом t
подчиняется закону больших чисел, если для соответствующих средних арифметических \zeta
и при любом постоянном \varepsilon>0
и формула (29) дает
что при t_1=-t,~t_2=t
снова приводит к формуле (20).
Также см. Предельные теоремы теории вероятностей
В вашем браузере отключен Javascript.
Чтобы произвести расчеты, необходимо разрешить элементы ActiveX!
![]() . (2)
. (2) . (3)
. (3) , (4)
, (4) . (5)
. (5) . (6)
. (6) . (7)
. (7)![]() .
.
![]()
 Корпускулярные и волновые свойства частиц
Корпускулярные и волновые свойства частиц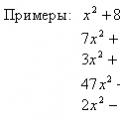 Уравнения онлайн X 5 0 решение
Уравнения онлайн X 5 0 решение Предельные монокарбоновые кислоты
Предельные монокарбоновые кислоты