Основные положения классической теории тестов. Основные понятия теории тестов
Что такое тестирование
В соответствие с IEEE Std 829-1983 Тестирование - это процесс анализа ПО, направленный на выявление отличий между его реально существующими и требуемыми свойствами (дефект) и на оценку свойств ПО.
По ГОСТ Р ИСО МЭК 12207-99 в жизненном цикле ПО определены среди прочих вспомогательные процессы верификации, аттестации, совместного анализа и аудита. Процесс верификации является процессом определения того, что программные продукты функционируют в полном соответствии с требованиями или условиями, реализованными в предшествующих работах. Данный процесс может включать анализ, проверку и испытание (тестирование). Процесс аттестации является процессом определения полноты соответствия установленных требований, созданной системы или программного продукта их функциональному назначению. Процесс совместного анализа является процессом оценки состояний и, при необходимости, результатов работ (продуктов) по проекту. Процесс аудита является процессом определения соответствия требованиям, планам и условиям договора. В сумме эти процессы и составляют то, что обычно называют тестированием.
Тестирование основывается на тестовых процедурах с конкретными входными данными, начальными условиями и ожидаемым результатом, разработанными для определенной цели, такой, как проверка отдельной программы или верификация соответствия на определенное требование. Тестовые процедуры могут проверять различные аспекты функционирования программы - от правильной работы отдельной функции до адекватного выполнения бизнес-требований.
При выполнении проекта необходимо учитывать, в соответствии с какими стандартами и требованиями будет проводиться тестирование продукта. Какие инструментальные средства будут (если будут) использоваться для поиска и для документирования найденных дефектов. Если помнить о тестировании с самого начала выполнения проекта, тестирование разрабатываемого продукта не доставит неприятных неожиданностей. А значит и качество продукта, скорее всего, будет достаточно высоким.
Жизненный цикл продукта и тестирование
Все чаще в наше время используются итеративные процессы разработки ПО, в частности, технология RUP - Rational Unified Process (Рис. 1). При использовании такого подхода тестирование перестает быть процессом «на отшибе», который запускается после того, как программисты написали весь необходимый код. Работа над тестами начинается с самого начального этапа выявления требований к будущему продукту и тесно интегрируется с текущими задачами. И это предъявляет новые требования к тестировщикам. Их роль не сводится просто к выявлению ошибок как можно полнее и как можно раньше. Они должны участвовать в общем процессе выявления и устранения наиболее существенных рисков проекта. Для этого на каждую итерацию определяется цель тестирования и методы ее достижения. А в конце каждой итерации определяется, насколько эта цель достигнута, нужны ли дополнительные испытания, и не нужно ли изменить принципы и инструменты проведения тестов. В свою очередь, каждый обнаруженный дефект должен пройти через свой собственный жизненный цикл.
Рис. 1. Жизненный цикл продукта по RUP
Тестирование обычно проводится циклами, каждый из которых имеет конкретный список задач и целей. Цикл тестирования может совпадать с итерацией или соответствовать ее определенной части. Как правило, цикл тестирования проводится для конкретной сборки системы.
Жизненный цикл программного продукта состоит из серии относительно коротких итераций (Рис. 2). Итерация - это законченный цикл разработки, приводящий к выпуску конечного продукта или некоторой его сокращенной версии, которая расширяется от итерации к итерации, чтобы, в конце концов, стать законченной системой.
Каждая итерация включает, как правило, задачи планирования работ, анализа, проектирования, реализации, тестирования и оценки достигнутых результатов. Однако соотношения этих задач может существенно меняться. В соответствие с соотношением различных задач в итерации они группируются в фазы. В первой фазе - Начало - основное внимание уделяется задачам анализа. В итерациях второй фазы - Разработка - основное внимание уделяется проектированию и опробованию ключевых проектных решений. В третьей фазе - Построение - наиболее велика доля задач разработки и тестирования. А в последней фазе - Передача - решаются в наибольшей мере задачи тестирования и передачи системы Заказчику.

Рис. 2. Итерации жизненного цикла программного продукта
Каждая фаза имеет свои специфические цели в жизненном цикле продукта и считается выполненной, когда эти цели достигнуты. Все итерации, кроме, может быть, итераций фазы Начало, завершаются созданием функционирующей версии разрабатываемой системы.
Категории тестирования
Тесты существенно различаются по задачам, которые с их помощью решаются, и по используемой технике.
| Категории тестирования | Описание категории | Виды тестирования |
|---|---|---|
| Текущее тестирование | Набор тестов, выполняемый для определения работоспособности добавленных новых возможностей системы. |
|
| Регрессионное тестирование | Цель регрессионного тестирования заключается в проверке того, что добавления к системе не уменьшили ее возможностей, т.е. тестирование проводится согласно требованиям, которые уже были выполнены перед добавлением новых возможностей. |
|
Подкатегории тестирования
| Подкатегории тестирования | Описание вида тестирования | Подвиды тестирования |
|---|---|---|
| Нагрузочное тестирование | Применяется для тестирования всех без исключения функций приложения. В данном случае последовательность тестирования функций не имеет значения. |
|
| Тестирование бизнес циклов | Применяется для тестирования функций приложения в последовательности их вызова пользователем. Например, имитация всех действия бухгалтера за 1 квартал. |
|
| Стрессовое тестирование |
Применяется для тестирования Производительности приложения. Цель данного тестирования - определить рамки стабильной работы приложения. При данном тестирование производится вызов всех доступных функций. |
|
Виды тестирования
Unit-тестирование (модульное тестирование) - данный вид подразумевает тестирование отдельных модулей приложения. Для получения максимального результата тестирование проводится одновременно с разработкой модулей.
Функциональное тестирование - цель данного тестирования состоит в том, чтобы убедиться в надлежащем функционировании объекта тестирования. Тестируется правильность навигации по объекту, а также ввод, обработка и вывод данных.
Тестирование БД - проверка работоспособности БД при нормальной работе приложения, в моменты перегрузок и многопользовательском режиме.
Unit-тестирование
Для ООП обычная организация модульного тестирования заключается в тестировании методов каждого класса, затем класса каждого пакета и.т.д. Постепенно мы переходим к тестированию всего проекта, а предыдущие тесты носят вид регрессионных.
В выходную документацию данных тестов входят тестовые процедуры, входные данные, код, исполняющий тест, выходные данные. Далее представлен вид выходной документации.
Функциональное тестирование
Функциональное тестирование объекта тестирования планируется и проводится на основе требований к тестированию, заданных на этапе определения требований. В качестве требований выступают бизнес-правила, диаграммы use-case, бизнес-функции, а также при наличии, диаграммы активности. Цель функциональных тестов состоит в том, чтобы проверить соответствие разработанных графических компонентов установленным требованиям.
Данный вид тестирования не может быть полностью автоматизирован. Следовательно, он подразделяется на:
- Автоматизированное тестирование (будет использоваться в случае, где можно проверить выходную информацию).
Цель: протестировать ввод, обработку и вывод данных;
- Ручное тестирование (в остальных случаях).
Цель: тестируется правильность выполнения пользовательских требований.
Необходимо исполнить (проиграть) каждый из use-case, используя как верные значения, так и заведомо ошибочные, для подтверждения правильного функционирования, по следующим критериям:
- продукт адекватно реагирует на все вводимые данные (выводятся ожидаемые результаты в ответ на правильно вводимые данные);
- продукт адекватно реагирует на неправильно вводимые данные (появляются соответствующие сообщения об ошибках).
Тестирование БД
Цель данного тестирования - убедиться в надежности методов доступа к базам данных, в их правильном исполнении, без нарушения целостности данных.
Необходимо последовательно использовать максимально возможное число обращений к базе данных. Используется подход, при котором тест составляется таким образом, чтобы «нагрузить» базу последовательностью, как верных значений, так и заведомо ошибочных. Определяется реакция БД на ввод данных, оцениваются временные интервалы их обработки.
Основы теории тестов 1. Основные понятия теории тестов 2. Надежность тестов и пути ее определения

 Контрольные вопросы 1. Что называется тестом? 2. Какие требования предъявляются к тесту? 3. Какие тесты называются аутентичными? 4. Что называется надежностью теста? 5. Перечислить причины, вызывающие вариацию результатов при повторном тестировании. 6. В чем отличие внутриклассовой вариации от межклассовой? 7. Как практически определить надежность теста? 8. В чем отличие согласованности тестов от стабильности? 9. В чем заключается эквивалентность тестов? 10. Что такое гомогенный комплекс тестов? 11. Что такое гетерогенный комплекс тестов? 12. Пути повышения надежности тестов.
Контрольные вопросы 1. Что называется тестом? 2. Какие требования предъявляются к тесту? 3. Какие тесты называются аутентичными? 4. Что называется надежностью теста? 5. Перечислить причины, вызывающие вариацию результатов при повторном тестировании. 6. В чем отличие внутриклассовой вариации от межклассовой? 7. Как практически определить надежность теста? 8. В чем отличие согласованности тестов от стабильности? 9. В чем заключается эквивалентность тестов? 10. Что такое гомогенный комплекс тестов? 11. Что такое гетерогенный комплекс тестов? 12. Пути повышения надежности тестов.
 Тест - это измерение или испытание, проводимое с целью определения состояния или способностей человека. Не всякие измерения могут быть использованы как тесты, а только те, которые отвечают специальным требованиям. К ним относятся: 1. стандартизованность (процедура и условия тестирования должны быть одинаковыми во всех случаях применения теста); 2. надежность; 3. информативность; 4. наличие системы оценок.
Тест - это измерение или испытание, проводимое с целью определения состояния или способностей человека. Не всякие измерения могут быть использованы как тесты, а только те, которые отвечают специальным требованиям. К ним относятся: 1. стандартизованность (процедура и условия тестирования должны быть одинаковыми во всех случаях применения теста); 2. надежность; 3. информативность; 4. наличие системы оценок.
 Требования тестов: n Информативность - степень точности, с которой он измеряет свойство (качество, способность, характеристику), для оценки которой используется. n Надежность - степень совпадения результатов при повторном тестировании одних и тех же людей в одинаковых условиях. Согласованность - (разные люди, но одинаковые приборы и одинаковые условия). n n Стандартность условий - (однаковые условия при повторных измерениях). n Наличие системы оценок - (перевод в систему оценок. Как в школе 5 -4 -3. . .).
Требования тестов: n Информативность - степень точности, с которой он измеряет свойство (качество, способность, характеристику), для оценки которой используется. n Надежность - степень совпадения результатов при повторном тестировании одних и тех же людей в одинаковых условиях. Согласованность - (разные люди, но одинаковые приборы и одинаковые условия). n n Стандартность условий - (однаковые условия при повторных измерениях). n Наличие системы оценок - (перевод в систему оценок. Как в школе 5 -4 -3. . .).
 Тесты, удовлетворяющие требованиям надежности и информативности, называют добротными или аутентичными (греч. аутентико - достоверным образом)
Тесты, удовлетворяющие требованиям надежности и информативности, называют добротными или аутентичными (греч. аутентико - достоверным образом)
 Процесс испытаний называется тестированием; полученное в итоге измерения числовое значение - результатом тестирования (или результатом теста). Например, бег 100 м - это тест, процедура проведения забегов и хронометража - тестирование, время забега - результат теста.
Процесс испытаний называется тестированием; полученное в итоге измерения числовое значение - результатом тестирования (или результатом теста). Например, бег 100 м - это тест, процедура проведения забегов и хронометража - тестирование, время забега - результат теста.

 Тесты, в основе которых лежат двигательные задания, называют двигательными или моторными. Результатами их могут быть либо двигательные достижения (время прохождения дистанции, число повторений, пройденное расстояние и т. п.), либо физиологические и биохимические показатели.
Тесты, в основе которых лежат двигательные задания, называют двигательными или моторными. Результатами их могут быть либо двигательные достижения (время прохождения дистанции, число повторений, пройденное расстояние и т. п.), либо физиологические и биохимические показатели.
 Иногда используется не один, а несколько тестов, имеющих единую конечную цель (например, оценку состояния спортсмена в соревновательном периоде тренировки). Такая группа тестов называется комплексом или батареей тестов.
Иногда используется не один, а несколько тестов, имеющих единую конечную цель (например, оценку состояния спортсмена в соревновательном периоде тренировки). Такая группа тестов называется комплексом или батареей тестов.
 Один и тот же тест, примененный к одним и тем же исследуемым, должен дать в одинаковых условиях совпадающие результаты (если только не изменились сами исследуемые). Однако при самой строгой стандартизации и точной аппаратуре результаты тестирования всегда несколько варьируют. Например, исследуемый, только что показавший в тесте становой динамометрии результат 215 к. Г, при повторном выполнении показывает лишь 190 к. Г.
Один и тот же тест, примененный к одним и тем же исследуемым, должен дать в одинаковых условиях совпадающие результаты (если только не изменились сами исследуемые). Однако при самой строгой стандартизации и точной аппаратуре результаты тестирования всегда несколько варьируют. Например, исследуемый, только что показавший в тесте становой динамометрии результат 215 к. Г, при повторном выполнении показывает лишь 190 к. Г.
 Надежность тестов и пути ее определения Надежностью теста называется степень совпадения результатов при повторном тестировании одних и тех же людей (или других объектов) в одинаковых условиях.
Надежность тестов и пути ее определения Надежностью теста называется степень совпадения результатов при повторном тестировании одних и тех же людей (или других объектов) в одинаковых условиях.
 Вариацию результатов при повторном тестировании называют внутри индивидуальной, или внутри групповой, либо внутриклассовой. Четыре основные причины вызывают эту вариацию: 1. Изменение состояния исследуемых (утомление, врабатывание, «научение» , изменение мотивации, концентрации внимания и т. п.). 2. Неконтролируемые изменения внешних условий и аппаратуры (температура, ветер, влажность, напряжение в электросети, присутствие посторонних лиц и т. п.), т. е. все то, что объединяется термином “случайная ошибка измерения”.
Вариацию результатов при повторном тестировании называют внутри индивидуальной, или внутри групповой, либо внутриклассовой. Четыре основные причины вызывают эту вариацию: 1. Изменение состояния исследуемых (утомление, врабатывание, «научение» , изменение мотивации, концентрации внимания и т. п.). 2. Неконтролируемые изменения внешних условий и аппаратуры (температура, ветер, влажность, напряжение в электросети, присутствие посторонних лиц и т. п.), т. е. все то, что объединяется термином “случайная ошибка измерения”.
 Четыре основные причины вызывают эту вариацию: 3. Изменение состояния человека, проводящего или оценивающего тест (и, конечно, замена одного экспериментатора или судьи другим). 4. Несовершенство теста (есть такие тесты, которые заведомо малонадежные. Например, если исследуемые выполняют штрафные броски в баскетбольную корзину, то даже баскетболист, имеющий высокий процент попаданий, может случайно ошибиться при первых бросках).
Четыре основные причины вызывают эту вариацию: 3. Изменение состояния человека, проводящего или оценивающего тест (и, конечно, замена одного экспериментатора или судьи другим). 4. Несовершенство теста (есть такие тесты, которые заведомо малонадежные. Например, если исследуемые выполняют штрафные броски в баскетбольную корзину, то даже баскетболист, имеющий высокий процент попаданий, может случайно ошибиться при первых бросках).
 Понятие об истинном результате теста является абстракцией (в опыте измерить нельзя). Поэтому приходится использовать косвенные методы. Наиболее предпочтителен для оценки надежности дисперсионный анализ с последующим расчетом внутриклассовых коэффициентов корреляции. Дисперсионный анализ позволяет разложить зарегистрированную в опыте вариацию результатов теста на составляющие, обусловленные влиянием отдельных факторов.
Понятие об истинном результате теста является абстракцией (в опыте измерить нельзя). Поэтому приходится использовать косвенные методы. Наиболее предпочтителен для оценки надежности дисперсионный анализ с последующим расчетом внутриклассовых коэффициентов корреляции. Дисперсионный анализ позволяет разложить зарегистрированную в опыте вариацию результатов теста на составляющие, обусловленные влиянием отдельных факторов.
 Если зарегистрировать у исследуемых их результаты в какомлибо тесте, повторяя этот тест в разные дни, причем каждый день делать по несколько попыток, периодически меняя экспериментаторов, то будут иметь место вариации: а) от испытуемого к испытуемому; n б) ото дня ко дню; n в) от экспериментатора к экспериментатору; n г) от попытки к попытке. Дисперсионный анализ дает возможность выделить и оценить эти вариации. n
Если зарегистрировать у исследуемых их результаты в какомлибо тесте, повторяя этот тест в разные дни, причем каждый день делать по несколько попыток, периодически меняя экспериментаторов, то будут иметь место вариации: а) от испытуемого к испытуемому; n б) ото дня ко дню; n в) от экспериментатора к экспериментатору; n г) от попытки к попытке. Дисперсионный анализ дает возможность выделить и оценить эти вариации. n
 Таким образом, чтобы оценить практически надежность теста надо, n во-первых, выполнить дисперсионный анализ, n во-вторых, рассчитать внутриклассовый коэффициент корреляции (коэффициент надежности).
Таким образом, чтобы оценить практически надежность теста надо, n во-первых, выполнить дисперсионный анализ, n во-вторых, рассчитать внутриклассовый коэффициент корреляции (коэффициент надежности).
 Говоря о надежности тестов, необходимо различать их стабильность (воспроизводимость), согласованность, эквивалентность. n n Под стабильностью теста понимают воспроизводимость результатов при его повторении через определенное время в одинаковых условиях. Повторное тестирование обычно называют ретестом. Согласованность теста характеризуется независимостью результатов тестирования от личных качеств лица, проводящего или оценивающего тест.
Говоря о надежности тестов, необходимо различать их стабильность (воспроизводимость), согласованность, эквивалентность. n n Под стабильностью теста понимают воспроизводимость результатов при его повторении через определенное время в одинаковых условиях. Повторное тестирование обычно называют ретестом. Согласованность теста характеризуется независимостью результатов тестирования от личных качеств лица, проводящего или оценивающего тест.
 Если все тесты, входящие в какойлибо комплекс тестов, высоко эквивалентны, он называется гомогенным. Весь этот комплекс измеряет одно какое -то свойство моторики человека (например, комплекс, состоящий из прыжков с места в длину, вверх и тройного; оценивается уровень развития скоростно-силовых качеств). Если в комплексе нет эквивалентных тестов, то есть тесты, входящие в него, измеряют разные свойства, то он называется гетерогенным (например, комплекс, состоящий из становой динамометрии, прыжка вверх по Абалакову, бега на 100 м).
Если все тесты, входящие в какойлибо комплекс тестов, высоко эквивалентны, он называется гомогенным. Весь этот комплекс измеряет одно какое -то свойство моторики человека (например, комплекс, состоящий из прыжков с места в длину, вверх и тройного; оценивается уровень развития скоростно-силовых качеств). Если в комплексе нет эквивалентных тестов, то есть тесты, входящие в него, измеряют разные свойства, то он называется гетерогенным (например, комплекс, состоящий из становой динамометрии, прыжка вверх по Абалакову, бега на 100 м).
 Надежность тестов может быть повышена до определенной степени путем: n n n а) более строгой стандартизации тестирования; б) увеличения числа попыток; в) увеличения числа оценщиков (судей, экспериментов) и повышения согласованности их мнений; г) увеличения числа эквивалентных тестов; д) лучшей мотивации исследуемых.
Надежность тестов может быть повышена до определенной степени путем: n n n а) более строгой стандартизации тестирования; б) увеличения числа попыток; в) увеличения числа оценщиков (судей, экспериментов) и повышения согласованности их мнений; г) увеличения числа эквивалентных тестов; д) лучшей мотивации исследуемых.

Первый компонент, теория тестов, содержит описание статистических моделей обработки диагностических данных. Здесь содержатся модели анализа ответов в тестовых заданиях и модели подсчета суммарных результатов теста. Мелленберг (1980, 1990) назвал это «психометрией». Классическая теория тестов, современная теория тестов (или модель анализа ответов на задания тестов - IRT) и модель
выборки заданий составляют три наиболее важных типа моделей теории тестов. Предметом рассмотрения психодиагностики являются первые две модели.
Классическая теория тестов. На основе этой теории разработано большинство интеллектуальных и личностных тестов. Центральным понятием этой теории является понятие «надежности». Под надежностью понимается согласованность результатов при повторном оценивании. В справочных пособиях это понятие обычно представляется очень кратко, а затем дается подробное описание аппарата математической статистики. В этой, вводной, главе мы представим сжатое описание основного значения отмеченного понятия. В классической теории тестов под надежностью понимается повторяемость результатов нескольких процедур измерения (преимущественно измерений при помощи тестов). Понятие надежности предполагает вычисление ошибки измерения. Результаты, полученные в процессе тестирования, могут быть представлены как сумма истинного результата и ошибки измерения:
Xi = Ti + Еj
где Xi - оценка полученных результатов, Ti - истинный результат, а Еj - ошибка измерения.
Оценка полученных результатов - это, как правило, количество правильных ответов на задания теста. Истинный результат можно рассматривать как истинную оценку в платоновском смысле (Gulliksen, 1950). Широко распространенным является понятие ожидаемых результатов, т.е. представлений о баллах, которые могут быть получены в результате большого числа повторений процедур измерения (Lord & Novich, 1968). Но проведение одной и той же процедуры оценивания с одним человеком не представляется возможным. Поэтому необходим поиск других вариантов решения проблемы (Witlman, 1988).
В рамках этой концепции делаются некоторые допущения относительно истинных результатов и ошибок измерения. Последние принимаются в качестве независимого фактора, что, конечно, является вполне обоснованным предположением, так как случайные колебания результатов не дают ковариаций: r ЕЕ =0.
Предполагается, что корреляции между истинными баллами и ошибками измерения не существует: r EE =0.
Суммарная ошибка равна 0, т.к. в качестве истинной оценки берется среднее арифметическое значение:
Эти допущения приводят нас в итоге к известному определению надежности как отношения истинного результата к общей дисперсии или выражению: 1 минус отношение, в числителе которого ошибка измерения, а в знаменателе - общая дисперсия:
 , ИЛИ
, ИЛИ 
Из этой формулы определения надежности получаем, что дисперсия ошибки S 2 (E) равна общей дисперсии в числе случаев (1 – r XX "); таким образом, стандартная ошибка измерения определяется по формуле:
![]()
После теоретического обоснования надежности и его производных необходимо определить индекс надежности того или иного теста. Существуют практические процедуры оценивания надежности тестов, такие как использование взаимозаменяемых форм (параллельные тесты), расщепление заданий на две части, повторное тестирование и измерение внутренней согласованности. Каждый справочник содержит индексы постоянства тестовых результатов:
r XX ’ =r(x 1 , x 2)
где r XX ’ - коэффициент стабильности, а x 1 и x 2 - результаты двух измерений.
Понятие надежности взаимозаменяемых форм введено и разработано Гулликсеном (1950). Данная процедура достаточно трудоемка, поскольку связана с необходимостью создания параллельной серии заданий
r XX ’ =r(x 1 , x 2)
где r XX ’ - коэффициент эквивалентности, а x 1 и x 2 - два параллельных теста.
Следующая процедура - расщепление основного теста на две части А и В - более проста в использовании. Показатели, полученные по обеим частям теста, коррелируются. С помощью формулы Спирмена-Брауна оценивается надежность теста в целом:
где А и В - две параллельные части теста.
Следующий метод - определение внутренней согласованности выполнения заданий теста. Этот метод основан на определении ковариаций отдельных заданий. Sg - дисперсия произвольно выбранного задания, и Sgh - ковариация двух произвольно выбранных заданий. Наиболее часто используемый коэффициент для определения внутренней согласованности - это «коэффициент альфа» Кронбаха. Используются также формула КР20 и λ-2 (лямбда-2).
В классической концепции надежности определяются ошибки измерения, возникающие как в процессе тестирования, так и в процессе наблюдений. Источники этих ошибок различны: это могут быть и личностные особенности, и особенности условий тестирования, и сами тестовые задания. Существуют конкретные методы вычисления ошибок. Мы знаем, что наши наблюдения могут оказаться ошибочными, наши методические инструменты несовершенны так же, как несовершенны и сами люди. (Как не вспомнить Шекспира: «Ненадежен ты, чье имя человек»). То, что в классической теории тестов ошибки измерения эксплицируются и объясняются, является важным положительным моментом.
Классическая теория тестов имеет ряд существенных особенностей, которые можно рассматривать и как ее недостатки. Некоторые из этих характеристик отмечаются в справочниках, но их значение (с житейской точки зрения) подчеркивается нечасто, как не отмечается и то, что с теоретической или методической точки зрения их следует считать недостатками.
Первое. Классическая теория тестов и понятие надежности ориентированы на подсчет суммарных тестовых показателей, представляющих собой результат сложения оценок, полученных в отдельных заданиях. Так, при работе
Второе. Коэффициент надежности предполагает оценку величины разброса измеряемых показателей. Отсюда следует, что коэффициент надежности будет ниже, если (при равенстве других показателей) выборка является более однородной. Не существует единого коэффициента внутренней согласованности заданий теста, этот коэффициент всегда «контекстуален». Крокер и Альджина (1986), например, предлагают специальную формулу «коррекции для гомогенной выборки», предназначенную для самых высоких и самых низких результатов, полученных проходящими тестирование. Для диагноста важно знать характеристики вариаций в выборочной совокупности, иначе он не сможет использовать коэффициенты внутренней согласованности, указанные в руководстве к данному тесту.
Третье. Феномен сведения к показателю среднего арифметического является логическим следствием классической концепции надежности. Если оценка в тесте колеблется (т.е. она недостаточно надежна), то вполне возможно, что при повторении процедуры субъекты, имеющие низкие показатели, получат более высокие баллы, и наоборот, субъекты с высокими показателями - низкие. Этот артефакт процедуры измерения нельзя ошибочно принять за истинное изменение или проявление процессов развития. Но в то же время разграничить их нелегко, т.к. никогда нельзя исключить возможность изменения в ходе развития. Для полной уверенности необходимо"сравнение с контрольной группой.
Четвертая характеристика тестов, разработанных в соответствии с принципами классической теории,- это наличие нормативных данных. Знание тестовых норм позволяет исследователю адекватно интерпретировать результаты тестируемых. Вне норм тестовые оценки лишены смысла. Выработка тестовых норм - это достаточно дорогостоящее предприятие, поскольку психолог должен получить результаты тестирования на репрезентативной выборке.
2 Я. тер Лаак
Если говорить о недостатках классической концепции надежности, то здесь уместно привести высказывание Сий-тсма (1992, р. 123-125). Он отмечает, что первое и главное предположение классической теории тестов состоит в том, что тестовые результаты подчиняются интервальному принципу. Однако никаких исследований, подтверждающих это предположение, нет. По сути, это «измерение по произвольно установленному правилу». Данная особенность ставит классическую теорию тестов в менее выгодное положение по сравнению со шкалами измерения установок и, конечно же, по сравнению с современной теорией тестов. Многие методы анализа данных (дисперсионный анализ. регрессионный анализ, корреляционный и факторный анализ) основаны на допущении существования интервальной шкалы. Однако оно не имеет твердого обоснования. Рассматривать шкалу истинных результатов как шкалу значений психологических характеристик (например, арифметических способностей, интеллекта, нейротизма) можно только предположительно.
Второе замечание касается того, что результаты выполнения теста - это не абсолютные показатели той или иной психологической характеристики тестируемого, их необходимо рассматривать лишь как результаты выполнения того или иного теста. Два теста могут претендовать на изучение одних и тех же психологических характеристик (например, интеллекта, вербальных способностей, экстраверсии), но это не означает, что эти два теста равноценны и обладают одинаковыми возможностями. Сравнение показателей двух людей, прошедших тестирование разными тестами, некорректно. То же относится и к заполнению двух разных тестов одним испытуемым. Третье замечание относится к предположению, что стандартная ошибка измерения одинакова применительно к любому уровню измеряемых способностей индивида. Однако не существует эмпирической проверки этого предположения. Так, например, нет гарантии того, что тестируемый с хорошими математическими способностями при работе с относительно простым арифметическим тестом получит высокие баллы. В этом случае высокую оценку скорее получит человек с низкими или средними способностями.
В рамках современной теории тестов или теории анализа ответов в заданиях теста содержится описание большого
количества моделей возможных ответов респондентов. Эти модели различаются положенными в их основу допущениями, а также требованиями по отношению к получаемым данным. Модель Раша часто рассматривается в качестве синонима теорий анализа ответов в заданиях теста (1RT). На самом деле это только одна из моделей. Представленная в ней формула для описания характеристической кривой задания g выглядит следующим образом:

где g - отдельное задание теста; ехр - функция экспоненты (нелинейная зависимость); δ («дельта») - уровень трудности теста.
Другие задания теста, например h, также получают собственные характеристические кривые. Выполнение условия δ h >δ g (g означает, что h - более трудное задание. Следовательно, для любого значения показателя Θ («тета» - латентные свойства способностей тестируемых) вероятность успешного выполнения задания h меньше. Эта модель называется строгой, поскольку очевидно, что при низкой степени выраженности черты вероятность выполнения задания близка к нулю. В этой модели нет места угадыванию и предположениям. Для заданий с вариантами выбора нет необходимости делать предположения о вероятности успеха. Кроме того, эта модель строга в том смысле, что все задания теста должны иметь одинаковую дискриминатив-ную способность (высокая дискриминативность отражается в крутизне кривой; здесь возможно построение шкалы Гут-тмана, согласно которой в каждой точке характеристической кривой вероятность выполнения задания меняется от О до 1). Из-за этого условия не все задания могут быть включены в тесты, созданные на основе модели Раша.
Существует несколько вариантов этой модели (например, Birnbaura, 1968, См. Lord & Novik). Она допускает существование заданий с различной дискриминативной
способностью.
Голландский исследователь Моккен (1971) разработал две модели анализа ответов в заданиях теста, требования которых не так строги, как в модели Раша, и поэтому, возможно, более реалистичны. В качестве основного усло-
вия Моккен выдвигает положение о том, что характеристическая кривая задания должна следовать монотонно, без обрывов. Все задания теста при этом направлены на изучение одной и той же психологической характеристики, измерять которую должна в. Допускается любая форма этой зависимости, пока она не прервется. Следовательно, форма характеристической кривой не определяется какой-либо специфической функцией. Такая «свобода» позволяет использовать больше заданий теста, и уровень оценивания при этом оказывается не выше, чем обычный.
Методология моделей ответов на задания теста (IRT) отличается от методологии большинства экспериментальных и корреляционных исследований. Математическая модель предназначена для изучения поведенческих, когнитивных, эмоциональных характеристик, а также феноменов развития. Эти рассматриваемые феномены часто ограничиваются ответами на задания, что позволило Мел-ленбергу (1990) назвать теорию IRT «мини-теорией о мини-поведении». Результаты исследования могут быть в определенной степени представлены как кривые согласованности, особенно в тех случаях, когда теоретические представления об изучаемых характеристиках отсутствуют. До сих пор в нашем распоряжении имеются лишь единицы тестов интеллекта, способностей и личностных тестов, созданных на основе многочисленных моделей теории IRT. Варианты модели Раша чаще используются при разработке тестов достижений (Verhelst, 1993), а модели Моккена больше подходят для феноменов развития (см. также гл. 6).
Ответ тестируемого на задания теста является основной единицей моделей IRT. Тип ответа определяется степенью выраженности у человека изучаемой характеристики. Такой характеристикой могут быть, например, арифметические или пространственные способности. В большинстве случаев это тот или иной аспект интеллекта, характеристики достижений или личностные особенности. Предполагается, что между положением данного конкретного человека в некотором диапазоне изучаемой характеристики и вероятностью успешного выполнения того или иного задания существует нелинейная зависимость. Нелинейность этой зависимости в определенном смысле интуитивно понятна. Известные фразы «Всякое начало трудно» (медленный не-
линейный старт) и «Стать святым не так просто», означают что дальнейшее совершенствование после достижения определенного уровня идет трудно. Кривая медленно приближается, но почти никогда не достигает 100%-го уровня успеха.
Некоторые модели скорее противоречат нашему интуитивному пониманию. Возьмем такой пример. Человек с индексом выраженности произвольной характеристики равным 1,5 имеет 60-процентную вероятность успеха при выполнении задания. Это противоречит нашему интуитивному пониманию такой ситуации, ведь можно либо успешно справиться с заданием, либо не справиться с ним вообще. Возьмем такой пример: 100 раз человек пытается взять высоту 1м 50 см. Успех сопутствует ему 60 раз, т.е. он имеет 60-процентную вероятность успеха.
Для оценки степени выраженности характеристики необходимо, по крайней мере, два задания. Модель Раша предполагает определение выраженности характеристик вне зависимости от трудности задания. Это также противоречит нашему интуитивному пониманию: предположим, что человек имеет 80-процентную вероятность прыгнуть выше 1,30 м. Если это так, то в соответствии с характеристической кривой заданий он имеет 60-процентную вероятность прыгнуть выше 1,50 м и 40-процентную вероятность прыгнуть выше 1,70 м. Следовательно, вне зависимости от значения независимой переменной (высоты) можно оценить способность человека прыгать в высоту.
Существует около 50 моделей IRT (Goldstein & Wood, 1989).Имеется множество нелинейных функций, описывающих (объясняющих) вероятность успеха в выполнении задания или группы заданий. Требования и ограничения этих моделей различны, и эти различия могут быть обнаружены при сопоставлении модели Раша и шкалы Моккена. К требованиям этих моделей можно отнести:
1) необходимость определения исследуемой характеристики и оценку позиции человека в диапазоне этой черты;
2) оценку последовательности заданий;
3) проверку конкретных моделей. В психометрии разработано множество процедур для проверки модели.
В некоторых справочных пособиях теория IRT рассматривается как форма анализа заданий теста (см., например,
Croker& Algina, J 986). Можно, однако, отстаивать ту точку зрения, что теория IRT - это «мини-теория о мини-поведении». Сторонники теории IRT замечают, что если-несовершенны концепции (модели) среднего уровня, то что же можно сказать о более сложных конструктах в психологии?
Классическая и современная теории тестов. Люди не могут не сравнивать вещи, которые выглядят почти одинаково. (Возможно, житейский эквивалент психометрии и состоит, главным образом, в сравнении людей по значимым характеристикам и выборе между ними). Каждая из представленных теорий - и теория измерения ошибок оценивания, и математическая модель ответов на задания теста - имеет своих сторонников (Goldstein & Wood, 1986).
Модели IRT не вызывают упреков в том, что это «оценивание по правилам», в отличие от классической теории тестов. Модель IRT ориентирована на анализ оцениваемых характеристик. Характеристики личности и характеристики заданий оцениваются с помощью шкал (порядковых или интервальных). Более того, возможно сопоставление показателей выполнения разных тестов, направленных на изучение сходных характеристик. Наконец, надежность неодинакова для каждого значения на шкале, а средние показатели обычно являются более надежными, чем показатели, расположенные в начале и в конце шкалы. Таким образом, модели IRT в теоретическом отношении представляются более совершенными. Существует и различия в практическом использовании современной теории тестов и классической теории (Sijstma, 1992, стр. 127-130). Современная теория тестов более сложна по сравнению с классической, поэтому она реже используется неспециалистами. Более того, IRT предъявляет особые требования к заданиям. Это означает, что задания должны быть исключены из теста, если они не удовлетворяют требованиям модели. Данное правило относится далее к тем заданиям, которые входили в состав широко используемых тестов, построенных по принципам классической теории. Тест становится короче, и, следовательно, надежность его снижается.
IRT предлагает математические модели для изучения реальных феноменов. Модели должны помочь нам понять ключевые аспекты этих феноменов. Однако здесь кроется основной теоретический вопрос. Модели можно рассматри-
ватькак подход к изучению сложной реальности, в которой мы живем. Но модель и реальность - не одно и то же. Согласно пессимистическому взгляду, возможно моделирование лишь единичных (и притом не самых интересных) типов поведения. Также можно встретить утверждение, что реальность вообще не подлежит моделированию, т.к. она подчиняется не одним лишь причинно-следственным законам. В лучшем случае возможно моделирование отдельных (идеальных) поведенческих феноменов. Существует и другой, более оптимистичный, взгляд на возможности модели-рования. Приведенная выше позиция блокирует возможность глубокого постижения природы феноменов человеческого поведения. Применение той или иной модели поднимает некоторые обшие, фундаментальные вопросы. На наш взгляд, не подлежит сомнению, что IRT является концепцией теоретически и технически превосходящей классическую теорию тестов.
Практическим назначением тестов, на какой бы теоретической основе они не создавались, является определение значимых критериев и установление на их основе характеристик тех или иных психологических конструктов. Имеет ли модель IRT преимущества и в этом отношении? Вполне возможно, что тесты, созданные на основе этой модели, не дают более точного прогноза по сравнению с тестами, созданными на основе классической теории, и возможно, что их вклад в разработку психологических конструктов не является более весомым. Диагносты предпочитают такие критерии, которые непосредственно относятся к отдельному человеку, институту или сообществу. Модель, более совершенная в научном отношении, «ipso facto»* не определяет более подходящий критерий и в определенной степени ограничена в объяснении научных конструктов. Очевидно, что разработка тестов на основе классической теории будет продолжаться, но вместе с тем будут создаваться и новые модели IRT, распространяющиеся на изучение большего числа психологических феноменов.
В классической теории тестов различаются понятия «надежности» и «валидности». Тестовхяе результаты должны быть надежны, т.е. результаты первоначального и повторного тестировании должны согласовываться. Кроме того,
* ipso facto (лак) - сама по себе (прим. перев.).
результаты должны быть свободны (насколько это возможно) от ошибок оценивания. Наличие валидности - одно из требований, предъявляемых к полученным результатам. При этом надежность рассматривается как необходимое, но еще не достаточное условие валидности теста.
Понятие валидности предполагает, что полученные результаты относятся к чему-либо важному в практическом или теоретическом отношении. Выводы, сделанные на основе тестовых оценок, должны быть валидными. Наиболее часто говорят о двух видах валидности: прогностической (критериальной) и конструктной. Существуют также и другие виды валидности (см. гл. 3). Кроме того, валидность может быть определена и в случае квазиэкспериментов (Cook & Campbell, 1976, Cook & Shadish, 1994). Однако основным видом валидности все же является прогностическая валидность, под которой понимается возможность предсказывать по тестовому результату нечто существенное о поведении в будущем, а также возможность более глубокого понимания того или иного психологического свойства или качества.
Представленные типы валидности обсуждаются в каждом справочнике и сопровождаются описанием методов анализа валидности теста. Факторный анализ более подходит для определения конструктной валидизации, а уравнения линейной регрессии используются для анализа прогностической валидности. Те или иные характеристики (успеваемость, эффективность терапии) могут быть предсказаны на основе одного или нескольких показателей, пол-ученных при работе с интеллектуальными или личностными тестами. Такие техники обработки данных, как корреляционный, регрессионный, дисперсионный анализ, анализ частичных корреляций и дисперсий, служат для определения прогностической валидности теста.
Также часто описывается содержательная валидность. Предполагается, что все задачи и задания теста должны принадлежать специфической области (психических свойств, поведения и т.д.). Понятие содержательной валидности характеризует соответствие каждого задания теста измеряемой области. Содержательная валидность иногда рассматривается как часть надежности или «обобщаемость» (Cronbach, Gleser, Nanda & Rajaratnam, 1972). Однако при
выборе заданий для тестов достижений в конкретной предметной области важно также обращать внимание на правила включения заданий в тест.
В классической теории тестов надежность и валидность рассматриваются относительно независимо друг от друга. Но существует и другое понимание соотношения этих понятий. Современная теория тестов основывается на применении моделей. Параметры оцениваются внутри некоторой модели. Если задание не соответствует требованиям модели, то в рамках этой модели оно признается невалидным. Конструктная валидизации представляет собой часть проверки самой модели. Эта валидизации относится главным образом к проверке существования одномерной латентной исследуемой черты с известными шкальными характеристиками. Шкальные оценки, несомненно, могут быть использованы для определения соответствующих критериев, и возможна их корреляция с показателями других конструктов для сбора информации о конвергентной и дивергентной валидности конструкта.
Психодиагностика аналогична языку, описываемому как единство четырех компонентов, представленных на трех уровнях. Первый компонент, теория тестов, аналогичен синтаксису, грамматике языка. Порождающая (генеративная) грамматика - это, с одной стороны, остроумная модель, с другой - система, подчиняющаяся правилам. С помощью этих правил на основе простых утвердительных предложений строятся сложные. При этом, однако, данная модель оставляет в стороне описание того, как организован процесс коммуникации (что передается и что воспринимается), и с какими целями он осуществляется. Для понимания этого требуются дополнительные знания. То же можно сказать и о теории тестов: она является необходимой в психодиагностике, но она не способна объяснить, что психодиагност делает и каковы его цели.
1.3.2. Психологические теории и психологические конструкты
Психодиагностика - это всегда диагностика чего-то конкретного: личностных характеристик, поведения, мышления, эмоций. Тесты предназначены оценивать индивидуальные различия. Существует несколько концепций
индивидуальных различий, каждая из которых имеет свои отличительные особенности. Если признается, что психодиагностика не ограничивается только оценкой индивидуальных различий, то тогда и другие теории приобретают существенное значение для психодиагностики. Примером является оценка различий процессов психического развития и различий в социальном окружении. Хотя оценка индивидуальных различий не является непременным атрибутом психодиагностики, тем не менее существуют определенные традиции исследования в этой области. Психодиагностика начиналась с оценки различий интеллекта. Основной задачей тестов было «определение наследственной передачи гениальности» (Gallon) или отбор детей для обучения (Binet, Simon). Измерение коэффициента интеллектуальности получило теоретическое осмысление и прак-тическую разработку в трудах Спирмена (Великобритания) и Терстоуна (США). Раймонд Б.Кеттел сделал подобное для оценки личностных характеристик. Психодиагностика становится неразрывно связанной с теориями и представлениями об индивидуальных различиях в достижениях (оценка предельных возможностей) и формах поведения (уровень типичного функционирования). Эта традиция продолжает оставаться эффективной и сегодня. В учебных пособиях по психодиагностике гораздо реже оцениваются различия в социальном окружении по сравнению с рассмотрением особенностей самих процессов развития. Для этого не существует каких-либо разумных объяснений. С одной стороны, диагностика не ограничивается определенными теориями и понятиями. С другой стороны, она нуждается в теориях, поскольку именно в них определяется диагностируемое содержание (т.е. «что» диагностируется). Так, например, интеллект может рассматриваться и как общая характеристика, и как основание для множества независимых друг от друга способностей. Если психодиагностика пытается «уйти» от той или иной теории, то тогда основой психодиагностического процесса становятся представления здравого смысла. В исследованиях применяются различные способы анализа данных, и общая логика исследований определяет выбор той или иной математической модели и определяет структуру используемых психологических понятий. Такие методы математической статисти-
ки, как дисперсионный анализ, регрессионный анализ, факторный анализ, подсчет корреляций предполагают существование линейных зависимостей. В случае некорректного применения этих методов они «привносят» свою структуру в полученные данные и используемые конструкты.
Представления о различиях в социальном окружении и о развитии личности почти не оказали влияния на психодиагностику. В учебных пособиях (см., например, Murphy & Davidshofer, 1988) рассматривается классическая теория тестов и обсуждаются соответствующие методы статистической обработки, описываются известные тесты, рассматриваются вопросы использования психодиагностики в практике: в психологии управления, при отборе персонала, при оценке психологических характеристик человека.
Теории индивидуальных различий (а также представления о различиях между социальным окружением и о психическом развитии) аналогичны изучению семантики языка. Это изучение и сущности, и содержания, и значения. Значения структурируются определенным образом (подобно психологическим конструктам), например, по сходству или контрасту (аналогия, конвергенция, дивергенция).
1.3.3. Психологические тесты и другие методические средства
Третий компонент предложенной схемы - тесты, процедуры и методические средства, с помощью которых происходит сбор информации о характеристиках личности. Дрене и Сийтсма (1990, стр. 31) дают следующее определение тестам: «Психологический тест рассматривается как классификация согласно определенной системе или как процедура измерения, которая позволяет вынести определенное суждение об одной или нескольких эмпирически выделенных или теоретически обоснованных характеристиках конкретной стороны поведения человека (за рамками тестовой ситуации). При этом рассматривается реакция респондентов на определенное число тщательно подобранных стимулов, а полученные ответы сравниваются с тестовыми нормами».
Диагностике необходимы тесты и методики для сбора надежной, точной и валидной информации об особенностях
и характерных чертах личности, о мышлении, эмоциях и поведении человека. Помимо разработки тестовых процедур в этот компонент входят также следующие вопросы: как создаются тесты, как формулируются и отбираются задания, как протекает процесс тестирования, каковы требования к условиям проведения тестирования, как учитываются ошибки измерения, как подсчитываются и интерпретируются тестовые результаты.
В процессе разработки тестов различаются рациональная и эмпирическая стратегии. Применение рациональной стратегии начинается с определения основных понятий (например, понятия интеллекта, экстраверсии), и в соответствии с этими представлениями формулируются задания теста. Примером такой стратегии может служить концепция аспектного анализа (the facet theory) Гуттмана (1957, 1968, 1978). Сначала определяются различные аспекты основных конструктов, затем подбираются задачи и задания таким образом, чтобы был учтен каждый из этих аспектов. Вторая стратегия состоит в том, что задания подбираются на эмпирической основе. Например, если исследователь попытается создать тест профессиональных интересов, который бы позволял дифференцировать медиков от инженеров, то процедура должна быть такой. Обе группы респондентов должны ответить на все задания теста, и те пункты, в ответах на которые обнаружены статистически значимые различия, входят в окончательный вариант теста. Если, например, между группами существуют различия в ответах на утверждение «Я люблю ловить рыбу», то это утверждение становится элементом теста. Основным положением этой книги является то, что тест связан с концептуальной или таксономической теорией, определяющей эти характеристики.
Назначение теста обычно определено в инструкции по его применению. Тест должен быть стандартизирован для того, чтобы с его помощью можно было оценить различия между людьми, а не между условиями тестирования. Существуют, однако, отклонения от стандартизации в процедурах, называемых «тестированием границ возможностей» (testing the limits) и «тесты оценки потенциальных возможностей в обучении» (learning potential tests). В этих условиях респонденту оказывается помощь в процессе
тестирования и затем оценивается влияние такой процедуры на результат. Подсчет баллов за ответы на задания объективен, т.е. осуществляется в соответствии со стандартной процедурой. Интерпретация полученных результатов также строго определена и осуществляется на основе тестовых норм.
Третий компонент психодиагностики - психологические тесты, инструменты, процедуры - содержит определенные задания, которые являются наименьшими единицами психодиагностики и в этом смысле задания аналогичны фонемам языка. Число возможных сочетаний фонем ограничено. Лишь определенные фонематические структуры могут образовывать слова и предложения, обеспечивающие доведение информации до слушателя. Также и тестовые задания: лишь в определенном сочетании друг с другом они могут стать эффективным средством оценки соответствующего конструкта.
Основные вопросы: Тест как инструмент измерения. Основные теории тестирования. Функции, возможности и ограничения тестирования. Применение тестов в оценке персонала. Преимущества и недостатки использования тестов. Формы и виды тестовых заданий. Технология построения задания. Оценка качества теста. Достоверность и валидность. Программное обеспечение для разработки тестов. 2


Тест как инструмент измерения Основные понятия в тестологии: измерение, тест, содержание и форма заданий, надежность и валидность результатов измерения. Кроме того, в тестологии используются такие понятия статистической науки, как выборочная и генеральная совокупность, средние показатели, вариация, корреляция, регрессия и др. 4


Тестовое задание - это дидактически и технологически эффективная единица контрольного материала, часть теста, которая отвечает требованиям предметной чистоты содержания (или одномерности), содержательной и логической правильности, правильности формы, приемлемости геометрического образа задания. 6


Традиционный тест представляет собой стандартизованный метод диагностики уровня и структуры подготовленности. В таком тесте все испытуемые отвечают на одни и те же задания, в одинаковое время, в одинаковых условиях и с одинаковыми правилами оценивания ответов. Для достижения цели тестирования можно создать бесчисленное количество тестов, и все они могут соответствовать достижению поставленной задаче. 8

Профессиограмма (от лат. Professio специальность + Gramma запись) система признаков, описывающих ту или иную профессию, а также включающая в себя перечень норм и требований, предъявляемых этой профессией или специальностью к работнику. В частности, профессиограмма может включать в себя перечень психологических характеристик, которым должны соответствовать представители конкретных профессиональных групп. 9

Основные теории тестирования Первые научные труды по теории тестов появилась в начале ХХ века, на стыке психологии, социологии, педагогики и других, так называемых поведенческих наук. Зарубежные психологи называют эту науку психометрикой (Psychometrika), а педагоги - педагогическим измерением (Educational measurement). Незамутненная идеологией и политикой, интерпретация названия « тестология » проста и прозрачна: наука о тестах. 10

Первый этап - предыстория - с древности до конца XIX века, когда были распространены донаучные формы контроля знаний и способностей; второй период, классический, продолжался с начала 20- х до конца 60- х годов, в течение которого создавалась классическая теория тестов; третий период - технологический - начавшийся с 70- х годов - время разработки методов адаптивного тестирования и обучения, методологию эффективной разработки тестов и тестовых заданий для параметрической оценки испытуемых по измеряемому латентному качеству. 11

Функции, возможности и ограничения тестирования Применяемые при отборе тесты предназначены для того, чтобы получить психологический портрет кандидата, оценить его способности, а также профессиональные знания и навыки. Тесты позволяют сравнивать кандидатов между собой или с эталонами, то есть идеальным кандидатом. Тесты используются для измерения качеств человека, необходимых для результативного выполнения работы. Некоторые тесты устроены таким образом, чтобы работодатель сам администрировал тестирование и подсчитывал результаты. Другие требуют услуг опытных консультантов, чтобы обеспечить их правильное применение. 12

Ограничения использования тестов связаны - с их дорогим администрированием; - с пригодностью для оценки способностей человека; - тесты более успешны для прогнозирования успешности в работе, которая содержит короткие по времени профессиональные задачи, и не очень удобны в случаях, когда задачи, решаемые на работе, занимают несколько дней или недель. 13




2. Используемая терминология должна быть подобрана в расчете на конкретную целевую аудиторию. Также нужно исключить излишние статьи или статьи, включающие два или более вопроса, так как они иногда сбивают с толку респондента и затрудняют интерпретацию. 17

3. Чтобы удовлетворить всем этим требованиям, следует просмотреть весь банк вопросов статью за статьей и проанализировать, какой цели служит каждая из них. Например, если тест разрабатывается для измерения аналитических способностей стажеров - бухгалтеров, стоит подумать, что в этом случае означает понятие « аналитические способности ». 18


5. Когда вопросы и форматы подсчета результатов выбраны, их нужно преобразовать в удобный для пользователя формат, с ясно написанными инструкциями и вопросами - примерами; так, чтобы выполняющие тест кандидаты полностью понимали, что от них требуется. 20

6. Очень часто на этом этапе разработки в тест включают больше вопросов, чем нужно. По некоторым оценкам, в три раза больше, чем останется в окончательном тесте или системе измерения. Тогда исходной мерой станет проверка разрабатываемого теста на относительно широкой выборке из числа существующих работников, чтобы убедиться в том, что все вопросы легко понятны. 21

7. Тесты на определение знаний обычно начинаются с простых вопросов, постепенно усложняющихся к концу. Когда тесты предназначаются для измерения социальных установок и личностных характеристик, возможно, будет полезным чередовать негативно и позитивно сформулированные статьи, чтобы избежать непродуманных ответов. 22

8. Последний этап представляет собой применение теста на широкой репрезентативной выборке, чтобы установить нормы выполнения, достоверности и валидности еще до начала его использования в качестве инструмента отбора. Кроме того, необходимо определить справедливость теста, чтобы убедиться, что он не дискриминирует никакие подгруппы населения (например, этническим отличиям). 23

Оценка качества теста Чтобы методы отбора были достаточно результативными они должны быть надежными, валидными и достоверными. Достоверность метода отбора характеризуется его неподверженностью систематическим ошибкам при измерении, то есть его состоятельности при разных условиях. 24

На практике достоверность при вынесении суждений достигается сравнением результатов двух и более аналогичных тестов, проведенных в разные дни. Другой путь повышения достоверности – сравнение результатов нескольких альтернативных методов отбора (например, тест и беседа). Если результаты сходны или одинаковы, можно считать их верными. 25

Надежность означает, что проведенные замеры дадут тот же результат, что и предыдущие, то есть на результаты оценки не влияют сторонние факторы. Валидность означает, что этот метод измеряет именно то, для чего он предназначен. Максимально возможная точность информации, получаемой специально разработанными методиками в научных исследованиях, ограничена техническими факторами и не превышает 0,8. 26

В практике отбора персонала отмечается, что надежность различных методов оценки располагается в интервалах: 0,1 – 0,2 – традиционное интервью; 0,2 – 0,3 – рекомендации; 0,3 – 0,5 – профессиональные тесты; 0,5 – 0,6 – структурированное интервью, интервью по компетенциям; 0,5 – 0,7 – когнитивные и личностные тесты; 0,6 – 0,7 – компетентностный подход (ассессмент - центр). 27

Под обоснованностью понимается то, с какой степенью точности данный результат, метод или критерий « предсказывает » будущую результативность тестируемого человека. Обоснованность методов относится к выводам, сделанным на основе той или иной процедуры, а не к самой процедуре. То есть метод отбора может сам по себе быть достоверным, но не соответствовать конкретной задаче: измерять не то, что требуется в данном случае. 28

Программное обеспечение для разработки тестов В отечественной практике представлены различные комплексные программы с модулем « Психодиагностика », например, программа «1 С: Зарплата и Управление Персоналом 8.0» с модулем « Психодиагностика », разработанная совместно с группой преподавателей кафедры психологии личности и общей психологии факультета психологии МГУ им. М. В. Ломоносова под руководством д. псих. наук, проф. А. Н. Гусева. Учебный тренажер для разработки систем оценки персонала и адаптации тестовых методик факультета психологии ТГУ, разработанный также на базе «1 С: Предприятие 8.2» фирмой Персонал Софт. 29

Литература: Отбор и найм персонала: технологии тестирования и оценки / Доминик Купер, Иван Т. Робертсон, Гордон Тинлайн. – М., изд - во « Вершина, – 156 с. Психологическое обеспечение профессиональной деятельности: теория и практика / Под ред. Проф. Г. С. Никифорова. – СПб.: Речь, – 816 с. 30

Основные понятия теории тестов.
Измерение или испытание, проводимое с целью определения состояния или способностей спортсмена, называется тестом. Любой тест включает в себя измерение. Но не всякое изменение служит тестом. Процедура измерений или испытаний называется тестированием.
Тест, в основе которого лежат двигательные задания, называется двигательным. Существует три группы двигательных тестов:
- 1. Контрольные упражнения, выполняя которые спортсмен получает задание показать максимальный результат.
- 2. Стандартные функциональные пробы, в ходе которых задание, одинаковое для всех, дозируется либо по величине выполненной работы, либо по величине физиологических сдвигов.
- 3. Максимальные функциональные пробы, в ходе которых спортсмен должен показать максимальный результат.
Высококачественное тестирование предполагает знание теории измерений.
Основные понятия теории измерений.
Измерение--это выявление соответствия между изучаемым явлением с одной стороны, и числами--с другой.
Основы теории измерений составляют три понятия: шкалы измерений, единицы измерений и точность измерений.
Шкалы измерений.
Шкала измерения -- это закон, по которому численное значение присваивается измеряемому результату по мере его возрастания или убывания. Рассмотрим некоторые из применяемых в спорте шкал.
Шкала наименований (номинальная шкала).
Это самая простая из всех шкал. В ней числа выполняют роль ярлыков и служат для обнаружения и различения изучаемых объектов (например, нумерация игроков футбольной команды). Числа, составляющие шкалу наименований, разрешается менять метами. В этой шкале нет отношений типа «больше-- меньше», поэтому некоторые полагают, что применение шкалы наименований не стоит считать измерением. При использовании шкалы, наименований могут проводиться только некоторые математические операции. Например, ее числа нельзя складывать или вычитать, но можно подсчитывать, сколько раз (как часто) встречается то или иное число.
Шкала порядка.
Есть виды спорта, где результат спортсмена определяется только местом, занятым на соревнованиях (например, единоборства). После таких соревнований ясно, кто из спортсменов сильнее, а кто слабее. Но насколько сильнее или слабее, сказать нельзя. Если три спортсмена заняли соответственно первое, второе и третье места, то каковы различие в их спортивном мастерстве, остается неясным: второй спортсмен может быть почти равен первому, а может быть слабее его и быть почти одинаковым с третьим. Места, занимаемые в шкале порядка, называются рангами, а сама шкала называется ранговой или неметрической. В такой шкале составляющие ее числа упорядочены по рангам (т.е. занимаемым местам), но интервалы между ними точно измерить нельзя. В отличие от шкалы наименований шкала порядка позволяет не только установить факт равенства или неравенства измеряемых объектов, но и определить характер неравенства в виде суждений: «больше -- меньше», «лучше--хуже» и т.п.
С помощью шкал порядка можно измерять качественные, не имеющие строгой количественной меры, показатели. Особенно широко эти шкалы используются в гуманитарных науках: педагогике, психологии, социологии.
К рангам шкалы порядка можно применять большее число математических операций, чем к числам шкалы наименований.
Шкала интервалов.
Это шкала, в которой числа не только упорядочены по рангам, но и разделены определенными интервалами. Особенность, отличающая ее от описываемой дальше шкалы отношений, состоит в том, что нулевая точка выбирается произвольно. Примерами могут быть календарное время (начало летоисчисления в разных календарях устанавливалось по случайным причинам), суставной угол (угол в локтевом суставе при полном разгибании предплечья может приниматься равным либо нулю, либо 180°), температура, потенциальная энергия поднятого груза, потенциал электрического поля и др.
Результаты измерений по шкале интервалов можно обрабатывать всеми математическими методами, кроме вычисления отношений. Данные шкалы интервалов дают ответ на вопрос: «на сколько больше», но не позволяют утверждать, что одно значение измеренной величины во столько-то раз больше или меньше другого. Например, если температура повысилась с 10 до 20 С, то нельзя сказать, что стало в два раза теплее.
Шкала отношений.
Эта шкала отличается от шкалы интервалов только тем, что в ней строго определено положение нулевой точки. Благодаря этому шкала отношений не накладывает никаких ограничений на математический аппарат, используемый для обработки результатов наблюдений.
В спорте по шкале отношений измеряют расстояние, силу, скорость и десятки других переменных. По шкале отношений измеряют и те величины, которые образуются как разности чисел, отсчитанных по шкале интервалов. Так, календарное время отсчитывается по шкале интервалов, а интервалы времени -- по шкале отношений. При использовании шкалы отношений (и только в этом случае!) измерение какой-либо величины сводится к экспериментальному определению отношения этой величины к другой подобной, принятой за единицу. Измеряя длину прыжка, мы узнаем, во сколько раз эта длина больше длины другого тела, принятого за единицу длины (метровой линейки в частном случае); взвешивая штангу, определяем отношение ее массы к массе другого тела -- единичной гири «килограмма» и т.п. Если ограничиться только применением шкал отношений, то можно дать другое (более узкое, частное) определение измерению: измерить какую-либо величину -- значит найти опытным путем ее отношение к соответствующей единице измерения.
Единицы измерений.
Чтобы результаты разных измерений можно было сравнить друг с другом, они должны быть выражены в одних и тех же единицах. В 1960 году на Международной генеральной конференции по мерам и весам была принята Международная система единиц, получившая сокращенное название СИ (от начальных букв слов System International). В настоящее время установлено предпочтительное применение этой системы во всех областях науки и техники, в народном хозяйстве, а также при преподавании.
СИ в настоящее время включает семь независимых друг от друга основных единиц (см. таблицу 2.1.)
Таблица 1.1.
Из указанных основных единиц в качестве производных выводят единицы остальных физических величин. Производные единицы определяются на основе формул, связывающих между собой физические величины. Например, единица длины (метр) и единица времени (секунда) -- основные единицы, а единица скорости (метр в секунду) -- производная.
Кроме основных, в СИ выделены две дополнительные единицы: радиан-- единица плоского угла и стерадиан--единица телесного угла (угла в пространстве).
Точность измерений.
Никакое измерение не может быть выполнено абсолютно точно. Результат измерения неизбежно содержит погрешность, величина которой тем меньше, чем точнее метод измерения и измерительный прибор. Например, с помощью обычной линейки с миллиметровыми делениями нельзя измерить длину с точностью до 0,01 мм.
Основная и дополнительная погрешность.
Основная погрешность -- это погрешность метода измерения или измерительного прибора, которая имеет место в нормальных условиях их применения.
Дополнительная погрешность--это погрешность измерительного прибора, вызванная отклонением условий его работы от нормальных. Понятно, что приборы, предназначенный для работы при комнатной температуре будет давать не точные показания, если пользоваться им летом на стадионе под палящим солнцем или зимой на морозе. Погрешности измерения могут возникать в том случае, когда напряжение электрической сети или батарейного источника питания ниже нормы или непостоянно по величине.
Абсолютная и относительная погрешности.
Величина E = А--Ао, равное разности между показанием измерительного прибора (А) и истинным значением измеряемой величины (Ао), называется абсолютной погрешностью измерения. Она измеряется в тех же единицах, что и сама измеряемая величина.
На практике часто удобно пользоваться не абсолютной, а относительной погрешностью. Относительная погрешность измерения бывает двух видов-- действительной и приведенной. Действительной относительной погрешностью называется отношение абсолютной погрешности к истинному значению измеряемой величины:
А Д =---------* 100%
Приведенная относительная погрешность--это отношение абсолютной погрешности к максимально возможному значению измеряемой величины:
Ап =----------* 100%
Систематическая и случайная погрешности.
Систематической называется погрешность, величина которой не изменяется от измерения к измерению. В силу этой своей особенности систематическая погрешность часто может быть предсказана заранее или, в крайнем случае, обнаружена и устранена по окончании процесса измерения.
Способ устранения систематической погрешности зависит в первую очередь от ее природы. Систематические погрешности измерения можно разделить на три группы:
погрешности известного происхождения и известной величины;
погрешности известного происхождения, но неизвестной величины;
погрешности неизвестного происхождения и неизвестной величины. Самые безобидные -- погрешности первой группы. Они легко устраняются
путем введения соответствующих поправок в результат измерения.
Ко второй группе относятся, прежде всего, погрешности, связанные с несовершенством метода измерения и измерительной аппаратуры. Например, погрешность измерения физической работоспособности с помощью маски для забора выдыхаемого воздуха: маска затрудняет дыхание, и спортсмен закономерно демонстрирует физическую работоспособность, заниженную по сравнению с истинной, измеряемой без маски. Величину этой погрешности нельзя предсказать заранее: она зависит от индивидуальных способностей спортсмена и его самочувствия в момент исследования.
Другой пример систематической погрешности этой группы-- погрешность, связанная с несовершенством аппаратуры, когда измерительный прибор заведомо завышает или занижает истинное значение измеряемой величины, но величина погрешности неизвестна.
Погрешности третьей группы наиболее опасны, их появление бывает связано как с несовершенством метода измерения, так и с особенностями объекта измерения -- спортсмена.
Случайные погрешности возникают под действием разнообразных факторов, которые ни предсказать заранее, ни точно учесть не удается. Случайные погрешности принципиально не устранимы. Однако, воспользовавшись методами математической статистики, можно оценить величину случайной погрешности и учесть ее при интерпретации результатов измерения. Без статистической обработки результаты измерений не могут считаться достоверными.
 История древнего китая доклад, сообщение Где жили древние люди китая
История древнего китая доклад, сообщение Где жили древние люди китая Уроки химии Йодом смочим мы обильно, чтобы было все стерильно
Уроки химии Йодом смочим мы обильно, чтобы было все стерильно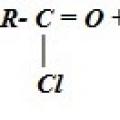 Химические свойства. Получение. Получение карбоновых кислот Получение карбоновых кислот окислением углеводородов
Химические свойства. Получение. Получение карбоновых кислот Получение карбоновых кислот окислением углеводородов