Nacrtajte graf stanja za Markovljev lanac. Homogeni Markovljevi lanci
1. matrica R2 lančani prelaz iz stanja i u stanje j dva
korak;
2. raspodjela vjerovatnoće po stanjima u ovom trenutku t=2;
3. vjerovatnoća da u ovom trenutku t=1 stanje kola će biti A2;
4. stacionarna distribucija.
Rješenje. Za diskretni Markovljev lanac u slučaju njegove homogenosti, relacija
gdje je P1 matrica vjerovatnoća tranzicije u jednom koraku;
Pn - matrica prelaznih verovatnoća za n koraka;
1. Pronađite prijelaznu matricu P2 u dva koraka
Neka je distribucija vjerovatnoće po stanjima uključena S-ti korak je određen vektorom
.
Poznavanje matrice PN tranzicije u n koraka, moguće je odrediti distribuciju vjerovatnoće po stanjima na (S+n)-th korak ![]() . (5)
. (5)
2. Naći distribuciju vjerovatnoće po stanjima sistema u ovom trenutku t=2. Stavljamo (5) S=0 i n=2. Onda ![]() .
.
Dobijamo .
3. Naći distribuciju vjerovatnoće po stanjima sistema u ovom trenutku t=1.
Stavljamo (5) s=0 i n=1, onda .
Kako možete vidjeti da je vjerovatnoća da u ovom trenutku t=1 stanje kola će biti A2, je jednako p2(1)=0,69.
Raspodjela vjerovatnoće po stanjima naziva se stacionarnom ako se ne mijenja od koraka do koraka, tj
Tada iz relacije (5) at n=1 dobijamo
4. Pronađite stacionarnu distribuciju. Pošto =2 imamo =(p1; p2). Hajde da zapišemo sistem linearne jednačine(6) u koordinatnom obliku

Poslednji uslov se zove normalizacija. U sistemu (6) jedna jednačina je uvijek linearna kombinacija drugih. Stoga se može izbrisati. Hajde da zajednički rešimo prvu jednačinu sistema i onu normalizaciju. Imamo 0.6 p1=0,3p2, to je p2=2p1. Onda p1+2p1=1 ili , odnosno . Dakle, .
odgovor:
1) matrica prelaza u dva koraka za dati Markovljev lanac ima oblik ![]() ;
;
2) distribucija vjerovatnoće po stanjima u ovom trenutku t=2 jednako ![]() ;
;
3) vjerovatnoća da u ovom trenutku t=1 stanje kola će biti A2, je jednako p2(t)=0,69;
4) stacionarna distribucija ima oblik
Zadana matrica  intenziteti prelaza kontinuiranog Markovljevog lanca. Sastaviti označeni graf stanja koji odgovara matrici Λ; izraditi sistem diferencijalne jednadžbe Kolmogorov za vjerovatnoće stanja; pronaći graničnu distribuciju vjerovatnoće. Rješenje. Homogeni Markov lanac sa konačan broj države A1, A2,…A karakterizirana matricom intenziteta tranzicije
intenziteti prelaza kontinuiranog Markovljevog lanca. Sastaviti označeni graf stanja koji odgovara matrici Λ; izraditi sistem diferencijalne jednadžbe Kolmogorov za vjerovatnoće stanja; pronaći graničnu distribuciju vjerovatnoće. Rješenje. Homogeni Markov lanac sa konačan broj države A1, A2,…A karakterizirana matricom intenziteta tranzicije  ,
,
Gdje ![]() - intenzitet tranzicije Markovljevog lanca iz stanja AI u stanje Aj; rij(Δt)- vjerovatnoća tranzicije Ai→Aj po vremenskom intervalu Δ
t.
- intenzitet tranzicije Markovljevog lanca iz stanja AI u stanje Aj; rij(Δt)- vjerovatnoća tranzicije Ai→Aj po vremenskom intervalu Δ
t.
Pogodno je specificirati prijelaze sistema iz stanja u stanje pomoću označenog grafa stanja, na kojem su označeni lukovi koji odgovaraju intenzitetima λ
ij>0. Sastavite označeni graf stanja za zadata matrica intenziteta tranzicije 
Neka je vektor vjerovatnoće Rj(t),
j=1, 2,…,, sistem je u stanju Aj u momentu t.
Očigledno je da je 0≤ Rj(t)≤1 i . Zatim po pravilu diferencijacije vektorska funkcija skalarni argument dobijamo ![]() . Vjerovatnoće Rj(t) zadovoljavaju Kolmogorovljev sistem diferencijalnih jednadžbi (SDUK), koji u matričnom obliku ima oblik . (7)
. Vjerovatnoće Rj(t) zadovoljavaju Kolmogorovljev sistem diferencijalnih jednadžbi (SDUK), koji u matričnom obliku ima oblik . (7)
Ako je u početnom trenutku sistem bio u stanju Aj, onda SDUK treba riješiti pod početnim uslovima
Ri(0)=1, rj(0)=0, j≠i,j=1, 2,…,.
(8)
Skup SDUK (7) i početnih uslova (8) jedinstveno opisuje homogeni Markovljev lanac sa kontinuirano vrijeme i konačan broj stanja.
Hajde da sastavimo SDUK za dati Markovljev lanac. Pošto je =3, onda j=1, 2, 3.
Iz relacije (7) dobijamo  .
.
Stoga ćemo imati 
Poslednji uslov se zove normalizacija.
Raspodjela vjerovatnoće po stanjima se zove stacionarno, ako se ne mijenja tokom vremena, odnosno gdje Rj=konst, j=1,2,…,. Odavde ![]() .
.
Tada iz SDUK-a (7) dobijamo sistem za pronalaženje stacionarne distribucije ![]() (9)
(9)
Za ovaj problem iz SDUK-a ćemo imati 
Iz uslova normalizacije dobijamo 3p2+p2+p2=1 ili ![]() . Prema tome, granična raspodjela ima oblik .
. Prema tome, granična raspodjela ima oblik .
Imajte na umu da se ovaj rezultat može dobiti direktno iz označenog grafa stanja koristeći pravilo: za stacionarnu distribuciju, zbir proizvoda λ
jipi, j≠i, za strelice koje izlaze iz i stanje je jednako zbroju proizvoda λ
jipi, j≠i, za strelice uključene u i th state. stvarno, 
Očigledno je da je rezultirajući sistem ekvivalentan onom sastavljenom prema SDUK-u. Dakle, ima isto rješenje.
Odgovor: stacionarna raspodjela ima oblik .
Markovljev lanac je niz događaja u kojem svaki naredni događaj zavisi od prethodnog. U članku ćemo detaljnije analizirati ovaj koncept.
Markov lanac je uobičajen i prilično jednostavan način modeliranja slučajni događaji. Koristi se u raznim oblastima, od generisanja teksta do finansijskog modeliranja. po najviše poznati primjer je SubredditSimulator . IN ovaj slučaj Markov lanac se koristi za automatizaciju kreiranja sadržaja kroz subreddit.
Markovljev lanac je jasan i jednostavan za korištenje jer se može implementirati bez korištenja statističkih ili matematičkih koncepata. Markov lanac je idealan za proučavanje probabilističkog modeliranja i nauke o podacima.
Scenario
Zamislite da postoje samo dva vremenskim uvjetima: može biti sunčano ili oblačno. Uvijek možete tačno odrediti vrijeme u ovog trenutka. Garantovano vedro ili oblačno.
Sada želite da naučite kako da predvidite vreme za sutra. Intuitivno shvatate da se vreme ne može dramatično promeniti u jednom danu. Mnogi faktori utiču na to. Sutrašnje vrijeme direktno zavisi od trenutnog, itd. Dakle, da biste predvidjeli vrijeme, prikupljate podatke tokom nekoliko godina i dolazite do zaključka da je nakon oblačnog dana vjerovatnoća sunčanog dana 0,25. Logično je pretpostaviti da je vjerovatnoća dva oblačna dana zaredom 0,75, budući da imamo samo dva moguća vremenska uslova.

Sada možete predvidjeti vrijeme za nekoliko dana unaprijed na osnovu trenutnog vremena.
Ovaj primjer pokazuje ključni koncepti Markovski lanci. Markovljev lanac se sastoji od skupa prijelaza koji su definirani distribucijom vjerovatnoće, koji zauzvrat zadovoljavaju Markovljevo svojstvo.
Imajte na umu da u primjeru distribucija vjerovatnoće zavisi samo od prijelaza iz tekućeg dana u sljedeći. Ovo jedinstvena nekretnina Markov proces - to radi bez upotrebe memorije. Po pravilu, takav pristup nije u stanju da stvori sekvencu u kojoj bi se uočio bilo koji trend. Na primjer, dok je Markovljev lanac u stanju da simulira stil pisanja zasnovan na učestalosti riječi, nije u mogućnosti da kreira tekstove sa duboko značenje, jer može raditi samo s velikim tekstovima. To je razlog zašto Markovljev lanac ne može proizvesti sadržaj ovisan o kontekstu.
Model
Formalno, Markovljev lanac je probabilistički automat. Distribucija vjerovatnoće prijelaza se obično predstavlja kao matrica. Ako Markovljev lanac ima N mogućih stanja, tada će matrica izgledati kao N x N, u kojoj će unos (I, J) biti vjerovatnoća prijelaza iz stanja I u stanje J. Osim toga, takva matrica mora biti stohastička , to jest, redovi ili kolone treba da budu jedan. U takvoj matrici, svaki red će imati svoju distribuciju vjerovatnoće.

Opšti pogled na Markovljev lanac sa stanjima u obliku krugova i ivicama u obliku prijelaza.

Približna prijelazna matrica sa tri moguća stanja.
Markovljev lanac ima početni vektor stanja, predstavljen kao matrica N x 1. On opisuje distribuciju vjerovatnoće početka u svakom od N mogućih stanja. Unos I opisuje vjerovatnoću pokretanja lanca u stanju I.
Ove dvije strukture su dovoljne da predstavljaju Markovljev lanac.
Već smo raspravljali o tome kako dobiti vjerovatnoću prijelaza iz jednog stanja u drugo, ali šta je sa dobijanjem ove vjerovatnoće u nekoliko koraka? Da bismo to učinili, moramo odrediti vjerovatnoću prijelaza iz stanja I u stanje J u M koraka. Zapravo je vrlo jednostavno. Prijelazna matrica P može se odrediti izračunavanjem (I, J) podizanjem P na stepen M. Za male vrijednosti M, to se može uraditi ručno ponovljenim množenjem. Ali za velike vrijednosti M ako ste upoznati s linearnom algebrom, više efikasan način podizanje matrice na stepen će prvo dijagonalizirati tu matricu.
Markov lanac: zaključak
Sada, znajući šta je Markovljev lanac, možete ga lako implementirati u jednom od programskih jezika. Jednostavni Markovljevi lanci su osnova za učenje više složene metode modeliranje.
Sva moguća stanja sistema u homogenom Markovljevom lancu, i stohastička matrica koja definiše ovaj lanac, sastavljena od prelaznih verovatnoća ![]() (Vidi stranicu 381).
(Vidi stranicu 381).
Označimo vjerovatnoćom da je sistem u nekom stanju ako je poznato da je u to vrijeme sistem bio u stanju (,). Očigledno, ![]() . Koristeći teoreme o sabiranju i množenju vjerovatnoća, lako možemo pronaći:
. Koristeći teoreme o sabiranju i množenju vjerovatnoća, lako možemo pronaći:
![]()
![]()
ili u matričnom zapisu
![]()
Dakle, dajući sukcesivno vrijednosti , dobijamo važnu formulu
Ako postoje granice
![]()
ili u matričnom zapisu
![]()
zatim količine ![]() nazivaju se granične ili konačne tranzicijske vjerovatnoće.
nazivaju se granične ili konačne tranzicijske vjerovatnoće.
Da bismo saznali u kojim slučajevima postoje granične prijelazne vjerovatnoće i da bismo izveli odgovarajuće formule, uvodimo sljedeću terminologiju.
Stohastičku matricu i odgovarajući homogeni Markovljev lanac ćemo nazvati regularnim ako matrica nema karakteristične brojeve različite od jedinice i jednake po modulu jedinici, i regularne ako je dodatno jedinica jednostavan korijen karakteristična jednačina matrice.
Regularnu matricu karakteriše činjenica da su u svom normalnom obliku (69) (str. 373) matrice primitivne. Za redovnu matricu, dodatno .
Osim toga, homogeni Markovljev lanac se naziva nerazložljivim, razložljivim, acikličnim, cikličnim, ako je za ovaj lanac stohastička matrica nerazložljiva, razloživa, primitivna, iprimitivna.
Pošto je primitivna stohastička matrica posebna vrsta regularne matrice, aciklički Markovljev lanac je posebna vrsta regularnog lanca.
Pokazaćemo da granične prelazne verovatnoće postoje samo za regularne homogene Markovljeve lance.
Zaista, neka je minimalni polinom regularne matrice . Onda
Prema teoremi 10, možemo to pretpostaviti
Na osnovu formule (24) Ch. V (stranica 113)
 (96)
(96)
Gdje ![]() je redukovana pridružena matrica i
je redukovana pridružena matrica i

Ako je regularna matrica, onda
i stoga na desnoj strani formule (96) svi članovi, osim prvog, teže nuli kao . Stoga, za regularnu matricu postoji matrica sastavljena od graničnih prijelaznih vjerovatnoća, i
Očigledno je suprotno. Ako postoji praznina
onda matrica ne može imati karakterističan broj, za koje , i , od tada granica ne bi postojala [Ista granica mora postojati zbog postojanja granice (97").]
Dokazali smo da za ispravan (i jedini ispravan) homogeni Markovljev lanac postoji matrica . Ova matrica je određena formulom (97).
Pokažimo kako se matrica može izraziti u terminima karakterističnog polinoma
i pripadajuću matricu ![]() .
.
Iz identiteta
na osnovu (95), (95") i (98) slijedi:

Stoga se formula (97) može zamijeniti formulom
 (97)
(97)
Za regularni Markovljev lanac, budući da je poseban tip regularnog lanca, matrica postoji i određena je bilo kojom od formula (97), (97"). U ovom slučaju formula (97") također ima oblik
2. Razmotrite regularni lanac opšteg tipa (nepravilan). Odgovarajuću matricu zapisujemo u normalnom obliku
 (100)
(100)
gdje su primitivne stohastičke matrice, a nerazložljive matrice imaju maksimalne karakteristične brojeve . Pretpostavljam
 ,
, 
napišite u formularu

 (101)
(101)

Ali ![]() , pošto su svi karakteristični brojevi matrice apsolutne vrijednosti manji od jedinice. Zbog toga
, pošto su svi karakteristični brojevi matrice apsolutne vrijednosti manji od jedinice. Zbog toga
 (102)
(102)
Pošto su primitivne stohastičke matrice, onda su matrice prema formulama (99) i (35) (str. 362) pozitivne
![]()
i u svakom stupcu bilo koje od ovih matrica, svi elementi su međusobno jednaki:
![]() .
.
Imajte na umu da normalni oblik (100) stohastičke matrice odgovara podjeli stanja sistema u grupe:
Svaka grupa u (104) odgovara svojoj grupi nizova u (101). Prema terminologiji L. N. Kolmogorova, stanja sistema koja su uključena nazivaju se suštinskim, a stanja uključena u preostale grupe nazivaju se nebitnim.
Iz oblika (101) matrice slijedi da je za bilo koji konačan broj koraka (od trenutka do trenutka) moguć samo prijelaz sistema a) iz suštinskog stanja u bitno stanje iste grupe, b ) iz beznačajnog stanja u suštinsko stanje i c) iz beznačajnog stanja u nebitno stanje iste ili ranije grupe.
Iz oblika (102) matrice proizilazi da u procesu kada je prijelaz moguć samo iz bilo kojeg stanja u bitno stanje, odnosno vjerovatnoća prijelaza u bilo koje beznačajno stanje teži nuli sa brojem koraka. Stoga se bitna stanja ponekad nazivaju i graničnim stanjima.
3. Iz formule (97) slijedi:
![]() .
.
Ovo pokazuje da je svaki stupac matrice svojstveni vektor stohastičke matrice za karakteristični broj.
Za regularnu matricu, broj 1 je jednostavan korijen karakteristične jednadžbe, a ovaj broj odgovara samo jednom (do skalarnog faktora) svojstvenom vektoru matrice. Dakle, u bilo kojoj koloni matrice, svi elementi su jednaki istom nenegativnom broju:
Dakle, u redovnom lancu, granične prelazne verovatnoće zavise od početnog stanja.
Obrnuto, ako u nekom regularnom homogenom Markovljevom lancu pojedinačne prelazne vjerovatnoće ne zavise od početnog stanja, tj. vrijede formule (104), onda je u šemi (102) za matricu to obavezno . Ali onda je i lanac redovan.
Jer aciklički lanac, koji je poseban slučaj regularnog lanca, je primitivna matrica. Prema tome, za neke (vidjeti teoremu 8 na str. 377). Ali onda i ![]() .
.
Obrnuto, iz toga slijedi da za neke , a to, prema teoremi 8, znači da je matrica primitivna i da je, prema tome, dati homogeni Markovljev lanac acikličan.
Dobijene rezultate formuliramo u obliku sljedeće teoreme:
Teorema 11. 1. Da bi sve granične prelazne verovatnoće postojale u homogenom Markovljevom lancu, neophodno je i dovoljno da lanac bude pravilan. U ovom slučaju, matrica , sastavljena od graničnih prijelaznih vjerovatnoća, određena je formulom (95) ili (98).
2. Da bi granične prelazne verovatnoće bile nezavisne od početnog stanja u pravilnom homogenom Markovom lancu, neophodno je i dovoljno da lanac bude pravilan. U ovom slučaju, matrica je određena formulom (99).
3. Da bi sve granične prelazne verovatnoće bile različite od nule u regularnom homogenom Markovom lancu, neophodno je i dovoljno da lanac bude acikličan.
4. Hajde da uvedemo kolone apsolutnih vjerovatnoća
![]() (105)
(105)
gdje je vjerovatnoća da je sistem u stanju (,) u ovom trenutku. Koristeći teoreme sabiranja i množenja vjerovatnoća, nalazimo:
![]() (,),
(,),
ili u matričnom zapisu
gdje je transponirana matrica za matricu .
Sve apsolutne vjerovatnoće (105) određuju se iz formule (106) ako su poznate početne vjerovatnoće i matrica prijelaznih vjerovatnoća
Uvedemo u razmatranje granične apsolutne vjerovatnoće
![]()
Prelaskom u oba dijela jednakosti (106) do granice na , dobivamo:
Imajte na umu da postojanje matrice graničnih prijelaznih vjerovatnoća implicira postojanje graničnih apsolutnih vjerovatnoća ![]() za bilo koje početne vjerovatnoće
za bilo koje početne vjerovatnoće ![]() i obrnuto.
i obrnuto.
Iz formule (107) i iz oblika (102) matrice proizilazi da su granične apsolutne vjerovatnoće koje odgovaraju beznačajnim stanjima jednake nuli.
Množenje obje strane matrične jednakosti
desno, na osnovu (107) dobijamo:
tj. stupac graničnih apsolutnih vjerovatnoća je svojstveni vektor matrice za karakteristični broj .
Ako dati lanac Markov regular, tada je jednostavan korijen karakteristične jednadžbe matrice. U ovom slučaju, stupac graničnih apsolutnih vjerovatnoća je jedinstveno određen iz (108) (pošto i ).
Neka je dat regularni Markovljev lanac. Tada iz (104) i iz (107) slijedi:
![]() (109)
(109)
U ovom slučaju, granične apsolutne vjerovatnoće ne zavise od početnih vjerovatnoća.
Suprotno tome, ne može ovisiti o prisutnosti formule (107) ako i samo ako su svi redovi matrice isti, tj.
![]() ,
,
i stoga je (prema teoremi 11) regularna matrica.
Ako je primitivna matrica, onda , i stoga zbog (109)
Obrnuto, ako sve i ne zavise od početnih vjerovatnoća, tada su u svakom stupcu matrice svi elementi isti i prema (109) , a to, prema teoremi 11, znači da je primitivna matrica, tj. lanac je acikličan.
Iz navedenog slijedi da se teorema 11 može formulirati na sljedeći način:
Teorema 11. 1. Da bi sve granične apsolutne vjerovatnoće postojale u homogenom Markovljevom lancu za bilo koje početne vjerovatnoće, potrebno je i dovoljno da lanac bude pravilan.
2. Da bi homogeni Markovljev lanac imao granične apsolutne vjerovatnoće za bilo koje početne vjerovatnoće i da ne bi zavisio od ovih početnih vjerovatnoća, potrebno je i dovoljno da lanac bude pravilan.
3. Da bi homogeni Markovljev lanac imao pozitivne granične apsolutne vjerovatnoće za bilo koje početne vjerovatnoće i da te granične vjerovatnoće ne bi zavise od početnih, potrebno je i dovoljno da lanac bude acikličan.
5. Razmotrimo sada homogeni Markovljev lanac opšti tip sa matricom vjerovatnoća tranzicije .
Uzmimo normalni oblik (69) matrice i označimo je indeksima imprimitivnosti matrica u (69). Neka biti najmanji zajednički višekratnik cijelih brojeva . Tada matrica nema karakteristične brojeve jednake po apsolutnoj vrijednosti jedinici, već različite od jedinice, tj. regularna je matrica; istovremeno - najmanji indikator, pri čemu - ispravna matrica. Broj nazivamo periodom datog homogenog Markovljevog lanca i. Obrnuto, ako i ![]() definisane formulama (110) i (110").
definisane formulama (110) i (110").
Prosječne granične apsolutne vjerovatnoće koje odgovaraju neesencijalnim stanjima uvijek su jednake nuli.
Ako postoji broj u normalnom obliku matrice (i to samo u ovom slučaju), prosječne granične apsolutne vjerovatnoće ne zavise od početnih vjerovatnoća i jedinstveno su određene iz jednačine (111).
Ovaj članak daje opšta ideja o tome kako generirati tekstove modeliranjem Markovljevih procesa. Konkretno, upoznaćemo se sa Markovljevim lancima, a kao praksu ćemo implementirati mali generator teksta u Python-u.
Za početak ispisujemo definicije koje su nam potrebne, ali nam još ne baš jasne sa stranice Wikipedije, kako bismo barem otprilike zamislili s čime imamo posla:
Markov proces t t
Markov lanac
Šta sve ovo znači? Hajde da to shvatimo.
Osnove
Prvi primjer je krajnje jednostavan. Pomoću rečenice iz dječije knjige savladat ćemo osnovni koncept Markovljevog lanca, kao i definirati šta je u našem kontekstu korpus, veze, distribucija vjerovatnoće i histogrami. Iako je prijedlog engleski jezik, bit će lako shvatiti suštinu teorije.
Ova ponuda je okvir, odnosno baza na osnovu koje će se u budućnosti generisati tekst. Sastoji se od osam riječi, ali istovremeno jedinstvene riječi samo pet je linkovi(govorimo o Markovu lancima). Radi jasnoće, obojimo svaku vezu u svoju boju:

I zapišite broj pojavljivanja svake od veza u tekstu:

Slika iznad pokazuje da je riječ riba pojavljuje se u tekstu 4 puta češće od svake druge riječi ( Jedan, dva, crvena, plava). Odnosno, vjerovatnoća susreta u našem korpusu riječi riba 4 puta veća od vjerovatnoće da ćete upoznati svaku drugu riječ na slici. Govoreći jezikom matematike, možemo odrediti zakon raspodjele slučajne varijable i izračunati s kojom vjerovatnoćom će se jedna od riječi pojaviti u tekstu iza trenutne. Vjerovatnoća se izračunava na sljedeći način: potrebno je podijeliti broj pojavljivanja riječi koja nam je potrebna u korpusu sa ukupan broj sve reči u njemu. Za riječ riba ova vjerovatnoća je 50% jer se pojavljuje 4 puta u rečenici od 8 riječi. Za svaku od preostalih veza ova vjerovatnoća je 12,5% (1/8).
Grafički predstavite distribuciju slučajne varijable moguće uz pomoć histogrami. U ovom slučaju, učestalost pojavljivanja svakog od linkova u rečenici je jasno vidljiva:

Dakle, naš tekst se sastoji od riječi i jedinstvenih veza, a distribuciju vjerovatnoće pojavljivanja svake od veza u rečenici prikazali smo na histogramu. Ako vam se čini da se ne treba petljati sa statistikom, pročitajte. I možda spasiti svoj život.
Suština definicije
Sada dodajmo našem tekstu elemente koji se uvijek podrazumijevaju, ali nisu izraženi u svakodnevnom govoru - početak i kraj rečenice:

Bilo koja rečenica sadrži ove nevidljive "početak" i "kraj", dodajmo ih kao linkove na našu distribuciju:

Vratimo se na definiciju datu na početku članka:
Markov proces je slučajan proces čija evolucija nakon bilo kojeg postavljena vrijednost vremenski parametar t ne zavisi od evolucije koja je prethodila t, pod uslovom da je vrijednost procesa u ovom trenutku fiksna.
Markov lanac - poseban slučaj Markovljev proces, kada je prostor njegovih stanja diskretan (tj. ne više od prebrojiv).
Šta to znači? Grubo govoreći, modeliramo proces u kojem stanje sistema u narednom trenutku zavisi samo od njegovog stanja u trenutnom trenutku, a ni na koji način ne zavisi od svih prethodnih stanja.
Zamislite šta je pred vama prozor, koji prikazuje samo trenutno stanje sistema (u našem slučaju to je jedna reč), a samo na osnovu podataka prikazanih u ovom prozoru treba da odredite koja će sledeća reč biti. U našem korpusu riječi slijede jedna za drugom prema sljedećem obrascu:

Tako se formiraju parovi riječi (čak i kraj rečenice ima svoj par - praznu vrijednost):

Grupirajmo ove parove prema prvoj riječi. Vidjet ćemo da svaka riječ ima svoj skup veza, što je u kontekstu naše rečenice svibanj prati ga:

Predstavimo ovu informaciju na drugačiji način - svakom linku će biti dodijeljen niz svih riječi koje se mogu pojaviti u tekstu nakon ovog linka:

Pogledajmo izbliza. Vidimo da svaka veza ima riječi koje svibanj doći nakon toga u rečenici. Ako bismo gornji dijagram pokazali nekom drugom, ta osoba bi, sa određenom vjerovatnoćom, mogla rekonstruirati naš početna ponuda, odnosno korpusa.
Primjer. Počnimo od riječi Počni. Zatim odaberite riječ Jedan, pošto prema našoj šemi jeste jednu riječ, koji može pratiti početak rečenice. Iza reči Jedan takođe samo jedna reč može da sledi - riba. Sada izgleda novi prijedlog u srednjoj verziji Jedna riba. Dalje, situacija postaje komplikovanija riba riječi mogu ići sa jednakom vjerovatnoćom za 25% "dva", "crvena", "plava" i kraj rečenice Kraj. Ako pretpostavimo da je sljedeća riječ - "dva" rekonstrukcija će se nastaviti. Ali možemo izabrati vezu Kraj. U ovom slučaju, na osnovu naše šeme, nasumično će se generirati rečenica koja se jako razlikuje od korpusa - Jedna riba.
Upravo smo modelirali Markovljev proces - svaku narednu riječ smo odredili samo na osnovu znanja o trenutnoj. Za potpunu asimilaciju gradiva napravimo dijagrame koji pokazuju zavisnosti između elemenata unutar našeg korpusa. Ovali predstavljaju veze. Strelice vode do potencijalnih veza koje mogu pratiti riječ u ovalu. Blizu svake strelice - vjerovatnoća s kojom će se sljedeća veza pojaviti nakon trenutne:

Odlično! Naucili smo potrebne informacije da idemo dalje i analiziramo složenije modele.
Proširivanje baze vokabulara
U ovom dijelu članka ćemo izgraditi model po istom principu kao i prije, ali ćemo izostaviti neke korake u opisu. Ako imate poteškoća, vratite se na teoriju u prvom bloku.
Uzmimo još četiri citata istog autora (također na engleskom, neće nam škoditi):
„Danas si ti. To je istinitije nego istina. Nema nikog živog ko je ti - stariji od tebe."
„Imaš mozak u glavi. Imate stopala u cipelama. Možete se usmjeravati u bilo kojem smjeru koji odaberete. Sami ste."
"Više da tičitaj, više stvari koje ćete znati. Što više naučite, na više mjesta ćete otići."
Misli lijevo i misli desno i misli nisko i misli visoko. Oh, misli da možeš smisliti samo ako pokušaš."
Složenost korpusa je povećana, ali u našem slučaju to je samo plus - sada će generator teksta moći proizvesti smislenije rečenice. Činjenica je da u bilo kojem jeziku postoje riječi koje se pojavljuju u govoru češće od drugih (na primjer, koristimo prijedlog "u" mnogo češće od riječi "kriogeni"). Kako više riječi u našem korpusu (a samim tim i zavisnosti između njih), generator ima više informacija o tome koja će se riječ najvjerovatnije pojaviti u tekstu nakon tekuće.
Najlakši način da se ovo objasni je sa stanovišta programa. Znamo da za svaku vezu postoji skup riječi koje ga mogu pratiti. Takođe, svaku riječ karakterizira broj njenih pojavljivanja u tekstu. Moramo nekako uhvatiti sve ove informacije na jednom mjestu; rečnik koji pohranjuje parove "(ključ, vrijednost)" je najprikladniji za ovu svrhu. Ključ rječnika će zabilježiti trenutno stanje sistema, odnosno jednu od veza u korpusu (npr. "the" na slici ispod); i drugi rječnik će biti pohranjen u vrijednosti rječnika. U ugniježđenom rječniku, ključevi će biti riječi koje se mogu pojaviti u tekstu nakon trenutne jedinice korpusa ( "misliti" I više može ići u tekstu nakon "the"), i vrijednosti - broj pojavljivanja ovih riječi u tekstu nakon našeg linka (riječ "misliti" pojavljuje se u tekstu iza riječi "the" 1 put, riječ više posle reči "the"- 4 puta):

Ponovo pročitajte gornji pasus nekoliko puta da biste ga ispravili. Imajte na umu da je ugniježđeni rječnik u ovom slučaju isti histogram, pomaže nam da pratimo veze i učestalost njihovog pojavljivanja u tekstu u odnosu na druge riječi. Treba napomenuti da je čak i takva baza vokabulara vrlo mala za pravilno generiranje tekstova u prirodni jezik- trebalo bi da sadrži više od 20 000 riječi, a po mogućnosti više od 100 000. I još bolje - više od 500 000. Ali pogledajmo bazu rječnika koju imamo.
Markovljev lanac u ovom slučaju je konstruiran slično kao u prvom primjeru - svaka sljedeća riječ se bira samo na osnovu znanja o trenutnoj riječi, sve ostale riječi se ne uzimaju u obzir. Ali zbog skladištenja u rječniku podataka o tome koje se riječi pojavljuju češće od drugih, možemo odabrati da prihvatimo ponderisana odluka. Pogledajmo konkretan primjer:
Više:
To jest, ako je trenutna riječ riječ više, iza njega mogu biti riječi sa jednakom vjerovatnoćom za 25% "stvari" I "mjesta", a sa vjerovatnoćom od 50% - riječ "to". Ali vjerovatnoće mogu biti i sve su jednake jedna drugoj:
misliti:
Rad sa prozorima
Do sada smo razmatrali samo prozore od jedne riječi. Možete povećati veličinu prozora tako da generator teksta proizvodi više "provjerenih" rečenica. To znači da što je veći prozor, to će biti manje odstupanja od trupa tokom generacije. Povećanje veličine prozora odgovara prelasku Markovljevog lanca na više high order. Prethodno smo izgradili lanac prvog reda, za prozor od dvije riječi dobijamo lanac drugog reda, od tri - trećeg i tako dalje.
Prozor su podaci u trenutna drzava sistema koji se koriste za donošenje odluka. Ako kombiniramo veliki prozor i mali skup podataka, vjerovatno ćemo svaki put dobiti istu rečenicu. Uzmimo bazu rječnika iz našeg prvog primjera i proširimo prozor na veličinu 2:

Proširenje je dovelo do toga da svaki prozor sada ima samo jednu opciju za sljedeće stanje sistema - bez obzira šta radimo, uvijek ćemo dobiti istu rečenicu, identičnu našem korpusu. Stoga, da biste eksperimentirali s prozorima, i da bi generator teksta vratio jedinstveni sadržaj, nabavite bazu rječnika od 500.000 riječi ili više.
Implementacija u Pythonu
Struktura podataka diktograma
Diktogram (dict je ugrađeni tip podataka rječnika u Pythonu) će prikazati odnos između linkova i njihove učestalosti pojavljivanja u tekstu, odnosno njihovu distribuciju. Ali u isto vrijeme, imat će svojstvo rječnika koje nam je potrebno - vrijeme izvršavanja programa neće ovisiti o količini ulaznih podataka, što znači da kreiramo efikasan algoritam.
Uvezite slučajnu klasu Dictogram(dict): def __init__(self, iterable=None): # Inicijalizirajte našu distribuciju kao novi objekt klase, # dodajte postojeće elemente super(Dictogram, self).__init__() self.types = 0 # broj jedinstveni ključevi u distribuciji self.tokens = 0 # ukupno svih riječi u distribuciji if iterable: self.update(iterable) def update(self, iterable): # Ažuriraj distribuciju sa stavkama iz # postojećeg iterable skupa podataka za stavku u iterable: if item in self: self += 1 self .tokens += 1 else: self = 1 self.types += 1 self.tokens += 1 def count(self, item): # Vrati vrijednost brojača stavke, ili 0 ako je stavka u self: return self return 0 def return_random_word (self): random_key = random.sample(self, 1) # Drugi način: # random.choice(histogram.keys()) return random_key def return_weighted_random_word(self): # Generiraj pseudo-slučajni broj između 0 i (n- 1), # gdje je n ukupan broj riječi random_int = random.randint(0, self.tokens-1) index = 0 list_of_keys = self.keys() # print "random index:", random_int za i u rasponu( 0, self.types): index += self] # ispis indeksa if(index > random_int): # print list_of_keys[i] return list_of_keys[i]
Bilo koji objekat koji se može ponoviti može se proslijediti konstruktoru strukture Diktograma. Elementi ovog objekta bit će riječi za inicijalizaciju diktograma, na primjer, sve riječi iz neke knjige. U ovom slučaju, brojimo elemente tako da za pristup bilo kojem od njih ne bi bilo potrebno svaki put prolaziti kroz cijeli skup podataka.
Također smo napravili dvije funkcije povratka random word. Jedna funkcija bira nasumični ključ u rječniku, a druga, uzimajući u obzir broj pojavljivanja svake riječi u tekstu, vraća riječ koja nam je potrebna.
Struktura Markovljevog lanca
from histograms import Dictogram def make_markov_model(data): markov_model = dict() za i u rasponu(0, len(data)-1): if data[i] u markov_model: # Samo dodajte već postojećoj distribuciji markov_model].update ( ]) else: markov_model] = Diktogram(]) vraća markov_modelU gornjoj implementaciji imamo rječnik koji pohranjuje prozore kao ključ u paru "(ključ, vrijednost)" i distribucije kao vrijednosti u tom paru.
Struktura Markovljevog lanca N-og reda
from histograms import Dictogram def make_higher_order_markov_model(order, data): markov_model = dict() for i in range(0, len(data)-order): # Kreiraj prozor prozora = tuple(data) # Dodaj u rječnik if prozor u markov_model: # Priložite postojećoj distribuciji markov_model.update(]) inače: markov_model = Dictogram(]) vrati markov_modelVrlo sličan Markovljevom lancu prvog reda, ali u ovom slučaju mi skladištimo tuple kao ključ u paru "(ključ, vrijednost)" u rječniku. Koristimo ga umjesto liste, jer je tuple zaštićen od bilo kakvih promjena, a to je za nas važno - na kraju krajeva, ključevi u rječniku ne bi trebali mijenjati.
Parsing modela
Odlično, implementirali smo rječnik. Ali kako sada generirati sadržaj na osnovu trenutnog stanja i preći u sljedeće stanje? Idemo kroz naš model:
Iz histograma import Dictogram import random iz kolekcija import deque import re def generate_random_start(model): # Za generiranje bilo koje početne riječi, dekomentirajte red: # vratite random.choice(model.keys()) # Da biste generirali "ispravnu" početnu riječ , koristite kod ispod: # Ispravno početne riječi su one koje su bile početak rečenica u if "END" u korpusu modela: seed_word = "END" dok seed_word == "END": seed_word = model["END"].return_weighted_random_word() return seed_word return random.choice( model .keys()) def generate_random_sentence(length, markov_model): current_word = generate_random_start(markov_model) rečenica = for i in range(0, length): current_dictogram = markov_model random_weighted_word = current_dictogram.return_weighted_current_word_end(current_random_word) ) rečenica = rečenica.capitalize() return " ".join(rečenica) + "." povratna rečenica
Šta je sledeće?
Pokušajte smisliti gdje i sami možete koristiti generator teksta baziran na Markovim lancima. Samo nemojte zaboraviti da je najvažnije kako analizirate model i koja posebna ograničenja postavljate na generaciju. Autor ovog članka je, na primjer, koristio veliki prozor prilikom kreiranja tweet generatora, ograničio generirani sadržaj na 140 znakova i koristio samo “ispravne” riječi za početak rečenica, odnosno one koje su bile početak rečenica u korpus.
Načini matematički opisi Markovljevski stohastički procesi u sistemu sa diskretnim stanjima (DS) zavise od toga u kojim vremenskim tačkama (unapred poznatim ili nasumično) može doći do prelazaka sistema iz stanja u stanje.
Ako je prijelaz sistema iz stanja u stanje moguć u unaprijed određeno vrijeme, imamo posla nasumično Markov proces sa diskretnim vremenom. Ako je tranzicija moguća u bilo kojem nasumičnom trenutku, onda imamo posla slučajni Markovljev proces sa kontinuiranim vremenom.
Neka bude fizički sistem S, koji može biti u n države S 1 , S 2 , …, S n. Prijelazi iz stanja u stanje mogući su samo povremeno t 1 , t 2 , …, t k Nazovimo ove trenutke vremenskim koracima. Razmotrićemo SP u sistemu S kao funkcija cjelobrojnog argumenta 1, 2, ..., k, gdje je argument broj koraka.
primjer: S 1 → S 2 → S 3 → S 2 .
Označimo Si (k) je događaj koji se sastoji u činjenici da nakon k koraka sistem je u stanju S i.
Za bilo koje k događaji S 1 ( k), S 2 ( k),…, S n (k) obrazac kompletna grupa događaja i su nekompatibilno.
Proces u sistemu se može predstaviti kao lanac događaja.
primjer: S 1 (0) , S 2 (1) , S 3 (2) , S 5 (3) ,….
Takav niz se zove Markov lanac
, ako je za svaki korak vjerovatnoća prijelaza iz bilo kojeg stanja Si u bilo kojoj državi S j ne zavisi od toga kada i kako je sistem došao u stanje Si.
Neka u bilo koje vrijeme nakon bilo kojeg k-go step sistem S može biti u jednoj od država S 1 , S 2 , …, S n, tj. može se desiti jedan događaj iz kompletne grupe događaja: S 1 (k), S 2 ( k) , …, S n (k) . Označimo vjerovatnoće ovih događaja:
P 1 (1) = P(S 1 (1)); P 2 (1) = P(S 2 (1)); …; P n(1) = P(S n (k));
P 1 (2) = P(S 1 (2)); P 2 (2) = P(S2(2)); …; P n(2) = P(S n (2));
P 1 (k) = P(S 1 (k)); P 2 (k) = P(S 2 (k)); …; P n(k) = P(S n (k)).
Lako je vidjeti da je za svaki korak broj uslov
P 1 (k) + P 2 (k) +…+ P n(k) = 1.
Nazovimo ove vjerovatnoće vjerovatnoće stanja.shodno tome, zadatak će zvučati ovako: pronaći vjerovatnoće stanja sistema za bilo koje k.
Primjer. Neka postoji neki sistem koji može biti u bilo kojem od šest stanja. tada se procesi koji se dešavaju u njemu mogu prikazati ili u obliku grafikona promena stanja sistema (slika 7.9, A), ili u obliku grafa stanja sistema (slika 7.9, b).
A) 
Rice. 7.9
Takođe, procesi u sistemu se mogu prikazati kao niz stanja: S 1 , S 3 , S 2 , S 2 , S 3 , S 5 , S 6 , S 2 .
Vjerovatnoća stanja na ( k+ 1)-ti korak zavisi samo od stanja u k- m korak.
Za bilo koji korak k postoje neke vjerovatnoće prijelaza sistema iz bilo kojeg stanja u bilo koje drugo stanje, nazovimo te vjerovatnoće tranzicijske vjerovatnoće Markovljevog lanca.
Neke od ovih vjerovatnoća će biti 0 ako prijelaz iz jednog stanja u drugo nije moguć u jednom koraku.
Markov lanac se zove homogena ako prelazna stanja ne zavise od broja koraka, u suprotnom se poziva heterogena.
Neka postoji homogeni Markovljev lanac i neka sistem S Ima n moguća stanja: S 1 , …, S n. Neka je za svako stanje poznata vjerovatnoća prelaska u drugo stanje u jednom koraku, tj. P ij(od Si V S j u jednom koraku), tada možemo zapisati vjerovatnoće tranzicije kao matricu.
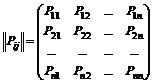 . (7.1)
. (7.1)
Na dijagonali ove matrice su vjerovatnoće da sistem prelazi iz stanja Si u istom stanju Si.
Koristeći prethodno uvedene događaje ![]() , vjerovatnoće tranzicije se mogu napisati kao uslovne vjerovatnoće:
, vjerovatnoće tranzicije se mogu napisati kao uslovne vjerovatnoće: ![]() .
.
Očigledno, zbir pojmova ![]() u svakom redu matrice (1) jednak je jedan, budući da su događaji
u svakom redu matrice (1) jednak je jedan, budući da su događaji ![]() čine kompletnu grupu nespojivih događaja.
čine kompletnu grupu nespojivih događaja.
Kada se razmatraju Markovljevi lanci, kao i kada se analiziraju Markovljevi lanci slučajni proces, koriste se različiti grafovi stanja (slika 7.10). 
Rice. 7.10
Ovaj sistem može biti u bilo kojem od šest stanja, dok P ij je vjerovatnoća prijelaza sistema iz stanja Si u stanje S j. Za ovaj sistem zapisujemo jednačine da je sistem bio u nekom stanju i iz njega tokom vremena t nije izašlo: 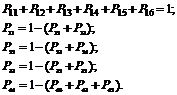
IN opšti slučaj Markovljev lanac je nehomogen, tj. vjerovatnoća P ij mijenja se od koraka do koraka. Pretpostavimo da je data matrica vjerovatnoća tranzicije u svakom koraku, zatim vjerovatnoća da sistem S on k-th korak će biti u stanju Si, može se pronaći pomoću formule ![]()
Poznavanje matrice vjerovatnoća tranzicije i početno stanje sistema, možete pronaći vjerovatnoće stanja ![]() nakon bilo kojeg k-th korak. Neka je u početnom trenutku sistem u stanju S m. Tada za t = 0
nakon bilo kojeg k-th korak. Neka je u početnom trenutku sistem u stanju S m. Tada za t = 0
.
Pronađite vjerovatnoće nakon prvog koraka. Van države S m sistem će preći u stanja S 1 , S 2, itd. sa vjerovatnoćama pm 1 , pm 2 , …, P mm, …, Pmn. Tada će nakon prvog koraka vjerovatnoće biti jednake
. (7.2)
Nađimo vjerovatnoće stanja nakon drugog koraka: . Ove vjerovatnoće ćemo izračunati koristeći formulu puna verovatnoća sa hipotezama: ![]() .
.
Hipoteze će biti sljedeće tvrdnje:
- nakon prvog koraka sistem je bio u stanju S 1 -H 1 ;
- nakon drugog koraka sistem je bio u stanju S 2 -H 2 ;
- poslije n-th korak sistem je bio u stanju S n -H n .
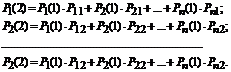
Vjerovatnoća bilo kojeg stanja nakon drugog koraka:
![]() (7.3)
(7.3)
Formula (7.3) sumira sve vjerovatnoće tranzicije P ij, ali se uzimaju u obzir samo oni različiti od nule. Vjerovatnoća bilo kojeg stanja nakon k-ti korak:
![]() (7.4)
(7.4)
Dakle, vjerovatnoća stanja nakon k-th korak je određen ponavljajuća formula(7.4) u smislu vjerovatnoće ( k- 1) korak.
Zadatak 6. Data je matrica prelaznih vjerovatnoća za Markovljev lanac u jednom koraku. Pronađite prijelaznu matricu datog kola u tri koraka  .
.
Rješenje. Prijelazna matrica sistema je matrica koja sadrži sve vjerovatnoće prijelaza ovog sistema: 
Svaki red matrice sadrži vjerovatnoće događaja (prelazak iz stanja i u stanje j), koji čine kompletnu grupu, pa je zbir vjerovatnoća ovih događaja jednak jedan: ![]()
Označiti sa p ij (n) vjerovatnoću da će kao rezultat n koraka (testova) sistem preći iz stanja i u stanje j. Na primjer p 25 (10) - vjerovatnoća prelaska iz drugog stanja u peto u deset koraka. Imajte na umu da za n=1 dobijamo prelazne verovatnoće p ij (1)=p ij .
Suočeni smo sa zadatkom: znajući vjerovatnoće tranzicije p ij , pronaći vjerovatnoće p ij (n) prijelaza sistema iz stanja i u stanje j iza n stepenice. Da bismo to učinili, uvodimo međuproizvod (između i I j) stanje r. Drugim riječima, to ćemo pretpostaviti iz početnog stanja i iza m koraka, sistem će preći u srednje stanje r sa vjerovatnoćom p ij (n-m) , nakon čega, za preostale n-m koraka iz srednjeg stanja r prelazi u konačno stanje j sa vjerovatnoćom p ij (n-m) . Prema formuli ukupne vjerovatnoće dobijamo: ![]() .
.
Ova formula se zove Markovljeva jednakost. Koristeći ovu formulu, možete pronaći sve vjerovatnoće p ij (n) i, shodno tome, samu matricu P n. Kako matrični račun brže vodi do cilja, zapišemo matrični odnos koji proizlazi iz dobijene formule u opštem obliku.
Izračunajte prijelaznu matricu Markovljevog lanca u tri koraka koristeći rezultirajuću formulu: 
odgovor: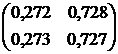 .
.
Zadatak #1. Matrica vjerovatnoće prijelaza za Markovljev lanac je: 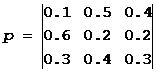 .
.
Distribucija po stanjima u trenutku t=0 određena je vektorom:
π 0 \u003d (0,5; 0,2; 0,3)
Nađi: a) raspodjela po stanjima u momentima t=1,2,3,4 .
c) stacionarna distribucija.
 Stara ruska književnost
Stara ruska književnost Kako odrediti poetsku veličinu
Kako odrediti poetsku veličinu Pravopis glagola. Glagoli I klase (završavaju na “-er”) Tvorba imperativa
Pravopis glagola. Glagoli I klase (završavaju na “-er”) Tvorba imperativa