Примерни данни. Статистическа извадка
типове проби:
Всъщност-случаен;
Механични;
типичен;
Сериен;
Комбиниран.
Самослучайно вземане на пробие да изберете единици от населениена случаен принцип или на случаен принцип без никакви елементи на последователност. Въпреки това, преди да направите правилен случаен подбор, е необходимо да се уверите, че всички единици от генералната съвкупност без изключение имат абсолютно еднакви шансове да попаднат в извадката, няма пропуски в списъците или списъка, игнориране на отделни единици и т.н. Трябва също така да се установят ясни граници за населението, така че включването или изключването на отделни единици да не предизвиква съмнение. Така например, когато се изследват ученици, е необходимо да се посочи дали лицата, които са в академичен отпуск, студенти недържавни университети, военни училища и др.; когато се изследват търговски обекти, е важно да се определи дали генералната съвкупност ще включва търговски павилиони, търговски шатри и други подобни обекти. Самослучайният избор може да бъде както повтарящ се, така и неповтарящ се. За неповтаряща се селекцияпо време на тегленето на жребий, изтеглените жребии не се връщат към първоначалния комплект и не участват в по-нататъшния избор. При използване на таблици произволни числанеповтарящ се избор се постига чрез пропускане на числа, ако те се повтарят в избраната колона или колони.
Механично вземане на пробисе използва в случаите, когато генералната съвкупност е подредена по някакъв начин, т.е. има определена последователност в подреждането на звената (номера на заплатите на служителите, избирателни списъци, телефонни номерареспонденти, номера на къщи и апартаменти и др.).
Генералната популация по време на механична селекция може да бъде класирана или подредена според стойността на изследваната черта или корелирана с нея, което ще увеличи представителността на извадката. В този случай обаче се увеличава рискът от систематична грешка, свързана с подценяване на стойностите на изследвания признак (ако първата стойност е записана от всеки интервал) или с надценяването му (ако последна стойност). Затова е препоръчително да започнете селекцията от средата на първия интервал
типична селекция.Този метод на подбор се използва в случаите, когато всички единици от генералната съвкупност могат да бъдат разделени на няколко типични групи. При изследване на населението такива групи могат да бъдат например области, социални, възрастови или образователни групи, при изследване на предприятия - отрасъл или подотрасъл, форма на собственост и др. Типичният подбор включва подбор на единици от всяка типична група по чисто случаен или механичен начин. Защото в рамка за вземане на пробипредставители на всички групи задължително попадат в една или друга пропорция, типизацията на генералната съвкупност позволява да се изключи влиянието междугрупова дисперсияна средна грешкапроба, която в този случай се определя само от вътрешногрупова вариация.
Изборът на единици в типична извадка може да бъде организиран или пропорционално на обема на типичните групи, или пропорционално на вътрешногруповата диференциация на даден признак.
сериен избор.Този метод на подбор е удобен в случаите, когато единиците на съвкупността са групирани в малки групи или серии. Като такива серии, пакети с определено количество готови продукти, партиди стоки, ученически групи, бригади и други сдружения. Същността на серийната извадка се състои в действителния случаен или механичен подбор на серии, в рамките на който се извършва пълно изследване на единици.
Често се случва да е необходимо да се анализира определено социално явление и да се получи информация за него. Такива задачи често възникват в статистиката и в статистическите изследвания. Верификацията на напълно дефиниран социален феномен често е невъзможна. Например, как да разберете мнението на населението или на всички жители на даден град по всеки въпрос? Да попиташ абсолютно всички е почти невъзможно и много трудоемко. В такива случаи се нуждаем от проба. Това е точно концепцията, на която се основават почти всички изследвания и анализи.
Какво е проба
При анализ на конкретен социален феноментрябва да получите информация за това. Ако вземем каквото и да е изследване, можем да видим, че не всяка единица от съвкупността на обекта на изследване подлежи на изследване и анализ. Само определена част от тази съвкупност се взема предвид. Този процес е вземане на проби: когато се изследват само определени единици от набора.
Разбира се, много зависи от вида на пробата. Но има и основни правила. Основният гласи, че изборът от популацията трябва да бъде абсолютно случаен. Единиците от съвкупността, които ще се използват, не трябва да се избират поради никакъв критерий. Грубо казано, ако е необходимо да се събере население от населението на определен град и да се изберат само мъже, тогава ще има грешка в изследването, тъй като подборът не е извършен на случаен принцип, а е избран според пола. Почти всички методи за вземане на проби се основават на това правило.
Правила за вземане на проби
За да може избраната съвкупност да отразява основните качества на цялото явление, тя трябва да бъде изградена по определени закони, като основното внимание трябва да се обърне на следните категории:
- извадка (извадкова съвкупност);
- общо население;
- представителност;
- грешка в представителността;
- популационна единица;
- методи за вземане на проби.
Особености селективно наблюдениеи вземането на проби са както следва:
- Всички получени резултати се основават на математически закони и правила, тоест при правилно провеждане на изследването и при правилни изчисления резултатите няма да бъдат изкривени на субективна основа
- Позволява да се получи резултат много по-бързо и с по-малко време и ресурси, като се изучава не целият набор от събития, а само част от тях.
- Може да се използва за изследване на различни обекти: от конкретни проблеми, например възраст, пол на групата, която ни интересува, за изучаване обществено мнениеили нивото на материалната подкрепа на населението.
Селективно наблюдение
Селективно е статистическо наблюдение, при което на изследване се подлага не цялата съвкупност от изучаваното, а само част от нея, избрана по определен начин, като резултатите от изучаването на тази част се отнасят за цялата съвкупност. Тази част се нарича рамка за вземане на проби. то единствения начинизучаване на голям масив от обекта на изследване.
Но селективното наблюдение може да се използва само в случаите, когато е необходимо само да се изследва малка групаединици. Например, когато се изучава съотношението мъже и жени в света, ще се използва селективно наблюдение. По очевидни причини е невъзможно да се вземе предвид всеки жител на нашата планета.
Но със същото изследване, но не всички жители на земята, а определен 2 "А" клас в конкретно училище, определен град, определена държава, може без произволно наблюдение. В крайна сметка е напълно възможно да се анализира целият масив от обекта на изследване. Трябва да се преброят момчетата и момичетата от този клас - това ще бъде съотношението.

Извадка и популация
Всъщност не е толкова трудно, колкото звучи. Във всеки обект на изследване има две системи: генерална и извадкова съвкупност. Какво е? Всички единици принадлежат на генерала. И към извадката - онези единици от общата съвкупност, които са взети за извадката. Ако всичко е направено правилно, тогава избраната част ще бъде намалено оформление на цялата (обща) популация.
Ако говорим за генералната съвкупност, тогава можем да различим само две от нейните разновидности: определена и неопределена генерална съвкупност. Зависи от това дали общият брой единици на дадена система е известен или не. Ако това е определена популация, тогава вземането на проби ще бъде по-лесно поради факта, че се знае какъв процент от обща сумаединици ще бъдат взети проби.
Този момент е много необходим в изследването. Например, ако е необходимо да се изследва процентът на нискокачествени сладкарски изделия в конкретен завод. Да приемем, че населението вече е дефинирано. Известно е със сигурност, че това предприятие произвежда 1000 сладкарски изделия годишно. Ако от тази хиляда направим извадка от 100 произволни сладкарски изделия и ги изпратим на изследване, тогава грешката ще бъде минимална. Грубо казано, 10% от всички продукти са били обект на изследване и въз основа на резултатите, като се вземе предвид грешката в представителността, можем да говорим за лошо качество на всички продукти.
И ако вземете проба от 100 сладкарски продукта от неопределена генерална популация, където всъщност има, да речем, 1 милион единици, тогава резултатът от извадката и самото изследване ще бъдат критично неправдоподобни и неточни. Почувствай разликата? Следователно сигурността на общата популация в повечето случаи е изключително важна и силно влияе върху резултата от изследването.

Представителност на населението
И така, сега един от най-важните въпроси - каква трябва да бъде пробата? Това е най Основната точкаизследвания. На този етап е необходимо да се изчисли извадката и да се изберат единици от нея общ бройв нея. Популацията е избрана правилно, ако някои характеристики и характеристики на генералната популация остават в извадката. Това се нарича представителност.
С други думи, ако след селекция една част запазва същите тенденции и характеристики като цялото количество изследвани, тогава такава популация се нарича представителна. Но не всяка конкретна извадка може да бъде избрана от представителна популация. Има и такива обекти на изследване, чиято извадка просто не може да бъде представителна. Оттук идва понятието грешка в представителността. Но нека поговорим малко повече за това.
Как се прави проба
И така, за да се постигне максимална представителност, има три основни правила за вземане на проби:

Грешка (грешка) на представителността
Основна характеристикакачество на избраната извадка е понятието "грешка на представителността". Какво е? Това са известни несъответствия между показателите на избирателното и непрекъснатото наблюдение. Според показателите за грешки представителността се разделя на достоверна, обикновена и приблизителна. С други думи, допустими са отклонения съответно до 3%, от 3 до 10% и от 10 до 20%. Въпреки че в статистиката е желателно грешката да не надвишава 5-6%. В противен случай има основание да се говори за недостатъчна представителност на извадката. За да се изчисли грешката на представителността и как тя влияе върху извадка или популация, се вземат предвид много фактори:
- Вероятността, с която да получите точен резултат.
- Брой единици за вземане на проби. Както бе споменато по-рано, колкото по-малък е броят на единиците в извадката, толкова по-голяма ще бъде грешката в представителността и обратно.
- Хомогенност на изследваната популация. Колкото по-хетерогенна е съвкупността, толкова по-голяма ще бъде грешката в представителността. Способността на една съвкупност да бъде представителна зависи от хомогенността на всички нейни съставни единици.
- Метод за подбор на единици в извадкова съвкупност.
В бетон назначени изследванияпроцентната грешка на средната стойност обикновено се определя от изследователя въз основа на програмата за наблюдение и според данните от предишни изследвания. По правило максималната грешка на извадката (грешка на представителност) в рамките на 3-5% се счита за приемлива.

Повече не винаги е по-добре
Също така си струва да запомните, че основното при организирането на селективно наблюдение е да се сведе обемът му до приемлив минимум. В същото време не трябва да се стремите към прекомерно намаляване на границите на грешките при вземане на проби, тъй като това може да доведе до неоправдано увеличаване на количеството данни от извадката и следователно до увеличаване на разходите за вземане на проби.
В същото време размерът на грешката в представителността не трябва да се увеличава прекомерно. В крайна сметка, в този случай, въпреки че ще има намаляване на размера на извадката, това ще доведе до влошаване на надеждността на получените резултати.
Какви въпроси обикновено се задават от изследователя?
Всяко изследване, ако се провежда, е с някаква цел и за получаване на някакви резултати. При провеждане извадково изследванеобикновено се задават първоначални въпроси:

Методи за подбор на изследователски единици в извадката
Не всяка извадка е представителна. Понякога един и същ знак е различно изразен в цялото и в част от него. За постигане на изискванията за представителност е препоръчително да се използват различни методи за вземане на проби. Освен това използването на един или друг метод зависи от конкретните обстоятелства. Някои от тези методи за вземане на проби включват:
- случаен избор;
- механична селекция;
- типична селекция;
- сериен (вложен) избор.
Случайният подбор е система от дейности, насочени към случаен подбор на единици от съвкупността, когато вероятността да бъдат включени в извадката е еднаква за всички единици от генералната съвкупност. Тази техника е препоръчително да се прилага само в случай на хомогенност и малък брой присъщи характеристики. Иначе някои черти на характерарискуват да не бъдат включени в извадката. Характеристиките на случайния подбор са в основата на всички други методи за вземане на проби.
При механичен избор на единици се извършва на определен интервал. При необходимост от формиране на извадка от конкретни престъпления е възможно да се премахне всяка 5-та, 10-та или 15-та карта от всички статистически записи на регистрираните престъпления, в зависимост от техния общ брой и наличните размери на извадката. Недостатъкът на този метод е, че преди селекцията е необходимо да има пълна сметка на единиците от съвкупността, след това е необходимо да се извърши класиране и едва след това е възможно да се направи извадка през определен интервал. Този метод отнема много време, така че не се използва често.

Типичен (районизиран) подбор - вид извадка, в която генералната съвкупност е разделена на еднородни групина определена база. Понякога изследователите използват други термини вместо "групи": "райони" и "зони". След това определен брой единици се избират произволно от всяка група пропорционално на специфично теглогрупи от общото население. Типичният подбор често се извършва на няколко етапа.
Серийната извадка е метод, при който подборът на единици се извършва в групи (серии) и всички единици от избраната група (серия) подлежат на изследване. Предимството на този метод е, че понякога е по-трудно да се изберат отделни единици, отколкото серии, например, когато се изучава лице, което излежава присъда. В рамките на избраните райони, зони се прилага изследване на всички звена без изключение, например изследване на всички лица, изтърпяващи присъди в определена институция.
Интервална оценка на вероятността за събитие. Формули за изчисляване на броя на пробите в случай на метод на случаен подбор.За да определим вероятностите на събитията, които ни интересуват, ние използваме метода на вземане на проби: ние извършваме ннезависими експерименти, във всеки от които събитие А може да се случи (или да не се случи) (вероятност Рпоявата на събитие А във всеки експеримент е постоянна). Тогава относителната честота p* на възникване на събития НОв поредица от нтестовете се приемат като точкова оценказа вероятност стрнастъпване на събитие НОв отделен тест. В този случай се извиква стойността p* примерен дял събития НО, и r - общ дял .
По силата на следствие от центр гранична теорема(теорема на Moivre-Laplace) относителната честота на събитие с голям размер на извадката може да се счита за нормално разпределена с параметрите M(p*)=p и
Следователно, за n>30 доверителен интервалза общия дял може да се конструира с помощта на формулите:

където u cr се намира по таблиците на функцията на Лаплас, като се вземе предвид дадената доверителна вероятност γ: 2Ф(u cr)=γ.
При малък размер на извадката n≤30, пределната грешка ε се определя от таблицата за разпределение на Student: ![]() където t cr =t(k; α) и броя на степените на свобода k=n-1 вероятност α=1-γ (двустранна област).
където t cr =t(k; α) и броя на степените на свобода k=n-1 вероятност α=1-γ (двустранна област).
Формулите са валидни, ако изборът е извършен на случаен принцип по многократен начин (генералната съвкупност е безкрайна), в противен случай е необходимо да се направи корекция за неповтарящия се избор (таблица).
Средна извадкова грешка за общата пропорция
| Население | Безкраен | краен обем н |
| Тип селекция | Повтаря се | неповтарящ се |
| Средна извадкова грешка |
Формули за изчисляване на размера на извадката с подходящ метод на случаен подбор
| Метод на избор | Формули за размер на извадката | ||
| за средата | за споделяне | ||
| Повтаря се | |||
| неповтарящ се | |||
Проблеми за общия дял
На въпроса "Дадената стойност на p 0 покрива ли доверителния интервал?" - може да се отговори с проверка статистическа хипотезаН 0:р=р 0 . Предполага се, че експериментите се провеждат по схемата на теста на Бернули (независима, вероятностна стрнастъпване на събитие НОпостоянен). По обемна проба нопределяне на относителната честота p * на поява на събитие A: където м- брой появявания на събитието НОв поредица от нтестове. За проверка на хипотезата H 0 се използват статистики, които при достатъчно голям размер на извадката имат стандарта нормална дистрибуция(Маса 1).Таблица 1 - Хипотези за общия дял
Хипотеза | H0:p=p0 | H 0: p 1 \u003d p 2 |
| Предположения | Схема на теста на Бернули | Схема на теста на Бернули |
| Примерни оценки |  |
|
| Статистика К |  | 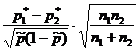 |
| Разпределение на статистиката К | Стандартно нормално N(0,1) |
Пример #1. Използвайки произволна повторна извадка, ръководството на компанията проведе произволно проучване на 900 свои служители. Сред анкетираните има 270 жени. Начертайте доверителен интервал, който с вероятност от 0,95 покрива истинския дял на жените в целия екип на фирмата.
Решение. По условие извадковият дял на жените е (относителната честота на жените сред всички респонденти). Тъй като селекцията се повтаря и размерът на извадката е голям (n=900), пределната грешка на извадката се определя по формулата ![]()
Стойността на u cr се намира от таблицата на функцията на Лаплас от връзката 2Ф(u cr)=γ, т.е. ![]() Функцията на Лаплас (Приложение 1) приема стойност 0,475 при u cr =1,96. Следователно пределната грешка
Функцията на Лаплас (Приложение 1) приема стойност 0,475 при u cr =1,96. Следователно пределната грешка ![]() и желания доверителен интервал
и желания доверителен интервал
(p – ε, p + ε) = (0,3 – 0,18; 0,3 + 0,18) = (0,12; 0,48)
Така че с вероятност от 0,95 може да се гарантира, че делът на жените в целия екип на фирмата е в диапазона от 0,12 до 0,48.
Пример #2. Собственикът на паркинга смята деня за "щастлив", ако паркингът е пълен над 80%. През годината са извършени 40 проверки на паркинги, от които 24 са „успешни“. С вероятност от 0,98 намерете доверителния интервал за оценка на истинския процент на "щастливите" дни през годината.
Решение. Примерната част от „добрите“ дни е
Според таблицата на функцията на Лаплас намираме стойността на u cr за дадена
ниво на увереност
Ф(2,23) = 0,49, u кр = 2,33.
Като се има предвид, че изборът не се повтаря (т.е. две проверки не са извършени в един и същи ден), откриваме пределната грешка: ![]()
където n=40, N=365 (дни). Оттук ![]()
и доверителен интервал за общата фракция: (p – ε, p + ε) = (0,6 – 0,17; 0,6 + 0,17) = (0,43; 0,77)
С вероятност от 0,98 може да се очаква делът на "добрите" дни през годината да е в диапазона от 0,43 до 0,77.
Пример #3. След като провериха 2500 артикула в партидата, те установиха, че 400 артикула са от най-висок клас, но n–m не са. Колко продукта трябва да проверите, за да определите дела на първокласния клас с точност 0,01 с 95% сигурност?
Търсим решение по формулата за определяне на размера на извадката за повторен подбор.
Ф(t) = γ/2 = 0,95/2 = 0,475 и според таблицата на Лаплас тази стойност съответства на t=1,96
Фракция на пробата w = 0.16; грешка на извадката ε = 0,01
Пример #4. Партида от продукти се приема, ако вероятността продуктът да отговаря на стандарта е най-малко 0,97. Сред произволно избраните 200 продукта от тестваната партида беше установено, че 193 продукта отговарят на стандарта. Възможно ли е да се приеме партидата при ниво на значимост α=0,02?
Решение. Формулираме основната и алтернативните хипотези.
H 0: p \u003d p 0 \u003d 0,97 - неизвестен общ дял стре равно на зададена стойностр 0 =0.97. Във връзка с условието - вероятността частта от тестваната партида да отговаря на стандарта е 0,97; тези. партида от продукти може да бъде приета.
H1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдавана статистическа стойност К(таблица) изчислете за дадени стойности p 0 =0,97, n=200, m=193

Критичната стойност се намира от таблицата на функцията на Лаплас от равенството
![]()
Съгласно условието α=0,02, следователно F(Kcr)=0,48 и Kcr=2,05. Критичният регион е ляв, т.е. е интервалът (-∞;-K kp)= (-∞;-2,05). Наблюдаваната стойност Kobs = -0,415 не принадлежи към критичната област, следователно при това ниво на значимост няма причина да се отхвърли основната хипотеза. Може да се приеме партида от продукти.
Пример номер 5. Две фабрики произвеждат един и същи тип части. За оценка на качеството им са взети проби от продуктите на тези фабрики и са получени следните резултати. Сред 200 избрани продукта на първата фабрика 20 бяха дефектни, а сред 300 продукта на втората фабрика 15 бяха дефектни.
При ниво на значимост от 0,025 разберете дали има значителна разлика в качеството на частите, произведени от тези фабрики.
Съгласно условието α=0.025, следователно F(Kcr)=0.4875 и Kcr=2.24. При двустранна алтернатива областта на допустимите стойности има формата (-2,24; 2,24). Наблюдаваната стойност Kobs =2,15 попада в този интервал, т.е. при това ниво на значимост няма причина да се отхвърли основната хипотеза. Фабриките произвеждат продукти с еднакво качество.
Планирайте
- Въведение
- 1. Ролята на вземането на проби
- Заключение
- Библиография
Въведение
Статистиката е аналитична наука, необходима на всички съвременни специалисти. Съвременният специалист не може да бъде грамотен, ако не притежава статистическа методология. Статистиката е най-важният инструмент за комуникация между предприятието и обществото. Статистиката е една от най-важните дисциплини в учебния план на всички специалности. статистическата грамотност е неразделна част от висшето образование и по брой часове в учебния план заема едно от първите места. Работейки с цифри, всеки специалист трябва да знае как са получени определени данни, какъв е техният характер на изчисление, колко пълни и надеждни са те.
1. Ролята на вземането на проби
Съвкупността от всички единици от съвкупността, които имат определен признак и подлежат на изследване, се нарича в статистиката генерална съвкупност.
На практика, по една или друга причина, не винаги е възможно или непрактично да се разглежда цялата популация. Тогава те се ограничават до изучаване само на част от него, чиято крайна цел е да разширят получените резултати върху цялата генерална съвкупност, т.е. използвайки метод за вземане на проби.
За да направите това, част от елементите, така наречената извадка, се избира от генералната съвкупност по специален начин и резултатите от обработката на извадкови данни (например средни аритметични) се обобщават за цялата популация.
Теоретичната основа на извадковия метод е законът за големите числа. По силата на този закон, с ограничена дисперсия на признак в генералната съвкупност и достатъчно голяма извадка с вероятност, близка до пълна надеждност, средната стойност на извадката може да бъде произволно близка до общата средна стойност. Този закон, който включва група от теореми, е доказан строго математически. По този начин средноаритметичното, изчислено за извадката, може с основание да се разглежда като показател, характеризиращ генералната съвкупност като цяло.
2. Методи за вероятностен подбор, които осигуряват представителност
За да може да се направи извод за свойствата на генералната съвкупност от извадката, извадката трябва да е представителна (представителна), т.е. тя трябва напълно и адекватно да представя свойствата на общата съвкупност. Представителността на извадката може да бъде гарантирана само ако подборът на данните е обективен.
Извадката се формира на принципа на масовите вероятностни процеси без изключения от приетата схема за подбор; необходимо е да се осигури относителна хомогенност на извадката или нейното разделяне на хомогенни групи единици. При формирането на извадкова съвкупност трябва да се даде ясна дефиниция на извадковата единица. Желателен е приблизително еднакъв размер на единиците за вземане на проби и резултатите ще бъдат по-точни, колкото по-малка е единицата за вземане на проби.
Възможни са три метода на избор: случаен избор, избор на единици по определена схема, комбинация от първия и втория метод.
Ако селекцията в съответствие с приетата схема се извършва от общата популация, предварително разделена на типове (слоеве или слоеве), тогава такава извадка се нарича типична (или стратифицирана, или стратифицирана, или зонирана). Друго разделяне на извадката по видове се определя от това коя е единицата за вземане на проби: единица за наблюдение или поредица от единици (понякога се използва терминът "гнездо"). В последния случай извадката се нарича серийна или вложена. В практиката често се използва комбинация от типична проба с подбор на серия. В математическата статистика, когато се обсъжда проблемът за избора на данни, е необходимо да се въведе разделянето на извадката на повторна и неповторена. Първата съответства на схемата на връщаща се топка, втората - неотменима (когато се разглежда процесът на избор на данни по примера на избор на топки с различни цветове от урната). В социално-икономическата статистика няма смисъл да се използва повторна извадка, следователно по правило се има предвид неповтаряща се извадка.
Тъй като социално-икономическите обекти имат сложна структура, може да бъде доста трудно да се организира извадка. Например, за да изберете домакинства, когато изучавате потреблението от населението на голям град, е по-лесно първо да изберете териториални клетки, жилищни сгради, след това апартаменти или домакинства, след това респондента. Такава проба се нарича многоетапна. На всеки етап се използват различни единици за вземане на проби: по-големи в началните етапи, в последния етап единицата за подбор съвпада с единицата за наблюдение.
Друг вид наблюдение на проби е многофазното вземане на проби. Такава извадка включва определен брой фази, всяка от които се различава в детайлите на програмата за наблюдение. Например 25% от цялата генерална съвкупност се изследва по кратка програма, всеки 4-ти от тази извадка се изследва по по-пълна програма и т.н.
За всеки тип извадка изборът на единици се извършва по три начина. Помислете за процедура на случаен подбор. Първо се съставя списък на единиците на съвкупността, в който на всяка единица се присвоява цифров код (номер или етикет). След това се прави равенство. В барабана се поставят топки със съответните номера, смесват се и се избират топките. Изпадналите числа отговарят на единиците в извадката; броят на числата е равен на планирания размер на извадката.
Изборът чрез жребий може да бъде обект на пристрастия, причинени от технически недостатъци (качество на топките, барабан) и други причини. По-надежден от гледна точка на обективност е изборът чрез таблица със случайни числа. Такава таблица съдържа поредица от числа, редуващи се произволно, избрани чрез електронни сигнали. Тъй като използваме десетичната числова система 0, 1, 2,., 9, вероятността всяка цифра да се появи е 1/10. Следователно, ако е необходимо да се създаде таблица с произволни числа, включваща 500 знака, тогава около 50 от тях ще бъдат 0, същото число ще бъде 1 и т.н.
Често се използва подбор по някаква схема (т.нар. насочена извадка). Схемата за подбор се приема така, че да отразява основните свойства и пропорции на генералната съвкупност. Най-простият начин: според списъците с единици от генералната съвкупност, съставени по такъв начин, че подреждането на единиците да не е свързано с изследваните свойства, се извършва механичен подбор на единици със стъпка, равна на N: н. Обикновено селекцията не започва от първата единица, а се отстъпва с половин стъпка, за да се намали възможността за отклонение в извадката. Честотата на поява на единици с определени характеристики, например студенти с определено ниво на академично представяне, живеещи в общежитие и др. ще се определя от структурата, която се е развила в генералната съвкупност.
За да бъде по-сигурно, че извадката ще отразява структурата на популацията, последната се подразделя на типове (страти или области), като от всеки тип се прави случаен или механичен подбор. Общият брой единици, избрани от различни типове, трябва да съответства на размера на извадката.
Особени трудности възникват, когато няма списък с единици и изборът трябва да се извърши или на място, или от мостри на продукти в склада за готов продукт. В тези случаи е важно да се разработи в детайли схемата за ориентиране на терена и схемата за избор и да се следват без да се допускат отклонения. Например, измервателният уред получава инструкции да се движи от определена автобусна спирка на север от четната страна на улицата и след като преброи две къщи от първия ъгъл, да влезе в третата и да анкетира всяко 5-то жилище. Стриктното спазване на възприетата схема осигурява изпълнението на основното условие за формиране на представителна извадка - обективността на подбора на единици.
от произволна извадкатрябва да се прави разлика между квотен подбор, когато извадката е съставена от единици от определени категории (квоти), които трябва да бъдат представени в определени пропорции. Например, в проучване на клиенти на универсален магазин може да се планира избор от 150 респондента, включително 90 жени, от които 25 са момичета, 20 са млади жени с малки деца, 35 са жени на средна възраст, облечени в бизнес костюм, 10 са жени на 50 и повече години; освен това е планирано изследване на 70 мъже, от които 25 юноши и младежи, 20 млади мъже с деца, 15 мъже, облечени в костюми, 10 мъже, облечени в спортно облекло. За определяне на потребителските ориентации и предпочитания такава извадка може да е добра, но ако искаме да установим средния размер на покупките, тяхната структура, ще получим непредставителни резултати. Това е така, защото извадката от квоти е насочена към избор на определени категории.
Извадката може да е непредставителна, дори ако е формирана в съответствие с известни пропорции на генералната съвкупност, но подборът се извършва без схема - единиците се набират по всякакъв начин, само за да се осигури съотношението на техните категории в същите пропорции както в общата съвкупност (например съотношението мъже и жени, респонденти на възраст по-млади и по-възрастни от трудоспособни и трудоспособни и т.н.).
Тези забележки трябва да ви предупредят срещу подобни подходи за вземане на проби и да подчертаят отново необходимостта от обективно вземане на проби.
3. Организационни и методични особености на случайното, механичното, типовото и серийното вземане на проби
В зависимост от това как се извършва подборът на елементите на съвкупността в извадката, има няколко вида извадкови изследвания. Изборът може да бъде случаен, механичен, типичен и сериен.
Случайният подбор е такъв подбор, при който всички елементи от генералната съвкупност имат еднаква възможност да бъдат избрани. С други думи, всеки елемент от популацията има еднаква вероятност да бъде включен в извадката.
вземане на извадки статистически вероятностен случаен
Изискването за случаен избор се постига на практика с помощта на партиди или таблица със случайни числа.
При избор чрез жребий всички елементи от генералната съвкупност предварително се номерират и номерата им се поставят върху картите. След внимателно разбъркване от пакета по какъвто и да е начин (в ред или в друг ред) се избира необходимия брой карти, съответстващ на размера на извадката. В този случай можете или да оставите избраните карти настрана (като по този начин извършвате така наречената неповтаряща се селекция), или, като извадите карта, запишете номера й и я върнете в пакета, като по този начин й дадете възможност да се появи в извадката отново (повторен избор). При повторен избор, всеки път след връщане на картата, пакетът трябва да бъде внимателно разбъркан.
Методът на теглене се използва в случаите, когато броят на елементите на цялата изследвана популация е малък. При голям обем на общата съвкупност прилагането на случаен подбор чрез лотария става трудно. По-надежден и по-малко отнемащ време в случай на голямо количество данни, които се обработват, е методът с използване на таблица със случайни числа.
Механичният избор се извършва по следния начин. Ако се образува 10% проба, т.е. трябва да бъде избран един от всеки десет елемента, след което целият набор условно се разделя на равни части от 10 елемента. След това произволно се избира елемент от първите десет. Например тегленето посочи деветото число. Изборът на останалите елементи от извадката се определя изцяло от определената пропорция на селекция N от броя на първия избран елемент. В разглеждания случай извадката ще се състои от елементи 9, 19, 29 и т.н.
Механичният подбор трябва да се използва с повишено внимание, тъй като съществува реален риск от така наречените систематични грешки. Следователно, преди да се направи механично вземане на проби, е необходимо да се анализира изследваната популация. Ако неговите елементи са разположени произволно, тогава пробата, получена механично, ще бъде произволна. Въпреки това, често елементите на оригиналния комплект са частично или дори напълно подредени. Силно нежелателно е механичният подбор да има ред от елементи, който има правилната повторяемост, чийто период може да съвпадне с периода на механично вземане на проби.
Често елементите на съвкупността са подредени по стойността на изследваната характеристика в низходящ или нарастващ ред и нямат периодичност. Механичният подбор от такава популация придобива характера на насочена селекция, тъй като отделни части от популацията са представени в извадката пропорционално на техния размер в цялата популация, т.е. селекцията има за цел да направи извадката представителна.
Друг вид насочена селекция е типичната селекция. Типичният избор трябва да се разграничава от избора на типични обекти. Изборът на типични обекти се използва в статистиката на земството, както и в бюджетните проучвания. В същото време изборът на „типични села“ или „типични ферми“ се извършва според определени икономически характеристики, например според размера на собствеността върху земята на домакинство, според професията на жителите и т.н. . Подбор от този вид не може да бъде основа за прилагане на извадковия метод, тъй като тук не е изпълнено основното му изискване - случайността на подбора.
При действителния типичен подбор при извадковия метод популацията се разделя на групи, които са качествено хомогенни, след което се прави произволен подбор във всяка група. Типичният подбор е по-труден за организиране от самия случаен подбор, тъй като са необходими определени познания за състава и свойствата на общата популация, но дава по-точни резултати.
При сериен подбор цялата популация се разделя на групи (серии). След това чрез произволен или механичен подбор се изолира определена част от тези серии и се извършва непрекъснатата им обработка. По същество серийният подбор е случаен или механичен подбор, извършен за увеличени елементи от първоначалната популация.
Теоретично, серийното вземане на проби е най-несъвършеното от разглежданите. По правило не се използва за обработка на материал, но предоставя известни удобства при организиране на проучвания, особено при изучаване на селското стопанство. Например годишните извадкови проучвания на селските стопанства в годините преди колективизацията се извършват по метода на серийния подбор. Полезно е за историка да знае серийно вземане на пробитъй като той може да се срещне с резултатите от такива проучвания.
В допълнение към класическите методи за подбор, описани по-горе, в практиката на метода на вземане на проби се използват и други методи. Нека разгледаме две от тях.
Изследваната популация може да има многостепенна структура, може да се състои от единици от първия етап, които от своя страна се състоят от единици от втория етап и т.н. Например, провинциите включват уезди, уездите могат да се разглеждат като колекция от волости, волостите се състоят от села, а селата се състоят от домакинства.
Към такива популации може да се приложи многоетапна селекция, т.е. последователно изберете на всеки етап. По този начин, от набор от провинции, чрез механичен, типичен или случаен метод, човек може да избере окръзи (първи етап), след това да избере волости (втори етап), като използва един от посочените методи, след това да избере села (трети етап) и, накрая, домакинства (четвърти етап).
Пример за двуетапен механичен подбор е дълго практикуваният подбор на бюджетите на работниците. На първия етап механично се избират предприятията, на втория - работниците, чийто бюджет се разглежда.
Изменчивостта на признаците на изследваните обекти може да бъде различна. Например осигуреността на селските стопанства със собствена работна сила варира по-малко от, да речем, размера на техните култури. Следователно по-малка извадка от предлагането на работна ръка ще бъде също толкова представителна, колкото и по-голяма извадка от данни за размера на културите. В този случай от извадката, използвана за определяне на размера на културите, е възможно да се направи извадка, която е достатъчно представителна, за да се определи наличието на работна сила, като по този начин се извършва двуфазен подбор. В общия случай могат да се добавят и следните фази, т.е. от получената подпроба, направете друга подпроба и т.н. Същият метод за подбор се използва в случаите, когато целите на изследването изискват различна точност при изчисляване на различни показатели.
Задача 1. Описателна статистика
На изпита 20 студенти получиха следните оценки (по 100-точкова скала):
1) Изградете поредица от честотни разпределения, относителни и натрупани честоти за 5 интервала;
2) Изграждане на многоъгълник, хистограма и кумулативен многоъгълник;
3) Намерете средната аритметична стойност, модата, медианата, първия и третия квартил, тримесечния диапазон, стандартното отклонение и коефициентите на вариация. Анализирайте данните с помощта на тези характеристики и посочете интервал, който включва 50% от централните стойности на посочените стойности.
1) x (мин.) =53, x (макс.) =98
R=x (max) - x (min) =98-53=45
h=R/1+3.32lgn, където n е размерът на извадката, n=20
h= 45/1+3,32*lg20= 9
a (i) - долната граница на интервала, b (i) - горната граница на интервала.
a (1) = x (min) - h/2, b (1) = a (1) + h, тогава ако b (i) е горната граница на i-тия интервал (и a (i+1) =b (i)), тогава b (2) = a (2) + h, b (3) = a (3) + h и т.н. Изграждането на интервали продължава, докато началото на следващия интервал по ред е равно или по-голямо от x (max).
a(1) = 47,5 b(1) = 56,5
a(2) = 56,5 b(2) = 65,5
a(3) = 65,5 b(3) = 74,5
a(4) = 74,5 b(4) = 83,5
a(5) = 83,5 b(5) = 92,5
a(6) = 92,5 b(6) = 101,5
|
Интервали, a (i) - b (i) |
Преброяване на честотата |
Честота, n(i) |
Кумулативна честота, n (hi) |
||
2) За да начертаем графики, записваме вариационните серии на разпределение (интервални и дискретни) на относителните честоти W (i) = n (i) / n, натрупаните относителни честоти W (hi) и намираме отношението W (i) / h като попълните таблицата.
x(i)=a(i)+b(i)/2; W(hi)=n(hi)/n
Статистическа разпределителна поредица от оценки:
|
Интервали, a (i) - b (i) |
|||||
За да изградим хистограма на относителните честоти по абсцисата, отделяме частични интервали, върху всеки от които изграждаме правоъгълник, чиято площ е равна на относителната честота W (i) на дадения i-ти интервал. Тогава височината на елементарния правоъгълник трябва да бъде равна на W (i) / h.
Многоъгълник със същото разпределение може да се получи от хистограмата, ако средните точки на горните основи на правоъгълниците са свързани с прави сегменти.
За да изградим кумулацията на дискретна серия, ние нанасяме стойностите на характеристиката по абсцисната ос и относителните натрупани честоти W (hi) по ординатната ос. Получените точки са свързани с линейни сегменти. За интервалните серии по абсцисата отделяме горните граници на групирането.
3) Средната аритметична стойност се намира по формулата:
Режимът се изчислява по формулата:
Долната граница на модалния интервал; h - ширина на груповия интервал; - модална интервална честота; - честота на интервала, предшестващ модалния; - честота на интервала след модала. = 23,125.
Нека намерим медианата:
n=20: 53.58.59.59.63.67.68.69.71.73.78.79.85.86.87.89.91.91.98.98
Като заместим стойностите, получаваме: Q1=65;
Стойността на втория квартил е същата като стойността на медианата, така че Q2=75,5; Q3=88.
Тримесечният диапазон е:
Средното квадратично (стандартно) отклонение се намира по формулата:
Коефициентът на вариация:
От тези изчисления се вижда, че 50% от централните стойности на посочените величини включват интервала 74,5 - 83,5.
Задача 2. Статистическа проверка на хипотези.
Спортните предпочитания за мъже, жени и тийнейджъри са както следва:
Тествайте хипотезата за независимост на предпочитанията от пола и възрастта b = 0,05.
1) Тестване на хипотезата за независимостта на предпочитанията в спорта.
Коефициент на Pearsen:
Табличната стойност на теста хи-квадрат със степен на свобода 4 при b \u003d 0,05 е равна на h 2 таблица \u003d 9,488.
Тъй като хипотезата е отхвърлена. Разликите в предпочитанията са значителни.
2. Хипотеза за съответствие.
Волейболът като спорт е най-близо до баскетбола. Нека проверим съответствието в предпочитанията за мъже, жени и тийнейджъри.
Ф 2 = 0,1896+0,1531+0,1624+0,1786+0,1415+0,1533 = 0,979.
При ниво на значимост b = 0,05 и степен на свобода k = 2, табличната стойност h 2 tabl = 9,210.
Тъй като Ф 2 >, разликите в предпочитанията са значителни.
Задача 3. Корелационен и регресионен анализ.
Анализът на пътнотранспортните произшествия дава следната статистика относно процента на водачите под 21 години и броя на тежките произшествия на 1000 водачи:
Извършете графичен и корелационно-регресионен анализ на данните, прогнозирайте броя на произшествията с тежки последици за град, в който броят на водачите на възраст под 21 години е равен на 20% от общия брой на водачите.
Получаваме извадка с размер n = 10.
x е процентът на шофьорите на възраст под 21 години,
y е броят на произшествията на 1000 водачи.
Уравнението линейна регресияизглежда като:
Изчисляваме последователно:
По същия начин намираме
Примерен регресионен коефициент
Връзката между x, y е силна.
Уравнението на линейната регресия приема формата:
На фигура подадено поле разсейване и график линеен регресия . Ние харчим прогноза за х н =20 .
Получаваме г н =0 .2 9*20-1 .4 6 = 4 .3 4 .
Предсказуем значение се случи Повече ▼ всичко стойности, подадено в оригинален маса . то следствие Да отида, Какво корелация пристрастяване прав и коефициент се равнява 0,29 достатъчно голям . На всеки мерна единица нараствания Dx той дава нарастване Dy =0 .3
Упражнение 4 . Анализ временно редици и прогнозиране .
прогнозирамстойности на индекса за следващата седмица, използвайки:
а) методът на пълзящата средна, като за изчисляването му се избират триседмични данни;
б) експоненциално претеглена средна, като b = 0,1.
От таблицата със случайни числа намираме числата 41, 51, 69, 135, 124, 93, 91, 144, 10, 24.
Подреждаме ги във възходящ ред: 10, 24, 41, 51, 69, 91, 93, 124, 135, 144.
Извършваме ново номериране от 1 до 10. Получаваме първоначалните данни за десет седмици:
Експоненциалното изглаждане при b = 0,1 дава само една стойност.
За средата на целия период получаваме три прогнози: 12.855; 1309; 12,895.
Има съгласие между тези прогнози.
Упражнение 5 . индекс анализ.
Фирмата се занимава с превоз на товари. Има данни за редица години за обема на превоза на 4 вида товари и себестойността на превоза на единица товар.
Определете прости индекси на цена, количество и стойност за всеки вид продукт, както и индекси на Laspeyres и Pasche и индекс на стойност. Коментирайте смислено получените резултати.
Решение. Нека изчислим прости индекси:
Индекс на Ласпейрес:
Паша индекс:
Турция цена:
Индивидуалните индекси показват несъответствието в промените в цените и количествата за стоки A, B, C, D. Агрегираните индекси показват общите тенденции в изменението. Като цяло себестойността на транспортираните стоки е намаляла с 13%. Причината е, че най-скъпият товар е намалял с 42% като количество, а тарифата му не се е променила много.
Години 16-20 са номерирани от 1 до 5. Първоначалните данни са във формата:
Първо, изучаваме динамиката на количеството товар А.
|
Индекс |
Абсолютни печалби |
Темпове на растеж, % |
Темп на растеж, % |
|||||
При това темпо растеж осреднено На формули :
, .
За темпо растеж в всякакви случай T и т.н = Т Р -1 .
Сега обмисли товари д .
|
Индекс |
Абсолютни печалби |
Темпове на растеж, % |
Темп на растеж, % |
|||||
Заключение
Средните стойности и техните разновидности играят важна роля в статистиката. Средните показатели се използват широко в анализа, тъй като именно в тях се проявяват закономерностите. масови явленияи процеси както във времето, така и в пространството. Така например моделът на нарастваща производителност на труда намира своя израз в статистиканарастването на средната продукция на един работещ в промишлеността, закономерността на устойчивото нарастване на нивото на благосъстоянието на населението се проявява в статистическите показатели за увеличаване на средните доходи на работниците и служителите и др.
Такива описателни характеристики на разпределението на променлива характеристика като мода и медиана се използват широко. Те са специфични характеристики, тяхното значение е всяка конкретна опция в вариационната серия.
И така, за да се характеризира най-често срещаната стойност на признак, се използва режим, а за да се покаже количествената граница на стойността на променлив признак, която се достига от половината от членовете на съвкупността, медианата е използвани.
По този начин средните стойности помагат да се проучат моделите на развитие на индустрията, определена индустрия, обществото и страната като цяло.
Библиография
1. Теория на статистиката: Учебник / R.A. Шмойлова, В.Г. Минашкин, Н.А. Садовникова, Е.Б. Шувалов; Под редакцията на R.A. Шмойлова. - 4-то изд., преработено. и допълнителни - М.: Финанси и статистика, 2005. - 656s.
2. Гусаров В.М. Статистика: Урокза университети. - М.: ЮНИТИ-ДАНА, 2001.
4. Сборник от задачи по теория на статистиката: Учебник / Изд. проф.В. В. Глински и д-р. д-р доц. Л.К. Серга. Изд. З-е. - М.: ИНФРА-М; Новосибирск: Сибирско споразумение, 2002 г.
5. Статистика: Учебник / Kharchenko L-P., Dolzhenkova V.G., Ionin V.G. и др., изд. В.Г. Йонина. - Изд.2-ро, преработено. и допълнителни - М.: ИНФРА-М. 2003 г.
Подобни документи
Описателна статистика и статистическо заключение. Методи за подбор, които осигуряват представителност на извадката. Влияние на вида на извадката върху големината на грешката. Задачи при прилагане на извадковия метод. Разпространение на данните от наблюденията сред общата популация.
тест, добавен на 27.02.2011 г
Метод на вземане на проби и неговата роля. развитие съвременна теорияселективно наблюдение. Типология на методите за подбор. Начини за практическо прилагане на проста случайна извадка. Организация на типична (стратифицирана) извадка. Размер на извадката при избор на квота.
доклад, добавен на 03.09.2011 г
Цел на вземане на проби и вземане на проби. Характеристики на организацията различни видовеселективно наблюдение. Грешки селективна селекцияи методи за тяхното изчисляване. Прилагане на метода за вземане на проби за анализ на предприятия от горивно-енергийния комплекс.
курсова работа, добавена на 06.10.2014 г
Избирателното наблюдение като метод статистическо изследване, неговите характеристики. Случаен, механичен, типичен и сериен видове подбор при формиране на набори от проби. Концепцията и причините за грешката на извадката, методите за нейното определяне.
резюме, добавено на 04.06.2010 г
Понятие и роля на статистиката в механизма на управление модерна икономика. Непрекъснато и непродължително статистическо наблюдение, описание на извадковия метод. Видове селекция при селективно наблюдение, извадкови грешки. Производствени и финансови показатели.
курсова работа, добавена на 17.03.2011 г
Проучване изпълнението на плана. Проучване на случайна извадка от 10%. Фабрична производствена цена. пределна грешкапроби. Динамика на средните цени и обема на продажбите на продукта. Индекс на цените с променлив състав.
контролна работа, добавена на 09.02.2009 г
Получаване на обемна проба n-нормално разпределение случайна величина. Намиране числови характеристикипроби. групиране на данни и вариационна серия. Честотна хистограма. Емпирична функция на разпределение. Статистическа оценка на параметрите.
лабораторна работа, добавена на 31.03.2013 г
Същността на понятията вземане на проби и наблюдение на пробите, основните видове и категории селекция. Определяне на обема и размера на пробата. Практическа употреба Статистически анализселективно наблюдение. Изчисляване на грешките във фракцията на пробата и средната стойност на пробата.
курсова работа, добавена на 17.02.2015 г
Концепцията за селективно наблюдение. Грешки на представителността, измерване на грешката на извадката. Определяне на необходимия размер на извадката. Използването на метод на вземане на проби вместо непрекъснат. Дисперсия в генералната съвкупност и сравнение на показателите.
тест, добавен на 23.07.2009 г
Видове грешки при подбор и наблюдение. Методи за подбор на единици в извадкова съвкупност. Характеристика търговски дейностипредприятия. Примерно проучванепотребители на продукта. Разпределение на характеристиките на извадката към генералната съвкупност.
Част от обектите от популацията, избрани за изследване, за да се направи заключение за цялата популация. За да може заключението, получено чрез изследване на извадката, да се разпространи върху цялата популация, извадката трябва да има свойството да бъде представителна.
Представителност на извадката
Свойството на извадката да отразява правилно генералната съвкупност. Една и съща извадка може или не може да бъде представителна за различни популации.
Пример:
Извадка, състояща се изцяло от московчани, които притежават кола, не представлява цялото население на Москва.
Извадката от руски предприятия с до 100 служители не представлява всички предприятия в Русия.
Извадката от московчани, които правят покупки на пазара, не представя покупателното поведение на всички московчани.
В същото време тези проби (при други условия) могат перфектно да представят московските собственици на автомобили, съответно малки и средни руски предприятия и купувачи, които правят покупки на пазарите.
Важно е да се разбере, че представителността на извадката и грешката на извадката са различни явления. Представителността, за разлика от грешката, не зависи от размера на извадката.
Колкото и да увеличим броя на анкетираните московчани-собственици на автомобили, няма да можем да представим всички московчани с тази извадка.
Грешка на извадката (доверителен интервал)
Отклонението на резултатите, получени с помощта на извадково наблюдение, от истинските данни на генералната съвкупност.
Има два вида грешки на извадката: статистическа и систематична. Статистическата грешка зависи от размера на извадката. Колкото по-голям е размерът на извадката, толкова по-малък е той.
Пример:
За проста произволна извадка от 400 единици, максималната статистическа грешка (от 95% ниво на увереност) е 5%, за извадка от 600 единици - 4%, за извадка от 1100 единици - 3%.Обикновено, когато се говори за извадкова грешка, се има предвид точно статистическата грешка.
Систематичната грешка зависи от различни факторикоито оказват постоянно влияние върху изследването и изместват резултатите от изследването в определена посока.
Пример:
- Използването на каквато и да е вероятностна извадка подценява дела на водещите хора с високи доходи активно изображениеживот. Това се дължи на факта, че такива хора са много по-трудни за намиране на определено място (например у дома).
Проблемът с респондентите, които отказват да отговорят на въпросите на въпросника (делът на "отказниците" в Москва за различни проучвания варира от 50% до 80%)
В някои случаи, когато са известни истинските разпределения, систематична грешкаможе да бъде изравнено чрез въвеждане на квоти или повторно претегляне на данните, но в повечето реални проучвания дори оценяването му може да бъде доста проблематично.
Примерни типове
Пробите са разделени на два вида:
вероятностен
невероятност
Вероятностни проби
1.1 Случайна извадка (прост произволен избор)
Такава извадка предполага хомогенността на генералната съвкупност, същата вероятност за наличие на всички елементи, присъствие пълен списъквсички елементи. При избора на елементи по правило се използва таблица с произволни числа.
1.2 Механично (систематично) вземане на проби
Един вид произволна извадка, сортирана по някакъв признак (азбучен ред, телефонен номер, дата на раждане и др.). Първият елемент се избира произволно, след което всеки „k'-ти елемент се избира на стъпки от „n“. Размерът на генералната съвкупност, докато - N=n*k
1.3 Стратифицирани (зонирани)
Използва се в случай на хетерогенност на генералната съвкупност. Генералната съвкупност е разделена на групи (страти). Във всяка страта селекцията се извършва на случаен принцип или механично.
1.4 Серийно (вложено или клъстерно) вземане на проби
При серийно вземане на проби единиците за селекция не са самите обекти, а групи (клъстери или гнезда). Групите се избират на случаен принцип. Обектите в групите се изследват навсякъде.
Невероятни мостри
Подборът в такава извадка се извършва не по принципите на случайността, а по субективни критерии - достъпност, типичност, равно представителство и др.
Квотна извадка
Първоначално се разпределят определен брой групи обекти (например мъже на възраст 20-30 години, 31-45 години и 46-60 години; лица с доход до 30 хиляди рубли, с доход от 30 до 60 рубли). хиляди рубли и с доход над 60 хиляди рубли ) За всяка група е посочен броят на обектите, които ще бъдат изследвани. Броят на обектите, които трябва да попаднат във всяка от групите, се определя най-често или пропорционално на предварително известния дял на групата в генералната съвкупност, или еднакъв за всяка група. В рамките на групите обектите се избират на случаен принцип. Квотните проби се използват доста често в маркетинговите проучвания.
Метод на снежна топка
Пробата е конструирана по следния начин. Всеки респондент, като се започне от първия, е помолен да се свърже със своите приятели, колеги, познати, които отговарят на условията за подбор и биха могли да участват в проучването. Така, с изключение на първата стъпка, извадката се формира с участието на самите обекти на изследване. Методът често се използва, когато е необходимо да се намерят и интервюират труднодостъпни групи от респонденти (например респонденти с високи доходи, респонденти, принадлежащи към същата професионална група, респонденти, които имат сходни хобита / страсти и др. )
2.3 Спонтанно вземане на проби
Анкетират се най-достъпните респонденти. Типични примерипроизволни извадки - анкети във вестници/списания, въпросници, дадени на респондентите за самостоятелно попълване, повечето интернет анкети. Размерът и съставът на спонтанните извадки не е предварително известен и се определя само от един параметър – активността на респондентите.
2.4 Примерни типични случаи
Избират се единици от генералната съвкупност, които имат средна (типична) стойност на признака. Това повдига проблема с избора на характеристика и определянето на нейната типична стойност.
Изпълнение на изследователския план
Този етап, припомняме, включва събирането на информация и нейния анализ. Процесът на прилагане на план за маркетингово проучване обикновено изисква най-много изследвания и е източник на най-голямата грешка.
При събирането на статистически данни възникват редица недостатъци и проблеми:
първо, някои респонденти може да не са на уговореното място и трябва да се свържат отново или да бъдат заменени;
второ, някои респонденти може да не сътрудничат или да дават пристрастни, съзнателно неверни отговори.
Благодарение на съвременните компютърни и телекомуникационни технологии, методите за събиране на данни се развиват и подобряват.
Някои фирми провеждат проучвания от един център. В този случай професионалните интервюиращи седят в офиси и набират произволни телефонни номера. Ако чуят отговора на обаждащите се, интервюиращият моли лицето, което е отговорило на телефона, да отговори на няколко въпроса. Последните се четат от екрана на компютърния монитор и отговорите на респондентите се набират на клавиатурата. Този метод премахва необходимостта от форматиране и кодиране на данни, намалява броя на грешките.
 Сюжетът на чичо ваня. „Чичо Иван. Отношение към професора на др
Сюжетът на чичо ваня. „Чичо Иван. Отношение към професора на др Малкият Цахес, по прякор Цинобър
Малкият Цахес, по прякор Цинобър Майков, Аполон Николаевич - кратка биография
Майков, Аполон Николаевич - кратка биография