Методи на математическата статистика във VK. За студенти и ученици - книги, математическа статистика
„Някои хора си мислят, че винаги са прави. Такива хора не могат нито да бъдат добри учени, нито да се интересуват от статистика... Случаят беше свален от небето на земята, където стана част от света на науката.“ (Дименд С.)
„Шансът е само мярка за нашето невежество. Случайни явления, ако ги дефинираме, ще бъдат тези, чиито закони не познаваме. (А. Поанкаре "Наука и хипотеза")
„Слава на случая. Не е ли случай
Винаги наравно с неизменното...
Шансът често управлява събитието,
Генерира едновременно радост и болка.
И животът поставя задача пред нас:
Как да разберем ролята на случайността"
(от книгата на Б. А. Кордемски „Математиката изучава случайността“)
Самият свят е закономерен - така често мислим и изучаваме законите на физиката, химията и т.н., но нищо не се случва без намесата на случайността, възникваща под влиянието на непостоянни, вторични причинно-следствени връзки, които променят хода на явление или преживяване, когато се повтаря. Създава се „случаен ефект” с присъщата закономерност на „скритата предопределеност”, т.е. случайността има нужда от редовен резултат.
Математиците разглеждат случайните събития само в дилемата „да бъде или да не бъде“ – да дойде или да не дойде.
Определение.Разделът от приложната математика, който изучава количествените характеристики на масови случайни събития или явления, се нарича математическа статистика.
Определение.Комбинацията от елементи на теорията на вероятностите и математическата статистика се нарича стохастика.
Определение. Стохастичен- това е клонът на математиката, който възниква и се развива в тясна връзка с практическата дейност на човека. Днес елементите на стохастиката са включени в математиката за всички, превръщайки се в нов, важен аспект на математическото и общото образование.
Определение. Математическа статистика- науката за математическите методи за систематизиране, обработка и използване на статистически данни за научни и практически изводи.
Нека поговорим за това по-подробно.
Гледната точка на математическата статистика като наука за общите методи за обработка на резултатите от експеримента вече е общоприета. При решаването на тези проблеми какво трябва да има един експеримент, за да бъдат правилни преценките, направени въз основа на него. Математическата статистика отчасти се превръща в наука за експериментален дизайн.
Значението на думата "статистика" през последните два века е претърпяло значителни промени, пишат известните съвременни учени Ходжис и Леман, - думата "статистика" има същия корен като думата "държава" (държава) и първоначално е означавала изкуство и наука за управление: първите преподаватели по университетска статистика в Германия през 18 век днес биха били наречени социални учени. Защото решенията на правителството донякъде се основават на данни за населението, индустрията и т.н. статистиците, разбира се, започнаха да се интересуват от такива данни и постепенно думата "статистика" започна да означава събиране на данни за населението, за държавата и след това въобще събиране и обработка на данни. Няма смисъл да се извличат данни, ако няма полза от тях, и статистиците естествено се включват в тълкуването на данните.
Съвременният статистик изучава методите, чрез които могат да се правят изводи за съвкупност от данни, които обикновено се получават от извадка от „популация“.
Определение. Статистик- лице, което се занимава с науката за математическите методи за систематизиране, обработка и използване на статистически данни за научни и практически изводи.
Математическата статистика възниква през 17 век и се развива успоредно с теорията на вероятностите. По-нататъшното развитие на математическата статистика (втората половина на 19-ти и началото на 20-ти век) се дължи предимно на P.L. Чебишев, А.А. Марков, А.М. Ляпунов, К. Гаус, А. Кетле, Ф. Галтън, К. Пиърсън и др.. През 20-те години най-значимият принос в математическата статистика е на А.Н. Колмогоров, В.И. Романовски, E.E. Слуцки, Н.В. Смирнов, Б.В. Gnedenko, както и английски студент, R. Fisher, E. Purson и американски (Yu. Neumann, A Wald) учени.
Проблеми на математическата статистика и значението на грешката в света на науката
Установяването на закономерностите, на които са подложени масовите случайни явления, се основава на изследването на статистически данни от резултатите от наблюдението чрез методите на теорията на вероятностите.
Първата задача на математическата статистика е да посочи методите за събиране и групиране на статистическа информация, получена в резултат на наблюдения или в резултат на специално проектирани експерименти.
Втората задача на математическата статистика е да разработи методи за анализ на статистически данни в зависимост от целите на изследването.
Съвременната математическа статистика разработва начини за определяне на броя на необходимите тестове преди началото на изследването (планиране на експеримента), по време на изследването (последователен анализ). Може да се определи като наука за вземане на решения при несигурност.
Накратко можем да кажем, че задачата на математическата статистика е да създаде методи за събиране и обработка на статистически данни.
Когато се изучава масово случайно явление, се приема, че всички тестове се провеждат при едни и същи условия, т.е. групата от основни фактори, които могат да бъдат взети предвид (измерени) и имат значително влияние върху резултата от теста, запазва същите стойности, доколкото е възможно.
Случайните фактори изкривяват резултата, който би се получил, ако бяха налице само основните фактори, което го прави случаен. Отклонението на резултата от всеки тест от истинския се нарича грешка на наблюдението, която е случайна променлива. Необходимо е да се прави разлика между систематични и случайни грешки.
Научен експеримент е немислим без грешка, както океанът без сол. Всеки поток от факти, който добавя към нашите знания, носи някаква грешка. Според една добре позната поговорка в живота на повечето хора нищо не може да бъде сигурно, освен смъртта и данъците, а ученият добавя: „И грешките на опита“.
Статистикът е „хрътка“, която търси бъг. Статистически инструмент за откриване на грешки.
Думата "грешка" не означава просто "грешна преценка". Последствията от погрешно изчисление са малък и относително безинтересен източник на експериментална грешка.
Наистина нашите инструменти се чупят; нашите очи и уши могат да ни измамят; нашите измервания никога не са идеално точни, понякога дори нашите аритметични изчисления са грешни. Експерименталната грешка е нещо по-съществено от неточна рулетка или оптична илюзия. И тъй като най-важната задача на статистиката е да помогне на учените да анализират експерименталната грешка, трябва да се опитаме да разберем какво всъщност представлява грешката.
По какъвто и проблем да работи един учен, той със сигурност ще се окаже по-сложен, отколкото би искал. Да предположим, че измерва радиоактивните отпадъци на различни географски ширини. Резултатите ще зависят от надморската височина на местата, където са взети пробите, от количеството на местните валежи и от височинните циклони в по-широка област.
Експерименталната грешка е неразделна част от всеки истински научен опит.
Същият резултат може да бъде грешка и информация в зависимост от проблема и гледната точка. Ако един биолог иска да изследва как промяната в диетата влияе върху растежа, тогава наличието на свързана конституция е източник на грешка; ако той изучава връзката между наследствеността и растежа, източникът на грешка ще бъдат разликите в храненето. Ако един физик иска да изследва връзката между електрическата проводимост и температурата, разликите в плътността на проводящия материал са източник на грешка; ако той изследва връзката между тази плътност и електрическата проводимост, температурните промени ще бъдат източник на грешка.
Тази употреба на думата грешка може да изглежда съмнителна и може би би било за предпочитане да се каже, че произтичащите ефекти са изкривени от „непреднамерени“ или „нежелани“ влияния. Планираме експеримент за изследване на известни влияния, но случайни фактори, които не сме в състояние да предвидим или анализираме, изкривяват резултатите, като добавят свои собствени ефекти към тях.
Разликата между планираните въздействия и въздействията, дължащи се на случайни причини, е като разликата между движението на кораб по морето, плаващ по определен курс, и кораб, който се носи безцелно по заповед на променящите се ветрове и течения. Движението на втория кораб може да се нарече произволно движение. Възможно е този кораб да стигне до всяко пристанище, но е по-вероятно да не стигне до някое конкретно място.
Статистиците използват думата „случаен“, за да обозначат явление, чийто изход в предстоящ момент е напълно невъзможно да се предвиди.
Грешката, дължаща се на ефектите, предвидени в експеримента, понякога е по-систематична, отколкото случайна.
Систематичната грешка е по-подвеждаща от случайната грешка. Смущението от друга радиостанция може да създаде систематичен музикален съпровод, който понякога можете да предвидите, ако знаете мелодията. Но този „акомпанимент“ може да ни накара да направим грешна преценка относно думите или музиката на програмата, която се опитваме да чуем.
Но откриването на систематична грешка често ни води по следите на ново откритие. Знаейки как възникват случайни грешки, ни помага да открием системни грешки и следователно да ги отстраним.
Същият характер на разсъждение е често срещан в нашите светски дела. Колко често забелязваме: „Това не е инцидент!“. Винаги, когато можем да кажем това, ние сме на пътя към откритието.
Например A.L. Чижевски, анализирайки исторически процеси: увеличаване на смъртността, епидемии, избухване на войни, големи преселения на народите, резки промени в климата и др. откри връзката между тези несвързани процеси и периодите на слънчева активност, които имат цикли: 11 години, 33 години.
Определение. при систематична грешкасе разбира като грешка, която се повтаря и е еднаква за всички тестове. Обикновено се свързва с неправилно провеждане на експеримента.
Определение. При случайни грешкисе отнася до грешки, възникващи под влиянието на случайни фактори и променящи се произволно от опит на опит.
Обикновено разпределението на случайните грешки е симетрично около нулата, което води до важен извод: при липса на систематични грешки, истинският резултат от теста е математическото очакване на случайна променлива, чиято специфична стойност е фиксирана във всеки тест.
Обектите на изследване в математическата статистика могат да бъдат качествени или количествени характеристики на изучаваното явление или процес.
В случай на качествен признак се брои броят на появяванията на този признак в разглежданата серия от експерименти; това число е (дискретната) случайна променлива, която се изследва. Примери за качествени атрибути са дефекти на завършена част, демографски данни и т.н. Ако знакът е количествен, тогава в експеримента се извършва пряко или косвено измерване чрез сравнение с определен стандарт - единица за измерване - с помощта на различни измервателни уреди. Например, ако има партида части, тогава стандартът на частта може да служи като качествен знак, а контролираният размер на частта може да служи като количествен знак.
Основни определения
Значителна част от математическата статистика е свързана с необходимостта да се опише голям набор от обекти.
Определение.Цялата съвкупност от обекти, които трябва да се изследват, се нарича общото население.
Генералната съвкупност може да бъде цялото население на страната, месечната продукция на растението, популацията на рибите, живеещи в даден водоем и др.
Но общата съвкупност не е просто набор. Ако наборът от обекти, които ни интересуват, е твърде многоброен, или обектите са труднодостъпни, или има други причини, които не позволяват изучаването на всички обекти, те прибягват до изучаване на част от обектите.
Определение.Тази част от обектите, които трябва да се проверят, проучат и т.н., се наричат извадкова популацияили просто проба.
Определение.Броят на елементите в генералната съвкупност и извадката се нарича техен обеми.
Как да се гарантира, че извадката представя най-добре цялото, т.е. ще бъде представителен?
Ако цяло число, т.е. ако общото население е малко или напълно непознато за нас, нищо по-добро не може да бъде предложено от чисто случаен избор. По-голямата информираност ви позволява да действате по-добре, но все пак на някакъв етап се появява невежество и в резултат на това случаен избор.
Но как да направите чисто случаен избор? По правило селекцията се основава на лесно забележими признаци, за чието изследване се провеждат изследвания.
Нарушаването на принципите на случайния подбор доведе до сериозни грешки. Анкета, проведена от американското списание "Литературное обозрение" за изхода от президентските избори през 1936 г., стана известна с неуспеха си. Кандидатите на този избор бяха Ф.Д. Рузвелт и А.М. Ландън.
Кой спечели?
Като цяло редакторите са използвали телефонни указатели. След произволен избор на 4 милиона адреса, тя разпрати картички с въпроси за отношението към кандидатите за президент в цялата страна. След като похарчи голяма сума за изпращане и обработка на пощенски картички, списанието обяви, че Ландън ще спечели предстоящите президентски избори със съкрушителна победа. Изборният резултат се оказа обратен на тази прогноза.
Тук бяха направени две грешки. Първо, телефонните указатели не предоставят представителна извадка от населението на САЩ - предимно богати глави на семейства. Второ, не всички изпратиха отговори, но значителна част от представителите на бизнеса, които подкрепиха Ландън.
В същото време социолозите J. Gallan и E. Warner правилно прогнозираха победата на F.D. Рузвелт, въз основа на само четири хиляди въпросника. Причината за този успех беше не само правилният подбор на извадката. Те взеха предвид, че обществото се разпада на социални групи, които са по-хомогенни по отношение на кандидатите за президент. Следователно пробата от слоя може да бъде относително малка със същия точен резултат. В крайна сметка спечели Рузвелт, който беше привърженик на реформите за по-малко богатите слоеве от населението.
Имайки резултатите от проучването по слоеве, е възможно да се характеризира обществото като цяло.
Какво представляват пробите?
Това са редове от числа.
Нека се спрем по-подробно на основните понятия, които характеризират примерната серия.
Извадка с размер n е взета от общата популация > n 1 , където n 1 е броят пъти, в които е наблюдавана появата на x 1 , n 2 - x 2 и т.н.
Наблюдаваните стойности на x i се наричат опции, а последователността от опции, записани във възходящ ред, се нарича вариационна серия. Броят на наблюденията n i се наричат честоти, а n i /n - относителни честоти (или честоти).
Определение.Извикват се различни стойности на случайна променлива настроики.
Определение. вариационна сериянаречена серия, подредена във възходящ (или низходящ) ред от опции със съответните им честоти (честоти).
При изучаване на вариационни серии, наред с понятията за честота, се използва понятието за натрупана честота. Натрупаните честоти (честоти) за всеки интервал се намират чрез последователно сумиране на честотите на всички предишни интервали.
Определение.Натрупването на честоти или честоти се нарича кумулация. Можете да кумулирате честотни опции и интервали.
Характеристиките на една серия могат да бъдат количествени и качествени.
Количествени (вариационни) характеристикиса характеристики, които могат да бъдат изразени в числа. Делят се на дискретни и непрекъснати.
Качествени (атрибутни) характеристикиса характеристики, които не се изразяват с числа.
Непрекъснати променливиса променливи, които се изразяват като реални числа.
Дискретни променливиса променливи, които се изразяват само като цели числа.
Пробите се характеризират централни тенденции: средна стойност, мода и медиана. Средната стойност на извадката е средноаритметичното на всички нейни стойности. Примерният режим е стойностите, които се срещат най-често. Медианата на извадката е числото, което "дели" наполовина подредения набор от всички стойности в извадката.
Вариационните серии могат да бъдат дискретни или непрекъснати.
Задача
Дадена проба: 1,3; 1.8; 1.2; 3.0; 2.1; 5; 2.4; 1.2; 3.2;1.2; четири; 2.4.
Това е набор от опции. Подреждайки тези опции във възходящ ред, получаваме вариационна серия: 1.2; 1.2; 1.2; 1.3; 1.8; 2.1; 2.4; 2.4; 3.0; 3.2; четири; 5.
Средната стойност на тази серия е 2,4.
Медианата на серията е 2,25.
Режимът на серията е -1,2.
Нека дефинираме тези понятия.
Определение. Медианата на вариационната сериясе нарича тази стойност на случайна променлива, която попада в средата на вариационната серия (Me).
Медианата на подредена редица от числа с нечетен брой членове е числото, записано в средата, а медианата на подредена редица от числа с четен брой членове е средноаритметичното на двете числа, записани в средата. Медианата на произволна серия от числа е медианата на съответната подредена серия.
Определение. Серия Vogueименувайте варианта (стойността на случайна променлива), който съответства на най-високата честота (Mo), т.е. което е по-често срещано от другите.
Определение. Средната аритметична стойност на вариационния редсе нарича резултатът от разделянето на сумата от стойности на статистическа променлива на броя на тези стойности, тоест на броя на термините.
Правилото за намиране на средната аритметична стойност на извадката:
- умножете всяка опция по нейната честота (кратност);
- съберете всички получени произведения;
- разделете намерената сума на сумата от всички честоти.
Определение. Ред за почистванее разликата между R=x max -x min , т.е. най-голямата и най-малката стойност на тези опции.
Нека проверим дали сме намерили правилно средната стойност на тази серия, медианата и модата въз основа на дефинициите.
Преброихме броя на членовете, има 12 от тях - четен брой членове, така че трябва да намерите средноаритметичното на двете числа, написани в средата, тоест 6-та и 7-ма опция. (2,1+2,4) \ 2 \u003d 2,25 - медиана.
Мода. Модът е 1.2, защото само това число се среща 3 пъти, а останалите се срещат по-малко от 3 пъти.
Средната аритметична стойност намираме, както следва:
(1,2*3+1,3+1,8+2,1+2,4*2+3,0+3,2 +4+5)\12=2,4
Да направим маса
Такива таблици се наричат честотни таблици. В тях числата на втория ред са честоти; те показват колко често една или друга от неговите стойности се срещат в извадката.
Определение. Относителна честотаизвадковите стойности са съотношението на неговата честота към броя на всички извадкови стойности.
Относителните честоти иначе се наричат честоти. Честотите и честотите се наричат тегла. Намерете диапазона на редицата: R=5-1.2=3.8; Обхватът на серията е 3.8.
Информация за размисъл
Средната аритметична стойност е условна стойност. Наистина не съществува. Реално има тотална. Следователно средноаритметичната стойност не е характеристика на едно наблюдение; характеризира сериала като цяло.
Означаваможе да се интерпретира като център на дисперсия на стойностите на наблюдаваната характеристика, т.е. стойност, около която се колебаят всички наблюдавани стойности, а алгебричната сума на отклоненията от средната винаги е равна на нула, т.е. сумата от отклоненията от средната стойност нагоре или надолу са равни помежду си.
Средно аритметичное абстрактна (обобщаваща) величина. Дори когато се указва поредица само от естествени числа, средната стойност може да бъде изразена като дробно число. Пример: средният резултат от теста е 3,81.
Означавасе намира не само за еднородни количества. Среден добив на зърно в цялата страна (царевица - 50-60 центнера на хектар и елда - 5-6 центнера на хектар, ръж, пшеница и др.), средно потребление на храна, среден национален доход на глава от населението, средно предлагане на жилища, среднопретеглена жилищна площ себестойност, средна трудоемкост на строителството на сградата и др. - това са характеристиките на държавата като единна икономическа система, това са така наречените системни средни стойности.
В статистиката такива характеристики се използват широко като режим и медиана. Те се наричат структурни средни, т.к стойностите на тези характеристики се определят от общата структура на серията данни.
Понякога един ред може да има два режима, понякога един ред може да няма режим.
Модае най-приемливият показател за идентифициране на опаковката на даден продукт, който е предпочитан от купувачите; цени за стоки от този тип, често срещани на пазара; като размер на обувките, облекло, най-търсени; спорт, който е предпочитан от по-голямата част от населението на страната, града, училището в селото и др.
В строителството има 8 варианта на плочи по ширина, като по-често се използват 3 вида: 1 м. 1,2 м. и 1,5 м. Има 33 варианта на плочи по дължина, но най-често се използват плочи с дължина 4,8 м; 5,7 m и 6,0 m, моделът на плочите е най-често срещаният сред тези 3 размера. Същото може да се каже и за марките прозорци.
Режимът на поредица от данни се намира, когато искат да идентифицират някакъв типичен индикатор.
Режимът може да бъде изразен с числа и думи, по отношение на статистиката режимът е честотният екстремум.
Медианави позволява да вземете предвид информация за поредица от данни, която дава средно аритметично и обратно.
Методи на математическата статистика
1. Въведение
Математическата статистика е наука, която разработва методи за получаване, описание и обработка на експериментални данни с цел изследване на моделите на случайни масови явления.
В математическата статистика могат да се разграничат две области: дескриптивна статистика и индуктивна статистика (статистически извод). Описателната статистика се занимава с натрупване, систематизиране и представяне на експериментални данни в удобна форма. Индуктивната статистика въз основа на тези данни ни позволява да направим определени изводи за обектите, за които се събират данните, или оценки на техните параметри.
Типичните области на математическата статистика са:
1) теория на вземането на проби;
2) теорията на оценките;
3) проверка на статистически хипотези;
4) регресионен анализ;
5) дисперсионен анализ.
Математическата статистика се основава на редица първоначални концепции, без които е невъзможно да се изучават съвременните методи за обработка на експериментални данни. В редица от първите от тях можем да поставим понятието генерална съвкупност и извадка.
При масовото промишлено производство често е необходимо да се установи дали качеството на продукта отговаря на стандартите, без да се проверява всеки произведен продукт. Тъй като броят на произведените продукти е много голям или проверката на продуктите е свързана с привеждането им в неизправност, се проверяват малък брой продукти. Въз основа на тази проверка трябва да се направи заключение за цялата серия продукти. Разбира се, не можете да кажете, че всички транзистори от партида от 1 милион броя са добри или лоши, като проверите един от тях. От друга страна, тъй като процесът на подбор на проби за тестване и самите тестове могат да отнемат време и да доведат до високи разходи, обхватът на проверката на продукта трябва да бъде такъв, че да може да даде надеждно представяне на цялата партида продукти, като от минималния размер. За тази цел въвеждаме редица понятия.
Цялата съвкупност от изследвани обекти или експериментални данни се нарича генерална съвкупност. Ще обозначим с N броя на обектите или количеството данни, които съставляват генералната съвкупност. Стойността на N се нарича размер на популацията. Ако N>>1, тоест N е много голямо, тогава обикновено се разглежда N = ¥.
Случайна извадка или просто извадка е част от генералната съвкупност, избрана на случаен принцип от нея. Думата "на случаен принцип" означава, че вероятността да се избере всеки обект от общата съвкупност е една и съща. Това е важно предположение, но често е трудно да се провери на практика.
Размерът на извадката се нарича броят на обектите или количеството данни, които съставляват извадката, и обозначават н. В бъдеще ще приемем, че на елементите на извадката могат да бъдат присвоени съответно числени стойности x 1, x 2, ... x n. Например, в процеса на контрол на качеството на произведени биполярни транзистори, това може да бъде измерване на тяхното усилване по DC.
2. Числени характеристики на извадката
2.1 Извадкова средна стойност
За конкретна извадка с размер n, нейната извадкова средна стойност
се определя от съотношениетокъдето x i е стойността на елементите на извадката. Обикновено се изисква да се опишат статистическите свойства на произволни случайни извадки, а не на една от тях. Това означава, че се разглежда математически модел, който предполага достатъчно голям брой проби с размер n. В този случай елементите на извадката се разглеждат като случайни променливи X i , като се приемат стойности x i с плътност на вероятността f(x), която е плътността на вероятността на общата съвкупност. Тогава средната стойност на извадката също е случайна променлива
равенКакто и преди, ще обозначаваме случайните променливи с главни букви, а стойностите на случайните променливи с малки букви.
Средната стойност на генералната съвкупност, от която е направена извадката, ще се нарича обща средна и ще се означава с m x . Може да се очаква, че ако размерът на извадката е значителен, тогава средната стойност на извадката няма да се различава значително от общата средна стойност. Тъй като примерната средна стойност е случайна променлива, можете да намерите математическото очакване за нея:

По този начин математическото очакване на средната стойност на извадката е равно на общата средна стойност. В този случай се казва, че средната стойност на извадката е безпристрастна оценка на средната стойност на съвкупността. Ще се върнем към този термин по-късно. Тъй като средната стойност на извадката е случайна променлива, която се колебае около общата средна стойност, желателно е това колебание да се оцени, като се използва дисперсията на средната стойност на извадката. Помислете за извадка, чийто размер n е много по-малък от размера на общата съвкупност N (n<< N). Предположим, что при формировании выборки характеристики генеральной совокупности не меняются, что эквивалентно предположению N = ¥. Тогда
Случайните променливи X i и X j (i¹j) могат да се считат за независими, следователно,

Заместете резултата във формулата за дисперсията:
където s 2 е дисперсията на популацията.
От тази формула следва, че с увеличаване на размера на извадката, флуктуациите на средната стойност на извадката около общата средна намаляват като s 2 /n. Нека илюстрираме горното с пример. Нека има случаен сигнал с математическо очакване и съответно дисперсия, равна на m x = 10, s 2 = 9.
Пробите на сигнала се вземат на еднакво разстояние от времена t 1 , t 2 , ... ,
 X(t)
X(t) x1
t 1 t 2 . . . t n t
Тъй като показанията са случайни променливи, ще ги обозначим като X(t 1), X(t 2), . . . ,X(tn).
Нека определим броя на пробите, така че стандартното отклонение на оценката на математическото очакване на сигнала да не надвишава 1% от неговото математическо очакване. Тъй като m x = 10, е необходимо, че
От друга страна, следователно или Следователно, получаваме, че n ³ 900 се брои.2.2 Дисперсия на извадката
От извадковите данни е важно да се знае не само средната стойност на извадката, но и разпространението на стойностите на извадката около средната извадка. Ако средната стойност на извадката е оценка на общата средна стойност, тогава дисперсията на извадката трябва да бъде оценка на общата дисперсия. Дисперсия на извадката
за извадка, състояща се от случайни променливи, се определя, както следва
Използвайки това представяне на дисперсията на извадката, намираме нейното математическо очакване
В рамките на образователната програма на университета е малко вероятно да намерите отделна дисциплина с името "математическа статистика", но елементите на математическата статистика често се изучават във връзка с теорията на вероятностите, но само след изучаване на основния курс на теория на вероятностите.
Математическа статистика: обща информация
Математическата статистика е дял от математиката, който разработва методи за записване, описание и анализ на данните от всякакви наблюдения и експерименти, чиято цел е да се изградят вероятностни модели на масови случайни явления.
Математическата статистика като наука възниква през 17 век. и се развива паралелно с теорията на вероятностите. Голям принос за развитието на науката има през XIX-XX век. Чебишев П.Л., Гаус К., Колмогоров А.Н. и т.н.
Общата задача на математическата статистика е да създаде методи за събиране и обработка на статистически данни за получаване на научни и практически изводи.
Основните раздели на математическата статистика са:
- метод на вземане на проби (запознаване с концепцията за вземане на проби, методи за събиране и обработка на данни и др.);
- статистическа оценка на параметрите на извадката (оценки, доверителни интервали и др.);
- изчисляване на обобщената характеристика на извадката (изчисляване на варианта, моменти и др.);
- корелационна теория (регресионни уравнения и др.);
- статистическа проверка на хипотези;
- еднопосочен дисперсионен анализ.
Да се най-честоЗадачите на математическата статистика, които се изучават в университета и често се срещат в практиката, включват:
- задачи за определяне на оценки на параметрите на извадката;
- задачи за проверка на статистически хипотези;
- проблеми на определяне на вида на закона за разпределение по статистически данни.
Проблеми при определяне на оценките на параметрите на извадката
Изучаването на математическата статистика започва с дефинирането на такива понятия като "извадка", "честота", "относителна честота", "емпирична функция", "многоъгълник", "кумулативен", "хистограма" и др. Следва изучаването на концепциите за оценки (предубедени и непредубедени): средна стойност на извадката, дисперсия, коригирана дисперсия и т.н.
Задача
Измерването на растежа на децата в по-младата група на детската градина е представено от извадка:
92, 96, 95, 96, 94, 97, 98, 94, 95, 96.
Нека намерим някои характеристики на тази извадка.
Решение
Размер на извадката (брой измервания; н): 10.
Най-малката стойност на извадката: 92. Най-голямата стойност на извадката: 98.
Примерен обхват: 98 - 92 = 6.
Нека напишем класирана серия (опции във възходящ ред):
92, 94, 94, 95, 95, 96, 96, 96, 97, 98.
Нека групираме серията и я запишем в таблица (на всяка опция ще бъде присвоен броят на нейните повторения):
| x i | 92 | 94 | 95 | 96 | 97 | 98 | н |
| n i | 1 | 2 | 2 | 3 | 1 | 1 | 10 |
Нека изчислим относителните честоти и натрупаните честоти, запишете резултата в таблицата:
| x i | 92 | 94 | 95 | 96 | 97 | 98 | Обща сума |
| n i | 1 | 2 | 2 | 3 | 1 | 1 | 10 |
| 0,1 | 0,2 | 0,2 | 0,3 | 0,1 | 0,1 | 1 | |
| Натрупани честоти | 1 | 3 | 5 | 8 | 1 | 10 |
Нека изградим полигон от честоти на дискретизация (маркирайте опциите по оста OX, честотите по оста OY на графиката, свържете точките с линия).
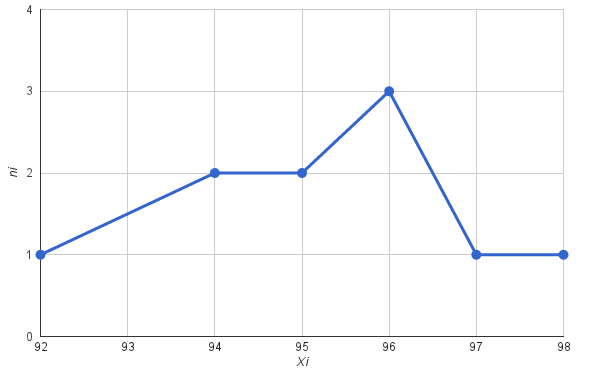
Средната стойност на извадката и дисперсията се изчисляват по формулите (съответно):

Можете да намерите други характеристики на извадката, но за обща представа намерените характеристики са напълно достатъчни.
Задачи за проверка на статистически хипотези
Задачите, свързани с този тип, са по-трудни от задачите от предишния тип и тяхното решение често е по-обемно и отнема много време. Преди да започнете да решавате проблеми, първо се изучават концепциите за статистическа хипотеза, нулева и конкурираща се хипотеза и т.н.
Помислете за най-простия проблем от този тип.
Задача
Дадени са две независими проби с размер 11 и 14, извлечени от нормалните популации X, Y. Известни са също коригирани дисперсии, равни съответно на 0,75 и 0,4. Необходимо е да се провери нулевата хипотеза за равенството на общите дисперсии на ниво на значимост γ
=0,05. Изберете конкурентна хипотеза по желание.
Решение
Нулевата хипотеза за нашия проблем е написана по следния начин:
Разгледайте следното като конкурентна хипотеза:
Нека изчислим отношението на по-голямата коригирана дисперсия към по-малката и да получим наблюдаваната стойност на критерия:
![]()
Тъй като конкурентната хипотеза, която избрахме, е , критичната област е дясна.
Според таблицата за ниво на значимост 0,05 и брой степени на свобода, равни съответно на 10 (11 - 1 = 10) и 13 (14 - 1 = 13), намираме критичната точка:
Тъй като наблюдаваната стойност на критерия е по-малка от критичната стойност (1,875<2,67), то нет оснований отвергнуть гипотезу о равенстве генеральных дисперсий. Таким образом, исправленные дисперсии различаются между собой незначимо.
Разгледаната задача не е лесна на пръв поглед, но е съвсем стандартна и се решава по шаблон. Такива проблеми се различават един от друг, като правило, в стойностите на критериите и критичната област.
По-трудоемки (тъй като съдържат много изчисления, някои от които са таблични) са задачите за проверка на хипотезата за вида на разпределението на генералната съвкупност. При решаването на такива проблеми се използват различни критерии, например критерият на Пиърсън.
Проблеми на определяне на вида на закона за разпределение по статистически данни
Този тип проблеми принадлежат към раздела, който изучава елементите на теорията на корелацията. Ако разгледаме зависимостта на Y от X, тогава можем да си припомним метода на най-малките квадрати, за да определим типа на зависимостта. Въпреки това, в математическата статистика всичко е много по-сложно и в теорията на корелацията се разглеждат двумерни количества, чиито стойности, като правило, са дадени под формата на таблици.
| х 1 | х 1 | … | x n | n y | |
| y 1 | n 11 | n 21 | … | n n1 | |
| y 1 | n 12 | n 22 | … | n n2 | |
| … | … | … | … | … | … |
| y m | n 1m | n 2m | … | n nm | |
| n x | … | н |
Представяме формулировката на един от проблемите на този раздел.
Задача
Определете примерното уравнение на правата регресия Y върху X. Данните са дадени в корелационната таблица.
| Y | х | n y | |||
| 10 | 20 | 30 | 40 | ||
| 5 | 1 | 3 | 4 | ||
| 6 | 2 | 1 | 3 | ||
| 7 | 3 | 2 | 5 | ||
| 8 | 1 | 1 | |||
| n x | 1 | 5 | 4 | 3 | н=13 |
Заключение
В заключение отбелязваме, че нивото на сложност на задачите в математическата статистика варира доста при преминаване от един тип към друг. Проблемите от първия тип са доста прости и не изискват специално разбиране на теорията, можете просто да напишете формулите и да решите почти всеки проблем. Задачите от втория и третия тип са малко по-сложни и за успешното им решаване е необходима определена „чанта със знания“ по тази дисциплина.
Ето списък само с две книги, но именно тези книги отдавна са станали настолни за автора на статията.
- Гмурман В.Е. Теория на вероятностите и математическа статистика: Учебник. - 12-то изд., преработено. - М .: ID Юрайт, 2010. - 479 с.
- Гмурман В.Е. Ръководство за решаване на задачи по теория на вероятностите и математическа статистика. - М.: Висше училище, 2005. - 404 с.
Решението на математическата статистика по поръчка
Желаем ви успех в овладяването на математическата статистика. Ще има проблеми - свържете се с нас. Ще се радваме да помогнем!
Въведение
2. Основни понятия на математическата статистика
2.1 Основни понятия за вземане на проби
2.2 Вземане на проби
2.3 Емпирична функция на разпределение, хистограма
Заключение
Библиография
Въведение
Математическата статистика е наука за математическите методи за систематизиране и използване на статистически данни за научни и практически изводи. В много от своите клонове математическата статистика се основава на теорията на вероятностите, което дава възможност да се оцени надеждността и точността на заключенията, направени от ограничен статистически материал (например да се оцени необходимия размер на извадката, за да се получат резултати с необходимата точност в извадково проучване).
В теорията на вероятностите се разглеждат случайни променливи с дадено разпределение или случайни експерименти, чиито свойства са напълно известни. Предмет на теорията на вероятностите са свойствата и връзките на тези величини (разпределения).
Но често експериментът е черна кутия, даваща само някои резултати, според които се изисква да се направи заключение за свойствата на самия експеримент. Наблюдателят има набор от числени (или те могат да бъдат направени числени) резултати, получени чрез повтаряне на същия случаен експеримент при същите условия.
В този случай, например, възникват следните въпроси: Ако наблюдаваме една случайна променлива, как можем да направим най-точното заключение за нейното разпределение от набор от нейните стойности в няколко експеримента?
Пример за такава поредица от експерименти е социологическо проучване, набор от икономически индикатори или накрая поредица от гербове и опашки по време на хилядократно хвърляне на монети.
Всички горепосочени фактори водят до уместности значението на темата за работа на настоящия етап, насочена към задълбочено и цялостно изучаване на основните понятия на математическата статистика.
В тази връзка целта на тази работа е да систематизира, натрупа и консолидира знанията за понятията на математическата статистика.
1. Предмет и методи на математическата статистика
Математическата статистика е наука за математическите методи за анализ на данни, получени по време на масови наблюдения (измервания, експерименти). В зависимост от математическата природа на конкретните резултати от наблюденията, математическата статистика се разделя на статистика на числата, многовариантен статистически анализ, анализ на функции (процеси) и времеви редове и статистика на нечислови обекти. Значителна част от математическата статистика се основава на вероятностни модели. Разпределете общи задачи за описание на данни, оценка и тестване на хипотези. Те също така разглеждат по-специфични задачи, свързани с провеждане на извадкови проучвания, възстановяване на зависимости, изграждане и използване на класификации (типологии) и др.
За описание на данните се изграждат таблици, диаграми и други визуални представяния, например корелационни полета. Вероятностните модели обикновено не се използват. Някои методи за описание на данни разчитат на напреднала теория и на възможностите на съвременните компютри. Те включват по-специално клъстерен анализ, насочен към идентифициране на групи от обекти, които са подобни един на друг, и многомерно мащабиране, което позволява визуализиране на обекти в равнина, изкривявайки разстоянията между тях в най-малка степен.
Методите за оценка и тестване на хипотези разчитат на вероятностни модели за генериране на данни. Тези модели се делят на параметрични и непараметрични. При параметричните модели се приема, че изследваните обекти се описват чрез функции на разпределение, които зависят от малък брой (1-4) числени параметри. В непараметричните модели се приема, че функциите на разпределение са произволно непрекъснати. В математическата статистика параметрите и характеристиките на разпределението (математическо очакване, медиана, дисперсия, квантили и т.н.), плътности и функции на разпределение, зависимости между променливи (на базата на линейни и непараметрични корелационни коефициенти, както и параметрични или не- параметрични оценки на функции, изразяващи зависимости) се оценяват и т.н. Използвайте точкови и интервални (даващи граници за истинските стойности) оценки.
В математическата статистика има обща теория за проверка на хипотези и голям брой методи, посветени на проверка на специфични хипотези. Разглеждат се хипотези за стойностите на параметрите и характеристиките, за проверка на хомогенността (т.е. за съвпадението на характеристики или функции на разпределение в две проби), за съгласието на емпиричната функция на разпределение с дадена функция на разпределение или с параметрична семейство от такива функции, за симетрията на разпределението и др.
От голямо значение е разделът на математическата статистика, свързан с провеждането на извадкови изследвания, със свойствата на различните извадкови схеми и изграждането на адекватни методи за оценка и проверка на хипотези.
Проблемите с възстановяването на зависимостта се изучават активно повече от 200 години, след разработването на метода на най-малките квадрати от К. Гаус през 1794 г. В момента най-актуални са методите за търсене на информативно подмножество от променливи и непараметричните методи.
Разработването на методи за апроксимация на данни и намаляване на размерността на описанието започва преди повече от 100 години, когато К. Пиърсън създава метода на главните компоненти. По-късно бяха разработени факторен анализ и множество нелинейни обобщения.
Различни методи за конструиране (клъстерен анализ), анализ и използване (дискриминантен анализ) на класификации (типологии) се наричат още методи за разпознаване на образи (с и без учител), автоматична класификация и др.
Математическите методи в статистиката се основават или на използването на суми (на базата на централната гранична теорема на теорията на вероятностите), или на индикатори за разлика (разстояния, метрики), както в статистиката на нечислови обекти. Обикновено само асимптотични резултати са строго обосновани. В наши дни компютрите играят голяма роля в математическата статистика. Те се използват както за изчисления, така и за симулационно моделиране (по-специално в методите за вземане на проби и при изследване на пригодността на асимптотични резултати).
Основни понятия на математическата статистика
2.1 Основни понятия на пробовземния метод
Нека е случайна променлива, наблюдавана в случаен експеримент. Предполага се, че вероятностното пространство е дадено (и няма да ни интересува).
Ще приемем, че след като извършихме този експеримент веднъж при същите условия, получихме числата , , , - стойностите на тази случайна променлива в първия, втория и т.н. експерименти. Случайната променлива има някакво разпределение, което е частично или напълно неизвестно за нас.
Нека разгледаме по-подробно набор, наречен проба.
В серия от вече проведени експерименти, извадката е набор от числа. Но ако тази серия от експерименти се повтори отново, тогава вместо този набор ще получим нов набор от числа. Вместо число ще се появи друго число - една от стойностите на случайна променлива. Тоест (и , и и т.н.) е променлива, която може да приема същите стойности като случайната променлива и също толкова често (със същите вероятности). Следователно преди експеримента - случайна променлива, разпределена по равно с , а след експеримента - числото, което наблюдаваме в този първи експеримент, т.е. една от възможните стойности на случайната променлива.
Извадка от обем е набор от независими и идентично разпределени случайни променливи („копия“), които, подобно на и , имат разпределение.
Какво означава да „направите заключение за разпределението от извадка“? Разпределението се характеризира с функция на разпределение, плътност или таблица, набор от числени характеристики - , , и др. Въз основа на извадката трябва да можете да изградите приближения за всички тези характеристики.
.2 Вземане на проби
Помислете за прилагането на извадката върху един елементарен резултат - набор от числа ![]() , ,
, , ![]() . В подходящо вероятностно пространство въвеждаме случайна променлива, приемаща стойностите, , с вероятности в (ако някои от стойностите съвпадат, добавяме вероятностите съответния брой пъти). Таблицата за разпределение на вероятностите и функцията за разпределение на случайна променлива изглеждат така:
. В подходящо вероятностно пространство въвеждаме случайна променлива, приемаща стойностите, , с вероятности в (ако някои от стойностите съвпадат, добавяме вероятностите съответния брой пъти). Таблицата за разпределение на вероятностите и функцията за разпределение на случайна променлива изглеждат така:
Разпределението на дадено количество се нарича емпирично или извадково разпределение. Нека изчислим математическото очакване и дисперсията на дадено количество и въведем обозначението за тези количества:
По същия начин изчисляваме момента на поръчка

В общия случай означаваме с количеството

Ако, когато конструираме всички въведени от нас характеристики, ние разглеждаме извадката , , като набор от случайни променливи, тогава самите тези характеристики - , , , , - ще станат случайни променливи. Тези характеристики на извадковото разпределение се използват за оценка (приближаване) на съответните неизвестни характеристики на истинското разпределение.
Причината за използването на характеристиките на разпределението за оценка на характеристиките на истинското разпределение (или ) е в близостта на тези разпределения за големи .
Помислете например за хвърляне на обикновен зар. Позволявам ![]() - броят на точките, паднали при -тото хвърляне, . Да приемем, че един в извадката ще се появи веднъж, двама - веднъж и т.н. Тогава случайната променлива ще приеме стойностите 1
, , 6
с вероятности , съответно. Но тези пропорции се приближават с нарастване според закона на големите числа. Това означава, че разпределението на големината в известен смисъл се доближава до истинското разпределение на броя на точките, които падат при хвърлянето на правилния зар.
- броят на точките, паднали при -тото хвърляне, . Да приемем, че един в извадката ще се появи веднъж, двама - веднъж и т.н. Тогава случайната променлива ще приеме стойностите 1
, , 6
с вероятности , съответно. Но тези пропорции се приближават с нарастване според закона на големите числа. Това означава, че разпределението на големината в известен смисъл се доближава до истинското разпределение на броя на точките, които падат при хвърлянето на правилния зар.
Няма да уточняваме какво се има предвид под близостта на извадката и истинските разпределения. В следващите параграфи ще разгледаме по-подробно всяка от характеристиките, въведени по-горе, и ще разгледаме нейните свойства, включително поведението й с увеличаване на размера на извадката.
.3 Емпирична функция на разпределение, хистограма
Тъй като неизвестното разпределение може да бъде описано, например, чрез неговата функция на разпределение, ние ще изградим „оценка“ за тази функция от извадката.
Определение 1.
Емпирична функция на разпределение, изградена върху извадка от обем, се нарича произволна функция, за всяка равна на
Напомняне:произволна функция

наречен индикатор за събитие. За всяко това е случайна променлива с разпределение на Бернули с параметър . защо?
С други думи, за всяка стойност на , равна на истинската вероятност случайната променлива да е по-малка от , се оценява делът на елементите на извадката, по-малък от.
Ако примерните елементи , , се сортират във възходящ ред (за всеки елементарен резултат), ще се получи нов набор от случайни променливи, наречен вариационна серия:
Елементът , , се нарича ти член на вариационната редица или статистика от ти порядък.
Пример 1
проба:
Вариационен ред:
| Ориз. един.Пример 1 |
 |
Емпиричната функция на разпределение има скокове в извадкови точки, стойността на скока в точката е , където е броят на извадковите елементи, които съвпадат с .
Възможно е да се конструира емпирична функция на разпределение за вариационния ред:

Друга характеристика на разпределението е таблицата (за дискретни разпределения) или плътността (за абсолютно непрекъснати разпределения). Емпиричен или селективен аналог на таблица или плътност е така наречената хистограма.
Хистограмата се основава на групирани данни. Изчисленият диапазон от стойности на случайна променлива (или диапазонът от примерни данни) е разделен, независимо от извадката, на определен брой интервали (не непременно еднакви). Нека , , са интервали на линията, наречени интервали на групиране . Нека означим за с броя на примерните елементи, които попадат в интервала:
| (1) |
На всеки от интервалите е изграден правоъгълник, чиято площ е пропорционална на. Общата площ на всички правоъгълници трябва да бъде равна на единица. Нека е дължината на интервала. Височината на правоъгълника отгоре е
Получената фигура се нарича хистограма.
Пример 2
Има вариационна серия (вижте пример 1):
Ето десетичния логаритъм, следователно, т.е. когато извадката се удвои, броят на интервалите на групиране се увеличава с 1. Имайте предвид, че колкото повече интервали на групиране, толкова по-добре. Но ако вземем броя на интервалите, да речем, от порядъка на , тогава с растеж хистограмата няма да се доближи до плътността.
Вярно е следното твърдение:
Ако плътността на разпределение на елементите на извадката е непрекъсната функция, тогава за така че , има точкова конвергенция на вероятността на хистограмата към плътността.
Така че изборът на логаритъм е разумен, но не е единственият възможен.
Заключение
Математическата (или теоретична) статистика се основава на методите и концепциите на теорията на вероятностите, но в известен смисъл решава обратни проблеми.
Ако наблюдаваме едновременното проявление на два (или повече) признака, т.е. имаме набор от стойности на няколко случайни променливи - какво може да се каже за тяхната зависимост? Има ли я или я няма? И ако да, каква е тази зависимост?
Често е възможно да се направят някои предположения за разпределението, скрито в "черната кутия", или за неговите свойства. В този случай, според експерименталните данни, е необходимо да се потвърдят или опровергаят тези предположения („хипотези“). В същото време трябва да помним, че отговорът „да“ или „не“ може да бъде даден само с известна степен на сигурност и колкото по-дълго можем да продължим експеримента, толкова по-точни могат да бъдат заключенията. Най-благоприятната ситуация за изследване е, когато може уверено да се твърди за някои свойства на наблюдавания експеримент - например за наличието на функционална зависимост между наблюдаваните величини, за нормалността на разпределението, за неговата симетричност, за наличието на плътност в разпределението или за дискретния му характер и др.
Така че има смисъл да помним за (математическата) статистика, ако
има случаен експеримент, чиито свойства са частично или напълно неизвестни,
Ние сме в състояние да възпроизведем този експеримент при едни и същи условия няколко (или по-добре произволен) брой пъти.
Библиография
1. Baumol W. Икономическа теория и изследователски операции. – М.; Наука, 1999.
2. Болшев Л.Н., Смирнов Н.В. Таблици на математическата статистика. Москва: Наука, 1995.
3. Боровков А.А. Математическа статистика. Москва: Наука, 1994.
4. Корн Г., Корн Т. Наръчник по математика за учени и инженери. - Санкт Петербург: Издателство Лан, 2003 г.
5. Коршунов Д.А., Чернова Н.И. Сборник задачи и упражнения по математическа статистика. Новосибирск: Издателство на Института по математика. S.L. Соболев SB RAS, 2001.
6. Пехелецки И.Д. Математика: учебник за студенти. - М.: Академия, 2003.
7. Суходолски В.Г. Лекции по висша математика за хуманитарни науки. - Санкт Петербургско издателство на Санкт Петербургския държавен университет. 2003 г
8. Фелер В. Въведение в теорията на вероятностите и нейните приложения. - М .: Мир, Т.2, 1984 г.
9. Харман Г., Съвременен факторен анализ. - М.: Статистика, 1972.
Харман Г., Съвременен факторен анализ. - М.: Статистика, 1972.
 Сюжетът на чичо ваня. „Чичо Иван. Отношение към професора на др
Сюжетът на чичо ваня. „Чичо Иван. Отношение към професора на др Малкият Цахес, по прякор Цинобър
Малкият Цахес, по прякор Цинобър Майков, Аполон Николаевич - кратка биография
Майков, Аполон Николаевич - кратка биография