Данные по выборке. Статистическая выборка
виды выборки:
Собственно-случайная;
Механическая;
Типическая;
Серийная;
Комбинированная.
Собственно-случайная выборка заключается в отборе единиц из генеральной совокупности наугад или наудачу без каких-либо элементов системности. Однако прежде чем производить собственно-случайный отбор, необходимо убедиться, что все без исключения единицы генеральной совокупности имеют абсолютно равные шансы попадания в выборку, в списках или перечне отсутствуют пропуски, игнорирования отдельных единиц и т.п. Следует также установить четкие границы генеральной совокупности таким образом, чтобы включение или невключение в нее отдельных единиц не вызывало сомнений. Так, например, при обследовании студентов необходимо указать, будут ли приниматься во внимание лица, находящиеся в академическом отпуске, студенты негосударственных вузов, военных училищ и т.п.; при обследовании торговых предприятий важно определиться, включит ли генеральная совокупность торговые павильоны, коммерческие палатки и прочие подобные объекты. Собственно-случайный отбор может быть как повторным, так и бесповторным. Для проведения бесповторного отбора в процессе жеребьевки выпавшие жребии обратно в исходную совокупность не возвращаются и в дальнейшем отборе не участвуют. При использовании таблиц случайных чисел бесповторность отбора достигается пропуском чисел в случае их повторения в выбранном столбце или столбцах.
Механическая выборка применяется в случаях, когда генеральная совокупность каким-либо образом упорядочена, т.е. имеется определенная последовательность в расположении единиц (табельные номера работников, списки избирателей, телефонные номера респондентов, номера домов и квартир и т.п.).
Генеральную совокупность при механическом отборе можно ранжировать или упорядочить по величине изучаемого или коррелирующего с ним признака, что позволит повысить репрезентативность выборки. Однако в этом случае возрастает опасность систематической ошибки, связанной с занижением значений изучаемого признака (если из каждого интервала регистрируется первое значение) или с его завышением (если из каждого интервала регистрируется последнее значение). Поэтому целесообразно отбор начинать с середины первого интервала
Типический отбор. Этот способ отбора используется в тех случаях, когда все единицы генеральной совокупности можно разбить на несколько типических групп. При обследовании населения такими группами могут быть, например, районы, социальные, возрастные или образовательные группы, при обследовании предприятий – отрасль или под-отрасль, форма собственности и т.п. Типический отбор предполагает выборку единиц из каждой типической группы собственно-случайным или механическим способом. Поскольку в выборочную совокупность в той или иной пропорции обязательно попадают представители всех групп, типизация генеральной совокупности позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки, которая в этом случае определяется только внутригрупповой вариацией.
Отбор единиц в типическую выборку может быть организован либо пропорционально объему типических групп, либо пропорционально внутригрупповой дифференциации признака.
Серийный отбор. Данный способ отбора удобен в тех случаях, когда единицы совокупности объединены в небольшие группы или серии. В качестве таких серий могут рассматриваться упаковки с определенным количеством готовой продукции, партии товара, студенческие группы, бригады и другие объединения. Сущность серийной выборки заключается в собственно-случайном или механическом отборе серий, внутри которых производится сплошное обследование единиц.
Часто бывает так, что необходимо проанализировать какое-либо конкретное социальное явление и получить информацию о нем. Такие задания часто возникают в статистике и при статистических исследованиях. Проверить полностью определенное социальное явление чаще всего бывает невозможным. Например, как узнать мнение населения или всех жителей определенного города по какому-либо вопросу? Спрашивать абсолютно всех - дело практически невозможное и очень трудоемкое. В таких случаях нам и необходима выборка. Это именно то понятие, на котором основаны практически все исследования и анализы.
Что такое выборка
При анализе конкретного социального явления необходимо получить информацию о нем. Если взять любое исследование, то можно заметить, что исследованию и анализу подлежит не каждая единица совокупности объекта исследования. Во внимание берется только определенная часть всей этой совокупности. Вот этот процесс и является выборкой: когда исследуются только определенные единицы из множества.
Конечно же, многое зависит от вида выборки. Но есть и основные правила. Главное из них гласит, что отбор из совокупности должен быть абсолютно случайным. Единицы совокупности, которые будут использованы, не должны быть выбраны из-за какого-либо критерия. Грубо говоря, если необходимо набрать совокупность из населения определенного города и отобрать только мужчин, то в исследовании будет ошибка, потому что отбор был проведен не случайно, а отобран по гендерному признаку. Практически все методы выборки основаны на этом правиле.
Правила выборки
Для того чтобы отобранная совокупность отражала основные качества всего явления, она должна быть построена по конкретным законам, где основное внимание необходимо уделять следующим категориям:
- выборка (выборочная совокупность);
- генеральная совокупность;
- репрезентативность;
- ошибка репрезентативности;
- единица совокупности;
- способы построения выборки.
Особенности выборочного наблюдения и составления выборки заключаются в следующем:
- Все полученные результаты основаны на математических законах и правилах, то есть при правильном проведении исследования и при правильных расчетах результаты не будут искажены по субъективному признаку
- Дает возможность значительно быстрее и с меньшими затратами времени и ресурсов получить результат, изучая не весь массив событий, а только их часть.
- Может быть применено для изучения различных объектов: от конкретных вопросов, например, возраст, пол интересующей нас группы, к изучению общественного мнения или уровня материального обеспечения населения.
Выборочное наблюдение
Выборочное - это такое статистическое наблюдение, при котором исследованию подвергается не вся совокупность изучаемого, а лишь некоторая, отобранная определенным образом ее часть, а полученные результаты изучения этой части распространяются на всю совокупность. Эта часть называется выборочной совокупностью. Это единственный способ изучения большого массива объекта исследования.
Но выборочное наблюдение может использоваться только в тех случаях, когда необходимо исследовать лишь малую группу единиц. Например, при исследовании соотношения мужчин к женщинам в мире, будет использоваться выборочное наблюдение. По понятным причинам - взять во внимание каждого жителя нашей планеты невозможно.
А вот при таком же исследовании, но не всех жителей земли, а определенного 2 «А» класса в конкретной школе, определенного города, определенной страны, может обойтись без выборочного наблюдения. Ведь проанализировать весь массив объекта исследования - вполне возможно. Необходимо посчитать мальчиков и девочек этого класса - вот и будет соотношение.

Выборочная и генеральная совокупность
На самом деле все не так сложно, как звучит. В любом объекте изучения есть две системы: генеральная и выборочная совокупность. Что же это такое? Все единицы относятся к генеральной. А к выборочной - те единицы общей совокупности, которые были взяты для выборки. Если все правильно сделано, то отобранная часть будет составлять уменьшенный макет всей (генеральной) совокупности.
Если говорить о генеральной совокупности, то можно выделить всего две ее разновидности: определенная и неопределенная генеральная совокупность. Зависит от того, известно ли общее количество единиц данной системы или нет. Если это определенная генеральная совокупность, то выборку будет делать легче из-за того, что известно, какой процент от общего количества единиц будет составлять выборка.
Этот момент очень необходим в исследованиях. Например, если необходимо исследовать процент недоброкачественной продукции кондитерских изделий на конкретном заводе. Допустим, что генеральная совокупность уже определена. Точно известно, что в год это предприятие производит 1000 кондитерских изделий. Если сделать выборку 100 случайных кондитерских изделий из этой тысячи и отправить их на экспертизу, то погрешность будет минимальной. Грубо говоря, исследованию подлежало 10 % всей продукции, и по результатам можем, приняв во внимание ошибку репрезентативности, говорить о недоброкачественности всей продукции.
А если провести выборку 100 кондитерских изделий из неопределенной генеральной совокупности, где их на самом деле было, допустим, 1 млн единиц, то результат выборки и самого исследования будет критически неправдоподобным и неточным. Чувствуете разницу? Поэтому определенность генеральной совокупности в большинстве случаев крайне важна и очень сильно влияет на результат исследования.

Репрезентативность совокупности
Итак, теперь один из самых главных вопросов - какой должна быть выборка? Это самый главный момент исследования. На этом этапе необходимо рассчитать выборку и отобрать единицы из общего числа в нее. Совокупность была отобрана правильно, если определенные особенности и характеристики генеральной совокупности остается и в выборочной. Это называется репрезентативностью.
Иными словами, если после отбора часть сохраняет те же самые тенденции и особенности что и все количество исследуемого, то такая совокупность называется репрезентативной. Но не каждая определенная выборка может быть отобрана из репрезентативной совокупности. Бывают и такие объекты исследования, выборка которых просто не может быть репрезентативной. Отсюда и возникает понятие ошибки репрезентативности. Но об этом поговорим подробнее чуть больше.
Как сделать выборку
Итак, чтобы репрезентативность была максимальной, выделяют три основные правила выборки:

Погрешность (ошибка) репрезентативности
Главной характеристикой качества выбранной выборки является понятие «погрешности репрезентативности». Что же это такое? Это определенные расхождения между показателями выборочного и сплошного наблюдения. По показателям погрешности репрезентативность делят на надежную, обычную и приближенную. Иначе говоря, допустимыми являются отклонения в размере до 3 %, от 3 до 10 % и от 10 до 20 % соответственно. Хотя в статистике желательно, чтобы погрешность не превышал 5-6 %. В противном случае есть повод говорить о недостаточной репрезентативности выборки. Для вычисления погрешности репрезентативности и того, как она влияет на выборочную или генеральную совокупность, во внимание берутся многие факторы:
- Вероятность, с которой необходимо получить точный результат.
- Количества единиц выборочной совокупности. Как уже упоминалось ранее, чем меньше единиц составит выборка, тем больше будет ошибка репрезентативности, и наоборот.
- Однородность исследуемой совокупности. Чем более разнородной является совокупность, тем больше будет погрешность репрезентативности. Возможность совокупности быть репрезентативной зависит от однородности всех ее составляющих единиц.
- Способ отбора единиц в выборочную совокупность.
В конкретно заданных исследованиях процент погрешности среднего значения обычно задается самим исследователем на основании программы наблюдения и согласно данным ранее проведенных исследований. Как правило, считается допустимой предельная ошибка выборки (ошибка репрезентативности) в пределах 3-5 %.

Больше - не всегда лучше
Также стоит помнить, что главное при организации выборочного наблюдения - это доведение его объема до допустимого минимума. При этом не следует стремиться к чрезмерному уменьшению границ погрешности выборки, так как это может привести к неоправданному увеличению объема данных выборки и, следовательно, к повышению расходов на проведение выборочного наблюдения.
В то же время нельзя и чрезмерно увеличивать размер погрешности репрезентативности. Ведь в этом случае, хотя и произойдет уменьшение объема выборочной совокупности, это приведет к ухудшению достоверности полученных результатов.
Какие вопросы обычно ставится перед исследователем
Любое исследование если и проводится, то для какой-то цели и для получения каких-то результатов. При проведении выборочного исследования, как правило, ставятся начальные вопросы:

Способы отбора единиц исследования в выборку
Не каждая выборка является репрезентативной. Иногда один и тот же признак по-разному выражен в целом и в ее части. Для достижения требований репрезентативности целесообразным является использование различных приемов создания выборки. Причем использование того или иного способа зависит от конкретных обстоятельств. Среди таких приемов создания выборки выделяют:
- случайный отбор;
- механический отбор;
- типичный отбор;
- серийный (гнездовой) отбор.
Случайный отбор представляет собой систему мероприятий, направленных на случайный отбор единиц совокупности, когда вероятность попасть в выборку является равной для всех единиц генеральной совокупности. Этот прием целесообразно применять только в случае однородности и небольшого количества присущих ей признаков. В противном случае некоторые характерные черты рискуют быть не отраженным в выборке. Признаки случайного отбора лежат в основе всех других способов построения выборки.
При механическом отбор единиц проводится через определенный интервал. Если необходимо сформировать выборку конкретных преступлений, можно изымать из всех карточек статистического учета зарегистрированных преступлений каждую 5-ю, 10-ю или 15-ю карточку в зависимости от их общего количества и имеющихся размеров выборки. Недостатком этого способа является то, что перед отбором необходимо иметь полный учет единиц совокупности, затем нужно провести ранжирование и только после этого можно проводить выборку с определенным интервалом. Этот метод занимает много времени, поэтому он и не часто используется.

Типичный (районированный) отбор - вид выборки, при котором генеральную совокупность разделяют на однородные группы по определенному признаку. Иногда исследователи употребляют вместо «групп» другие термины: «районы» и «зоны». Затем из каждой группы в случайном порядке отбирается определенное количество единиц пропорционально удельному весу группы в общей совокупности. Типичный отбор часто осуществляется в несколько этапов.
Серийный отбор - это такой метод, при котором отбор единиц проводится группами (сериями) и обследованию подлежат все единицы отобранной группы (серии). Преимуществом этого способа является то, что иногда отобрать отдельные единицы сложнее, чем серии, например, при изучении личности, которая отбывает наказание. В рамках отобранных районов, зон применяется изучение всех единиц без исключения, например, изучение всех лиц, отбывающих наказание в каком-то определенном учреждении.
Интервальное оценивание вероятности события. Формулы расчета численности выборки при собственно-случайном способе отбора.Для определения вероятностей интересующих нас событий мы применяем выборочный метод : проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А , а р - генеральной долей .
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:

где u кр находится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(u кр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента :
![]() где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
| Генеральная совокупность | Бесконечная | Конечная объема N |
| Тип отбора | Повторный | Бесповторный |
| Средняя ошибка выборки |
Формулы расчета численности выборки при собственно-случайном способе отбора
| Способ отбора | Формулы определения численности выборки | ||
| для средней | для доли | ||
| Повторный | |||
| Бесповторный | |||
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p 0 ?» - можно ответить, проверив статистическую гипотезу H 0:p=p 0 . При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p * появления события A: где m - количество появлений события А в серии из n испытаний. Для проверки гипотезы H 0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).Таблица 1 - Гипотезы о генеральной доле
Гипотеза | H 0:p=p 0 | H 0:p 1 =p 2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  | 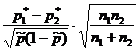 |
| Распределение статистики K | Стандартное нормальное N(0,1) |
Пример №1
. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал , с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение u кр находим по таблице функции Лапласа из соотношения 2Ф(u кр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2
. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение
. Выборочная доля «удачных» дней составляет
По таблице функции Лапласа найдем значение u кр при заданной
доверительной вероятности
Ф(2.23) = 0.49, u кр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40 , N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3
. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01 ?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4
. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение
. Сформулируем основную и альтернативную гипотезы.
H 0:p=p 0 =0,97 - неизвестная генеральная доля p
равна заданному значению p 0 =0,97. Применительно к условию - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K
(таблица) вычислим при заданных значениях p 0 =0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-K kp)= (-∞;-2,05). Наблюдаемое значение К набл =-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5
. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода - 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение K набл =2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
План
- Введение
- 1. Роль выборки
- Заключение
- Список литературы
Введение
Статистика - аналитическая наука, которая необходима всем современным специалистам. Современный специалист не может быть грамотным, если он не владеет статистической методологией. Статистика - важнейший инструмент связи предприятия с обществом. Статистика одна из важнейших дисциплин в учебном плане всех специальностей, т.к. статистическая грамотность - неотъемлемая составляющая высшего образования, а по количеству отведенных часов в учебном плане она занимает одно из первых мест. Работая с цифрами, каждый специалист должен знать, как получены те или иные данные, какова их природа исчисления, насколько они полны и достоверны.
1. Роль выборки
Множество всех единиц совокупности, обладающих определенным признаком и подлежащих изучению, носит в статистике название генеральной совокупности.
На практике по тем или иным причинам не всегда возможно или же нецелесообразно рассматривать всю генеральную совокупность. Тогда ограничиваются изучением лишь некоторой части ее, конечной целью которого является распространение полученных результатов на всю генеральную совокупность, т.е. применяют выборочный метод.
Для этого из генеральной совокупности особым образом отбирается часть элементов, так называемая выборка, и результаты обработки выборочных данных (например, средние арифметические значения) обобщаются на всю совокупность.
Теоретической основой выборочного метода является закон больших чисел. В силу этого закона при ограниченном рассеивании признака в генеральной совокупности и достаточно большой выборке с вероятностью, близкой к полной достоверности, выборочная средняя может быть сколь угодно близка к генеральной средней. Закон этот, включающий в себя группу теорем, доказан строго математически. Таким образом, средняя арифметическая, рассчитанная по выборке, может с достаточным основанием рассматриваться как показатель, характеризующий генеральную совокупность в целом.
2. Методы вероятностного отбора, обеспечивающие репрезентативность
Для того чтобы можно было по выборке делать вывод о свойствах генеральной совокупности, выборка должна быть репрезентативной (представительной), т.е. она должна полно и адекватно представлять свойства генеральной совокупности. Репрезентативность выборки может быть обеспечена только при объективности отбора данных.
Выборочная совокупность формируется по принципу массовых вероятностных процессов без каких бы то ни было исключений от принятой схемы отбора; необходимо обеспечить относительную однородность выборочной совокупности или ее разделение на однородные группы единиц. При формировании выборочной совокупности должно быть дано четкое определение единицы отбора. Желателен приблизительно одинаковый размер единиц отбора, причем результаты будут тем точнее, чем меньше единица отбора.
Возможны три способа отбора: случайный отбор, отбор единиц по определенной схеме, сочетание первого и второго способов.
Если отбор в соответствии с принятой схемой проводится из генеральной совокупности, предварительно разделенной на типы (слои или страты), то такая выборка называется типической (или расслоенной, или стратифицированной, или районированной). Еще одно деление выборки по видам определяется тем, что является единицей отбора: единица наблюдения или серия единиц (иногда используют термин "гнездо"). В последнем случае выборка называется серийной, или гнездовой. На практике часто используется сочетание типической выборки с отбором сериями. В математической статистике, обсуждая проблему отбора данных, обязательно вводят деление выборки на повторную и бесповторную. Первая соответствует схеме возвратного шара, вторая - безвозвратного (при рассмотрении процесса отбора данных на примере отбора шаров разного цвета из урны). В социально-экономической статистике нет смысла применять повторную выборку, поэтому, как правило, имеется в виду бесповторный отбор.
Так как социально-экономические объекты имеют сложную структуру, то выборку бывает довольно трудно организовать. Например, чтобы провести отбор домохозяйств при изучении потребления населением крупного города, легче произвести сначала отбор территориальных ячеек, жилых домов, потом квартир или домохозяйств, затем респондента. Такая выборка называется многоступенчатой. На каждой ступени используются разные единицы отбора: более крупные - на начальных ступенях, на последней ступени единица отбора совпадает с единицей наблюдения.
Еще один вид выборочного наблюдения - многофазовая выборка. Такая выборка включает определенное количество фаз, каждая из которых отличается подробностью программы наблюдения. Например, 25% всей генеральной совокупности обследуются по краткой программе, каждая 4-я единица из этой выборки обследуется по более полной программе и т.д.
При любом виде выборки отбор единиц производится тремя отмеченными способами. Рассмотрим процедуру случайного отбора. Прежде всего, составляется список единиц совокупности, в котором каждой единице присваивается цифровой код (номер или метка). Затем производится жеребьевка. Закладываются в барабан шары с соответствующими номерами, они перемешиваются и проводится отбор шаров. Выпавшие номера соответствуют единицам, попавшим в выборку; число номеров равно запланированному объему выборки.
Отбор жеребьевкой может быть подвержен смещениям, вызванным недостатками техники (качеством шаров, барабана) и другими причинами. Более надежен с точки зрения объективности отбор по таблице случайных чисел. Такая таблица содержит серии цифр, чередующихся случайным образом, отобранных путем электронных сигналов. Так как мы пользуемся десятичной цифровой системой 0, 1, 2,., 9, вероятность появления любой цифры равна 1/10. Следовательно, если бы нужно было создать таблицу случайных чисел, включающую 500 знаков, то из них около 50 были бы 0, столько же - 1 и т.д.
Часто используется отбор по какой-либо схеме (так называемая направленная выборка). Схема отбора принимается такой, чтобы отразить основные свойства и пропорции генеральной совокупности. Простейший способ: по спискам единиц генеральной совокупности, составленным так, чтобы упорядочивание единиц было бы не связано с изучаемыми свойствами, проводится механический отбор единиц с шагом, равным N: п. Обычно отбор начинают не с первой единицы, а отступив полшага, чтобы уменьшить возможность смещения выборки. Частота появления единиц с теми или иными особенностями, например студентов с тем или иным уровнем успеваемости, живущих в общежитии, и т.д. будет определяться той структурой, которая сложилась в генеральной совокупности.
Для большей уверенности в том, что выборка отразит структуру генеральной совокупности, последняя подразделяется на типы (страты или районы), и проводится случайный или механический отбор из каждого типа. Общее число единиц, отобранных из разных типов, должно соответствовать объему выборки.
Особые трудности возникают, когда нет списка единиц, а отбор нужно произвести либо на местности, либо из образцов продукции на складе готовой продукции. В этих случаях важно детально разработать схему ориентации на местности и схему отбора и следовать ей, не допуская отклонений. Например, счетчик имеет указание двигаться от определенной автобусной остановки на север по четной стороне улицы и, отсчитав два дома от первого угла, войти в третий и провести опрос в каждом 5-м жилом помещении. Неукоснительное следование принятой схеме обеспечивает выполнение главного условия формирования репрезентативной выборки - объективности отбора единиц.
От случайной выборки следует отличать квотный отбор, когда выборка конструируется из единиц определенных категорий (квот), которые должны быть представлены в заданных пропорциях. Например, при опросе покупателей универмага может быть запланировано провести отбор 150 респондентов, в том числе 90 женщин, из них 25 - девушек,20 - молодых женщин с маленькими детьми, 35 - женщин среднего возраста, одетых в деловой костюм, 10 - женщин 50 лет и старше; кроме того, планировался опрос 70 мужчин, из них 25 - подростков и юношей,20 - молодых мужчин с детьми, 15 - мужчин, которые одеты в костюмы, 10 - мужчин, одетых в спортивную одежду. Для определения потребительских ориентаций и предпочтений такая выборка, может быть, и хороша, но если мы захотим по ней установить среднюю сумму покупок, их структуру, мы получим непредставительные результаты. Это происходит потому, что квотная выборка нацелена на отбор определенных категорий.
Выборка может быть нерепрезентативной, даже если она формируется в соответствии с известными пропорциями генеральной совокупности, но отбор проводится без какой-либо схемы - единицы набираются как угодно, лишь бы обеспечить соотношение их категорий в тех же пропорциях, что и в генеральной совокупности (например, соотношение мужчин и женщин, респондентов в возрасте моложе и старше трудоспособного и в трудоспособном и т.д.).
Эти замечания должны предостеречь вас от подобных подходов к формированию выборки и еще раз подчеркнуть необходимость объективного отбора.
3. Организационные и методологические особенности случайной, механической, типической и серийной выборки
В зависимости от того, как осуществляется отбор элементов совокупности в выборку, различают несколько видов выборочного обследования. Отбор может быть случайным, механическим, типическим и серийным.
Случайным является такой отбор, при котором все элементы генеральной совокупности имеют равную возможность быть отобранными. Другими словами, для каждого элемента генеральной совокупности обеспечена равная вероятность попасть в выборку.
выборка статистическая вероятностный случайный
Требование случайности отбора достигается на практике с помощью жребия или таблицы случайных чисел.
При отборе способом жеребьевки все элементы генеральной совокупности предварительно нумеруются и номера их наносятся на карточки. После тщательной перетасовки из пачки любым способом (подряд или в любом другом порядке) выбирается нужное число карточек, соответствующее объему выборки. При этом можно либо откладывать отобранные карточки в сторону (тем самым осуществляется так называемый бесповторный отбор), либо, вытащив карточку, записать ее номер и возвратить в пачку, тем самым давая ей возможность появиться в выборке еще раз (повторный отбор). При повторном отборе всякий раз после возвращения карточки пачка должна быть тщательно перетасована.
Способ жеребьевки применяется в тех случаях, когда число элементов всей изучаемой совокупности невелико. При большом объеме генеральной совокупности осуществление случайного отбора методом жеребьевки становится сложным. Более надежным и менее трудоемким в случае большого объема обрабатываемых данных является метод использования таблицы случайных чисел.
Механический отбор производится следующим образом. Если формируется 10% -ная выборка, т.е. из каждых десяти элементов должен быть отобран один, то вся совокупность условно разбивается на равные части по 10 элементов. Затем из первой десятки выбирается случайным образом элемент. Например, жеребьевка указала девятый номер. Отбор остальных элементов выборки полностью определяется указанной пропорцией отбора N номером первого отобранного элемента. В рассматриваемом случае выборка будет состоять из элементов 9, 19, 29 и т.д.
Механическим отбором следует пользоваться осторожно, так как существует реальная опасность возникновения так называемых систематических ошибок. Поэтому прежде чем делать механическую выборку, необходимо проанализировать изучаемую совокупность. Если ее элементы расположены случайным образом, то выборка, полученная механическим способом, будет случайной. Однако нередко элементы исходной совокупности бывают частично или даже полностью упорядочены. Весьма нежелательным для механического отбора является порядок элементов, имеющий правильную повторяемость, период которой может совпасть с периодом механической выборки.
Нередко элементы совокупности бывают упорядочены по величине изучаемого признака в убывающем или возрастающем порядке и не имеют периодичности. Механический отбор из такой совокупности приобретает характер направленного отбора, так как отдельные части совокупности оказываются представленными в выборке пропорционально их численности во всей совокупности, т.е. отбор направлен на то, чтобы сделать выборку представительной.
Другим видом направленного отбора является типический отбор. Следует отличать типический отбор от отбора типичных объектов. Отбор типичных объектов применялся в земской статистике, а также при бюджетных обследованиях. При этом отбор "типичных селений" или "типичных хозяйств" производился по некоторым экономическим признакам, например по размерам землевладения на двор, по роду занятий жителей и т.п. Отбор такого рода не может быть основой для применения выборочного метода, так как здесь не выполнено основное его требование - случайность отбора.
При собственно типическом отборе в выборочном методе совокупность разбивается на группы, однородные в качественном отношении, а затем уже внутри каждой группы производится случайный отбор. Типический отбор организовать сложнее, чем собственно случайный, так как необходимы определенные знания о составе и свойствах генеральной совокупности, но зато он дает более точные результаты.
При серийном отборе вся совокупность разбивается на группы (серии). Затем путем случайного или механического отбора выделяют определенную часть этих серий и производят их сплошную обработку. По сути дела, серийный отбор представляет собой случайный или механический отбор, осуществленный для укрупненных элементов исходной совокупности.
В теоретическом плане серийная выборка является самой несовершенной из рассмотренных. Для обработки материала она, как правило, не используется, но представляет определенные удобства при организации обследования, особенно в изучении сельского хозяйства. Например, ежегодные выборочные обследования крестьянских хозяйств в годы, предшествовавшие коллективизации, проводились способом серийного отбора. Историку полезно знать о серийной выборке, поскольку он может встретиться с результатами таких обследований.
Кроме описанных выше классических способов отбора в практике выборочного метода используются и другие способы. Рассмотрим два из них.
Изучаемая совокупность может иметь многоступенчатую структуру, она может состоять из единиц первой ступени, которые, в свою очередь, состоят из единиц второй ступени, и т.д. Например, губернии включают в себя уезды, уезды можно рассматривать как совокупность волостей, волости состоят из сел, а села - из дворов.
К таким совокупностям можно применять многоступенчатый отбор, т.е. последовательно осуществлять отбор на каждой ступени. Так, из совокупности губерний механическим, типическим или случайным способом можно отобрать уезды (первая ступень), затем одним из указанных способов выбрать волости (вторая ступень), далее провести отбор сел (третья ступень) и, наконец, дворов (четвертая ступень).
Примером двухступенчатого механического отбора может служить давно практикуемый отбор бюджетов рабочих. На первой ступени механически выбираются предприятия, на второй - рабочие, бюджет которых обследуется.
Изменчивость признаков исследуемых объектов может быть различной. Например, обеспеченность крестьянских хозяйств собственной рабочей силой колеблется меньше, чем, скажем, размеры их посевов. В связи с этим меньшая по объему выборка по обеспеченности рабочей силой будет столь же представительной, как и большая по числу элементов выборка данных о размерах посевов. В этом случае из выборки, по которой определяются размеры посевов, можно сделать под выборку, достаточно репрезентативную для определения обеспеченности рабочей силой, осуществив тем самым двухфазный отбор. В общем случае можно добавить и следующие фазы, т.е. из полученной подвыборки сделать еще подвыборку и т.д. Этот же способ отбора применяется в тех случаях, когда цели исследования требуют различной точности при исчислении разных показателей.
Задание 1. Описательная статистика
На экзамене 20 студентов получили следующие оценки (по 100 бальной шкале):
1) Построить ряд распределения частот, относительных и накопленных частот для 5 интервалов;
2) Построить полигон, гистограмму и кумулятивный полигон;
3) Найти среднюю арифметическую, моду, медиану, первый и третий квартили, межквартальный размах, стандартное отклонение и коэффициенты вариации. Проанализировать данные с использованием этих характеристик и указать интервал, включающий 50% центральных значений указанных величин.
1) x (min) =53, x (max) =98
R=x (max) - x (min) =98-53=45
h=R/1+3.32lgn, где n - объем выборки, n=20
h= 45/1+3.32*lg20= 9
a (i) - нижняя граница интервала, b (i) - верхняя граница интервала.
a (1) = x (min) - h/2, b (1) = a (1) +h, тогда, если b (i) - верхняя граница i-го интервала (причем a (i+1) =b (i)), то b (2) =a (2) +h, b (3) =a (3) +h и т.д. Построение интервалов продолжается до тех пор, пока начало следующего по порядку интервала не будет равно или больше x (max).
a (1) = 47.5 b (1) = 56.5
a (2) = 56.5 b (2) = 65.5
a (3) = 65.5 b (3) = 74.5
a (4) = 74.5 b (4) = 83.5
a (5) = 83.5 b (5) = 92.5
a (6) = 92.5 b (6) = 101.5
|
Интервалы, a (i) - b (i) |
Подсчет частот |
Частота, n (i) |
Накопленная частота, n (hi) |
||
2) Для построения графиков запишем вариационные ряды распределения (интервальный и дискретный) относительных частот W (i) = n (i) /n, накопленных относительных частот W (hi) и найдем отношение W (i) /h, заполнив таблицу.
x (i) =a (i) +b (i) /2; W (hi) =n (hi) /n
Статистический ряд распределения оценок:
|
Интервалы, a (i) - b (i) |
|||||
Для построения гистограммы относительных частот по оси абсцисс откладываем частичные интервалы, на каждом из которых строим прямоугольник, площадь которого равна относительной частоте W (i) данного i-го интервала. Тогда высота элементарного прямоугольника должна быть равна W (i) /h.
Из гистограммы можно получить полигон того же распределения, если середины верхних оснований прямоугольников соединить отрезками прямой.
Для построения кумуляты дискретного ряда по оси абсцисс откладываем значения признака, а по оси ординат - относительные накопленные частоты W (hi). Полученные точки соединяем отрезками прямых. Для интервального ряда по оси абсцисс откладываем верхние границы группировки.
3) Среднее арифметическое значение находим по формуле:
Мода рассчитывается по формуле:
Нижняя граница модального интервала; h - ширина интервала группировки; - частота модального интервала; - частота интервала, предшествующего модальному; - частота интервала, следующего за модальным. = 23,125.
Найдем медиану:
n=20: 53,58,59,59,63,67,68,69,71,73,78,79,85,86,87,89,91,91,98,98
Подставив значения, получаем: Q1=65;
Значение второго квартиля совпадает со значением медианы, поэтому Q2=75.5; Q3= 88.
Межквартальный размах равен:
Среднеквадратическое (стандартное) отклонение находим по формуле:
Коэффициент вариации:
Из данных расчетов видно, что 50% центральных значений указанных величин включает в себя интервал 74,5 - 83,5.
Задание 2. Статистическая проверка гипотез.
Предпочтения в спорте для мужчин, женщин и подростков следующие:
Проверить гипотезу о независимости предпочтения от пола и возраста б = 0,05.
1) Проверка гипотезы о независимости предпочтений в спорте.
Коэффициент Пирсена:
Табличное значение критерия хи-квадрат со степенью свободы 4 при б = 0,05 равно ч 2 табл =9,488.
Так как, то гипотеза отвергается. Различия в предпочтениях существенные.
2. Гипотеза о соответствии.
Волейбол как вид спорта ближе всего к баскетболу. Проверим соответствие в предпочтениях для мужчин, женщин и подростков.
Ф 2 =0.1896+0.1531+0.1624+0.1786+0.1415+0.1533 = 0.979.
При уровне значимости б = 0,05 и степени свободы k = 2 табличное значение ч 2 табл =9,210.
Так как Ф 2 >, то различия в предпочтениях существенные.
Задание 3. Корреляционно-регрессионный анализ.
Анализ дорожно-транспортных происшествий дал следующую статистику относительно процента водителей, моложе 21 года и числа происшествий с тяжелыми последствиями на 1000 водителей:
Провести графический и корреляционно-регрессионный анализ данных, спрогнозировать число ДТП с тяжелыми последствиями для города, в котором число водителей, моложе 21 года равно 20% от общего числа водителей.
Получаем выборку объема n = 10.
x - процент водителей моложе 21 года,
y - число происшествий на 1000 водителей.
Уравнение линейной регрессии имеет вид:
Последовательно вычисляем:
Аналогично находим
Выборочный коэффициент регрессии
Связь между x, y сильная.
Уравнение линейной регрессии принимает вид:
На рисунке представлено поле рассеяния и график линейной регрессии . Проводим прогноз для x n =20 .
Получаем y n =0 .2 9*20-1 .4 6 = 4 .3 4 .
Прогнозное значение получилось больше всех значений, представленный в исходной таблице . Это следствие того, что корреляционная зависимость прямая и коэффициент равен 0,29 достаточно большой . На каждую единицу приращения Дx он дает приращение Дy =0 .3
Задание 4 . Анализ временных рядов и прогнозирование .
Спрогнозировать значения индексов на ближайшую неделю, используя:
а) метод скользящей средней, выбрав для ее вычисления трехнедельные данные;
б) экспоненциальную взвешенную среднюю, выбрав в качестве б=0,1.
Из таблицы случайных чисел находим номера 41, 51, 69, 135, 124, 93, 91, 144, 10, 24.
Располагаем их в порядке возрастания: 10, 24, 41, 51, 69, 91, 93, 124, 135, 144.
Проводим новую нумерацию от 1 до 10. Получаем исходные данные для десяти недель:
Экспоненциальное сглаживание при б = 0,1 дает только одно значение.
Для середины всего срока получаем три прогноза: 12,855; 1309; 12,895.
Наблюдается согласование этих прогнозов.
Задание 5 . Индексный анализ .
Компания занимается перевозкой грузов. Имеются данные за ряд лет по объемам перевозки 4-х видов грузов и стоимости перевозки единицы груза.
Определите простые индексы цен, количества и стоимости для каждого вида продукта, а также индексы Ласпейреса и Паше и индекс стоимости. Прокомментируйте полученные результаты содержательно.
Решение. Вычислим простые индексы:
Индекс Ласпейреса:
Индекс Паше:
Индеек стоимости:
Индивидуальные индексы указывают на разнобой в изменении цен и количеств по грузам А, В, С, Д. Агрегатные индексы указывают на общие тенденции изменения. В целом стоимость перевозимых грузов уменьшилась на 13%. Причина в том, что самый дорогой груз уменьшился на 42% по количеству, а его тариф почти не изменился.
Годы 16-20 нумеруем по порядку от 1 до 5. Исходные данные принимают вид:
Сначала исследуем динамику количества груза А.
|
Показатель |
Абсолютные приросты |
Темпы роста, % |
Темпы прироста, % |
|||||
При этом темпы роста усреднялись по формулам :
, .
Для темпа прироста в любом случае Т пр =Т р -1 .
Теперь рассматриваем груз Д .
|
Показатель |
Абсолютные приросты |
Темпы роста, % |
Темпы прироста, % |
|||||
Заключение
Средние величины и их разновидности в статистике играют большую роль. Средние показатели широко применяются в анализе, так как именно в них находят свое проявление закономерности массовых явлений и процессов как во времени, так и в пространстве. Так, например, закономерность повышения производительности труда находит свое выражение в статистических показателях роста средней выработки на одного работающего в промышленности, закономерность неуклонного роста уровня благосостояния населения проявляется в статистических показателях увеличения средних доходов рабочих и служащих и т.д.
Широкое применение имеют такие описательные характеристики распределения варьирующего признака как мода и медиана. Они являются конкретными характеристиками, их значение имеет какая-либо конкретная варианта в вариационном ряду.
Так, чтобы охарактеризовать наиболее часто встречающуюся величину признака, применяют моду, а чтоб показать количественную границу значения варьирующего признака, которую достигла половина членов совокупности - медиану.
Таким образом, средние величины помогают изучать закономерности развития промышленности, конкретной отрасли, общества и страны в целом.
Список литературы
1. Теория статистики: Учебник / Р.А. Шмойлова, В.Г. Минашкин, Н.А. Садовникова, Е.Б. Шувалова; Под ред.Р.А. Шмойловой. - 4-е изд., перераб. и доп. - М.: Финансы и статистика, 2005. - 656с.
2. Гусаров В.М. Статистика: Учебное пособие для вузов. - М.: ЮНИТИ-ДАНА, 2001.
4. Сборник задач по теории статистики: Учебное пособие/ Под ред. проф.В. В. Глинского и к. э. н., доц.Л.К. Серга. Изд. З-е. - М.: ИНФРА-М; Новосибирск: Сибирское соглашение, 2002.
5. Статистика: Учебное пособие/Харченко Л-П., Долженкова В.Г., Ионин В.Г. и др., Под ред. В.Г. Ионина. - Изд.2-е, перераб. и доп. - М.: ИНФРА-М. 2003.
Подобные документы
Дескриптивная статистика и статистический вывод. Способы отбора, обеспечивающие репрезентативность выборки. Влияние вида выборки на величину ошибки. Задачи при применении выборочного метода. Распространение данных наблюдения на генеральную совокупность.
контрольная работа , добавлен 27.02.2011
Выборочный метод и его роль. Развитие современной теории выборочного наблюдения. Типология методов отбора. Способы практической реализации простой случайной выборки. Организация типической (стратифицированной) выборки. Объем выборки при квотном отборе.
доклад , добавлен 03.09.2011
Цель выборочного наблюдения и формирование выборки. Особенности организации различных видов выборочного наблюдения. Ошибки выборочного отбора и методы их расчета. Применение выборочного метода для анализа предприятий топливно-энергетического комплекса.
курсовая работа , добавлен 06.10.2014
Выборочное наблюдение как метод статистического исследования, его особенности. Случайный, механический, типический и серийный виды отбора при образовании выборочных совокупностей. Понятие и причины возникновения ошибки выборки, методы ее определения.
реферат , добавлен 04.06.2010
Понятие и роль статистики в механизме управления современной экономикой. Сплошное и несплошное статистическое наблюдение, описание выборочного метода. Виды отбора при выборочном наблюдении, ошибки выборки. Производственные и финансовые показатели.
курсовая работа , добавлен 17.03.2011
Изучение выполнения плана. Десятипроцентное выборочное обследование по методу случайного бесповторного отбора. Себестоимость продукции завода. Предельная ошибка выборки. Динамика средних цен и объема продажи продукта. Индекс цен переменного состава.
контрольная работа , добавлен 09.02.2009
Получение выборки объема n-нормального распределения случайной величины. Нахождение числовых характеристик выборки. Группировка данных и вариационный ряд. Гистограмма частот. Эмпирическая функция распределения. Статистическое оценивание параметров.
лабораторная работа , добавлен 31.03.2013
Сущность понятий выборки и выборочного наблюдения, основные виды и категории отбора. Определение объема и численности выборки. Практическое применение статистического анализа выборочного наблюдения. Расчет ошибок выборочной доли и выборочной средней.
курсовая работа , добавлен 17.02.2015
Понятие о выборочном наблюдении. Ошибки репрезентативности, измерение ошибки выборки. Определение необходимой численности выборки. Применение выборочного метода вместо сплошного. Дисперсия в генеральной совокупности и сопоставление показателей.
контрольная работа , добавлен 23.07.2009
Виды отбора и ошибки наблюдения. Способы отбора единиц в выборочную совокупность. Характеристика коммерческой деятельности предприятия. Выборочное обследование потребителей продукции. Распространение характеристик выборки на генеральную совокупность.
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и нерепрезентативной для разных генеральных совокупностей.
Пример:
Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от ошибки никак не зависит от размера выборки.
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
Проблема респондентов, отказывающихся отвечать на вопросы анкеты (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
· вероятностные
· невероятностные
Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов, наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы (страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются случайным образом. Объекты внутри групп обследуются сплошняком.
Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности, типичности, равного представительства и т.д..
Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60 лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки используются в маркетинговых исследованиях достаточно часто.
Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход, респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром – активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает проблема выбора признака и определения его типичного значения.
Реализация плана исследований
Этот этап, напоминаем, включает в себя сбор информации и ее анализ. Процесс реализации плана маркетинговых исследований, как правило, требует самых больших исследований и служит источником максимальных ошибок.
При сборе статистических данных возникает ряд недочетов и проблем:
во-первых, некоторых респондентов может не оказаться в условленном месте и с ними приходится связываться повторно или заменять;
во-вторых, некоторые респонденты могут отказаться от сотрудничества или давать предвзятые заведомо ложные ответы.
Благодаря современным вычислительным и телекоммуникационным технологиям методы сбора данных развиваются и совершенствуются.
Некоторые фирмы проводят опросы из одного центра. В этом случае профессиональные интервьюеры сидят в кабинетах и набирают случайные телефонные номера. Если они слышат ответ абонентов, интервьюер просит поднявшего трубку ответить на несколько вопросов. Последние зачитываются с экрана монитора компьютера и набираются ответы респондентов на клавиатуре. Такой метод исключает необходимость в оформлении и кодировки данных, уменьшает число ошибок.
 Откуда берутся вода и кислород на МКС?
Откуда берутся вода и кислород на МКС? Оборона Берлина: Французы-эсэсовцы и голландские военные
Оборона Берлина: Французы-эсэсовцы и голландские военные Раздвоенный подбородок у мужчин что значит
Раздвоенный подбородок у мужчин что значит