Нарисуйте граф состояний для марковской цепи. Однородные цепи маркова
1. матрицу Р2
перехода цепи из состояния i
в состояние j
за два
шага;
2. распределение вероятностей по состояниям в момент t =2;
3. вероятность того, что в момент t =1 состоянием цепи будет А2 ;
4. стационарное распределение.
Решение. Для дискретной цепи Маркова в случае ее однородности справедливо соотношение
где Р1 – матрица переходных вероятностей за один шаг;
Рn - матрица переходных вероятностей за n шагов;
1. Найдем матрицу Р2 перехода за два шага
Пусть распределение вероятностей по состояниям на S
-ом шаге определяется вектором
.
Зная матрицу Pn
перехода за n шагов, можно определить распределение вероятностей по состояниям на (S+
n)
–ом шаге ![]() . (5)
. (5)
2. Найдем распределение вероятностей по состояниям системы в момент t
=2. Положим в (5) S
=0 и n
=2. Тогда ![]() .
.
Получим .
3. Найдем распределение вероятностей по состояниям системы в момент t =1.
Положим в (5) s
=0 и n
=1, тогда .
Откуда видно, что вероятность того, что в момент t
=1 состоянием цепи будет А2
,равна р2(1)
=0,69.
Распределение вероятностей по состояниям называется стационарным, если оно не меняется от шага к шагу, то есть
Тогда из соотношения (5) при n
=1 получим
4. Найдем стационарное распределение. Так как =2 имеем =(р1; р2). Запишем систему линейных уравнений (6) в координатной форме

Последнее условие называется нормировочным. В системе (6) всегда одно уравнение является линейной комбинацией других. Следовательно, его можно вычеркнуть. Решим совместно первое уравнение системы и нормировочное. Имеем 0,6р1
=0,3р2
, то есть р2
=2р1
. Тогда р1
+2 р1
=1 или , то есть . Следовательно, .
Ответ:
1) матрица перехода за два шага для данной цепи Маркова имеет вид ![]() ;
;
2) распределение вероятностей по состояниям в момент t
=2 равно ![]() ;
;
3) вероятность того, что в момент t
=1 состоянием цепи будет А2
, равна р2(t)
=0,69;
4) стационарное распределение имеет вид
Задана матрица  интенсивностей переходов непрерывной цепи Маркова. Составить размеченный граф состояний, соответствующий матрице Λ; составить систему дифференциальных уравнений Колмогорова для вероятностей состояний; найти предельное распределение вероятностей.
Решение.
Однородная цепь Маркова с конечным числом состояний А1
, А2
,…А
характеризуется матрицей интенсивностей переходов
интенсивностей переходов непрерывной цепи Маркова. Составить размеченный граф состояний, соответствующий матрице Λ; составить систему дифференциальных уравнений Колмогорова для вероятностей состояний; найти предельное распределение вероятностей.
Решение.
Однородная цепь Маркова с конечным числом состояний А1
, А2
,…А
характеризуется матрицей интенсивностей переходов  ,
,
где ![]() - интенсивность перехода цепи Маркова из состояния Аi
в состояние Аj
; рij(Δt)
-вероятность перехода Ai→
Aj
за интервал времени Δ
t
.
- интенсивность перехода цепи Маркова из состояния Аi
в состояние Аj
; рij(Δt)
-вероятность перехода Ai→
Aj
за интервал времени Δ
t
.
Переходы системы из состояния в состояние удобно задавать с помощью размеченного графа состояний, на котором отмечаются дуги, соответствующие интенсивностям λ
ij
>0. Составим размеченный граф состояний для заданной матрицы интенсивностей переходов
Пусть - вектор вероятностей р
j(t)
,
j
=1, 2,…,, нахождения системы в состоянии А
j
в момент t
.
Очевидно, что 0≤р
j(t)
≤1 и . Тогда по правилу дифференцирования векторной функции скалярного аргумента получим ![]() . Вероятности р
j(t)
удовлетворяют системе дифференциальных уравнений Колмогорова (СДУК), которая в матричной форме имеет вид . (7)
. Вероятности р
j(t)
удовлетворяют системе дифференциальных уравнений Колмогорова (СДУК), которая в матричной форме имеет вид . (7)
Если в начальный момент система находилась в состоянии Аj
, то СДУК следует решать при начальных условиях
р
i
(0)=1, рj(0)=0, j≠i,
j=1, 2,…,
.
(8)
Совокупность СДУК (7) и начальных условий (8) однозначно описывает однородную цепь Маркова с непрерывным временем и конечным числом состояний.
Составим СДУК для заданной цепи Маркова. Поскольку =3, то j
=1, 2, 3.
Из соотношения (7) получим  .
.
Отсюда будем иметь
Последнее условие называется нормировочным.
Распределение вероятностей по состояниям называется стационарным
, если оно не меняется с течением времени, то есть , где р
j=
const
, j
=1,2,…,. Отсюда ![]() .
.
Тогда из СДУК (7) получаем систему для нахождения стационарного распределения![]() (9)
(9)
Для данной задачи из СДУК будем иметь
Из нормировочного условия получим 3р2+р2+р2=1
или ![]() . Следовательно, предельное распределение имеет вид .
. Следовательно, предельное распределение имеет вид .
Заметим, что этот результат можно получить непосредственно по размеченному графу состояний, если воспользоваться правилом: для стационарного распределения сумма произведений λ
ji
pi
, j≠
i
, для стрелок, выходящих из i
-го состояния, равна сумме произведений λ
ji
pi
, j≠
i
, для стрелок, входящих в i
-ое состояние. Действительно,
Очевидно, что полученная система эквивалентна той, которая составлена по СДУК. Следовательно, она имеет то же решение.
Ответ: стационарное распределение имеет вид .
Цепь Маркова – череда событий, в которой каждое последующее событие зависит от предыдущего. В статье мы подробнее разберём это понятие.
Цепь Маркова – это распространенный и довольно простой способ моделирования случайных событий. Используется в самых разных областях, начиная генерацией текста и заканчивая финансовым моделированием. Самым известным примером является SubredditSimulator . В данном случае Цепь Маркова используется для автоматизации создания контента во всем subreddit.
Цепь Маркова понятна и проста в использовании, т. к. она может быть реализована без использования каких-либо статистических или математических концепций. Цепь Маркова идеально подходит для изучения вероятностного моделирования и Data Science.
Сценарий
Представьте, что существует только два погодных условия: может быть либо солнечно, либо пасмурно. Всегда можно безошибочно определить погоду в текущий момент. Гарантированно будет ясно или облачно.
Теперь вам захотелось научиться предсказывать погоду на завтрашний день. Интуитивно вы понимаете, что погода не может кардинально поменяться за один день. На это влияет множество факторов. Завтрашняя погода напрямую зависит от текущей и т. д. Таким образом, для того чтобы предсказывать погоду, вы на протяжении нескольких лет собираете данные и приходите к выводу, что после пасмурного дня вероятность солнечного равна 0,25. Логично предположить, что вероятность двух пасмурных дней подряд равна 0,75, так как мы имеем всего два возможных погодных условия.

Теперь вы можете прогнозировать погоду на несколько дней вперед, основываясь на текущей погоде.
Этот пример показывает ключевые понятия цепи Маркова. Цепь Маркова состоит из набора переходов, которые определяются распределением вероятностей, которые в свою очередь удовлетворяют Марковскому свойству.
Обратите внимание, что в примере распределение вероятностей зависит только от переходов с текущего дня на следующий. Это уникальное свойство Марковского процесса – он делает это без использования памяти. Как правило, такой подход не способен создать последовательность, в которой бы наблюдалась какая-либо тенденция. Например, в то время как цепь Маркова способна сымитировать стиль письма, основанный на частоте использования какого-то слова, она не способна создать тексты с глубоким смыслом, так как она может работать только с большими текстами. Именно поэтому цепь Маркова не может производить контент, зависящий от контекста.
Модель
Формально, цепь Маркова – это вероятностный автомат. Распределение вероятностей переходов обычно представляется в виде матрицы. Если цепь Маркова имеет N возможных состояний, то матрица будет иметь вид N x N, в которой запись (I, J) будет являться вероятностью перехода из состояния I в состояние J. Кроме того, такая матрица должна быть стохастической, то есть строки или столбцы в сумме должны давать единицу. В такой матрице каждая строка будет иметь собственное распределение вероятностей.

Общий вид цепи Маркова с состояниями в виде окружностей и ребрами в виде переходов.

Примерная матрица перехода с тремя возможными состояниями.
Цепь Маркова имеет начальный вектор состояния, представленный в виде матрицы N x 1. Он описывает распределения вероятностей начала в каждом из N возможных состояний. Запись I описывает вероятность начала цепи в состоянии I.
Этих двух структур вполне хватит для представления цепи Маркова.
Мы уже обсудили, как получить вероятность перехода из одного состояния в другое, но что насчет получения этой вероятности за несколько шагов? Для этого нам необходимо определить вероятность перехода из состояния I в состояние J за M шагов. На самом деле это очень просто. Матрицу перехода P можно определить вычислением (I, J) с помощью возведения P в степень M. Для малых значений M это можно делать вручную, с помощью повторного умножения. Но для больших значений M, если вы знакомы с линейной алгеброй, более эффективным способом возведения матрицы в степень будет сначала диагонализировать эту матрицу.
Цепь Маркова: заключение
Теперь, зная, что из себя представляет цепь Маркова, вы можете легко реализовать её на одном из языков программирования. Простые цепи Маркова являются фундаментом для изучения более сложных методов моделирования.
Все возможные состояния системы в однородной цепи Маркова, а - определяющая эту
цепь стохастическая матрица, составленная из переходных вероятностей ![]() (см. стр. 381).
(см. стр. 381).
Обозначим
через вероятность
нахождения системы в состоянии в момент времени если известно, что в
момент времени система
находилась в состоянии (,). Очевидно, ![]() . Пользуясь
теоремами о сложении и умножении вероятностей, мы легко найдем:
. Пользуясь
теоремами о сложении и умножении вероятностей, мы легко найдем:
![]()
![]()
или в матричной записи
![]()
Отсюда, давая последовательно значения , получим важную формулу
Если существуют пределы
![]()
или в матричной записи
![]()
то величины ![]() называются предельными или
финальными переходными вероятностями.
называются предельными или
финальными переходными вероятностями.
Для выяснения, в каких случаях существуют предельные переходные вероятности, и для вывода соответствующих формул введем следующую терминологию.
Мы будем стохастическую матрицу и соответствующую ой однородную цепь Маркова называть правильной, если у матрицы нет характеристических чисел, отличных от единицы и равных по модулю единице, и регулярной, если дополнительно единица является простым корнем характеристического уравнения матрицы .
Правильная матрица характеризуется том, что в ее нормальной форме (69) (стр. 373) матрицы являются примитивными. Для регулярной матрицы дополнительно .
Кроме того, однородная цепь Маркова называется неразложимой, разложимой, ациклической, циклической, если для этой цепи стохастическая матрица является соответственно неразложимой, разложимой, примитивной, импримитивной.
Поскольку примитивная стохастическая матрица является частным видом правильной матрицы, постольку ациклическая цепь Маркова является частным видом правильной цепи.
Мы покажем, что предельные переходные вероятности существуют только у правильных однородных цепей Маркова.
Действительно, пусть - минимальный многочлен правильной матрицы . Тогда
Согласно теореме 10 можно принять, что
На основании формулы (24) гл. V (стр. 113)
 (96)
(96)
где
![]() -
приведенная присоединенная матрица и
-
приведенная присоединенная матрица и

Если - правильная матрица, то
и потому в правой части формулы (96) все слагаемые, кроме первого, при стремится к нулю. Поэтому для правильной матрицы существует матрица , составленная из предельных переходных вероятностей, и
Обратное положение очевидно. Если существует продел
то матрица не может иметь характеристического числа , для которого , а , так как тогда не существовал бы предел [Этот же предел должен существовать в силу существования предела (97").]
Мы доказали, что для правильной (и только для правильной) однородной цепи Маркова существует матрица . Эта матрица определяется формулой (97).
Покажем, как можно выразить матрицу через характеристический многочлен
и
присоединенную матрицу ![]() .
.
Из тождества
в силу (95), (95") и (98) вытекает:

Поэтому формулу (97) можно заменить формулой
 (97)
(97)
Для регулярной цепи Маркова, поскольку она является частным видом правильной цепи, матрица существует и определяется любой из формул (97), (97"). В этом случае и формула (97") имеет вид
2. Рассмотрим правильную цепь общего типа (нерегулярную). Соответствующую матрицу запишем в нормальной форме
 (100)
(100)
где - примитивные стохастические матрицы, а у неразложимых матриц максимальные характеристические числа . Полагая
 ,
, 
запишем в виде

 (101)
(101)

Но
![]() , поскольку
все характеристические числа матрицы
по модулю
меньше единицы. Поэтому
, поскольку
все характеристические числа матрицы
по модулю
меньше единицы. Поэтому
 (102)
(102)
Поскольку - примитивные стохастические матрицы, то матрицы согласно формулам (99) и (35) (стр. 362) положительны
![]()
и в каждом столбце любой из этих матриц все элементы равны между собой:
![]() .
.
Заметим, что нормальному виду (100) стохастической матрицы соответствует разбиение состояний системы на группы:
Каждой группе в (104) соответствует своя группа рядов в (101). По терминологии Л. Н. Колмогорова состояния системы, входящие в , называются существенными, а состояния, входящие в остальные группы - несущественными.
Из вида (101) матрицы следует, что при любом коночном числе шагов (от момента к моменту ) возможен только переход системы а) из существенного состояния в существенное состояние той же группы, б) из несущественного состояния в существенное состояние и в) из несущественного состояния в несущественное состояние той же или предшествующей группы.
Из вида (102) матрицы следует, что в продело при переход возможен только из любого состояния в существенное состояние, т. е. вероятность перехода в любое несущественное состояние при числе шагов стремится к нулю. Поэтому существенные состояния иногда называются и предельными состояниями.
3. Из формулы (97) следует:
![]() .
.
Отсюда видно, что каждый столбец матрицы является собственным вектором стохастической матрицы для характеристического числа .
Для регулярной матрицы число 1 является простым корнем характеристического уравнения и этому числу соответствует только один (с точностью до скалярного множителя) собственный вектор матрицы . Поэтому в любом -м столбце матрицы все элементы равны одному и тому же неотрицательному числу :
Таким образом, в регулярной цепи предельные переходные вероятности но зависят от начального состояния.
Обратно, если в некоторой правильной однородной цепи Маркова продельные переходные вероятности не зависят от начального состояния, т. е. имеют место формулы (104), то в схеме (102) для матрицы обязательно . Но тогда и цепь является регулярной.
Для
ациклической цепи, которая является частным случаем регулярной цепи,
-
примитивная матрица. Поэтому при некотором (см.
теорему 8 на стр. 377). Но тогда и ![]() .
.
Обратно, из следует, что при некотором , а это по теореме 8 означает примитивность матрицы и, следовательно, ацикличность данной однородной цепи Маркова.
Полученные результаты мы сформулируем в виде следующей теоремы:
Теорема 11. 1 .Для того чтобы в однородной цепа Маркова существовали все предельные переходные вероятности, необходимо и достаточно, чтобы цепь была правильной. В этом случае матрица , составленная из предельных переходных вероятностей, определяется формулой (95) или (98).
2. Для того чтобы в правильной однородной цепи Маркова предельные переходные вероятности не зависели от начального состояния, необходимо и достаточно, чтобы цепь была регулярной. В этом случае матрица определяется формулой (99).
3. Для того чтобы в правильной однородной цепи Маркова все предельные переходные вероятности были отличны от нуля, необходимо и достаточно, чтобы цепь была ациклической.
4. Введем в рассмотрение столбцы из абсолютных вероятностей
![]() (105)
(105)
где - вероятность нахождения системы в момент в состоянии (,). Пользуясь теоремами сложения и умножения вероятностей, найдем:
![]() (,),
(,),
или в матричной записи
где - транспонированная матрица для матрицы .
Все абсолютные вероятности (105) определяются из формулы (106), если известны начальные вероятности и матрица переходных вероятностей
Введем в рассмотрение предельные абсолютные вероятности
![]()
Переходя в обоих частях равенства (106) к пределу при , получим:
Заметим,
что существование матрицы предельных переходных вероятностей влечет
существование предельных абсолютных вероятностей ![]() при любых начальных вероятностях
при любых начальных вероятностях
![]() и
наоборот.
и
наоборот.
Из формулы (107) и из вида (102) матрицы вытекает, что предельные абсолютные вероятности, соответствующие несущественным состояниям, равны нулю.
Умножая обе части матричного равенства
справа на , мы в силу (107) получим:
т. е. столбец предельных абсолютных вероятностей является собственным вектором матрицы для характеристического числа .
Если данная цепь Маркова регулярна, то является простым корнем характеристического уравнения матрицы . В этом случае столбец предельных абсолютных вероятностей однозначно определяется из (108) (поскольку и ).
Пусть дана регулярная цепь Маркова. Тогда из (104) и из (107) следует:
![]() (109)
(109)
В этом случае предельные абсолютные вероятности не зависят от начальных вероятностей .
Обратно, может не зависеть от при наличии формулы (107) тогда и только тогда, когда все строки матрицы одинаковы, т. е.
![]() ,
,
и потому (согласно теореме 11) - регулярная матрица.
Если - примитивная матрица, то , а отсюда в силу (109)
Наоборот, если все и не зависят от начальных вероятностен, то в каждом столбце матрицы все элементы одинаковы и согласно (109) , а это по теореме 11 означает, что - примитивная матрица, т. е. данная цепь ациклична.
Из изложенного вытекает, что теорему 11 можно сформулировать так:
Теорема 11". 1. Для того чтобы в однородной цепи Маркова существовали все предельные абсолютные вероятности при любых начальных вероятностях, необходимо и достаточно, чтобы цепь была правильной.
2. Для того чтобы в однородной цепи Маркова существовали предельные абсолютные вероятности при любых начальных вероятностях и не зависели от этих начальных вероятностей, необходимо и достаточно, чтобы цепь была регулярной.
3. Для того чтобы в однородной цепи Маркова при любых начальных вероятностях существовали положительные предельные абсолютные вероятности и эти предельные вероятности не зависели от начальных, необходимо и достаточно, чтобы цепь была ациклической.
5. Рассмотрим теперь однородную цепь Маркова общего типа с матрицей переходных вероятностей .
Возьмем
нормальную форму (69) матрицы и обозначим через индексы
импримитивности матриц в
(69). Пусть - наименьшее общее
кратное целых чисел . Тогда
матрица не имеет характеристических
чисел, равных по модулю единице, но отличных от единицы, т. е. -
правильная матрица; при этом - наименьший
показатель, при котором - правильная матрица.
Число назовем периодом
данной однородной цепи Маркова и.. Обратно, если и ![]() ,
определяемые формулами (110) и (110").
,
определяемые формулами (110) и (110").
Средние предельные абсолютные вероятности, соответствующие несущественным состояниям, всегда равны нулю.
Если в нормальной форме матрицы число (и только в этом случае), средние предельные абсолютные вероятности не зависят от начальных вероятностей и однозначно определяются из уравнения (111).
Эта статья дает общее представление о том, как генерировать тексты при помощи моделирования марковских процессов. В частности, мы познакомимся с цепями Маркова, а в качестве практики реализуем небольшой генератор текста на Python.
Для начала выпишем нужные, но пока не очень понятные нам определения со страницы в Википедии , чтобы хотя бы примерно представлять, с чем мы имеем дело:
Марковский процесс t t
Марковская цепь
Что все это значит? Давайте разбираться.
Основы
Первый пример предельно прост. Используя предложение из детской книжки , мы освоим базовую концепцию цепи Маркова, а также определим, что такое в нашем контексте корпус, звенья, распределение вероятностей и гистограммы . Несмотря на то, что предложение приведено на английском языке, суть теории будет легко уловить.
Это предложение и есть корпус , то есть база, на основе которой в дальнейшем будет генерироваться текст. Оно состоит из восьми слов, но при этом уникальных слов только пять - это звенья (мы ведь говорим о марковской цепи ). Для наглядности окрасим каждое звено в свой цвет:

И выпишем количество появлений каждого из звеньев в тексте:

На картинке выше видно, что слово «fish» появляется в тексте в 4 раза чаще, чем каждое из других слов («One», «two», «red», «blue» ). То есть вероятность встретить в нашем корпусе слово «fish» в 4 раза выше, чем вероятность встретить каждое другое слово из приведенных на рисунке. Говоря на языке математики, мы можем определить закон распределения случайной величины и вычислить, с какой вероятностью одно из слов появится в тексте после текущего. Вероятность считается так: нужно разделить число появлений нужного нам слова в корпусе на общее число всех слов в нем. Для слова «fish» эта вероятность - 50%, так как оно появляется 4 раза в предложении из 8 слов. Для каждого из остальных звеньев эта вероятность равна 12,5% (1/8).
Графически представить распределение случайных величин можно с помощью гистограммы . В данном случае, наглядно видна частота появления каждого из звеньев в предложении:

Итак, наш текст состоит из слов и уникальных звеньев, а распределение вероятностей появления каждого из звеньев в предложении мы отобразили на гистограмме. Если вам кажется, что возиться со статистикой не стоит, прочитайте . И, возможно, сохранит вам жизнь.
Суть определения
Теперь добавим к нашему тексту элементы, которые всегда подразумеваются, но не озвучиваются в повседневной речи - начало и конец предложения:

Любое предложение содержит эти невидимые «начало» и «конец», добавим их в качестве звеньев к нашему распределению:

Вернемся к определению, данному в начале статьи:
Марковский процесс - случайный процесс, эволюция которого после любого заданного значения временного параметра t не зависит от эволюции, предшествовавшей t , при условии, что значение процесса в этот момент фиксировано.
Марковская цепь - частный случай марковского процесса, когда пространство его состояний дискретно (т.е. не более чем счетно).
Так что же это значит? Грубо говоря, мы моделируем процесс, в котором состояние системы в следующий момент времени зависит только от её состояния в текущий момент, и никак не зависит от всех предыдущих состояний .
Представьте, что перед вами окно , которое отображает только текущее состояние системы (в нашем случае, это одно слово), и вам нужно определить, каким будет следующее слово, основываясь только на данных, представленных в этом окне. В нашем корпусе слова следуют одно за другим по такой схеме:

Таким образом, формируются пары слов (даже у конца предложения есть своя пара - пустое значение):

Сгруппируем эти пары по первому слову. Мы увидим, что у каждого слова есть свой набор звеньев, которые в контексте нашего предложения могут за ним следовать:

Представим эту информацию другим способом - каждому звену поставим в соответствие массив из всех слов, которые могут появиться в тексте после этого звена:

Разберем подробнее. Мы видим, что у каждого звена есть слова, которые могут стоять после него в предложении. Если бы мы показали схему выше кому-то еще, этот человек с некоторой вероятностью мог бы реконструировать наше начальное предложение, то есть корпус.
Пример. Начнем со слова «Start» . Далее выбираем слово «One» , так как по нашей схеме это единственное слово, которое может следовать за началом предложения. За словом «One» тоже может следовать только одно слово - «fish» . Теперь новое предложение в промежуточном варианте выглядит как «One fish» . Дальше ситуация усложняется - за «fish» могут с равной вероятностью в 25% идти слова «two», «red», «blue» и конец предложения «End» . Если мы предположим, что следующее слово - «two» , реконструкция продолжится. Но мы можем выбрать и звено «End» . В таком случае на основе нашей схемы будет случайно сгенерировано предложение, сильно отличающееся от корпуса - «One fish» .
Мы только что смоделировали марковский процесс - определили каждое следующее слово только на основании знаний о текущем. Давайте для полного усвоения материала построим диаграммы, отображающие зависимости между элементами внутри нашего корпуса. Овалы представляют собой звенья. Стрелки ведут к потенциальным звеньям, которые могут идти за словом в овале. Около каждой стрелки - вероятность, с которой следующее звено появится после текущего:

Отлично! Мы усвоили необходимую информацию, чтобы двигаться дальше и разбирать более сложные модели.
Расширяем словарную базу
В этой части статьи мы будем строить модель по тому же принципу, что и раньше, но при описании опустим некоторые шаги. Если возникнут затруднения, возвращайтесь к теории в первом блоке.
Возьмем еще четыре цитаты того же автора (также на английском, нам это не помешает):
«Today you are you. That is truer than true. There is no one alive who is you-er than you.»
«You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose. You’re on your own.»
«The more that you read, the more things you will know. The more that you learn, the more places you’ll go.»
«Think left and think right and think low and think high. Oh, the thinks you can think up if only you try.»
Сложность корпуса увеличилась, но в нашем случае это только плюс - теперь генератор текста сможет выдавать более осмысленные предложения. Дело в том, что в любом языке есть слова, которые встречаются в речи чаще, чем другие (например, предлог «в» мы используем гораздо чаще, чем слово «криогенный»). Чем больше слов в нашем корпусе (а значит, и зависимостей между ними), тем больше у генератора информации о том, какое слово вероятнее всего должно появиться в тексте после текущего.
Проще всего это объясняется с точки зрения программы. Мы знаем, что для каждого звена существует набор слов, которые могут за ним следовать. А также, каждое слово характеризуется числом его появлений в тексте. Нам нужно каким-то образом зафиксировать всю эту информацию в одном месте; для этой цели лучше всего подойдет словарь, хранящий пары «(ключ, значение)». В ключе словаря будет записано текущее состояние системы, то есть одно из звеньев корпуса (например, «the» на картинке ниже); а в значении словаря будет храниться еще один словарь. Во вложенном словаре ключами будут слова, которые могут идти в тексте после текущего звена корпуса («thinks» и «more» могут идти в тексте после «the» ), а значениями - число появлений этих слов в тексте после нашего звена (слово «thinks» появляется в тексте после слова «the» 1 раз, слово «more» после слова «the» - 4 раза):

Перечитайте абзац выше несколько раз, чтобы точно разобраться. Обратите внимание, что вложенный словарь в данном случае - это та же гистограмма, он помогает нам отслеживать звенья и частоту их появления в тексте относительно других слов. Надо заметить, что даже такая словарная база очень мала для надлежащей генерации текстов на естественном языке - она должна содержать более 20 000 слов, а лучше более 100 000. А еще лучше - более 500 000. Но давайте рассмотрим ту словарную базу, которая получилась у нас.
Цепь Маркова в данном случае строится аналогично первому примеру - каждое следующее слово выбирается только на основании знаний о текущем слове, все остальные слова не учитываются. Но благодаря хранению в словаре данных о том, какие слова появляются чаще других, мы можем при выборе принять взвешенное решение . Давайте разберем конкретный пример:
More:
То есть если текущим словом является слово «more» , после него могут с равной вероятностью в 25% идти слова «things» и «places» , и с вероятностью 50% - слово «that» . Но вероятности могут быть и все равны между собой:
Think:
Работа с окнами
До настоящего момента мы с вами рассматривали только окна размером в одно слово. Можно увеличить размер окна, чтобы генератор текста выдавал более «выверенные» предложения. Это значит, что чем больше окно, тем меньше будет отклонений от корпуса при генерации. Увеличение размера окна соответствует переходу цепи Маркова к более высокому порядку. Ранее мы строили цепь первого порядка, для окна из двух слов получится цепь второго порядка, из трех - третьего, и так далее.
Окно - это те данные в текущем состоянии системы, которые используются для принятия решений. Если мы совместим большое окно и маленький набор данных, то, скорее всего, каждый раз будем получать одно и то же предложение. Давайте возьмем словарную базу из нашего первого примера и расширим окно до размера 2:

Расширение привело к тому, что у каждого окна теперь только один вариант следующего состояния системы - что бы мы ни делали, мы всегда будем получать одно и то же предложение, идентичное нашему корпусу. Поэтому, чтобы экспериментировать с окнами, и чтобы генератор текста возвращал уникальный контент, запаситесь словарной базой от 500 000 слов.
Реализация на Python
Структура данных Dictogram
Dictogram (dict - встроенный тип данных словарь в Python) будет отображать зависимость между звеньями и их частотой появления в тексте, то есть их распределение. Но при этом она будет обладать нужным нам свойством словаря - время выполнения программы не будет зависеть от объема входных данных, а это значит, мы создаем эффективный алгоритм.
Import random class Dictogram(dict): def __init__(self, iterable=None): # Инициализируем наше распределение как новый объект класса, # добавляем имеющиеся элементы super(Dictogram, self).__init__() self.types = 0 # число уникальных ключей в распределении self.tokens = 0 # общее количество всех слов в распределении if iterable: self.update(iterable) def update(self, iterable): # Обновляем распределение элементами из имеющегося # итерируемого набора данных for item in iterable: if item in self: self += 1 self.tokens += 1 else: self = 1 self.types += 1 self.tokens += 1 def count(self, item): # Возвращаем значение счетчика элемента, или 0 if item in self: return self return 0 def return_random_word(self): random_key = random.sample(self, 1) # Другой способ: # random.choice(histogram.keys()) return random_key def return_weighted_random_word(self): # Сгенерировать псевдослучайное число между 0 и (n-1), # где n - общее число слов random_int = random.randint(0, self.tokens-1) index = 0 list_of_keys = self.keys() # вывести "случайный индекс:", random_int for i in range(0, self.types): index += self] # вывести индекс if(index > random_int): # вывести list_of_keys[i] return list_of_keys[i]
В конструктор структуре Dictogram можно передать любой объект, по которому можно итерироваться. Элементами этого объекта будут слова для инициализации Dictogram, например, все слова из какой-нибудь книги. В данном случае мы ведем подсчет элементов, чтобы для обращения к какому-либо из них не нужно было пробегать каждый раз по всему набору данных.
Мы также сделали две функции для возврата случайного слова. Одна функция выбирает случайный ключ в словаре, а другая, принимая во внимание число появлений каждого слова в тексте, возвращает нужное нам слово.
Структура цепи Маркова
from histograms import Dictogram def make_markov_model(data): markov_model = dict() for i in range(0, len(data)-1): if data[i] in markov_model: # Просто присоединяем к уже существующему распределению markov_model].update(]) else: markov_model] = Dictogram(]) return markov_modelВ реализации выше у нас есть словарь, который хранит окна в качестве ключа в паре «(ключ, значение)» и распределения в качестве значений в этой паре.
Структура цепи Маркова N-го порядка
from histograms import Dictogram def make_higher_order_markov_model(order, data): markov_model = dict() for i in range(0, len(data)-order): # Создаем окно window = tuple(data) # Добавляем в словарь if window in markov_model: # Присоединяем к уже существующему распределению markov_model.update(]) else: markov_model = Dictogram(]) return markov_modelОчень похоже на цепь Маркова первого порядка, но в данном случае мы храним кортеж в качестве ключа в паре «(ключ, значение)» в словаре. Мы используем его вместо списка, так как кортеж защищен от любых изменений, а для нас это важно - ведь ключи в словаре меняться не должны.
Парсинг модели
Отлично, мы реализовали словарь. Но как теперь совершить генерацию контента, основываясь на текущем состоянии и шаге к следующему состоянию? Пройдемся по нашей модели:
From histograms import Dictogram import random from collections import deque import re def generate_random_start(model): # Чтобы сгенерировать любое начальное слово, раскомментируйте строку: # return random.choice(model.keys()) # Чтобы сгенерировать "правильное" начальное слово, используйте код ниже: # Правильные начальные слова - это те, что являлись началом предложений в корпусе if "END" in model: seed_word = "END" while seed_word == "END": seed_word = model["END"].return_weighted_random_word() return seed_word return random.choice(model.keys()) def generate_random_sentence(length, markov_model): current_word = generate_random_start(markov_model) sentence = for i in range(0, length): current_dictogram = markov_model random_weighted_word = current_dictogram.return_weighted_random_word() current_word = random_weighted_word sentence.append(current_word) sentence = sentence.capitalize() return " ".join(sentence) + "." return sentence
Что дальше?
Попробуйте придумать, где вы сами можете использовать генератор текста на основе марковских цепей. Только не забывайте, что самое главное — это то, как вы парсите модель и какие особые ограничения устанавливаете на генерацию. Автор этой статьи, например, при создании генератора твитов использовал большое окно, ограничил генерируемый контент до 140 символов и использовал для начала предложений только «правильные» слова, то есть те, которые являлись началом предложений в корпусе.
Способы математических описаний марковских случайных процессов в системе с дискретными состояниями (ДС) зависят от того, в какие моменты времени (заранее известные или случайные) могут происходить переходы системы из состояния в состояние.
Если переход системы из состояния в состояние возможен в заранее фиксированные моменты времени, имеем дело со случайным марковским процессом с дискретным временем.
Если переход возможен в любой случайный момент времени, то имеем дело со случайным марковским процессом с непрерывным временем.
Пусть имеется физическая система S
, которая может находиться в n
состояниях S
1 , S
2 , …, S n
. Переходы из состояния в состояние возможны только в моменты времени t
1 , t
2 , …, t k
, назовём эти моменты времени шагами. Будем рассматривать СП в системе S
как функцию целочисленного аргумента 1, 2, …, k
, где аргументом является номер шага.
Пример: S
1 → S
2 → S
3 → S
2 .
Условимся обозначать S i
( k
) – событие, состоящее в том, что после k
шагов система находится в состоянии S i
.
При любом k
события S 1 ( k
) , S 2 ( k
) ,…, S n
( k
) образуют полную группу событий
и являются несовместными.
Процесс в системе можно представить как цепочку событий.
Пример:S
1 (0) , S
2 (1) , S 3 (2) , S 5 (3) ,….
Такая последовательность называется марковской цепью
, если для каждого шага вероятность перехода из любого состояния S i
в любое состояние S j
не зависит от того, когда и как система пришла в состояние S i
.
Пусть в любой момент времени после любого k
-го шага система S
может находиться в одном из состояний S
1 , S
2 , …, S n
, т. е. может произойти одно событие из полной группы событий: S
1 ( k
) , S 2 ( k
) , …, S n
( k
) . Обозначим вероятности этих событий:
P
1 (1) = P
(S
1 (1)); P
2 (1) = P
(S
2 (1)); …; P n
(1) = P
(S n
( k
));
P
1 (2) = P
(S
1 (2)); P
2 (2) = P
(S 2 (2)); …; P n
(2) = P
(S n
(2));
P
1 (k
) = P
(S
1 (k
)); P
2 (k
) = P
(S
2 (k
)); …; P n
(k
) = P
(S n
(k
)).
Легко заметить, что для каждого номера шага выполняется условие
P
1 (k
) + P
2 (k
) +…+ P n
(k
) = 1.
Назовём эти вероятности вероятностями состояний
.следовательно, задача будет звучать следующим образом: найти вероятности состояний системы для любого k
.
Пример.
Пусть имеется какая-то система, которая может находиться в любом из шести состояний. тогда процессы, происходящие в ней, можно изобразить либо в виде графика изменения состояния системы (рис. 7.9, а
), либо в виде графа состояний системы (рис. 7.9, б
).
а) 
Рис. 7.9
Также процессы в системе можно изобразить в виде последовательности состояний: S
1 , S
3 , S
2 , S
2 , S
3 , S
5 , S
6 , S
2 .
Вероятность состояния на (k
+ 1)-м шаге зависит только от состояния на k-
м шаге.
Для любого шага k
существуют какие-то вероятности перехода системы из любого состояния в любое другое состояние, назовем эти вероятности переходными вероятностями марковской цепи.
Некоторые из этих вероятностей будут равны 0, если переход из одного состояния в другое невозможен за один шаг.
Марковская цепь называется однородной
, если переходные состояния не зависят от номера шага, в противном случае она называется неоднородной
.
Пусть имеется однородная марковская цепь и пусть система S
имеет n
возможных состояний: S
1 , …, S n
. Пусть для каждого состояния известна вероятность перехода в другое состояние за один шаг, т. е. P ij
(из S i
в S j
за один шаг), тогда мы можем записать переходные вероятности в виде матрицы.
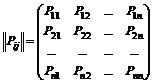 . (7.1)
. (7.1)
По диагонали этой матрицы расположены вероятности того, что система переходит из состояния S i
в то же состояние S i
.
Пользуясь введенными ранее событиями ![]() , можно переходные вероятности записать как условные вероятности:
, можно переходные вероятности записать как условные вероятности:
![]() .
.
Очевидно, что сумма членов ![]() в каждой строке матрицы (1) равна единице, поскольку события
в каждой строке матрицы (1) равна единице, поскольку события ![]() образуют полную группу несовместных событий.
образуют полную группу несовместных событий.
При рассмотрении марковских цепей, так же как и при анализе марковского случайного процесса, используются различные графы состояний (рис. 7.10).

Рис. 7.10
Данная система может находиться в любом из шести состояний, при этом P ij
– вероятность перехода системы из состояния S i
в состояние S j
. Для данной системы запишем уравнения, что система находилась в каком-либо состоянии и из него за время t
не вышла:
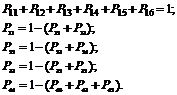
В общем случае марковская цепь является неоднородной, т. е. вероятность P ij
меняется от шага к шагу. Предположим, что задана матрица вероятностей перехода на каждом шаге, тогда вероятность того, что система S
на k
-м шаге будет находиться в состоянии S i
, можно найти по формуле
![]()
Зная матрицу переходных вероятностей и начальное состояние системы, можно найти вероятности состояний ![]() после любого k
-го шага. Пусть в начальный момент времени система находится в состоянии S m
. Тогда для t = 0
после любого k
-го шага. Пусть в начальный момент времени система находится в состоянии S m
. Тогда для t = 0
.
Найдем вероятности после первого шага. Из состояния S m
система перейдет в состояния S
1 , S
2 и т. д. с вероятностями P m
1 , P m
2 , …, P mm
, …, P mn
. Тогда после первого шага вероятности будут равны
. (7.2)
Найдем вероятности состояния после второго шага: . Будем вычислять эти вероятности по формуле полной вероятности с гипотезами:
![]() .
.
Гипотезами будут следующие утверждения:
- после первого шага система была в состоянии S 1 -H 1 ;
- после второго шага система была в состоянии S 2 -H 2 ;
- после n -го шага система была в состоянии S n -H n .
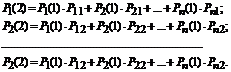
Вероятность любого состояния после второго шага:
![]() (7.3)
(7.3)
В формуле (7.3) суммируются все переходные вероятности P ij
, но учитываются только отличные от нуля. Вероятность любого состояния после k
-го шага:
![]() (7.4)
(7.4)
Таким образом, вероятность состояния после k
-го шага определяется по рекуррентной формуле (7.4) через вероятности (k –
1)-го шага.
Задача 6.
Задана матрица вероятностей перехода для цепи Маркова за один шаг. Найти матрицу перехода данной цепи за три шага .
.
Решение.
Матрицей перехода системы называют матрицу, которая содержит все переходные вероятности этой системы:

В каждой строке матрицы помещены вероятности событий (перехода из состояния i
в состояние j
), которые образуют полную группу, поэтому сумма вероятностей этих событий равна единице:
![]()
Обозначим через p ij (n) вероятность того, что в результате n шагов (испытаний) система перейдет из состояния i в состояние j . Например p 25 (10) - вероятность перехода из второго состояния в пятое за десять шагов. Отметим, что при n=1 получаем переходные вероятности p ij (1)=p ij .
Перед нами поставлена задача: зная переходные вероятности p ij , найти вероятности p ij (n) перехода системы из состояния i
в состояние j
заn
шагов. Для этого введем промежуточное (между i
и j
) состояние r
. Другими словами, будем считать, что из первоначального состояния i
за m
шагов система перейдет в промежуточное состояние r
с вероятностью p ij (n-m) , после чего, за оставшиеся n-m шагов из промежуточного состояния r она перейдет в конечное состояние j с вероятностью p ij (n-m) . По формуле полной вероятности получаем:
![]() .
.
Эту формулу называют равенством Маркова. С помощью этой формулы можно найти все вероятности p ij (n) , а, следовательно, и саму матрицу P n . Так как матричное исчисление ведет к цели быстрее, запишем вытекающее из полученной формулы матричное соотношение в общем виде.
Вычислим матрицу перехода цепи Маркова за три шага, используя полученную формулу:

Ответ:
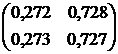 .
.
Задача №1
. Матрица вероятностей перехода цепи Маркова имеет вид:
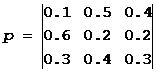 .
.
Распределение по состояниям в момент времени t=0 определяется вектором:
π 0 =(0.5; 0.2; 0.3)
Найти:
а) распределение по состояниям в моменты t=1,2,3,4 .
в) стационарное распределение.
 Проблема молодости, юности, детства
Проблема молодости, юности, детства Владимир Маяковский — Левый марш: Стих
Владимир Маяковский — Левый марш: Стих Химические свойства аминокислот по карбоксильной группе
Химические свойства аминокислот по карбоксильной группе