Какво е извадка в статистиката. Повече не винаги е по-добре
За да определим вероятностите на събитията, които ни интересуват, ние използваме метода на вземане на проби: ние извършваме ннезависими експерименти, във всеки от които събитие А може да се случи (или да не се случи) (вероятност Рпоявата на събитие А във всеки експеримент е постоянна). Тогава относителната честота p* на възникване на събития НОв поредица от нтестове се приема като точкова оценка за вероятността стрнастъпване на събитие НОв отделен тест. В този случай се извиква стойността p* примерен дял събития НО, и r - общ дял .
По силата на следствието от централната гранична теорема (теоремата на Moivre-Laplace), относителната честота на събитие с голям размер на извадката може да се счита за нормално разпределена с параметрите M(p*)=p и
Следователно, за n>30, доверителният интервал за общата фракция може да се изгради с помощта на формулите:
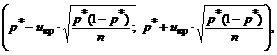
където u cr се намира по таблиците на функцията на Лаплас, като се вземе предвид дадената доверителна вероятност γ: 2Ф(u cr)=γ.
При малък размер на извадката n≤30, пределната грешка ε се определя от таблицата за разпределение на Student: ![]() където t cr =t(k; α) и броя на степените на свобода k=n-1 вероятност α=1-γ (двустранна област).
където t cr =t(k; α) и броя на степените на свобода k=n-1 вероятност α=1-γ (двустранна област).
Формулите са валидни, ако изборът е извършен на случаен принцип по многократен начин (генералната съвкупност е безкрайна), в противен случай е необходимо да се направи корекция за неповтарящия се избор (таблица).
Средна извадкова грешка за общата пропорция
| Население | Безкраен | краен обем н |
| Тип селекция | Повтаря се | неповтарящ се |
| Средна извадкова грешка |
Формули за изчисляване на размера на извадката с подходящ метод на случаен подбор
| Метод на избор | Формули за размер на извадката | ||
| за средата | за споделяне | ||
| Повтаря се | |||
| неповтарящ се | |||
Проблеми за общия дял
На въпроса "Дадената стойност на p 0 покрива ли доверителния интервал?" - може да се отговори чрез тестване на статистическата хипотеза H 0:p=p 0 . Предполага се, че експериментите се провеждат по схемата на теста на Бернули (независима, вероятностна стрнастъпване на събитие НОпостоянен). По обемна проба нопределяне на относителната честота p * на поява на събитие A: където м- брой появявания на събитието НОв поредица от нтестове. За проверка на хипотезата H 0 се използват статистики, които при достатъчно голям размер на извадката имат стандартно нормално разпределение (Таблица 1).Таблица 1 - Хипотези за общия дял
Хипотеза | H0:p=p0 | H 0: p 1 \u003d p 2 |
| Предположения | Схема на теста на Бернули | Схема на теста на Бернули |
| Примерни оценки | 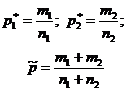 |
|
| Статистика К | 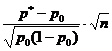 |  |
| Разпределение на статистиката К | Стандартно нормално N(0,1) |
Пример #1. Използвайки произволна повторна извадка, ръководството на компанията проведе произволно проучване на 900 свои служители. Сред анкетираните има 270 жени. Начертайте доверителен интервал, който с вероятност от 0,95 покрива истинския дял на жените в целия екип на фирмата.
Решение. По условие извадковият дял на жените е (относителната честота на жените сред всички респонденти). Тъй като селекцията се повтаря и размерът на извадката е голям (n=900), пределната грешка на извадката се определя по формулата ![]()
Стойността на u cr се намира от таблицата на функцията на Лаплас от връзката 2Ф(u cr)=γ, т.е. ![]() Функцията на Лаплас (Приложение 1) приема стойност 0,475 при u cr =1,96. Следователно пределната грешка
Функцията на Лаплас (Приложение 1) приема стойност 0,475 при u cr =1,96. Следователно пределната грешка ![]() и желания доверителен интервал
и желания доверителен интервал
(p – ε, p + ε) = (0,3 – 0,18; 0,3 + 0,18) = (0,12; 0,48)
Така че с вероятност от 0,95 може да се гарантира, че делът на жените в целия екип на фирмата е в диапазона от 0,12 до 0,48.
Пример #2. Собственикът на паркинга смята деня за "щастлив", ако паркингът е пълен над 80%. През годината са извършени 40 проверки на паркинги, от които 24 са „успешни“. С вероятност от 0,98 намерете доверителния интервал за оценка на истинския процент на "щастливите" дни през годината.
Решение. Примерната част от „добрите“ дни е
Според таблицата на функцията на Лаплас намираме стойността на u cr за дадена
ниво на увереност
Ф(2,23) = 0,49, u кр = 2,33.
Като се има предвид, че изборът не се повтаря (т.е. две проверки не са извършени в един и същи ден), откриваме пределната грешка: ![]()
където n=40, N=365 (дни). Оттук ![]()
и доверителен интервал за общата фракция: (p – ε, p + ε) = (0,6 – 0,17; 0,6 + 0,17) = (0,43; 0,77)
С вероятност от 0,98 може да се очаква делът на "добрите" дни през годината да е в диапазона от 0,43 до 0,77.
Пример #3. След като провериха 2500 артикула в партидата, те установиха, че 400 артикула са от най-висок клас, но n–m не са. Колко продукта трябва да проверите, за да определите дела на първокласния клас с точност 0,01 с 95% сигурност?
Търсим решение по формулата за определяне на размера на извадката за повторен подбор.
Ф(t) = γ/2 = 0,95/2 = 0,475 и според таблицата на Лаплас тази стойност съответства на t=1,96
Фракция на пробата w = 0.16; грешка на извадката ε = 0,01
Пример #4. Партида от продукти се приема, ако вероятността продуктът да отговаря на стандарта е най-малко 0,97. Сред произволно избраните 200 продукта от тестваната партида беше установено, че 193 продукта отговарят на стандарта. Възможно ли е да се приеме партидата при ниво на значимост α=0,02?
Решение. Формулираме основната и алтернативните хипотези.
H 0: p \u003d p 0 \u003d 0,97 - неизвестен общ дял стрравна на зададената стойност p 0 =0,97. Във връзка с условието - вероятността частта от тестваната партида да отговаря на стандарта е 0,97; тези. партида от продукти може да бъде приета.
H1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдавана статистическа стойност К(таблица) изчислете за дадени стойности p 0 =0,97, n=200, m=193
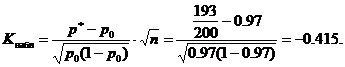
Критичната стойност се намира от таблицата на функцията на Лаплас от равенството
![]()
Съгласно условието α=0,02, следователно F(Kcr)=0,48 и Kcr=2,05. Критичният регион е ляв, т.е. е интервалът (-∞;-K kp)= (-∞;-2,05). Наблюдаваната стойност Kobs = -0,415 не принадлежи към критичната област, следователно при това ниво на значимост няма причина да се отхвърли основната хипотеза. Може да се приеме партида от продукти.
Пример номер 5. Две фабрики произвеждат един и същи тип части. За оценка на качеството им са взети проби от продуктите на тези фабрики и са получени следните резултати. Сред 200 избрани продукта на първата фабрика 20 бяха дефектни, а сред 300 продукта на втората фабрика 15 бяха дефектни.
При ниво на значимост от 0,025 разберете дали има значителна разлика в качеството на частите, произведени от тези фабрики.
Съгласно условието α=0.025, следователно F(Kcr)=0.4875 и Kcr=2.24. При двустранна алтернатива областта на допустимите стойности има формата (-2,24; 2,24). Наблюдаваната стойност Kobs =2,15 попада в този интервал, т.е. при това ниво на значимост няма причина да се отхвърли основната хипотеза. Фабриките произвеждат продукти с еднакво качество.
проба
пробаили рамка за вземане на проби- набор от случаи (субекти, обекти, събития, проби), използвайки определена процедура, избрани от генералната съвкупност за участие в изследването.
Примерни характеристики:
- Качествени характеристики на извадката - кого точно избираме и какви методи за изграждане на извадката използваме за това.
- Количествената характеристика на извадката е колко случая избираме, с други думи, размерът на извадката.
Необходимост от вземане на проби
- Обектът на изследване е много широк. Например, потребителите на продуктите на една глобална компания са огромен брой географски разпръснати пазари.
- Има нужда от събиране на първична информация.
Размер на извадката
Размер на извадката- броя на случаите, включени в извадката. Поради статистически причини се препоръчва броят на случаите да бъде поне 30-35.
Зависими и независими проби
При сравняване на две (или повече) проби, тяхната зависимост е важен параметър. Ако е възможно да се установи хомоморфна двойка (т.е. когато един случай от проба X съответства на един и само един случай от проба Y и обратно) за всеки случай в две проби (и тази основа на връзка е важна за чертата измерени в пробите), такива проби се наричат зависим. Примери за зависими селекции:
- двойка близнаци
- две измервания на всяка характеристика преди и след експериментална експозиция,
- съпрузи и съпруги
- и т.н.
Ако няма такава връзка между пробите, тогава тези проби се вземат предвид независима, например:
Съответно зависимите проби винаги имат еднакъв размер, докато размерът на независимите проби може да се различава.
Пробите се сравняват с помощта на различни статистически критерии:
- и т.н.
Представителност
Извадката може да се счита за представителна или непредставителна.
Пример за непредставителна извадка
- Изследване с експериментални и контролни групи, които са поставени в различни условия.
- Проучете с експериментални и контролни групи, като използвате стратегия за подбор на двойки
- Проучване, като се използва само една група - експериментална.
- Изследване по смесен (факториален) план – всички групи са поставени в различни условия.
Примерни типове
Пробите са разделени на два вида:
- вероятностен
- невероятност
Вероятностни проби
- Проста вероятностна извадка:
- Просто повторно вземане на проби. Използването на такава извадка се основава на предположението, че всеки респондент е еднакво вероятно да бъде включен в извадката. Въз основа на списъка на генералната съвкупност се съставят карти с броя на респондентите. Те се поставят в тесте, разбъркват се и от тях се изважда карта на случаен принцип, записва се число, след което се връща обратно. Освен това процедурата се повтаря толкова пъти, колкото е необходимият размер на пробата. Минус: повторение на единиците за избор.
Процедурата за конструиране на проста произволна извадка включва следните стъпки:
1. трябва да получите пълен списък на членовете на общата популация и да номерирате този списък. Такъв списък, припомнете си, се нарича рамка за вземане на проби;
2. определяне на очаквания размер на извадката, т.е. очаквания брой респонденти;
3. извличаме толкова числа от таблицата със случайни числа, колкото са ни необходими примерни единици. Ако извадката трябва да включва 100 души, от таблицата се вземат 100 произволни числа. Тези произволни числа могат да бъдат генерирани от компютърна програма.
4. изберете от основния списък онези наблюдения, чиито номера отговарят на записаните произволни числа
- Простата произволна извадка има очевидни предимства. Този метод е изключително лесен за разбиране. Резултатите от изследването могат да бъдат разширени до изследваната популация. Повечето подходи за статистически изводи включват събиране на информация с помощта на проста произволна извадка. Простият метод на произволна извадка обаче има поне четири съществени ограничения:
1. Често е трудно да се създаде рамка за вземане на проби, която би позволила проста произволна извадка.
2. Една проста произволна извадка може да доведе до голяма популация или популация, разпределена в голяма географска област, което значително увеличава времето и разходите за събиране на данни.
3. Резултатите от прилагането на проста случайна извадка често се характеризират с ниска точност и по-голяма стандартна грешка, отколкото резултатите от прилагането на други вероятностни методи.
4. В резултат на прилагането на СРС може да се образува непредставителна извадка. Въпреки че извадките, получени чрез обикновен случаен подбор, средно адекватно представят общата популация, някои от тях изключително неправилно представят изследваната популация. Вероятността за това е особено висока при малък размер на извадката.
- Обикновено неповтарящо се вземане на проби. Процедурата за конструиране на извадката е същата, само че картите с номерата на респондентите не се връщат обратно в тестето.
- Систематична вероятностна извадка. Това е опростена версия на проста вероятностна извадка. Въз основа на списъка на генералната съвкупност се избират респонденти на определен интервал (K). Стойността на K се определя произволно. Най-надеждният резултат се постига с хомогенна генерална съвкупност, в противен случай размерът на стъпката и някои вътрешни циклични модели на извадката може да съвпаднат (смесване на пробата). Недостатъци: същото като при проста вероятностна извадка.
- Серийно (вложено) вземане на проби. Извадковите единици са статистически серии (семейство, училище, екип и др.). Избраните елементи се подлагат на непрекъснато изследване. Изборът на статистически единици може да бъде организиран според вида на случайна или систематична извадка. Минуси: Възможност за по-голяма хомогенност, отколкото в общата популация.
- Зонирана проба. В случай на хетерогенна популация, преди да се използва вероятностна извадка с която и да е техника за подбор, се препоръчва популацията да се раздели на хомогенни части, такава извадка се нарича зонирана извадка. Групите за зониране могат да бъдат както природни образувания (например градски квартали), така и всяка характеристика, която е в основата на изследването. Признакът, въз основа на който се извършва разделянето, се нарича признак на стратификация и райониране.
- "Удобна" селекция. Процедурата за вземане на проби "удобство" се състои в установяване на контакти с "удобни" единици за вземане на проби - с група ученици, спортен отбор, с приятели и съседи. Ако е необходимо да се получи информация за реакциите на хората към нова концепция, такава извадка е напълно разумна. „Удобната“ извадка често се използва за предварително тестване на въпросници.
Невероятни мостри
Подборът в такава извадка се извършва не по принципите на случайността, а по субективни критерии - достъпност, типичност, равно представителство и др.
- Квотна извадка - извадката е изградена като модел, който възпроизвежда структурата на генералната съвкупност под формата на квоти (пропорции) на изследваните характеристики. Броят на елементите на извадката с различна комбинация от изследваните характеристики се определя по такъв начин, че да съответства на техния дял (пропорция) в генералната съвкупност. Така например, ако имаме общо население от 5000 души, от които 2000 жени и 3000 мъже, тогава в квотната извадка ще имаме 20 жени и 30 мъже, или 200 жени и 300 мъже. Квотните извадки най-често се основават на демографски критерии: пол, възраст, регион, доход, образование и др. Минуси: обикновено такива проби не са представителни, т.к невъзможно е да се вземат предвид едновременно няколко социални параметъра. Плюсове: лесно достъпен материал.
- Метод на снежна топка. Пробата е конструирана по следния начин. Всеки респондент, като се започне от първия, е помолен да се свърже със своите приятели, колеги, познати, които отговарят на условията за подбор и биха могли да участват в проучването. Така, с изключение на първата стъпка, извадката се формира с участието на самите обекти на изследване. Методът често се използва, когато е необходимо да се намерят и интервюират труднодостъпни групи от респонденти (например респонденти с високи доходи, респонденти, принадлежащи към същата професионална група, респонденти, които имат сходни хобита / страсти и др. )
- Спонтанно вземане на проби - вземане на проби от т. нар. "първият попаднал". Често се използва в телевизионни и радио анкети. Размерът и съставът на спонтанните извадки не е предварително известен и се определя само от един параметър – активността на респондентите. Недостатъци: невъзможно е да се установи каква генерална съвкупност представляват респондентите и в резултат на това е невъзможно да се определи представителността.
- Маршрутно проучване - често се използва, ако единицата за изследване е семейството. На картата на населеното място, в което ще се извършва проучването, всички улици са номерирани. С помощта на таблица (генератор) на произволни числа се избират големи числа. Всяко голямо число се счита за състоящо се от 3 компонента: номер на улица (2-3 първи числа), номер на къща, номер на апартамент. Например числото 14832: 14 е номерът на улицата на картата, 8 е номерът на къщата, 32 е номерът на апартамента.
- Зонирано вземане на проби с избор на типични обекти. Ако след райониране от всяка група се избере типичен обект, т.е. обект, който се доближава до средното по отношение на повечето от характеристиките, изследвани в изследването, такава извадка се нарича зонирана с подбор на типични обекти.
6.Модален избор. 7. експертна проба. 8. Хетерогенна проба.
Стратегии за изграждане на група
Подборът на групи за тяхното участие в психологически експеримент се извършва с помощта на различни стратегии, които са необходими, за да се осигури възможно най-голямо съответствие с вътрешната и външната валидност.
Рандомизиране
Рандомизиране, или случаен избор, се използва за създаване на прости произволни проби. Използването на такава извадка се основава на предположението, че всеки член на популацията е еднакво вероятно да бъде включен в извадката. Например, за да направите произволна извадка от 100 студенти, можете да поставите листчета с имената на всички студенти в шапка и след това да вземете 100 листа от нея - това ще бъде случаен избор (Goodwin J., p 147).
Избор по двойки
Избор по двойки- стратегия за конструиране на извадкови групи, при която групи от субекти са съставени от субекти, еквивалентни по странични параметри, които са значими за експеримента. Тази стратегия е ефективна за експерименти, използващи експериментални и контролни групи с най-добрия вариант - привличане на двойки близнаци (моно- и дизиготни), тъй като ви позволява да създадете ...
Стратометрична селекция
Стратометрична селекция- рандомизиране с разпределяне на страти (или клъстери). С този метод на извадка генералната съвкупност се разделя на групи (страти) с определени характеристики (пол, възраст, политически предпочитания, образование, ниво на доходи и т.н.) и се избират субекти със съответните характеристики.
Приблизително моделиране
Приблизително моделиране- изготвяне на ограничени извадки и обобщаване на заключенията за тази извадка за по-широка популация. Например, когато участвате в проучване на студенти от 2-ра година на университета, данните от това проучване се разширяват до „хора на възраст от 17 до 21 години“. Допустимостта на подобни обобщения е изключително ограничена.
Приблизителното моделиране е формирането на модел, който за ясно дефиниран клас системи (процеси) описва неговото поведение (или желани явления) с приемлива точност.
Бележки
Литература
Наследов А. Д.Математически методи на психологическо изследване. - Санкт Петербург: Реч, 2004.
- Илясов Ф. Н. Представителност на резултатите от проучването в маркетинговите изследвания. 2011. № 3. С. 112-116.
Вижте също
- При някои видове изследвания извадката се разделя на групи:
- експериментален
- контрол
- Кохорта
Връзки
- Концепцията за вземане на проби. Основните характеристики на извадката. Примерни типове
Фондация Уикимедия. 2010 г.
Синоними:Вижте какво е "Избор" в други речници:
проба- група субекти, представляващи определена популация и избрани за експеримент или изследване. Противоположното понятие е съвкупността от общото. Извадката е част от генералната съвкупност. Речник на практическия психолог. М .: AST, ... ... Голяма психологическа енциклопедия
проба- извадка Частта от общата съвкупност от елементи, която е обхваната от наблюдението (често наричана извадкова популация, а извадката е методът на самото извадково наблюдение). В математическата статистика се приема ... ... Наръчник за технически преводач
- (проба) 1. Малко количество от стока, избрано да представлява цялото й количество. Вижте: продажба по мостра. 2. Малко количество продукт, дадено на потенциални купувачи, за да им даде възможност да го похарчат ... ... Речник на бизнес термините
проба- част от общата съвкупност от елементи, която е обхваната от наблюдението (често се нарича извадкова популация, а извадката е методът на самото извадково наблюдение). В математическата статистика се възприема принципът на случайния подбор; това е… … Икономически и математически речник
- (извадка) Случаен избор на подгрупа елементи от основната популация, чиито характеристики се използват за оценка на цялата популация като цяло. Извадката се използва, когато е твърде дълго или твърде скъпо да се изследва цялото население... Икономически речник
См … Речник на синонимите
Статистическите изследвания са много времеемки и скъпи, затова възникна идеята непрекъснатото наблюдение да се замени със селективно.
Основната цел на непродължителното наблюдение е да се получат характеристиките на изследваната статистическа съвкупност за изследваната част от нея.
Селективно наблюдение- това е метод на статистическо изследване, при който се установяват обобщаващи показатели на съвкупността само за една част, въз основа на условията на случаен подбор.
При извадковия метод се изследва само определена част от изследваната съвкупност, докато статистическата съвкупност, която трябва да се изследва, се нарича генерална съвкупност.
Извадка или просто извадка може да се нарече част от единиците, избрани от генералната съвкупност, които ще бъдат подложени на статистическо изследване.
Стойността на извадковия метод: с минимален брой изследвани единици, статистическите изследвания ще се извършват за по-кратки периоди от време и с най-ниски разходи за средства и труд.
В общата съвкупност делът на единиците, които имат изследваната характеристика, се нарича общ дял (обозначен R),а средната стойност на изследваната променлива характеристика е общата средна (обозначена Х).
В извадковата съвкупност делът на изследваната характеристика се нарича извадков дял или част (обозначава се с w), средната стойност в извадката е извадкова средна стойност.
Ако по време на периода на изследването се спазват всички правила на неговата научна организация, тогава методът на вземане на проби ще даде доста точни резултати и затова е препоръчително да се използва този метод за проверка на данните от непрекъснато наблюдение.
Този метод е широко разпространен в държавната и извънведомствената статистика, тъй като при изследване на минималния брой изследвани единици позволява задълбочено и точно проучване.
Изследваната статистическа съвкупност се състои от единици с различни характеристики. Съставът на извадката може да се различава от състава на генералната съвкупност, това несъответствие между характеристиките на извадката и генералната съвкупност представлява грешката на извадката.
Грешките, присъщи на селективното наблюдение, характеризират размера на несъответствието между данните от селективното наблюдение и цялата популация. Грешките, които възникват по време на извадката, се наричат грешки на представителността и се делят на случайни и систематични.
Ако извадката от популацията не възпроизвежда точно цялата популация поради непродължителния характер на наблюдението, тогава това се нарича случайни грешки и техните размери се определят с достатъчна точност въз основа на закона за големите числа и теорията на вероятностите.
Систематичните грешки възникват в резултат на нарушаване на принципа на случаен подбор на единици съвкупност за наблюдение.
2. Видове и схеми на селекция
Размерът на извадковата грешка и методите за нейното определяне зависят от вида и схемата на подбор.
Има четири вида избор на набор от единици за наблюдение:
1) случаен;
2) механични;
3) типичен;
4) сериен (вложен).
случаен избор- най-често срещаният метод за подбор в случайна извадка, наричан още метод на лотария, при който за всяка единица от статистическата съвкупност се изготвя билет с пореден номер.
След това необходимият брой единици от статистическата съвкупност се избира на случаен принцип. При тези условия всеки от тях има една и съща вероятност да попадне в извадката, например тегления на печалби, когато определена част от числата, които отчитат печалбите, е избрана на случаен принцип от общия брой издадени билети. В този случай всички числа имат еднаква възможност да попаднат в извадката.
Механична селекция- това е метод, при който цялата съвкупност се разделя на групи с хомогенна големина по случаен критерий, след което от всяка група се взема само една единица.Всички единици от изследваната статистическа съвкупност са предварително подредени в определен ред, но в зависимост от върху размера на извадката, необходимият брой единици се избира механично на определен интервал.
Типичен избор -това е метод, при който изследваната статистическа съвкупност се разделя според съществен, типичен признак на качествено хомогенни, сходни групи, след което произволно се избира определен брой единици от всяка от тази група, пропорционален на дела на групата в цялото население.
Типичният подбор дава по-точни резултати, тъй като включва представители на всички типични групи в извадката.
Сериен (гнездов) избор.На селекция подлежат цели групи (серии, гнезда), избрани произволно или механично. За всяка такава група, серия, се извършва непрекъснато наблюдение и резултатите се прехвърлят към цялата популация.
Точността на вземане на проби зависи и от схемата за избор. Вземането на проби може да се извърши по схемата на повторна и неповторна селекция.
Повторна селекция.Всяка избрана единица или серия се връща към цялата съвкупност и може да бъде повторно взета проба.Това е така наречената схема с върната топка.
Повтарящ се избор.Всяка изследвана единица се изтегля и не се връща в популацията, така че не се изследва повторно. Тази схема се нарича невърната топка.
Неповтарящият се подбор дава по-точни резултати, тъй като при еднакъв размер на извадката наблюдението обхваща повече единици от изследваната съвкупност.
Комбинирана селекцияможе да премине през един или повече етапа. Извадката се нарича едноетапна, ако единиците от съвкупността, избрани веднъж, са подложени на изследване.
Извадката се нарича многоетапна, ако подборът на популацията преминава през етапи, последователни етапи и всеки етап, етап на подбор има своя собствена единица за подбор.
Многофазно вземане на проби - на всички етапи на вземане на проби се запазва една и съща единица за вземане на проби, но се извършват няколко етапа, фази на извадкови изследвания, които се различават една от друга по ширината на програмата за изследване и размера на извадката.
Характеристиките на параметрите на генералните и извадковите съвкупности са обозначени със следните символи:
н- обемът на генералната съвкупност;
н– размер на извадката;
х– обща авария;
хе средната стойност на извадката;
Р– общ дял;
w -примерен дял;
2 - обща дисперсия (разсейване на признак в генералната съвкупност);
2 - примерна дисперсия на същия признак;
? - стандартно отклонение в генералната съвкупност;
? е стандартното отклонение в извадката.
3. Грешки при вземане на проби
Всяка единица в извадковото наблюдение трябва да има еднаква възможност да бъде избрана с останалите - това е основата на случайната извадка.
Самослучайно вземане на проби - това е подбор на единици от цялата генерална съвкупност чрез лотария или по друг подобен начин.
Принципът на случайността е, че включването или изключването на обект от извадката не може да бъде повлияно от друг фактор освен случайността.
Примерен дяле отношението на броя на единиците в извадката към броя на единиците в генералната съвкупност:
Самослучайният подбор в чист вид е първоначалният сред всички други видове подбор, той съдържа и реализира основните принципи на селективното статистическо наблюдение.
Двата основни вида обобщаващи показатели, които се използват в извадковия метод, са средната стойност на количествен признак и относителната стойност на алтернативен признак.
Делът на извадката (w) или особеността се определя от съотношението на броя единици, които имат изследваната характеристика м,към общия брой единици за вземане на проби (n):
За да се характеризира надеждността на извадковите показатели, се разграничават средната и пределната грешка на извадката.
Грешката на извадката, наричана още грешка на представителността, е разликата между съответната извадка и общите характеристики:
?x = | x - x |;
?w =|х – p|.
Само извадкови наблюдения имат извадкова грешка
Извадкова средна стойност и извадково съотношение- това са случайни променливи, които приемат различни стойности в зависимост от единиците на изследваната статистическа съвкупност, включени в извадката. Съответно, извадковите грешки също са случайни променливи и също могат да приемат различни стойности. Следователно се определя средната стойност на възможните грешки - средната извадкова грешка.
Средната извадкова грешка се определя от размера на извадката: колкото по-голяма е популацията, при равни други условия, толкова по-малка е средната извадкова грешка. Покривайки извадково изследване с нарастващ брой единици от генералната съвкупност, ние все по-точно характеризираме цялата съвкупност.
Средната извадкова грешка зависи от степента на вариация на изследвания признак, от своя страна степента на вариация се характеризира с дисперсия? 2 или w(l - w)- за алтернативен знак. Колкото по-малка е вариацията и дисперсията на характеристиките, толкова по-малка е средната грешка на извадката и обратно.
За произволно повторно вземане на проби, средните грешки се изчисляват теоретично, като се използват следните формули:
1) за средния количествен признак:
където? 2 - средната стойност на дисперсията на количествен признак.
2) за дял (алтернативен знак):
Каква е дисперсията на признака в популацията? 2 не е точно известна, на практика те използват стойността на дисперсията S 2, изчислена за извадковата популация въз основа на закона за големите числа, според който извадковата популация с достатъчно голям размер на извадката точно възпроизвежда характеристиките на генералната съвкупност .
Формулите за средната грешка при вземане на проби за случайно повторно вземане на проби са както следва. За средната стойност на количествен признак: общата дисперсия се изразява чрез избираемия чрез следното съотношение:
където S 2 е стойността на дисперсията.
Механично вземане на проби- това е подбор на единици в извадково множество от общото, което се разделя на равни групи по неутрален критерий; се извършва по такъв начин, че от всяка такава група в извадката се избира само една единица.
При механичния подбор единиците от изследваната статистическа съвкупност предварително се подреждат в определен ред, след което механично през определен интервал се избира даден брой единици. В този случай размерът на интервала в генералната съвкупност е равен на реципрочната стойност на извадковия дял.
При достатъчно голяма съвкупност механичният подбор по отношение на точността на резултатите е близък до случайния.Затова за определяне на средната грешка на механичното вземане на проби се използват формулите на случайното еднократно вземане на проби.
За да изберете единици от хетерогенна съвкупност, се използва така наречената типична извадка, която се използва, когато всички единици от генералната съвкупност могат да бъдат разделени на няколко качествено хомогенни, подобни групи според характеристиките, от които зависят изследваните показатели.
След това от всяка типична група се прави индивидуален подбор на единици в извадката чрез произволна или механична извадка.
Типичната извадка обикновено се използва при изследване на сложни статистически съвкупности.
Типичното вземане на проби дава по-точни резултати. Типизацията на генералната съвкупност осигурява представителността на такава извадка, представянето на всяка типологична група в нея, което позволява да се изключи влиянието на междугруповата вариация върху средната грешка на извадката. Следователно, когато се определя средната грешка на типична извадка, средната стойност на вътрешногруповите дисперсии действа като индикатор за вариация.
Серийното вземане на проби включва случаен подбор от обща съвкупност от групи с еднакъв размер, за да се подложат всички единици без изключение на наблюдение в такива групи.
Тъй като всички единици без изключение се изследват в рамките на групи (серии), средната грешка на извадката (при избиране на равни серии) зависи само от междугруповата (междусерийната) вариация.
4. Начини за разширяване на резултатите от извадката към популацията
Характеризирането на генералната съвкупност въз основа на резултатите от извадката е крайната цел на извадковото наблюдение.
Извадковият метод се използва за получаване на характеристиките на генералната съвкупност по определени показатели на извадката. В зависимост от целите на изследването това се извършва чрез директно преизчисляване на извадковите показатели за генералната съвкупност или чрез метода на изчисляване на корекционни коефициенти.
Методът на директното преизчисляване е, че с него показателите на извадката споделят wили средно хсе разширяват към генералната съвкупност, като се вземе предвид грешката на извадката.
Методът на корекционните коефициенти се използва, когато целта на извадковия метод е да прецизира резултатите от цялостното счетоводно отчитане. Този метод се използва за прецизиране на данните от годишните преброявания на добитъка на населението.
план:
1. Проблеми на математическата статистика.
2. Примерни типове.
3. Методи за подбор.
4. Статистическо разпределение на извадката.
5. Емпирична функция на разпределение.
6. Многоъгълник и хистограма.
7. Числени характеристики на вариационния ред.
8. Статистически оценки на параметрите на разпределението.
9. Интервални оценки на параметрите на разпределението.
1. Задачи и методи на математическата статистика
Математическа статистика е дял от математиката, посветен на методите за събиране, анализиране и обработка на резултатите от статистически наблюдения за научни и практически цели.
Нека се изисква да се изследва набор от еднородни обекти по отношение на някаква качествена или количествена характеристика, която характеризира тези обекти. Например, ако има партида части, тогава стандартът на частта може да служи като качествен знак, а контролираният размер на частта може да служи като количествен знак.
Понякога се провежда непрекъснато проучване, т.е. изследвайте всеки обект по отношение на желаната характеристика. На практика рядко се използва цялостно проучване. Например, ако популацията съдържа много голям брой обекти, тогава е физически невъзможно да се проведе пълно проучване. Ако проучването на обекта е свързано с неговото унищожаване или изисква големи материални разходи, тогава няма смисъл да се провежда пълно проучване. В такива случаи ограничен брой обекти (набор от проби) се избират произволно от цялата популация и се подлагат на тяхното изследване.
Основната задача на математическата статистика е да изследва цялата съвкупност въз основа на извадкови данни, в зависимост от целта, т.е. изследването на вероятностните свойства на популацията: законът за разпределение, числените характеристики и др. за вземане на управленски решения в условия на несигурност.
2. Примерни типове
Население е съвкупността от обекти, от които се прави извадката.
Извадкова популация (извадка) е колекция от произволно избрани обекти.
Размер на населението е броят на обектите в тази колекция. Обемът на генералната съвкупност е означен N, селективно - n.
Пример:
Ако от 1000 части 100 части са избрани за изследване, тогава обемът на генералната съвкупностн = 1000 и размера на извадката n = 100.
Вземането на проби може да се извърши по два начина: след като обектът е избран и наблюдаван върху него, той може да бъде върнат или не върнат в генералната съвкупност. Че. Пробите се разделят на повторни и неповтарящи се.
Повтаря сеНаречен вземане на проби, при което избраният обект (преди избор на следващия) се връща към генералната съвкупност.
Неповтаряща сеНаречен вземане на проби, при което избраният обект не се връща в генералната съвкупност.
На практика обикновено се използва неповтарящ се случаен избор.
За да може данните от извадката да могат да преценят с достатъчна увереност за характеристиката, представляваща интерес в генералната съвкупност, е необходимо обектите на извадката да я представят правилно. Извадката трябва правилно да представя пропорциите на популацията. Пробата трябва да бъде представител (представител).
По силата на закона за големите числа може да се твърди, че извадката ще бъде представителна, ако е направена на случаен принцип.
Ако размерът на генералната съвкупност е достатъчно голям и извадката е само незначителна част от тази популация, тогава разликата между повторни и неповторени извадки се изтрива; в ограничаващия случай, когато се разглежда безкрайна генерална съвкупност и извадката има краен размер, тази разлика изчезва.
Пример:
В американското списание Literary Review, използвайки статистически методи, е направено проучване на прогнози за изхода от предстоящите президентски избори в САЩ през 1936 г. Кандидати за този пост бяха F.D. Рузвелт и А. М. Ландън. Справочниците на телефонните абонати са взети като източник за общата популация на изследваните американци. От тях на случаен принцип бяха избрани 4 милиона адреса, на които редакторите на списанието изпратиха картички с молба да изразят отношението си към кандидатите за президент. След обработка на резултатите от допитването списанието публикува социологическа прогноза, че Ландън ще спечели предстоящите избори с голяма преднина. И ... грешах: Рузвелт спечели.
Този пример може да се разглежда като пример за непредставителна извадка. Факт е, че в Съединените щати през първата половина на ХХ век само богатата част от населението, която подкрепяше възгледите на Ландън, имаше телефони.
3. Методи за подбор
На практика се използват различни методи за селекция, които могат да бъдат разделени на 2 вида:
1. Селекцията не изисква разделяне на популацията на части (a) просто произволно без повторение; б) просто произволно повторение).
2. Подбор, при който генералната съвкупност се разделя на части. (а) типична селекция; б) механична селекция; в) сериен селекция).
Обикновено произволно наречете това селекция, в който обектите се извличат един по един от цялата генерална съвкупност (на случаен принцип).
ТипичноНаречен селекция, в който обектите се избират не от цялата генерална съвкупност, а от всяка нейна „типична“ част. Например, ако една част се произвежда на няколко машини, тогава изборът се прави не от целия набор от части, произведени от всички машини, а от продуктите на всяка машина поотделно. Такава селекция се използва, когато изследваната черта се колебае забележимо в различни "типични" части от общата популация.
МеханичниНаречен селекция, при което генералната съвкупност се разделя "механично" на толкова групи, колкото са обектите за включване в извадката, като от всяка група се избира по един обект. Например, ако трябва да изберете 20% от частите, направени от машината, тогава се избира всяка 5-та част; ако се изисква избор на 5% от частите - на всеки 20 и т.н. Понякога такъв избор може да не осигури представителна извадка (ако се избере всяка 20-та въртяща ролка и ножът се смени веднага след избора, тогава ще бъдат избрани всички ролки, струговани с тъпи ножове).
СериенНаречен селекция, при който обектите се избират от генералната съвкупност не един по един, а в „серии“, които се подлагат на непрекъснато проучване. Например, ако продуктите се произвеждат от голяма група автоматични машини, тогава продуктите само на няколко машини се подлагат на непрекъснато изследване.
В практиката често се използва комбиниран подбор, при който се комбинират горните методи.
4. Статистическо разпределение на извадката
Нека се вземе проба от генералната съвкупност и стойността x 1-наблюдава се веднъж, x 2 -n 2 пъти, ... x k - n k пъти. n= n 1 +n 2 +...+n k е размерът на извадката. Наблюдавани стойностиНаречен настроики, а последователността е вариант, написан във възходящ ред - вариационни серии. Брой наблюденияНаречен честоти (абсолютни честоти)и тяхната връзка с размера на извадката- относителни честотиили статистически вероятности.
Ако броят на опциите е голям или извадката е направена от непрекъсната генерална съвкупност, тогава серията от вариации се съставя не от индивидуални точкови стойности, а от интервали от стойности на генералната съвкупност. Такава поредица се нарича интервал.Дължините на интервалите трябва да са еднакви.
Статистическото разпределение на извадката наречен списък с опции и съответните им честоти или относителни честоти.
Статистическото разпределение може също да бъде определено като последователност от интервали и съответните им честоти (сумата от честотите, които попадат в този интервал от стойности)
Точковите вариационни серии от честоти могат да бъдат представени чрез таблица:
| x i |
х 1 |
x2 |
… |
x k |
| n i |
n 1 |
n 2 |
… |
нк |
По подобен начин може да се представи точкова вариационна серия от относителни честоти.
И:
Пример:
Броят на буквите в някакъв текст X се оказа равен на 1000. Първата буква беше "i", втората - буквата "i", третата - буквата "a", четвъртата - "u". След това се появиха буквите "o", "e", "y", "e", "s".
Нека запишем местата, които те заемат в азбуката, съответно имаме: 33, 10, 1, 32, 16, 6, 21, 31, 29.
След като подредим тези числа във възходящ ред, получаваме вариационна серия: 1, 6, 10, 16, 21, 29, 31, 32, 33.
Честотите на появата на букви в текста: "a" - 75, "e" -87, "i" - 75, "o" - 110, "y" - 25, "s" - 8, "e" - 3, "ю" - 7, "аз" - 22.
Съставяме точкова вариационна серия от честоти:
Пример:
Определено разпределение на честотата на вземане на проби от обема n = 20.
Направете точкови вариационни серии от относителни честоти.
| x i |
2 |
6 |
12 |
| n i |
3 |
10 |
7 |
Решение:
Намерете относителните честоти:
| x i |
2 |
6 |
12 |
| w i |
0,15 |
0,5 |
0,35 |
При конструирането на интервално разпределение има правила за избор на броя на интервалите или размера на всеки интервал. Критерият тук е оптималното съотношение: с увеличаване на броя на интервалите се подобрява представителността, но се увеличава количеството на данните и времето за тяхната обработка. Разлика x max - x min между най-голямата и най-малката стойност се нарича вариант в голям мащабпроби.
За да преброите броя на интервалитек обикновено прилагат емпиричната формула на Стърджис (предполага закръгляване до най-близкото удобно цяло число): k = 1 + 3,322 log n.
Съответно стойността на всеки интервалч може да се изчисли с помощта на формулата:
5. Емпирична функция на разпределение
Помислете за извадка от общата съвкупност. Нека е известно статистическото разпределение на честотите на количествения признак X. Нека въведем обозначението: n xе броят на наблюденията, при които е наблюдавана стойност на характеристиката, по-малка от x;н е общият брой наблюдения (размер на извадката). Относителна честота на събитието X<х равна n x /n . Ако x се промени, тогава се променя и относителната честота, т.е. относителна честотаn x /nе функция на x. защото намира се емпирично, нарича се емпирично.
Емпирична функция на разпределение (функция на извадково разпределение) извикайте функцията, което определя за всяко x относителната честота на събитието X<х.
където е броят на опциите по-малък от x,
n - размер на извадката.
За разлика от емпиричната функция на разпределение на извадката се нарича функцията на разпределение F(x) на съвкупността теоретична функция на разпределение.
Разликата между емпиричните и теоретичните функции на разпределение е, че теоретичната функция F (x) определя вероятността от събитие X
Че. препоръчително е да се използва емпиричната функция на разпределение на извадката за приблизително представяне на теоретичната (интегрална) функция на разпределение на генералната съвкупност.
F*(x)има всички свойства F(x).
1. Ценности F*(x)принадлежат на интервала.
2. F*(x) е ненамаляваща функция.
3. Ако е най-малкият вариант, тогава F*(x) = 0, при x < x1; ако x k е най-големият вариант, тогава F*(x) = 1, за x > x k.
Тези. F*(x)служи за оценка на F(x).
Ако извадката е дадена от вариационна серия, тогава емпиричната функция има формата:
Графиката на емпиричната функция се нарича кумулативна.
Пример:
Начертайте емпирична функция върху даденото извадково разпределение.
Решение:
Обем на извадката n = 12 + 18 +30 = 60. Най-малката опция е 2, т.е. при х <
2. Събитие X<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F*(x)=12/60=0,2на 2 <
х <
6. Събитие X<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
х <
10. Защото Тогава x=10 е най-голямата опция F*(x) = 1при х>10. Желаната емпирична функция има формата:
Кумулация:
Кумулатът позволява да се разбере информацията, представена графично, например, за да се отговори на въпросите: „Определете броя на наблюденията, при които стойността на атрибута е по-малка от 6 или не по-малка от 6. F*(6) = 0,2 » Тогава броят на наблюденията, при които стойността на наблюдаваната характеристика е по-малка от 6, е 0,2*н \u003d 0,2 * 60 \u003d 12. Броят на наблюденията, при които стойността на наблюдаваната характеристика е не по-малка от 6, е (1-0,2) * n \u003d 0,8 * 60 \u003d 48.
Ако е дадена интервална вариационна серия, тогава за съставяне на емпиричната функция на разпределение се намират средните точки на интервалите и от тях се получава емпиричната функция на разпределение подобно на точковата вариационна серия.
6. Многоъгълник и хистограма
За по-голяма яснота са изградени различни графики на статистическото разпределение: полиномни и хистограмни
Честотен полигон-това е прекъсната линия, чиито отсечки свързват точките ( x 1 ;n 1 ), ( x 2 ;n 2 ),…, ( x k ; n k ), където са опциите, са честотите, съответстващи на тях.
Многоъгълник на относителните честоти -това е прекъсната линия, чиито сегменти свързват точките ( x 1 ;w 1 ), (x 2 ;w 2 ),…, ( x k ;w k ), където x i са опции, w i са относителни честоти, съответстващи им.
Пример:
Начертайте относителния честотен полином върху даденото извадково разпределение:
Решение:
В случай на непрекъсната характеристика е препоръчително да се изгради хистограма, за която интервалът, който съдържа всички наблюдавани стойности на характеристиката, се разделя на няколко частични интервала с дължина h и за всеки частичен интервал n i се намира - сумата от вариантните честоти, които попадат в i-тия интервал. (Например, когато измерваме височината или теглото на човек, имаме работа с непрекъснат знак).
Честотна хистограма-това е стъпаловидна фигура, състояща се от правоъгълници, чиито основи са частични интервали с дължина h, а височините са равни на съотношението (честотна плътност).
Квадрат i-ти частичен правоъгълник е равен на сумата от честотите на варианта на i-тия интервал, т.е. площта на честотната хистограма е равна на сумата от всички честоти, т.е. размер на извадката.
Пример:
Дадени са резултатите от изменението на напрежението (във волтове) в електрическата мрежа. Съставете вариационна серия, изградете полигон и честотна хистограма, ако стойностите на напрежението са както следва: 227, 215, 230, 232, 223, 220, 228, 222, 221, 226, 226, 215, 218, 220, 216, 220, 225, 212, 217, 220.
Решение:
Нека създадем серия от варианти. Имаме n = 20, x min = 212, x max = 232.
Нека използваме формулата на Стърджис, за да изчислим броя на интервалите.
Интервалната вариационна серия от честоти има формата:
|
|
Честотна плътност |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
Нека изградим хистограма на честотите:
Нека изградим многоъгълник от честоти, като първо намерим средните точки на интервалите:
Хистограма на относителните честотинаричаме стъпаловидна фигура, състояща се от правоъгълници, чиито основи са частични интервали с дължина h, а височините са равни на отношението w аз/h (относителна честотна плътност).
Квадрат i-тият частичен правоъгълник е равен на относителната честота на варианта, попаднал в i-тия интервал. Тези. площта на хистограмата на относителните честоти е равна на сумата от всички относителни честоти, т.е. мерна единица.
7. Числени характеристики на вариационния ред
Помислете за основните характеристики на генералната и извадкова популации.
Общо средносе нарича средно аритметично на стойностите на характеристиката на генералната съвкупност.
За различни стойности x 1 , x 2 , x 3 , …, x n . знак на генералната съвкупност от том N имаме:
Ако стойностите на атрибута имат съответните честоти N 1 +N 2 +…+N k =N , тогава
извадкова средна стойностсе нарича средно аритметично на стойностите на характеристиката на извадката.
Ако стойностите на атрибута имат съответстващи честоти n 1 +n 2 +…+n k = n, тогава
Пример:
Изчислява се средната стойност на извадката: x 1 = 51,12; x 2 \u003d 51,07 x 3 \u003d 52,95; x 4 = 52,93; x 5 = 51,1; x 6 = 52,98; х 7 \u003d 52,29; x 8 \u003d 51,23; x 9 \u003d 51,07; х10 = 51,04.
Решение:
Обща вариациясе нарича средно аритметично на квадратните отклонения на стойностите на характеристиката X на генералната съвкупност от общата средна стойност.
За различни стойности x 1 , x 2 , x 3 , …, x N на знака на съвкупността от обем N имаме:
Ако стойностите на атрибута имат съответните честоти N 1 +N 2 +…+N k =N , тогава
Общо стандартно отклонение (стандарт)наречен корен квадратен от общата дисперсия
Дисперсия на извадкатасе нарича средно аритметично на квадратите на отклоненията на наблюдаваните стойности на характеристиката от средната стойност.
За различни стойности x 1 , x 2 , x 3 , ..., x n на знака на извадката от обем n имаме:
Ако стойностите на атрибута имат съответстващи честоти n 1 +n 2 +…+n k = n, тогава
Примерно стандартно отклонение (стандарт)се нарича корен квадратен от дисперсията на извадката.
Пример:
Наборът за вземане на проби се дава от таблицата за разпределение. Намерете дисперсията на извадката.
Решение:
Теорема: Дисперсията е равна на разликата между средната стойност на квадратите на стойностите на характеристиките и квадрата на общата средна стойност.
Пример:
Намерете дисперсията за това разпределение.
Решение:
8. Статистически оценки на параметрите на разпределението
Нека генералната съвкупност се изследва чрез някаква извадка. В този случай е възможно да се получи само приблизителна стойност на неизвестния параметър Q, която служи за неговата оценка. Очевидно е, че оценките могат да варират от една извадка до друга.
Статистическа оценкаQ*неизвестният параметър на теоретичното разпределение се нарича функция f, която зависи от наблюдаваните стойности на извадката. Задачата на статистическата оценка на неизвестни параметри от извадка е да се изгради такава функция от наличните данни от статистически наблюдения, които да дадат най-точните приблизителни стойности на реални, неизвестни на изследователя, стойности на тези параметри.
Статистическите оценки се разделят на точкови и интервални, в зависимост от начина, по който са предоставени (число или интервал).
Точковата оценка се нарича статистическа оценка.параметър Q на теоретичното разпределение, определено от една стойност на параметъра Q *=f (x 1 , x 2 , ..., x n), къдетоx 1, x 2, ...,xn- резултатите от емпирични наблюдения върху количествения признак X на определена проба.
Такива оценки на параметрите, получени от различни проби, най-често се различават една от друга. Абсолютната разлика /Q *-Q / се нарича грешка на извадката (оценка).
За да могат статистическите оценки да дават надеждни резултати за оценяваните параметри, е необходимо те да бъдат безпристрастни, ефективни и последователни.
Точкова оценка, чието математическо очакване е равно (не равно) на оценявания параметър, се нарича неизместен (изместен). M(Q *)=Q .
Разлика M( Q *)-Q се нарича пристрастие или систематична грешка. За безпристрастни оценки систематичната грешка е 0.
ефикасен Оценяване Q *, което за даден размер на извадката n има най-малката възможна дисперсия: D min(n = const). Ефективният оценител има най-малък спред в сравнение с други безпристрастни и последователни оценители.
Богатсе нарича такава статистика Оценяване Q *, което за nклони по вероятност към оценения параметър Q , т.е. с увеличаване на размера на извадкатан оценката клони по вероятност към истинската стойност на параметъра Q.
Изискването за последователност е в съответствие със закона за големите числа: колкото повече първоначална информация за изследвания обект, толкова по-точен е резултатът. Ако размерът на извадката е малък, точковата оценка на параметъра може да доведе до сериозни грешки.
Всякакви проба (обемн)може да се разглежда като подреден наборx 1, x 2, ...,xnнезависими еднакво разпределени случайни променливи.
Проба означава за различни обемни пробин от една и съща популация ще бъдат различни. Тоест извадковата средна може да се разглежда като случайна променлива, което означава, че можем да говорим за разпределение на извадковата средна и нейните числени характеристики.
Средната стойност на извадката отговаря на всички изисквания, наложени на статистическите оценки, т.е. дава безпристрастна, ефективна и последователна оценка на средната популация.
Може да се докаже, че. По този начин дисперсията на извадката е предубедена оценка на общата дисперсия, което й дава подценена стойност. Тоест при малък размер на извадката ще даде систематична грешка. За безпристрастна, последователна оценка е достатъчно да се вземе количеството, което се нарича коригирана дисперсия. т.е.
На практика за оценка на общата дисперсия се използва коригираната дисперсия, когатон < 30. В други случаи ( n >30) отклонение от едва забележимо. Следователно, за големи стойностин грешката на отклонението може да бъде пренебрегната.
Може също да се докаже, че относителната честотаn i / n е безпристрастна и последователна оценка на вероятността P(X=x i ). Емпирична функция на разпределение F*(x ) е безпристрастна и последователна оценка на теоретичната функция на разпределение F(x)=P(X< x ).
Пример:
Намерете безпристрастните оценки на средната стойност и дисперсията от примерната таблица.
| x i |
|||
| n i |
Решение:
Размер на извадката n=20.
Безпристрастната оценка на математическото очакване е средната стойност на извадката.
За да изчислим безпристрастната оценка на дисперсията, първо намираме дисперсията на извадката:
Сега нека намерим безпристрастната оценка:
9. Интервални оценки на параметрите на разпределението
Интервалът е статистическа оценка, определена от две числени стойности - краищата на изследвания интервал.
Номер> 0, където | Q - Q*|< , характеризира точността на оценката на интервала.
ДоверенНаречен интервал , което с дадена вероятностобхваща неизвестна стойност на параметъра Q . Допълване на доверителния интервал към набора от всички възможни стойности на параметри Q Наречен критична зона. Ако критичната област е разположена само от едната страна на доверителния интервал, тогава се извиква доверителният интервал едностранно: ляво, ако критичната област съществува само отляво, и деснякосвен ако не е отдясно. В противен случай се извиква доверителният интервал двустранно.
Надеждност или ниво на увереност, Q оценки (с помощта на Q *) назовете вероятността, с която се изпълнява следното неравенство: | Q - Q*|< .
Най-често доверителната вероятност се задава предварително (0,95; 0,99; 0,999) и се налага изискването тя да бъде близка до единица.
ВероятностНаречен вероятността за грешка или нивото на значимост.
Нека | Q - Q*|< , тогава. Това означава, че с вероятностможе да се твърди, че истинската стойност на параметъра Q принадлежи на интервала. Колкото по-малко е отклонението, толкова по-точна е оценката.
Границите (краищата) на доверителния интервал се наричат граници на доверието или критични граници.
Стойностите на границите на доверителния интервал зависят от закона за разпределение на параметъра Q*.
Стойност на отклонениетонарича се половината от ширината на доверителния интервал точност на оценката.
Методите за конструиране на доверителни интервали са разработени за първи път от американския статистик Y. Neumann. Точност на оценката, вероятност за доверие и размер на извадката n взаимосвързани. Следователно, знаейки специфичните стойности на две количества, винаги можете да изчислите третото.
Намиране на доверителния интервал за оценка на математическото очакване на нормално разпределение, ако стандартното отклонение е известно.
Нека се направи извадка от генералната съвкупност, подчинена на закона за нормалното разпределение. Нека общото стандартно отклонение е известно, но математическото очакване на теоретичното разпределение е неизвестноа().
Валидна е следната формула:
Тези. според зададената стойност на отклонениевъзможно е да се намери с каква вероятност неизвестната обща средна принадлежи на интервала. И обратно. От формулата се вижда, че при увеличаване на размера на извадката и фиксирана стойност на доверителната вероятност стойността- намалява, т.е. точността на оценката се повишава. С увеличаване на надеждността (вероятност за доверие), стойността-увеличава, т.е. точността на оценката намалява.
Пример:
В резултат на тестовете са получени следните стойности -25, 34, -20, 10, 21. Известно е, че те се подчиняват на нормалния закон на разпределение със стандартно отклонение 2. Намерете оценката a* за математическо очакване а. Начертайте 90% доверителен интервал за него.
Решение:
Нека намерим безпристрастната оценка
Тогава
Доверителният интервал за a има формата: 4 - 1,47< а< 4+ 1,47 или 2,53 < a < 5, 47
Намиране на доверителния интервал за оценка на математическото очакване на нормално разпределение, ако стандартното отклонение е неизвестно.
Нека да се знае, че генералната съвкупност е подчинена на закона за нормалното разпределение, където a и. Точност на покриване на доверителния интервал с надеждностистинската стойност на параметъра a в този случай се изчислява по формулата:
, където n е размерът на извадката, , - Коефициент на Студент (следва да се намери от дадените стойности n и от таблицата "Критични точки на разпределението на Стюдънт").
Пример:
В резултат на тестовете са получени следните стойности -35, -32, -26, -35, -30, -17. Известно е, че те се подчиняват на закона за нормалното разпределение. Намерете доверителния интервал за средната стойност на съвкупността a с ниво на достоверност 0,9.
Решение:
Нека намерим безпристрастната оценка.
Да намерим.
Тогава
Доверителният интервал ще приеме формата(-29,2 - 5,62; -29,2 + 5,62) или (-34,82; -23,58).
Намиране на доверителния интервал за дисперсията и стандартното отклонение на нормално разпределение
Нека се вземе произволна извадка от обем от някакъв общ набор от стойности, разпределени според нормалния законн < 30, за които се изчисляват дисперсиите на извадката: отклонениеи коригирано s 2. След това да се намерят интервални оценки с дадена надеждностза обща дисперсиядобщо стандартно отклонениесе използват следните формули.
или,
Стойности- намерете с помощта на таблицата със стойности на критичните точкиРазпределения на Пиърсън.
Доверителният интервал за дисперсията се намира от тези неравенства чрез повдигане на квадрат на всички части на неравенството.
Пример:
Проверено е качеството на 15 болта. Ако приемем, че грешката при тяхното производство е подчинена на нормалния закон за разпределение и стандартното отклонение на извадкатаравна на 5 mm, определете с надеждностдоверителен интервал за неизвестен параметър
Представяме границите на интервала като двойно неравенство:
Краищата на двустранния доверителен интервал за дисперсията могат да бъдат определени без извършване на аритметика за дадено ниво на сигурност и размер на извадката, като се използва съответната таблица (Граници на доверителните интервали за дисперсията в зависимост от броя на степените на свобода и надеждност) . За да направите това, краищата на интервала, получени от таблицата, се умножават по коригираната дисперсия s 2.
Пример:
Нека решим предишния проблем по различен начин.
Решение:
Нека намерим коригираната дисперсия:
Според таблицата "Граници на доверителния интервал за дисперсията в зависимост от броя на степените на свобода и надеждност", намираме границите на доверителния интервал за дисперсията прик=14 и: долна граница 0,513 и горна граница 2,354.
Умножете получените граници поs 2 и извлечете корена (защото имаме нужда от доверителен интервал не за дисперсията, а за стандартното отклонение).
Както се вижда от примерите, стойността на доверителния интервал зависи от метода на неговото изграждане и дава близки, но различни резултати.
За проби с достатъчно голям размер (н>30) границите на доверителния интервал за общото стандартно отклонение могат да бъдат определени по формулата: - някакво число, което е таблично и дадено в съответната справочна таблица.
Ако 1- р<1, то формула имеет вид:
Пример:
Нека решим предишната задача по третия начин.
Решение:
Намерен преди товас= 5,17. р(0,95; 15) = 0,46 - намираме според таблицата.
Тогава:
Често се случва да е необходимо да се анализира определено социално явление и да се получи информация за него. Такива задачи често възникват в статистиката и в статистическите изследвания. Верификацията на напълно дефиниран социален феномен често е невъзможна. Например, как да разберете мнението на населението или на всички жители на даден град по всеки въпрос? Да попиташ абсолютно всички е почти невъзможно и много трудоемко. В такива случаи се нуждаем от проба. Това е точно концепцията, на която се основават почти всички изследвания и анализи.
Какво е проба
Когато се анализира конкретно социално явление, е необходимо да се получи информация за него. Ако вземем каквото и да е изследване, можем да видим, че не всяка единица от съвкупността на обекта на изследване подлежи на изследване и анализ. Само определена част от тази съвкупност се взема предвид. Този процес е вземане на проби: когато се изследват само определени единици от набора.
Разбира се, много зависи от вида на пробата. Но има и основни правила. Основният гласи, че изборът от популацията трябва да бъде абсолютно случаен. Единиците от съвкупността, които ще се използват, не трябва да се избират поради никакъв критерий. Грубо казано, ако е необходимо да се събере население от населението на определен град и да се изберат само мъже, тогава ще има грешка в изследването, тъй като подборът не е извършен на случаен принцип, а е избран според пола. Почти всички методи за вземане на проби се основават на това правило.
Правила за вземане на проби
За да може избраната съвкупност да отразява основните качества на цялото явление, тя трябва да бъде изградена по определени закони, като основното внимание трябва да се обърне на следните категории:
- извадка (извадкова съвкупност);
- общо население;
- представителност;
- грешка в представителността;
- популационна единица;
- методи за вземане на проби.
Характеристиките на селективното наблюдение и вземане на проби са следните:
- Всички получени резултати се основават на математически закони и правила, тоест при правилно провеждане на изследването и при правилни изчисления резултатите няма да бъдат изкривени на субективна основа
- Позволява да се получи резултат много по-бързо и с по-малко време и ресурси, като се изучава не целият набор от събития, а само част от тях.
- Може да се използва за изучаване на различни обекти: от конкретни въпроси, например възрастта, пола на групата, която ни интересува, до изследване на общественото мнение или нивото на материална подкрепа на населението.
Селективно наблюдение
Селективно - това е такова статистическо наблюдение, при което не цялата изследвана популация е подложена на изследване, а само част от нея, избрана по определен начин, като резултатите от изследването на тази част се отнасят за цялата популация. Тази част се нарича рамка за вземане на проби. Това е единственият начин да се изследва голям масив от обекта на изследване.
Но селективното наблюдение може да се използва само в случаите, когато е необходимо да се изследва само малка група единици. Например, когато се изучава съотношението мъже и жени в света, ще се използва селективно наблюдение. По очевидни причини е невъзможно да се вземе предвид всеки жител на нашата планета.
Но при едно и също изследване, но не на всички жители на земята, а на определен 2 "А" клас в конкретно училище, определен град, определена държава, може да се откаже от избирателно наблюдение. В крайна сметка е напълно възможно да се анализира целият масив от обекта на изследване. Трябва да се преброят момчетата и момичетата от този клас - това ще бъде съотношението.

Извадка и популация
Всъщност не е толкова трудно, колкото звучи. Във всеки обект на изследване има две системи: генерална и извадкова съвкупност. Какво е? Всички единици принадлежат на генерала. И към извадката - онези единици от общата съвкупност, които са взети за извадката. Ако всичко е направено правилно, тогава избраната част ще бъде намалено оформление на цялата (обща) популация.
Ако говорим за генералната съвкупност, тогава можем да различим само две от нейните разновидности: определена и неопределена генерална съвкупност. Зависи от това дали общият брой единици на дадена система е известен или не. Ако става дума за определена популация, тогава вземането на проби ще бъде по-лесно поради факта, че се знае какъв процент от общия брой единици ще бъдат взети за извадка.
Този момент е много необходим в изследването. Например, ако е необходимо да се изследва процентът на нискокачествени сладкарски изделия в конкретен завод. Да приемем, че населението вече е дефинирано. Известно е със сигурност, че това предприятие произвежда 1000 сладкарски изделия годишно. Ако от тази хиляда направим извадка от 100 произволни сладкарски изделия и ги изпратим на изследване, тогава грешката ще бъде минимална. Грубо казано, 10% от всички продукти са били обект на изследване и въз основа на резултатите, като се вземе предвид грешката в представителността, можем да говорим за лошо качество на всички продукти.
И ако вземете проба от 100 сладкарски продукта от неопределена генерална популация, където всъщност има, да речем, 1 милион единици, тогава резултатът от извадката и самото изследване ще бъдат критично неправдоподобни и неточни. Почувствай разликата? Следователно сигурността на общата популация в повечето случаи е изключително важна и силно влияе върху резултата от изследването.

Представителност на населението
И така, сега един от най-важните въпроси - каква трябва да бъде пробата? Това е най-важният момент от изследването. На този етап е необходимо да се изчисли извадката и да се изберат единици от общия брой в нея. Популацията е избрана правилно, ако някои характеристики и характеристики на генералната популация остават в извадката. Това се нарича представителност.
С други думи, ако след селекция една част запазва същите тенденции и характеристики като цялото количество изследвани, тогава такава популация се нарича представителна. Но не всяка конкретна извадка може да бъде избрана от представителна популация. Има и такива обекти на изследване, чиято извадка просто не може да бъде представителна. Оттук идва понятието грешка в представителността. Но нека поговорим малко повече за това.
Как да направите избор
И така, за да се постигне максимална представителност, има три основни правила за вземане на проби:

Грешка (грешка) на представителността
Основната характеристика на качеството на избраната извадка е понятието "грешка на представителността". Какво е? Това са известни несъответствия между показателите на избирателното и непрекъснатото наблюдение. Според показателите за грешки представителността се разделя на достоверна, обикновена и приблизителна. С други думи, допустими са отклонения съответно до 3%, от 3 до 10% и от 10 до 20%. Въпреки че в статистиката е желателно грешката да не надвишава 5-6%. В противен случай има основание да се говори за недостатъчна представителност на извадката. За да се изчисли грешката на представителността и как тя влияе върху извадка или популация, се вземат предвид много фактори:
- Вероятността, с която да се получи точен резултат.
- Брой единици за вземане на проби. Както бе споменато по-рано, колкото по-малък е броят на единиците в извадката, толкова по-голяма ще бъде грешката в представителността и обратно.
- Хомогенност на изследваната популация. Колкото по-хетерогенна е съвкупността, толкова по-голяма ще бъде грешката в представителността. Способността на една съвкупност да бъде представителна зависи от хомогенността на всички нейни съставни единици.
- Метод за подбор на единици в извадкова съвкупност.
При специфични проучвания процентната грешка на средната стойност обикновено се определя от самия изследовател въз основа на програмата за наблюдение и според данни от предишни изследвания. По правило максималната грешка на извадката (грешка на представителност) в рамките на 3-5% се счита за приемлива.

Повече не винаги е по-добре
Също така си струва да запомните, че основното при организирането на селективно наблюдение е да се сведе обемът му до приемлив минимум. В същото време не трябва да се стремите към прекомерно намаляване на границите на грешките при вземане на проби, тъй като това може да доведе до неоправдано увеличаване на количеството данни от извадката и следователно до увеличаване на разходите за вземане на проби.
В същото време размерът на грешката в представителността не трябва да се увеличава прекомерно. В крайна сметка, в този случай, въпреки че ще има намаляване на размера на извадката, това ще доведе до влошаване на надеждността на получените резултати.
Какви въпроси обикновено се задават от изследователя?
Всяко изследване, ако се провежда, е с някаква цел и за получаване на някакви резултати. При провеждане на извадково проучване, като правило, първоначалните въпроси са:

Методи за подбор на изследователски единици в извадката
Не всяка извадка е представителна. Понякога един и същ знак е различно изразен в цялото и в част от него. За постигане на изискванията за представителност е препоръчително да се използват различни техники за вземане на проби. Освен това използването на един или друг метод зависи от конкретните обстоятелства. Някои от тези методи за вземане на проби включват:
- случаен избор;
- механична селекция;
- типична селекция;
- сериен (вложен) избор.
Случайният подбор е система от дейности, насочени към случаен подбор на единици от съвкупността, когато вероятността да бъдат включени в извадката е еднаква за всички единици от генералната съвкупност. Тази техника е препоръчително да се прилага само в случай на хомогенност и малък брой присъщи характеристики. В противен случай има риск някои характерни черти да не бъдат отразени в извадката. Характеристиките на случайния подбор са в основата на всички други методи за вземане на проби.
При механичен избор на единици се извършва на определен интервал. При необходимост от формиране на извадка от конкретни престъпления е възможно да се премахне всяка 5-та, 10-та или 15-та карта от всички статистически записи на регистрираните престъпления, в зависимост от техния общ брой и наличните размери на извадката. Недостатъкът на този метод е, че преди селекцията е необходимо да има пълна сметка на единиците от съвкупността, след това е необходимо да се извърши класиране и едва след това е възможно да се направи извадка през определен интервал. Този метод отнема много време, така че не се използва често.

Типичният (районизиран) подбор е вид извадка, при която генералната съвкупност е разделена на хомогенни групи по определен признак. Понякога изследователите използват други термини вместо "групи": "райони" и "зони". След това от всяка група произволно се избира определен брой единици, пропорционални на дела на групата в общата популация. Типичният подбор често се извършва на няколко етапа.
Серийната извадка е метод, при който подборът на единици се извършва в групи (серии) и всички единици от избраната група (серия) подлежат на изследване. Предимството на този метод е, че понякога е по-трудно да се изберат отделни единици, отколкото серии, например, когато се изучава лице, което излежава присъда. В рамките на избраните райони, зони се прилага изследване на всички звена без изключение, например изследване на всички лица, изтърпяващи присъди в определена институция.
 Ораторското изкуство като първообраз на журналистиката
Ораторското изкуство като първообраз на журналистиката Цитати за Наполеон - dslinkov — LiveJournal
Цитати за Наполеон - dslinkov — LiveJournal Аз отмъщение Човекът на булдозера унищожи града
Аз отмъщение Човекът на булдозера унищожи града