Статистический анализ числовых величин (непараметрическая статистика). Нормальный закон распределения вероятностей
К сожалению, параметрические семейства существуют лишь в головах авторов учебников по теории вероятностей и математической статистике. В реальной жизни их нет. Поэтому эконометрика использует в основном непараметрические методы, в которых распределения результатов наблюдений могут иметь произвольный вид.
Сначала на примере нормального распределения подробнее обсудим невозможность практического использования параметрических семейств для описания распределений конкретных экономических данных. Затем разберем параметрические методы отбраковки резко выделяющихся наблюдений и продемонстрируем невозможность практического использования ряда методов параметрической статистики, ошибочность выводов, к которым они приводят. Затем разберем непараметрические методы доверительного оценивания основных характеристик числовых случайных величин - математического ожидания, медианы, дисперсии, среднего квадратического отклонения, коэффициента вариации . Завершат лекцию методы проверки однородности двух выборок, независимых или связанных.
Часто ли распределение результатов наблюдений является нормальным?
В эконометрических и экономико-математических моделях, применяемых, в частности, при изучении и оптимизации процессов маркетинга и менеджмента, управления предприятием и регионом, точности и стабильности технологических процессов, в задачах надежности, обеспечения безопасности, в том числе экологической, функционирования технических устройств и объектов, разработки организационных схем часто применяют понятия и результаты теории вероятностей и математической статистики. При этом зачастую используют те или иные параметрические семейства распределений вероятностей. Наиболее популярно нормальное распределение . Используют также логарифмически нормальное распределение , экспоненциальное распределение, гамма-распределение, распределение Вейбулла-Гнеденко и т.д.
Очевидно, всегда необходимо проверять соответствие моделей реальности. Возникают два вопроса. Отличаются ли реальные распределения от используемых в модели? Насколько это отличие влияет на выводы?
Ниже на примере нормального распределения и основанных на нем методов отбраковки резко отличающихся наблюдений (выбросов) показано, что реальные распределения практически всегда отличаются от включенных в классические параметрические семейства, а имеющиеся отклонения от заданных семейств делают неверными выводы, в рассматриваемом случае, об отбраковке, основанные на использовании этих семейств.
Есть ли основания априори предполагать нормальность результатов измерений?
Иногда утверждают, что в случае, когда погрешность измерения (или иная случайная величина ) определяется в результате совокупного действия многих малых факторов, то в силу Центральной Предельной Теоремы (ЦПТ) теории вероятностей эта величина хорошо приближается ( по распределению) нормальной случайной величиной. Такое утверждение справедливо, если малые факторы действуют аддитивно и независимо друг от друга. Если же они действуют мультипликативно, то в силу той же ЦПТ аппроксимировать надо логарифмически нормальным распределением. В прикладных задачах обосновать аддитивность, а не мультипликативность действия малых факторов обычно не удается. Если же зависимость имеет общий характер, не приводится к аддитивному или мультипликативному виду, а также нет оснований принимать модели, дающие экспоненциальное, Вейбулла-Гнеденко, гамма или иные распределения, то о распределении итоговой случайной величины практически ничего не известно, кроме внутриматематических свойств типа регулярности.
При обработке конкретных данных иногда считают, что погрешности измерений имеют нормальное распределение . На предположении нормальности построены классические модели регрессионного, дисперсионного, факторного анализов , метрологические модели, которые еще продолжают встречаться как в отечественной ноpмативно-технической документации, так и в международных стандартах. На то же предположение опираются модели расчетов максимально достигаемых уровней тех или иных характеристик, применяемые при проектировании систем обеспечения безопасности функционирования экономических структур, технических устройств и объектов. Однако теоретических оснований для такого предположения нет. Необходимо экспериментально изучать распределения погрешностей.
Что же показывают результаты экспериментов? Сводка, данная в монографии , позволяет утверждать, что в большинстве случаев распределение погрешностей измерений отличается от нормального. Так, в Машинно-электротехническом институте (г. Варна в Болгарии) было исследовано распределение погрешностей градуировки шкал аналоговых электроизмерительных приборов. Изучались приборы, изготовленные в Чехословакии, СССР и Болгарии. Закон распределения погрешностей оказался одним и тем же. Он имеет плотность
Были проанализированы данные о параметрах 219 фактических распределениях погрешностей, исследованных разными авторами, при измерении как электрических, так и не электрических величин самыми разнообразными (электрическими) приборами. В результате этого исследования оказалось, что 111 распределений, т.е. примерно 50% , принадлежат классу распределений с плотностью
где - параметр степени; - параметр сдвига; - параметр масштаба; - гамма- функция от аргумента ;

В лаборатории прикладной математики Тартуского государственного университета проанализировано 2500 выбоpок из архива реальных статистических данных. В 92% гипотезу нормальности пришлось отвергнуть.
Приведенные описания экспеpиментальных данных показывают, что погрешности измерений в большинстве случаев имеют распределения, отличные от нормальных. Это означает, в частности, что большинство применений критерия Стьюдента, классического регрессионного анализа и других статистических методов, основанных на нормальной теории, строго говоря, не является обоснованным, поскольку неверна лежащая в их основе аксиома нормальности распределений соответствующих случайных величин.
Очевидно, для оправдания или обоснованного изменения существующей практики анализа статистических данных требуется изучить свойства процедур анализа данных при "незаконном" применении. Изучение процедур отбраковки показало, что они крайне неустойчивы к отклонениям от нормальности, а потому применять их для обработки реальных данных нецелесообразно (см. ниже); поэтому нельзя утверждать, что произвольно взятая процедура устойчива к отклонениям от нормальности.
Иногда предлагают перед применением, например, критерия Стьюдента однородности двух выбоpок проверять нормальность. Хотя для этого имеется много критериев, но проверка нормальности - более сложная и трудоемкая статистическая процедура, чем проверка однородности (как с помощью статистик типа Стьюдента, так и с помощью непараметрических критериев). Для достаточно надежного установления нормальности требуется весьма большое число наблюдений. Так, чтобы гарантировать, что функция распределения результатов наблюдений отличается от некоторой нормальной не более, чем на 0,01 (при любом значении аргумента), требуется порядка 2500 наблюдений. В большинстве экономических, технических, медико-биологических и других прикладных исследований число наблюдений существенно меньше. Особенно это справедливо для данных, используемых при изучении проблем, связанных с обеспечением безопасности функционирования экономических структур и технических объектов.
Иногда пытаются использовать ЦПТ для приближения распределения погрешности к нормальному, включая в технологическую схему измерительного прибора специальные сумматоры. Оценим полезность
этой меры. Пусть - независимые одинаково распределенные случайные величины с функцией распределения ![]() такие, что Рассмотрим
такие, что Рассмотрим
Показателем обеспечиваемой сумматором близости к нормальности является
Правое неравенство в последнем соотношении вытекает из оценок константы в неравенстве Берри-Эссеена, полученном в книге , а левое - из примера в монографии . Для нормального закона , для равномерного , для двухточечного (это - нижняя граница для ). Следовательно, для обеспечения расстояния (в метрике Колмогорова) до нормального распределения не более 0,01 для "неудачных" распределений необходимо не менее слагаемых, где вероятность попасть в дискретное множество десятичных чисел с заданным числом знаков после запятой равна 0.
Из сказанного выше следует, что результаты измерений и вообще статистические данные имеют свойства, приводящие к тому, что моделировать их следует случайными величинами с распределениями, более или менее отличными от нормальных. В большинстве случаев распределения существенно отличаются от нормальных, в других нормальные распределения могут, видимо, рассматриваться как некоторая аппроксимация , но никогда нет полного совпадения. Отсюда вытекает как необходимость изучения свойств классических статистических процедур в неклассических вероятностных моделях (подобно тому, как это сделано ниже для критерия Стьюдента), так и необходимость разработки устойчивых (учитывающих наличие отклонений от нормальности) и непараметрических, в том числе свободных от распределения процедур, их широкого внедрения в практику статистической обработки данных.
Опущенные здесь рассмотрения для других параметрических семейств приводят к аналогичным выводам. Итог можно сформулировать так. Распределения реальных данных практически никогда не входят в какое-либо конкретное параметрическое семейство. Реальные распределения всегда отличаются от тех, что включены в параметрические семейства. Отличия могут быть большие или маленькие, но они всегда есть. Попробуем понять, насколько важны эти различия для проведения эконометрического анализа.
Нормальное распределение (распределение Гаусса) всегда играло центральную роль в теории вероятностей, так как возникает очень часто как результат воздействия множества факторов, вклад любого одного из которых ничтожен. Центральная предельная теорема (ЦПТ), находит применение фактически во всех прикладных науках, делая аппарат статистики универсальным. Однако, весьма часты случаи, когда ее применение невозможно, а исследователи пытаются всячески организовать подгонку результатов под гауссиану. Вот про альтернативный подход в случае влияния на распределение множества факторов я сейчас и расскажу.
Краткая история ЦПТ.
Еще при живом Ньютоне Абрахам де Муавр доказал теорему о сходимости центрированного и нормированного числа наблюдений события в серии независимых испытаний к нормальному распределению. Весь 19 и начало 20 веков эта теорема послужила ученым образцом для обобщений. Лаплас доказал случай равномерного распределения, Пуассон – локальную теорему для случая с разными вероятностями. Пуанкаре, Лежандр и Гаусс разработали богатую теорию ошибок наблюдений и метод наименьших квадратов, опираясь на сходимость ошибок к нормальному распределению. Чебышев доказал еще более сильную теорему для суммы случайных величин, походу разработав метод моментов. Ляпунов в 1900 году, опираясь на Чебышева и Маркова, доказал ЦПТ в нынешнем виде, но только при существовании моментов третьего порядка. И только в 1934 году Феллер поставил точку, показав, что существование моментов второго порядка, является и необходимым и достаточным условием.
ЦПТ можно сформулировать так: если случайные величины независимы, одинаково распределены и имеют конечную дисперсию отличную от нуля, то суммы (центрированные и нормированные) этих величин сходятся к нормальному закону. Именно в таком виде эту теорему и преподают в вузах и ее так часто используют наблюдатели и исследователи, которые не профессиональны в математике. Что в ней не так? В самом деле, теорема отлично применяется в областях, над которыми работали Гаусс, Пуанкаре, Чебышев и прочие гении 19 века, а именно: теория ошибок наблюдений, статистическая физика, МНК, демографические исследования и может что-то еще. Но ученые, которым не достает оригинальности для открытий, занимаются обобщениями и хотят применить эту теорему ко всему, или просто притащить за уши нормальное распределение, где его просто быть не может. Хотите примеры, они есть у меня.
Коэффициент интеллекта IQ. Изначально подразумевает, что интеллект людей распределен нормально. Проводят тест, который заранее составлен таким образом, при котором не учитываются незаурядные способности, а учитываются по-отдельности с одинаковыми долевыми факторами: логическое мышление , мысленное проектирование, вычислительные способности, абстрактное мышление и что-то еще. Способность решать задачи, недоступные большинству, или прохождение теста за сверхбыстрое время никак не учитывается, а прохождение теста ранее, увеличивает результат (но не интеллект) в дальнейшем. А потом филистеры и полагают, что «никто в два раза умнее их быть не может», «давайте у умников отнимем и поделим».
Второй пример: изменения финансовых показателей. Исследования изменения курса акций, котировок валют, товарных опционов требует применения аппарата математической статистики, а особенно тут важно не ошибиться с видом распределения. Показательный пример: в 1997 году нобелевская премия по экономике была выплачена за предложение модели Блэка - Шоулза, основанной на предположении нормальности распределения прироста фондовых показателей (так называемый белый шум). При этом авторы явно заявили, что данная модель нуждается в уточнении, но всё, на что решилось большинство дальнейших исследователей – просто добавить к нормальному распределению распределение Пуассона. Здесь, очевидно, будут неточности при исследовании длинных временных рядов, так как распределение Пуассона слишком хорошо удовлетворяет ЦПТ, и уже при 20 слагаемых неотличимо от нормального распределения. Гляньте на картинку снизу (а она из очень серьезного экономического журнала), на ней видно, что, несмотря на достаточно большое количество наблюдений и очевидные перекосы, делается предположение о нормальности распределения.

Весьма очевидно, что нормальными не будет распределения заработной платы среди населения города, размеров файлов на диске, населения городов и стран.
Общее у распределений из этих примеров – наличие так называемого «тяжелого хвоста», то есть значений, далеко лежащих от среднего, и заметной асимметрии, как правило, правой. Рассмотрим, какими еще, кроме нормального могли бы быть такие распределения. Начнем с упоминаемого ранее Пуассона: у него есть хвост, но мы же хотим, чтобы закон повторялся для совокупности групп, в каждой из которых он наблюдается (считать размер файлов по предприятию, зарплату по нескольким городам) или масштабировался (произвольно увеличивать или уменьшать интервал модели Блэка - Шоулза), как показывают наблюдения, хвосты и асимметрия не исчезают, а вот распределение Пуассона, по ЦПТ, должно стать нормальным. По этим же соображениям не подойдут распределения Эрланга, бета, логонормальное, и все другие, имеющие дисперсию. Осталось только отсечь распределение Парето, а вот оно не подходит в связи с совпадением моды с минимальным значением, что почти не встречается при анализе выборочных данных.
Распределения, обладающее необходимыми свойствами, существуют и носят название устойчивых распределений.
Их история также весьма интересна, а основная теорема была доказана через год после работы Феллера, в 1935 году, совместными усилиями французского математика Поля Леви и советского математика А.Я. Хинчина. ЦПТ была обобщена, из нее было убрано условие существования дисперсии. В отличие от нормального, ни плотность ни функция распределения у устойчивых случайных величин не выражаются (за редким исключением, о котором ниже), все что о них известно, это характеристическая функция (обратное преобразование Фурье плотности распределения, но для понимания сути это можно и не знать).
Итак, теорема: если случайные величины независимы, одинаково распределены, то суммы этих величин сходятся к устойчивому закону.
Теперь определение. Случайная величина X будет устойчивой тогда и только тогда, когда логарифм ее характеристической функции представим в виде:

где .
В самом деле, ничего сильно сложного здесь нет, просто надо объяснить смысл четырех параметров. Параметры сигма и мю – обычные масштаб и смещение, как и в нормальном распределении, мю будет равно математическому ожиданию, если оно есть, а оно есть, когда альфа больше одного. Параметр бета – асимметрия, при его равенстве нулю, распределение симметрично. А вот альфа это характеристический параметр, обозначает какого порядка моменты у величины существуют, чем он ближе к двум, тем больше распределение похоже на нормальное, при равенстве двум распределение становиться нормальным, и только в этом случае у него существуют моменты больших порядков, также в случае нормального распределения, асимметрия вырождается. В случае, когда альфа равна единице, а бета нулю, получается распределение Коши, а в случае, когда альфа равна половине, а бета единице – распределение Леви, в других случаях не существует представления в квадратурах для плотности распределения таких величин.
В 20 веке была разработана богатая теория устойчивых величин и процессов (получивших название процессов Леви), показана их связь с дробными интегралами, введены различные способы параметризации и моделирования, несколькими способами были оценены параметры и показана состоятельность и устойчивость оценок. Посмотрите на картинку, на ней смоделированная траектория процесса Леви с увеличенным в 15 раз фрагментом.

Именно занимаясь такими процессами и их приложением в финансах, Бенуа Мандельброт придумал фракталы. Однако не везде было так хорошо. Вторая половина 20 века прошла под повальным трендом прикладных и кибернетических наук, а это означало кризис чистой математики, все хотели производить, но не хотели думать, гуманитарии со своей публицистикой оккупировали математические сферы. Пример: книга «Пятьдесят занимательных вероятностных задач с решениями» американца Мостеллера, задача №11:

Авторское решение этой задачи, это просто поражение здравого смысла:

Такая же ситуация и с 25 задачей, где даются ТРИ противоречащих ответа.
Но вернемся к устойчивым распределениям. В оставшейся части статьи я попытаюсь показать, что не должно возникать дополнительных сложностей при работе с ними. А именно, существуют численные и статистические методы, позволяющие оценивать параметры, вычислять функцию распределения и моделировать оные, то есть работать так же, как и с любым другим распределением.
Моделирование устойчивых случайных величин. Так как все познается в сравнении, то напомню сначала наиболее удобный, с точки зрения вычислений, метод генерирования нормальной величины (метод Бокса – Мюллера): если – базовые случайные величины (равномерно распределены на }
 Корпускулярные и волновые свойства частиц
Корпускулярные и волновые свойства частиц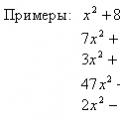 Уравнения онлайн X 5 0 решение
Уравнения онлайн X 5 0 решение Предельные монокарбоновые кислоты
Предельные монокарбоновые кислоты