Uzorak podataka. Statističko uzorkovanje
tipovi uzoraka:
Zapravo-slučajno;
Mechanical;
tipično;
Serial;
Kombinovano.
Samonasumično uzorkovanje je da odaberete jedinice iz stanovništva nasumično ili nasumično bez ikakvih elemenata konzistentnosti. Međutim, prije pravilnog slučajnog odabira, potrebno je osigurati da sve jedinice opće populacije bez izuzetka imaju apsolutno jednake šanse da uđu u uzorak, da nema praznina u listama ili listi, zanemarivanja pojedinačnih jedinica itd. Jasne granice bi također trebale biti uspostavljene za stanovništvo tako da uključivanje ili isključivanje pojedinačnih jedinica nije upitno. Tako je, na primjer, prilikom ispitivanja učenika potrebno naznačiti da li su osobe koje su u akademsko odsustvo, studenti nedržavni univerziteti, vojne škole itd.; prilikom anketiranja komercijalnih objekata, važno je odrediti da li će opća populacija uključiti trgovinski paviljoni, komercijalne šatore i druge slične objekte. Samonasumični odabir može se ponavljati i ne ponavljati. Za neponovljeni izbor prilikom izvlačenja žreba, izvučeni se ne vraćaju u prvobitni set i ne učestvuju u daljem odabiru. Kada koristite tabele slučajni brojevi neponavljajući izbor se postiže preskakanjem brojeva ako se ponavljaju u odabranoj koloni ili kolonama.
Mehaničko uzorkovanje koristi se u slučajevima kada je opšta populacija nekako uređena, tj. postoji određeni redosled u rasporedu jedinica (platni spiskovi zaposlenih, birački spiskovi, brojevi telefona ispitanici, brojevi kuća i stanova itd.).
Opšta populacija tokom mehaničke selekcije može se rangirati ili poredati prema vrijednosti osobine koja se proučava ili u korelaciji s njom, što će povećati reprezentativnost uzorka. Međutim, u ovom slučaju povećava se rizik od sistematske greške, povezane s podcjenjivanjem vrijednosti proučavane osobine (ako je prva vrijednost zabilježena iz svakog intervala) ili s njenim precijenjenjem (ako je posljednja vrijednost). Stoga je preporučljivo započeti odabir od sredine prvog intervala
tipičan izbor. Ova metoda selekcije se koristi u slučajevima kada se sve jedinice opće populacije mogu podijeliti u nekoliko tipičnih grupa. U anketi stanovništva, takve grupe mogu biti, na primjer, okruzi, društvene, starosne ili edukativne grupe, prilikom anketiranja preduzeća - industrija ili podsektor, oblik vlasništva itd. Tipična selekcija uključuje odabir jedinica iz svake tipične grupe na čisto slučajan ili mehanički način. Jer u okvir za uzorkovanje predstavnici svih grupa nužno spadaju u jednu ili drugu proporciju, tipizacija opšte populacije omogućava da se isključi uticaj međugrupna varijansa na prosečna greška uzorak, koji je u ovom slučaju određen samo unutargrupnom varijacijom.
Odabir jedinica u tipičnom uzorku može se organizirati ili proporcionalno volumenu tipičnih grupa, ili proporcionalno unutargrupnoj diferencijaciji osobine.
serijski izbor. Ova metoda selekcije je pogodna u slučajevima kada su jedinice stanovništva grupisane u male grupe ili serije. Kao takve serije, paketi sa određenom količinom gotovih proizvoda, serije robe, studentske grupe, brigade i druga udruženja. Suština serijskog uzorkovanja leži u stvarnom slučajnom ili mehaničkom odabiru serija, u okviru kojeg se vrši kompletan pregled jedinica.
Često se dešava da je potrebno analizirati određenu društvenu pojavu i dobiti informacije o njoj. Takvi zadaci se često javljaju u statistici i statističkim istraživanjima. Verifikacija potpuno definisanog društvenog fenomena je često nemoguća. Na primjer, kako saznati mišljenje stanovništva ili svih stanovnika određenog grada o bilo kojem pitanju? Pitati apsolutno sve je gotovo nemoguće i vrlo naporno. U takvim slučajevima nam je potreban uzorak. Upravo je to koncept na kojem se zasnivaju gotovo sva istraživanja i analize.
Šta je uzorak
Prilikom analize određenog društveni fenomen treba dobiti informacije o tome. Ako uzmemo bilo koju studiju, možemo vidjeti da nije svaka jedinica totaliteta predmeta proučavanja predmet istraživanja i analize. U obzir se uzima samo određeni dio ove ukupnosti. Ovaj proces je uzorkovanje: kada se ispituju samo određene jedinice iz skupa.
Naravno, mnogo zavisi od vrste uzorka. Ali postoje i osnovna pravila. Glavni kaže da odabir iz populacije mora biti apsolutno slučajan. Jedinice stanovništva koje će se koristiti ne bi trebale biti odabrane zbog bilo kojeg kriterija. Grubo govoreći, ako je potrebno prikupiti populaciju od stanovništva određenog grada i odabrati samo muškarce, onda će doći do greške u istraživanju, jer odabir nije izvršen nasumično, već je odabran prema spolu. Gotovo sve metode uzorkovanja temelje se na ovom pravilu.
Pravila uzorkovanja
Da bi odabrani skup odražavao glavne kvalitete čitavog fenomena, on mora biti izgrađen prema određenim zakonima, pri čemu glavnu pažnju treba obratiti na sljedeće kategorije:
- uzorak (populacija uzorka);
- opća populacija;
- reprezentativnost;
- greška reprezentativnosti;
- jedinica stanovništva;
- metode uzorkovanja.
Posebnosti selektivno posmatranje a uzorkovanje je kako slijedi:
- Svi dobijeni rezultati temelje se na matematičkim zakonima i pravilima, odnosno, uz pravilno izvođenje studije i ispravne proračune, rezultati neće biti iskrivljeni na subjektivnoj osnovi
- Omogućuje postizanje rezultata mnogo brže i sa manje vremena i sredstava, proučavajući ne cijeli niz događaja, već samo dio njih.
- Može se koristiti za proučavanje različitih objekata: od specifična pitanja, na primjer, godine, spol grupe koja nas zanima, za učenje javno mnjenje ili nivo materijalne podrške stanovništva.
Selektivno posmatranje
Selektivno je statističko posmatranje, u kojoj se ne istražuje čitav skup onoga što se proučava, već samo neki njegov dio, odabran na određeni način, a rezultati proučavanja ovog dijela odnose se na cijeli skup. Ovaj dio se naziva okvir uzorkovanja. to jedini način proučavanje velikog niza predmeta proučavanja.
Ali selektivno posmatranje se može koristiti samo u slučajevima kada je potrebno samo istražiti mala grupa jedinice. Na primjer, kada se proučava omjer muškaraca i žena u svijetu, koristit će se selektivno posmatranje. Iz očiglednih razloga, nemoguće je uzeti u obzir svakog stanovnika naše planete.
Ali sa istom studijom, ali ne svim stanovnicima zemlje, već određenim 2 "A" klase u posebnoj školi, određeni grad, određena država, može bez slučajnog posmatranja. Uostalom, sasvim je moguće analizirati čitav niz predmeta proučavanja. Treba pobrojati dječake i djevojčice ovog razreda - to će biti omjer.

Uzorak i populacija
Zapravo i nije tako teško kao što zvuči. U svakom predmetu proučavanja postoje dva sistema: opšta i uzorkovana populacija. Šta je? Sve jedinice pripadaju generalu. A uzorku - one jedinice ukupne populacije koje su uzete za uzorak. Ako je sve urađeno kako treba, tada će odabrani dio biti smanjeni raspored cijele (opće) populacije.
Ako govorimo o općoj populaciji, onda možemo razlikovati samo dvije njene varijante: određenu i neodređenu opću populaciju. Zavisi od toga da li je ukupan broj jedinica datog sistema poznat ili ne. Ako se radi o određenoj populaciji, onda će uzorkovanje biti lakše jer se zna koliki je procenat ukupno jedinice će biti uzorkovane.
Ovaj trenutak je veoma neophodan u istraživanju. Na primjer, ako je potrebno istražiti postotak nekvalitetnih konditorskih proizvoda u određenom pogonu. Pretpostavimo da je populacija već definirana. Pouzdano se zna da ovo preduzeće proizvodi 1000 konditorskih proizvoda godišnje. Ako od ove hiljade napravimo uzorak od 100 nasumičnih konditorskih proizvoda i pošaljemo ih na ispitivanje, onda će greška biti minimalna. Grubo govoreći, 10% svih proizvoda je bilo predmet istraživanja, a na osnovu rezultata, uzimajući u obzir grešku reprezentativnosti, možemo govoriti o lošem kvalitetu svih proizvoda.
A ako uzmete uzorak od 100 konditorskih proizvoda iz neodređene opće populacije, gdje je zapravo bilo, recimo, milion jedinica, onda će rezultat uzorka i samo istraživanje biti kritično nevjerojatan i netačan. Osjetite razliku? Stoga je sigurnost opće populacije u većini slučajeva izuzetno važna i uvelike utiče na rezultat studije.

Reprezentativnost stanovništva
Dakle, sada jedno od najvažnijih pitanja – kakav bi trebao biti uzorak? Ovo je najviše glavna tačka istraživanja. U ovoj fazi potrebno je izračunati uzorak i odabrati jedinice iz kojih ukupan broj u nju. Populacija je odabrana ispravno ako su određene karakteristike i karakteristike opšte populacije ostale u uzorku. To se zove reprezentativnost.
Drugim riječima, ako dio nakon selekcije zadrži iste tendencije i karakteristike kao i cijela količina ispitivanog, onda se takva populacija naziva reprezentativnom. Ali ne može se svaki određeni uzorak odabrati iz reprezentativne populacije. Postoje i takvi objekti istraživanja čiji uzorak jednostavno ne može biti reprezentativan. Odatle dolazi koncept greške reprezentativnosti. Ali hajde da pričamo o ovome još malo.
Kako napraviti uzorak
Dakle, kako bi se maksimizirala reprezentativnost, postoje tri osnovna pravila uzorkovanja:

Greška (greška) reprezentativnosti
Glavna karakteristika kvaliteta odabranog uzorka je koncept "greške reprezentativnosti". Šta je? To su određena odstupanja između indikatora selektivnog i kontinuiranog posmatranja. Prema indikatorima greške, reprezentativnost se dijeli na pouzdanu, običnu i približnu. Drugim riječima, prihvatljiva su odstupanja do 3%, od 3 do 10%, odnosno od 10 do 20%. Iako je u statistici poželjno da greška ne prelazi 5-6%. Inače, ima razloga govoriti o nedovoljnoj reprezentativnosti uzorka. Da bi se izračunala greška reprezentativnosti i kako ona utiče na uzorak ili populaciju, uzimaju se u obzir mnogi faktori:
- Vjerovatnoća s kojom ćete dobiti tačan rezultat.
- Broj jedinica uzorkovanja. Kao što je ranije spomenuto, što je manji broj jedinica u uzorku, to će biti veća greška reprezentativnosti, i obrnuto.
- Homogenost ispitivane populacije. Što je populacija heterogena, to će biti veća greška reprezentativnosti. Sposobnost populacije da bude reprezentativna zavisi od homogenosti svih njenih sastavnih jedinica.
- Metoda odabira jedinica u populaciji uzorka.
U betonu dodeljene studije procenat greške srednje vrednosti obično postavlja istraživač na osnovu programa posmatranja i prema podacima prethodnih studija. U pravilu se prihvatljivom smatra maksimalna greška uzorkovanja (greška reprezentativnosti) unutar 3-5%.

Više nije uvijek bolje
Također je vrijedno zapamtiti da je glavna stvar u organizaciji selektivnog promatranja svesti njegov volumen na prihvatljiv minimum. Istovremeno, ne treba težiti pretjeranom smanjenju granica greške uzorkovanja, jer to može dovesti do neopravdanog povećanja količine podataka uzorka i, posljedično, do povećanja cijene uzorkovanja.
U isto vrijeme, veličina greške reprezentativnosti ne bi trebala biti pretjerano povećana. Uostalom, u ovom slučaju, iako će doći do smanjenja veličine uzorka, to će dovesti do pogoršanja pouzdanosti dobivenih rezultata.
Koja pitanja obično postavlja istraživač?
Svako istraživanje, ako se provodi, ima neku svrhu i da dobije neke rezultate. Prilikom dirigovanja uzorak studije su obično postavljeni početna pitanja:

Metode odabira istraživačkih jedinica u uzorku
Nije svaki uzorak reprezentativan. Ponekad je jedan te isti znak različito izražen u cjelini i u svom dijelu. Da bi se postigli zahtjevi reprezentativnosti, preporučljivo je koristiti različite tehnike uzorkovanja. Štoviše, korištenje jedne ili druge metode ovisi o specifičnim okolnostima. Neke od ovih metoda uzorkovanja uključuju:
- slučajni odabir;
- mehanički odabir;
- tipičan izbor;
- serijski (ugniježđeni) odabir.
Slučajni odabir je sistem aktivnosti usmjerenih na slučajni odabir jedinica populacije, kada je vjerovatnoća uključenja u uzorak jednaka za sve jedinice opšte populacije. Ovu tehniku je preporučljivo primijeniti samo u slučaju homogenosti i malog broja njezinih svojstava. Inače, neki karakterne osobine rizik da ne bude uključen u uzorak. Karakteristike slučajnog odabira su u osnovi svih drugih metoda uzorkovanja.
Sa mehaničkim odabirom jedinica se vrši u određenom intervalu. Ukoliko je potrebno formirati uzorak konkretnih krivičnih djela, moguće je ukloniti svaki 5., 10. ili 15. karton iz svih statističkih evidencija evidentiranih krivičnih djela, u zavisnosti od njihovog ukupnog broja i raspoloživih veličina uzorka. Nedostatak ove metode je što je prije selekcije potrebno imati kompletan obračun jedinica populacije, zatim je potrebno izvršiti rangiranje, a tek nakon toga moguće je uzorkovanje u određenom intervalu. Ova metoda oduzima dosta vremena, pa se ne koristi često.

Tipična (regionalizirana) selekcija – tip uzorka u kojem se dijeli opća populacija homogene grupe na određenoj osnovi. Ponekad istraživači koriste druge termine umjesto "grupa": "okruzi" i "zone". Zatim se iz svake grupe nasumično bira određeni broj jedinica proporcionalno specifična gravitacija grupe u opštoj populaciji. Tipičan odabir se često provodi u nekoliko faza.
Serijsko uzorkovanje je metoda u kojoj se odabir jedinica vrši po grupama (serijama) i sve jedinice odabrane grupe (serije) podliježu ispitivanju. Prednost ove metode je što je ponekad teže odabrati pojedinačne jedinice nego serije, na primjer, kada se proučava osoba koja služi kaznu. U okviru odabranih područja, zona primjenjuje se proučavanje svih jedinica bez izuzetka, na primjer, proučavanje svih lica na izdržavanju kazne u određenoj ustanovi.
Intervalna procjena vjerovatnoće događaja. Formule za izračunavanje broja uzoraka u slučaju metode slučajnog odabira.Da bismo odredili vjerovatnoće događaja koji nas zanimaju, koristimo metodu uzorkovanja: provodimo n nezavisni eksperimenti, u svakom od kojih se događaj A može dogoditi (ili se ne dogoditi) (vjerovatnost R pojava događaja A u svakom eksperimentu je konstantna). Zatim relativna učestalost p* pojavljivanja događaja ALI u nizu n testovi se prihvataju kao tačka procene za vjerovatnoću str pojava događaja ALI u posebnom testu. U ovom slučaju se poziva vrijednost p* uzorak udjela pojave događaja ALI, i r - generalni udio .
Na osnovu posledica iz centralnog granična teorema(Moivre-Laplaceov teorem) relativna frekvencija događaja sa velikom veličinom uzorka može se smatrati normalno distribuiranom sa parametrima M(p*)=p i
Dakle, za n>30 interval povjerenja za opšti udeo može se konstruisati korišćenjem formula:

gdje se u cr nalazi prema tabelama Laplaceove funkcije, uzimajući u obzir datu vjerovatnoću pouzdanosti γ: 2F(u cr)=γ.
Sa malom veličinom uzorka n≤30, marginalna greška ε se određuje iz Studentove distributivne tabele: ![]() gdje je t cr =t(k; α) i broj stupnjeva slobode k=n-1 vjerovatnoća α=1-γ (dvostrano područje).
gdje je t cr =t(k; α) i broj stupnjeva slobode k=n-1 vjerovatnoća α=1-γ (dvostrano područje).
Formule su važeće ako je selekcija izvršena nasumično na ponovljen način (opšta populacija je beskonačna), u suprotnom je potrebno izvršiti korekciju za neponovljiv izbor (tabela).
Prosječna greška uzorkovanja za opću proporciju
| Populacija | Beskrajno | krajnji volumen N |
| Vrsta odabira | Ponovljeno | neponavljanje |
| Prosječna greška uzorkovanja |
Formule za izračunavanje veličine uzorka uz odgovarajuću metodu slučajnog odabira
| Metoda odabira | Formule veličine uzorka | ||
| za sredinu | za dionicu | ||
| Ponovljeno | |||
| neponavljanje | |||
Problemi oko opšteg udela
Na pitanje "Da li data vrijednost p 0 pokriva interval povjerenja?" - može se odgovoriti provjerom statistička hipoteza H 0:p=p 0 . Pretpostavlja se da se eksperimenti izvode prema Bernoullijevoj šemi testa (nezavisno, vjerovatnoća str pojava događaja ALI konstantan). Po zapremini uzorka n odrediti relativnu frekvenciju p* pojave događaja A: gdje m- broj pojavljivanja događaja ALI u nizu n testovi. Za testiranje hipoteze H 0 koriste se statistike koje, uz dovoljno veliku veličinu uzorka, imaju standard normalna distribucija(Tabela 1).Tabela 1 - Hipoteze o opštem udjelu
Hipoteza | H0:p=p0 | H 0: p 1 = p 2 |
| Pretpostavke | Bernoullijeva testna shema | Bernoullijeva testna shema |
| Uzorak procjena |  |
|
| Statistika K |  | 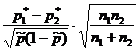 |
| Distribucija statistike K | Standardno normalno N(0,1) |
Primjer #1. Koristeći nasumično ponovno uzorkovanje, menadžment kompanije sproveo je nasumično istraživanje među 900 zaposlenih. Među ispitanicima je bilo 270 žena. Nacrtajte interval povjerenja koji, s vjerovatnoćom od 0,95, pokriva pravi udio žena u cijelom timu firme.
Rješenje. Po stanju, udio žena u uzorku je (relativna učestalost žena među svim ispitanicima). Budući da se selekcija ponavlja i veličina uzorka je velika (n=900), marginalna greška uzorkovanja se određuje formulom ![]()
Vrijednost u cr nalazi se iz tabele Laplaceove funkcije iz relacije 2F(u cr)=γ, tj. ![]() Laplaceova funkcija (Dodatak 1) uzima vrijednost 0,475 pri ucr =1,96. Dakle, marginalna greška
Laplaceova funkcija (Dodatak 1) uzima vrijednost 0,475 pri ucr =1,96. Dakle, marginalna greška ![]() i željeni interval pouzdanosti
i željeni interval pouzdanosti
(p – ε, p + ε) = (0,3 – 0,18; 0,3 + 0,18) = (0,12; 0,48)
Dakle, sa vjerovatnoćom od 0,95, može se garantovati da je udio žena u cijelom timu firme u rasponu od 0,12 do 0,48.
Primjer #2. Vlasnik parkinga dan smatra "srećnim" ako je parking popunjen više od 80%. Tokom godine obavljeno je 40 kontrola parkirališta, od kojih su 24 „uspješne“. Sa vjerovatnoćom od 0,98, pronađite interval povjerenja za procjenu pravog procenta "sretnih" dana u godini.
Rješenje. Uzorak frakcije „dobrih“ dana je
Prema tabeli Laplaceove funkcije nalazimo vrijednost u cr za datu
nivo samopouzdanja
F(2.23) = 0.49, u cr = 2.33.
S obzirom da se odabir ne ponavlja (tj. dvije provjere nisu obavljene istog dana), nalazimo marginalnu grešku: ![]()
gdje je n=40 , N = 365 (dana). Odavde ![]()
i interval povjerenja za opći razlomak: (p – ε, p + ε) = (0,6 – 0,17; 0,6 + 0,17) = (0,43; 0,77)
Sa vjerovatnoćom od 0,98, može se očekivati da je udio "dobrih" dana u toku godine u rasponu od 0,43 do 0,77.
Primjer #3. Nakon provjere 2500 artikala iz serije, ustanovili su da je 400 predmeta najviše ocjene, ali n–m nije. Koliko proizvoda trebate provjeriti da biste utvrdili udio premium razreda sa tačnošću od 0,01 sa sigurnošću od 95%?
Tražimo rješenje prema formuli za određivanje veličine uzorka za ponovnu selekciju.
F(t) = γ/2 = 0,95/2 = 0,475 i prema Laplaceovoj tabeli ova vrijednost odgovara t=1,96
Frakcija uzorka w = 0,16; greška uzorkovanja ε = 0,01
Primjer #4. Serija proizvoda je prihvaćena ako je vjerovatnoća da će proizvod zadovoljiti standard najmanje 0,97. Među nasumično odabranih 200 proizvoda iz testirane serije, 193 proizvoda zadovoljavaju standard. Da li je moguće prihvatiti seriju na nivou značajnosti α=0,02?
Rješenje. Formuliramo glavne i alternativne hipoteze.
H 0: p = p 0 \u003d 0,97 - nepoznati opći dio str je jednako postavljena vrijednost p 0 =0,97. U odnosu na uslov - vjerovatnoća da će dio iz testirane partije biti u skladu sa standardom je 0,97; one. serija proizvoda može biti prihvaćena.
H1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Uočena statistička vrijednost K(tabela) izračunati za date vrijednosti p 0 =0,97, n=200, m=193

Kritična vrijednost se nalazi iz tablice Laplaceove funkcije iz jednakosti
![]()
Prema uslovu α=0,02, dakle F(Kcr)=0,48 i Kcr=2,05. Kritično područje je lijevo, tj. je interval (-∞;-K kp)= (-∞;-2,05). Uočena vrijednost Kobs = -0,415 ne pripada kritičnom području, stoga, na ovom nivou značajnosti, nema razloga da se odbaci glavna hipoteza. Može se prihvatiti serija proizvoda.
Primjer broj 5. Dvije fabrike proizvode istu vrstu dijelova. Za procjenu njihovog kvaliteta uzeti su uzorci proizvoda ovih tvornica i dobijeni su sljedeći rezultati. Od 200 odabranih proizvoda prve fabrike, 20 je bilo neispravnih, a od 300 proizvoda druge fabrike 15 je bilo neispravno.
Na nivou značajnosti od 0,025 saznajte postoji li značajna razlika u kvaliteti dijelova koje proizvode ove tvornice.
Prema uslovu α=0,025, dakle F(Kcr)=0,4875 i Kcr=2,24. Kod dvostrane alternative, površina dozvoljenih vrijednosti ima oblik (-2,24; 2,24). Posmatrana vrijednost Kobs =2,15 spada u ovaj interval, tj. na ovom nivou značaja, nema razloga da se odbaci glavna hipoteza. Fabrike proizvode proizvode istog kvaliteta.
Plan
- Uvod
- 1. Uloga uzorkovanja
- Zaključak
- Bibliografija
Uvod
Statistika je analitička nauka koja je neophodna svim savremenim stručnjacima. Savremeni specijalista ne može biti pismen ako ne posjeduje statističku metodologiju. Statistika je najvažniji alat za komunikaciju između preduzeća i društva. Statistika je jedna od najvažnijih disciplina u nastavnom planu i programu svih specijalnosti. statistička pismenost je sastavni dio visokog obrazovanja, a po broju sati predviđenih nastavnim planom i programom zauzima jedno od prvih mjesta. Radeći sa brojkama, svaki specijalista mora znati kako su određeni podaci dobijeni, kakva je njihova priroda izračunavanja, koliko su potpuni i pouzdani.
1. Uloga uzorkovanja
Skup svih jedinica populacije koje imaju određeni atribut i koje su predmet proučavanja naziva se u statistici opća populacija.
U praksi, iz ovog ili onog razloga, nije uvijek moguće ili nepraktično uzeti u obzir cjelokupnu populaciju. Tada se ograničavaju na proučavanje samo nekog njegovog dijela, čiji je krajnji cilj proširiti dobivene rezultate na cjelokupnu populaciju, tj. koristeći metodu uzorkovanja.
Da bi se to postiglo, dio elemenata, tzv. uzorak, se bira iz opće populacije na poseban način, a rezultati obrade podataka uzorka (na primjer, aritmetički prosjek) generaliziraju se na cijelu populaciju.
Teorijska osnova metode uzorkovanja je zakon velikih brojeva. Na osnovu ovog zakona, sa ograničenom disperzijom karakteristike u opštoj populaciji i dovoljno velikim uzorkom sa verovatnoćom bliskom punoj pouzdanosti, srednja vrednost uzorka može biti proizvoljno blizu opšte srednje vrednosti. Ovaj zakon, koji uključuje grupu teorema, dokazan je strogo matematički. Dakle, aritmetička sredina izračunata za uzorak može se razumno smatrati indikatorom koji karakteriše opštu populaciju u celini.
2. Metode probabilističke selekcije koje osiguravaju reprezentativnost
Da bi se iz uzorka mogao izvesti zaključak o svojstvima opće populacije, uzorak mora biti reprezentativan (reprezentativan), tj. mora u potpunosti i na adekvatan način predstavljati svojstva opšte populacije. Reprezentativnost uzorka može se osigurati samo ako je odabir podataka objektivan.
Skup uzoraka se formira po principu masovnih probabilističkih procesa bez ikakvih izuzetaka od prihvaćene šeme selekcije; potrebno je osigurati relativnu homogenost uzorka ili njegovu podjelu na homogene grupe jedinica. Prilikom formiranja populacije uzorka treba dati jasnu definiciju jedinice uzorka. Poželjna je približno ista veličina jedinica uzorkovanja, a rezultati će biti tačniji što je jedinica uzorkovanja manja.
Moguća su tri načina odabira: slučajni odabir, odabir jedinica prema određenoj shemi, kombinacija prve i druge metode.
Ako se odabir u skladu s prihvaćenom shemom provodi iz opće populacije, prethodno podijeljene na tipove (slojeve ili slojeve), tada se takav uzorak naziva tipičan (ili stratificiran, ili stratificiran, ili zoniran). Druga podjela uzorka po vrstama određena je onim što je jedinica uzorkovanja: jedinica promatranja ili niz jedinica (ponekad se koristi izraz "gnijezdo"). U potonjem slučaju, uzorak se naziva serijski ili ugniježđeni. U praksi se često koristi kombinacija tipičnog uzorka sa selekcijom serije. U matematičkoj statistici, kada se govori o problemu selekcije podataka, potrebno je uvesti podjelu uzorka na ponovljene i neponovljene. Prvi odgovara shemi povratne lopte, drugi - neopozivi (kada se uzme u obzir proces odabira podataka na primjeru odabira loptica različitih boja iz urne). U socio-ekonomskoj statistici nema smisla koristiti ponovljeno uzorkovanje, stoga se u pravilu misli na nerepetitivno uzorkovanje.
Budući da društveno-ekonomski objekti imaju složenu strukturu, može biti prilično teško organizirati uzorak. Na primjer, da bi se odabrali domaćinstva pri proučavanju potrošnje stanovništva velikog grada, lakše je prvo odabrati teritorijalne ćelije, stambene zgrade, zatim stanove ili domaćinstva, pa onda ispitanika. Takav uzorak se naziva višestepeni. U svakoj fazi koriste se različite jedinice uzorkovanja: veće u početnim fazama, u posljednjoj fazi, jedinica odabira se poklapa s jedinicom promatranja.
Druga vrsta posmatranja uzorka je višefazno uzorkovanje. Takav uzorak uključuje određeni broj faza, od kojih se svaka razlikuje po detaljima programa posmatranja. Na primjer, 25% cjelokupne opšte populacije anketira se po kratkom programu, svaka 4. jedinica iz ovog uzorka anketira se po potpunijem programu itd.
Za bilo koju vrstu uzorka, odabir jedinica se vrši na tri načina. Razmotrite postupak slučajnog odabira. Prije svega, sastavlja se lista jedinica stanovništva u kojoj se svakoj jedinici dodjeljuje digitalni kod (broj ili oznaka). Zatim se pravi žreb. U bubanj se stavljaju kuglice s odgovarajućim brojevima, miješaju se i odabiru loptice. Brojevi koji su ispali odgovaraju jedinicama u uzorku; broj brojeva je jednak planiranoj veličini uzorka.
Odabir žrijebom može biti podložan pristranostima uzrokovanim tehničkim nedostacima (kvalitet lopti, bubnja) i drugim razlozima. Pouzdaniji sa stanovišta objektivnosti je odabir pomoću tablice slučajnih brojeva. Takva tabela sadrži niz brojeva, koji se nasumično izmjenjuju, odabranih elektronskim signalima. Budući da koristimo decimalni numerički sistem 0, 1, 2,., 9, vjerovatnoća pojave bilo koje cifre je 1/10. Prema tome, ako bi bilo potrebno kreirati tabelu slučajnih brojeva, uključujući 500 karaktera, onda bi oko 50 njih bilo 0, isti broj bi bio 1 i tako dalje.
Često se koristi selekcija prema nekoj shemi (tzv. usmjereno uzorkovanje). Šema odabira je usvojena na način da odražava glavna svojstva i proporcije opšte populacije. Najjednostavniji način: prema listama jedinica opće populacije, sastavljene na način da poredak jedinica ne bi bio povezan sa osobinama koje se proučavaju, vrši se mehanički odabir jedinica sa korakom jednakim N: n. Obično selekcija ne počinje od prve jedinice, već se povlači pola koraka kako bi se smanjila mogućnost pristranosti uzorka. Učestalost pojavljivanja jedinica sa određenim karakteristikama, na primjer, studenti sa određenim nivoom akademskog uspjeha, koji žive u hostelu itd. biće određena strukturom koja se razvila u opštoj populaciji.
Kako bi bili sigurniji da će uzorak odražavati strukturu populacije, potonja se dijeli na tipove (stratu ili područja), a od svakog tipa se vrši slučajni ili mehanički odabir. Ukupan broj jedinica odabranih iz različitih tipova treba da odgovara veličini uzorka.
Posebne poteškoće nastaju kada ne postoji spisak jedinica, a odabir se mora vršiti ili na terenu ili iz uzoraka proizvoda u skladištu gotovih proizvoda. U ovim slučajevima važno je detaljno izraditi orijentacijsku šemu terena i šemu izbora i pratiti je bez dopuštanja odstupanja. Na primjer, brojilo je upućeno da se kreće od određene autobuske stanice na sjever na parnu stranu ulice i nakon brojanja dvije kuće iz prvog ugla uđe u treću i ispita svaki 5. stan. Strogo pridržavanje usvojene šeme osigurava ispunjenje glavnog uslova za formiranje reprezentativnog uzorka - objektivnost odabira jedinica.
Od slučajni uzorak treba razlikovati kvotni odabir, kada se uzorak konstruiše od jedinica određenih kategorija (kvota), koje moraju biti zastupljene u datim proporcijama. Na primjer, u anketi kupaca robnih kuća može se planirati odabir od 150 ispitanika, uključujući 90 žena, od kojih su 25 djevojčice, 20 mlade žene sa malom djecom, 35 su žene srednjih godina obučene u poslovno odijelo, 10 su žene u 50-im i starije; Osim toga, planirano je istraživanje od 70 muškaraca, od čega 25 tinejdžera i mladića, 20 mladića sa djecom, 15 muškaraca obučenih u odijela, 10 muškaraca obučenih u sportsku odjeću. Za utvrđivanje potrošačkih orijentacija i preferencija takav uzorak može biti dobar, ali ako želimo ustanoviti prosječan iznos kupovina, njihovu strukturu, dobićemo nereprezentativne rezultate. To je zato što je uzorkovanje kvota usmjereno na odabir određenih kategorija.
Uzorak može biti nereprezentativan, čak i ako je formiran u skladu sa poznatim proporcijama opšte populacije, ali se selekcija vrši bez ikakve šeme – jedinice se regrutuju na bilo koji način, samo da bi se osigurao odnos njihovih kategorija u istim omjerima kao iu opštoj populaciji (npr. odnos muškaraca i žena, ispitanika mlađih i starijih od radno sposobnih i radno sposobnih itd.).
Ove napomene bi vas trebale upozoriti na takve pristupe uzorkovanju i ponovo naglasiti potrebu za objektivnim uzorkovanjem.
3. Organizacione i metodološke karakteristike slučajnog, mehaničkog, tipskog i serijskog uzorkovanja
U zavisnosti od toga kako se vrši selekcija populacijskih elemenata u uzorku, postoji nekoliko tipova istraživanja uzorka. Odabir može biti slučajan, mehanički, tipičan i serijski.
Slučajni odabir je takav odabir u kojem svi elementi opće populacije imaju jednaku mogućnost da budu odabrani. Drugim riječima, svaki element populacije ima jednaku vjerovatnoću da bude uključen u uzorak.
uzorkovanje statistički probabilistički slučajni
Zahtjev slučajnog odabira se u praksi ostvaruje uz pomoć žreba ili tabele slučajnih brojeva.
Prilikom odabira žrijebom svi elementi opće populacije se preliminarno numerišu i njihovi brojevi se stavljaju na karte. Nakon pažljivog miješanja iz paketa na bilo koji način (u nizu ili bilo kojim drugim redoslijedom), odabire se potreban broj karata, koji odgovara veličini uzorka. U tom slučaju možete ili ostaviti odabrane karte na stranu (na taj način izvršiti tzv. neponavljajući odabir) ili, izvlačeći karticu, zapisati njen broj i vratiti je u paket, dajući joj tako priliku da se pojavi ponovo u uzorku (ponovljeni odabir). Prilikom ponovnog odabira, svaki put nakon vraćanja kartice, paket se mora pažljivo promiješati.
Metoda izvlačenja koristi se u slučajevima kada je broj elemenata cjelokupne populacije koja se proučava mali. Uz veliki broj opće populacije, provođenje slučajnog odabira lutrijom postaje teško. Pouzdaniji i manje vremenski zahtjevan u slučaju velike količine podataka koji se obrađuju je metoda korištenja tablice slučajnih brojeva.
Mehanički odabir se vrši na sljedeći način. Ako se formira uzorak od 10%, tj. mora se odabrati jedan od svakih deset elemenata, a zatim se cijeli skup uvjetno podijeli na jednake dijelove od 10 elemenata. Zatim se nasumično bira element od prvih deset. Na primjer, izvlačenje je označilo deveti broj. Odabir preostalih elemenata uzorka u potpunosti je određen specificiranim omjerom selekcije N brojem prvog odabranog elementa. U slučaju koji se razmatra, uzorak će se sastojati od elemenata 9, 19, 29, itd.
Mehanički odabir treba koristiti s oprezom, jer postoji stvarni rizik od tzv. sistematskih grešaka. Stoga je prije mehaničkog uzorkovanja potrebno analizirati proučavanu populaciju. Ako su njegovi elementi locirani nasumično, tada će uzorak dobiven mehanički biti nasumičan. Međutim, često su elementi originalnog skupa djelomično ili čak potpuno uređeni. Veoma je nepoželjno da mehanička selekcija ima red elemenata koji ima ispravnu ponovljivost, čiji se period može poklopiti sa periodom mehaničkog uzorkovanja.
Često su elementi populacije poredani prema vrijednosti osobine koja se proučava u opadajućem ili rastućem redoslijedu i nemaju periodičnost. Mehanička selekcija iz takve populacije poprima karakter usmjerene selekcije, budući da su pojedini dijelovi populacije zastupljeni u uzorku srazmjerno njihovoj veličini u cjelokupnoj populaciji, tj. selekcija ima za cilj da uzorak učini reprezentativnim.
Druga vrsta usmjerene selekcije je tipična selekcija. Tipičan odabir treba razlikovati od odabira tipičnih objekata. Odabir tipičnih objekata korišćen je u statistici zemstva, kao iu proračunskim istraživanjima. Istovremeno, odabir "tipičnih sela" ili "tipičnih farmi" vršio se prema određenim ekonomskim karakteristikama, na primjer, prema veličini posjeda zemlje po domaćinstvu, prema zanimanju stanovnika i sl. . Ovakva selekcija ne može biti osnova za primjenu metode uzorkovanja, jer ovdje nije ispunjen njen glavni zahtjev - slučajnost odabira.
U stvarnom tipičnom odabiru u metodi uzorkovanja, populacija se dijeli na grupe koje su kvalitativno homogene, a zatim se vrši slučajni odabir unutar svake grupe. Tipičnu selekciju je teže organizovati nego samu slučajnu selekciju, jer su potrebna određena znanja o sastavu i svojstvima opće populacije, ali daje tačnije rezultate.
Serijskom selekcijom cijela populacija se dijeli na grupe (serije). Zatim se slučajnim ili mehaničkim odabirom izoluje određeni dio ovih serija i vrši njihova kontinuirana obrada. U suštini, serijska selekcija je slučajna ili mehanička selekcija koja se provodi za uvećane elemente izvorne populacije.
U teorijskom smislu, serijsko uzorkovanje je najnesavršenije od razmatranih. Po pravilu se ne koristi za obradu materijala, ali predstavlja određene pogodnosti u organizovanju anketa, posebno u proučavanju poljoprivrede. Na primjer, godišnja istraživanja uzorka seljačkih gazdinstava u godinama koje su prethodile kolektivizaciji vršena su metodom serijske selekcije. Istoričaru je korisno znati serijsko uzorkovanje jer se može susresti sa rezultatima takvih istraživanja.
Pored klasičnih metoda selekcije opisanih gore, u praksi metode uzorkovanja koriste se i druge metode. Razmotrimo dva od njih.
Proučavana populacija može imati višestepenu strukturu, može se sastojati od jedinica prve faze, koje se, pak, sastoje od jedinica druge faze, itd. Na primjer, pokrajine uključuju kneževine, okruzi se mogu smatrati skupom volosti, volosti se sastoje od sela, a sela se sastoje od domaćinstava.
Višestepena selekcija se može primijeniti na takve populacije, tj. sukcesivno birati u svakoj fazi. Dakle, iz skupa provincija, mehaničkim, tipičnim ili slučajnim metodom, mogu se odabrati županije (prva faza), zatim odabrati volosti (druga faza) pomoću jedne od navedenih metoda, zatim odabrati sela (treća faza) i, konačno, domaćinstva (četvrta faza).
Primjer dvostepene mehaničke selekcije je dugo praktikovana selekcija radničkih budžeta. U prvoj fazi se vrši mehanički odabir preduzeća, u drugoj - radnici, čiji se budžet ispituje.
Varijabilnost karakteristika proučavanih objekata može biti različita. Na primjer, opremljenost seljačkih farmi vlastitom radnom snagom varira manje od, recimo, veličine njihovih usjeva. Stoga će manji uzorak ponude radne snage biti jednako reprezentativan kao i veći uzorak podataka o veličini usjeva. U ovom slučaju, iz uzorka koji se koristi za određivanje veličine usjeva, moguće je napraviti uzorak koji je dovoljno reprezentativan za određivanje raspoloživosti radne snage, čime se vrši dvofazna selekcija. U opštem slučaju mogu se dodati i sledeće faze, tj. od rezultirajućeg poduzorka, napravite drugi poduzorak i tako dalje. Ista metoda odabira koristi se u slučajevima kada ciljevi studije zahtijevaju različitu tačnost pri izračunavanju različitih indikatora.
Zadatak 1. Deskriptivna statistika
Na ispitu je 20 studenata dobilo sljedeće ocjene (na skali od 100 bodova):
1) Izgraditi niz frekvencijskih distribucija, relativnih i akumuliranih frekvencija za 5 intervala;
2) Izgraditi poligon, histogram i kumulativni poligon;
3) Pronađite aritmetičku sredinu, mod, medijan, prvi i treći kvartil, kvartalni opseg, standardnu devijaciju i koeficijente varijacije. Analizirajte podatke koristeći ove karakteristike i označite interval koji uključuje 50% središnjih vrijednosti navedenih vrijednosti.
1) x (min) =53, x (max) =98
R=x (max) - x (min) =98-53=45
h=R/1+3.32lgn, gdje je n veličina uzorka, n=20
h= 45/1+3,32*lg20= 9
a (i) - donja granica intervala, b (i) - gornja granica intervala.
a (1) = x (min) - h/2, b (1) = a (1) + h, onda ako je b (i) gornja granica i-tog intervala (i a (i+1) =b (i)), zatim b (2) = a (2) + h, b (3) = a (3) + h, itd. Konstrukcija intervala se nastavlja do početka sljedećeg intervala po redu koji je jednak ili veći od x (max).
a(1) = 47,5 b(1) = 56,5
a(2) = 56,5 b(2) = 65,5
a(3) = 65,5 b(3) = 74,5
a(4) = 74,5 b(4) = 83,5
a(5) = 83,5 b(5) = 92,5
a(6) = 92,5 b(6) = 101,5
|
Intervali, a (i) - b (i) |
Frequency Counting |
Frekvencija, n(i) |
Kumulativna frekvencija, n (hi) |
||
2) Da bismo nacrtali grafove, zapisujemo varijacione serije distribucije (intervalne i diskretne) relativnih frekvencija W (i) = n (i) / n, akumuliranih relativnih frekvencija W (hi) i nalazimo omjer W (i) / h popunjavanjem tabele.
x(i)=a(i)+b(i)/2; W(hi)=n(hi)/n
Statistička distribucija serija procjena:
|
Intervali, a (i) - b (i) |
|||||
Da bismo izgradili histogram relativnih frekvencija duž apscise, izdvajamo parcijalne intervale, na svakom od kojih gradimo pravougaonik, čija je površina jednaka relativnoj frekvenciji W (i) datog i-tog intervala. Tada bi visina osnovnog pravokutnika trebala biti jednaka W (i) / h.
Poligon iste distribucije može se dobiti iz histograma ako su sredine gornjih osnova pravougaonika povezane ravnim segmentima.
Da bismo izgradili kumulat diskretne serije, iscrtavamo vrijednosti značajke duž ose apscise, a relativne akumulirane frekvencije W (hi) duž ose ordinate. Rezultirajuće tačke su povezane linijskim segmentima. Za intervalne serije duž apscise, izdvajamo gornje granice grupisanja.
3) Srednja aritmetička vrijednost se nalazi po formuli:
Režim se izračunava po formuli:
Donja granica modalnog intervala; h - širina intervala grupisanja; - frekvencija modalnog intervala; - učestalost intervala koji prethodi modalnom; - učestalost intervala nakon modalnog. = 23,125.
Nađimo medijanu:
n=20: 53.58.59.59.63.67.68.69.71.73.78.79.85.86.87.89.91.91.98.98
Zamjenom vrijednosti dobijamo: Q1=65;
Vrijednost drugog kvartila je ista kao i vrijednost medijane, pa je Q2=75,5; Q3=88.
Kvartalni raspon je:
Srednja kvadratna (standardna) devijacija se nalazi po formuli:
Koeficijent varijacije:
Iz ovih proračuna se može vidjeti da 50% centralnih vrijednosti naznačenih veličina uključuje interval 74,5 - 83,5.
Zadatak 2. Statističko testiranje hipoteza.
Sportske preferencije za muškarce, žene i tinejdžere su sljedeće:
Testirati hipotezu o nezavisnosti preferencije od pola i starosti b = 0,05.
1) Testiranje hipoteze o nezavisnosti preferencija u sportu.
Pearsenov koeficijent:
Tabelarna vrijednost hi-kvadrat testa sa stupnjem slobode od 4 na b = 0,05 jednaka je h 2 tablici = 9,488.
Pošto se hipoteza odbacuje. Razlike u preferencijama su značajne.
2. Hipoteza usklađenosti.
Odbojka je kao sport najbliža košarci. Provjerimo korespondenciju u preferencijama za muškarce, žene i tinejdžere.
F 2 = 0,1896+0,1531+0,1624+0,1786+0,1415+0,1533 = 0,979.
Na nivou značajnosti b = 0,05 i stepenu slobode k = 2, tabelarna vrijednost h 2 tabl = 9,210.
Pošto F 2 >, razlike u preferencijama su značajne.
Zadatak 3. Korelaciona i regresiona analiza.
Analizom saobraćajnih nezgoda dobijena je sledeća statistika o procentu vozača mlađih od 21 godine i broju teških nezgoda na 1.000 vozača:
Sprovesti grafičku i korelaciono-regresionu analizu podataka, predvideti broj nezgoda sa teškim posledicama za grad u kojem je broj vozača mlađih od 21 godine jednak 20% od ukupnog broja vozača.
Dobijamo uzorak veličine n = 10.
x je procenat vozača mlađih od 21 godine,
y je broj nesreća na 1000 vozača.
Jednačina linearna regresija izgleda kao:
Uzastopno računamo:
Slično, nalazimo
Koeficijent regresije uzorka
Veza između x, y je jaka.
Jednačina linearne regresije ima oblik:
Na figure predstavljeno polje rasipanje i raspored linearno regresija . Trošimo prognoza za x n =20 .
Dobijamo y n =0 .2 9*20-1 .4 6 = 4 .3 4 .
Prediktivno značenje dogodilo više sve vrijednosti, dostavljeno in početni sto . to posljedica Ići, šta korelacija ovisnost ravno i koeficijent jednaki 0,29 dosta veliki . Na svaki jedinica inkrementi Dx on daje prirast Dy =0 .3
Vježbajte 4 . Analiza privremeni činovi i prognoziranje .
predvidjeti vrijednosti indeksa za sljedeću sedmicu koristeći:
a) metodom pokretnog prosjeka, odabirom tronedeljnih podataka za njegovo izračunavanje;
b) eksponencijalni ponderisani prosek, birajući kao b = 0,1.
Iz tabele slučajnih brojeva nalazimo brojeve 41, 51, 69, 135, 124, 93, 91, 144, 10, 24.
Raspoređujemo ih u rastućem redoslijedu: 10, 24, 41, 51, 69, 91, 93, 124, 135, 144.
Vršimo novu numeraciju od 1 do 10. Dobijamo početne podatke za deset sedmica:
Eksponencijalno izglađivanje na b = 0,1 daje samo jednu vrijednost.
Za sredinu čitavog perioda dobijamo tri prognoze: 12.855; 1309; 12.895.
Između ovih prognoza postoji saglasnost.
Vježbajte 5 . index analiza.
Preduzeće se bavi transportom robe. Postoje podaci za niz godina o obimu transporta 4 vrste tereta i troškovima transporta jedinice tereta.
Odredite jednostavne indekse cijena, količine i vrijednosti za svaku vrstu proizvoda, kao i Laspeyresove i Pascheove indekse i indeks vrijednosti. Suvislo komentirajte dobijene rezultate.
Rješenje. Izračunajmo jednostavne indekse:
Laspeyresov indeks:
Pašina indeks:
Cijena Turske:
Pojedinačni indeksi ukazuju na disparitet u promjenama cijena i količina robe A, B, C, D. Zbirni indeksi ukazuju na opšte trendove promjena. Općenito, trošak prevezene robe smanjen je za 13%. Razlog je taj što je najskuplji teret smanjen za 42% u količini, a njegova tarifa se nije mnogo promijenila.
Godine 16-20 numerisane su redom od 1 do 5. Početni podaci imaju oblik:
Prvo, proučavamo dinamiku količine tereta A.
|
Indeks |
Apsolutni dobici |
Stope rasta, % |
Stopa rasta, % |
|||||
At ovo tempo rast u prosjeku on formule :
, .
Za tempo rast in bilo koji slučaj T itd =T R -1 .
Sad razmotriti tereta D .
|
Indeks |
Apsolutni dobici |
Stope rasta, % |
Stopa rasta, % |
|||||
Zaključak
Prosjeci i njihove varijante igraju važnu ulogu u statistici. Prosječni indikatori se široko koriste u analizi, jer se u njima očituju pravilnosti. masovne pojave i procesi u vremenu i prostoru. Tako, na primjer, obrazac povećanja produktivnosti rada nalazi svoj izraz u statistika rast prosječne proizvodnje po zaposlenom u industriji, pravilnost stalnog rasta stepena blagostanja stanovništva očituje se u statističkim pokazateljima povećanja prosječnih primanja radnika i zaposlenih itd.
Takve deskriptivne karakteristike distribucije varijabilne karakteristike kao što su mod i medijan se široko koriste. One su specifične karakteristike, njihovo značenje je svaka posebna opcija u varijantnoj seriji.
Dakle, da bi se okarakterisala najčešća vrijednost nekog obilježja, koristi se modus, a da bi se prikazala kvantitativna granica vrijednosti varijabilnog obilježja, koju dostiže polovina pripadnika populacije, medijan je korišteno.
Dakle, prosječne vrijednosti pomažu u proučavanju obrazaca razvoja industrije, određene industrije, društva i zemlje u cjelini.
Bibliografija
1. Teorija statistike: Udžbenik / R.A. Šmojlova, V.G. Minashkin, N.A. Sadovnikova, E.B. Shuvalov; Pod uredništvom R.A. Shmoylova. - 4. izd., revidirano. i dodatne - M.: Finansije i statistika, 2005. - 656s.
2. Gusarov V.M. Statistika: Tutorial za univerzitete. - M.: UNITI-DANA, 2001.
4. Zbirka zadataka iz teorije statistike: Udžbenik / Ed. prof.V. V. Glinsky i dr. sc. dr L.K. Serga. Ed. Z-e. - M.: INFRA-M; Novosibirsk: Sibirski sporazum, 2002.
5. Statistika: Udžbenik / Kharchenko L-P., Dolzhenkova V.G., Ionin V.G. i drugi, ur. V.G. Ionina. - Ed.2nd, revidirano. i dodatne - M.: INFRA-M. 2003.
Slični dokumenti
Deskriptivna statistika i statističko zaključivanje. Metode selekcije koje osiguravaju reprezentativnost uzorka. Utjecaj vrste uzorka na veličinu greške. Zadaci primjene metode uzorkovanja. Distribucija podataka opservacije općoj populaciji.
test, dodano 27.02.2011
Metoda uzorkovanja i njena uloga. Razvoj moderna teorija selektivno posmatranje. Tipologija metoda selekcije. Načini praktične implementacije jednostavnog slučajnog uzorkovanja. Organizacija tipičnog (stratifikovanog) uzorka. Veličina uzorka u odabiru kvote.
izvještaj, dodano 09.03.2011
Svrha uzorkovanja i uzorkovanja. Organizacijske karakteristike razne vrste selektivno posmatranje. Greške selektivna selekcija i metode za njihovo izračunavanje. Primena metode uzorkovanja za analizu preduzeća energetskog kompleksa.
seminarski rad, dodan 06.10.2014
Selektivno posmatranje kao metoda statističko istraživanje, njegove karakteristike. Slučajni, mehanički, tipični i serijski tipovi selekcije u formiranju skupova uzoraka. Pojam i uzroci greške uzorkovanja, metode za njeno određivanje.
sažetak, dodan 04.06.2010
Koncept i uloga statistike u mehanizmu upravljanja moderna ekonomija. Kontinuirano i nekontinuirano statističko posmatranje, opis metode uzorkovanja. Vrste selekcije tokom selektivnog posmatranja, greške uzorkovanja. Proizvodni i finansijski pokazatelji.
seminarski rad, dodan 17.03.2011
Proučavanje implementacije plana. Anketa slučajnog uzorka od 10%. Troškovi fabričke proizvodnje. marginalna greška uzorci. Dinamika prosječne cijene i obima prodaje proizvoda. Indeks cijena varijabilnog sastava.
kontrolni rad, dodano 09.02.2009
Dobivanje uzorka zapremine n-normalna distribucija slučajna varijabla. Pronalaženje numeričke karakteristike uzorci. grupisanje podataka i varijantne serije. Histogram frekvencije. Empirijska funkcija distribucije. Statistička procjena parametara.
laboratorijski rad, dodato 31.03.2013
Suština pojmova uzorkovanja i posmatranja uzorkovanja, glavne vrste i kategorije selekcije. Određivanje zapremine i veličine uzorka. Praktična upotreba Statistička analiza selektivno posmatranje. Proračun grešaka u frakciji uzorka i srednjoj vrijednosti uzorka.
seminarski rad, dodan 17.02.2015
Koncept selektivnog posmatranja. Greške reprezentativnosti, mjerenje greške uzorkovanja. Određivanje potrebne veličine uzorka. Upotreba metode uzorkovanja umjesto kontinuirane. Disperzija u opštoj populaciji i poređenje indikatora.
test, dodano 23.07.2009
Vrste grešaka selekcije i posmatranja. Metode za odabir jedinica u populaciji uzorka. Karakteristično komercijalne aktivnosti preduzeća. Uzorak ankete potrošači proizvoda. Distribucija karakteristika uzorka na opću populaciju.
Dio objekata iz populacije odabran je za proučavanje kako bi se izveo zaključak o cjelokupnoj populaciji. Da bi se zaključak dobijen proučavanjem uzorka proširio na cijelu populaciju, uzorak mora imati svojstvo reprezentativnosti.
Reprezentativnost uzorka
Svojstvo uzorka da ispravno odražava opštu populaciju. Isti uzorak može, ali ne mora biti reprezentativan za različite populacije.
primjer:
Uzorak koji se u potpunosti sastoji od Moskovljana koji posjeduju automobil ne predstavlja cjelokupnu populaciju Moskve.
Uzorak ruskih preduzeća sa do 100 zaposlenih ne predstavlja sva preduzeća u Rusiji.
Uzorak Moskovljana koji kupuju na tržištu ne predstavlja kupovno ponašanje svih Moskovljana.
Istovremeno, ovi uzorci (podložno drugim uslovima) mogu savršeno predstavljati vlasnike automobila iz Moskve, mala i srednja ruska preduzeća i kupce koji kupuju na tržištima.
Važno je shvatiti da su reprezentativnost uzorka i greška uzorkovanja različite pojave. Reprezentativnost, za razliku od greške, ne zavisi od veličine uzorka.
Koliko god povećali broj anketiranih Moskovljana-vlasnika automobila, ovim uzorkom nećemo moći predstaviti sve Moskovljane.
Greška uzorkovanja (interval pouzdanosti)
Odstupanje rezultata dobijenih uz pomoć posmatranja uzorka od istinitih podataka opšte populacije.
Postoje dvije vrste greške uzorkovanja: statistička i sistematska. Statistička greška zavisi od veličine uzorka. Što je veći uzorak, to je manji.
primjer:
Za jednostavan slučajni uzorak od 400 jedinica, maksimalna statistička greška (od 95% nivo samopouzdanja) je 5%, za uzorak od 600 jedinica - 4%, za uzorak od 1100 jedinica - 3%.Uobičajeno, kada se govori o grešci uzorka, misli se upravo na statističku grešku.
Sistematska greška zavisi od razni faktori koji imaju trajni uticaj na studiju i pomeraju rezultate studije u određenom pravcu.
primjer:
- Upotreba bilo kojeg uzorka vjerovatnoće potcjenjuje udio ljudi s visokim primanjima koji vode aktivna slikaživot. To se događa zbog činjenice da je takve ljude mnogo teže pronaći na nekom određenom mjestu (na primjer, kod kuće).
Problem ispitanika koji odbijaju da odgovore na pitanja iz upitnika (udio "odbijača" u Moskvi, za različita istraživanja, kreće se od 50% do 80%)
U nekim slučajevima, kada su poznate prave distribucije, sistematska greška može se izjednačiti uvođenjem kvota ili ponovnim ponderisanjem podataka, ali u većini stvarnih studija čak i njegova procjena može biti prilično problematična.
Tipovi uzoraka
Uzorci su podijeljeni u dvije vrste:
vjerovatnoća
nevjerovatnost
Uzorci vjerovatnoće
1.1 Slučajno uzorkovanje (jednostavan slučajni odabir)
Takav uzorak pretpostavlja homogenost opšte populacije, istu vjerovatnoću dostupnosti svih elemenata, prisutnost kompletna lista svi elementi. Prilikom odabira elemenata, u pravilu se koristi tabela slučajnih brojeva.
1.2 Mehaničko (sistematsko) uzorkovanje
Neka vrsta slučajnog uzorka, sortiranog po nekom atributu (abecedni red, broj telefona, datum rođenja, itd.). Prvi element se bira nasumično, zatim svaki 'k'-ti element se bira u koracima od 'n'. Veličina opšte populacije, dok je - N=n*k
1.3 Stratificirano (zonirano)
Koristi se u slučaju heterogenosti opšte populacije. Opća populacija je podijeljena na grupe (stratume). U svakom stratumu selekcija se vrši nasumično ili mehanički.
1.4 Serijsko (ugniježđeno ili grupisano) uzorkovanje
Kod serijskog uzorkovanja, jedinice selekcije nisu sami objekti, već grupe (klasteri ili gnijezda). Grupe se biraju nasumično. Objekti unutar grupa se pregledavaju posvuda.
Incredible Samples
Odabir u takvom uzorku se ne vrši po principu slučajnosti, već prema subjektivnim kriterijima - dostupnosti, tipičnosti, ravnopravnoj zastupljenosti itd.
Uzorkovanje kvota
U početku se dodjeljuje određeni broj grupa objekata (na primjer, muškarci u dobi od 20-30 godina, 31-45 godina i 46-60 godina; osobe s prihodom do 30 hiljada rubalja, s prihodom od 30 do 60 godina). hiljada rubalja i sa prihodom većim od 60 hiljada rubalja ) Za svaku grupu naveden je broj objekata koji se ispituju. Broj objekata koji treba da spadaju u svaku od grupa određuje se, najčešće, ili proporcionalno ranije poznatom udelu grupe u opštoj populaciji, ili isti za svaku grupu. Unutar grupa, objekti se biraju nasumično. Uzorci kvota se često koriste u marketinškim istraživanjima.
Snowball Method
Uzorak je konstruiran na sljedeći način. Od svakog ispitanika, počevši od prvog, traži se da kontaktira svoje prijatelje, kolege, poznanike koji bi odgovarali uslovima selekcije i koji bi mogli učestvovati u istraživanju. Dakle, sa izuzetkom prvog koraka, uzorak se formira uz učešće samih objekata proučavanja. Metoda se često koristi kada je potrebno pronaći i intervjuisati teško dostupne grupe ispitanika (npr. ispitanici sa visokim primanjima, ispitanici koji pripadaju istoj profesionalnoj grupi, ispitanici koji imaju slične hobije/strasti, itd. )
2.3 Spontano uzorkovanje
Anketirani su najpristupačniji ispitanici. Tipični primjeri nasumični uzorci - ankete u novinama/časopisima, upitnici koji se daju ispitanicima na samostalno popunjavanje, većina internet anketa. Veličina i sastav spontanih uzoraka nije unaprijed poznat, a određen je samo jednim parametrom – aktivnošću ispitanika.
2.4 Uzorak tipičnih slučajeva
Odabiru se jedinice opće populacije koje imaju prosječnu (tipičnu) vrijednost atributa. Ovo otvara problem odabira karakteristike i određivanja njene tipične vrijednosti.
Implementacija plana istraživanja
Ova faza, podsjećamo, uključuje prikupljanje informacija i njihovu analizu. Proces implementacije plana marketinškog istraživanja obično zahtijeva najviše istraživanja i izvor je najveće greške.
Prilikom prikupljanja statističkih podataka javlja se niz nedostataka i problema:
prvo, neki ispitanici možda nisu na dogovorenom mjestu i moraju ih se ponovo kontaktirati ili zamijeniti;
drugo, neki ispitanici mogu biti nekooperativni ili davati pristrasne, svjesno lažne odgovore.
Zahvaljujući savremenim računarskim i telekomunikacionim tehnologijama, metode prikupljanja podataka se razvijaju i unapređuju.
Neke firme sprovode ankete iz jednog centra. U ovom slučaju, profesionalni anketari sjede u uredima i biraju nasumične telefonske brojeve. Ako čuju odgovor pozivatelja, anketar traži od osobe koja se javila na telefon da odgovori na nekoliko pitanja. Potonji se čitaju sa ekrana kompjuterskog monitora, a odgovori ispitanika se kucaju na tastaturi. Ova metoda eliminira potrebu za formatiranjem i kodiranjem podataka, smanjuje broj grešaka.
 Ujak Vanja radnja drame. „Ujka Ivane. Odnos prema profesoru drugih
Ujak Vanja radnja drame. „Ujka Ivane. Odnos prema profesoru drugih Mali Tsakhes, nadimak Zinnober
Mali Tsakhes, nadimak Zinnober Maikov, Apolon Nikolajevič - kratka biografija
Maikov, Apolon Nikolajevič - kratka biografija