Що таке вибіркова сукупність у статистиці | Більше - не завжди краще
Для визначення ймовірностей цікавих для нас подій ми застосовуємо вибірковий метод: проводимо nнезалежних експериментів, у кожному з яких може статися (або не відбутися) подія А (імовірність рПоява події А в кожному експерименті постійна). Тоді відносна частота p* появи подій Ау серії з nвипробувань приймається як точкова оцінка для ймовірності pпояви події Ау окремому випробуванні. У цьому величину p* називають вибірковою часткою появи події А, а р - генеральною часткою .
Внаслідок слідства з центральної граничної теореми (теорема Муавра-Лапласа) відносну частоту події при великому обсязі вибірки можна вважати нормально розподіленою з параметрами M(p*)=p
Тому за n>30 довірчий інтервал для генеральної частки можна побудувати, використовуючи формули:
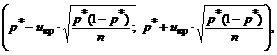
де u кр знаходиться за таблицями функції Лапласа з урахуванням заданої вірогідності γ: 2Ф(u кр)=γ.
При малому обсязі вибірки n≤30 гранична помилка ε визначається за таблицею розподілу Стьюдента: ![]() де t кр =t(k; α) та число ступенів свободи k=n-1 ймовірність α=1-γ (двостороння область).
де t кр =t(k; α) та число ступенів свободи k=n-1 ймовірність α=1-γ (двостороння область).
Формули справедливі, якщо відбір проводився випадковим повторним чином (генеральна сукупність нескінченна), інакше необхідно зробити виправлення на безповторність відбору (таблиця).
Середня помилка вибірки для генеральної частки
| Генеральна сукупність | Нескінченна | Кінцева обсягу N |
| Тип відбору | Повторний | Неповторний |
| Середня помилка вибірки |
Формули розрахунку чисельності вибірки при власне-випадковому способі відбору
| Спосіб відбору | Формули визначення чисельності вибірки | ||
| для середньої | для частки | ||
| Повторний | |||
| Неповторний | |||
Завдання про генеральну частку
На запитання «Чи накриває довірчий інтервал задане значення p 0?» - можна відповісти, перевіривши статистичну гіпотезу H0:p=p0. При цьому передбачається, що досліди проводяться за схемою випробувань Бернуллі (незалежні, ймовірність pпояви події Апостійна). За вибіркою обсягу nвизначають відносну частоту p* появи події A: де m- кількість появи події Ау серії з nвипробувань. Для перевірки гіпотези H 0 використовується статистика, що має при досить великому обсязі вибірки стандартний нормальний розподіл (табл. 1).Таблиця 1 – Гіпотези про генеральну частку
Гіпотеза | H 0: p = p 0 | H 0: p 1 = p 2 |
| Припущення | Схема випробувань Бернуллі | Схема випробувань Бернуллі |
| Оцінки за вибіркою | 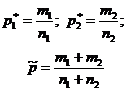 |
|
| Статистика K | 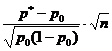 |  |
| Розподіл статистики K | Стандартне нормальне N(0,1) |
Приклад №1. За допомогою випадкового повторного відбору керівництво фірми провело опитування 900 своїх службовців. Серед опитаних виявилося 270 жінок. Побудуйте довірчий інтервал, що з ймовірністю 0.95 накриває справжню частку жінок у всьому колективі фірми.
Рішення. За умовою вибіркова частка жінок становить (відносна частота жінок серед усіх опитаних). Оскільки відбір є повторним, обсяг вибірки великий (n=900) гранична помилка вибірки визначається за формулою ![]()
Значення u кр знаходимо таблиці функції Лапласа із співвідношення 2Ф(u кр)=γ, тобто. ![]() Функція Лапласа (додаток 1) набуває значення 0.475 при u кр = 1.96. Отже, гранична помилка
Функція Лапласа (додаток 1) набуває значення 0.475 при u кр = 1.96. Отже, гранична помилка ![]() та шуканий довірчий інтервал
та шуканий довірчий інтервал
(p - ε, p + ε) = (0.3 - 0.18; 0.3 + 0.18) = (0.12; 0.48)
Отже, з ймовірністю 0.95 можна гарантувати, частка жінок у всьому колективі фірми перебуває у інтервалі від 0.12 до 0.48.
Приклад №2. Власник автостоянки вважає день «вдалим», якщо автостоянка заповнена більш ніж на 80%. Протягом року було проведено 40 перевірок автостоянки, з яких 24 виявилися «вдалими». З ймовірністю 0.98 знайдіть довірчий інтервал для оцінки справжньої частки "вдалих" днів протягом року.
Рішення. Вибіркова частка «вдалих» днів складає
За таблицею функції Лапласа знайдемо значення u кр за заданої
довірчої ймовірності
Ф(2.23) = 0.49, u кр = 2.33.
Вважаючи відбір безповторним (тобто дві перевірки одного дня не проводилося), знайдемо граничну помилку: ![]()
де n = 40, N = 365 (днів). Звідси ![]()
та довірчий інтервал для генеральної частки: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
З ймовірністю 0.98 очікується, що частка «вдалих» днів протягом року перебуває в інтервалі від 0.43 до 0.77.
Приклад №3. Перевіривши 2500 виробів у партії, виявили, що 400 виробів вищого ґатунку, а n-m – ні. Скільки треба перевірити виробів, щоб із впевненістю 95% визначити частку вищого ґатунку з точністю до 0.01?
Рішення шукаємо за формулою визначення чисельності вибірки для повторного відбору.
Ф(t) = γ/2 = 0.95/2 = 0.475 і цьому значенню за таблицею Лапласа відповідає t=1.96
Вибіркова частка w = 0.16; помилка вибірки ε = 0.01
Приклад №4. Партія виробів приймається, якщо ймовірність того, що виріб виявиться таким, що відповідає стандарту, становить не менше 0.97. Серед випадково відібраних 200 виробів партії, що перевіряється, виявилося 193 відповідних стандарту. Чи можна на рівні значення α=0,02 прийняти партію?
Рішення. Сформулюємо основну та альтернативну гіпотези.
H 0: p = p 0 = 0,97 - невідома генеральна частка pдорівнює заданому значенню p 0 = 0,97. Щодо умови - ймовірність того, що деталь з партії, що перевіряється, виявиться відповідною стандарту, дорівнює 0.97; тобто. партію виробів можна прийняти.
H 1: p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Спостережуване значення статистики K(Таблиця) обчислимо при заданих значеннях p 0 =0,97, n=200, m=193
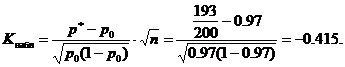
Критичне значення знаходимо за таблицею функції Лапласа з рівності
![]()
За умовою α=0,02 звідси Ф(Ккр)=0,48 і Ккр=2,05. Критична область лівостороння, тобто. є інтервалом (-∞; -K kp) = (-∞; -2,05). Спостережуване значення К набл =-0,415 належить критичної області, отже, цьому рівні значимості немає підстав відхиляти основну гіпотезу. Партію виробів можна прийняти.
Приклад №5. Два заводи виготовляють однотипні деталі. Для оцінки їх якості зроблено вибірки з продукції цих заводів та отримано такі результати. Серед 200 відібраних виробів першого заводу виявилося 20 бракованих, серед 300 виробів другого заводу – 15 бракованих.
На рівні значимості 0.025 з'ясувати, чи є істотна відмінність як деталі, що виготовляються цими заводами.
За умовою α=0,025 звідси Ф(Ккр)=0,4875 і Ккр=2,24. При двосторонній альтернативі область допустимих значень має вигляд (-2,24; 2,24). Спостережуване значення K набл =2,15 потрапляє у цей інтервал, тобто. цьому рівні значимості немає підстав відкидати основну гіпотезу. Заводи виготовляють вироби однакової якості.
Вибірка
Вибіркаабо вибіркова сукупність- безліч випадків (випробуваних, об'єктів, подій, зразків), за допомогою певної процедури обраних із генеральної сукупності для участі у дослідженні.
Характеристики вибірки:
- Якісна характеристика вибірки – кого саме ми вибираємо та які способи побудови вибірки ми для цього використовуємо.
- Кількісна характеристика вибірки – скільки випадків вибираємо, тобто обсяг вибірки.
Необхідність вибірки
- Об'єкт дослідження дуже великий. Наприклад, споживачі продукції глобальної компанії – величезна кількість територіально розкиданих ринків.
- Існує потреба у зборі первинної інформації.
Обсяг вибірки
Обсяг вибірки- Число випадків, включених у вибіркову сукупність. Зі статистичних міркувань рекомендується, щоб кількість випадків становила не менше 30-35.
Залежні та незалежні вибірки
При порівнянні двох (і більше) вибірок важливим параметром є їхня залежність. Якщо можна встановити гомоморфну пару (тобто коли одному випадку з вибірки X відповідає один і тільки один випадок з вибірки Y і навпаки) для кожного випадку у двох вибірках (і ця підстава взаємозв'язку є важливою для вимірюваної на вибірках ознаки), такі вибірки називаються залежними. Приклади залежних вибірок:
- пари близнюків,
- два виміри будь-якої ознаки до і після експериментального впливу,
- чоловіки та дружини
- і т.п.
Якщо такий взаємозв'язок між вибірками відсутня, то ці вибірки вважаються незалежними, наприклад:
Відповідно, залежні вибірки мають однаковий обсяг, а обсяг незалежних може відрізнятися.
Порівняння вибірок здійснюється за допомогою різних статистичних критеріїв:
- та ін.
Репрезентативність
Вибірка може розглядатися як репрезентативна або нерепрезентативна.
Приклад нерепрезентативної вибірки
- Дослідження з експериментальною та контрольною групами, які ставляться у різні умови.
- Дослідження з експериментальною та контрольною групами із залученням стратегії попарного відбору
- Дослідження з використанням лише однієї групи – експериментальної.
- Дослідження з використанням змішаного (факторного) плану – всі групи ставляться у різні умови.
Типи вибірки
Вибірки поділяються на два типи:
- імовірнісні
- неймовірні
Імовірнісні вибірки
- Проста ймовірнісна вибірка:
- Проста повторна вибірка. Використання такої вибірки ґрунтується на припущенні, що кожен респондент з часткою ймовірності може потрапити у вибірку. За підсумками списку генеральної сукупності складаються картки з номерами респондентів. Вони поміщаються в колоду, перемішуються і їх навмання виймається картка, записується номер, потім повертається назад. Далі процедура повторюється стільки разів, який обсяг вибірки нам необхідний. Мінус: повторення одиниць відбору.
Процедура побудови простої випадкової вибірки включає наступні кроки:
1. необхідно отримати повний список членів генеральної сукупності та пронумерувати цей список. Такий список, нагадаємо, називається основою вибірки;
2. визначити очікуваний обсяг вибірки, тобто очікуване число опитаних;
3. Витягти з таблиці випадкових чисел стільки чисел, скільки нам потрібно вибіркових одиниць. Якщо у вибірці має бути 100 людина, з таблиці беруть 100 випадкових чисел. Ці випадкові числа можуть генеруватись комп'ютерною програмою.
4. вибрати зі списку-основи спостереження, номери яких відповідають виписаним випадковим числам
- Проста випадкова вибірка має очевидні переваги. Цей метод дуже простий для розуміння. Результати дослідження можна поширювати на сукупність, що вивчається. Більшість підходів до отримання статистичних висновків передбачають збирання інформації за допомогою простої випадкової вибірки. Однак метод простої випадкової вибірки має як мінімум чотири суттєві обмеження:
1. часто складно створити основу вибіркового спостереження, яка б провести просту випадкову вибірку.
2. результатом застосування простої випадкової вибірки може стати більша сукупність, або сукупність, розподілена на великій географічній території, що значно збільшує час і вартість збору даних.
3. результати застосування простої випадкової вибірки часто характеризуються низькою точністю та більшою стандартною помилкою, ніж результати застосування інших ймовірнісних методів.
4. в результаті застосування SRS може сформуватися нерепрезентативна вибірка. Хоча вибірки, отримані простим випадковим відбором, в середньому адекватно представляють генеральну сукупність, деякі з них вкрай некоректно представляють сукупність, що вивчається. Імовірність цього особливо велика за невеликого обсягу вибірки.
- Проста неповторна вибірка. Процедура побудови вибірки така сама, тільки картки з номерами респондентів не повертаються назад у колоду.
- Систематична імовірнісна вибірка. Є спрощеним варіантом простої імовірнісної вибірки. За підсумками списку генеральної сукупності через певний інтервал (К) відбираються респонденти. Розмір До визначається випадково. Найбільш достовірний результат досягається при однорідній генеральній сукупності, інакше можливі збіг величини кроку та якихось внутрішніх циклічних закономірностей вибірки (змішування вибірки). Мінуси: такі ж, як і в простій імовірнісній вибірці.
- Серійна (гніздова) вибірка. Одиниці відбору є статистичні серії (сім'я, школа, бригада тощо). Відібрані елементи зазнають суцільного обстеження. Відбір статистичних одиниць може бути організований на кшталт випадкової чи систематичної вибірки. Мінус: Можливість більшої однорідності, ніж у генеральній сукупності.
- Районована вибірка. У разі неоднорідної генеральної сукупності, перш ніж використовувати ймовірнісну вибірку з будь-якою технікою відбору, рекомендується розділити генеральну сукупність на однорідні частини, така вибірка називається районованою. Групами районування можуть бути як природні освіти (наприклад, райони міста), і будь-який ознака, закладений основою дослідження. Ознака, на основі якої здійснюється поділ, називається ознакою розшарування та районування.
- «Зручна» вибірка. Процедура «зручної» вибірки полягає у встановленні контактів із «зручними» одиницями вибірки – з групою студентів, спортивною командою, з друзями та сусідами. Якщо необхідно отримати інформацію про реакцію людей на нову концепцію, така вибірка цілком обґрунтована. «Зручну» вибірку часто використовують із попереднього тестування анкет.
Неймовірні вибірки
Відбір у такій вибірці здійснюється за принципами випадковості, а, по суб'єктивним критеріям – доступності, типовості, рівного представництва тощо.
- Квотна вибірка – вибірка будується як модель, яка відтворює структуру генеральної сукупності як квот (пропорцій) досліджуваних ознак. Число елементів вибірки з різним поєднанням ознак, що вивчаються, визначається з таким розрахунком, щоб воно відповідало їх частці (пропорції) в генеральній сукупності. Так, наприклад, якщо генеральна сукупність у нас представлена 5000 чоловік, з них 2000 жінок та 3000 чоловіків, тоді у квотній вибірці у нас будуть 20 жінок та 30 чоловіків, або 200 жінок та 300 чоловіків. Квотовані вибірки найчастіше ґрунтуються на демографічних умовах: стать, вік, регіон, дохід, освіта та інші. Мінуси: зазвичай такі вибірки нерепрезентативні, т.к. не можна врахувати відразу кілька соціальних параметрів. Плюси: доступний матеріал.
- Спосіб снігового кома. Вибірка будується в такий спосіб. У кожного респондента, починаючи з першого, просяться контакти його друзів, колег, знайомих, які б підходили під умови відбору і могли б взяти участь у дослідженні. Отже, крім першого кроку, вибірка формується з участю самих об'єктів дослідження. Метод часто застосовується, коли необхідно знайти та опитати важкодоступні групи респондентів (наприклад, респондентів, які мають високий дохід, респондентів, що належать до однієї професійної групи, респондентів, які мають схожі хобі/захоплення тощо)
- Стихійна вибірка - вибірка так званого "першого зустрічного". Часто використовується в теле- та радіоопитуваннях. Розмір та склад стихійних вибірок заздалегідь не відомий, і визначається лише одним параметром – активністю респондентів. Мінуси: неможливо встановити якусь генеральну сукупність представляють опитані, і як наслідок – неможливість визначити репрезентативність.
- Маршрутне опитування часто використовується, якщо одиницею вивчення є сім'я. На карті населеного пункту, в якому опитуватиметься, нумеруються всі вулиці. З допомогою таблиці (генератора) випадкових чисел відбираються великі числа. Кожне велике число розглядається як 3-х компонентів: номер вулиці (2-3 перших числа), номер будинку, номер квартири. Наприклад, число 14832: 14 – це номер вулиці на карті, 8 – номер будинку, 32 – номер квартири.
- Районована вибірка із відбором типових об'єктів. Якщо після районування кожної групи відбирається типовий об'єкт, тобто. об'єкт, який переважно досліджуваних у дослідженні показників наближається до середніх показників, така вибірка називається районованої з відбором типових об'єктів.
6.Модальна вибірка. 7. Експертна вибірка. 8. Гетерогенна вибірка.
Стратегії побудови груп
Відбір груп для їхньої участі в психологічному експерименті здійснюється за допомогою різних стратегій, які потрібні для того, щоб забезпечити максимально можливе дотримання внутрішньої та зовнішньої валідності.
Рандомізація
Рандомізація, або випадковий відбірвикористовується для створення простих випадкових вибірок. Використання такої вибірки ґрунтується на припущенні, що кожен член популяції з рівною ймовірністю може потрапити у вибірку. Наприклад, щоб зробити випадкову вибірку зі 100 студентів вузу, можна скласти папірці з іменами всіх студентів вузу в капелюх, а потім дістати з нього 100 папірців - це буде випадковим відбором (Гудвін Дж., с. 147).
Попарний відбір
Попарний відбір- стратегія побудови груп вибірки, у якому групи піддослідних складаються з суб'єктів, еквівалентних за значними експерименту побічним параметрам. Ця стратегія ефективна для експериментів з використанням експериментальних та контрольних груп з кращим варіантом - залученням близнюкових пар (моно- та дизиготних), оскільки дозволяє створити...
Стратометричний відбір
Стратометричний відбір- рандомізація із виділенням страт (чи кластерів). При даному способі формування вибірки генеральна сукупність ділиться на групи (страти), що мають певні характеристики (стаття, вік, політичні переваги, освіта, рівень доходів та ін), і відбираються піддослідні з відповідними характеристиками.
Наближене моделювання
Наближене моделювання- Складання обмежених вибірок та узагальнення висновків про цю вибірку на ширшу популяцію. Наприклад, за участю у дослідженні студентів 2-го курсу університету дані цього дослідження поширюються на «людей віком від 17 до 21 року». Допустимість подібних узагальнень вкрай обмежена.
Наближене моделювання – формування моделі, яка чітко обумовленого класу систем (процесів) визначає його поведінка (чи необхідні явища) з прийнятною точністю.
Примітки
Література
Наслідів А. Д.Математичні методи психологічного дослідження. - СПб.: Мова, 2004.
- Ільясов Ф. Н. Репрезентативність результатів опитування у маркетинговому дослідженні // Соціологічні дослідження. 2011. № 3. С. 112-116.
Див. також
- У деяких типах досліджень вибірку ділять на групи:
- експериментальна
- контрольна
- Когорта
Посилання
- Концепція вибірки. Основні характеристики вибірки. Типи вибірки
Wikimedia Foundation. 2010 .
Синоніми:Дивитись що таке "Вибірка" в інших словниках:
вибірка- група піддослідних, які мають певну популяцію і відібраних для експерименту чи дослідження. Протилежне поняття - сукупність генеральна. Вибірка є частиною сукупності генеральної. Словник практичного психолога. М: АСТ, … … Велика психологічна енциклопедія
вибірка- Вибірка Частина генеральної сукупності елементів, яка охоплюється спостереженням (часто її називають вибірковою сукупністю, а вибіркою - сам метод вибіркового спостереження). У математичній статистиці прийнято… Довідник технічного перекладача
- (sample) 1. Невелика кількість товару, відібрана, щоб представляти всю його кількість. Див: продаж за зразком (sale by sample). 2. Невелика кількість товару, передана потенційним покупцям, щоб дати їм можливість провести його. Словник бізнес-термінів
Вибірка- Частина генеральної сукупності елементів, яка охоплюється спостереженням (часто її називають вибірковою сукупністю, а вибіркою сам метод вибіркового спостереження). У математичній статистиці прийнято принцип випадкового відбору; це… … Економіко-математичний словник
- (sample) Довільний відбір підгрупи елементів з основної сукупності, характеристики яких використовуються з метою оцінки всієї сукупності загалом. Вибірковий метод використовується, коли занадто довго чи надто дорого обстежити всю сукупність … Економічний словник
Див … Словник синонімів
Статистичні дослідження дуже трудомісткі та дорогі, тому виникла думка про заміну суцільного спостереження вибірковим.
Основна мета несплошного спостереження полягає у отриманні характеристик вивчається статистичної сукупності по обстеженої її частини.
Вибіркове спостереження– це метод статистичного дослідження, у якому узагальнюючі показники сукупності встановлюються лише з окремо взятої частини з урахуванням положень випадкового добору.
При вибірковому методі вивченню піддається лише деяка частина досліджуваної сукупності, у своїй підлягає вивченню статистична сукупність називається генеральної сукупністю.
Вибірковою сукупністю або просто вибіркою можна називати відібрану з генеральної сукупності частину одиниць, яка піддаватиметься статистичному дослідженню.
Значення вибіркового методу: при мінімальній чисельності досліджуваних одиниць проведення статистичного дослідження відбуватиметься у більш короткі проміжки часу та з найменшими витратами коштів та праці.
У генеральній сукупності частка одиниць, яка володіє ознакою, що вивчається, називається генеральною часткою (позначається р),а середня величина досліджуваного ознаки, що варіює, - це генеральна середня (позначається х).
У вибірковій сукупності частку ознаки, що вивчається, називають вибірковою часткою, або частиною (позначається w), середня величина у вибірці - це вибіркова середня.
Якщо під час обстеження будуть дотримані правила його наукової організації, то вибірковий метод дасть досить точні результати, і тому цей метод доцільно застосовувати перевірки даних суцільного спостереження.
Цей метод набув широкого поширення в державній та позавідомчій статистиці, тому що при дослідженні мінімальної чисельності одиниць, що вивчаються, дозволяє ретельно і точно провести дослідження.
Статистична сукупність, що вивчається, складається з одиниць з варіюючими ознаками. Склад вибіркової сукупності може відрізнятись від складу генеральної сукупності, ця розбіжність між характеристиками вибірки та генеральної сукупності становить помилку вибірки.
Помилки, властиві вибірковому спостереженню, характеризують розмір розбіжності між даними вибіркового спостереження та всієї сукупності. Помилки, що виникають у ході вибіркового спостереження, називаються помилками репрезентативності та поділяються на випадкові та систематичні.
Якщо вибіркова сукупність недостатньо точно відтворює всю сукупність через несуцільний характер спостереження, це називають випадковими помилками, та його розміри визначаються з достатньої точністю виходячи з закону великих чисел і теорії ймовірностей.
Систематичні помилки виникають у результаті порушення принципу випадковості відбору одиниць сукупності спостереження.
2. Види та схеми відбору
Розмір помилки вибірки та методи її визначення залежать від виду та схеми відбору.
Розрізняють чотири види відбору сукупності одиниць спостереження:
1) випадковий;
2) механічний;
3) типовий;
4) серійний (гніздовий).
Випадковий відбір- Найпоширеніший спосіб відбору у випадковій вибірці, його ще називають методом жеребкування, при ньому на кожну одиницю статистичної сукупності заготовляється квиток із порядковим номером.
Далі у випадковому порядку відбирається необхідну кількість одиниць статистичної сукупності. За цих умов кожна з них має однакову ймовірність потрапити у вибірку, наприклад, тиражі виграшів, коли із загальної кількості випущених квитків у випадковому порядку навмання відбирається певна частина номерів, на які припадають виграші. При цьому всім номерам забезпечується можливість потрапити у вибірку.
Механічний відбір- це спосіб, коли вся сукупність розбивається на однорідні за обсягом групи за випадковою ознакою, потім з кожної групи береться тільки одна одиниця. .
Типовий відбірце спосіб, при якому досліджувана статистична сукупність розбивається за істотною, типовою ознакою якісно однорідні, однотипні групи, потім з кожної цієї групи випадковим способом відбирається певна кількість одиниць, пропорційне питомій вазі групи у всій сукупності.
Типовий відбір дає більш точні результати, оскільки за нього у вибірку потрапляють представники всіх типових груп.
Серійний (гніздовий) відбір.Добору підлягають цілі групи (серії, гнізда), відібрані випадковим чи механічним способом. За кожною такою групою серії проводиться суцільне спостереження, а результати переносяться на всю сукупність.
Точність вибірки залежить від схеми відбору. Вибірка може бути проведена за схемою повторного та безповторного відбору.
Повторний вибір.Кожна відібрана одиниця або серія повертається на всю сукупність і може знову потрапити у вибірку. Це так звана схема повернутої кулі.
Неповторний відбір.Кожна обстежена одиниця вилучається і повертається у сукупність, тому вона потрапляє у повторне обстеження. Ця схема отримала назву неповернутої кулі.
Безповторний відбір дає більш точні результати, тому що при тому самому обсязі вибірки спостереження охоплює більшу кількість одиниць сукупності, що вивчається.
Комбінований відбірможе проходити один або кілька ступенів. Вибірка називається одноступеневою, якщо відібрані одиниці одиниці сукупності піддаються вивченню.
Вибірка називається багатоступінчастою, якщо відбір сукупності проходить щаблями, послідовним стадіям, причому кожен ступінь, стадія відбору має власну одиницю відбору.
Багатофазна вибірка – на всіх щаблях вибірки зберігається та сама одиниця відбору, але проводиться кілька стадій, фаз вибіркових обстежень, які різняться між собою широтою програми обстеження та обсягом вибірки.
Характеристики параметрів генеральної та вибіркової сукупностей позначаються такими символами:
N- Обсяг генеральної сукупності;
n- Обсяг вибірки;
X- Генеральна середня;
х- Вибіркова середня;
р- Генеральна частка;
w –вибіркова частка;
2 – генеральна дисперсія (дисперсія ознаки у генеральній сукупності);
2 – вибіркова дисперсія тієї самої ознаки;
? - Середнє квадратичне відхилення в генеральній сукупності;
? - Середнє квадратичне відхилення у вибірці.
3. Помилки вибірки
Кожна одиниця при вибірковому спостереженні повинна мати рівну коїться з іншими можливість бути відібраною – це є основою власновипадкової вибірки.
Власневипадкова вибірка - Це відбір одиниць з усієї генеральної сукупності за допомогою жеребкування або іншим способом.
Принципом випадковості і те, що у включення чи виключення об'єкта з вибірки неспроможна вплинути будь-який чинник, крім випадку.
Частка вибірки– це відношення числа одиниць вибіркової сукупності до одиниць генеральної сукупності:
Власневипадковий відбір у чистому вигляді є вихідним серед інших видів відбору, у ньому полягають і реалізуються основні засади вибіркового статистичного спостереження.
Два основні види узагальнюючих показників, які використовують у вибірковому методі – це середня величина кількісної ознаки та відносна величина альтернативної ознаки.
Вибіркова частка (w), або зокрема, визначається ставленням числа одиниць, що володіють ознакою, що вивчається m,до загального числа одиниць вибіркової сукупності (n):
Для характеристики надійності вибіркових показників розрізняють середню та граничну помилки вибірки.
Помилка вибірки, її ще називають помилкою репрезентативності, є різницею відповідних вибіркових і генеральних характеристик:
?х = | х - х |;
?w = | х - p |.
Тільки вибірковим спостереженням властива помилка вибірки
Вибіркова середня та вибіркова частка- Це випадкові величини, що приймають різні значення в залежності від одиниць статистичної сукупності, що вивчається, які потрапили у вибірку. Відповідно помилки вибірки – теж випадкові величини і можуть приймати різні значення. Тому визначають середню із можливих помилок – середню помилку вибірки.
Середня помилка вибірки визначається обсягом вибірки: що більше чисельність за інших рівних умов, то менше величина середньої помилки вибірки. Охоплюючи вибірковим обстеженням дедалі більше одиниць генеральної сукупності, дедалі точніше характеризуємо всю генеральну сукупність.
Середня помилка вибірки залежить від ступеня варіювання ознаки, що вивчається, у свою чергу ступінь варіювання характеризується дисперсією? 2 або w(l – w)- Для альтернативної ознаки. Чим менша варіація ознаки та дисперсія, тим менша середня помилка вибірки, і навпаки.
При випадковому повторному відборі середні помилки розраховують теоретично за такими формулами:
1) для середньої кількісної ознаки:
де? 2 – середня величина дисперсії кількісної ознаки.
2) для частки (альтернативної ознаки):
Так як дисперсія ознаки у генеральній сукупності? 2 точно невідома, практично користуються значенням дисперсії S 2 , розрахованим для вибіркової сукупності виходячи з закону великих чисел, за яким вибіркова сукупність за досить великому обсязі вибірки досить точно відтворює характеристики генеральної сукупності.
Формули середньої помилки вибірки при випадковому повторному відборі такі. Для середньої величини кількісної ознаки: генеральна дисперсія виражається через виборну наступним співвідношенням:
де S2 – значення дисперсії.
Механічна вибірка- Це відбір одиниць у вибіркову сукупність з генеральної, яка розбита за нейтральною ознакою на рівні групи; виробляється так, що з кожної такої групи вибірку відбирається лише одна одиниця.
При механічному відборі одиниці досліджуваної статистичної сукупності попередньо розташовують у порядку, після чого відбирають задане число одиниць механічно через певний інтервал. У цьому розмір інтервалу у генеральній сукупності дорівнює зворотному значенню частки вибірки.
При досить великій сукупності механічний відбір за точністю результатів близький до власневипадкового Тому визначення середньої помилки механічної вибірки використовують формули власневипадкової безповторної вибірки.
Для відбору одиниць з неоднорідної сукупності застосовується так звана типова вибірка, що використовується, коли всі одиниці генеральної сукупності можна розбити на кілька якісно однорідних, однотипних груп за ознаками, від яких залежать показники, що вивчаються.
Потім із кожної типової групи власневипадковою або механічною вибіркою проводиться індивідуальний відбір одиниць у вибіркову сукупність.
Типова вибірка зазвичай застосовується щодо складних статистичних сукупностей.
Типова вибірка дає точніші результати. Типізація генеральної сукупності забезпечує репрезентативність такої вибірки, представництво у ній кожної типологічної групи, що дозволяє виключити вплив міжгрупової дисперсії на середню помилку вибірки. Тому при визначенні середньої помилки типової вибірки як показник варіації виступає середня з внутрішньогрупових дисперсій.
Серійна вибірка передбачає випадковий відбір із генеральної сукупності рівновеликих груп у тому, щоб у таких групах піддавати спостереженню все без винятку одиниці.
Оскільки всередині груп (серій) обстежуються всі без винятку одиниці, середня помилка вибірки (при відборі рівновеликих серій) залежить від міжгрупової (міжсерійної) дисперсії.
4. Способи поширення вибіркових результатів на генеральну сукупність
Характеристика генеральної сукупності з урахуванням вибіркових результатів – це кінцева мета вибіркового спостереження.
Вибірковий метод застосовується отримання характеристик генеральної сукупності за певними показниками вибірки. Залежно від цілей дослідження це здійснюється прямим перерахуванням показників вибірки для генеральної сукупності або шляхом розрахунку поправочних коефіцієнтів.
Спосіб прямого перерахунку в тому, що за нього показники вибіркової частки wабо середньої хпоширюються генеральну сукупність з урахуванням помилки вибірки.
Спосіб поправних коефіцієнтів застосовується, коли метою вибіркового методу є уточнення результатів суцільного обліку. Цей спосіб використовується при уточненні даних щорічних переписів худоби у населення.
План:
1. Завдання математичної статистики.
2. Види вибірок.
3. Методи відбору.
4. Статистичне розподілення вибірки.
5. Емпірична функція розподілу.
6. Полігон та гістограма.
7. Числові характеристики варіаційного ряду.
8. Статистичні оцінки параметрів розподілу.
9. Інтервальні оцінки параметрів розподілу.
1. Завдання та методи математичної статистики
Математична статистика - це розділ математики, присвячений методам збору, аналізу та обробки результатів статистичних даних спостережень для наукових та практичних цілей.
Нехай потрібно вивчити сукупність однорідних об'єктів щодо деякої якісної чи кількісної ознаки, що характеризує ці об'єкти. Наприклад, якщо є партія деталей, то якісною ознакою може бути стандартність деталі, а кількісним- контрольований розмір деталі.
Іноді проводять суцільне дослідження, тобто. обстежують кожен об'єкт щодо необхідної ознаки. Насправді суцільне обстеження застосовується рідко. Наприклад, якщо сукупність містить дуже багато об'єктів, то провести суцільне обстеження фізично неможливо. Якщо обстеження об'єкта пов'язані з його знищенням чи потребують великих матеріальних витрат, проводити суцільне обстеження немає сенсу. У таких випадках випадково відбирають із усієї сукупності обмежену кількість об'єктів (вибіркову сукупність) і піддають їх вивченню.
Основне завдання математичної статистики полягає у дослідженні всієї сукупності за вибірковими даними залежно від поставленої мети, тобто. вивчення імовірнісних властивостей сукупності: закону розподілу, числових характеристик тощо. для ухвалення управлінських рішень в умовах невизначеності.
2. Види вибірок
Генеральна сукупність - Це сукупність об'єктів, з якої проводиться вибірка.
Вибіркова сукупність (вибірка) - Це сукупність випадково відібраних об'єктів.
Обсяг сукупності - Це кількість об'єктів цієї сукупності. Обсяг генеральної сукупності позначається N, вибірковою - n.
Приклад:
Якщо з 1000 деталей відібрано для обстеження 100 деталей, обсяг генеральної сукупності N = 1000, а обсяг вибірки n = 100.
При складанні вибірки можна надійти двома способами: після того, як об'єкт відібраний і над ним зроблено спостереження, він може бути повернутий або не повернутий у генеральну сукупність. Т.о. вибірки поділяються на повторні та безповторні.
Повторнийназивають вибірку, коли відібраний об'єкт (перед відбором наступного) повертається у генеральну сукупність.
Безповторнийназивають вибірку, коли відібраний об'єкт у генеральну сукупність не повертається.
Насправді зазвичай користуються безповторним випадковим добором.
Для того, щоб за даними вибірки можна було досить впевнено судити про ознаку генеральної сукупності, що цікавить, необхідно, щоб об'єкти вибірки правильно його представляли. Вибірка має правильно представляти пропорції генеральної сукупності. Вибірка має бути репрезентативної (представницької).
Через закон великих чисел можна стверджувати, що вибірка буде репрезентативною, якщо її здійснювати випадково.
Якщо обсяг генеральної сукупності досить великий, а вибірка становить лише незначну частину цієї сукупності, то різницю між повторної і безповторної вибірками стирається; в граничному випадку, коли розглядається нескінченна генеральна сукупність, а вибірка має кінцевий обсяг, ця різниця зникає.
Приклад:
В американському журналі «Літературний огляд» за допомогою статистичних методів було проведено дослідження прогнозів щодо результату майбутніх виборів президента США у 1936 році. Претендентами цей пост були Ф.Д. Рузвельт та А. М. Ландон. Як джерело для генеральної сукупності досліджуваних американців було взято довідники телефонних абонентів. З них випадково було обрано 4 мільйони адрес., за якими редакція журналу розіслала листівки з проханням висловити своє ставлення до кандидатів на пост президента. Опрацювавши результати опитування, журнал опублікував соціологічний прогноз про те, що на майбутніх виборах із великою перевагою переможе Ландон. І… помилився: перемогу здобув Рузвельт.
Цей приклад можна як приклад нерепрезентативної вибірки. Річ у тім, що у першій половині ХХ століття телефони мала лише заможна частина населення, які підтримували погляди Ландона.
3. Способи відбору
На практиці застосовуються різні способи відбору, які можна поділити на 2 види:
1. Відбір не вимагає розчленування генеральної сукупності на частини (а) простий випадковий безповторний; б) простий випадковий повторний).
2. Відбір, у якому генеральна сукупність розбивається на частини. (а) типовий відбір; б) механічний відбір; в) серійний відбір).
Простим випадковим називають такою відбір, при якому об'єкти витягуються по одному з усієї генеральної сукупності (випадково).
Типовимназивають відбір, у якому об'єкти відбираються не з усієї генеральної сукупності, та якщо з її «типової» частини. Наприклад, якщо деталь виготовляють на кількох верстатах, то відбір виробляють не з усієї сукупності деталей, вироблених усіма верстатами, а з продукції кожного верстата окремо. Таким добором користуються тоді, коли обстежуваний ознака помітно коливається у різних «типових» частинах генеральної сукупності.
Механічнимназивають відбір, у якому генеральну сукупність «механічно» ділять стільки груп, скільки об'єктів має увійти вибірку, та якщо з кожної групи відбирають один об'єкт. Наприклад, якщо потрібно відібрати 20 % виготовлених верстатом деталей, то відбирають кожну 5 деталь; якщо потрібно відібрати 5% деталей-кожну 20-ту і т.д. Іноді такий відбір може не забезпечувати репрезентативність вибірки (якщо відбирають кожен 20-й валик, що обточується, причому відразу ж після відбору проводиться заміна різця, то відібраними виявляться всі валики, обточені затупленими різцями).
Серійнимназивають відбір, при якому об'єкти відбирають із генеральної сукупності не по одному, а «серіями», які піддають суцільному обстеженню. Наприклад, якщо вироби виготовляються великою групою верстатів-автоматів, піддають суцільному обстеженню продукцію лише кількох верстатів.
Насправді часто застосовують комбінований відбір, у якому поєднуються зазначені вище способи.
4. Статистичне розподілення вибірки
Нехай із генеральної сукупності вилучено вибірку, причому значення x 1-Спостерігалося раз, x 2 -n 2 раз, ... x k - N k разів. n = n 1 +n 2 +...+n k – обсяг вибірки. Значення, що спостерігаютьсяназиваються варіантами, А послідовність варіант, записаних у зростаючому порядку- варіаційним рядом. Числа спостереженьназиваються частотами (абсолютними частотами), а їхнє ставлення до обсягу вибірки- відносними частотамиабо статистичними ймовірностями.
Якщо кількість варіант велике чи вибірка виробляється з безперервної генеральної сукупності, то варіаційний ряд складається за окремими точковими значеннями, а, по інтервалам значень генеральної сукупності. Такий варіаційний ряд називається інтервальним.Довжини інтервалів при цьому мають бути рівними.
Статистичним розподілом вибірки називається перелік варіантів і відповідних їм частот або відносних частот.
Статистичне розподіл можна задати також як послідовності інтервалів і відповідних їм частот (суми частот, які у цей інтервал значень)
Точковий варіаційний ряд частот може бути представлений таблицею:
| x i |
x 1 |
x 2 |
… |
x k |
| n i |
n 1 |
n 2 |
… |
n k |
Аналогічно можна уявити точковий варіаційний ряд відносних частот.
Причому:
Приклад:
Число літер у деякому тексті Х виявилося рівним 1000. Першою зустрілася буква «я», другою-літера «і», третьою-літера «а», четвертою-«ю». Потім йшли літери "о", "е", "у", "е", "и".
Випишемо місця, які вони займають в алфавіті, відповідно маємо: 33, 10, 1, 32, 16, 6, 21, 31, 29.
Після впорядкування цих чисел за зростанням отримуємо варіаційний ряд: 1, 6, 10, 16, 21, 29, 31, 32, 33.
Частоти появи букв у тексті: "а" - 75, "е" -87, "і" - 75, "о" - 110, "у" - 25, "и" - 8, "е" - 3, "ю" »- 7, «я»-22.
Складемо точковий варіаційний ряд частот:
Приклад:
Задано розподіл частот вибірки обсягу n = 20.
Складіть точковий варіаційний ряд відносних частот.
| x i |
2 |
6 |
12 |
| n i |
3 |
10 |
7 |
Рішення:
Знайдемо відносні частоти:
| x i |
2 |
6 |
12 |
| w i |
0,15 |
0,5 |
0,35 |
При побудові інтервального розподілу існують правила вибору числа інтервалів чи величини кожного інтервалу. Критерієм тут служить оптимальне співвідношення: зі збільшенням кількості інтервалів поліпшується репрезентативність, але збільшується обсяг даних, і час їх обробку. Різниця x max - x min між найбільшим та найменшим значеннями варіант називають розмахомвибірки.
Для підрахунку кількості інтервалів k зазвичай застосовують емпіричну формулу Стреджесса (маючи на увазі округлення до найближчого зручного цілого): k = 1 + 3.322 lg n.
Відповідно, величину кожного інтервалу h можна обчислити за формулою:
5. Емпірична функція розподілу
Розглянемо деяку вибірку із генеральної сукупності. Нехай відомий статистичний розподіл частот кількісної ознаки Х. Введемо позначення: n x- Число спостережень, при яких спостерігалося значення ознаки, менше х; n – загальна кількість спостережень (обсяг вибірки). Відносна частота події Х<х равна n x /n. Якщо змінюється, то змінюється і відносна частота, тобто. відносна частотаn x /n- Є функція від х. Т.к. вона знаходиться емпіричним шляхом, вона називається емпіричною.
Емпіричною функцією розподілу (функцією розподілу вибірки) називають функцію, Що визначає для кожного х відносну частоту події Х<х.
де число варіант, менших х,
n – обсяг вибірки.
На відміну від емпіричної функції розподілу вибірки, функцію розподілу F (x ) генеральної сукупності називають теоретичною функцією розподілу.
Відмінність між емпіричною та теоретичною функціями розподілу полягає в тому, що теоретична функція F (x ) визначає ймовірність події Х
Т.о. доцільно використовувати емпіричну функцію розподілу вибірки для наближеного уявлення теоретичної (інтегральної) функції розподілу генеральної сукупності.
F*(x)має всі властивості F(x).
1. Значення F*(x)належать інтервалу.
2. F * (x) - Незменшується функція.
3. Якщо - найменша варіанта, то F * (x) = 0, при х < x 1; якщо x k - Найбільша варіанта, то F * (x) = 1, при х > x k .
Тобто. F*(x)служить для оцінки F(x).
Якщо вибірка задана варіаційним рядом, то емпірична функція має вигляд:
Графік емпіричної функції називається кумулятою.
Приклад:
Побудуйте емпіричну функцію даного розподілу вибірки.
Рішення:
Обсяг вибірки n = 12 + 18 +30 = 60. Найменша варіанта 2, тобто. при х <
2. Подія X<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F * (x) = 12/60 = 0,2при 2 <
x <
6. Подія Х<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
x <
10. Т.к. х = 10 найбільша варіанта, то F * (x) = 1при х>10. Шукана емпірична функція має вигляд:
Кумулята:
Кумулята дає можливість розуміти графічно подану інформацію, наприклад, відповісти на запитання: «Визначте число спостережень, при яких значення ознаки було менше 6 або не менше 6. F*(6) =0,2 » Тоді число спостережень, при яких значення ознаки, що спостерігається, було менше 6 дорівнює 0,2 * n = 0,2 * 60 = 12. Число спостережень, при яких значення спостерігається ознаки було не менше 6 дорівнює (1-0,2) * n = 0,8 * 60 = 48.
Якщо заданий інтервальний варіаційний ряд, то складання емпіричної функції розподілу знаходять середини інтервалів і з них отримують емпіричну функцію розподілу аналогічно точковому варіаційному ряду.
6. Полігон та гістограма
Для наочності будують різні графіки статистичного розподілу: поліном та гістограми
Полігон частот-це ламана, відрізки якої з'єднують точки ( x 1 ; n 1 ), ( x 2 ; n 2 ), ..., ( x k ; n k ), де - варіанти, - відповідні їм частоти.
Полігон відносних частот-це ламана, відрізки якої з'єднують точки (x1; w1), (x2; w2), ..., (xk; wk), де x i -варіанти, w i - відповідні їм відносні частоти.
Приклад:
Побудуйте поліном відносних частот за цим розподілом вибірки:
Рішення:
У разі безперервної ознаки доцільно будувати гістограму, для чого інтервал, в якому укладені всі значення ознаки, що спостерігаються, розбивають на кілька часткових інтервалів довжиною h і знаходять для кожного часткового інтервалу n i – суму частот варіант, що потрапили в i-ий інтервал. (Наприклад, при вимірі зростання людини або ваги ми маємо справу з безперервною ознакою).
Гістограма частот-це ступінчаста фігура, що складається з прямокутників, основами яких служать часткові інтервали довжиною h, а висоти дорівнюють відношенню (щільність частот).
Площа i -го часткового прямокутника дорівнює- сумі частот варіант i - го інтервалу, тобто. площа гістограми частот дорівнює сумі всіх частот, тобто. обсягу вибірки.
Приклад:
Дано результати зміни напруги (у вольтах) в електромережі. Складіть варіаційний ряд, побудуйте полігон і гістограму частот, якщо значення напруги такі: 227, 215, 230, 232, 223, 220, 228, 222, 221, 226, 226, 215, 218, 222, 22 , 217, 220.
Рішення:
Складемо варіаційний ряд. Маємо n = 20, x min = 212, x max = 232.
Застосуємо формулу Стреджесу для підрахунку числа інтервалів.
Інтервальний варіаційний ряд частот має вигляд:
|
|
Щільність частот |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
Побудуємо гістограму частот:
Побудуємо полігон частот, знайшовши попередньо середини інтервалів:
Гістограмою відносних частотназивають ступінчасту фігуру, що складається з прямокутників, основами яких є часткові інтервали довжиною h, а висоти рівні відношенню w i/h (Щільність відносної частоти).
Площа i-го часткового прямокутника дорівнює-відносній частоті варіант, що потрапили в i-ий інтервал. Тобто. площа гістограми відносних частот дорівнює сумі відносних частот, тобто. одиниці.
7. Числові характеристики варіаційного ряду
Розглянемо основні характеристики генеральної та вибіркової сукупностей.
Генеральним середнімназивається середнє арифметичне значень ознаки генеральної сукупності.
Для різних значень x 1 x 2 x 3 … x n . ознаки генеральної сукупності обсягу N маємо:
Якщо значення ознаки мають відповідні частоти N 1 +N 2 +…+N k =N ,
Вибірковим середнімназивається середнє арифметичне значень ознаки вибіркової сукупності.
Якщо значення ознаки мають відповідні частоти n 1 +n 2 +…+n k = n, то
Приклад:
Обчисліть середнє вибіркове для вибірки: x 1 = 51,12; x 2 = 51,07; x 3 = 52,95; x 4 = 52,93; x 5 = 51,1; x 6 = 52,98; x7 = 52,29; x 8 = 51,23; x9 = 51,07; x 10 = 51,04.
Рішення:
Генеральною дисперсієюназивається середнє арифметичне квадратів відхилень значень ознаки Х генеральної сукупності від генерального середнього.
Для різних значень x 1 x 2 x 3 … x N ознаки генеральної сукупності обсягу N маємо:
Якщо значення ознаки мають відповідні частоти N 1 +N 2 +…+N k =N ,
Генеральним середньоквадратичним відхиленням (стандартом)називають квадратний корінь із генеральної дисперсії
Вибірковою дисперсієюназивається середнє арифметичне квадратів відхилень значень ознаки від середнього значення.
Для різних значень x 1 x 2 x 3 … x n ознаки вибіркової сукупності обсягу n маємо:
Якщо значення ознаки мають відповідні частоти n 1 +n 2 +…+n k = n, то
Вибірковим середньоквадратичним відхиленням (стандартом)називається квадратний корінь із вибіркової дисперсії.
Приклад:
Вибіркова сукупність задана таблицею розподілу. Знайдіть вибіркову дисперсію.
Рішення:
Теорема: Дисперсія дорівнює різниці середнього квадратів значень ознаки та квадрата загального середнього.
Приклад:
Знайдіть дисперсію за цим розподілом.
Рішення:
8. Статистичні оцінки параметрів розподілу
Нехай генеральна сукупність досліджується певною вибіркою. При цьому можна отримати лише наближене значення невідомого параметра Q, який є його оцінкою. Очевидно, що оцінки можуть змінюватися від однієї вибірки до іншої.
Статистичною оцінкоюQ *невідомого параметра теоретичного розподілу називається функція f, яка залежить від значень вибірки, що спостерігаються. Завданням статистичного оцінювання невідомих параметрів за вибіркою полягає у побудові такої функції від наявних даних статистичних спостережень, яка давала б найточніші наближені значення реальних, не відомих досліднику значень цих параметрів.
Статистичні оцінки поділяються на точкові та інтервальні, залежно від способу їх надання (числом чи інтервалом).
Точковою називають статистичну оцінкупараметра Q теоретичного розподілу, що визначається одним значенням параметра Q *=f (x 1 , x 2 , ..., x n), деx 1 , x 2 , ..., x n- Результати емпіричних спостережень над кількісною ознакою Х деякої вибірки.
Такі оцінки параметрів, отримані за різними вибірками, найчастіше відрізняються одна від одної. Абсолютна різницю /Q *-Q / називають помилкою вибірки (оцінювання).
Для того, щоб статистичні оцінки давали достовірні результати про оцінювані параметри, необхідно, щоб вони були незміщеними, ефективними та заможними.
Точкова оцінка, математичне очікування якої дорівнює (не дорівнює) оцінюваному параметру, називається незміщеною (зміщеною). М(Q *) = Q.
Різниця М( Q *)-Q називають зміщенням чи систематичною помилкою. Для незміщених оцінок систематична помилка дорівнює 0.
Ефективною оцінку Q *, яка при заданому обсязі вибірки n має найменшу можливу дисперсію: D min (n = const). Ефективна оцінка має найменший розкид у порівнянні з іншими незміщеними та заможними оцінками.
Заможноюназивають таку статистичну оцінку Q*, яка при nпрагне ймовірності до оцінюваного параметра Q , тобто. зі збільшенням обсягу вибірки n оцінка прагне ймовірності до справжнього значення параметра Q.
Вимога спроможності узгоджується із законом великих числа: що більше вихідної інформації про досліджуваному об'єкті, то точніше результат. Якщо обсяг вибірки малий, то точкова оцінка параметра може призвести до серйозних помилок.
Будь-яку вибірку (обсягуn)можна розглядати як упорядкований набірx 1 , x 2 , ..., x nнезалежних однаково розподілених випадкових величин.
Вибіркові середні для різних вибірок обсягу n з однієї й тієї самої генеральної сукупності будуть різні. Т. е. вибіркове середнє можна розглядати як випадкову величину, а значить, можна говорити про розподіл вибіркового середнього та його числові характеристики.
Вибіркове середнє задовольняє всім накладеним до статистичних оцінок вимог, тобто. дає незміщену, ефективну та заможну оцінку генерального середнього.
Можна довести, що. Таким чином, вибіркова дисперсія є зміщеною оцінкою генеральної дисперсії, даючи занижене значення. Т. е. при невеликому обсязі вибірки вона даватиме систематичну помилку. Для незміщеної, заможної оцінки достатньо взяти величину, яку називають виправленою дисперсією Т. е.
На практиці для оцінки генеральної дисперсії застосовують виправлену дисперсію при n < 30. В інших випадках ( n >30) відхилення від малопомітно. Тому при великих значеннях n помилкою усунення можна знехтувати.
Можна також довести, що відносна частотаn i / n є незміщеною та заможною оцінкою ймовірності P (X = x i ). Емпірична функція розподілу F * (x ) є незміщеною та заможною оцінкою теоретичної функції розподілу F (x) = P (X< x ).
Приклад:
Знайдіть незміщені оцінки математичного очікування та дисперсії за таблицею вибірки.
| x i |
|||
| n i |
Рішення:
Об'єм вибірки n =20.
Незміщеною оцінкою математичного очікування є середнє вибіркове.
Для обчислення незміщеної оцінки дисперсії спочатку знайдемо вибіркову дисперсію:
Тепер знайдемо незміщену оцінку:
9. Інтервальні оцінки параметрів розподілу
Інтервальної називається статистична оцінка, яка визначається двома числовими значеннями-кінцями досліджуваного інтервалу.
Число> 0, у якому | Q - Q * |< , характеризує точність інтервальної оцінки
Довірчимназивається інтервал , який із заданою ймовірністюпокриває невідоме значення параметра Q . Доповнення довірчого інтервалу до багатьох можливих значень параметра Q називається критичною областю. Якщо критична область розташована лише з одного боку від довірчого інтервалу, то довірчий інтервал називається одностороннім: лівостороннімякщо критична область існує тільки зліва, і правостороннім-якщо лише справа. В іншому випадку, довірчий інтервал називається двостороннім.
Надійністю, чи довірчою ймовірністю, оцінки Q (за допомогою Q *) називають ймовірність, з якою виконується така нерівність: | Q - Q * |< .
Найчастіше довірчу ймовірність задають заздалегідь (0,95; 0,99; 0,999) і неї накладають вимога бути близькою до одиниці.
Ймовірністьназивають ймовірністю помилки, чи рівнем значимості.
Нехай | Q - Q * |< тоді. Це означає, що з ймовірністюможна стверджувати, що дійсне значення параметра Q належить інтервалу. Чим менша величина відхилення, Тим точніше оцінка.
Межі (кінці) довірчого інтервалу називають довірчими кордонами, чи критичними кордонами.
Значення меж довірчого інтервалу залежить від закону розподілу параметра Q*.
Величину відхиленнярівну половині ширини довірчого інтервалу, називають точністю оцінки.
Методи побудови довірчих інтервалів уперше розроблено американським статистом Ю. Нейманом. Точність оцінки, довірча ймовірність та обсяг вибірки n зв'язані між собою. Тому, знаючи конкретні значення двох величин, можна обчислити третю.
Знаходження довірчого інтервалу з метою оцінки математичного очікування нормального розподілу, якщо відомо середньоквадратичне відхилення.
Нехай зроблено вибірку з генеральної сукупності, підпорядкованої закону нормального розподілу. Нехай відоме генеральне середньоквадратичне відхилення, але невідомо математичне очікування теоретичного розподілу a ().
Справедлива наступна формула:
Тобто. за заданим значенням відхиленняможна знайти, з якою ймовірністю невідоме генеральне середнє належить інтервалу. І навпаки. З формули видно, що при зростанні обсягу вибірки та фіксованій величині довірчої ймовірності величина- Зменшується, тобто. точність оцінки зростає. Зі збільшенням надійності (довірчої ймовірності), величина-Збільшується, тобто. точність оцінки зменшується.
Приклад:
В результаті випробувань були отримані такі значення -25, 34, -20, 10, 21. Відомо, що вони підпорядковуються закону нормального розподілу із середньоквадратичним відхиленням 2. Знайдіть оцінку а* для математичного очікування а. Побудуйте для нього 90% довірчий інтервал.
Рішення:
Знайдемо незміщену оцінку
Тоді
Довірчий інтервал для має вигляд: 4 – 1,47< a< 4+ 1,47 или 2,53 < a < 5, 47
Знаходження довірчого інтервалу з метою оцінки математичного очікування нормального розподілу, якщо невідомо середньоквадратичне відхилення.
Нехай відомо, що генеральна сукупність підпорядкована закону нормального розподілу, де невідомі а і. Точність довірчого інтервалу, що покриває з надійністюсправжнє значення параметра а, у разі обчислюється по формуле:
, де n - обсяг вибірки, , - Коефіцієнт Стьюдента (його слід знаходити за заданими значеннями n та з таблиці "Критичні точки розподілу Стьюдента").
Приклад:
В результаті випробувань були отримані наступні значення -35 -32 -26 -35 -30 -17. Відомо, що вони підпорядковуються закону нормального розподілу. Знайдіть довірчий інтервал для математичного очікування, а генеральної сукупності з довірчою ймовірністю 0,9.
Рішення:
Знайдемо незміщену оцінку.
Знайдемо.
Тоді
Довірчий інтервал набуде вигляду(-29,2 - 5,62; -29,2 + 5,62) або (-34,82; -23,58).
Знаходження довірчого інтерлу для дисперсії та середньоквадратичного відхилення нормального розподілу
Нехай із деякої генеральної сукупності значень, розподіленої за нормальним законом, взято випадкову вибірку обсягуn < 30, для якої обчислені вибіркові дисперсії: зміщената виправлена s 2. Тоді для знаходження інтервальних оцінок із заданою надійністюдля генеральної дисперсіїDгенерального середньоквадратичного відхиленнявикористовуються такі формули.
або,
Значення- Знаходять за допомогою таблиці значень критичних точокрозподілу Пірсона.
Довірчий інтервал дисперсії перебуває з цих нерівностей шляхом зведення всіх частин нерівності в квадрат.
Приклад:
Було перевірено якість 15 болтів. Припускаючи, що помилка під час їх виготовлення підпорядкована нормальному закону розподілу, причому вибіркове середньоквадратичне відхиленнярівно 5 мм, визначити з надійністюдовірчий інтервал для невідомого параметра
Межі інтервалу представимо у вигляді подвійної нерівності:
Кінці двостороннього довірчого інтервалу для дисперсії можна визначити і без виконання арифметичних дій за заданим рівнем довіри та обсягом вибірки за допомогою відповідної таблиці (Кордони довірчих інтервалів для дисперсії в залежності від кількості ступенів свободи та надійності). Для цього отримані з таблиці кінці інтервалу множать виправлену дисперсію s 2.
Приклад:
Вирішимо попереднє завдання іншим способом.
Рішення:
Знайдемо виправлену дисперсію:
За таблицею «Кордони довірчих інтервалів для дисперсії в залежності від числа ступенів свободи та надійності» знайдемо межі довірчого інтервалу для дисперсії приk=14 і: нижня межа 0,513 та верхня 2,354.
Помножимо отримані межі наs 2 і витягнемо корінь (бо нам потрібен довірчий інтервал не для дисперсії, а для середньоквадратичного відхилення).
Як видно з прикладів, величина довірчого інтервалу залежить від способу його побудови та дає близькі між собою, але неоднакові результати.
При вибірках досить великого обсягу (n>30) межі довірчого інтервалу для генерального середньоквадратичного відхилення можна визначити за такою формулою: - деяке число, яке табульоване та наводиться у відповідній довідковій таблиці.
Якщо 1- q<1, то формула имеет вид:
Приклад:
Розв'яжемо попереднє завдання третім способом.
Рішення:
Раніше було знайденоs= 5,17. q(0,95; 15) = 0,46 – знаходимо за таблицею.
Тоді:
Часто буває так, що необхідно проаналізувати якесь конкретне соціальне явище та отримати інформацію про нього. Такі завдання часто виникають у статистиці та при статистичних дослідженнях. Перевірити певне соціальне явище найчастіше буває неможливим. Наприклад, як дізнатися думку населення чи всіх мешканців певного міста з якогось питання? Запитувати всіх - справа практично неможлива і дуже трудомістка. У таких випадках нам і потрібна вибірка. Це саме те поняття, на якому ґрунтуються практично всі дослідження та аналізи.
Що таке вибірка
Під час аналізу конкретного соціального явища необхідно отримати інформацію про нього. Якщо взяти будь-яке дослідження, можна помітити, що дослідженню та аналізу підлягає не кожна одиниця сукупності об'єкта дослідження. До уваги береться лише певна частина всієї цієї сукупності. Ось цей процес і є вибіркою: коли досліджуються лише певні одиниці з множини.
Звичайно ж, багато залежить від виду вибірки. Але й основні правила. Головне з них свідчить, що відбір із сукупності має бути абсолютно випадковим. Одиниці сукупності, які будуть використані, не повинні бути обрані за будь-яким критерієм. Грубо кажучи, якщо необхідно набрати сукупність із населення певного міста та відібрати лише чоловіків, то у дослідженні буде помилка, тому що відбір було проведено не випадково, а відібрано за ґендерною ознакою. Практично всі методи вибірки ґрунтуються на цьому правилі.
Правила вибірки
Для того, щоб відібрана сукупність відображала основні якості всього явища, вона повинна бути побудована за конкретними законами, де основну увагу необхідно приділяти таким категоріям:
- вибірка (вибіркова сукупність);
- Генеральна сукупність;
- репрезентативність;
- помилка репрезентативності;
- одиниця сукупності;
- методи побудови вибірки.
Особливості вибіркового спостереження та складання вибірки полягають у наступному:
- Усі отримані результати засновані на математичних законах та правилах, тобто при правильному проведенні дослідження та при правильних розрахунках результати не будуть спотворені за суб'єктивною ознакою
- Дає можливість значно швидше і з меншими витратами часу та ресурсів отримати результат, вивчаючи не весь масив подій, а лише їхню частину.
- Може бути застосовано для вивчення різних об'єктів: від конкретних питань, наприклад, вік, стать цікавої для нас групи, до вивчення громадської думки або рівня матеріального забезпечення населення.
Вибіркове спостереження
Вибіркове - це таке статистичне спостереження, у якому дослідженню піддається не вся сукупність досліджуваного, лише деяка, відібрана певним чином її частина, а отримані результати вивчення цієї частини поширюються протягом усього сукупність. Ця частина називається вибірковою сукупністю. Це єдиний спосіб вивчення великого масиву об'єкта дослідження.
Але вибіркове спостереження можна використовувати лише у випадках, коли необхідно досліджувати лише малу групу одиниць. Наприклад, при дослідженні співвідношення чоловіків до жінок у світі використовуватиметься вибіркове спостереження. Зі зрозумілих причин - взяти до уваги кожного жителя нашої планети неможливо.
А ось при такому ж дослідженні, але не всіх мешканців землі, а певного 2 «А» класу в конкретній школі, певного міста, певної країни може обійтися без вибіркового спостереження. Адже проаналізувати весь масив об'єкта дослідження – цілком можливо. Необхідно порахувати хлопчиків та дівчаток цього класу – от і буде співвідношення.

Вибіркова та генеральна сукупність
Насправді, все не так складно, як звучить. У будь-якому об'єкті вивчення є дві системи: генеральна та вибіркова сукупність. Що це таке? Усі одиниці відносяться до генеральної. А до вибіркової – ті одиниці загальної сукупності, які було взято для вибірки. Якщо все правильно зроблено, то відібрана частина складатиме зменшений макет усієї (генеральної) сукупності.
Якщо говорити про генеральну сукупність, то можна виділити всього два її різновиди: певна та невизначена генеральна сукупність. Залежить від того, чи відома загальна кількість одиниць даної системи чи ні. Якщо це певна генеральна сукупність, то вибірку робитиме легше через те, що відомо, який відсоток від загальної кількості одиниць складатиме вибірка.
Цей момент дуже потрібний у дослідженнях. Наприклад, якщо необхідно досліджувати відсоток недоброякісної продукції кондитерських виробів конкретному заводі. Припустимо, що генеральну сукупність вже визначено. Достеменно відомо, що на рік це підприємство виробляє 1000 кондитерських виробів. Якщо зробити вибірку 100 випадкових кондитерських виробів із цієї тисячі та відправити їх на експертизу, то похибка буде мінімальною. Грубо кажучи, дослідженню підлягало 10% всієї продукції, і за результатами можемо, взявши до уваги помилку репрезентативності, говорити про недоброякісність усієї продукції.
А якщо провести вибірку 100 кондитерських виробів із невизначеної генеральної сукупності, де їх насправді було, припустимо, 1 млн одиниць, то результат вибірки та самого дослідження буде критично неправдоподібним та неточним. Відчуваєте різницю? Тому визначеність генеральної сукупності здебільшого є вкрай важливою і дуже сильно впливає на результат дослідження.

Репрезентативність сукупності
Отже, тепер одне з найголовніших питань – якою має бути вибірка? Це найголовніший момент дослідження. На цьому етапі необхідно розрахувати вибірку та відібрати одиниці із загального числа до неї. Сукупність була відібрана правильно, якщо певні особливості та характеристики генеральної сукупності залишається і у вибірковій. Це називається репрезентативністю.
Іншими словами, якщо після відбору частина зберігає ті ж самі тенденції та особливості, що і вся кількість досліджуваного, то така сукупність називається репрезентативною. Не кожна певна вибірка може бути відібрано з репрезентативної сукупності. Бувають і такі об'єкти дослідження, вибірка яких просто не може бути репрезентативною. Звідси і виникає поняття помилки репрезентативності. Але про це поговоримо трохи більше.
Як зробити вибірку
Отже, щоб репрезентативність була максимальною, виділяють три основні правила вибірки:

Похибка (помилка) репрезентативності
Головною характеристикою якості обраної вибірки є поняття «похибки репрезентативності». Що це таке? Це певні розбіжності між показниками вибіркового та суцільного спостереження. За показниками похибки репрезентативність ділять на надійну, звичайну та наближену. Інакше висловлюючись, допустимими є відхилення у вигляді 3 %, від 3 до 10 % і від 10 до 20 % відповідно. Хоча у статистиці бажано, щоб похибка не перевищувала 5-6%. В іншому випадку є привід говорити про недостатню репрезентативність вибірки. Для обчислення похибки репрезентативності та того, як вона впливає на вибіркову чи генеральну сукупність, до уваги беруться багато факторів:
- Імовірність, з якою потрібно отримати точний результат.
- Кількості одиниць вибіркової сукупності. Як згадувалося раніше, що менше одиниць складе вибірка, то більше вписуватиметься помилка репрезентативності, і навпаки.
- Однорідність досліджуваної сукупності. Чим більш різнорідною є сукупність, тим більшою буде похибка репрезентативності. Можливість сукупності бути репрезентативною залежить від однорідності її складових одиниць.
- Спосіб відбору одиниць у вибіркову сукупність.
У конкретно заданих дослідженнях відсоток похибки середнього значення зазвичай задається самим дослідником виходячи з програми спостереження і за даними раніше проведених досліджень. Як правило, вважається припустимою гранична помилка вибірки (помилка репрезентативності) у межах 3-5%.

Більше - не завжди краще
Також варто пам'ятати, що головне при організації вибіркового спостереження – це доведення його обсягу до мінімуму. При цьому не слід прагнути надмірного зменшення меж похибки вибірки, оскільки це може призвести до невиправданого збільшення обсягу даних вибірки і, отже, підвищення витрат на проведення вибіркового спостереження.
У той самий час не можна надмірно збільшувати розмір похибки репрезентативності. Адже в цьому випадку, хоч і станеться зменшення обсягу вибіркової сукупності, це призведе до погіршення достовірності отриманих результатів.
Які питання зазвичай ставиться перед дослідником
Будь-яке дослідження якщо і проводиться, то для якоїсь мети та для отримання якихось результатів. Під час проведення вибіркового дослідження, зазвичай, ставляться початкові питання:

Способи відбору одиниць дослідження у вибірку
Не кожна вибірка є репрезентативною. Іноді та сама ознака по-різному виражений загалом й у її частини. Для досягнення вимог репрезентативності є доцільним використання різних прийомів створення вибірки. Причому використання тієї чи іншої способу залежить від конкретних обставин. Серед таких прийомів створення вибірки виділяють:
- випадковий відбір;
- механічний відбір;
- типовий відбір;
- серійний (гніздовий) відбір.
Випадковий відбір є систему заходів, вкладених у випадковий відбір одиниць сукупності, коли ймовірність потрапити у вибірку є рівної всім одиниць генеральної сукупності. Цей прийом доцільно застосовувати лише у разі однорідності та невеликої кількості властивих їй ознак. В іншому випадку деякі характерні риси ризикують бути не відображеним у вибірці. Ознаки випадкового відбору є основою всіх інших способів побудови вибірки.
При механічному відборі одиниць проводиться через певний інтервал. Якщо необхідно сформувати вибірку конкретних злочинів, можна вилучати зі всіх карток статистичного обліку зареєстрованих злочинів кожну 5-ту, 10-ту або 15-ту картку в залежності від їх загальної кількості та наявних розмірів вибірки. Недоліком цього є те, що перед відбором необхідно мати повний облік одиниць сукупності, потім потрібно провести ранжування і тільки після цього можна проводити вибірку з певним інтервалом. Цей метод займає багато часу, тому і не часто використовується.

Типовий (районований) відбір - вид вибірки, у якому генеральну сукупність поділяють на однорідні групи за певною ознакою. Іноді дослідники вживають замість «груп» інші терміни: «райони» та «зони». Потім із кожної групи у випадковому порядку відбирається певна кількість одиниць пропорційно до питомої ваги групи в загальній сукупності. Типовий відбір часто здійснюється у кілька етапів.
Серійний відбір - це метод, у якому відбір одиниць проводиться групами (серіями) і обстеженню підлягають всі одиниці відібраної групи (серії). Перевагою цього є те, що іноді відібрати окремі одиниці складніше, ніж серії, наприклад, щодо особистості, яка відбуває покарання. У межах відібраних районів зон застосовується вивчення всіх одиниць без винятку, наприклад, вивчення всіх осіб, які відбувають покарання в певній установі.
 Ораторське мистецтво як прообраз публіцистики
Ораторське мистецтво як прообраз публіцистики Цитати про Наполеона - dslinkov — LiveJournal
Цитати про Наполеона - dslinkov — LiveJournal Мені помста Людина на бульдозері зруйнувала місто
Мені помста Людина на бульдозері зруйнувала місто