Čemu služi disperzija? Zaostala disperzija
Koraci
Izračun varijance uzorka
-
Zabilježite vrijednosti uzorka. U većini slučajeva statističarima su dostupni samo uzorci određenih populacija. Na primjer, statističari u pravilu ne analiziraju troškove održavanja agregata svih automobila u Rusiji - oni analiziraju nasumični uzorak od nekoliko tisuća automobila. Takav uzorak pomoći će u određivanju prosječnog troška po automobilu, ali najvjerojatnije će rezultirajuća vrijednost biti daleko od stvarne.
- Na primjer, analizirajmo broj peciva prodanih u kafiću u 6 dana, uzetih slučajnim redoslijedom. Uzorak ima sljedeći pogled: 17, 15, 23, 7, 9, 13. Ovo je uzorak, a ne populacija, jer nemamo podatke o prodanim pecivima za svaki dan kada je kafić otvoren.
- Ako vam je dana populacija, a ne uzorak vrijednosti, prijeđite na sljedeći odjeljak.
-
Zapišite formulu za izračun varijance uzorka. Disperzija je mjera širenja vrijednosti neke veličine. Što je vrijednost disperzije bliža nuli, to su vrijednosti bliže grupirane. Kada radite s uzorkom vrijednosti, koristite sljedeću formulu za izračun varijance:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-x) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2)) je disperzija. Disperzija se mjeri u kvadratnih jedinica mjerenja.
- x i (\displaystyle x_(i))- svaka vrijednost u uzorku.
- x i (\displaystyle x_(i)) trebate oduzeti x̅, kvadrirati ga i zatim zbrojiti rezultate.
- x̅ – srednja vrijednost uzorka (srednja vrijednost uzorka).
- n je broj vrijednosti u uzorku.
-
Izračunajte srednju vrijednost uzorka. Označava se kao x̅. Srednja vrijednost uzorka izračunava se kao normalna aritmetička sredina: zbrojite sve vrijednosti u uzorku, a zatim rezultat podijelite s brojem vrijednosti u uzorku.
- U našem primjeru zbrojite vrijednosti u uzorku: 15 + 17 + 23 + 7 + 9 + 13 = 84
Sada podijelite rezultat s brojem vrijednosti u uzorku (u našem primjeru ih je 6): 84 ÷ 6 = 14.
Prosječna vrijednost uzorka x̅ = 14. - Srednja vrijednost uzorka je središnja vrijednost oko koje se raspoređuju vrijednosti u uzorku. Ako su vrijednosti u uzorku grupirane oko srednje vrijednosti uzorka, tada je varijanca mala; inače je disperzija velika.
- U našem primjeru zbrojite vrijednosti u uzorku: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Oduzmite srednju vrijednost uzorka od svake vrijednosti u uzorku. Sada izračunajte razliku x i (\displaystyle x_(i))- x̅, gdje x i (\displaystyle x_(i))- svaka vrijednost u uzorku. Svaki dobiveni rezultat pokazuje u kojoj mjeri pojedina vrijednost odstupa od prosjeka uzorka, odnosno koliko je ta vrijednost daleko od prosjeka uzorka.
- U našem primjeru:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Točnost dobivenih rezultata lako je provjeriti jer njihov zbroj mora biti jednak nuli. Ovo je povezano s definicijom prosječne vrijednosti, jer negativne vrijednosti(udaljenosti od prosječne vrijednosti do manjih vrijednosti) u potpunosti su kompenzirane pozitivne vrijednosti(udaljenosti od prosječnih do velikih vrijednosti).
- U našem primjeru:
-
Kao što je gore navedeno, zbroj razlika x i (\displaystyle x_(i))- x̅ mora biti jednak nuli. To znači da prosječna varijanca je uvijek jednaka nuli, što ne daje nikakvu predodžbu o širenju vrijednosti određene veličine. Da biste riješili ovaj problem, kvadrirajte svaku razliku x i (\displaystyle x_(i))- x. To će rezultirati time da ćete dobiti samo pozitivni brojevi, koji kada se doda nikada neće dati 0.
- U našem primjeru:
(x 1 (\displaystyle x_(1))-x) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))-x) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Našli ste kvadrat razlike - x̅) 2 (\displaystyle ^(2)) za svaku vrijednost u uzorku.
- U našem primjeru:
-
Izračunaj zbroj kvadrata razlika. Odnosno, pronađite dio formule koji je napisan ovako: ∑[( x i (\displaystyle x_(i))-x) 2 (\displaystyle ^(2))]. Ovdje znak Σ označava zbroj kvadrata razlike za svaku vrijednost x i (\displaystyle x_(i)) u uzorku. Već ste pronašli razlike na kvadrat (x i (\displaystyle (x_(i))-x) 2 (\displaystyle ^(2)) za svaku vrijednost x i (\displaystyle x_(i)) u uzorku; sada samo dodajte ove kvadrate.
- U našem primjeru: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Rezultat podijelite s n - 1, gdje je n broj vrijednosti u uzorku. Prije nekog vremena, kako bi izračunali varijancu uzorka, statističari su jednostavno podijelili rezultat s n; u ovom slučaju, dobit ćete srednju vrijednost kvadrata varijance, što je idealno za opisivanje varijance danog uzorka. No zapamtite da je svaki uzorak samo mali dio. populacija vrijednosti. Ako uzmete drugačiji uzorak i napravite iste izračune, dobit ćete drugačiji rezultat. Kako se pokazalo, dijeljenje s n - 1 (a ne samo s n) daje više točna procjena populacijska varijanca, što je ono što vas zanima. Dijeljenje s n - 1 postalo je uobičajeno, pa je uključeno u formulu za izračun varijance uzorka.
- U našem primjeru uzorak uključuje 6 vrijednosti, odnosno n = 6.
Varijanca uzorka = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- U našem primjeru uzorak uključuje 6 vrijednosti, odnosno n = 6.
-
Razlika između varijance i standardne devijacije. Imajte na umu da formula sadrži eksponent, pa se varijanca mjeri u kvadratnim jedinicama analizirane vrijednosti. Ponekad je takvom vrijednošću prilično teško upravljati; u takvim slučajevima koristi se standardna devijacija, koja je jednaka kvadratnom korijenu varijance. Zato se varijanca uzorka označava kao s 2 (\displaystyle s^(2)), A standardna devijacija uzorci - kako s (\displaystyle s).
- U našem primjeru standardna devijacija uzorka je: s = √33,2 = 5,76.
Izračun varijance populacije
-
Analizirajte neki skup vrijednosti. Set uključuje sve vrijednosti količine koja se razmatra. Na primjer, ako proučavate starost stanovnika Lenjingradska oblast, tada stanovništvo uključuje starost svih stanovnika ovog područja. U slučaju rada s agregatom, preporuča se izraditi tablicu i unijeti vrijednosti agregata u nju. Razmotrite sljedeći primjer:
- U određenoj prostoriji nalazi se 6 akvarija. Svaki akvarij sadrži sljedeći broj riba:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- U određenoj prostoriji nalazi se 6 akvarija. Svaki akvarij sadrži sljedeći broj riba:
-
Zapišite formulu za izračunavanje varijance populacije. Budući da populacija uključuje sve vrijednosti određene količine, sljedeća formula omogućuje vam da dobijete točnu vrijednost varijance populacije. Kako bi razlikovali varijancu populacije od varijance uzorka (koja je samo procjena), statističari koriste različite varijable:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n
- σ 2 (\displaystyle ^(2))- varijanca populacije (čita se kao "sigma na kvadrat"). Disperzija se mjeri u kvadratnim jedinicama.
- x i (\displaystyle x_(i))- svaka vrijednost u agregatu.
- Σ je predznak zbroja. Odnosno za svaku vrijednost x i (\displaystyle x_(i)) oduzmite μ, kvadrirajte i zatim zbrojite rezultate.
- μ je srednja vrijednost populacije.
- n je broj vrijednosti u općoj populaciji.
-
Izračunajte srednju vrijednost populacije. Kada se radi s općom populacijom, njegova prosječna vrijednost se označava kao μ (mu). Srednja vrijednost populacije izračunava se kao uobičajena aritmetička sredina: zbrojite sve vrijednosti u populaciji, a zatim rezultat podijelite s brojem vrijednosti u populaciji.
- Imajte na umu da se prosjeci ne izračunavaju uvijek kao aritmetička sredina.
- U našem primjeru, populacija znači: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Od svake vrijednosti u populaciji oduzmite srednju vrijednost populacije.Što je vrijednost razlike bliža nuli, to je određena vrijednost bliža prosjeku populacije. Pronađite razliku između svake vrijednosti u populaciji i njezine srednje vrijednosti i dobit ćete prvi uvid u distribuciju vrijednosti.
- U našem primjeru:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- U našem primjeru:
-
Kvadratirajte svaki rezultat koji dobijete. Vrijednosti razlike će biti i pozitivne i negativne; ako ove vrijednosti stavite na brojevnu liniju, tada će ležati desno i lijevo od srednje vrijednosti populacije. Ovo nije prikladno za izračun varijance, budući da su pozitivne i negativni brojevi nadoknađuju jedni druge. Stoga kvadrirajte svaku razliku kako biste dobili isključivo pozitivne brojeve.
- U našem primjeru:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) za svaku vrijednost populacije (od i = 1 do i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), Gdje x n (\displaystyle x_(n)) – zadnja vrijednost u općoj populaciji. - Da biste izračunali prosječnu vrijednost dobivenih rezultata, trebate pronaći njihov zbroj i podijeliti ga s n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / n
- Sada napišimo gornje objašnjenje koristeći varijable: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n i dobiti formulu za izračunavanje varijance populacije.
- U našem primjeru:
Izračunajmo uMSEXCELvarijance i standardne devijacije uzorka. Također izračunavamo varijancu slučajne varijable ako je poznata njezina distribucija.
Prvo razmislite disperzija, onda standardna devijacija.
Varijanca uzorka
Varijanca uzorka (varijanca uzorka,uzorakvarijanca) karakterizira širenje vrijednosti u nizu u odnosu na .
Sve 3 formule su matematički ekvivalentne.
Iz prve formule se vidi da varijanca uzorka je zbroj kvadrata odstupanja svake vrijednosti u nizu od prosjeka podijeljeno s veličinom uzorka minus 1.
disperzija uzorci koristi se funkcija DISP(), eng. naziv VAR-a, tj. VARIJANCIJA. Od MS EXCEL-a 2010 preporuča se koristiti njegov analog DISP.V() , eng. naziv VARS, tj. Odstupanje uzorka. Osim toga, počevši od verzije MS EXCEL 2010, postoji funkcija DISP.G (), eng. VARP naziv, tj. VARIJANCIJA populacije koja se izračunava disperzija Za populacija. Cijela razlika se svodi na nazivnik: umjesto n-1 kao DISP.V() , DISP.G() ima samo n u nazivniku. Prije MS EXCEL 2010, funkcija VARP() se koristila za izračun varijance populacije.
Varijanca uzorka
=KVADRAT(Uzorak)/(BROJ(Uzorak)-1)
=(SUMSQ(Uzorak)-BROJ(Uzorak)*PROSJEK(Uzorak)^2)/ (BROJ(Uzorak)-1)- uobičajena formula
=SUM((Uzorak -PROSJEK(Uzorak))^2)/ (BROJ(Uzorak)-1) –
Varijanca uzorka je jednak 0 samo ako su sve vrijednosti međusobno jednake i, prema tome, jednake Srednja vrijednost. Obično, što je veća vrijednost disperzija, veće je širenje vrijednosti u nizu.
Varijanca uzorka je bodovna procjena disperzija distribucija slučajne varijable iz koje se uzorak. O gradnji intervali povjerenja prilikom ocjenjivanja disperzija može se pročitati u članku.
Varijanca slučajne varijable
Izračunati disperzija slučajna varijabla, morate je znati.
Za disperzija slučajna varijabla X često koristi oznaku Var(X). Disperzija jednak je kvadratu odstupanja od srednje vrijednosti E(X): Var(X)=E[(X-E(X)) 2 ]
disperzija izračunava se formulom:

gdje je x i vrijednost koju može uzeti slučajna vrijednost, a μ je srednja vrijednost (), p(x) je vjerojatnost da će slučajna varijabla poprimiti vrijednost x.
Ako slučajna varijabla ima , tada disperzija izračunava se formulom:

Dimenzija disperzija odgovara kvadratu mjerne jedinice izvornih vrijednosti. Na primjer, ako su vrijednosti u uzorku mjere težine dijela (u kg), tada bi dimenzija varijance bila kg 2 . Ovo može biti teško protumačiti, dakle, za karakterizaciju širenja vrijednosti, vrijednosti jednake kvadratnom korijenu disperzija – standardna devijacija.
Neka svojstva disperzija:
Var(X+a)=Var(X), gdje je X slučajna varijabla, a a konstanta.
Var(aH)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Ovo svojstvo disperzije koristi se u članak o linearnoj regresiji.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), gdje su X i Y slučajne varijable, Cov(X;Y) je kovarijanca ovih slučajnih varijabli.
Ako su slučajne varijable nezavisne, onda su njihove kovarijanca je 0, i stoga Var(X+Y)=Var(X)+Var(Y). Ovo svojstvo varijance koristi se u izlazu.
Pokažimo to za nezavisne količine Var(X-Y)=Var(X+Y). Doista, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Ovo svojstvo varijance koristi se za iscrtavanje.
Standardna devijacija uzorka
Standardna devijacija uzorka je mjera koliko su široko raspršene vrijednosti u uzorku u odnosu na njihove .
A-priorat, standardna devijacija jednako je kvadratnom korijenu od disperzija:

Standardna devijacija ne uzima u obzir veličinu vrijednosti u uzorkovanje, već samo stupanj raspršenosti vrijednosti oko njih sredini. Uzmimo primjer da to ilustriramo.
Izračunajmo standardnu devijaciju za 2 uzorka: (1; 5; 9) i (1001; 1005; 1009). U oba slučaja je s=4. Očito je da je omjer standardne devijacije prema vrijednostima niza značajno različit za uzorke. Za takve slučajeve koristite Koeficijent varijacije(Coefficient of Variation, CV) - omjer standardna devijacija do prosjeka aritmetika, izraženo u postocima.
U MS EXCEL 2007 i novijim verzijama rane verzije izračunati Standardna devijacija uzorka koristi se funkcija =STDEV(), eng. naziv STDEV, tj. standardna devijacija. Od MS EXCEL-a 2010 preporuča se koristiti njegov analog = STDEV.B () , eng. ime STDEV.S, tj. Standardno odstupanje uzorka.
Osim toga, počevši od verzije MS EXCEL 2010, postoji funkcija STDEV.G () , eng. naziv STDEV.P, tj. Standartno odstupanje populacije koje izračunava standardna devijacija Za populacija. Cijela razlika se svodi na nazivnik: umjesto n-1 kao STDEV.V() , STDEV.G() ima samo n u nazivniku.
Standardna devijacija također se može izračunati izravno iz formula u nastavku (pogledajte datoteku primjera)
=SQRT(SQUADROTIV(uzorak)/(BROJ(uzorak)-1))
=SQRT((SUMSQ(Uzorak)-BROJ(Uzorak)*PROSJEK(Uzorak)^2)/(BROJ(Uzorak)-1))
Ostale mjere disperzije
Funkcija SQUADRIVE() računa s umm kvadratnih odstupanja vrijednosti od njihovih sredini. Ova funkcija će vratiti isti rezultat kao formula =VAR.G( Uzorak)*ČEK( Uzorak) , Gdje Uzorak- referenca na raspon koji sadrži niz vrijednosti uzorka (). Izračuni u funkciji QUADROTIV() rade se prema formuli:

Funkcija SROOT() također je mjera raspršenosti skupa podataka. Funkcija AVERAGE() izračunava prosjek apsolutne vrijednosti odstupanja od sredini. Ova funkcija će vratiti isti rezultat kao formula =SUMPROIZVOD(ABS(Uzorak-PROSJEK(Uzorak)))/BROJ(Uzorak), Gdje Uzorak- referenca na raspon koji sadrži niz vrijednosti uzorka.
Izračuni u funkciji SROOTKL () izrađuju se prema formuli:

Međutim, sama ta karakteristika još nije dovoljna za proučavanje slučajne varijable. Zamislite dva strijelca koji gađaju metu. Jedan puca precizno i pogađa blizu centra, a drugi ... samo se zabavlja i uopće ne cilja. Ali ono što je smiješno je to prosjek rezultat će biti potpuno isti kao i kod prvog strijelca! Ovu situaciju uvjetno ilustriraju sljedeće slučajne varijable:
"Snajpersko" matematičko očekivanje jednako je, međutim, " zanimljiva ličnost»: - također je nula!
Stoga je potrebno kvantificirati koliko daleko raštrkani metaka (slučajne vrijednosti) u odnosu na središte mete ( matematičko očekivanje). dobro i raspršivanje prevedeno s latinskog samo kao disperzija .
Pogledajmo kako je to definirano. numerička karakteristika na jednom od primjera 1. dijela lekcije: 
Tamo smo pronašli razočaravajuće matematičko očekivanje ove igre, a sada moramo izračunati njegovu varijancu, koja označeno kroz .
Saznajmo koliko su dobici/gubici "raspršeni" u odnosu na prosječnu vrijednost. Očito, za ovo moramo izračunati Razlike između vrijednosti slučajne varijable i nju matematičko očekivanje:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Sada se čini da je potrebno zbrojiti rezultate, ali ovaj način nije dobar - iz razloga što će se oscilacije ulijevo poništiti s oscilacijama udesno. Tako, na primjer, strijelac "amater". (primjer iznad) razlike će biti ![]() , a kada se zbroje dat će nulu, pa nećemo dobiti nikakvu procjenu raspršenosti njegova pucanja.
, a kada se zbroje dat će nulu, pa nećemo dobiti nikakvu procjenu raspršenosti njegova pucanja.
Da biste izbjegli ovu smetnju, razmislite moduli razlike, ali je iz tehničkih razloga zaživio pristup kada su one na kvadrat. Pogodnije je rasporediti rješenje u tablicu: 
I ovdje se da izračunati prosječne težine vrijednost kvadrata odstupanja. Što je? Njihovo je očekivana vrijednost, što je mjera raspršenja:
![]() – definicija disperzija. Iz definicije je odmah jasno da varijanca ne može biti negativna- zabilježite za vježbu!
– definicija disperzija. Iz definicije je odmah jasno da varijanca ne može biti negativna- zabilježite za vježbu!
Prisjetimo se kako pronaći očekivanje. Pomnožite kvadrat razlike s odgovarajućim vjerojatnostima (nastavak tablice):
- slikovito rečeno, to je "vlačna sila",
i rezimirati rezultate:
Ne mislite li da je u pozadini dobitaka rezultat ispao prevelik? Tako je – kvadrirali smo, a da bismo se vratili na dimenziju naše igre, trebamo izvaditi kvadratni korijen. Ova vrijednost nazvao standardna devijacija
i označava se grčkim slovom "sigma":
Ponekad se ovo značenje naziva standardna devijacija .
Koje je njegovo značenje? Ako od matematičkog očekivanja odstupimo lijevo i desno za srednju vrijednost standardna devijacija:![]()
– tada će najvjerojatnije vrijednosti slučajne varijable biti “koncentrirane” na ovom intervalu. Što zapravo vidimo:
Međutim, dogodilo se da se u analizi raspršenja gotovo uvijek radi s pojmom disperzije. Pogledajmo što to znači u odnosu na igre. Ako u slučaju strijelaca govorimo o "točnosti" pogodaka u odnosu na središte mete, onda ovdje disperzija karakterizira dvije stvari:
Prvo, očito je da kako se stope povećavaju, varijanca se također povećava. Tako, na primjer, ako povećamo za 10 puta, tada će se matematičko očekivanje povećati za 10 puta, a varijanca će se povećati za 100 puta (čim je kvadratna vrijednost). Ali imajte na umu da se pravila igre nisu promijenila! Samo su se tečajevi promijenili, grubo rečeno, prije smo se kladili u 10 rubalja, sada u 100.
Drugo, više zanimljiva točka je da varijanca karakterizira stil igre. Mentalno popravite stope igre na nekoj određenoj razini, i pogledajte što je što ovdje:
Igra niske varijance je oprezna igra. Igrač nastoji odabrati najpouzdanije sheme, gdje ne gubi/pobjeđuje previše odjednom. Na primjer, crveno/crni sustav u ruletu (vidi primjer 4 članka slučajne varijable) .
Igra visoke varijance. Često je zovu disperzija igra. Ovo je avanturistički ili agresivni stil igre gdje igrač bira "adrenalinske" sheme. Da se barem prisjetimo "Posrtaljka", u kojoj su iznosi koji su u pitanju redovi veličina veći od "tihe" igre iz prethodnog paragrafa.
Indikativno je stanje u pokeru: postoje tzv tijesno igrači koji su skloni biti oprezni i "tresti" svojim sredstvima za igru (gomila novca). Nije iznenađujuće da njihov bankroll ne fluktuira puno (niska varijanca). Suprotno tome, ako igrač ima visoku varijancu, onda je on agresor. Često riskira, stavlja velike oklade i može razbiti veliku banku i raspasti se.
Ista stvar se događa na Forexu, i tako dalje - ima puno primjera.
Štoviše, u svim slučajevima nije važno je li igra za peni ili za tisuće dolara. Svaka razina ima svoje igrače niske i visoke varijance. Pa, za prosječnu pobjedu, kako se sjećamo, "zaslužan" očekivana vrijednost.
Vjerojatno ste primijetili da je pronalaženje varijance dug i mukotrpan proces. Ali matematika je velikodušna:
Formula za pronalaženje varijance
Ova formula proizašao izravno iz definicije varijance, te smo ga odmah stavili u promet. Kopirat ću ploču s našom igrom odozgo: 
i pronađeno očekivanje .
Varijancu računamo na drugi način. Prvo, pronađimo matematičko očekivanje - kvadrat slučajne varijable. Po definicija matematičkog očekivanja:
U ovaj slučaj:
Dakle, prema formuli:
Kako kažu, osjetite razliku. I u praksi je, naravno, bolje primijeniti formulu (osim ako uvjet ne zahtijeva drugačije).
Savladavamo tehniku rješavanja i projektiranja:
Primjer 6

Nađite njegovo matematičko očekivanje, varijancu i standardnu devijaciju.
Ova zadaća se nalazi posvuda, i u pravilu prolazi bez suvislog smisla.
Možete zamisliti nekoliko žarulja s brojevima koje svijetle u ludnici s određenim vjerojatnostima :)
Riješenje: Prikladno je sažeti glavne izračune u tablici. Prvo upisujemo početne podatke u gornja dva retka. Zatim izračunavamo umnoške, zatim i na kraju zbrojeve u desnom stupcu: 
Zapravo, gotovo je sve spremno. U trećem retku iscrtano je gotovo matematičko očekivanje: ![]() .
.
Disperzija se izračunava po formuli:
I na kraju, standardna devijacija:
- osobno obično zaokružujem na 2 decimale.
Svi izračuni mogu se provesti na kalkulatoru, a još bolje - u Excelu:
Ovdje je teško pogriješiti :)
Odgovor:
Oni koji žele mogu si još više pojednostaviti život i iskoristiti moje prednosti kalkulator (demo), koji ne samo da će trenutno riješiti ovaj zadatak, ali i graditi tematska grafika (dođi uskoro). Program može preuzeti u knjižnici– ako ste preuzeli barem jedan obrazovni materijal ili dobiti drugi način. Hvala na podršci projektu!
Par zadataka za neovisna odluka:
Primjer 7
Izračunajte varijancu slučajne varijable prethodnog primjera po definiciji.
I sličan primjer:
Primjer 8
Diskretna slučajna varijabla dana je vlastitim zakonom raspodjele:

Da, vrijednosti slučajne varijable mogu biti prilično velike (primjer iz pravi posao) , a ovdje po mogućnosti koristite Excel. Kao, usput, u primjeru 7 - brži je, pouzdaniji i ugodniji.
Rješenja i odgovori na dnu stranice.
Na kraju 2. dijela lekcije analizirat ćemo još jednu tipičan zadatak, reklo bi se, mali rebus:
Primjer 9
Diskretna slučajna varijabla može imati samo dvije vrijednosti: i , i . Poznati su vjerojatnost, matematičko očekivanje i varijanca.
Riješenje: Počnimo s nepoznatom vjerojatnošću. Budući da slučajna varijabla može imati samo dvije vrijednosti, tada je zbroj vjerojatnosti odgovarajućih događaja:
a budući da , onda .
Ostalo je pronaći..., lako je reći :) No, eto, počelo je. Prema definiciji matematičkog očekivanja: ![]() - zamijenite poznate vrijednosti:
- zamijenite poznate vrijednosti:
![]() - i ništa se više ne može izvući iz ove jednadžbe, osim što je možete prepisati u uobičajenom smjeru:
- i ništa se više ne može izvući iz ove jednadžbe, osim što je možete prepisati u uobičajenom smjeru: ![]()

ili: ![]()
OKO Sljedeći koraci Mislim da možete pogoditi. Kreirajmo i riješimo sustav: 
Decimale- ovo je, naravno, potpuna sramota; pomnožite obje jednadžbe s 10: 
i podijeliti sa 2: 
Tako je bolje. Iz 1. jednadžbe izražavamo: ![]() (ovo je lakši način)- zamjena u 2. jednadžbi:
(ovo je lakši način)- zamjena u 2. jednadžbi:
![]()
Mi gradimo na kvadrat i napraviti pojednostavljenja: 
Množimo sa: 
Kao rezultat, kvadratna jednadžba, pronađite njegovu diskriminantu:
- Sjajno!
i dobivamo dva rješenja:
1) ako ![]() , To
, To ![]() ;
;
2) ako ![]() , To .
, To .
Prvi par vrijednosti zadovoljava uvjet. S velikom vjerojatnošću, sve je točno, ali, ipak, zapisujemo zakon distribucije: 
i izvršite provjeru, naime, pronađite očekivanje:
Disperzija je mjera disperzije koja opisuje relativno odstupanje između vrijednosti podataka i srednje vrijednosti. To je najčešće korištena mjera disperzije u statistici, izračunata zbrajanjem, na kvadrat, odstupanja svake vrijednosti podataka od srednje vrijednosti. Formula za izračun varijance je prikazana u nastavku:
![]()
s 2 - varijanca uzorka;
x cf srednja vrijednost uzorka;
n — veličina uzorka (broj vrijednosti podataka),
(x i – x cf) je odstupanje od srednje vrijednosti za svaku vrijednost skupa podataka.
Za bolje razumijevanje formule, uzmimo primjer. Ne volim baš kuhati pa se time rijetko bavim. Međutim, kako ne bih umro od gladi, s vremena na vrijeme moram otići do štednjaka kako bih proveo plan zasićenja tijela bjelančevinama, mastima i ugljikohidratima. Skup podataka u nastavku pokazuje koliko puta Renat kuha hranu svaki mjesec:
Prvi korak u izračunavanju varijance je određivanje srednje vrijednosti uzorka, koja u našem primjeru iznosi 7,8 puta mjesečno. Preostali izračuni mogu se olakšati uz pomoć sljedeće tablice.

Konačna faza izračuna varijance izgleda ovako:
![]()
Za one koji vole sve izračune raditi odjednom, jednadžba će izgledati ovako:
Korištenje metode sirovog brojanja (primjer kuhanja)
Ima toga još učinkovita metoda izračunavanje varijance, poznato kao metoda "sirovog brojanja". Iako se na prvi pogled jednadžba može činiti prilično glomaznom, zapravo i nije tako strašna. To možete provjeriti, a zatim odlučiti koja vam se metoda najviše sviđa.

je zbroj svake vrijednosti podataka nakon kvadriranja,
je kvadrat zbroja svih vrijednosti podataka.
Nemoj sada izgubiti razum. Stavimo sve to u obliku tablice, pa ćete vidjeti da ovdje ima manje izračuna nego u prethodnom primjeru.


Kao što vidite, rezultat je isti kao kod prethodne metode. Prednosti ovu metodu postaju vidljivi kako veličina uzorka (n) raste.
Izračunavanje varijance u Excelu
Kao što ste vjerojatno već pogodili, Excel ima formulu koja vam omogućuje izračunavanje varijance. Štoviše, počevši od Excela 2010, možete pronaći 4 varijante disperzijske formule:
1) VAR.V - Vraća varijancu uzorka. Booleove vrijednosti i tekst se zanemaruju.
2) VAR.G - Vraća varijancu populacije. Booleove vrijednosti i tekst se zanemaruju.
3) VASP - Vraća varijancu uzorka, uzimajući u obzir Booleove i tekstualne vrijednosti.
4) VARP - Vraća varijancu populacije, uzimajući u obzir logičke i tekstualne vrijednosti.
Prvo, pogledajmo razliku između uzorka i populacije. Svrha opisne statistike je sažeti ili prikazati podatke na takav način da se brzo dobije velika slika, da tako kažemo, pregled. Statističko zaključivanje omogućuje vam da donosite zaključke o populaciji na temelju uzorka podataka iz te populacije. Populacija predstavlja sve moguće ishode ili mjerenja koja su nam od interesa. Uzorak je podskup populacije.
Na primjer, zanima nas ukupnost grupe učenika jednog od Ruska sveučilišta i trebamo odrediti prosječni rezultat grupe. Možemo računati prosječna izvedba učenika, a tada će rezultirajuća brojka biti parametar, jer će cijela populacija biti uključena u naše izračune. Međutim, ako želimo izračunati GPA svih učenika u našoj zemlji, onda će ova grupa biti naš uzorak.
Razlika u formuli za izračun varijance između uzorka i populacije je u nazivniku. Pri čemu će za uzorak biti jednak (n-1), a za opću populaciju samo n.
Sada se pozabavimo funkcijama izračuna varijance sa završecima A, u čijem opisu je rečeno da izračun uzima u obzir tekstualne i logičke vrijednosti. U ovom slučaju, kada se izračunava varijanca određenog niza podataka, tamo gdje ih nema brojčane vrijednosti, Excel će interpretirati tekst i lažne Booleove vrijednosti kao 0, a prave Booleove vrijednosti kao 1.
Dakle, ako imate niz podataka, neće biti teško izračunati njegovu varijancu pomoću jedne od gore navedenih Excel funkcija.

Raspon varijacije (ili raspon varijacije) - je razlika između maksimuma i minimalne vrijednosti znak:
U našem primjeru raspon varijacije smjenskog učinka radnika je: u prvoj brigadi R=105-95=10 djece, u drugoj brigadi R=125-75=50 djece. (5 puta više). To sugerira da je proizvodnja 1. brigade "stabilnija", ali druga brigada ima više rezervi za rast proizvodnje, jer. ako svi radnici postignu maksimalni učinak za ovu brigadu, ona može proizvesti 3 * 125 = 375 dijelova, au 1. brigadi samo 105 * 3 = 315 dijelova.
Ako ekstremne vrijednosti osobine nisu tipične za populaciju, tada se koriste kvartilni ili decilni rasponi. Kvartilni raspon RQ= Q3-Q1 pokriva 50% stanovništva, prvi decilni raspon RD1 = D9-D1 pokriva 80% podataka, drugi decilni raspon RD2= D8-D2 pokriva 60%.
Nedostatak indikatora raspon varijacija jest, ali da njegova vrijednost ne odražava sve fluktuacije atributa.
Najjednostavniji generalizirajući pokazatelj koji odražava sve fluktuacije neke osobine je srednje linearno odstupanje, što je aritmetička sredina apsolutnih odstupanja pojedinih opcija od njihove prosječne vrijednosti:
,
za grupirane podatke ![]() ,
,
gdje je hi vrijednost obilježja u diskretne serije ili sredina intervala u intervalnoj distribuciji.
U gornjim formulama, razlike u brojniku se uzimaju modulo, inače će prema svojstvu aritmetičke sredine brojnik uvijek biti jednak nuli. Stoga se prosječno linearno odstupanje u statističkoj praksi rijetko koristi, samo u slučajevima kada zbrajanje pokazatelja bez uzimanja u obzir predznaka ima ekonomski smisao. Uz njegovu pomoć analizira se, primjerice, sastav zaposlenih, rentabilnost proizvodnje, vanjskotrgovinski promet.
Varijanca obilježja- Ovo srednji trg odstupanja varijante od njihove prosječne vrijednosti:
jednostavna varijanca ![]() ,
,
ponderirana varijanca  .
.
Formula za izračun varijance može se pojednostaviti:
Dakle, varijanca je jednaka razlici između srednje vrijednosti kvadrata varijante i kvadrata srednje vrijednosti varijante populacije:  .
.
Međutim, zbog zbrajanja kvadrata odstupanja, varijanca daje iskrivljenu predodžbu o odstupanjima, pa se iz nje izračunava prosjek. standardna devijacija, koji pokazuje koliko pojedine varijante atributa u prosjeku odstupaju od svoje prosječne vrijednosti. Izračunato izdvajanjem korijen iz disperzije:
za negrupirane podatke 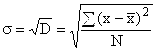 ,
,
Za varijacijske serije
Kako manje vrijednosti disperzije i standardne devijacije, što je populacija homogenija, to će biti pouzdanija (tipična). Prosječna vrijednost.
Linearna sredina i srednja vrijednost standardna devijacija- imenovani brojevi, odnosno izraženi su mjernim jedinicama atributa, identični su po sadržaju i bliski po značenju.
računati apsolutni pokazatelji varijacije se preporučuju korištenjem tablica.
Tablica 3 - Izračun karakteristika varijacije (na primjeru razdoblja podataka o smjenskom učinku radnih timova)
Broj radnika |
Sredina intervala |
Procijenjene vrijednosti |
|||||
Ukupno: |
|||||||
Prosječna smjena rada radnika: ![]()
Prosječno linearno odstupanje: ![]()
Izlazna disperzija: 
Standardna devijacija učinka pojedinačnih radnika od prosječnog učinka:
.
1 Proračun disperzije metodom momenata
Izračun varijanci povezan je s glomaznim izračunima (osobito ako je izražena prosječna vrijednost veliki broj s više decimalnih mjesta). Izračuni se mogu pojednostaviti korištenjem pojednostavljene formule i svojstava disperzije.
Disperzija ima sljedeća svojstva:
- ako su sve vrijednosti atributa smanjene ili povećane za istu vrijednost A, tada se varijanca neće smanjiti od ovoga:
 ,
,
 , zatim ili
, zatim ili 
Koristeći svojstva varijance i prvo reducirajući sve varijante populacije za vrijednost A, a zatim dijeleći s vrijednošću intervala h, dobivamo formulu za izračunavanje varijance u varijacijskom nizu s u jednakim razmacima put od trenutaka: ,
,
gdje je disperzija izračunata metodom momenata;
h je vrijednost intervala varijacijskog niza;
– nove (transformirane) varijantne vrijednosti;
A- konstantno, koji se koristi kao sredina intervala s najvećom frekvencijom; ili opciju koja ima najveća frekvencija;  je kvadrat momenta prvog reda;
je kvadrat momenta prvog reda;
je moment drugog reda.
Izračunajmo varijancu metodom momenata na temelju podataka o smjenskom učinku radnog tima.
Tablica 4 - Proračun disperzije metodom momenata
Grupe proizvodnih radnika, kom. |
Broj radnika |
Sredina intervala |
Procijenjene vrijednosti |
||
Postupak izračuna:


- izračunaj varijancu:
2 Izračun varijance alternativnog obilježja
Među znakovima koje proučava statistika postoje oni koji imaju samo dva međusobno isključiva značenja. Ovo su alternativni znakovi. Daju im se dva kvantitativne vrijednosti: opcije 1 i 0. Učestalost opcije 1, koja je označena s p, je udio jedinica koje imaju određeno svojstvo. Razlika 1-p=q je frekvencija opcija 0. Dakle,
xi |
|
Aritmetička sredina alternativnog obilježja ![]() , jer je p+q=1.
, jer je p+q=1.
Varijanca obilježja
, jer 1-p=q
Dakle, varijanca alternativnog atributa jednaka je umnošku udjela jedinica koje imaju taj atribut i udjela jedinica koje ga nemaju.
Ako su vrijednosti 1 i 0 jednako učestale, tj. p=q, varijanca dostiže svoj maksimum pq=0,25.
Varijanca alternativnog obilježja koristi se u ogledna istraživanja kao što je kvaliteta proizvoda.
3 Međugrupna disperzija. Pravilo zbrajanja varijance
Disperzija, za razliku od drugih karakteristika varijacije, je aditivna količina. Odnosno u agregatu koji je podijeljen u skupine prema faktorskom kriteriju x , rezultantna varijanca g može se rastaviti na varijancu unutar svake skupine (unutar skupine) i varijancu između skupina (između skupina). Zatim, uz proučavanje varijacije svojstva kroz populaciju kao cjelinu, postaje moguće proučavati varijacije u svakoj skupini, kao i između tih skupina.
Ukupna varijanca mjeri varijaciju osobine na nad cijelom populacijom pod utjecajem svih faktora koji su uzrokovali tu varijaciju (odstupanja). Jednaka je srednjem kvadratu odstupanja pojedinačne vrijednosti znak na ukupne srednje vrijednosti i može se izračunati kao jednostavna ili ponderirana varijanca.
Međugrupna varijanca karakterizira varijaciju efektivne značajke na, uzrokovan utjecajem predznaka-faktora x u osnovi grupiranja. On karakterizira varijaciju grupnih srednjih vrijednosti i jednak je srednjem kvadratu odstupanja grupnih srednjih vrijednosti od ukupne srednje vrijednosti:  ,
,
gdje je aritmetička sredina i-te skupine;
– broj jedinica u i-toj skupini (učestalost i-te skupine);
- Općenito populacijska srednja vrijednost.
Intragrupna varijanca odražava slučajnu varijaciju, tj. onaj dio varijacije koji je uzrokovan utjecajem neobračunatih čimbenika i ne ovisi o faktoru atributa koji je u osnovi grupiranja. Karakterizira varijaciju pojedinačne vrijednosti u odnosu na grupne sredine, jednake srednjem kvadratu odstupanja pojedinačnih vrijednosti atributa na unutar skupine iz aritmetičke sredine te skupine (srednja vrijednost skupine) i izračunava se kao jednostavna ili ponderirana varijanca za svaku skupinu: ![]() ili
ili ![]() ,
,
gdje je broj jedinica u grupi.
Na temelju unutargrupne varijance za svaku skupinu može se odrediti ukupni prosjek varijanci unutar grupe:
.
Odnos između tri varijance naziva se pravila zbrajanja varijance, prema kojem je ukupna varijanca jednaka zbroju međugrupne varijance i prosjeka unutargrupne varijance:
Primjer. Proučavanjem utjecaja tarifnog razreda (kvalifikacije) radnika na razinu proizvodnosti njihova rada došlo se do sljedećih podataka.
Tablica 5 - Raspodjela radnika po prosječnom satnom učinku.
№ p/p |
Radnici 4. kategorije |
Radnici V kategorije |
|||||
Vježbati |
Vježbati |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
U ovaj primjer radnici su prema faktorskom kriteriju podijeljeni u dvije skupine x- kvalifikacije, koje karakterizira njihov rang. Efektivno svojstvo - proizvodnja - varira kako pod njegovim utjecajem (međugrupna varijacija), tako i zbog drugih slučajnih čimbenika (unutargrupna varijacija). Izazov je izmjeriti te varijacije koristeći tri varijance: ukupnu, između grupa i unutar grupe. Empirijski koeficijent determinacije pokazuje udio varijacije rezultirajuće značajke na pod utjecajem znaka faktora x. Ostatak opća varijacija na uzrokovane promjenama drugih čimbenika.
U primjeru, empirijski koeficijent determinacije je: ![]() ili 66,7 posto
ili 66,7 posto
To znači da je 66,7% varijacija u produktivnosti rada radnika posljedica razlika u kvalifikacijama, a 33,3% utjecaja drugih čimbenika.
Empirijski korelacijski odnos pokazuje tijesnost odnosa između grupiranja i učinkovitih značajki. Izračunava se kao kvadratni korijen empirijskog koeficijenta determinacije:
Empirijski omjer korelacije, kao i , može poprimiti vrijednosti od 0 do 1.
Ako nema veze, tada je =0. U ovom slučaju =0, tj. grupne srednje vrijednosti su međusobno jednake i nema međugrupne varijacije. To znači da znak grupiranja - faktor ne utječe na formiranje opće varijacije.
Ako je odnos funkcionalan, tada je =1. U ovom slučaju, varijanca grupne sredine je ukupna varijanca(), to jest, nema unutargrupne varijacije. To znači da značajka grupiranja u potpunosti određuje varijaciju rezultirajuće značajke koja se proučava.
Što je vrijednost korelacijskog odnosa bliža jedinici, to je odnos između obilježja bliži, bliži funkcionalnoj ovisnosti.
Za kvalitativnu procjenu bliskosti veze između znakova koriste se Chaddockovi odnosi.
U primjeru ![]() , što ukazuje bliska veza između produktivnosti radnika i njihove kvalifikacije.
, što ukazuje bliska veza između produktivnosti radnika i njihove kvalifikacije.
 "Ne odgađaj za sutra ono što možeš odgoditi za prekosutra" - Mark Twain
"Ne odgađaj za sutra ono što možeš odgoditi za prekosutra" - Mark Twain "Tajna promjene je fokusiranje na stvaranje novog, a ne borba protiv starog" - Sokrat
"Tajna promjene je fokusiranje na stvaranje novog, a ne borba protiv starog" - Sokrat Tumačenje heksagrama 15 je najtočnije
Tumačenje heksagrama 15 je najtočnije