Vẽ biểu đồ trạng thái cho một chuỗi Markov. Chuỗi Markov đồng nhất
1. ma trận R2 chuỗi chuyển đổi từ trạng thái tôi vào một trạng thái j hai
bước chân;
2. phân phối xác suất qua các trạng thái tại thời điểm này t=2;
3. xác suất mà tại thời điểm này t= 1 trạng thái mạch sẽ là A2;
4. phân phối tĩnh.
Quyết định.Đối với một chuỗi Markov rời rạc trong trường hợp đồng nhất của nó, mối quan hệ
trong đó P1 là ma trận xác suất chuyển đổi trong một bước;
Pn - ma trận xác suất chuyển đổi cho n bước;
1. Tìm ma trận chuyển tiếp P2 trong hai bước
Hãy để phân phối xác suất trên các trạng thái trên S-bước thứ được xác định bởi vectơ
.
Biết ma trận PN chuyển đổi trong n bước, có thể xác định phân phối xác suất qua các trạng thái trên (S +N)-bước thứ ![]() . (5)
. (5)
2. Tìm phân phối xác suất qua các trạng thái của hệ thống tại thời điểm t= 2. Chúng tôi đưa vào (5) S= 0 và N= 2. sau đó ![]() .
.
Chúng tôi nhận được .
3. Tìm phân phối xác suất qua các trạng thái của hệ thống tại thời điểm t=1.
Chúng tôi đưa vào (5) S= 0 và N= 1, sau đó.
Làm thế nào bạn có thể thấy rằng xác suất mà tại thời điểm này t= 1 trạng thái mạch sẽ là A2, bằng p2 (1)=0,69.
Phân bố xác suất qua các trạng thái được gọi là tĩnh nếu nó không thay đổi từ bước này sang bước khác, nghĩa là
Thì từ quan hệ (5) lúc N= 1 chúng tôi nhận được
4. Tìm sự phân bố tĩnh. Vì = 2 nên ta có = (p1; p2). Hãy viết hệ phương trình tuyến tính (6) dưới dạng tọa độ

Điều kiện cuối cùng được gọi là chuẩn hóa. Trong hệ (6), một phương trình luôn là tổ hợp tuyến tính của các phương trình khác. Do đó, nó có thể bị xóa. Chúng ta hãy cùng nhau giải phương trình đầu tiên của hệ thống và phương trình chuẩn hóa. Chúng tôi có 0,6 p1=0,3p2, I E p2=2p1. sau đó p1+2p1= 1 hoặc, nghĩa là. Vì thế, .
Trả lời:
1) ma trận chuyển tiếp hai bước cho một chuỗi Markov nhất định có dạng ![]() ;
;
2) phân phối xác suất trên các trạng thái tại thời điểm này t= 2 bằng ![]() ;
;
3) xác suất mà tại thời điểm này t= 1 trạng thái mạch sẽ là A2, bằng p2 (t)=0,69;
4) phân phối tĩnh có dạng
Cho một ma trận  cường độ chuyển đổi của một chuỗi Markov liên tục. Lập đồ thị trạng thái có nhãn tương ứng với ma trận Λ; soạn một hệ phương trình vi phân Kolmogorov cho các xác suất trạng thái; tìm phân phối xác suất giới hạn. Quyết định. Chuỗi Markov đồng nhất với một số trạng thái hữu hạn A1, A2,…NHƯNGđược đặc trưng bởi ma trận cường độ chuyển tiếp
cường độ chuyển đổi của một chuỗi Markov liên tục. Lập đồ thị trạng thái có nhãn tương ứng với ma trận Λ; soạn một hệ phương trình vi phân Kolmogorov cho các xác suất trạng thái; tìm phân phối xác suất giới hạn. Quyết định. Chuỗi Markov đồng nhất với một số trạng thái hữu hạn A1, A2,…NHƯNGđược đặc trưng bởi ma trận cường độ chuyển tiếp  ,
,
ở đâu ![]() - cường độ của quá trình chuyển đổi chuỗi Markov từ trạng thái AI vào một trạng thái Aj; рij (Δt)- xác suất chuyển tiếp Ai & rarr;Aj mỗi khoảng thời gian Δ
t.
- cường độ của quá trình chuyển đổi chuỗi Markov từ trạng thái AI vào một trạng thái Aj; рij (Δt)- xác suất chuyển tiếp Ai & rarr;Aj mỗi khoảng thời gian Δ
t.
Thật tiện lợi khi chỉ định chuyển đổi hệ thống từ trạng thái này sang trạng thái khác bằng cách sử dụng biểu đồ trạng thái được gắn nhãn, trên đó các cung tương ứng với cường độ được đánh dấu λ
ij> 0. Soạn một biểu đồ trạng thái được gắn nhãn cho một ma trận cường độ chuyển đổi nhất định 
Gọi là vectơ xác suất Rj (t),
j= 1, 2,… ,, hệ thống ở trạng thái NHƯNGj trong thời điểm này t.
Rõ ràng là 0≤ Rj (t)≤1 và. Sau đó, theo quy tắc phân biệt của hàm vectơ của đối số vô hướng, chúng ta thu được ![]() . Xác suất Rj (t) thỏa mãn hệ phương trình vi phân Kolmogorov (SDUK), ở dạng ma trận có dạng. (7)
. Xác suất Rj (t) thỏa mãn hệ phương trình vi phân Kolmogorov (SDUK), ở dạng ma trận có dạng. (7)
Nếu tại thời điểm ban đầu, hệ thống ở trạng thái Aj, thì SDUK sẽ được giải quyết trong các điều kiện ban đầu
Rtôi(0) = 1, рj (0) = 0, j ≠ i,j = 1, 2,…,.
(8)
Tập hợp SDUK (7) và điều kiện ban đầu (8) mô tả duy nhất một chuỗi Markov thuần nhất với thời gian liên tục và một số trạng thái hữu hạn.
Hãy để chúng tôi tạo SDUK cho một chuỗi Markov nhất định. Kể từ = 3, sau đó j=1, 2, 3.
Từ quan hệ (7) chúng ta thu được  .
.
Do đó chúng tôi sẽ có 
Điều kiện cuối cùng được gọi là chuẩn hóa.
Phân phối xác suất qua các trạng thái được gọi là đứng im, nếu nó không thay đổi theo thời gian, nghĩa là, ở đâu Rj =hăng sô, j= 1,2,…,. Từ đây ![]() .
.
Sau đó, từ SDUK (7), chúng tôi thu được một hệ thống để tìm phân phối tĩnh ![]() (9)
(9)
Đối với vấn đề này từ SDUK, chúng tôi sẽ có 
Từ điều kiện chuẩn hóa, chúng tôi thu được 3p2 + p2 + p2 = 1 hoặc ![]() . Do đó, phân phối giới hạn có dạng.
. Do đó, phân phối giới hạn có dạng.
Lưu ý rằng kết quả này có thể thu được trực tiếp từ biểu đồ trạng thái được dán nhãn bằng cách sử dụng quy tắc: đối với phân phối tĩnh, tổng các sản phẩm λ
jisố Pi, j ≠tôi, cho các mũi tên xuất hiện từ tôi trạng thái thứ bằng tổng của các sản phẩm λ
jisố Pi, j ≠tôi, đối với các mũi tên được bao gồm trong tôi trạng thái thứ. Thật sự, 
Rõ ràng là hệ thống kết quả tương đương với hệ thống được biên dịch theo SDUK. Do đó, nó có cùng một giải pháp.
Trả lời: phân phối tĩnh có dạng.
Chuỗi Markov là một chuỗi các sự kiện trong đó mỗi sự kiện tiếp theo phụ thuộc vào sự kiện trước đó. Trong bài viết chúng tôi sẽ phân tích chi tiết hơn về khái niệm này.
Chuỗi Markov là một cách phổ biến và khá đơn giản để lập mô hình các sự kiện ngẫu nhiên. Nó được sử dụng trong nhiều lĩnh vực khác nhau, từ tạo văn bản đến mô hình tài chính. Ví dụ nổi tiếng nhất là SubredditSimulator. Trong trường hợp này, Chuỗi Markov đang được sử dụng để tự động tạo nội dung trên toàn bộ subreddit.
Chuỗi Markov rõ ràng và dễ sử dụng vì nó có thể được thực hiện mà không cần sử dụng bất kỳ khái niệm thống kê hoặc toán học nào. Chuỗi Markov lý tưởng để nghiên cứu mô hình xác suất và khoa học dữ liệu.
Kịch bản
Hãy tưởng tượng rằng chỉ có hai điều kiện thời tiết: trời nắng hoặc trời nhiều mây. Bạn luôn có thể xác định chính xác thời tiết tại thời điểm hiện tại. Đảm bảo trong hoặc nhiều mây.
Bây giờ bạn muốn học cách dự đoán thời tiết cho ngày mai. Bằng trực giác, bạn hiểu rằng thời tiết không thể thay đổi đột ngột trong một ngày. Nhiều yếu tố ảnh hưởng đến điều này. Thời tiết ngày mai phụ thuộc trực tiếp vào thời tiết hiện tại, v.v. Vì vậy, để dự đoán thời tiết, bạn thu thập dữ liệu của nhiều năm và đi đến kết luận rằng sau một ngày nhiều mây, xác suất ngày nắng là 0,25. Thật hợp lý khi giả định rằng xác suất của hai ngày nhiều mây liên tiếp là 0,75, vì chúng ta chỉ có hai điều kiện thời tiết có thể xảy ra.

Bây giờ bạn có thể dự đoán thời tiết trong vài ngày tới dựa trên thời tiết hiện tại.
Ví dụ này cho thấy các khái niệm chính của chuỗi Markov. Chuỗi Markov bao gồm một tập hợp các chuyển đổi được xác định bởi phân phối xác suất, do đó thỏa mãn thuộc tính Markov.
Lưu ý rằng trong ví dụ này, phân phối xác suất chỉ phụ thuộc vào sự chuyển đổi từ ngày hiện tại sang ngày tiếp theo. Đây là một thuộc tính duy nhất của quy trình Markov - nó thực hiện điều này mà không cần sử dụng bộ nhớ. Theo quy luật, cách tiếp cận như vậy không thể tạo ra một chuỗi trong đó bất kỳ xu hướng nào sẽ được quan sát. Ví dụ, trong khi chuỗi Markov có thể mô phỏng phong cách viết dựa trên tần suất xuất hiện của một từ, nó không thể tạo ra các văn bản có ý nghĩa sâu sắc, vì nó chỉ có thể hoạt động với các văn bản lớn. Đây là lý do tại sao một chuỗi Markov không thể tạo ra nội dung phụ thuộc vào ngữ cảnh.
Mô hình
Về mặt hình thức, chuỗi Markov là một máy tự động hóa có xác suất. Phân phối xác suất chuyển đổi thường được biểu diễn dưới dạng ma trận. Nếu chuỗi Markov có N trạng thái khả dĩ, thì ma trận sẽ có dạng N x N, trong đó mục nhập (I, J) sẽ là xác suất chuyển từ trạng thái I sang trạng thái J. Ngoài ra, ma trận như vậy phải ngẫu nhiên. nghĩa là các hàng hoặc cột phải thêm vào một. Trong một ma trận như vậy, mỗi hàng sẽ có phân phối xác suất riêng.

Hình ảnh tổng quát của một chuỗi Markov với các trạng thái ở dạng vòng tròn và các cạnh ở dạng chuyển tiếp.

Ma trận chuyển tiếp gần đúng với ba trạng thái khả dĩ.
Một chuỗi Markov có một vectơ trạng thái ban đầu, được biểu diễn dưới dạng ma trận N x 1. Nó mô tả các phân phối xác suất của việc bắt đầu trong mỗi N trạng thái có thể có. Mục nhập I mô tả xác suất bắt đầu chuỗi ở trạng thái I.
Hai cấu trúc này đủ để đại diện cho một chuỗi Markov.
Chúng ta đã thảo luận về cách lấy xác suất chuyển từ trạng thái này sang trạng thái khác, nhưng còn xác suất này trong một số bước thì sao? Để làm được điều này, chúng ta cần xác định xác suất chuyển từ trạng thái I sang trạng thái J trong M bước. Nó thực sự rất đơn giản. Ma trận chuyển tiếp P có thể được xác định bằng cách tính (I, J) bằng cách nâng P lên lũy thừa của M. Đối với các giá trị nhỏ của M, điều này có thể được thực hiện thủ công bằng phép nhân lặp lại. Nhưng đối với các giá trị lớn của M, nếu bạn đã quen thuộc với đại số tuyến tính, thì một cách hiệu quả hơn để tính lũy thừa ma trận là đầu tiên phải tính đường chéo ma trận đó.
Chuỗi Markov: kết luận
Giờ đây, khi biết chuỗi Markov là gì, bạn có thể dễ dàng triển khai nó bằng một trong các ngôn ngữ lập trình. Chuỗi Markov đơn giản là nền tảng để học các kỹ thuật mô hình phức tạp hơn.
Tất cả các trạng thái có thể có của hệ thống trong một chuỗi Markov đồng nhất và là ma trận ngẫu nhiên xác định chuỗi này, bao gồm các xác suất chuyển đổi ![]() (Xem trang 381).
(Xem trang 381).
Biểu thị bằng xác suất hệ thống ở trạng thái tại một thời điểm nếu biết rằng tại thời điểm đó hệ thống đang ở trạng thái (,). Chắc chắn, ![]() . Sử dụng các định lý về phép cộng và phép nhân các xác suất, chúng ta có thể dễ dàng tìm thấy:
. Sử dụng các định lý về phép cộng và phép nhân các xác suất, chúng ta có thể dễ dàng tìm thấy:
![]()
![]()
hoặc trong ký hiệu ma trận
![]()
Do đó, liên tiếp đưa ra các giá trị của, chúng ta thu được công thức quan trọng
Nếu có giới hạn
![]()
hoặc trong ký hiệu ma trận
![]()
sau đó số lượng ![]() được gọi là xác suất chuyển tiếp giới hạn hoặc cuối cùng.
được gọi là xác suất chuyển tiếp giới hạn hoặc cuối cùng.
Để tìm ra những trường hợp nào có xác suất chuyển tiếp giới hạn và để suy ra các công thức tương ứng, chúng tôi giới thiệu thuật ngữ sau.
Chúng ta sẽ gọi một ma trận ngẫu nhiên và chuỗi Markov thuần nhất tương ứng là đúng nếu ma trận không có các số đặc trưng khác với sự thống nhất và bằng nhau về giá trị tuyệt đối cho sự thống nhất, và chính quy nếu sự đồng nhất cũng là một căn đơn giản của phương trình đặc trưng của ma trận .
Một ma trận thông thường được đặc trưng bởi thực tế là ở dạng bình thường của nó (69) (trang 373), các ma trận là nguyên thủy. Đối với một ma trận thông thường, ngoài ra.
Ngoài ra, một chuỗi Markov đồng nhất được gọi là không thể phân hủy, có thể phân hủy, xoay vòng, tuần hoàn, nếu đối với chuỗi này, ma trận ngẫu nhiên tương ứng là không thể phân hủy, có thể phân hủy, nguyên thủy, dấu ấn.
Vì ma trận ngẫu nhiên nguyên thủy là một loại đặc biệt của ma trận chính quy, nên chuỗi Markov xoay chiều là một loại đặc biệt của chuỗi thông thường.
Chúng tôi sẽ chỉ ra rằng giới hạn xác suất chuyển đổi chỉ tồn tại đối với các chuỗi Markov đồng nhất thông thường.
Thật vậy, hãy là đa thức tối giản của một ma trận thông thường. sau đó
Theo Định lý 10, chúng ta có thể giả định rằng
Dựa trên công thức (24) Ch. V (trang 113)
 (96)
(96)
ở đâu ![]() là ma trận liền kề rút gọn và
là ma trận liền kề rút gọn và

Nếu là một ma trận thông thường, thì
và do đó ở phía bên phải của công thức (96) tất cả các số hạng, ngoại trừ số hạng đầu tiên, có xu hướng bằng không. Do đó, đối với một ma trận thông thường, có một ma trận bao gồm các xác suất chuyển đổi giới hạn, và
Điều ngược lại là hiển nhiên. Nếu có một khoảng cách
thì ma trận không thể có một số đặc trưng cho nó, nhưng, vì từ đó sẽ không có giới hạn [Phải tồn tại cùng một giới hạn do sự tồn tại của giới hạn (97 ").]
Chúng tôi đã chứng minh rằng đối với một chuỗi Markov đồng nhất đúng (và duy nhất) thì tồn tại một ma trận. Ma trận này được xác định theo công thức (97).
Hãy để chúng tôi chỉ ra cách ma trận có thể được biểu diễn dưới dạng đa thức đặc trưng
và ma trận liên quan ![]() .
.
Từ danh tính
nhờ (95), (95 ") và (98) nó như sau:

Do đó, công thức (97) có thể được thay thế bằng công thức
 (97)
(97)
Đối với chuỗi Markov thông thường, vì nó là một loại cụ thể của chuỗi thông thường, ma trận tồn tại và được xác định bởi bất kỳ công thức nào trong số các công thức (97), (97 "). Trong trường hợp này, công thức (97") cũng có dạng
2. Hãy xem xét một chuỗi đều đặn thuộc loại tổng quát (không thường xuyên). Ta viết ma trận tương ứng ở dạng bình thường
 (100)
(100)
đâu là ma trận ngẫu nhiên nguyên thủy và ma trận không phân hủy có số đặc trưng tối đa. Giả định
 ,
, 
viết theo mẫu

 (101)
(101)

Nhưng ![]() , vì tất cả các số đặc trưng của ma trận nhỏ hơn sự thống nhất về giá trị tuyệt đối. Cho nên
, vì tất cả các số đặc trưng của ma trận nhỏ hơn sự thống nhất về giá trị tuyệt đối. Cho nên
 (102)
(102)
Vì là ma trận ngẫu nhiên nguyên thủy, nên ma trận theo công thức (99) và (35) (trang 362) là dương
![]()
và trong mỗi cột của bất kỳ ma trận nào trong số này, tất cả các phần tử đều bằng nhau:
![]() .
.
Lưu ý rằng dạng chuẩn (100) của ma trận ngẫu nhiên tương ứng với việc phân chia các trạng thái của hệ thống thành các nhóm:
Mỗi nhóm trong (104) tương ứng với nhóm riêng của chuỗi trong (101). Theo thuật ngữ của L. N. Kolmogorov, các trạng thái của hệ thống bao gồm trong đó được gọi là bản chất, và các trạng thái trong các nhóm còn lại được gọi là không thiết yếu.
Nó theo sau dạng (101) của ma trận mà đối với bất kỳ số lượng hữu hạn bước nào (từ thời điểm này sang thời điểm khác), chỉ có thể chuyển hệ thống a) từ trạng thái cơ bản sang trạng thái cơ bản của cùng một nhóm, b ) từ trạng thái không đáng kể sang trạng thái cơ bản và c) từ trạng thái không đáng kể sang trạng thái không thiết yếu của cùng một nhóm hoặc một nhóm trước đó.
Từ dạng (102) của ma trận, theo đó, trong quá trình chuyển đổi chỉ có thể từ bất kỳ trạng thái nào sang trạng thái cơ bản, tức là xác suất chuyển đổi sang bất kỳ trạng thái không đáng kể nào có xu hướng bằng không với số bước. Do đó, các trạng thái thiết yếu đôi khi còn được gọi là trạng thái giới hạn.
3. Từ công thức (97) nó như sau:
![]() .
.
Điều này cho thấy rằng mỗi cột của ma trận là một ký hiệu riêng của ma trận ngẫu nhiên cho số đặc trưng.
Đối với ma trận thông thường, số 1 là căn đơn giản của phương trình đặc trưng và số này chỉ tương ứng với một ký hiệu ma trận (tối đa là hệ số vô hướng). Do đó, trong bất kỳ cột thứ nào của ma trận, tất cả các phần tử đều bằng cùng một số không âm:
Do đó, trong một chuỗi thông thường, các xác suất chuyển đổi giới hạn không phụ thuộc vào trạng thái ban đầu.
Ngược lại, nếu trong một số chuỗi Markov thuần nhất thông thường, các xác suất chuyển đổi riêng lẻ không phụ thuộc vào trạng thái ban đầu, tức là các công thức (104) được giữ, thì trong sơ đồ (102) cho ma trận,. Nhưng sau đó dây chuyền cũng đều đặn.
Đối với một chuỗi mạch hở, là một trường hợp đặc biệt của chuỗi thông thường, là một ma trận nguyên thủy. Do đó, đối với một số (xem Định lý 8 trên trang 377). Nhưng sau đó và ![]() .
.
Ngược lại, từ đó kéo theo điều đó đối với một số, và điều này, theo Định lý 8, có nghĩa là ma trận là nguyên thủy và do đó, chuỗi Markov thuần nhất đã cho là mạch hở.
Chúng ta lập các kết quả thu được dưới dạng định lý sau:
Định lý 11. 1. Để tất cả các xác suất chuyển tiếp giới hạn tồn tại trong một chuỗi Markov thuần nhất, thì cần và đủ rằng chuỗi đó phải đều đặn. Trong trường hợp này, ma trận, bao gồm các xác suất chuyển đổi giới hạn, được xác định theo công thức (95) hoặc (98).
2. Để xác suất chuyển đổi giới hạn không phụ thuộc vào trạng thái ban đầu trong chuỗi Markov đồng nhất thông thường, thì cần và đủ rằng chuỗi phải đều đặn. Trong trường hợp này, ma trận được xác định theo công thức (99).
3. Để tất cả các xác suất chuyển tiếp giới hạn khác 0 trong một chuỗi Markov đồng nhất thông thường, thì cần và đủ rằng chuỗi đó phải là mạch vòng.
4. Hãy để chúng tôi giới thiệu các cột xác suất tuyệt đối
![]() (105)
(105)
xác suất hệ thống đang ở trạng thái (,) vào lúc này là ở đâu. Sử dụng các định lý cộng và nhân các xác suất, chúng ta thấy:
![]() (,),
(,),
hoặc trong ký hiệu ma trận
đâu là ma trận chuyển vị cho ma trận.
Tất cả các xác suất tuyệt đối (105) được xác định từ công thức (106) nếu biết các xác suất ban đầu và ma trận xác suất chuyển đổi
Hãy để chúng tôi giới thiệu về các xác suất tuyệt đối giới hạn
![]()
Chuyển cả hai phần của bằng nhau (106) đến giới hạn tại, chúng ta thu được:
Lưu ý rằng sự tồn tại của một ma trận giới hạn các xác suất chuyển đổi ngụ ý rằng sự tồn tại của các xác suất tuyệt đối giới hạn ![]() cho bất kỳ xác suất ban đầu nào
cho bất kỳ xác suất ban đầu nào ![]() và ngược lại.
và ngược lại.
Từ công thức (107) và từ dạng (102) của ma trận, xác suất tuyệt đối giới hạn tương ứng với các trạng thái không đáng kể bằng không.
Nhân cả hai vế của đẳng thức ma trận
ở bên phải, chúng tôi, nhờ (107), có được:
tức là, cột xác suất tuyệt đối cận biên là ký hiệu riêng của ma trận cho số đặc trưng.
Nếu chuỗi Markov đã cho là chính quy, thì nó là một căn đơn giản của phương trình đặc trưng của ma trận. Trong trường hợp này, cột giới hạn xác suất tuyệt đối được xác định duy nhất từ (108) (vì và).
Cho một chuỗi Markov thông thường. Sau đó từ (104) và từ (107) nó như sau:
![]() (109)
(109)
Trong trường hợp này, các xác suất tuyệt đối giới hạn không phụ thuộc vào các xác suất ban đầu.
Ngược lại, có thể không phụ thuộc vào sự có mặt của công thức (107) nếu và chỉ khi tất cả các hàng của ma trận đều giống nhau, tức là
![]() ,
,
và do đó (theo Định lý 11) là một ma trận chính quy.
Nếu là một ma trận nguyên thủy, thì, và do đó do (109)
Ngược lại, nếu tất cả và không phụ thuộc vào các xác suất ban đầu, thì trong mỗi cột của ma trận, tất cả các phần tử đều giống nhau và theo (109), và điều này, theo Định lý 11, có nghĩa là ma trận nguyên thủy, tức là, điều này chuỗi là mạch hở.
Từ trên, Định lý 11 có thể được xây dựng như sau:
Định lý 11 ". 1. Để tất cả các xác suất tuyệt đối có giới hạn tồn tại trong một chuỗi Markov thuần nhất đối với bất kỳ xác suất ban đầu nào, thì cần và đủ rằng chuỗi đó phải đều.
2. Để một chuỗi Markov thuần nhất có giới hạn xác suất tuyệt đối đối với bất kỳ xác suất ban đầu nào và không phụ thuộc vào các xác suất ban đầu này, thì cần và đủ rằng chuỗi phải ổn định.
3. Để một chuỗi Markov thuần nhất có xác suất tuyệt đối giới hạn dương đối với bất kỳ xác suất ban đầu nào và các xác suất giới hạn này không phụ thuộc vào các xác suất ban đầu, thì cần và đủ rằng chuỗi đó phải là mạch vòng.
5. Bây giờ hãy xem xét một chuỗi Markov thuần nhất kiểu tổng quát với một ma trận xác suất chuyển đổi.
Hãy để chúng ta có dạng chuẩn (69) của ma trận và biểu thị bằng các chỉ số độ nhạy của các ma trận trong (69). Hãy là bội số chung nhỏ nhất của các số nguyên. Khi đó, ma trận không có các số đặc trưng có giá trị tuyệt đối bằng một, nhưng khác với một, tức là, là ma trận thông thường; đồng thời - chỉ số nhỏ nhất, tại đó - ma trận chính xác. Chúng tôi gọi một số là chu kỳ của một chuỗi Markov thuần nhất nhất định và. Ngược lại, nếu và ![]() được xác định bởi công thức (110) và (110 ").
được xác định bởi công thức (110) và (110 ").
Xác suất tuyệt đối giới hạn trung bình tương ứng với các trạng thái không thiết yếu luôn bằng không.
Nếu có một số ở dạng thông thường của ma trận (và chỉ trong trường hợp này), xác suất tuyệt đối giới hạn trung bình không phụ thuộc vào xác suất ban đầu và được xác định duy nhất từ phương trình (111).
Bài viết này đưa ra ý tưởng chung về cách tạo văn bản bằng cách sử dụng mô hình quy trình Markov. Đặc biệt, chúng ta sẽ làm quen với chuỗi Markov và như một thông lệ, chúng ta sẽ triển khai một trình tạo văn bản nhỏ bằng Python.
Để bắt đầu, chúng tôi viết ra các định nghĩa mà chúng tôi cần, nhưng vẫn chưa rõ ràng đối với chúng tôi từ trang Wikipedia, để ít nhất có thể hình dung một cách đại khái những gì chúng tôi đang giải quyết:
Quá trình Markov t t
Chuỗi Markov
Vậy tất cả những điều này có ý nghĩa gì? Hãy tìm ra nó.
Khái niệm cơ bản
Ví dụ đầu tiên là cực kỳ đơn giản. Sử dụng một câu trong sách dành cho trẻ em, chúng ta sẽ nắm vững khái niệm cơ bản về chuỗi Markov, cũng như xác định những gì trong ngữ cảnh của chúng ta kho dữ liệu, liên kết, phân phối xác suất và biểu đồ. Mặc dù câu này bằng tiếng Anh, nhưng cốt lõi của lý thuyết sẽ dễ dàng nắm bắt.
Ưu đãi này là khung, nghĩa là, cơ sở trên cơ sở đó văn bản sẽ được tạo ra trong tương lai. Nó bao gồm tám từ, nhưng chỉ có năm từ duy nhất - đây là liên kết(chúng ta đang nói về Markov dây chuyền). Để rõ ràng, hãy tô màu từng liên kết bằng màu riêng của nó:

Và ghi lại số lần xuất hiện của mỗi liên kết trong văn bản:

Hình trên cho thấy từ cá xuất hiện trong văn bản thường xuyên hơn 4 lần so với mỗi từ khác ( Một, hai, đỏ, xanh lam). Đó là, xác suất gặp trong kho tài liệu của chúng tôi từ cá Cao gấp 4 lần xác suất gặp mọi từ khác trong hình. Nói theo ngôn ngữ toán học, chúng ta có thể xác định quy luật phân phối của một biến ngẫu nhiên và tính xác suất một trong các từ sẽ xuất hiện trong văn bản sau biến hiện tại. Xác suất được tính như sau: chúng ta cần chia số lần xuất hiện của từ chúng ta cần trong kho ngữ liệu cho tổng số tất cả các từ trong đó. Cho từ cá xác suất này là 50% vì nó xuất hiện 4 lần trong một câu 8 từ. Đối với mỗi liên kết còn lại, xác suất này là 12,5% (1/8).
Bạn có thể biểu diễn bằng đồ thị sự phân bố của các biến ngẫu nhiên bằng cách sử dụng biểu đồ. Trong trường hợp này, tần suất xuất hiện của mỗi liên kết trong câu có thể thấy rõ:

Vì vậy, văn bản của chúng tôi bao gồm các từ và các liên kết duy nhất, và chúng tôi đã hiển thị phân phối xác suất xuất hiện của từng liên kết trong câu trên biểu đồ. Nếu đối với bạn, bạn không nên nhầm lẫn với số liệu thống kê, hãy đọc. Và có thể cứu mạng bạn.
Bản chất của định nghĩa
Bây giờ chúng ta hãy thêm vào các thành phần văn bản của chúng ta luôn luôn ngụ ý, nhưng không được lồng tiếng trong lời nói hàng ngày - phần đầu và phần cuối của câu:

Bất kỳ câu nào chứa "phần đầu" và "phần cuối" vô hình này, hãy thêm chúng làm liên kết đến bản phân phối của chúng tôi:

Hãy quay lại định nghĩa được đưa ra ở đầu bài viết:
Quá trình Markov- quá trình ngẫu nhiên, sự phát triển của nó sau bất kỳ giá trị nhất định nào của tham số thời gian t không phụ thuộc vào sự tiến hóa trước đó t, với điều kiện là giá trị của quá trình tại thời điểm này là cố định.
Chuỗi Markov- một trường hợp đặc biệt của quá trình Markov, khi không gian của các trạng thái của nó là rời rạc (tức là không nhiều hơn có thể đếm được).
Vì vậy, điều này có nghĩa là gì? Nói một cách đại khái, chúng ta đang mô hình hóa một quá trình trong đó trạng thái của hệ thống tại thời điểm tiếp theo chỉ phụ thuộc vào trạng thái của nó tại thời điểm hiện tại, và không phụ thuộc vào bất kỳ cách nào vào tất cả các trạng thái trước đó.
Hãy tưởng tượng những gì ở phía trước của bạn cửa sổ, chỉ hiển thị trạng thái hiện tại của hệ thống (trong trường hợp của chúng tôi, đó là một từ) và bạn cần xác định từ tiếp theo sẽ chỉ dựa trên dữ liệu được trình bày trong cửa sổ này. Trong kho ngữ liệu của chúng tôi, các từ nối tiếp nhau theo mẫu sau:

Do đó, các cặp từ được hình thành (ngay cả cuối câu cũng có cặp riêng - một giá trị trống):

Hãy nhóm các cặp này theo từ đầu tiên. Chúng ta sẽ thấy rằng mỗi từ có một tập hợp các liên kết riêng, trong ngữ cảnh của câu chúng ta có thể theo dõi anh ấy:

Hãy trình bày thông tin này theo một cách khác - mỗi liên kết sẽ được gán một mảng gồm tất cả các từ có thể xuất hiện trong văn bản sau liên kết này:

Chúng ta hãy xem xét kỹ hơn. Chúng tôi thấy rằng mỗi liên kết có các từ có thể đến sau nó trong một câu. Nếu chúng tôi cho người khác xem sơ đồ trên, thì người đó, với một số xác suất, có thể xây dựng lại câu đầu tiên của chúng tôi, tức là ngữ liệu.
Ví dụ. Hãy bắt đầu với từ Khởi đầu. Tiếp theo, chọn một từ Một, vì theo sơ đồ của chúng tôi, đây là từ duy nhất có thể đứng sau đầu câu. Đằng sau từ Một cũng chỉ một từ có thể theo sau - cá. Bây giờ, đề xuất mới trong phiên bản trung gian trông giống như Một con cá. Hơn nữa, tình hình trở nên phức tạp hơn cá các từ có thể đi với xác suất bằng nhau trong 25% "hai", "đỏ", "xanh lam" và cuối câu Chấm dứt. Nếu chúng ta giả định rằng từ tiếp theo là - "hai" việc tái thiết sẽ tiếp tục. Nhưng chúng ta có thể chọn một liên kết Chấm dứt. Trong trường hợp này, dựa trên lược đồ của chúng tôi, một câu sẽ được tạo ngẫu nhiên rất khác với ngữ liệu - Một con cá.
Chúng tôi vừa lập mô hình quy trình Markov - chúng tôi chỉ xác định từng từ tiếp theo trên cơ sở kiến thức về quy trình hiện tại. Để đồng hóa hoàn toàn tài liệu, hãy xây dựng các sơ đồ thể hiện sự phụ thuộc giữa các phần tử trong kho tài liệu của chúng tôi. Hình bầu dục đại diện cho các liên kết. Các mũi tên dẫn đến các liên kết tiềm năng có thể theo sau từ trong hình bầu dục. Gần mỗi mũi tên - xác suất mà liên kết tiếp theo sẽ xuất hiện sau liên kết hiện tại:

Tốt! Chúng tôi đã học được thông tin cần thiết để tiếp tục và phân tích các mô hình phức tạp hơn.
Mở rộng vốn từ vựng
Trong phần này của bài viết, chúng ta sẽ xây dựng một mô hình theo nguyên tắc tương tự như phần trước, nhưng chúng ta sẽ lược bỏ một số bước trong phần mô tả. Nếu gặp khó khăn thì quay lại lý thuyết ở khối đầu tiên.
Hãy xem thêm bốn câu trích dẫn của cùng một tác giả (cũng bằng tiếng Anh, điều đó sẽ không gây hại cho chúng ta):
“Hôm nay bạn là bạn. Đó là sự thật hơn là sự thật. Không có ai còn sống là bạn-er hơn bạn. "
"Trong đầu bạn có não. Chân bạn vừa cái giày rồi. Bạn có thể điều khiển bản thân bất cứ hướng nào bạn chọn. Bạn là của riêng bạn. "
“Bạn càng đọc nhiều, bạn sẽ càng biết nhiều điều. Bạn càng học được nhiều, bạn sẽ đi được nhiều nơi hơn. "
Nghĩ trái và nghĩ phải, nghĩ thấp và nghĩ cao. Ồ, bạn có thể nghĩ ra nếu chỉ cần bạn cố gắng. "
Độ phức tạp của ngữ liệu đã tăng lên, nhưng trong trường hợp của chúng tôi, đây chỉ là một điểm cộng - bây giờ trình tạo văn bản sẽ có thể tạo ra các câu có ý nghĩa hơn. Thực tế là trong bất kỳ ngôn ngữ nào, có những từ xuất hiện trong lời nói thường xuyên hơn những từ khác (ví dụ, chúng ta sử dụng giới từ "in" thường xuyên hơn nhiều so với từ "cryogenic"). Càng nhiều từ trong kho ngữ liệu của chúng ta (và do đó là sự phụ thuộc giữa chúng), trình tạo càng có nhiều thông tin về từ nào có nhiều khả năng xuất hiện trong văn bản sau từ hiện tại.
Cách dễ nhất để giải thích điều này là từ quan điểm của chương trình. Chúng tôi biết rằng đối với mỗi liên kết có một tập hợp các từ có thể theo sau nó. Ngoài ra, mỗi từ được đặc trưng bởi số lần xuất hiện của nó trong văn bản. Chúng ta cần nắm bắt bằng cách nào đó tất cả thông tin này ở một nơi; một từ điển lưu trữ các cặp "(khóa, giá trị)" là phù hợp nhất cho mục đích này. Khóa từ điển sẽ ghi lại trạng thái hiện tại của hệ thống, nghĩa là một trong các liên kết trong kho ngữ liệu (ví dụ: "các" trong hình bên dưới); và một từ điển khác sẽ được lưu trong giá trị từ điển. Trong từ điển lồng nhau, các khóa sẽ là những từ có thể xuất hiện trong văn bản sau đơn vị ngữ liệu hiện tại ( "nghĩ" và hơn có thể đi trong văn bản sau "các"), và các giá trị - số lần xuất hiện của những từ này trong văn bản sau liên kết của chúng tôi (từ "nghĩ" xuất hiện trong văn bản sau từ "các" 1 lần, từ hơn sau từ "các"- 4 lần):

Đọc lại đoạn trên vài lần để hiểu đúng. Xin lưu ý rằng từ điển lồng nhau trong trường hợp này là cùng một biểu đồ, nó giúp chúng tôi theo dõi các liên kết và tần suất xuất hiện của chúng trong văn bản so với các từ khác. Cần lưu ý rằng ngay cả một cơ sở từ vựng như vậy là rất nhỏ để tạo ra các văn bản thích hợp bằng ngôn ngữ tự nhiên - nó phải chứa hơn 20.000 từ và tốt hơn là hơn 100.000. Và thậm chí tốt hơn - hơn 500.000. Nhưng chúng ta hãy nhìn vào cơ sở dữ liệu từ vựng mà chúng tôi nhận được.
Chuỗi Markov trong trường hợp này được xây dựng tương tự như ví dụ đầu tiên - mỗi từ tiếp theo chỉ được chọn trên cơ sở kiến thức về từ hiện tại, tất cả các từ khác không được tính đến. Nhưng do được lưu trữ trong từ điển dữ liệu về những từ xuất hiện thường xuyên hơn những từ khác, chúng tôi có thể chọn chấp nhận quyết định có trọng số. Hãy xem một ví dụ cụ thể:
Hơn:
Đó là, nếu từ hiện tại là từ hơn, sau nó có thể có các từ với xác suất bằng nhau trong 25% "đồ đạc" và "nơi" và với xác suất là 50% - từ "điều đó". Nhưng các xác suất có thể là và tất cả đều bằng nhau:
nghĩ:
Làm việc với các cửa sổ
Cho đến nay, chúng tôi chỉ xem xét các cửa sổ một từ. Bạn có thể tăng kích thước của cửa sổ để trình tạo văn bản tạo ra nhiều câu "đã được xác minh" hơn. Điều này có nghĩa là cửa sổ càng lớn thì độ lệch so với thân tàu càng ít trong quá trình tạo ra. Việc tăng kích thước cửa sổ tương ứng với sự chuyển đổi của chuỗi Markov lên một thứ tự cao hơn. Trước đây, chúng tôi đã xây dựng một chuỗi của đơn hàng đầu tiên, đối với một cửa sổ gồm hai từ, chúng tôi nhận được một chuỗi của thứ tự thứ hai, của ba - của thứ ba, v.v.
Cửa sổ- đây là dữ liệu ở trạng thái hiện tại của hệ thống được sử dụng để đưa ra quyết định. Nếu chúng ta kết hợp một cửa sổ lớn và một tập dữ liệu nhỏ, thì chúng ta có khả năng nhận được cùng một câu mọi lúc. Hãy lấy cơ sở từ điển từ ví dụ đầu tiên của chúng tôi và mở rộng cửa sổ thành kích thước 2:

Phần mở rộng đã dẫn đến việc mỗi cửa sổ hiện chỉ có một tùy chọn cho trạng thái hệ thống tiếp theo - bất kể chúng tôi làm gì, chúng tôi sẽ luôn nhận được cùng một câu, giống hệt với ngữ liệu của chúng tôi. Do đó, để thử nghiệm với windows và để trình tạo văn bản trả về nội dung độc đáo, hãy tích trữ cơ sở từ vựng 500.000 từ trở lên.
Triển khai bằng Python
Cấu trúc dữ liệu biểu đồ
Dictogram (dict là kiểu dữ liệu từ điển được tích hợp sẵn trong Python) sẽ hiển thị mối quan hệ giữa các liên kết và tần suất xuất hiện của chúng trong văn bản, tức là sự phân bố của chúng. Nhưng đồng thời, nó sẽ có thuộc tính từ điển mà chúng ta cần - thời gian thực hiện chương trình sẽ không phụ thuộc vào lượng dữ liệu đầu vào, có nghĩa là chúng ta đang tạo ra một thuật toán hiệu quả.
Nhập biểu đồ lớp ngẫu nhiên (dict): def __init __ (self, iterable = None): # Khởi tạo phân phối của chúng ta như một đối tượng lớp mới, # thêm các phần tử hiện có super (Dictogram, self) .__ init __ () self.types = 0 # number of khóa duy nhất trong phân phối self.tokens = 0 # tổng số tất cả các từ trong phân phối nếu có thể lặp lại: self.update (có thể lặp lại) def update (self, iterable): # Cập nhật bản phân phối với các mục từ tập dữ liệu có thể lặp lại # hiện có cho mục ở dạng có thể lặp lại : if item in self: self + = 1 self.tokens + = 1 else: self = 1 self.types + = 1 self.tokens + = 1 def count (self, item): # Trả về giá trị bộ đếm của item, hoặc 0 if item in self: return self return 0 def return_random_word (self): random_key = random.sample (self, 1) # Một cách khác: # random.choice (histogram.keys ()) return random_key def return_weighted_random_word (self): # Tạo một số giả ngẫu nhiên từ 0 đến (n-1), # trong đó n là tổng số từ random_int = random.randint (0, self.tokens-1) index = 0 list_of_keys = self.keys () # print "chỉ mục ngẫu nhiên:", random_int cho tôi trong phạm vi (0, self.types): index + = self] # in chỉ mục if (index> random_int ): # đầu ra list_of_keys [i] return list_of_keys [i]
Bất kỳ đối tượng nào có thể được lặp lại đều có thể được chuyển đến phương thức khởi tạo của cấu trúc Dictogram. Các phần tử của đối tượng này sẽ là các từ để khởi tạo Biểu đồ, ví dụ, tất cả các từ từ một cuốn sách nào đó. Trong trường hợp này, chúng tôi đang đếm các phần tử để truy cập bất kỳ phần tử nào trong số chúng, không cần thiết phải chạy qua toàn bộ tập dữ liệu mỗi lần.
Chúng tôi cũng thực hiện hai hàm để trả về một từ ngẫu nhiên. Một chức năng chọn một khóa ngẫu nhiên trong từ điển và chức năng kia, tính đến số lần xuất hiện của mỗi từ trong văn bản, trả về từ mà chúng ta cần.
Cấu trúc chuỗi Markov
from histogram import Dictogram def make_markov_model (data): markov_model = dict () for i in range (0, len (data) -1): if data [i] in markov_model: # Chỉ cần thêm vào một bản phân phối markov_model đã có]. cập nhật (]) else: markov_model] = Biểu đồ (]) trả về markov_modelTrong cách triển khai ở trên, chúng ta có một từ điển lưu trữ các cửa sổ dưới dạng khóa trong cặp "(khóa, giá trị)" và các bản phân phối dưới dạng các giá trị trong cặp đó.
Cấu trúc của chuỗi Markov bậc N
from histogram import Dictogram def make_higher_order_markov_model (order, data): markov_model = dict () for i in range (0, len (data) -order): # Tạo cửa sổ window = tuple (data) # Thêm vào từ điển nếu cửa sổ trong markov_model: # Đính kèm vào phân phối hiện tại markov_model.update (]) else: markov_model = Dictogram (]) return markov_modelRất giống với chuỗi Markov đơn đặt hàng đầu tiên, nhưng trong trường hợp này, chúng tôi lưu trữ tuple làm khóa trong cặp "(khóa, giá trị)" trong từ điển. Chúng tôi sử dụng nó thay vì một danh sách, vì tuple được bảo vệ khỏi bất kỳ thay đổi nào và điều này rất quan trọng đối với chúng tôi - sau cùng, các khóa trong từ điển không được thay đổi.
Phân tích cú pháp mô hình
Tuyệt vời, chúng tôi đã triển khai một từ điển. Nhưng làm thế nào bây giờ để tạo nội dung dựa trên trạng thái hiện tại và chuyển sang trạng thái tiếp theo? Hãy xem qua mô hình của chúng tôi:
Từ biểu đồ nhập Biểu đồ biểu đồ nhập ngẫu nhiên từ các tập hợp import deque import re def create_random_start (model): # Để tạo bất kỳ từ bắt đầu nào, hãy bỏ ghi chú dòng: # return random.choice (model.keys ()) # Để tạo từ bắt đầu "đúng" , hãy sử dụng mã bên dưới: # Từ gốc hợp lệ là những từ bắt đầu câu trong kho ngữ liệu nếu "END" trong model: seed_word = "END" trong khi seed_word == "END": seed_word = model ["END"]. return_weighted_random_word () return seed_word return random.choice (model.keys ()) def create_random_sentence (length, markov_model): current_word = generate_random_start (markov_model) câu = cho tôi trong phạm vi (0, length): current_dictogram = markov_model random_weighted_word = current_dictogram.return_weighted ) current_word = random_weighted_word câu.append (current_word) câu = câu.capitalize () return "" .join (câu) + "." câu trả lại
Cái gì tiếp theo?
Hãy thử nghĩ xem bản thân bạn có thể sử dụng trình tạo văn bản dựa trên chuỗi Markov ở đâu. Chỉ cần đừng quên rằng điều quan trọng nhất là cách bạn phân tích cú pháp mô hình và những hạn chế đặc biệt nào bạn đặt ra khi tạo. Ví dụ: tác giả của bài viết này đã sử dụng một cửa sổ lớn khi tạo trình tạo tweet, giới hạn nội dung được tạo ở 140 ký tự và chỉ sử dụng các từ "đúng" để bắt đầu câu, tức là những từ là đầu câu trong kho ngữ liệu.
Phương pháp mô tả toán học của các quá trình ngẫu nhiên Markov trong một hệ thống có trạng thái rời rạc (DS) phụ thuộc vào những thời điểm (đã biết trước hoặc ngẫu nhiên) sự chuyển đổi của hệ thống từ trạng thái này sang trạng thái khác có thể xảy ra.
Nếu quá trình chuyển đổi của hệ thống từ trạng thái này sang trạng thái có thể xảy ra vào những thời điểm đã được ấn định trước, chúng tôi đang giải quyết quá trình Markov ngẫu nhiên với thời gian rời rạc. Nếu quá trình chuyển đổi có thể xảy ra vào bất kỳ thời điểm ngẫu nhiên nào, thì chúng tôi đang xử lý quá trình Markov ngẫu nhiên với thời gian liên tục.
Hãy để có một hệ thống vật lý S, có thể ở trong N Những trạng thái S 1 , S 2 , …, S n. Đôi khi chỉ có thể chuyển đổi từ trạng thái này sang trạng thái khác t 1 , t 2 , …, t k Hãy gọi những khoảnh khắc này là những bước thời gian. Chúng tôi sẽ xem xét SP trong hệ thống S dưới dạng một hàm của đối số nguyên 1, 2, ..., k, trong đó đối số là số bước.
Ví dụ: S 1 → S 2 → S 3 → S 2 .
Hãy để chúng tôi biểu thị Si (k) là một sự kiện bao gồm thực tế là sau k các bước hệ thống ở trạng thái S tôi.
Bất cứ gì k sự kiện S 1 ( k), S 2 ( k),…, S N (k) biểu mẫu nhóm đầy đủ các sự kiện và đang không tương thích.
Quá trình trong hệ thống có thể được biểu diễn dưới dạng một chuỗi các sự kiện.
Ví dụ: S 1 (0) , S 2 (1), S 3 (2), S 5 (3),….
Một chuỗi như vậy được gọi là Chuỗi Markov
, nếu đối với mỗi bước, xác suất chuyển đổi từ bất kỳ trạng thái nào Siở bất kỳ trạng thái nào Sj không phụ thuộc vào thời điểm và cách thức hệ thống đến trạng thái Si.
Hãy để bất cứ lúc nào sau khi bất kỳ k-đi bước hệ thống S có thể ở một trong các tiểu bang S 1 , S 2 , …, S n, tức là, một sự kiện từ một nhóm sự kiện hoàn chỉnh có thể xảy ra: S 1 (k), S 2 ( k) , …, S n (k). Hãy để chúng tôi biểu thị xác suất của các sự kiện này:
P 1 (1) = P(S 1 (1)); P 2 (1) = P(S 2 (1)); …; P n(1) = P(S n (k));
P 1 (2) = P(S 1 (2)); P 2 (2) = P(S2 (2)); …; P n(2) = P(S n (2));
P 1 (k) = P(S 1 (k)); P 2 (k) = P(S 2 (k)); …; P n(k) = P(S n (k)).
Dễ dàng thấy rằng đối với mỗi bước số điều kiện
P 1 (k) + P 2 (k) +…+ P n(k) = 1.
Hãy gọi những xác suất này là xác suất trạng thái. Do đó, nhiệm vụ sẽ có âm thanh như sau: tìm xác suất của các trạng thái hệ thống cho bất kỳ k.
Ví dụ. Hãy để có một hệ thống nào đó có thể ở bất kỳ trạng thái nào trong sáu trạng thái. thì các quá trình xảy ra trong nó có thể được mô tả dưới dạng một biểu đồ về những thay đổi trong trạng thái của hệ thống (Hình 7.9, một), hoặc dưới dạng biểu đồ trạng thái hệ thống (Hình 7.9, b).
một) 
Cơm. 7.9
Ngoài ra, các quá trình trong hệ thống có thể được mô tả như một chuỗi các trạng thái: S 1 , S 3 , S 2 , S 2 , S 3 , S 5 , S 6 , S 2 .
Xác suất trạng thái trên ( k+ 1) -bước thứ chỉ phụ thuộc vào trạng thái tại k- m bước.
Đối với bất kỳ bước nào k có một số xác suất của việc chuyển đổi hệ thống từ bất kỳ trạng thái nào sang bất kỳ trạng thái nào khác, chúng ta hãy gọi những xác suất này xác suất chuyển đổi của một chuỗi Markov.
Một số xác suất này sẽ bằng 0 nếu không thể thực hiện chuyển đổi từ trạng thái này sang trạng thái khác trong một bước.
Chuỗi Markov được gọi là đồng nhất nếu các trạng thái chuyển tiếp không phụ thuộc vào số bước, nếu không nó được gọi là không đồng nhất.
Để có một chuỗi Markov đồng nhất và để hệ thống S Nó có N các trạng thái có thể xảy ra: S 1 , …, S n. Giả sử xác suất chuyển đổi sang trạng thái khác trong một bước được biết đối với mỗi trạng thái, tức là P ij(từ Si trong Sj trong một bước), sau đó chúng ta có thể viết các xác suất chuyển đổi dưới dạng ma trận.
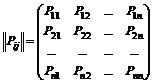 . (7.1)
. (7.1)
Trên đường chéo của ma trận này là các xác suất mà hệ thống chuyển từ trạng thái Si trong cùng một trạng thái Si.
Sử dụng các sự kiện đã giới thiệu trước đó ![]() , xác suất chuyển đổi có thể được viết dưới dạng xác suất có điều kiện:
, xác suất chuyển đổi có thể được viết dưới dạng xác suất có điều kiện: ![]() .
.
Rõ ràng, tổng các điều khoản ![]() trong mỗi hàng của ma trận (1) bằng một, vì các sự kiện
trong mỗi hàng của ma trận (1) bằng một, vì các sự kiện ![]() tạo thành một nhóm hoàn chỉnh các sự kiện không tương thích.
tạo thành một nhóm hoàn chỉnh các sự kiện không tương thích.
Khi xem xét chuỗi Markov, cũng như khi phân tích một quá trình ngẫu nhiên Markov, các đồ thị trạng thái khác nhau được sử dụng (Hình 7.10). 
Cơm. 7.10
Hệ thống này có thể ở bất kỳ trạng thái nào trong số sáu trạng thái, trong khi P ij là xác suất hệ thống chuyển đổi từ trạng thái Si vào một trạng thái Sj. Đối với hệ thống này, chúng tôi viết các phương trình mà hệ thống ở trạng thái nào đó và từ nó trong thời gian tđã không đi ra: 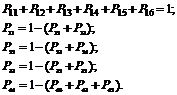
Trong trường hợp chung, chuỗi Markov không đồng nhất, tức là xác suất P ij thay đổi từ bước này sang bước khác. Giả sử rằng một ma trận xác suất chuyển đổi ở mỗi bước được đưa ra, thì xác suất hệ thống S trên k-bước thứ sẽ ở trạng thái Si, có thể được tìm thấy bằng cách sử dụng công thức ![]()
Biết được ma trận xác suất chuyển tiếp và trạng thái ban đầu của hệ thống, người ta có thể tìm được xác suất của các trạng thái ![]() sau bất kỳ k-bước thứ. Để tại thời điểm ban đầu hệ thống ở trạng thái S m. Sau đó cho t = 0
sau bất kỳ k-bước thứ. Để tại thời điểm ban đầu hệ thống ở trạng thái S m. Sau đó cho t = 0
.
Tìm xác suất sau bước đầu tiên. Ngoài tiểu bang S m hệ thống sẽ chuyển sang trạng thái S 1 , S 2, v.v. với xác suất Buổi chiều 1 , Buổi chiều 2 , …, Pmm, …, Pmn. Sau đó, sau bước đầu tiên, xác suất sẽ bằng
. (7.2)
Hãy tìm xác suất của trạng thái sau bước thứ hai:. Chúng tôi sẽ tính toán các xác suất này bằng cách sử dụng công thức xác suất tổng với các giả thuyết: ![]() .
.
Các giả thuyết sẽ là các câu sau:
- sau bước đầu tiên hệ thống ở trạng thái S 1 -H 1;
- sau bước thứ hai hệ thống ở trạng thái S 2 -H 2;
- sau N-bước thứ hệ thống ở trạng thái S n -H n.
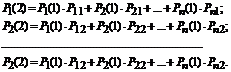
Xác suất của bất kỳ trạng thái nào sau bước thứ hai:
![]() (7.3)
(7.3)
Công thức (7.3) tóm tắt tất cả các xác suất chuyển đổi P ij, nhưng chỉ những giá trị khác 0 mới được tính đến. Xác suất của bất kỳ trạng thái nào sau k-bước thứ:
![]() (7.4)
(7.4)
Như vậy, xác suất của trạng thái sau k-bước thứ được xác định bằng công thức đệ quy (7.4) thông qua các xác suất ( k- 1) bước thứ.
Nhiệm vụ 6. Ma trận xác suất chuyển đổi cho một chuỗi Markov trong một bước được đưa ra. Tìm ma trận chuyển tiếp của một mạch đã cho theo ba bước  .
.
Quyết định. Ma trận chuyển tiếp của hệ thống là ma trận chứa tất cả các xác suất chuyển tiếp của hệ thống này: 
Mỗi hàng của ma trận chứa các xác suất của các sự kiện (chuyển từ trạng thái tôi vào một trạng thái j), tạo thành một nhóm hoàn chỉnh, vì vậy tổng xác suất của những sự kiện này bằng một: ![]()
Biểu thị bằng p ij (n) xác suất mà kết quả của n bước (phép thử) hệ thống sẽ chuyển từ trạng thái i sang trạng thái j. Ví dụ p 25 (10) - xác suất chuyển từ trạng thái thứ hai sang trạng thái thứ năm trong mười bước. Lưu ý rằng với n = 1, chúng ta thu được xác suất chuyển đổi p ij (1) = p ij.
Chúng ta phải đối mặt với nhiệm vụ sau: biết xác suất chuyển đổi p ij, tìm xác suất p ij (n) của quá trình chuyển đổi hệ thống từ trạng thái tôi vào một trạng thái j phía sau N các bước. Để làm điều này, chúng tôi giới thiệu một trung gian (giữa tôi và j) điều kiện r. Nói cách khác, chúng tôi sẽ giả định rằng từ trạng thái ban đầu tôi phía sau m bước, hệ thống sẽ chuyển sang trạng thái trung gian r với xác suất p ij (n-m), sau đó, trong n-m bước còn lại từ trạng thái trung gian r, nó sẽ chuyển sang trạng thái cuối cùng j với xác suất p ij (n-m). Theo công thức xác suất tổng, ta nhận được: ![]() .
.
Công thức này được gọi là đẳng thức Markov. Sử dụng công thức này, bạn có thể tìm thấy tất cả các xác suất p ij (n) và do đó, chính ma trận P n. Vì phép tính ma trận dẫn đến mục tiêu nhanh hơn, chúng ta hãy viết ra quan hệ ma trận sau đây từ công thức thu được ở dạng tổng quát.
Tính toán ma trận chuyển tiếp của chuỗi Markov theo ba bước sử dụng công thức kết quả: 
Trả lời: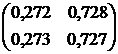 .
.
Nhiệm vụ 1. Ma trận xác suất chuyển đổi cho chuỗi Markov là: 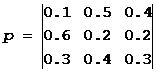 .
.
Sự phân bố trên các trạng thái tại thời điểm t = 0 được xác định bởi vectơ:
π 0 \ u003d (0,5; 0,2; 0,3)
Để tìm: a) phân bố trên các trạng thái tại thời điểm t = 1,2,3,4.
c) phân phối tĩnh.
 Trò chơi "Skyrim": tất cả những tiếng hét Skyrim hét lên 4 từ
Trò chơi "Skyrim": tất cả những tiếng hét Skyrim hét lên 4 từ The Elder Scrolls V: Skyrim
The Elder Scrolls V: Skyrim The Elder Scrolls V: Skyrim Walkthrough
The Elder Scrolls V: Skyrim Walkthrough