Дисперсія вимірює. Розрахунок групової, міжгрупової та загальної дисперсії (за правилом складання дисперсій)
Де σ 2 j - внутрішньогрупова дисперсія j-ї групи.
Для не згрупованих даних залишкова дисперсія– міра точності апроксимації, тобто. наближення лінії регресії до вихідних даних: 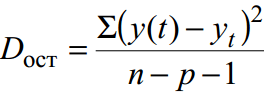
де y(t) – прогноз рівняння тренда; yt – вихідний ряд динаміки; n - кількість точок; p – число коефіцієнтів рівняння регресії (кількість змінних, що пояснюють).
У цьому прикладі вона називається незміщена оцінка дисперсії.
Приклад №1. Розподіл робітників трьох підприємств одного об'єднання за тарифними розрядами характеризується такими даними:
| Тарифний розряд робітника | Чисельність робітників на підприємстві | ||
| підприємство 1 | підприємство 2 | підприємство 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Визначити:
1. дисперсію по кожному підприємству (внутрішньогрупові дисперсії);
2. середню із внутрішньогрупових дисперсій;
3. міжгрупову дисперсію;
4. загальну дисперсію.
Рішення.
Перш ніж приступити до вирішення завдання необхідно з'ясувати, яка ознака є результативною, а якою є факторною. У прикладі результативною ознакою є «Тарифний розряд», а факторною ознакою – «Номер (назва) підприємства».
Тоді маємо три групи (підприємства), для яких необхідно розрахувати групову середню та внутрішньогрупові дисперсії:

| Підприємство | Групова середня, | Внутрішньогрупова дисперсія, |
| 1 | 4 | 1,8 |
Середня з внутрішньогрупових дисперсій ( залишкова дисперсія) розрахуємо за формулою:

де можна розрахувати:
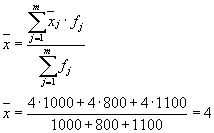
або:

тоді:
Загальна дисперсія дорівнюватиме: s 2 = 1,6 + 0 = 1,6.
Загальну дисперсію також можна розрахувати і за однією з наступних двох формул:

При вирішенні практичних завдань часто доводиться мати справу з ознакою, яка приймає лише два альтернативні значення. У цьому випадку говорять не про вагу того чи іншого значення ознаки, а про його частку в сукупності. Якщо частку одиниць сукупності, які мають досліджувану ознаку, позначити через « р», а не володіють – через « q», то дисперсію можна розрахувати за такою формулою:
s 2 = p×q
Приклад №2. За даними про вироблення шести робочих бригади визначити міжгрупову дисперсію та оцінити вплив робочої зміни на їх продуктивність праці, якщо загальна дисперсія дорівнює 12,2.
| № робітника бригади | Вироблення робітника, шт. | |
| в I зміну | у II зміну | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Рішення. Початкові дані
| X | f 1 | f 2 | f 3 | f 4 | f 5 | f 6 | Разом |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Разом | 31 | 33 | 37 | 37 | 40 | 38 |
Тоді маємо 6 групи, для яких необхідно розрахувати групову середню та внутрішньогрупові дисперсії.
1. Знаходимо середні значення кожної групи.
2. Знаходимо середнє квадратичне кожної групи.
Результати розрахунку зведемо до таблиці:
| Номер групи | Групова середня | Внутрішньогрупова дисперсія |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. Внутрішньогрупова дисперсіяхарактеризує зміну (варіацію) досліджуваної (результативної) ознаки в межах групи під впливом на нього всіх факторів, крім фактора, покладеного в основу угруповання:
Середню із внутрішньогрупових дисперсій розрахуємо за формулою:
4. Міжгрупова дисперсіяхарактеризує зміну (варіацію) досліджуваного (результативного) ознаки під впливом нього чинника (факторного ознаки), покладеного в основу угруповання.
Міжгрупову дисперсію визначимо як:
де
Тоді
Загальна дисперсіяхарактеризує зміна (варіацію) досліджуваного (результативного) ознаки під впливом нею всіх без винятку чинників (факторних ознак). За умовою завдання вона дорівнює 12.2.
Емпіричне кореляційне ставленнявимірює, яку частину загальної коливання результативної ознаки викликає фактор, що вивчається. Це відношення факторної дисперсії до загальної дисперсії:
Визначаємо емпіричне кореляційне відношення:
Зв'язки між ознаками можуть бути слабкими та сильними (тісними). Їхні критерії оцінюються за шкалою Чеддока:
0.1 0.3 0.5 0.7 0.9 У нашому прикладі зв'язок між ознакою Y фактором X слабкий
Коефіцієнт детермінації.
Визначимо коефіцієнт детермінації:
Таким чином, на 0.67% варіація обумовлена відмінностями між ознаками, а на 99.37% іншими факторами.
Висновок: у разі вироблення робочих залежить від роботи у конкретну зміну, тобто. вплив робочої зміни з їхньої продуктивність праці не значний і зумовлено іншими чинниками.
Приклад №3. На основі даних про середню заробітну плату та квадрати відхилень від її величини за двома групами робітників знайти загальну дисперсію, застосувавши правило складання дисперсій:
Рішення:Середня із внутрішньогрупових дисперсій
Міжгрупову дисперсію визначимо як:
Загальна дисперсія дорівнюватиме: 480 + 13824 = 14304
На цій сторінці описано стандартний приклад знаходження дисперсії, також Ви можете переглянути інші завдання на її знаходження
Приклад 1. Визначення групової, середньої з групової, міжгрупової та загальної дисперсії
Приклад 2. Знаходження дисперсії та коефіцієнта варіації у групувальній таблиці
Приклад 3. Знаходження дисперсії у дискретному ряду
Приклад 4. Є такі дані щодо групи з 20 студентів заочного відділення. Потрібно побудувати інтервальний ряд розподілу ознаки, розрахувати середнє значення ознаки та вивчити його дисперсію
Побудуємо інтервальне угруповання. Визначимо розмах інтервалу за формулою:
![]()
де X max - максимальне значення групувального ознаки;
X min-мінімальне значення групувальної ознаки;
n – кількість інтервалів:
Приймаємо n=5. Крок дорівнює: h = (192 - 159) / 5 = 6,6
Складемо інтервальне угруповання

Для подальших розрахунків збудуємо допоміжну таблицю:

X"i - середина інтервалу. (наприклад середина інтервалу 159 - 165,6 = 162,3)
Середню величину зростання студентів визначимо за формулою середньої арифметичної зваженої:

Визначимо дисперсію за такою формулою:
Формулу можна перетворити так:

З цієї формули випливає, що дисперсія дорівнює різниці середньої з квадратів варіантів і квадрата та середньої.
Дисперсія у варіаційних рядахз рівними інтервалами за способом моментів може бути розрахована наступним способом при використанні другої властивості дисперсії (розділивши всі варіанти на величину інтервалу). Визначення дисперсії, обчисленої за способом моментів, за такою формулою менш трудомісткий:

де i – величина інтервалу;
А - умовний нуль, як який зручно використовувати середину інтервалу, що володіє найбільшою частотою;
m1 – квадрат моменту першого порядку;
m2 – момент другого порядку
Дисперсія альтернативної ознаки (якщо в статистичній сукупності ознака змінюється так, що є тільки два варіанти, що взаємно виключають один одного, то така мінливість називається альтернативною) може бути обчислена за формулою:

Підставляючи до цієї формули дисперсії q =1- р, отримуємо:

Види дисперсії
Загальна дисперсіявимірює варіацію ознаки у всій сукупності загалом під впливом всіх чинників, що зумовлюють цю варіацію. Вона дорівнює середньому квадрату відхилень окремих значень ознаки х від загального середнього значення х може бути визначена як проста дисперсія або зважена дисперсія.
Внутрішньогрупова дисперсія характеризує випадкову варіацію, тобто. частина варіації, яка обумовлена впливом неврахованих факторів і не залежить від ознаки-фактора, покладеної в основу угруповання. Така дисперсія дорівнює середньому квадрату відхилень окремих значень ознаки всередині групи X від середньої арифметичної групи і може бути обчислена як проста дисперсія або зважена дисперсія.
Таким чином, внутрішньогрупова дисперсія вимірюєваріацію ознаки всередині групи та визначається за формулою:

де хі - групова середня;
ni – число одиниць у групі.
Наприклад, внутрішньогрупові дисперсії, які треба визначити в задачі вивчення впливу кваліфікації робітників на рівень продуктивності праці в цеху показують варіації виробітку в кожній групі, викликані всіма можливими факторами (технічний стан обладнання, забезпеченість інструментами та матеріалами, вік робітників, інтенсивність праці тощо) .), крім відмінностей у кваліфікаційному розряді (всередині групи всі робітники мають одну й ту саму кваліфікацію).
Математичне очікування та дисперсія – найчастіше застосовувані числові характеристики випадкової величини. Вони характеризують найважливіші риси розподілу: його становище та рівень розкиданості. Багато завдань практики повна, вичерпна характеристика випадкової величини - закон розподілу - або взагалі може бути отримана, або взагалі не потрібна. У таких випадках обмежуються приблизним описом випадкової величини з допомогою числових характеристик.
Математичне очікування часто називають просто середнім значенням випадкової величини. Дисперсія довільної величини - характеристика розсіювання, розкиданості довільної величини у її математичного очікування.
Математичне очікування дискретної випадкової величини
Підійдемо до поняття математичного очікування спочатку виходячи з механічної інтерпретації розподілу дискретної випадкової величини. Нехай одинична маса розподілена між точками осі абсцис x1 , x 2 , ..., x n, причому кожна матеріальна точка має відповідну їй масу p1 , p 2 , ..., p n. Потрібно вибрати одну точку на осі абсцис, що характеризує становище всієї системи матеріальних точок, з урахуванням їх мас. Природно як таку точку взяти центр маси системи матеріальних точок. Це середнє зважене значення випадкової величини X, в яке абсциса кожної точки xiвходить з "вагою", що дорівнює відповідній ймовірності. Отримане в такий спосіб середнє значення випадкової величини Xназивається її математичним очікуванням.
Математичним очікуванням дискретної випадкової величини називається сума творів всіх можливих її значень на ймовірності цих значень:
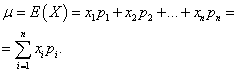
приклад 1.Організована безпрограшна лотерея. Є 1000 виграшів, їх 400 по 10 крб. 300 – по 20 руб. 200 – по 100 руб. і 100 – по 200 руб. Який середній розмір виграшу для того, хто купив один квиток?
Рішення. Середній виграш ми знайдемо, якщо загальну суму виграшів, яка дорівнює 10 * 400 + 20 * 300 + 100 * 200 + 200 * 100 = 50 000 руб, розділимо на 1000 (загальна сума виграшів). Тоді отримаємо 50 000/1000 = 50 руб. Але вираз для підрахунку середнього виграшу можна уявити й у такому вигляді:
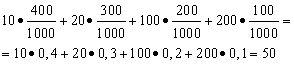
З іншого боку, в умовах розмір виграшу є випадковою величиною, яка може приймати значення 10, 20, 100 і 200 руб. із ймовірностями, рівними відповідно 0,4; 0,3; 0,2; 0,1. Отже, очікуваний середній виграш дорівнює сумі творів розмірів виграшів на ймовірність їх отримання.
приклад 2.Видавець вирішив видати нову книгу. Продавати книгу він збирається за 280 руб., З яких 200 отримає він сам, 50 - книгарня і 30 - автор. У таблиці наведено інформацію про витрати на видання книги та ймовірність продажу певної кількості екземплярів книги.
Знайти очікуваний прибуток видавця.
Рішення. Випадкова величина "прибуток" дорівнює різниці доходів від продажу та вартості витрат. Наприклад, якщо буде продано 500 екземплярів книги, то доходи від продажу дорівнюють 200 * 500 = 100000, а витрати на видання 225 000 руб. Таким чином, видавцеві загрожує збиток розміром 125000 руб. У наступній таблиці узагальнено очікувані значення випадкової величини - прибутку:
| Число | Прибуток xi | Ймовірність pi | xi p i |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Всього: | 1,00 | 25000 |
Таким чином, отримуємо математичне очікування прибутку видавця:
![]() .
.
приклад 3.Імовірність влучення при одному пострілі p= 0,2. Визначити витрату снарядів, які забезпечують математичне очікування числа влучень, що дорівнює 5.
Рішення. З тієї ж формули математичного очікування, яку ми використовували досі, висловлюємо x- Витрата снарядів:
![]() .
.
приклад 4.Визначити математичне очікування випадкової величини xчисла попадань при трьох пострілах, якщо ймовірність попадання при кожному пострілі p = 0,4 .
Підказка: ймовірність значень випадкової величини знайти за формулі Бернуллі .
Властивості математичного очікування
Розглянемо властивості математичного очікування.
Властивість 1.Математичне очікування постійної величини дорівнює цій постійній:
Властивість 2.Постійний множник можна виносити за знак математичного очікування:
![]()
Властивість 3.Математичне очікування суми (різниці) випадкових величин дорівнює сумі (різниці) їх математичних очікувань:
Властивість 4.Математичне очікування добутку випадкових величин дорівнює добутку їх математичних очікувань:
Властивість 5.Якщо всі значення випадкової величини Xзменшити (збільшити) на одне й те саме число З, то її математичне очікування зменшиться (збільшиться) на те число:
![]()
Коли не можна обмежуватися лише математичним очікуванням
Найчастіше лише математичне очікування неспроможна достатньою мірою характеризувати випадкову величину.
Нехай випадкові величини Xі Yзадані такими законами розподілу:
| Значення X | Ймовірність |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Значення Y | Ймовірність |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
Математичні очікування цих величин однакові - дорівнюють нулю:
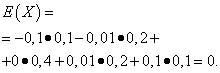
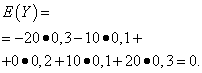
Проте характер розподілу їх різний. Випадкова величина Xможе приймати тільки значення, що мало відрізняються від математичного очікування, а випадкова величина Yможе приймати значення, які значно відхиляються від математичного очікування. Аналогічний приклад: середня заробітна плата не дає можливості судити про питому вагу високо-і низькооплачуваних робітників. Іншими словами, з математичного очікування не можна судити про те, які відхилення від нього, хоч би в середньому, можливі. Для цього необхідно знайти дисперсію випадкової величини.
Дисперсія дискретної випадкової величини
Дисперсієюдискретної випадкової величини Xназивається математичне очікування квадрата відхилення її від математичного очікування:
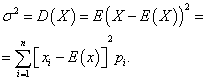
Середнім квадратичним відхиленням випадкової величини Xназивається арифметичне значення квадратного кореня її дисперсії:
![]() .
.
Приклад 5.Обчислити дисперсії та середні квадратичні відхилення випадкових величин Xі Y, закони розподілу яких наведені у таблицях вище.
Рішення. Математичні очікування випадкових величин Xі YЯк було знайдено вище, дорівнюють нулю. Згідно з формулою дисперсії при Е(х)=Е(y)=0 отримуємо:

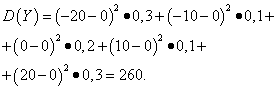
Тоді середні квадратичні відхилення випадкових величин Xі Yскладають
![]() .
.
Таким чином, при однакових математичних очікуваннях дисперсія випадкової величини Xдуже мала, а випадкової величини Y- Значна. Це наслідок розбіжності у тому розподілі.
Приклад 6.У інвестора є 4 альтернативні проекти інвестицій. У таблиці узагальнено дані про очікуваний прибуток у цих проектах з відповідною ймовірністю.
| Проект 1 | Проект 2 | Проект 3 | Проект 4 |
| 500, P=1 | 1000, P=0,5 | 500, P=0,5 | 500, P=0,5 |
| 0, P=0,5 | 1000, P=0,25 | 10500, P=0,25 | |
| 0, P=0,25 | 9500, P=0,25 |
Знайти для кожної альтернативи математичне очікування, дисперсію та середнє квадратичне відхилення.
Рішення. Покажемо, як обчислюються ці величини для 3 альтернативи:
У таблиці узагальнено знайдені величини всім альтернатив.
У всіх альтернатив однакові математичні очікування. Це означає, що у довгостроковому періоді в усіх - однакові доходи. Стандартне відхилення можна інтерпретувати як одиницю виміру ризику - що більше, тим більше ризик інвестицій. Інвестор, який бажає великого ризику, вибере проект 1, оскільки він має найменше стандартне відхилення (0). Якщо ж інвестор віддає перевагу ризику та більшим доходам у короткий період, він вибере проект найбільшим стандартним відхиленням - проект 4.
Властивості дисперсії
Наведемо властивості дисперсії.
Властивість 1.Дисперсія постійної величини дорівнює нулю:
Властивість 2.Постійний множник можна виносити за знак дисперсії, зводячи його у квадрат:
![]() .
.
Властивість 3.Дисперсія випадкової величини дорівнює математичному очікуванню квадрата цієї величини, з якого віднімається квадрат математичного очікування самої величини:
![]() ,
,
де ![]() .
.
Властивість 4.Дисперсія суми (різниці) випадкових величин дорівнює сумі (різниці) їх дисперсій:
Приклад 7.Відомо, що дискретна випадкова величина Xприймає лише два значення: −3 та 7. Крім того, відоме математичне очікування: E(X) = 4 . Знайти дисперсію дискретної випадкової величини.
Рішення. Позначимо через pймовірність, з якою випадкова величина набуває значення x1 = −3 . Тоді ймовірністю значення x2 = 7 буде 1 − p. Виведемо рівняння для математичного очікування:
E(X) = x 1 p + x 2 (1 − p) = −3p + 7(1 − p) = 4 ,
звідки отримуємо ймовірність: p= 0,3 та 1 − p = 0,7 .
Закон розподілу випадкової величини:
| X | −3 | 7 |
| p | 0,3 | 0,7 |
Дисперсію даної випадкової величини обчислимо за формулою з якості дисперсії 3:
D(X) = 2,7 + 34,3 − 16 = 21 .
Знайти математичне очікування випадкової величини самостійно, а потім переглянути рішення
Приклад 8.Дискретна випадкова величина Xнабуває лише два значення. Більше значень 3 вона приймає з ймовірністю 0,4. Крім того, відома дисперсія випадкової величини D(X) = 6 . Знайти математичне очікування випадкової величини.
Приклад 9.В урні 6 білих і 4 чорні кулі. З урни виймають 3 кулі. Число білих куль серед вийнятих куль є дискретною випадковою величиною X. Знайти математичне очікування та дисперсію цієї випадкової величини.
Рішення. Випадкова величина Xможе приймати значення 0, 1, 2, 3. Відповідні їм ймовірності можна обчислити за правилу множення ймовірностей. Закон розподілу випадкової величини:
| X | 0 | 1 | 2 | 3 |
| p | 1/30 | 3/10 | 1/2 | 1/6 |
Звідси математичне очікування цієї випадкової величини:
M(X) = 3/10 + 1 + 1/2 = 1,8 .
Дисперсія даної випадкової величини:
D(X) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Математичне очікування та дисперсія безперервної випадкової величини
Для безперервної випадкової величини механічна інтерпретація математичного очікування збереже той самий зміст: центр маси для одиничної маси, розподіленої безперервно на осі абсцис із щільністю f(x). На відміну від дискретної випадкової величини, яка має аргумент функції xiзмінюється стрибкоподібно, у безперервної випадкової величини аргумент змінюється безперервно. Але математичне очікування безперервної випадкової величини пов'язане з її середнім значенням.
Щоб знаходити математичне очікування та дисперсію безперервної випадкової величини, потрібно знаходити певні інтеграли . Якщо дана функція щільності безперервної випадкової величини, вона безпосередньо входить у подынтегральное вираз. Якщо дана функція розподілу ймовірностей, то, диференціюючи її, необхідно визначити функцію щільності.
Арифметичне середнє всіх можливих значень безперервної випадкової величини називається її математичним очікуванням, що позначається або .
Дисперсія випадкової величини є мірою розкиду значень цієї величини. Мала дисперсія означає, що значення згруповані близько одне до одного. Велика дисперсія свідчить про сильний розкид значень. Поняття дисперсії випадкової величини застосовується у статистиці. Наприклад, якщо порівняти дисперсію значень двох величин (таких як результати спостережень за пацієнтами чоловічої та жіночої статі), можна перевірити значущість певної змінної. Також дисперсія використовується при побудові статистичних моделей, оскільки мала дисперсія може бути ознакою того, що ви надмірно підганяєте значення.Кроки
Обчислення дисперсії вибірки
-
Запишіть значення вибірки.Найчастіше статистикам доступні лише вибірки певних генеральних сукупностей. Наприклад, як правило, статистики не аналізують витрати на утримання сукупності всіх автомобілів у Росії – вони аналізують випадкову вибірку з кількох тисяч автомобілів. Така вибірка допоможе визначити середні витрати на автомобіль, але швидше за все отримане значення буде далеко від реального.
- Наприклад, проаналізуємо кількість булочок, проданих у кафе за 6 днів, взятих у випадковому порядку. Вибірка має такий вигляд: 17, 15, 23, 7, 9, 13. Це вибірка, а не сукупність, тому що ми не маємо даних про продані булочки за кожен день роботи кафе.
- Якщо вам дано сукупність, а не вибірка значень, перейдіть до наступного розділу.
-
Запишіть формулу обчислення дисперсії вибірки.Дисперсія є мірою розкиду значень певної величини. Чим ближче значення дисперсії до нуля, тим ближчі значення згруповані один до одного. Працюючи з вибіркою значень, використовуйте таку формулу для обчислення дисперсії:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))– це дисперсія. Дисперсія вимірюється у квадратних одиницях виміру.
- x i (\displaystyle x_(i))– кожне значення у вибірці.
- x i (\displaystyle x_(i))треба відняти x̅, звести у квадрат, та був скласти отримані результати.
- x̅ – вибіркове середнє (середнє значення вибірки).
- n – кількість значень вибірці.
-
Обчисліть середнє значення вибірки.Воно позначається як x. Середнє значення вибірки обчислюється як звичайне середнє арифметичне: складіть усі значення у вибірці, а потім отриманий результат поділіть на кількість значень у вибірці.
- У нашому прикладі складіть значення у вибірці: 15 + 17 + 23 + 7 + 9 + 13 = 84
Тепер результат поділіть на кількість значень у вибірці (у нашому прикладі їх 6): 84 ÷ 6 = 14.
Вибіркове середнє x = 14. - Вибіркове середнє – це центральне значення, навколо якого розподілені значення вибірці. Якщо значення вибірці групуються навколо вибіркового середнього, то дисперсія мала; інакше дисперсія велика.
- У нашому прикладі складіть значення у вибірці: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Відніміть середнє вибіркове з кожного значення у вибірці.Тепер обчисліть різницю x i (\displaystyle x_(i))- x̅, де x i (\displaystyle x_(i))– кожне значення у вибірці. Кожен отриманий результат свідчить про відхилення конкретного значення від вибіркового середнього, тобто як далеко це значення перебуває від середнього значення вибірки.
- У нашому прикладі:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Правильність отриманих результатів легко перевірити, оскільки їх сума має дорівнювати нулю. Це з визначенням середнього значення, оскільки негативні значення (відстань від середнього значення до менших значень) повністю компенсуються позитивними значеннями (відстанями від середнього значення до великих значень).
- У нашому прикладі:
-
Як зазначалося вище, сума різниць x i (\displaystyle x_(i))- x̅ повинна дорівнювати нулю. Це означає, що середня дисперсія завжди дорівнює нулю, що не дає уявлення про розкид значень деякої величини. Для вирішення цієї проблеми зведіть у квадрат кожну різницю x i (\displaystyle x_(i))- x̅. Це призведе до того, що ви отримаєте лише позитивні числа, які при додаванні ніколи не дадуть 0.
- У нашому прикладі:
(x 1 (\displaystyle x_(1))- x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2)))- x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Ви знайшли квадрат різниці - x̅) 2 (\displaystyle ^(2))для кожного значення у вибірці.
- У нашому прикладі:
-
Обчисліть суму квадратів різниці.Тобто знайдіть ту частину формули, яка записується так: ∑[( x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))]. Тут знак Σ означає суму квадратів різниць для кожного значення x i (\displaystyle x_(i))у вибірці. Ви вже знайшли квадрати різниць (x i (\displaystyle (x_(i)))- x̅) 2 (\displaystyle ^(2))для кожного значення x i (\displaystyle x_(i))у вибірці; Тепер просто складіть ці квадрати.
- У нашому прикладі: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Отриманий результат розділіть на n - 1, де n – кількість значень вибірки.Якийсь час тому для обчислення дисперсії вибірки статистики ділили результат просто на n; у цьому випадку ви отримаєте середнє значення квадрата дисперсії, що ідеально підходить для опису дисперсії даної вибірки. Але пам'ятайте, що будь-яка вибірка – це лише невелика частина генеральної сукупності значень. Якщо взяти іншу вибірку і виконати такі самі обчислення, ви отримаєте інший результат. Як з'ясувалося, розподіл на n - 1 (а не просто на n) дає більш точну оцінку дисперсії генеральної сукупності, в чому ви зацікавлені. Розподіл на n – 1 став загальноприйнятим, тому воно включено до формули для обчислення дисперсії вибірки.
- У прикладі вибірка включає 6 значень, тобто n = 6.
Дисперсія вибірки = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- У прикладі вибірка включає 6 значень, тобто n = 6.
-
Відмінність дисперсії стандартного відхилення.Зауважте, що у формулі є показник ступеня, тому дисперсія вимірюється у квадратних одиницях вимірювання аналізованої величини. Іноді такою величиною досить складно оперувати; у таких випадках користуються стандартним відхиленням, яке дорівнює квадратному кореню з дисперсії. Саме тому дисперсія вибірки позначається як s 2 (\displaystyle s^(2)), а стандартне відхилення вибірки – як s (\displaystyle s).
- У прикладі стандартне відхилення вибірки: s = √33,2 = 5,76.
Обчислення дисперсії сукупності
-
Проаналізуйте деяку сукупність значень.Сукупність включає всі значення аналізованої величини. Наприклад, якщо ви вивчаєте вік жителів Ленінградської області, сукупність включає вік всіх жителів цієї області. У разі роботи із сукупністю рекомендується створити таблицю та внести до неї значення сукупності. Розглянемо наступний приклад:
- У деякій кімнаті є 6 акваріумів. У кожному акваріумі мешкає така кількість риб:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- У деякій кімнаті є 6 акваріумів. У кожному акваріумі мешкає така кількість риб:
-
Запишіть формулу обчислення дисперсії генеральної сукупності.Так як сукупність входять всі значення деякої величини, то наведена нижче формула дозволяє отримати точне значення дисперсії сукупності. Для того щоб відрізнити дисперсію сукупності від дисперсії вибірки (значення якої є лише оцінним), статистики використовують різні змінні:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n
- σ 2 (\displaystyle ^(2))- Дисперсія сукупності (читається як "сигма в квадраті"). Дисперсія вимірюється у квадратних одиницях виміру.
- x i (\displaystyle x_(i))- Кожне значення в сукупності.
- Σ – знак суми. Тобто з кожного значення x i (\displaystyle x_(i))потрібно відняти μ, звести у квадрат, та був скласти отримані результати.
- μ – середнє значення сукупності.
- n – кількість значень у генеральній сукупності.
-
Обчисліть середнє значення сукупності.Працюючи з генеральною сукупністю її середнє значення позначається як μ (мю). Середнє значення сукупності обчислюється як звичайне середнє арифметичне: складіть усі значення в генеральній сукупності, а потім отриманий результат розділіть на кількість значень у генеральній сукупності.
- Майте на увазі, що середні величини не завжди обчислюються як середнє арифметичне.
- У прикладі середнє значення сукупності: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Відніміть середнє значення сукупності з кожного значення в генеральній сукупності.Чим ближче значення різниці нанівець, тим ближче конкретне значення до середнього значення сукупності. Знайдіть різницю між кожним значенням у сукупності та її середнім значенням, і ви отримаєте перше уявлення про розподіл значень.
- У нашому прикладі:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- У нашому прикладі:
-
Зведіть у квадрат кожен отриманий результат.Значення різниць будуть як позитивними, і негативними; якщо нанести ці значення на числову пряму, всі вони лежатимуть праворуч і ліворуч від середнього значення сукупності. Це не годиться для обчислення дисперсії, оскільки позитивні та негативні числа компенсують одна одну. Тому зведіть у квадрат кожну різницю, щоб отримати винятково позитивні числа.
- У нашому прикладі:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))для кожного значення сукупності (від i = 1 до i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), де x n (\displaystyle x_(n))– останнє значення у генеральній сукупності. - Для обчислення середнього значення отриманих результатів потрібно знайти їхню суму та розділити її на n:(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/n
- Тепер запишемо наведене пояснення з використанням змінних: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n і отримаємо формулу для обчислення дисперсії сукупності.
- У нашому прикладі:
Дисперсія у статистицізнаходиться як індивідуальних значень ознаки у квадраті від . Залежно від вихідних даних вона визначається за формулами простої та зваженої дисперсій:
1. (Для несгрупованих даних) обчислюється за формулою:
2. Зважена дисперсія (для варіаційного ряду):
 де n - Частота (повторюваність фактора Х)
де n - Частота (повторюваність фактора Х)
Приклад знаходження дисперсії
На цій сторінці описано стандартний приклад знаходження дисперсії, також Ви можете переглянути інші завдання на її знаходження
Приклад 1. Є такі дані щодо групи з 20 студентів заочного відділення. Потрібно побудувати інтервальний ряд розподілу ознаки, розрахувати середнє значення ознаки та вивчити його дисперсію
 Побудуємо інтервальне угруповання. Визначимо розмах інтервалу за формулою:
Побудуємо інтервальне угруповання. Визначимо розмах інтервалу за формулою:
![]() де X max - максимальне значення групувального ознаки;
де X max - максимальне значення групувального ознаки;
X min-мінімальне значення групувальної ознаки;
n – кількість інтервалів:
Приймаємо n=5. Крок дорівнює: h = (192 - 159) / 5 = 6,6
Складемо інтервальне угруповання
 Для подальших розрахунків збудуємо допоміжну таблицю:
Для подальших розрахунків збудуємо допоміжну таблицю:
 X'i - середина інтервалу. (наприклад, середина інтервалу 159 – 165,6 = 162,3)
X'i - середина інтервалу. (наприклад, середина інтервалу 159 – 165,6 = 162,3)
Середню величину зростання студентів визначимо за формулою середньої арифметичної зваженої:
 Визначимо дисперсію за такою формулою:
Визначимо дисперсію за такою формулою:
Формулу дисперсії можна перетворити так:

З цієї формули випливає, що дисперсія дорівнює різниці середньої з квадратів варіантів і квадрата та середньої.
Дисперсія у варіаційних рядахз рівними інтервалами за способом моментів може бути розрахована наступним способом при використанні другої властивості дисперсії (розділивши всі варіанти на величину інтервалу). Визначення дисперсії, обчисленої за способом моментів, за такою формулою менш трудомісткий:

де i – величина інтервалу;
А - умовний нуль, як який зручно використовувати середину інтервалу, що володіє найбільшою частотою;
m1 - квадрат моменту першого порядку;
m2 - момент другого порядку
(якщо в статистичній сукупності ознака змінюється так, що є тільки два варіанти, що взаємно виключають один одного, то така мінливість називається альтернативною) може бути обчислена за формулою:

Підставляючи до цієї формули дисперсії q =1- р, отримуємо:

Види дисперсії
Загальна дисперсіявимірює варіацію ознаки у всій сукупності загалом під впливом всіх чинників, що зумовлюють цю варіацію. Вона дорівнює середньому квадрату відхилень окремих значень ознаки х від загального середнього значення х може бути визначена як проста дисперсія або зважена дисперсія.
характеризує випадкову варіацію, тобто. частина варіації, яка обумовлена впливом неврахованих факторів і не залежить від ознаки-фактора, покладеної в основу угруповання. Така дисперсія дорівнює середньому квадрату відхилень окремих значень ознаки всередині групи X від середньої арифметичної групи і може бути обчислена як проста дисперсія або зважена дисперсія.
Таким чином, внутрішньогрупова дисперсія вимірюєваріацію ознаки всередині групи та визначається за формулою:

де хі - групова середня;
ni – число одиниць у групі.
Наприклад, внутрішньогрупові дисперсії, які треба визначити в задачі вивчення впливу кваліфікації робітників на рівень продуктивності праці в цеху показують варіації виробітку в кожній групі, викликані всіма можливими факторами (технічний стан обладнання, забезпеченість інструментами та матеріалами, вік робітників, інтенсивність праці тощо) .), крім відмінностей у кваліфікаційному розряді (всередині групи всі робітники мають одну й ту саму кваліфікацію).
Середня з внутрішньо групових дисперсій відображає випадкову , тобто ту частину варіації, яка відбувалася під впливом всіх інших факторів, за винятком фактора угруповання. Вона розраховується за такою формулою:

Характеризує систематичну варіацію результативної ознаки, яка обумовлена впливом ознаки-фактора, покладеного в основу угруповання. Вона дорівнює середньому квадрату відхилень групових середніх від загальної середньої. Міжгрупова дисперсія розраховується за такою формулою:

Правило складання дисперсії у статистиці
Згідно правилу складання дисперсійзагальна дисперсія дорівнює сумі середньої із внутрішньогрупових та міжгрупових дисперсій:
![]()
Сенс цього правилаполягає в тому, що загальна дисперсія, яка виникає під впливом всіх факторів, дорівнює сумі дисперсій, що виникають під впливом всіх інших факторів, та дисперсії, що виникає за рахунок угруповання.
Користуючись формулою складання дисперсій, можна визначити за двома відомими дисперсіями третю невідому, а також судити про силу впливу групувальної ознаки.
Властивості дисперсії
1. Якщо всі значення ознаки зменшити (збільшити) на ту саму постійну величину, то дисперсія від цього не зміниться.
2. Якщо всі значення ознаки зменшити (збільшити) в те саме число разів n, то дисперсія відповідно зменшиться (збільшити) в n^2 разів.
 Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих
Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих Крихітка Цахес по прозвищу Циннобер
Крихітка Цахес по прозвищу Циннобер Майков, Аполлон Миколайович – коротка біографія
Майков, Аполлон Миколайович – коротка біографія