Намалюйте графік станів для марківського ланцюга. Однорідні ланцюги маркова
1. матрицю Р2переходу ланцюга зі стану iу стан jза два
кроку;
2. розподіл ймовірностей за станами у момент t=2;
3. ймовірність того, що в момент t=1 станом ланцюга буде А2;
4. стаціонарний розподіл.
Рішення.Для дискретного ланцюга Маркова у разі його однорідності справедливе співвідношення
де Р1 - матриця перехідних ймовірностей за один крок;
Рn – матриця перехідних ймовірностей за n кроків;
1. Знайдемо матрицю Р2 переходу за два кроки
Нехай розподіл ймовірностей за станами на S-ом кроці визначається вектором
.
Знаючи матрицю Pnпереходу за n кроків, можна визначити розподіл ймовірностей за станами на (S+n)На кроці ![]() . (5)
. (5)
2. Знайдемо розподіл ймовірностей за станами системи у момент t=2. Покладемо (5) S=0 і n=2. Тоді ![]() .
.
Отримаємо.
3. Знайдемо розподіл ймовірностей за станами системи у момент t=1.
Покладемо (5) s=0 і n=1, тоді .
Звідки видно, що ймовірність того, що в момент t=1 станом ланцюга буде А2,рівна р2(1)=0,69.
Розподіл ймовірностей за станами називається стаціонарним, якщо він не змінюється від кроку до кроку, тобто
Тоді із співвідношення (5) при n=1 отримаємо
4. Знайдемо стаціонарний розподіл. Оскільки =2 маємо =(р1; р2). Запишемо систему лінійних рівнянь (6) у координатній формі

Остання умова називається нормувальною. У системі (6) завжди одне рівняння є лінійною комбінацією інших. Отже, його можна викреслити. Вирішимо спільно перше рівняння системи та нормувальне. Маємо 0,6 р1=0,3р2, тобто р2=2р1. Тоді р1+2р1=1 або, тобто. Отже, .
Відповідь:
1) матриця переходу за два кроки для даного ланцюга Маркова має вигляд ![]() ;
;
2) розподіл ймовірностей за станами у момент t=2 дорівнює ![]() ;
;
3) ймовірність того, що в момент t=1 станом ланцюга буде А2, дорівнює р2(t)=0,69;
4) стаціонарний розподіл має вигляд
Задано матрицю  інтенсивностей переходів безперервного ланцюга Маркова Скласти розмічений граф станів, що відповідає матриці Λ; скласти систему диференціальних рівнянь Колмогорова для ймовірностей станів; знайти граничне розподіл ймовірностей. Рішення.Однорідний ланцюг Маркова з кінцевим числом станів А1, А2,…Ахарактеризується матрицею інтенсивностей переходів
інтенсивностей переходів безперервного ланцюга Маркова Скласти розмічений граф станів, що відповідає матриці Λ; скласти систему диференціальних рівнянь Колмогорова для ймовірностей станів; знайти граничне розподіл ймовірностей. Рішення.Однорідний ланцюг Маркова з кінцевим числом станів А1, А2,…Ахарактеризується матрицею інтенсивностей переходів  ,
,
де ![]() - Інтенсивність переходу ланцюга Маркова зі стану Аiу стан Аj; рij(Δt)-ймовірність переходу Ai→Ajза інтервал часу Δ
t.
- Інтенсивність переходу ланцюга Маркова зі стану Аiу стан Аj; рij(Δt)-ймовірність переходу Ai→Ajза інтервал часу Δ
t.
Переходи системи зі стану до стану зручно задавати за допомогою розміченого графа станів, на якому відзначаються дуги, що відповідають інтенсивностям λ
ij>0. Складемо розмічений граф станів для заданої матриці інтенсивностей переходів 
Нехай - вектор ймовірностей рj(t),
j=1, 2,…,, знаходження системи може Аjу момент t.
Очевидно, що 0≤ рj(t)≤1 і . Тоді за правилом диференціювання векторної функції скалярного аргументу отримаємо ![]() . Ймовірності рj(t)задовольняють системі диференціальних рівнянь Колмогорова (СДУК), що у матричної формі має вигляд . (7)
. Ймовірності рj(t)задовольняють системі диференціальних рівнянь Колмогорова (СДУК), що у матричної формі має вигляд . (7)
Якщо в початковий момент система перебувала в стані Аj, то СДУК слід вирішувати за початкових умов
рi(0)=1, рj(0)=0, j≠i,j=1, 2,…,.
(8)
Сукупність СДУК (7) та початкових умов (8) однозначно описує однорідний ланцюг Маркова з безперервним часом та кінцевим числом станів.
Складемо СДУК для заданого ланцюга Маркова. Оскільки =3, то j=1, 2, 3.
Зі співвідношення (7) отримаємо  .
.
Звідси матимемо 
Остання умова називається нормувальною.
Розподіл ймовірностей за станами називається стаціонарнимякщо воно не змінюється з плином часу, тобто , де рj=const, j=1,2,…,. Звідси ![]() .
.
Тоді із СДУК (7) отримуємо систему для знаходження стаціонарного розподілу ![]() (9)
(9)
Для цього завдання з СДУК будемо мати 
З нормувальної умови отримаємо 3р2+р2+р2=1або ![]() . Отже, граничний розподіл має вигляд .
. Отже, граничний розподіл має вигляд .
Зауважимо, що цей результат можна отримати безпосередньо за розміченим графом станів, якщо скористатися правилом: для стаціонарного розподілу сума творів λ
jipi, j≠iдля стрілок, що виходять з i-го стану, що дорівнює сумі творів λ
jipi, j≠iдля стрілок, що входять у i-е стан. Справді, 
Очевидно, що отримана система еквівалентна тій, яка складена за СДУК. Отже, вона має те саме рішення.
Відповідь: стаціонарний розподіл має вигляд.
Ланцюг Маркова - низка подій, в якій кожна наступна подія залежить від попередньої. У статті докладніше розберемо це поняття.
Ланцюг Маркова - це поширений і досить простий спосіб моделювання випадкових подій. Використовується в різних областях, починаючи генерацією тексту і закінчуючи фінансовим моделюванням. Найвідомішим прикладом є SubredditSimulator. У даному випадку Ланцюг Маркова використовується для автоматизації створення контенту у всьому subreddit.
Ланцюг Маркова зрозуміла і проста у використанні, тому що вона може бути реалізована без використання будь-яких статистичних або математичних концепцій. Ланцюг Маркова ідеально підходить для вивчення ймовірнісного моделювання та Data Science.
Сценарій
Уявіть, що є лише дві погодні умови: може бути або сонячно, або похмуро. Завжди можна безпомилково визначити погоду зараз. Гарантовано буде ясно чи хмарно.
Тепер вам захотілося навчитися пророкувати погоду на завтрашній день. Інтуїтивно ви розумієте, що погода не може кардинально змінитись за один день. На це впливає багато факторів. Завтрашня погода безпосередньо залежить від поточної і т. д. Таким чином, для того, щоб передбачати погоду, ви протягом декількох років збираєте дані і приходите до висновку, що після похмурого дня ймовірність сонячного дорівнює 0,25. Логічно припустити, що ймовірність двох похмурих днів поспіль дорівнює 0,75, тому що ми маємо лише дві можливі погодні умови.

Тепер ви можете прогнозувати погоду на кілька днів уперед, ґрунтуючись на поточній погоді.
Цей приклад показує ключові поняття ланцюга Маркова. Ланцюг Маркова складається з набору переходів, що визначаються розподілом ймовірностей, які у свою чергу задовольняють Марківську властивість.
Зверніть увагу, що у прикладі розподіл ймовірностей залежить лише від переходів із поточного дня наступного. Це унікальна властивість Марковського процесу - він робить це без пам'яті. Як правило, такий підхід не здатний створити послідовність, в якій спостерігалася б якась тенденція. Наприклад, у той час як ланцюг Маркова здатна зімітувати стиль листа, заснований на частоті використання якогось слова, він не здатний створити тексти з глибоким змістом, оскільки він може працювати лише з великими текстами. Саме тому ланцюг Маркова не може виробляти контент, що залежить від контексту.
Модель
Формально ланцюг Маркова - це ймовірнісний автомат. Розподіл ймовірностей переходів зазвичай представляється як матриці. Якщо ланцюг Маркова має N можливих станів, то матриця матиме вигляд N x N, в якій запис (I, J) буде ймовірністю переходу зі стану I у стан J. Крім того, така матриця має бути стохастичною, тобто рядки або стовпці у сумі мають давати одиницю. У такій матриці кожен рядок матиме власний розподіл ймовірностей.

Загальний вид ланцюга Маркова зі станами як кіл і ребрами як переходів.

Зразкова матриця переходу із трьома можливими станами.
Ланцюг Маркова має початковий вектор стану, представлений у вигляді матриці N x 1. Він описує розподіл ймовірностей початку в кожному з N можливих станів. Запис I визначає ймовірність початку ланцюга у стані I.
Цих двох структур цілком вистачить на уявлення ланцюга Маркова.
Ми вже обговорили, як отримати можливість переходу з одного стану в інший, але що щодо отримання цієї можливості за кілька кроків? Для цього нам необхідно визначити можливість переходу зі стану I в стан J за M кроків. Насправді, це дуже просто. Матрицю переходу P можна визначити обчисленням (I, J) за допомогою зведення P у ступінь M. Для малих значень M це можна робити вручну за допомогою повторного множення. Але для великих значень M, якщо ви знайомі з лінійною алгеброю, більш ефективним способом зведення матриці в ступінь спочатку буде діагоналізувати цю матрицю.
Ланцюг Маркова: висновок
Тепер, знаючи, що собою являє ланцюг Маркова, ви можете легко реалізувати її однією з мов програмування. Прості ланцюги Маркова є фундаментом вивчення більш складних методів моделювання.
Всі можливі стани системи в однорідному ланцюгу Маркова, а - стохастична матриця, що визначає цей ланцюг, складена з перехідних ймовірностей ![]() (Див. стор. 381).
(Див. стор. 381).
Позначимо через ймовірність знаходження системи в стані в момент часу, якщо відомо, що в момент часу система перебувала в стані (,). Очевидно, ![]() . Користуючись теоремами про складання та множення ймовірностей, ми легко знайдемо:
. Користуючись теоремами про складання та множення ймовірностей, ми легко знайдемо:
![]()
![]()
або в матричному записі
![]()
Звідси, даючи послідовно значення, отримаємо важливу формулу
Якщо існують межі
![]()
або в матричному записі
![]()
то величини ![]() називаються граничними чи фінальними перехідними ймовірностями.
називаються граничними чи фінальними перехідними ймовірностями.
Для з'ясування, у яких існують граничні перехідні ймовірності, і висновку відповідних формул введемо наступну термінологію.
Ми будемо стохастичну матрицю і відповідний однорідний ланцюг Маркова називати правильною, якщо у матриці немає характеристичних чисел, відмінних від одиниці і рівних по модулю одиниці, і регулярної, якщо додатково одиниця є простим коренем характеристичного рівняння матриці .
Правильна матриця характеризується тим, що у її нормальній формі (69) (стор. 373) матриці є примітивними. Для регулярної матриці додатково.
Крім того, однорідний ланцюг Маркова називається нерозкладним, розкладним, ациклічним, циклічним, якщо для цього ланцюга стохастична матриця є відповідно нерозкладним, розкладним, примітивним, імпримітивним.
Оскільки примітивна стохастична матриця є приватним видом правильної матриці, остільки ациклічний ланцюг Маркова є приватним видом правильного ланцюга.
Ми покажемо, що граничні перехідні можливості існують тільки у правильних однорідних ланцюгів Маркова.
Справді, нехай - мінімальний багаточлен правильної матриці. Тоді
Відповідно до теореми 10 можна прийняти, що
З формули (24) гол. V (стор. 113)
 (96)
(96)
де ![]() - наведена приєднана матриця та
- наведена приєднана матриця та

Якщо – правильна матриця, то
і тому в правій частині формули (96) всі доданки, крім першого, при прагне до нуля. Тому для правильної матриці існує матриця , складена з граничних перехідних ймовірностей, і
Зворотне становище очевидне. Якщо існує межа
то матриця не може мати характеристичного числа , для якого , а , так як тоді не існувала б межа [Ця ж межа повинна існувати через існування межі (97").]
Ми довели, що для правильного (і тільки для правильного) однорідного ланцюга Маркова існує матриця. Ця матриця визначається формулою (97).
Покажемо, як можна виразити матрицю через характеристичний багаточлен
та приєднану матрицю ![]() .
.
З тотожності
в силу (95), (95") та (98) випливає:

Тому формулу (97) можна замінити формулою
 (97)
(97)
Для регулярного ланцюга Маркова, оскільки він є приватним видом правильного ланцюга, матриця існує і визначається будь-якою з формул (97), (97"). У цьому випадку і формула (97") має вигляд
2. Розглянемо правильний ланцюг загального типу (нерегулярний). Відповідну матрицю запишемо у нормальній формі
 (100)
(100)
де - примітивні стохастичні матриці, а у нерозкладних матриць максимальні характеристичні числа. Вважаючи
 ,
, 
запишемо у вигляді

 (101)
(101)

Але ![]() , Оскільки всі характеристичні числа матриці за модулем менше одиниці. Тому
, Оскільки всі характеристичні числа матриці за модулем менше одиниці. Тому
 (102)
(102)
Оскільки - примітивні стохастичні матриці, то матриці згідно з формулами (99) та (35) (стор. 362) позитивні
![]()
і в кожному стовпці будь-якої з цих матриць всі елементи рівні між собою:
![]() .
.
Зауважимо, що нормальному виду (100) стохастичної матриці відповідає розбиття станів системи на групи:
Кожній групі (104) відповідає своя група рядів (101). По термінології Л. Н. Колмогорова стану системи, що входять до , називаються суттєвими, а стани, що входять до інших груп - несуттєвими.
З виду (101) матриці випливає, що при будь-якому коночному числі кроків (від моменту до моменту) можливий тільки перехід системи а) із суттєвого стану у суттєвий стан тієї ж групи, б) з несуттєвого стану у суттєвий стан та в) з несуттєвого стану у несуттєвий стан тієї ж чи попередньої групи.
З виду (102) матриці випливає, що в проділ при переході можливий тільки з будь-якого стану в суттєвий стан, тобто ймовірність переходу в будь-який несуттєвий стан при числі кроків прагне нуля. Тому суттєві стани іноді називаються і граничними станами.
3. З формули (97) випливає:
![]() .
.
Звідси видно, кожен стовпець матриці є власним вектором стохастичної матриці для характеристичного числа .
Для регулярної матриці число 1 є простим коренем характеристичного рівняння і цьому числу відповідає лише один (з точністю до скалярного множника) власний вектор матриці. Тому в будь-якому стовпці матриці всі елементи рівні одному й тому ж невід'ємному числу:
Таким чином, у регулярній ланцюга граничні перехідні ймовірності залежать від початкового стану.
Назад, якщо в деякому правильному однорідному ланцюгу Маркова граничні перехідні ймовірності не залежать від початкового стану, тобто мають місце формули (104), то в схемі (102) для матриці обов'язково. Але тоді і ланцюг є регулярним.
Для ациклічної ланцюга, яка є окремим випадком регулярного ланцюга, - примітивна матриця. Тому при деякому (див. теорему 8 на стор. 377). Але тоді й ![]() .
.
Назад, слід, що при деякому , а це по теоремі 8 означає примітивність матриці і, отже, ациклічність даної однорідної ланцюга Маркова.
Отримані результати ми сформулюємо у вигляді наступної теореми:
Теорема 11. 1. Для того щоб у однорідному ланцюзі Маркова існували всі граничні перехідні ймовірності, необхідно і достатньо, щоб ланцюг був правильним. І тут матриця , складена з граничних перехідних ймовірностей, визначається формулою (95) чи (98).
2. Для того, щоб у правильному однорідному ланцюгу Маркова граничні перехідні ймовірності не залежали від початкового стану, необхідно і достатньо, щоб ланцюг був регулярним. І тут матриця визначається формулою (99).
3. Для того щоб у правильному однорідному ланцюгу Маркова всі граничні перехідні ймовірності були відмінними від нуля, необхідно і достатньо, щоб ланцюг був ациклічним.
4. Введемо на розгляд стовпці з абсолютних ймовірностей
![]() (105)
(105)
де - ймовірність знаходження системи у момент у стані (,). Користуючись теоремами складання та множення ймовірностей, знайдемо:
![]() (,),
(,),
або в матричному записі
де - транспонована матриця для матриці.
Усі абсолютні ймовірності (105) визначаються з формули (106), якщо відомі початкові ймовірності та матриця перехідних ймовірностей
Введемо на розгляд граничні абсолютні ймовірності
![]()
Переходячи в обох частинах рівності (106) до межі при , отримаємо:
Зауважимо, що існування матриці граничних перехідних ймовірностей тягне за собою існування граничних абсолютних ймовірностей ![]() за будь-яких початкових ймовірностей
за будь-яких початкових ймовірностей ![]() і навпаки.
і навпаки.
З формули (107) і виду (102) матриці випливає, що граничні абсолютні ймовірності, що відповідають несуттєвим станам, дорівнюють нулю.
Помножуючи обидві частини матричної рівності
праворуч на , ми в силу (107) отримаємо:
тобто стовпець граничних абсолютних ймовірностей є власним вектором матриці для характеристичного числа.
Якщо цей ланцюг Маркова регулярна, то є простим коренем характеристичного рівняння матриці. У цьому випадку стовпець граничних абсолютних ймовірностей однозначно визначається (108) (оскільки і ).
Нехай даний регулярний ланцюг Маркова. Тоді з (104) і (107) випливає:
![]() (109)
(109)
У цьому випадку граничні абсолютні ймовірності не залежать від початкових ймовірностей.
Назад, може не залежати від наявності формули (107) тоді і тільки тоді, коли всі рядки матриці однакові, тобто.
![]() ,
,
і тому (відповідно до теореми 11) - регулярна матриця.
Якщо - примітивна матриця, то , а звідси (109)
Навпаки, якщо всі і не залежать від початкових ймовірностей, то в кожному стовпці матриці всі елементи однакові і згідно (109) , а це по теоремі 11 означає, що - примітивна матриця, тобто даний ланцюг ациклічна.
З викладеного випливає, що теорему 11 можна сформулювати так:
Теорема 11". 1. Для того щоб в однорідному ланцюгу Маркова існували всі граничні абсолютні ймовірності при будь-яких початкових ймовірностях, необхідно і достатньо, щоб ланцюг був правильним.
2. Для того, щоб у однорідному ланцюгу Маркова існували граничні абсолютні ймовірності при будь-яких початкових ймовірностях і не залежали від цих початкових ймовірностей, необхідно і достатньо, щоб ланцюг був регулярним.
3. Для того щоб в однорідному ланцюгу Маркова за будь-яких початкових ймовірностей існували позитивні граничні абсолютні ймовірності і ці граничні ймовірності не залежали від початкових, необхідно і достатньо, щоб ланцюг був ациклічним.
5. Розглянемо тепер однорідний ланцюг Маркова загального типу з матрицею перехідних ймовірностей.
Візьмемо нормальну форму (69) матриці і позначимо через індекси імпримітивності матриць (69). Нехай - найменше загальне кратне цілих чисел. Тоді матриця немає характеристичних чисел, рівних по модулю одиниці, але відмінних від одиниці, т. е. - правильна матриця; при цьому – найменший показник, при якому – правильна матриця. Число назвемо періодом даного однорідного ланцюга Маркова і.. Назад, якщо і ![]() , Які визначаються формулами (110) і (110").
, Які визначаються формулами (110) і (110").
Середні граничні абсолютні ймовірності, що відповідають несуттєвим станам, завжди дорівнюють нулю.
Якщо в нормальній формі матриці число (і тільки в цьому випадку), середні абсолютні граничні ймовірності не залежать від початкових ймовірностей і однозначно визначаються з рівняння (111).
Ця стаття надає загальне уявлення про те, як генерувати тексти за допомогою моделювання марківських процесів. Зокрема, ми познайомимося з ланцюгами Маркова, а як практика реалізуємо невеликий генератор тексту на Python.
Для початку випишемо потрібні, але поки не дуже зрозумілі нам визначення зі сторінки у Вікіпедії, щоб хоча б приблизно уявляти, з чим ми маємо справу:
Марківський процес t t
Марківський ланцюг
Що це все означає? Давайте розумітися.
Основи
Перший приклад гранично простий. Використовуючи пропозицію з дитячої книжки, ми освоїмо базову концепцію ланцюга Маркова, а також визначимо, що таке у нашому контексті. корпус, ланки, розподіл ймовірностей та гістограми. Незважаючи на те, що пропозиція наведена англійською мовою, суть теорії буде легко вловити.
Ця пропозиція і є корпус, тобто база, на основі якої надалі генеруватиметься текст. Воно складається з восьми слів, але при цьому унікальних слів лише п'ять – це ланки(адже ми говоримо про марківську ланцюги). Для наочності пофарбуємо кожну ланку у свій колір:

І випишемо кількість появи кожної з ланок у тексті:

На зображенні вище видно, що слово "fish"з'являється в тексті в 4 рази частіше, ніж кожне з інших слів ( "One", "two", "red", "blue"). Тобто можливість зустріти в нашому корпусі слово "fish"в 4 рази вище, ніж можливість зустріти кожне інше слово з наведених на малюнку. Говорячи мовою математики, ми можемо визначити закон розподілу випадкової величини та обчислити, з якою ймовірністю одне зі слів з'явиться у тексті після поточного. Імовірність вважається так: потрібно розділити кількість появлень потрібного нам слова в корпусі на загальну кількість усіх слів у ньому. Для слова "fish"ця ймовірність - 50%, тому що воно з'являється 4 рази в реченні з 8 слів. Для кожної з інших ланок ця ймовірність дорівнює 12,5% (1/8).
Графічно уявити розподіл випадкових величин можна за допомогою гістограми. В даному випадку, наочно видно частоту появи кожної з ланок у реченні:

Отже, наш текст складається зі слів та унікальних ланок, а розподіл ймовірностей появи кожної з ланок у реченні ми відобразили на гістограмі. Якщо вам здається, що поратися зі статистикою не варто, прочитайте . І, можливо, збереже вам життя.
Суть визначення
Тепер додамо до нашого тексту елементи, які завжди маються на увазі, але не озвучуються в повсякденному мовленні - початок і кінець речення:

Будь-яка пропозиція містить ці невидимі «початок» і «кінець», додамо їх як ланок до нашого розподілу:

Повернемося до визначення, даного на початку статті:
Марківський процес- Випадковий процес, еволюція якого після будь-якого заданого значення тимчасового параметра tне залежить від еволюції, що передувала t, за умови, що значення процесу у цей момент фіксовано.
Марківський ланцюг- окремий випадок марківського процесу, коли простір його станів дискретний (тобто не більше ніж рахунковий).
То що це означає? Грубо кажучи, ми моделюємо процес, в якому стан системи в наступний момент часу залежить тільки від її стану в даний момент і ніяк не залежить від усіх попередніх станів.
Уявіть, що перед вами вікно, що відображає лише поточний стан системи (у нашому випадку, це одне слово), і вам потрібно визначити, яким буде наступне слово, ґрунтуючись лише на даних, представлених у цьому вікні. У нашому корпусі слова йдуть одне за одним за такою схемою:

Таким чином, формуються пари слів (навіть у кінця речення є своя пара – порожнє значення):

Згрупуємо ці пари за першим словом. Ми побачимо, що у кожного слова є свій набір ланок, які в контексті нашої пропозиції можутьза ним слідувати:

Представимо цю інформацію іншим способом - кожній ланці поставимо у відповідність масив із усіх слів, які можуть з'явитися в тексті після цієї ланки:

Розберемо докладніше. Ми бачимо, що кожна ланка має слова, які можуть стояти після нього у реченні. Якби ми показали схему вище комусь ще, ця людина з деякою ймовірністю могла б реконструювати нашу початкову пропозицію, тобто корпус.
приклад.Почнемо зі слова "Start". Далі вибираємо слово "One", оскільки за нашою схемою це єдине слово, яке може йти за початком речення. За словом "One"теж може слідувати лише одне слово - "fish". Тепер нова пропозиція у проміжному варіанті виглядає як "One fish". Далі ситуація ускладнюється – за "fish"можуть з рівною ймовірністю 25% йти слова "two", "red", "blue"і кінець речення "End". Якщо ми припустимо, що таке слово - "two", реконструкція продовжиться Але ми можемо вибрати і ланку "End". У такому разі на основі нашої схеми буде випадково згенерована пропозиція, що сильно відрізняється від корпусу - "One fish".
Ми щойно змоделювали марківський процес – визначили кожне наступне слово лише на підставі знань про поточне. Давайте для повного засвоєння матеріалу побудуємо діаграми, що відображають залежність між елементами всередині нашого корпусу. Овали є ланками. Стрілки ведуть до потенційних ланок, які можуть іти за словом у овалі. Біля кожної стрілки - ймовірність, з якою наступна ланка з'явиться після поточного:

Чудово! Ми засвоїли необхідну інформацію, щоб рухатися далі та розбирати складніші моделі.
Розширюємо словникову базу
У цій частині статті ми будуватимемо модель за тим самим принципом, що й раніше, але при описі опустимо деякі кроки. Якщо виникнуть труднощі, повертайтеся до теорії у першому блоці.
Візьмемо ще чотири цитати того ж автора (також англійською, нам це не завадить):
«Today you are you. That is truer than true. There is no one alive who is you-er than you.»
«You have brains in your head. You have feet in your shoes. Ви можете вийти з будь-якого напряму, щоб вибрати. You're on your own.»
«The more that you read, the more things you will know. The more that you learn, the more places you’ll go.»
«Think left and think right and think low and think high. Oh, thinks you can think up if only you try.»
Складність корпусу збільшилася, але в нашому випадку це лише плюс – тепер генератор тексту зможе видавати осмисленіші пропозиції. Справа в тому, що в будь-якій мові є слова, які зустрічаються у мовленні частіше, ніж інші (наприклад, прийменник «в» ми використовуємо набагато частіше, ніж слово «криогенний»). Чим більше слів у нашому корпусі (а отже, і залежностей між ними), тим більше у генератора інформації про те, яке слово найімовірніше має з'явитися в тексті після поточного.
Найпростіше це пояснюється з погляду програми. Ми знаємо, що для кожної ланки існує набір слів, які можуть слідувати за ним. А також кожне слово характеризується числом його появ у тексті. Нам потрібно якось зафіксувати всю цю інформацію в одному місці; з цією метою найкраще підійде словник, який зберігає пари «(ключ, значення)». У ключі словника буде записано поточний стан системи, тобто одна з ланок корпусу (наприклад, "the"на зображенні нижче); а в значенні словника зберігатиметься ще один словник. У вкладеному словнику ключами будуть слова, які можуть йти в тексті після поточної ланки корпусу ( "thinks"і «more»можуть йти в тексті після "the"), а значеннями - кількість появ цих слів у тексті після нашої ланки (слово "thinks"з'являється у тексті після слова "the" 1 раз, слово «more»після слова "the"- 4 рази):

Перечитайте абзац кілька разів, щоб точно розібратися. Зверніть увагу, що вкладений словник у цьому випадку - це та ж гістограма, він допомагає нам відстежувати ланки та частоту їх появи в тексті щодо інших слів. Треба зауважити, що навіть така словникова база дуже мала для належної генерації текстів природною мовою - вона повинна містити більше 20 000 слів, а краще більше 100 000. А ще краще - понад 500 000. Але давайте розглянемо ту словникову базу, яка вийшла у нас.
Ланцюг Маркова в даному випадку будується аналогічно першому прикладу - кожне наступне слово вибирається тільки на підставі знань про поточне слово, всі інші слова не враховуються. Але завдяки зберіганню в словнику даних про те, які слова з'являються найчастіше, ми можемо при виборі прийняти зважене рішення. Давайте розберемо конкретний приклад:
Більше:
Тобто, якщо поточним словом є слово «more»після нього можуть з рівною ймовірністю в 25% йти слова "things"і «places», І з ймовірністю 50% - слово "that". Але ймовірності можуть бути й усі рівні між собою:
Think:
Робота з вікнами
До цього моменту ми з вами розглядали лише вікна розміром в одне слово. Можна збільшити розмір вікна, щоб генератор тексту видавав більш вивірені пропозиції. Це означає, що чим більше вікно, тим менше відхилень від корпусу при генерації. Збільшення розміру вікна відповідає переходу ланцюга Маркова до вищого порядку. Раніше ми будували ланцюг першого порядку, для вікна з двох слів вийде ланцюг другого порядку, з трьох - третього, і таке інше.
Вікно- це дані в поточному стані системи, що використовуються прийняття рішень. Якщо ми сумісним велике вікно і маленький набір даних, то, швидше за все, щоразу отримуватимемо одну і ту ж пропозицію. Давайте візьмемо словникову базу з нашого першого прикладу та розширимо вікно до розміру 2:

Розширення призвело до того, що у кожного вікна тепер тільки один варіант наступного стану системи - що б ми не робили, ми завжди будемо отримувати одну і ту ж пропозицію, ідентичну нашому корпусу. Тому, щоб експериментувати з вікнами, і щоб генератор тексту повертав унікальний контент, запасіться словниковою базою від 500 000 слів.
Реалізація на Python
Структура даних Dictogram
Dictogram (dict - вбудований тип даних словник у Python) відображатиме залежність між ланками та їх частотою появи в тексті, тобто їх розподіл. Але при цьому вона матиме потрібну нам властивість словника - час виконання програми не залежатиме від обсягу вхідних даних, а це означає, що ми створюємо ефективний алгоритм.
Import random class Dictogram(dict): def __init__(self, iterable=None): # Ініціалізуємо наш розподіл як новий об'єкт класу, # додаємо наявні елементи super(Dictogram, self).__init__() self.types = 0 # число унікальних ключів у розподілі self.tokens = 0 # загальна кількість всіх слів у розподілі if iterable: self.update(iterable) def update(self, iterable): # Оновлюємо розподіл елементами з наявного # набору даних, що ітерується for item in iterable: if item in self : self += 1 self.tokens += 1 else: self = 1 self.types += 1 self.tokens += 1 def count(self, item): # Повертаємо значення лічильника елемента, або 0 if item in self: return self return 0 def return_random_word(self): random_key = random.sample(self, 1) # Інший спосіб: # random.choice(histogram.keys()) return random_key def return_weighted_random_word(self): n-1), де n - загальна кількість слів random_int = random.randint(0, self.tokens-1) index = 0 list_of_keys = self.keys() # вивести "випадковий індекс:", random_int for i in range(0, self.types): index += self] # вивести індекс if(index > random_int ): # вивести list_of_keys[i] return list_of_keys[i]
У конструктор структурі Dictogram можна передати будь-який об'єкт, яким можна итерироваться. Елементами цього об'єкта будуть слова для ініціалізації Dictogram, наприклад, усі слова з якоїсь книги. В даному випадку ми ведемо підрахунок елементів, щоб для звернення до якогось із них не потрібно було пробігати щоразу по всьому набору даних.
Ми також зробили дві функції для повернення довільного слова. Одна функція вибирає випадковий ключ у словнику, а інша, зважаючи на кількість появ кожного слова в тексті, повертає потрібне нам слово.
Структура ланцюга Маркова
з імпорту import Dictogram def make_markov_model(data): markov_model = dict() for i in range(0, len(data)-1): if data[i] in markov_model: # Просто приєднуємо до існуючого розподілу markov_model].update( ]) else: markov_model] = Dictogram(]) return markov_modelУ реалізації вище у нас є словник, який зберігає вікна як ключ у парі «(ключ, значення)» та розподіл як значення в цій парі.
Структура ланцюга Маркова N-го порядку
з histograms import Dictogram def make_higher_order_markov_model(order, data): markov_model = dict() for i in range(0, len(data)-order): # Створюємо вікно window = tuple(data) # Додаємо до словника if windo # Приєднуємо до існуючого розподілу markov_model.update(]) else: markov_model = Dictogram(]) return markov_modelДуже схоже на ланцюг Маркова першого ладу, але в даному випадку ми зберігаємо кортежяк ключ у парі «(ключ, значення)» у словнику. Ми використовуємо його замість списку, оскільки кортеж захищений від будь-яких змін, а для нас це важливо – ключі у словнику змінюватися не повинні.
Парсинг моделі
Добре, ми реалізували словник. Але як тепер здійснити генерацію контенту, ґрунтуючись на поточному стані та кроці до наступного стану? Пройдемося за нашою моделлю:
З histograms import Dictogram import random from collections import deque import re def generate_random_start(model): # Щоб згенерувати будь-яке початкове слово, розкоментуйте рядок: # return random.choice(model.keys()) # Щоб згенерувати "правильне" початкове слово код нижче: # Правильні початкові слова - це ті, що були початком речень у корпусі if "END" in model: seed_word = "END" while seed_word == "END": seed_word = model["END"].return_weighted_random_word() return seed_word return random.choice(model.keys()) def generate_random_sentence(length, markov_model): current_word = generate_random_start(markov_model) sentence = for i in range(0, length): current_dictogram = markov_model random_weighted_word sentence.append(current_word) sentence = sentence.capitalize() return " ".join(sentence) + "." return sentence
Що далі?
Спробуйте вигадати, де ви самі можете використовувати генератор тексту на основі марківських ланцюгів. Тільки не забувайте, що найголовніше це те, як ви парсіте модель і які особливі обмеження встановлюєте на генерацію. Автор цієї статті, наприклад, при створенні генератора твітів використовував велике вікно, обмежив контент, що генерується, до 140 символів і використовував для початку речень лише «правильні» слова, тобто ті, які були початком речень в корпусі.
Способи математичних описів марківських випадкових процесів у системі з дискретними станами (ДС) залежать від того, в які моменти часу (заздалегідь відомі або випадкові) можуть відбуватися переходи системи зі стану.
Якщо перехід системи зі стану в стан можливий в заздалегідь фіксовані моменти часу, маємо справу з випадковим марківським процесом із дискретним часом.Якщо перехід можливий у будь-який випадковий момент часу, то маємо справу з випадковим марківським процесом із безперервним часом.
Нехай є фізична система S, яка може перебувати в nстанах S 1 , S 2 , …, S n. Переходи зі стану до стану можливі лише в моменти часу t 1 , t 2 , …, t k, Назвемо ці моменти часу кроками. Розглянемо СП у системі Sяк функцію цілісного аргументу 1, 2, …, kде аргументом є номер кроку.
Приклад: S 1 → S 2 → S 3 → S 2 .
Умовимося позначати S i (k) – подія, яка полягає в тому, що після kкроків система знаходиться в стані S i.
За будь-якого kподії S 1 ( k) , S 2 ( k), ..., S n (k) утворюють повну групу подійі є несумісними.
Процес у системі можна як ланцюжок подій.
Приклад: S 1 (0) , S 2 (1), S 3 (2), S 5 (3), ….
Така послідовність називається марківським ланцюгом
якщо для кожного кроку ймовірність переходу з будь-якого стану S iу будь-який стан S jне залежить від того, коли і як система прийшла в стан S i.
Нехай у будь-який момент часу після будь-якого k-го кроку система Sможе перебувати в одному із станів S 1 , S 2 , …, S n, тобто може статися одна подія з повної групи подій: S 1 (k) , S 2 ( k) , …, S n (k). Позначимо ймовірність цих подій:
P 1 (1) = P(S 1 (1)); P 2 (1) = P(S 2 (1)); …; P n(1) = P(S n (k));
P 1 (2) = P(S 1 (2)); P 2 (2) = P(S 2 (2)); …; P n(2) = P(S n (2));
P 1 (k) = P(S 1 (k)); P 2 (k) = P(S 2 (k)); …; P n(k) = P(S n (k)).
Легко помітити, що для кожного номера кроку виконується умова
P 1 (k) + P 2 (k) +…+ P n(k) = 1.
Назвемо ці ймовірності ймовірностями станів.Отже, завдання звучатиме наступним чином: знайти ймовірності станів системи для будь-якого k.
приклад.Нехай є якась система, яка може бути в будь-якому з шести станів. тоді процеси, які у ній, можна зобразити чи вигляді графіка зміни стану системи (рис. 7.9, а), або у вигляді графа станів системи (рис. 7.9, б).
а) 
Рис. 7.9
Також процеси у системі можна зобразити у вигляді послідовності станів: S 1 , S 3 , S 2 , S 2 , S 3 , S 5 , S 6 , S 2 .
Імовірність стану на ( k+ 1)-му кроці залежить тільки від стану на k-м кроку.
Для будь-якого кроку kіснують якісь ймовірності переходу системи з будь-якого стану в будь-який інший стан, назвемо ці ймовірності перехідними ймовірностями марківського ланцюга.
Деякі з цих ймовірностей дорівнюватимуть 0, якщо перехід з одного стану в інший неможливий за один крок.
Марківський ланцюг називається однорідний, якщо перехідні стани не залежать від номера кроку, інакше вона називається неоднорідний.
Нехай є однорідний марківський ланцюг і нехай система Sмає nможливих станів: S 1 , …, S n. Нехай кожному стану відома можливість переходу на інший стан за крок, тобто. P ij(з S iв S jза один крок) тоді ми можемо записати перехідні ймовірності у вигляді матриці.
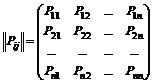 . (7.1)
. (7.1)
По діагоналі цієї матриці розташовані ймовірності того, що система переходить із стану S iу той же стан S i.
Користуючись введеними раніше подіями ![]() , можна перехідні можливості записати як умовні можливості:
, можна перехідні можливості записати як умовні можливості: ![]() .
.
Очевидно, що сума членів ![]() у кожному рядку матриці (1) дорівнює одиниці, оскільки події
у кожному рядку матриці (1) дорівнює одиниці, оскільки події ![]() утворюють повну групу несумісних подій.
утворюють повну групу несумісних подій.
При розгляді марківських ланцюгів, як і під час аналізу марковського випадкового процесу, використовуються різні графи станів (рис. 7.10). 
Рис. 7.10
Дана система може перебувати в будь-якому із шести станів, при цьому P ij- Імовірність переходу системи зі стану S iу стан S j. Для даної системи запишемо рівняння, що система перебувала в будь-якому стані та з нього за час tне вийшла: 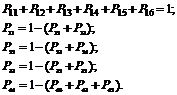
У загальному випадку марківський ланцюг є неоднорідним, тобто ймовірність P ijзмінюється від кроку до кроку. Припустимо, що задана матриця ймовірностей переходу кожному кроці, тоді ймовірність те, що система Sна k-м кроці перебуватиме в стані S i, можна знайти за формулою ![]()
Знаючи матрицю перехідних ймовірностей та початковий стан системи, можна знайти ймовірності станів ![]() після будь-якого k-го кроку. Нехай у початковий момент часу система перебуває в стані S m. Тоді для t = 0
після будь-якого k-го кроку. Нехай у початковий момент часу система перебуває в стані S m. Тоді для t = 0
.
Знайдемо ймовірність після першого кроку. Зі стану S mсистема перейде у стани S 1 , S 2 і т. д. з ймовірностями P m 1 , P m 2 , …, P mm, …, P mn. Тоді після першого кроку ймовірності дорівнюватимуть
. (7.2)
Знайдемо ймовірність стану після другого кроку: . Обчислюватимемо ці ймовірності за формулою повної ймовірності з гіпотезами: ![]() .
.
Гіпотезами будуть такі твердження:
- після першого кроку система була в стані S1-H1;
- після другого кроку система була в стані S 2 -H 2;
- після n-го кроку система була у стані S n -H n .
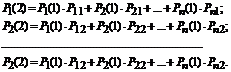
Імовірність будь-якого стану після другого кроку:
![]() (7.3)
(7.3)
У формулі (7.3) підсумовуються всі перехідні можливості P ij, але враховуються лише відмінні від нуля. Імовірність будь-якого стану після k-го кроку:
![]() (7.4)
(7.4)
Таким чином, ймовірність стану після k-го кроку визначається за рекурентною формулою (7.4) через ймовірність ( k – 1)-го кроку.
Завдання 6.Задано матрицю ймовірностей переходу для ланцюга Маркова за один крок. Знайти матрицю переходу даного ланцюга за три кроки  .
.
Рішення.Матрицею переходу системи називають матрицю, яка містить усі перехідні ймовірності цієї системи: 
У кожному рядку матриці вміщено ймовірність подій (переходу зі стану iу стан j), які утворюють повну групу, тому сума ймовірностей цих подій дорівнює одиниці: ![]()
Позначимо через p ij (n) ймовірність того, що в результаті n кроків (випробувань) система перейде зі стану i стан j . Наприклад p 25 (10) - можливість переходу з другого стану в п'яте за десять кроків. Зазначимо, що з n=1 отримуємо перехідні ймовірності p ij (1)=p ij .
Перед нами поставлене завдання: знаючи перехідні можливості p ij , знайти можливості p ij (n) переходу системи зі стану iу стан jза nкроків. Для цього введемо проміжне (між iі j) стан r. Іншими словами, вважатимемо, що з первісного стану iза mкроків система перейде у проміжний стан rз ймовірністю p ij (n-m) , після чого, за n-m, що залишилися кроків з проміжного стану r вона перейде в кінцевий стан j з ймовірністю p ij (n-m) . За формулою повної ймовірності отримуємо: ![]() .
.
Цю формулу називають рівністю Маркова. За допомогою цієї формули можна знайти всі ймовірності p ij (n) а, отже, і саму матрицю P n . Оскільки матричне обчислення веде до мети швидше, запишемо матричне співвідношення, що випливає з отриманої формули, у загальному вигляді.
Обчислимо матрицю переходу ланцюга Маркова за три кроки, використовуючи отриману формулу: 
Відповідь: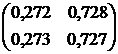 .
.
Завдання №1. Матриця ймовірностей переходу ланцюга Маркова має вигляд: 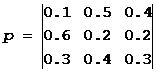 .
.
Розподіл за станами на момент часу t=0 визначається вектором:
π 0 =(0.5; 0.2; 0.3)
Знайти:а) розподіл за станами в моменти t = 1,2,3,4.
в) стаціонарний розподіл.
 Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих
Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих Крихітка Цахес по прозвищу Циннобер
Крихітка Цахес по прозвищу Циннобер Майков, Аполлон Миколайович – коротка біографія
Майков, Аполлон Миколайович – коротка біографія