Функція Біноміальний розподіл. Дисперсія біномного розподілу
Звичайно, при обчисленні кумулятивної функції розподілу слід скористатися згаданим зв'язком біномного та бета-розподілу. Цей спосіб наперед краще безпосереднього підсумовування, коли n > 10.
У класичних підручниках зі статистики для отримання значень біномного розподілу часто рекомендують використовувати формули, що базуються на граничних теоремах (типу формули Муавра-Лапласа). Необхідно відмітити, що з суто обчислювальної точки зоруЦінність цих теорем близька до нуля, особливо зараз, коли практично на кожному столі стоїть потужний комп'ютер. Основний недолік наведених апроксимацій – їх зовсім недостатня точність при значеннях n, характерних більшості додатків. Не меншим недоліком є і відсутність скільки-небудь чітких рекомендацій щодо застосування тієї чи іншої апроксимації (у стандартних текстах наводяться лише асимптотичні формулювання, вони не супроводжуються оцінками точності і, отже, мало корисні). Я б сказав, що обидві формули придатні лише за n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Не розглядаю тут завдання пошуку квантилей: для дискретних розподілів вона тривіальна, а тих завданнях, де такі розподіли виникають, вона, зазвичай, і актуальна. Якщо ж кванти все-таки знадобляться, рекомендую так переформулювати завдання, щоб працювати з p-значеннями (спостереженими значущістю). Ось приклад: при реалізації деяких перебірних алгоритмів на кожному кроці потрібно перевіряти статистичну гіпотезупро біноміальну випадкову величину. Згідно класичного підходуна кожному кроці потрібно обчислити статистику критерію та порівняти її значення з межею критичної множини. Оскільки, однак, алгоритм перебірний, доводиться визначати межу критичної множини щоразу заново (адже від кроку до кроку обсяг вибірки змінюється), що непродуктивно збільшує тимчасові витрати. Сучасний підхідрекомендує обчислювати спостережене значення і порівнювати її з довірчою ймовірністюекономити на пошуку квантилей.
Тому в наведених нижче кодах відсутнє обчислення зворотної функції, натомість наведена функція rev_binomialDF , яка обчислює ймовірність p успіху в окремому випробуванні за заданою кількістю n випробувань, числу m успіхів в них і значення y ймовірності отримати ці m успіхів. При цьому використовується вищезгаданий зв'язок між біноміальним та бета-розподілом.
Фактично ця функція дозволяє отримувати межі довірчих інтервалів. Справді, припустимо, що у n біноміальних випробуваннях ми здобули m успіхів. Як відомо, ліва межа двостороннього довірчого інтервалудля параметра p з довірчим рівнем дорівнює 0, якщо m = 0, а є рішенням рівняння  . Аналогічно, права межа дорівнює 1, якщо m = n, а є рішенням рівняння
. Аналогічно, права межа дорівнює 1, якщо m = n, а є рішенням рівняння  . Звідси випливає, що для пошуку лівого кордону ми маємо вирішувати щодо рівняння
. Звідси випливає, що для пошуку лівого кордону ми маємо вирішувати щодо рівняння  , а для пошуку правої – рівняння
, а для пошуку правої – рівняння  . Вони і вирішуються у функціях binom_leftCI та binom_rightCI , що повертають верхню та нижню межі двостороннього довірчого інтервалу відповідно.
. Вони і вирішуються у функціях binom_leftCI та binom_rightCI , що повертають верхню та нижню межі двостороннього довірчого інтервалу відповідно.
Хочу зауважити, що якщо не потрібна зовсім неймовірна точність, то при досить великих n можна скористатися наступною апроксимацією [Б.Л. ван дер Варден, математична статистика. М: ІЛ, 1960, гол. 2, розд. 7]:  де g – квантиль нормального розподілу. Цінність цієї апроксимації в тому, що є дуже прості наближення, що дозволяють обчислювати квантил нормального розподілу (див. текст про обчислення нормального розподілу та відповідний розділ даного довідника). У моїй практиці (в основному, при n > 100) ця апроксимація давала приблизно 3-4 знаки, чого, як правило, цілком достатньо.
де g – квантиль нормального розподілу. Цінність цієї апроксимації в тому, що є дуже прості наближення, що дозволяють обчислювати квантил нормального розподілу (див. текст про обчислення нормального розподілу та відповідний розділ даного довідника). У моїй практиці (в основному, при n > 100) ця апроксимація давала приблизно 3-4 знаки, чого, як правило, цілком достатньо.
Для обчислень за допомогою нижченаведених кодів будуть потрібні файли betaDF.h , betaDF.cpp (див. розділ про бета-розподіл), а також logGamma.h , logGamma.cpp (див. додаток А). Ви також можете подивитися приклад використання функцій.
Файл binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(double trials, double successes, double p); /* * Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному. * Обчислюється ймовірність B(successes|trials,p) те, що число * успіхів укладено між 0 і "successes" (включно). */ double rev_binomialDF(double trials, double successes, double y); /* * Нехай відома ймовірність y настання не менше m успіхів * у trials випробуваннях схеми Бернуллі. Функція знаходить можливість p * успіху в окремому випробуванні. * * У обчисленнях використовується наступне співвідношення * * 1 - p = rev_Beta(trials-successes| successes+1, y). */ double binom_leftCI(double trials, double successes, double level); /* Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному * і кількість успіхів дорівнює "successes". * Обчислюється ліва межа двостороннього довірчого інтервалу * з рівнем значущості level. */ double binom_rightCI(double n, double successes, double level); /* Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному * і кількість успіхів дорівнює "successes". * Обчислюється правий кордон двостороннього довірчого інтервалу * з рівнем значущості level. */ #endif /* Ends #ifndef __BINOMIAL_H__ */ |
Файл binomialDF.cpp
| /************************************************* **********/ /* Біноміальний розподіл */ /************************************* ***************************/ #include |
Розглянемо Біноміальний розподіл, обчислимо його математичне очікування, дисперсію, моду. За допомогою функції MS EXCEL БІНОМ.РАСП() побудуємо графіки функції розподілу та щільності ймовірності. Зробимо оцінку параметра розподілу p, математичного очікуваннярозподілу та стандартного відхилення. Також розглянемо розподіл Бернуллі.
Визначення. Нехай проводяться nвипробувань, у кожному з яких може відбутися лише дві події: подія «успіх» з ймовірністю p або подія «невдача» з ймовірністю q =1-p (так звана Схема Бернуллі,Bernoullitrials).
Імовірність отримання рівно x успіхів у цих n випробуваннях дорівнює:
Кількість успіхів у вибірці x є випадковою величиною, яка має Біноміальний розподіл(англ. Binomialdistribution) pі n– є параметрами цього розподілу.
Нагадаємо, що для застосування схеми Бернулліі відповідно Біноміального розподілу,повинні бути виконані такі умови:
- кожне випробування повинно мати рівно два результати, що умовно називають «успіхом» і «невдачею».
- результат кожного випробування повинен залежати від результатів попередніх випробувань (незалежність випробувань).
- ймовірність успіху p має бути постійною для всіх випробувань.
Біноміальний розподіл у MS EXCEL
У MS EXCEL, починаючи з версії 2010, для Біноміального розподілує функція БІНОМ.РАСП() , англійська назва- BINOM.DIST(), яка дозволяє обчислити ймовірність того, що у вибірці буде рівно х"Успіхів" (тобто. функцію щільності ймовірності p(x), див. формулу вище), і інтегральну функцію розподілу(ймовірність того, що у вибірці буде xабо менше "успіхів", включаючи 0).
До MS EXCEL 2010 EXCEL була функція БІНОМРАСП() , яка також дозволяє обчислити функцію розподілуі щільність імовірності p(x). БІНОМРАСП() залишено в MS EXCEL 2010 для сумісності.
У файлі прикладу наведено графіки густини розподілу ймовірностіі .

Біноміальний розподілмає позначення B(n; p) .
Примітка: Для побудови інтегральної функції розподілуідеально підходить діаграма типу Графік, для густини розподілу – Гістограма з угрупуванням. Докладніше про побудову діаграм читайте статтю Основні типи діаграм.
Примітка: Для зручності написання формул у файлі прикладу створено Імена для параметрів Біноміального розподілу: n та p.

У прикладному файлі наведено різні розрахунки ймовірності за допомогою функцій MS EXCEL:

Як видно на картинці вище, передбачається, що:
- У нескінченній сукупності, з якої робиться вибірка, міститься 10% (або 0,1) придатних елементів (параметр p, Третій аргумент функції = БІНОМ.РАСП() )
- Щоб обчислити ймовірність того, що у вибірці з 10 елементів (параметр n, другий аргумент функції) буде рівно 5 придатних елементів (перший аргумент), потрібно записати формулу: =БІНОМ.РАСП(5; 10; 0,1; БРЕХНЯ)
- Останній, четвертий елемент, встановлений = БРЕХНЯ, тобто. повертається значення функції густини розподілу.
Якщо значення четвертого аргументу = ІСТИНА, то функція БІНОМ.РАСП() повертає значення інтегральної функції розподілуабо просто Функцію розподілу. У цьому випадку можна розрахувати ймовірність того, що у вибірці кількість придатних елементів певного діапазонунаприклад, 2 або менше (включаючи 0).
Для цього потрібно записати формулу:
= БІНОМ.РАСП(2; 10; 0,1; ІСТИНА)
Примітка: При нецілому значенні х, . Наприклад, такі формули повернуть одне й теж значення:
=БІНОМ.РАСП( 2
; 10; 0,1; ІСТИНА)
=БІНОМ.РАСП( 2,9
; 10; 0,1; ІСТИНА)
Примітка: У файлі прикладу щільність імовірностіі функція розподілутакож обчислені з використанням визначення та функції ЧИСЛКОМБ() .
Показники розподілу
У файл прикладу на аркуші Прикладє формули для розрахунку деяких показників розподілу:
- =n * p;
- (квадрату стандартного відхилення) = n * p * (1-p);
- = (n + 1) * p;
- =(1-2*p)*КОРІНЬ(n*p*(1-p)).
Виведемо формулу математичного очікування Біноміального розподілу, використовуючи Схему Бернуллі.
За визначенням випадкова величинаХ ст схемою Бернуллі(Bernoulli random variable) має функцію розподілу:
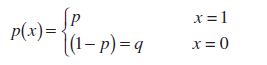
Цей розподіл називається розподіл Бернуллі.
Примітка: розподіл Бернуллі – окремий випадок Біноміального розподілуіз параметром n=1.
Згенеруємо 3 масиви по 100 чисел з різними ймовірностямиуспіху: 0,1; 0,5 та 0,9. Для цього у вікні Генерація випадкових чиселвстановимо наступні параметридля кожної ймовірності p:

Примітка: Якщо встановити опцію Випадкове розсіювання (Random Seed), то можна вибрати певний випадковий набірзгенерованих чисел. Наприклад, встановивши цю опцію =25 можна згенерувати різних комп'ютерах одні й самі набори випадкових чисел (якщо, звісно, інші параметри розподілу збігаються). Значення опції може приймати цілі значення від 1 до 32767. Назва опції Випадкове розсіюванняможе заплутати. Краще було б її перекласти як Номер набору з довільними числами.
У результаті матимемо 3 стовпці по 100 чисел, на підставі яких можна, наприклад, оцінити ймовірність успіху pза формулою: Число успіхів/100(Див. файл прикладу лист ГенераціяБернуллі).

Примітка: Для розподілу Бернулліз p = 0,5 можна використовувати формулу = ВИПАД МІЖ (0; 1), яка відповідає .
Генерація випадкових чисел. Біноміальний розподіл
Припустимо, що у вибірці виявилося 7 дефектних виробів. Це означає, що «дуже ймовірна» ситуація, що змінилася частка дефектних виробів pяка є характеристикою нашого виробничого процесу. Хоча така ситуація «дуже ймовірна», але існує ймовірність (альфа-ризик, помилка 1-го роду, «хибна тривога»), що все ж таки pзалишилася без змін, а збільшена кількість дефектних виробів зумовлена випадковістю вибірки.
Як видно на малюнку нижче, 7 – кількість дефектних виробів, яка припустима для процесу з p=0,21 при тому ж значенні Альфа. Це є ілюстрацією, що з перевищенні порогового значення дефектних виробів у вибірці, p«швидше за все» збільшилося. Фраза «швидше за все» означає, що існує лише 10% ймовірність (100%-90%) того, що відхилення частки дефектних виробів вище порогового викликане лише сучайними причинами.
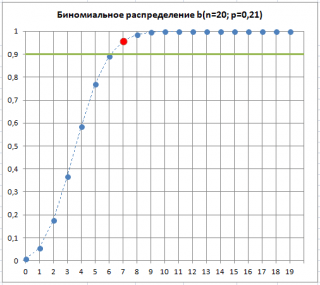
Таким чином, перевищення порогової кількості дефектних виробів у вибірці, може бути сигналом, що процес засмутився і став випускати б ольший відсоток бракованих виробів.
Примітка: До MS EXCEL 2010 у EXCEL була функція КРИТБІНОМ(), яка еквівалентна БІНОМ.ОБР(). КРИТБІНОМ залишена в MS EXCEL 2010 і вище для сумісності.
Зв'язок Біноміального розподілу з іншими розподілами
Якщо параметр n Біноміального розподілупрагне нескінченності, а pпрагне до 0, то в цьому випадку Біноміальний розподілможе бути апроксимовано.
Можна сформулювати умови, коли наближення розподілом Пуассонапрацює добре:
- p<0,1 (чим менше pі більше n, Тим наближення точніше);
- p>0,9 (враховуючи що q=1- p, обчислення в цьому випадку необхідно проводити через q(а хпотрібно замінити на n- x). Отже, чим менше qі більше n, Тим наближення точніше).
При 0,1<=p<=0,9 и n*p>10 Біноміальний розподілможна апроксимувати.
В свою чергу, Біноміальний розподілможе бути хорошим наближенням , коли розмір сукупності N Гіпергеометричного розподілунабагато більше розміру вибірки n (тобто N>>n або n/N<<1).
Докладніше про зв'язок вищезгаданих розподілів, можна прочитати у статті . Там же наведено приклади апроксимації, і пояснено умови, коли вона можлива і з якоюсь точністю.
ПОРАДА: Про інші розподіли MS EXCEL можна прочитати у статті .
Вітаю всіх читачів!
Статистичний аналіз, як відомо, займається збиранням та обробкою реальних даних. Справа корисна, а найчастіше і вигідна, т.к. правильні висновки дозволяють уникнути помилок і втрат у майбутньому, інколи ж і правильно вгадати це майбутнє. Зібрані дані відображають стан деякого явища, що спостерігається. Дані часто (але не завжди) мають числовий вигляд і з ними можна робити різні математичні маніпуляції, витягуючи цим додаткову інформацію.
Однак не всі явища вимірюються в кількісній шкалі типу 1, 2, 3…100500… Не завжди явище може приймати нескінченну чи велику кількість різних станів. Наприклад, стать у людини може бути М, або Ж. Стрілець або потрапляє в ціль, або не потрапляє. Голосувати можна або "За", або "Проти" і т.д. і т.п. Інакше кажучи, такі дані відбивають стан альтернативного ознаки – або «так» (подія настала), або «ні» (подія не наступило). Подію, що настала (позитивний результат) ще називають «успіхом». Такі явища також можуть мати масовий і випадковий характер. Отже, їх можна вимірювати та робити статистично обґрунтовані висновки.
Експерименти з такими даними називаються схемою Бернуллі, на честь відомого швейцарського математика, який встановив, що при великій кількості випробувань співвідношення позитивних результатів та загальної кількості випробувань прагне ймовірності настання цієї події.
Змінна альтернативна ознака
Для того щоб в аналізі задіяти математичний апарат, результати подібних спостережень слід записати у числовому вигляді. Для цього позитивному результату надають число 1, негативному – 0. Іншими словами, ми маємо справу зі змінною, яка може набувати лише двох значень: 0 або 1.
Яку користь звідси можна отримати? Взагалі не меншу, ніж від звичайних даних. Так, легко підрахувати кількість позитивних наслідків – досить підсумувати всі значення, тобто. всі 1 (успіхи). Можна піти далі, але для цього потрібно ввести кілька позначок.
Насамперед слід зазначити, що позитивні результати (які рівні 1) мають певну ймовірність появи. Наприклад, випадання орла при підкиданні монети дорівнює ½ або 0,5. Така ймовірність традиційно позначається латинською літерою. p. Отже, ймовірність наступу альтернативної події дорівнює 1 - p, яку ще позначають через q, тобто q = 1 - p. Зазначені позначення можна наочно систематизувати у вигляді таблички розподілу змінної X.
Тепер ми маємо перелік можливих значень та їх ймовірності. Можна приступити до розрахунку таких чудових характеристик випадкової величини, як математичне очікуванняі дисперсія. Нагадаю, що математичне очікування розраховується як сума творів усіх можливих значень на відповідні їм ймовірності:
![]()
Обчислимо маточування, використовуючи позначення в таблиці вище.
Виходить, що математичне очікування альтернативної ознаки дорівнює ймовірності цієї події. p.
Тепер визначимо, що таке дисперсія альтернативної ознаки. Також нагадаю, що дисперсія є середнім квадратом відхилень від математичного очікування. Загальна формула (для дискретних даних) має вигляд:
Звідси дисперсія альтернативної ознаки:

Неважко помітити, що ця дисперсія має максимум 0,25 (при p = 0,5).
Середнє квадратичне відхилення – корінь із дисперсії:
Максимальне значення вбирається у 0,5.
Як видно, і математичне очікування, і дисперсія альтернативної ознаки мають дуже компактний вигляд.
Біноміальний розподіл випадкової величини
Тепер розглянемо ситуацію під іншим кутом. Справді, кому цікаво, що середнє випадання орлів за одного кидання дорівнює 0,5? Це навіть неможливо уявити. Цікавіше порушити питання про кількість випадання орлів при заданій кількості підкидань.
Іншими словами, дослідника часто цікавить ймовірність настання деякої кількості успішних подій. Це може бути кількість бракованих виробів у партії, що перевіряється (1- бракована, 0 - придатна) або кількість одужань (1 - здоровий, 0 - хворий) і т.д. Кількість таких «успіхів» дорівнюватиме сумі всіх значень змінної X, тобто. кількості поодиноких результатів.
Випадкова величина Bназивається біномною і набуває значення від 0 до n(при B= 0 - всі деталі придатні, при B = n- Усі деталі браковані). Передбачається, що всі значення xнезалежні між собою. Розглянемо основні характеристики біномної змінної, тобто встановимо її математичне очікування, дисперсію та розподіл.
Маточка біноміальної змінної отримати дуже легко. Згадаймо, що є сума математичних очікувань кожної величини, що складається, а воно у всіх однакове, тому:
Наприклад, математичне очікування кількості орлів, що випали, при 100 підкиданнях дорівнює 100 × 0,5 = 50.
Тепер виведемо формулу дисперсії біноміальної змінної. є сума дисперсій. Звідси
Середнє квадратичне відхилення, відповідно
Для 100 підкидань монети середньоквадратичне відхилення дорівнює
І, нарешті, розглянемо розподіл биномиальной величини, тобто. ймовірності того, що випадкова величина Bприйматиме різні значення k, де 0≤ k ≤n. Для монети це завдання може звучати так: якою є ймовірність випадання 40 орлів при 100 кидках?
Щоб зрозуміти метод розрахунку, уявімо, що монета підкидається лише 4 рази. Кожного разу може випасти кожна зі сторін. Ми запитуємо: яка ймовірність випадання 2 орлів з 4 кидків. Кожен кидок незалежний один від одного. Отже, ймовірність випадання будь-якої комбінації дорівнюватиме добутку ймовірностей заданого результату для кожного окремого кидка. Нехай О – це орел, Р – решка. Тоді, наприклад, одна з комбінацій, що влаштовують нас, може виглядати як ООРР, тобто:

Імовірність такої комбінації дорівнює добутку двох ймовірностей випадання орла та ще двох ймовірностей не випадання орла (зворотна подія, що розраховується як 1 - p), тобто. 0,5×0,5×(1-0,5)×(1-0,5)=0,0625. Така ймовірність однієї з комбінацій, що влаштовують нас. Але ж питання стояло про загальну кількість орлів, а не про якийсь певний порядок. Тоді потрібно скласти ймовірності всіх комбінацій, у яких є рівно 2 орла. Зрозуміло, всі вони однакові (від зміни місць множників твір не змінюється). Тому потрібно обчислити їх кількість, а потім помножити на ймовірність будь-якої комбінації. Підрахуємо всі варіанти поєднань із 4 кидків по 2 орли: РРОО, РОРО, РООР, ОРРО, ОРОР, ООРР. Усього 6 варіантів.

Отже, шукана можливість випадання 2 орлів після 4 кидків дорівнює 6×0,0625=0,375.
Однак підрахунок подібним чином стомливий. Вже для 10 монет шляхом перебору отримати загальну кількість варіантів буде дуже складно. Тому розумні люди давно винайшли формулу, за допомогою якої розраховують кількість різних поєднань з nелементів по k, де n– загальна кількість елементів, k- Кількість елементів, варіанти розташування яких і підраховуються. Формула поєднання з nелементів по kтака:
![]()
Подібні речі відбуваються у розділі комбінаторики. Усіх охочих підтягнути знання відправляю туди. Звідси, до речі, і назва біномного розподілу (формула вище є коефіцієнтом розкладання бінома Ньютона).
Формулу для визначення ймовірності легко узагальнити на будь-яку кількість nі k. У результаті формула біномного розподілу має такий вигляд.
Словами: кількість відповідних за умов комбінацій помножити на ймовірність однієї з них.
Для практичного використання досить просто знати формулу біномного розподілу. А можна навіть не знати – нижче показано, як визначити ймовірність за допомогою Excel. Але краще все-таки знати.
Розрахуємо за цією формулою можливість випадання 40 орлів при 100 кидках:
Або лише 1,08%. Для порівняння, ймовірність настання математичного очікування цього експерименту, тобто 50 орлів, дорівнює 7,96%. Максимальна ймовірність біноміальної величини належить значенню, що відповідає математичному очікуванню.
Розрахунок ймовірностей біномного розподілу в Excel
Якщо використовувати лише папір та калькулятор, то розрахунки за формулою біномінального розподілу, незважаючи на відсутність інтегралів, даються досить важко. Наприклад значення 100! – має понад 150 знаків. Вручну розрахувати таке неможливо. Раніше, та й зараз, для обчислення подібних величин використовували наближені формули. На даний момент доцільно використовувати спеціальне програмне забезпечення, типу MS Excel. Таким чином, будь-який користувач (навіть гуманітарій за освітою) може обчислити ймовірність значення біноміально розподіленої випадкової величини.
Для закріплення матеріалу задіємо Excel поки як звичайний калькулятор, тобто. зробимо поетапне обчислення за формулою біномного розподілу. Розрахуємо, наприклад, можливість випадання 50 орлів. Нижче наведено картинку з етапами обчислень та кінцевим результатом.

Як видно, проміжні результати мають такий масштаб, що не поміщаються в комірку, хоча скрізь і використовуються прості функції типу: ФАКТР (обчислення факторіалу), СТУПЕНЬ (зведення числа до ступеня), а також оператори множення та поділу. Понад те, цей розрахунок досить громіздкий, у разі випадковий перестав бути компактним, т.к. задіяно багато осередків. Та й розібратися з ходу важкувато.
Загалом у Excel передбачено готову функцію для обчислення ймовірностей біномного розподілу. Функція називається БІНОМ.РАСП.

Число успіхів– кількість успішних випробувань. В нас їх 50.
Число випробувань- Кількість підкидань: 100 разів.
Ймовірність успіху- Імовірність випадання орла при одному підкиданні 0,5.
Інтегральна- Вказується або 1, або 0. Якщо 0, то розрахується ймовірність P(B=k); якщо 1, то розрахується функція біномного розподілу, тобто. сума всіх ймовірностей від B=0до B=kвключно.
Натискаємо ОК і отримуємо той самий результат, що і вище, тільки все розрахувалося однією функцією.

Дуже зручно. Для експерименту замість останнього параметра 0 поставимо 1. Отримаємо 0,5398. Це означає, що при 100 підкидання монети ймовірність випадання орлів у кількості від 0 до 50 дорівнює майже 54%. А спочатку щось здавалося, що має бути 50%. Загалом розрахунки проводяться легко і швидко.
Справжній аналітик повинен розуміти, як поводиться функція (який її розподіл), тому зробимо розрахунок ймовірностей для всіх значень від 0 до 100. Тобто поставимо питання: яка ймовірність, що не випаде жодного орла, що випаде 1 орел, 2, 3 , 50, 90 або 100. Розрахунок наведено в нижченаведеній картині, що саморухається. Синя лінія – саме біноміальний розподіл, червона точка – ймовірність для певної кількості успіхів k.

Хтось може запитати, а чи не схожий на біноміальний розподіл на… Так, дуже схоже. Ще Муавр (1733 р.) говорив, що біноміальний розподіл при великих вибірках наближається до (не знаю, як це тоді називалося), але його ніхто не слухав. Тільки Гаусс, а потім і Лаплас через 60-70 років знову відкрили і ретельно вивчили нормальний закон розподілу. На графіці вище добре видно, що максимальна ймовірність посідає математичне очікування, а в міру відхилення від нього, різко знижується. Так само, як і у нормального закону.
Біноміальний розподіл має велике практичне значення, трапляється досить часто. За допомогою Excel розрахунки проводяться легко та швидко. Тож можна сміливо використовувати.
На цьому пропоную попрощатися до наступної зустрічі. Усіх благ, будьте здорові!
Розділ 7.
Конкретні закони розподілу випадкових величин
Види законів розподілу дискретних випадкових величин
Нехай дискретна випадкова величина може набувати значення х 1 , х 2 , …, х n, …. Імовірності цих значень можуть бути обчислені за різними формулами, наприклад, за допомогою основних теорем теорії ймовірностей, формули Бернуллі або інших формул. Для деяких із цих формул закон розподілу має свою назву.
Найбільш поширеними законами розподілу дискретної випадкової величини є біноміальний, геометричний, гіпергеометричний, закон розподілу Пуассона.
Біноміальний закон розподілу
Нехай проводиться nнезалежних випробувань, у кожному з яких може з'явитися чи не з'явитися подія А. Імовірність появи цієї події в кожному одиничному випробуванні постійна, не залежить від номера випробування і дорівнює р=Р(А). Звідси ймовірність не появи події Ау кожному випробуванні також постійна і рівна q=1–р. Розглянемо випадкову величину Хрівну числу події Ав nвипробуваннях. Очевидно, що значення цієї величини дорівнюють
х 1 = 0 - подія Ав nвипробуваннях не з'явилося;
х 2 = 1 - подія Ав nвипробування з'явилося один раз;
х 3 = 2 - подія Ав nвипробування з'явилося двічі;
…………………………………………………………..
х n +1 = n– подія Ав nвипробуваннях з'явилося все nразів.
Імовірності цих значень можуть бути обчислені за формулою Бернуллі (4.1):
де до=0, 1, 2, …,n .
Біноміальним законом розподілу Х, що дорівнює кількості успіхів у nвипробуваннях Бернуллі, з ймовірністю успіху р.
Отже, дискретна випадкова величина має біномний розподіл (або розподілена за біноміальним законом), якщо її можливі значення 0, 1, 2, …, n, А відповідні ймовірності обчислюються за формулою (7.1).
Біноміальний розподіл залежить від двох параметрів рі n.
Ряд розподілу випадкової величини, розподіленої за біноміальним законом, має вигляд:
| Х | … | k | … | n | ||
| Р | | … | … | |
приклад 7.1 . Здійснюється три незалежні постріли по мішені. Імовірність влучення при кожному пострілі дорівнює 0,4. Випадкова величина Х- Число попадань в ціль. Побудувати її низку розподілу.
Рішення. Можливими значеннями випадкової величини Хє х 1 =0; х 2 =1; х 3 =2; х 4 =3. Знайдемо відповідні можливості, використовуючи формулу Бернуллі. Неважко показати, що застосування цієї формули тут цілком виправдане. Зазначимо, що ймовірність не влучення в ціль при одному пострілі дорівнюватиме 1-0,4 = 0,6. Отримаємо

Ряд розподілу має такий вигляд:
| Х | ||||
| Р | 0,216 | 0,432 | 0,288 | 0,064 |
Неважко перевірити, що сума всіх ймовірностей дорівнює 1. Сама випадкова величина Хрозподілено за біноміальним законом. ■
Знайдемо математичне очікування та дисперсію випадкової величини, розподіленої за біноміальним законом.
При рішенні прикладу 6.5 було показано, що математичне очікування кількості події Ав nнезалежних випробувань, якщо ймовірність появи Ау кожному випробуванні постійна і рівна р, одно n· р
У цьому прикладі використовувалася випадкова величина, розподілена за біноміальним законом. Тому рішення прикладу 6.5 по суті є доказом наступної теореми.
Теорема 7.1.Математичне очікування дискретної випадкової величини, розподіленої за біноміальним законом, дорівнює добутку числа випробувань на можливість " успіху " , тобто. М(Х)=n· нар.
Теорема 7.2.Дисперсія дискретної випадкової величини, розподіленої по биномиальному закону, дорівнює добутку числа випробувань на ймовірність " успіху " і ймовірність " невдачі " , тобто. D(Х)=nрq.
Асиметрія та ексцес випадкової величини, розподіленої за біноміальним законом, визначаються за формулами
Ці формули можна отримати, скориставшись поняттям початкових та центральних моментів.
Біноміальний закон розподілу є основою багатьох реальних ситуацій. При великих значеннях nбіномний розподіл може бути апроксимований за допомогою інших розподілів, зокрема за допомогою розподілу Пуассона.
Розподіл Пуассона
Нехай є nвипробувань Бернуллі, при цьому кількість випробувань nдосить велике. Раніше було показано, що в цьому випадку (якщо до того ж ймовірність рподії Адуже мала) для знаходження ймовірності того, що подія Аз'явитися траз у випробуваннях можна скористатися формулою Пуассона (4.9). Якщо випадкова величина Хозначає кількість появи події Ав nвипробуваннях Бернуллі, то ймовірність того, що Хнабуде значення kможе бути обчислена за формулою
 , (7.2)
, (7.2)
де λ = nр.
Законом розподілу Пуассонаназивається розподіл дискретної випадкової величини Х, для якої можливими значеннями є цілі невід'ємні числа, а ймовірності р тцих значень перебувають за формулою (7.2).
Величина λ = nрназивається параметромрозподілу Пуассона.
Випадкова величина, розподілена за законом Пуассона, може набувати безліч значень. Так як для цього розподілу ймовірність рПоява події в кожному випробуванні мала, то цей розподіл іноді називають законом рідкісних явищ.
Ряд розподілу випадкової величини, розподіленої згідно із законом Пуассона, має вигляд
| Х | … | т | … | ||||
| Р | … | … |
Неважко переконатися, що сума ймовірностей другого рядка дорівнює 1. Для цього необхідно згадати, що функцію можна розкласти до ряду Маклорена, який сходиться для будь-якого х. В даному випадку маємо
 . (7.3)
. (7.3)
Як зазначалося, закон Пуассона у певних граничних випадках замінює биномиальный закон. Як приклад можна навести випадкову величину Хзначення якої рівні кількості збоїв за певний проміжок часу при багаторазовому застосуванні технічного пристрою. У цьому передбачається, що це пристрій високої надійності, тобто. ймовірність збою при одному застосуванні дуже мала.
Крім таких граничних випадків, на практиці трапляються випадкові величини, розподілені за законом Пуассона, не пов'язані з біномним розподілом. Наприклад, розподіл Пуассона часто використовується тоді, коли мають справу з кількістю подій, що з'являються в проміжку часу (кількість надходжень викликів на телефонну станцію протягом години, кількість машин, що прибули на автомийку протягом доби, кількість зупинок верстатів на тиждень і т.п. .). Всі ці події повинні утворювати так званий потік подій, який є одним з основних понять теорії масового обслуговування. Параметр λ характеризує середню інтенсивність потоку подій.
Біноміальний розподіл - один з найважливіших розподілів ймовірностей випадкової величини, що дискретно змінюється. Біноміальним розподілом називається розподіл ймовірностей числа mнастання події Ав nвзаємно незалежні спостереження. Часто подія Аназивають "успіхом" спостереження, а протилежна йому подія - "неуспіхом", але це позначення дуже умовне.
Умови біномного розподілу:
- загалом проведено nвипробувань, у яких подія Аможе наступити чи наступити;
- подія Ау кожному з випробувань може наступити з однією і тією самою ймовірністю p;
- випробування є взаємно незалежними.
Імовірність того, що в nвипробуваннях подія Анастане саме mраз, можна обчислити за формулою Бернуллі:
![]()
![]() ,
,
де p- ймовірність настання події А;
q = 1 - p- Імовірність настання протилежної події.
Розберемося, чому біномний розподіл описаним вище чином пов'язаний з формулою Бернуллі . Подія - кількість успіхів при nвипробуваннях розпадається на ряд варіантів, у кожному з яких успіх досягається в mвипробуваннях, а неуспіх - у n - mвипробуваннях. Розглянемо один із таких варіантів - B1 . За правилом складання ймовірностей примножуємо ймовірності протилежних подій:
![]() ,
,
а якщо позначимо q = 1 - p, то
![]() .
.
Таку ж ймовірність матиме будь-який інший варіант, у якому mуспіхів та n - mнеуспіхів. Число таких варіантів дорівнює - числу способів, якими можна з nвипробувань отримати mуспіхів.
Сума ймовірностей усіх mчисел настання події А(чисел від 0 до n) дорівнює одиниці:
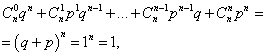
де кожен доданок являє собою доданок бінома Ньютона. Тому розподіл, що розглядається, і називається біноміальним розподілом.
Насправді часто необхідно обчислювати ймовірності " трохи більше mуспіхів у nвипробуваннях" або "не менше mуспіхів у nвипробуваннях". Для цього використовуються наступні формули.
Інтегральну функцію, тобто ймовірність F(m) того, що в nспостереженнях подія Анастане не більше mраз, Можна обчислити за формулою:
В свою чергу ймовірність F(≥m) того, що в nспостереженнях подія Анастане не менше mраз, обчислюється за такою формулою:
Іноді буває зручніше обчислювати ймовірність того, що в nспостереженнях подія Анастане не більше mраз, через ймовірність протилежної події:
![]() .
.
Який із формул користуватися, залежить від того, в якій із них сума містить менше доданків.
Характеристики біномного розподілу обчислюються за такими формулами .
Математичне очікування: .
Дисперсія: .
Середньоквадратичне відхилення: .
Біноміальний розподіл та розрахунки в MS Excel
Імовірність біномного розподілу P n ( m) та значення інтегральної функції F(m) можна обчислити за допомогою функції MS Excel БІНОМ.РАСП. Вікно для відповідного розрахунку показано нижче (для збільшення натиснути лівою кнопкою миші).

MS Excel вимагає ввести такі дані:
- кількість успіхів;
- кількість випробувань;
- ймовірність успіху;
- інтегральна – логічне значення: 0 – якщо потрібно обчислити ймовірність P n ( m) і 1 - якщо ймовірність F(m).
приклад 1.Менеджер фірми узагальнив інформацію про кількість проданих протягом останніх 100 днів фотокамер. У таблиці узагальнено інформацію та розраховано ймовірність того, що в день буде продано певну кількість фотокамер.
День завершено із прибутком, якщо продано 13 або більше фотокамер. Імовірність, що день буде відпрацьовано із прибутком:
![]()
Імовірність того, що день буде відпрацьовано без прибутку:
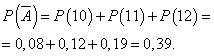
Нехай ймовірність того, що день відпрацьований з прибутком, є постійною і дорівнює 0,61 і кількість проданих в день фотокамер не залежить від дня. Тоді можна використовувати біномний розподіл, де подія А- день буде відпрацьовано із прибутком, - без прибутку.
Імовірність того, що з 6 днів усі будуть відпрацьовані із прибутком:
![]() .
.
Той самий результат отримаємо, використовуючи функцію MS Excel БІНОМ.РАСП (значення інтегральної величини - 0):
P 6 (6 ) = БІНОМ.РАСП(6; 6; 0,61; 0) = 0,052.
Імовірність того, що з 6 днів 4 і більше днів будуть відпрацьовані із прибутком:
де ![]() ,
,
![]() ,
,
Використовуючи функцію MS Excel БІНОМ.РАСП, обчислимо ймовірність того, що з 6 днів не більше 3 днів буде завершено з прибутком (значення інтегральної величини - 1):
P 6 (≤3 ) = БІНОМ.РАСП(3; 6; 0,61; 1) = 0,435.
Імовірність того, що з 6 днів усі будуть відпрацьовані зі збитками:
![]() ,
,
Той самий показник обчислимо, використовуючи функцію MS Excel БІНОМ.РАСП:
P 6 (0 ) = БІНОМ.РАСП(0; 6; 0,61; 0) = 0,0035.
Вирішити завдання самостійно, а потім переглянути рішення
приклад 2.В урні 2 білі кулі та 3 чорні. З урни виймають кулю, встановлюють колір та кладуть назад. Спробу повторюють 5 разів. Число появи білих куль - дискретна випадкова величина X, Розподілена за біноміальним законом. Скласти закон розподілу випадкової величини. Визначити моду, математичне очікування та дисперсію.
Продовжуємо вирішувати завдання разом
приклад 3.З кур'єрської служби вирушили на об'єкти n= 5 кур'єрів. Кожен кур'єр з ймовірністю p= 0,3 незалежно від інших спізнюється об'єкт. Дискретна випадкова величина X- Кількість кур'єрів, що запізнилися. Побудувати низку розподілу це випадкової величини. Знайти її математичне очікування, дисперсію, середнє відхилення. Знайти ймовірність того, що на об'єкти запізняться щонайменше два кур'єри.
 Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих
Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих Крихітка Цахес по прозвищу Циннобер
Крихітка Цахес по прозвищу Циннобер Майков, Аполлон Миколайович – коротка біографія
Майков, Аполлон Миколайович – коротка біографія