Навіщо потрібна дисперсія. Залишкова дисперсія
Кроки
Обчислення дисперсії вибірки
-
Запишіть значення вибірки.Найчастіше статистикам доступні лише вибірки певних генеральних сукупностей. Наприклад, як правило, статистики не аналізують витрати на утримання сукупності всіх автомобілів у Росії – вони аналізують випадкову вибіркуіз кількох тисяч автомобілів. Така вибірка допоможе визначити середні витрати на автомобіль, але швидше за все отримане значення буде далеко від реального.
- Наприклад, проаналізуємо кількість булочок, проданих у кафе за 6 днів, взятих у випадковому порядку. Вибірка має наступний вигляд: 17, 15, 23, 7, 9, 13. Це вибірка, а не сукупність, тому що у нас немає даних про продані булочки за кожен день роботи кафе.
- Якщо вам дано сукупність, а не вибірка значень, перейдіть до наступного розділу.
-
Запишіть формулу обчислення дисперсії вибірки.Дисперсія є мірою розкиду значень певної величини. Чим ближче значення дисперсії до нуля, тим ближчі значення згруповані один до одного. Працюючи з вибіркою значень, використовуйте таку формулу для обчислення дисперсії:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))– це дисперсія. Дисперсія вимірюється в квадратних одиницяхвимірювання.
- x i (\displaystyle x_(i))– кожне значення у вибірці.
- x i (\displaystyle x_(i))треба відняти x̅, звести у квадрат, та був скласти отримані результати.
- x̅ – вибіркове середнє (середнє значення вибірки).
- n – кількість значень вибірці.
-
Обчисліть середнє значення вибірки.Воно позначається як x. Середнє значення вибірки обчислюється як звичайне середнє арифметичне: складіть усі значення у вибірці, а потім отриманий результат поділіть на кількість значень у вибірці.
- У нашому прикладі складіть значення у вибірці: 15 + 17 + 23 + 7 + 9 + 13 = 84
Тепер результат поділіть на кількість значень у вибірці (у нашому прикладі їх 6): 84 ÷ 6 = 14.
Вибіркове середнє x = 14. - Вибіркове середнє – це центральне значення, навколо якого розподілені значення вибірці. Якщо значення вибірці групуються навколо вибіркового середнього, то дисперсія мала; інакше дисперсія велика.
- У нашому прикладі складіть значення у вибірці: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Відніміть середнє вибіркове з кожного значення у вибірці.Тепер обчисліть різницю x i (\displaystyle x_(i))- x̅, де x i (\displaystyle x_(i))– кожне значення у вибірці. Кожен отриманий результат свідчить про відхилення конкретного значення від вибіркового середнього, тобто як далеко це значення перебуває від середнього значення вибірки.
- У нашому прикладі:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Правильність отриманих результатів легко перевірити, оскільки їх сума має дорівнювати нулю. Це з визначенням середнього значення, оскільки від'ємні значення(відстань від середнього значення до менших значень) повністю компенсуються позитивними значеннями(Відстанями від середнього значення до великих значень).
- У нашому прикладі:
-
Як зазначалося вище, сума різниць x i (\displaystyle x_(i))- x̅ повинна дорівнювати нулю. Це означає, що середня дисперсіязавжди дорівнює нулю, що дає уявлення про розкид значень деякої величини. Для вирішення цієї проблеми зведіть у квадрат кожну різницю x i (\displaystyle x_(i))- x̅. Це призведе до того, що ви отримаєте лише позитивні числа, які при додаванні ніколи не дадуть 0.
- У нашому прикладі:
(x 1 (\displaystyle x_(1))- x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2)))- x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Ви знайшли квадрат різниці - x̅) 2 (\displaystyle ^(2))для кожного значення у вибірці.
- У нашому прикладі:
-
Обчисліть суму квадратів різниці.Тобто знайдіть ту частину формули, яка записується так: ∑[( x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))]. Тут знак Σ означає суму квадратів різниць для кожного значення x i (\displaystyle x_(i))у вибірці. Ви вже знайшли квадрати різниць (x i (\displaystyle (x_(i)))- x̅) 2 (\displaystyle ^(2))для кожного значення x i (\displaystyle x_(i))у вибірці; Тепер просто складіть ці квадрати.
- У нашому прикладі: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Отриманий результат розділіть на n - 1, де n – кількість значень вибірки.Якийсь час тому для обчислення дисперсії вибірки статистики ділили результат просто на n; у цьому випадку ви отримаєте середнє значення квадрата дисперсії, що ідеально підходить для опису дисперсії даної вибірки. Але пам'ятайте, що будь-яка вибірка – це лише невелика частина генеральної сукупностізначень. Якщо взяти іншу вибірку і виконати такі самі обчислення, ви отримаєте інший результат. Як з'ясувалося, розподіл на n - 1 (а не просто на n) дає більше точну оцінкудисперсії генеральної сукупності, у чому ви зацікавлені. Розподіл на n – 1 став загальноприйнятим, тому воно включено до формули для обчислення дисперсії вибірки.
- У прикладі вибірка включає 6 значень, тобто n = 6.
Дисперсія вибірки = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- У прикладі вибірка включає 6 значень, тобто n = 6.
-
Відмінність дисперсії стандартного відхилення.Зауважте, що у формулі є показник ступеня, тому дисперсія вимірюється у квадратних одиницях вимірювання аналізованої величини. Іноді такою величиною досить складно оперувати; у таких випадках користуються стандартним відхиленням, яке дорівнює квадратному кореню з дисперсії. Саме тому дисперсія вибірки позначається як s 2 (\displaystyle s^(2)), а стандартне відхиленнявибірки – як s (\displaystyle s).
- У прикладі стандартне відхилення вибірки: s = √33,2 = 5,76.
Обчислення дисперсії сукупності
-
Проаналізуйте деяку сукупність значень.Сукупність включає всі значення аналізованої величини. Наприклад, якщо ви вивчаєте вік мешканців Ленінградської області, Сукупність включає вік всіх жителів цієї області. У разі роботи із сукупністю рекомендується створити таблицю та внести до неї значення сукупності. Розглянемо наступний приклад:
- У деякій кімнаті є 6 акваріумів. У кожному акваріумі мешкає така кількість риб:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- У деякій кімнаті є 6 акваріумів. У кожному акваріумі мешкає така кількість риб:
-
Запишіть формулу обчислення дисперсії генеральної сукупності.Так як сукупність входять всі значення деякої величини, то наведена нижче формула дозволяє отримати точне значення дисперсії сукупності. Для того щоб відрізнити дисперсію сукупності від дисперсії вибірки (значення якої є лише оцінним), статистики використовують різні змінні:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n
- σ 2 (\displaystyle ^(2))- Дисперсія сукупності (читається як "сигма в квадраті"). Дисперсія вимірюється у квадратних одиницях виміру.
- x i (\displaystyle x_(i))- Кожне значення в сукупності.
- Σ – знак суми. Тобто з кожного значення x i (\displaystyle x_(i))потрібно відняти μ, звести у квадрат, та був скласти отримані результати.
- μ – середнє значення сукупності.
- n – кількість значень у генеральній сукупності.
-
Обчисліть середнє значення сукупності.Працюючи з генеральною сукупністю її середнє значення позначається як μ (мю). Середнє значення сукупності обчислюється як звичайне середнє арифметичне: складіть усі значення в генеральній сукупності, а потім отриманий результат розділіть на кількість значень у генеральній сукупності.
- Майте на увазі, що середні величини не завжди обчислюються як середнє арифметичне.
- У прикладі середнє значення сукупності: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Відніміть середнє значення сукупності з кожного значення в генеральній сукупності.Чим ближче значення різниці нанівець, тим ближче конкретне значення до середнього значення сукупності. Знайдіть різницю між кожним значенням у сукупності та її середнім значенням, і ви отримаєте перше уявлення про розподіл значень.
- У нашому прикладі:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- У нашому прикладі:
-
Зведіть у квадрат кожен отриманий результат.Значення різниць будуть як позитивними, і негативними; якщо нанести ці значення на числову пряму, всі вони лежатимуть праворуч і ліворуч від середнього значення сукупності. Це не годиться для обчислення дисперсії, так як позитивні та негативні числакомпенсують одне одного. Тому зведіть у квадрат кожну різницю, щоб отримати винятково позитивні числа.
- У нашому прикладі:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))для кожного значення сукупності (від i = 1 до i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), де x n (\displaystyle x_(n)) – останнє значенняу генеральній сукупності. - Для обчислення середнього значення отриманих результатів потрібно знайти їхню суму та розділити її на n:(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/n
- Тепер запишемо наведене пояснення з використанням змінних: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n і отримаємо формулу для обчислення дисперсії сукупності.
- У нашому прикладі:
Обчислимо вMSEXCELдисперсію та стандартне відхилення вибірки. Також обчислимо дисперсію випадкової величини, якщо відомий її розподіл.
Спочатку розглянемо дисперсію, потім стандартне відхилення.
Дисперсія вибірки
Дисперсія вибірки (вибіркова дисперсія,samplevariance) характеризує розкид значень у масиві щодо .
Усі 3 формули математично еквівалентні.
З першої формули видно, що дисперсія вибіркице сума квадратів відхилень кожного значення в масиві від середнього, Поділена на розмір вибірки мінус 1.
дисперсії вибіркивикористовується функція ДИСП(), англ. назва VAR, тобто. VARiance. З версії MS EXCEL 2010 рекомендується використовувати аналог ДИСП.В() , англ. назва VARS, тобто. Sample VARiance. Крім того, починаючи з версії MS EXCEL 2010 є функція ДИСП.Г(), англ. назва VARP, тобто. Population VARiance, яка обчислює дисперсіюдля генеральної сукупності. Вся відмінність зводиться до знаменника: замість n-1 як у ДИСП.В(), у ДИСП.Г() у знаменнику просто n. До MS EXCEL 2010 для обчислення дисперсії генеральної сукупності використовувалась функція ДИСПР().
Дисперсію вибірки
=КВАДРОТКЛ(Вибірка)/(РАХУНОК(Вибірка)-1)
=(СУММКВ(Вибірка)-РАХУНОК(Вибірка)*СРЗНАЧ(Вибірка)^2)/ (РАХУНОК(Вибірка)-1)- Звичайна формула
= СУМ((Вибірка-СРЗНАЧ(Вибірка))^2)/ (РАХУНОК(Вибірка)-1) –
Дисперсія вибіркидорівнює 0, тільки в тому випадку, якщо всі значення рівні між собою і відповідно рівні середнього значення. Зазвичай, чим більша величина дисперсіїтим більше розкид значень у масиві.
Дисперсія вибіркиє точковою оцінкою дисперсіїрозподілу випадкової величини, з якої було зроблено вибірка. Про побудову довірчих інтервалів при оцінці дисперсіїможна прочитати у статті.
Дисперсія випадкової величини
Щоб обчислити дисперсіювипадкової величини необхідно знати її .
Для дисперсіївипадкової величини Х часто використовують позначення Var(Х). Дисперсіядорівнює квадрату відхилення від середнього E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсіяобчислюється за такою формулою:

де x i – значення, яке може набувати випадкова величина, а μ – середнє значення (), р(x) – ймовірність, що випадкова величина набуде значення х.
Якщо випадкова величина має, то дисперсіяобчислюється за такою формулою:

Розмірність дисперсіївідповідає квадрату одиниці виміру вихідних значень. Наприклад, якщо значення у вибірці є вимірювання ваги деталі (в кг), то розмірність дисперсії буде кг 2 . Це буває складно інтерпретувати, тому для характеристики розкиду значень частіше використовують величину рівну квадратному кореню. дисперсії – стандартне відхилення.
Деякі властивості дисперсії:
Var(Х + a) = Var (Х), де Х - випадкова величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Ця властивість дисперсії використовується в статті про лінійну регресію.
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), де Х та Y - випадкові величини, Cov(Х;Y) - коваріація цих випадкових величин.
Якщо випадкові величини незалежні (independent), їх коваріаціядорівнює 0, отже, Var(Х+Y)=Var(Х)+Var(Y). Ця властивість дисперсії використовується при виведенні.
Покажемо, що для незалежних величин Var(Х-Y) = Var(Х+Y). Справді, Var(Х-Y)=Var(Х-Y)=Var(Х+(-Y))=Var(Х)+Var(-Y)=Var(Х)+Var(-Y)=Var( Х)+(-1) 2 Var(Y)=Var(Х)+Var(Y)=Var(Х+Y). Ця властивість дисперсії використовується для побудови.
Стандартне відхилення вибірки
Стандартне відхилення вибірки- це міра того, наскільки широко розкидані значення у вибірці щодо них.
За визначенням, стандартне відхиленняодно квадратному кореню з дисперсії:

Стандартне відхиленняне враховує величину значень у вибірці, а тільки ступінь розсіювання значень навколо них середнього. Щоб проілюструвати це наведемо приклад.
Обчислимо стандартне відхилення для 2-х вибірок: (1; 5; 9) та (1001; 1005; 1009). В обох випадках s=4. Очевидно, що відношення величини стандартного відхилення до значень масиву вибірок істотно відрізняється. Для таких випадків використовується Коефіцієнт варіації(Coefficient of Variation, CV) - ставлення Стандартне відхиленнядо середнього арифметичному, Вираженого у відсотках.
У MS EXCEL 2007 і більше ранніх версіяхдля обчислення Стандартне відхилення вибіркивикористовується функція = СТАНДОТКЛОН (), англ. назва STDEV, тобто. STandard DEViation. З версії MS EXCEL 2010 рекомендується використовувати її аналог = СТАНДОТКЛОН.В(), англ. назва STDEV.S, тобто. Sample STandard DEViation.
Крім того, починаючи з версії MS EXCEL 2010 є функція СТАНДОТКЛОН.Г() , англ. назва STDEV.P, тобто. Population STandard DEViation, яка обчислює стандартне відхиленнядля генеральної сукупності. Вся відмінність зводиться до знаменника: замість n-1 як у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() у знаменнику просто n.
Стандартне відхиленняможна також обчислити безпосередньо за нижченаведеними формулами (див. файл прикладу)
=КОРІНЬ(КВАДРОТКЛ(Вибірка)/(РАХУНОК(Вибірка)-1))
=КОРІНЬ((СУММКВ(Вибірка)-РАХУНОК(Вибірка)*СРЗНАЧ(Вибірка)^2)/(РАХУНОК(Вибірка)-1))
Інші заходи розкиду
Функція КВАДРОТКЛ() обчислює з умму квадратів відхилень значень від них середнього. Ця функція поверне той самий результат, як і формула =ДИСП.Г( Вибірка)*РАХУНОК( Вибірка), де Вибірка- Посилання на діапазон, що містить масив значень вибірки (). Обчислення функції КВАДРОТКЛ() проводяться за формулою:

Функція СРОТКЛ() є мірою розкиду безлічі даних. Функція СРОТКЛ() обчислює середнє абсолютних значеньвідхилень значень від середнього. Ця функція поверне той самий результат, що й формула =СУМПРОВИЗВ(ABS(Вибірка-СРЗНАЧ(Вибірка)))/РАХУНОК(Вибірка), де Вибірка- Посилання на діапазон, що містить масив значень вибірки.
Обчислення функції СРОТКЛ () проводяться за формулою:

Однак цієї характеристики ще мало для дослідження випадкової величини. Уявимо двох стрільців, які стріляють по мішені. Один стріляє влучно і потрапляє близько до центру, а інший просто розважається і навіть не цілиться. Але що кумедно, його середнійрезультат буде таким самим, як і в першого стрілка! Цю ситуацію умовно ілюструють такі випадкові величини:
«Снайперське» математичне очікування рівне, проте і в « цікавої особистості»: - Воно теж нульове!
Таким чином, виникає потреба кількісно оцінити, наскільки далеко розпорошенікулі (значення випадкової величини) щодо центру мішені ( математичного очікування). Ну а розсіюванняз латині перекладається не інакше, як дисперсія .
Подивимося, як визначається ця числова характеристикаодному з прикладів 1-ї частини уроку: 
Там ми знайшли невтішне математичне очікування цієї гри, і зараз ми маємо обчислити її дисперсію, яка позначаєтьсячерез.
З'ясуємо, наскільки далеко розкидані виграші/програші щодо середнього значення. Очевидно, що для цього потрібно вирахувати різниціміж значеннями випадкової величиниі її математичним очікуванням:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Тепер начебто потрібно підсумувати результати, але цей шлях не годиться – тому, що коливання вліво взаємознижуватимуться з коливаннями вправо. Так, наприклад, у стрільця-«любителя» (Приклад вище)різниці складуть ![]() , і при додаванні дадуть нуль, тому ніякої оцінки розсіювання його стрілянини ми не отримаємо.
, і при додаванні дадуть нуль, тому ніякої оцінки розсіювання його стрілянини ми не отримаємо.
Щоб обійти цю неприємність, можна розглянути модулірізниць, але з технічних причин прижився підхід, коли їх зводять у квадрат. Рішення зручніше оформити таблицею: 
І тут напрошується вирахувати середньозваженезначення квадратів відхилень. А це що таке? Це їх математичне очікування, яке і є мірилом розсіювання:
![]() – визначеннядисперсії. З визначення одразу зрозуміло, що дисперсія не може бути негативною- Візьміть на замітку для практики!
– визначеннядисперсії. З визначення одразу зрозуміло, що дисперсія не може бути негативною- Візьміть на замітку для практики!
Згадуємо, як знаходити матожидання. Розмножуємо квадрати різниць на відповідні ймовірності (продовження таблиці):
– образно кажучи, це «сила тяги»,
та підсумовуємо результати:
Чи не здається вам, що на тлі виграшів результат вийшов завеликим? Все вірно - ми зводили в квадрат, і щоб повернутися до розмірності нашої гри, потрібно витягти квадратний корінь. Ця величинаназивається середнім квадратичним відхиленням
і позначається грецькою літерою "сигма":
Іноді це значення називають стандартним відхиленням .
У чому його зміст? Якщо ми відхилимося від математичного очікування вліво та вправо на середнє квадратичне відхилення:![]()
– то цьому інтервалі будуть «сконцентровані» найімовірніші значення випадкової величини. Що ми, власне, і спостерігаємо:
Проте так склалося, що з аналізі розсіювання майже завжди оперують поняттям дисперсії. Давайте розберемося, що вона означає стосовно ігор. Якщо у випадку зі стрілками йдеться про «купність» попадань щодо центру мішені, то дисперсія характеризує дві речі:
По-перше, очевидно, що зі збільшенням ставок, дисперсія теж зростає. Так, наприклад, якщо ми збільшимо у 10 разів, то математичне очікування збільшиться у 10 разів, а дисперсія – у 100 разів (якщо це квадратична величина). Але, зауважте, що самі правила гри не змінилися! Змінилися лише ставки, грубо кажучи, раніше ми ставили 10 карбованців, тепер 100.
Другий, більше цікавий моментполягає в тому, що дисперсія характеризує стиль гри. Подумки зафіксуємо ігрові ставки на якомусь певному рівні, і подивимося, що тут до чого:
Гра з низькою дисперсією – це обережна гра. Гравець схильний вибирати найнадійніші схеми, де за 1 раз він не програє/виграє занадто багато. Наприклад, система «червоне/чорне» в рулетці (див. Приклад 4 статті Випадкові величини) .
Гра із високою дисперсією. Її часто називають дисперсійноїгрою. Це авантюрний чи агресивний стиль гри, де гравець обирає "адреналінові" схеми. Згадаймо хоча б «Мартінгейл», в якому на кону виявляються суми, що на порядки перевершують «тиху» гру попереднього пункту.
Показовою є ситуація в покері: тут є так звані тайтовігравці, які схильні обережно і «труситися» над своїми ігровими засобами (Банкролом). Не дивно, що їхній банкрол не піддається значним коливанням (низька дисперсія). Навпаки, якщо у гравця висока дисперсія, це агресор. Він часто ризикує, робить великі ставки і може, як зірвати величезний банк, так і програтися вщент.
Те саме відбувається на Форексі, і так далі – прикладів маса.
Причому, у всіх випадках не важливо – чи на копійки йде гра, чи на тисячі доларів. На будь-якому рівні є свої низько- та високодисперсійні гравці. Ну, а за середній виграш, як ми пам'ятаємо, «відповідає» математичне очікування.
Напевно, ви помітили, що знаходження дисперсії – процес тривалий і копіткий. Але математика щедра:
Формула для знаходження дисперсії
Ця формулавиводиться безпосередньо з визначення дисперсії, і ми негайно пускаємо її в обіг. Скопіюю зверху табличку з нашою грою: 
і знайдене маточування.
Обчислимо дисперсію другим способом. Спочатку знайдемо математичне очікування – квадрата випадкової величини. за визначення математичного очікування:
Таким чином, за формулою:
Як кажуть, відчуйте різницю. І на практиці, звичайно, краще застосовувати формулу (якщо іншого не потребує умова).
Освоюємо техніку рішення та оформлення:
Приклад 6

Знайти її математичне очікування, дисперсію та середнє квадратичне відхилення.
Це завдання зустрічається повсюдно, і, зазвичай, йде без змістовного сенсу.
Можете уявляти кілька лампочок з числами, які загоряються в дурдомі з певними ймовірностями:)
Рішення: Основні обчислення зручно звести до таблиці Спочатку у верхні два рядки записуємо вихідні дані. Потім розраховуємо твори, потім і, нарешті, суми у правому стовпці: 
Власне, майже все готове. У третьому рядку намалювалося готове математичне очікування: ![]() .
.
Дисперсію обчислимо за такою формулою:
І, нарешті, середнє квадратичне відхилення:
- особисто я зазвичай округляю до 2 знаків після коми.
Усі обчислення можна провести на калькуляторі, а ще краще – в Екселі:
ось тут вже важко помилитися:)
Відповідь:
Бажаючі можуть ще більше спростити своє життя та скористатися моїм калькулятором (Демо), який не тільки вмить вирішить дане завдання, але й збудує тематичні графіки (скоро дійдемо). Програму можна скачати в бібліотеці- якщо ви завантажили хоча б один навчальний матеріал, або отримати іншим способом. Дякуємо за підтримку проекту!
Пара завдань для самостійного рішення:
Приклад 7
Обчислити дисперсію випадкової величини попереднього прикладу визначення.
І аналогічний приклад:
Приклад 8
Дискретна випадкова величина задана своїм законом розподілу:

Так, значення випадкової величини бувають досить великими (Приклад з реальної роботи) , і тут, по можливості, використовуйте Ексель. Як, до речі, і в Прімері 7 – це швидше, надійніше та приємніше.
Рішення та відповіді внизу сторінки.
На закінчення 2-ї частини уроку розберемо ще одну типове завдання, можна навіть сказати, невеликий ребус:
Приклад 9
Дискретна випадкова величина може набувати лише два значення: і , причому . Відома ймовірність, математичне очікування та дисперсія.
Рішення: почнемо з невідомої ймовірності Так як випадкова величина може прийняти лише два значення, то сума ймовірностей відповідних подій:
і оскільки, то.
Залишилося знайти …, легко сказати:) Але так гаразд, понеслося. За визначенням математичного очікування: ![]() - Підставляємо відомі величини:
- Підставляємо відомі величини:
![]() - І більше з цього рівняння нічого не вичавити, хіба що можна переписати його у звичному напрямку:
- І більше з цього рівняння нічого не вичавити, хіба що можна переписати його у звичному напрямку: ![]()

або: ![]()
Про подальших діяхДумаю, ви здогадуєтеся. Складемо і вирішимо систему: 
Десяткові дроби- це, звичайно, повне неподобство; множимо обидва рівняння на 10: 
і ділимо на 2: 
Ось так то краще. З 1-го рівняння виражаємо: ![]() (Це більш простий шлях)- Підставляємо в 2-е рівняння:
(Це більш простий шлях)- Підставляємо в 2-е рівняння:
![]()
Зводимо у квадратта проводимо спрощення: 
Помножуємо на: 
В результаті отримано квадратне рівняння, знаходимо його дискримінант:
- Чудово!
і у нас виходить два рішення:
1) якщо ![]() , то
, то ![]() ;
;
2) якщо ![]() , то.
, то.
Умові задовольняє перша пара значень. З високою ймовірністю все правильно, проте запишемо закон розподілу: 
і виконаємо перевірку, а саме, знайдемо матожидання:
Дисперсія - це міра розсіювання, що описує порівняльне відхилення між значеннями даних та середньою величиною. Є найбільш використовуваною мірою розсіювання в статистиці, що обчислюється шляхом підсумовування, зведеного квадрат, відхилення кожного значення даних від середньої величини. Формула для обчислення дисперсії представлена нижче:
![]()
s 2 – дисперсія вибірки;
x ср - середнє значення вибірки;
n — розмір вибірки (кількість значень даних),
(x i - x ср) - відхилення від середньої величини для кожного значення набору даних.
Для кращого розумінняформули, розберемо приклад. Я не дуже люблю готування, тому заняттям цим займаюся дуже рідко. Проте, щоб не померти з голоду, час від часу мені доводиться підходити до плити для реалізації задуму щодо насичення мого організму білками, жирами та вуглеводами. Набір даних, поданий нижче, показує, скільки разів Ренат готує їжу щомісяця:
Першим кроком при обчисленні дисперсії є визначення середнього значення вибірки, яке в прикладі дорівнює 7,8 рази на місяць. Інші обчислення можна полегшити за допомогою наступної таблиці.

Фінальна фаза обчислення дисперсії виглядає так:
![]()
Для тих, хто любить робити всі обчислення за один раз, рівняння виглядатиме так:
Використання методу «сирого рахунку» (приклад із готуванням)
Існує більше ефективний спосібобчислення дисперсії відомий як метод «сирого рахунку». Хоча з першого погляду рівняння може здатися дуже громіздким, насправді воно не таке страшне. Можете в цьому переконатись, а потім і вирішіть, який метод вам більше подобається.

- Сума кожного значення даних після зведення в квадрат,
- Квадрат суми всіх значень даних.
Не втрачайте розум прямо зараз. Дозвольте уявити все це у вигляді таблиці, і тоді ви побачите, що обчислень тут менше, ніж у попередньому прикладі.


Як бачите, результат вийшов той самий, що й під час використання попереднього методу. Переваги даного методустають очевидними зі зростанням розміру вибірки (n).
Розрахунок дисперсії в Excel
Як ви вже, напевно, здогадалися, в Excel є формула, що дозволяє розрахувати дисперсію. Причому, починаючи з Excel 2010, можна знайти 4 різновиди формули дисперсії:
1) ДИСП.В - Повертає дисперсію за вибіркою. Логічні значення та текст ігноруються.
2) ДИСП.Г - Повертає дисперсію по генеральній сукупності. Логічні значення та текст ігноруються.
3) ДИСПА - Повертає дисперсію за вибіркою з урахуванням логічних та текстових значень.
4) ДИСПРА - Повертає дисперсію по генеральній сукупності з урахуванням логічних та текстових значень.
Для початку розберемося в різниці між вибіркою та генеральною сукупністю. Призначення описової статистикиполягає в тому, щоб підсумовувати або відображати дані так, щоб оперативно отримувати загальну картину, так би мовити, огляд. Статистичний висновок дозволяє робити висновки про будь-яку сукупність на основі вибірки даних із цієї сукупності. Сукупність є всі можливі результати чи виміри, які становлять нам інтерес. Вибірка - це підмножина сукупності.
Наприклад, нас цікавить сукупність групи студентів одного з Російських ВНЗнам необхідно визначити середній бал групи. Ми можемо порахувати середню успішністьстудентів і тоді отримана цифра буде параметром, оскільки в наших розрахунках буде задіяна ціла сукупність. Однак якщо ми хочемо розрахувати середній бал усіх студентів нашої країни, тоді ця група буде нашою вибіркою.
Різниця у формулі розрахунку дисперсії між вибіркою та сукупністю полягає у знаменнику. Де для вибірки він дорівнюватиме (n-1), а для генеральної сукупності тільки n.
Тепер розберемося з функціями розрахунку дисперсії із закінченнями А,в описі яких сказано, що при розрахунку враховуються текстові та логічні значення. В даному випадку при розрахунку дисперсії певного масиву даних, де не зустрічаються числові значення, Excel інтерпретуватиме текстові та помилкові логічні значення як рівними 0, а справжні логічні значення як рівними 1.
Отже, якщо у вас є масив даних, розрахувати його дисперсію не складе ніяких труднощів, скориставшись однією з перерахованих вище функцій Excel.

Варіаційний розмах (або розмах варіації)це різниця між максимальним і мінімальними значеннямиознаки:
У прикладі розмах варіації змінної вироблення робочих становить: у першій бригаді R=105-95=10 дет., у другій бригаді R=125-75=50 дет. (У 5 разів більше). Це свідчить, що вироблення 1-ї бригади більш «стійка», але резервів зростання вироблення більше в другій бригади, т.к. у разі досягнення всіма робітниками максимальної для цієї бригади виробітку, нею може бути виготовлено 3*125=375 деталей, а в 1-й бригаді лише 105*3=315 деталей.
Якщо крайні значенняознаки не типові для сукупності, використовують квартильний або децильний розмахи. Квартильний розмах RQ = Q3-Q1 охоплює 50% обсягу сукупності, децильний розмах перший RD1 = D9-D1охоплює 80% даних, другий децильний розмах RD2 = D8-D2 - 60%.
Недоліком показника варіаційного розмахує, але його величина не відбиває всі коливання ознаки.
Найпростішим узагальнюючим показником, що відображає всі коливання ознаки, є середнє лінійне відхилення, що являє собою середню арифметичну абсолютних відхилень окремих варіантів від їх середньої величини:
,
для згрупованих даних ![]() ,
,
де хi - значення ознаки в дискретному рядуабо середина інтервалу в інтервальному розподілі.
У вищенаведених формулах різниці в чисельнику взяті за модулем, інакше, згідно з властивістю середньої арифметичної, чисельник завжди дорівнюватиме нулю. Тому середнє лінійне відхилення у статистичній практиці застосовують рідко, лише у випадках, коли підсумовування показників без урахування знака має економічний сенс. З його допомогою, наприклад, аналізується склад працюючих, рентабельність виробництва, оборот зовнішньої торгівлі.
Дисперсія ознаки– це середній квадратвідхилень варіант від їх середньої величини:
проста дисперсія ![]() ,
,
зважена дисперсія  .
.
Формулу для розрахунку дисперсії можна спростити:
Таким чином, дисперсія дорівнює різниці середньої з квадратів варіант і квадрата середньої з варіант сукупності:  .
.
Однак, внаслідок підсумовування квадратів відхилень дисперсія дає спотворене уявлення про відхилення, тому її на основі розраховують середнє квадратичне відхиленнящо показує, наскільки в середньому відхиляються конкретні варіанти ознаки від їхнього середнього значення. Обчислюється шляхом вилучення квадратного кореняз дисперсії:
для несгрупованих даних 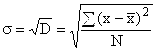 ,
,
для варіаційного ряду
Чим менше значеннядисперсії та середнього квадратичного відхилення, тим однорідніша сукупність, тим більш надійною (типовою) буде середня величина.
Середнє лінійне та середнє квадратичне відхилення- іменовані числа, тобто виражаються в одиницях виміру ознаки, ідентичні за змістом та близькі за значенням.
Розраховувати абсолютні показникиваріації рекомендується з допомогою таблиць.
Таблиця 3 - Розрахунок показників варіації (на прикладі терміну даних про змінну вироблення робочих бригади)
Число робітників, |
Середина інтервалу, |
Розрахункові значення |
|||||
Разом: |
|||||||
Середнє зміна вироблення робітників: ![]()
Середнє лінійне відхилення: ![]()
Дисперсія виробітку: 
Середнє квадратичне відхилення виробітку окремих робітників від середнього виробітку:
.
1 Розрахунок дисперсії способом моментів
Обчислення дисперсій пов'язане з громіздкими розрахунками (особливо якщо середня величина виражена більшим числомз кількома десятковими знаками). Розрахунки можна спростити, якщо використовувати спрощену формулу та властивості дисперсії.
Дисперсія має такі властивості:
- якщо всі значення ознаки зменшити або збільшити на ту саму величину А, то дисперсія від цього не зменшиться:
 ,
,
 , то чи
, то чи 
Використовуючи властивості дисперсії і спочатку зменшивши всі варіанти сукупності на величину А, а потім розділивши величину інтервалу h, отримаємо формулу обчислення дисперсії в варіаційних рядах з рівними інтервалами способом моментів: ,
,
де - Дисперсія, обчислена за способом моментів;
h – величина інтервалу варіаційного ряду;
- Нові (перетворені) значення варіант;
А- постійна величина, Якою використовують середину інтервалу, що володіє найбільшою частотою; або варіант, що має найбільшу частоту;  - Квадрат моменту першого порядку;
- Квадрат моменту першого порядку;
- Момент другого порядку.
Виконаємо розрахунок дисперсії способом моментів на основі даних про змінне вироблення робітників бригади.
Таблиця 4 - Розрахунок дисперсії за способом моментів
Групи робітників з вироблення, шт. |
Число робітників, |
Середина інтервалу, |
Розрахункові значення |
||
Порядок розрахунку:


- розраховуємо дисперсію:
2 Розрахунок дисперсії альтернативної ознаки
Серед ознак, що вивчаються статистикою, є такі, яким властиві лише два взаємно виключають значення. Це альтернативні ознаки. Їм надається відповідно два кількісні значення: варіанти 1 і 0. Частиною варіанти 1, яка позначається p, є частка одиниць, що мають дану ознаку. Різниця 1-р=q є частотою варіанти 0. Таким чином,
хі |
|
Середня арифметична альтернативна ознака ![]() , Оскільки p+q=1.
, Оскільки p+q=1.
Дисперсія альтернативної ознаки
, т.к. 1-р = q
Таким чином, дисперсія альтернативної ознаки дорівнює добутку частки одиниць, що володіють даною ознакою, і частки одиниць, що не мають цієї ознаки.
Якщо значення 1 і 0 зустрічаються однаково часто, тобто p = q, дисперсія досягає свого максимуму pq = 0,25.
Дисперсія альтернативної ознаки використовується в вибіркових обстеженняхнаприклад, якості продукції.
3 Міжгрупова дисперсія. Правило складання дисперсій
Дисперсія, на відміну інших характеристик варіації, є адитивною величиною. Тобто в сукупності, яка поділена на групи за факторною ознакою х , дисперсія результативної ознаки yможе бути розкладена на дисперсію у кожній групі (внутрішньогрупову) та дисперсію між групами (міжгрупову). Тоді, поряд із вивченням варіації ознаки по всій сукупності загалом, стає можливим вивчення варіації у кожній групі, а також між цими групами.
Загальна дисперсіявимірює варіацію ознаки упо всій сукупності під впливом всіх факторів, що спричинили цю варіацію (відхилення). Вона дорівнює середньому квадрату відхилень окремих значеньознаки увід загальної середньої та може бути обчислена як проста або зважена дисперсія.
Міжгрупова дисперсіяхарактеризує варіацію результативної ознаки у, спричинену впливом ознаки-фактора х, покладеного в основу угруповання. Вона характеризує варіацію групових середніх і дорівнює середньому квадрату відхилень групових середніх від загальної середньої.  ,
,
де – середня арифметична i-та група;
– чисельність одиниць у i-тій групі (частота i-тої групи);
– загальна середня сукупності.
Внутрішньогрупова дисперсіявідбиває випадкову варіацію, т. е. ту частину варіації, що викликана впливом неврахованих чинників і залежить від ознаки-фактора, покладеного основою угруповання. Вона характеризує варіацію індивідуальних значеньщодо групових середніх, дорівнює середньому квадрату відхилень окремих значень ознаки увсередині групи від середньої арифметичної цієї групи (групової середньої) та обчислюється як проста або зважена дисперсія для кожної групи: ![]() або
або ![]() ,
,
де – число одиниць групи.
На підставі внутрішньогрупових дисперсійпо кожній групі можна визначити загальну середню із внутрішньогрупових дисперсій:
.
Взаємозв'язок між трьома дисперсіями отримав назву правила складання дисперсій, згідно з яким загальна дисперсія дорівнює сумі міжгрупової дисперсії та середньої з внутрішньогрупових дисперсій:
приклад. При вивченні впливу тарифного розряду (кваліфікації) робітників на рівень продуктивності їхньої праці отримані такі дані.
Таблиця 5 - Розподіл робітників по середньогодинному виробітку.
№ п/п |
Робочі 4-го розряду |
Робочі 5-го розряду |
|||||
Вироблення |
Вироблення |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
У даному прикладіробітники розділені на дві групи за факторною ознакою х- кваліфікації, що характеризується їх розрядом. Результативна ознака – вироблення – варіюється як під його впливом (міжгрупова варіація), так і за рахунок інших випадкових факторів (внутрішньогрупова варіація). Завдання полягає у вимірі цих варіацій за допомогою трьох дисперсій: загальної, міжгрупової та внутрішньогрупової. Емпіричний коефіцієнт детермінації показує частку варіації результативної ознаки упід впливом факторної ознаки х. Решта загальної варіації увикликана зміною інших чинників.
У прикладі емпіричний коефіцієнт детермінації дорівнює: ![]() або 66,7%,
або 66,7%,
Це означає, що у 66,7% варіація продуктивність праці робочих зумовлена відмінностями у кваліфікації, але в 33,3% – впливом інших чинників.
Емпіричне кореляційне ставленняпоказує тісноту зв'язку між групувальною та результативними ознаками. Розраховується як квадратний корінь з емпіричного коефіцієнта детермінації:
Емпіричне кореляційне відношення, як і може приймати значення від 0 до 1.
Якщо зв'язок немає, то =0. І тут =0, тобто групові середні рівні між собою міжгрупової варіації немає. Значить групувальний ознака – чинник впливає освіту загальної варіації.
Якщо зв'язок функціональний, то =1. У цьому випадку дисперсія групових середніх дорівнює загальної дисперсії(), Тобто внутрішньогрупової варіації немає. Це означає, що групувальна ознака повністю визначає варіацію результативної ознаки, що вивчається.
Чим ближче значення кореляційного ставлення до одиниці, тим більше, ближче до функціональної залежності зв'язок між ознаками.
Для якісної оцінки тісноти зв'язок між ознаками користуються співвідношеннями Чеддока.
У прикладі ![]() , що свідчить про тісного зв'язкуміж продуктивністю праці робітників та його кваліфікацією.
, що свідчить про тісного зв'язкуміж продуктивністю праці робітників та його кваліфікацією.
 Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих
Дядько Ваня сюжет п'єси. "Дядя Ваня. Ставлення до професора оточуючих Крихітка Цахес по прозвищу Циннобер
Крихітка Цахес по прозвищу Циннобер Майков, Аполлон Миколайович – коротка біографія
Майков, Аполлон Миколайович – коротка біографія