Dispersioonimeetmed. Rühma, rühmadevahelise ja kogu dispersiooni arvutamine (vastavalt dispersioonide liitmise reeglile)
Kus σ 2 j on j-nda rühma rühmasisene dispersioon.
Grupeerimata andmete jaoks jääkdispersioon on ligikaudse täpsuse mõõt, st. regressioonijoone lähendamine algandmetele: 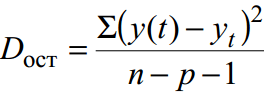
kus y(t) on prognoos vastavalt trendi võrrandile; y t – dünaamika algrida; n on punktide arv; p on regressioonivõrrandi kordajate arv (selgitavate muutujate arv).
Selles näites nimetatakse seda dispersiooni erapooletu hinnang.
Näide nr 1. Ühe ühingu kolme ettevõtte töötajate jaotust tariifikategooriate kaupa iseloomustavad järgmised andmed:
| Töötaja palgakategooria | Tööliste arv ettevõttes | ||
| ettevõte 1 | ettevõte 2 | ettevõte 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Määratlege:
1. hajutamine iga ettevõtte kohta (grupisisene dispersioon);
2. rühmasiseste dispersioonide keskmine;
3. rühmadevaheline hajutamine;
4. summaarne dispersioon.
Lahendus.
Enne probleemi lahendamise jätkamist tuleb välja selgitada, milline funktsioon on tõhus ja milline faktoriaalne. Vaadeldavas näites on efektiivseks tunnuseks "Tariifikategooria" ja teguri tunnuseks "Ettevõtte number (nimi).
Siis on meil kolm rühma (ettevõtteid), mille jaoks on vaja arvutada grupi keskmine ja grupisisesed dispersioonid:

| Ettevõte | rühma keskmine, | rühmasisene dispersioon, |
| 1 | 4 | 1,8 |
Grupisisese dispersiooni keskmine ( jääkdispersioon) arvutatakse järgmise valemiga:

kus saab arvutada:
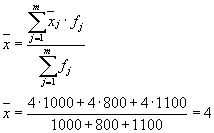
või:

siis:
Kogu dispersioon on võrdne: s 2 \u003d 1,6 + 0 \u003d 1,6.
Kogu dispersiooni saab arvutada ka ühe kahest järgmisest valemist:

Praktiliste probleemide lahendamisel tuleb sageli tegeleda märgiga, mis võtab vaid kaks alternatiivset väärtust. Sel juhul ei räägi nad mitte tunnuse konkreetse väärtuse kaalust, vaid selle osatähtsusest agregaadis. Kui uuritavat tunnust omavate populatsiooniüksuste osakaal on tähistatud " R"ja mitte omamine - läbi" q”, siis saab dispersiooni arvutada valemiga:
s2 = p × q
Näide nr 2. Brigaadi kuue töötaja toodangu andmete põhjal määrake rühmadevaheline dispersioon ja hinnake töövahetuse mõju nende tööviljakusele, kui summaarne dispersioon on 12,2.
| Töötava brigaadi nr | Tööväljund, tk. | |
| esimeses vahetuses | 2. vahetuses | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Lahendus. Esialgsed andmed
| X | f1 | f2 | f 3 | f4 | f5 | f6 | Kokku |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Kokku | 31 | 33 | 37 | 37 | 40 | 38 |
Siis on meil 6 rühma, mille jaoks on vaja arvutada rühma keskmised ja rühmasisesed dispersioonid.
1. Leidke iga rühma keskmised väärtused.
2. Leidke iga rühma keskmine ruut.
Arvutuse tulemused võtame kokku tabelis:
| Grupi number | Grupi keskmine | Grupisisene dispersioon |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. Grupisisene dispersioon iseloomustab uuritava (tulemusliku) tunnuse muutust (variatsiooni) rühma sees kõigi tegurite mõjul, välja arvatud rühmitamise aluseks olev tegur:
Arvutame rühmasiseste dispersioonide keskmise valemi abil:
4. Gruppidevaheline dispersioon iseloomustab uuritava (tulemusliku) tunnuse muutumist (variatsiooni) rühmituse aluseks oleva teguri (faktoriaalse tunnuse) mõjul.
Rühmadevaheline hajutamine on määratletud järgmiselt:
kus
Siis
Kogu dispersioon iseloomustab uuritava (tulemusliku) tunnuse muutumist (variatsiooni) eranditult kõigi tegurite (faktoriaalsete tunnuste) mõjul. Ülesande tingimuse järgi on see võrdne 12,2-ga.
Empiiriline korrelatsiooniseos mõõdab, kui suure osa saadud atribuudi kogukõikumistest põhjustab uuritav tegur. See on faktoriaalse dispersiooni ja kogu dispersiooni suhe:
Määrame empiirilise korrelatsiooni:
Tunnustevahelised seosed võivad olla nõrgad või tugevad (lähedased). Nende kriteeriume hinnatakse Chaddocki skaalal:
0,1 0,3 0,5 0,7 0,9 Meie näites on seos tunnuse Y teguri X vahel nõrk
Määramiskoefitsient.
Määratleme määramiskoefitsiendi:
Seega on 0,67% variatsioonist tingitud tunnuste erinevustest ja 99,37% muudest teguritest.
Järeldus: sel juhul ei sõltu töötajate toodang konkreetse vahetuse tööst, s.t. töövahetuse mõju nende tööviljakusele ei ole märkimisväärne ja on tingitud muudest teguritest.
Näide nr 3. Tuginedes kahe töötajate rühma keskmise palga ja selle väärtusest kõrvalekallete ruutude andmetele, leidke kogu dispersioon, rakendades dispersiooni liitmise reeglit:
Lahendus:Grupisiseste erinevuste keskmine
Rühmadevaheline hajutamine on määratletud järgmiselt:
Kogu dispersioon on: 480 + 13824 = 14304
Sellel lehel on kirjeldatud dispersiooni leidmise standardnäide, selle leidmiseks võite vaadata ka muid ülesandeid
Näide 1. Rühma, rühma keskmise, rühmadevahelise ja kogu dispersiooni määramine
Näide 2. Dispersiooni ja variatsioonikordaja leidmine rühmitustabelis
Näide 3. Diskreetse rea dispersiooni leidmine
Näide 4. Meil on järgmised andmed 20-liikmelise korrespondentüliõpilase rühma kohta. On vaja koostada tunnusjaotuse intervalljada, arvutada tunnuse keskmine väärtus ja uurida selle dispersiooni
Koostame intervallrühma. Määrame intervalli vahemiku valemiga:
![]()
kus X max on rühmitamise tunnuse maksimaalne väärtus;
X min on rühmitamistunnuse minimaalne väärtus;
n on intervallide arv:
Aktsepteerime n=5. Samm on järgmine: h \u003d (192–159) / 5 \u003d 6,6
Teeme intervallrühma

Edasiste arvutuste jaoks koostame abitabeli:

X "i - intervalli keskpaik. (näiteks intervalli keskpaik 159 - 165,6 \u003d 162,3)
Õpilaste keskmine kasv määratakse aritmeetilise kaalutud keskmise valemiga:

Dispersiooni määrame valemiga:
Valemit saab teisendada järgmiselt:

Sellest valemist järeldub, et dispersioon on valikute ruutude keskmise ning ruudu ja keskmise vahe.
Variatsioonirea hälve võrdsete intervallidega vastavalt momentide meetodile saab arvutada järgmiselt, kasutades dispersiooni teist omadust (jagades kõik valikud intervalli väärtusega). Dispersiooni definitsioon, mis on arvutatud hetkede meetodil, on järgmise valemi järgi vähem aeganõudev:

kus i on intervalli väärtus;
A - tingimuslik null, mida on mugav kasutada kõrgeima sagedusega intervalli keskpunktis;
m1 on esimest järku hetke ruut;
m2 - teise järjekorra hetk
Funktsiooni dispersioon (kui statistilises üldkogumis atribuut muutub nii, et on ainult kaks teineteist välistavat varianti, siis nimetatakse sellist varieeruvust alternatiivseks) saab arvutada valemiga:

Asendades selles dispersioonivalemis q = 1- p, saame:

Dispersiooni tüübid
Kogu dispersioon mõõdab tunnuse varieerumist kogu populatsioonis tervikuna kõigi seda varieerumist põhjustavate tegurite mõjul. See võrdub tunnuse x üksikute väärtuste kõrvalekallete keskmise ruuduga keskmisest koguväärtusest x ja seda saab määratleda kui lihtsat dispersiooni või kaalutud dispersiooni.
Grupisisene dispersioon iseloomustab juhuslikku varieerumist, s.t. osa variatsioonist, mis on tingitud arvestamata tegurite mõjust ja ei sõltu rühmituse aluseks olevast tunnustegurist. Selline dispersioon on võrdne X-rühma tunnuse üksikute väärtuste kõrvalekallete keskmise ruuduga rühma aritmeetilisest keskmisest ja seda saab arvutada lihtsa dispersioonina või kaalutud dispersioonina.
Sellel viisil, rühmasisese dispersiooni mõõdikud tunnuse varieerumine rühmas ja määratakse järgmise valemiga:

kus xi - rühma keskmine;
ni on ühikute arv rühmas.
Näiteks grupisisesed dispersioonid, mida tuleb määrata ülesandes uurida töötajate kvalifikatsiooni mõju tööviljakuse tasemele kaupluses, näitavad toodangu kõikumisi igas rühmas, mis on põhjustatud kõigist võimalikest teguritest (seadmete tehniline seisund, tööriistade ja materjalide olemasolu, töötajate vanus, töömahukus jne.), välja arvatud kvalifikatsioonikategooria erinevused (rühmasiseselt on kõigil töötajatel sama kvalifikatsioon).
Matemaatiline ootus ja dispersioon on juhusliku suuruse kõige sagedamini kasutatavad numbrilised karakteristikud. Need iseloomustavad jaotuse kõige olulisemaid tunnuseid: selle asukohta ja hajuvusastet. Paljude praktikaprobleemide puhul pole juhusliku suuruse - jaotusseaduse - täielikku ja ammendavat kirjeldust kas üldse võimalik saada või pole seda üldse vaja. Nendel juhtudel piirduvad need juhusliku suuruse ligikaudse kirjeldusega, kasutades numbrilisi tunnuseid.
Matemaatilisele ootusele viidatakse sageli lihtsalt kui juhusliku suuruse keskmisele väärtusele. Juhusliku suuruse dispersioon on dispersiooni tunnus, juhusliku suuruse hajumine selle matemaatilise ootuse ümber.
Diskreetse juhusliku suuruse matemaatiline ootus
Lähenegem matemaatilise ootuse mõistele, lähtudes esmalt diskreetse juhusliku suuruse jaotuse mehaanilisest tõlgendamisest. Olgu ühikmass jaotatud x-telje punktide vahel x1 , x 2 , ..., x n, ja igal materiaalsel punktil on sellele vastav mass lk1 , lk 2 , ..., lk n. On vaja valida x-teljel üks punkt, mis iseloomustab kogu materiaalsete punktide süsteemi asukohta, võttes arvesse nende massi. Selliseks punktiks on loomulik võtta materiaalsete punktide süsteemi massikese. See on juhusliku suuruse kaalutud keskmine X, milles iga punkti abstsiss xi siseneb vastava tõenäosusega võrdse "kaaluga". Nii saadud juhusliku suuruse keskmine väärtus X nimetatakse selle matemaatiliseks ootuseks.
Diskreetse juhusliku suuruse matemaatiline ootus on kõigi selle võimalike väärtuste ja nende väärtuste tõenäosuste korrutised:
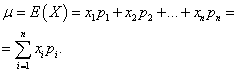
Näide 1 Korraldati win-win loterii. Seal on 1000 võitu, millest 400 on igaüks 10 rubla. 300-20 rubla igaüks 200-100 rubla igaüks. ja igaüks 100-200 rubla. Kui suur on ühe pileti ostnud inimese keskmine võit?
Lahendus. Keskmise võidu leiame, kui võitude kogusumma, mis võrdub 10*400 + 20*300 + 100*200 + 200*100 = 50 000 rubla, jagatakse 1000-ga (võitude kogusumma). Siis saame 50000/1000 = 50 rubla. Kuid keskmise võimenduse arvutamise avaldist saab esitada ka järgmisel kujul:
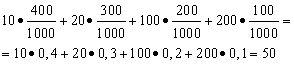
Teisest küljest on nendel tingimustel võitude suurus juhuslik suurus, mis võib olla 10, 20, 100 ja 200 rubla. tõenäosustega, mis on vastavalt 0,4; 0,3; 0,2; 0.1. Seetõttu on oodatav keskmine väljamakse võrdne väljamaksete suuruse ja nende saamise tõenäosuse korrutistega.
Näide 2 Kirjastus otsustas välja anda uue raamatu. Ta kavatseb raamatu müüa 280 rubla eest, millest 200 antakse talle, 50 raamatupoele ja 30 autorile. Tabel annab teavet raamatu väljaandmise maksumuse ja teatud arvu eksemplaride müügi tõenäosuse kohta.
Leidke väljaandja eeldatav kasum.
Lahendus. Juhuslik suurus "kasum" võrdub müügitulu ja kulude maksumuse vahega. Näiteks kui raamatut müüakse 500 eksemplari, siis müügist saadav tulu on 200 * 500 = 100 000 ja kirjastamiskulu 225 000 rubla. Seega ootab kirjastust 125 000 rubla kahjum. Järgmine tabel võtab kokku juhusliku suuruse - kasumi - eeldatavad väärtused:
| Number | Kasum xi | Tõenäosus lki | xi lk i |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Kokku: | 1,00 | 25000 |
Seega saame kirjastaja kasumi matemaatilise ootuse:
![]() .
.
Näide 3 Võimalus lüüa ühe löögiga lk= 0,2. Määrake kestade tarbimine, mis annab matemaatilise ootuse, et tabamuste arv on 5.
Lahendus. Samast ootusvalemist, mida oleme siiani kasutanud, väljendame x- kestade tarbimine:
![]() .
.
Näide 4 Määrake juhusliku suuruse matemaatiline ootus x tabamuste arv kolme lasuga, kui iga löögiga tabamise tõenäosus lk = 0,4 .
Vihje: leidke juhusliku suuruse väärtuste tõenäosus järgmiselt Bernoulli valem .
Ootuste omadused
Mõelge matemaatilise ootuse omadustele.
Vara 1. Konstantse väärtuse matemaatiline ootus on võrdne selle konstandiga:
Vara 2. Konstantse teguri saab ootusmärgist välja võtta:
![]()
Vara 3. Juhuslike muutujate summa (erinevuse) matemaatiline ootus on võrdne nende matemaatiliste ootuste summaga (erinevus):
Vara 4. Juhuslike muutujate korrutise matemaatiline ootus on võrdne nende matemaatiliste ootuste korrutisega:
Vara 5. Kui kõik juhusliku suuruse väärtused X vähenema (suurendada) sama arvu võrra FROM, siis selle matemaatiline ootus väheneb (suureneb) sama arvu võrra:
![]()
Kui te ei saa piirduda ainult matemaatiliste ootustega
Enamasti ei suuda ainult matemaatiline ootus juhuslikku muutujat adekvaatselt iseloomustada.
Olgu juhuslikud muutujad X ja Y on antud järgmiste jaotusseadustega:
| Tähendus X | Tõenäosus |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Tähendus Y | Tõenäosus |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
Nende suuruste matemaatilised ootused on samad - võrdne nulliga:
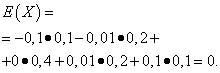
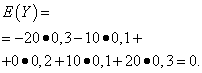
Nende jaotus on aga erinev. Juhuslik väärtus X saab võtta ainult selliseid väärtusi, mis erinevad vähe matemaatilisest ootusest ja juhuslikust muutujast Y võib võtta väärtusi, mis erinevad oluliselt matemaatilisest ootusest. Sarnane näide: keskmine palk ei võimalda hinnata kõrge ja madalapalgaliste töötajate osakaalu. Teisisõnu, matemaatilise ootuse järgi ei saa hinnata, millised kõrvalekalded sellest, vähemalt keskmiselt, on võimalikud. Selleks tuleb leida juhusliku suuruse dispersioon.
Diskreetse juhusliku suuruse dispersioon
dispersioon diskreetne juhuslik suurus X nimetatakse matemaatiliseks ootuseks selle ruudu kõrvalekaldumisest matemaatilisest ootusest:
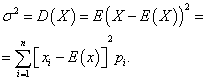
Juhusliku suuruse standardhälve X on selle dispersiooni ruutjuure aritmeetiline väärtus:
![]() .
.
Näide 5 Arvutage juhuslike suuruste dispersioonid ja standardhälbed X ja Y, mille jaotusseadused on toodud ülaltoodud tabelites.
Lahendus. Juhuslike suuruste matemaatilised ootused X ja Y, nagu ülalpool leiti, on võrdsed nulliga. Vastavalt dispersiooni valemile E(X)=E(y)=0 saame:

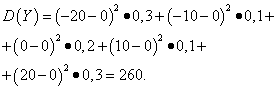
Seejärel juhuslike suuruste standardhälbed X ja Y moodustavad
![]() .
.
Seega samade matemaatiliste ootuste korral juhusliku suuruse dispersioon X väga väike ja juhuslik Y- märkimisväärne. See on nende leviku erinevuse tagajärg.
Näide 6 Investoril on 4 alternatiivset investeerimisprojekti. Tabelis on kokku võetud andmed eeldatava kasumi kohta nendes projektides vastava tõenäosusega.
| Projekt 1 | Projekt 2 | Projekt 3 | Projekt 4 |
| 500, P=1 | 1000, P=0,5 | 500, P=0,5 | 500, P=0,5 |
| 0, P=0,5 | 1000, P=0,25 | 10500, P=0,25 | |
| 0, P=0,25 | 9500, P=0,25 |
Leidke iga alternatiivi jaoks matemaatiline ootus, dispersioon ja standardhälve.
Lahendus. Näitame, kuidas need kogused arvutatakse 3. alternatiivi jaoks:
Tabel võtab kokku kõigi alternatiivide leitud väärtused.
Kõigil alternatiividel on samad matemaatilised ootused. See tähendab, et pikas perspektiivis on kõigil sama sissetulek. Standardhälvet võib tõlgendada kui riski mõõdikut – mida suurem see on, seda suurem on investeeringu risk. Investor, kes ei soovi suurt riski, valib projekti 1, kuna sellel on väikseim standardhälve (0). Kui investor eelistab riski ja kõrget tootlust lühikese perioodi jooksul, siis valib ta suurima standardhälbega projekti - projekt 4.
Dispersiooniomadused
Toome välja dispersiooni omadused.
Vara 1. Konstantse väärtuse dispersioon on null:
Vara 2. Konstantse teguri saab dispersioonimärgist välja võtta selle ruudustamisel:
![]() .
.
Vara 3. Juhusliku suuruse dispersioon on võrdne selle väärtuse ruudu matemaatilise ootusega, millest lahutatakse väärtuse enda matemaatilise ootuse ruut:
![]() ,
,
kus ![]() .
.
Vara 4. Juhuslike suuruste summa (erinevuse) dispersioon on võrdne nende dispersioonide summaga (erinevus):
Näide 7 On teada, et diskreetne juhuslik suurus X võtab ainult kaks väärtust: −3 ja 7. Lisaks on teada matemaatiline ootus: E(X) = 4. Leia diskreetse juhusliku suuruse dispersioon.
Lahendus. Tähistage lk tõenäosus, millega juhuslik suurus omandab väärtuse x1 = −3 . Siis väärtuse tõenäosus x2 = 7 saab olema 1 − lk. Tuletame matemaatilise ootuse võrrandi:
E(X) = x 1 lk + x 2 (1 − lk) = −3lk + 7(1 − lk) = 4 ,
kust saame tõenäosused: lk= 0,3 ja 1 − lk = 0,7 .
Juhusliku suuruse jaotuse seadus:
| X | −3 | 7 |
| lk | 0,3 | 0,7 |
Arvutame selle juhusliku suuruse dispersiooni, kasutades dispersiooni omaduse 3 valemit:
D(X) = 2,7 + 34,3 − 16 = 21 .
Leidke ise juhusliku suuruse matemaatiline ootus ja seejärel vaadake lahendust
Näide 8 Diskreetne juhuslik suurus X võtab ainult kaks väärtust. See võtab suurema väärtuse 3 tõenäosusega 0,4. Lisaks on teada juhusliku suuruse dispersioon D(X) = 6. Leidke juhusliku suuruse matemaatiline ootus.
Näide 9 Urnis on 6 valget ja 4 musta palli. Urnist võetakse 3 palli. Valgete pallide arv väljatõmmatud pallide hulgas on diskreetne juhuslik suurus X. Leidke selle juhusliku suuruse matemaatiline ootus ja dispersioon.
Lahendus. Juhuslik väärtus X võib võtta väärtused 0, 1, 2, 3. Vastavad tõenäosused saab arvutada tõenäosuste korrutamise reegel. Juhusliku suuruse jaotuse seadus:
| X | 0 | 1 | 2 | 3 |
| lk | 1/30 | 3/10 | 1/2 | 1/6 |
Siit ka selle juhusliku muutuja matemaatiline ootus:
M(X) = 3/10 + 1 + 1/2 = 1,8 .
Antud juhusliku suuruse dispersioon on:
D(X) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Pideva juhusliku suuruse matemaatiline ootus ja dispersioon
Pideva juhusliku suuruse korral jääb matemaatilise ootuse mehaaniline tõlgendus sama tähendusega: massikese massikese jaoks, mis on jaotatud pidevalt x-teljel tihedusega. f(x). Erinevalt diskreetsest juhuslikust muutujast, mille jaoks funktsiooni argument xi muutub järsult, pideva juhusliku muutuja puhul muutub argument pidevalt. Kuid pideva juhusliku suuruse matemaatiline ootus on samuti seotud selle keskmise väärtusega.
Pideva juhusliku suuruse matemaatilise ootuse ja dispersiooni leidmiseks peate leidma kindlad integraalid . Kui on antud pideva juhusliku suuruse tihedusfunktsioon, siis see siseneb otse integrandi. Kui on antud tõenäosusjaotuse funktsioon, siis seda eristades tuleb leida tihedusfunktsioon.
Pideva juhusliku suuruse kõigi võimalike väärtuste aritmeetilist keskmist nimetatakse selleks matemaatiline ootus, tähistatud või .
Juhusliku muutuja dispersioon on selle muutuja väärtuste leviku mõõt. Väike dispersioon tähendab, et väärtused on rühmitatud üksteise lähedal. Suur dispersioon näitab väärtuste tugevat hajumist. Statistikas kasutatakse juhusliku suuruse dispersiooni mõistet. Näiteks kui võrrelda kahe suuruse väärtuste dispersiooni (näiteks mees- ja naispatsientide vaatlustulemusi), saate testida mõne muutuja olulisust. Dispersiooni kasutatakse ka statistiliste mudelite koostamisel, kuna väike dispersioon võib olla märk sellest, et sobitate väärtusi üle.Sammud
Näidise dispersiooni arvutamine
-
Salvestage näidisväärtused. Enamasti on statistikutele kättesaadavad ainult teatud populatsioonide valimid. Näiteks statistikud ei analüüsi reeglina kõigi Venemaa autode populatsiooni ülalpidamiskulusid – nad analüüsivad mitme tuhande auto suurust juhuslikku valimit. Selline valim aitab määrata keskmist kulu auto kohta, kuid tõenäoliselt on saadud väärtus tegelikust kaugel.
- Näiteks analüüsime juhuslikus järjekorras võetuna kohvikus müüdud kuklite arvu 6 päeva jooksul. Valimi kuju on järgmine: 17, 15, 23, 7, 9, 13. See on valim, mitte üldkogum, sest meil puuduvad andmed iga kohviku lahtioleku päeva kohta müüdud kuklite kohta.
- Kui teile antakse üldkogum, mitte väärtuste valim, liikuge järgmise jaotise juurde.
-
Kirjutage üles valimi dispersiooni arvutamise valem. Dispersioon on mõne suuruse väärtuste leviku mõõt. Mida lähemal on dispersiooni väärtus nullile, seda lähemal on väärtused rühmitatud. Kui töötate väärtuste valimiga, kasutage dispersiooni arvutamiseks järgmist valemit:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2)) on dispersioon. Dispersiooni mõõdetakse ruutühikutes.
- x i (\displaystyle x_(i))- iga väärtus proovis.
- x i (\displaystyle x_(i)) peate lahutama x̅, ruudu ja seejärel liitma tulemused.
- x̅ – valimi keskmine (valimi keskmine).
- n on valimi väärtuste arv.
-
Arvutage valimi keskmine. Seda tähistatakse kui x̅. Valimi keskmine arvutatakse nagu tavaline aritmeetiline keskmine: liidetakse kõik valimi väärtused ja jagatakse tulemus valimi väärtuste arvuga.
- Meie näites lisage näidis olevad väärtused: 15 + 17 + 23 + 7 + 9 + 13 = 84
Nüüd jagage tulemus valimi väärtuste arvuga (meie näites on neid 6): 84 ÷ 6 = 14.
Valimi keskmine x̅ = 14. - Valimi keskmine on keskväärtus, mille ümber valimi väärtused jaotuvad. Kui valimi ümber olevad valimiklastri väärtused on keskmised, on dispersioon väike; vastasel juhul on dispersioon suur.
- Meie näites lisage näidis olevad väärtused: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Lahutage valimi igast väärtusest valimi keskmine. Nüüd arvutage erinevus x i (\displaystyle x_(i))- x̅, kus x i (\displaystyle x_(i))- iga väärtus proovis. Iga saadud tulemus näitab, mil määral erineb konkreetne väärtus valimi keskmisest, st kui kaugel see väärtus on valimi keskmisest.
- Meie näites:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Saadud tulemuste õigsust on lihtne kontrollida, kuna nende summa peab olema võrdne nulliga. See on seotud keskmise väärtuse määramisega, kuna negatiivsed väärtused (kaugused keskmisest väärtusest väiksemate väärtusteni) kompenseeritakse täielikult positiivsete väärtustega (kaugused keskmisest väärtusest suuremate väärtusteni).
- Meie näites:
-
Nagu eespool märgitud, erinevuste summa x i (\displaystyle x_(i))- x̅ peab olema võrdne nulliga. See tähendab, et keskmine dispersioon on alati null, mis ei anna mingit aimu mingi suuruse väärtuste levikust. Selle probleemi lahendamiseks tehke kõik erinevused ruuduga x i (\displaystyle x_(i))- x̅. Selle tulemusel saate ainult positiivseid numbreid, mis kokku liidetuna ei anna kunagi 0-ni.
- Meie näites:
(x 1 (\displaystyle x_(1))-x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2)))-x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Olete leidnud erinevuse ruudu - x̅) 2 (\displaystyle ^(2)) iga valimi väärtuse kohta.
- Meie näites:
-
Arvutage erinevuste ruudu summa. See tähendab, et leidke valemi osa, mis on kirjutatud järgmiselt: ∑[( x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))]. Siin tähistab märk Σ iga väärtuse ruudu erinevuste summat x i (\displaystyle x_(i)) proovis. Olete juba leidnud erinevused ruudus (x i (\displaystyle (x_(i))-x̅) 2 (\displaystyle ^(2)) iga väärtuse jaoks x i (\displaystyle x_(i)) proovis; nüüd lihtsalt lisage need ruudud.
- Meie näites: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Jagage tulemus n - 1-ga, kus n on valimi väärtuste arv. Mõni aeg tagasi jagasid statistikud valimi dispersiooni arvutamiseks tulemuse lihtsalt n-ga; sel juhul saad ruudu dispersiooni keskmise, mis sobib ideaalselt antud valimi dispersiooni kirjeldamiseks. Kuid pidage meeles, et mis tahes valim on vaid väike osa väärtuste üldkogumist. Kui võtate teistsuguse proovi ja teete samad arvutused, saate erineva tulemuse. Nagu selgub, annab n-ga jagamine 1-ga (mitte lihtsalt n-ga) parema hinnangu populatsiooni dispersioonile, mida te taotlete. Jagamine n - 1-ga on muutunud tavapäraseks, mistõttu see sisaldub valimi dispersiooni arvutamise valemis.
- Meie näites sisaldab valim 6 väärtust, st n = 6.
Valimi dispersioon = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- Meie näites sisaldab valim 6 väärtust, st n = 6.
-
Dispersiooni ja standardhälbe erinevus. Pange tähele, et valem sisaldab eksponenti, seega mõõdetakse dispersiooni analüüsitud väärtuse ruutühikutes. Mõnikord on sellist väärtust üsna raske kasutada; sellistel juhtudel kasutatakse standardhälvet, mis võrdub dispersiooni ruutjuurega. Seetõttu tähistatakse valimi dispersiooni kui s 2 (\displaystyle s^(2)), ja valimi standardhälve kui s (\displaystyle s).
- Meie näites on valimi standardhälve: s = √33,2 = 5,76.
Rahvastiku dispersiooni arvutamine
-
Analüüsige mõnda väärtuste kogumit. Komplekt sisaldab kõiki vaadeldava koguse väärtusi. Näiteks kui uurite Leningradi oblasti elanike vanust, hõlmab rahvaarv kõigi selle piirkonna elanike vanust. Agregaadiga töötamise korral on soovitatav luua tabel ja sisestada sinna agregaadi väärtused. Kaaluge järgmist näidet:
- Ühes kindlas ruumis on 6 akvaariumi. Igas akvaariumis on järgmine arv kalu:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4) = 12)
x 5 = 15 (\displaystyle x_(5) = 15)
x 6 = 18 (\displaystyle x_(6) = 18)
- Ühes kindlas ruumis on 6 akvaariumi. Igas akvaariumis on järgmine arv kalu:
-
Kirjutage üles populatsiooni dispersiooni arvutamise valem. Kuna populatsioon sisaldab teatud suuruse kõiki väärtusi, võimaldab järgmine valem saada populatsiooni dispersiooni täpse väärtuse. Populatsiooni dispersiooni eristamiseks valimi dispersioonist (mis on vaid hinnang) kasutavad statistikud erinevaid muutujaid:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n
- σ 2 (\displaystyle ^(2))- populatsiooni dispersioon (sigma ruudus). Dispersiooni mõõdetakse ruutühikutes.
- x i (\displaystyle x_(i))- iga koondväärtus.
- Σ on summa märk. See tähendab iga väärtuse kohta x i (\displaystyle x_(i)) lahutage μ, ruudus ja seejärel lisage tulemused.
- μ on rahvastiku keskmine.
- n on väärtuste arv üldpopulatsioonis.
-
Arvutage rahvastiku keskmine.Üldrahvastikuga töötades tähistatakse selle keskmist väärtust kui μ (mu). Populatsiooni keskmine arvutatakse tavalise aritmeetilise keskmisena: liidetakse kõik üldkogumi väärtused ja jagatakse tulemus üldkogumi väärtuste arvuga.
- Pidage meeles, et keskmisi ei arvutata alati aritmeetilise keskmisena.
- Meie näites tähendab populatsioon: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Lahutage üldkogumi igast väärtusest üldkogumi keskmine. Mida lähemal on erinevuse väärtus nullile, seda lähemal on konkreetne väärtus üldkogumi keskmisele. Leidke erinevus populatsiooni iga väärtuse ja selle keskmise vahel ning näete esmalt väärtuste jaotust.
- Meie näites:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- Meie näites:
-
Ruudu iga saadud tulemus. Erinevused on nii positiivsed kui ka negatiivsed; kui paned need väärtused numbrireale, siis asuvad need rahvastiku keskmisest paremal ja vasakul. See ei sobi dispersiooni arvutamiseks, kuna positiivsed ja negatiivsed arvud tühistavad üksteist. Seetõttu asetage iga erinevus ruuduga, et saada ainult positiivsed arvud.
- Meie näites:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) iga populatsiooni väärtuse kohta (i = 1 kuni i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), kus x n (\displaystyle x_(n)) on populatsiooni viimane väärtus. - Saadud tulemuste keskmise väärtuse arvutamiseks peate leidma nende summa ja jagama selle n-ga: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / n
- Nüüd kirjutame ülaltoodud selgituse muutujate abil: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n ja saada valem populatsiooni dispersiooni arvutamiseks.
- Meie näites:
Dispersioon statistikas leitakse tunnuse individuaalsete väärtustena ruudus . Sõltuvalt algandmetest määratakse see lihtsate ja kaalutud dispersioonivalemite abil:
1. (rühmitamata andmete puhul) arvutatakse järgmise valemiga:
2. Kaalutud dispersioon (variatsiooniseeria jaoks):
 kus n on sagedus (kordatavustegur X)
kus n on sagedus (kordatavustegur X)
Näide dispersiooni leidmisest
Sellel lehel on kirjeldatud dispersiooni leidmise standardnäide, selle leidmiseks võite vaadata ka muid ülesandeid
Näide 1. Meil on järgmised andmed 20-liikmelise korrespondentüliõpilase rühma kohta. On vaja koostada tunnusjaotuse intervalljada, arvutada tunnuse keskmine väärtus ja uurida selle dispersiooni
 Koostame intervallrühma. Määrame intervalli vahemiku valemiga:
Koostame intervallrühma. Määrame intervalli vahemiku valemiga:
![]() kus X max on rühmitamise tunnuse maksimaalne väärtus;
kus X max on rühmitamise tunnuse maksimaalne väärtus;
X min on rühmitamistunnuse minimaalne väärtus;
n on intervallide arv:
Aktsepteerime n=5. Samm on järgmine: h \u003d (192–159) / 5 \u003d 6,6
Teeme intervallrühma
 Edasiste arvutuste jaoks koostame abitabeli:
Edasiste arvutuste jaoks koostame abitabeli:
 X'i on intervalli keskpaik. (näiteks intervalli keskpaik 159 – 165,6 = 162,3)
X'i on intervalli keskpaik. (näiteks intervalli keskpaik 159 – 165,6 = 162,3)
Õpilaste keskmine kasv määratakse aritmeetilise kaalutud keskmise valemiga:
 Dispersiooni määrame valemiga:
Dispersiooni määrame valemiga:
Dispersiooni valemi saab teisendada järgmiselt:

Sellest valemist järeldub, et dispersioon on valikute ruutude keskmise ning ruudu ja keskmise vahe.
Variatsioonirea hälve võrdsete intervallidega vastavalt momentide meetodile saab arvutada järgmiselt, kasutades dispersiooni teist omadust (jagades kõik valikud intervalli väärtusega). Dispersiooni definitsioon, mis on arvutatud hetkede meetodil, on järgmise valemi järgi vähem aeganõudev:

kus i on intervalli väärtus;
A - tingimuslik null, mida on mugav kasutada kõrgeima sagedusega intervalli keskpunktis;
m1 on esimest järku hetke ruut;
m2 - teise järjekorra hetk
(kui statistilises üldkogumis atribuut muutub nii, et on ainult kaks teineteist välistavat varianti, siis nimetatakse sellist varieeruvust alternatiivseks) saab arvutada valemiga:

Asendades selles dispersioonivalemis q = 1- p, saame:

Dispersiooni tüübid
Kogu dispersioon mõõdab tunnuse varieerumist kogu populatsioonis tervikuna kõigi seda varieerumist põhjustavate tegurite mõjul. See võrdub tunnuse x üksikute väärtuste kõrvalekallete keskmise ruuduga keskmisest koguväärtusest x ja seda saab määratleda kui lihtsat dispersiooni või kaalutud dispersiooni.
iseloomustab juhuslikku varieerumist, s.t. osa variatsioonist, mis on tingitud arvestamata tegurite mõjust ja ei sõltu rühmituse aluseks olevast tunnustegurist. Selline dispersioon on võrdne X-rühma tunnuse üksikute väärtuste kõrvalekallete keskmise ruuduga rühma aritmeetilisest keskmisest ja seda saab arvutada lihtsa dispersioonina või kaalutud dispersioonina.
Sellel viisil, rühmasisese dispersiooni mõõdikud tunnuse varieerumine rühmas ja määratakse järgmise valemiga:

kus xi - rühma keskmine;
ni on ühikute arv rühmas.
Näiteks grupisisesed dispersioonid, mida tuleb määrata ülesandes uurida töötajate kvalifikatsiooni mõju tööviljakuse tasemele kaupluses, näitavad toodangu kõikumisi igas rühmas, mis on põhjustatud kõigist võimalikest teguritest (seadmete tehniline seisund, tööriistade ja materjalide olemasolu, töötajate vanus, töömahukus jne.), välja arvatud kvalifikatsioonikategooria erinevused (rühmasiseselt on kõigil töötajatel sama kvalifikatsioon).
Grupisiseste dispersioonide keskmine peegeldab juhuslikku, st seda osa variatsioonist, mis toimus kõigi muude tegurite mõjul, välja arvatud rühmitustegur. See arvutatakse järgmise valemiga:

See iseloomustab saadud tunnuse süstemaatilist varieerumist, mis on tingitud rühmituse aluseks oleva tunnusteguri mõjust. See on võrdne grupi keskmiste üldkeskmisest kõrvalekallete keskmise ruuduga. Gruppidevaheline dispersioon arvutatakse järgmise valemiga:

Dispersiooni liitmise reegel statistikas
Vastavalt dispersiooni liitmise reegel kogu dispersioon on võrdne grupisiseste ja rühmadevaheliste dispersioonide keskmise summaga:
![]()
Selle reegli tähendus on see, et kõigi tegurite mõjul tekkiv summaarne dispersioon võrdub kõigi teiste tegurite mõjul tekkivate dispersioonide ja rühmitusteguri mõjul tekkiva dispersiooni summaga.
Kasutades dispersioonide liitmise valemit, on võimalik kahe teadaoleva dispersiooni hulgast määrata kolmas tundmatu ning hinnata ka rühmitava atribuudi mõju tugevust.
Dispersiooniomadused
1. Kui atribuudi kõiki väärtusi vähendatakse (suurendatakse) sama konstantse väärtuse võrra, siis dispersioon sellest ei muutu.
2. Kui atribuudi kõiki väärtusi vähendatakse (suurendatakse) sama arv kordi n, väheneb (suureneb) dispersioon vastavalt n^2 korda.
 Ege füüsikatulemustes
Ege füüsikatulemustes Kuidas kandideerida eelmiste aastate lõpetajate eksamile
Kuidas kandideerida eelmiste aastate lõpetajate eksamile Millised on võimalused eelarvesse pääseda: punktide arvu, ülikooli, eriala järgi
Millised on võimalused eelarvesse pääseda: punktide arvu, ülikooli, eriala järgi