Čemu služi disperzija? Preostala disperzija
Koraci
Izračun varijance uzorka
-
Zabilježite vrijednosti uzorka. U većini slučajeva statističarima su dostupni samo uzorci određenih populacija. Na primjer, statističari u pravilu ne analiziraju troškove održavanja agregata svih automobila u Rusiji - oni analiziraju slučajni uzorak od nekoliko hiljada automobila. Takav uzorak pomoći će u određivanju prosječne cijene po automobilu, ali najvjerovatnije će rezultirajuća vrijednost biti daleko od stvarne.
- Na primjer, hajde da analiziramo broj peciva prodanih u kafiću u 6 dana, uzetih nasumično. Uzorak ima sljedeći pogled: 17, 15, 23, 7, 9, 13. Ovo je uzorak, a ne populacija, jer nemamo podatke o prodatim pecivama za svaki dan rada kafića.
- Ako vam je data populacija, a ne uzorak vrijednosti, pređite na sljedeći odjeljak.
-
Zapišite formulu za izračunavanje varijanse uzorka. Disperzija je mjera širenja vrijednosti neke veličine. Što je vrijednost disperzije bliža nuli, to su vrijednosti bliže grupisane. Kada radite s uzorkom vrijednosti, koristite sljedeću formulu za izračunavanje varijanse:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2)) je disperzija. Disperzija se meri u kvadratne jedinice mjerenja.
- x i (\displaystyle x_(i))- svaku vrijednost u uzorku.
- x i (\displaystyle x_(i)) trebate oduzeti x̅, kvadrirati ga, a zatim dodati rezultate.
- x̅ – srednja vrijednost uzorka (srednja vrijednost uzorka).
- n je broj vrijednosti u uzorku.
-
Izračunajte srednju vrijednost uzorka. Označava se kao x̅. Srednja vrijednost uzorka se izračunava kao normalna aritmetička sredina: zbrojite sve vrijednosti u uzorku, a zatim podijelite rezultat s brojem vrijednosti u uzorku.
- U našem primjeru dodajte vrijednosti u uzorku: 15 + 17 + 23 + 7 + 9 + 13 = 84
Sada podijelite rezultat s brojem vrijednosti u uzorku (u našem primjeru ima 6): 84 ÷ 6 = 14.
Srednja vrijednost uzorka x̅ = 14. - Srednja vrijednost uzorka je središnja vrijednost oko koje se distribuiraju vrijednosti u uzorku. Ako se vrijednosti u uzorku grupišu oko srednje vrijednosti uzorka, tada je varijansa mala; inače, disperzija je velika.
- U našem primjeru dodajte vrijednosti u uzorku: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Oduzmite srednju vrijednost uzorka od svake vrijednosti u uzorku. Sada izračunajte razliku x i (\displaystyle x_(i))- x̅, gdje x i (\displaystyle x_(i))- svaku vrijednost u uzorku. Svaki rezultat pokazuje stepen odstupanja određene vrijednosti od srednje vrijednosti uzorka, odnosno koliko je ta vrijednost udaljena od srednje vrijednosti uzorka.
- U našem primjeru:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Ispravnost dobijenih rezultata je lako provjeriti, jer njihov zbir mora biti jednak nuli. Ovo se odnosi na definiciju prosječne vrijednosti, pošto negativne vrijednosti(udaljenosti od prosječne vrijednosti do manjih vrijednosti) su u potpunosti kompenzirane pozitivne vrijednosti(udaljenosti od prosječnih do velikih vrijednosti).
- U našem primjeru:
-
Kao što je gore navedeno, zbir razlika x i (\displaystyle x_(i))- x̅ mora biti jednako nuli. To znači da prosječna varijansa je uvijek jednak nuli, što ne daje nikakvu predstavu o širenju vrijednosti određene veličine. Da biste riješili ovaj problem, kvadrirajte svaku razliku x i (\displaystyle x_(i))- x̅. Ovo će rezultirati samo dobijanjem pozitivni brojevi, koji kada se doda nikada neće dati 0.
- U našem primjeru:
(x 1 (\displaystyle x_(1))-x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))-x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Našli ste kvadrat razlike - x̅) 2 (\displaystyle ^(2)) za svaku vrijednost u uzorku.
- U našem primjeru:
-
Izračunajte zbir kvadrata razlika. Odnosno, pronađite dio formule koji je napisan ovako: ∑[( x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))]. Ovdje znak Σ označava zbir kvadrata razlika za svaku vrijednost x i (\displaystyle x_(i)) u uzorku. Već ste pronašli kvadratne razlike (x i (\displaystyle (x_(i))-x̅) 2 (\displaystyle ^(2)) za svaku vrijednost x i (\displaystyle x_(i)) u uzorku; sada samo dodajte ove kvadrate.
- U našem primjeru: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Podijelite rezultat sa n - 1, gdje je n broj vrijednosti u uzorku. Prije nekog vremena, da bi izračunali varijansu uzorka, statističari su jednostavno podijelili rezultat sa n; u ovom slučaju, dobićete srednju vrednost kvadratne varijanse, koja je idealna za opisivanje varijanse datog uzorka. Ali zapamtite da je svaki uzorak samo mali dio. stanovništva vrijednosti. Ako uzmete drugačiji uzorak i izvršite iste proračune, dobit ćete drugačiji rezultat. Kako se ispostavilo, dijeljenje sa n - 1 (a ne samo n) daje više tačna procjena varijabilnost populacije, što je ono što vas zanima. Dijeljenje sa n - 1 postalo je uobičajeno, pa je uključeno u formulu za izračunavanje varijanse uzorka.
- U našem primjeru uzorak uključuje 6 vrijednosti, odnosno n = 6.
Varijanca uzorka = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- U našem primjeru uzorak uključuje 6 vrijednosti, odnosno n = 6.
-
Razlika između varijanse i standardne devijacije. Imajte na umu da formula sadrži eksponent, pa se varijansa mjeri u kvadratnim jedinicama analizirane vrijednosti. Ponekad je takvom vrijednošću prilično teško upravljati; u takvim slučajevima se koristi standardna devijacija, koja je jednaka kvadratnom korijenu varijanse. Zbog toga se varijansa uzorka označava kao s 2 (\displaystyle s^(2)), a standardna devijacija uzorci - kako s (\displaystyle s).
- U našem primjeru, standardna devijacija uzorka je: s = √33,2 = 5,76.
Proračun varijanse stanovništva
-
Analizirajte neki skup vrijednosti. Skup uključuje sve vrijednosti količine koja se razmatra. Na primjer, ako proučavate starost stanovnika Lenjingradska oblast, tada je u populaciju uključena starost svih stanovnika ovog područja. U slučaju rada sa agregatom, preporučuje se kreiranje tabele i unos vrednosti agregata u nju. Razmotrite sljedeći primjer:
- U jednoj prostoriji se nalazi 6 akvarijuma. Svaki akvarij sadrži sljedeći broj riba:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- U jednoj prostoriji se nalazi 6 akvarijuma. Svaki akvarij sadrži sljedeći broj riba:
-
Zapišite formulu za izračunavanje varijanse stanovništva. Budući da populacija uključuje sve vrijednosti određene količine, sljedeća formula vam omogućava da dobijete točnu vrijednost varijanse populacije. Da bi razlikovali varijansu populacije od varijance uzorka (koja je samo procjena), statističari koriste različite varijable:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n
- σ 2 (\displaystyle ^(2))- varijansa stanovništva (čita se kao "sigma na kvadrat"). Disperzija se mjeri u kvadratnim jedinicama.
- x i (\displaystyle x_(i))- svaka vrijednost u agregatu.
- Σ je predznak zbira. Odnosno, za svaku vrijednost x i (\displaystyle x_(i)) oduzmite μ, kvadratirajte ga, a zatim dodajte rezultate.
- μ je srednja vrijednost populacije.
- n je broj vrijednosti u općoj populaciji.
-
Izračunajte srednju vrijednost stanovništva. Kada se radi sa opštom populacijom, njena prosečna vrednost se označava kao μ (mu). Srednja populacija se izračunava kao uobičajena aritmetička sredina: zbrojite sve vrijednosti u populaciji, a zatim podijelite rezultat s brojem vrijednosti u populaciji.
- Imajte na umu da se prosjeci ne računaju uvijek kao aritmetička sredina.
- U našem primjeru, populacija znači: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Oduzmite srednju vrijednost populacije od svake vrijednosti u populaciji.Što je vrijednost razlike bliža nuli, to je određena vrijednost bliža srednjoj vrijednosti stanovništva. Pronađite razliku između svake vrijednosti u populaciji i njene srednje vrijednosti, i dobićete prvi pogled na distribuciju vrijednosti.
- U našem primjeru:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- U našem primjeru:
-
Kvadrirajte svaki rezultat koji dobijete. Vrijednosti razlike bit će i pozitivne i negativne; ako ove vrijednosti stavite na brojevnu pravu, onda će ležati desno i lijevo od srednje vrijednosti populacije. Ovo nije prikladno za izračunavanje varijanse, budući da su pozitivni i negativni brojevi nadoknaditi jedni druge. Stoga kvadrirajte svaku razliku da dobijete isključivo pozitivne brojeve.
- U našem primjeru:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) za svaku populacijsku vrijednost (od i = 1 do i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), gdje x n (\displaystyle x_(n)) – posljednja vrijednost u opštoj populaciji. - Da biste izračunali prosječnu vrijednost dobijenih rezultata, potrebno je pronaći njihov zbir i podijeliti ga sa n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / n
- Sada napišimo gornje objašnjenje koristeći varijable: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n i dobijemo formulu za izračunavanje varijanse populacije.
- U našem primjeru:
Hajde da izračunamoGOSPOĐAEXCELvarijansu i standardnu devijaciju uzorka. Također izračunavamo varijansu slučajne varijable ako je poznata njena distribucija.
Prvo razmislite disperzija, onda standardna devijacija.
Varijanca uzorka
Varijanca uzorka (varijansa uzorka,uzorakvarijansa) karakterizira širenje vrijednosti u nizu u odnosu na .
Sve 3 formule su matematički ekvivalentne.
Iz prve formule se vidi da varijansa uzorka je zbir kvadrata odstupanja svake vrijednosti u nizu od prosjeka podijeljeno s veličinom uzorka minus 1.
disperzija uzorci koristi se funkcija DISP(), eng. naziv VAR-a, tj. Varijanca. Od MS EXCEL 2010, preporučuje se korištenje njegovog analognog DISP.V() , eng. naziv VARS, tj. Varijanca uzorka. Osim toga, počevši od verzije MS EXCEL 2010, postoji funkcija DISP.G (), eng. VARP naziv, tj. Varijanca stanovništva koja se izračunava disperzija za stanovništva. Cela razlika se svodi na nazivnik: umesto n-1 kao DISP.V() , DISP.G() ima samo n u nazivniku. Prije MS EXCEL 2010, funkcija VARP() se koristila za izračunavanje varijanse populacije.
Varijanca uzorka
=SQUARE(Uzorak)/(COUNT(Uzorak)-1)
=(SUMSQ(Uzorak)-BROJ(Uzorak)*PROSEK(Uzorak)^2)/ (BROJ(Uzorak)-1)- uobičajena formula
=SUM((Uzorak -PROSEK(Uzorak))^2)/ (BROJ(Uzorak)-1) –
Varijanca uzorka je jednako 0 samo ako su sve vrijednosti jednake jedna drugoj i, shodno tome, jednake srednja vrijednost. Obično je veća vrijednost disperzija, veća je širina vrijednosti u nizu.
Varijanca uzorka je tačka procjene disperzija distribucija slučajne varijable iz koje je uzorak. O izgradnji intervali povjerenja prilikom evaluacije disperzija može se pročitati u članku.
Varijanca slučajne varijable
Da izračunam disperzija slučajna varijabla, morate je znati.
Za disperzija slučajna varijabla X često koristi notaciju Var(X). Disperzija jednak je kvadratu odstupanja od srednje vrijednosti E(X): Var(X)=E[(X-E(X)) 2 ]
disperzija izračunato po formuli:

gdje je x i vrijednost koja može poprimiti slučajna vrijednost, a μ je srednja vrijednost (), p(x) je vjerovatnoća da će slučajna varijabla uzeti vrijednost x.
Ako slučajna varijabla ima , onda disperzija izračunato po formuli:

Dimenzija disperzija odgovara kvadratu mjerne jedinice originalnih vrijednosti. Na primjer, ako su vrijednosti u uzorku mjerenja težine dijela (u kg), tada bi dimenzija varijanse bila kg 2 . Ovo može biti teško protumačiti, stoga, za karakterizaciju širenja vrijednosti, vrijednosti jednake kvadratnom korijenu disperzija – standardna devijacija.
Neke nekretnine disperzija:
Var(X+a)=Var(X), gdje je X slučajna varijabla, a a konstanta.
Var(aH)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Ovo svojstvo disperzije se koristi u članak o linearnoj regresiji.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), gdje su X i Y slučajne varijable, Cov(X;Y) je kovarijansa ovih slučajnih varijabli.
Ako su slučajne varijable nezavisne, onda njihove kovarijansa je 0, i stoga Var(X+Y)=Var(X)+Var(Y). Ovo svojstvo varijanse se koristi u izlazu.
Pokažimo to za nezavisne količine Var(X-Y)=Var(X+Y). Zaista, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Ovo svojstvo varijanse se koristi za crtanje .
Standardna devijacija uzorka
Standardna devijacija uzorka je mjera koliko su široko rasute vrijednosti u uzorku u odnosu na njihov .
A-prioritet, standardna devijacija jednak kvadratnom korijenu disperzija:

Standardna devijacija ne uzima u obzir veličinu vrijednosti u uzorkovanje, već samo stepen raspršenosti vrijednosti oko njih srednji. Uzmimo primjer da to ilustriramo.
Izračunajmo standardnu devijaciju za 2 uzorka: (1; 5; 9) i (1001; 1005; 1009). U oba slučaja s=4. Očigledno je da se omjer standardne devijacije prema vrijednostima niza značajno razlikuje za uzorke. Za takve slučajeve koristite Koeficijent varijacije(Koeficijent varijacije, CV) - odnos standardna devijacija do prosjeka aritmetika, izraženo u procentima.
U MS EXCEL 2007 i novijim verzijama rane verzije izračunati Standardna devijacija uzorka koristi se funkcija =STDEV(), eng. naziv STDEV, tj. standardna devijacija. Od MS EXCEL 2010, preporučljivo je koristiti njegov analog = STDEV.B () , eng. naziv STDEV.S, tj. Standardno odstupanje uzorka.
Osim toga, počevši od verzije MS EXCEL 2010, postoji funkcija STDEV.G () , eng. naziv STDEV.P, tj. Standardna devijacija stanovništva koja se izračunava standardna devijacija za stanovništva. Cela razlika se svodi na nazivnik: umesto n-1 kao STDEV.V() , STDEV.G() ima samo n u nazivniku.
Standardna devijacija također se može izračunati direktno iz formula ispod (pogledajte primjer fajla)
=SQRT(SQUADROTIV(Uzorak)/(BROJ(Uzorak)-1))
=SQRT((SUMSQ(Sample)-COUNT(Sample)*AVERAGE(Sample)^2)/(COUNT(Sample)-1))
Druge mjere disperzije
Funkcija SQUADRIVE() izračunava sa umm kvadrata odstupanja vrijednosti od njihovih srednji. Ova funkcija će vratiti isti rezultat kao formula =VAR.G( Uzorak)*PROVJERI( Uzorak) , gdje Uzorak- referenca na raspon koji sadrži niz vrijednosti uzorka (). Proračuni u funkciji QUADROTIV() vrše se prema formuli:

Funkcija SROOT() je također mjera raspršenosti skupa podataka. Funkcija AVERAGE() izračunava prosjek apsolutne vrijednosti odstupanja od srednji. Ova funkcija će vratiti isti rezultat kao i formula =SUMPRODUCT(ABS(Uzorak-PROSEK(Uzorak)))/BROJ(Uzorak), gdje Uzorak- referenca na raspon koji sadrži niz vrijednosti uzorka.
Izračuni u funkciji SROOTKL () vrše se prema formuli:

Međutim, samo ova karakteristika još uvijek nije dovoljna za proučavanje slučajne varijable. Zamislite dva strijelca koji pucaju u metu. Jedan precizno šutira i pogađa blizu centra, a drugi ... samo se zabavlja a ni ne cilja. Ali ono što je smiješno je to prosjek rezultat će biti potpuno isti kao kod prvog strijelca! Ovu situaciju uslovno ilustruju sljedeće slučajne varijable:
Međutim, matematičko očekivanje "snajperista" jednako je " zanimljiva ličnost»: - takođe je nula!
Stoga, postoji potreba da se kvantifikuje koliko daleko rasuti metke (slučajne vrijednosti) u odnosu na centar mete ( matematičko očekivanje). dobro i rasipanje prevedeno sa latinskog samo kao disperzija .
Hajde da vidimo kako je ovo definisano. numerička karakteristika na jednom od primjera iz 1. dijela lekcije: 
Tamo smo pronašli razočaravajuće matematičko očekivanje ove igre, a sada moramo izračunati njenu varijansu, koja označeno kroz .
Hajde da saznamo koliko su pobede/gubici "razbacani" u odnosu na prosečnu vrednost. Očigledno, za ovo moramo izračunati razlike između vrijednosti slučajne varijable i ona matematičko očekivanje:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Čini se da je sada potrebno sumirati rezultate, ali ovaj način nije dobar - iz razloga što će se oscilacije lijevo poništiti jedna drugu sa oscilacijama udesno. Tako, na primjer, "amaterski" strijelac (primjer iznad) razlike će biti ![]() , a kada se dodaju dat će nulu, tako da nećemo dobiti nikakvu procjenu raspršenosti njegovog pucanja.
, a kada se dodaju dat će nulu, tako da nećemo dobiti nikakvu procjenu raspršenosti njegovog pucanja.
Da biste zaobišli ovu smetnju, razmislite moduli razlike, ali iz tehničkih razloga, pristup se ukorijenio kada se kvadriraju. Pogodnije je rasporediti rješenje u tablicu: 
I ovdje počinje računati prosjećna težina vrijednost kvadrata odstupanja. Šta je? Njihovo je očekivana vrijednost, što je mjera raspršenja:
![]() – definicija disperzija. Iz definicije je odmah jasno da varijansa ne može biti negativna- obratite pažnju na vežbu!
– definicija disperzija. Iz definicije je odmah jasno da varijansa ne može biti negativna- obratite pažnju na vežbu!
Prisjetimo se kako pronaći očekivanje. Pomnožite kvadratne razlike sa odgovarajućim vjerovatnoćama (nastavak tabele):
- figurativno rečeno, ovo je "vlačna sila",
i sumirajte rezultate:
Ne mislite li da je na pozadini dobitaka rezultat ispao prevelik? Tako je – bili smo na kvadrat, a da bismo se vratili na dimenziju naše igre, moramo uzeti kvadratni korijen. Ova vrijednost pozvao standardna devijacija
i označava se grčkim slovom "sigma":
Ponekad se ovo značenje naziva standardna devijacija .
Šta je njegovo značenje? Ako odstupimo od matematičkog očekivanja lijevo i desno po sredini standardna devijacija:![]()
– tada će najvjerovatnije vrijednosti slučajne varijable biti „koncentrirane“ na ovom intervalu. Šta zapravo vidimo:
Međutim, dogodilo se da se u analizi raspršenja gotovo uvijek operira konceptom disperzije. Hajde da vidimo šta to znači u vezi sa igricama. Ako u slučaju strijelaca govorimo o "preciznosti" pogodaka u odnosu na centar mete, onda ovdje disperzija karakterizira dvije stvari:
Prvo, očigledno je da kako se stope povećavaju, varijansa se takođe povećava. Dakle, na primjer, ako povećamo za 10 puta, onda će se matematičko očekivanje povećati za 10 puta, a varijansa će se povećati za 100 puta (čim je kvadratna vrijednost). Ali imajte na umu da se pravila igre nisu promijenila! Samo su se stope promijenile, grubo govoreći, prije smo se kladili na 10 rubalja, sada 100.
Drugo, više zanimljiva poenta je da varijansa karakteriše stil igre. Mentalno popravi stopu igre na nekom određenom nivou, i pogledajte šta je šta ovdje:
Igra niske varijance je oprezna igra. Igrač ima tendenciju da bira najpouzdanije šeme, u kojima ne gubi/pobeđuje previše u jednom trenutku. Na primjer, crveno/crni sistem u ruletu (vidi primjer 4 članka slučajne varijable) .
Igra velike varijance. Često je zovu disperzija igra. Ovo je avanturistički ili agresivni stil igre gdje igrač bira "adrenalinske" šeme. Da se barem setimo "Martingale", u kojoj su sume u igri za redove veličine veće od „tihe“ igre iz prethodnog paragrafa.
Situacija u pokeru je indikativna: postoje tzv čvrsto igrače koji imaju tendenciju da budu oprezni i "tresaju" svojim sredstvima za igru (bankroll). Nije iznenađujuće da njihov bankroll ne fluktuira mnogo (mala varijansa). Suprotno tome, ako igrač ima veliku varijansu, onda je to agresor. Često rizikuje, pravi velike opklade i može i razbiti ogromnu banku i propasti.
Ista stvar se dešava i na Forexu, i tako dalje - ima mnogo primera.
Štaviše, u svim slučajevima nije bitno da li je igra za peni ili za hiljade dolara. Svaki nivo ima svoje igrače niske i velike varijacije. Pa za prosječnu pobjedu, koliko se sjećamo, "odgovorno" očekivana vrijednost.
Vjerovatno ste primijetili da je pronalaženje varijanse dug i mukotrpan proces. Ali matematika je velikodušna:
Formula za pronalaženje varijanse
Ova formula proizilazi direktno iz definicije varijanse i odmah je puštamo u promet. Kopiraću ploču sa našom igrom odozgo: 
i pronađeno očekivanje.
Izračunavamo varijansu na drugi način. Prvo, pronađimo matematičko očekivanje - kvadrat slučajne varijable. By definicija matematičkog očekivanja:
AT ovaj slučaj:
Dakle, prema formuli:
Kako kažu, osjetite razliku. A u praksi je, naravno, bolje primijeniti formulu (osim ako uvjet ne zahtijeva drugačije).
Savladavamo tehniku rešavanja i projektovanja:
Primjer 6

Pronađite njegovo matematičko očekivanje, varijansu i standardnu devijaciju.
Ovaj zadatak se nalazi svuda i, po pravilu, nema smislenog značenja.
Možete zamisliti nekoliko sijalica sa brojevima koje svijetle u ludnici sa određenim vjerovatnoćama :)
Odluka: Pogodno je sumirati glavne proračune u tabeli. Prvo upisujemo početne podatke u gornja dva reda. Zatim izračunavamo proizvode, zatim i na kraju zbrojeve u desnoj koloni: 
Zapravo, skoro sve je spremno. U trećem redu nacrtano je gotovo matematičko očekivanje: ![]() .
.
Disperzija se izračunava po formuli:
I na kraju, standardna devijacija:
- lično, obično zaokružujem na 2 decimale.
Svi proračuni se mogu izvršiti na kalkulatoru, a još bolje - u Excelu:
Ovde je teško pogrešiti :)
Odgovori:
Oni koji žele mogu još više pojednostaviti svoj život i iskoristiti moje kalkulator (demo), što ne samo da će odmah riješiti ovaj zadatak, ali i graditi tematske grafike (dođi uskoro). Program može preuzeti u biblioteci– ako ste preuzeli barem jedan edukativni materijal ili dobiti drugi način. Hvala na podršci projektu!
Par zadataka za nezavisna odluka:
Primjer 7
Izračunajte varijansu slučajne varijable iz prethodnog primjera po definiciji.
I sličan primjer:
Primjer 8
Diskretna slučajna varijabla je data vlastitim zakonom distribucije:

Da, vrijednosti slučajne varijable mogu biti prilično velike (primjer iz pravi posao) , a ovdje, ako je moguće, koristite Excel. Kao, usput, u primjeru 7 - brže je, pouzdanije i ugodnije.
Rješenja i odgovori na dnu stranice.
Na kraju 2. dijela lekcije analiziraćemo još jednu tipičan zadatak, moglo bi se čak reći, mali rebus:
Primjer 9
Diskretna slučajna varijabla može uzeti samo dvije vrijednosti: i , i . Vjerovatnoća, matematičko očekivanje i varijansa su poznati.
Odluka: Počnimo s nepoznatom vjerovatnoćom. Kako slučajna varijabla može uzeti samo dvije vrijednosti, onda je zbir vjerovatnoća odgovarajućih događaja:
i od tada .
Ostaje da se pronađe..., lako je reći :) Ali dobro, počelo je. Po definiciji matematičkog očekivanja: ![]() - zamijeniti poznate vrijednosti:
- zamijeniti poznate vrijednosti:
![]() - i ništa se više ne može istisnuti iz ove jednadžbe, osim što je možete prepisati u uobičajenom smjeru:
- i ništa se više ne može istisnuti iz ove jednadžbe, osim što je možete prepisati u uobičajenom smjeru: ![]()

ili: ![]()
O sljedeći koraci Mislim da možete pogoditi. Kreirajmo i riješimo sistem: 
Decimale- ovo je, naravno, potpuna sramota; pomnožite obje jednačine sa 10: 
i podijeli sa 2: 
To je mnogo bolje. Iz 1. jednačine izražavamo: ![]() (ovo je lakši nacin)- zamjena u 2. jednačini:
(ovo je lakši nacin)- zamjena u 2. jednačini:
![]()
Mi gradimo na kvadrat i napravi pojednostavljenja: 
Množimo sa: 
Kao rezultat, kvadratna jednačina, pronađite njegov diskriminant:
- savršeno!
i dobijamo dva rješenja:
1) ako ![]() , onda
, onda ![]() ;
;
2) ako ![]() , zatim .
, zatim .
Prvi par vrijednosti zadovoljava uslov. Sa velikom vjerovatnoćom, sve je tačno, ali, ipak, zapisujemo zakon distribucije: 
i izvršite provjeru, odnosno pronađite očekivanje:
Disperzija je mjera disperzije koja opisuje relativno odstupanje između vrijednosti podataka i srednje vrijednosti. To je najčešće korištena mjera disperzije u statistici, izračunata sumiranjem, kvadratom, odstupanja svake vrijednosti podataka od srednje vrijednosti. Formula za izračunavanje varijanse prikazana je u nastavku:
![]()
s 2 - varijansa uzorka;
x cf je srednja vrijednost uzorka;
n — veličina uzorka (broj vrijednosti podataka),
(x i – x cf) je odstupanje od srednje vrijednosti za svaku vrijednost skupa podataka.
Za bolje razumijevanje formule, uzmimo primjer. Ne volim baš da kuvam, pa to retko radim. Međutim, da ne bih umrla od gladi, s vremena na vrijeme moram ići do štednjaka kako bih ostvarila plan za zasićenje tijela proteinima, mastima i ugljikohidratima. Donji skup podataka pokazuje koliko puta Renat kuha hranu svakog mjeseca:
Prvi korak u izračunavanju varijanse je određivanje srednje vrijednosti uzorka, koja je u našem primjeru 7,8 puta mjesečno. Preostali proračuni se mogu olakšati uz pomoć sljedeće tabele.

Završna faza izračunavanja varijanse izgleda ovako:
![]()
Za one koji vole da sve proračune rade u jednom potezu, jednadžba će izgledati ovako:
Korištenje metode sirovog brojanja (primjer kuhanja)
Ima još efikasan metod izračunavanje varijanse, poznato kao metoda "sirovog brojanja". Iako na prvi pogled jednačina može izgledati prilično glomazna, u stvari nije toliko strašna. Možete to provjeriti, a zatim odlučiti koja vam se metoda najviše sviđa.

je zbir svake vrijednosti podataka nakon kvadriranja,
je kvadrat zbira svih vrijednosti podataka.
Ne gubi razum sada. Hajde da sve to stavimo u obliku tabele, a onda ćete videti da je ovde manje proračuna nego u prethodnom primeru.


Kao što vidite, rezultat je isti kao pri korištenju prethodne metode. Prednosti ovu metodu postaju očigledni kako veličina uzorka (n) raste.
Izračunavanje varijanse u Excel-u
Kao što ste verovatno već pretpostavili, Excel ima formulu koja vam omogućava da izračunate varijansu. Štaviše, počevši od Excel 2010, možete pronaći 4 varijante formule disperzije:
1) VAR.V - Vraća varijansu uzorka. Booleove vrijednosti i tekst se zanemaruju.
2) VAR.G - Vraća varijansu populacije. Booleove vrijednosti i tekst se zanemaruju.
3) VASP - Vraća varijansu uzorka, uzimajući u obzir logičke i tekstualne vrijednosti.
4) VARP - Vraća varijansu populacije, uzimajući u obzir logičke i tekstualne vrijednosti.
Prvo, pogledajmo razliku između uzorka i populacije. Svrha deskriptivna statistika je sažeti ili prikazati podatke na takav način da se brzo dobije šira slika, da tako kažemo, pregled. Statističko zaključivanje vam omogućava da napravite zaključke o populaciji na osnovu uzorka podataka iz ove populacije. Populacija predstavlja sve moguće ishode ili mjerenja koja nas zanimaju. Uzorak je podskup populacije.
Na primjer, zanima nas ukupnost grupe učenika jednog od ruski univerziteti i moramo odrediti prosječan rezultat grupe. Možemo računati prosječne performanse studenata, a onda će rezultirajući broj biti parametar, jer će u naše proračune biti uključena cijela populacija. Međutim, ako želimo da izračunamo GPA svih učenika u našoj zemlji, onda će ova grupa biti naš uzorak.
Razlika u formuli za izračunavanje varijanse između uzorka i populacije je u nazivniku. Pri čemu će za uzorak biti jednako (n-1), a za opštu populaciju samo n.
Sada se pozabavimo funkcijama izračunavanja varijanse sa završetcima ALI, u čijem opisu se kaže da se u proračunu uzimaju u obzir tekstualne i logičke vrijednosti. U ovom slučaju, kada se izračuna varijansa određenog niza podataka, gdje ih nema numeričke vrijednosti, Excel će tumačiti tekst i lažne logičke vrijednosti kao 0, a prave logičke vrijednosti kao 1.
Dakle, ako imate niz podataka, neće biti teško izračunati njegovu varijansu pomoću jedne od gore navedenih Excel funkcija.

Raspon varijacije (ili raspon varijacije) - je razlika između maksimalnog i minimalne vrijednosti znak:
U našem primjeru raspon varijacije smjenskog rada radnika je: u prvoj brigadi R=105-95=10 djece, u drugoj brigadi R=125-75=50 djece. (5 puta više). Ovo sugeriše da je proizvodnja 1. brigade „stabilnija“, ali druga brigada ima više rezervi za rast proizvodnje, jer. ako svi radnici dostignu maksimalan učinak za ovu brigadu, može proizvesti 3 * 125 = 375 dijelova, au 1. brigadi samo 105 * 3 = 315 dijelova.
Ako a ekstremne vrednosti osobine nisu tipične za populaciju, tada se koriste kvartilni ili decilni rasponi. Kvartilni raspon RQ= Q3-Q1 pokriva 50% populacije, prvi decilni raspon RD1 = D9-D1 pokriva 80% podataka, drugi decilni raspon RD2= D8-D2 pokriva 60%.
Nedostatak indikatora raspon varijacije je, ali da njegova vrijednost ne odražava sve fluktuacije atributa.
Najjednostavniji generalizirajući indikator koji odražava sve fluktuacije osobine je srednje linearno odstupanje, što je aritmetička sredina apsolutnih odstupanja pojedinačnih opcija od njihove prosječne vrijednosti:
,
za grupisane podatke ![]() ,
,
gdje je hi vrijednost karakteristike u diskretne serije ili sredina intervala u intervalnoj distribuciji.
U gornjim formulama, razlike u brojiocu se uzimaju po modulu, inače će, prema svojstvu aritmetičke sredine, brojilac uvijek biti jednak nuli. Zbog toga se prosječna linearna devijacija rijetko koristi u statističkoj praksi, samo u slučajevima kada zbrajanje indikatora bez uzimanja u obzir predznaka ima ekonomski smisao. Uz nju se, na primjer, analizira sastav zaposlenih, profitabilnost proizvodnje, spoljnotrgovinski promet.
Varijanca karakteristika- Ovo srednji kvadrat odstupanja varijante od njihove prosječne vrijednosti:
jednostavna varijansa ![]() ,
,
ponderisana varijansa  .
.
Formula za izračunavanje varijanse može se pojednostaviti:
Dakle, varijansa je jednaka razlici između srednje vrijednosti kvadrata varijante i kvadrata srednje vrijednosti varijante populacije:  .
.
Međutim, zbog zbrajanja kvadrata odstupanja, varijansa daje iskrivljenu predstavu o devijacijama, pa se iz nje izračunava prosjek. standardna devijacija, koji pokazuje koliko specifične varijante atributa u prosjeku odstupaju od njihove prosječne vrijednosti. Izračunato ekstrahiranjem kvadratni korijen iz disperzije:
za negrupisane podatke 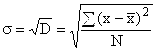 ,
,
za varijantne serije
Kako manje vrijednosti disperzija i standardna devijacija, što je populacija homogenija, to će biti pouzdanija (tipična). prosječna vrijednost.
Linearna sredina i srednja vrijednost standardna devijacija- imenovani brojevi, odnosno izraženi su u mjernim jedinicama atributa, identični su sadržajem i bliski po značenju.
count apsolutni pokazatelji varijacije se preporučuju korištenjem tabela.
Tabela 3 - Proračun karakteristika varijacije (na primjeru perioda podataka o smjenskom izlazu radnih timova)
Broj radnika |
Sredina intervala |
Procijenjene vrijednosti |
|||||
Ukupno: |
|||||||
Prosječan učinak radnika u smjeni: ![]()
Prosječna linearna devijacija: ![]()
Izlazna disperzija: 
Standardna devijacija proizvodnje pojedinih radnika od prosječne proizvodnje:
.
1 Proračun disperzije metodom momenata
Izračunavanje varijansi povezano je sa glomaznim proračunima (posebno ako je izražena prosječna vrijednost veliki broj sa više decimala). Proračuni se mogu pojednostaviti korištenjem pojednostavljene formule i svojstava disperzije.
Disperzija ima sledeća svojstva:
- ako se sve vrijednosti atributa smanje ili povećaju za istu vrijednost A, tada se varijansa neće smanjiti iz ovoga:
 ,
,
 , zatim ili
, zatim ili 
Koristeći svojstva varijanse i prvo smanjivši sve varijante populacije za vrijednost A, a zatim podijelivši sa vrijednošću intervala h, dobijamo formulu za izračunavanje varijanse u varijantnom nizu sa u jednakim intervalima način trenutaka: ,
,
gdje je disperzija izračunata metodom momenata;
h je vrijednost intervala serije varijacije;
– nove (transformisane) vrednosti varijante;
ALI- konstantan, koji se koristi kao sredina intervala sa najvećom frekvencijom; ili opciju koja ima najviša frekvencija;  je kvadrat momenta prvog reda;
je kvadrat momenta prvog reda;
je trenutak drugog reda.
Izračunajmo varijansu metodom momenata na osnovu podataka o smjenskom učinku radnog tima.
Tabela 4 - Proračun disperzije metodom momenata
Grupe proizvodnih radnika, kom. |
Broj radnika |
Sredina intervala |
Procijenjene vrijednosti |
||
Procedura obračuna:


- izračunaj varijansu:
2 Izračunavanje varijanse alternativne karakteristike
Među znakovima koje proučava statistika, postoje oni koji imaju samo dva međusobno isključiva značenja. Ovo su alternativni znakovi. Daju im se dva kvantitativne vrijednosti: opcije 1 i 0. Učestalost opcija 1, koja je označena p, je udio jedinica koje imaju dati atribut. Razlika 1-p=q je frekvencija opcija 0. Dakle,
xi |
|
Aritmetička sredina alternativnog svojstva ![]() , budući da je p+q=1.
, budući da je p+q=1.
Varijanca karakteristika
, jer 1-p=q
Dakle, varijansa alternativnog obilježja jednaka je proizvodu udjela jedinica koje imaju datu osobinu i udjela jedinica koje nemaju tu osobinu.
Ako su vrijednosti 1 i 0 podjednako česte, tj. p=q, varijansa dostiže svoj maksimum pq=0,25.
Alternativna varijansa karakteristika se koristi u uzorkovana istraživanja kao što je kvalitet proizvoda.
3 Međugrupna disperzija. Pravilo dodavanja varijanse
Disperzija, za razliku od drugih karakteristika varijacije, jeste količina aditiva. Odnosno, u agregatu, koji je podijeljen u grupe prema faktorskom kriteriju X , rezultujuća varijansa y može se razložiti na varijansu unutar svake grupe (unutar grupe) i varijansu između grupa (između grupe). Zatim, uz proučavanje varijacije osobine u populaciji u cjelini, postaje moguće proučavati varijacije u svakoj grupi, kao i između ovih grupa.
Ukupna varijansa mjeri varijaciju osobine at na cjelokupnu populaciju pod uticajem svih faktora koji su uzrokovali ovu varijaciju (odstupanja). Ona je jednaka srednjem kvadratu devijacije individualne vrednosti sign at ukupne srednje vrijednosti i može se izračunati kao jednostavna ili ponderisana varijansa.
Međugrupna varijansa karakteriše varijaciju efektivne karakteristike at, uzrokovana uticajem znak-faktora X u osnovi grupisanja. Karakterizira varijaciju grupnih srednjih vrijednosti i jednak je srednjem kvadratu odstupanja srednjih vrijednosti grupe od ukupne srednje vrijednosti:  ,
,
gdje je aritmetička sredina i-te grupe;
– broj jedinica u i-oj grupi (učestalost i-te grupe);
– general populacija srednja.
Unutargrupna varijansa odražava slučajnu varijaciju, tj. onaj dio varijacije koji je uzrokovan utjecajem neobračunatih faktora i ne ovisi o faktoru atributa koji leži u osnovi grupisanja. Karakterizira varijaciju individualne vrednosti u odnosu na grupne sredine, jednake srednjem kvadratu odstupanja pojedinačnih vrijednosti atributa at unutar grupe iz aritmetičke sredine ove grupe (srednja vrijednost grupe) i izračunava se kao jednostavna ili ponderirana varijansa za svaku grupu: ![]() ili
ili ![]() ,
,
gdje je broj jedinica u grupi.
Na osnovu varijanse unutar grupe za svaku grupu može se odrediti ukupni prosjek varijansi unutar grupe:
.
Odnos između tri varijanse se naziva pravila sabiranja varijanse, prema kojem je ukupna varijansa jednaka zbroju međugrupne varijanse i prosjeku unutargrupnih varijansi:
Primjer. Proučavanjem uticaja tarifne kategorije (kvalifikacije) radnika na nivo produktivnosti njihovog rada dobijeni su sljedeći podaci.
Tabela 5 - Distribucija radnika po prosječnom satu.
№ p/p |
Radnici 4. kategorije |
Radnici 5. kategorije |
|||||
Vježbati |
Vježbati |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
AT ovaj primjer radnici su podijeljeni u dvije grupe prema faktorskom kriteriju X- kvalifikacije koje karakteriše njihov rang. Efektivna osobina - proizvodnja - varira i pod njenim uticajem (međugrupna varijacija) i zbog drugih slučajnih faktora (unutargrupna varijacija). Izazov je izmjeriti ove varijacije korištenjem tri varijanse: ukupne, između grupe i unutar grupe. Empirijski koeficijent determinacije pokazuje proporciju varijacije rezultirajuće karakteristike at pod uticajem faktorskog znaka X. Ostalo opšta varijacija at uzrokovane promjenama drugih faktora.
U primjeru, empirijski koeficijent determinacije je: ![]() ili 66,7%
ili 66,7%
To znači da je 66,7% varijacija u produktivnosti rada radnika posledica razlika u kvalifikacijama, a 33,3% je posledica uticaja drugih faktora.
Empirijska korelacija pokazuje čvrstoću odnosa između grupisanja i efektivnih karakteristika. Izračunava se kao kvadratni korijen empirijskog koeficijenta determinacije:
Empirijski korelacijski omjer, kao i , može imati vrijednosti od 0 do 1.
Ako nema veze, onda =0. U ovom slučaju, =0, to jest, srednje su grupe jednake jedna drugoj i nema međugrupnih varijacija. To znači da znak grupisanja - faktor ne utiče na formiranje opšte varijacije.
Ako je odnos funkcionalan, onda je =1. U ovom slučaju, varijansa grupne sredine je totalna varijansa(), to jest, nema unutargrupnih varijacija. To znači da karakteristika grupisanja u potpunosti određuje varijaciju rezultirajuće karakteristike koja se proučava.
Što je vrijednost korelacijskog omjera bliža jedinici, to je odnos između karakteristika bliži, bliži funkcionalnoj zavisnosti.
Za kvalitativnu procjenu bliskosti veze između znakova koriste se Chaddock relacije.
U primjeru ![]() , što ukazuje zatvoriti vezu između produktivnosti radnika i njihovih kvalifikacija.
, što ukazuje zatvoriti vezu između produktivnosti radnika i njihovih kvalifikacija.
 Dvije glave i šest nogu; četiri hodaju, a dvojica mirno leže
Dvije glave i šest nogu; četiri hodaju, a dvojica mirno leže Samopoštovanje - šta je to: koncept, struktura, vrste i nivoi
Samopoštovanje - šta je to: koncept, struktura, vrste i nivoi Kasandrin put, ili Pasta Adventures Rat na Zemlji i pod zemljom
Kasandrin put, ili Pasta Adventures Rat na Zemlji i pod zemljom